4.2. Statistical Results on UCI Data Sets
In order to verify the efficiency and effectiveness of the proposed FHDF, we conduct experiments on 43 data sets from the UCI machine learning repository.
Table 3 summarizes the characteristics of each data set, including the number of instances, attributes and classes. Large data sets with an instance number greater than 3000 are annotated with the symbol “*”. Missing values for qualitative attributes are replaced with modes, and those for quantitative attributes are replaced with means from the training data. For each benchmark data set, numeric attributes are discretized using MDL discretization [
17]. The following techniques are compared:
NB, standard naive Bayes.
TAN [
18], tree-augmented naive Bayes applying incremental learning.
C4.5, standard decision tree.
NBTree [
19], decision tree with naive Bayes as the leaf node.
RTAN [
20], tree-augmented naive Bayes ensembles.
All algorithms were coded in MATLAB 7.0 on a Pentium 2.93 GHz/1 G RAM computer.
Base probability estimates P(c), P(c, xi) and P(c, xi, xj) were smoothed using the Laplace estimate, which can be described as follows:
where F(·) is the frequency with which a combination of terms appears in the training data, K is the number of training instances for which the class value is known, Ki is the number of training instances for which both the class and attribute Xi are known and Kij is the number of training instances for which all of the class and attributes Xi and Xj are known. k is the number of attribute values of class C, ki is the number of attribute value combinations of C and Xi and kij is the number of attribute value combinations of C, Xj and Xi.
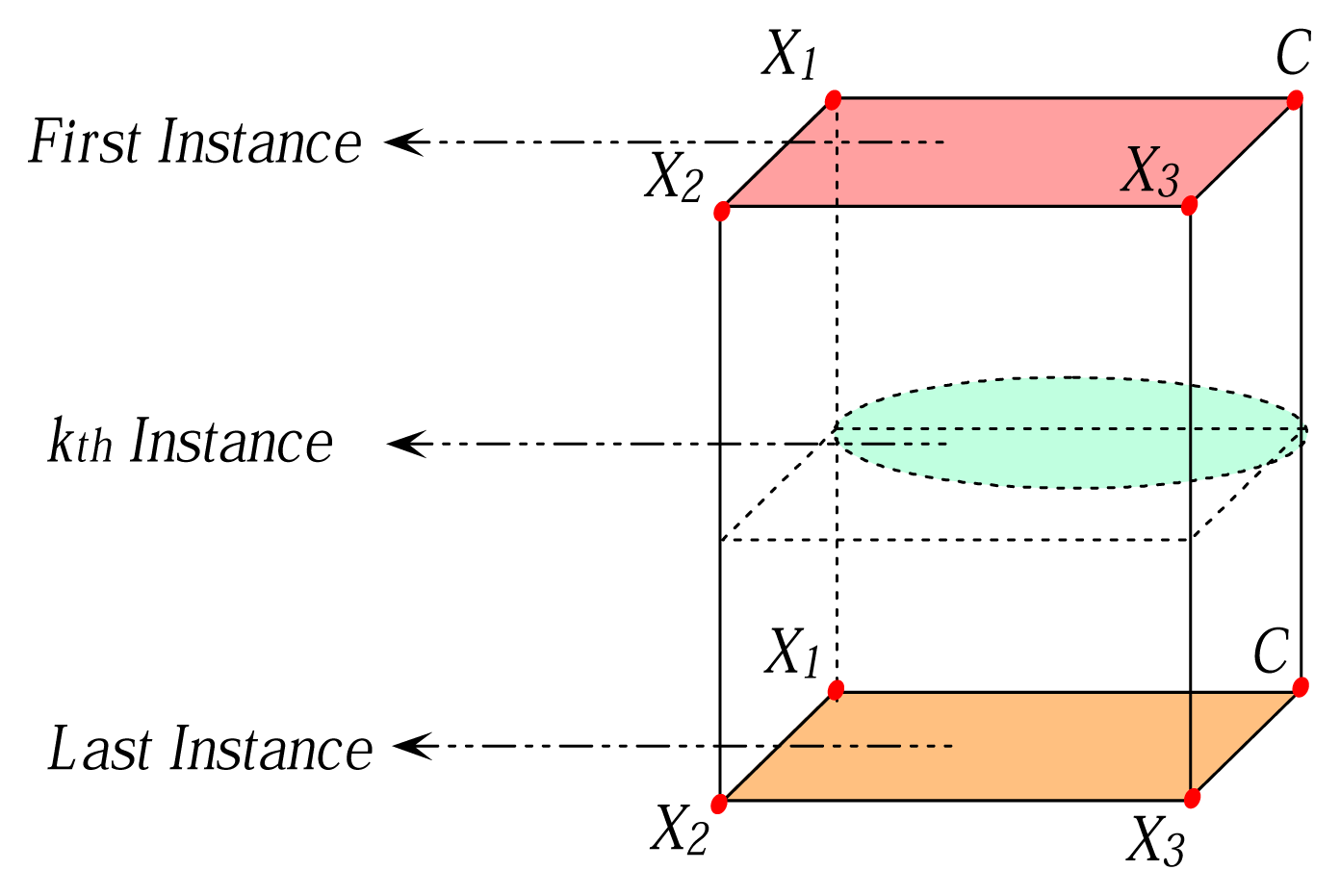
Semi-supervised learning falls between unsupervised learning (without any labeled training data) and supervised learning (with completely labeled training data). Semi-supervised learning is a class of machine learning techniques that uses both labeled and unlabeled data for training. Typically, a small amount of labeled data with a large amount of unlabeled data is used. Many machine learning researchers have found that when unlabeled data are used in conjunction with a small amount of labeled data, a considerable improvement in learning accuracy can be achieved. The acquisition of labeled data for a learning problem often requires a skilled human agent (e.g., to transcribe an audio segment) or a physical experiment (e.g., determining the 3D structure of a protein or determining whether oil is present at a particular location). Given data set S with attribute set X, suppose FD α → β has been deduced from whole data set and α, β ⊂ X. From the representation equivalence of probability, we can obtain:
By applying the augmentation rule of probability, we will get:
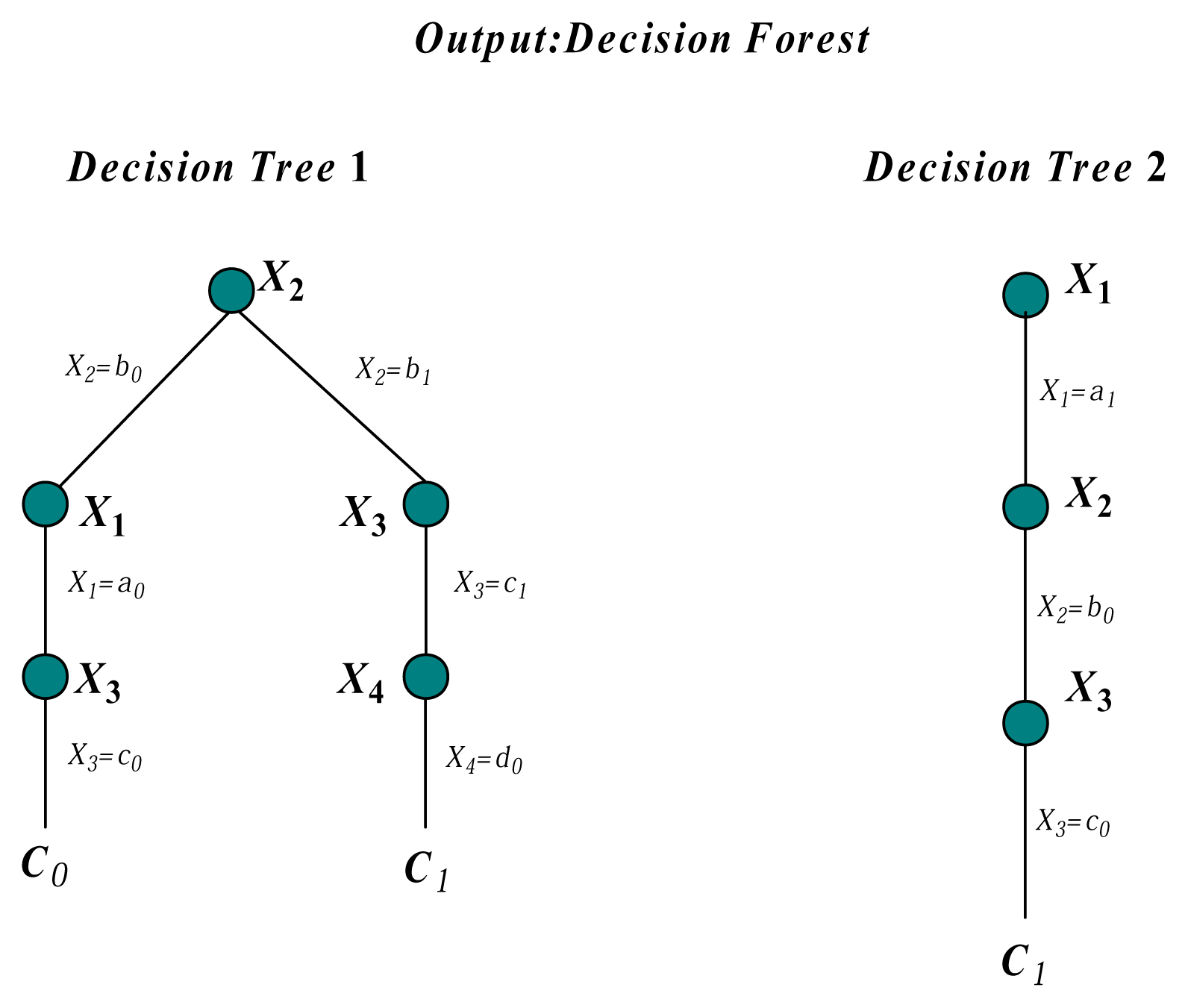
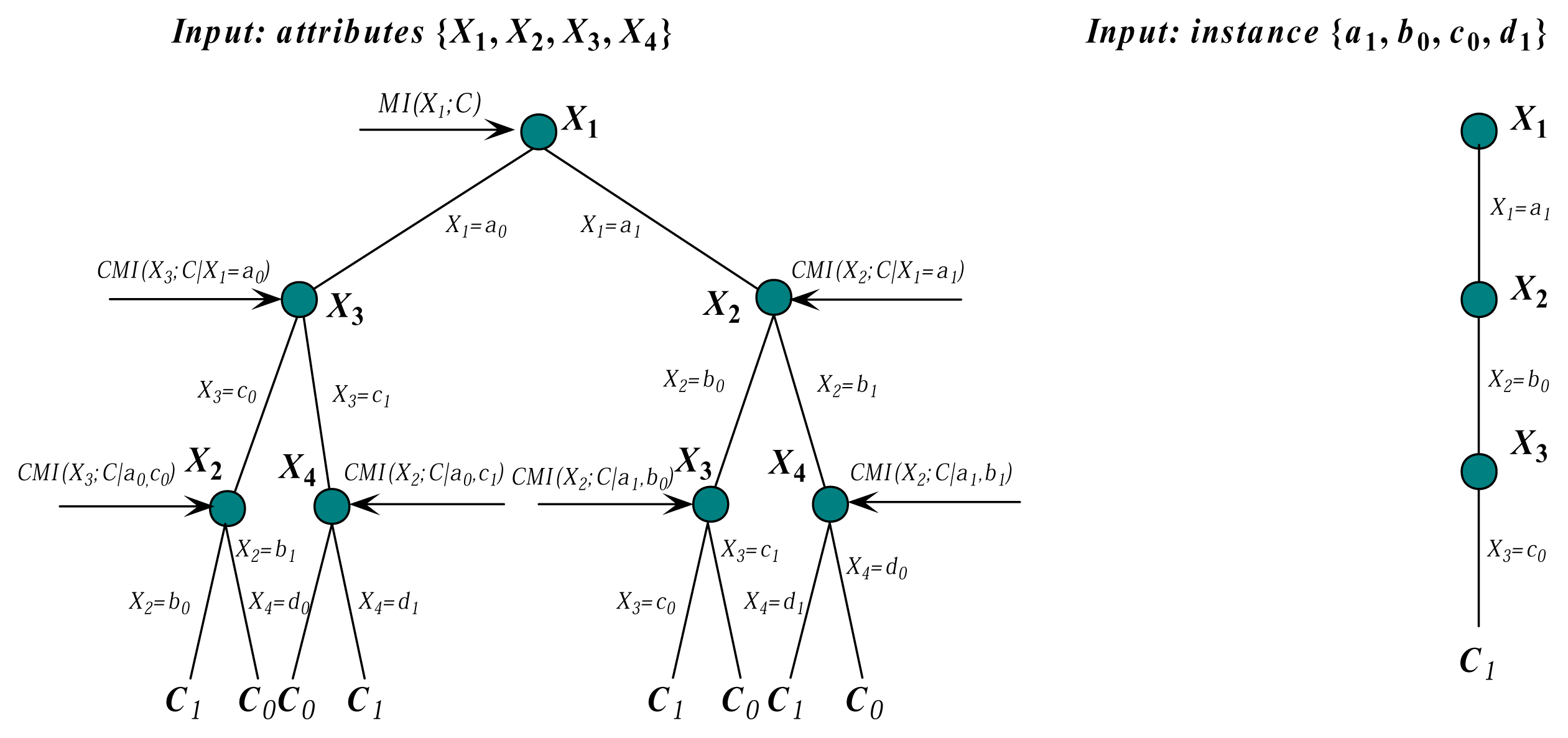
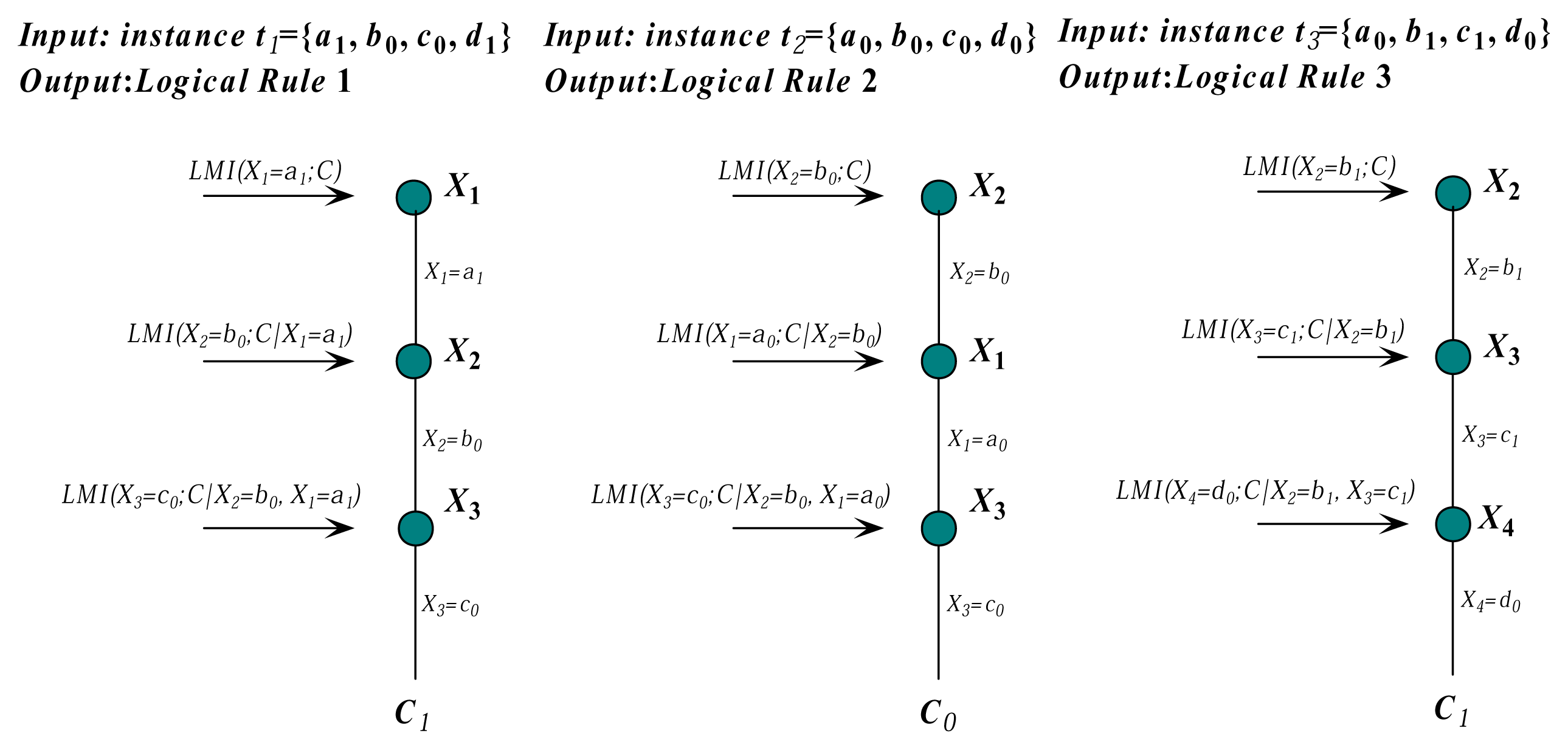
Therefore, FD α → β still holds in the training data regardless of the class label. Thus, we can use the whole data set to extract FDs with high confidence. Additionally, the framework of FHDF is semi-supervised learning. In the following discussion, we use FDs that are extracted based on the association rule analysis as the domain knowledge. These rules can be effective in uncovering unknown relationships, thereby providing results that can be the basis of forecast and decision. They have proven to be useful tools for an enterprise, as they strive to improve their competitiveness and profitability. To ensure the validity of FDs, the minimum number of instances that satisfies FD is 100. With the increasing number of attributes, more RAM is needed to store joint probability distributions. An important restriction of our algorithm is that the number of the left side of FD, i.e., the number of key attributes, should be no more than two.
Table 4 presents for each data set the zero-one loss, which is estimated by 10-fold cross-validation to give an accurate estimation of the average performance of an algorithm. The bias and variance results are shown in
Tables 5 and
6, respectively, in which only 15 large data sets are selected, because of statistical significance. The zero-one loss, bias or variance across multiple data sets provides a gross measure of relative performance. Statistically, a win/draw/loss record (W/D/L) is calculated for each pair of competitors
A and
B with regard to a performance measure
M. The record represents the number of data sets in which
A respectively beats, loses to or ties with
B on
M. Small improvements in leave-one-out error may be attributable to chance. Consequently, it may be beneficial to use a statistical test to assess whether an improvement is significant. A standard binomial sign test, assuming that wins and losses are equiprobable, is applied to these records. A difference is considered significant when the outcome of a two-tailed binomial sign test is less than 0.05.
Tables 7–
10 show the W/D/L records corresponding to zero-one loss, bias and variance, respectively.
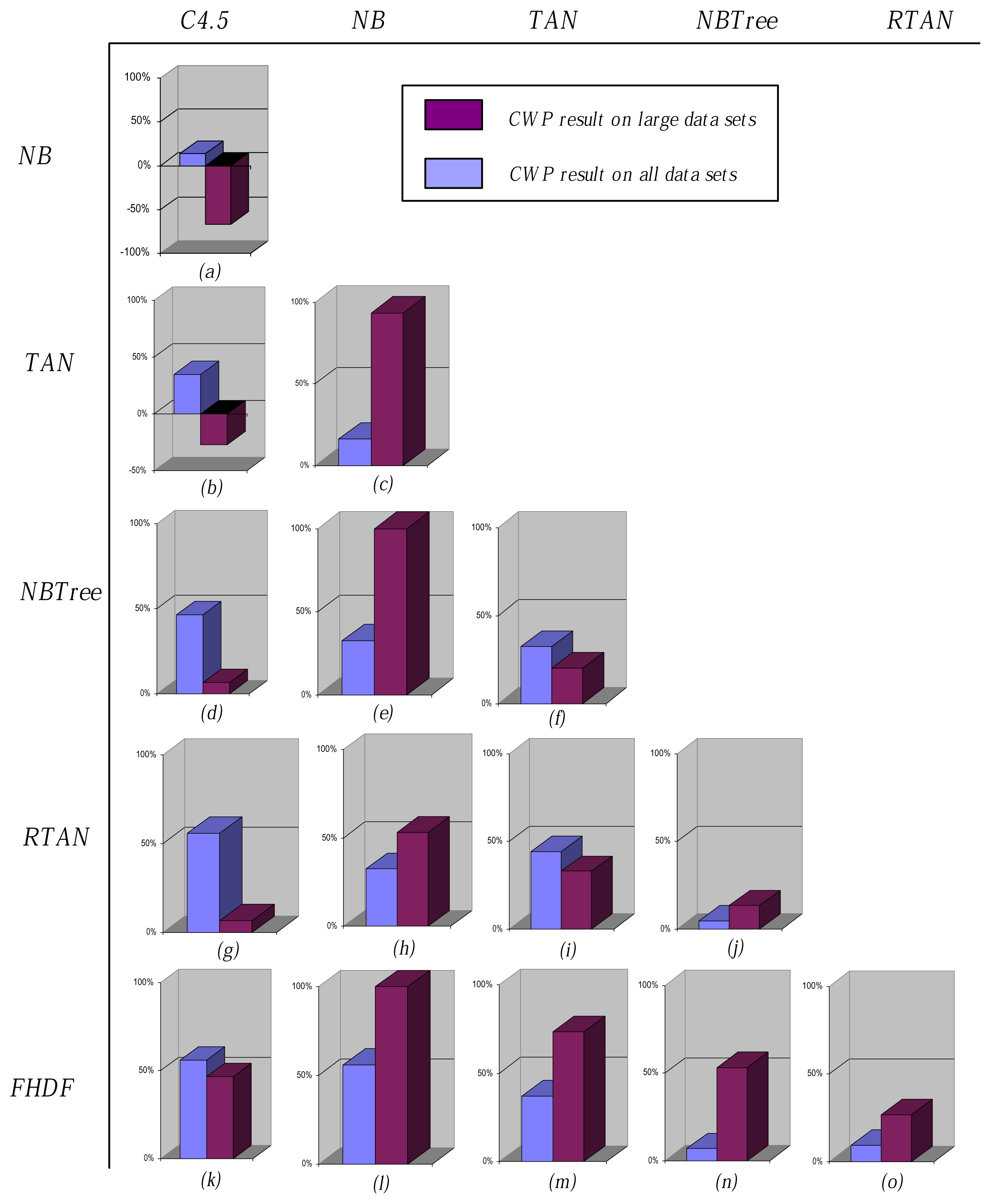
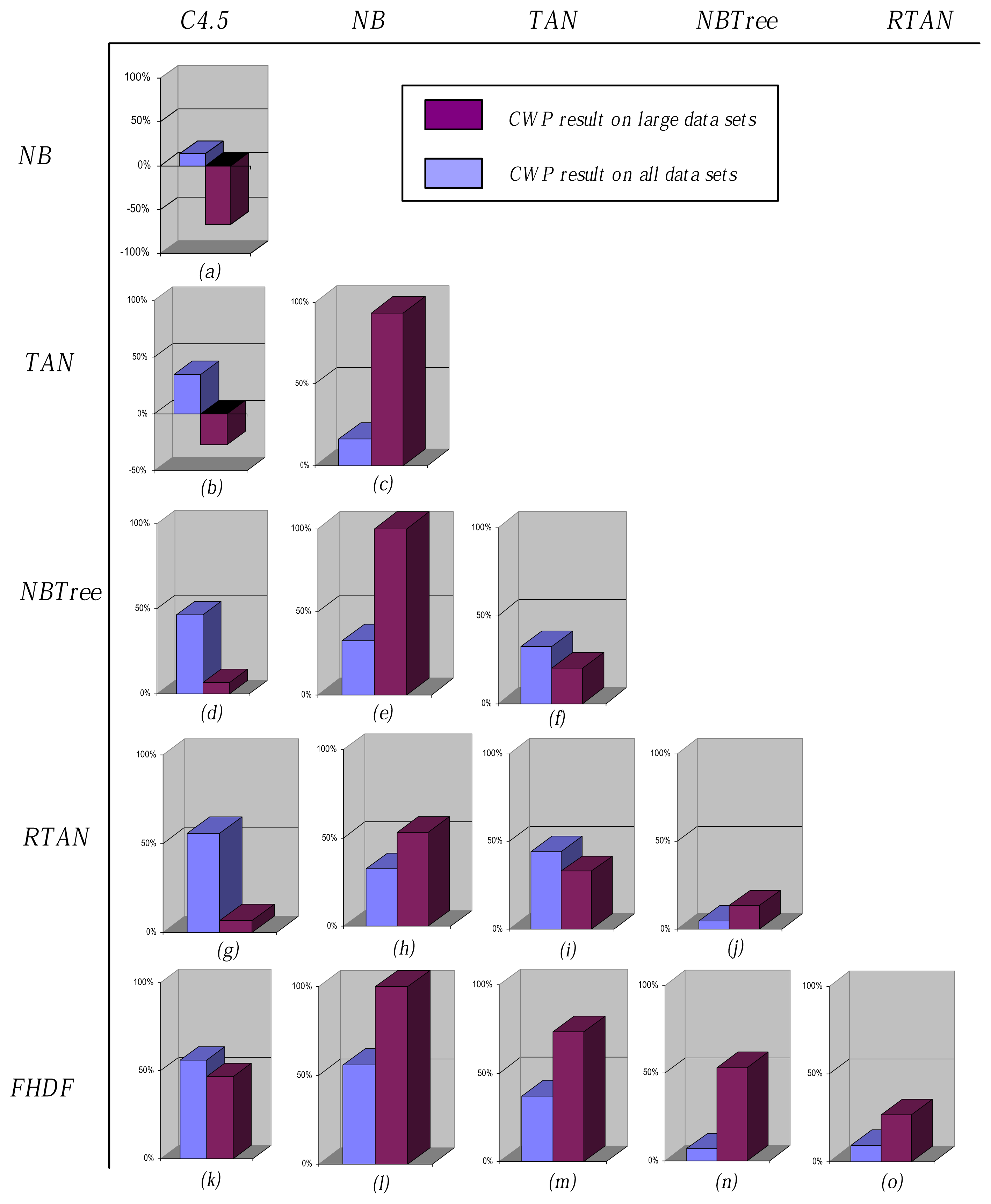
To clarify the main reason why the same classifier performs differently when data size changes, in the following discussion, we propose a new parameter, named clear winning percentage (CWP), which is defined as follows, to evaluate the extent to which one classifier is relatively superior to another.
If
CWP > 0, then the classifier performs better. Otherwise, it performs worse.
Figure 7 shows the comparison results of CWP corresponding to
Tables 7 and
8.
NB delivers fast and effective classification with a clear theoretical foundation. However, NB is confronted with the limitations of the conditional independence assumption. From
Figure 7a, we can see that, although the conditional independence assumption rarely holds in the real world, NB exhibits competitive performance compared to C4.5,
CWP = (22
– 16)
/43 = 0
.14
> 0. When dealing with small data sets, the instances can be regarded as sparsely distributed, and the conditional independence assumption is satisfied to some extent. For example, there are as many as 38 attributes and only 894 instances for data set “Anneal”. After calculating and comparing the sum of CMI between one attribute and all of the other attributes, most attributes have weak relationships to other attributes or are even nearly independent of them. However, when dealing with large data sets, the relationships between attributes become much more obvious, and the limitation of this assumption cannot be neglected,
CWP = (2
–12)
/15 = −0
.67
< 0. As
Figure 7b shows, similar result appears when TAN and C4.5 are compared. The main reason may be that logical rules, which are extracted based on information theory, take the main role for classification and can represent credible linear dependency among attributes as data size increases. Besides, as
Figure 7c shows, although TAN is restricted to have at most one parent node for each predictive attribute, its structure is more reasonable than NB and can exhibit the relationship between attributes to some extent. From
Figure 7d–f, when compared with these three single-structure models, the hybrid model,
i.e., NBTree, shows superior or at least equivalent performance. To decrease the computational overhead, NB and TAN simplify the network structure given different independence assumption; whereas the hybrid model can utilize the advantages of both logical rule and probabilistic estimation. Because the leaf of the tree structure contains only limited number instances, NB can evenly make use of the rest of the attributes. RTAN investigates the diversity of TAN by the
K statistic. From
Figure 7g–j, this bagging mechanism helps RTAN to achieve superior performance to NB and TAN. However, when compared to decision tree learning algorithms,
i.e., C4.5 and NBTree, the advantage of RTAN is not obvious. FHDF is motivated by the desire to weaken the assumption by removing correlated attributes on the basis of FD analysis. It also applies the bagging mechanism to describe the hyperplane in which each instance exist. From
Figure 7k–o, FHDF demonstrates comprehensive and superior performance.
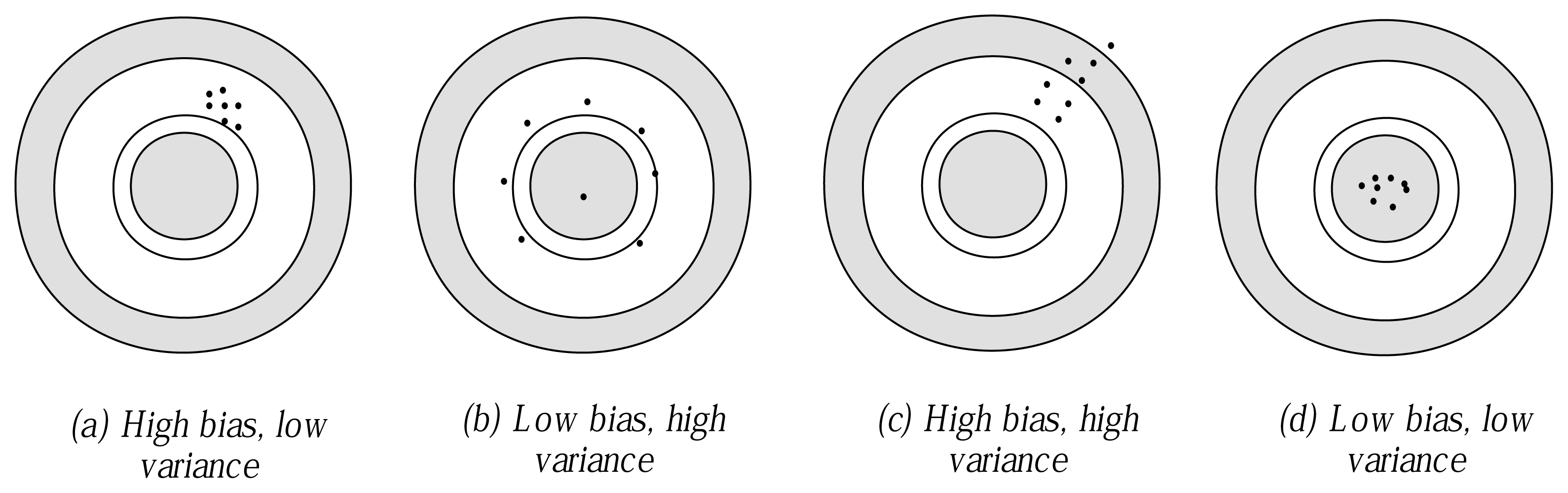
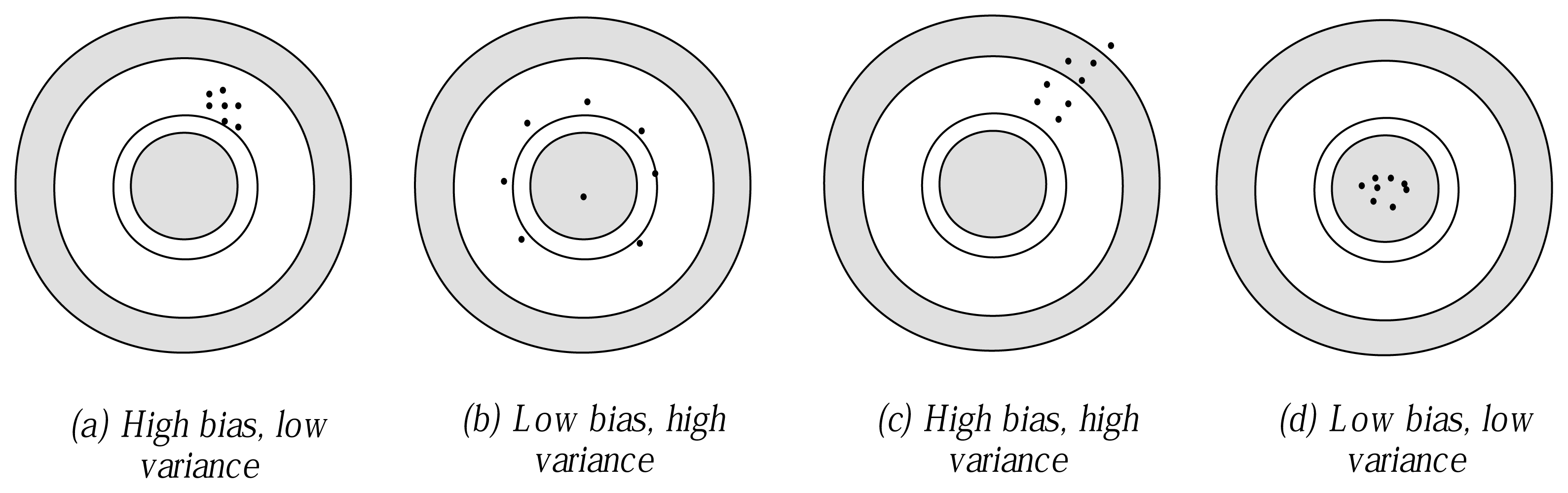
Bias can help to evaluate the extent to which the final model learned from training data fits the whole data set. From
Table 9, we can see that the fitness of NB is the poorest, because its structure is definite regardless of what the true data distribution is. In contrast, TAN performs much better than C4.5 and NBTree. The main reason may be that each predictive attribute of TAN is affected by its direct parent node, which is selected by calculating CMI from the global viewpoint. As for C4.5 and NBTree, the final prediction greatly relies on the first few attributes corresponding to the main parts of the singletree structure,
i.e., the root and the branch nodes. Thus, C4.5 and NBTree can easily achieve local rather than global optimization solution. Additionally, in view of this, the bagging mechanism can help RTAN and FHDF to make full use of the information that training data supply, since the knowledge hierarchy implicated in the training data can be described in different submodels, and the negative effect caused by data distribution change will be mitigated to a certain extent. The complicated relationship among attributes are measured and depicted from the viewpoint of information theory; thus, performance robustness can be achieved.
With respect to variance, as
Table 10 shows, of these algorithms, NB performs the best, because its network structure is definite and, thus, not sensitive to changes in the training set. By contrast, C4.5 performs the worst. The main reason may be that the logical rules resemble the hierarchical process of human decision making. The attributes that locate at the back must correlate with those in the front. If any attribute changes the location, the following attributes will be affected greatly. Thus, for different training sets, especially when the branch contains a very small number of instances, the conditional distribution estimates may differ greatly and different attribute orders may be obtained. For example, there are 58 attributes and 4601 instances for data set “Spambase”. When 10-fold cross-validation is applied, only 4601×0
.9 = 4141 instances can be used for training. Suppose each attribute contains two values and the leaf node must have at least 100 instances to ensure statistical significance: each logical rule will use at most five attributes for prediction. That means that the order of the rest of the 53 attributes may be at random. TAN and RTAN need to calculate CMI to build a maximal spanning tree, which may cause overfitting. On the other hand, FHDF and NBTree both use NB as the leaf node, thus retaining the simplicity and direct theoretical foundation of the decision tree, while mitigating the negative effect of the probability distribution of the training set. Besides, when different training and testing sets were given, FHDF uses the same FDs in the semi-supervised learning framework to eliminate redundant attributes. These FDs are extracted from the whole data set and entirely unrelated to the training set.
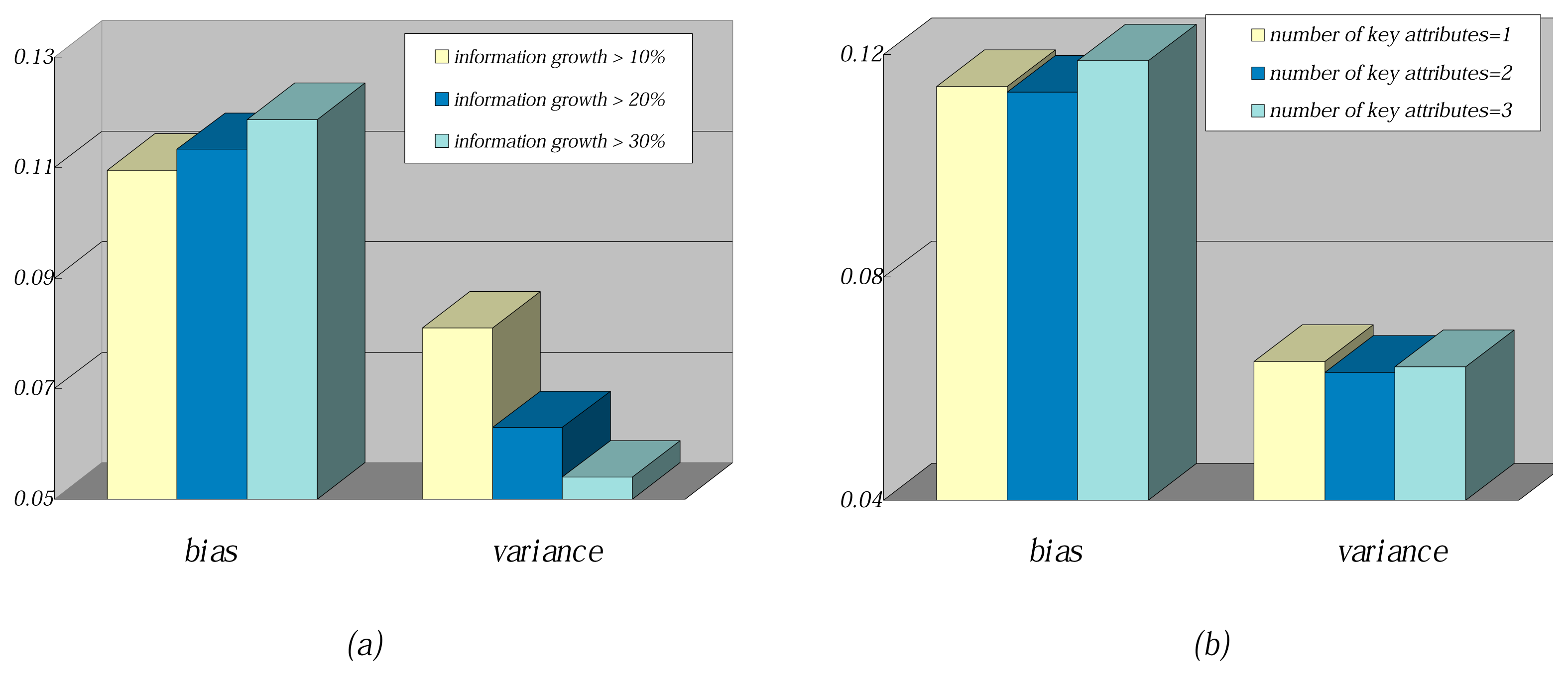
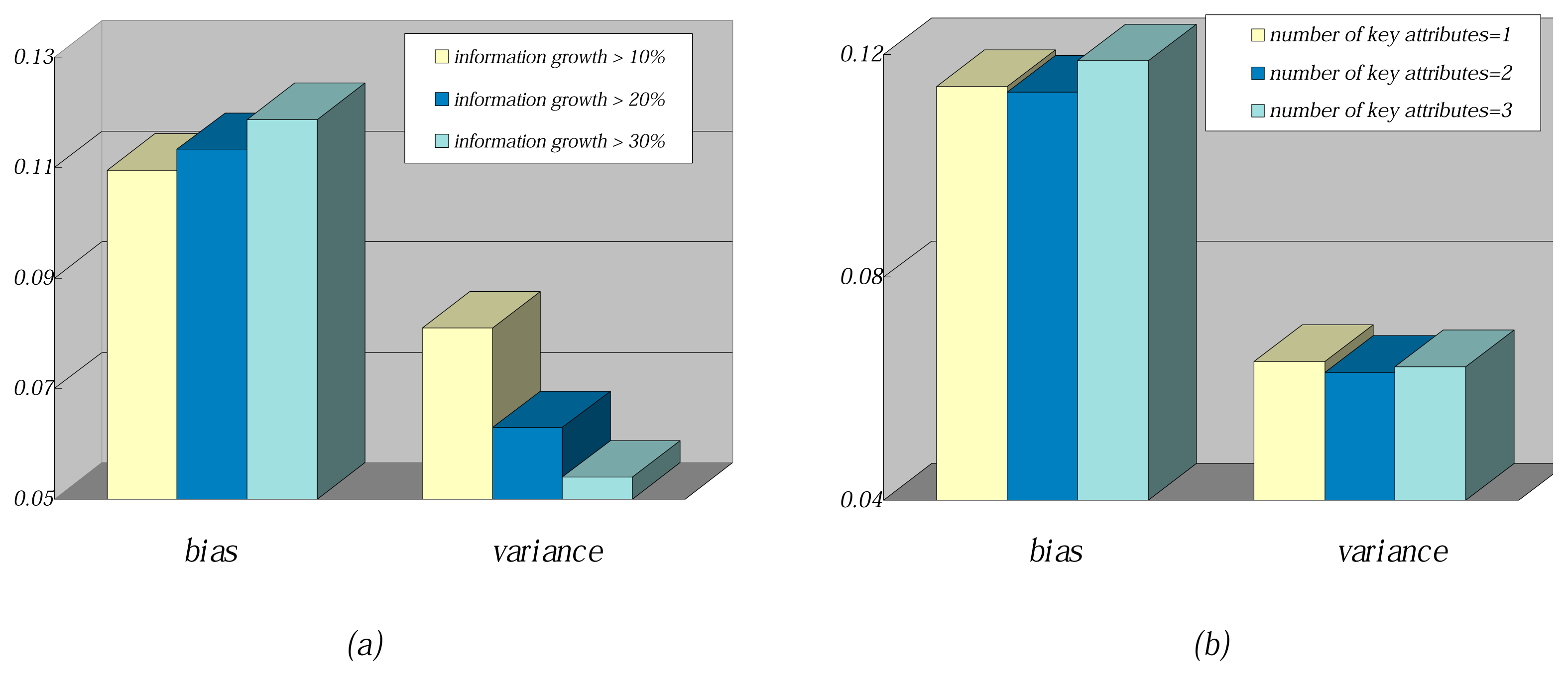
To further describe the working mechanism of FHDF, the information growth and the number of key attributes are changed while learning from training data. The comparison results of average bias and average variance are shown in
Figure 8. When information growth increased from 10% to 30%, as can be seen from
Figure 8a, the bias increased correspondingly, while the variance decreased. The main reason may be that if instance
t needs to be converted into the classification rule, higher information growth will cause fewer attribute values to be selected. Thus, the classification rule will be too short to precisely fit instance
t. However, when given different training data, the short rule may roughly hold for many instances. When the number of key attributes increased from one to three, as can be seen from
Figure 8b, the bias and variance almost remain the same. With more key attributes used, according to Occam’s razor rule, the extracted FDs may be coincidental and not credible. Furthermore, the number of FDs with one key attribute are much more than those with two or three key attributes; the negative effect on bias and variance can be neglected.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}