1. Introduction
Objective Bayesian epistemology is a theory about the strength of belief. As formulated by Williamson [
1], it invokes three norms:
Probability: The strengths of an agent’s beliefs should satisfy the axioms of probability. That is, there should be a probability function, , such that for each sentence θ of the agent’s language , measures the degree to which the agent with evidence E believes sentence θ. (Here, will be construed as a finite propositional language and as the set of sentences of , formed by recursively applying the usual connectives.)
Calibration: The strengths of an agent’s beliefs should satisfy constraints imposed by her evidence E. In particular, if the evidence determines just that physical probability (aka chance), , is in some set of probability functions defined on , then should be calibrated to physical probability insofar as it should lie in the convex hull, , of the set . (We assume throughout this paper that chance is probabilistic, i.e., that is a probability function.)
Equivocation: The agent should not adopt beliefs that are more extreme than is demanded by her evidence E. That is, should be a member of that is sufficiently close to the equivocator function, , which gives the same probability to each , where the state descriptions or states, ω, are sentences describing the most fine-grained possibilities expressible in the agent’s language.
One way of explicating these norms proceeds as follows. Measure closeness of
to the equivocator by Kullback-Leibler divergence,
. Then, if there is some function in
that is closest to the equivocator,
should be such a function. If
is closed, then there is guaranteed to be some function in
closest to the equivocator; as
is convex, there is at most one such function. Then we have the maximum entropy principle [
2]:
is the function in
that has maximum entropy
H, where
.
The question arises as to how the three norms of objective Bayesianism should be justified, and whether the maximum entropy principle provides a satisfactory explication of the norms.
The probability norm is usually justified by a
Dutch book argument. Interpret the strength of an agent’s belief in
θ to be a
betting quotient,
i.e., a number
x, such that the agent is prepared to bet
on
θ with return
S if
θ is true, where
S is an unknown stake, positive or negative. Then the only way to avoid the possibility that stakes may be chosen so as to force the agent to lose money, whatever the true state of the world, is to ensure that the betting quotients satisfy the axioms of probability (see e.g., Theorem 3.2 in [
1]).
The calibration norm may be justified by a different sort of betting argument. If the agent bets repeatedly on sentences with known chance
y with some fixed betting quotient
x, then she is sure to lose money in the long run unless
(see, e.g., pp. 40–41 in [
1]). Alternatively, on a single bet with known chance
y, the agent’s
expected loss is positive unless her betting quotient
, where the expectation is determined with respect to the chance function
(pp. 41–42 in [
1]). More generally, if evidence
E determines that
and the agent makes such bets, then sure loss/positive expected loss can be forced unless
.
The equivocation norm may be justified by appealing to a third notion of loss. In the absence of any particular information about the loss
one incurs when one’s strengths of beliefs are represented by
P and
ω turns out to be the true state, one can argue that one should take the loss function
L to be logarithmic,
(pp. 64–65 in [
1]). Then the probability function
P that minimises the worst case expected loss, subject to the information that
, where
is closed and convex, is simply the probability function
closest to the equivocator—equivalently, the probability function in
that has maximum entropy [
3,
4].
The advantage of these three lines of justification is that they make use of the rather natural connection between strength of belief and betting. This connection was highlighted by Frank Ramsey:
All our lives, we are in a sense betting. Whenever we go to the station, we are betting that a train will really run, and if we had not a sufficient degree of belief in this, we should decline the bet and stay at home.
The problem is that the three norms are justified in rather different ways. The probability norm is motivated by avoiding sure loss. The calibration norm is motivated by avoiding sure long-run loss or by avoiding positive expected loss. The equivocation norm is motived by minimising worst-case expected loss. In particular, the loss function appealed to in the justification of the equivocation norm differs from that invoked by the justifications of the probability and calibration norms.
In this paper, we seek to rectify this problem. That is, we seek a single justification of the three norms of objective Bayesian epistemology.
The approach we take is to generalise the justification of the equivocation norm, outlined above, in order to show that only the strengths of beliefs that are probabilistic, calibrated and equivocal minimise worst-case expected loss. We shall adopt the following starting point: as discussed above,
is taken to be convex and non-empty throughout this paper; we shall also assume that the strengths of the agent’s beliefs can be measured by non-negative real numbers—an assumption that is rejected by advocates of
imprecise probability, a position that we will discuss separately in
Section 5.3. We do not assume throughout that
is such that it admits some function that has maximum entropy—e.g., that
is closed—but we will be particularly interested in the case in which
does contain its entropy maximiser, in order to see whether some version of the maximum entropy principle is justifiable in that case.
In
Section 2, we shall consider the scenario in which the agent’s belief function,
, is defined over propositions,
i.e., sets of possible worlds. Using
ω to denote a possible world as well as the state of
that picks out that possible world, we have that
is a function from the power set of a finite set Ω of possible worlds
ω to the non-negative real numbers,
. When it comes to justifying the probability norm, this will give us enough structure to show that degrees of belief should be additive. Then, in
Section 3, we shall consider the richer framework in which the belief function is defined over sentences,
i.e.,
. This will allow us to go further by showing that different sentences that express the same proposition should be believed to the same extent. In
Section 4, we shall explain how the preceding results can be used to motivate a version of the maximum entropy principle. In
Section 5, we draw out some of the consequences of our results for Bayes’ theorem. In particular, conditional probabilities and Bayes’ theorem play a less central role under this approach than they do under subjective Bayesianism. Furthermore, in
Section 5 we relate our work to the imprecise probability approach and suggest that the justification of the norms of objective Bayesianism presented here can be reinterpreted in a non-pragmatic way.
The key results of the paper are intended to demonstrate the following points. Theorem 1 (which deals with beliefs defined over propositions) and Theorem 4 (respectively, belief over sentences) show that only a logarithmic loss function satisfies certain desiderata that, we suggest, any default loss function should satisfy. This allows us to focus our attention on logarithmic loss. Theorems 2, 3 (for propositions) and Theorems 5, 6 (for sentences) show that minimising worst-case expected logarithmic loss corresponds to maximising a generalised notion of entropy. Theorem 7 justifies maximising standard entropy, by viewing this maximiser as a limit of generalised entropy maximisers. Theorem 9 demonstrates a level of agreement between updating beliefs by Bayesian conditionalisation and updating by maximising generalised entropy. Theorem 10 shows that the generalised notion of entropy considered in this paper is pitched at precisely the right level of generalisation.
Three appendices to the paper help to shed light on the generalised notion of entropy introduced in this paper.
Appendix A motivates the notion by offering justifications of generalised entropy that mirror Shannon’s original justification of standard entropy.
Appendix B explores some of the properties of the functions that maximise generalised entropy.
Appendix C justifies the level of generalisation of entropy to which we appeal.
2. Belief over Propositions
In this section, we shall show that if a belief function defined on propositions is to minimise worst-case expected loss, then it should be a probability function, calibrated to physical probability, which maximises a generalised notion of entropy. The argument will proceed in several steps. As a technical convenience, in
Section 2.1, we shall normalise the belief functions under consideration. In
Section 2.2, we introduce the appropriate generalisation of entropy. In
Section 2.3, we argue that, by default, loss should be taken to be logarithmic. Then, in
Section 2.4, we introduce scoring rules, which measure expected loss. Finally, in
Section 2.5, we show that worst-case expected loss is minimised just when generalised entropy is maximised.
For the sake of concreteness, we will take Ω to be generated by a propositional language, , with propositional variables, . The states, ω, take the form , where is just and is . Thus, there are states, . We can think of each such state as representing a possible world. A proposition (or, in the terminology of the mathematical theory of probability, an ‘event’) may be thought of as a subset of Ω, and a belief function, , thus assigns a degree of belief to each proposition that can be expressed in the agent’s language. For a proposition , we will use to denote . denotes the size of proposition , i.e., the number of states under which it is true.
Let Π be the set of partitions of Ω; a partition is a set of mutually exclusive and jointly exhaustive propositions. To control the proliferation of partitions, we shall take the empty set, ∅, to be contained only in one partition, namely .
2.1. Normalisation
There are finitely many propositions ( has members), so any particular belief function, , takes values in some interval . It is just a matter of convention as to the scale on which belief is measured, i.e., as to what upper bound M we might consider. For convenience, we shall normalise the scale to the unit interval, , so that all belief functions are considered on the same scale.
Definition 1 (Normalised belief function on propositions). Let
. Given a belief function,
, that is not zero everywhere, its
normalisation,
, is defined by setting
for each
. We shall denote the set of normalised belief functions by
, so:
Without loss of generality, we rule out of consideration the non-normalised belief function that gives zero degree of belief to each proposition; it will become clear in
Section 2.4 that this belief function is of little interest, as it can never minimise worst-case expected loss. For purely technical convenience, we will often consider the convex hull,
, of
. In which case, we rule into consideration certain belief functions that are not normalised, but which are convex combinations of normalised belief functions. Henceforth, then, we shall focus our attention on belief functions in
and
.
Note that we do not impose any further restrictions on the agent’s belief function—such as additivity; or the requirement that whenever ; or that the empty proposition, ∅, has belief zero; or the sure proposition, Ω, is assigned belief of one. Our aim is to show that belief functions that do not satisfy such conditions will expose the agent to avoidable loss.
For any
and every
, we have
, because
is a partition. Indeed:
Recall that a subset of is compact, if and only if it is closed and bounded.
Lemma 1 (Compactness). and are compact.
Proof: is bounded, where ⊂ denotes strict subset inclusion. Now, consider a sequence, which converges to some Then, for all , we find Assume that . Thus for all , we have However, then there has to exist a , such that for all and all , . This contradicts Thus, is closed and, hence, compact.
is the convex hull of a compact set. Hence, is closed and bounded and so compact. ■
We will be particularly interested in the subset,
, of belief functions defined by:
is the set of probability functions:
Proposition 1. if and only if satisfies the axioms of probability:- P1:
and .
- P2:
If , then .
Proof: Suppose . , because is a partition. , because is a partition and . If are disjoint, then , because and are both partitions, so .
On the other hand, suppose P1 and P2 hold. can be seen by induction on the size of π. If , then and by P1. Suppose, then, that for . Now, by the induction hypothesis and by P2, so , as required. ■
Example 1 (Contrasting with ). Using Equation (
1), we find
for all
and
For probability functions,
, probability is evenly distributed among the propositions of fixed size in the following sense:
where
abbreviates
For
and
, we have, in general, only the following inequality:
For
, defined as
, for some specific
ω, and
for all other
, we have that the lower bound is tight. For
, defined as
, for
, and
, for all other
, the upper bound is tight.
To illustrate the potentially uneven distribution of beliefs for a let be the propositional variables in so Ω contains four elements. Now, consider the such that for for for and Note, in particular, that there is no such that for all
2.2. Entropy
The entropy of a probability function is standardly defined as:
We shall adopt the usual convention that
, if
and
.
We will need to extend the standard notion of entropy to apply to normalised belief functions, not just to probability functions. Note that the standard entropy only takes into account those propositions that are in the partition which partitions Ω into states. This is appropriate when entropy is applied to probability functions, because a probability function is determined by its values on the states. However, this is not appropriate if entropy is to be applied to belief functions: in that case, one cannot simply disregard all those propositions that are not in the partition of Ω into states—one needs to consider propositions in other partitions, too. In fact, there are a range of entropies of a belief function, according to how much weight is given to each partition π in the entropy sum:
Definition 2 (g-entropy). Given a weighting function
, the
generalised entropy or
g-entropy of a normalised belief function is defined as:
The standard entropy,
, corresponds to
-entropy, where
We can define the
partition entropy,
, to be the
-entropy, where
for all
. Then:
where
is the number of partitions in which
F occurs. Note that according to our convention,
and
, because Ω occurs in partitions,
and
. Otherwise,
, where
is the
k’th
Bell number,
i.e., the number of partitions of a set of
k elements.
We can define the
proposition entropy to be the
-entropy, where
Then:
In general, we can express
in the following way, which reverses the order of the summations:
As noted above, one might reasonably demand of a measure of the entropy of a belief function that each belief should contribute to the entropy sum, i.e., for each , :
Definition 3 (Inclusive weighting function). A weighting function is inclusive if for all , there is some partition π containing F such that .
This desideratum rules out the standard entropy in favour of other candidate measures, such as the partition entropy and the proposition entropy.
We have seen so far that
g-entropy is a natural generalisation of standard entropy from probability functions to belief functions. In
Section 2.5, we shall see that
g-entropy is of particular interest, because maximising
g-entropy corresponds to minimising worst-case expected loss—this is our main reason for introducing the concept. However, there is a third reason why
g-entropy is of interest. Shannon (§6 in [
6]) provided an axiomatic justification of standard entropy as a measure of the uncertainty encapsulated in a probability function. Interestingly, as we show in
Appendix A, Shannon’s argument can be adapted to give a justification of our generalised entropy measure. Thus,
g-entropy can also be thought of as a measure of the uncertainty of a belief function.
In the remainder of this section, we will examine some of the properties of g-entropy.
Lemma 2. The function is continuous in the standard topology on
Proof: To obtain the standard topology on , take as open sets infinite unions and finite intersections over the open sets of and sets of the form, , where In this topology on a set is open if and only if it is open in the standard topology in Hence, is continuous in this topology on
Let be a sequence in with limit zero. For all , there exists a such that for all Hence, for all open sets U containing , there exists a K such that if Therefore, converges to Thus, ■
Proposition 2. g-entropy is non-negative and, for inclusive g, strictly concave on .
Proof: for all F, so , and . Hence, i.e., g-entropy is non-negative.
Take distinct
and
, and let
. Now,
is strictly convex on
,
i.e.,
with equality just when
.
Consider an inclusive weighting function,
g.
with equality iff for all
F,
, since
g is inclusive. However,
and
are distinct, so equality does not obtain. In other words,
g-entropy is strictly concave. ■
Corollary 1. For inclusive g, if g-entropy is maximised by a function in convex , it is uniquely maximised by in .
Corollary 2. For inclusive g, g-entropy is uniquely maximised in the closure, , of .
If g is not inclusive, concavity is not strict. For example, if the standard entropy, , is maximised by , then it is also maximised by any belief function that agrees with on the states .
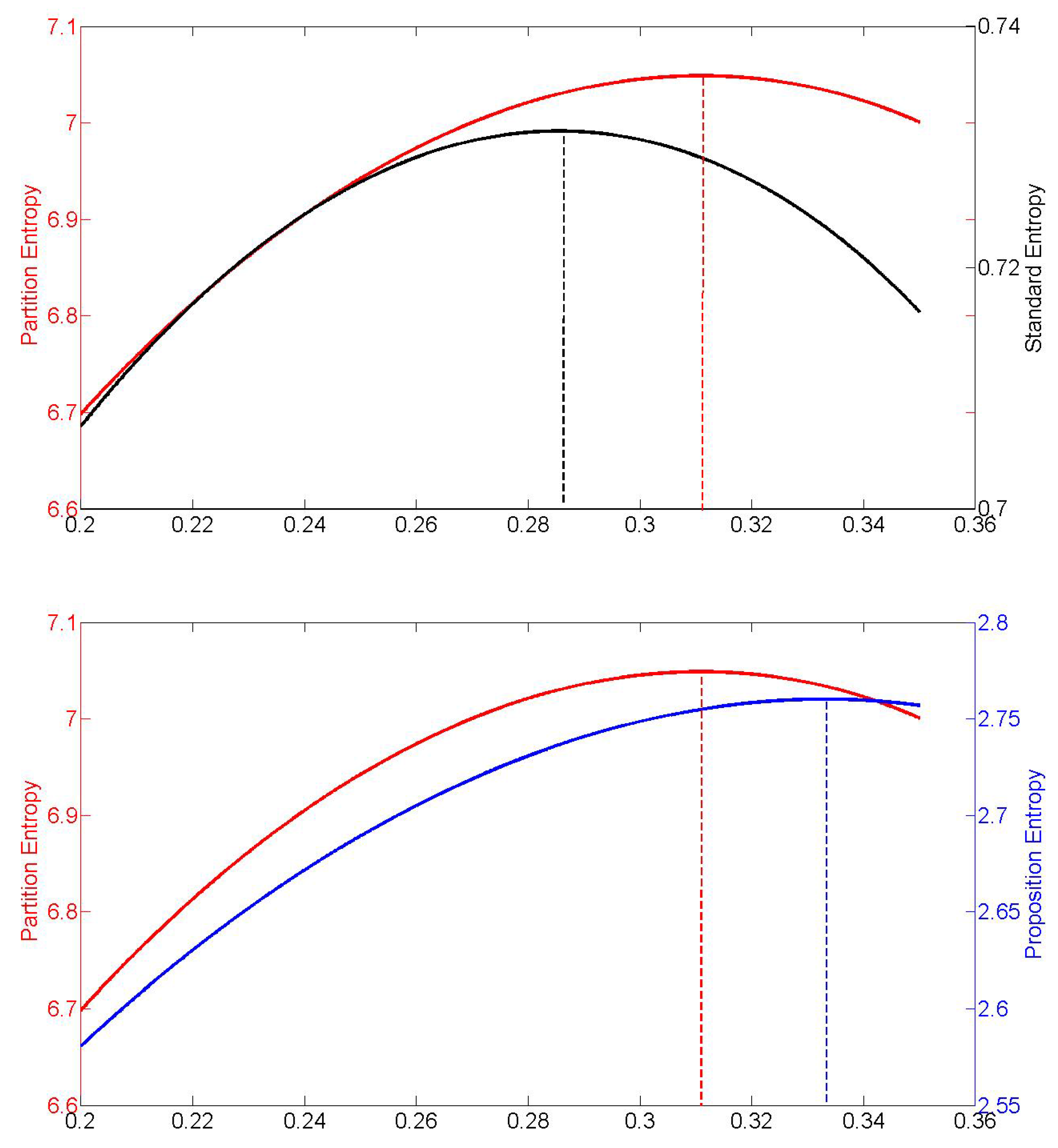
Note that different
g-entropy measures can have different maximisers on a convex subset
of probability functions. For example, when
and
, then the proposition entropy maximiser, the standard entropy maximiser and the partition entropy maximiser are all different, as can be seen from
Figure 1.
Figure 1.
Plotted are the partition entropy, the standard entropy and the proposition entropy under the constraints, , , as a function of The dotted lines indicate the respective maxima, which obtain for different values of
Figure 1.
Plotted are the partition entropy, the standard entropy and the proposition entropy under the constraints, , , as a function of The dotted lines indicate the respective maxima, which obtain for different values of
2.3. Loss
As Ramsey observed, all our lives, we are, in a sense, betting. The strengths of our beliefs guide our actions and expose us to possible losses. If we go to the station when the train happens not to run, we incur a loss: a wasted journey to the station and a delay in getting to where we want to go. Normally, when we are deliberating about how strongly to believe a proposition, we have no realistic idea as to the losses to which that belief will expose us. That is, when determining a belief function B, we do not know the true loss function, .
Now, a loss function L is standardly defined as a function , where is the loss one incurs by adopting probability function when ω is the true state of the world. Note that a standard loss function will only evaluate an agent’s beliefs about the states, not the extent to which she believes other propositions. This is appropriate when belief is assumed to be probabilistic, because a probability function is determined by its values on the states. But we are concerned with justifying the probability norm here and, hence, need to consider the full range of the agent’s beliefs, in order to show that they should satisfy the axioms of probability. Hence, we need to extend the concept of a loss function to evaluate all of the agent’s beliefs:
Definition 4 (Loss function). A loss function is a function .
is the loss incurred by a belief function B, when proposition F turns out to be true. We shall interpret this loss as the loss that is attributable to F in isolation from all other propositions, rather than the total loss incurred when proposition F turns out to be true. When F turns out to be true, so does any proposition G, for . Thus, the total loss when F turns out to be true includes , as well as . The total loss on F turning out to be true might therefore be represented by , with being the loss distinctive to F, i.e., the loss on F turning out to be true over and above the loss incurred by .
Is there anything that one can presume about a loss function in the absence of any information about the true loss function,
? Plausibly:
- L1.
if .
- L2.
strictly increases as decreases from one towards zero.
- L3.
depends only on .
To express the next condition, we need some notation. Suppose
: say that
,
,
for some
. Then,
takes the form
, where
is a state of
, and
is a state of
. Given propositions,
and
, we can define
, a proposition of
. Given a fixed belief function,
B, such that
,
and
are
independent sublanguages, written
, if
for all
and
, where
and
. The restriction
of
B to
is a belief function on
defined by
and similarly for
.
- L4.
Losses are additive when the language is composed of independent sublanguages: if for , then , where are loss functions defined on , respectively.
L1 says that one should presume that fully believing a true proposition will not incur loss. L2 says that one should presume that the less one believes a true proposition, the more loss will result. L3 expresses the interpretation of
as the loss attributable to
F in isolation of all other propositions. This condition, which is sometimes called
locality, rules out that
depends on
for
; it also rules out a dependence on
, for instance. L4 expresses the intuition that, at least if one supposes two propositions to be unrelated, one should presume that the loss on both turning out to be true is the sum of the losses on each. (These four conditions correspond to conditions L1–4 of pp. 64–65 in [
1], which were put forward in the special case of loss functions defined over probability functions, as opposed to belief functions.)
The four conditions taken together tightly constrain the form of a presumed loss function, L:
Theorem 1. If loss functions are assumed to satisfy L1–4, then for some constant, , that does not depend on .
Proof: We shall first focus on a loss function, L, defined with respect to a language, , that contains at least two propositional variables.
L3 implies that , for some function, .
For our fixed and each , choose some particular , such that , where , and . This is possible, because has at least two propositional variables. Note in particular that since and are independent sublanguages, we have .
Note that
and, similarly,
. By L1, then,
.
Therefore, by applying L4 twice:
The negative logarithm on
is characterisable up to a multiplicative constant,
, in terms of this additivity, together with the condition that
, which is implied by L1–2 (see, e.g., Theorem 0.2.5 in [
7]). L2 ensures that
is not zero everywhere, so
.
We thus know that for Now, note that for all , it needs to be the case that , if is to satisfy for all Since takes values in , it follows that
Thus far, we have shown that for a fixed language, , with at least two propositional variables, on
Now consider an arbitrary language,
, and a loss function
on
which satisfies L1–L4. There exists some other language,
, and a belief function
B on
such that
By the above, for the loss function
L on
, it holds that
on
By reasoning analogous to that above:
Therefore, the loss function for is Thus, the constant does not depend on the particular language after all.
In general, then, for some positive k. ■
Since multiplication by a constant is equivalent to a change of base, we can take log to be the natural logarithm. Since we will be interested in the belief functions that minimise loss, rather than in the absolute value of any particular losses, we can take
without loss of generality. Theorem 1 thus allows us to focus on the logarithmic loss function:
2.4. Score
In this paper, we are concerned with showing that the norms of objective Bayesianism must hold if an agent is to control her worst-case expected loss. Now, an
expected loss function or
scoring rule is standardly defined as
such that
. This is interpretable as the expected loss incurred by adopting probability function
Q as one’s belief function, when the probabilities are actually determined by
P. (This is the statistical notion of a scoring rule as defined in [
8]. More recently, a different, ‘epistemic’ notion of a scoring rule has been considered in the literature on non-pragmatic justifications of Bayesian norms; see, e.g., [
9,
10] and, also, a forthcoming paper by Landes, where similarities and differences of these two notions of a scoring rule are discussed. One difference that is significant to our purposes is that Predd
et al.’s result in [
11]—that for every epistemic scoring rule that is continuous and strictly proper, the set of non-dominated belief functions is the set
of probability functions—does not apply to statistical scoring rules. Furthermore, Predd
et al. are only interested in justifying the probability norm by appealing to dominance as a decision theoretic norm. We are concerned with justifying three norms at once using worst-case loss avoidance as a desideratum. The epistemic approach is considered further in
Section 5.4.)
While this standard definition of scoring rule is entirely appropriate when belief is assumed to be probabilistic, we make no such assumption here and need to consider scoring rules that evaluate all the agent’s beliefs, not just those concerning the states. In line with our discussion of entropy in
Section 2.2, we shall consider the following generalisation:
Definition 5 (g-score). Given a loss function,
L, and an inclusive weighting function,
, the
g-expected loss function or
g-scoring rule or, simply,
g-score is
, such that
Clearly,
corresponds to
, where
, which is not inclusive, is defined as in
Section 2.2. We require that
g be inclusive in Definition 5, since only in that case does the
g-score genuinely evaluate all the agent’s beliefs. We will focus on
,
i.e., the case in which the loss function is logarithmic and the expectation is taken with respect to the chance function,
, in order to show that an agent should satisfy the norms of objective Bayesianism if she is to control her worst-case
g-expected logarithmic loss when her evidence determines that the chance function,
, is in
.
For example, with the logarithmic loss function, the
partition Π-score is defined by setting
:
Similarly, the
proposition -score is defined by setting
:
It turns out that the various logarithmic scoring rules have the following useful property:
Definition 6 (Strictly proper g-score). A scoring rule, , is strictly proper, if for all , the function has a unique global minimum at .
Definition 6 can be generalised: a scoring rule is
strictly -proper if it is strictly proper for belief functions taken to be from a set
. In Definition 6,
. The logarithmic scoring rule in the standard sense,
i.e.,
, is well known to be the only strictly
-proper local scoring rule—see McCarthy [
12] (p. 654), who credits Andrew Gleason for the uniqueness result; Shuford
et al. [
13] (p. 136) for the case of continuous scoring rules; Aczel and Pfanzagl [
14] (Theorem 3, p. 101) for the case of differentiable scoring rules; and Savage [
15] (§9.4). The logarithmic score in our sense,
i.e.,
, is not strictly
-proper when
is the set of non-normalised belief functions:
is a global minimum, where
is the belief function such that
for all
F. (While Joyce [
9] (p. 276) suggests that logarithmic score is strictly
-proper for
a set of non-normalised belief functions, he is referring to a logarithmic scoring rule that is different to the usual one considered above and that does not satisfy the locality condition, L3.)
On the way to showing that logarithmic g-scores are strictly proper, it will be useful to consider the following natural generalisation of Kullback-Leibler divergence to our framework:
Definition 7 (g-divergence). For a weighting function,
, the
g-divergence is the function,
, defined by:
Here, we adopt the usual convention that
and
for
We shall see that
is a sensible notion of the divergence of
P from
B by appealing to the following useful inequality (see, e.g., Theorem 2.7.1 in [
16]):
Lemma 3 (Log sum inequality). For ,with equality, iff for some constant, c, and . Proposition 3. The following are equivalent: Proof: First we shall see that if
g is inclusive, then
with equality iff
.
where the first inequality is an application of the log-sum inequality and the second inequality is a consequence of
B being in
. There is equality at the first inequality iff for all
and all
π such that
and
,
for all
, and equality at the second inequality iff for all
π such that
,
.
Clearly, if for all F, then these two equalities obtain. Conversely, suppose the two equalities obtain. Then, for each F, there is some such that , because g is inclusive. The first equality condition implies that for . The second equality implies that . Hence, , and so, for . In particular, .
Next, we shall see that the condition that g is inclusive is essential.
If
g were not inclusive, then there would be some
such that
, for all
such that
. There are two cases.
- (i)
. Take some such that Now, define and for all other Then, and for all other , so . Furthermore, .
- (ii)
or . Define and for all Then, and for all other , so . Furthermore, .
In either case, then,
is not uniquely minimised by
. ■
Corollary 3. The logarithmic g-score is strictly proper.
Proof: Recall that in the context of a
g-score,
g is inclusive.
Proposition 3 then implies that
with equality, iff
,
i.e.,
is strictly proper. ■
Finally, logarithmic g-scores are non-negative strictly convex functions in the following qualified sense:
Proposition 4. The logarithmic g-score is non-negative and convex as a function of . Convexity is strict, i.e., for , unless and agree everywhere, except where .
Proof: The logarithmic g-score is non-negative, because for all F; so, , , and .
That
is strictly convex as a function of
follows from the strict concavity of
. Take distinct
and
, and let
. Now:
with equality iff either
or
.
Hence:
with equality iff
and
agree everywhere, except possibly where
. ■
2.5. Minimising the Worst-Case Logarithmic g-Score
In this section, we shall show that the g-entropy maximiser minimises the worst-case logarithmic g-score.
In order to prove our main result (Theorem 2), we would like to apply a game-theoretic minimax theorem, which will allow us to conclude that:
Note that the expression on the left-hand side describes the minimising worst-case
g-score, where the worst case refers to
P ranging in
Speaking in game-theoretic lingo: the player playing first on the left-hand side aims to find the belief function(s) that minimises worst-case
g-expected loss; again, the worst case is taken with respect to varying
For this approach to work, we would normally need
to be some set of mixed strategies. It is not obvious how
could be represented as a mixing of finitely many pure strategies. However, there exists a broad literature on minimax theorems [
17], and we shall apply a theorem proven in König [
18]. This theorem requires that certain level sets, in the set of functions in which the player aiming to minimise may chose his functions, are connected. To apply König’s result, we will thus allow the belief functions,
B, to range in
which has this property. It will follow that the
are never good choices for the minimising player playing first: the best choice is in
, which is a subset of
Having established that the inf and the sup commute, the rest is straightforward. Since the scoring rule we employ,
, is strictly proper, we have that the best strategy for the minimising player, answering a move by the maximising player, is to select the same function as the maximising player. Thus, it is best for the maximising player playing first to choose a/the function that maximises
We will thus find that:
Thus, worst-case
g-expected loss and
g-entropy have the same value. In game-theoretic terms: we find that our zero-sum
g-log-loss game has a value. It remains to be shown that both players, when playing first, have a unique best choice,
First, then, we shall apply König’s result.
Definition 8 (König [18], p. 56). For
, we call
a
border interval of
F, if and only if
I is an interval of the form
is called a
border set of
F if and only if
For
and
, define
and
to consist of
and of subsets of
of the form:
For
and finite
, define
and
to consist of subsets of
of the form:
The following may be found in König [
18] (Theorem 1.3, p. 57):
Lemma 4 (König’s Minimax). Let be topological spaces, be compact and Hausdorff and let be lower semicontinuous. Then, if Λ is some border set, I some border interval of F and if at least one of the following conditions holds:for all , all members of and are connected;
for all , all members of are connected and all all are connected;
for all , all members of and are connected;
for all , all members of are connected and all all are connected;
then: Lemma 5. is lower semicontinuous.
Proof: It suffices to show that
is closed for all
For
consider a sequence
with
, such that
for all
t. Then:
If
and
converges to zero, then there is an
such that for all
,
Thus,
cannot converge to zero if
Since
converges, it has to converge to some
Thus, when
we have that
From
, we conclude that:
■
Proposition 5. For all : Proof: It suffices to verify that the conditions of Lemma 4 are satisfied.
are subsets of , respectively, thus naturally equipped with the induced topology. is compact and Hausdorff (see Lemma 1). is lower semicontinuous (see Lemma 5).
We need to show that one of the connectivity conditions holds. In fact, they all hold, as we shall see.
Note that are connected, since they are convex.
For the
and
consider any
and suppose that
are such that
and
Then for
we have:
Thus,
is convex for all
Thus, every intersection of such sets is convex. Hence, these intersections are connected. (If any such intersection is empty, then it is trivially connected.)
For the
and
, note that for every
, we have that
is convex, which follows from Proposition 4 by noting that for a convex function (here,
) on a convex set (here,
), the set of elements in the domain that are mapped to a number (strictly) less than
λ is convex for all
Thus, every intersection of such sets is convex. Hence, these intersections are connected. ■
The suprema and infima referred to in Proposition 5 may not be achieved at points of . If not, they will be achieved instead at points in the closure, , of . We shall use (and ) to refer to the points in that achieve the supremum (respectively, infimum), whether or not these points are in .
Theorem 2. As usual, is taken to be convex and g inclusive. We have that: Proof: We shall prove the following slightly stronger equality, allowing
B to range in
, instead of
:
The theorem then follows from the following fact. The right-hand side of Equation (
34) is an optimization problem, where the optimum (here, we look for the infimum of
) uniquely obtains for a certain value (here,
). Restricting the domain of the variables (here, from
to
) in the optimization problem, to a subdomain that contains optimum
, does not change where the optimum obtains nor the value of the optimum.
Note that:
The first equality is simply the definition of
The second equality follows directly from strict propriety (Corollary 3). To obtain the third line, we apply Proposition 5.
It remains to show that we can introduce arg on both sides of Equation (
33).
The following sort of argument seems to be folklore in game theory; we here adapt (Lemma 4.1 on p. 1384 in [
3]) for our purposes. We have:
The
in Equation (
36) is unique (Corollary 2). Equation (37) follows from strict propriety of
(Corollary 3). Now let:
Then:
The first equality follows from the definition of
; see Equations (
36) and (37). That we may drop the sup again follows from the definition of
since
maximises
The inequalities hold, since dropping a minimisation and introducing a maximisation can only lead to an increase. The final inequality is immediate from the definition of
minimising
By Proposition 5, all inequalities above are in fact equalities. From and strict propriety, we may now infer that ■
In sum, then, if an agent is to minimise her worst-case
g-score, then her belief function needs to be the probability function in
that maximises
g-entropy, as long as this entropy maximiser is in
. That the belief function is to be a probability function is the content of the probability norm; that it is to be in
is the content of the calibration norm; that it is to maximise
g-entropy is related to the equivocation norm. We shall defer a full discussion of the equivocation norm to
Section 4. In the next section, we shall show that the arguments of this section generalise to belief as defined over sentences rather than propositions. This will imply that logically equivalent sentences should be believed to the same extent—an important component of the probability norm in the sentential framework.
We shall conclude this section by providing a slight generalisation of the previous result. Note that, thus far, when considering worst-case g-score, this worst case is with respect to a chance function taken to be in . However, the evidence determines something more precise, namely that the chance function is in , which is not assumed to be convex. The following result indicates that our main argument will carry over to this more precise setting.
Theorem 3. Suppose is such that the unique g-entropy maximiser, , for , is in . Then: Proof: As in the previous proof, we shall prove a slightly stronger equality:
The result follows for the same reasons given in the proof of Theorem 2.
From the strict propriety of
, we have:
where the last two equalities are simply Theorem 2. Hence:
That is, the lowest worst case expected loss is the same for
and
Furthermore, since and since , we have . Thus, minimises
Now, suppose that
is different from
Then:
where the strict inequality follows from strict propriety. This shows that adopting
leads to an avoidably bad score.
Hence, is the unique function in which minimises ■
3. Belief over Sentences
Armed with our results for beliefs defined over propositions, we now tackle the case of beliefs defined over sentences,
, of a propositional language,
The plan is as follows. First, we normalise the belief functions in
Section 3.1. In
Section 3.2, we motivate the use of logarithmic loss as a default loss function. We are able to define our logarithmic scoring rule in
Section 3.3, and we show there that, with respect to our scoring rule, the generalised entropy maximiser is the unique belief function that minimises the worst-case expected loss.
Again, we shall not impose any restriction—such as additivity—on the agent’s belief function, now defined on the sentences of the propositional language . In particular, we do not assume that the agent’s belief function assigns logically equivalent sentences the same degree of belief. We shall show that any belief function violating this property incurs an avoidable loss. Thus, the results of this section allow us to show more than we could in the case of belief functions defined over propositions.
Several of the proofs in this section are analogous to the proofs of corresponding results presented in
Section 2. They are included here in full for the sake of completeness; the reader may wish to skim over those details that are already familiar.
3.1. Normalisation
is the set of sentences of propositional language
, formed as usual by recursively applying the connectives,
, to the propositional variables,
. A non-normalised belief function,
, is thus a function that maps any sentence of the language to a non-negative real number. As in
Section 2.1, for technical convenience, we shall focus our attention on normalised belief functions.
Definition 9 (Representation). A sentence, , represents the proposition . Let be a set of pairwise distinct propositions. We say that is a set of representatives of if and only if each sentence in Θ represents some proposition in and each proposition in is represented by a unique sentence in Θ. A set, ρ, of representatives of will be called a representation. We denote by ϱ the set of all representations. For a set of pairwise distinct propositions, , and a representation, , we denote by the set of sentences in ρ that represent the propositions in
We call a partition of if and only if it is a set of representatives of some partition of propositions. We denote by the set of these
Definition 10 (Normalised belief function on sentences). Define the set of normalized belief functions on
as:
The set of probability functions is defined as:
As in the proposition case, we have:
Proposition 6. iff satisfies the axioms of probability:- P1:
for all tautologies
- P2:
If then .
Proof: Suppose . For any tautology, , it holds that , because is a partition in , because is a partition in and .
Suppose that
are such that
. We shall proceed by cases to show that
. In the first three cases, one of the sentences is a contradiction, in the last two cases, there are no contradictions.
- (i)
and then Thus, by the above and , and hence,
- (ii)
and then Thus,
- (iii)
and then and are both partitions in Thus, Putting these observations together, we now find
- (iv)
and then is a partition and is a tautology. Hence, and . This now yields .
- (v)
and then none of the following sentences is a tautology or a contradiction: Since and are both partitions in , we obtain . So, .
On the other hand, suppose P1 and P2 hold. That holds for all can be seen by induction on the size of . If , then for some tautology , and by P1. Suppose then that for . Now, by the induction hypothesis. Furthermore, by P2, so , as required. ■
Definition 11 (Respects logical equivalence). We say that a belief function respects logical equivalence if and only if implies
Proposition 7. The probability functions respect logical equivalence.
Proof: Suppose
and assume that
are logically equivalent. Note that
and that
and
are partitions in
Hence:
Therefore,
Thus, the assign logically equivalent formulae the same probability. ■
3.2. Loss
By analogy with the line of argument of
Section 2.3, we shall suppose that a default loss function,
, satisfies the following requirements:
- L1.
if
- L2.
strictly increases as decreases from one towards zero.
- L3.
only depends on .
Suppose we have a fixed belief function,
, such that
for any tautology,
τ, and
, where
and
are
independent sublanguages, written
,
i.e.,
for all
and
. Let
,
.
- L4.
Losses are additive when the language is composed of independent sublanguages: if for , then , where are loss functions defined on , respectively.
Theorem 4. If a loss function, L, on satisfies L1–4, then , where the constant, , does not depend on the language, .
Proof: We shall first focus on a loss function, L, defined with respect to a language, , that contains at least two propositional variables.
L3 implies that for some function, . For our fixed and all , choose some such that , , and for some This is possible, because contains at least two propositional variables.
Note that since
and
are independent sublanguages, given some specific tautology,
, of
:
is well defined, since
is a tautology of
, and every sentence in
is a sentence in
. Similarly,
for some specific tautology
of
. By L1, then,
where
respectively,
are the loss functions with respect to
and
satisfying L1–4. Thus:
The negative logarithm on
is characterisable up to a multiplicative constant,
, in terms of this additivity, together with the condition that
, which is implied by L1–2 (see, e.g., Theorem 0.2.5 in [
7]). L2 ensures that
is not zero everywhere, so
. As in the corresponding proof for propositions, it follows that
Thus far, we have shown that for a fixed language, , with at least two propositional variables, on
Now, focus on an arbitrary language,
, and a corresponding loss function,
. We can choose
such that
is composed of independent sublanguages,
and
By reasoning analogous to that above:
Therefore, the loss function for is Thus, the constant, , does not depend on after all.
In general, then, for some positive k. ■
Since multiplication by a constant is equivalent to a change of base, we can take log to be the natural logarithm. Since we will be interested in the belief functions that minimise loss, rather than in the absolute value of any particular losses, we can take
without loss of generality. Theorem 4 thus allows us to focus on the logarithmic loss function:
3.3. Score, Entropy and Their Connection
In the case of belief over sentences, the expected loss varies according to which sentences are used to represent the various partitions of propositions. We can define the g-score to be the worst-case expected loss, where this worst case is taken over all possible representations:
Definition 12 (g-score). Given a loss function,
an inclusive weighting function,
, and a representation,
, we define the
representation-relative g-score by
and the
(representation-independent) g-score by
In particular, for the logarithmic loss function under consideration here, we have:
and:
We can thus define the
g-entropy of a belief function on
as:
There is a canonical one-to-one correspondence between the which respect logical equivalence and the In particular, can be identified with Moreover, any convex is in one-to-one correspondence with a convex In the following, we shall make frequent use of this correspondence. For a which respects logical equivalence, we denote by B the function in with which it stands in one-to-one correspondence.
Lemma 6. If respects logical equivalence, then for all , we have
Proof: Simply note that does not depend on ■
Lemma 7. For all convex :respects logical equivalence. Proof: Suppose that:
and assume that
does not respect logical equivalence. Then, define:
Since
does not respect logical equivalence, there are logically equivalent
such that
Hence,
Thus, for every
with
, we have
Thus,
respects logical equivalence by definition.
Now, consider the function which is determined by Clearly, There are two cases to consider.
(a)
Since
, by Theorem 2, we have that:
(b)
. Then, define
by
for all
, where
is minimal such that
In particular,
thus
Moreover, whenever
, it holds that
For the remainder of this proof, we shall extend the definition of the logarithmic
g-score
by allowing the belief function,
B, to be any non-negative function defined on
rather than just
—if
, we shall be careful not to appeal to results that assume
. We thus find for all
that
Thus, by Theorem 2, we obtain the sharp inequality in the following:
For both cases, we will obtain a contradiction:
We obtain Equation (
59) by noticing that
is the unique function minimising worst-case
g-expected loss (Theorem 2) and recalling that the expressions in Equation (
39) and Equation (40) are equal.
Equation (60) is immediate, as the probability functions respect logical equivalence. For Equation (63), note that respects logical equivalence. Furthermore, since is strictly decreasing, a smaller value of leads to a greater score.
Equation (64) follows from Equation (
56) and Lemma 6, since
respects logical equivalence. Hence,
does not depend on the partition
The inequality (66), we have seen above in the two cases, Equation (
57) and Equation (
58). Equation (67) is again implied by Theorem 2.
We have thus found a contradiction. Hence, the
have to respect logical equivalence. ■
Theorem 2, the key result in the case of belief over propositions, generalises to the case of belief over sentences:
Theorem 5. As usual, is taken to be convex and g inclusive. We have that: Proof: As in the corresponding theorem for the proposition (Theorem 2), we shall prove a slightly stronger equality:
Theorem 5 then follows for the same reasons given in the previous section.
Denote by
the convex hull of functions
that respect logical equivalence. Let
be the bijective map that assigns to any
the unique
which represents it (
i.e.,
whenever
is represented by
).
Equation (
69) is simply Lemma 7. Equation (70) follows directly from applying Lemma 6, and Equation (71) is simply Theorem 2. ■
In the above, we used to denote the probability function in which represents the g-entropy maximiser, Now, note that Thus, is not only the function representing ; it is also the unique function in which maximises g-entropy .
Theorem 3 also extends to the sentence framework. As we shall now see, the worst-case g-score can be taken with respect to a chance function in , rather than .
Theorem 6. If is such that the unique g-entropy maximiser, , of , is in then: Proof: Again, we shall prove a slightly stronger statement with ranging in
Since g is inclusive, we have that is a strictly proper scoring rule. Hence, for a fixed , is minimal if and only if for all
Now, suppose
is different from a fixed
Then, there is some
such that
Now, pick some
such that
Then, strict propriety implies the sharp inequality below:
The second equality follows since the
respect logical equivalence, and hence,
does not depend on
Thus, for all
, we find
Hence, for
, we obtain:
where the last two equalities are simply Theorem 5. Hence:
That is, the lowest worst-case expected loss is the same for
and
Furthermore, since and since , we have Thus, minimises
Now, suppose that
is different from
Then:
where the strict inequality follows as seen above. This now shows that adopting
leads to an avoidably bad score.
Hence, is the unique function in which minimises ■
We see, then, that the results of
Section 2 concerning beliefs defined on propositions extend naturally to beliefs defined on the sentences of a propositional language. In light of these findings, our subsequent discussions will, for ease of exposition, solely focus on propositions. It should be clear how our remarks generalise to sentences.
4. Relationship to Standard Entropy Maximisation
We have seen so far that there is a sense in which our notions of entropy and expected loss depend on the weight given to each partition under consideration—i.e., on the weighting function, g. It is natural to demand that no proposition should be entirely dismissed from consideration by being given zero weight—that g be inclusive. In which case, the belief function that minimises worst-case g-expected loss is just the probability function in that maximises g-entropy, if there is such a function. This result provides a single justification of the three norms of objective Bayesianism: the belief function should be a probability function, it should be in , i.e., calibrated to evidence of physical probability, and it should otherwise be equivocal, where the degree to which a belief function is equivocal can be measured by its g-entropy.
This line of argument gives rise to two questions. Which g-entropy should be maximised? Does the standard entropy maximiser count as a rational belief function?
On the former question, the task is to isolate some set, , of appropriate weighting functions. Thus far, the only restriction imposed on a weighting function, g, has been that it should be inclusive; this is required in order that scoring rules evaluate all beliefs, rather than just a select few. We shall put forward two further conditions that can help to narrow down a proper subclass, , of weighting functions.
A second natural desideratum is the following:
Definition 13 (Symmetric weighting function). A weighting function, g, is symmetric, if and only if whenever can be obtained from π by permuting the in then
For example, for and symmetric g, we have that Note that and are all symmetric. The symmetry condition can also be stated as follows: is only a function of the spectrum of π, i.e., of the multi-set of sizes of the members of π. In the above example, the spectrum of both partitions is .
It turns out that inclusive and symmetric weighting functions lead to
g-entropy maximisers that satisfy a variety of intuitive and plausible properties—see
Appendix B.
In addition, it is natural to suppose that if
is a refinement of partition
π, then
g should not give any less weight to
than it does to
π—there are no grounds to favour coarser partitions over more fine-grained partitions; although, as Keynes (Chapter 4 in [
19]) argued, there may be grounds to prefer finer-grained partitions over coarser partitions.
Definition 14 (Refined weighting function). A weighting function, g, is refined, if and only if whenever refines π, then
and are refined, but is not.
Let be the set of weighting functions that are inclusive, symmetric and refined. One might plausibly set . We would at least suggest that all the weighting functions in are appropriate weighting functions for scoring rules; we shall leave it open as to whether should contain some weighting functions—such as the proposition weighting, —that lie outside . We shall thus suppose in what follows that the set of appropriate weighting functions is such that , where is the set of inclusive weighting functions.
One might think that the second question posed above—does the standard entropy maximiser count as a rational belief function?—should be answered in the negative. We saw in
Section 2.2 that the standard entropy,
-entropy, has a weighting function,
, that is not inclusive. Therefore, there is no guarantee that the standard entropy maximiser minimises worst-case
g-expected loss for some
Indeed,
Figure 1 showed that the standard entropy maximiser need neither coincide with the partition entropy maximiser nor the proposition entropy maximiser.
However, it would be too hasty to conclude that the standard entropy maximiser fails to qualify as a rational belief function. Recall that the equivocation norm says that an agent’s belief function should be
sufficiently equivocal, rather than maximally equivocal. This qualification is essential to cope with the situation in which there is no maximally equivocal function in
,
i.e., the situation in which for any function in
, there is another function in
that is more equivocal. This arises, for instance, when one has evidence that a coin is biased in favour of tails,
. In this case,
is achieved by the probability function which gives probability
to tails, which is outside
. This situation also arises in certain cases when evidence is determined by quantified propositions (§2 in [
20]). The best one can do in such a situation is adopt a probability function in
that is sufficiently equivocal, where what counts as sufficiently equivocal may depend on pragmatic factors, such as the required numerical accuracy of predictions and the computational resources available to isolate a suitable function.
Let
be the set of belief functions that are sufficiently equivocal. Plausibly:
- E1:
. An agent is always entitled to hold some beliefs.
- E2:
. Sufficiently equivocal belief functions are calibrated with evidence.
- E3:
For all , there is some such that if and , then , i.e., if R has sufficiently low worst-case g-expected loss for some appropriate g, then R is sufficiently equivocal.
- E4:
. Any function, from those that are calibrated with evidence, that is sufficiently equivocal, is a function, from those that are calibrated with evidence and are sufficiently equivocal, that is sufficiently equivocal.
- E5:
If P is a limit point of and , then .
A closely related set of conditions was put forward in [
20]. Note that we will not need to appeal to E4 in this paper. E1 is a consequence of the other principles together with the fact that
.
Conditions E2, E3 and E5 allow us to answer our two questions. Which g-entropy should be maximised? By E3, it is rational to adopt any g-entropy maximiser that is in , for . Does the standard entropy maximiser count as a rational belief function? Yes, if it is in (which is the case, for instance, if is closed):
Theorem 7 (Justification of maxent). If contains its standard entropy maximiser, , then .
Proof: We shall first see that there is a sequence of in such that the -entropy maximisers converge to . All respective entropy maximisers are unique, due to Corollary 2.
Let
and put
for all other
The
are in
, because they are inclusive, symmetric and refined.
-entropy has the following form:
Now note that
converges to
and that
is finite for all
Thus, for all
,
converges to
as
t approaches infinity. Hence,
tends to
Let us now compute:
As we noted above,
converges to
Furthermore,
is a bounded sequence. Hence,
converges to
Furthermore, recall that
tends to
Overall, we find that
Since is a strictly concave function on and is convex, it follows that converges to
Note that the are not necessarily in . However, they are in , and there will be some sequence of close to such that , as we shall now see.
If then simply let which is in by E3.
If then there exists a which is different from , such that all the points on the line segment between and are in with the exception of Now define Note that for we have, for all , that implies
Then, with
and
, it follows from Proposition 18 that for all
and all
,
implies
Thus, for such an
F, we have
Adopting the purely notational convention that
, we find for
and
that:
For fixed and all becomes arbitrarily small for small moreover, the upper bound we established does not depend on In particular, for all , there exists a such that for all and all , it holds that
Now, let
Then, with
, we have for big enough
that:
Thus:
Hence,
by E3 for small enough
since worst-case
-expected loss of
becomes arbitrarily close to
.
Now, pick a sequence , such that is small enough to ensure that for every t, it holds that Clearly, the sequence converges to the limit of the sequence and this limit is Therefore, the sequence converges to , which is, by our assumption, in
By E5, we have ■
So far, we have seen that, as long as the standard entropy maximiser is not ruled out by the available evidence, it is sufficiently equivocal, and hence, it is rational for an agent to adopt this function as her belief function. On the other hand, the above considerations also imply that if the entropy maximiser is ruled out by the available evidence (i.e., ), it is rational to adopt some function P close enough to because such a function will be sufficiently equivocal:
Corollary 4. For all , there exists a such that for all
Proof: Consider the same sequence, , as in the above proof. Recall that converges to Now, pick a t such that for all For this t, it holds that for small enough and that converges to Thus, for small enough , we have for all Thus, for all ■
Is there anything that makes the standard entropy maximiser stand out among all those functions that are sufficiently equivocal? One consideration is language invariance. Suppose is a family of weighting functions, defined for each . is language invariant, as long as merely adding new propositional variables to the language does not undermine the -entropy maximiser:
Definition 15 (Language invariant family of weighting functions). Suppose we are given, as usual, a set of probability functions on a fixed language . For any extending , let be the translation of into the richer language . A family of weighting functions is language invariant, if for any such any on , and for any language extending , there is some on such that , i.e., for each state ω of .
It turns out that many families of weighting functions—including the partition weightings and the proposition weightings—are not language invariant:
Proposition 8. The family of partition weightings, , and the family of proposition weightings, , are not language invariant.
Proof: Let and The partition entropy maximiser and the proposition entropy maximiser for this language and this set of calibrated functions are given in the first two rows of the table below.
Table 1.
Partition entropy and proposition entropy maximisers on and .
Table 1.
Partition entropy and proposition entropy maximisers on and .
| | | | | |
| | | | |
| | | | |
| | | | | | | | | |
| | | | | | | | |
| | | | | | | | |
We now add one propositional variable, , to and, thus, obtain Denote the states of by , and so on. Assuming that we have no information at all concerning , the set of calibrated probability functions is given by the solutions of the constraint, Language invariance would now entail that However, neither the partition entropy maximisers nor the proposition entropy maximisers form a language invariant family, as can be seen from the last two rows of the above table. ■
On the other hand, it is well known that standard entropy maximisation is language invariant (p. 76 in [
21]). This can be seen to follow from the fact that certain families of weighting functions that only assign positive weight to a single partition are language invariant:
Lemma 8. Suppose a function f picks out a partition π for any language , in such a way that if , then is a refinement of , with each being refined into the same number k of members , for . Suppose is such that for any , , but for all other partitions π. Then, is language invariant.
Proof: Let denote a -entropy maximiser (in ), and let denote a -entropy maximiser in . Since and need not be inclusive, and need not be strictly concave. Thus, there need not be unique entropy maximisers. Given refined into subsets of , is defined by . One can restrict to by setting for , so, in particular, for .
The
-entropy of
is closely related to the
-entropy of
:
LSI refers to the log sum inequality introduced in Lemma 3. The first and last inequality above follow from the fact that
and
are entropy maximisers over
, respectively. Hence, all inequalities are indeed equalities. These entropy maximisers are unique on
, so
for
.
Now, take an arbitrary , and suppose . Any such that and will be a -entropy maximiser on . Thus, is language invariant.
Note that if, for some , where denotes the set of states of then Likewise, if then For such g-entropies, every probability maximises g-entropy trivially, since all probability functions have the same g-entropy. ■
Taking and , we have the language invariance of standard entropy maximisation:
Corollary 5. The family of weighting functions is language invariant.
While giving weight in this way to just one partition is sufficient for language invariance, it is not necessary, as we shall now see. Define a family of weighting functions, the
substate weighting functions, by giving weight to just those partitions that are partitions of states of sublanguages. For any sublanguage,
, let
be the set of states of
, and let
be the partition of propositions of
that represents the partition of states of the sublanguage,
,
i.e.,
. Then,
Example 2. For , there are three sublanguages: itself and the two proper sublanguages, Then, assigns the following three partitions of Ω the same positive weight: , , . assigns all other weight zero.
Note that there are non-empty sublanguages of , so gives positive weight to partitions.
Proposition 9. The family of substate weighting functions is language invariant.
Proof: Consider an extension,
, of
. Let
be
-entropy maximisers on
, respectively. For simplicity of exposition, we shall view these functions as defined over sentences, so that we can talk of
,
etc. For the purposes of the following calculation we shall consider the empty language to be a language. Entropies over the empty language vanish. Summing over the empty language ensures, for example, that the expression
appears in Equation (
81).
where
c is some constant and where the second inequality is an application of the log-sum inequality. As in the previous proof, all inequalities are thus equalities,
and
extends
, as required. ■
In general the substate entropy maximisers differ from the standard entropy maximisers, as well as the partition entropy maximisers and the proposition entropy maximisers:
Example 3. For and the substate weighting function, on (see Example 2), we find for that the standard entropy maximiser, the partition entropy maximiser, the proposition entropy maximiser and the substate weighting entropy maximiser are pairwise different.
Table 2.
Standard, partition, proposition and substate entropy maximisers.
Table 2.
Standard, partition, proposition and substate entropy maximisers.
| | | | | |
|---|
| | | | |
| | | | |
| | | | |
| | | | |
Observe that the standard entropy maximiser, the partition entropy maximiser and the proposition entropy maximiser are all symmetric in and while the substate weighting entropy maximiser is not. This break of symmetry is caused by the fact that is not symmetric in and
We have seen that the substate weighting functions are not symmetric. Neither are they inclusive nor refined. We conjecture that if , the set of inclusive, symmetric and refined g, then the only language invariant family, , that gives rise to entropy maximisers that are sufficiently equivocal is the family that underwrites standard entropy maximisation: if is language invariant and the -entropy maximiser is in , then .
In sum, there is a compelling reason to prefer the standard entropy maximiser over other
g-entropy maximisers: the standard entropy maximiser is language invariant, while other—perhaps, all other—appropriate
g-entropy maximisers are not. In
Appendix B.3, we show that there are three further ways in which the standard entropy maximiser differs from other
g-entropy maximisers: it satisfies the principles of irrelevance, relativisation and independence.


{kind=link}