An Artificial Bee Colony Algorithm for the Job Shop Scheduling Problem with Random Processing Times

Abstract
:1. Introduction
- (1)
- Most research on JSSP has focused on the makespan criterion (i.e., minimizing the maximum completion time). However, in the make-to-order (MTO) manufacturing environment, due date related performances are apparently more relevant for decision makers, because the in-time delivery of goods is vital for maintaining a high service reputation. Therefore, the research that aims at minimizing lateness/tardiness in JSSP deserves more attention.
- (2)
- Most existing algorithms are designed for the deterministic JSSP, in which all the data (e.g., the processing times) are assumed to be fixed and precisely known in advance. In real-world manufacturing, however, the processing of operations is constantly affected by uncertain factors. Machine breakdowns, worker absenteeism, order changes, etc. can all lead to variations in the operation times. In this case, solving the deterministic JSSP will not result in a robust production schedule. Therefore, it is rewarding to focus more research effort on the stochastic JSSP.
2. Literature Review
2.1. The Stochastic Job Shop Scheduling Problem
2.2. The Artificial Bee Colony Algorithm
3. The Preliminaries
3.1. Formulation of the SJSSP
3.2. Principles of the Artificial Bee Colony (ABC) Algorithm
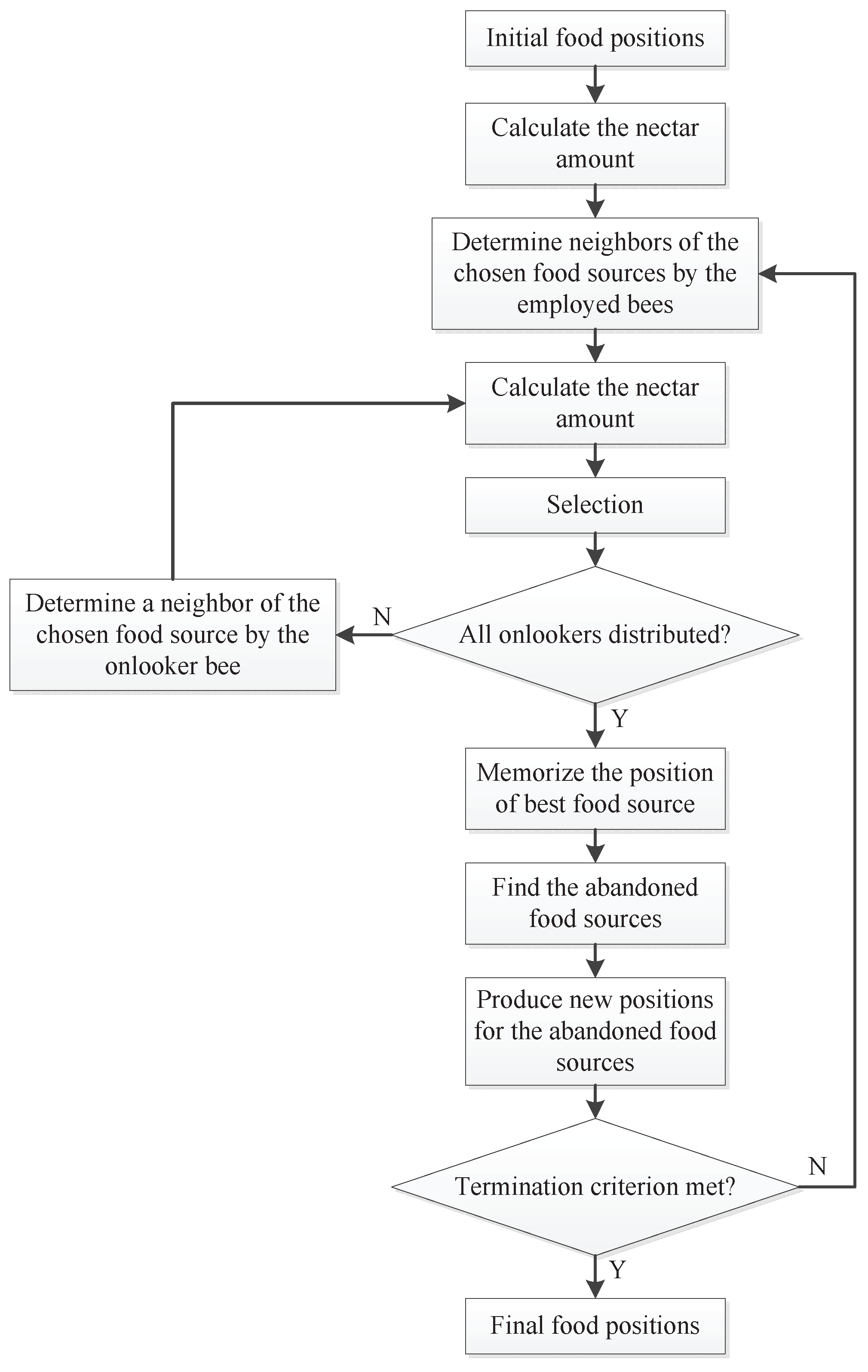
- Step 1:
- Initialize the food sources.
- Step 2:
- Each employed bee starts to work on a food source.
- Step 3:
- Each onlooker bee selects a food source according to the nectar information shared by the employed.
- Step 4:
- Determine the scout bees, which will search for food sources in a random manner.
- Step 5:
- Test whether the termination condition is met. If not, go back to Step 2.
- (1)
- The initialization phase. The initial solutions are randomly-generated D-dimensional real vectors. Let represent the i-th food source, which is obtained bywhere r is a uniform random number in the range , and and are the lower and upper bounds for dimension d, respectively.
- (2)
- The employed bee phase. In this stage, each employed bee is associated with a solution. She exerts a random modification on the solution (original food source) for finding a new solution (new food source). This implements the function of neighborhood search. The new solution is generated from using a differential expression:where d is randomly selected from , k is randomly selected from such that , and is a uniform random number in the range .Once is obtained, it will be evaluated and compared to . If the fitness of is better than that of (i.e., the nectar amount of the new food source is higher than the old one), the bee will forget the old solution and memorize the new one. Otherwise, she will keep working on .
- (3)
- The onlooker bee phase. When all employed bees have finished their local search, they share the nectar information of their food source with the onlookers, each of whom will then select a food source in a probabilistic manner. The probability by which an onlooker bee chooses food source is calculated as follows:where is the fitness value of . Obviously, the onlooker bees tend to choose the food sources with higher nectar amount.Once the onlooker has selected a food source , she will also conduct a local search on according to Equation (2). As in the previous case, if the modified solution has a better fitness, the new solution will replace .
- (4)
- The scout bee phase. In ABC, if the quality of a solution cannot be improved after a predetermined number () of trials, the food source is assumed to be abandoned, and the corresponding employed bee becomes a scout. The scout will then produce a food source randomly by using Equation (1).
4. An Estimate for the Expected Maximum Lateness
5. The Proposed ABC Algorithm for Solving SJSSP
5.1. Adaptation to the Discrete Problem
5.1.1. Encoding and Decoding
- Step 1:
- Let σ be an empty matrix of size .
- Step 2:
- If , output σ (and the corresponding if necessary) and terminate the procedure. Otherwise, continue the following steps.
- Step 3:
- Find the first schedulable operation in the sequence π, denoted by .
- Step 4:
- Identify the machine required to process and denote it by . Record the expected processing time of as .
- Step 5:
- Schedule the operation :
- (5.1)
- Scan the Gantt chart of machine (which records the processing information of the already scheduled operations) from time zero and test whether can be inserted into each idle period , i.e., whether the following condition is met: (where denotes the completion time of the immediate job predecessor of operation ).
- (5.2)
- If the above inequality is satisfied for the idle interval between operation and on machine , then insert between and in the -th row of σ. Otherwise (no idle intervals can hold ), insert it at the back of the -th row of σ. Update the Gantt chart records for the starting time and completion time of operation .
- Step 6:
- Delete operation from π. Go back to Step 2.
5.1.2. Initialization
5.1.3. Neighborhood Structure
5.2. The Comparison of Solutions
5.3. The Allocation of Simulation Replications
- The player tends to concentrate his efforts on the machines that gave the highest rewards in the past plays. Intuitively, this choice will maximize the potential gains.
- The player also wants to try the machines which he has played very few times in the past. The reward distributions of these machines are quite unclear, but it is likely that they provide even higher rewards.
- Step 1:
- Perform δ simulation replications for each solution . Denote the mean objective value by , and denote the standard deviation by . Calculate the estimated “reward” as . Set () and .
- Step 2:
- Calculate a priority index for each solution : .
- Step 3:
- Perform δ additional simulation replications for the solution with the maximum ρ value. Update , and for this solution. Let and .
- Step 4:
- If , go back to Step 2. Otherwise, terminate the procedure.
5.4. Revised Implementation of the Local Search in ABC
- Step 1:
- Use A-UCB1 to allocate a total of T simulation replications to the solutions in the current population P. Save the estimated mean objective value and variance for each solution.
- Step 2:
- Generate a new solution based on each original solution using the SWAP operator. Apply the pre-screening method (Corollary 1) to ensure the quality of each new solution [39]. Denote the set of new solutions by .
- Step 3:
- Use A-UCB1 to allocate a total of T simulation replications to the solutions in . Save the estimated mean objective value and variance for each solution.
- Step 4:
- Perform hypothesis tests to determine the new population: 0pt
- (4.1)
- Sort all the solutions in in non-decreasing order of the estimated objective values, yielding a sequence . Put into the ultimate population . Let , .
- (4.2)
- Perform hypothesis test for and the i-th solution (the latest) in . If the null hypothesis holds, is rejected. Otherwise, is appended to and let .
- (4.3)
- If and , then let and go to Step 4.2. Otherwise, go to Step 4.4.
- (4.4)
- If , the ultimate population has been determined. Otherwise, generate new solutions randomly, evaluate them (each one is evaluated with simulation replications) and append them to .
- Step 5:
- Compare with P and check whether each new solution has been accepted (i.e., in ). If accepted, let the corresponding bee fly to the new solution.
6. The Computational Experiments
6.1. Generation of Test Instances
6.2. The Computational Results and Comparisons

{kind=link}
{kind=link}
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 46.1 | 52.1 | 58.0 | 50.5 | 53.2 | 59.8 | |
| 2 | 47.4 | 49.1 | 53.2 | 46.7 | 53.1 | 54.8 | |
| 3 | 50.0 | 51.7 | 54.0 | 50.4 | 52.3 | 54.9 | |
| 4 | 56.2 | 61.8 | 62.7 | 60.8 | 62.5 | 66.2 | |
| 5 | 50.9 | 56.0 | 61.3 | 53.5 | 56.3 | 61.1 | |
| 6 | 66.0 | 69.0 | 75.3 | 70.3 | 75.8 | 86.1 | |
| 7 | 63.0 | 67.6 | 71.6 | 67.0 | 72.1 | 83.8 | |
| 8 | 61.8 | 65.5 | 67.5 | 65.0 | 70.9 | 75.8 | |
| 9 | 64.9 | 70.0 | 74.9 | 69.4 | 76.7 | 78.2 | |
| 10 | 60.5 | 68.7 | 70.0 | 64.0 | 70.5 | 76.1 | |
| 11 | 80.6 | 83.1 | 84.1 | 85.1 | 86.2 | 88.2 | |
| 12 | 80.9 | 84.8 | 89.2 | 86.1 | 87.8 | 90.9 | |
| 13 | 67.1 | 72.5 | 83.2 | 75.7 | 77.0 | 84.5 | |
| 14 | 77.4 | 81.8 | 85.6 | 79.1 | 83.7 | 89.3 | |
| 15 | 72.3 | 78.6 | 83.6 | 74.9 | 81.8 | 86.6 | |
| 16 | 99.9 | 106.9 | 121.2 | 103.5 | 111.0 | 124.7 | |
| 17 | 97.4 | 103.2 | 118.2 | 114.9 | 128.0 | 134.9 | |
| 18 | 104.6 | 114.9 | 123.8 | 120.8 | 129.8 | 137.1 | |
| 19 | 111.4 | 117.5 | 120.3 | 120.7 | 123.9 | 131.6 | |
| 20 | 98.5 | 115.2 | 121.4 | 121.5 | 128.6 | 132.7 | |
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 51.1 | 62.7 | 67.8 | 60.0 | 63.3 | 68.5 | |
| 2 | 53.1 | 55.6 | 60.6 | 54.9 | 60.2 | 64.9 | |
| 3 | 54.3 | 57.5 | 60.8 | 58.0 | 60.1 | 66.1 | |
| 4 | 63.8 | 70.7 | 75.4 | 70.0 | 74.2 | 80.6 | |
| 5 | 59.0 | 62.7 | 69.0 | 63.5 | 66.5 | 69.5 | |
| 6 | 67.1 | 72.6 | 76.1 | 73.3 | 81.1 | 93.0 | |
| 7 | 64.2 | 69.4 | 71.3 | 72.1 | 75.8 | 86.6 | |
| 8 | 64.6 | 66.9 | 69.8 | 64.2 | 73.1 | 78.9 | |
| 9 | 64.6 | 72.1 | 74.7 | 73.9 | 80.6 | 82.3 | |
| 10 | 61.1 | 68.4 | 71.2 | 67.2 | 73.9 | 82.2 | |
| 11 | 84.0 | 87.6 | 90.1 | 84.6 | 90.6 | 94.1 | |
| 12 | 86.5 | 91.5 | 93.2 | 96.7 | 98.6 | 103.8 | |
| 13 | 74.2 | 80.3 | 90.8 | 81.0 | 87.3 | 96.7 | |
| 14 | 84.8 | 88.8 | 90.7 | 85.1 | 91.2 | 98.8 | |
| 15 | 79.4 | 83.9 | 90.9 | 85.3 | 89.2 | 94.4 | |
| 16 | 111.3 | 117.5 | 133.5 | 115.4 | 122.7 | 137.3 | |
| 17 | 100.2 | 108.8 | 127.6 | 127.1 | 131.1 | 148.9 | |
| 18 | 110.9 | 118.1 | 126.9 | 127.3 | 138.4 | 146.8 | |
| 19 | 118.5 | 123.7 | 129.2 | 131.5 | 139.2 | 143.6 | |
| 20 | 101.7 | 122.2 | 130.0 | 128.7 | 136.7 | 140.8 | |
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 53.4 | 67.4 | 69.1 | 60.6 | 67.5 | 73.3 | |
| 2 | 56.0 | 60.0 | 63.1 | 56.5 | 66.1 | 68.6 | |
| 3 | 60.2 | 61.9 | 65.1 | 62.5 | 63.5 | 69.6 | |
| 4 | 69.1 | 72.8 | 74.5 | 74.7 | 77.8 | 82.5 | |
| 5 | 60.9 | 67.7 | 71.7 | 66.0 | 70.1 | 71.1 | |
| 6 | 74.3 | 77.3 | 81.4 | 81.8 | 86.8 | 100.5 | |
| 7 | 70.8 | 75.8 | 81.6 | 77.1 | 80.6 | 95.6 | |
| 8 | 69.3 | 70.4 | 74.5 | 70.9 | 79.2 | 88.1 | |
| 9 | 72.0 | 76.5 | 81.9 | 77.6 | 87.5 | 90.4 | |
| 10 | 66.5 | 77.9 | 78.9 | 71.8 | 80.0 | 85.5 | |
| 11 | 91.2 | 92.6 | 96.0 | 87.4 | 95.2 | 99.8 | |
| 12 | 90.5 | 94.6 | 98.9 | 101.0 | 104.6 | 105.7 | |
| 13 | 76.1 | 83.2 | 95.0 | 87.1 | 89.8 | 98.6 | |
| 14 | 88.6 | 91.7 | 97.8 | 86.3 | 93.1 | 99.1 | |
| 15 | 79.7 | 88.6 | 92.0 | 85.9 | 92.8 | 99.4 | |
| 16 | 116.5 | 120.3 | 131.1 | 115.3 | 124.4 | 140.1 | |
| 17 | 104.4 | 111.2 | 130.9 | 128.6 | 146.3 | 151.2 | |
| 18 | 114.8 | 121.7 | 134.5 | 140.7 | 151.3 | 157.3 | |
| 19 | 121.3 | 125.7 | 131.3 | 133.7 | 137.6 | 147.0 | |
| 20 | 105.8 | 126.5 | 133.8 | 139.1 | 145.7 | 152.6 | |
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 38.0 | 41.9 | 47.5 | 40.8 | 44.7 | 50.4 | |
| 2 | 38.9 | 41.0 | 44.4 | 39.1 | 44.4 | 46.7 | |
| 3 | 41.6 | 42.7 | 45.6 | 40.6 | 42.7 | 45.1 | |
| 4 | 46.2 | 51.7 | 53.2 | 48.7 | 52.1 | 54.5 | |
| 5 | 41.6 | 46.5 | 51.4 | 43.5 | 45.8 | 51.4 | |
| 6 | 55.8 | 58.6 | 64.7 | 59.6 | 63.2 | 71.3 | |
| 7 | 51.4 | 58.1 | 59.6 | 54.4 | 59.8 | 68.9 | |
| 8 | 52.9 | 53.7 | 55.1 | 53.0 | 57.6 | 62.0 | |
| 9 | 54.7 | 58.8 | 60.1 | 59.1 | 61.8 | 64.2 | |
| 10 | 50.7 | 57.2 | 59.0 | 53.5 | 59.0 | 64.3 | |
| 11 | 65.8 | 68.4 | 71.6 | 67.2 | 70.2 | 73.9 | |
| 12 | 67.0 | 70.3 | 75.3 | 69.1 | 73.0 | 76.8 | |
| 13 | 56.7 | 58.4 | 66.7 | 61.0 | 62.4 | 71.7 | |
| 14 | 62.3 | 67.7 | 70.6 | 64.1 | 68.9 | 75.8 | |
| 15 | 60.2 | 67.3 | 69.0 | 62.6 | 66.6 | 70.5 | |
| 16 | 80.1 | 86.9 | 103.4 | 88.4 | 93.3 | 106.9 | |
| 17 | 82.8 | 88.1 | 100.8 | 97.1 | 104.0 | 115.6 | |
| 18 | 86.5 | 95.9 | 105.6 | 99.1 | 108.2 | 115.4 | |
| 19 | 89.3 | 96.9 | 98.7 | 101.8 | 106.2 | 108.3 | |
| 20 | 83.2 | 92.5 | 103.7 | 103.3 | 107.0 | 110.9 | |
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 42.5 | 54.6 | 59.4 | 51.0 | 54.0 | 60.1 | |
| 2 | 44.6 | 46.6 | 52.1 | 46.4 | 53.3 | 54.6 | |
| 3 | 47.8 | 49.7 | 52.3 | 51.0 | 52.2 | 58.0 | |
| 4 | 54.2 | 62.5 | 67.1 | 58.9 | 64.7 | 67.7 | |
| 5 | 51.8 | 53.0 | 58.5 | 56.3 | 58.5 | 60.7 | |
| 6 | 58.4 | 64.3 | 67.3 | 64.7 | 71.4 | 82.2 | |
| 7 | 54.9 | 60.1 | 63.3 | 61.6 | 66.8 | 72.4 | |
| 8 | 54.8 | 57.6 | 59.7 | 53.9 | 64.2 | 65.9 | |
| 9 | 56.5 | 61.9 | 67.2 | 62.4 | 70.5 | 72.1 | |
| 10 | 53.0 | 61.2 | 62.9 | 56.6 | 63.6 | 69.9 | |
| 11 | 71.5 | 75.8 | 77.9 | 74.5 | 79.9 | 81.5 | |
| 12 | 77.0 | 80.0 | 84.2 | 84.4 | 87.2 | 90.9 | |
| 13 | 65.6 | 70.5 | 79.9 | 69.1 | 73.8 | 82.8 | |
| 14 | 72.6 | 78.8 | 85.0 | 71.6 | 77.3 | 87.5 | |
| 15 | 67.8 | 70.6 | 79.2 | 73.5 | 77.8 | 81.2 | |
| 16 | 95.6 | 98.5 | 113.0 | 101.0 | 105.7 | 114.8 | |
| 17 | 83.4 | 90.7 | 111.5 | 99.4 | 109.5 | 130.4 | |
| 18 | 93.9 | 98.9 | 108.0 | 112.2 | 121.1 | 125.9 | |
| 19 | 99.9 | 102.8 | 109.3 | 115.0 | 119.2 | 120.4 | |
| 20 | 86.9 | 102.0 | 111.4 | 108.4 | 117.3 | 120.6 | |
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 48.1 | 58.4 | 60.4 | 52.5 | 61.0 | 63.3 | |
| 2 | 51.2 | 52.2 | 54.5 | 48.7 | 58.2 | 61.3 | |
| 3 | 53.2 | 55.6 | 58.7 | 56.6 | 58.3 | 61.8 | |
| 4 | 60.9 | 63.0 | 65.6 | 66.7 | 67.9 | 74.2 | |
| 5 | 55.0 | 60.0 | 62.7 | 59.5 | 61.5 | 63.9 | |
| 6 | 67.9 | 69.4 | 70.8 | 75.2 | 78.9 | 87.4 | |
| 7 | 61.1 | 68.9 | 73.5 | 68.8 | 71.7 | 84.8 | |
| 8 | 60.2 | 63.2 | 66.2 | 64.8 | 71.4 | 78.7 | |
| 9 | 63.5 | 66.1 | 73.1 | 68.0 | 78.1 | 79.3 | |
| 10 | 57.9 | 69.2 | 72.0 | 64.5 | 71.5 | 76.0 | |
| 11 | 79.5 | 81.8 | 85.7 | 81.4 | 85.4 | 90.4 | |
| 12 | 83.2 | 85.5 | 90.2 | 90.7 | 92.3 | 95.6 | |
| 13 | 67.9 | 76.1 | 86.4 | 75.7 | 80.5 | 88.2 | |
| 14 | 78.6 | 80.3 | 87.0 | 79.5 | 85.3 | 89.9 | |
| 15 | 71.6 | 79.1 | 81.0 | 74.0 | 81.5 | 90.9 | |
| 16 | 101.3 | 107.2 | 113.2 | 102.5 | 110.2 | 127.3 | |
| 17 | 93.0 | 100.0 | 116.8 | 111.6 | 126.5 | 139.0 | |
| 18 | 101.0 | 105.4 | 122.2 | 129.3 | 132.1 | 143.9 | |
| 19 | 108.9 | 110.3 | 114.8 | 122.4 | 125.6 | 133.0 | |
| 20 | 91.9 | 115.5 | 121.5 | 122.1 | 127.7 | 139.3 | |
| Size | Instance No. | ABC | PSO-SA | ||||
|---|---|---|---|---|---|---|---|
| best | average | worst | best | average | worst | ||
| 1 | 85.6 | 109.6 | 114.3 | 100.8 | 109.4 | 118.2 | |
| 2 | 91.3 | 100.2 | 102.0 | 93.3 | 109.4 | 114.1 | |
| 3 | 96.1 | 98.3 | 108.3 | 103.1 | 104.3 | 111.5 | |
| 4 | 114.4 | 121.0 | 129.7 | 123.3 | 128.5 | 132.1 | |
| 5 | 101.1 | 111.4 | 119.9 | 106.2 | 115.7 | 117.7 | |
| 6 | 123.7 | 126.8 | 131.9 | 135.2 | 145.8 | 161.8 | |
| 7 | 113.8 | 124.8 | 134.2 | 124.6 | 134.9 | 154.3 | |
| 8 | 113.3 | 116.2 | 123.0 | 116.2 | 130.2 | 143.2 | |
| 9 | 116.6 | 125.7 | 132.7 | 130.3 | 146.4 | 147.6 | |
| 10 | 107.9 | 126.1 | 131.4 | 117.6 | 131.3 | 141.9 | |
| 11 | 141.5 | 149.4 | 156.9 | 146.0 | 157.0 | 160.2 | |
| 12 | 148.8 | 153.4 | 162.4 | 167.5 | 175.2 | 177.0 | |
| 13 | 122.8 | 139.3 | 159.5 | 142.9 | 146.8 | 158.3 | |
| 14 | 143.7 | 150.5 | 160.7 | 144.5 | 149.8 | 163.6 | |
| 15 | 129.3 | 146.8 | 150.0 | 138.2 | 149.7 | 164.9 | |
| 16 | 193.8 | 199.8 | 215.2 | 192.4 | 202.4 | 229.1 | |
| 17 | 168.0 | 184.4 | 217.6 | 213.0 | 242.9 | 251.8 | |
| 18 | 185.7 | 196.2 | 215.7 | 226.8 | 242.4 | 251.9 | |
| 19 | 199.6 | 209.5 | 213.6 | 214.6 | 225.0 | 241.9 | |
| 20 | 170.2 | 209.2 | 221.0 | 228.5 | 240.0 | 249.9 | |
| Instance No. | Normal | Uniform | Exponential | ||||
|---|---|---|---|---|---|---|---|
| 1 | 97 | 94 | 82 | 99 | 97 | 86 | 76 |
| 2 | 93 | 85 | 79 | 94 | 89 | 78 | 70 |
| 3 | 95 | 84 | 79 | 94 | 87 | 80 | 76 |
| 4 | 87 | 78 | 70 | 90 | 79 | 72 | 68 |
| 5 | 90 | 80 | 79 | 89 | 81 | 78 | 72 |
| 6 | 80 | 74 | 68 | 83 | 76 | 69 | 62 |
| 7 | 82 | 78 | 69 | 84 | 78 | 69 | 64 |
| 8 | 84 | 79 | 70 | 86 | 79 | 73 | 66 |
| 9 | 79 | 71 | 64 | 78 | 72 | 63 | 61 |
| 10 | 81 | 74 | 67 | 83 | 73 | 65 | 64 |
| 11 | 86 | 81 | 74 | 85 | 81 | 76 | 70 |
| 12 | 91 | 86 | 79 | 90 | 86 | 78 | 70 |
| 13 | 93 | 79 | 77 | 90 | 79 | 81 | 73 |
| 14 | 88 | 87 | 84 | 91 | 88 | 86 | 82 |
| 15 | 96 | 84 | 78 | 94 | 89 | 81 | 73 |
| 16 | 88 | 77 | 70 | 89 | 76 | 70 | 64 |
| 17 | 77 | 68 | 60 | 74 | 70 | 63 | 59 |
| 18 | 70 | 66 | 59 | 72 | 64 | 61 | 55 |
| 19 | 80 | 67 | 66 | 84 | 66 | 66 | 61 |
| 20 | 69 | 64 | 60 | 70 | 64 | 62 | 53 |
- (1)
- According to the tables, the advantage of ABC over PSO-SA is greater when the variability level of processing times is higher (represented by larger θ or the case of exponential distribution). This can be attributed to the function of A-UCB1, which is responsible for the allocation of the limited computational resources. If θ is small, the objective value of a solution can be obtained with only a few replications. In this case, the A-UCB1 strategy is not significantly better than an equal allocation of the available replications (the case of PSO-SA). However, when the variability increases, the computational time becomes a relatively scarce resource. In order to correctly identify high-quality solutions, the limited replications should be allocated in an efficient manner rather than evenly. So in this case, the advantage of using A-UCB1 becomes evident.
- (2)
- According to the tables, ABC outperforms PSO-SA to a greater extent when solving the larger-scale instances. If the solution space is huge, PSO must rely on the additional local search module (SA) to promote the searching efficiency. However, SA is not so efficient as the inherent local search mechanism (employed and onlooker bees) in ABC, especially under tight time budgets. From another perspective, ABC systematically combines the exploration and exploitation abilities, and thus it works in a coordinated fashion. By contrast, the hybrid algorithm uses PSO for exploration and SA for exploitation, but the two algorithms have different search patterns. This may weaken the cooperation between PSO and SA in solving large-scale SJSSP. Therefore, ABC alone is more efficient than the hybrid algorithm.
7. Conclusions
- (1)
- It is worthwhile to consider other types of randomness in job shops, for example, the uncertainty in the processing routes of certain jobs.
- (2)
- It is worthwhile to investigate the method for discovering and utilizing problem-specific characteristics of SJSSP. This will make the ABC algorithm more pertinent to this problem.
Acknowledgment
References and Notes
- Lenstra, J.K.; Kan, A.H.G.R.; Brucker, P. Complexity of machine scheduling problems. Ann. Discret. Math. 1977, 1, 343–362. [Google Scholar]
- Pezzella, F.; Morganti, G.; Ciaschetti, G. A genetic algorithm for the flexible job-shop scheduling problem. Comput. Oper. Res. 2008, 35, 3202–3212. [Google Scholar] [CrossRef]
- Chen, S.H.; Chen, M.C.; Chang, P.C.; Chen, Y.M. EA/G-GA for single machine scheduling problems with earliness/tardiness costs. Entropy 2011, 13, 1152–1169. [Google Scholar] [CrossRef]
- Nowicki, E.; Smutnicki, C. An advanced tabu search algorithm for the job shop problem. J. Sched. 2005, 8, 145–159. [Google Scholar] [CrossRef]
- Lei, D. Pareto archive particle swarm optimization for multi-objective fuzzy job shop scheduling problems. Int. J. Adv. Manuf. Technol. 2008, 37, 157–165. [Google Scholar] [CrossRef]
- Rossi, A.; Dini, G. Flexible job-shop scheduling with routing flexibility and separable setup times using ant colony optimisation method. Robot. Comput. Integr. Manuf. 2007, 23, 503–516. [Google Scholar] [CrossRef]
- Li, J.; Pan, Q.; Xie, S.; Wang, S. A hybrid artificial bee colony algorithm for flexible job shop scheduling problems. Int. J. Comput. Commun. Control 2011, 6, 286–296. [Google Scholar]
- Yoshitomi, Y. A genetic algorithm approach to solving stochastic job-shop scheduling problems. Int. Trans. Oper. Res. 2002, 9, 479–495. [Google Scholar] [CrossRef]
- Yoshitomi, Y.; Yamaguchi, R. A genetic algorithm and the Monte Carlo method for stochastic job-shop scheduling. Int. Trans. Oper. Res. 2003, 10, 577–596. [Google Scholar] [CrossRef]
- Golenko-Ginzburg, D.; Gonik, A. Optimal job-shop scheduling with random operations and cost objectives. Int. J. Prod. Econ. 2002, 76, 147–157. [Google Scholar] [CrossRef]
- Tavakkoli-Moghaddam, R.; Jolai, F.; Vaziri, F.; Ahmed, P.K.; Azaron, A. A hybrid method for solving stochastic job shop scheduling problems. Appl. Math. Comput. 2005, 170, 185–206. [Google Scholar] [CrossRef]
- Luh, P.; Chen, D.; Thakur, L. An effective approach for job-shop scheduling with uncertain processing requirements. IEEE Trans. Robot. Autom. 1999, 15, 328–339. [Google Scholar] [CrossRef]
- Lai, T.; Sotskov, Y.; Sotskova, N.; Werner, F. Mean flow time minimization with given bounds of processing times. Eur. J. Oper. Res. 2004, 159, 558–573. [Google Scholar] [CrossRef]
- Singer, M. Forecasting policies for scheduling a stochastic due date job shop. Int. J. Prod. Res. 2000, 38, 3623–3637. [Google Scholar] [CrossRef]
- Lei, D. Scheduling stochastic job shop subject to random breakdown to minimize makespan. Int. J. Adv. Manuf. Technol. 2011, 55, 1183–1192. [Google Scholar] [CrossRef]
- Lei, D. Simplified multi-objective genetic algorithms for stochastic job shop scheduling. Appl. Soft Comput. 2011. [Google Scholar] [CrossRef]
- Gu, J.; Gu, X.; Gu, M. A novel parallel quantum genetic algorithm for stochastic job shop scheduling. J. Math. Anal. Appl. 2009, 355, 63–81. [Google Scholar] [CrossRef]
- Gu, J.; Gu, M.; Cao, C.; Gu, X. A novel competitive co-evolutionary quantum genetic algorithm for stochastic job shop scheduling problem. Comput. Oper. Res. 2010, 37, 927–937. [Google Scholar] [CrossRef]
- Mahdavi, I.; Shirazi, B.; Solimanpur, M. Development of a simulation-based decision support system for controlling stochastic flexible job shop manufacturing systems. Simul. Model. Pract. Theory 2010, 18, 768–786. [Google Scholar] [CrossRef]
- Azadeh, A.; Negahban, A.; Moghaddam, M. A hybrid computer simulation-artificial neural network algorithm for optimisation of dispatching rule selection in stochastic job shop scheduling problems. Int. J. Prod. Res. 2011. [Google Scholar] [CrossRef]
- Bianchi, L.; Dorigo, M.; Gambardella, L.; Gutjahr, W. A survey on metaheuristics for stochastic combinatorial optimization. Nat. Comput. 2009, 8, 239–287. [Google Scholar] [CrossRef]
- Karaboga, D.; Akay, B. A survey: algorithms simulating bee swarm intelligence. Artif. Intell. Rev. 2009, 31, 61–85. [Google Scholar] [CrossRef]
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report for Computer Engineering Department, Erciyes University: Kayseri, Turkey, October 2005. [Google Scholar]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Karaboga, D.; Akay, B. A comparative study of artificial bee colony algorithm. Appl. Math. Comput. 2009, 214, 108–132. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Kang, F.; Li, J.; Xu, Q. Structural inverse analysis by hybrid simplex artificial bee colony algorithms. Comput. Struct. 2009, 87, 861–870. [Google Scholar] [CrossRef]
- Sonmez, M. Discrete optimum design of truss structures using artificial bee colony algorithm. Struct. Multidiscip. Optim. 2011, 43, 85–97. [Google Scholar] [CrossRef]
- Samanta, S.; Chakraborty, S. Parametric optimization of some non-traditional machining processes using artificial bee colony algorithm. Eng. Appl. Artif. Intell. 2011, 24, 946–957. [Google Scholar] [CrossRef]
- Huang, Y.; Lin, J. A new bee colony optimization algorithm with idle-time-based filtering scheme for open shop-scheduling problems. Expert Syst. Appl. 2011, 38, 5438–5447. [Google Scholar] [CrossRef]
- Jain, A.S.; Meeran, S. Deterministic job-shop scheduling: past, present and future. Eur. J. Oper. Res. 1999, 113, 390–434. [Google Scholar] [CrossRef]
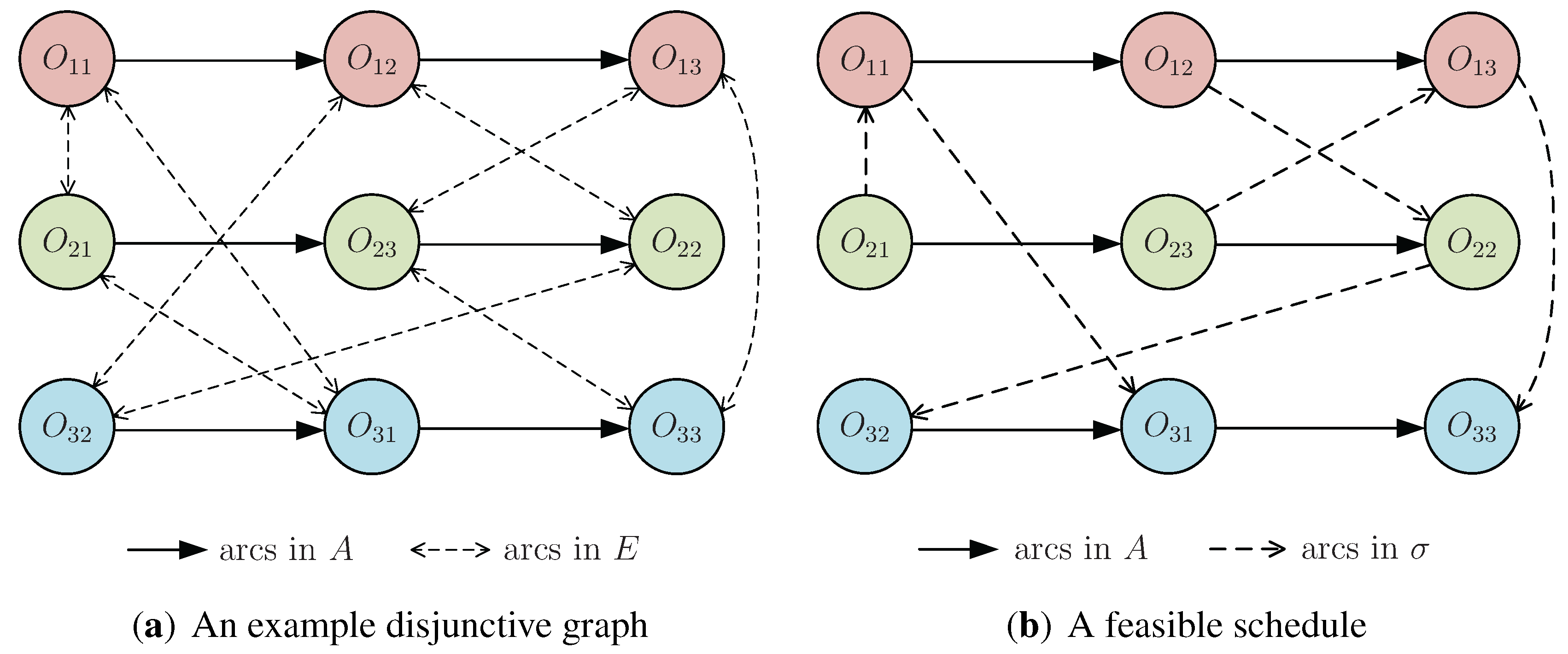
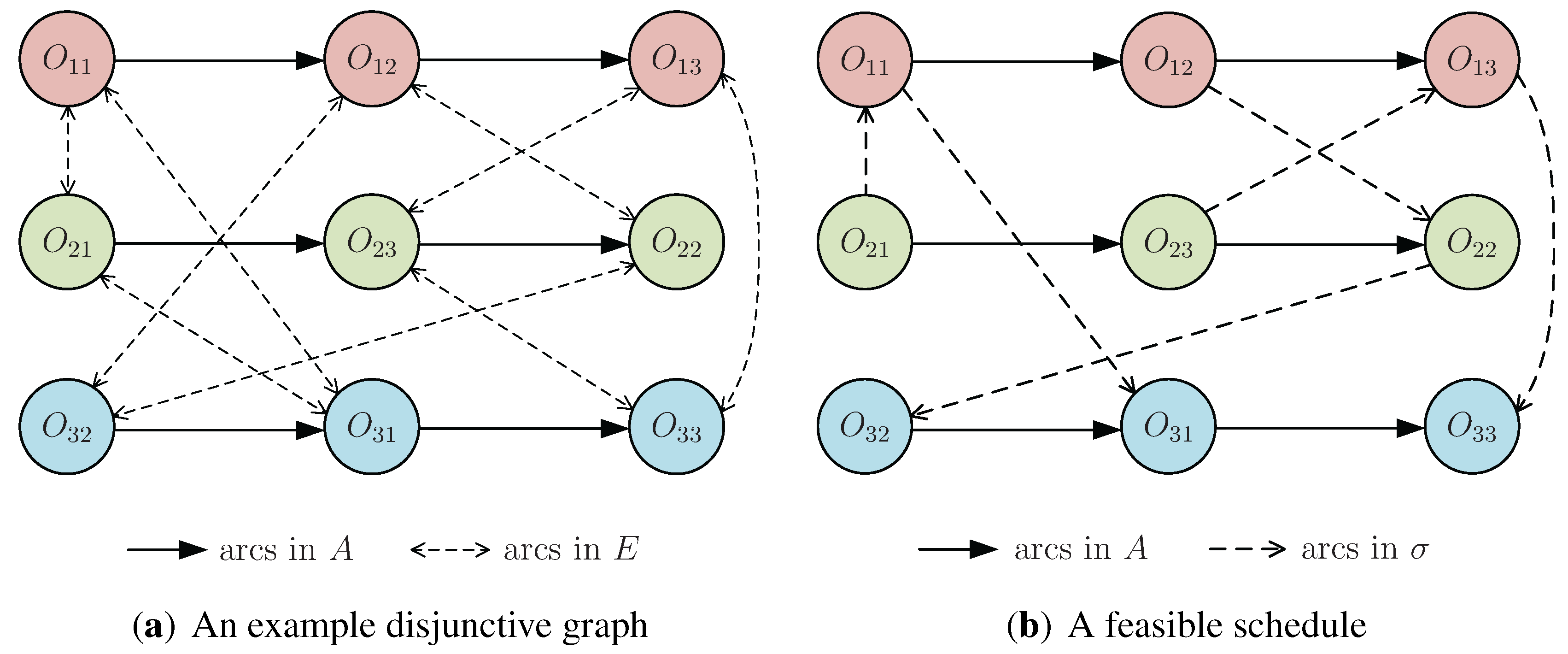
- In the rest of the paper, we do not distinguish between σ and the schedule. For the convenience of expression, we will write σ as a matrix. The k-th row of σ represents the processing order of the operations on machine k.
- Akay, B.; Karaboga, D. Artificial bee colony algorithm for large-scale problems and engineering design optimization. J. Intell. Manuf. 2011. [Google Scholar] [CrossRef]
- An operation is schedulable if its immediate job predecessor has already been scheduled or if it is the first operation of a certain job.
- Vepsalainen, A.P.; Morton, T.E. Priority rules for job shops with weighted tardy costs. Manag. Sci. 1987, 33, 1035–1047. [Google Scholar] [CrossRef]
- A sequence of operations in the critical path is called a block if (1) it contains at least two operations and (2) the sequence includes a maximum number of operations that are consecutively processed by the same machine [37].
- Pinedo, M. Scheduling: Theory, Algorithms and Systems, 3rd ed.; Springer: New York, NY, USA, 2008. [Google Scholar]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- If a newly-generated solution does not pass the pre-screening test, then simply generate another solution from the neighborhood, and so on.
- Liu, B.; Wang, L.; Jin, Y.H. Hybrid Particle Swarm Optimization for Flow Shop Scheduling with Stochastic Processing Time. In Lecture Notes in Computer Science; Springer: Berlin, Heidelberg, Germany, 2005; Volume 3801, pp. 630–637. [Google Scholar]
- The mean value resulted from 1000 simulation replications (which is large enough for the considered test instances) is regarded as the exact evaluation of a solution.
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Zhang, R.; Wu, C. An Artificial Bee Colony Algorithm for the Job Shop Scheduling Problem with Random Processing Times. Entropy 2011, 13, 1708-1729. https://doi.org/10.3390/e13091708
Zhang R, Wu C. An Artificial Bee Colony Algorithm for the Job Shop Scheduling Problem with Random Processing Times. Entropy. 2011; 13(9):1708-1729. https://doi.org/10.3390/e13091708
Chicago/Turabian StyleZhang, Rui, and Cheng Wu. 2011. "An Artificial Bee Colony Algorithm for the Job Shop Scheduling Problem with Random Processing Times" Entropy 13, no. 9: 1708-1729. https://doi.org/10.3390/e13091708
APA StyleZhang, R., & Wu, C. (2011). An Artificial Bee Colony Algorithm for the Job Shop Scheduling Problem with Random Processing Times. Entropy, 13(9), 1708-1729. https://doi.org/10.3390/e13091708