1. Introduction
As in classical computer science, randomized proofs and constructions are ubiquitous in quantum information. Since quantum mechanics is non commutative, the random objects of study are matrices. Therefore, quantum information theory provides a rich source of random matrix problems.
One of the most important classes of problems in the mathematical aspects of quantum information theory is the study of data transmission through noisy quantum channels. A famous conjecture reduced the calculation of the channel capacity for classical data to the question of the additivity of Minimum channel Output Entropy. The conjecture was stated in 1999 by King and Ruskai [
1] and shown to be equivalent to the additivity of the Holevo capacity (and to other quantities of interest) by Shor [
2]. For a long time, no counterexamples were available and additivity was proven to hold in many cases. A stronger,
version of this question was also available and relevant to operator algebra and operator space theory. This version was disproved by Hayden and Winter in 2007, for all
[
3]. The original conjecture, regarding von Neumann entropies, was disproved by Hastings in 2008 [
4]. His very innovative argument exploited the idea of tubular neighborhoods so as to considerably refine available estimates on random quantum channels. However, constructive, non-random counterexamples to any of these conjectures are still elusive.
The random counterexamples to the various forms of the additivity conjecture rely on bounds on the Minimum Output Entropies (MOE) for single and product channels that follow mainly from two important ideas. Let Φ be a random quantum channel between matrix spaces such that the dimensions of the input and output spaces are large enough. The first key idea is that, with high probability, the Minimum Output Entropy of Φ is almost maximal: all output states are highly mixed. On the other hand, if one considers the product channel (where is obtained by replacing the Stinespring unitary U defining the channel by its conjugate), then if one takes a maximally entangled (or Bell) state as an input, the output density matrix has always a large eigenvalue. This second important fact was observed by Winter, and it implies that the output state in question has low entropy, allowing for a violation of additivity.
Our work addresses bounds for conjugate product channels, and improves them in several cases. We provide a complete spectral description of the output of product channels when the input is maximally entangled. In [
5] and [
6], we have studied situations when the channels are conjugate (
) or independent (
) in two different asymptotic regimes.
In this work, after recalling the aforementioned results and reviewing the techniques used in deriving them, we consider more general models of random quantum channels, from two different perspectives. We first generalize the linear scaling asymptotic regime to include the situations where the dimension of the input space is different from the dimension of the output of a quantum channel; however, all three parameters (the respective dimensions of the input, output and ancilla spaces) scale linearly. Then we move beyond the linear regime, considering situations where the dimensions of the output space and of the ancilla space scale in a non-linear fashion. Motivated by the search of improved bounds one may use in the study of additivity questions, we compute asymptotic expressions for the von Neumann entropies of output matrices for the models under consideration.
The paper is organized as follows: in
Section 2, we first review the tools available to study moments of outputs of random quantum channels. These techniques were introduced in [
7,
8] and [
5] and their first applications to quantum information theory were developed in [
5,
6] and [
9]. In
Section 3, we generalize the results of [
6] to the case where the relative dimensions of the input and the output are different. In
Section 4, we generalize the setting of [
6] to the case where the relative dimensions of the input space and the ancilla space have relative polynomial growth. This is motivated by the recent results of [
10], where the authors consider the case
(
n being the dimension of the input/output space and
k being the dimension of the ancilla space). We show that depending on the growth, different results occur and that the case where the ancilla space and the input space have the same dimension has a potential for yielding a bigger violation for the additivity of the entropy. Finally, in
Section 5, we use these results to provide new bounds for von Neumann entropy of the output of product random quantum channels.
2. Studying Moments of Outputs of Random Quantum Channels: Techniques and First Examples
In this section, we recall, for the convenience of the reader and for the sake of being self-contained, techniques to compute the eigenvalue distribution of random quantum channels, as well as a few results obtained recently with these techniques.
2.1. Weingarten calculus
In this section, we recall a few facts about the Weingarten calculus, useful to evaluate averages with respect to the Haar measure on the unitary group.
Definition 2.1. The unitary Weingarten function is a function of a dimension parameter n and of a permutation σ in the symmetric group on p elements, defined as the pseudo-inverse of the function under the convolution for the symmetric group ( denotes the number of cycles of the permutation σ).
Note that the function
is invertible for
, (to see that it is invertible for
n large enough, observe that it behaves like
as
). In this case, we can replace the pseudo-inverse by the inverse. We refer to [
8] for historical references and further details. We shall use the shorthand notation
when the dimension parameter
n is obvious.
The following theorem relates integrals with respect to the Haar measure on the unitary group
and the Weingarten function Wg. (see for example [
11]):
Theorem 2.2. Let n be a positive integer and , , , be p-tuples of positive integers from . Then We are interested in the values of the Weingarten function in the limit
. The following result encloses all the data we need for our computations about the asymptotics of the Wg function; see [
11] for a proof.
Theorem 2.3. For a permutation , let denote the set of cycles of σ. Then and where is the i-th Catalan number. The Catalan numbers and Wg are related to the Moebius function on the lattice of non-crossing partitions, as follows:
where
is the
length of
σ,
i.e., the minimal number of transpositions that multiply to
σ. We refer to [
8] for details about the function Mob.
2.2. Planar expansion
The purpose of the graphical calculus introduced in [
5] is to yield an effective method to evaluate the expectation of random tensors with respect to the Haar measure on a unitary group. In graphical language, a tensor corresponds to a
box, and an appropriate Hilbertian structure yields a correspondence between boxes and tensors. However, the calculus yielding expectations only relies on diagrammatic operations.
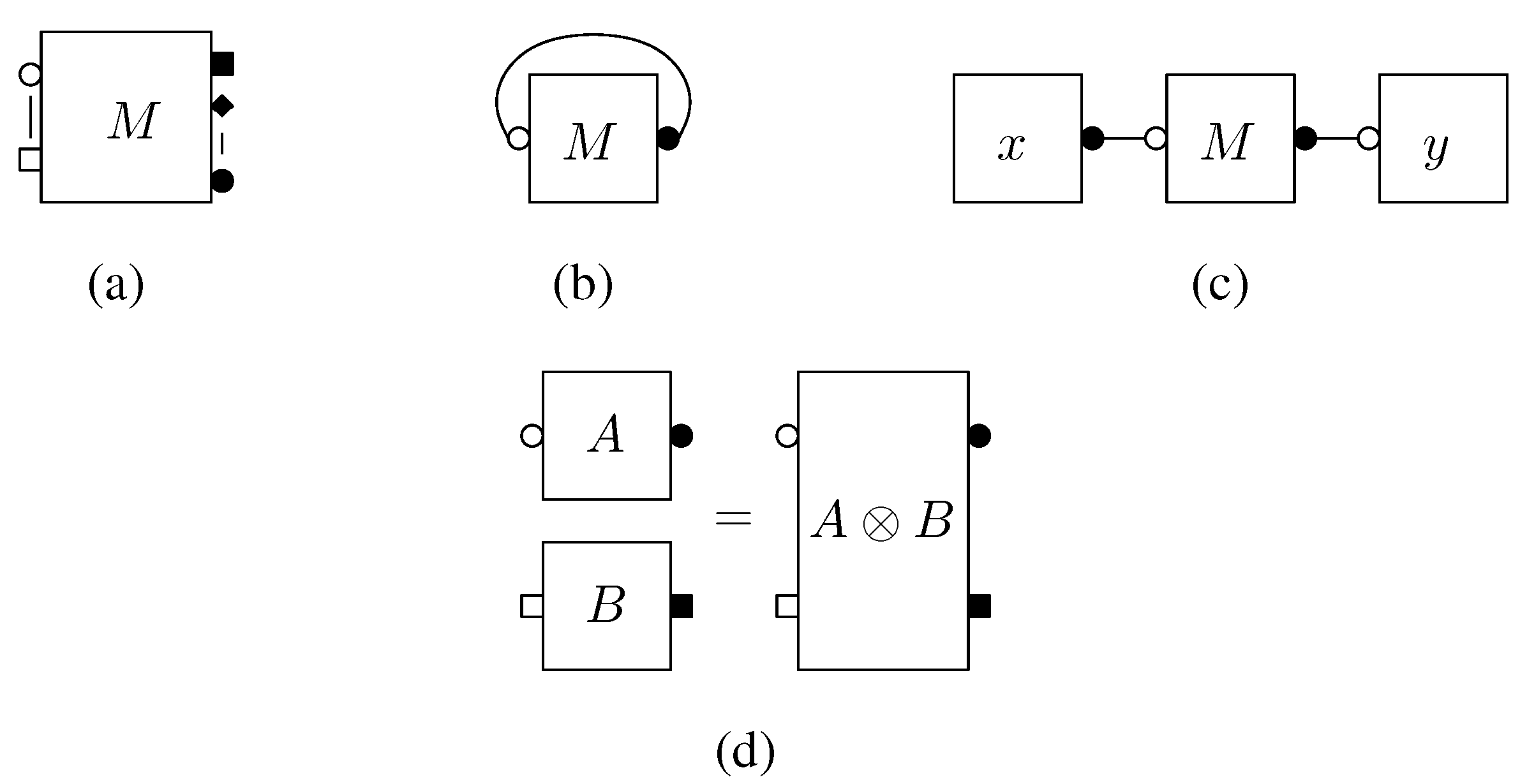
Each box
B is represented as a rectangle with decorations on its boundary. The decorations are either white or black, and belong to
.
Figure 1 depicts an example of boxes and diagrams.
Figure 1.
Basic diagrams and axioms: (a) diagram for a general tensor M; (b) trace of a -tensor (matrix) M; (c) Scalar product ; (d) tensor product of two diagrams. The round, square and diamond-shaped labels correspond to pairs of dual finite dimensional complex Hilbert spaces.
Figure 1.
Basic diagrams and axioms: (a) diagram for a general tensor M; (b) trace of a -tensor (matrix) M; (c) Scalar product ; (d) tensor product of two diagrams. The round, square and diamond-shaped labels correspond to pairs of dual finite dimensional complex Hilbert spaces.
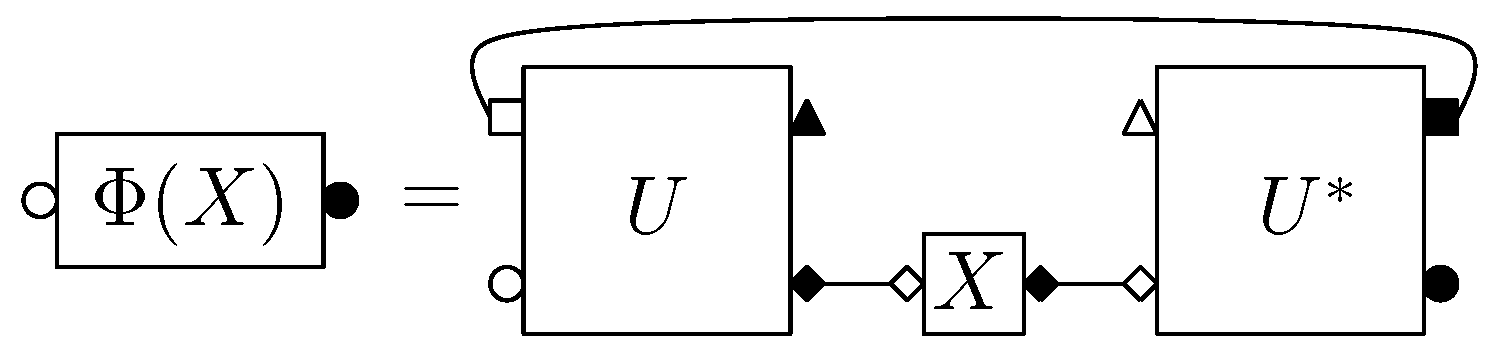
It is possible to construct new boxes out of old ones by formal algebraic operations such as sums or products. We call diagram a picture consisting in boxes and wires according to the following rule: a wire may link a white decoration in to its black counterpart in . A diagram can be turned into a box by choosing an orientation and a starting point.
Regarding the Hilbertian structure, wires correspond to tensor contractions. There exists an involution for boxes and diagrams. It is antilinear and it turns a decoration in
into its counterpart in
. Our conventions are close to those of [
12,
13]. They should be familiar to the reader acquainted with existing graphical calculus of various types (planar algebra theory, Feynman diagrams theory, traced category theory). Our notations are designed to fit well to the problem of computing expectations, as shown in the next section. In
Figure 2(b), 2(c) and 2(d) we depict the trace of a matrix, multiplication of tensors and the tensor product operation. For details, we refer to [
5].
The main application of our calculus is to compute expectation of diagrams where some boxes represent random matrices (e.g., Haar distributed or Gaussian). For this, we need a concept of removal of boxes U and . A removal r is a way to pair decorations of the U and boxes appearing in a diagram. It therefore consists in a pairing α of the white decorations of U boxes with the white decorations of boxes, together with a pairing β between the black decorations of U boxes and the black decorations of boxes. Assuming that contains p boxes of type U and that the boxes U (resp. )are labeled from 1 to p, then r = (α, β) where α, β are permutations of Sp.
Given a removal , we construct a new diagram associated to r, which has the important property that it no longer contains boxes of type U or . One starts by erasing the boxes U and but keeps the decorations attached to them. Assuming that one has labeled the erased boxes U and with integers from , one connects all the (inner parts of the) white decorations of the i-th erased U box with the corresponding (inner parts of the) white decorations of the -th erased box. In a similar manner, one uses the permutation β to connect black decorations.
In [
5], we proved the following result:
Theorem 2.4. The following holds true: 2.3. Wishart matrices, Marchenko-Pastur distributions and their entropy
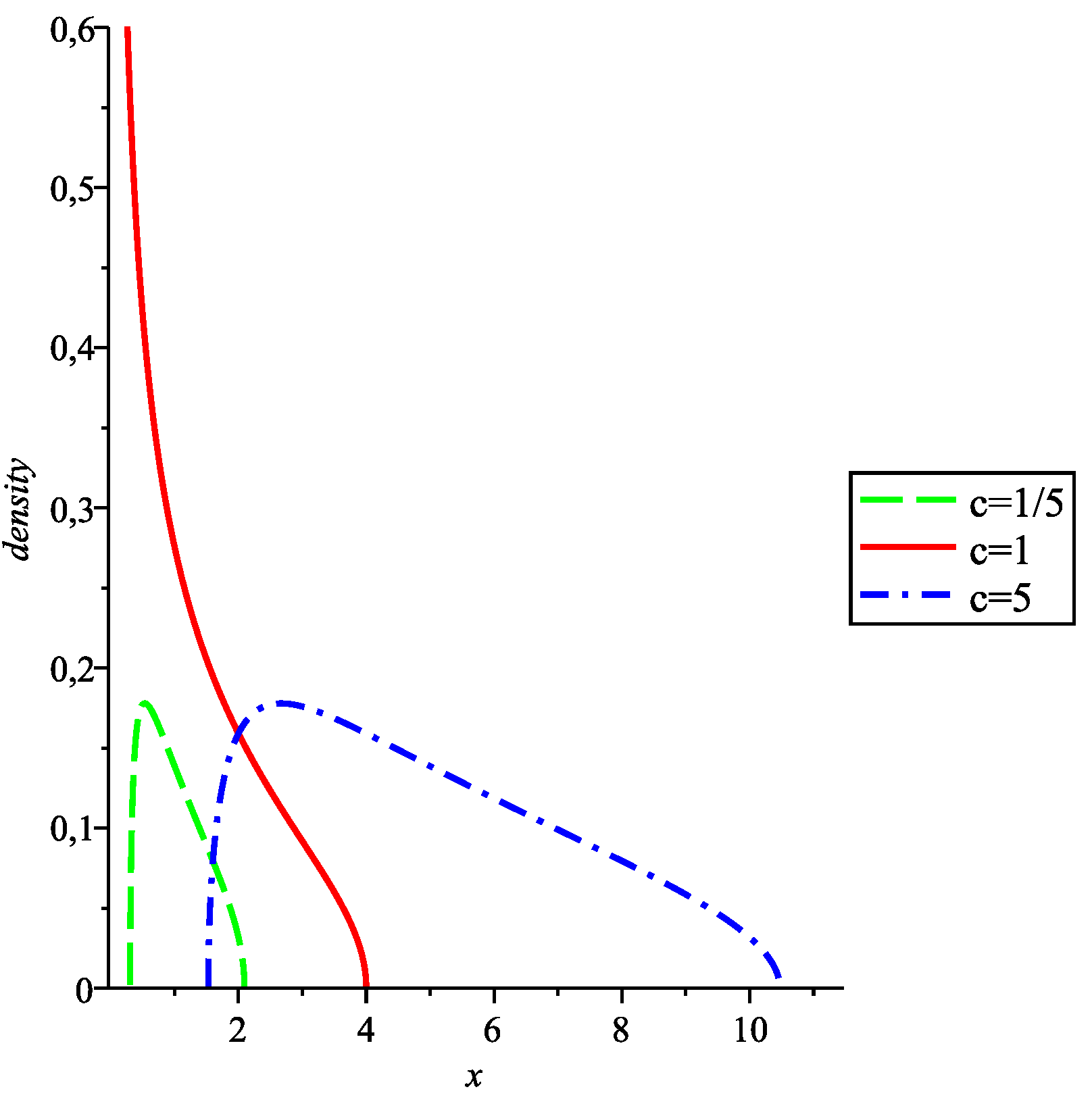
We recall the definition of a
free Poisson (or Marchenko-Pastur) random variable [
14]. For
, the probability measure
is called a free Poisson measure of parameter
c. The plots of the densities for these measures are plotted in
Figure 2.
The free Poisson distribution arises in random matrix theory as the almost sure limit of the eigenvalue counting distribution for Wishart matrices, i.e., matrices where is an matrix whose entries are i.i.d. standard complex Gaussian random variables of variance .
From a combinatorial perspective, the free Poisson distribution
has the nice property that all its
free cumulants are equal to
c. Hence, the free moment-cumulant formula (see [
15], Lecture 11, pp. 173) reads
Figure 2.
Densities for the Marchenko-Pastur measures of parameters , and . For , only the absolutely continuous part of the measure was plotted; has a Dirac mass of at which is not represented.
Figure 2.
Densities for the Marchenko-Pastur measures of parameters , and . For , only the absolutely continuous part of the measure was plotted; has a Dirac mass of at which is not represented.
where
denotes the number of blocks of the non-crossing partition
σ. From the moment formula, one can obtain the value of the following integral, useful in the computation of von Neumann entropies [
16]:
2.4. Application 1: Fixed ancilla space
The counterexamples to the additivity conjecture obtained so far arise from the random choice of a quantum channel from the ensemble
given by
, where
is a random unitary matrix and
is an ancilla rank-one projector. The counterexamples rely on the idea of using a tensor product of conjugate channels
and, more precisely, the output of this channel when the input is the Bell state (
is some fixed basis of
m):
In the regime where
with
n and
k integers and
a fixed parameter, we gave in [
5] a complete spectral description of the (random) density matrix
. The following result improves on the previously known bound of Winter,
:
Theorem 2.5. Almost surely, as , the non-zero eigenvalues of the random matrix converge towards the deterministic probability vector In the particular case , corresponding to , the eigenvalues are , with multiplicity one and , with multiplicity . Not only the value of the largest eigenvalue is improved from to , but the lower eigenvalues are also computed.
A better understanding of the spectrum of the output matrix for the product channel yields immediately better bounds for the Minimum Output Entropy of
. Applications of this result are twofold. First, it allows for violations of additivity of Rényi entropies, for all
, just by using a qubit as an ancilla state for the input (
). Second, the improvements on the bound for the entropy of the product channel can yield better minimum values of
k needed to obtain violations of additivity for
(see [
17,
18]).
2.5. Application 2: Ancilla and input space of linear dimensions
Theorem 2.5 is highly non-intuitive: it is not clear why the small eigenvalues should all behave in the same way. Moreover, there was numerical evidence [
3] that the spectrum should not be flat beyond the second eigenvalue. This raises the question of what happens when the ancilla space is not of fixed dimension, but rather of dimension comparable to the input space.
The study of such asymptotic regimes was initiated in [
6]. After stating the main result obtained in that paper, we shall generalize in
Section 3 the setting, allowing for the dimension of the input space to vary linearly with the dimension of the output.
In [
6], Section 6.3, we considered random quantum channels
obtained from random Haar unitary matrices
via the Stinespring representation
where
is a non-random rank-one projector (pure state) and both
n and
k grow to infinity at a constant ration
. The diagram for such a channel is represented in
Figure 3.
Figure 3.
Diagram for a quantum channel with equal input and output spaces. The state of the ancilla space is omitted, since it has no role to play in the computations. Round labels attached to boxes correspond to input/output spaces n and square symbols correspond to ancilla spaces k.
Figure 3.
Diagram for a quantum channel with equal input and output spaces. The state of the ancilla space is omitted, since it has no role to play in the computations. Round labels attached to boxes correspond to input/output spaces n and square symbols correspond to ancilla spaces k.
For the regime where both
n and
k grow to infinity at a constant ratio
c, the main result of [
6] is as follows.
Theorem 2.6. Consider a pair of conjugate random quantum channels in the regime where , . The eigenvalues of the random matrix are such that: Here we see that a new phenomenon of two different convergence rates for eigenvalues appears. This is due to the fact that the
model for the product channel contains the “conjugation” symmetry. Instead of considering a channel and its complex conjugate, we looked in [
6] at two
independent quantum channels, taken from the same ensemble.
Theorem 2.7. In the regime , , let be the output of the product of two independent quantum channels Φ and Ψ, when the input is a maximally entangled state . Then, almost surely, the distribution of the rescaled output matrix converges towards a free Poisson of parameter .
A striking feature of this asymptotic regime is that the von Neumann entropies of the and models are almost the same. It is then natural to ask whether the symmetry is in fact needed to obtain violations of the additivity. Indeed, it seems that the largest eigenvalue for the output of the product channel does not play a big role in the bounds for the entropy. Having counterexamples with independent channels will be an important step to a better understanding of additivity violations. Possible violations with independent channels would be generic, as opposed to conjugate-channels violations which are not. Also, these considerations give concrete hope that larger violations of additivity could be achieved.
3. Generalized Linear Setting—Input and Output Spaces of Different Dimension
In this section, we generalize the model of quantum channels we have considered, by allowing input and output spaces of different dimensions. We consider random quantum channels
defined by
where
and
is a deterministic rank-one projector in
; we tacitly assume that
l is an integer. All three dimensions
and
k grow to infinity, at constant ratios:
and
, with
fixed constants. The generalized diagram corresponding to Φ ias depicted in
Figure 4.
Figure 4.
Diagram for a quantum channel with different input and output spaces. Round labels attached to boxes correspond to output spaces n, square symbols correspond to ancilla spaces k and diamonds correspond to input spaces m. The rank-one projector is omitted.
Figure 4.
Diagram for a quantum channel with different input and output spaces. Round labels attached to boxes correspond to output spaces n, square symbols correspond to ancilla spaces k and diamonds correspond to input spaces m. The rank-one projector is omitted.
When presented with the maximally entangled (or Bell state)
as an input, the product conjugate channel
produces a random density matrix
The remaining of this section is dedicated to the study of the random matrix
Z, depicted in
Figure 5. The analysis of the spectrum of
Z follows closely corresponding results in [
6], Section 6.3, which is a specialization of this section, in the case
(
i.e.,
). The spectral properties of the output random matrix
Z are summarized in Theorem 3.4, the main result of this section. The reader in invited to compare the conclusions of Theorems 2.6 and 3.4.
Figure 5.
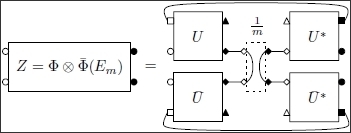
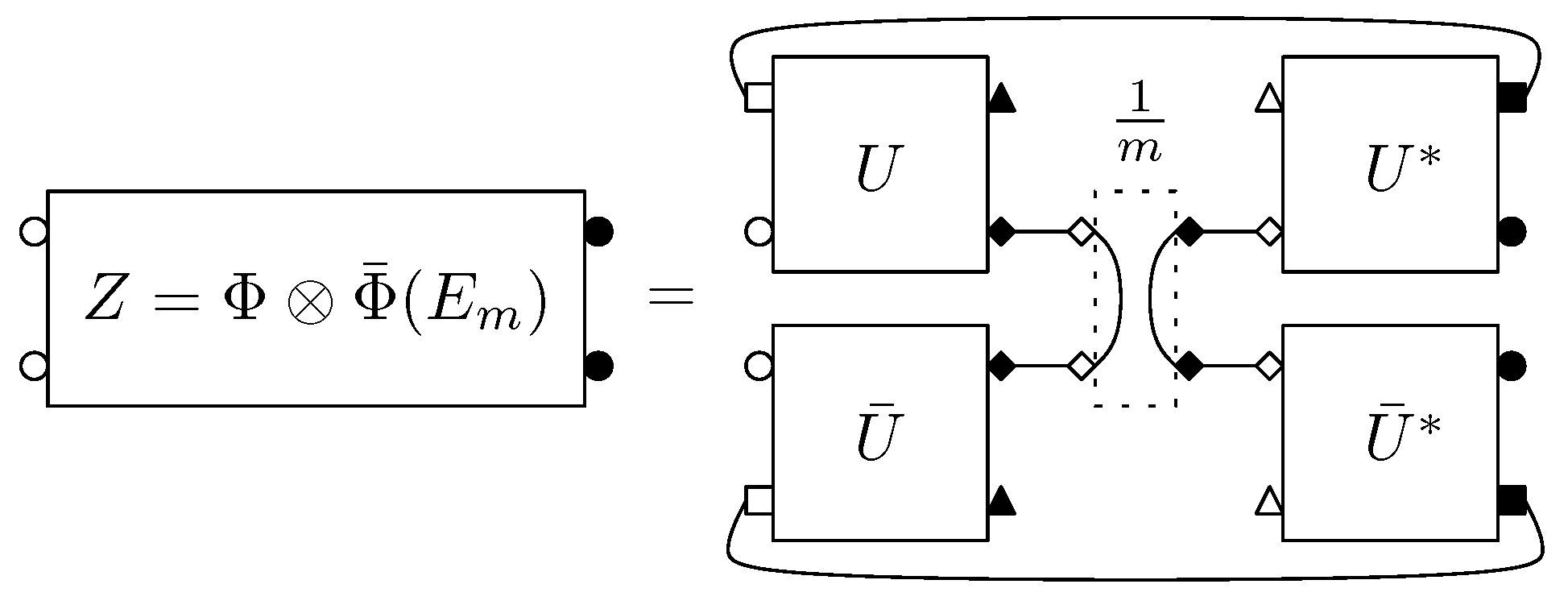
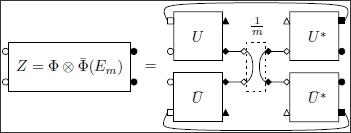
Diagram for the output of a product of two conjugate channels, when the input is the maximally entangled state. The complex Hilbert spaces associated to labels are as follows: , , and .
Figure 5.
Diagram for the output of a product of two conjugate channels, when the input is the maximally entangled state. The complex Hilbert spaces associated to labels are as follows: , , and .
The first step of our analysis of the output matrix is the computation of the asymptotic moments.
Proposition 3.1. Consider a sequence of random quantum channels where , and . The asymptotic moments of the output matrix are given by: Proof. The starting point of the proof is the following exact formula for the moments of the random matrix
Z, obtained from the graph expansion technique detailed in [
5]:
where the permutations
are defined as follows. We relabel the index set
as
in order to make precise the association of indices with blocks corresponding to the “top” channel Φ (
) and blocks corresponding to the “bottom” channel
(
). With this notation, we define the permutations
Using the asymptotic expressions for the dimensions
,
and for the Weingarten function (see Theorem 2.3)
equation (
13) becomes
where the function
is given by
In order to find the dominating terms in the sums (
13) or (
16), one has to minimize the quantity
over the permutation group
. This has been done in the proof of Theorem 6.8 of [
6]:
for , , with equality iff. ;
for , , with equality iff. ;
for , , with equality iff. .
One concludes now by plugging the optimal values for the permutations
α and
β into equation (
16).
Theorem 3.1 only gives a partial description of the spectrum of the random matrix Z; from the moment information one can deduce that there are some eigenvalues on the scale and that the rest of the spectrum is distributed on lower scales, such as . Obtaining information on the lower scale eigenvalues by brute force via the moment method is a difficult task, since their asymptotic contribution is negligible with respect to the contribution of the eigenvalue(s) on the scale . The trick we using to obtain information about the smaller eigenvalues is inspired by Hayden and Winter’s proof of the existence of a large eigenvalue. Their proof contains, as a byproduct, some information on the eigenvector for the large eigenvalue. We introduce the orthogonal projection , where is the maximally entangled state on a product of two copies of the output space . Using the (rank ) projector Q, we shall obtain some information on the smallest eigenvalues of the random output matrix Z, by analyzing the “compressed” matrix (which, in a suitable basis, corresponds to considering the minor of Q).
Proposition 3.2. Almost surely, the matrix converges in distribution, to a free Poisson (or Marchenko-Pastur) law of parameter .
Remark 3.3. By `almost surely’, we mean with probability one, in any probability space on which the whole sequence (indexed by the input dimension) of random quantum channels is defined. In this paper, we supply no proofs of almost sure convergence results, as they require further -not so enlightening- technicalities. We refer the interested reader to the appendix of [6] for details. Let us just mention that the proofs rely on the Borel-Cantelli lemma. More precisely, one proves that the covariance of any moment behaves as as the dimension goes to infinity. The fact that is summable over n makes it possible to use the Borel-Cantelli lemma. To prove this result, one can use the arguments of Theorem 6.9 from [
6]
mutatis mutandis. The method of moments is employed by computing the moments of the random matrix
and showing that they converge to the corresponding moments of the free Poisson distribution of parameter
:
The reader can note that the parameter b (describing the size of the entangled input) has no influence on the lower part of the spectrum. It only appears in the expression of the largest eigenvalue of Z, as stated in the following Theorem, which is the main result of this section.
Theorem 3.4. Consider a pair of conjugate random quantum channels in the regime where , and . The eigenvalues of the random matrix are such that: The proof of this result combines Theorems 3.1, 3.2 and Cauchy’s interlacing theorem ([
19], Corollary III.1.5).
Remark 3.5. The almost sure convergence argument described in Remark 3.3 does not extend to the first item of Theorem 3.4, as the covariances tend to zero but are not summable.
4. Non-linear Output Dimension
In this section we generalize the “linear” model of [
6] in a different direction than we did in
Section 3. We shall consider random quantum channels
defined by the Stinespring representation (
10), where the dimension of the ancilla space
k scales with
n in a non-linear fashion:
Here,
and
are two real parameters of the model. As before, we are interested in the spectral properties of the random matrix
, where
is the rank-one projection on the maximally entangled state in the input space of the product channel,
.
Before performing a detailed analysis of the spectrum of
Z, let us make some observations on the role of the parameters
c and
d, as well as on several particular cases already treated in the literature. Generally, in such models, the parameter
c will play the role of a
scaling parameter in the limiting spectral distribution. This phenomenon can be observed in [
20], Theorem 5 or in [
6], Theorem 6.11. On the other hand, the exponent parameter
d will have a more
qualitative role to play, as it will decide the type of behavior of the spectrum of the random matrix
Z.
Several particular cases of this very general model of random quantum channels have already been studied in the literature. In [
5], we studied the case where the dimension
k of the ancillary system is fixed, which corresponds in our setting to the case
(hence
). It has been shown (
Section 2.4, Theorem 2.5) that in this situation, the random matrix
Z has one large eigenvalue (
) and that the rest of the spectrum is “flat”:
. In [
6], the case
was investigated; this corresponds to a coupling with an ancilla space of dimension
k which scales as
. The situation was rather different in this case: one large eigenvalue of size
was observed, and the lower spectrum was not flat, having a free Poisson
shape. As a final remark, note that the model under study here is different than the one in
Section 3, where inputs of arbitrary size were considered.
The main result of this section is the following theorem, which classifies the spectral behavior of the output random matrix Z in terms of the parameter d.
Proposition 4.1. The asymptotic moments of the random output matrix are given by: Proof. The starting point of the proof is the following exact moment formula, obtained via the graphical calculus introduced in [
5] and the Weingarten formula:
After using the asymptotic expression for the ancillary dimension
and the Weingarten function
we obtain the following expression (which holds if the right-hand-side is non-zero):
where
is the exponent of
n in the preceding sum:
In this proof, since the permutation
δ is a product of disjoint transpositions, thus an involution, we shall use the fact that
. In order to find the dominating terms in the sum (
27), one has to minimize the quantity
over
. The solution to this problem is obtained in three steps. First, using the following triangular inequalities:
we obtain that
where the inequality can be saturated if , e.g.,
. The minimization problem for the
function, although much simpler that the two-variable problem for
S, can be further simplified by replacing the two-cycle permutation
γ with the full-cycle:
where
. Since the permutation
δ is an element of the geodesic
, the solution for the
minimization problem is easy to find using one or more of the following inequalities:
The solution for the
problem, in terms of the value of the parameter
d, is summarized in
Table 1.
Table 1.
Solution to the
minimization problem of equation (
31).
Table 1.
Solution to the minimization problem of equation (31).
| d | Minorant for | Equality cases |
| 0 | | |
| | δ |
| 2 | | |
| | id |
Next, we move towards finding the minimum of
, defined in equation (
30). The permutations
γ and
are at distance one:
hence the same holds for
and
. We have thus
and, even more precisely,
In the same manner that is was argued in [
6],
and
belong to the same block of
if and only if
(the permutations being compared with the partial order relation on the corresponding non-crossing partitions). Analyzing the different equality cases in
Table 1 and using the fact that the unique element of the geodesic set
which is smaller than
γ is
, we conclude that, for
,
, with equality iff.
. The case
is more intricate, since one cannot have
and saturate at the same time the lower bound for
.
For
, it was shown in [
5] that
, with equality iff
. Choose
and consider
such that
. Then, since
, one has
and thus
We conclude that, for
,
and
β such that
,
. Thus, for
and
, the minimum
is attained only at the point
. For
, an exhaustive search in
reveals that, for
,
, with equality iff
, and, for
,
, with equality iff
.
In the case
, the situation is different. We shall consider three cases:
. Since
β is not a geodesic permutation, we have that
,
,
and
. It follows that
. In this situation,
and thus (we use the fact that
in this case)
with equality iff.
.
. In this situation,
and thus
with equality iff.
.
Analyzing the three cases, we conclude that if
, we have
, otherwise
, the unique minimizers being respectively
,
and
for the interface case
. The answer to the
minimization problem is summarized in
Table 2.
In order to solve the initial problem for the two-variable function
, one needs to notice that, for a fixed value of
β, the only possibility to saturate the inequalities (
29) at the same time is
. Since,
Table 2.
Solution to the
minimization problem of equation (
30).
Table 2.
Solution to the minimization problem of equation (30).
| d | Minorant for | Equality cases |
| 0 | 0 | |
| | |
| 2 | |
| | δ |
| | id |
| | |
| | δ |
| | id |
for
, both these inequalities are used to go from
S to
, we conclude that for strictly positive
d, the solution for the
S minimization problem can be found in
Table 2, with
. The solution for
has been entirely described in [
5]. One concludes by replacing the values for the minimizing permutations into equation (
27).
In the cases
and
, the behavior of the eigenvalues can be easily deduced from the moment information, since one can identify in the formulas the moments of some probability distribution. In the case
, as it was argued in [
5], the larges eigenvalue of
Z converges to
and the
others converge to
. Such a behavior is typical for the model we study, with a spectrum containing one large eigenvalue and
(or
) identical smaller eigenvalues. The case
is somehow atypical: all the
eigenvalues behave like
. This is due to the fact that the “large” eigenvalue, which usually behaves as
has no contribution asymptotically. We summarize these facts in the following proposition.
Proposition 4.2. In the regime (which corresponds to considering a fixed ancilla dimension ), the eigenvalues of the random matrix Z are such that, almost surely, in the limit , In the regime , the (rescaled) empirical spectral distribution of Z converges to the Dirac mass at 1, : As in
Section 3, in order to understand fully the eigenvalues of the random matrix
Z, we need to understand the lower part of the spectrum, in the remaining cases
and
(the case
being treated in [
6]). This is done by “pinching” the matrix
Z by the projector
, orthogonal to the maximally entangled state
.
Proposition 4.3. The matrix converges, in moments, to the Dirac mass at 1, .
Proof. We follow the idea of the proof of Theorem 6.10 in [
6], compute the moments of the rank
matrix
, and show that they converge to the corresponding moments of the limit law:
After replacing
and developing the product, we get
where
is a set of the
choice functions
. The factor
is due to the normalization of the Bell states
. The moment
is computed via the graphical Weingarten calculus:
where
is the permutation associated to the choice function
describing the way
f connects the different instances of the channel (the arithmetic operations of indices
i should be understood modulo
p):
Exactly as in the proof of Theorem 6.10 from [
5], one has to understand the possible cancellations of high powers in
n. In order to do this, we rewrite the non-asymptotic equation (
42) as
As in [
5], we can show that for all permutations
, the sum over all choices
is exactly zero, where
Hence,
where
Since
,
has no fixed point, and hence
. Using the facts that
,
and
, we obtain that
with equality if and only if
.
The number of cycles of
is easily shown to be:
hence,
, with equality iff
. We can conclude that
, with equality if and only if
. Replacing these values in equation (
46), we obtain the announced result.
Using Cauchy’s interlacing theorem ([
19], Corollary III.1.5) for the eigenvalues of
and those of
Z, we obtain the complete description of the spectrum of the random output matrix.
Theorem 4.4. In the regime , with , the eigenvalues of satisfy:In probability, .
Almost surely, converges in distribution to the Dirac mass at 1, .
The remaining eigenvalues are null: .
We finally treat the regime , stating the results and underlining the (small) differences between the proofs in this case and the proofs of Proposition 4.3 and, respectively, of Theorem 4.4.
Proposition 4.5. In the regime , the matrix converges, in moments, to the Dirac mass at 1, .
Proof. As in the proof of Proposition 4.3, we obtain
where
Using the same arguments as before, we obtain that
with equality if and only if
.
Counting the number of cycles of
, we have that
, with equality iff
. We conclude that
, with equality if and only if
. The result follows by plugging the minimizing values into the asymptotic expression (
49).
Theorem 4.6. In the regime , with , the eigenvalues of satisfy:In probability, .
Almost surely, converges in distribution to the Dirac mass at 1, .
5. Asymptotics of the Von Neumann Entropy
Using the moment information and the behavior of the lower part of the spectrum deduced in
Section 4, we now analyze the von Neumann entropy of the random output matrix
Z:
In the physical literature, the idea of using conjugate quantum channels to tackle important questions, such as the additivity of the minimum output entropy for quantum channels, dates back to the work of A. Winter and P. Hayden [
3]. To bound the entropy of
Z, they use the following fact, coming from linear algebra, which is independent of the random model used: the largest eigenvalue of
Z is larger that the inverse of the dimension of the ancilla space,
. This bound (which is actually a bound on the operator norm of
Z) yields the following bound on the von Neumann entropy:
One of the main applications of the results in this paper is the fact that our exact spectral information yield better upper bounds for the von Neumann entropy in some specific cases.
Theorem 5.1. The asymptotic von Neumann entropy of the random output matrix is given by: If ( is an integer):
One can make the following very instructive observations about the above theorem. First, notice that in all cases where
, the main contribution to the von Neumann entropy is given by the lower part of the spectrum, and not by the main eigenvalue. This is in contrast with the case of the
p-Rényi entropies (
), where the largest eigenvalue gives the main contribution [
3].
Another important point concerns the fixed dimension case
and the linear case,
,
. In these regimes, the entropy defect
is macroscopic (
53), (
55). This improves considerably the naive bound (
52) and may provide more insight into the question of additivity of minimal output entropies, as argued in [
4,
10,
21]. However, Hastings’ techniques [
4], as well as the recent developments of Aubrun, Szarek and Werner [
10] do not seem to apply to this linear regime. Studying additivity violations in the linear regime and using the bounds in Theorem 5.1 to provide larger violations remain interesting open problems.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}