
Towards a Machine Learning Snowfall Retrieval Algorithm for GPM-IMERG †

 ,
,  ,
,  ,
, 

Abstract
:1. Introduction
2. Materials and Methods
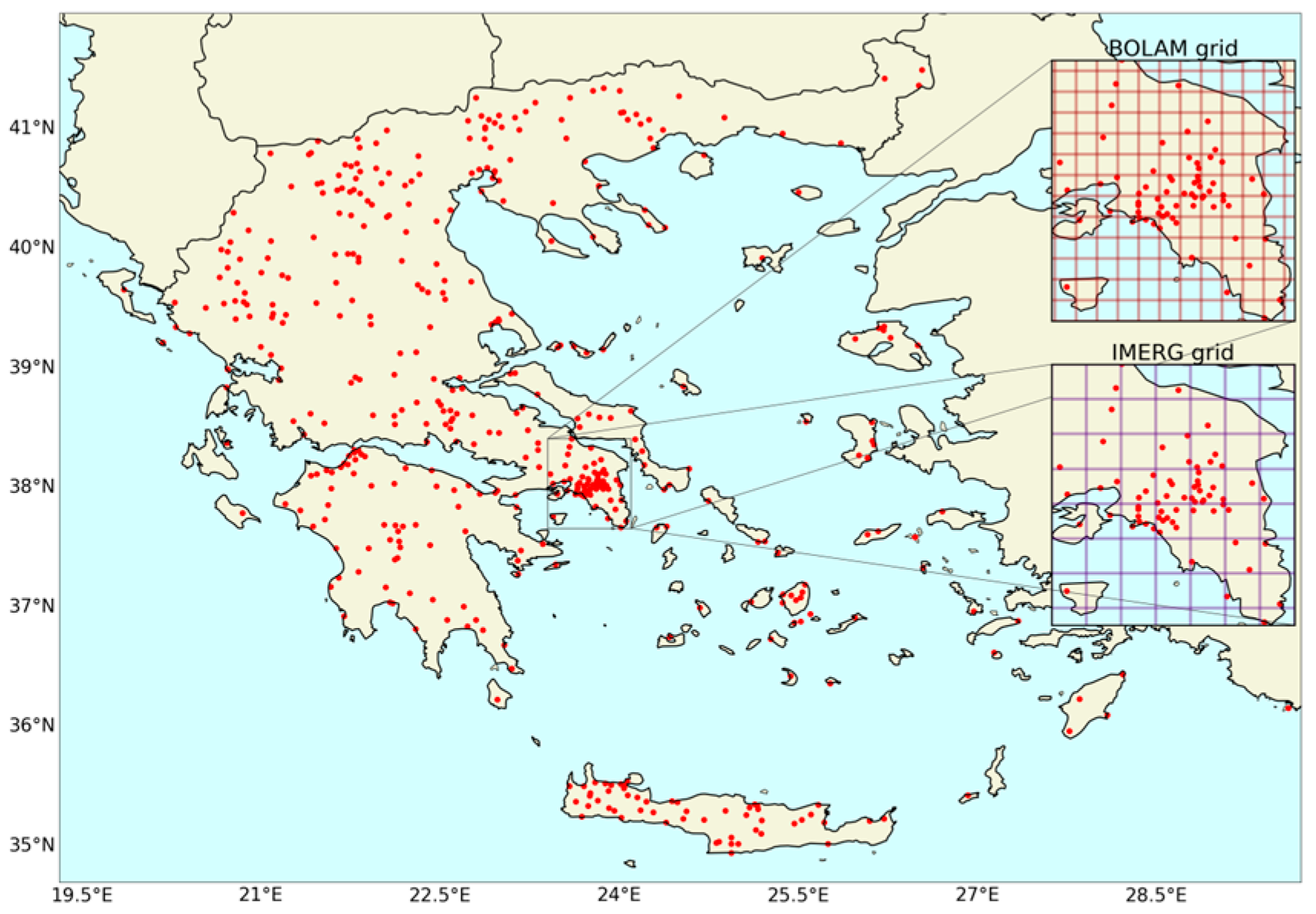
2.1. Description of the Acquired Data
2.2. Creation of a Custom Dataset
2.3. Machine Learning Models Used
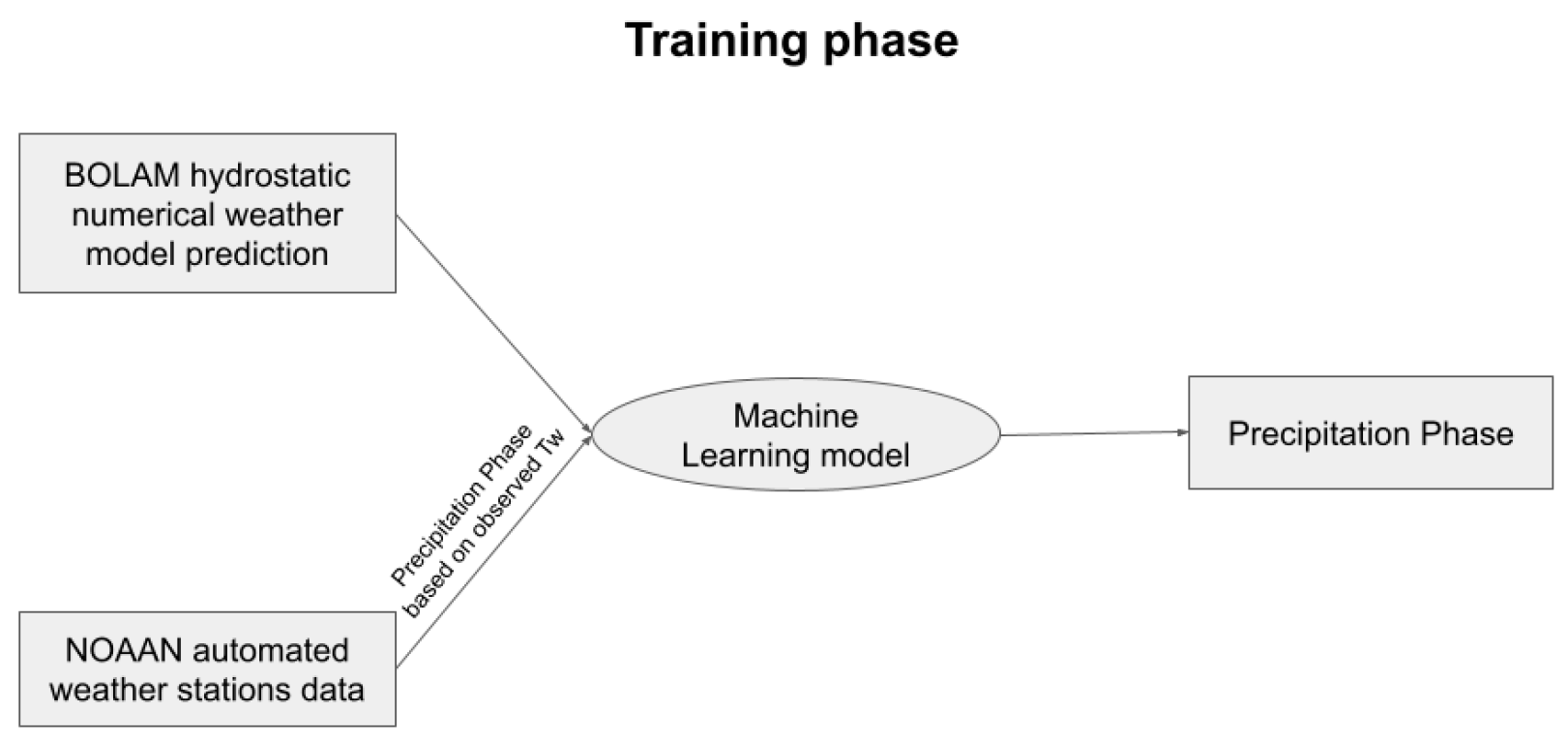
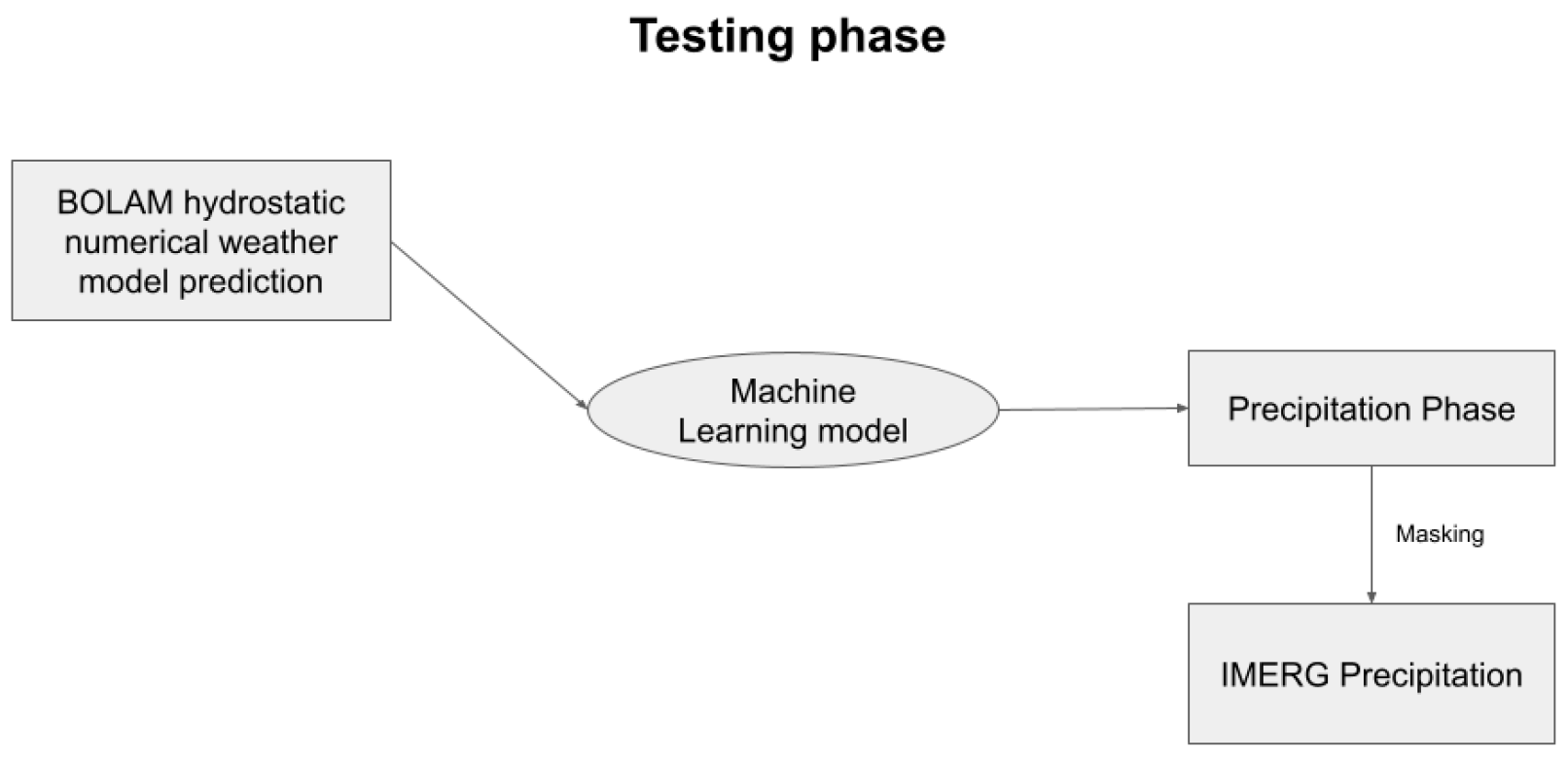
2.4. Training and Testing Process
2.5. Evaluation and Metrics
3. Results
Evaluation on the Testing Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Skofronick-Jackson, G.; Kulie, M.; Milani, L.; Munchak, S.J.; Wood, N.B.; Levizzani, V. Satellite estimation of falling snow: A global precipitation measurement (GPM) core observatory perspective. J. Appl. Meteorol. Clim. 2019, 58, 1429–1448. [Google Scholar] [CrossRef] [PubMed]
- Sims, E.M.; Liu, G. A Parameterization of the Probability of Snow–Rain Transition. J. Hydrometeorol. 2015, 16, 1466–1477. [Google Scholar] [CrossRef]
- Froidurot, S.; Zin, I.; Hingray, B.; Gautheron, A. Sensitivity of Precipitation Phase over the Swiss Alps to Different Meteorological Variables. J. Hydrometeorol. 2014, 15, 685–696. [Google Scholar] [CrossRef]
- Liao, L.; Meneghini, R.; Iguchi, T.; Detwiler, A. Use of Dual-Wavelength Radar for Snow Parameter Estimates. J. Atmos. Ocean. Technol. 2005, 22, 1494–1506. [Google Scholar] [CrossRef]
- NASA GPM. Available online: https://gpm.nasa.gov/resources/faq/how-do-various-forms-precipitation-map-imerg-probabilityliquidprecipitation-data (accessed on 12 May 2023).
- Behrangi, A.; Yin, X.; Rajagopal, S.; Stampoulis, D.; Ye, H. On distinguishing snowfall from rainfall using near-surface atmospheric information: Comparative analysis, uncertainties and hydrologic importance. Q. J. R. Meteorol. Soc. 2018, 144, 89–102. [Google Scholar] [CrossRef]
- Pradhan, R.K.; Markonis, Y.; Vargas Godoy, M.R.; Villalba-Pradas, A.; Andreadis, K.M.; Nikolopoulos, E.I.; Papalexiou, S.M.; Rahim, A.; Tapiador, F.J.; Hanel, M. Review of Gpm Imerg Performance: A Global Perspective. Remote Sens. Environ. 2022, 268, 12754. [Google Scholar] [CrossRef]
- You, Y.; Peters-Lidard, C.; Ringerud, S.; Haynes, J.M. Evaluation of Rainfall-Snowfall Separation Performance in Remote Sensing Datasets. Geophys. Res. Lett. 2021, 48, e2021GL094180. [Google Scholar] [CrossRef]
- Rebala, G.; Ravi, A.; Churiwala, S. An Introduction to Machine Learning; Springer: Cham, Switzerland, 2019; pp. 1–17. [Google Scholar] [CrossRef]
- Chase, R.J.; Harrison, D.R.; Burke, A.; Lackmann, G.M.; McGovern, A. A machine learning tutorial for operational meteorology. Part I: Traditional machine learning. Weather Forecast. 2022, 37, 1509–1529. [Google Scholar] [CrossRef]
- Matsuo, T.; Sasyo, Y. Melting of snowflakes below freezing level in the atmosphere. J. Meteor. Soc. Jpn. 1981, 59, 10–25. [Google Scholar] [CrossRef]
- Tang, G.; Long, D.; Behrangi, A.; Wang, C.; Hong, Y. Exploring Deep Neural Networks to Retrieve Rain and Snow in High Latitudes Using Multisensor and Reanalysis Data. Water Resour. Res. 2018, 54, 8253–8278. [Google Scholar] [CrossRef]
- Huffman, G.J.; Stocker, E.F.; Bolvin, D.T.; Nelkin, E.J.; Tan, J. GPM IMERG Early Precipitation L3 Half Hourly 0.1 Degree × 0.1 Degree V06; Goddard Earth Sciences Data and Information Services Center (GES DISC): Greenbelt, MD, USA, 2019. [Google Scholar] [CrossRef]
- Lagouvardos, K.; Kotroni, V.; Bezes, A.; Koletsis, I.; Kopania, T.; Lykoudis, S.; Mazarakis, N.; Papagiannaki, K.; Vougioukas, S. The automatic weather stations NOANN network of the National Observatory of Athens: Operation and database. Geosci. Data J. 2017, 4, 4–16. [Google Scholar] [CrossRef]
- Lagouvardos, K.; Kotroni, V.; Koussis, A.; Feidas, H.; Buzzi, A.; Malguzzi, P. The Meteorological Model BOLAM at the National Observatory of Athens: Assessment of Two-Year Operational Use. J. Appl. Meteorol. 2003, 42, 1667–1678. [Google Scholar] [CrossRef]
- Dafis, S.; Lolis, C.J.; Houssos, E.E.; Bartzokas, A. The atmospheric circulation characteristics favouring snowfall in an area with complex relief in Northwestern Greece. Int. J. Climatol. 2015, 36, 3561–3577. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Baum, E.B. On the capabilities of multilayer perceptrons. J. Complex. 1988, 4, 193–215. [Google Scholar] [CrossRef]
- NOAA Forecast Verification Glossary. Available online: https://www.swpc.noaa.gov/sites/default/files/images/u30/Forecast%20Verification%20Glossary.pdf (accessed on 12 May 2023).

{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall (POD) | Heidke Skill Score |
|---|---|---|---|
| Gradient Boosting | 0.87 | 0.76 | 0.80 |
| Feedforward Neural Network | 0.82 | 0.71 | 0.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dravilas, I.; Dafis, S.; Kyros, G.; Lagouvardos, K.; Koubarakis, M. Towards a Machine Learning Snowfall Retrieval Algorithm for GPM-IMERG. Environ. Sci. Proc. 2023, 26, 103. https://doi.org/10.3390/environsciproc2023026103
Dravilas I, Dafis S, Kyros G, Lagouvardos K, Koubarakis M. Towards a Machine Learning Snowfall Retrieval Algorithm for GPM-IMERG. Environmental Sciences Proceedings. 2023; 26(1):103. https://doi.org/10.3390/environsciproc2023026103
Chicago/Turabian StyleDravilas, Ioannis, Stavros Dafis, Georgios Kyros, Konstantinos Lagouvardos, and Manolis Koubarakis. 2023. "Towards a Machine Learning Snowfall Retrieval Algorithm for GPM-IMERG" Environmental Sciences Proceedings 26, no. 1: 103. https://doi.org/10.3390/environsciproc2023026103
APA StyleDravilas, I., Dafis, S., Kyros, G., Lagouvardos, K., & Koubarakis, M. (2023). Towards a Machine Learning Snowfall Retrieval Algorithm for GPM-IMERG. Environmental Sciences Proceedings, 26(1), 103. https://doi.org/10.3390/environsciproc2023026103