
Hybrid Surrogate Model for Timely Prediction of Flash Flood Inundation Maps Caused by Rapid River Overflow



Abstract
:1. Introduction
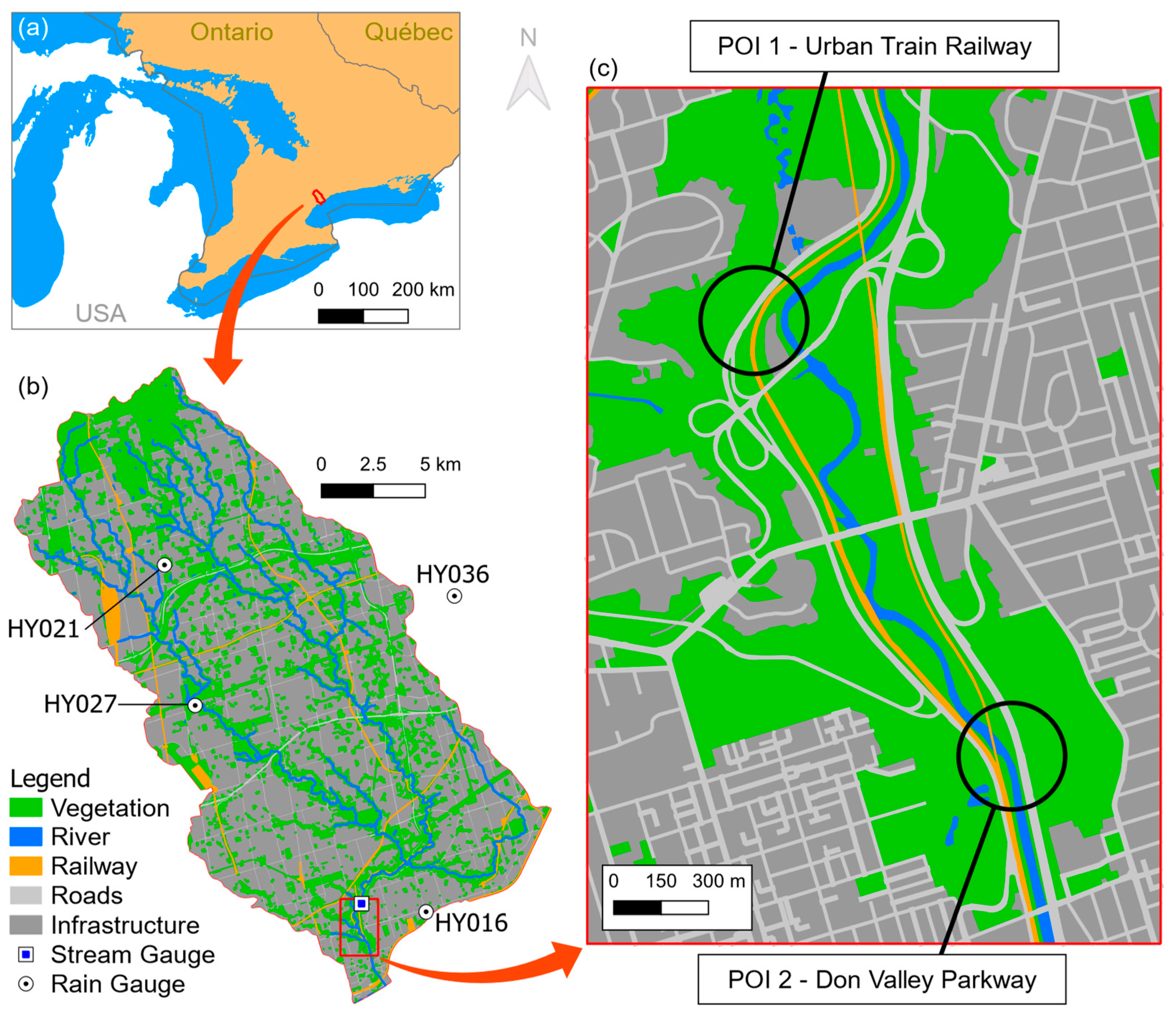
2. Study Area
3. Materials and Methods
3.1. Physically Based Model Used as Reference
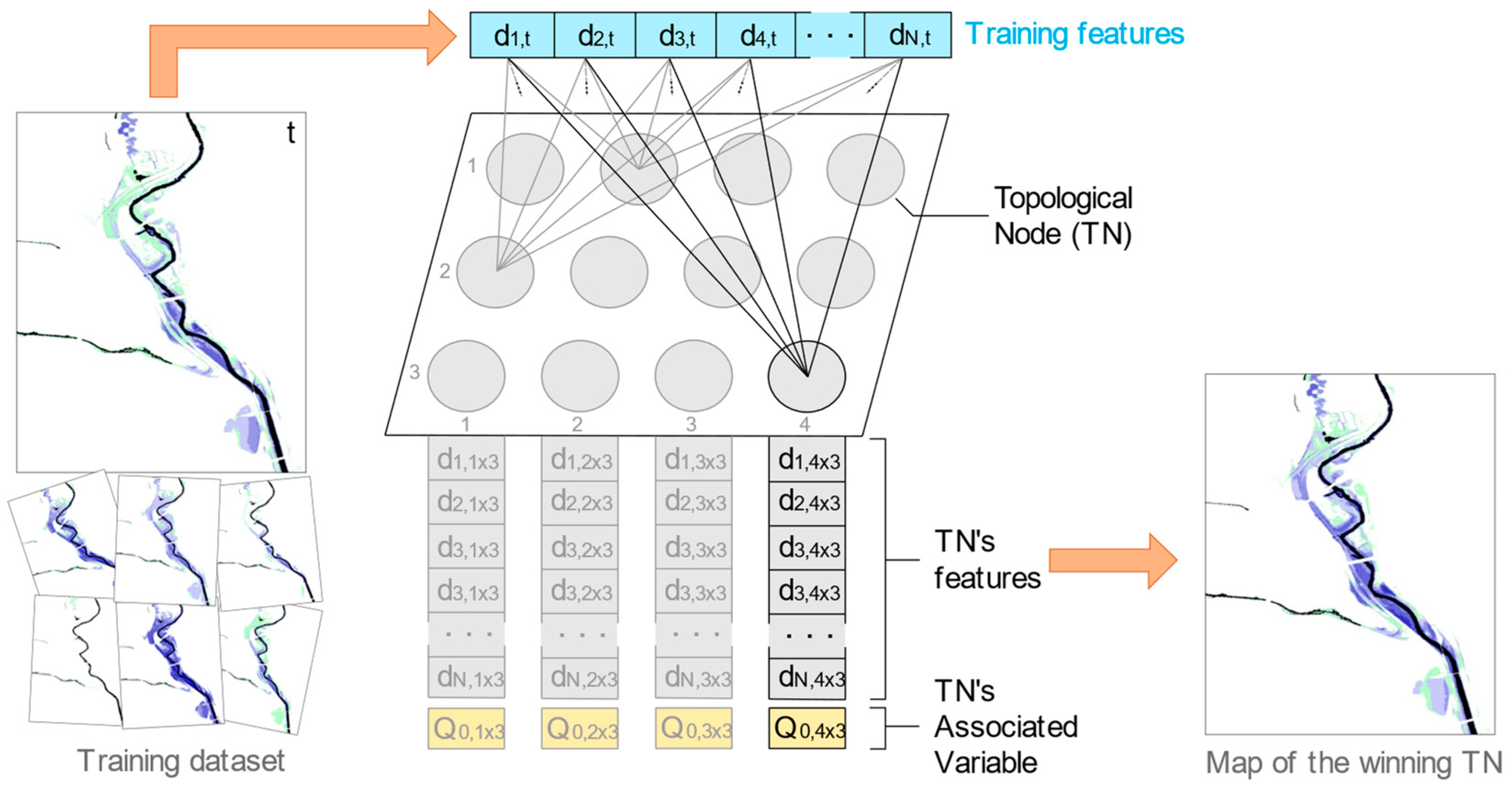
3.2. Self-Organizing Map (SOM)
3.3. Recurrent Network
3.3.1. Phase Space Composition
3.3.2. Nonlinear Autoregressive Neural Network with Exogenous Inputs (NARX)
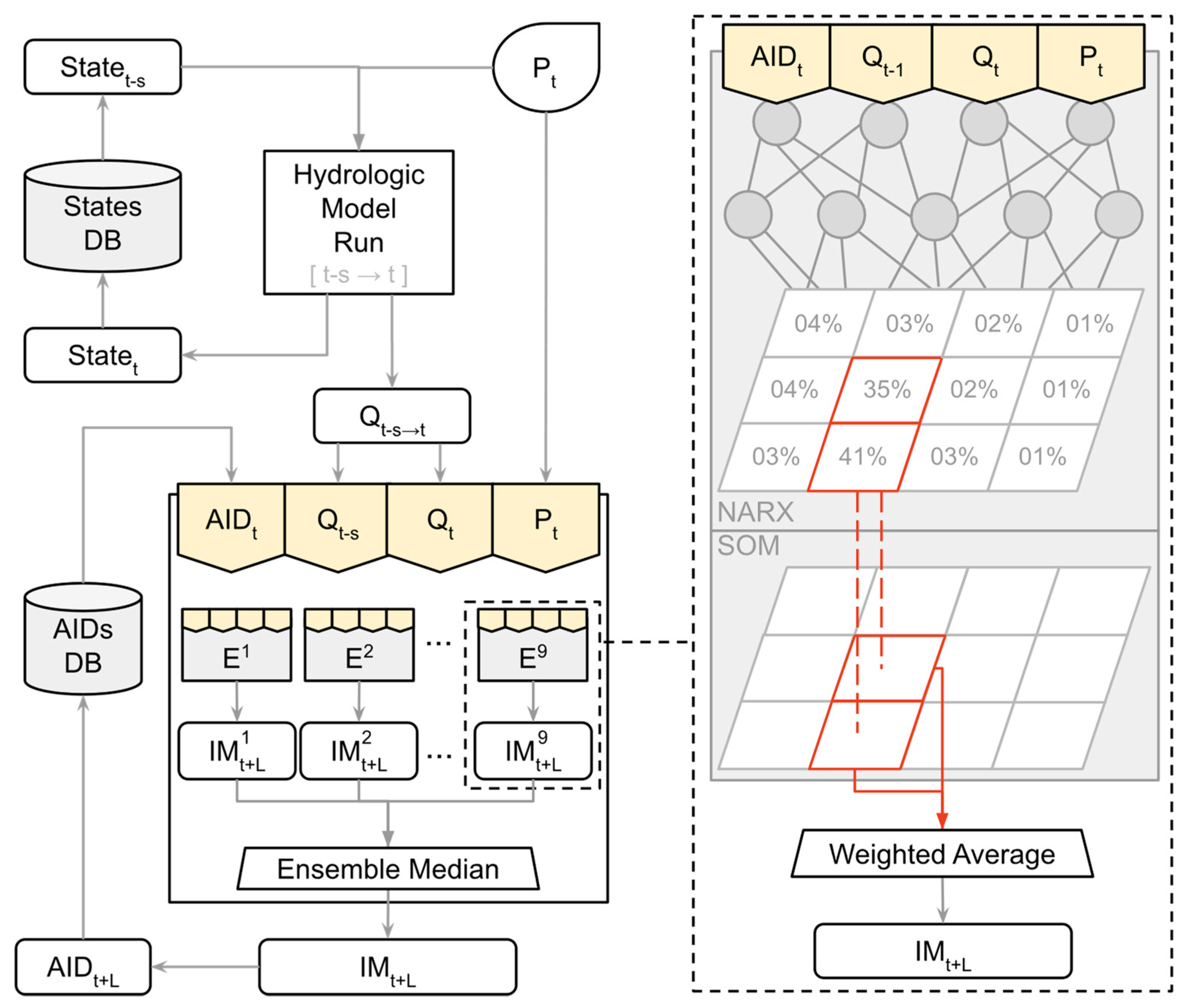
3.4. Update SOMs with Associated Variables
3.5. Hybrid Model Structure
3.6. Train/Validation and Test Datasets
3.7. Evaluation Metrics
4. Results and Discussion
4.1. Selected Rainfall-Runoff Events
4.2. Assessment of the SOM Models Trained
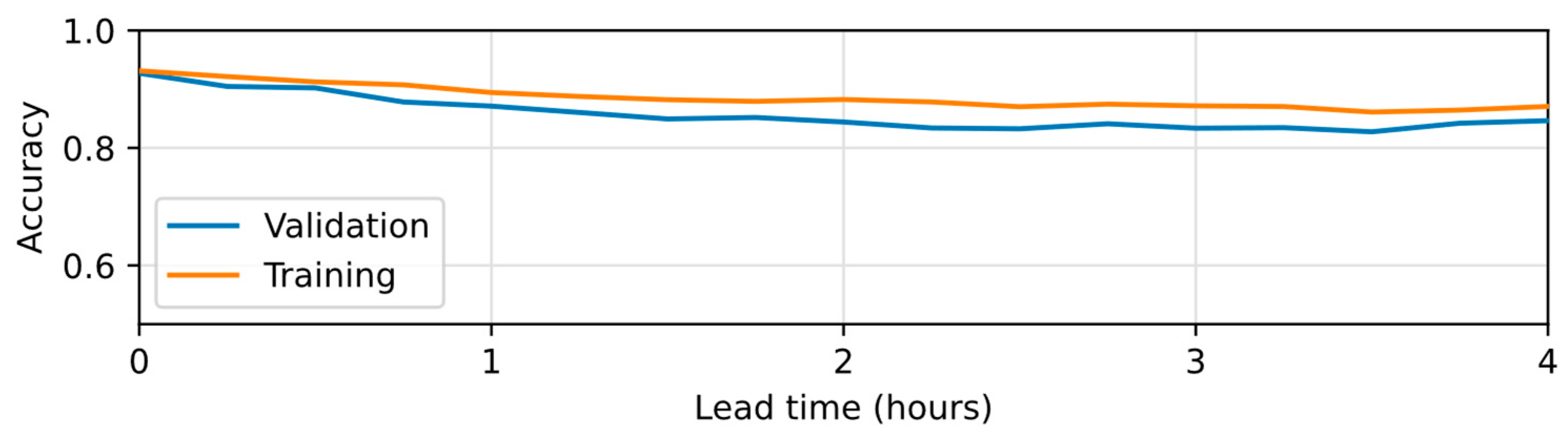
4.3. Assessment of the NARX Models Trained
4.4. Assessment of the Hybrid Model
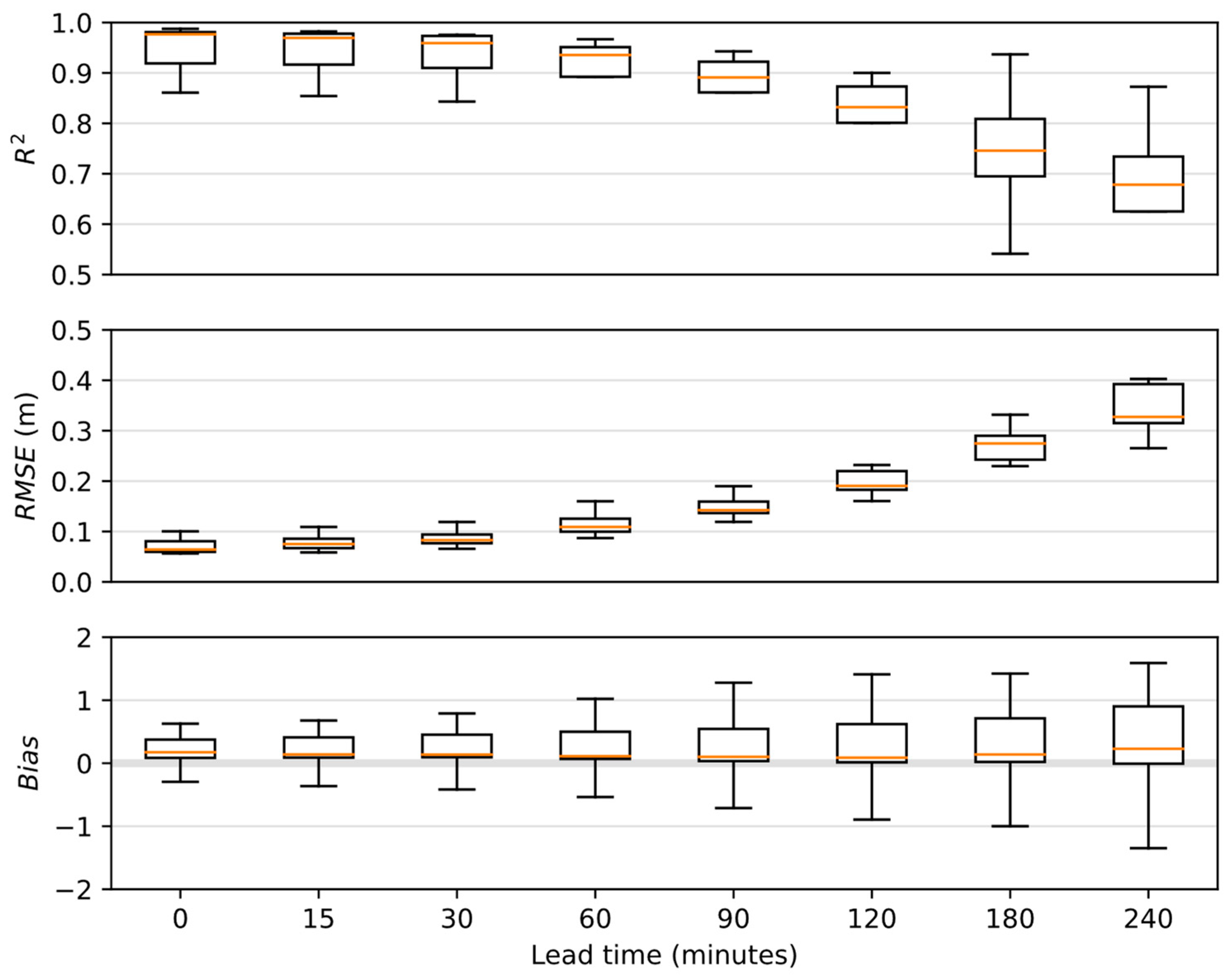
4.4.1. Global Performance
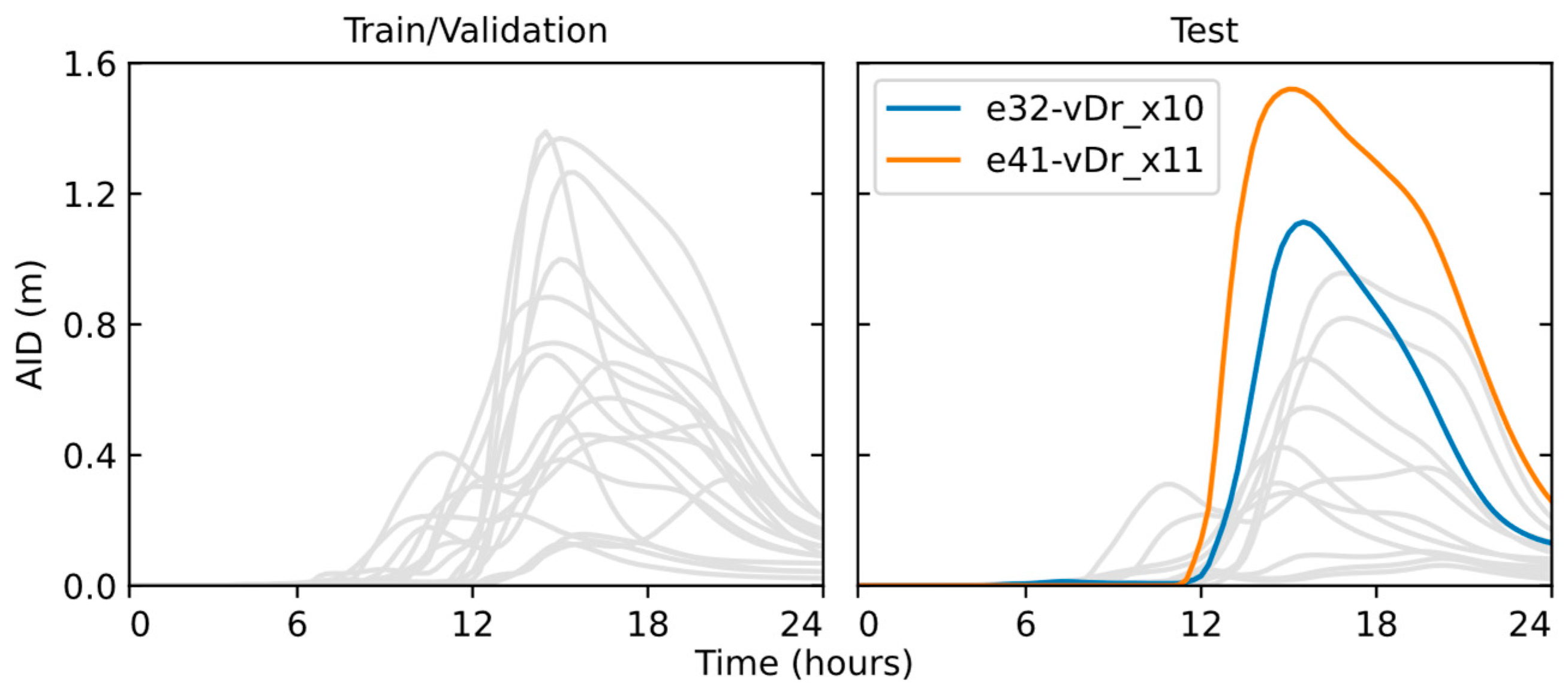
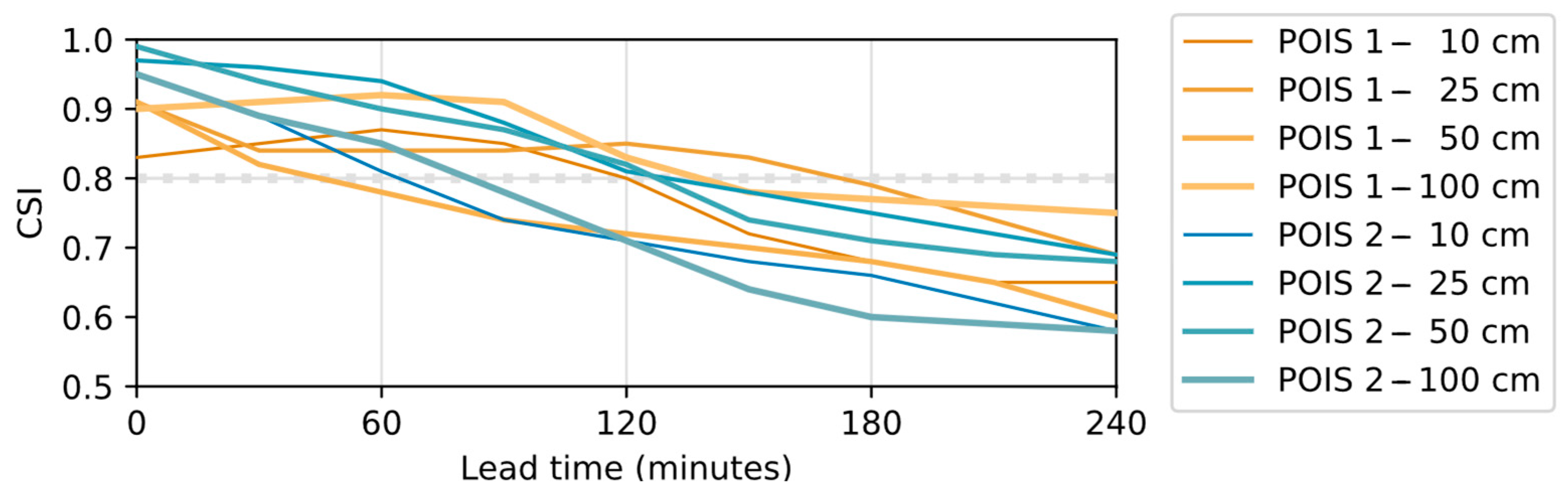
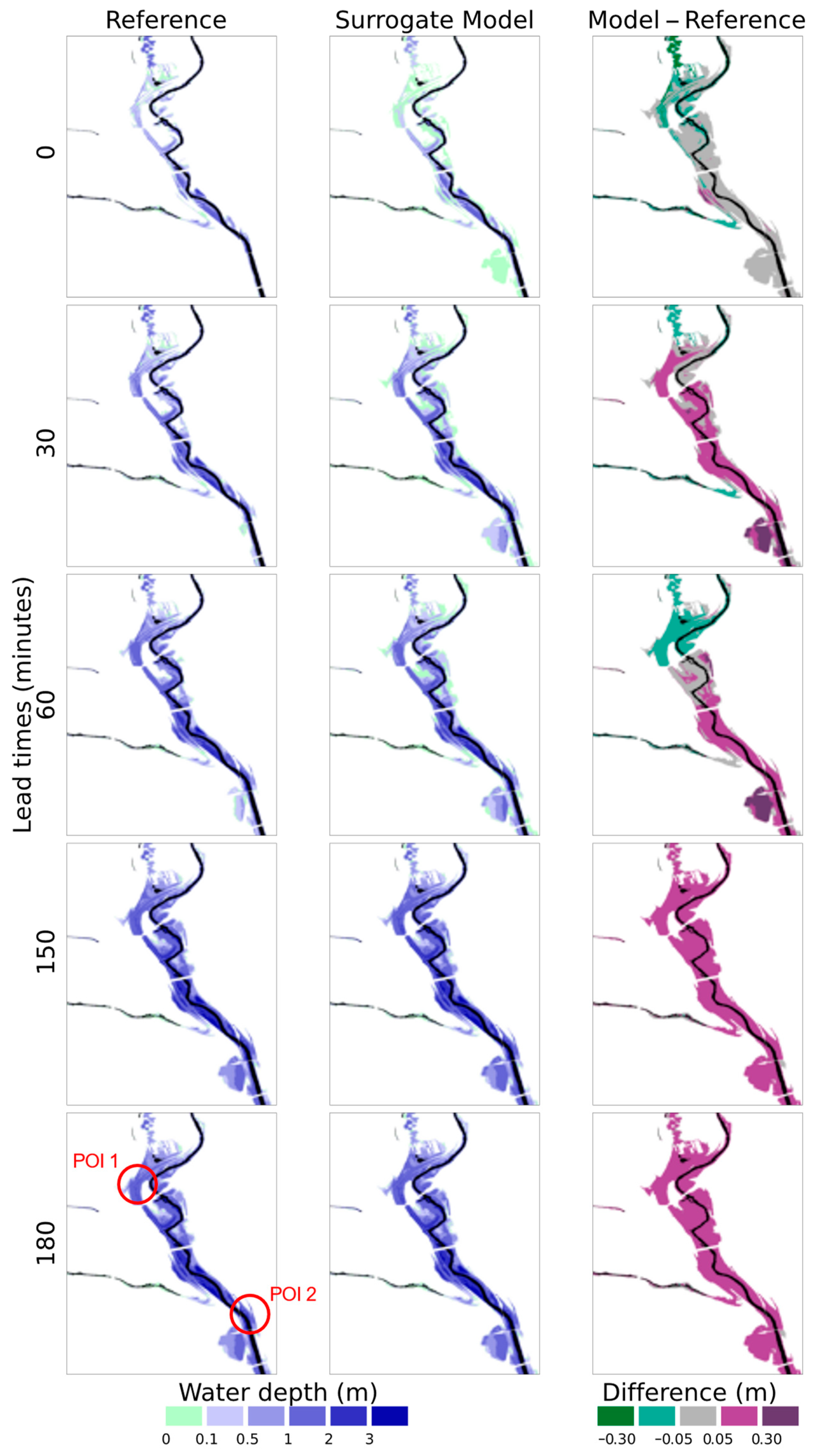
4.4.2. Performance on Selected Events
4.5. Runtime Comparison
4.6. Contraints and Limitations of the Methodology
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronyms | Meaning |
| AID | Average inundation depth |
| CMMF | Conditional Median/Mean Function |
| CSI | Critical Success Index |
| DEM | Digital Elevation Model |
| DRB | Don River Basin |
| EP | Estimated probability |
| NARX | Nonlinear Autoregressive neural network with exogenous inputs |
| POD | Probability of detection |
| POI | Point of interest |
| RE-O | Rainfall Events—Observations |
| RE-OH | Rainfall Events—Observations (Highest) |
| RE-SS | Rainfall Events—Synthetic by Shuffling |
| RE-SE | Rainfall Events—Synthetic by Extrapolation |
| RMSE | Root mean square error |
| SOM | Self-Organizing Maps |
| SR | Success Ratio |
| SWMM | Storm Water Management Model |
| TN | Topological node |
References
- WMO—World Meteorological Organization. Climate and Water; WMO: Geneva, Switzerland, 2020; Volume 69. [Google Scholar]
- Lehmann, J.; Coumou, D.; Frieler, K. Increased Record-Breaking Precipitation Events under Global Warming. Clim. Chang. 2015, 132, 501–515. [Google Scholar] [CrossRef]
- Zhao, G.; Gao, H.; Cuo, L. Effects of Urbanization and Climate Change on Peak Flows over the San Antonio River Basin, Texas. J. Hydrometeorol. 2016, 17, 2371–2389. [Google Scholar] [CrossRef]
- Sofia, G.; Roder, G.; Dalla Fontana, G.; Tarolli, P. Flood Dynamics in Urbanised Landscapes: 100 Years of Climate and Humans’ Interaction. Sci. Rep. 2017, 7, 40527. [Google Scholar] [CrossRef] [PubMed]
- Modrick, T.M.; Graham, R.; Shamir, E.; Jubach, R.; Spencer, C.R.; Sperfslage, J.A.; Georgakakos, K.P. Operational Flash Flood Warning Systems with Global Applicability. In Bold Visions for Environmental Modeling, Proceedings of the 7th International Congress on Environmental Modelling and Software (iEMSs 2014), San Diego, CA, USA, 15–19 June 2014; Brigham Young University: Provo, UT, USA; pp. 694–701.
- Hapuarachchi, H.A.P.; Wang, Q.J.; Pagano, T.C. A Review of Advances in Flash Flood Forecasting. Hydrol. Process. 2011, 25, 2771–2784. [Google Scholar] [CrossRef]
- Zanchetta, A.D.L.; Coulibaly, P. Recent Advances in Real-Time Pluvial Flash Flood Forecasting. Water 2020, 12, 570. [Google Scholar] [CrossRef] [Green Version]
- Costabile, P.; Costanzo, C.; de Lorenzo, G.; Macchione, F. Is Local Flood Hazard Assessment in Urban Areas Significantly Influenced by the Physical Complexity of the Hydrodynamic Inundation Model? J. Hydrol. 2020, 580, 124231. [Google Scholar] [CrossRef]
- Nobre, A.D.; Cuartas, L.A.; Hodnett, M.; Rennó, C.D.; Rodrigues, G.; Silveira, A.; Waterloo, M.; Saleska, S. Height Above the Nearest Drainage—A Hydrologically Relevant New Terrain Model. J. Hydrol. 2011, 404, 13–29. [Google Scholar] [CrossRef] [Green Version]
- Follum, M.L.; Tavakoly, A.A.; Niemann, J.D.; Snow, A.D. AutoRAPID: A Model for Prompt Streamflow Estimation and Flood Inundation Mapping over Regional to Continental Extents. J. Am. Water Resour. Assoc. 2017, 53, 280–299. [Google Scholar] [CrossRef]
- Samela, C.; Persiano, S.; Bagli, S.; Luzzi, V.; Mazzoli, P.; Humer, G.; Reithofer, A.; Essenfelder, A.; Amadio, M.; Mysiak, J.; et al. Safer_RAIN: A DEM-Based Hierarchical Filling-&-Spilling Algorithm for Pluvial Flood Hazard Assessment and Mapping across Large Urban Areas. Water 2020, 12, 1514. [Google Scholar] [CrossRef]
- Hu, A.; Demir, I. Real-Time Flood Mapping on Client-Side Web Systems Using Hand Model. Hydrology 2021, 8, 65. [Google Scholar] [CrossRef]
- Teng, J.; Jakeman, A.J.; Vaze, J.; Croke, B.F.W.; Dutta, D.; Kim, S. Flood Inundation Modelling: A Review of Methods, Recent Advances and Uncertainty Analysis. Environ. Model. Softw. 2017, 90, 201–216. [Google Scholar] [CrossRef]
- Hocini, N.; Payrastre, O.; Bourgin, F.; Gaume, E.; Davy, P.; Lague, D.; Poinsignon, L.; Pons, F.; Bouguenais, F.; Rennes, G.; et al. Performance of Automated Methods for Flash Flood Inundation Mapping: A Comparison of a Digital Terrain Model (DTM) Filling and Two Hydrodynamic Methods. Hydrol. Earth Syst. Sci. 2021, 25, 2979–2995. [Google Scholar] [CrossRef]
- Jan, A.; Coon, E.T.; Graham, J.D.; Painter, S.L. A Subgrid Approach for Modeling Microtopography Effects on Overland Flow. Water Resour. Res. 2018, 54, 6153–6167. [Google Scholar] [CrossRef]
- Cao, X.; Ni, G.; Qi, Y.; Liu, B. Does Subgrid Routing Information Matter for Urban Flood Forecasting? A Multiscenario Analysis at the Land Parcel Scale. J. Hydrometeorol. 2020, 21, 2083–2099. [Google Scholar] [CrossRef]
- Nkwunonwo, U.C.; Whitworth, M.; Baily, B. Urban Flood Modelling Combining Cellular Automata Framework with Semi-Implicit Finite Difference Numerical Formulation. J. Afr. Earth Sci. 2019, 150, 272–281. [Google Scholar] [CrossRef] [Green Version]
- Dazzi, S.; Vacondio, R.; Dal Palù, A.; Mignosa, P. A Local Time Stepping Algorithm for GPU-Accelerated 2D Shallow Water Models. Adv. Water Resour. 2018, 111, 274–288. [Google Scholar] [CrossRef]
- Ming, X.; Liang, Q.; Xia, X.; Li, D.; Fowler, H.J. Real-Time Flood Forecasting Based on a High-Performance 2-D Hydrodynamic Model and Numerical Weather Predictions. Water Resour. Res. 2020, 56, e2019WR025583. [Google Scholar] [CrossRef]
- Razavi, S.; Tolson, B.A.; Burn, D.H. Review of Surrogate Modeling in Water Resources. Water Resour. Res. 2012, 48, 7401. [Google Scholar] [CrossRef]
- Bermúdez, M.; Cea, L.; Puertas, J. A Rapid Flood Inundation Model for Hazard Mapping Based on Least Squares Support Vector Machine Regression. J. Flood Risk Manag. 2019, 12, e12522. [Google Scholar] [CrossRef] [Green Version]
- Berkhahn, S.; Fuchs, L.; Neuweiler, I. An Ensemble Neural Network Model for Real-Time Prediction of Urban Floods. J. Hydrol. 2019, 575, 743–754. [Google Scholar] [CrossRef]
- Chang, L.-C.; Amin, M.; Yang, S.-N.; Chang, F.-J. Building ANN-Based Regional Multi-Step-Ahead Flood Inundation Forecast Models. Water 2018, 10, 1283. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.I.; Keum, H.J.; Han, K.Y. Real-Time Urban Inundation Prediction Combining Hydraulic and Probabilistic Methods. Water 2019, 11, 293. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.I.; Han, K.Y. Data-Driven Approach for the Rapid Simulation of Urban Flood Prediction. KSCE J. Civ. Eng. 2020, 24, 1932–1943. [Google Scholar] [CrossRef]
- Ontario Ministry of Natural Resources and Forestry. Ontario Land Cover Compilation Data Specifications Version 2.0; Ontario Ministry of Natural Resources and Forestry: Peterborough, ON, Canada, 2014. [Google Scholar]
- Nirupama, N.; Armenakis, C.; Montpetit, M. Is Flooding in Toronto a Concern? Nat. Hazards 2014, 72, 1259–1264. [Google Scholar] [CrossRef]
- Devlin, M. Rain Causes Flooding on Low-Lying Toronto Highway Ramps. DailyHive News, 2 August 2020. Available online: https://dailyhive.com/toronto/highway-ramp-flooding-rain (accessed on 15 December 2021).
- Rossman, L.A. Storm Water Management Model User’s Manual Version 5.1; USA Environmental Protection Agency: Cincinnati, OH, USA, 2015. [Google Scholar]
- CHI; PCSWMM. Available online: https://www.pcswmm.com/ (accessed on 22 July 2021).
- Meesuk, V.; Vojinovic, Z.; Mynett, A.E.; Abdullah, A.F. Urban Flood Modelling Combining Top-View LiDAR Data with Ground-View SfM Observations. Adv. Water Resour. 2015, 75, 105–117. [Google Scholar] [CrossRef]
- Diakakis, M.; Andreadakis, E.; Nikolopoulos, E.I.; Spyrou, N.I.; Gogou, M.E.; Deligiannakis, G.; Katsetsiadou, N.K.; Antoniadis, Z.; Melaki, M.; Georgakopoulos, A.; et al. An Integrated Approach of Ground and Aerial Observations in Flash Flood Disaster Investigations. The Case of the 2017 Mandra Flash Flood in Greece. Int. J. Disaster Risk Reduct. 2019, 33, 290–309. [Google Scholar] [CrossRef]
- Ricketts, J.; Loftin, M.K.; Merritt, F. Standard Handbook for Civil Engineers, 5th ed.; McGraw-Hill Education: New York, NY, USA, 2004; ISBN 0071364730. [Google Scholar]
- Kohonen, T. Self-Organized Formation of Topologically Correct Feature Maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Ultsch, A.; Lötsch, J. Machine-Learned Cluster Identification in High-Dimensional Data. J. Biomed. Inform. 2017, 66, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Araújo, A.F.R.; Antonino, V.O.; Ponce-Guevara, K.L. Self-Organizing Subspace Clustering for High-Dimensional and Multi-View Data. Neural Netw. 2020, 130, 253–268. [Google Scholar] [CrossRef] [PubMed]
- Koua, E.L.; Maceachren, A.; Kraak, M.J. Evaluating the Usability of Visualization Methods in an Exploratory Geovisualization Environment. Int. J. Geogr. Inf. Sci. 2006, 20, 425–448. [Google Scholar] [CrossRef]
- Belkhiri, L.; Mouni, L.; Tiri, A.; Narany, T.S.; Nouibet, R. Spatial Analysis of Groundwater Quality Using Self-Organizing Maps. Groundw. Sustain. Dev. 2018, 7, 121–132. [Google Scholar] [CrossRef] [Green Version]
- Farsadnia, F.; Rostami Kamrood, M.; Moghaddam Nia, A.; Modarres, R.; Bray, M.T.; Han, D.; Sadatinejad, J. Identification of Homogeneous Regions for Regionalization of Watersheds by Two-Level Self-Organizing Feature Maps. J. Hydrol. 2014, 509, 387–397. [Google Scholar] [CrossRef]
- Li, M.; Jiang, Z.; Zhou, P.; Le Treut, H.; Li, L. Projection and Possible Causes of Summer Precipitation in Eastern China Using Self-Organizing Map. Clim. Dyn. 2020, 54, 2815–2830. [Google Scholar] [CrossRef]
- Rodríguez-Alarcón, R.; Lozano, S. SOM-Based Decision Support System for Reservoir Operation Management. J. Hydrol. Eng. 2017, 22, 04017012. [Google Scholar] [CrossRef]
- Clark, S.; Sisson, S.A.; Sharma, A. Tools for Enhancing the Application of Self-Organizing Maps in Water Resources Research and Engineering. Adv. Water Resour. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Kohonen, T. MATLAB Implementations and Applications of the Self-Organizing Map; Unigrafia Oy: Helsinki, Finland, 2014; ISBN 9789526036786. [Google Scholar]
- Vettigli, G. MiniSom: Minimalistic and NumPy-Based Implementation of the Self Organizing Map; Release 2.2.9. Available online: https://github.com/JustGlowing/minisom (accessed on 15 December 2021).
- Coulibaly, P.; Anctil, F.; Bobée, B. Daily Reservoir Inflow Forecasting Using Artificial Neural Networks with Stopped Training Approach. J. Hydrol. 2000, 230, 244–257. [Google Scholar] [CrossRef]
- Fukushima, K. Visual Feature Extraction by a Multilayered Network of Analog Threshold Elements. IEEE Trans. Syst. Sci. Cybern. 1969, 5, 322–333. [Google Scholar] [CrossRef]
- Bridle, J.S. Probabilistic Interpretation of Feedforward Classification Network Outputs, with Relationships to Statistical Pattern Recognition. In Neurocomputing; Springer: Berlin/Heidelberg, Germany, 1990; pp. 227–236. [Google Scholar] [CrossRef]
- Jung, Y. Multiple Predicting K-Fold Cross-Validation for Model Selection. J. Nonparametr. Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Erechtchoukova, M.; Khaiter, P.; Saffarpour, S. Short-Term Predictions of Hydrological Events on an Urbanized Watershed Using Supervised Classification. Water Resour. Manag. 2016, 30, 4329–4343. [Google Scholar] [CrossRef]
- CBC News. Toronto’s Don Valley Parkway Reopens after Severe Flooding. CBC News, 29 May 2013. Available online: https://www.cbc.ca/news/canada/toronto/toronto-s-don-valley-parkway-reopens-after-severe-flooding-1.1361421 (accessed on 15 December 2021).
- CBC News. Toronto’s All Wet: Some Images From The Flash Floods That Hit T.O. Last Nigh. CBC News, 9 July 2013. Available online: https://www.cbc.ca/strombo/news/torontos-all-wet-some-images-from-the-flash-floods-that-hit-to-last-night.h (accessed on 15 December 2021).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
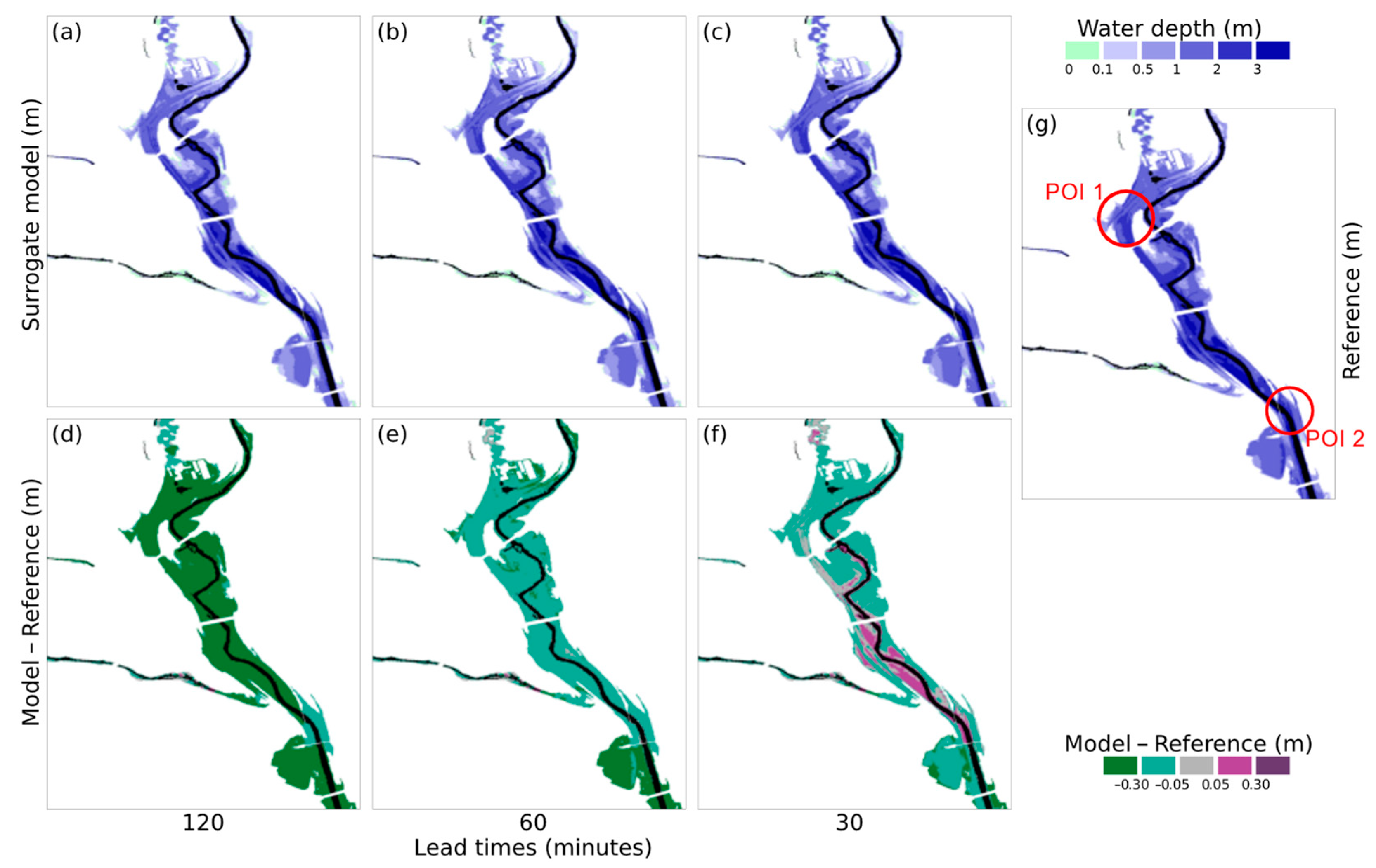{kind=link}
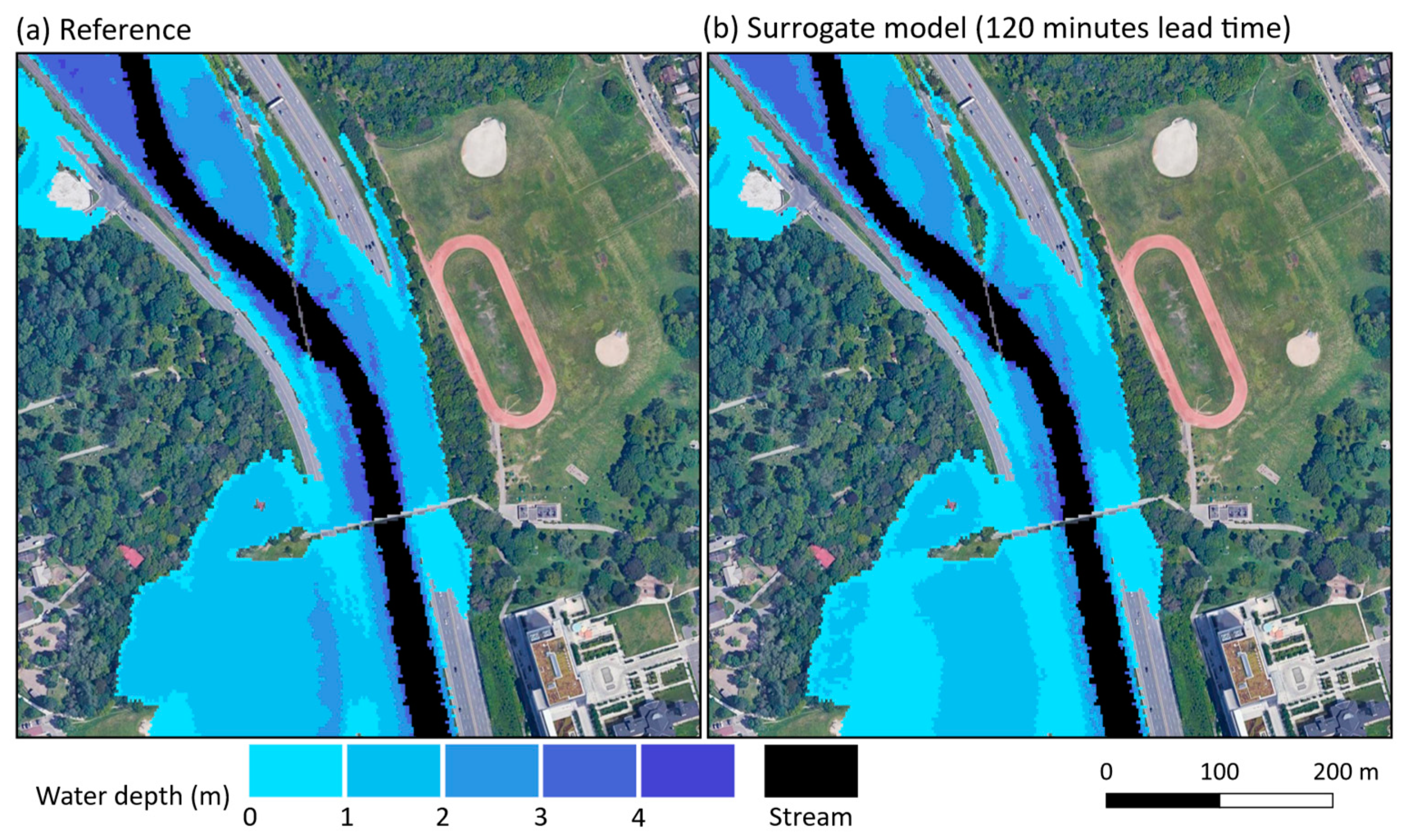{kind=link}
| Acronym | Description | Number of Events |
|---|---|---|
| RE-O | Rainfall Events—Observations | 87 |
| RE-OH | Rainfall Events—Observations (Highest) | 10 |
| RE-SS | Rainfall Events—Synthetic by Shuffling | 87 |
| RE-SE | Rainfall Events—Synthetic by Extrapolation | 10 |
| Dataset | Events | Total P (mm) | Peak Q (m3/s) | Peak AID (m) | |||
|---|---|---|---|---|---|---|---|
| Min | Max | Min | Max | Min | Max | ||
| Train/validation | 17 | 84.1 | 238.6 | 83.6 | 294.9 | 0.13 | 1.39 |
| Test | 13 | 95.2 | 246.9 | 64.1 | 274.9 | 0.06 | 1.52 |
| Metric | Water Depth (cm) | Lead Time (minutes) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 30 | 60 | 90 | 120 | 150 | 180 | 240 | ||
| POD | 10 | 0.97 | 0.97 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 | 1.00 |
| 25 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | |
| 50 | 0.97 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | |
| 100 | 0.91 | 0.93 | 0.95 | 0.96 | 0.97 | 0.97 | 0.97 | 0.97 | |
| SR | 10 | 0.86 | 0.87 | 0.89 | 0.86 | 0.80 | 0.73 | 0.68 | 0.65 |
| 25 | 0.93 | 0.85 | 0.85 | 0.85 | 0.85 | 0.83 | 0.79 | 0.70 | |
| 50 | 0.94 | 0.84 | 0.79 | 0.75 | 0.73 | 0.71 | 0.68 | 0.61 | |
| 100 | 0.99 | 0.98 | 0.97 | 0.94 | 0.85 | 0.81 | 0.79 | 0.76 | |
| CSI | 10 | 0.83 | 0.85 | 0.87 | 0.85 | 0.80 | 0.72 | 0.68 | 0.65 |
| 25 | 0.91 | 0.84 | 0.84 | 0.84 | 0.85 | 0.83 | 0.79 | 0.69 | |
| 50 | 0.91 | 0.82 | 0.78 | 0.74 | 0.72 | 0.70 | 0.68 | 0.60 | |
| 100 | 0.90 | 0.91 | 0.92 | 0.91 | 0.83 | 0.78 | 0.77 | 0.75 | |
| Metric | Water Depth (cm) | Lead Time (minutes) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 30 | 60 | 90 | 120 | 150 | 180 | 240 | ||
| POD | 10 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| 25 | 0.97 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 1.00 | |
| 50 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| 100 | 0.97 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| SR | 10 | 0.95 | 0.90 | 0.81 | 0.74 | 0.71 | 0.68 | 0.66 | 0.58 |
| 25 | 1.00 | 0.97 | 0.95 | 0.88 | 0.82 | 0.79 | 0.75 | 0.70 | |
| 50 | 0.99 | 0.94 | 0.90 | 0.87 | 0.82 | 0.74 | 0.71 | 0.68 | |
| 100 | 0.97 | 0.89 | 0.85 | 0.78 | 0.71 | 0.64 | 0.60 | 0.58 | |
| CSI | 10 | 0.95 | 0.89 | 0.81 | 0.74 | 0.71 | 0.68 | 0.66 | 0.58 |
| 25 | 0.97 | 0.96 | 0.94 | 0.88 | 0.81 | 0.78 | 0.75 | 0.69 | |
| 50 | 0.99 | 0.94 | 0.90 | 0.87 | 0.82 | 0.74 | 0.71 | 0.68 | |
| 100 | 0.95 | 0.89 | 0.85 | 0.78 | 0.71 | 0.64 | 0.60 | 0.58 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zanchetta, A.D.L.; Coulibaly, P. Hybrid Surrogate Model for Timely Prediction of Flash Flood Inundation Maps Caused by Rapid River Overflow. Forecasting 2022, 4, 126-148. https://doi.org/10.3390/forecast4010007
Zanchetta ADL, Coulibaly P. Hybrid Surrogate Model for Timely Prediction of Flash Flood Inundation Maps Caused by Rapid River Overflow. Forecasting. 2022; 4(1):126-148. https://doi.org/10.3390/forecast4010007
Chicago/Turabian StyleZanchetta, Andre D. L., and Paulin Coulibaly. 2022. "Hybrid Surrogate Model for Timely Prediction of Flash Flood Inundation Maps Caused by Rapid River Overflow" Forecasting 4, no. 1: 126-148. https://doi.org/10.3390/forecast4010007
APA StyleZanchetta, A. D. L., & Coulibaly, P. (2022). Hybrid Surrogate Model for Timely Prediction of Flash Flood Inundation Maps Caused by Rapid River Overflow. Forecasting, 4(1), 126-148. https://doi.org/10.3390/forecast4010007