
Switching Coefficients or Automatic Variable Selection: An Application in Forecasting Commodity Returns


Abstract
:1. Introduction
2. Methodology
- A simple AR(1) modelwhich represents the benchmark for our analysis and that sets the only asset-specific factor as the past performance of the asset. The standard benchmark in the forecasting literature should not be confused with our definition of the asset-specific momentum factor that also employs AR(p) models. Clearly, this model nests the standard no-change (constant mean) model often popular in empirical finance, under which the asset returns are IID. The use of the linear autoregressive models is common in the literature, see, e.g., Koki et al. [27]. Using more lag to capture stronger persistence worsened standard information criteria for the majority of the commodities examined;
- A macro factor-based HMM, where and the parameters are driven by a Markov state variable;
- A macro factor-based stepwise regression, which is obtained when and the macro variables are recursively selected by backward/forward stepwise procedures;
- An HMM model that includes macro as well as asset-specific factors, which is obtained when and the parameters (, , and ) are driven by a Markov state variable;
- An HMM model that includes macro as well as aggregate (across all commodities) asset-specific factors, obtained when and and the parameters (, , and ) are driven by a Markov state variable;
- A stepwise regression model that includes macro as well as asset-specific factors, where and the parameters are recursively selected by backward/forward stepwise procedures;
- A stepwise regression model that includes macro as well as aggregate (across all commodities) asset-specific factors, where (while ) and the variables are recursively selected by backward/forward stepwise procedures;
- A stepwise regression model that includes macro- as well as aggregate and individual asset-specific factors, which is obtained when all the dummy variables are active and the variables are recursively selected by backward/forward stepwise methods.
2.1. Stepwise Regressions
2.2. Hidden Markov Models
3. Data
3.1. Commodity Futures Return Series
3.2. Macroeconomic Factors
3.3. Commodity Factors
4. The Statistical Predictive Performance
5. Asset Allocation Performance
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Akyildirim, E.; Bariviera, A.F.; Nguyen, D.K.; Sensoy, A. Forecasting high-frequency stock returns: A comparison of alternative methods. Ann. Oper. Res. 2022, 1–52. [Google Scholar] [CrossRef]
- Rapach, D.E.; Wohar, M.E. In-sample vs. out-of-sample tests of stock return predictability in the context of data mining. J. Empir. Financ. 2006, 13, 231–247. [Google Scholar] [CrossRef]
- Ang, A.; Bekaert, G. How regimes affect asset allocation. Financ. Anal. J. 2004, 60, 86–99. [Google Scholar] [CrossRef]
- Paye, B.S.; Timmermann, A. Instability of return prediction models. J. Empir. Financ. 2006, 13, 274–315. [Google Scholar] [CrossRef]
- Welch, I.; Goyal, A. A comprehensive look at the empirical performance of equity premium prediction. Rev. Financ. Stud. 2008, 21, 1455–1508. [Google Scholar] [CrossRef]
- Campbell, J.Y.; Thompson, S.B. Predicting excess stock returns out of sample: Can anything beat the historical average? Rev. Financ. Stud. 2008, 21, 1509–1531. [Google Scholar] [CrossRef] [Green Version]
- Clark, T.E.; McCracken, M.W. The predictive content of the output gap for inflation: Resolving in-sample and out-of-sample evidence. J. Money, Credit. Bank. 2006, 38, 1127–1148. [Google Scholar] [CrossRef] [Green Version]
- Bossaerts, P.; Hillion, P. Implementing statistical criteria to select return forecasting models: What do we learn? Rev. Financ. Stud. 1999, 12, 405–428. [Google Scholar] [CrossRef] [Green Version]
- Giampietro, M.; Guidolin, M.; Pedio, M. Estimating stochastic discount factor models with hidden regimes: Applications to commodity pricing. Eur. J. Oper. Res. 2018, 265, 685–702. [Google Scholar] [CrossRef]
- Guidolin, M.; Pedio, M. Forecasting commodity futures returns with stepwise regressions: Do commodity-specific factors help? Ann. Oper. Res. 2021, 299, 1317–1356. [Google Scholar] [CrossRef]
- Bodie, Z.; Rosansky, V.I. Risk and return in commodity futures. Financ. Anal. J. 1980, 36, 27–39. [Google Scholar] [CrossRef]
- Breeden, D.T. Consumption risk in futures markets. J. Financ. 1980, 35, 503–520. [Google Scholar] [CrossRef]
- Bessembinder, H.; Chan, K. Time-varying risk premia and forecastable returns in futures markets. J. Financ. Econ. 1992, 32, 169–193. [Google Scholar] [CrossRef]
- Acharya, V.V.; Lochstoer, L.A.; Ramadorai, T. Limits to arbitrage and hedging: Evidence from commodity markets. J. Financ. Econ. 2013, 109, 441–465. [Google Scholar] [CrossRef] [Green Version]
- De Roon, F.A.; Nijman, T.E.; Veld, C. Hedging pressure effects in futures markets. J. Financ. 2000, 55, 1437–1456. [Google Scholar] [CrossRef] [Green Version]
- Gorton, G.B.; Hayashi, F.; Rouwenhorst, K.G. The fundamentals of commodity futures returns. Rev. Financ. 2013, 17, 35–105. [Google Scholar] [CrossRef]
- Gospodinov, N.; Ng, S. Commodity prices, convenience yields, and inflation. Rev. Econ. Stat. 2013, 95, 206–219. [Google Scholar] [CrossRef] [Green Version]
- Yang, F. Investment shocks and the commodity basis spread. J. Financ. Econ. 2013, 110, 164–184. [Google Scholar] [CrossRef] [Green Version]
- Bakshi, G.; Gao, X.; Rossi, A.G. Understanding the sources of risk underlying the cross section of commodity returns. Manag. Sci. 2019, 65, 619–641. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.; Tsvetanov, D. The predictive performance of commodity futures risk factors. J. Bank. Financ. 2016, 71, 20–36. [Google Scholar] [CrossRef]
- Gargano, A.; Timmermann, A. Forecasting commodity price indexes using macroeconomic and financial predictors. Int. J. Forecast. 2014, 30, 825–843. [Google Scholar] [CrossRef]
- Kwas, M.; Paccagnini, A.; Rubaszek, M. Common factors and the dynamics of industrial metal prices. A forecasting perspective. Resour. Policy 2021, 74, 102319. [Google Scholar] [CrossRef]
- Luo, J.; Klein, T.; Ji, Q.; Hou, C. Forecasting realized volatility of agricultural commodity futures with infinite Hidden Markov HAR models. Int. J. Forecast. 2022, 38, 51–73. [Google Scholar] [CrossRef]
- Ma, F.; Wei, Y.; Liu, L.; Huang, D. Forecasting realized volatility of oil futures market: A new insight. J. Forecast. 2018, 37, 419–436. [Google Scholar] [CrossRef]
- Drachal, K. Forecasting spot oil price in a dynamic model averaging framework—Have the determinants changed over time? Energy Econ. 2016, 60, 35–46. [Google Scholar] [CrossRef]
- Koki, C.; Meligkotsidou, L.; Vrontos, I. Forecasting under model uncertainty: Non-homogeneous hidden Markov models with Pòlya-Gamma data augmentation. J. Forecast. 2020, 39, 580–598. [Google Scholar] [CrossRef] [Green Version]
- Koki, C.; Leonardos, S.; Piliouras, G. Exploring the predictability of cryptocurrencies via Bayesian hidden Markov models. Res. Int. Bus. Financ. 2022, 59, 101554. [Google Scholar] [CrossRef]
- Date, P.; Mamon, R.; Tenyakov, A. Filtering and forecasting commodity futures prices under an ‘HMM’ framework. Energy Econ. 2013, 40, 1001–1013. [Google Scholar] [CrossRef] [Green Version]
- Leitch, G.; Tanner, J.E. Economic forecast evaluation: Profits versus the conventional error measures. Am. Econ. Rev. 1991, 81, 580–590. [Google Scholar]
- Dal Pra, G.; Guidolin, M.; Pedio, M.; Vasile, F. Regime shifts in excess stock return predictability: An out-of-sample portfolio analysis. J. Portf. Manag. 2018, 44, 10–24. [Google Scholar] [CrossRef]
- Abhyankar, A.; Basu, D.; Stremme, A. The optimal use of return predictability: An empirical study. J. Financ. Quant. Anal. 2012, 47, 973–1001. [Google Scholar] [CrossRef] [Green Version]
- Rapach, D.; Zhou, G. Forecasting stock returns. In Handbook of Economic Forecasting; Elsevier: Amsterdam, The Netherlands, 2013; Volume 2, pp. 328–383. [Google Scholar]
- Kwas, M.; Rubaszek, M. Forecasting Commodity Prices: Looking for a Benchmark. Forecasting 2021, 3, 447–459. [Google Scholar] [CrossRef]
- Ng, S. Variable selection in predictive regressions. Handb. Econ. Forecast. 2013, 2, 752–789. [Google Scholar]
- Akaike, H. Statistical predictor identification. Ann. Inst. Stat. Math. 1970, 22, 203–217. [Google Scholar] [CrossRef]
- Shibata, R. Asymptotically efficient selection of the order of the model for estimating parameters of a linear process. Ann. Stat. 1980, 8, 147–164. [Google Scholar] [CrossRef]
- Lee, S.; Karagrigoriou, A. An asymptotically optimal selection of the order of a linear process. Sankhyā Indian J. Stat. Ser. A 2001, 63, 93–106. [Google Scholar]
- Geweke, J.; Meese, R. Estimating regression models of finite but unknown order. Int. Econ. Rev. 1981, 22, 55–70. [Google Scholar] [CrossRef]
- Butler, R.W. The significance attained by the best-fitting regressor variable. J. Am. Stat. Assoc. 1984, 79, 341–348. [Google Scholar] [CrossRef]
- Smith, G. Step away from stepwise. J. Big Data 2018, 5, 1–12. [Google Scholar] [CrossRef]
- Chatfield, C. Model uncertainty, data mining and statistical inference. J. R. Stat. Soc. Ser. A (Stat. Soc.) 1995, 158, 419–444. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar]
- Hamilton, J.D. A new approach to the economic analysis of nonstationary time series and the business cycle. Econom. J. Econom. Soc. 1989, 57, 357–384. [Google Scholar] [CrossRef]
- Papanicolaou, A.; Sircar, R. A regime-switching Heston model for VIX and S&P 500 implied volatilities. Quant. Financ. 2014, 14, 1811–1827. [Google Scholar]
- Kang, S.H.; Maitra, D.; Dash, S.R.; Brooks, R. Dynamic spillovers and connectedness between stock, commodities, bonds, and VIX markets. Pac.-Basin Financ. J. 2019, 58, 101221. [Google Scholar] [CrossRef]
- Gorton, G.; Rouwenhorst, K.G. Facts and fantasies about commodity futures. Financ. Anal. J. 2006, 62, 47–68. [Google Scholar] [CrossRef] [Green Version]
- Basu, D.; Miffre, J. Capturing the risk premium of commodity futures: The role of hedging pressure. J. Bank. Financ. 2013, 37, 2652–2664. [Google Scholar] [CrossRef]
- Fuertes, A.M.; Miffre, J.; Fernandez-Perez, A. Commodity strategies based on momentum, term structure, and idiosyncratic volatility. J. Futur. Mark. 2015, 35, 274–297. [Google Scholar] [CrossRef] [Green Version]
- Ludvigson, S.C.; Ng, S. Macro factors in bond risk premia. Rev. Financ. Stud. 2009, 22, 5027–5067. [Google Scholar] [CrossRef] [Green Version]
- Khan, J.A.; Van Aelst, S.; Zamar, R.H. Building a robust linear model with forward selection and stepwise procedures. Comput. Stat. Data Anal. 2007, 52, 239–248. [Google Scholar] [CrossRef] [Green Version]
- Daskalaki, C.; Kostakis, A.; Skiadopoulos, G. Are there common factors in individual commodity futures returns? J. Bank. Financ. 2014, 40, 346–363. [Google Scholar] [CrossRef]
- Kang, W.; Rouwenhorst, K.G.; Tang, K. A tale of two premiums: The role of hedgers and speculators in commodity futures markets. J. Financ. 2020, 75, 377–417. [Google Scholar] [CrossRef]
- de Groot, W.; Karstanje, D.; Zhou, W. Exploiting commodity momentum along the futures curves. J. Bank. Financ. 2014, 48, 79–93. [Google Scholar] [CrossRef]
- Catania, L.; Grassi, S.; Ravazzolo, F. Forecasting cryptocurrencies under model and parameter instability. Int. J. Forecast. 2019, 35, 485–501. [Google Scholar] [CrossRef]
- Hotz-Behofsits, C.; Huber, F.; Zörner, T.O. Predicting crypto-currencies using sparse non-Gaussian state space models. J. Forecast. 2018, 37, 627–640. [Google Scholar] [CrossRef]
- Guidolin, M.; Pedio, M. Forecasting and trading monetary policy effects on the riskless yield curve with regime switching Nelson–Siegel models. J. Econ. Dyn. Control. 2019, 107, 103723. [Google Scholar] [CrossRef]
- Maruotti, A.; Punzo, A.; Bagnato, L. Hidden Markov and semi-Markov models with multivariate leptokurtic-normal components for robust modeling of daily returns series. J. Financ. Econom. 2019, 17, 91–117. [Google Scholar] [CrossRef]
- Gao, X.; Nardari, F. Do commodities add economic value in asset allocation? New evidence from time-varying moments. J. Financ. Quant. Anal. 2018, 53, 365–393. [Google Scholar] [CrossRef] [Green Version]
- Chong, J.; Miffre, J. Conditional correlation and volatility in commodityfutures and traditional asset markets. J. Altern. Investments 2009, 12, 061–075. [Google Scholar] [CrossRef]
- Lombardi, M.J.; Ravazzolo, F. On the correlation between commodity and equity returns: Implications for portfolio allocation. J. Commod. Mark. 2016, 2, 45–57. [Google Scholar] [CrossRef] [Green Version]
- Henriksen, T.E.S.; Pichler, A.; Westgaard, S.; Frydenberg, S. Can commodities dominate stock and bond portfolios? Ann. Oper. Res. 2019, 282, 155–177. [Google Scholar] [CrossRef]
- DeMiguel, V.; Garlappi, L.; Uppal, R. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? Rev. Financ. Stud. 2009, 22, 1915–1953. [Google Scholar] [CrossRef] [Green Version]
- Mei, X.; Nogales, F.J. Portfolio selection with proportional transaction costs and predictability. J. Bank. Financ. 2018, 94, 131–151. [Google Scholar] [CrossRef] [Green Version]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar] [CrossRef] [Green Version]
- Rapach, D.E.; Strauss, J.K.; Zhou, G. Out-of-sample equity premium prediction: Combination forecasts and links to the real economy. Rev. Financ. Stud. 2010, 23, 821–862. [Google Scholar] [CrossRef]
- Caldeira, J.F.; Moura, G.V.; Santos, A.A. Predicting the yield curve using forecast combinations. Comput. Stat. Data Anal. 2016, 100, 79–98. [Google Scholar] [CrossRef]
- Dangl, T.; Halling, M. Predictive regressions with time-varying coefficients. J. Financ. Econ. 2012, 106, 157–181. [Google Scholar] [CrossRef]
- Johnson, L.D.; Sakoulis, G. Maximizing equity market sector predictability in a Bayesian time-varying parameter model. Comput. Stat. Data Anal. 2008, 52, 3083–3106. [Google Scholar] [CrossRef]
- Lansang, J.R.; Barrios, E. Simultaneous dimension reduction and variable selection in modeling high dimensional data. Comput. Stat. Data Anal. 2017, 112, 242–256. [Google Scholar] [CrossRef]




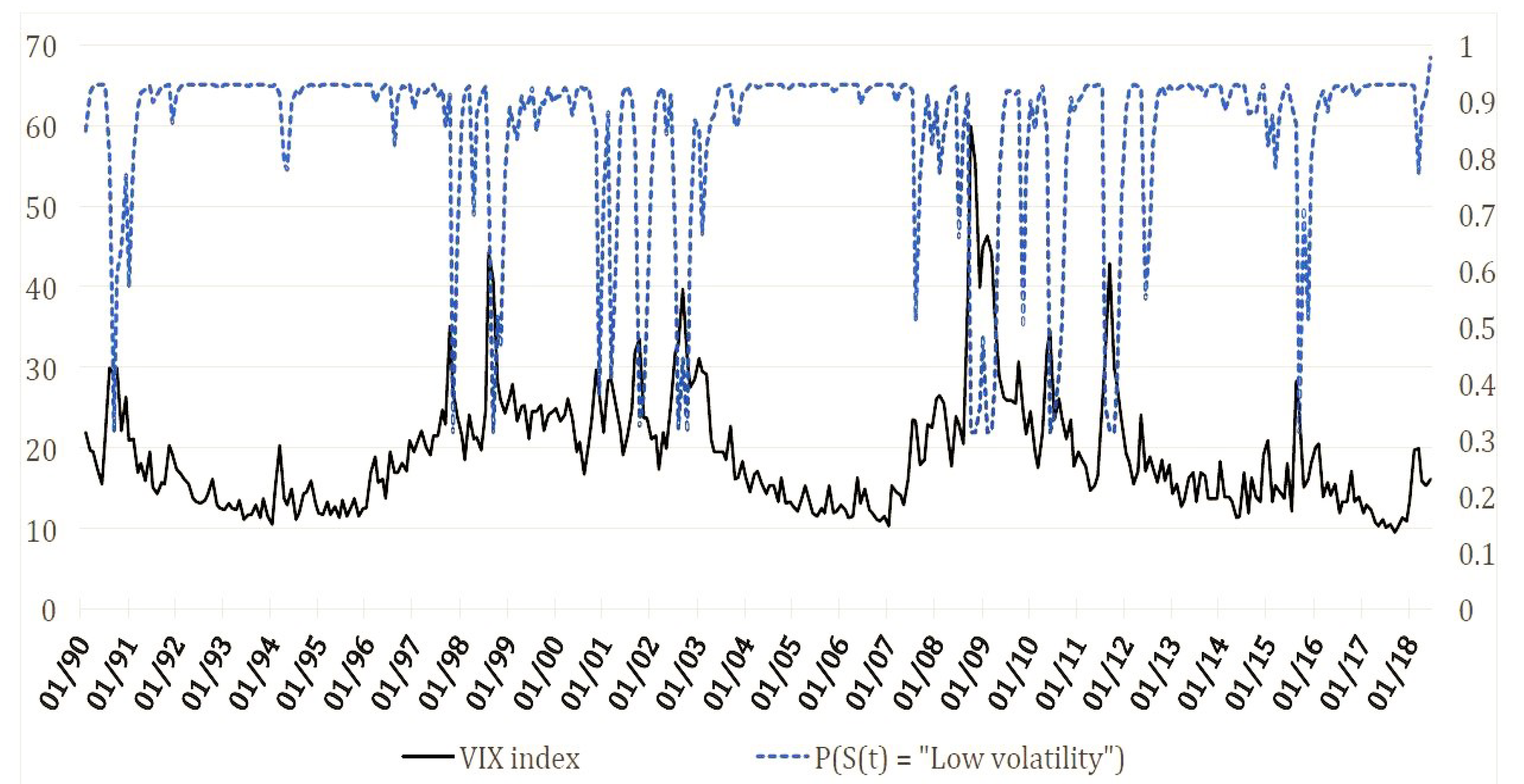{kind=link}
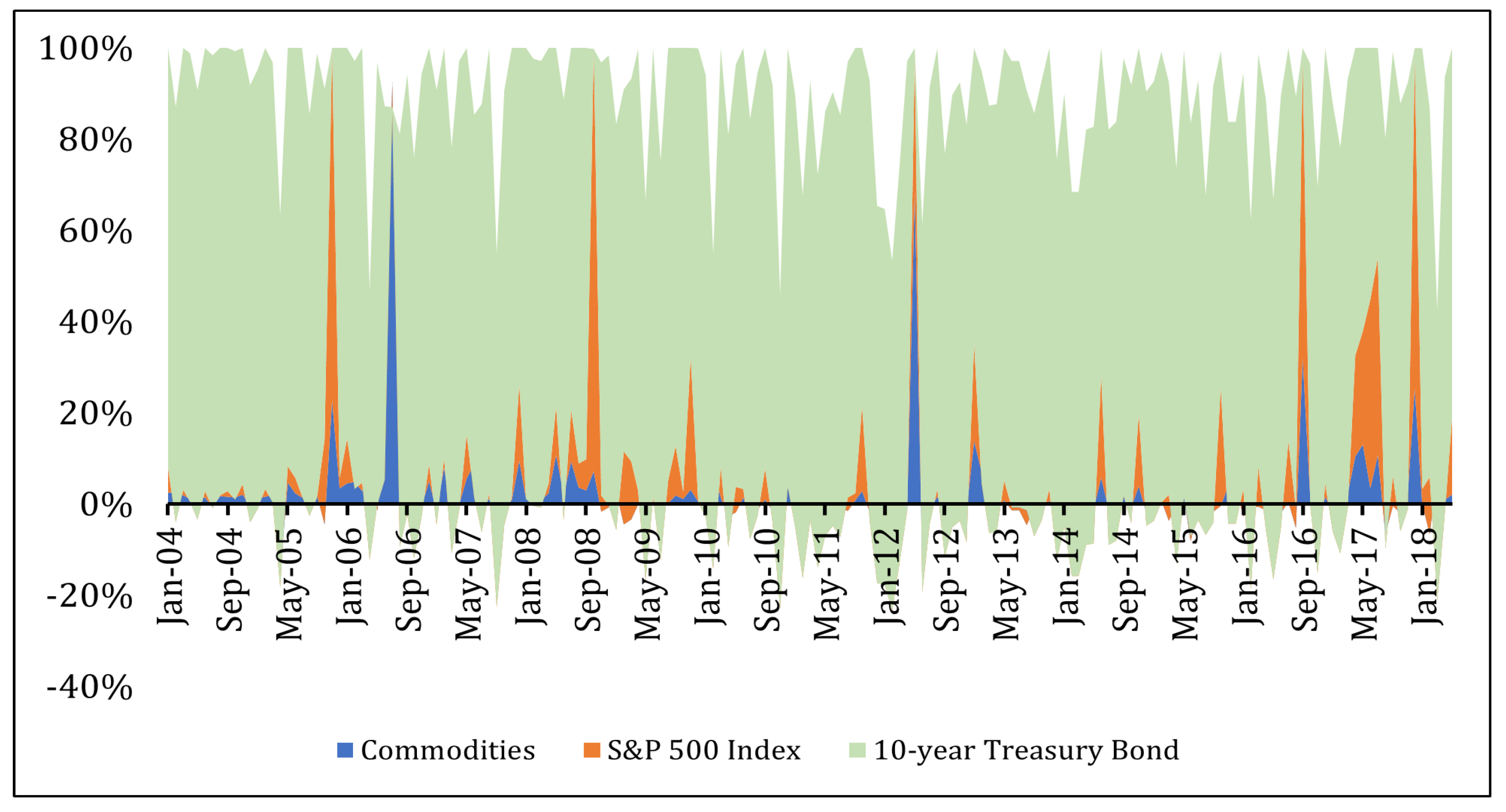{kind=link}
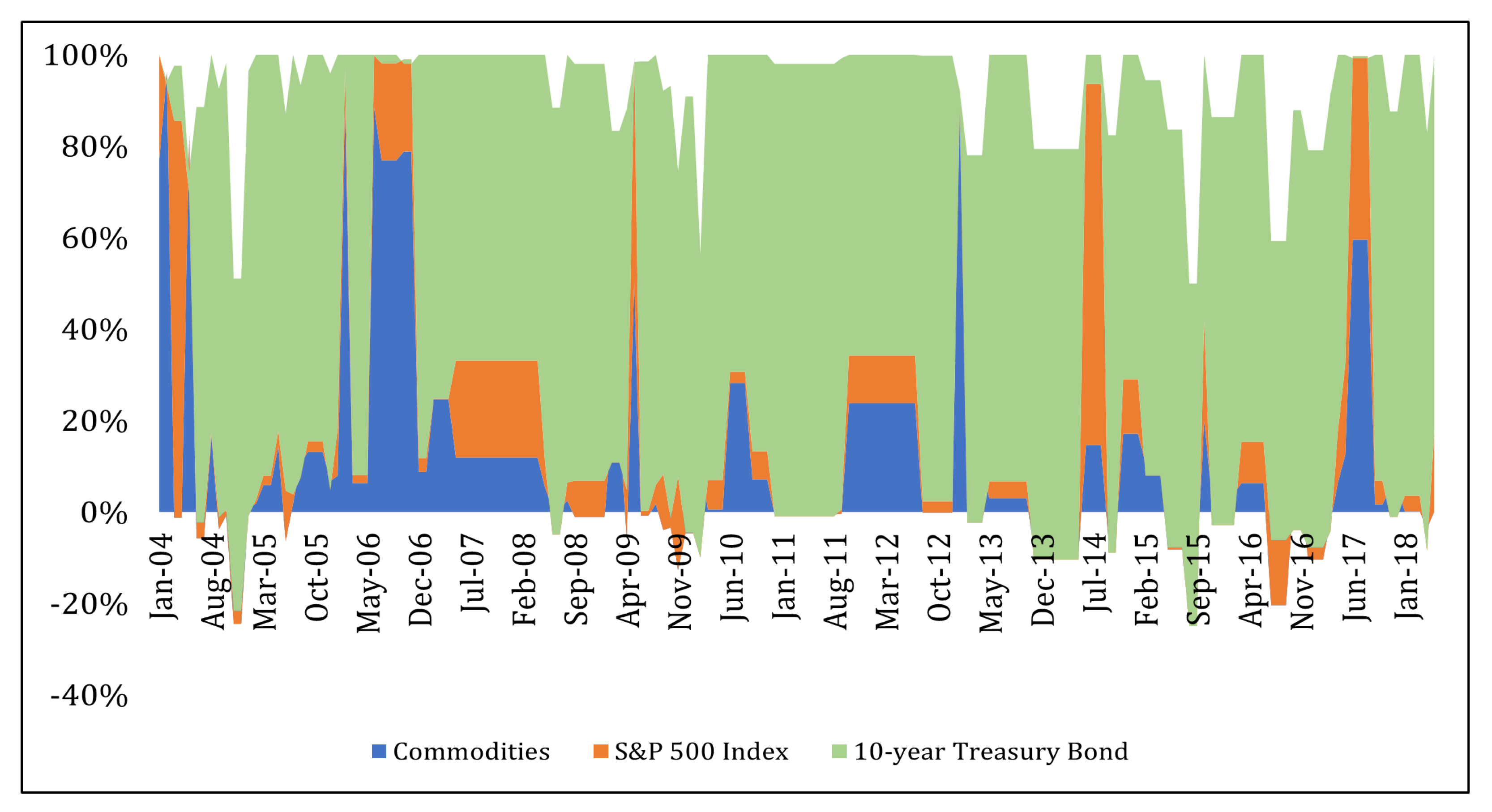{kind=link}
| Light Crude Oil | Corn | Soybeans | Wheat | Coffee | Cocoa | Sugar | Cotton No. 2 | Gold | Silver | Platinum | Orange Juice | Lumber | Live Cattle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Panel A | Macro Principal Components Only | |||||||||||||
| Forward—Low | 0.0768 | 0.0748 | 0.0764 | 0.0825 | 0.0918 | 0.0703 | 0.0707 | 0.0698 | 0.0454 | 0.0801 | 0.0786 | 0.0842 | 0.0755 | 0.0758 |
| Forward—High | 0.1142 | 0.1324 | 0.1149 | 0.1264 | 0.1006 | 0.1214 | 0.1113 | 0.1125 | 0.0655 | 0.1457 | 0.1498 | 0.1043 | 0.0973 | 0.0925 |
| Backward—Low | 0.0775 | 0.0749 | 0.0762 | 0.0823 | 0.0902 | 0.0703 | 0.0709 | 0.0695 | 0.0455 | 0.0820 | 0.0785 | 0.0842 | 0.0755 | 0.0752 |
| Backward—High | 0.1166 | 0.1407 | 0.1146 | 0.1286 | 0.1023 | 0.1620 | 0.1125 | 0.1139 | 0.0726 | 0.1458 | 0.1488 | 0.1057 | 0.1130 | 0.0926 |
| Panel B | Macro Principal Components + Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward—Low | 0.0823 | 0.0741 | 0.0788 | 0.0862 | 0.0990 | 0.0791 | 0.0755 | 0.0661 | 0.0493 | 0.0905 | 0.0869 | 0.0946 | 0.0813 | 0.1039 |
| Forward—High | 0.1182 | 0.1565 | 0.1140 | 0.1549 | 0.1339 | 0.1609 | 0.1180 | 0.1290 | 0.0824 | 0.1766 | 0.8282 | 0.1151 | 0.1247 | 0.1354 |
| Backward—Low | 0.0822 | 0.0736 | 0.0804 | 0.0861 | 0.1003 | 0.0798 | 0.0752 | 0.0694 | 0.0481 | 0.0912 | 0.0938 | 0.0944 | 0.0801 | 0.0984 |
| Backward—High | 0.1197 | 0.1780 | 0.1298 | 0.1666 | 0.1244 | 0.1659 | 0.1258 | 0.1414 | 0.0849 | 0.1768 | 0.7025 | 0.1270 | 0.1523 | 0.1538 |
| Panel C | Macro Principal Components + Commodity-Specific Factors | |||||||||||||
| Forward—Low | 0.0707 | 0.0725 | 0.0773 | 0.0846 | 0.0917 | 0.0728 | 0.0720 | 0.0682 | 0.0472 | 0.0829 | 0.0833 | 0.0900 | 0.0797 | 0.0833 |
| Forward—High | 0.0648 | 0.1526 | 0.1029 | 0.1468 | 0.1159 | 0.1898 | 0.1126 | 0.1214 | 0.0762 | 0.1510 | 0.1539 | 0.1086 | 0.1182 | 0.1117 |
| Backward—Low | 0.0696 | 0.0731 | 0.0780 | 0.0841 | 0.0925 | 0.0746 | 0.0717 | 0.0693 | 0.0471 | 0.0836 | 0.0840 | 0.0946 | 0.0791 | 0.0836 |
| Backward—High | 0.0634 | 0.1598 | 0.1186 | 0.1632 | 0.1248 | 0.1616 | 0.1120 | 0.1228 | 0.0825 | 0.1707 | 0.7496 | 0.1171 | 0.1448 | 0.1228 |
| Panel D | Macro Principal Components + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward—Low | 0.0851 | 0.0775 | 0.0894 | 0.0877 | 0.0971 | 0.0750 | 0.0788 | 0.0759 | 0.0661 | 0.0836 | 0.0792 | 0.0964 | 0.0852 | 0.1154 |
| Forward—High | 0.2179 | 0.1829 | 0.1810 | 0.2229 | 0.1574 | 0.1652 | 0.2498 | 0.1851 | 0.0958 | 0.2103 | 0.2792 | 0.1316 | 0.1854 | 0.1140 |
| Backward—Low | 0.0846 | 0.0780 | 0.0786 | 0.0873 | 0.0960 | 0.0750 | 0.0793 | 0.0767 | 0.0603 | 0.0837 | 0.0792 | 0.0960 | 0.0858 | 0.0909 |
| Backward—High | 0.2113 | 0.1822 | 0.1741 | 0.2233 | 0.1614 | 0.1549 | 0.2234 | 0.2726 | 0.1169 | 0.2345 | 0.2644 | 0.1312 | 0.1884 | 0.1139 |
| Panel E | Macro Principal Components + Aggregated Commodity-Specific Factors | |||||||||||||
| Forward—Low | 0.0789 | 0.0786 | 0.0757 | 0.0852 | 0.0929 | 0.0750 | 0.0744 | 0.0724 | 0.0448 | 0.0796 | 0.0782 | 0.0959 | 0.0807 | 0.0770 |
| Forward—High | 0.1265 | 0.1593 | 0.1107 | 0.1990 | 0.1444 | 0.1374 | 0.1220 | 0.1157 | 0.0761 | 0.1428 | 0.1701 | 0.1205 | 0.1212 | 0.0969 |
| Backward—Low | 0.0795 | 0.0780 | 0.0767 | 0.0864 | 0.0909 | 0.0735 | 0.0746 | 0.0734 | 0.0458 | 0.0802 | 0.0782 | 0.0951 | 0.0850 | 0.0760 |
| Backward—High | 0.1221 | 0.1589 | 0.1395 | 0.2050 | 0.1529 | 0.1340 | 0.1521 | 0.1691 | 0.0813 | 0.1700 | 0.1750 | 0.1233 | 0.1307 | 0.0979 |
| Panel F | Macro Principal Components + Commodity-Specific Factors + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward—Low | 0.0848 | 0.0795 | 0.0773 | 0.0945 | 0.1041 | 0.0815 | 0.0844 | 0.0746 | 0.0475 | 0.0953 | 0.0827 | 0.1038 | 0.0884 | 0.0855 |
| Forward—High | 0.2278 | 0.1739 | 0.1580 | 0.2322 | 0.1471 | 0.1722 | 0.2192 | 0.2086 | 0.1152 | 0.1963 | 0.5971 | 0.1322 | 0.1962 | 0.1467 |
| Backward—Low | 0.0862 | 0.0788 | 0.0801 | 0.0939 | 0.1064 | 0.0838 | 0.0850 | 0.0738 | 0.0481 | 0.1841 | 0.0821 | 0.1085 | 0.0882 | 0.0865 |
| Backward—High | 0.2264 | 0.1866 | 0.1607 | 0.2233 | 0.1663 | 0.1754 | 0.2242 | 0.3524 | 0.1360 | 0.2070 | 0.5627 | 0.1742 | 0.2487 | 0.1956 |
| Panel G | Benchmark AR(1) | |||||||||||||
| AR(1) | 0.0856 | 0.0867 | 0.0792 | 0.0946 | 0.0882 | 0.0799 | 0.0861 | 0.0800 | 0.0522 | 0.0955 | 0.0723 | 0.0916 | 0.0799 | 0.0463 |
| Light Crude Oil | Corn | Soybeans | Wheat | Coffee | Cocoa | Sugar | Cotton No.2 | Gold | Silver | Platinum | Orange Juice | Lumber | Live Cattle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Panel A | HMM—Macro Principal Components Only | |||||||||||||
| 0.1014 | 0.0970 | 0.1021 | 0.1069 | 0.2446 | 0.0909 | 0.1036 | 0.0958 | 0.1088 | 0.1215 | 0.0968 | 0.1213 | 0.0857 | 0.0472 | |
| Panel B | HMM—Macro Principal Components + Commodity-Specific Factors | |||||||||||||
| 0.0871 | 0.1025 | 0.1430 | 0.1280 | 0.1153 | 0.1151 | 0.1040 | 0.0966 | 0.0989 | 0.3136 | 0.0921 | 0.1084 | 0.1074 | 0.0515 | |
| Panel C | HMM—Macro Principal Components + Aggregated Commodity-Specific Factors | |||||||||||||
| 0.1326 | 0.0976 | 0.0877 | 0.1192 | 0.1074 | 0.1258 | 0.1414 | 0.1192 | 0.0815 | 0.1142 | 0.0834 | 0.1089 | 0.0978 | 0.0526 | |
| Panel D | Stepwise Regression—Macro Principal Components Only | |||||||||||||
| Forward | 0.0830 | 0.0920 | 0.0846 | 0.0973 | 0.0925 | 0.0836 | 0.0858 | 0.0821 | 0.0516 | 0.0962 | 0.0832 | 0.0911 | 0.0824 | 0.0829 |
| Backward | 0.0817 | 0.0918 | 0.0845 | 0.0976 | 0.0916 | 0.0847 | 0.0860 | 0.0820 | 0.0531 | 0.0972 | 0.0830 | 0.0913 | 0.0843 | 0.0825 |
| Panel E | Stepwise Regression—Macro Principal Components + Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward | 0.0841 | 0.0956 | 0.0838 | 0.1019 | 0.0981 | 0.0926 | 0.0880 | 0.0824 | 0.0546 | 0.1032 | 0.2508 | 0.0975 | 0.0901 | 0.0971 |
| Backward | 0.0840 | 0.0936 | 0.0867 | 0.1032 | 0.0974 | 0.0957 | 0.0887 | 0.0860 | 0.0545 | 0.1035 | 0.2128 | 0.0978 | 0.0909 | 0.0977 |
| Panel F | Stepwise Regression—Macro Principal Components + Commodity-Specific Factors | |||||||||||||
| Forward | 0.0733 | 0.0916 | 0.0824 | 0.1019 | 0.0938 | 0.0899 | 0.0862 | 0.0818 | 0.0546 | 0.0972 | 0.0853 | 0.0943 | 0.0883 | 0.0869 |
| Backward | 0.0723 | 0.0916 | 0.0849 | 0.1023 | 0.0934 | 0.0918 | 0.0862 | 0.0830 | 0.0536 | 0.0993 | 0.2267 | 0.0973 | 0.0892 | 0.0881 |
| Panel G | Stepwise Regression—Principal Components + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward | 0.0989 | 0.0982 | 0.1038 | 0.1159 | 0.0996 | 0.0871 | 0.1144 | 0.0931 | 0.0662 | 0.1144 | 0.1080 | 0.1008 | 0.1032 | 0.1051 |
| Backward | 0.0980 | 0.0984 | 0.0971 | 0.1159 | 0.0996 | 0.0858 | 0.1100 | 0.1151 | 0.0696 | 0.1146 | 0.1041 | 0.1000 | 0.1036 | 0.0922 |
| Panel H | Stepwise Regression—Macro Principal Components + Aggregated Commodity-Specific Factors | |||||||||||||
| Forward | 0.0826 | 0.0950 | 0.0822 | 0.1131 | 0.0969 | 0.0871 | 0.0890 | 0.0824 | 0.0524 | 0.0972 | 0.0896 | 0.0994 | 0.0876 | 0.0842 |
| Backward | 0.0802 | 0.0951 | 0.0887 | 0.1162 | 0.0953 | 0.0831 | 0.0944 | 0.0874 | 0.0541 | 0.0978 | 0.0891 | 0.0986 | 0.0907 | 0.0837 |
| Panel I | Stepwise Regression—Principal Components + Commodity-Specific Factors + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward | 0.0986 | 0.0963 | 0.0911 | 0.1185 | 0.0987 | 0.0914 | 0.1151 | 0.0945 | 0.0590 | 0.1096 | 0.1896 | 0.1037 | 0.1062 | 0.0914 |
| Backward | 0.0957 | 0.1001 | 0.0937 | 0.1193 | 0.1029 | 0.0934 | 0.1108 | 0.1347 | 0.0674 | 0.1600 | 0.1939 | 0.1116 | 0.1146 | 0.0990 |
| Panel J | Benchmark AR(1) | |||||||||||||
| AR(1) | 0.0856 | 0.0867 | 0.0792 | 0.0946 | 0.0882 | 0.0799 | 0.0861 | 0.0800 | 0.0522 | 0.0955 | 0.0723 | 0.0916 | 0.0799 | 0.0463 |
| Light Crude Oil | Corn | Soybeans | Wheat | Coffee | Cocoa | Sugar | Cotton No. 2 | Gold | Silver | Platinum | Orange Juice | Lumber | Live Cattle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Panel A | Macro Principal Components Only | |||||||||||||
| Forward—Low | 0.0613 | 0.0592 | 0.0547 | 0.0644 | 0.0688 | 0.0555 | 0.0583 | 0.0544 | 0.0356 | 0.0638 | 0.0653 | 0.0669 | 0.0610 | 0.0625 |
| Forward—High | 0.0829 | 0.0952 | 0.0872 | 0.0932 | 0.0801 | 0.0971 | 0.0866 | 0.0842 | 0.0494 | 0.1084 | 0.0916 | 0.0874 | 0.0721 | 0.0701 |
| Backward—Low | 0.0615 | 0.0597 | 0.0545 | 0.0641 | 0.0672 | 0.0555 | 0.0584 | 0.0543 | 0.0356 | 0.0645 | 0.0655 | 0.0670 | 0.0610 | 0.0618 |
| Backward—High | 0.0817 | 0.1019 | 0.0869 | 0.0947 | 0.0826 | 0.1077 | 0.0894 | 0.0861 | 0.0517 | 0.1077 | 0.0890 | 0.0884 | 0.0847 | 0.0703 |
| Panel B | Macro Principal Components + Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward—Low | 0.0644 | 0.0574 | 0.0605 | 0.0665 | 0.0791 | 0.0630 | 0.0610 | 0.0510 | 0.0378 | 0.0716 | 0.0702 | 0.0745 | 0.0659 | 0.0789 |
| Forward—High | 0.0902 | 0.1192 | 0.0866 | 0.1139 | 0.0976 | 0.1139 | 0.0918 | 0.0990 | 0.0572 | 0.1378 | 0.4112 | 0.0969 | 0.0972 | 0.0984 |
| Backward—Low | 0.0646 | 0.0570 | 0.0625 | 0.0660 | 0.0801 | 0.0642 | 0.0608 | 0.0542 | 0.0369 | 0.0723 | 0.0735 | 0.0741 | 0.0652 | 0.0736 |
| Backward—High | 0.0923 | 0.1260 | 0.0971 | 0.1267 | 0.0923 | 0.1175 | 0.0934 | 0.1059 | 0.0587 | 0.1385 | 0.3565 | 0.1059 | 0.1162 | 0.1134 |
| Panel C | Macro Principal Components + Commodity-Specific Factors | |||||||||||||
| Forward—Low | 0.0563 | 0.0579 | 0.0585 | 0.0651 | 0.0682 | 0.0575 | 0.0597 | 0.0523 | 0.0369 | 0.0658 | 0.0679 | 0.0701 | 0.0650 | 0.0671 |
| Forward—High | 0.0517 | 0.1089 | 0.0827 | 0.1080 | 0.0858 | 0.1129 | 0.0894 | 0.0905 | 0.0568 | 0.1214 | 0.0906 | 0.0893 | 0.0912 | 0.0868 |
| Backward—Low | 0.0549 | 0.0581 | 0.0593 | 0.0644 | 0.0693 | 0.0598 | 0.0594 | 0.0523 | 0.0365 | 0.0669 | 0.0675 | 0.0745 | 0.0647 | 0.0673 |
| Backward—High | 0.0507 | 0.1129 | 0.0918 | 0.1179 | 0.0930 | 0.1102 | 0.0883 | 0.0943 | 0.0586 | 0.1346 | 0.3724 | 0.0981 | 0.1083 | 0.0908 |
| Panel D | Macro Principal Components + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward—Low | 0.0675 | 0.0630 | 0.0620 | 0.0691 | 0.0749 | 0.0596 | 0.0649 | 0.0589 | 0.0461 | 0.0665 | 0.0644 | 0.0761 | 0.0658 | 0.0908 |
| Forward—High | 0.1292 | 0.1305 | 0.1195 | 0.1373 | 0.1172 | 0.1213 | 0.1761 | 0.1295 | 0.0708 | 0.1473 | 0.1526 | 0.1013 | 0.1174 | 0.0836 |
| Backward—Low | 0.0668 | 0.0633 | 0.0585 | 0.0687 | 0.0736 | 0.0597 | 0.0651 | 0.0600 | 0.0433 | 0.0663 | 0.0645 | 0.0760 | 0.0656 | 0.0754 |
| Backward—High | 0.1216 | 0.1304 | 0.1167 | 0.1394 | 0.1195 | 0.1205 | 0.1539 | 0.1517 | 0.0747 | 0.1576 | 0.1478 | 0.1014 | 0.1187 | 0.0830 |
| Panel E | Macro Principal Components + Aggregated Commodity-Specific Factors | |||||||||||||
| Forward—Low | 0.0625 | 0.0628 | 0.0563 | 0.0661 | 0.0686 | 0.0608 | 0.0614 | 0.0568 | 0.0350 | 0.0630 | 0.0653 | 0.0749 | 0.0631 | 0.0635 |
| Forward—High | 0.0896 | 0.1122 | 0.0889 | 0.1258 | 0.1076 | 0.1047 | 0.0973 | 0.0869 | 0.0536 | 0.1128 | 0.1091 | 0.0946 | 0.0950 | 0.0713 |
| Backward—Low | 0.0631 | 0.0621 | 0.0582 | 0.0679 | 0.0676 | 0.0586 | 0.0618 | 0.0573 | 0.0359 | 0.0630 | 0.0654 | 0.0746 | 0.0661 | 0.0631 |
| Backward—High | 0.0854 | 0.1127 | 0.0962 | 0.1322 | 0.1147 | 0.1081 | 0.1132 | 0.1123 | 0.0577 | 0.1342 | 0.1163 | 0.0985 | 0.1000 | 0.0726 |
| Panel F | Macro Principal Components + Commodity-Specific Factors + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward—Low | 0.0672 | 0.0615 | 0.0602 | 0.0734 | 0.0787 | 0.0650 | 0.0700 | 0.0588 | 0.0370 | 0.0760 | 0.0658 | 0.0829 | 0.0689 | 0.0688 |
| Forward—High | 0.1309 | 0.1352 | 0.1131 | 0.1714 | 0.1203 | 0.1244 | 0.1515 | 0.1536 | 0.0796 | 0.1532 | 0.3081 | 0.1029 | 0.1339 | 0.1055 |
| Backward—Low | 0.0678 | 0.0595 | 0.0626 | 0.0728 | 0.0815 | 0.0662 | 0.0702 | 0.0576 | 0.0377 | 0.0893 | 0.0641 | 0.0858 | 0.0690 | 0.0698 |
| Backward—High | 0.1376 | 0.1409 | 0.1157 | 0.1536 | 0.1390 | 0.1301 | 0.1587 | 0.1785 | 0.0879 | 0.1602 | 0.2736 | 0.1257 | 0.1548 | 0.1367 |
| Panel G | Benchmark AR(1) | |||||||||||||
| AR(1) | 0.0682 | 0.0676 | 0.0603 | 0.0711 | 0.0647 | 0.0635 | 0.0674 | 0.0610 | 0.0408 | 0.0748 | 0.0492 | 0.0727 | 0.0635 | 0.0356 |
| Light Crude Oil | Corn | Soybeans | Wheat | Coffee | Cocoa | Sugar | Cotton No. 2 | Gold | Silver | Platinum | Orange Juice | Lumber | Live Cattle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Panel A | HMM—Macro Principal Components Only | |||||||||||||
| 0.0691 | 0.0710 | 0.0673 | 0.0766 | 0.0899 | 0.0675 | 0.0786 | 0.0691 | 0.0511 | 0.0809 | 0.0588 | 0.0833 | 0.0656 | 0.0359 | |
| Panel B | HMM—Macro Principal Components + Commodity-Specific Factors | |||||||||||||
| 0.0656 | 0.0718 | 0.0757 | 0.0875 | 0.0862 | 0.0767 | 0.0781 | 0.0697 | 0.0510 | 0.1198 | 0.0611 | 0.0825 | 0.0763 | 0.0409 | |
| Panel C | HMM—Macro Principal Components + Aggregated Commodity-Specific Factors | |||||||||||||
| 0.0830 | 0.0724 | 0.0636 | 0.0861 | 0.0830 | 0.0801 | 0.0898 | 0.0783 | 0.0491 | 0.0834 | 0.0563 | 0.0877 | 0.0735 | 0.0405 | |
| Panel D | Stepwise Regression—Macro Principal Components Only | |||||||||||||
| Forward | 0.0653 | 0.0699 | 0.0628 | 0.0734 | 0.0700 | 0.0658 | 0.0678 | 0.0627 | 0.0404 | 0.0754 | 0.0672 | 0.0732 | 0.0645 | 0.0656 |
| Backward | 0.0638 | 0.0699 | 0.0626 | 0.0735 | 0.0692 | 0.0660 | 0.0684 | 0.0628 | 0.0410 | 0.0757 | 0.0671 | 0.0733 | 0.0656 | 0.0652 |
| Panel E | Stepwise Regression—Macro Principal Components + Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward | 0.0662 | 0.0711 | 0.0653 | 0.0759 | 0.0773 | 0.0709 | 0.0694 | 0.0619 | 0.0417 | 0.0815 | 0.1064 | 0.0781 | 0.0704 | 0.0752 |
| Backward | 0.0664 | 0.0697 | 0.0676 | 0.0762 | 0.0765 | 0.0733 | 0.0696 | 0.0642 | 0.0413 | 0.0822 | 0.1009 | 0.0784 | 0.0716 | 0.0748 |
| Panel F | Stepwise Regression—Macro Principal Components + Commodity-Specific Factors | |||||||||||||
| Forward | 0.0585 | 0.0692 | 0.0643 | 0.0751 | 0.0705 | 0.0680 | 0.0686 | 0.0617 | 0.0421 | 0.0764 | 0.0688 | 0.0751 | 0.0693 | 0.0687 |
| Backward | 0.0571 | 0.0691 | 0.0657 | 0.0748 | 0.0705 | 0.0696 | 0.0689 | 0.0624 | 0.0416 | 0.0782 | 0.1003 | 0.0784 | 0.0701 | 0.0696 |
| Panel G | Stepwise Regression—Macro Principal Components + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward | 0.0706 | 0.0733 | 0.0715 | 0.0793 | 0.0740 | 0.0681 | 0.0839 | 0.0685 | 0.0485 | 0.0818 | 0.0748 | 0.0791 | 0.0732 | 0.0814 |
| Backward | 0.0696 | 0.0735 | 0.0689 | 0.0792 | 0.0739 | 0.0683 | 0.0813 | 0.0729 | 0.0482 | 0.0814 | 0.0736 | 0.0787 | 0.0731 | 0.0731 |
| Panel H | Stepwise Regression—Macro Principal Components + Aggregated Commodity-Specific Factors | |||||||||||||
| Forward | 0.0650 | 0.0721 | 0.0631 | 0.0783 | 0.0716 | 0.0694 | 0.0704 | 0.0636 | 0.0404 | 0.0756 | 0.0696 | 0.0782 | 0.0681 | 0.0662 |
| Backward | 0.0642 | 0.0719 | 0.0660 | 0.0808 | 0.0706 | 0.0669 | 0.0732 | 0.0656 | 0.0417 | 0.0755 | 0.0707 | 0.0780 | 0.0701 | 0.0660 |
| Panel I | Stepwise Regression—Macro Principal Components + Commodity-Specific Factors + Aggregated Commodity-Specific Factors (Always Included) | |||||||||||||
| Forward | 0.0711 | 0.0730 | 0.0674 | 0.0857 | 0.0743 | 0.0719 | 0.0863 | 0.0697 | 0.0434 | 0.0856 | 0.0928 | 0.0824 | 0.0754 | 0.0706 |
| Backward | 0.0696 | 0.0735 | 0.0701 | 0.0833 | 0.0789 | 0.0732 | 0.0848 | 0.0732 | 0.0449 | 0.0928 | 0.0896 | 0.0860 | 0.0791 | 0.0750 |
| Panel J | Benchmark AR(1) | |||||||||||||
| AR(1) | 0.0682 | 0.0676 | 0.0603 | 0.0711 | 0.0647 | 0.0635 | 0.0674 | 0.0610 | 0.0408 | 0.0748 | 0.0492 | 0.0727 | 0.0635 | 0.0356 |
| Light Crude Oil | Corn | Soybeans | Wheat | Coffee | Cocoa | Sugar | Cotton No. 2 | Gold | Silver | Platinum | Orange Juice | Lumber | Live Cattle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Panel A | HMM | |||||||||||||
| 0.0936 | 0.1039 | 0.1136 | 0.1170 | 0.1485 | 0.1036 | 0.1000 | 0.0960 | 0.0916 | 0.1754 | 0.1141 | 0.1119 | 0.0914 | 0.0673 | |
| Panel B | Stepwise Regression Models | |||||||||||||
| 0.0860 | 0.0949 | 0.0886 | 0.1086 | 0.0966 | 0.0889 | 0.0962 | 0.0920 | 0.0576 | 0.1075 | 0.1430 | 0.0986 | 0.0943 | 0.0909 | |
| Panel C | Benchmark AR(1) | |||||||||||||
| AR(1) | 0.0856 | 0.0867 | 0.0792 | 0.0946 | 0.0882 | 0.0799 | 0.0861 | 0.0800 | 0.0522 | 0.0955 | 0.0723 | 0.0916 | 0.0799 | 0.0463 |
| Light Crude Oil | Corn | Soybeans | Wheat | Coffee | Cocoa | Sugar | Cotton No. 2 | Gold | Silver | Platinum | Orange Juice | Lumber | Live Cattle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Panel A | HMM | |||||||||||||
| 0.7530 | 0.0669 | 0.0646 | 0.0834 | 0.0801 | 0.0774 | 0.0762 | 0.0672 | 0.0488 | 0.0891 | 0.0606 | 0.0787 | 0.0718 | 0.0391 | |
| Panel B | Stepwise Regression Models | |||||||||||||
| 0.0656 | 0.0713 | 0.0663 | 0.0780 | 0.0731 | 0.0693 | 0.0744 | 0.0658 | 0.0429 | 0.0802 | 0.0818 | 0.0782 | 0.0709 | 0.0709 | |
| Panel C | Benchmark AR(1) | |||||||||||||
| AR(1) | 0.0682 | 0.0676 | 0.0603 | 0.0711 | 0.0647 | 0.0635 | 0.0674 | 0.0610 | 0.0408 | 0.0748 | 0.0492 | 0.0727 | 0.0635 | 0.0356 |
| = 0.1 | = 0.25 | = 0.5 | ||||||||||
| Mean Return | Std. Dev. | Sharpe Ratio | Realized MV | Mean Return | Std. Dev. | Sharpe Ratio | Realized MV | Mean Return | Std. Dev. | Sharpe Ratio | Realized MV | |
| HMM Macro Factors | 0.0006 | 0.0198 | 0.0962 | 0.0005 | 0.0001 | 0.0190 | 0.0258 | 0.0001 | 0.0002 | 0.0182 | 0.0328 | 0.0001 |
| HMM Macro and Commodity-Specific Factors | 0.0020 | 0.0388 | 0.1813 | 0.0020 | −0.0002 | 0.0351 | −0.0246 | −0.0004 | 0.0019 | 0.0268 | 0.2446 | 0.0017 |
| HMM Macro and Aggregate Commodity Factors | 0.0026 | 0.0429 | 0.2095 | 0.0025 | 0.0020 | 0.0185 | 0.3660 | 0.0019 | 0.0012 | 0.0213 | 0.1977 | 0.0011 |
| Stepwise PCs—Forward | 0.0001 | 0.0181 | 0.0035 | 0.0001 | −0.0001 | 0.0183 | −0.0109 | −0.0001 | 0.0002 | 0.0166 | 0.0318 | 0.0001 |
| Stepwise PCs—Backward | −0.0003 | 0.0220 | −0.0409 | −0.0003 | −0.0002 | 0.0202 | −0.0339 | −0.0002 | 0.0002 | 0.0182 | 0.0291 | 0.0001 |
| Stepwise PCs and Commodity-Specific Factors (always incl.)—Forward | 0.0032 | 0.0376 | 0.2932 | 0.0031 | 0.0032 | 0.0369 | 0.3000 | 0.0030 | 0.0037 | 0.0361 | 0.3548 | 0.0034 |
| Stepwise PCs and Commodity-Specific Factors (always incl.)—Backward | −0.0025 | 0.0388 | −0.2229 | −0.0026 | −0.0024 | 0.0379 | −0.2198 | −0.0026 | −0.0027 | 0.0381 | −0.2442 | −0.0030 |
| Stepwise PCs and Commodity-Specific Factors—Forward | −0.0021 | 0.0291 | −0.2505 | −0.0021 | −0.0005 | 0.0312 | −0.0527 | −0.0006 | 0.0011 | 0.0246 | 0.1578 | 0.0010 |
| Stepwise PCs and Commodity-Specific Factors—Backward | −0.0016 | 0.0274 | −0.1975 | −0.0016 | −0.0016 | 0.0271 | −0.1988 | −0.0016 | −0.0017 | 0.0253 | −0.2266 | −0.0018 |
| Stepwise PCs and Aggregate Commodity Factors (always incl.)—Forward | −0.0030 | 0.0334 | −0.3088 | −0.0030 | −0.0024 | 0.0322 | −0.2582 | −0.0025 | −0.0024 | 0.0322 | −0.2577 | −0.0026 |
| Stepwise PCs and Aggregate Commodity Factors (always incl.)—Backward | −0.0020 | 0.0329 | −0.2129 | −0.0021 | −0.0020 | 0.0361 | −0.1890 | −0.0021 | −0.0007 | 0.0322 | −0.0796 | −0.0010 |
| Stepwise PCs and Aggregate Commodity Factors—Forward | −0.0010 | 0.0179 | −0.2020 | −0.0011 | −0.0007 | 0.0184 | −0.1408 | −0.0008 | −0.0008 | 0.0183 | −0.1520 | −0.0009 |
| Stepwise PCs and Aggregate Commodity Factors—Backward | 0.0002 | 0.0319 | 0.0259 | 0.0002 | 0.0002 | 0.0319 | 0.0203 | 0.0001 | −0.0005 | 0.0320 | −0.0594 | −0.0008 |
| Stepwise PCs and Aggregate Commodity- Specific Factors (always incl.)—Forward | 0.0019 | 0.0427 | 0.1550 | 0.0018 | 0.0005 | 0.0417 | 0.0400 | 0.0003 | 0.0011 | 0.0337 | 0.1151 | 0.0008 |
| Stepwise PCs and Aggregate Commodity- Specific Factors (always incl.)—Backward | −0.0073 | 0.1213 | −0.2095 | −0.0081 | 0.0026 | 0.0370 | 0.2408 | 0.0024 | 0.0009 | 0.0341 | 0.0881 | 0.0006 |
| AR(1) Benchmark | −0.0001 | 0.0154 | −0.0296 | −0.0001 | −0.0001 | 0.0154 | −0.0298 | −0.0002 | −0.0001 | 0.0154 | −0.0302 | −0.0002 |
| = 0.1 | = 0.25 | = 0.5 | ||||||||||
| Mean Return | Std. Dev. | Sharpe Ratio | Realized MV | Mean Return | Std. Dev. | Sharpe Ratio | Realized MV | Mean Return | Std. Dev. | Sharpe Ratio | Realized MV | |
| HMM Macro Factors | 0.0002 | 0.0193 | 0.0330 | 0.0002 | −0.0020 | 0.0218 | −0.3101 | −0.0020 | −0.0016 | 0.0214 | −0.2637 | −0.0017 |
| HMM Macro and Commodity-Specific Factors | 0.0029 | 0.0333 | 0.3007 | 0.0028 | 0.0011 | 0.0211 | 0.1764 | 0.0010 | 0.0012 | 0.0213 | 0.1977 | 0.0012 |
| HMM Macro and Aggregate Commodity Factors | 0.0024 | 0.0473 | 0.1727 | 0.0022 | 0.0027 | 0.0277 | 0.3362 | 0.0026 | 0.0021 | 0.0194 | 0.3697 | 0.0020 |
| Stepwise PCs—Forward | 0.0027 | 0.0306 | 0.3008 | 0.0026 | 0.0022 | 0.0306 | 0.2445 | 0.0020 | 0.0021 | 0.0304 | 0.2447 | 0.0019 |
| Stepwise PCs—Backward | 0.0026 | 0.0363 | 0.2506 | 0.0026 | 0.0025 | 0.0360 | 0.2388 | 0.0023 | 0.0029 | 0.0346 | 0.2923 | 0.0026 |
| Stepwise PCs and Commodity-Specific Factors (always incl.)—Forward | 0.0022 | 0.0541 | 0.1378 | 0.0020 | 0.0030 | 0.0530 | 0.1942 | 0.0026 | 0.0015 | 0.0506 | 0.1035 | 0.0009 |
| Stepwise PCs and Commodity-Specific Factors (always incl.)—Backward | −0.0015 | 0.0352 | −0.1495 | −0.0016 | −0.0010 | 0.0341 | −0.1051 | −0.0012 | −0.0004 | 0.0347 | −0.0373 | −0.0007 |
| Stepwise PCs and Commodity-Specific Factors—Forward | 0.0011 | 0.0089 | 0.4356 | 0.0011 | 0.0010 | 0.0082 | 0.4170 | 0.0010 | 0.0010 | 0.0083 | 0.4304 | 0.0010 |
| Stepwise PCs and Commodity-Specific Factors—Backward | 0.0017 | 0.0248 | 0.2440 | 0.0017 | 0.0029 | 0.0214 | 0.4731 | 0.0029 | 0.0011 | 0.0217 | 0.1726 | 0.0010 |
| Stepwise PCs and Aggregate Commodity Factors (always incl.)—Forward | 0.0013 | 0.0213 | 0.2140 | 0.0013 | 0.0009 | 0.0240 | 0.1344 | 0.0009 | 0.0009 | 0.0240 | 0.1266 | 0.0007 |
| Stepwise PCs and Aggregate Commodity Factors (always incl.)—Backward | −0.0003 | 0.0219 | −0.0431 | −0.0003 | −0.0003 | 0.0218 | −0.0408 | −0.0003 | 0.0002 | 0.0238 | 0.0262 | 0.0000 |
| Stepwise PCs and Aggregate Commodity Factors—Forward | 0.0011 | 0.0198 | 0.1996 | 0.0011 | 0.0010 | 0.0194 | 0.1774 | 0.0009 | 0.0008 | 0.0169 | 0.1577 | 0.0007 |
| Stepwise PCs and Aggregate Commodity Factors—Backward | −0.0023 | 0.0447 | −0.1746 | −0.0024 | −0.0022 | 0.0446 | −0.1690 | −0.0024 | 0.0012 | 0.0164 | 0.2497 | 0.0011 |
| Stepwise PCs and Aggregate Commodity- Specific Factors (always incl.)—Forward | 0.0066 | 0.0410 | 0.5590 | 0.0065 | 0.0065 | 0.0337 | 0.6651 | 0.0063 | 0.0063 | 0.0338 | 0.6452 | 0.0060 |
| Stepwise PCs and Aggregate Commodity- Specific Factors (always incl.)—Backward | 0.0066 | 0.0410 | 0.5590 | 0.0065 | 0.0065 | 0.0337 | 0.6651 | 0.0063 | 0.0073 | 0.0325 | 0.7738 | 0.0070 |
| AR(1) Benchmark | 0.0011 | 0.0133 | 0.2958 | 0.0011 | 0.0011 | 0.0133 | 0.2962 | 0.0011 | 0.0011 | 0.0132 | 0.2975 | 0.0011 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guidolin, M.; Pedio, M. Switching Coefficients or Automatic Variable Selection: An Application in Forecasting Commodity Returns. Forecasting 2022, 4, 275-306. https://doi.org/10.3390/forecast4010016
Guidolin M, Pedio M. Switching Coefficients or Automatic Variable Selection: An Application in Forecasting Commodity Returns. Forecasting. 2022; 4(1):275-306. https://doi.org/10.3390/forecast4010016
Chicago/Turabian StyleGuidolin, Massimo, and Manuela Pedio. 2022. "Switching Coefficients or Automatic Variable Selection: An Application in Forecasting Commodity Returns" Forecasting 4, no. 1: 275-306. https://doi.org/10.3390/forecast4010016