
Similarity-Based Framework for Unsupervised Domain Adaptation: Peer Reviewing Policy for Pseudo-Labeling

Abstract
:1. Introduction
2. Related Work
3. Our Contribution
4. Materials and Methods
4.1. Case Study: Synthetic Basic Shapes Dataset
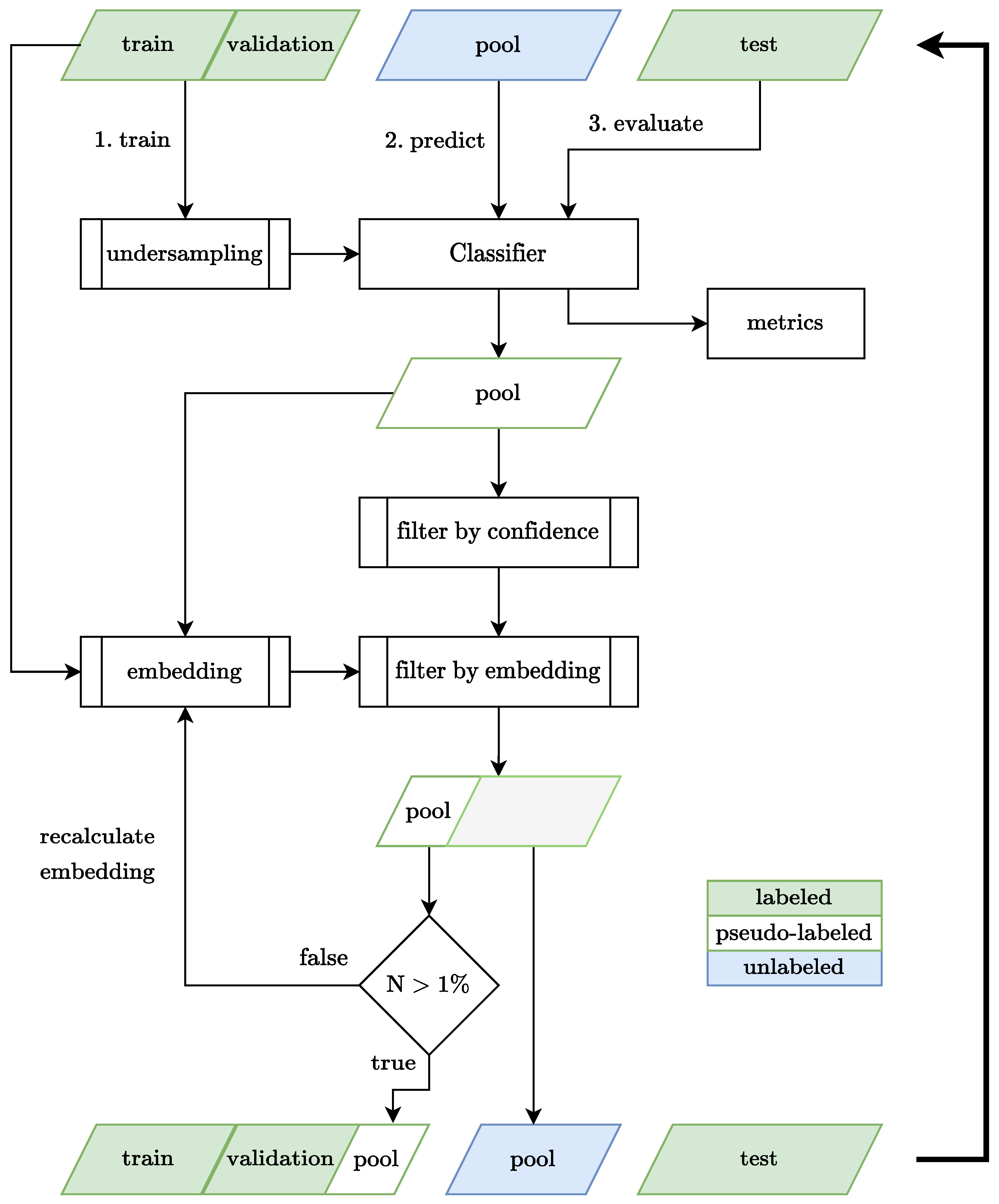
4.2. Algorithm Details
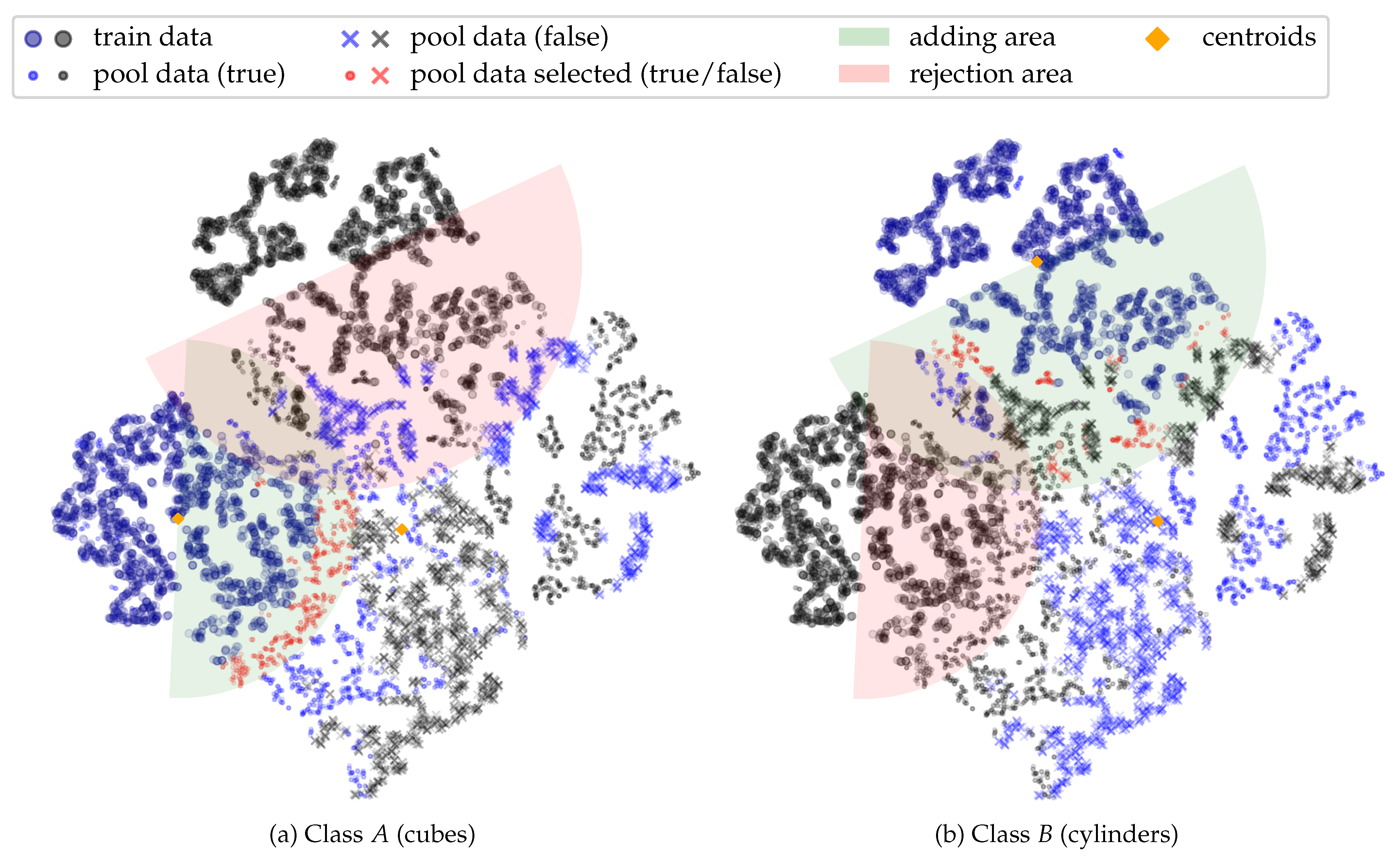
4.3. Reviewing Policy
| Algorithm 1 Algorithm details with Peer Reviewing Policy for Pseudo-Labeling |
Ensure:
Ensure:
▹ Dimensionality Reduction Require:
(in this work: ) scaling factor: for every iteration i do Train model on Predict pseudo-labels for target domain: Filter by confidence: for every class j do Calculate centroid of source domain embedding: Calculate centroid of target domain embedding: ▹ or according to Equation (2) Define semi-circle for each class: = sc(location = , direction = , radius = ) Target samples in semicircle: end for for everly class j do for every remaining class do Accepted samples: end for end for Test predictions: Update source domain: Update target domain: if then ▹ Refit embedding (non-deterministic) ▹ Increase semi-circle radius with scaling factor end if end for |
5. Results
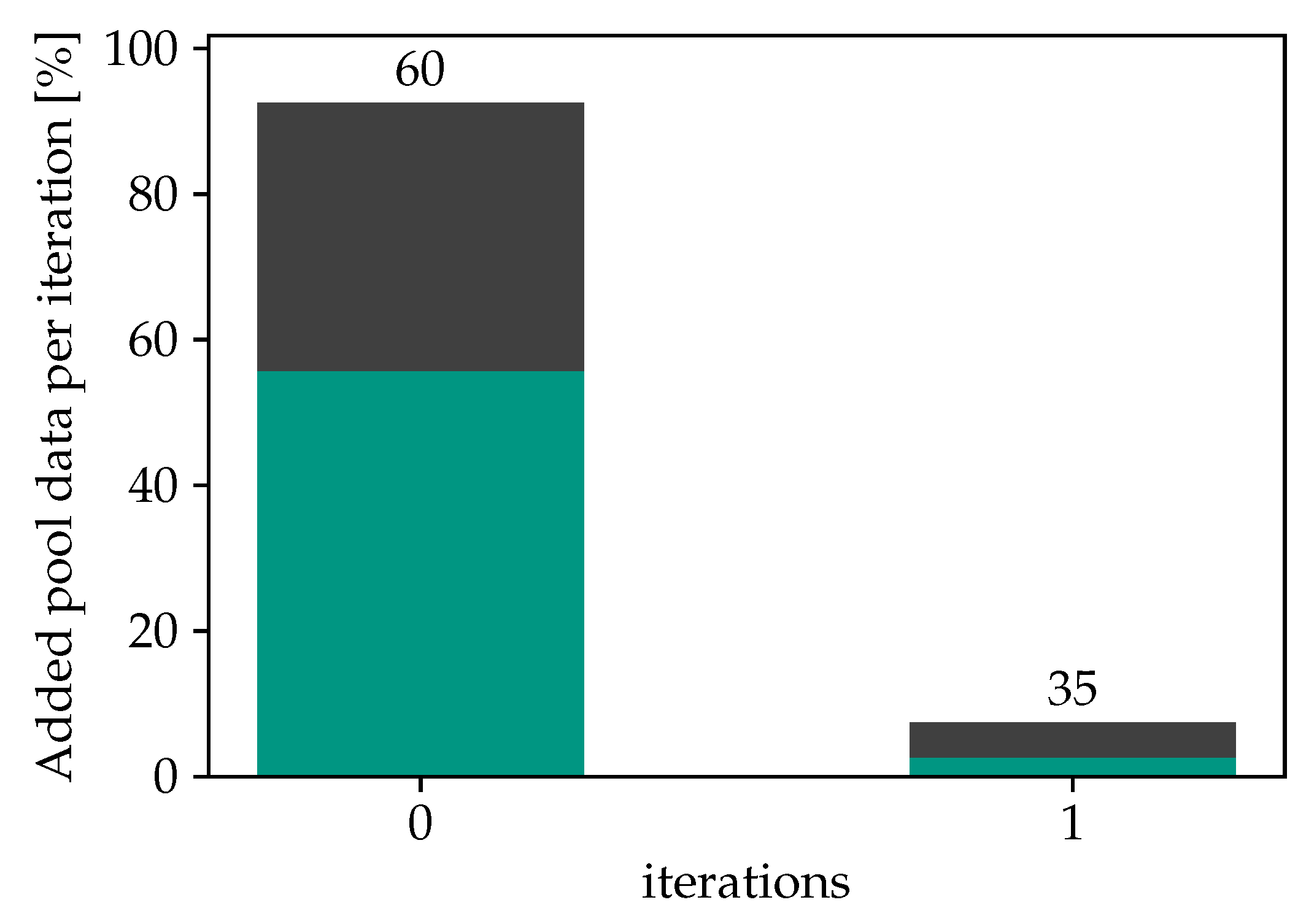
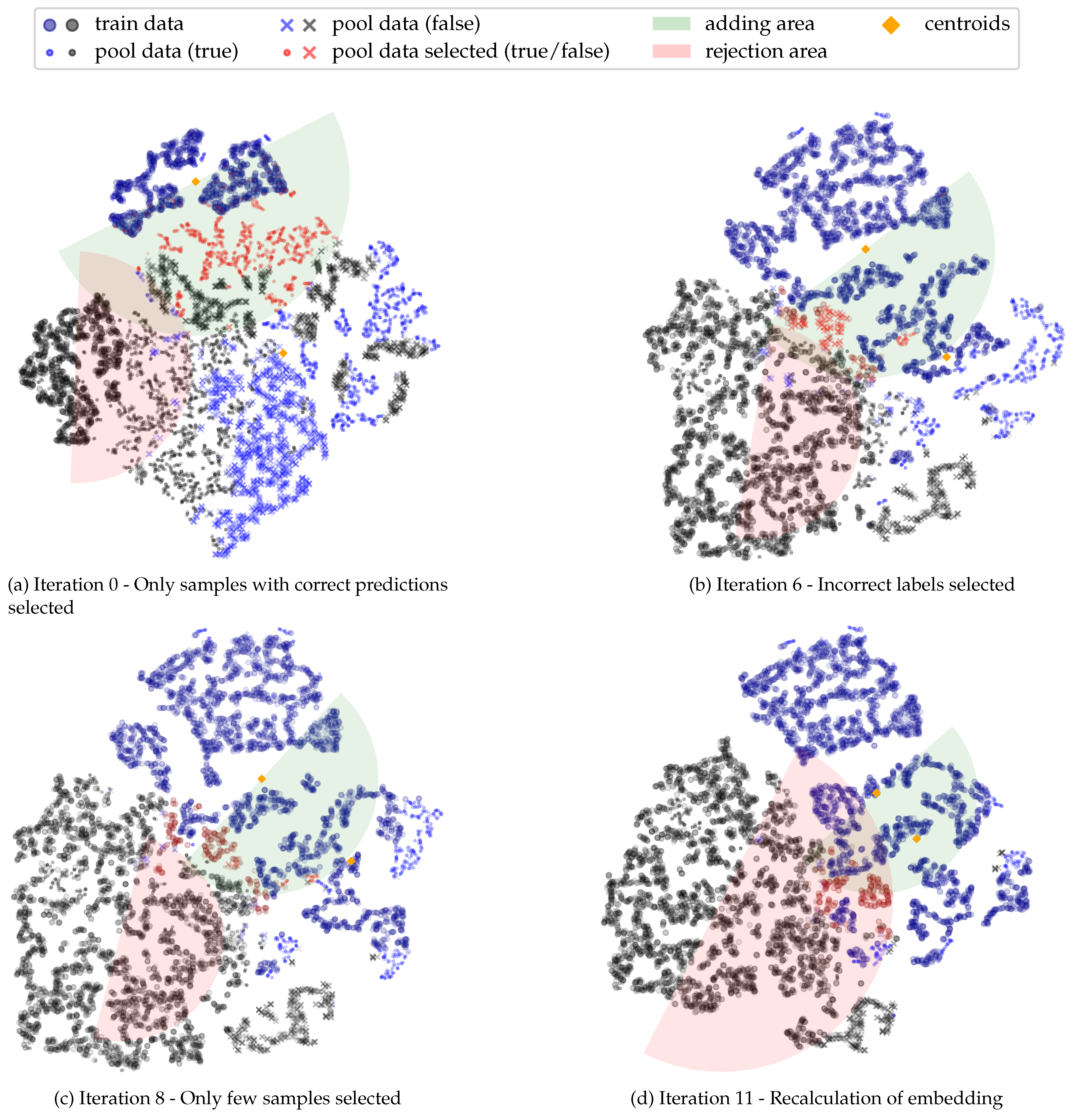
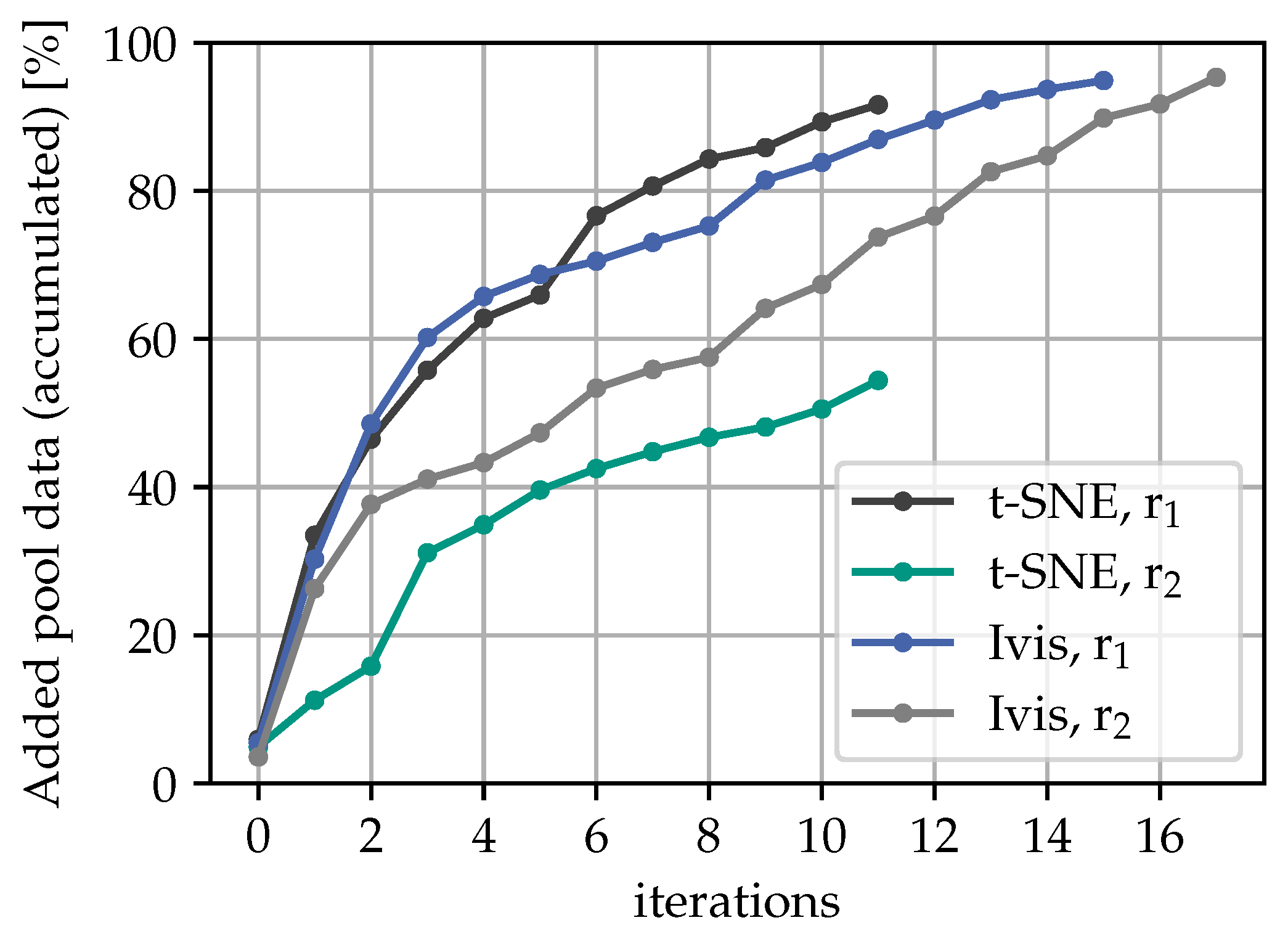
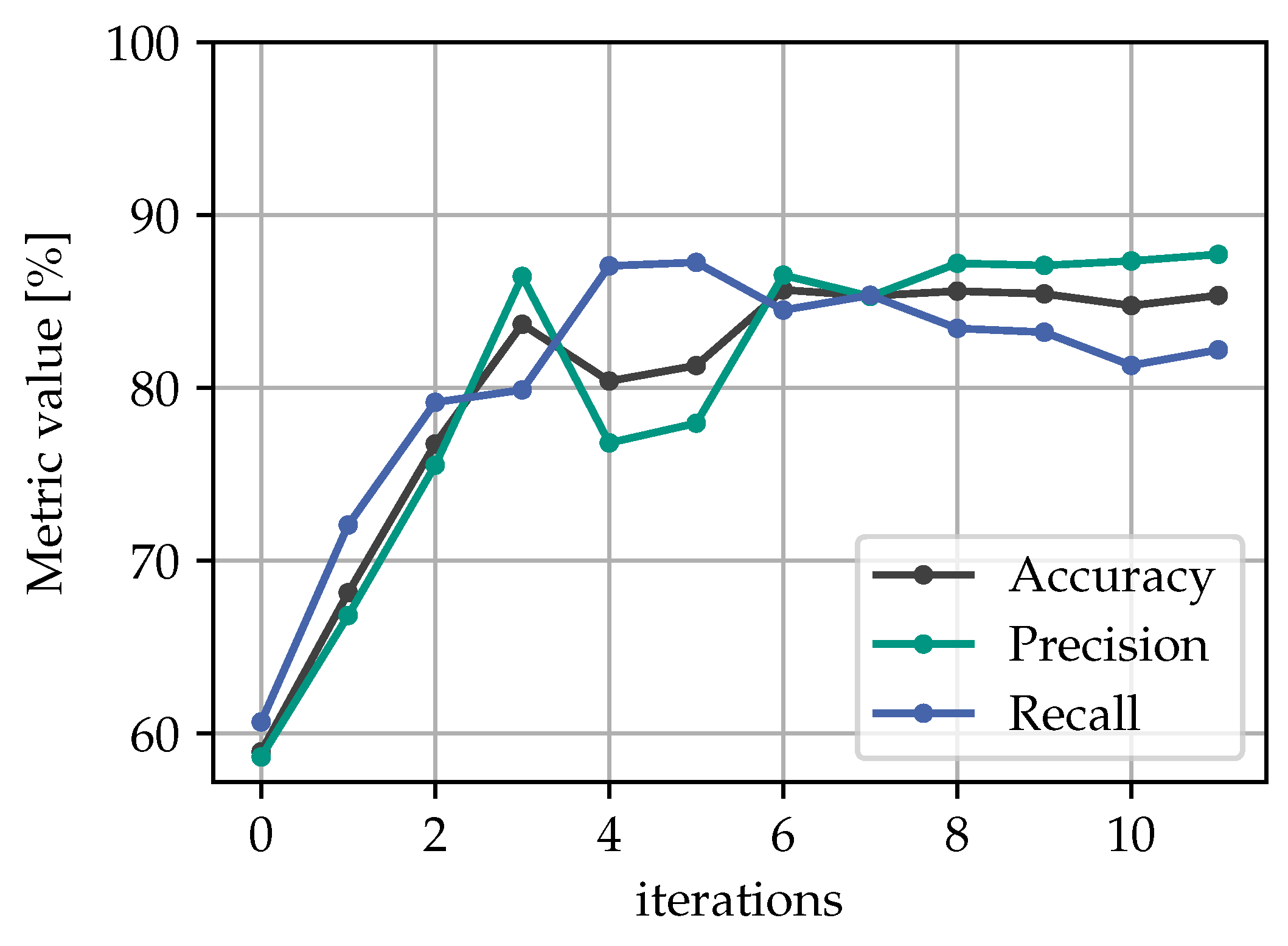
5.1. Learning Process
5.2. Evaluation of Alternative Review Procedures
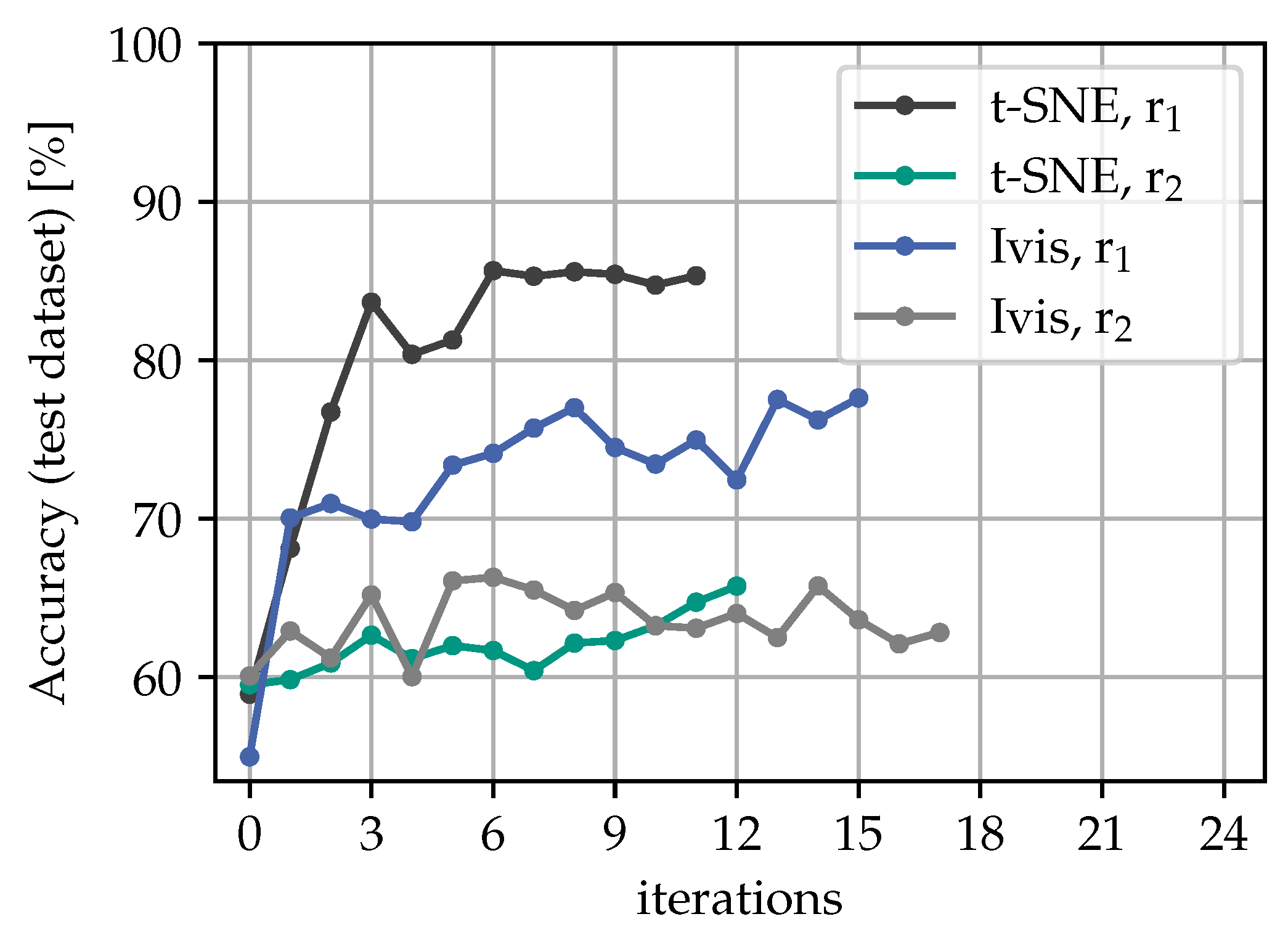
5.3. Accuracy Assessment on Test Dataset
5.4. Assessment of the Proposed Method with Alternative Classifiers
6. Discussions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AR | Aspect Ratio |
| DAN | Deep Adaptation Networks |
| DANN | Domain Adversarial Training for Neural Networks |
| D-CORAL | Deep-Correlation Alignment |
| JAN | Joint Adaptation Networks |
| MSTN | Moving Semantic Transfer Network |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
| VDA | Visual Domain Adaptation |
Appendix A. Algorithm Flowchart
References
- Ke, Z.; Qiu, D.; Li, K.; Yan, Q.; Lau, R.W.H. Guided Collaborative Training for Pixel-Wise Semi-Supervised Learning. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 429–445. [Google Scholar]
- Chum, L.; Subramanian, A.; Balasubramanian, V.N.; Jawahar, C.V. Beyond Supervised Learning: A Computer Vision Perspective. J. Indian Inst. Sci. 2019, 99, 177–199. [Google Scholar] [CrossRef]
- Schmarje, L.; Santarossa, M.; Schroder, S.M.; Koch, R. A Survey on Semi-, Self- and Unsupervised Learning for Image Classification. IEEE Access 2021, 9, 82146–82168. [Google Scholar] [CrossRef]
- Jeong, J.; Lee, S.; Kim, J.; Kwak, N. Consistency-based Semi-supervised Learning for Object detection. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4L: Self-Supervised Semi-Supervised Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar] [CrossRef]
- Zhang, R.; Liu, S.; Yu, Y.; Li, G. Self-supervised Correction Learning for Semi-supervised Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021, Strasbourg, France, 27 September–1 October 2021; pp. 134–144. [Google Scholar]
- Xu, H.M.; Liu, L.; Gong, D. Semi-supervised Learning via Conditional Rotation Angle Estimation. In Proceedings of the 2021 Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 29 November–1 December 2021; pp. 1–8. [Google Scholar]
- Fan, Y.; Kukleva, A.; Dai, D.; Schiele, B. Revisiting Consistency Regularization for Semi-Supervised Learning. Int. J. Comput. Vis. 2022, 131, 626–643. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-Supervised Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 8934–8954. [Google Scholar] [CrossRef]
- Su, J.C.; Cheng, Z.; Maji, S. A Realistic Evaluation of Semi-Supervised Learning for Fine-Grained Classification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Antonelli, S.; Avola, D.; Cinque, L.; Crisostomi, D.; Foresti, G.L.; Galasso, F.; Marini, M.R.; Mecca, A.; Pannone, D. Few-Shot Object Detection: A Survey. ACM Comput. Surv. 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Köhler, M.; Eisenbach, M.; Gross, H.M. Few-Shot Object Detection: A Comprehensive Survey. arXiv 2021, arXiv:2112.11699v2. [Google Scholar] [CrossRef]
- Calderon-Ramirez, S.; Yang, S.; Elizondo, D. Semisupervised Deep Learning for Image Classification with Distribution Mismatch: A Survey. IEEE Trans. Artif. Intell. 2022, 3, 1015–1029. [Google Scholar] [CrossRef]
- Pan, S.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Fan, M.; Cai, Z.; Zhang, T.; Wang, B. A survey of deep domain adaptation based on label set classification. Multimed. Tools Appl. 2022, 81, 39545–39576. [Google Scholar] [CrossRef]
- Gong, B.; Grauman, K.; Sha, F. Connecting the Dots with Landmarks: Discriminatively Learning Domain-Invariant Features for Unsupervised Domain Adaptation. PMLR 2013, 28, 222–230. [Google Scholar]
- Bruzzone, L.; Marconcini, M. Domain Adaptation Problems: A DASVM Classification Technique and a Circular Validation Strategy. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 770–787. [Google Scholar] [CrossRef]
- Noori Saray, S.; Tahmoresnezhad, J. Joint distinct subspace learning and unsupervised transfer classification for visual domain adaptation. Signal Image Video Process. 2021, 15, 279–287. [Google Scholar] [CrossRef]
- Dudley, A.; Nagabandi, B.; Venkateswara, H.; Panchanathan, S. Domain Adaptive Fusion for Adaptive Image Classification. In Proceedings of the Smart Multimedia, San Diego, CA, USA, 16–18 December 2019; pp. 357–371. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Venkatesan, R.; Swaminathan, G.; Majumder, O. d-SNE: Domain Adaptation Using Stochastic Neighborhood Embedding; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 43–56. [Google Scholar] [CrossRef]
- Deng, W.; Zhao, L.; Kuang, G.; Hu, D.; Pietikainen, M.; Liu, L. Deep Ladder-Suppression Network for Unsupervised Domain Adaptation. IEEE Trans. Cybern. 2022, 52, 10735–10749. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. Technical report. arXiv 2016, arXiv:1607.01719. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning Transferable Features with Deep Adaptation Networks. PMLR 2015, 37, 97–105. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. Technical report. arXiv 2017, arXiv:1605.06636. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, Z.; Huang, Z.; Lu, Y.; Lan, C.; Chu, P.; You, Q.; Wang, J.; Liu, Z.; Parulkar, A.; et al. Deep Frequency Filtering for Domain Generalization. Technical report. arXiv 2023, arXiv:2203.12198. [Google Scholar] [CrossRef]
- Gu, X.; Sun, J.; Xu, Z. Spherical Space Domain Adaptation with Robust Pseudo-Label Loss. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9098–9107. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Xie, S.; Zheng, Z.; Chen, L.; Chen, C. Learning Semantic Representations for Unsupervised Domain Adaptation. PMLR 2018, 80, 5423–5432. [Google Scholar]
- Karim, N.; Mithun, N.C.; Rajvanshi, A.; Chiu, H.P.; Samarasekera, S.; Rahnavard, N. C-SFDA: A Curriculum Learning Aided Self-Training Framework for Efficient Source Free Domain Adaptation. Technical report. arXiv 2023, arXiv:2303.17132. [Google Scholar] [CrossRef]
- Litrico, M.; Del Bue, A.; Morerio, P. Guiding Pseudo-labels with Uncertainty Estimation for Source-free Unsupervised Domain Adaptation. Technical report. arXiv 2023, arXiv:2303.03770. [Google Scholar] [CrossRef]
- Tahmoresnezhad, J.; Hashemi, S. Visual domain adaptation via transfer feature learning. Knowl. Inf. Syst. 2017, 50, 585–605. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, Z.; Sun, B. COT: Unsupervised Domain Adaptation with Clustering and Optimal Transport. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 19998–20007. [Google Scholar]
- Krueger, B.; Wirtz, S.; Scherer, V. Measurement of drag coefficients of non-spherical particles with a camera-based method. Powder Technol. 2015, 278, 157–170. [Google Scholar] [CrossRef]
- Ates, C.; Arweiler, J.; Hadad, H.; Koch, R.; Bauer, H.J. Secondary Motion of Non-Spherical Particles in Gas Solid Flows. Processes 2023, 11, 1369. [Google Scholar] [CrossRef]
- Cai, J.; Peng, Z.; Wu, C.; Zhao, X.; Yuan, Z.; Moghtaderi, B.; Doroodchi, E. Numerical Study of the Orientation of Cylindrical Particles in a Circulating Fluidized Bed. Ind. Eng. Chem. Res. 2016, 55, 12806–12817. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Szubert, B.; Drozdov, I. ivis: Dimensionality reduction in very large datasets using Siamese Networks. J. Open Source Softw. 2019, 4, 1596. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training | Validation | Pool | Test |
|---|---|---|---|---|
| Samples | 3200 | 800 | 10,000 | 10,000 |
| Rotation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arweiler, J.; Ates, C.; Cerquides, J.; Koch, R.; Bauer, H.-J. Similarity-Based Framework for Unsupervised Domain Adaptation: Peer Reviewing Policy for Pseudo-Labeling. Mach. Learn. Knowl. Extr. 2023, 5, 1474-1492. https://doi.org/10.3390/make5040074
Arweiler J, Ates C, Cerquides J, Koch R, Bauer H-J. Similarity-Based Framework for Unsupervised Domain Adaptation: Peer Reviewing Policy for Pseudo-Labeling. Machine Learning and Knowledge Extraction. 2023; 5(4):1474-1492. https://doi.org/10.3390/make5040074
Chicago/Turabian StyleArweiler, Joel, Cihan Ates, Jesus Cerquides, Rainer Koch, and Hans-Jörg Bauer. 2023. "Similarity-Based Framework for Unsupervised Domain Adaptation: Peer Reviewing Policy for Pseudo-Labeling" Machine Learning and Knowledge Extraction 5, no. 4: 1474-1492. https://doi.org/10.3390/make5040074