Learning Model Discrepancy of an Electric Motor with Bayesian Inference †

1
Engineering Mathematics and Computing Lab (EMCL), Interdisciplinary Center for Scientific Computing (IWR), Heidelberg University, 69120 Heidelberg, Germany
2
Corporate Research, Robert Bosch GmbH, 71272 Renningen, Germany
3
Data Mining and Uncertainty Quantification Group (DMQ), Heidelberg Institute for Theoretical Studies (HITS) GmbH, 69118 Heidelberg, Germany
*
Author to whom correspondence should be addressed.
†
Presented at the 39th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering, Garching, Germany, 30 June–5 July 2019.
Proceedings 2019, 33(1), 11; https://doi.org/10.3390/proceedings2019033011
Published: 25 November 2019
(This article belongs to the Proceedings of The 39th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering)
Abstract
:Uncertainty Quantification (UQ) is highly requested in computational modeling and simulation, especially in an industrial context. With the continuous evolution of modern complex systems demands on quality and reliability of simulation models increase. A main challenge is related to the fact that the considered computational models are rarely able to represent the true physics perfectly and demonstrate a discrepancy compared to measurement data. Further, an accurate knowledge of considered model parameters is usually not available. e.g., fluctuations in manufacturing processes of hardware components or noise in sensors introduce uncertainties which must be quantified in an appropriate way. Mathematically, such UQ tasks are posed as inverse problems, requiring efficient methods to solve. This work investigates the influence of model discrepancies onto the calibration of physical model parameters and further considers a Bayesian inference framework including an attempt to correct for model discrepancy. A polynomial expansion is used to approximate and learn model discrepancy. This work extends by discussion and specification of a guideline on how to define the model discrepancy term complexity, based on the available data. Application to an electric motor model with synthetic measurements illustrates the importance and promising perspective of the method.
1. Introduction
The increasing complexity of technical systems yields high demands on model quality and numerical accuracy. Quantification of these models under uncertainty is desired to make statements about reliability and accuracy. Consequently, there is a need for efficient solvers and new additional Uncertainty Quantification (UQ) methods, which are able to cope with the soaring complexity of models and that take into account all sources of uncertainty. Model calibration requires the solution of an inverse problem with uncertainties, such as parametric, observation, structural model and solution method uncertainty. Let , for , represent a simulation model that maps some input x to an output . An inverse problem is the task of finding an for a given measurement such that . Generally, this equality does not hold as the measurements y are usually corrupted. Hence, one considers , where represents the observation uncertainty due to measurement noise or other errors. Simply inverting is not possible as is unknown and in general does not exist. A classical approach to solve this problem is by minimizing the data misfit, i.e., . However, this problem is typically ill-posed in the sense of Hadamard, i.e., multiple solutions might exist and stability might be a problem. To obtain a well-posed problem regularization is necessary. One approach is Tikhonov regularization, also known as ridge regression in statistics [1]. However, the particular choice of regularization is somewhat arbitrary [2]. With the Bayesian approach one is interested in finding a probability measure on with probability density that expresses how likely for a certain describes y under consideration of noise. Then the problem is well-posed under slight assumptions and leads to a natural way of regularization due to the definition of prior distributions for unknown parameters, see [1,2,3]. Generally, the posterior distribution is intractable and one can not sample from it directly, hence approximative methods, such as filtering, variational and sampling methods, are required [2,4,5]. Metropolis-Hastings Markov-Chain Monte-Carlo (MH-MCMC) sampling is used in this work [4,6,7]. Note that methods to improve sampler efficiency [8,9,10] and surrogate modeling of , e.g. by Polynomial Chaos expansions [11,12] or GPs [13,14], could leverage overall simulation time and speed up the inference, if required.
A difficulty in solving the inverse problem is to capture and separate all sources of uncertainty, often called “identification problem”. A main challenge is related to the fact that the considered computational models are rarely able to represent the true physics perfectly and demonstrate a discrepancy compared to measurement data. To be more specific the term model discrepancy in this work denotes the difference between simulation model for the true physical parameters and the true system, hence structural model uncertainty (e.g., lack of knowledge, missing physics), but also implementation and numerical errors. However, this model discrepancy is usually unknown.
The Kennedy and O’Hagan (KO) framework [13] is one of the first attempts to model and explicitly take account of all the uncertainty sources that arise in the calibration of computer models. Model discrepancy is considered by an additional term and modeled by an Gaussian process (GP). Following [13], Arendt et al. [15,16] suggest a modular Bayesian approach and discuss the identification problem. Examples illustrate that sometimes this separation is possible under mild assumptions, e.g., smoothness of the model discrepancy, but also that it is not possible in other cases. In the companion work [16] they show an approach how to improve identifiability by using multiple responses and representing correlation between responses. Another work using multiple responses is [17]. Brynjarsdóttir and O’Hagan [18] state that with the KO framework in order to infer physical parameters and model discrepancy simultaneously sufficient prior distributions for at least one of those must be given. However, Tuo and Wu [19,20] showed that the choice of the model discrepancy prior has a permanent influence onto the parameter posterior distribution even in the large data limit. Plumlee [21] presented an approach to improve identifiability by defining a prior distribution of the model discrepancy that is orthogonal to the gradient of the model. However, computational costs are high. Nagel et al. [22] modeled the model discrepancy term by an polynomial expansion, assuming smoothness for the true underlying model discrepancy.
Following all these works we consider a Bayesian model with a term for measurement noise and a model discrepancy. We adapt the idea of representing model discrepancy by a polynomial expansion [22]. The major contribution of this work is to provide answers on how to select a polynomial degree by keeping the complexity of the model low while still providing high accuracy in discrepancy modeling. This is shown in a practical guideline, which recommends how to select a sufficient maximum polynomial degree of the truncated polynomial expansion, based on the available data and the estimation of measurement noise. Furthermore, critical points conditioning the choice of the model discrepancy term are discussed in detail. The framework is applied to the calibration of a direct current (DC) electric motor model in a synthetic setting. i.e., synthetic measurements are created and a modified electric motor model, containing an artificial model error are used to infer model parameters. Due to the synthetic setup, available references allow a quantitative evaluation of the considered methods performance and accuracy.
2. Electric Motor Model
A DC electric motor is a rotating electrical machine converting electrical energy into mechanical energy. Let denote the electric current and the angular velocity. For , the ODEs
with initial conditions , describe the electro-mechanical behavior of a DC electric motor [23]. The real valued parameters are: cable harness resistance , motor constants , voltage , friction , inductivity , inertia and constant torque required by the load. Here, only R is considered uncertain and all other parameters are fixed to .
Let and denote numerical approximations of I and at equidistant time points for and . For this work the explicit Runge-Kutta method dopri5 (Dormand and Prince) is used, see [24]. For notational convenience we define
depending only on . Synthetic measurements for a fixed reference value are created by , where is a realization of , with covariance . For independent and identically distributed (iid) measurement noise for current and angular velocity at each time step let , with . Figure 1 displays a measurement of I and with .
As the goal of this work is to learn about model discrepancy an artificial model error is introduced into . Let be the numerical approximation of the model for a given and denote it as simulation model. Obviously, . can be interpreted as missing physics, i.e. by damping or amplifying a part of the equation, or as a misspecified model. Define the discrepancy and the noisy discrepancy . Denote for the reference discrepancies by and .
3. Bayesian Inference Solution Process
Consider the inverse problem of finding an such that , where are noisy measurements and is the simulation model containing an artificial model error . The goal here is not just to infer an optimal , but also one that is as close as possible to the reference , i.e., the true physical value, which was used to create the measurements . Following [22] we introduce two Bayesian models that differ in their complexity. The simpler model only considers measurement noise, whereas the more complex model considers model discrepancy additionally.
3.1. Bayesian Model 1 (BM1): Measurement Noise
As the measurements are noisy, additive noise is added to the simulation model. Here, are considered as zero mean Gaussian and with unknown standard deviations , respectively. The Bayesian model 1 (BM1) is
Hence, the likelihood is , with . By expressing a-priori knowledge in terms of a prior probability density function , Bayes’ formula yields for the posterior probability density . The are defined as uninformative Inverse Gamma distributions . This is a common choice for conjugate priors of scale parameters in Bayesian statistics [4], in particular for a Gaussian likelihood with given mean.
3.2. Bayesian Model 2 (BM2): Measurement Noise and Model Discrepancy
BM2 extends BM1 by considering model discrepancy with an additive term , additionally to iid measurement noise. Note that this is already the discretized version and , are vectors of the, yet to define, model discrepancy terms evaluated at . Omitting the superscripts for a moment, we now assume that . Let be a basis of functions dense in . Then can be represented by the expansion For practicability reasons the expansion is truncated after a . Such an truncated expansion was also used in [22]. With this let, for the truncation parameter , the truncated functional expansions
be approximative models for the model discrepancy terms . The bases and are not necessarily identical. Note that each expansion could be truncated with own truncation parameters , but for notational convenience and due to later usage we stick to . Let be the coefficient vector and , . Hence denotes the approximation of the true underlying model discrepancy .The Bayesian model 2 (BM2) is
The number of unknown parameters is . With the additional unknown coefficients , the prior probability density function is defined as where . The prior distributions for and are specified as above. Now, with the likelihood the posterior is given by where denotes the dependence on K.
Choosing basis functions and priors for the coefficients: If knowledge about the discrepancy is available, this should be modeled accordingly by defining an appropriate prior distribution for , i.e., in the case of appropriate choices for and . However, in general this knowledge is not available and some modeling assumptions need to be made. With the assumption that is rather smooth, orthonormal polynomials with are a reasonable choice. As [22], we also opt for Legendre polynomials that are orthogonal to a constant weight. In [22] they argue about the prior for the coefficients and decide for zero mean Laplace distribution with the arbitrary choice of . It assigns the highest probability around zero and decays exponentially towards the tails, see [25].
Choosing the truncation parameter K: With the choice of Legendre polynomials K corresponds to the maximum polynomial degree. This K determines the complexity of the model discrepancy term . Important factors in order to specify the model discrepancy term complexity are: accuracy, computational costs, bias-variance tradeoff and non-identifiability. An optimal K should be large enough such that is accurate enough to approximate the underlying discrepancy correct, but at the same time it should be as small as possible since a large K increases the number of unknown parameters and consequently computational costs. Furthermore, a large K might yield non-identifiability of all unknowns, as the prior of gets non-informative. In [18] they state that in order to infer model discrepancy and model parameters at the same time, at least for one of those an informative prior must be given. The term bias-variance tradeoffdescribes the fact that with increasing model complexity K the bias of an estimator decreases, but at the same time the variance increases with the model complexity [26]. Consequently, the overall error as sum of squared bias and variance is minimal for an optimal model complexity.
Taking all these factors into account the approach in this work on how to find an optimal K is following: Start with an initial and increase K iteratively until the marginal posterior distribution of the noise standard deviations stabilizes. i.e., that some distance for a given tolerance and . Then select the K such that this condition holds. Why is this sufficient? If a model discrepancy is present in BM1, then the noise term is the only instance to capture it. As the noise term is modeled with zero mean, the standard deviation might be overestimated consequently. By adding the model discrepancy term in BM2 captures a fraction of the model discrepancy. As a consequence, the noise term needs to represent only the remaining discrepancy and is estimated by a smaller value. If the estimated standard deviation of the noise does not change anymore (within the tolerance) from K to for the smallest sufficient K is found. For this K the model discrepancy term should represent the underlying model discrepancy best within its current specification and a separation of model uncertainty and measurement uncertainty is achieved.
4. Numerical Results
The numerical results for BM1 and BM2 applied to the electric motor model are presented and compared to the reference. The prior distribution for R is chosen as . Variations of the prior mean by +/−15% did not influence the upcoming results much, thus simply was chosen as mean. An MH-MCMC implementation of the Python package PyMC3 [7] is used to approximate the posterior distribution probability density function. The marginal posterior moments are empirically approximated using Monte Carlo integration with a certain number of the obtained MH-MCMC samples. In order to compare and evaluate the solutions we define error measures.
Definition 1.
Define the relative error for a parameter estimate as , where is the reference value. might be the empirical approximation of the marginal posterior mean .
Definition 2.
Let x with be an estimation for and given . The mean square error (MSE) of x is , with . The mean is with respect to . In case of depending on K write .
4.1. Results Bayesian Model 1
In Figure 2 the index BM1 denotes marginal posterior moments for parameters and obtained with BM1 in comparison to the reference and BM2. With respect to a burn in phase, only the last 700 samples of three independently sampled Markov chains, each of total length 1500, are used to obtain the results. The marginal posterior distribution for is close to the reference, but for R and the marginal posteriors concentrate at values different to the references and do not even assign a significant probability to the references. The marginal posterior mean values of and and their respective relative error with respect to the reference are displayed in Table 1.
The noisy discrepancy for is displayed in Figure 3. (Remark: For simplicity the mean is approximated by assuming linearity for in a neighborhood of .) For this is basically the measurement noise, since and . But for there is some discrepancy, at least in the first half of the time interval, different to measurement noise. Calculating the empirical standard deviation for a fixed zero mean , where denotes the i-th component of , one obtains . The obtained value corresponds to the overestimated marginal posterior distribution of that centers around a similar value, see Figure 2 and Table 1. Obviously, BM1 leads to biased and overconfident parameter estimates.
4.2. Results Bayesian Model 2
Figure 2 also displays moments of the marginal posterior distributions of and , obtained via BM2 for . For each K the last samples of three independently sampled Markov chains of length are used to approximate the moments. In contrast to BM1 a larger number of MH-MCMC samples is required for convergence, due to an increased number of unknowns in BM2. For comparison, the index BM1 in the following figures denotes results without . Following the guideline specified in Section 3 the marginal posterior distributions of the noise standard deviations of and in Figure 2 are considered to pick an appropriate K. Both marginal posterior distributions and stabilize for and are almost identical for , considering mean and standard deviation of the marginal posterior distribution. This indicates that is a sufficient polynomial degree and increasing K further does not improve the results with the current specification of the model discrepancy term. Figure 4 displays for the concentration of the posterior distribution of around the reference discrepancy .
The relative error is 1.0 × for I and 9.2 × for . Also the marginal posterior distribution of R concentrates close to the reference value and the relative error of the posterior mean reduces around one order of magnitude compared to the result of BM1, see Table 1. Also, both noise standard deviations concentrate around the reference and significantly improve in relative errors compared to BM1. Overall, the posterior distribution of yields a good approximation of the measurements with only a small variance band. Figure 2 shows that for the marginal posterior mean of R roughly stabilizes in some kind of a plateau close to the reference , but the posterior standard deviation increases with K. For the model discrepancy term is not flexible enough to approximate the underlying discrepancy appropriate enough. As a consequence, the standard deviations of the measurement noise are overestimated and the estimation of the parameter R is still biased for those values of K.
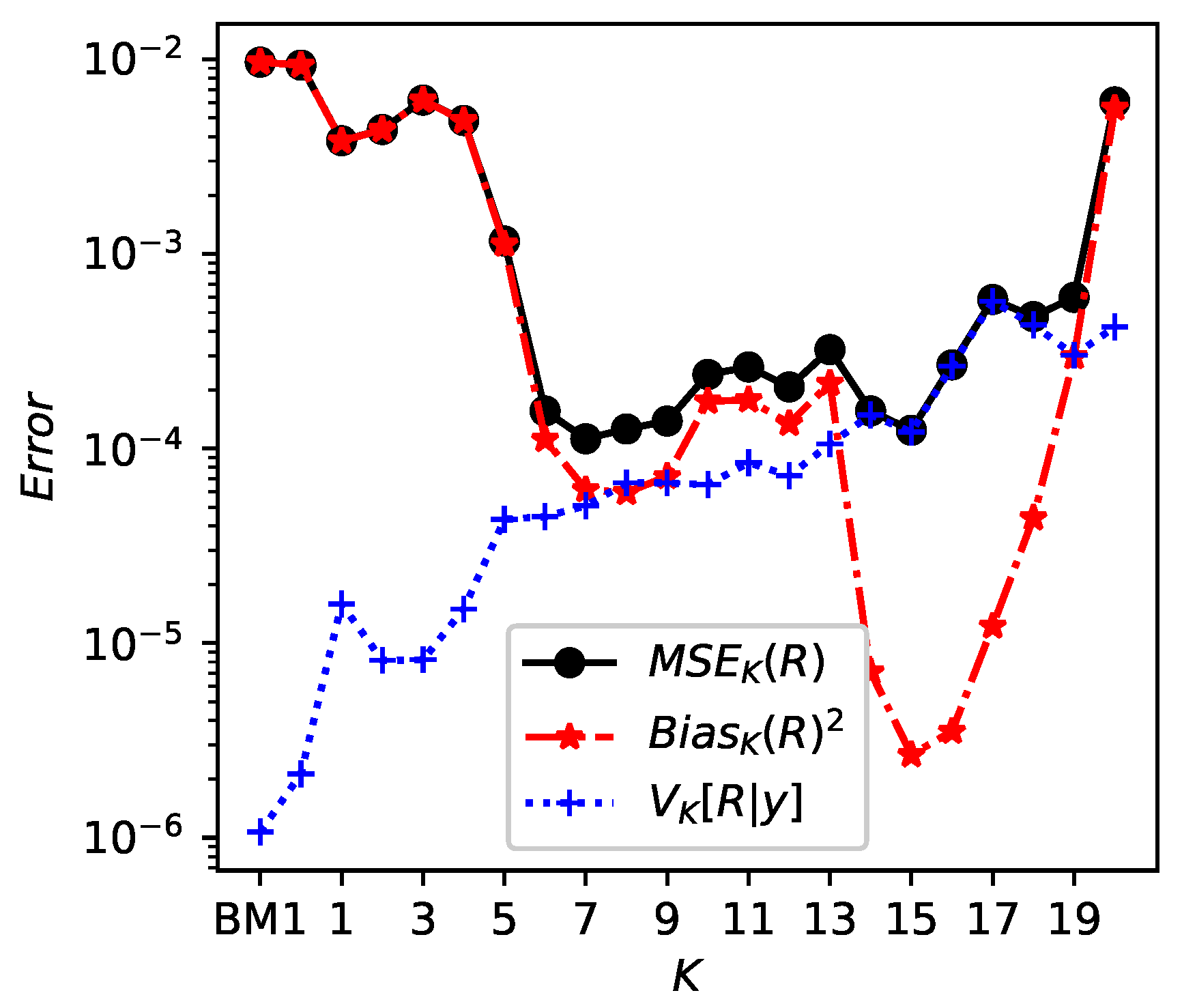
Adding on this, Figure 5 displays , variance and of R. The MSE of R is minimal around and , indicating those values as an optimal model complexity and backing up the decision of as sufficient polynomial degree. Figure 5 largely corresponds to the bias-variance tradeoff, since the variance increases with K and the bias decreases with K, at least until . For the bias increases as non-identifiability occurs additionally. Especially for overfitting and non-identifiability can be observed as the posterior distribution of R is spread out and biased, see Figure 2. For complimentary numerical results (e.g., posterior moments of for ) see the accompanying preprint of this work [27].
5. Conclusions
In this work a method to infer model parameters and model discrepancy is considered and applied to synthetic measurement data of an electric motor. The suggested Bayesian model 2 (BM2) considers measurement noise and model discrepancy, in order to separate these two sources of uncertainty and improve physical parameter estimation. The model discrepancy term is modeled as a truncated polynomial expansion with unknown coefficients and an maximum polynomial degree K. A discussion and a guideline on how to define appropriate model discrepancy term complexity, i.e., here the maximum polynomial degree K, based on the marginal posterior distribution of measurement noise standard deviation is presented. The framework applied to the electric motor showed promising perspectives by an improved estimation of the model parameters. Furthermore a good approximation of the a-priori unknown model discrepancy is learned with BM2 for a sufficient maximum polynomial degree . An appropriate choice of K is crucial. For K too small the accuracy of is not sufficient and estimation is just slightly improved. If K is too large the prior contains to less information about the reference discrepancy and consequently the posterior distribution does not converge anymore. Consequently, in order to identify both, the underlying parameter value and the reference discrepancy of the test scenario, it is important to find an optimal K and with this formulate at least for one of the unknowns a prior containing some information about the reference.
Next steps are to apply this approach to higher dimensional problems and further to real field data to test its capabilities. Then, as real data implies a more complex simulator, surrogate modeling will be mandatory to leverage computational expenses. Additionally, evidence approximation could be an another criteria to select a Bayesian model, which will be considered in future work.
Author Contributions
D.N.J. implemented and conceived the numerical results. D.N.J. and M.S. analyzed the data. D.N.J., M.S. and V.H. wrote the paper.
Acknowledgments
We thank Robert Bosch GmbH for funding this work.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Kaipio, J.; Somersalo, E. Statistical and Computational Inverse Problems; Applied Mathematical Sciences; Springer Science+Business Media, Inc.: New York, NY, USA, 2005. [Google Scholar]
- Stuart, A.M. Inverse problems: A Bayesian perspective. Acta Numer. 2010, 19, 451–559. [Google Scholar] [CrossRef]
- Dashti, M.; Stuart, A.M. The Bayesian Approach to Inverse Problems. In Handbook of Uncertainty Quantification; Ghanem, R., Higdon, D., Owhadi, H., Eds.; Springer: Cham, Switzerland, 2017; pp. 311–428. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B.; Stern, H.S. Bayesian Data Analysis, 3rd ed.; Texts in Statistical Science Series; CHAPMAN & HALL/CRC and CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Sullivan, T.J. Introduction to Uncertainty Quantification; Texts in Applied Mathematics 0939-2475; Springer: Berlin, Germany, 2015; Volume 63. [Google Scholar]
- Hastings, W.K. Monte Carlo Sampling Methods Using Markov Chains and Their Applications. Biometrika 1970, 57, 97. [Google Scholar] [CrossRef]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2016, 2, e55. [Google Scholar] [CrossRef]
- Schillings, C.; Schwab, C. Scaling limits in computational Bayesian inversion. ESAIM Math. Model. Numer. Anal. 2016, 50, 1825–1856. [Google Scholar] [CrossRef]
- Sprungk, B. Numerical Methods for Bayesian Inference in Hilbert Spaces, 1st ed.; Universitätsverlag der TU Chemnitz: Chemnitz, Germany, 2018. [Google Scholar]
- Hoffman, M.D.; Gelman, A. The No-U-turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. J. Mach. Learn. Res. 2014, 15, 1593–1623. [Google Scholar]
- Xiu, D.; Karniadakis, G.E. The Wiener-Askey polynomial chaos for stochastic differential equations. SIAM J. Sci. Comput. 2002, 24, 619–644. [Google Scholar] [CrossRef]
- Glaser, P.; Schick, M.; Petridis, K.; Heuveline, V. Comparison between a Polynomial Chaos surrogate model and Markov Chain Monte Carlo for inverse Uncertainty Quantification based on an electric drive test bench. In Proceedings of the ECCOMAS Congress 2016, Crete Island, Greece, 5–10 June 2016. [Google Scholar]
- Kennedy, M.C.; O’Hagan, A. Bayesian calibration of computer models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 425–464. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K. Gaussian Process for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Arendt, P.D.; Apley, D.W.; Chen, W. Quantification of Model Uncertainty: Calibration, Model Discrepancy, and Identifiability. J. Mech. Des. 2012, 134, 100908. [Google Scholar] [CrossRef]
- Arendt, P.D.; Apley, D.W.; Chen, W.; Lamb, D.; Gorsich, D. Improving Identifiability in Model Calibration Using Multiple Responses. J. Mech. Des. 2012, 134, 100909. [Google Scholar] [CrossRef]
- Paulo, R.; García-Donato, G.; Palomo, J. Calibration of computer models with multivariate output. Comput. Stat. Data Anal. 2012, 56, 3959–3974. [Google Scholar] [CrossRef]
- Brynjarsdóttir, J.; O’Hagan, A. Learning about physical parameters: The importance of model discrepancy. Inverse Probl. 2014, 30, 114007. [Google Scholar] [CrossRef]
- Tuo, R.; Wu, C.F.J. Efficient calibration for imperfect computer models. Ann. Stat. 2015, 43, 2331–2352. [Google Scholar] [CrossRef]
- Tuo, R.; Jeff Wu, C.F. A Theoretical Framework for Calibration in Computer Models: Parametrization, Estimation and Convergence Properties. SIAM/ASA J. Uncertain. Quantif. 2016, 4, 767–795. [Google Scholar] [CrossRef]
- Plumlee, M. Bayesian Calibration of Inexact Computer Models. J. Am. Stat. Assoc. 2016, 112, 1274–1285. [Google Scholar] [CrossRef]
- Nagel, J.B.; Rieckermann, J.; Sudret, B. Uncertainty Quantification in Urban Drainage Simulation: Fast Surrogates for Sensitivity Analysis and Model Calibration. 2017. Available online: http://arxiv.org/abs/1709.03283 (accessed on 23 March 2018).
- Toliyat, H.A. (Ed.) Handbook of Electric Motors, 2nd ed.; Electrical and Computer Engineering; Dekker: New York, NY, USA; Basel, Switzerland, 2004; Volume 120. [Google Scholar]
- Wanner, G.; Hairer, E. Solving Ordinary Differential Equations I; Springer: Berlin, Germany, 1991; Volume 1. [Google Scholar]
- Kotz, S.; Kozubowski, T.; Podgorski, K. The Laplace Distribution and Generalizations: A Revisit with Applications to Communications, Economics, Engineering, and Finance; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- John, D.; Schick, M.; Heuveline, V. Learning model discrepancy of an electric motor with Bayesian inference. Eng. Math. Comput. Lab 2018. [Google Scholar] [CrossRef]
Figure 1.
Noisy synthetic measurements of electric current and angular velocity .
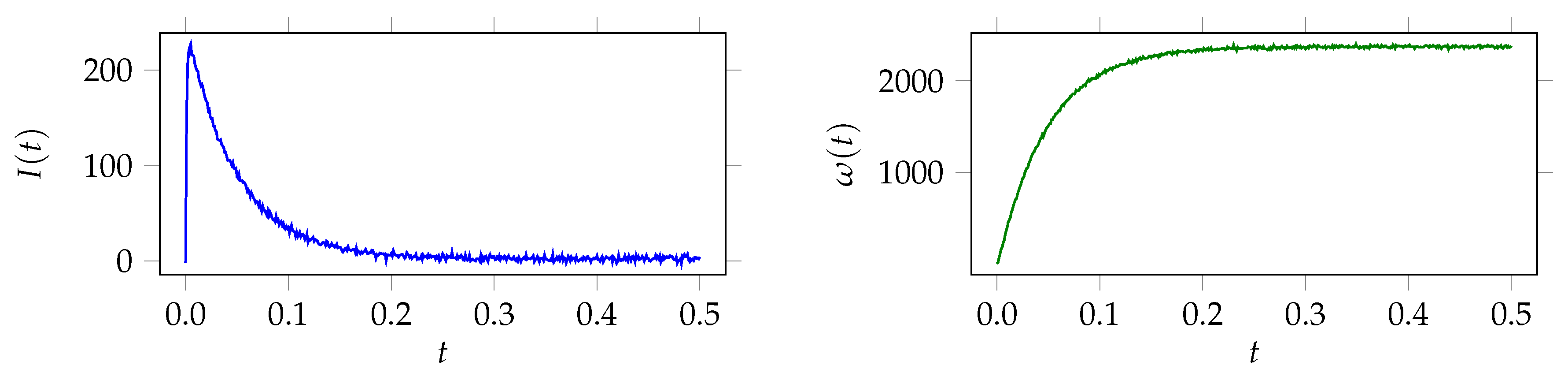
Figure 2.
Results obtained with BM1 (noted by index BM1) and BM2 for . Moments of the marginal posterior distributions of R are displayed on the left and moments of on the right.
Figure 2.
Results obtained with BM1 (noted by index BM1) and BM2 for . Moments of the marginal posterior distributions of R are displayed on the left and moments of on the right.
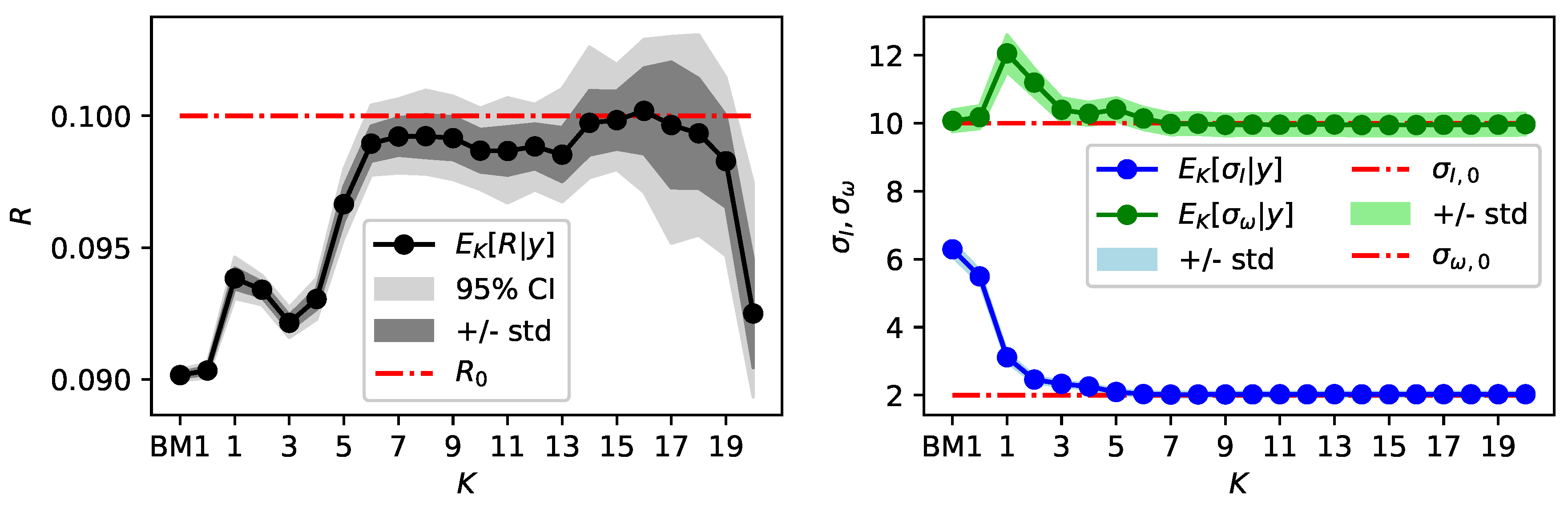
Figure 3.
Remaining discrepancy , for obtained with BM1.
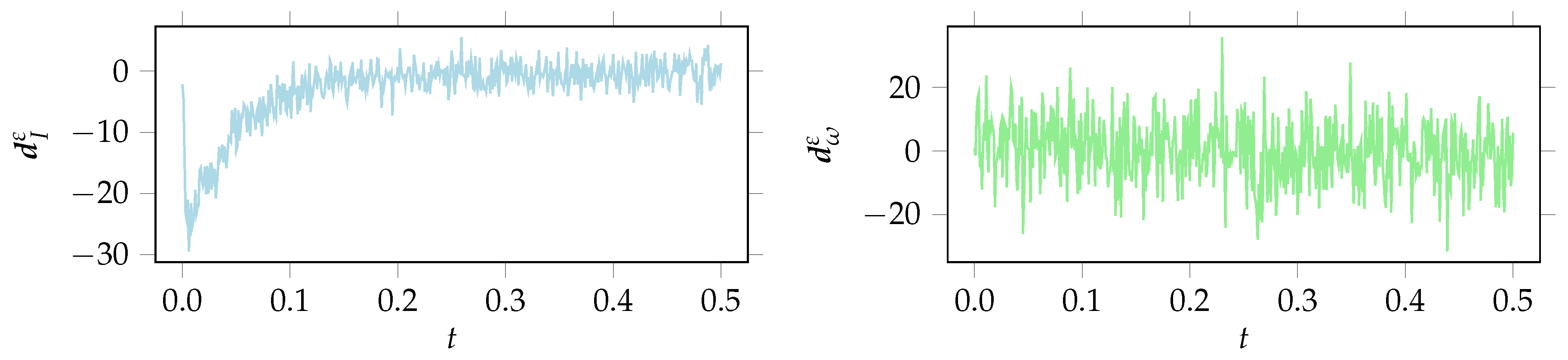
Figure 4.
Posterior moments of model discrepancy for in comparison to the reference discrepancy .
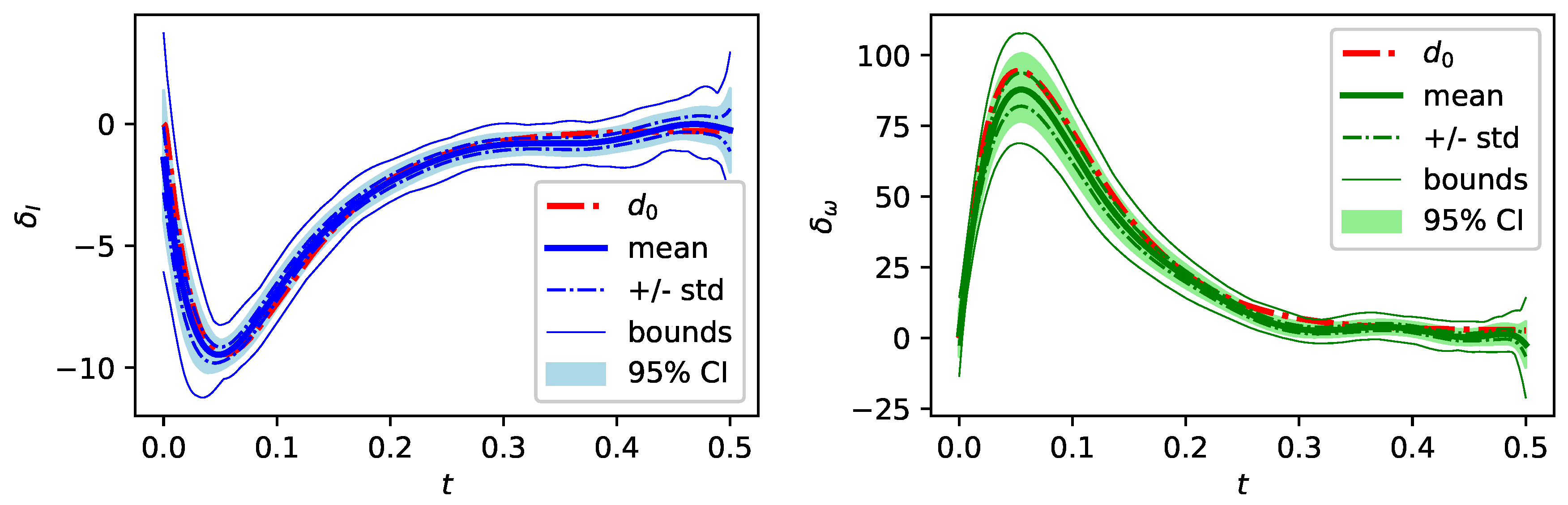
Figure 5.
Bias-variance tradeoff: Bias , variance and mean square error of R with respect to , depending on K, for from BM2. The index BM1 denotes the previous results without , obtained via Bayesian model 1.
Figure 5.
Bias-variance tradeoff: Bias , variance and mean square error of R with respect to , depending on K, for from BM2. The index BM1 denotes the previous results without , obtained via Bayesian model 1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Marginal posterior mean and relative error of parameters and for BM1 and BM2 with . The relative errors are with respect to the reference values , and .
Table 1.
Marginal posterior mean and relative error of parameters and for BM1 and BM2 with . The relative errors are with respect to the reference values , and .
| Marginal Posterior Mean | Relative Error | |||||
|---|---|---|---|---|---|---|
| BM1 | 9.03 × | 6.29 × | 1.03 × | 9.66 × | 2.14 × | 2.79 × |
| BM2 () | 9.92 × | 2.02 × | 9.95 × | 8.48 × | 1.03 × | 4.89 × |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
John, D.N.; Schick, M.; Heuveline, V. Learning Model Discrepancy of an Electric Motor with Bayesian Inference. Proceedings 2019, 33, 11. https://doi.org/10.3390/proceedings2019033011
AMA Style
John DN, Schick M, Heuveline V. Learning Model Discrepancy of an Electric Motor with Bayesian Inference. Proceedings. 2019; 33(1):11. https://doi.org/10.3390/proceedings2019033011
Chicago/Turabian StyleJohn, David N., Michael Schick, and Vincent Heuveline. 2019. "Learning Model Discrepancy of an Electric Motor with Bayesian Inference" Proceedings 33, no. 1: 11. https://doi.org/10.3390/proceedings2019033011