
Design, Development, and a Pilot Study of a Low-Cost Robot for Child–Robot Interaction in Autism Interventions




Abstract
:1. Introduction
2. Related Work
2.1. Socially Assistive Robots and Autism Spectrum Disorder
3. Materials and Methods
3.1. Robot’s Design
3.1.1. Design Requirements, Characteristics, and Restrictions
3.1.2. Mechanical Design of the Robot
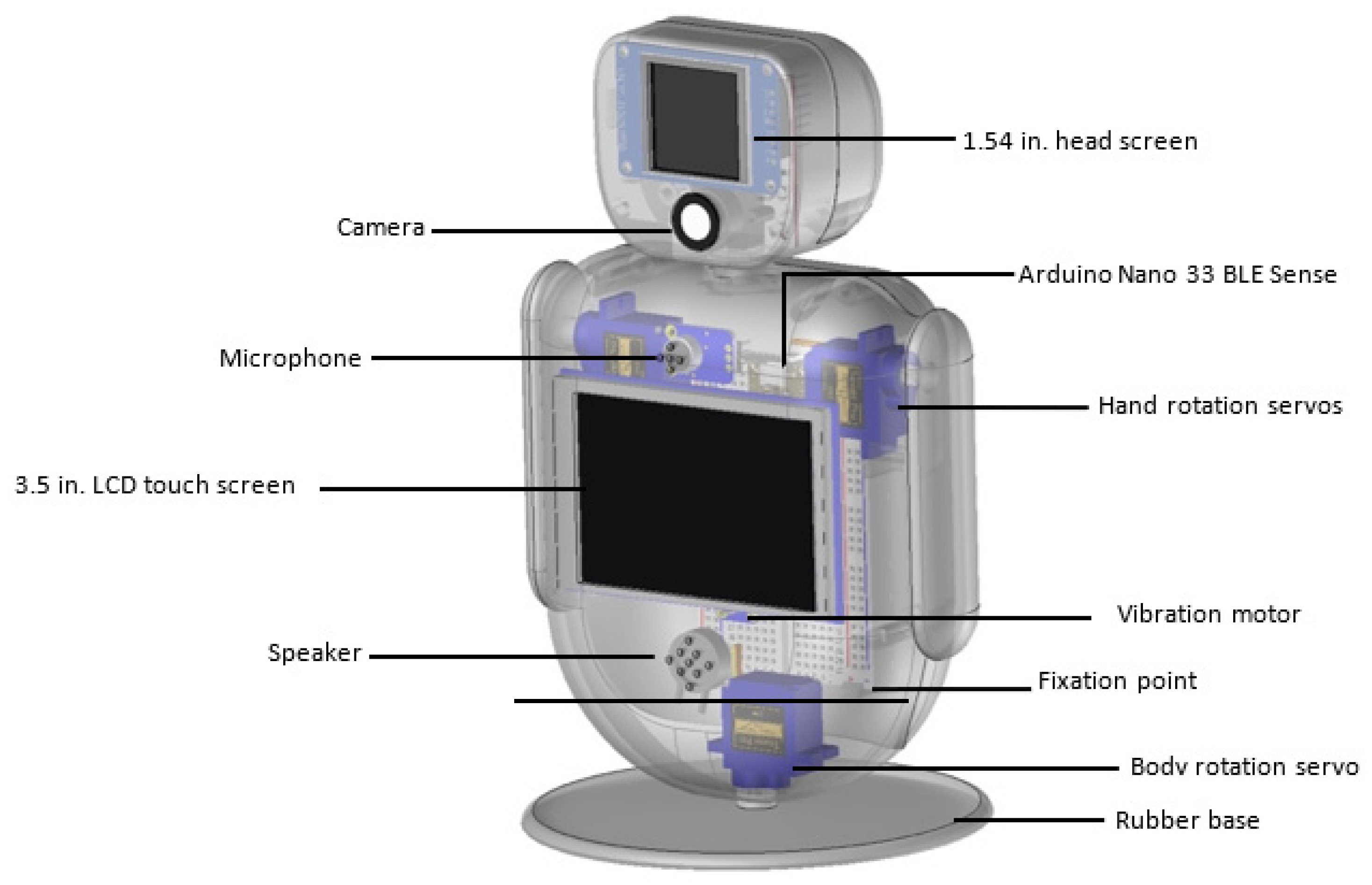
3.2. Robot’s Hardware and Electronics
- MCU: An Arduino Nano 33 BLE Sense is used. The unit contains several sensors, with the most important for the proposed robot to be the nine-axis Inertial Measurement Unit (IMU). Moreover, it can be programmed with the Python programming language.
- Camera: A state-of-the-art machine vision camera with a 115° field of view is used. The camera is capable of performing vision tasks such as face, object, and eye tracking and recognition, which are essentials for the interaction tasks.
- Screens: Two screens are integrated on the robot. The first one is mounted on its head, displaying basic emotions such as happiness, sadness, surprise, fear, and anger. The second one is mounted on the center of the robot and allows tactile interaction.
- Sensors: The robot uses one vibration motor, offering the sense of shiver when the robot is being hit or shake, and a gyroscope and accelerometer from the MCU, detecting hit and fall.
- Servos: Three MG90S 2.8 kg micro servos with metal gears, due to their small size and their elastic response to external forces, are used. These motors are used to move the hands and torso.
- Audio: One loudspeaker is implemented, expressing the voice of the robot, and a microphone with a 60x mic preamplifier is used to capture and amplify sounds near the robot.
3.3. Instructional Technology
3.3.1. Software Prototype
3.3.2. Robot’s Main Capabilities
3.3.3. Machine Learning Models’ Development
- The input layer had 650 inputs that came from the feature extraction, providing the MFCCs of the raw data.
- Layer 1: a 1D convolutional layer was created with eight neurons and three kernel sizes, which was the length of the 1D convolutional window, one convolutional layer, and the Relu activation function.
- Layer 2: a MaxPooling 1D layer was set with a pool size of 2; the maximum element from each region of incoming data covered by the filter was selected.
- Layer 3: a dropout layer was created with a value of 0.25; 25% of input units will drop at each epoch during training, preventing the NN from overfitting.
- Layer 4: a 1D convolutional layer was set with 16 neurons, with the same kernel size and activation function as previously stated.
- Layer 5: a max pool 1D layer was set, as in Layer 2.
- Layer 6: a dropout layer was set, as in Layer 3.
- Layer 7: a flatten layer was created, converting the data into a one-dimensional array for inputting it to the next layer. The output of the convolutional layers was flattened and connected to the final classification layer, which was a fully connected layer.
- Layer 8: a dense layer was created to densely connect the NN layers, where each neuron in this layer received input from all the neurons of the previous layers.
- Parameter 1: the Adam optimizer was selected due to its little memory requirement and its computationally efficiency [30]; the learning rate, which means how fast the NN learns, was equal to 0.005. The batch size was defined to 32.
- Parameter 2: for training the neural network, the Categorical Crossentropy loss function was selected, accuracy was defined as metric in order to calculate how often the predictions equal the labels, and epochs were set to 500.
- Parameter 3: 20% of the samples were set for testing.
- Layer 1: an input layer with 33 features that came from the spectral analysis, providing the frequency and spectral power of a motion.
- Layer 2: a dense layer with 20 neurons was set together with the Relu activation function.
- Layer 3: another dense layer with 10 neurons was set together with the Relu function.
- Layer 4: A final dense layer was used to connect the previous layers, with the SoftMax activation function.
- The Adam optimizer was selected with a learning rate of 0.0005, and the batch size was set to 32.
- The Categorical Crossentropy loss function was selected, accuracy was defined as metric, and the epochs were equal to 100.
- The data for testing were defined at 20% of the dataset (the remaining 80% of the dataset was used for training).
3.3.4. Evaluation Metrics
4. Results
4.1. Speech Detection Model
4.2. Motion Classification Model
4.3. Models’ Comparison
4.4. Deployment Results on Microcontroller
4.5. Evaluation Using Specialists
4.5.1. Procedure Description
4.5.2. Results of Software Prototype Session
4.5.3. Results of Robot Prototype
5. Discussion
6. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Focus Group 1 n = 7 | Specialist ID | Gender | Years of Experience | Type of School | Needs of Children |
| Specialist ID.1 | Female | 5 years | PSES | Autistic children | |
| Specialist ID.2 | Female | 16 years | PGES | ODD | |
| Specialist ID.3 | Female | 2 years | PSES | Autistic children | |
| Specialist ID.4 | Female | 19 years | PGES | ODD | |
| Specialist ID.5 | Female | 28 years | PGES | MSEN | |
| Specialist ID.6 | Female | 17 years | PGES | Autistic children | |
| Specialist ID.7 | Female | 2 years | PSES | Autistic children |
| Focus Group 2 n = 8 | Specialist ID | Gender | Years of Experience | Type of School | Needs of Children |
| Specialist ID.1 | Female | 5 years | PSES | Autistic children | |
| Specialist ID.2 | Female | 16 years | PGES | ODD | |
| Specialist ID.3 | Female | 2 years | PSES | Autistic children | |
| Specialist ID.4 | Female | 19 years | PGES | ODD | |
| Specialist ID.5 | Female | 28 years | PGES | MSEN | |
| Specialist ID.6 | Female | 17 years | PGES | Autistic children | |
| Specialist ID.7 | Female | 2 years | PSES | Autistic children | |
| Specialist ID.8 | Female | 16 years | PGES | MSEN |
Appendix B
| Prior to the demonstration of the prototype | Question 1. What Do You Expect to Do with the Software Prototype? |
| Question 2. How Do You Expect It to Look Like? | |
| After the demonstration of the prototype | Question 3. How did the software prototype look to you as a whole? |
| Question 4. What made it more difficult for you to use it? | |
| Question 5. Was there anything that did not look like as expected? If so, which one? | |
| Question 6. Was there something you expected to exist but was missing? | |
| Question 7. Is there any item that is not needed? | |
| Question 8. Which feature(s) of the prototype are most important to you? | |
| Question 9. Which feature(s) of the prototype is less important to you? | |
| Question 10. What is the most important function that You think should exist? | |
| Question 11. If you had a magic wand, what would you add to the software prototype? | |
| Question 12. What would you change in the appearance of the prototype? | |
| Question 13. What would prevent you from using the software? | |
| Likert Scale Questions | Question 14. What was the level of ease of use? (i) Excellent, (ii) Sufficient, (iii) Medium/Normal, (iv) No, and (v) Disappointing |
| Question 15. How satisfied are you with its use? (i) Excellent, (ii) Sufficient, (iii) Medium/Normal, (iv) No, and (v) Disappointing | |
| Question 16. How would you rate the overall experience? (i) Excellent, (ii) Sufficient, (iii) Medium/Normal, (iv) No, and (v) Disappointing | |
| Question 17. The process of using it was clear. (i) Strongly Agree, (ii) Agree, (iii) Disagree, (iv) Strongly Disagree | |
| Question 18. Navigating through the prototype was easy. (i) Strongly Agree, (ii) Agree, (iii) Disagree, (iv) Strongly Disagree | |
| Question 19. How important would such software be for using a robot? (i) Excellent, (ii) Sufficient, (iii) Medium/Normal, (iv) No, and (v) Disappointing | |
| Question 20. Have you ever had previous experience using similar software? (i) Very much, (ii) Very, (iii) Medium/Normal, (iv) Almost no, (v) Not at all | |
| Question 21. Do you have previous experience in applying robot to the educational process? (i) Very much, (ii) Very, (iii) Medium/Normal, (iv) Almost no, (v) Not at all | |
| Question 22. To what extent did you understand what software does? (i) Very much, (ii) Very, (iii) Medium/Normal, (iv) Almost no, (v) Not at all |
Appendix C
| Question 1. How would you describe the presented robot? |
| Question 2. How would you evaluate its shape and form? |
| Question 3. What emotions does its overall appearance evoke to you? |
| Question 4. Based on its morphological elements and functions, what do you think is its main advantage? |
| Question 5. Based on the table with its functions, which do you think are the most useful and important? |
| Question 6. What do you dislike about its morphological features? |
| Question 7. Why do you think this robot is worth? If not, please explain. |
| Question 8. What would you add about its morphological features? |
| Question 9. What would you add about its functions? |
| Question 10. What could we improve about the existing appearance? |
| Question 11. What could we improve about its existing features? |
| Question 12. How does our robot compare to the ones you saw before? |
| Question 13. What potential uses would you discern in ASD interventions? |
| Question 14. If not ours, which of the other robots would you like to use and why? |
References
- Feil-Seifer, D.; Mataric, M.J. Defining socially assistive robotics. In Proceedings of the 9th International Conference on Rehabilitation Robotics ICORR 2005, Chicago, IL, USA, 28 June–1 July 2005; pp. 465–468. [Google Scholar]
- Association, A.P. Neurodevelopmental Disorders: DSM-5® Selections; American Psychiatric Publishing: Washington, WA, USA, 2015. [Google Scholar]
- Lord, C.; Risi, S.; DiLavore, P.S.; Shulman, C.; Thurm, A.; Pickles, A. Autism from 2 to 9 years of age. Arch. Gen. Psychiatr. 2006, 63, 694–701. [Google Scholar] [CrossRef]
- Huijnen, C.A.; Lexis, M.A.; Jansens, R.; de Witte, L.P. Roles, strengths, and challenges of using robots in interventions for children with autism spectrum disorder (ASD). J. Autism Dev. Disord. 2019, 49, 11–21. [Google Scholar] [CrossRef]
- Begum, M.; Serna, R.W.; Yanco, H.A. Are robots ready to deliver autism interventions? A comprehensive review. Int. J. Soc. Robot. 2016, 8, 157–181. [Google Scholar] [CrossRef]
- Pennisi, P.; Tonacci, A.; Tartarisco, G.; Billeci, L.; Ruta, L.; Gangemi, S.; Pioggia, G. Autism and social robotics: A systematic review. Autism Res. 2016, 9, 165–183. [Google Scholar] [CrossRef]
- Huijnen, C.A.; Lexis, M.A.; Jansens, R.; de Witte, L.P. Mapping robots to therapy and educational objectives for children with autism spectrum disorder. J. Autism Dev. Disord. 2016, 46, 2100–2114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kahn, P.H., Jr.; Kanda, T.; Ishiguro, H.; Freier, N.G.; Severson, R.L.; Gill, B.T.; Shen, S. Robovie, you’ll have to go into the closet now: Children’s social and moral relationships with a humanoid robot. Dev. Psychol. 2012, 48, 303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breazeal, C.; Harris, P.L.; DeSteno, D.; Westlund, J.M.K.; Dickens, L.; Jeong, S. Young children treat robots as informants. Top. Cogn. Sci. 2016, 8, 481–491. [Google Scholar] [CrossRef] [Green Version]
- Bone, D.; Bishop, S.L.; Black, M.P.; Goodwin, M.S.; Lord, C.; Narayanan, S.S. Use of machine learning to improve autism screening and diagnostic instruments: Effectiveness, efficiency, and multi-instrument fusion. J. Child Psychol. Psychiatr. 2016, 57, 927–937. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Li, M.; Yi, L. Identifying children with autism spectrum disorder based on their face processing abnormality: A machine learning framework. Autism Res. 2016, 9, 888–898. [Google Scholar] [CrossRef] [PubMed]
- Bussu, G.; Jones, E.J.; Charman, T.; Johnson, M.H.; Buitelaar, J.K. Prediction of autism at 3 years from behavioural and developmental measures in high-risk infants: A longitudinal cross-domain classifier analysis. J. Autism Dev. Disord. 2018, 48, 2418–2433. [Google Scholar] [CrossRef] [Green Version]
- van Straten, C.L.; Smeekens, I.; Barakova, E.; Glennon, J.; Buitelaar, J.; Chen, A. Effects of robots’ intonation and bodily appearance on robot-mediated communicative treatment outcomes for children with autism spectrum disorder. Pers. Ubiquitous Comput. 2018, 22, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Linstead, E.; Dixon, D.R.; French, R.; Granpeesheh, D.; Adams, H.; German, R.; Kornack, J. Intensity and learning outcomes in the treatment of children with autism spectrum disorder. Behav. Modif. 2017, 41, 229–252. [Google Scholar] [CrossRef] [PubMed]
- Dautenhahn, K.; Werry, I.; Salter, T.; Boekhorst, R. Towards adaptive autonomous robots in autism therapy: Varieties of interactions. In Proceedings of the 2003 IEEE International Symposium on Computational Intelligence in Robotics and Automation. Computational Intelligence in Robotics and Automation for the New Millennium (Cat. No. 03EX694), Kobe, Japan, 16–20 July 2003; Volume 2, pp. 577–582. [Google Scholar]
- Wood, L.J.; Zaraki, A.; Robins, B.; Dautenhahn, K. Developing kaspar: A humanoid robot for children with autism. Int. J. Soc. Robot. 2021, 13, 491–508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gouaillier, D.; Hugel, V.; Blazevic, P.; Kilner, C.; Monceaux, J.; Lafourcade, P.; Maisonnier, B. Mechatronic design of NAO humanoid. In Proceedings of the 2009 IEEE international conference on robotics and automation, Kobe, Japan, 12–17 May 2009; pp. 769–774. [Google Scholar]
- Hegel, F.; Eyssel, F.; Wrede, B. The social robot ‘flobi’: Key concepts of industrial design. In Proceedings of the 19th International Symposium in Robot and Human Interactive Communication, Viareggio, Italy, 13–15 September 2010; pp. 107–112. [Google Scholar]
- Bonarini, A.; Garzotto, F.; Gelsomini, M.; Romero, M.; Clasadonte, F.; Yilmaz, A.N.Ç. A huggable, mobile robot for developmental disorder interventions in a multi-modal interaction space. In Proceedings of the 2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016; pp. 823–830. [Google Scholar]
- Duquette, A.; Michaud, F.; Mercier, H. Exploring the use of a mobile robot as an imitation agent with children with low-functioning autism. Auton. Robot. 2008, 24, 147–157. [Google Scholar] [CrossRef]
- Kozima, H.; Michalowski, M.P.; Nakagawa, C. Keepon. Int. J. Soc. Robot. 2009, 1, 3–18. [Google Scholar] [CrossRef]
- Cao, H.L.; Pop, C.; Simut, R.; Furnemónt, R.; Beir, A.D.; Perre, G.V.D.; Vanderborght, B. Probolino: A portable low-cost social device for home-based autism therapy. In International Conference on Social Robotics; Springer: Cham, Switzerland, 2015; pp. 93–102. [Google Scholar]
- Stanton, C.M.; Kahn, P.H.; Severson, R.L.; Ruckert, J.H.; Gill, B.T. Robotic animals might aid in the social development of children with autism. In Proceedings of the 2008 3rd ACM/IEEE International Conference on Human-Robot Interaction (HRI), Amsterdam, The Netherlands, 12–15 March 2008; pp. 271–278. [Google Scholar]
- Michaud, F.; Caron, S. Roball, the rolling robot. Auton. Robot. 2002, 12, 211–222. [Google Scholar] [CrossRef]
- Scassellati, B.; Admoni, H.; Matarić, M. Robots for use in autism research. Annu. Rev. Biomed. Eng. 2012, 14, 275–294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lord, C.; Bishop, S.L. Autism Spectrum Disorders: Diagnosis, Prevalence, and Services for Children and Families. Social Policy Report. Soc. Res. Child Dev. 2010, 24, 2. [Google Scholar]
- Available online: https://www.edgeimpulse.com/product (accessed on 18 March 2022).
- Sahidullah, M.; Saha, G. Design, analysis and experimental evaluation of block based transformation in MFCC computation for speaker recognition. Speech Commun. 2012, 54, 543–565. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Zheng, X. {TensorFlow}: A System for {Large-Scale} Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Koopmans, L.H. The Spectral Analysis of Time Series; Elsevier: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Banbury, C.R.; Reddi, V.J.; Lam, M.; Fu, W.; Fazel, A.; Holleman, J.; Yadav, P. Benchmarking TinyML systems: Challenges and direction. arXiv 2020, arXiv:2003.04821. [Google Scholar]
- Warden, P. Why the Future of Machine Learning Is Tiny. 2018. Available online: https://petewarden.com/2018/06/11/why-the-future-of-machine-learning-is-tiny/ (accessed on 11 March 2022).
- Available online: https://docs.opencv.org/3.4/db/d28/tutorial_cascade_classifier.html (accessed on 12 March 2022).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Available online: https://github.com/cmusatyalab/openface/tree/master/models/openface (accessed on 14 March 2022).

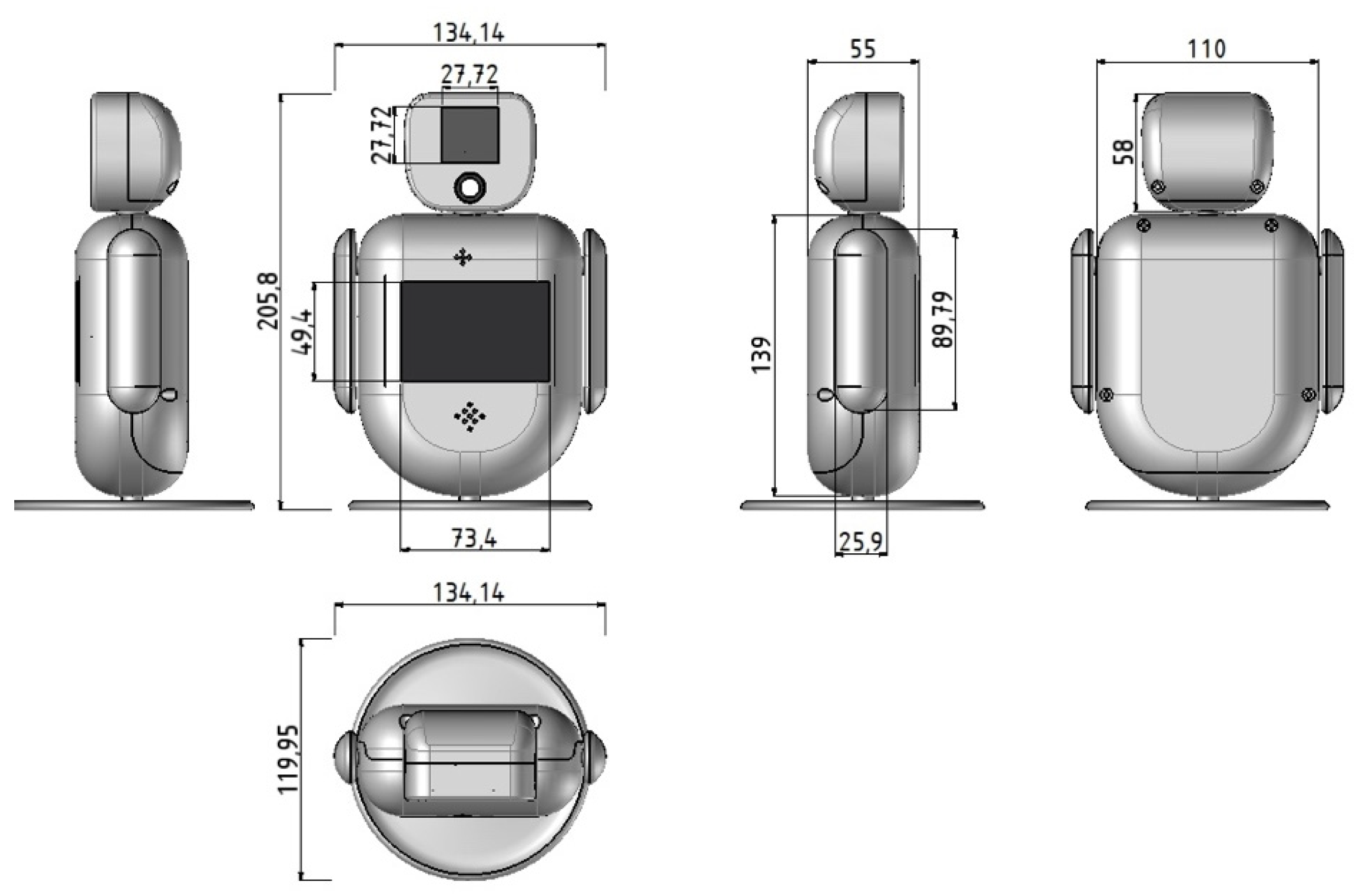















| Requirements | Characteristics | Constraints |
|---|---|---|
| Convey feelings | Removable parts | Low cost, under 250 euros |
| Facial expressions | Portable | Designed with curves |
| Tactile interaction | Lightweight | Use of soft materials |
| Perform movements | Robust and solid | Speed limitations |
| Produce voice and sounds | Durable | Use of mild colors |
| Speech recognition | Low space footprint | Not too high sounds |
| Face recognition | Environmentally friendly | Not exceeding 250 mm height |
| Not exceeding 1.2 kg weight |
| Size | 205 × 134.1 mm | Servos | 3 × MG90S 2.8 kg |
| Weight | 1.2 kg | Gyroscope and Accelerometer | 3-axis LSM9DS1 IMU sensor |
| Port | USB 2.0 Micro-B | Speaker | 1 × 3 W loudspeaker |
| Camera | 640 × 480 32-bit | Microphone | Electret 60× min preamplifier |
| Head Screen | 1.54″ 240 × 240 | Central screen | 3.5″ touch LCD screen 420 × 320 |
| Predicted Labels | ||||||||
| Actual Labels | DANCE | GOODBYE | HEY_ROBOT | NOISE | PHOTO | UNKNOWN | UNCERTAIN | |
| Dance | 56 | 0 | 0 | 0 | 0 | 0 | 1 | |
| Goodbye | 0 | 53 | 0 | 0 | 0 | 0 | 1 | |
| Hey_robot | 0 | 0 | 91 | 0 | 0 | 0 | 0 | |
| Noise | 0 | 0 | 0 | 64 | 0 | 1 | 2 | |
| Photo | 0 | 0 | 0 | 0 | 74 | 0 | 1 | |
| Unknown | 0 | 0 | 0 | 2 | 0 | 49 | 2 | |
| Class | ACC | TPR | TNR | PPV | F1 |
|---|---|---|---|---|---|
| dance | 0.997 | 0.982 | 1.00 | 1.00 | 0.991 |
| goodbye | 0.997 | 0.981 | 1.00 | 1.00 | 0.991 |
| hey_robot | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| noise | 0.992 | 0.955 | 0.994 | 0.970 | 0.962 |
| photo | 0.997 | 0.987 | 1.00 | 1.00 | 0.993 |
| unknown | 0.990 | 0.925 | 0.997 | 0.980 | 0.951 |
| Dance | Goodbye | Hey_Robot | Noise | Photo | Unknown | |
|---|---|---|---|---|---|---|
| Dance | 0.99609 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.00000 |
| Goodbye | 0.00000 | 0.99609 | 0.00000 | 0.00000 | 0.00000 | 0.00000 |
| Hey_robot | 0.00000 | 0.00000 | 0.99609 | 0.00000 | 0.01172 | 0.00000 |
| Noise | 0.00000 | 0.00000 | 0.00000 | 0.98047 | 0.02734 | 0.00391 |
| Photo | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.93359 | 0.09766 |
| Unknown | 0.00000 | 0.00000 | 0.00000 | 0.01953 | 0.02734 | 0.89844 |
| Timestamp | Fall | Hit | Stable |
|---|---|---|---|
| 80 | 0 | 0 | 1.00 |
| 560 | 0 | 1.00 | 0 |
| 80 | 1.00 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katsanis, I.A.; Moulianitis, V.C.; Panagiotarakos, D.T. Design, Development, and a Pilot Study of a Low-Cost Robot for Child–Robot Interaction in Autism Interventions. Multimodal Technol. Interact. 2022, 6, 43. https://doi.org/10.3390/mti6060043
Katsanis IA, Moulianitis VC, Panagiotarakos DT. Design, Development, and a Pilot Study of a Low-Cost Robot for Child–Robot Interaction in Autism Interventions. Multimodal Technologies and Interaction. 2022; 6(6):43. https://doi.org/10.3390/mti6060043
Chicago/Turabian StyleKatsanis, Ilias A., Vassilis C. Moulianitis, and Diamantis T. Panagiotarakos. 2022. "Design, Development, and a Pilot Study of a Low-Cost Robot for Child–Robot Interaction in Autism Interventions" Multimodal Technologies and Interaction 6, no. 6: 43. https://doi.org/10.3390/mti6060043
APA StyleKatsanis, I. A., Moulianitis, V. C., & Panagiotarakos, D. T. (2022). Design, Development, and a Pilot Study of a Low-Cost Robot for Child–Robot Interaction in Autism Interventions. Multimodal Technologies and Interaction, 6(6), 43. https://doi.org/10.3390/mti6060043