Text Mining in Cybersecurity: Exploring Threats and Opportunities

 ,
,
Abstract
:
1. Introduction
2. Related Work
2.1. Traditional Foresight Approaches
2.2. Text Mining Foresight Approaches and Tools
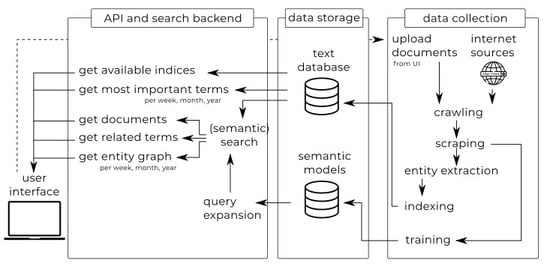
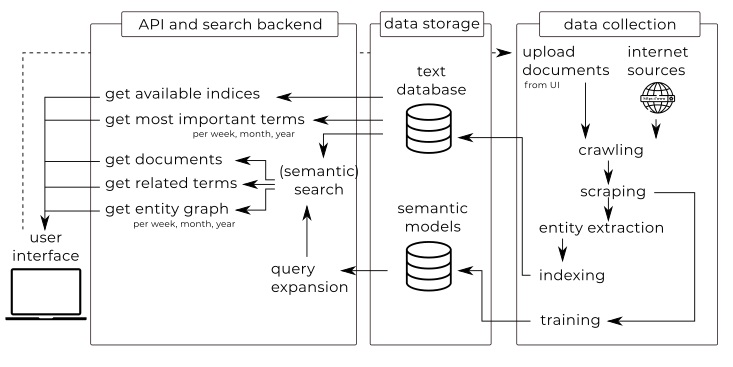
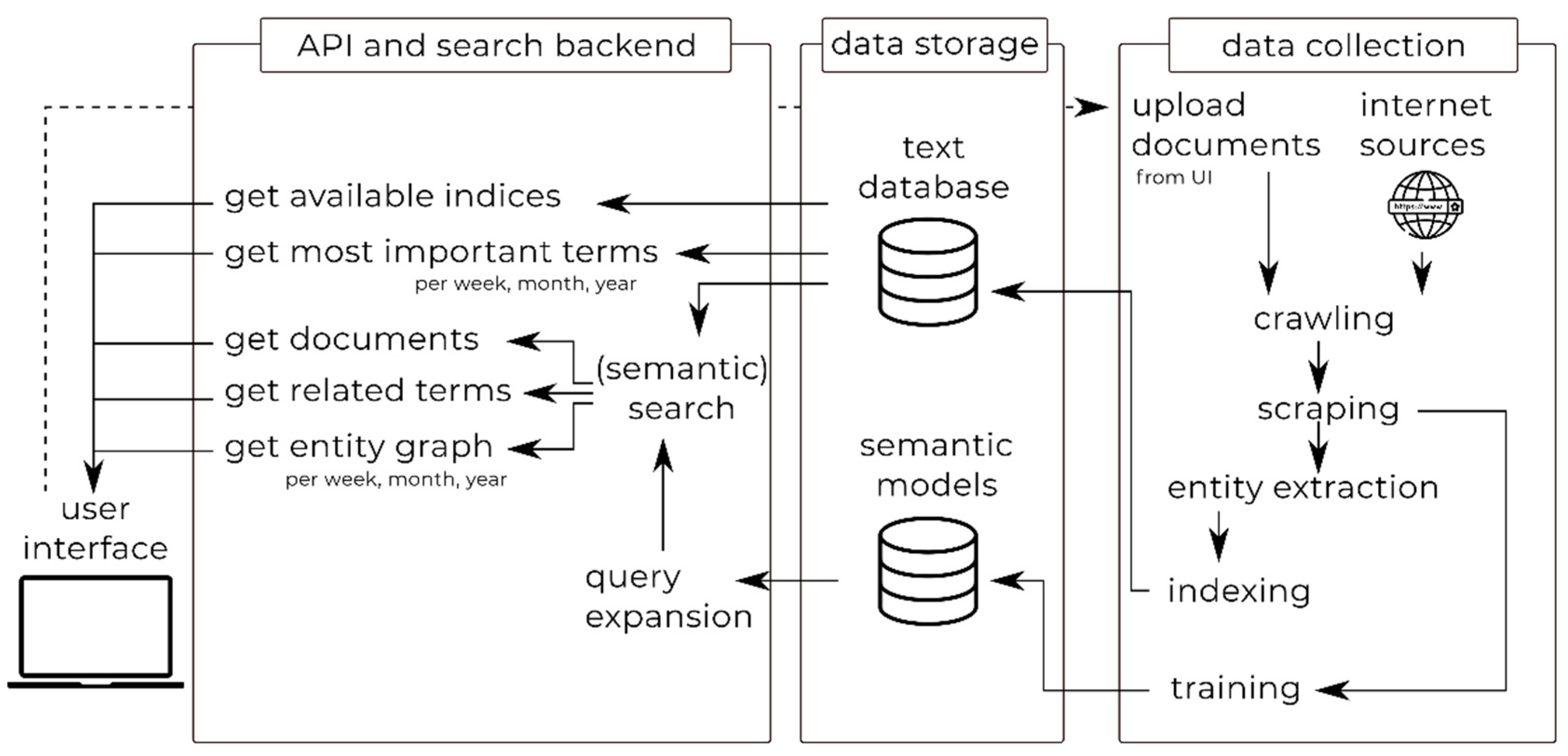
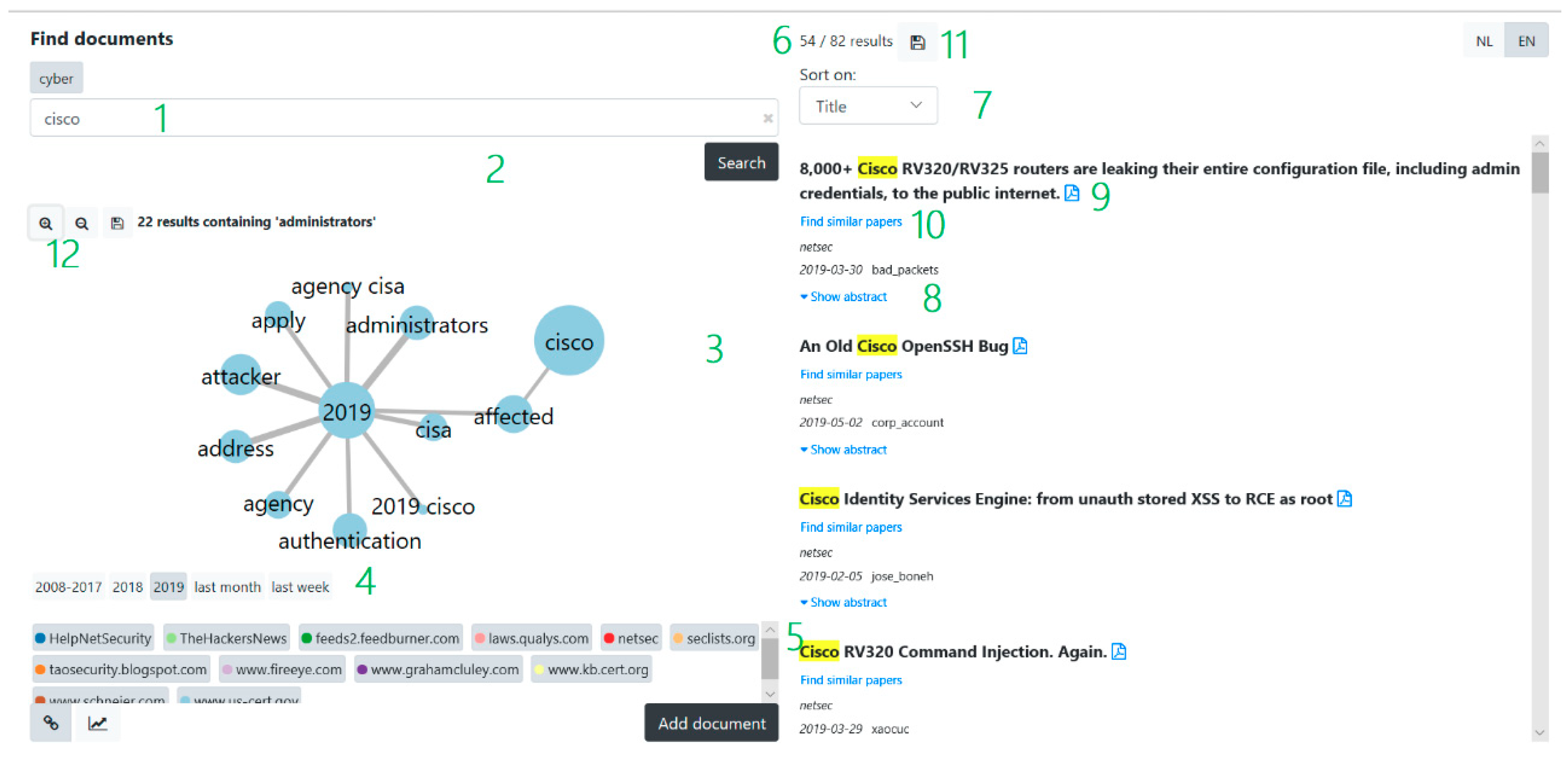
3. Horizon Scanner Tool
3.1. Overview of the Horizon Scanner Tool Architecture
3.2. Data Collection: Crawling, Scraping and Indexing
3.2.1. Entity Extraction
3.3. API and Search Backend: Search, Retrieval and Analysis
3.3.1. Most Important Terms
3.3.2. Entity Graph
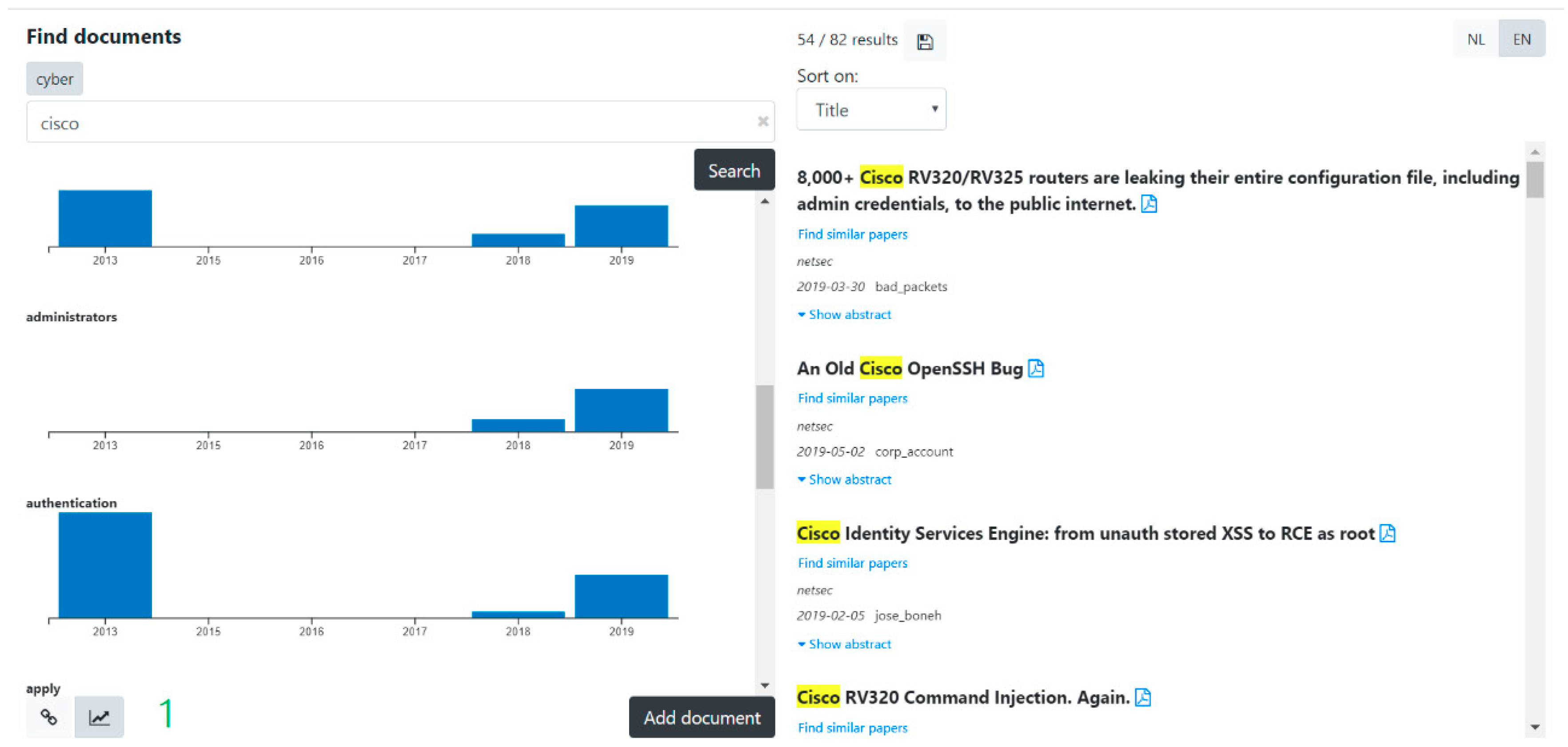
3.3.3. Trend Analysis
3.3.4. Query Expansion
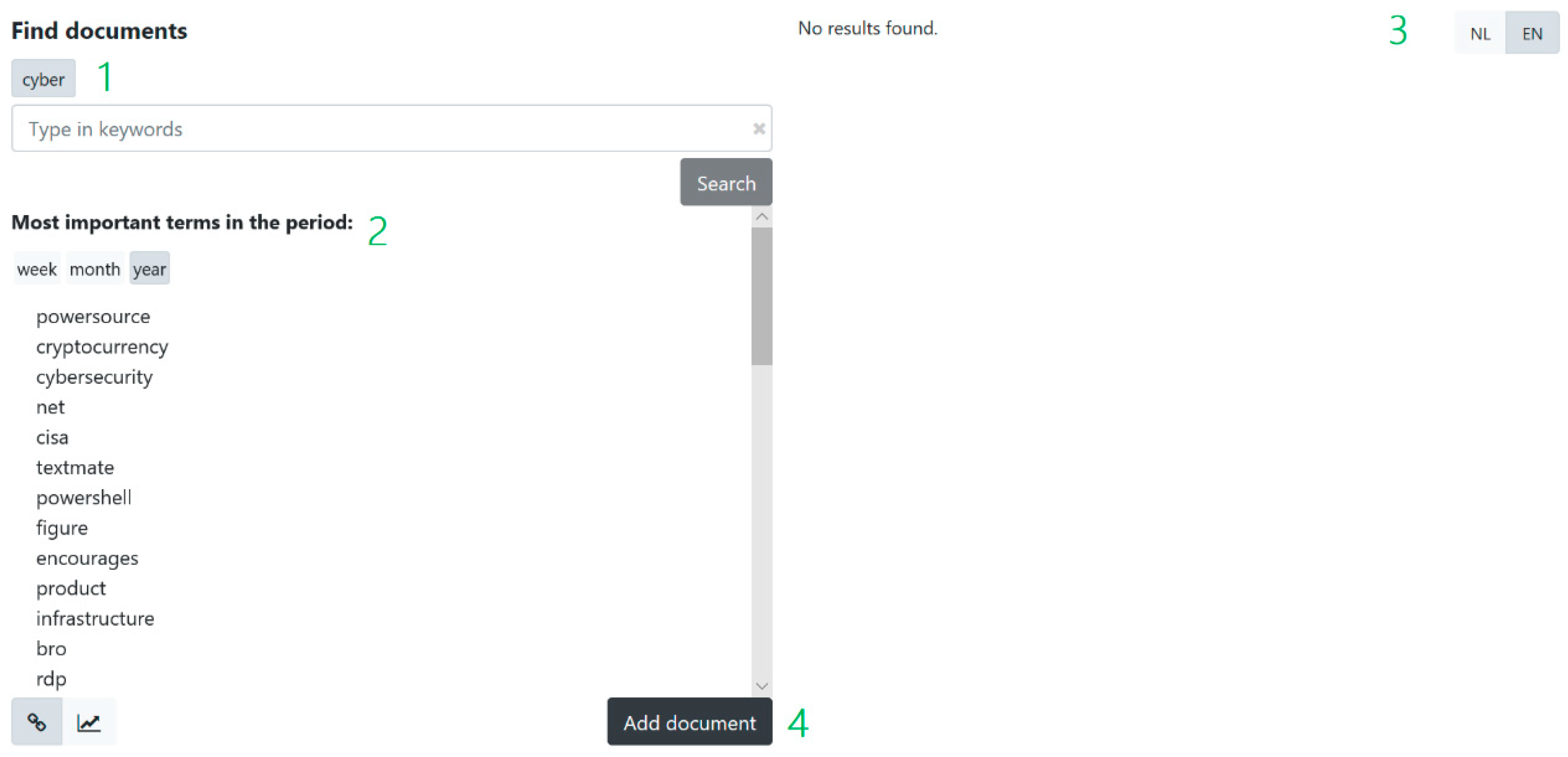
3.4. Graphical User Interface (GUI)
4. Qualitative User Evaluation and Discussion
4.1. Experimental Set-Up
4.2. Results
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bissell, C.K.; LaSalle, R.; Cin, P.D. Ninth Annual Cost of Cybercrime Study; Ponemon Institute: Dublin, Ireland, 6 March 2019. [Google Scholar]
- Paoli, L.; Visschers, J.; Verstraete, C. The impact of cybercrime on businesses: A novel conceptual framework and its application to Belgium. Crime Law Soc. Chang. 2018, 70, 397–420. [Google Scholar] [CrossRef]
- DiMase, D.; Collier, Z.A.; Heffner, K.; Linkov, I. Systems engineering framework for cyber physical security and resilience. Environ. Syst. Decis. 2015, 35, 291–300. [Google Scholar] [CrossRef]
- Van Der Kleij, R.; Leukfeldt, R. Cyber Resilient Behavior: Integrating Human Behavioral Models and Resilience Engineering Capabilities into Cyber Security. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, Washington, DC, USA, 24–28 July 2019; Springer Science and Business Media LLC: Berlin, Germany, 2019; pp. 16–27. [Google Scholar]
- Hollnagel, E. RAG-The resilience analysis grid. In Resilience Engineering in Practice: A Guidebook; Wreathall, J., Hollnagel, E., Eds.; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Bakdash, J.Z.; Hutchinson, S.; Zaroukian, E.G.; Marusich, L.R.; Thirumuruganathan, S.; Sample, C.; Hoffman, B.; Das, G. Malware in the future? Forecasting of analyst detection of cyber events. J. Cybersecur. 2018, 4, tyy007. [Google Scholar] [CrossRef]
- Denrell, J.; Fang, C. Predicting the Next Big Thing: Success as a signal of poor judgment. Manag. Sci. 2010, 56, 1653–1667. [Google Scholar] [CrossRef]
- Schatz, D.; Bashroush, R. Security predictions—A way to reduce uncertainty. J. Inf. Secur. Appl. 2019, 45, 107–116. [Google Scholar] [CrossRef]
- Paradis, C.; Kazman, R.; Wang, P. Indexing text related to software vulnerabilities in noisy communities through topic modelling. In Proceedings of the IEEE ICMLA 2018: 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–28 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 763–768. [Google Scholar]
- Van Der Kleij, R.; Kleinhuis, G.; Young, H. Computer Security Incident Response Team Effectiveness: A Needs Assessment. Front. Psychol. 2017, 8, 2179. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Shao, Z. Network Anomaly Detection Using Time Series Analysis. In Proceedings of the Joint International Conference on Autonomic and Autonomous Systems and International Conference on Networking and Services (ICAS-ISNS’05), Papeete, French Polynesia, 23–28 October 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 5, p. 42. [Google Scholar]
- Kim, D.H.; Lee, T.; Jung, S.O.D.; In, H.P.; Lee, H.J. Cyber Threat Trend Analysis Model Using HMM. In Proceedings of the Third International Symposium on Information Assurance and Security, Manchester, UK, 29–31 August 2007; IEEE: Piscataway, NJ, USA, 2015; pp. 177–182. [Google Scholar]
- Miles, I.; Harper, J.C.; Georghiou, L.; Keenan, M.; Popper, R. The many faces of foresight. In The Handbook of Technology Foresight: Concepts and Practice; Edward Elgar Publishing: Cheltenham, UK, 2008; pp. 3–23. [Google Scholar]
- Linstone, H.A.; Turoff, M. The Delphi Method: Techniques and Applications, 1st ed.; Addison-Wesley Educational Publishers: Boston, MA, USA, 1975. [Google Scholar]
- Hauptman, A.; Sharan, Y. Foresight of evolving security threats posed by emerging technologies. Foresight 2013, 15, 375–391. [Google Scholar] [CrossRef]
- Linden, A.; Fenn, J. Understanding Gartner’s Hype Cycles; Gartner: Stanford, CT, USA, 2003. [Google Scholar]
- TrendWatching. Available online: https://trendwatching.com/ (accessed on 23 June 2019).
- Thoughtworks. Available online: www.thoughtworks.com/radar/faq/ (accessed on 23 June 2019).
- Innoradar. Available online: https://www.innoradar.eu/ (accessed on 23 June 2019).
- Voros, J. A generic foresight process framework. Foresight 2003, 5, 10–21. [Google Scholar] [CrossRef]
- Kostoff, R.N.; Schaller, R.R. Science and Technology Roadmaps. IEEE Trans. Eng. Manag. 2001, 48, 132–143. [Google Scholar] [CrossRef]
- Chang, R.M.; Kauffman, R.J.; Kwon, Y. Understanding the paradigm shift to computational social science in the presence of big data. Decis. Support Syst. 2014, 63, 67–80. [Google Scholar] [CrossRef]
- Church, K.W.; Mercer, R.L. Introduction to the special issue on computational linguistics using large corpora. Comput. Linguist. 1997, 19, 1–24. [Google Scholar]
- Hearst, M.A. Untangling text data mining. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; Association for Computational Linguistics: Stroudsburg, PA, USA, 1999. [Google Scholar]
- Feldman, R.; Dagan, I. Knowledge Discovery in Textual Databases (KDT). In Proceedings of the First International Conference on Knowledge Discovery and Data Mining, Montreal, QC, Canada, 20–21 August 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 95, pp. 112–117. [Google Scholar]
- Eriksson, J.; Giacomello, G. Content Analysis in the Digital Age: Tools, Functions, and Implications for Security. In The Secure Information Society; Krüger, J., Nickolay, B., Gaycken, S., Eds.; Springer: London, UK, 2013; pp. 137–148. [Google Scholar]
- Porter, A.L.; Cunningham, S.W. Tech mining. Competitive Intell. Mag. 2005, 8, 30–36. [Google Scholar]
- Efimenko, I.V.; Khoroshevsky, V.F.; Noyons, E.C.M.; Daim, T.U.; Chiavetta, D.; Porter, A.L.; Saritas, O. Anticipating Future Pathways of Science, Technologies, and Innovations: (Map of Science)2 Approach. In Innovation, Technology, and Knowledge Management; Cambridge University Press: Cambridge, UK, 2016; pp. 71–96. [Google Scholar]
- Benson, C.L.; Magee, C.L. Using enhanced patent data for future-oriented technology analysis. In Anticipating Future Innovation Pathways through Large Data Analysis; Daim, T.U., Chiavetta, D., Porter, A.L., Saritas, O., Eds.; Springer: Cham, Switzerland, 2016; pp. 119–131. [Google Scholar]
- Finlay, S. Text Mining and Social Network Analysis. In Predictive Analytics, Data Mining and Big Data; Business in the Digital Economy; Palgrave Macmillan: London, UK, 2016; pp. 179–193. [Google Scholar]
- Kayser, V.; Blind, K. Extending the knowledge base of foresight: The contribution of text mining. Technol. Forecast. Soc. Chang. 2017, 116, 208–215. [Google Scholar] [CrossRef] [Green Version]
- Mikova, N. Recent Trends in Technology Mining Approaches: Quantitative Analysis of GTM Conference Proceedings. In Anticipating Future Innovation Pathways Through Large Data Analysis; Springer: Cham, Switzerland, 2016; pp. 59–69. [Google Scholar]
- Könnölä, T.; Amanatidou, E.; Butter, M.; Carabias, V.; Leis, M.; Saritas, O.; Schaper-Rinkel, P.; Van Rij, V. On concepts and methods in horizon scanning: Lessons from initiating policy dialogues on emerging issues. Sci. Public Policy 2012, 39, 208–221. [Google Scholar] [Green Version]
- Alltop. Available online: www.alltop.com (accessed on 23 June 2019).
- Reddit. Available online: https://www.reddit.com/r/TrendingReddits/ (accessed on 23 June 2019).
- BuzzSumo. Available online: www.buzzsumo.com (accessed on 23 June 2019).
- EU Science Hub Activities. European Commission. Available online: https://ec.europa.eu/jrc/en/text-mining-and-analysis/activities (accessed on 23 June 2019).
- ITONICS. Available online: www.itonics.de/software/itonics-scout-environmental-scanning (accessed on 23 June 2019).
- Powers, S. Practical RDF: Solving Problems with the Resource Description Framework; O’Reilly Media: Sevastopol, CA, USA, 2003. [Google Scholar]
- McKee, K. Feedparser. Available online: https://github.com/kurtmckee/feedparser (accessed on 23 June 2019).
- OSF. Available online: http://opensemanticframework.org (accessed on 23 June 2019).
- Lopez, P. GROBID: Combining Automatic Bibliographic Data Recognition and Term Extraction for Scholarship Publications. In Computer Visio-ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer Science and Business Media: Berlin, Germany, 2009; Volume 5714, pp. 473–474. [Google Scholar]
- Manning, C.; Raghavan, P.; Schütze, H. Introduction to information retrieval. Nat. Lang. Eng. 2010, 16, 100–103. [Google Scholar]
- The NLTK Toolkit. Available online: https://www.nltk.org/api/nltk.tag.html (accessed on 23 June 2019).
- Wikipedia. Available online: https://en.wikipedia.org/wiki/Stop_words (accessed on 23 June 2019).
- Verberne, S.; Sappelli, M.; Hiemstra, D.; Kraaij, W. Evaluation and analysis of term scoring methods for term extraction. Inf. Retr. 2016, 19, 510–545. [Google Scholar] [CrossRef] [Green Version]
- Termprofiling. Available online: https://github.com/suzanv/termprofiling (accessed on 23 June 2019).
- Chowdhury, G.G. Introduction to Modern Information Retrieval; Facet publishing: London, UK, 2010. [Google Scholar]
- Azad, H.K.; Deepak, A. Query expansion techniques for information retrieval: A survey. Inf. Process. Manag. 2019, 56, 1698–1735. [Google Scholar] [CrossRef] [Green Version]
- Kuzi, S.; Shtok, A.; Kurland, O. Query Expansion Using Word Embeddings. In Proceedings of the 25th ACM International, Indianapolis, IN, USA, 24–28 October 2016; pp. 1929–1932. [Google Scholar]
- De Boer, M.H.T.; Lu, Y.J.; Zhang, H.; Schutte, K.; Ngo, C.W.; Kraaij, W. Semantic Reasoning in Zero Example Video Event Retrieval. ACM Trans. Multimedia Comput. Commun. Appl. 2017, 13, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Rehurek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; University of Malta: Msida, Malta, 2010; Volume 5, pp. 46–50. [Google Scholar]
- Athukorala, K.; Glowacka, D.; Jacucci, G.; Oulasvirta, A.; Vreeken, J. Is exploratory search different? A comparison of information search behavior for exploratory and lookup tasks. J. Assoc. Inf. Sci. Tech. 2016, 67, 2635–2651. [Google Scholar] [CrossRef]
- Brooke, J. SUS—A quick and dirty usability scale. In Usability Evaluation in Industry; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statement (Translated Back from Dutch) | Average Score (1 = Strongly Disagree; 5 = Strongly Agree; N = 3) |
|---|---|
| I think I will use the tool frequently | 2 |
| I think this tool is useful in my organization | 2.67 |
| The tool is easy to use | 1.67 |
| I think I can use the tool without technical support | 2.33 |
| I belief that the different functionalities of this tool are well integrated | 2 |
| It is clear how I should use the tool | 2 |
| The tool does what I expect it to do | 2 |
| I feel confident when using the tool | 2 |
| The tool gives me valuable information | 1.67 |
| I can do my job better with the tool compared to without | 1.33 |
| The tool takes work from me/off my hands | 1.67 |
| The tool visualizes the data in an appealing way | 1.33 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Boer, M.H.T.; Bakker, B.J.; Boertjes, E.; Wilmer, M.; Raaijmakers, S.; van der Kleij, R. Text Mining in Cybersecurity: Exploring Threats and Opportunities. Multimodal Technol. Interact. 2019, 3, 62. https://doi.org/10.3390/mti3030062
de Boer MHT, Bakker BJ, Boertjes E, Wilmer M, Raaijmakers S, van der Kleij R. Text Mining in Cybersecurity: Exploring Threats and Opportunities. Multimodal Technologies and Interaction. 2019; 3(3):62. https://doi.org/10.3390/mti3030062
Chicago/Turabian Stylede Boer, Maaike H. T., Babette J. Bakker, Erik Boertjes, Mike Wilmer, Stephan Raaijmakers, and Rick van der Kleij. 2019. "Text Mining in Cybersecurity: Exploring Threats and Opportunities" Multimodal Technologies and Interaction 3, no. 3: 62. https://doi.org/10.3390/mti3030062