Sequential Hashing with Minimum Padding

Faculty of Engineering, University of Fukui, Fukui 910-8507, Japan
Cryptography 2018, 2(2), 11; https://doi.org/10.3390/cryptography2020011
Submission received: 10 May 2018
/
Revised: 5 June 2018
/
Accepted: 7 June 2018
/
Published: 10 June 2018
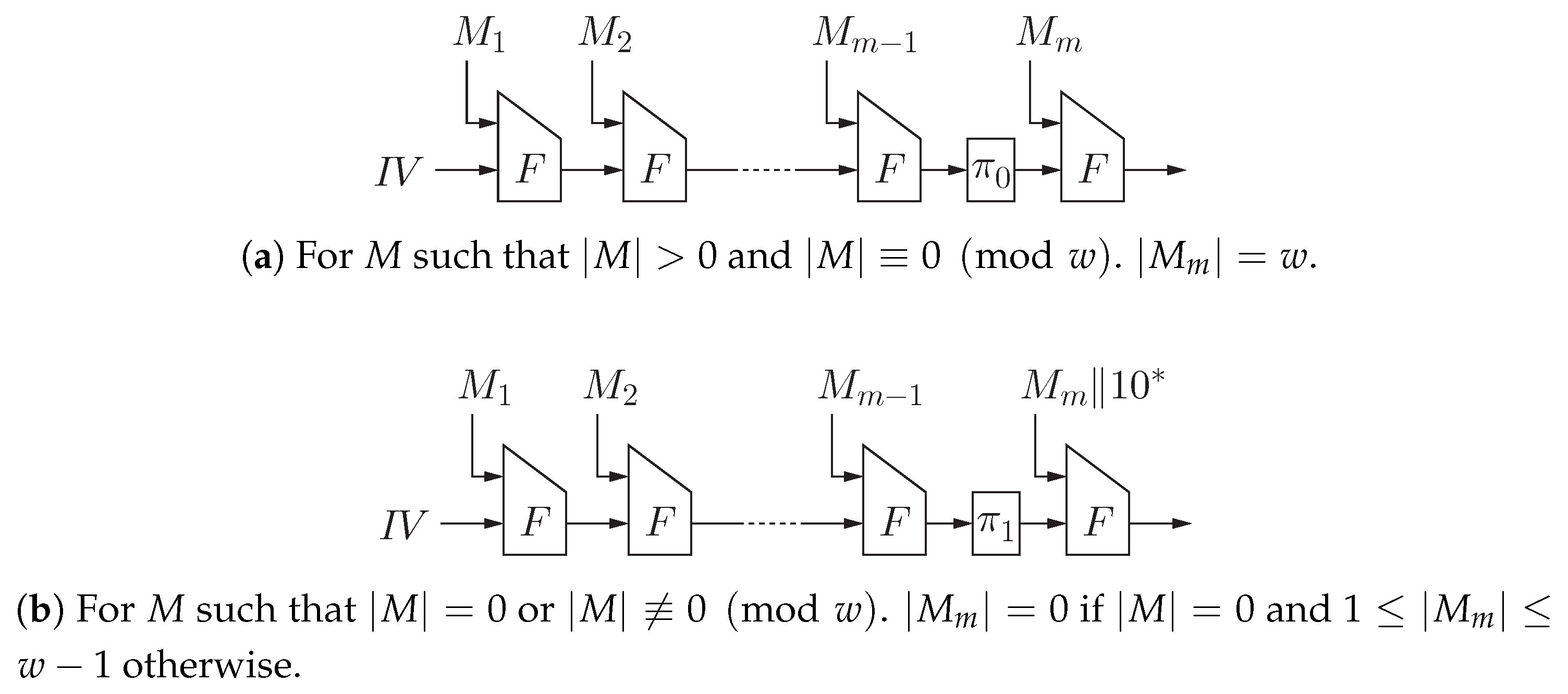{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
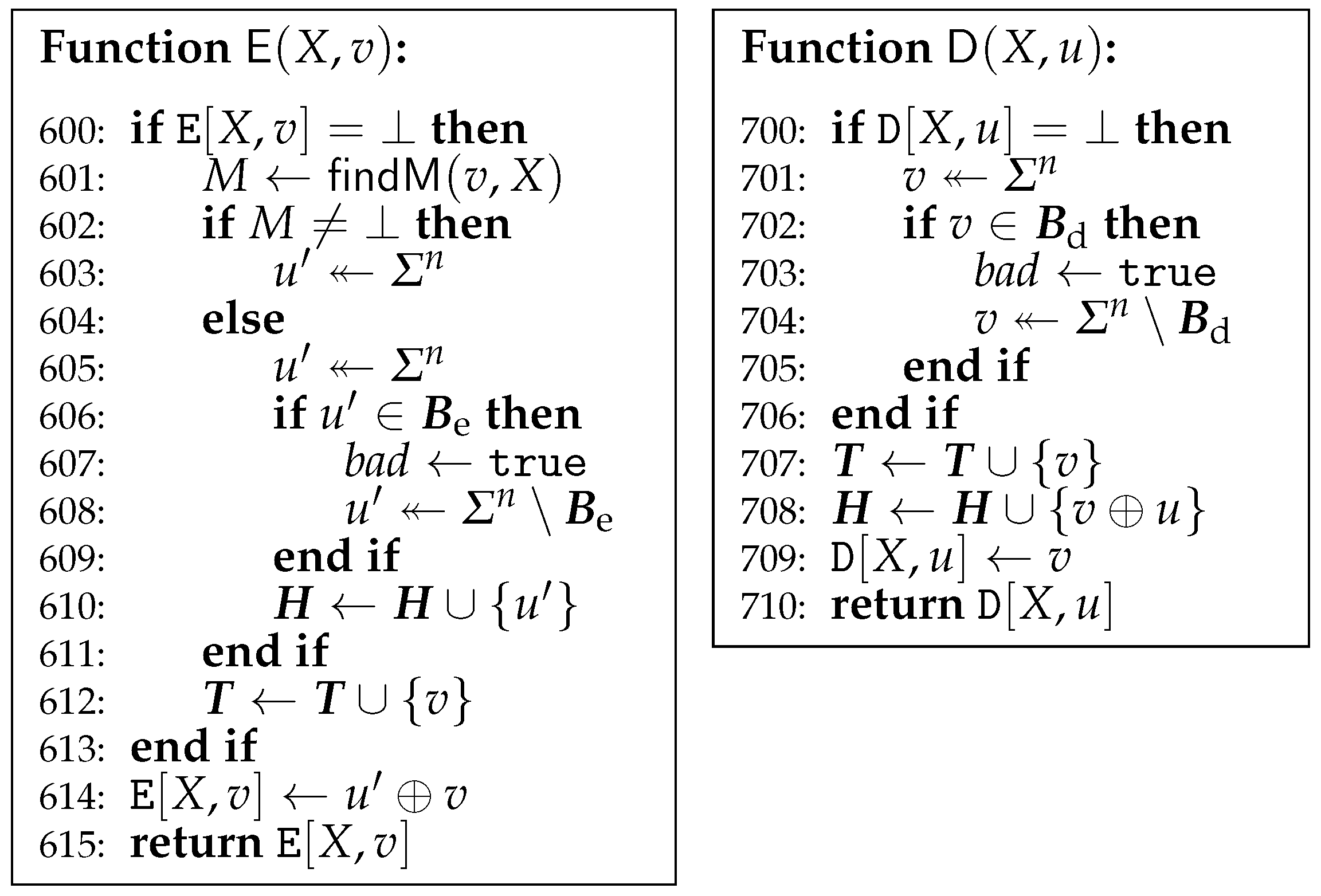{kind=link}
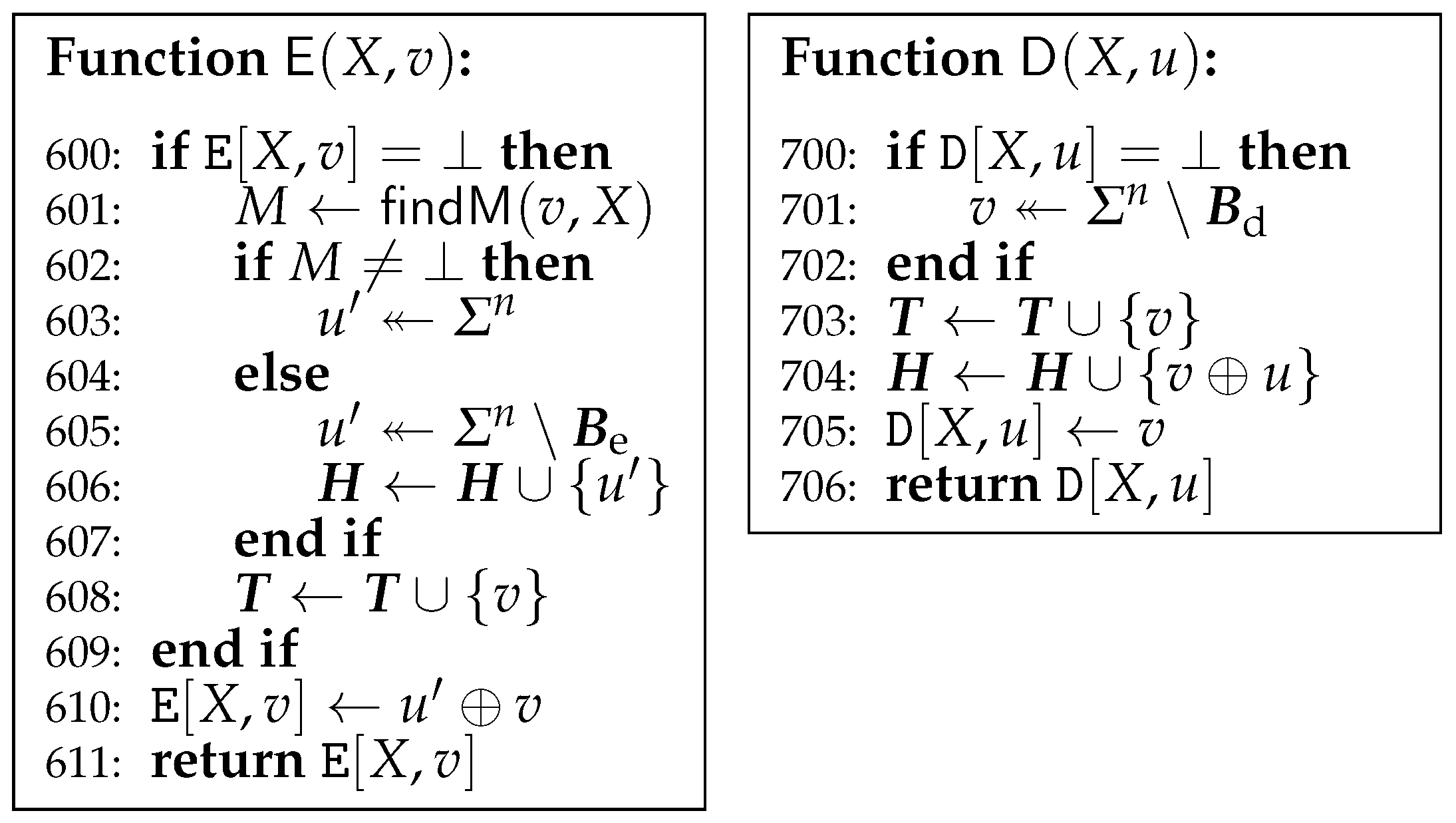{kind=link}
{kind=link}
{kind=link}
{kind=link}
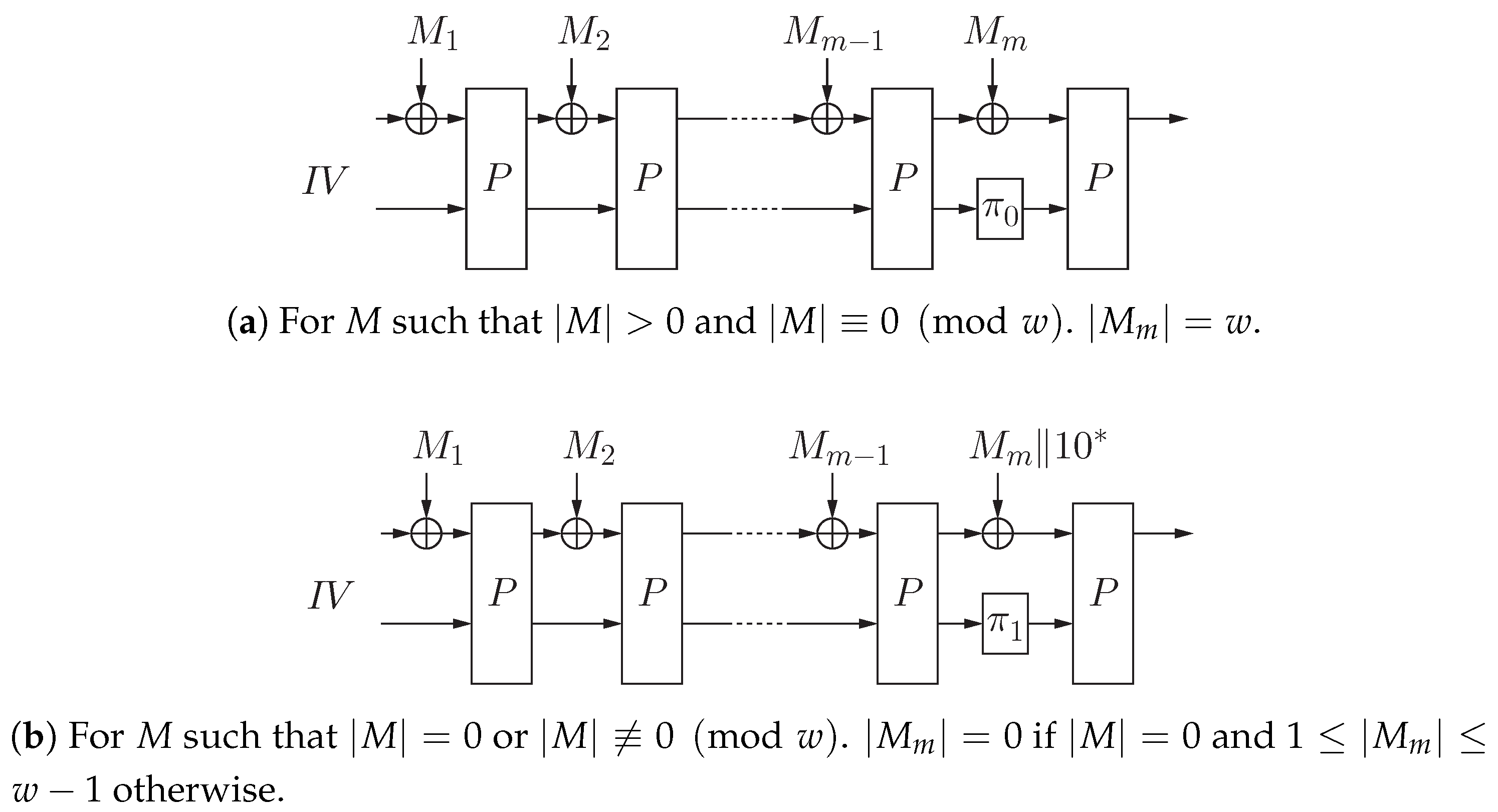{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:This article presents a sequential domain extension scheme with minimum padding for hashing using a compression function. The proposed domain extension scheme is free from the length extension property. The collision resistance of a hash function using the proposed domain extension is shown to be reduced to the collision resistance and the everywhere preimage resistance of the underlying compression function in the standard model, where the compression function is assumed to be chosen at random from a function family in some efficient way. Its indifferentiability from a random oracle up to the birthday bound is also shown on the assumption that the underlying compression function is a fixed-input-length random oracle or the Davies-Meyer mode of a block cipher chosen uniformly at random. The proposed domain extension is also applied to the sponge construction and the resultant hash function is shown to be indifferentiable from a random oracle up to the birthday bound in the ideal permutation model. The proposed domain extension scheme is expected to be useful for processing short messages.
1. Introduction
1.1. Background
A cryptographic hash function takes as input a sequence of arbitrary length and produces as output a sequence of fixed length. It usually consists of a primitive and a domain extension scheme. A primitive is a compression function or a permutation, which takes a fixed-length input and produces a fixed-length output. A domain extension scheme specifies how to process an input sequence with arbitrary length using a primitive with fixed input length.
The standardized hash functions SHA-2 [1] use dedicated compression functions and a domain extension scheme due to Merkle [2] and Damgård [3]. The domain extension scheme is called strengthened Merkle-Damgård (SMD). It is a sequential iteration of a compression function and its padding algorithm appends the binary representation of the length of an input message, which is called MD strengthening.
A positive point of SMD is its preservation of collision resistance. Namely, a hash function using SMD satisfies collision resistance if its underlying compression function satisfies it. On the other hand, a negative point of SMD is its length extension property. Due to this property, the MAC function HMAC [4] invokes the underlying hash function twice. It causes inefficiency for short messages. The other negative point is that message blocks after padding may include a message block consisting only of a padding sequence, which needs an additional call to the compression function.
A domain extension scheme with minimum padding and free from the length extension property seems useful especially for processing short messages. Informally, we say that padding is minimum if the produced message blocks include no message block only with the padding sequence for any non-empty input message.
1.2. Our Contribution
This article first presents a sequential domain extension scheme with minimum padding for hashing using a compression function. The padding function of the domain extension is not injective. It extends the MDP domain extension [5] and uses two distinct permutations for domain separation. The permutations also prevent the length extension property. The permutations need not be cryptographic transformations. A typical candidate for them is bitwise XOR with a nonzero constant.
Then, the security properties of a hash function using the proposed domain extension are analyzed. The properties considered are the collision resistance and the indifferentiability.
The proposed domain extension does not preserve the collision resistance. However, it is shown that the collision resistance of a hash function using the domain extension is reduced to the collision resistance and the everywhere preimage resistance of the underlying compression function.
It is also shown that a hash function using the domain extension is indifferentiable from a variable-input-length random oracle (VIL RO) up to the birthday bound if the underlying compression function is a fixed-input-length random oracle (FIL RO) or the Davies-Meyer mode of a block cipher chosen uniformly at random.
The proposed domain extension scheme can also be applied to the sponge construction in a straightforward way. It is shown that the resultant hash function is indifferentiable from a VIL RO up to the birthday bound if the underlying permutation is chosen uniformly at random.
1.3. Related Work
The presented domain extension of hashing was first considered for a pseudorandom function using a compression function [6]. It is shown in [6] that keying via IV to the domain extension presented in the current article produces a pseudorandom function if the underlying compression function is a pseudorandom function against related-key attacks with respect to the permutations used in the domain extension.
There are many proposals for domain extension of hashing. On the other hand, little attention has been paid to padding.
The most related work was done by Bagheri et al. [7]. They proposed a generic scheme to construct an iterated hash function which requires neither a fixed IV nor the MD strengthening. Their scheme uses three distinct compression functions to get prefix-free and suffix-free property. It assumes injective padding function. They also showed that their hash function is indifferentiable from a VIL RO if the underlying compression functions are FIL ROs.
Nandi [8] showed that the suffix-free property of padding is necessary and sufficient for the plain MD domain extension to preserve the collision resistance. He also presented a suffix-free padding scheme which works for any input message M of arbitrary length. It appends bits to M. The padding scheme for SHA-2, which is based on Merkle’s [2], also appends only bits. However, it works only for input messages of bounded length.
Coron et al. [9] formalized the indifferentiability notion for hash functions in the framework by Maurer et al. [10]. They also showed the indifferentiability of the following domain extension schemes: prefix-free plain MD, plain MD with output truncation (chopMD), NMAC construction, and HMAC construction, where HMAC construction is rather different from the MAC function HMAC [4]. They assumed injective padding. Their work was followed by Chang et al. [11,12].
Bellare and Ristenpart introduced the notion of multi-property preservation for domain extension [13]. They also presented the EMD (enveloped MD) domain extension and showed that it preserves collision resistance, pseudorandom function, and indifferentiability assuming injective padding.
Merkle-Damgård with permutation (MDP) [5] is a variant of plain MD preventing its length-extension property. A typical example of MDP was presented by Kelsey in [14]. It uses bitwise XOR with a nonzero constant for the permutation.
Minimum padding is already common among MAC functions based on a block cipher such as CMAC [15] and PMAC [16]. The idea to finalize the iteration with multiple non-cryptographic transformations for domain separation is used in the secure CBC-MAC variants GCBC1 and GCBC2 [17].
Sarkar [18] presented a domain extension scheme preserving the collision resistance based on directed acyclic graphs. Bertoni et al. [19] formulated sufficient conditions for domain extension schemes covering both tree and sequential structures to be indifferentiable up to the birthday bound. Based on the sufficient conditions, a coding scheme for tree domain extension schemes is specified in [20], which also covers sequential domain extension schemes.
The sponge construction [21] is a scheme to construct a hash function using a function with its input length equal to its output length, which is typically a permutation. It was invented for the SHA-3 hash function [22]. It is adopted by lightweight hash functions such as PHOTON [23] and SPONGENT [24]. It is also extended to design cryptographic schemes such as authenticated encryption [25].
1.4. Organization
Section 2 gives notations used in this article and defines some security properties required of cryptographic hash functions. The proposed scheme is described in Section 3. The collision resistance of the proposed hash function is discussed in the standard model in Section 4. The indifferentiability is discussed in Section 5. The proposed domain extension is applied to the sponge construction in Section 6. A concluding remark is given in Section 7.
2. Preliminaries
2.1. Notations
Let . Let , and .
For binary sequences x and y, let be their concatenation. The empty sequence is denoted by .
The operation of selecting an element from set S uniformly at random and assigning it to s is denoted by .
2.2. Collision Resistance and Preimage Resistance
In this section, the collision resistance and everywhere preimage resistance [26] are defined in the standard model. To do so, a family of hash functions should be introduced. Suppose that h is a hash function chosen at random from some set of hash functions from to in some efficient way.
Let A be an adversary which is given h as input and tries to find a collision pair for h. A collision pair for h are a pair of distinct inputs mapped to the same output by h. The col-advantage of A against h is given by
where the probability is taken over the coin tosses by A and the distribution of h.
Let A be an adversary which is given h as input and tries to find a preimage of an output for h. The pre-advantage of A against h is given by
where the probability is taken over the coin tosses by A and the distribution of h.
2.3. Indifferentiability from Random Oracle
Maurer et al. [10] formalized the notion of indifferentiability as a generalized notion of indistinguishability. Then, Coron et al. [9] tailored it for the security analysis of hash functions.
Let C be an algorithm with oracle access to an ideal primitive . Here in this article, C is a domain extension scheme using with fixed input length and defines a hash function. Let be a VIL random oracle and S be a simulator which has oracle access to . simulates in order to convince an adversary that is . The indiff-advantage of adversary A against is given by
where the probabilities are taken over the coin tosses by A, S and the oracles and . and are called VIL oracles, and and are called FIL oracles.
3. Proposed Scheme
The proposed hash function consists of a compression function , permutations and over , and an initialization vector . For and , it is assumed that , and for any .
Remark 1.
Let and be distinct constants in . Let for . Then, for any , , and .
Let be a permutation over . For , let . The MDP domain extension [5] for F is defined as follows: , where , for , and .
For , the padding function is defined as follows:
where d is the smallest non-negative integer such that . The length of any output of is a positive multiple of w. In particular, . If , then .
The proposed hash function is defined as follows:
It is also depicted in Figure 1.
4. Collision Resistance
The collision resistance of is discussed in the standard model. It is assumed that the compression function F is chosen at random from some set of functions from to in some efficient way.
The collision resistance of needs a new security requirement for F, which is a kind of collision resistance. A pair of distinct inputs and for F are called a -pseudo-collision pair if . The advantage of adversary A against F with respect to -pseudo-collision is defined similarly to the col-advantage. It is denoted by .
It will be shown that the collision resistance of is reduced to the collision resistance, the -pseudo-collision resistance and the everywhere preimage resistance of F.
Lemma 1.
Any collision pair for implies a collision pair, a -pseudo-collision pair, or a preimage of , , or for F.
Proof.
Let M and be any collision pair for . It is shown below that, by tracing back the computation of and , one can find a collision pair for F, a -pseudo-collision pair for F, or a preimage of , , or for F. Let and .
Suppose that . Then, one of and uses and the other uses . Notice that for any . If , then one finds a collision pair for F since . If , then one finds a collision pair or a -pseudo-collision pair for F since implies for any .
Suppose that .
- (i)
- Suppose that one of and uses and the other uses . Assume that uses and uses without loss of generality. If , then one finds a collision pair for F. If and , then one finds a collision pair for F or a preimage of for F. If and , then one finds a collision pair for F or a preimage of for F. If and , then one finds a collision pair or a -pseudo-collision pair for F.
- (ii)
- Suppose that both of and uses a same permutation. If , then one finds a collision pair for F. If and , or and , then one finds a collision pair for F or a preimage of for F. If and , then one finds a collision pair or a preimage of for F.
☐
Theorem 1.
For any adversary A trying to find a collision pair for with run time t, there exist adversaries , and such that
The run times of , and are about , where M and are a collision pair of output by A and is the time required to compute F.
Proof.
Let B be an algorithm which works as follows. B takes F as input. It first runs A with input . If A fails to find a collision pair for , then it aborts. Otherwise, for a collision pair M and output by A, it computes and .
Let be an adversary trying to find a collision pair for F. Let be an adversary trying to find a -pseudo-collision pair for F. Let be an adversary trying to find a preimage of , , or for F. All of them first run B. From Lemma 1, if A succeeds in finding a collision pair for , then , or succeed. ☐
5. Indifferentiability from Random Oracle
5.1. In the Random Oracle Model
In this section, to discuss the indifferentiability, the compression function F is assumed to be chosen uniformly at random from all the functions from to .
The following theorem implies that the proposed hash function is indifferentiable from a random oracle up to the birthday bound. The game-playing technique [27] is used for the proof.
Theorem 2.
Suppose that the compression function is chosen uniformly at random. Then, for the hash function , there exists a simulator S of F such that, for any adversary A making at most q queries to its FIL oracle and queries to its VIL oracle which cost at most σ message blocks in total,
and S makes at most q queries.
Proof.
Each game provides two interfaces to adversary A: for the hash function and for the compression function. It is assumed without loss of generality that A makes no repeated queries both to and to .
The game G1 is given in Figure 2. simply calls , which implements the compression function F by lazy evaluation. uses a partial function . Initially, for every . computes with the aid of . Thus,
Notice that may receive repeated queries since also calls as well as .
The game G2 is given in Figure 3a. and are not changed and omitted.
In G2, constructs and maintains a directed graph based on the queries to . It also uses a function , which will be described later. Initially, and . For a new query , if , then replaces with . On the other hand, if , then replaces with and with . The edge is labeled with X. and are the sets of tails and heads of edges in , respectively. Vertices with no adjacent edges in are also included in . Initially, and .
tries to find a path in corresponding to the computation for some M. Given as input, first searches a path from to or in . If equals or , then the single vertex is regarded as a path. If finds a path, then let be the labels of the edges on the path. If the path is , then , that is, . If there exists some such that , which depends on whether the terminal of the path is or , then returns M. Otherwise, returns ⊥. It will be shown that finds at most one path.
of G2 differs from of G1 only if gets in G2. This is because is chosen uniformly at random in G2 until gets . For the i-th call to , since
and . is called at most times. Thus,
For the game G3 in Figure 3b, the lines from 605 to 609 in G2 are replaced with the line 605 in G3. Since they are equivalent, .
The game G4 is given in Figure 4. It introduces a variable-input-length random oracle , which is implemented by lazy evaluation. Initially, for every . may receive repeated queries since it is called by both and . Different from of G3, assigns to at the line 603 in G4. Different from of G3, returns in G4. We will see that G4 is actually equivalent to G3 in spite of these changes.
First, let us see some properties of the graph . Both in G3 and in G4, at the beginning of each run of with such that , . Then, whenever this run adds to both and , is chosen from , where . Thus, every vertex in has at most one incoming edge, and has no incoming edge. It implies that every vertex in has at most one simple path from . In addition, for every path with , ’s are added to in this order. Furthermore, before is added to , neither nor were asked to for any since .
Suppose that finds two paths in . Then, one is from to and the other is from to . Notice that since for every . Suppose that both paths have two or more vertices. Then, both and are elements of , which implies that one was added to after the other since at most one vertex is added to during each run of . It contradicts for . Suppose that one path is the single vertex and the other has two or more vertices. contradicts for . Thus, finds at most a single path in .
In G4, for a new query to , suppose that finds a path in and returns M corresponding to the path and . Then, M is a new query to , that is , and it is assigned an element chosen uniformly at random from . On the other hand, for , . Thus, G4 is equivalent to G3, and .
From G4 to G5, only changes, which is given in Figure 5a. of G5 is augmented with the lines from 600 to 606 and the lines from 614 to 616. is the set of heads of edges in in the view of A. Initially, . These changes do not affect the output of . Thus, G5 is equivalent to G4, and .
From G5 to G6, only changes. of G6 is identical to that of G7, which is given in Figure b. In G6, does not call and just returns . In G6, is called only by and it does not receive any repeated queries, which implies that never gets . On the other hand, may get in G5. If gets in G5, then A may trace some computation path of in from its middle. since and . A knows at most elements in . Thus,
From G6 to G7, only changes. G7 is given in Figure 5b. of G7 is obtained from of G6 by removing the lines from 600 to 606 and the lines from 614 to 616. Since does not receive any repeated queries, the lines 607 and 619 are also removed. These changes do not affect the output of . Thus, . of G7 works as a simulator S of F.
From the discussion above, we have
☐
5.2. In the Ideal Cipher Model
In this section, is assumed to be the Davies-Meyer compression function [28] using a block cipher , where the key space of E is . Namely, . E is assumed to be chosen uniformly at random.
Theorem 3.
Suppose that the compression function is the Davies-Meyer mode of a block cipher E chosen uniformly at random. Let D be the decryption function of E. Then, for the hash function , there exists a simulator S of such that, for any adversary A making at most queries to its FIL encryption oracle, queries to its FIL decryption oracle, and queries to its VIL oracle which cost at most σ message blocks in total,
and S makes at most queries.
Proof.
Each game provides three interfaces to adversary A: for the hash function, for the encryption and for the decryption. It is assumed without loss of generality that A makes no repeated queries both to and to . For and , once A gets a tuple such that by a query to or , A never makes any query on the tuple.
The game G1 is given in Figure 6. and simply call and , respectively. and implement the encryption function and the decryption function by lazy evaluation, respectively. computes with the aid of . Thus,
Notice that and may receive repeated queries since also calls as well as .
From G1 to G2, only and are changed, which are given in Figure 7. In G2, and are chosen uniformly at random from . G1 and G2 are identical until gets in G2. Since and are called at most times in total and ,
From G2 to G3, only and are changed, which are given in Figure 8. In G3, and constructs and maintains a directed graph based on the queries to them. Initially, and . For a new query , if , then replaces with . If , then replaces with and with , where . The edge is labeled with X. On the other hand, for a new query , replaces with and with , where .
and are the sets of tails and heads of edges in , respectively. Vertices with no adjacent edges in are also in . Initially, .
tries to find a path in corresponding to the computation for some M. Given as input, first searches a path from to or in . If equals or , then the single vertex is regarded as a path. If finds a path, then let be the labels of the edges on the path. If the path is , then , that is, . If there exists some such that , which depends on whether the terminal of the path is or , then returns M. Otherwise, returns ⊥.
of G3 always assigns to a value chosen uniformly at random from until gets true at line 607. of G3 always assigns to a value chosen uniformly at random from until gets true at line 703. Thus, G3 is identical to G2 until gets in G3. Since and , and . is called at most times and is called at most times and Thus,
For the game G4 in Figure 9, the lines from 605 to 609 of G3 are replaced with the line 605 of G4, and the lines from 701 to 705 of G3 are replaced with the line 701 of G4. Since these changes do not affect the behavior, .
The game G5 is given in Figure 10. It introduces a variable-input-length random oracle , which is implemented by lazy evaluation. Initially, for every . may receive repeated queries since it is called by both and . Different from of G4, of G5 assigns to at the line 603. Different from of G4, of G5 returns . We will see that G5 is actually equivalent to G4 in spite of these changes.
First, let us see some properties of the graph . At the beginning of each run of with such that , . Whenever is added to both and by this run, it is chosen from , where . On the other hand, at the beginning of each run of with such that , . Then, v is chosen from , and is added to both and by this run, where . Thus, every vertex in has at most one incoming edge, and has no incoming edge. It implies that every vertex in has at most one simple path from . In addition, every path with is constructed only by queries to , and ’s are added to in this order. Furthermore, before is added to , neither nor existed in since . Neither nor are added to as tails by the queries to after since .
Suppose that finds two paths in . Then, one is from to and the other is from to . Notice that since for every . Suppose that both paths have two or more vertices. Then, both and are elements of , which implies that one was added to after the other since at most one vertex is added to during each run of . It contradicts for . Suppose that one path is the single vertex and the other has two or more vertices. contradicts for . Thus, finds at most a single path in .
In G5, for a new query to , suppose that finds a path in and returns M corresponding to the path and . Then, M is a new query to , that is , and it is assigned an element chosen uniformly at random from . On the other hand, for , . Thus, G5 is equivalent to G4, and .
From G5 to G6, and change, which are given in Figure 11. of G6 is augmented with the lines from 600 to 606 and the lines from 614 to 616. is the set of heads of edges in in the view of A. Initially, . These changes do not affect the output of . of G6 is augmented with the lines from 700 to 704 and the line 710. These changes do not affect the output of , either. Thus, G6 is equivalent to G5, and .
From G6 to G7, only changes. of G7 is identical to that of G8, which is given in Figure 12. In G7, does not call and just returns . In G7, is called only by and it does not receive any repeated queries. does not receive any repeated queries, either. Thus, never gets in G7. On the other hand, may get in G6. and since , , and . A knows at most elements in . Thus,
From G7 to G8, and changes. G8 is given in Figure 12. of G8 is obtained from of G7 by removing the lines from 600 to 606 and the lines from 614 to 616. Since does not receive any repeated queries, the lines 607 and 619 are also removed. These changes do not affect the output of . Similarly, of G8 is obtained from of G7 by removing the lines from 700 to 704, the lines 705, 707, and 710. These changes do not affect the output of . Thus, . of G8 works as a simulator S of .
From the discussion above, we have
☐
6. Application to Sponge Construction
6.1. Scheme
Let be a permutation and , where b, w and c are positive integers. The sponge hash function using the proposed domain extension consists of the permutation P, permutations and over , and an initialization vector . For and , it is assumed that , and for every .
For , let , where and . In the remaining parts, some notations are abused for simplicity. For permutation over and string , represents . Namely, is applied to the c least significant bits (LSBs) of y. For strings and , represents .
Let be a permutation over . For , let . The tweaked sponge construction is defined as follows: , where , for , , and is the n most significant bits (MSBs) of .
The sponge hash function based on the proposed domain extension is defined as follows:
It is also depicted in Figure 13.
6.2. IRO in the Ideal Permutation Model
In this section, is assumed to be chosen uniformly at random. The following theorem implies that the proposed hash function is indifferentiable from a random oracle up to the birthday bound.
Theorem 4.
Suppose that the permutation is chosen uniformly at random. Then, for the hash function , there exists a simulator S of such that, for any adversary A making at most queries to its FIL forward oracle, queries to its FIL backward oracle, and queries to its VIL oracle which cost at most σ message blocks in total,
and S makes at most queries.
Proof.
Each game provides three interfaces to adversary A: for the hash function, for the permutation and for its inverse. It is assumed without loss of generality that A makes no repeated queries both to and to . For and , once A gets a pair such that by a query to or , A never makes any query on the pair.
The game G1 is given in Figure 14. and simply call and , respectively. and implement P and by lazy evaluation, respectively. computes with the aid of and . Thus,
Notice that and may receive repeated queries since also calls as well as .
From G1 to G2, only and are changed, which are given in Figure 15. In G2, and are chosen uniformly at random from . G1 and G2 are identical until gets in G2. Since and are called at most times in total and ,
From G2 to G3, only and are changed, which are given in Figure 16. In G3, and constructs and maintains a directed graph based on the queries to them. Initially, and . For a new query Y, if , then replaces with and with . If there exists some such that or , and , then the edge is labeled with . Otherwise, it is labeled with ⊥. If , then replaces with . On the other hand, for a new query Z, replaces with and with . If there exists some such that or , and , then the edge is labeled with . Otherwise, it is labeled with ⊥.
and are the sets of tails and heads of edges in , respectively. Vertices with no adjacent edges in are also in . Initially, .
tries to find a path in corresponding to the computation for some M. Given Y as input, first searches a path from to or in . If equals or , then the single vertex is regarded as a path. If finds a path, then let be the labels of the edges on the path. If the path is , then , that is, . Suppose that is the terminal of the path and for some . If there exists some such that , which depends on whether equals or , then returns M. Otherwise, returns ⊥.
of G3 always assigns to a value chosen uniformly at random from until gets true at line 608. of G3 always assigns to a value chosen uniformly at random from until gets true at line 704. Thus, G3 is identical to G2 until gets in G3. Since and , and . is called at most times and is called at most times. Thus,
For the game G4 in Figure 17, the lines from 606 to 610 of G3 are replaced with the line 606 of G4, and the lines from 702 to 706 of G3 are replaced with the line 702 of G4. Since these changes do not affect the behaviour, .
The game G5 is given in Figure 18. It introduces a variable-input-length random oracle , which is implemented by lazy evaluation. Initially, for every . may receive repeated queries since it is called by both and . Different from of G4, of G5 assigns to Z an element chosen uniformly at random from at the line 603. Different from of G4, of G5 returns . We will see that G5 is actually equivalent to G4 in spite of these changes.
First, let us see some properties of the graph . At the beginning of each run of with Y such that , . Whenever is added to both and by this run, it is chosen from , where . On the other hand, at the beginning of each run of with Z such that , . Then, is chosen from , where . Thus, every vertex in has at most one incoming edge labeled with some element in , and every incoming edge of is labeled with ⊥. It implies that every vertex in has at most one simple path from without edges labeled by ⊥. In addition, every path with is constructed only by queries to , and ’s are added to in this order. Furthermore, before is added to , neither nor existed in since . Neither nor are added to as tails by the queries to after since .
Suppose that finds two paths in without edges labeled by ⊥. Then, one is from to and the other is from to . Notice that since for every . Suppose that both paths have two or more vertices. Then, both and are elements of , which implies that one was added to after the other since at most one vertex is added to during each run of . It contradicts for . Suppose that one path is the single vertex and the other has two or more vertices. contradicts for . Thus, finds at most a single path in without edges labeled by ⊥.
In G5, for a new query Y to , suppose that finds a path in and returns M corresponding to the path and Y. Then, M is a new query to , that is, , and it is assigned an element chosen uniformly at random from . On the other hand, for , the n MSBs of equals . Thus, G5 is equivalent to G4, and .
From G5 to G6, and change, which are given in Figure 19. of G6 is augmented with the lines from 600 to 606 and the lines from 615 to 617. is the set of heads of edges in in the view of A. Initially, . These changes do not affect the output of . of G6 is augmented with the lines from 700 to 704 and the line 711. These changes do not affect the output of . Thus, G6 is equivalent to G5, and .
From G6 to G7, only changes. of G7 is identical to that of G8, which is given in Figure 20. In G7, does not call and just returns . In G7, is called only by and it does not receive any repeated queries. does not receive any repeated queries, either. Thus, never gets in G7. On the other hand, may get in G6. since and . A knows at most elements in . Thus,
From G7 to G8, and change. G8 is given in Figure 20. of G8 is obtained from of G7 by removing the lines from 600 to 606 and the lines from 615 to 617. Since does not receive any repeated queries, the lines 607 and 620 are also removed. These changes do not affect the output of . Similarly, of G8 is obtained from of G7 by removing the lines from 700 to 704, the lines 705, 708 and 711. These changes do not affect the output of . Thus, . of G8 works as a simulator S of .
From the discussion above, we have
☐
7. Conclusions
In this article, a domain extension scheme which extends MDP [5] has been presented for iterated hashing. The collision resistance and indifferentiability from a random oracle of an iterated hash function using the domain extension have been confirmed under reasonable assumptions. For the pseudorandom-function property of the iterated hash function keyed via IV, readers are asked to see [6] for details.
The domain extension can also be applied to the sponge construction. The indifferentiability from a random oracle of the resultant hash function has been confirmed in the ideal permutation model.
The presented domain extension is simple and efficient. It is expected to be useful for lightweight cryptography.
Acknowledgments
This work was supported in part by JSPS KAKENHI Grant Number JP16H02828.
Conflicts of Interest
The author declares no conflict of interest.
References
- Dang, Q.H. Secure Hash Standard (SHS); FIPS PUB 180-4; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012.
- Merkle, R.C. One Way Hash Functions and DES. In Advances in Cryptology—CRYPTO 89, Proceedings of the 9th Annual International Cryptology Conference on Advances in Cryptology, Santa Barbara, CA, USA, 20–24 August 1989; Brassard, G., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1990; Volume 435, pp. 428–446. [Google Scholar]
- Damgård, I. A Design Principle for Hash Functions. In Advances in Cryptology—CRYPTO 89, Proceedings of the 9th Annual International Cryptology Conference on Advances in Cryptology, Santa Barbara, CA, USA, 20–24 August 1989; Brassard, G., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1990; Volume 435, pp. 416–427. [Google Scholar]
- Bellare, M.; Canetti, R.; Krawczyk, H. Keying Hash Functions for Message Authentication. In Advances in Cryptology—CRYPTO 96, Proceedings of the 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; Koblitz, N., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1996; Volume 1109, pp. 1–15. [Google Scholar]
- Hirose, S.; Park, J.H.; Yun, A. A Simple Variant of the Merkle-Damgård Scheme with a Permutation. In Advances in Cryptology—ASIACRYPT 2007, Proceedings of the 13th International Conference on the Theory and Application of Cryptology and Information Security, Kuching, Malaysia, 2–6 December 2007; Kurosawa, K., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4833, pp. 113–129. [Google Scholar]
- Hirose, S.; Yabumoto, A. A Tweak for a PRF Mode of a Compression Function and Its Applications. In Innovative Security Solutions for Information Technology and Communications, Proceedings of the 9th International Conference, SECITC 2016, Bucharest, Romania, 9–10 June 2016; Bica, I., Reyhanitabar, R., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 10006, pp. 103–114. [Google Scholar]
- Bagheri, N.; Gauravaram, P.; Knudsen, L.R.; Zenner, E. The suffix-free-prefix-free hash function construction and its indifferentiability security analysis. Int. J. Inf. Secur. 2012, 11, 419–434. [Google Scholar] [CrossRef] [Green Version]
- Nandi, M. Characterizing Padding Rules of MD Hash Functions Preserving Collision Security. In Information Security and Privacy, Proceedings of the 14th Australasian Conference, ACISP 2009, Brisbane, Australia, 1–3 July 2009; Boyd, C., Nieto, J.M.G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5594, pp. 171–184. [Google Scholar]
- Coron, J.S.; Dodis, Y.; Malinaud, C.; Puniya, P. Merkle-Damgård Revisited: How to Construct a Hash Function. In Advances in Cryptology—CRYPTO 2005, Proceedings of the 25th Annual International Cryptology Conference, Santa Barbara, CA, USA, 14-18 August 2005; Shoup, V., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3621, pp. 430–448. [Google Scholar]
- Maurer, U.M.; Renner, R.; Holenstein, C. Indifferentiability, Impossibility Results on Reductions, and Applications to the Random Oracle Methodology. In Theory of Cryptography, Proceedings of the First Theory of Cryptography Conference, TCC 2004, Cambridge, MA, USA, 19-21 February 2004; Naor, M., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; Volume 2951, pp. 21–39. [Google Scholar]
- Chang, D.; Lee, S.; Nandi, M.; Yung, M. Indifferentiable Security Analysis of Popular Hash Functions with Prefix-Free Padding. In Advances in Cryptology—ASIACRYPT 2006, Proceedings of the 12th International Conference on the Theory and Application of Cryptology and Information Security, Shanghai, China, 3–7 December 2006; Lai, X., Chen, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4284, pp. 283–298. [Google Scholar]
- Chang, D.; Nandi, M. Improved Indifferentiability Security Analysis of chopMD Hash Function. In Fast Software Encryption, Proceedings of the 15th International Workshop, FSE 2008, Lausanne, Switzerland, 10–13 February 2008; Nyberg, K., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5086, pp. 429–443. [Google Scholar]
- Bellare, M.; Ristenpart, T. Multi-property-preserving hash domain extension and the EMD transform. In Advances in Cryptology—ASIACRYPT 2006, Proceedings of the 12th International Conference on the Theory and Application of Cryptology and Information Security, Shanghai, China, 3–7 December 2006; Lai, X., Chen, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4284, pp. 299–314. [Google Scholar]
- Kelsey, J. Public Comments on the Draft Federal Information Processing Standard (FIPS) Draft FIPS 180-2, Secure Hash Standard (SHS), 2001. Available online: http://www.cs.utsa.edu/∼wagner/CS4363/SHS/dfips-180-2-comments1.pdf (accessed on 9 June 2018).
- Dworkin, M.J. Recommendation for Block Cipher Modes of Operation: The CMAC Mode for Authentication; NIST Special Publication 800-38B; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2005.
- Black, J.; Rogaway, P. A Block-Cipher Mode of Operation for Parallelizable Message Authentication. In Advances in Cryptology—EUROCRYPT 2002, Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Amsterdam, The Netherlands, 28 April–2 May 2002; Knudsen, L.R., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2332, pp. 384–397. [Google Scholar]
- Nandi, M. Fast and Secure CBC-Type MAC Algorithms. In Fast Software Encryption, Proceedings of the 16th International Workshop, FSE 2009, Leuven, Belgium, 22–25 February 2009; Dunkelman, O., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5665, pp. 375–393. [Google Scholar]
- Sarkar, P. Domain extender for collision resistant hash functions: Improving upon Merkle-Damgård iteration. Discret. Appl. Math. 2009, 157, 1086–1097. [Google Scholar] [CrossRef]
- Bertoni, G.; Daemen, J.; Peeters, M.; Assche, G.V. Sufficient conditions for sound tree and sequential hashing modes. Int. J. Inf. Secur. 2014, 13, 335–353. [Google Scholar] [CrossRef]
- Bertoni, G.; Daemen, J.; Peeters, M.; Assche, G.V. Sakura: A Flexible Coding for Tree Hashing. In Applied Cryptography and Network Security, Proceedings of the 12th International Conference, ACNS 2014, Lausanne, Switzerland, 10–13 June 2014; Boureanu, I., Owesarski, P., Vaudenay, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8479, pp. 217–234. [Google Scholar]
- Bertoni, G.; Daemen, J.; Peeters, M.; Van Assche, G. Sponge Functions. In Proceedings of the ECRYPT Hash Workshop 2007, Barcelona, Spain, 24–25 May 2007. [Google Scholar]
- Dworkin, M.J. SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions; FIPS PUB 202; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015.
- Guo, J.; Peyrin, T.; Poschmann, A. The PHOTON Family of Lightweight Hash Functions. In Advances in Cryptology—CRYPTO 2011, Proceedings of the 31st Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Rogaway, P., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6841, pp. 222–239. [Google Scholar]
- Bogdanov, A.; Knezevic, M.; Leander, G.; Toz, D.; Varici, K.; Verbauwhede, I. spongent: A Lightweight Hash Function. In Cryptographic Hardware and Embedded Systems—CHES 2011, Proceedings of the 13th International Workshop, Nara, Japan, 28 September–1 October 2011; Preneel, B., Takagi, T., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6917, pp. 312–325. [Google Scholar]
- Bertoni, G.; Daemen, J.; Peeters, M.; Van Assche, G. Duplexing the Sponge: Single-Pass Authenticated Encryption and Other Applications. In Selected Areas in Cryptography, Proceedings of the 18th International Workshop, SAC 2011, Toronto, ON, Canada, 11–12 August 2011; Miri, A., Vaudenay, S., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7118, pp. 320–337. [Google Scholar]
- Rogaway, P.; Shrimpton, T. Cryptographic Hash-Function Basics: Definitions, Implications, and Separations for Preimage Resistance, Second-Preimage Resistance, and Collision Resistance. In Fast Software Encryption, Proceedings of the 11th International Workshop, FSE 2004, Delhi, India, 5–7 February 2004; Roy, B.K., Meier, W., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3017, pp. 371–388. [Google Scholar]
- Bellare, M.; Rogaway, P. The Security of Triple Encryption and a Framework for Code-Based Game-Playing Proofs. In Advances in Cryptology—EUROCRYPT 2006, Proceedings of the 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; Vaudenay, S., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4004, pp. 409–426. [Google Scholar]
- Quisquater, J.; Girault, M. 2n-Bit Hash-Functions Using n-Bit Symmetric Block Cipher Algorithms. In Advances in Cryptology—EUROCRYPT ’89, Proceedings of the Workshop on the Theory and Application of of Cryptographic Techniques, Houthalen, Belgium, 10–13 April 1989; Quisquater, J.J., Vandewalle, J., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1989; Volume 434, pp. 102–109. [Google Scholar]
Figure 1.
The proposed hash function. , where for .
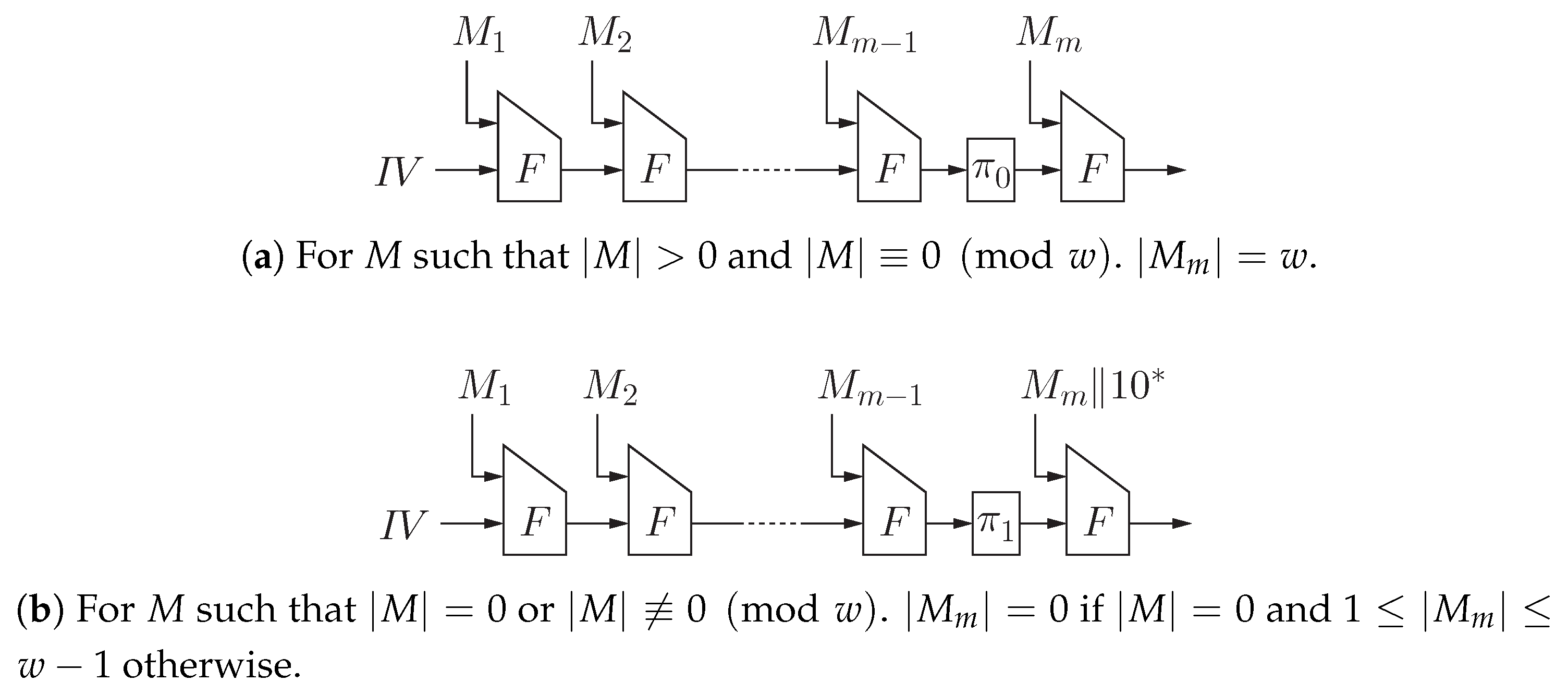
Figure 2.
Game G1. For the partial function used in , initially, for every .

Figure 3.
Games G2 and G3. and are omitted, which are identical to those of G1. . Initially, and .

Figure 4.
Game G4. Initially, for every .

Figure 5.
Games G5, G6 and G7.

Figure 6.
Game G1. For the partial functions and , initially, for every and for every . If u is assigned to , then v is assigned to . If v is assigned to , then u is assigned to . and are the sets of values already assigned as plaintexts and ciphertexts for key X, respectively.
Figure 6.
Game G1. For the partial functions and , initially, for every and for every . If u is assigned to , then v is assigned to . If v is assigned to , then u is assigned to . and are the sets of values already assigned as plaintexts and ciphertexts for key X, respectively.

Figure 7.
Game G2. , and , which are not changed, are omitted.

Figure 8.
Game G3. , and are not changed and omitted. . . Initially, .
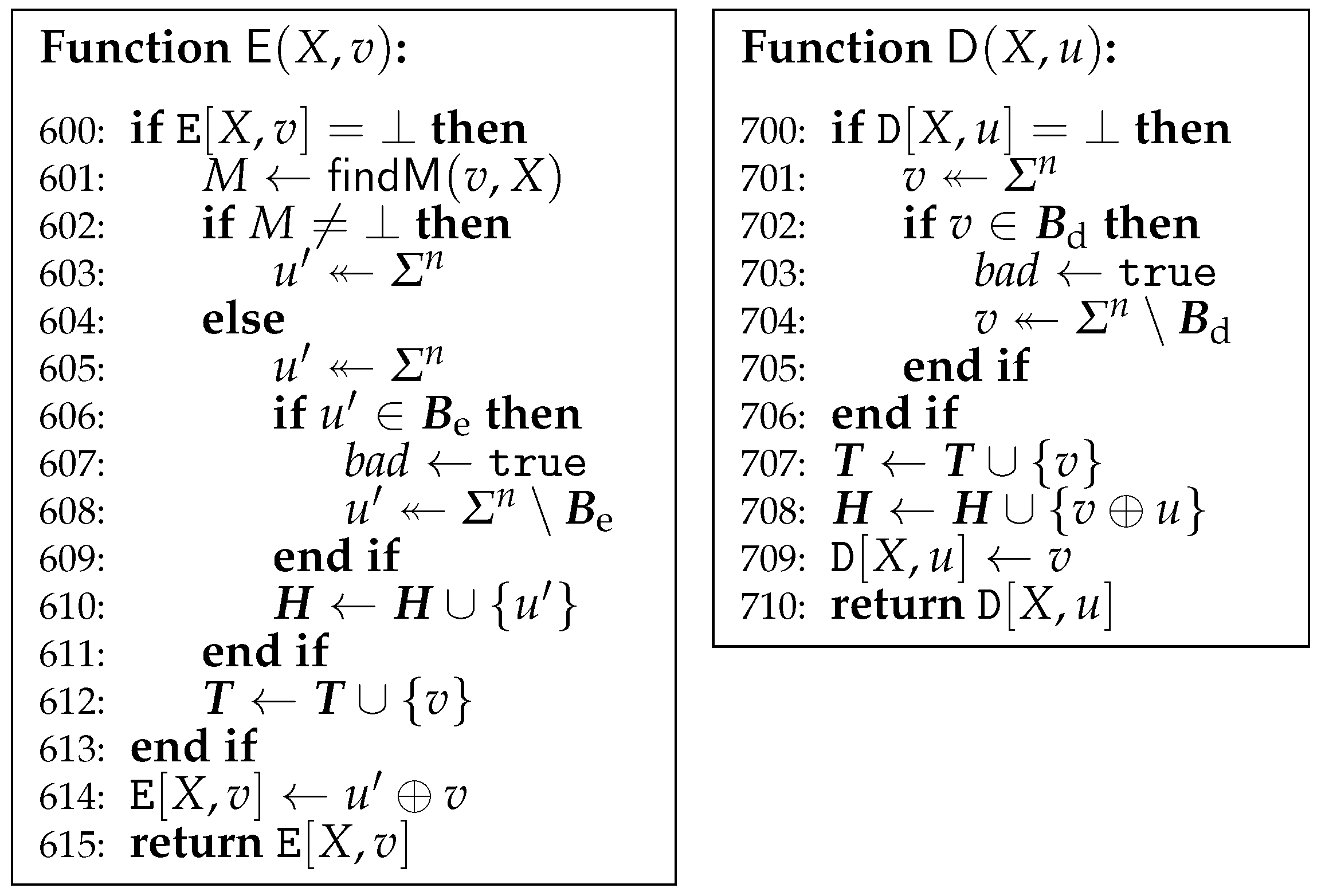
Figure 9.
Game G4. , and are not changed and omitted.
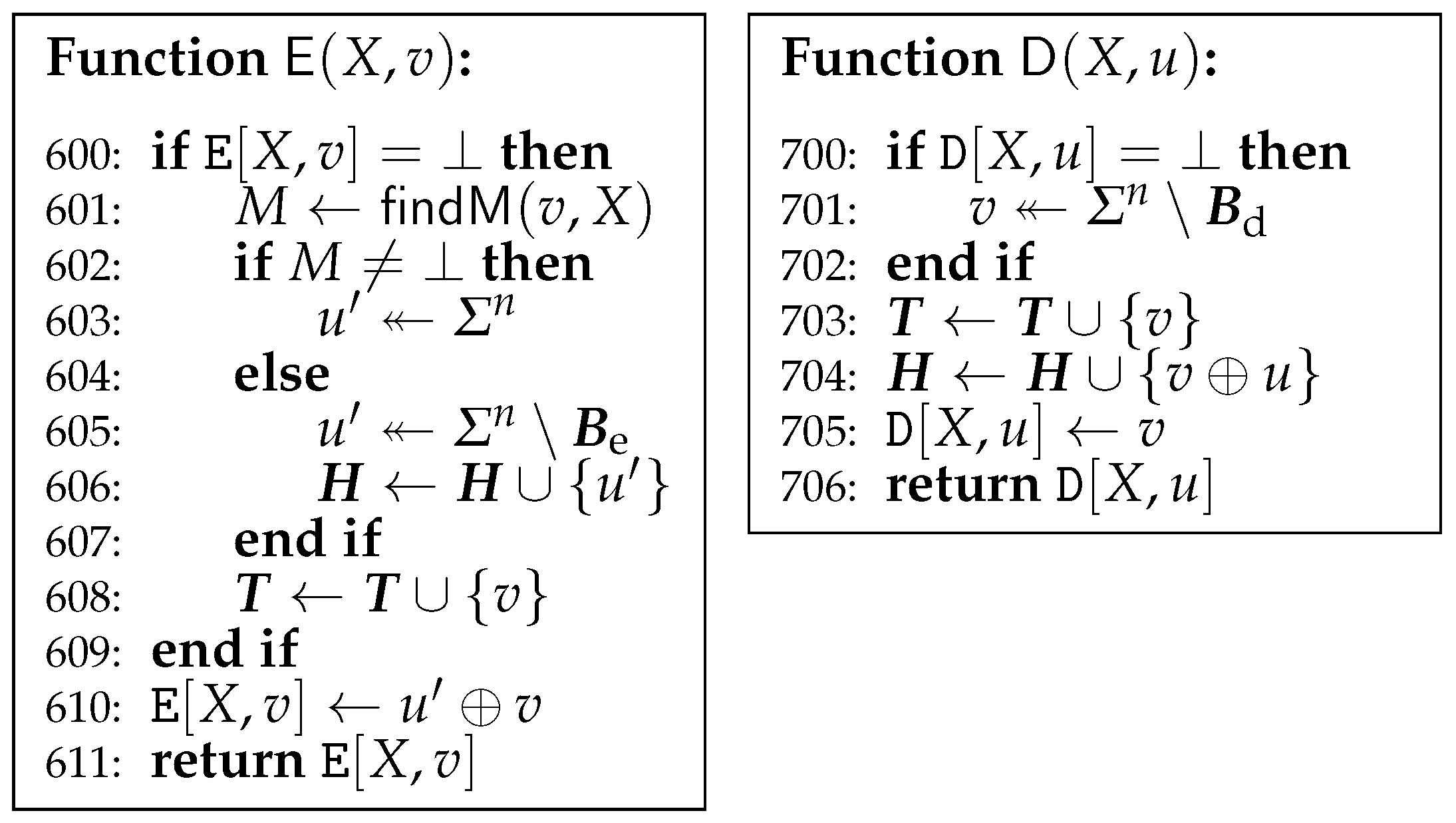
Figure 10.
Game G5. and are not changed and omitted. Initially, for every .

Figure 11.
and of G6 and G7. . , where and . Initially, .
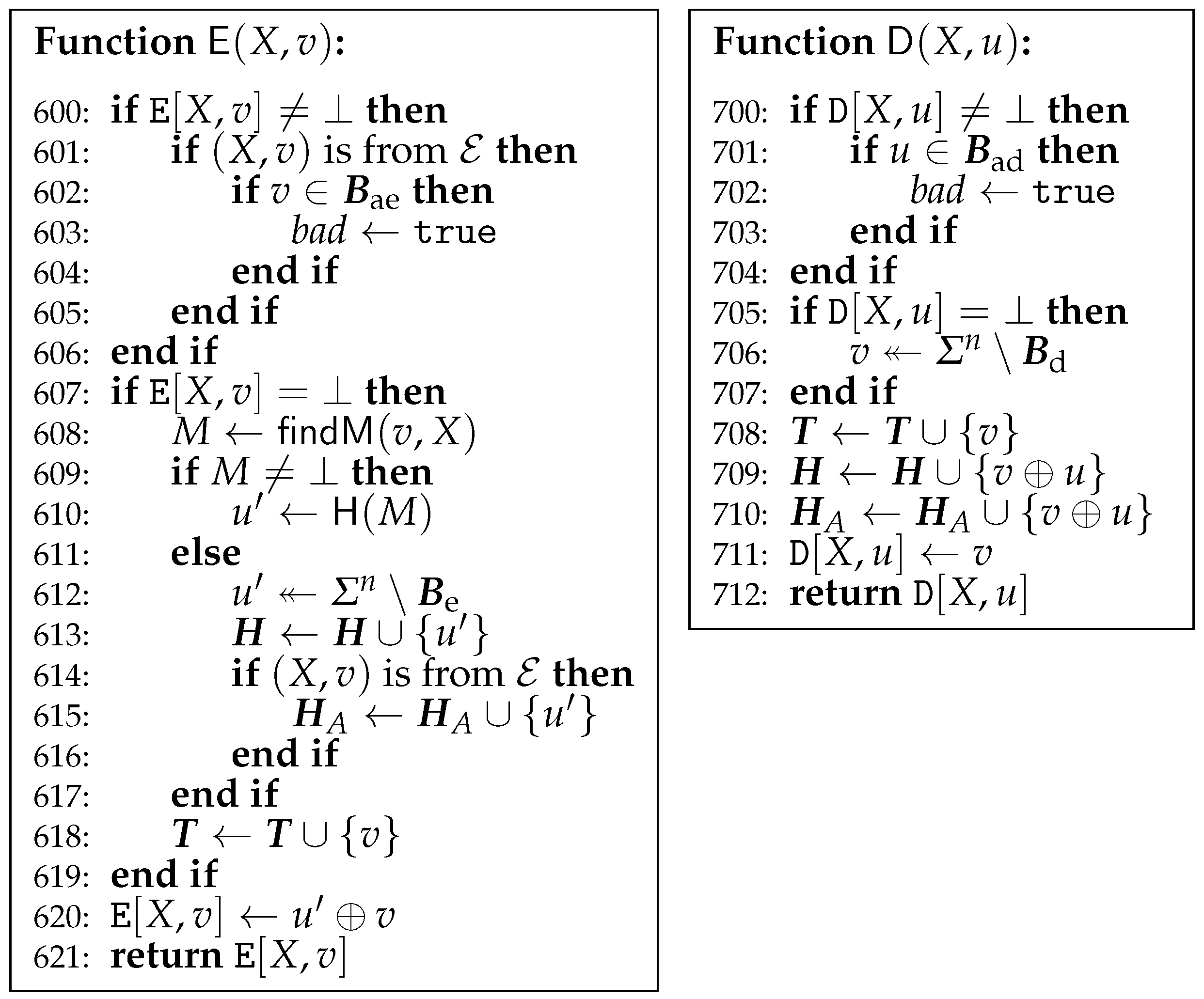
Figure 12.
Game G8.

Figure 13.
The sponge hash function based on the proposed domain extension. , where for .
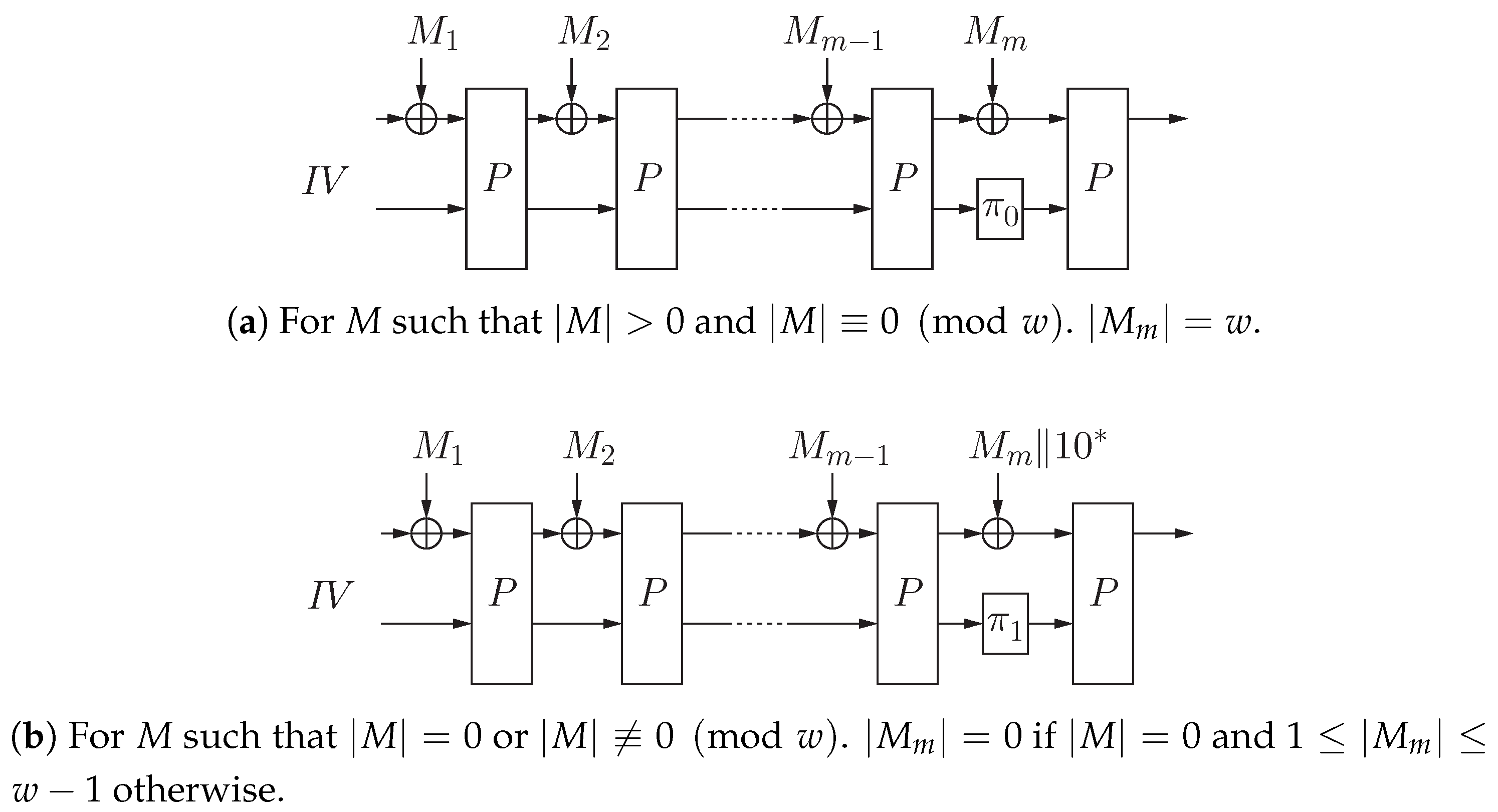
Figure 14.
Game G1. For the partial function and its inverse , initially, for every and for every . If Z is assigned to , then Y is assigned to . If Y is assigned to , then Z is assigned to . and are the sets of values already assigned as inputs and outputs of and , respectively. Initially, .
Figure 14.
Game G1. For the partial function and its inverse , initially, for every and for every . If Z is assigned to , then Y is assigned to . If Y is assigned to , then Z is assigned to . and are the sets of values already assigned as inputs and outputs of and , respectively. Initially, .

Figure 15.
Game G2. , and , which are not changed, are omitted.

Figure 16.
Game G3. , and are not changed and omitted. . . Initially, .

Figure 17.
Game G4. , and are not changed and omitted.

Figure 18.
Game G5. and are not changed and omitted. Initially, for every .

Figure 19.
and of G6 and G7. . Initially, .

Figure 20.
Game G8.

© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hirose, S. Sequential Hashing with Minimum Padding. Cryptography 2018, 2, 11. https://doi.org/10.3390/cryptography2020011
AMA Style
Hirose S. Sequential Hashing with Minimum Padding. Cryptography. 2018; 2(2):11. https://doi.org/10.3390/cryptography2020011
Chicago/Turabian StyleHirose, Shoichi. 2018. "Sequential Hashing with Minimum Padding" Cryptography 2, no. 2: 11. https://doi.org/10.3390/cryptography2020011