PedNet: A Spatio-Temporal Deep Convolutional Neural Network for Pedestrian Segmentation




Abstract
1. Introduction
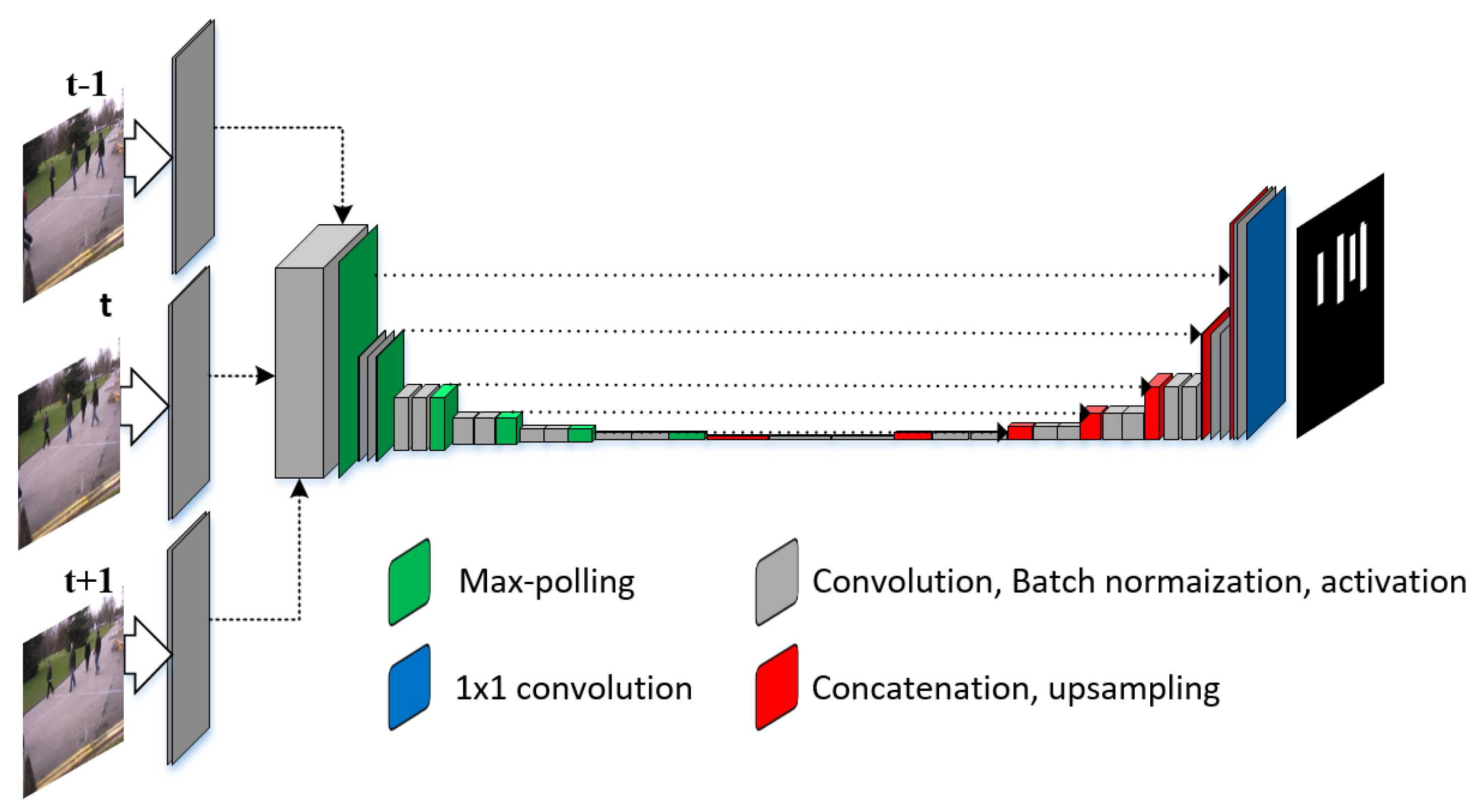
- Instead of a single input frame, our network takes three frames as input and exploits the temporal information for spatial segmentation.
- Our proposed PedNet is deeper and we fixed the size of convolution filter to 3 × 3 and a fixed max-pooling window size of 2 × 2 throughout the network. We tested ReLu and SeLu activation functions and used batch normalization after every convolution layer.
- The network is trained from scratch and data augmentation strategies are adopted which enables the network to train on a limited amount of data.
2. Related Work
2.1. Hand-Crafted Feature Based Segmentation
2.2. Deep Learning Based Segmentation
3. Proposed PedNet Overview
4. PedNet Architecture
5. Network Training
5.1. Objective Function
5.2. Data Augmentation
6. Experiment
6.1. Datasets
6.2. Feature Visualization
6.3. Implementation
6.4. Performance Metrics
6.5. Qualitative Comparison
7. Discussion and Future Work
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Coşar, S.; Donatiello, G.; Bogorny, V.; Garate, C.; Alvares, L.O.; Brémond, F. Toward abnormal trajectory and event detection in video surveillance. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 683–695. [Google Scholar] [CrossRef]
- Ullah, M.; Ullah, H.; Conci, N.; De Natale, F.G. Crowd behavior identification. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1195–1199. [Google Scholar]
- Kiy, K. Segmentation and detection of contrast objects and their application in robot navigation. Pattern Recognit. Image Anal. 2015, 25, 338–346. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Gowsikhaa, D.; Abirami, S.; Baskaran, R. Automated human behavior analysis from surveillance videos: A survey. Artif. Intell. Rev. 2014, 42, 747–765. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 297–312. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014; pp. 345–360. [Google Scholar]
- Sturgess, P.; Alahari, K.; Ladicky, L.; Torr, P.H. Combining appearance and structure from motion features for road scene understanding. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 7–10 September 2009; Springer: Berlin, Germany, 2009. [Google Scholar]
- Ladickỳ, L.; Sturgess, P.; Alahari, K.; Russell, C.; Torr, P.H. What, where and how many? combining object detectors and crfs. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin, Germany, 2010; pp. 424–437. [Google Scholar]
- Shotton, J.; Johnson, M.; Cipolla, R. Semantic texton forests for image categorization and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Berlin, Germany, 2008; pp. 44–57. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Yang, Y.; Li, Z.; Zhang, L.; Murphy, C.; Ver Hoeve, J.; Jiang, H. Local label descriptor for example based semantic image labeling. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; Springer: Berlin, Germany, 2012; pp. 361–375. [Google Scholar]
- Elad, M. Sparse and redundant representation modeling—What next? IEEE Signal Process. Lett. 2012, 19, 922–928. [Google Scholar] [CrossRef]
- Kontschieder, P.; Bulo, S.R.; Bischof, H.; Pelillo, M. Structured class-labels in random forests for semantic image labelling. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2190–2197. [Google Scholar]
- Zhang, C.; Wang, L.; Yang, R. Semantic segmentation of urban scenes using dense depth maps. In Proceedings of the European Conference on Computer Vision (ECCV), Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin, Germany, 2010; pp. 708–721. [Google Scholar]
- Ren, X.; Bo, L.; Fox, D. Rgb-(d) scene labeling: Features and algorithms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2759–2766. [Google Scholar]
- Bo, L.; Ren, X.; Fox, D. Depth kernel descriptors for object recognition. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 821–826. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv, 2015; arXiv:1512.03385. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Henaff, M.; Weston, J.; Szlam, A.; Bordes, A.; LeCun, Y. Tracking the world state with recurrent entity networks. arXiv, 2016; arXiv:1612.03969. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv, 2014; arXiv:1412.7062. [Google Scholar]
- Zanjani, F.G.; van Gerven, M. Improving Semantic Video Segmentation by Dynamic Scene Integration. In Proceedings of the NCCV 2016: The Netherlands Conference on Computer Vision, Lunteren, The Netherlands, 12–13 December 2016. [Google Scholar]
- Shelhamer, E.; Rakelly, K.; Hoffman, J.; Darrell, T. Clockwork convnets for video semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin, Germany, 2016; pp. 852–868. [Google Scholar]
- Luc, P.; Neverova, N.; Couprie, C.; Verbeek, J.; LeCun, Y. Predicting deeper into the future of semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 1. [Google Scholar]
- Ferryman, J.; Shahrokni, A. Pets2009: Dataset and challenge. In Proceedings of the Twelfth IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS-Winter), Snowbird, UT, USA, 7–9 December 2009; pp. 1–6. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. Monocular 3D pose estimation and tracking by detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 623–630. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. People-tracking-by-detection and people-detection-by-tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Milan, A.; Gade, R.; Dike, A.; Moeslund, T.B.; Ian, R. Improving global multi-target tracking with local updates. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 174–190. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Rmsprop: Divide the gradient by a running average of its recent magnitude. Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-cam: Why did you say that? visual explanations from deep networks via gradient-based localization. CoRR 2016, 7. [Google Scholar] [CrossRef]
- Shu, G.; Dehghan, A.; Oreifej, O.; Hand, E.; Shah, M. Part-based Multiple-Person Tracking with Partial Occlusion Handling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1815–1821. [Google Scholar]
- Dehghan, A.; Assari, S.M.; Shah, M. GMMCP-Tracker: Globally Optimal Generalized Maximum Multi Clique Problem for Multiple Object Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4091–4099. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filter | Param | Output |
|---|---|---|---|
| Input-1 | - | - | 512 × 512 × 3 |
| Input-2 | - | - | 512 × 512 × 3 |
| Input-3 | - | - | 512 × 512 × 3 |
| En_Conv2D-1 | 3 × 3 | 224 | 512 × 512 × 8 |
| En_Conv2D-3 | 3 × 3 | 896 | 512 × 512 × 32 |
| En_Conv2D-5 | 3 × 3 | 224 | 512 × 512 × 8 |
| En_Conv2D-2 | 3 × 3 | 584 | 512 × 512 × 8 |
| En_Conv2D-4 | 3 × 3 | 9248 | 512 × 512 × 32 |
| En_Conv2D-6 | 3 × 3 | 584 | 512 × 512 × 8 |
| Concat_1 | - | - | 512 × 512 × 48 |
| En_Conv2D-7 | 3 × 3 | 13,856 | 512 × 512 × 32 |
| En_Pool2D-1 | 2 × 2 | - | 256 × 256 × 32 |
| En_Conv2D-8 | 3 × 3 | 18,496 | 256 × 256 × 64 |
| En_Conv2D-9 | 3 × 3 | 36,928 | 256 × 256 × 64 |
| En_Pool2D-2 | 2 × 2 | - | 128 × 128 × 64 |
| En_Conv2D-10 | 3 × 3 | 73,856 | 128 × 128 × 128 |
| En_Conv2D-11 | 3 × 3 | 147,584 | 128 × 128 × 128 |
| En_Pool2D-3 | 2 × 2 | - | 64 × 64 × 128 |
| En_Conv2D-12 | 3 × 3 | 295,168 | 64 × 64 × 256 |
| En_Conv2D-13 | 3 × 3 | 590,080 | 64 × 64 × 256 |
| En_Pool2D-4 | 2 × 2 | - | 32 × 32 × 256 |
| En_Conv2D-14 | 3 × 3 | 1,180,160 | 32 × 32 × 512 |
| En_Conv2D-15 | 3 × 3 | 2,359,808 | 32 × 32 × 512 |
| En_Pool2D-5 | 2 × 2 | - | 16 × 16 × 512 |
| En_Conv2D-16 | 3 × 3 | 4,719,616 | 16 × 16 × 1024 |
| En_Conv2D-17 | 3 × 3 | 9,438,208 | 16 × 16 × 1024 |
| Dec_UpSample2D-1 | 2 × 2 | - | 32 × 32 × 1024 |
| Concat-2 | - | - | 32 × 32 × 1536 |
| Dec_Conv2D-18 | 3 × 3 | 7,078,400 | 32 × 32 × 512 |
| Dec_Conv2D-19 | 3 × 3 | 2,359,808 | 32 × 32 × 512 |
| Dec_UpSample2D-2 | 2 × 2 | - | 64 × 64 × 512 |
| Dec_Conv2D-18 | 3 × 3 | 7,078,400 | 32 × 32 × 512 |
| Dec_Conv2D-19 | 3 × 3 | 2,359,808 | 32 × 32 × 512 |
| Dec_UpSample2D-2 | 2 × 2 | - | 64 × 64 × 512 |
| Concat-3 | - | - | 64 × 64 × 768 |
| Dec_Conv2D-20 | 3 × 3 | 1,769,728 | 64 × 64 × 256 |
| Dec_Conv2D-21 | 3 × 3 | 590,080 | 64 × 64 × 256 |
| Dec_UpSample2D-3 | 2 × 2 | - | 128 × 128 × 256 |
| Concat-4 | - | - | 128 × 128 × 384 |
| Dec_Conv2D-22 | 3 × 3 | 44,2496 | 128 × 128 × 128 |
| Dec_Conv2D-23 | 3 × 3 | 147,584 | 128 × 128 × 128 |
| Dec_UpSample2D-4 | 2 × 2 | - | 256 × 256 × 128 |
| Concat-5 | - | - | 256 × 256 × 192 |
| Dec_Conv2D-24 | 3 × 3 | 110,656 | 256 × 256 × 64 |
| Dec_Conv2D-25 | 3 × 3 | 36,928 | 256 × 256 × 64 |
| Dec_UpSample2D-5 | 2 × 2 | - | 512 × 512 × 64 |
| Concat-6 | - | - | 512 × 512 × 96 |
| Dec_Conv2D-26 | 3 × 3 | 13,840 | 512 × 512 × 16 |
| Dec_Conv2D-27 | 3 × 3 | 2320 | 512 × 512 × 16 |
| Dec_Conv2D-28 | 3 × 3 | 17 | 512 × 512 × 1 |
| Datasets | Recall | Precision | F | F | mIoU | Accuracy |
|---|---|---|---|---|---|---|
| CamVid | 0.877 | 0.945 | 0.910 | 0.890 | 0.764 | 0.988 |
| Pets2009 (View) | 0.883 | 0.953 | 0.917 | 0.896 | 0.755 | 0.989 |
| TUD-crossing | 0.880 | 0.955 | 0.916 | 0.894 | 0.741 | 0.989 |
| AFL-football | 0.880 | 0.955 | 0.916 | 0.894 | 0.746 | 0.987 |
| Pets2009 (view) | 0.877 | 0.943 | 0.909 | 0.889 | 0.724 | 0.988 |
| Pets2009 (view) | 0.878 | 0.949 | 0.912 | 0.891 | 0.767 | 0.989 |
| TUD-Stadmitt | 0.880 | 0.955 | 0.916 | 0.894 | 0.741 | 0.988 |
| TUD-Campus | 0.886 | 0.944 | 0.914 | 0.897 | 0.692 | 0.989 |
| Methods | mIoU | Accuracy |
|---|---|---|
| SegNet [25] | 0.500 | 0.888 |
| Ladicky et al. [11] | - | 0457 |
| Chen et al. [32] | 0.501 | 0.859 |
| Long et al. [31] | 0.560 | 0.832 |
| Noh et al. [30] | 0.396 | 0.852 |
| Kontschider et al. [17] | - | 0.430 |
| Sturgess et al. [10] | - | 0.536 |
| Ours PedNet | 0.764 | 0.988 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, M.; Mohammed, A.; Alaya Cheikh, F. PedNet: A Spatio-Temporal Deep Convolutional Neural Network for Pedestrian Segmentation. J. Imaging 2018, 4, 107. https://doi.org/10.3390/jimaging4090107
Ullah M, Mohammed A, Alaya Cheikh F. PedNet: A Spatio-Temporal Deep Convolutional Neural Network for Pedestrian Segmentation. Journal of Imaging. 2018; 4(9):107. https://doi.org/10.3390/jimaging4090107
Chicago/Turabian StyleUllah, Mohib, Ahmed Mohammed, and Faouzi Alaya Cheikh. 2018. "PedNet: A Spatio-Temporal Deep Convolutional Neural Network for Pedestrian Segmentation" Journal of Imaging 4, no. 9: 107. https://doi.org/10.3390/jimaging4090107
APA StyleUllah, M., Mohammed, A., & Alaya Cheikh, F. (2018). PedNet: A Spatio-Temporal Deep Convolutional Neural Network for Pedestrian Segmentation. Journal of Imaging, 4(9), 107. https://doi.org/10.3390/jimaging4090107