On a Multiplicative Multivariate Gamma Distribution with Applications in Insurance


1
Department of Mathematics and Statistics, York University, Toronto, ON M3J 1P3, Canada
2
Department of Statistics, Purdue University, West Lafayette, IN 47906, USA
*
Author to whom correspondence should be addressed.
Risks 2018, 6(3), 79; https://doi.org/10.3390/risks6030079
Submission received: 13 July 2018
/
Revised: 8 August 2018
/
Accepted: 8 August 2018
/
Published: 12 August 2018
(This article belongs to the Special Issue Risk, Ruin and Survival: Decision Making in Insurance and Finance)
{kind=link}
{kind=link}
Abstract
:One way to formulate a multivariate probability distribution with dependent univariate margins distributed gamma is by using the closure under convolutions property. This direction yields an additive background risk model, and it has been very well-studied. An alternative way to accomplish the same task is via an application of the Bernstein–Widder theorem with respect to a shifted inverse Beta probability density function. This way, which leads to an arguably equally popular multiplicative background risk model (MBRM), has been by far less investigated. In this paper, we reintroduce the multiplicative multivariate gamma (MMG) distribution in the most general form, and we explore its various properties thoroughly. Specifically, we study the links to the MBRM, employ the machinery of divided differences to derive the distribution of the aggregate risk random variable explicitly, look into the corresponding copula function and the measures of nonlinear correlation associated with it, and, last but not least, determine the measures of maximal tail dependence. Our main message is that the MMG distribution is (1) very intuitive and easy to communicate, (2) remarkably tractable, and (3) possesses rich dependence and tail dependence characteristics. Hence, the MMG distribution should be given serious considerations when modelling dependent risks.
1. Introduction
Let be a collection of actuarial risks, that is let it contain random variables (r.v.’s) defined on the probability space and interpreted as the financial risks an insurer is exposed to. Often, for applications in insurance, actuaries would consider those , whose distributions are supported on the non-negative real half-line, have positive skewness, and allow for a certain degree of heavy-tailness. One such distribution, which has been of prominent importance in insurance applications, is gamma. We refer to Hürlimann (2001), Dornheim and Brazauskas (2007), Furman et al. (2018), and Zhou et al. (2018) for applications in solvency assessment, loss reserving, and aggregate risk approximation, respectively.
Furthermore, let and denote, correspondingly, the shape and scale parameters, then the r.v. X is said to be distributed gamma, succinctly , if it has the probability density function (p.d.f.)
where stands for the complete gamma function. The popularity of the r.v.’s distributed gamma in insurance applications is not surprising: the p.d.f.’s of the (aggregate) insurance losses have as a rule the same shape as p.d.f. (1), i.e., they are positively skewed, unimodal and have positive supports; p.d.f. (1) is log-convex for and so has decreasing failure rate, thus allowing for moderate heavy-tailness (Klugman et al. 2012); p.d.f. (1) has been very well studied and has turned out remarkably tractable.
When it comes to multivariate extensions of p.d.f. (1), there are an ample number of dependence structures with univariate margins distributed gamma to consider (e.g., Kotz et al. 2000; Balakrishnan and Ristić 2016, for a recent development and a comprehensive reference, respectively). However, irrespective of whether the two-steps copula approach or the more ‘natural’ stochastic representation approach to formulate the desired multivariate gamma distribution is pursued, the tractability of the end-result is often an issue. For the former approach, the cumulative distribution function (c.d.f.) of (1) cannot be written in a closed form, and consequently intensive numerical algorithms are often needed to implement copula-based multivariate gamma models (e.g., Cossette et al. 2018; Bahraoui et al. 2015). For the latter approach, consider the following example. Let for and be mutually independent r.v.’s, and set . Then the distribution of the r.v. is the multivariate gamma of Mathai and Moschopoulos (1991) (also, e.g., Avanzi et al. 2016; Furman and Landsman 2005, for recent applications in insurance). Consequently, for the p.d.f. of the r.v. , we have
for all , which inconveniently takes distinct forms for each of the orderings of .
Remark 1.
The r.v.’s and are often interpreted as, respectively, the specific and systematic risk factors. The systematic risk factor, , has also been referred to as the background risk (Gollier and Pratt 1996), and so the distribution of the r.v. can be associated with an Additive Background Risk Model with risk components distributed gamma (G-ABRM). Succinctly, for , we write , where serves as the dependence parameter.
An alternative way to link the specific risk factors and the systematic (or background) risk factor is with the help of multiplication. Namely, in order to formulate a Multiplicative Background Risk Model with the risk components distributed gamma (G-MBRM), we must find a sequence of independent r.v.’s , say, such that results in the coordinates of the r.v. being distributed gamma. One solution of this exercise, which is of pivotal importance for this paper, can be found in Feller (1968) (also, Albrecher et al. 2011; Sarabia et al. 2018). We organize the rest of the paper as follows: in Section 2, we explore the basic distributional properties of—what we call—the multiplicative multivariate gamma (MMG) distribution. Then, in Section 3 and Section 4, respectively, we discuss in detail and elucidate with examples of actuarial interest the aggregation and (tail) dependence properties of the MMG distribution. Section 5 concludes the paper. All proofs are relegated to Appendix A to facilitate the reading.
2. Definition and Basic Properties
Multivariate distributions lay the very foundation of the successful (insurance) risk measurement—and thus of the consequent risk management—processes. However, the toolbox of the available stochastic dependencies that can be used to link stand-alone risk components into risk portfolios is somewhat overwhelming. Indeed, there are infinitely many ways to formulate the joint distribution of two dependent risk r.v.’s, whereas there is a single way only to write this distribution under the assumption of independence. The case of the multivariate distributions with the margins distributed gamma is of course not an exception (e.g., Kotz et al. 2000).
Nevertheless, real applications impose significant constraints on the model choice. Namely, practitioners often opt for those multivariate distributions that: (i) admit meaningful and relevant interpretations; (ii) allow for an adequate fit to the modelled data, be it in the ‘tail’, in the ‘body’, and/or in the dependence; and (iii) can be readily implemented. We feel that the multivariate distribution with the univariate margins distributed gamma that we put forward next (also, Albrecher et al. 2011; Sarabia et al. 2018) is exactly such.
Formally, let and denote, respectively, an exponentially distributed r.v. with the rate parameter and an arbitrarily distributed r.v. with the range ; assume that the r.v.’s and are independent. In addition, let ‘∗’ represent the mixture operator (e.g., Feller 1968; Su and Furman 2017a), such that, for ‘’ denoting equality in distribution, it holds that . We note in passing that the just-mentioned mixture operator is referred to as ‘randomization’ in Feller (1968), and is closely related—via the Bernstein–Widder theorem—to the notion of the Laplace transform of the p.d.f. of . More specifically, if and denote, correspondingly, the p.d.f. of and its Laplace transform, which is
then (3) establishes the decumulative distribution function (d.d.f.) of the r.v. .
Recall that in this paper we are interested in formulating a multivariate distribution with the univariate margins distributed gamma and a dependence. To this end, we assume that the r.v. is distributed as a special shifted inverse Beta, succinctly , with the p.d.f.
where is the shape parameter. In our context, the choice of p.d.f. (4) is unique, which readily follows from the Bernstein–Widder theorem. The next few facts are used frequently later on in the paper, and are hence formulated as a lemma. In the following, the k-th order derivative of the Laplace transform is denoted by , also .
Lemma 1.
Let with p.d.f. (4), then:
- (i)
- (ii)
- The negative k-th order moment of the r.v. Λ is
- (iii)
- The alternating sign k-th order derivative of is
Let denote independent copies of , and let . In addition, let denote a vector of positive parameters.
Definition 1.
Set , and then the r.v. has a multiplicative multivariate distribution with univariate margins distributed gamma, and we succinctly write , where and are parameters.
Remark 2.
Let denote independent copies of a r.v. distributed exponentially with unit scale, then the joint distribution of the r.v. in Definition 1 admits the following multiplicative background risk model representation (see, Asimit et al. 2016; Frank et al. 2006, for the corresponding economic implication and application)
Theorem 1.
Let , and let be positive scale parameters, then the following assertions hold:
- (i)
- The r.v. has the d.d.f.which is X is distributed gamma with the shape and scale parameters equal to and , respectively.
- (ii)
- The r.v. with the j-th coordinate , has the joint d.d.f.for all .
- (iii)
- The p.d.f. that corresponds to d.d.f. (7) is, for all ,
The following facts are immediate from Theorem 1: (i) the distribution of is marginally closed, namely, ; (ii) the mathematical expectation of the j-th coordinate is ; and (iii) the variance of the j-th coordinate is .
We further explore some less obvious properties of the MMG/G-MBRM and note with satisfaction that the risk portfolios with the joint distributions within this class are often more tractable than the portfolios having stochastically independent risk components distributed gamma. At the outset, we note in passing that the MMG distribution put forward in Definition 1 is a non-exchangeable generalization of the multivariate distributions having univariate margins distributed gamma that are discussed in Albrecher et al. (2011); Sarabia et al. (2018). As such, the MMG distribution requires a more delicate treatment when deriving the results below, which hinge crucially on the stochastic characteristics of the univariate margins of the r.v. .
We look into the minima and maxima r.v.’s first; both are of evident importance in insurance. To this end, denote by and by the minima and maxima r.v.’s. Then we have—unlike in the independent case—that the coordinates of the r.v. in Definition 1 are closed under minima.
Theorem 2.
Let , then is distributed gamma. More specifically, we have , where is the positive scale parameter, and is the shape parameter. In addition, the d.d.f. of is a linear combination of the d.d.f.’s of the univariate r.v.’s distributed gamma, such that
where and with .
Another r.v. of pivotal interest in insurance is the aggregate risk r.v. denoted by ; in addition, let . It is well known that, if are mutually independent and distributed gamma with arbitrary parameters, then admits an infinite sum representation (Moschopoulos 1985; Provost 1989). We further show that for and when all the scale parameters are distinct, then is noticeably more elegant. The derivation of in the general case—i.e., for arbitrary (possibly equal) scale parameters—is more cumbersome and is presented in Section 3.
Let
We often write omitting the vector of scale parameters for the simplicity of notation.
Proposition 1.
Let and assume that all the scale parameters are distinct, which is for , then the d.d.f. of is
The last result in this section provides an expression for the higher-order (product) moments of the r.v. . We employ a special form of this expression later on in Section 4 to derive the formula for the Pearson index of linear correlation.
Theorem 3.
Let , then, for , we have
3. Aggregation Properties of the Multiplicative Multivariate Gamma Distribution
One of the key paradigms in the modern enterprise risk management requires that all risks are treated on a holistic basis. As a result, risk aggregation is of fundamental importance for the effective conglomerate-wide risk management, risk-sensitive supervision, and a great variety of other business decision making processes. In the context of the MMG distribution, when all scale parameters are distinct, the decumulative distribution function of the aggregate risk r.v. is given by (10). The situation with arbitrary (possibly equal) scales is more involved. We further show that, within the MMG/G-MBRM class, that is for with arbitrary scale parameters and , the d.d.f. of the aggregate risk r.v. admits a finite sum representation. To this end, we employ the well-studied machinery of divided differences (e.g., Milne-Thomson 2000, for a comprehensive treatment). The rest of the section is divided into two: theoretical considerations and applications.
3.1. Theoretical Considerations
We remind at the outset that the divided differences, denoted by , on a grid for a function can be written as (e.g., Milne-Thomson 2000)
Denote
Then the following corollary is merely a rearrangement of Equation (10).
Corollary 1 (of Proposition 1).
The d.d.f. of the r.v. can be formulated, for distinct , as
where is the divided differences representation of defined as per Equation (13).
Obviously, Equation (12) does not yield sensible results when some of the scale parameters of the r.v. are equal. To circumvent this inconvenience, we formulate and prove the following lemma.
Lemma 2.
Consider , and the grid as before. For , , assume ω is at least times differentiable; then, we have
where for denotes the falling factorial, .
The next assertion establishes the distribution of the aggregate risk r.v. with arbitrary scale parameters. Its proof follows by rearranging d.d.f. (10) using the divided differences operator and consequently evoking Lemma 2.
Theorem 4.
Consider , where and with arbitrary coordinates in the latter vector of parameters. Let for and , then, for , the d.d.f. of admits the following finite sum form:
where
Remark 3.
A close look at Theorem 4 reveals that the distribution of the r.v. can be considered a finite mixture of the r.v.’s distributed Erlang with stochastic scale parameters. To see this, first note that
in which denotes the r.v. distributed Erlang with the shape parameter and the random scale parameter . Then rewrite as
where
By setting , it is clear that are generalized weights in the sense that . However, these weights are not necessarily positive. For an example, consider the bivariate case with and . A simple calculation yields
where , , , and . Therefore, depending on the values of and , one of the weights must be negative.
3.2. Applications
Herein we confine the discussion to the individual and collective risk models. In this respect, recall that we call the r.v. the individual risk model, where we let the severity r.v.’s be possibly non-homogeneous. In the collective risk model case, for denoting the frequency r.v., we are interested in exploring the distribution of the random sum . In the context of the MMG/G-MBRM, we have
and
P.d.f.’s—rather than d.d.f.’s—often play an important role in the individual/collective risk model contexts. Therefore, the p.d.f.’s of and engage us in the rest of this section. We start with the p.d.f. of the former r.v. in the following proposition. Recall that are given in (14), and denotes the k-th order derivative of the Laplace transform.
Proposition 2.
Let with for and , then, for , the p.d.f. of the r.v. is given by
The next corollary follows immediately from Proposition 2, by setting and .
Corollary 2.
Let , where and . Then, for , the p.d.f. of the r.v. is given by
Remark 4.
It is not difficult to see that p.d.f. (16) admits the following finite mixture representation
where and the weights are given by
for . Remarkably, in this special case, the weights are ‘proper’ in the sense that and . This observation complements Theorem 6 in Sarabia et al. (2018).
We further derive the p.d.f. of the r.v. .
Proposition 3.
Let with , then, for , the p.d.f. of the r.v. is
where for denotes the rising factorial, .
We conclude this section by specializing the p.d.f. of the r.v. reported in Proposition 3 for particular choices of the frequency r.v. In actuarial science, some popular choices of the r.v. N are, e.g., the Poisson, negative binomial, and logarithmic (e.g., Klugman et al. 2012). Below, we first remind the reader in passing the probability mass functions (p.m.f.’s) of the just-mentioned r.v.’s, and we then present the p.d.f.’s of the aggregate r.v.’s within the framework of the corresponding collective risk models.
- If with , then the p.m.f. is given by
- If , the negative binomial distribution with and , then
- If , the logarithmic distribution with , then the p.m.f. is
Let and , respectively, denote the two-variable confluent hypergeometric series of the first and third kind (see, e.g., Srivastava and Karlsson 1985), that is with ,
for , , and
for . The following corollary follows readily.
Corollary 3 (of Proposition 3).
In the context of the collective risk model, we have, for all and , that
- If , then
- If , then
- If , then
4. Dependence Properties of the Multiplicative Multivariate Gamma Distribution
At first sight, the dependence structure that underlies the MMG distribution—that is d.d.f. (7)— is not as versatile as the one behind the additive counterpart of Mathai and Moschopoulos (1991). This is because the Pearson correlation, , for the former class of distributions does not attain every value in the interval , whereas it does so in the context of the latter class of distributions (e.g., Das et al. 2007; Su and Furman 2017a, 2017b, for a similar constraint in the context of default risk). More formally, we have the following proposition, the proof of which is a direct application of Theorem 3 and is thus omitted.
Proposition 4.
Let , then the Pearson correlation between any pair of and , for is
where . In addition, we have and it is a decreasing function of .
In the rest of this section, we show that the just-mentioned seeming shortcoming should in fact be attributed to the Pearson index of correlation, , itself, rather than to the dependence structure of the MMG distribution. As hitherto, we divide our observations herein into two subsections.
4.1. Theoretical Considerations
At the outset, we observe that the dependence structure that underlies the MMG/G-MBRM is not linear in the—common—background r.v. . Therefore, the machinery of copulas lands itself very naturally to exploring the relevant dependence properties. The next theorem states the copula function (e.g., Joe 1997) of .
Theorem 5.
Assume that , then the copula function underlying the d.d.f. of is given, for , by
where and denotes the inverse incomplete gamma function evaluated at . Moreover, the p.d.f. associated with is given by
where f denotes the p.d.f. of , and is obtained in Lemma 1.
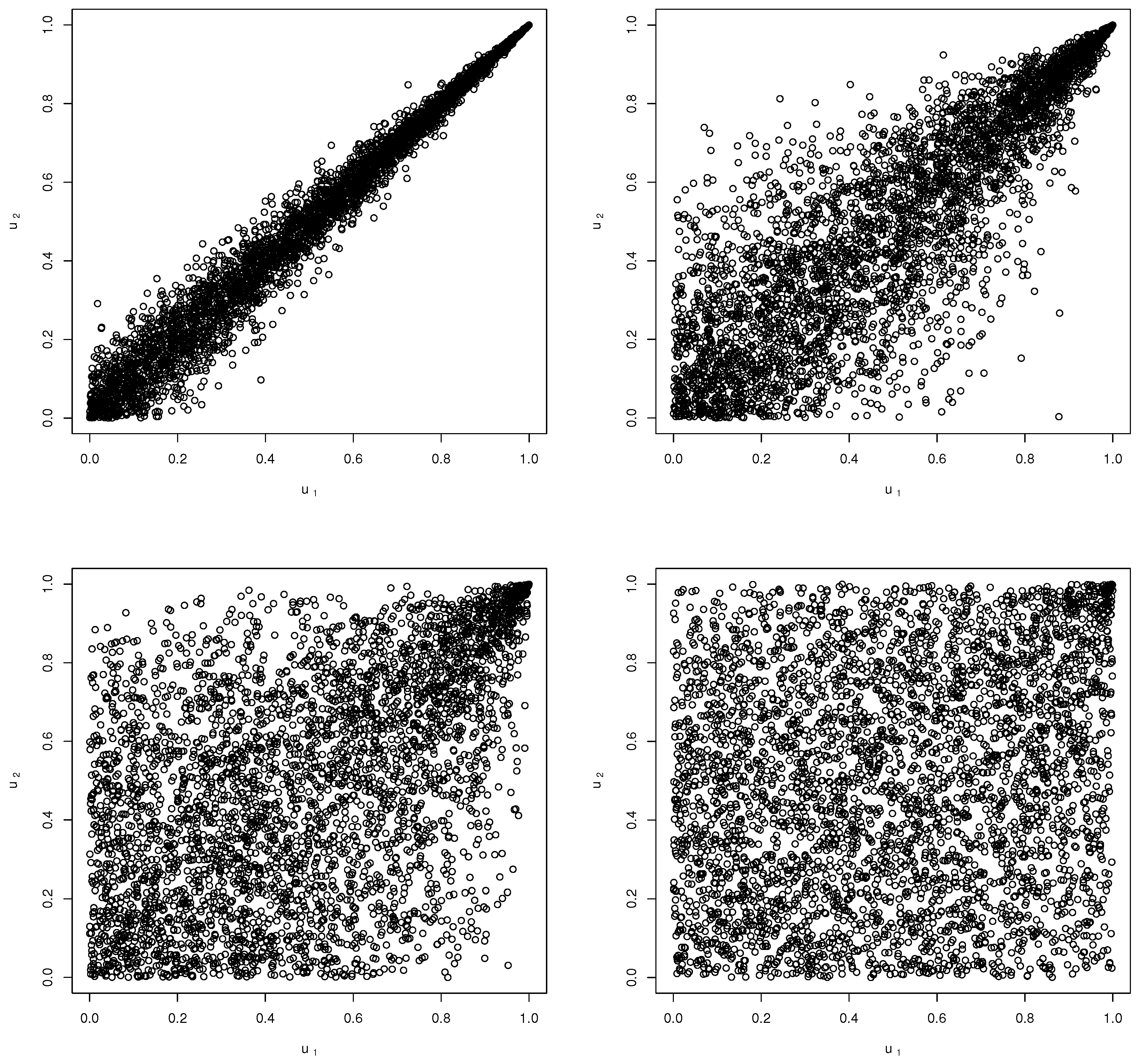
Figure 1 depicts the simulated scatter plots of the copula function for varying values of the parameter.
Remark 5.
Copula function (19) is a member of the encompassing class of the Archimedean copulas. Specifically, set
and observe that (19) admits the following form, for ,
where is a legitimate completely monotonic function—known as the Archimedean generator—and is its inverse (e.g., McNeil and Nešlehová 2009). The MMG copula therefore enriches the encompassing toolbox of the distinct Archimedean copulas available to researchers and practitioners.
We have already mentioned at the end of Section 2 that the maximum likelihood approach can be used in order to numerically estimate the parameters of the MMG distribution. An alternative way to estimate the parameters is via the two-step copula approach. That is, we first fit the MMG copula to the pseudo uniform samples based on the empirical c.d.f.’s of , and estimate the parameter (e.g., Embrechts and Hofert 2013; Genest et al. 2011, and references therein), and we then estimate the parameters based on the univariate marginal distributions assuming that the parameter is known. Given the cumbersome form of p.d.f. (8), the copula-based approach is computationally simpler.
Besides the just-mentioned statistical inference, a useful contribution of copulas to the vast literature of multivariate modelling is that they have given rise to a number of indices of dependence that circumvent the known fallacies of the Pearson . Such indices of dependence are, e.g., the Kendall and Spearman measures of rank correlation, and we derive these two in the next subsection in the context of the MMG copula function .
In the rest of this subsection, we build up the theoretical groundwork necessary for exploring the tail dependence of . As tail dependence represents the co-movement of extreme risks, it is of particular importance in the era following the financial crisis of 2007–2009. We note in passing that, since the majority of the existing methods for quantifying tail dependence mainly aim at random pairs, we specialize the discussion in this part of the present report to the bivariate case only.
Let denote the survival copula that corresponds to C, that is , for . Then the first order lower and upper tail dependence parameters (e.g., Joe 1997) are given by
whereas the second order tail dependence parameters (Coles et al. 1999) are given by
Recently, an argument has been put forward that tail dependence measures (21) and (22) may underestimate the extent of the tail dependence inherent in a copula. More specifically, Furman et al. (2015) claim and elucidate with numerous examples that as measures (21) and (22) are computed along the main diagonal , their values are not necessarily maximal when alternative paths in are considered. This motivated the following definitions of the admissible paths and the paths of maximal dependence in ibid.
Definition 2.
A function is called admissible if it satisfies the following conditions:
- (C1)
- for every ; and
- (C2)
- and converge to 0 when .
Then the path is admissible whenever the function φ is admissible. In addition, we denote by the set of all admissible functions φ.
Definition 3.
The path(s) in are called paths of maximal dependence if they maximize the probability
or, equivalently, the distance function
where is the independence copula, i.e., for all .
Obviously, the function is admissible and yields the representation of the diagonal path that serves as a building block for classical indices (21) and (22). For the Archimedean class of copulas, the following property of the maximal dependence path holds. The verification of the condition stated in Lemma 3 below is not trivial, and is carried out for the MMG copula in Theorem 6.
Lemma 3
(Furman et al. 2015). For an Archimedean copula with generator ϕ, if is increasing on then the path of maximal dependence coincides with the main diagonal.
The next lemma on a L’Hospital type rule for monotonicity, plays an importantly auxiliary role when deriving the maximal dependence path for .
Lemma 4
(Pinelis 2002). Let , also and be differentiable functions over the interval . Assume that for , and and . Then, is increasing on if is increasing.
Our last result in this subsection implies that measures of tail dependence (21) and (22) are in fact maximal in the context of the MMG copula .
Theorem 6.
The maximal dependence path of the copula function in (19) is diagonal.
4.2. Applications
The next assertion reports the Kendall tau and Spearman rho rank correlations, implied by the MMG copula (19). The hypergeometric function plays a pivotal role in deriving the Spearman rho correlation in the following proposition, and it is given in Gradshteyn and Ryzhik (2014)
For all positive, and these are the cases of interest in the present report. The radius of convergence of the series is the open disk . On the boundary , the series converges absolutely if , and it converges except at if .
Proposition 5.
For the copula , the Kendall τ rank correlation is given by
and the Spearman rank correlation is given by
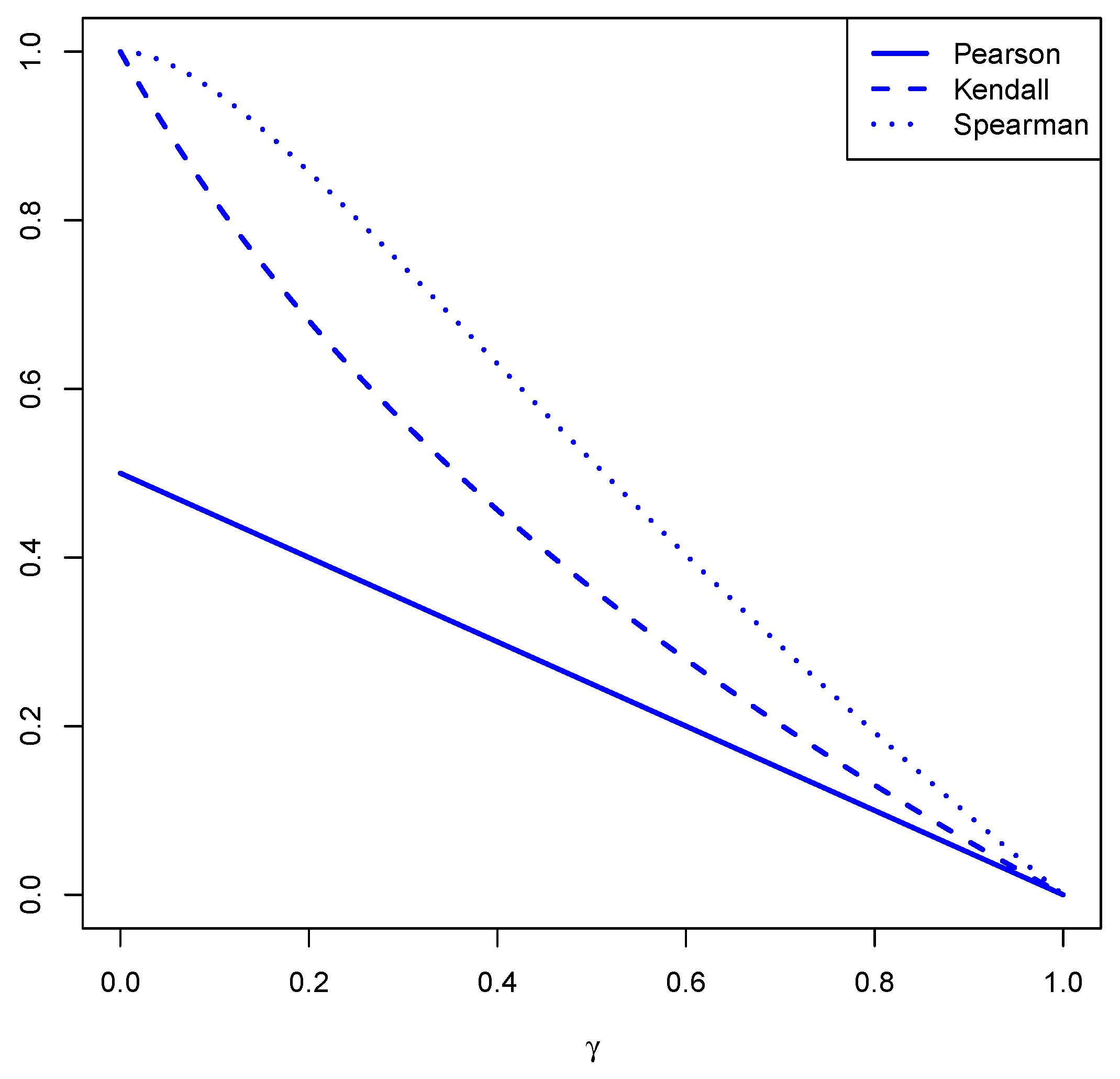
Figure 2 depicts the values for the Pearson , Kendall and Spearman indices of correlation with varying . The figure confirms that, while the Pearson does not attain all values in for the MMG/G-MBRM distribution, the other two indices are able to achieve this goal.
Proposition 6.
Assume that has copula , the lower maximal tail dependence of is
The upper maximal tail dependence of is
Proposition 6 readily implies—recall to this end that the copula is in fact a survival copula (by construction)—that the coordinates of are asymptotically dependent in the lower tail, but independent in the upper tail. Speaking bluntly, this means that is more likely to take smaller values simultaneously, but less likely to form a cluster of large values. This conforms to the already made intuitive observation that the copula can serve as a reflected variant of the well-studied Clayton copula.
5. Conclusions
In the present report, we have systematically studied a class of multivariate multiplicative gamma distributions. We have demonstrated that the MMG distribution admits a very meaningful background risk model representation, where the interdependencies among risks are implied by a common systematic risk factor. Moreover, we have shown that the MMG distribution enjoys a remarkable level of analytical tractability, that is, the risk r.v.’s distributed MMG are straightforward to simulate, easy to aggregate and take maxima, closed under minima, and have attractive dependence and tail dependence characteristics. In view of the above, we think that the potential applications of the MMG distribution in actuarial science are vast, and we hope to draw the attention of the community to this class of distributions. In fact, reduced forms of the proposed MMG distribution have been recently heuristically adopted in the actuarial literature to model a variety of dependent insurance risks (e.g., Sarabia et al. 2018, also, Albrecher et al. 2011).
Author Contributions
All authors contributed equally to this work.
Funding
Vadim Semenikhine is grateful to the Natural Sciences and Engineering Research Council (NSERC) of Canada for its Undergraduate Summer Research Award. Edward Furman acknowledges the continuous support of his research by NSERC.
Acknowledgments
We are indebted to three anonymous referees for their very thorough reading of the paper, and the many suggestions that resulted in a clearer presentation.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs
Proof of Lemma 1.
The proof of (i) is due to Equation 3.383(9) in Gradshteyn and Ryzhik (2014); (ii) follows readily via the integral representation of the Beta function. In order to check (iii), we have
This completes the proof of the lemma. ☐
Proof of Theorem 1.
The d.d.f.’s of the r.v.’s X and follow immediately from Lemma 1, Statement (i) and Chapter 4 in Joe (1997). The joint p.d.f. follows from Lemma 1, Statement (iii) since
This completes the proof of the theorem. ☐
Proof of Theorem 2.
The closure under the minima operation is trivial by evoking Theorem 1, Statement (ii). The distribution of the r.v. follows immediately (e.g., Corollary 2.2 in Su and Furman 2017a, for a similar result in the context of a multivariate Pareto distribution). This completes the proof of the theorem. ☐
Proof of Proposition 1.
Recall (e.g., Akkouchi 2008) that, for the convolution of with , we have
Therefore we also have
and the assertion of the proposition follows evoking Lemma 1, Statement (i). ☐
Proof of Theorem 3.
We immediately have
where ‘’ holds due to the moments’ formula in the case of the exponentially distributed r.v.’s (see, e.g., Klugman et al. 2012). The proof is then completed by evoking Lemma 1, Statement (ii). ☐
Proof of Lemma 2.
Then we differentiate term-by-term to obtain
Finally, we apply the Leibniz rule and readily have, for ,
This concludes the proof of the lemma. ☐
Proof of Proposition 2.
The proof of the proposition follows from Remark 3 that reports the mixture representation. Namely,
This completes the proof. ☐
Proof of Proposition 3.
We have the following string of equations, for all ,
This completes the proof of the proposition. ☐
Proof of Theorem 5.
The proof is a direct application of the Sklar’s theorem. Namely, recall that
and thus, for , we have
where denotes a r.v. distributed uniformly on . Hence, the desired copula function is computed as
where .
We next turn to study the p.d.f. of . By definition, we readily obtain
where f denotes the p.d.f. of . This completes the proof of the theorem. ☐
Proof of Theorem 6.
Let , for all , so
where is the p.d.f. of . Note that, for , which is exactly the case in the present report, is decreasing for all .
Now, set and . Clearly, , , and is decreasing on . Moreover,
is increasing on . Evoking Lemma 4, we conclude that is increasing for . Finally, based on Lemma 3, the path of maximal dependence for is the diagonal, and the proof is completed. ☐
Proof of Proposition 5.
Recall that copula function (19) is a special member of the Archimedean class of copulas having generator
The expression for the Kendall is obtained by simplifying (A1).
We further proceed to the case of the Spearman . For , denote by and the marginal p.d.f.’s of the random pair , then by definition (see, Section 2.1.9 in Joe 1997), we have
where
Here, the equality ‘’ holds because of (6.455(1)) in Gradshteyn and Ryzhik (2014). This completes the proof of the proposition. ☐
Proof of Proposition 6.
Let us first study the lower tail dependence of . The following string of equations holds:
We know that, as , the following asymptotic expansion holds (Temme 1996):
with . Then, we have
and thus , which automatically implies .
We now turn to study the upper tail dependence of . Note that the mixture r.v. has d.d.f. that varies regularly at infinity with order (Bingham et al. 1987). The expressions for and are readily obtained by evoking Corollary 3.3 in Su and Hua (2017). This completes the proof of this proposition. ☐
References
- Akkouchi, Mohamed. 2008. On the convolution of exponential distributions. Journal of the Chungcheong Mathematical Society 21: 501–10. [Google Scholar]
- Albrecher, Hansjörg, Corina Constantinescu, and Stephane Loisel. 2011. Explicit ruin formulas for models with dependence among risks. Insurance: Mathematics and Economics 48: 265–70. [Google Scholar] [CrossRef]
- Asimit, Alexandru V., Raluca Vernic, and Ricardas Zitikis. 2016. Background risk models and stepwise portfolio construction. Methodology and Computing in Applied Probability 18: 805–27. [Google Scholar] [CrossRef]
- Avanzi, Benjamin, Greg Taylor, Phuong Anh Vu, and Bernard Wong. 2016. Stochastic loss reserving with dependence: A flexible multivariate Tweedie approach. Insurance: Mathematics and Economics 71: 63–78. [Google Scholar] [CrossRef]
- Bahraoui, Zuhair, Catalina Bolancé, Elena Pelican, and Raluca Vernic. 2015. On the bivariate Sarmanov distribution and copula. An application on insurance data using truncated marginal distributions. Statistics & Operations Research Transactions 39: 209–30. [Google Scholar]
- Balakrishnan, Narayanaswamy, and Miroslav M. Ristić. 2016. Multivariate families of gamma-generated distributions with finite or infinite support above or below the diagonal. Journal of Multivariate Analysis 143: 194–207. [Google Scholar] [CrossRef]
- Bingham, Nicholas H., Charles M. Goldie, and Jef L. Teugels. 1987. Regular Variation. Cambridge: Cambridge University Press. [Google Scholar]
- Coles, Stuart, Janet Heffernan, and Jonathan Tawn. 1999. Dependence measures for extreme value analyses. Extremes 2: 339–65. [Google Scholar] [CrossRef]
- Cossette, Hélène, Etienne Marceau, Itre Mtalai, and Déry Veilleux. 2018. Dependent risk models with Archimedean copulas: A computational strategy based on common mixtures and applications. Insurance: Mathematics and Economics 78: 53–71. [Google Scholar] [CrossRef]
- Das, Sanjiv R., Darrell Duffie, Nikunj Kapadia, and Leandro Saita. 2007. Common failings: How corporate defaults are correlated. Journal of Finance 62: 93–117. [Google Scholar] [CrossRef]
- Dornheim, Harald, and Vytaras Brazauskas. 2007. Robust and efficient methods for credibility when claims are approximately gamma distributed. North American Actuarial Journal 11: 138–58. [Google Scholar] [CrossRef]
- Embrechts, Paul, and Marius Hofert. 2013. Statistical inference for copulas in high dimensions: A simulation study. ASTIN Bulletin 43: 81–95. [Google Scholar] [CrossRef]
- Feller, William. 1968. An Introduction to Probability Theory and Its Applications. New York: Wiley. [Google Scholar]
- Frank, Günter, Harris Schlesinger, and Richard C. Stapleton. 2006. Multiplicative background risk. Management Science 52: 146–53. [Google Scholar] [CrossRef]
- Furman, Edward, Daniel Hackmann, and Alexey Kuznetsov. 2018. On Log-Normal Convolutions: An Analytical-Numerical Method with Applications to Economic Capital Determination. Technical Report. Haifa: Actuarial Research Center—University of Haifa. [Google Scholar]
- Furman, Edward, and Zinoviy Landsman. 2005. Risk capital decomposition for a multivariate dependent gamma portfolio. Insurance: Mathematics and Economics 37: 635–49. [Google Scholar] [CrossRef]
- Furman, Edward, Jianxi Su, and Ričardas Zitikis. 2015. Paths and indices of maximal tail dependence. ASTIN Bulletin 45: 661–78. [Google Scholar] [CrossRef]
- Genest, Christian, Johanna Nešlehová, and Johanna Ziegel. 2011. Inference in multivariate archimedean copula models. Test 20: 223–56. [Google Scholar] [CrossRef]
- Gollier, Christian, and John W. Pratt. 1996. Risk vulnerability and the tempering effect of background risk. Econometrica 64: 1109–23. [Google Scholar] [CrossRef]
- Gradshteyn, Izrail Solomonovich, and Iosif Moiseevich Ryzhik. 2014. Table of Integrals, Series, and Products, 8th ed. New York: Academic Press. [Google Scholar] [CrossRef]
- Hürlimann, Werner. 2001. Analytical evaluation of economic risk capital for portfolios of gamma risks. ASTIN Bulletin 31: 107–22. [Google Scholar] [CrossRef]
- Joe, Harry. 1997. Multivariate Models and Dependence Concepts. London: Chapman and Hall. [Google Scholar]
- Klugman, Stuart A., Harry H. Panjer, and Gordon E. Willmot. 2012. Loss Models: From Data to Decisions, 4th ed. Hoboken: Wiley. [Google Scholar]
- Kotz, Samuel, Narayanaswamy Balakrishnan, and Norman L. Johnson. 2000. Continuous Multivariate Distributions: Models and Applications. New York: Wiley. [Google Scholar]
- Kunz, Karls S. 1956. High accuracy quadrature formulas from divided differences with repeated arguments. Mathematical Tables and Other Aids to Computation 10: 87–90. [Google Scholar] [CrossRef]
- Mathai, Arak M., and Panagis G. Moschopoulos. 1991. On a multivariate gamma. Journal of Multivariate Analysis 39: 135–53. [Google Scholar] [CrossRef]
- McNeil, Alexander J., and Johanna Nešlehová. 2009. Multivariate Archimedean copulas, d-monotone functions and l1-norm symmetric distributions. Annals of Statistics 37: 3059–97. [Google Scholar] [CrossRef]
- Milne-Thomson, Louis Melville. 2000. The Calculus of Finite Differences. Rhode Island: American Mathematical Society. [Google Scholar]
- Moschopoulos, Peter G. 1985. The distribution of the sum of independent gamma random variables. Annals of the Institute of Statistical Mathematics 37: 541–44. [Google Scholar] [CrossRef]
- Pinelis, Iosif. 2002. L’Hospital type rules for monotonicity: Applications to probability inequalities for sums of bounded random variables. Journal of Inequalities in Pure and Applied Mathematics 3: 7. [Google Scholar]
- Provost, Serge. 1989. On sums of independent gamma eandom yariames. Statistics 20: 583–91. [Google Scholar] [CrossRef]
- Sarabia, José María, Emilio Gómez-Déniz, Faustino Prieto, and Vanesa Jordá. 2018. Aggregation of dependent risks in mixtures of exponential distributions and extensions. ASTIN Bulletin. [Google Scholar] [CrossRef]
- Srivastava, Hari M., and Per Wennerberg Karlsson. 1985. Multiple Gaussian Hypergeometric Series. Chichester: Ellis Horwood. [Google Scholar]
- Su, Jianxi, and Edward Furman. 2017a. A form of multivariate Pareto distribution with applications to financial risk measurement. ASTIN Bulletin 47: 331–57. [Google Scholar] [CrossRef]
- Su, Jianxi, and Edward Furman. 2017b. Multiple risk factor dependence structures: Distributional properties. Insurance: Mathematics and Economics 76: 56–68. [Google Scholar] [CrossRef]
- Su, Jianxi, and Lei Hua. 2017. A general approach to full-range tail dependence copulas. Insurance: Mathematics and Economics 77: 49–64. [Google Scholar] [CrossRef]
- Temme, Nico. 1996. Special Functions: An Introduction to the Classical Functions of Mathematical Physics. New York: Wiley. [Google Scholar]
- Zhou, Ming, Jan Dhaene, and Jing Yao. 2018. An approximation method for risk aggregations and capital allocation rules based on additive risk factor models. Insurance: Mathematics and Economics 79: 92–100. [Google Scholar] [CrossRef]
Figure 1.
Scatter plots of the MMG copula (4000 simulation points) for varying values of the parameter: (top left), (top right), (bottom left), (bottom right).
Figure 1.
Scatter plots of the MMG copula (4000 simulation points) for varying values of the parameter: (top left), (top right), (bottom left), (bottom right).
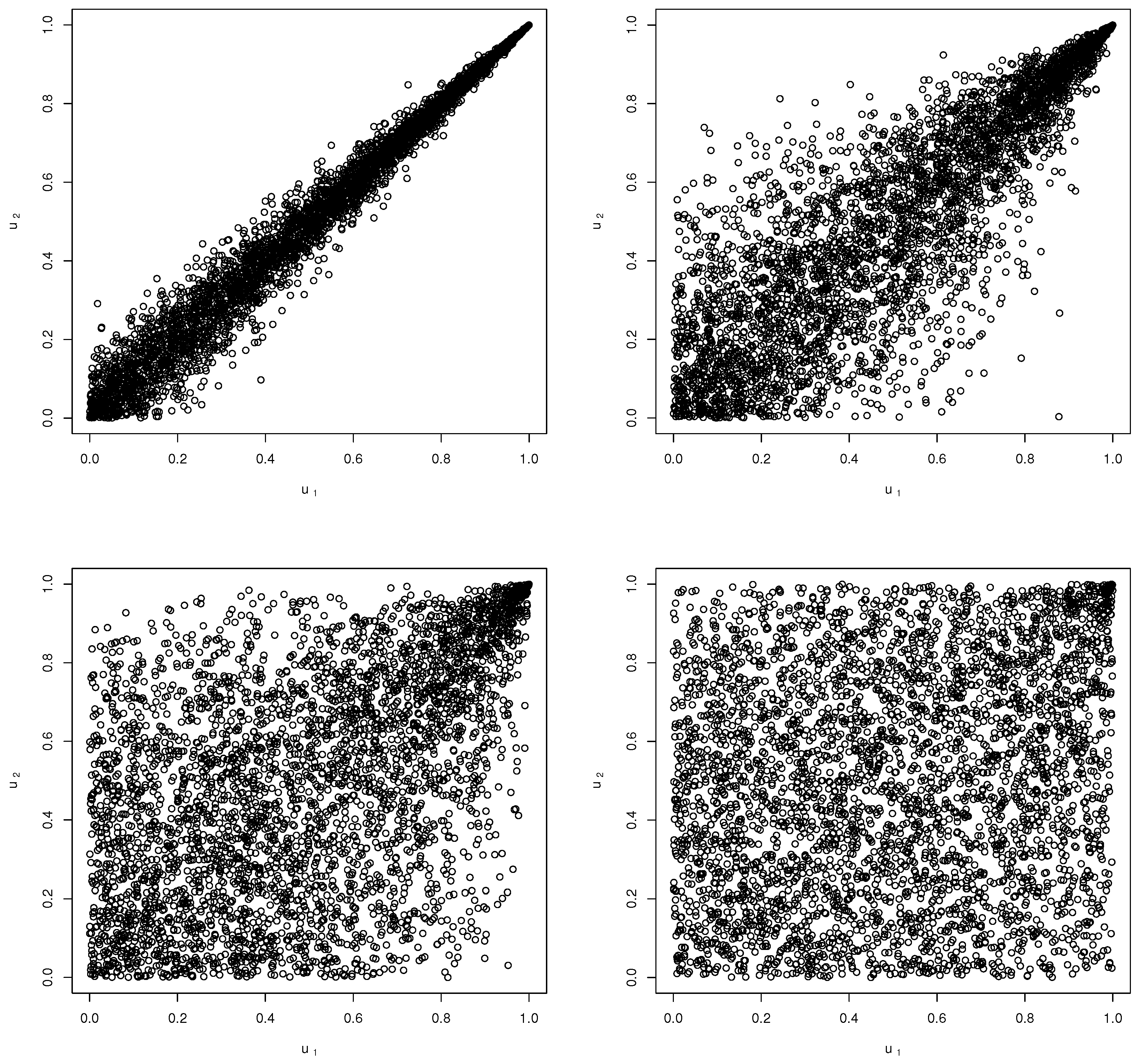
Figure 2.
The plot of the Pearson rho, Kendall tau, and Spearman rho measures of correlation for varying values of .
Figure 2.
The plot of the Pearson rho, Kendall tau, and Spearman rho measures of correlation for varying values of .

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Semenikhine, V.; Furman, E.; Su, J. On a Multiplicative Multivariate Gamma Distribution with Applications in Insurance. Risks 2018, 6, 79. https://doi.org/10.3390/risks6030079
AMA Style
Semenikhine V, Furman E, Su J. On a Multiplicative Multivariate Gamma Distribution with Applications in Insurance. Risks. 2018; 6(3):79. https://doi.org/10.3390/risks6030079
Chicago/Turabian StyleSemenikhine, Vadim, Edward Furman, and Jianxi Su. 2018. "On a Multiplicative Multivariate Gamma Distribution with Applications in Insurance" Risks 6, no. 3: 79. https://doi.org/10.3390/risks6030079
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.