1. Introduction
It has been proven empirically that asset returns do not only evolve continuously over time, as proposed in [
1], but also include jumps. Cox and Ross in [
2] and Merton in [
3] argue that the theories developed for asset pricing based on the continuous evolution of returns have to be modified in order to incorporate exposure to the jump risk. Afterward, there were plenty of papers adopting models with jumps in order to describe the empirical data of asset returns (see for example [
4,
5,
6]). Furthermore, in [
7] jumps appearing in small or high frequencies were examined. Among the studies concerning the detection of jumps in high frequency financial data, Barndorff-Nielsen and Shephard ([
8,
9]) contributed significantly to the literature. In [
10] jumps in daily returns are considered to be hidden random variables (RVs) and they are divided into two categories: positive (upward) jumps due to the arrival of positive news in the market and negative (downward) jumps due to the arrival of negative news in the market. In [
11] a sensitivity analysis of the model proposed in [
10] was developed, whereas in [
12] the adjustment of that model to real data was examined.
The first target in the present paper is to estimate the positive and negative jumps in the daily asset (log-) return time series. Due to the fact that the two sided jumps are thought of as hidden RVs, i.e., not observable RVs, the use of a time-homogeneous stochastic-state space model is adopted, as presented in [
13]. Time series analysis based on state space methods can be found for example in [
14,
15,
16,
17]. The estimations of the hidden jumps are provided by the recursive Kalman filter algorithm ([
18]). However, due to the fact that the daily return is expressed as the difference between the positive and negative jump under noise inclusion ([
13]), the estimated jumps have to be non-negative for every
t. For that purpose, the method of the common (bivariate) pdf truncation of the jumps is used and the mean values derived through the truncation are considered to be the corrected estimations of the jumps. Finally, in order to overcome the underestimation of the empirical time series due to the truncation, an appropriate scaling procedure follows.
The second target in the present paper is to apply a change point analysis concerning the variance–covariance of the data, as well the estimated bivariate jump series derived via the state space model proposed in [
13] and each jump component separately. This analysis allows us to detect similarities and differences between the estimated structural breaks in the aforementioned time series.
The data used in the paper in order to analyze the targets stated above and get the relevant results concern the NASDAQ time series during the three-year period of 2006–2008 (755 observations) and three of its stocks, namely Google, Intel and Microsoft (historical prices were derived from finance.yahoo.com). This data sample is a strongly declining period for the NASDAQ index and was used for analysis in [
10,
11,
12,
13].
The paper is organized as follows:
In
Section 2, the state space model proposed in [
13] and the estimation of the NASDAQ index via the aforementioned model are briefly presented. In
Section 3.1, the change points regarding the NASDAQ time series and the estimated jumps are illustrated, while in
Section 3.2 a similar presentation is exhibited for the NASDAQ stocks. Finally, in
Section 4, conclusions and remarks concerning the structural breaks of the time series examined are provided.
2. The Model
In [
13] a linear Markovian state space model was established for the estimation of the two-sided jumps of the daily asset (log-) returns. In this model the states, which are the hidden RVs of the model, represent the daily positive and negative return jumps. If we denote the following:
: the positive (upward) jump of NASDAQ return at time t,
: the negative (downward) jump of NASDAQ return at time t,
: the return at time
t,
1
the state equation of the proposed model becomes
or in matrix form
where
The asset return measurement equation of the model is of the form
or in matrix form
where
H = (1,−1). Moreover, we assume that
and
are normal white noises with variance–covariance matrices
Q and V respectively, i.e.,
and
Notice that model (1)–(2) is time-homogeneous, in the sense that the matrices G, H, Q and V are time-invariant.
Our target is to estimate the hidden jumps Χt and Yt by using model (1)–(2). Given that the return Rt is expressed as the difference between the positive and negative jump at time t under noise inclusion, the estimated jumps Χt and Yt that satisfy relation (2) must be non-negative, i.e., Χt, Yt ≥ 0 for every t = 1,2,... .
The estimation of the hidden states Χt and Yt in model (1)–(2) is attained by first using (stage 1) the recursive algorithm of the standard Kalman filter, which provides the optimal linear estimators, that is, the minimum mean squared error estimators. The Kalman filter proceeds in two steps; in the first step (prediction step), the hidden state zt as well as the related error variance–covariance matrix are predicted, using all the information till time t−1. At the second step (updating step), the estimation of zt is updated-corrected by taking into account the measurement at time t.
Now, let
,
be the a priori and a posteriori estimation of some state
zt respectively, and
,
the variance–covariance matrices of the a priori and a posteriori error estimations of
zt, respectively, i.e.,
Then, the recursive equations of Kalman filtering in discrete time are given in
Table 1.
Now in order to initialize the filter, since there are no measurements at time
t = 0, we assume that
Note that before running the Kalman filter algorithm in order to get the estimates of the hidden states
zt, the unknown parameters of model (1)–(2) have to be estimated, i.e., the transition matrix
G and the variances s
x 2, s
y 2 and V. For that purpose, the method of maximum likelihood estimation is used (MLE). Since the RV R
t conditional on R
t−1 follows in the standard Kalman filter procedure a normal distribution, i.e.,
, the log-likelihood function (LogL) has the form
In the case of NASDAQ index using the data from the period 2006-2008, we get the estimates ([
13])
In [
13] the positive and negative jumps of the daily NASDAQ returns during the 3-year period 2006–2008 are estimated by using the Kalman filter recursive algorithm based on model (1)–(2) (stage 1). However, the resulting estimated jumps do not satisfy the non-negativity condition for every
t. Therefore, the initial estimations of the jumps derived at stage 1 are corrected through an additional two-stage procedure ([
13]), first by truncating the bivariate common distribution of the positive and negative jumps (stage 2). Through this truncation, new (non-negative) estimations of the state vectors are derived, which are considered to be the mean values of the truncated distributions.
Next, comparing the resulting return time series based on the pdf truncation method with the empirical returns of the NASDAQ index, it is found that the estimated time series underestimates the empirical returns for every
t (Figure 3 in [
13]).For that reason, a new correction procedure to the last estimations is applied (stage 3), where the estimated jumps resulted through the pdf truncation method are rescaled by a scaling factor evaluated via linear regression.
Notice that the 3-stage estimation process presented above goes beyond the linear Kalman filtering process (applied at stage 1), because of the additional estimation stages 2 and 3. So the resulting model constitutes an extension-modification of the Kalman filter.
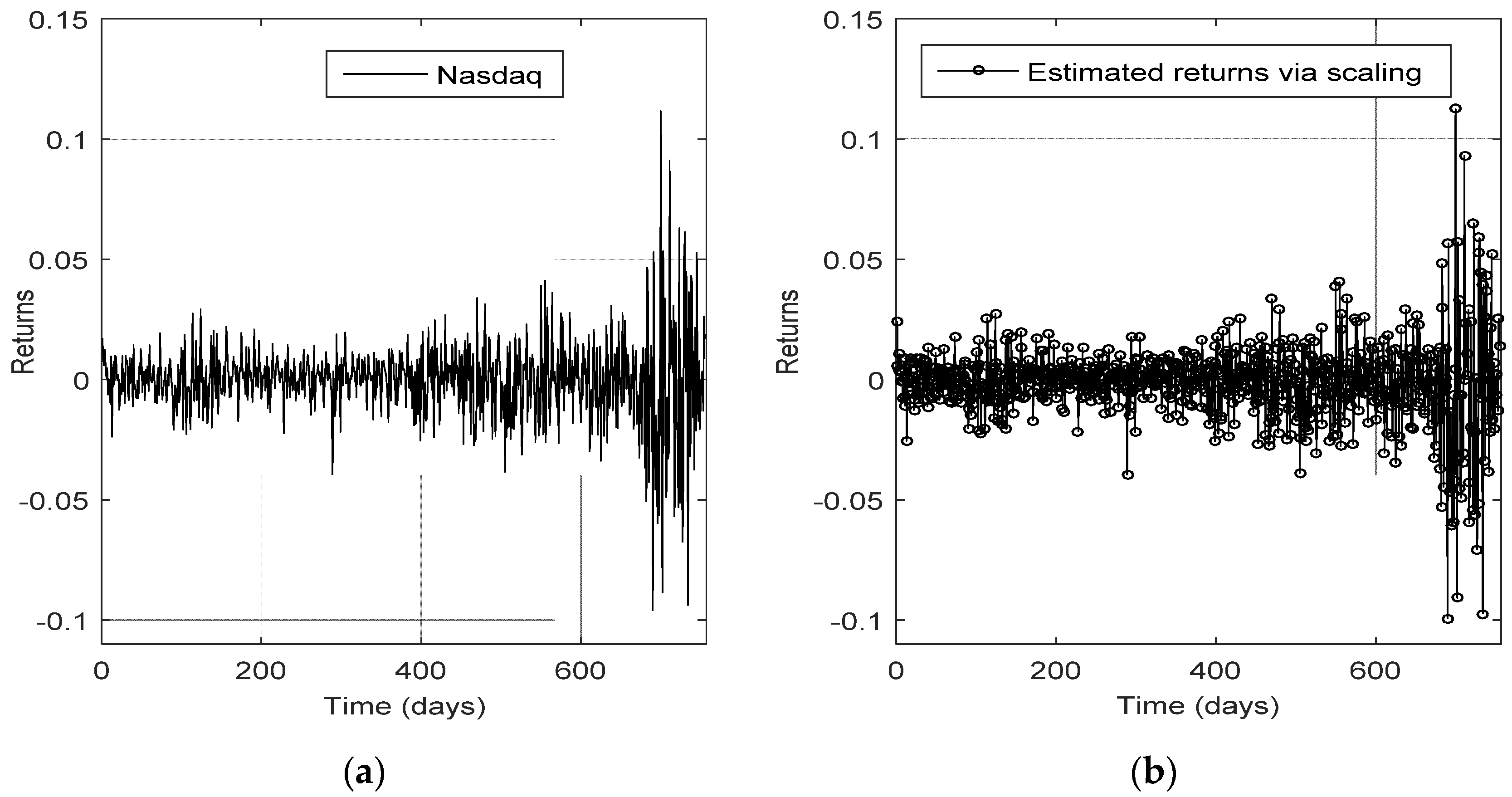
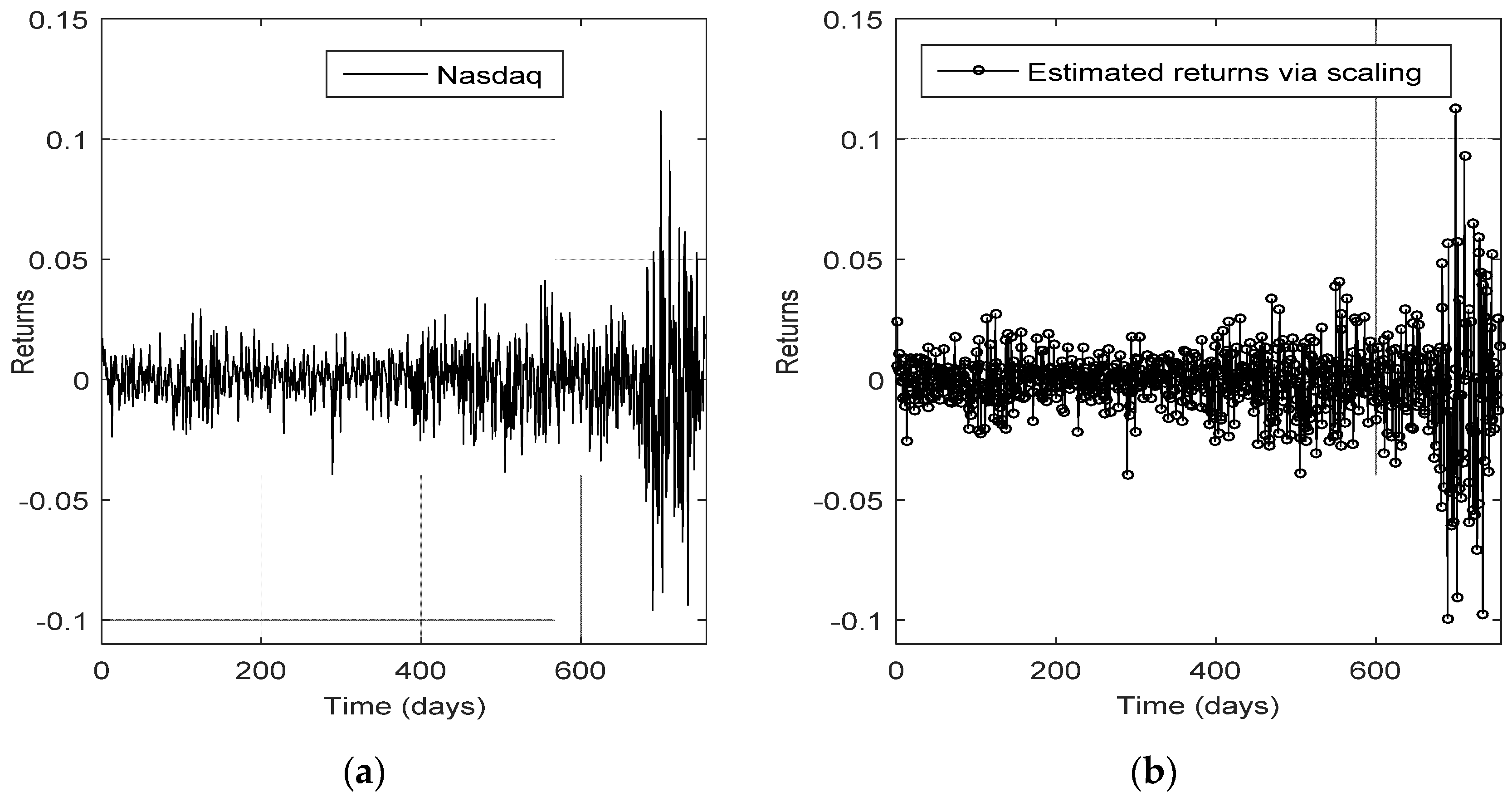
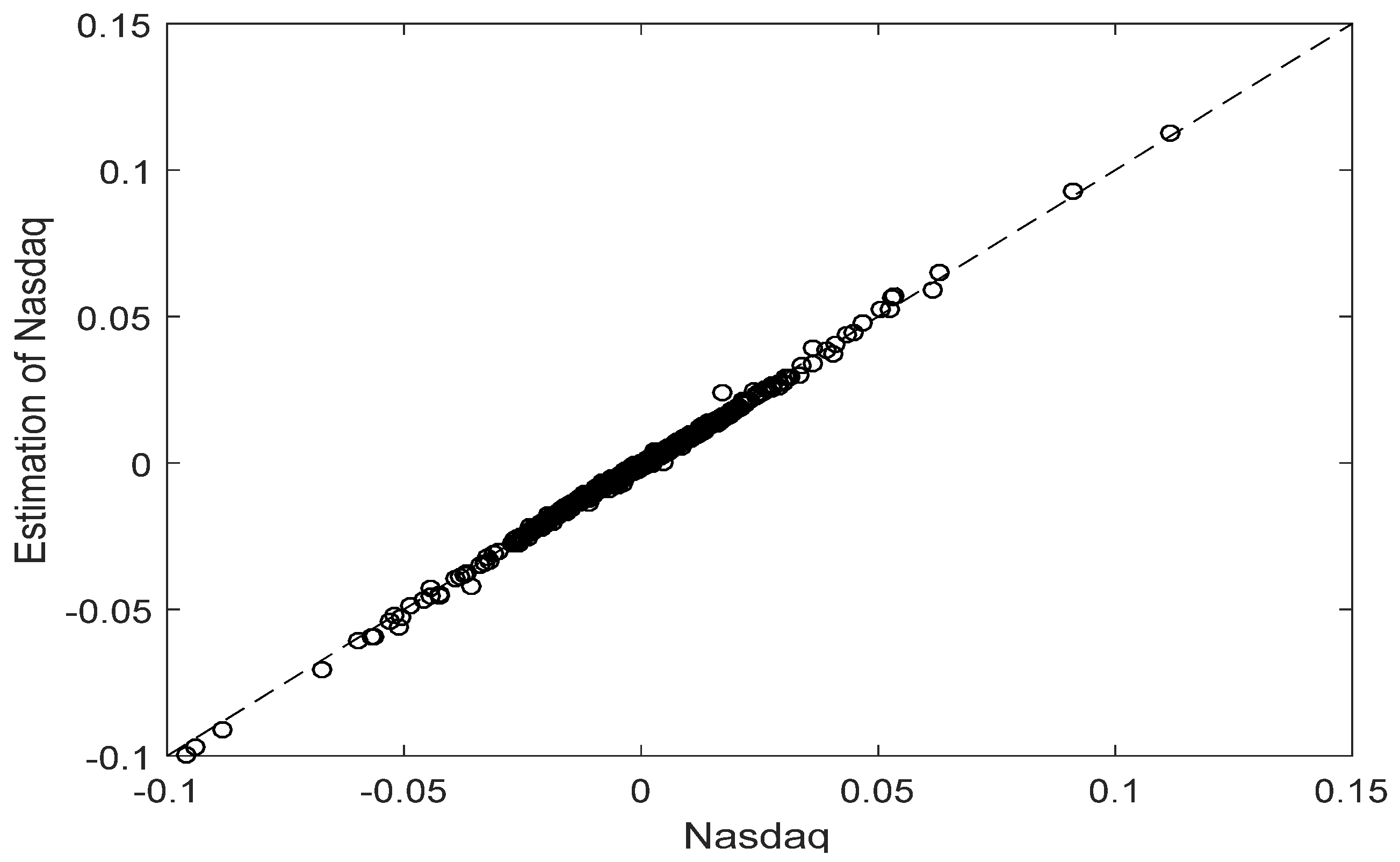
The very satisfactory adjustment of the estimated NASDAQ return time series derived by means of the aforementioned procedure can be seen in
Figure 1, in which the graphs of the empirical and the estimated returns almost coincide with each other.
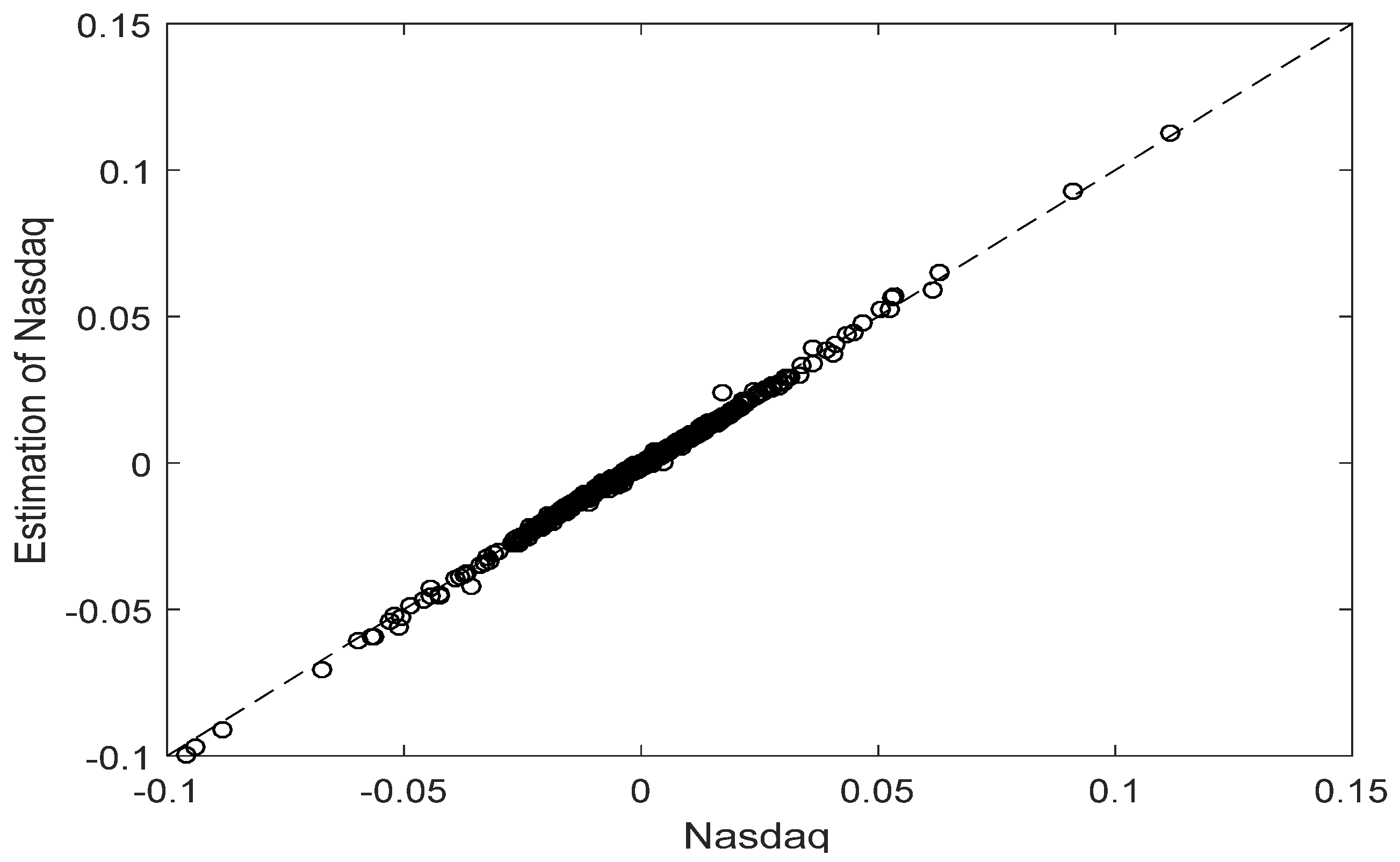
Alternatively, the associated Q-Q (Quantile-Quantile) plot verifying the very satisfactory adjustment can be seen in the following
Figure 2.
The result of Kolmogorov-Smirnov goodness of fit test and the small value of the mean squared error (MSE) confirm the above conclusion, as
4. Conclusions
In this paper, the positive and negative jumps of NASDAQ index and four of its stocks are estimated in order to detect the (variance–) covariance structural breaks (change points) in the related time series. The estimation of the positive and negative jumps is achieved by means of the methodology presented in [
13], i.e., using Kalman filtering, accompanied by truncation and scaling of the resulting jump distributions.
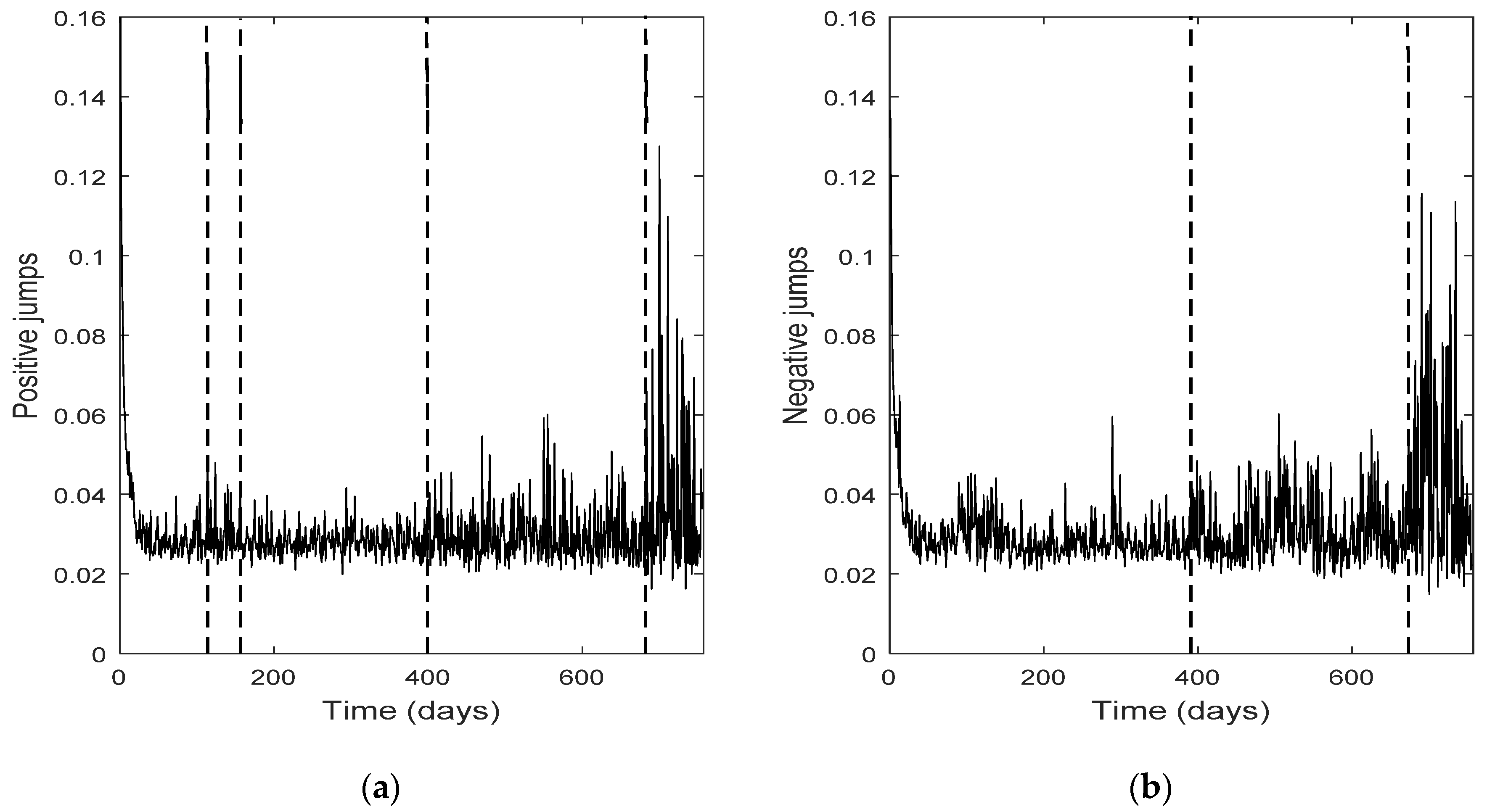
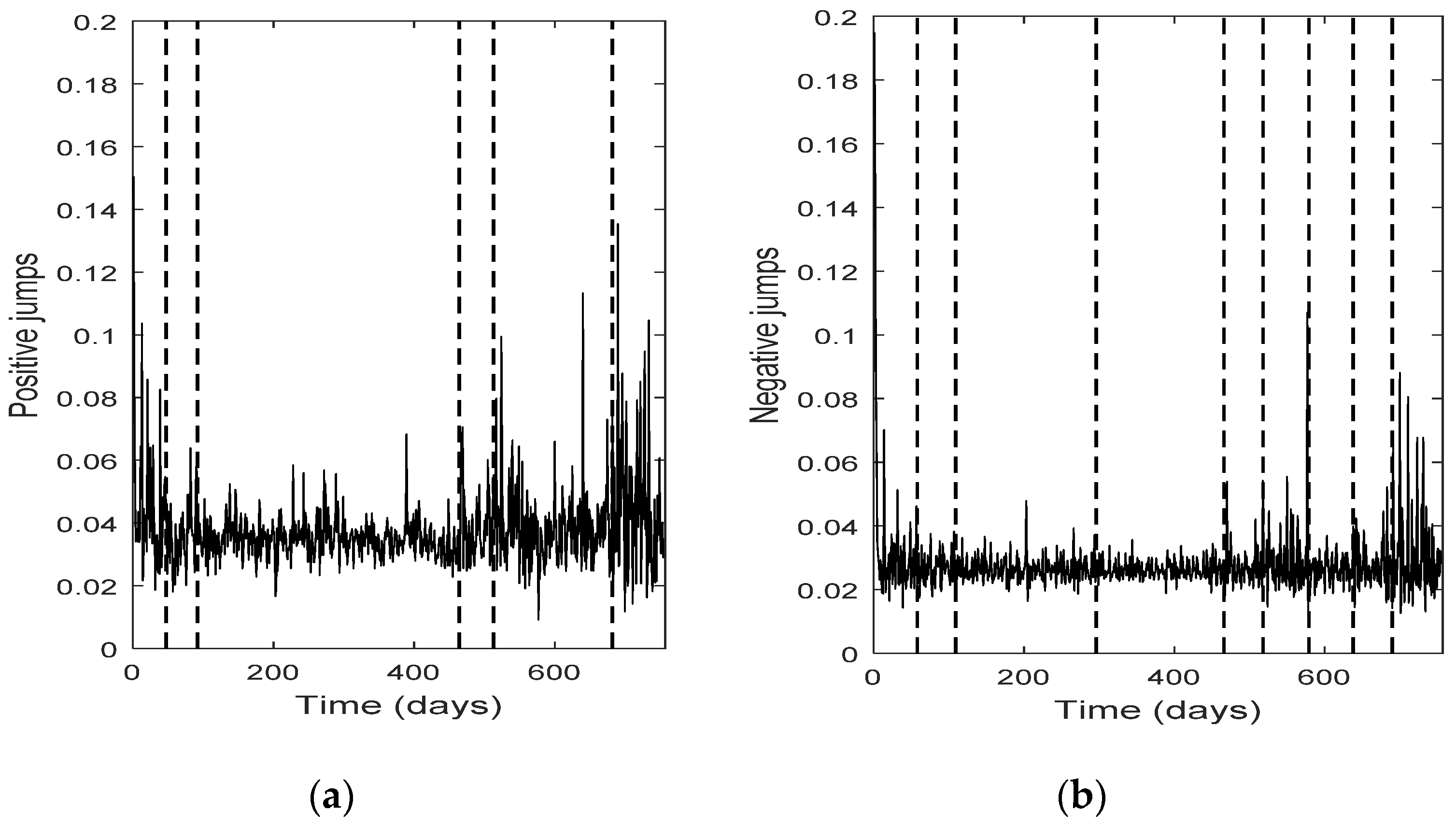
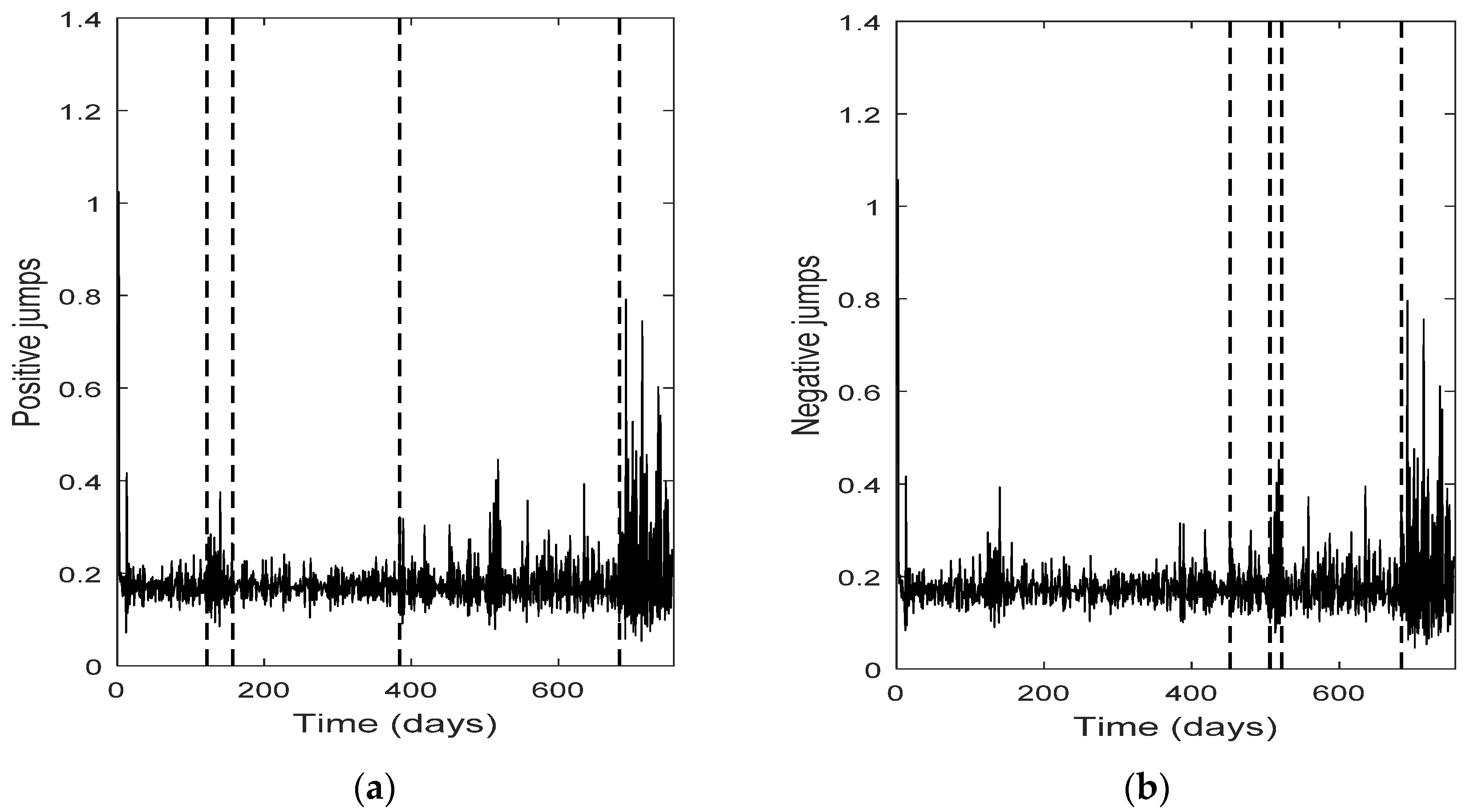
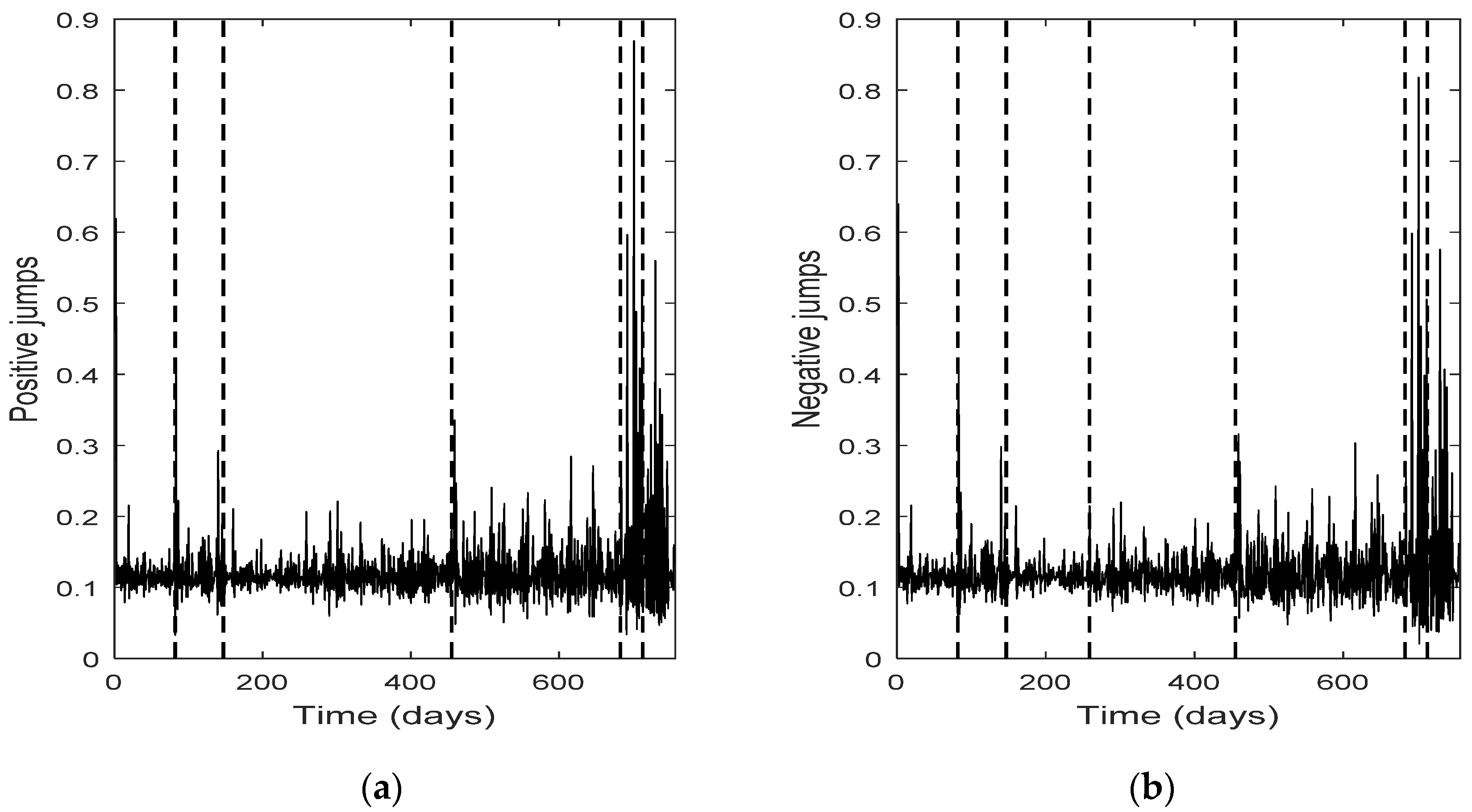
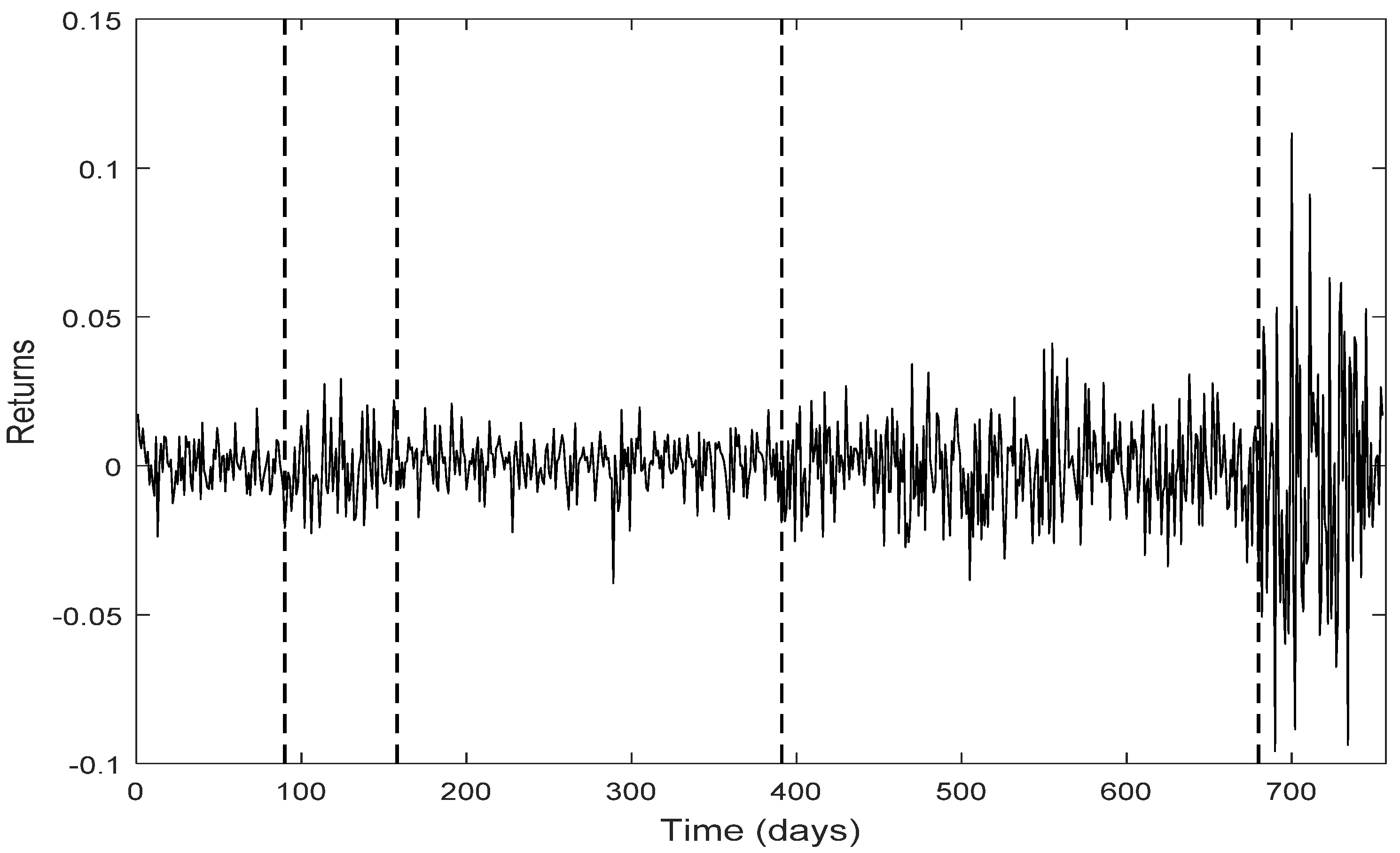
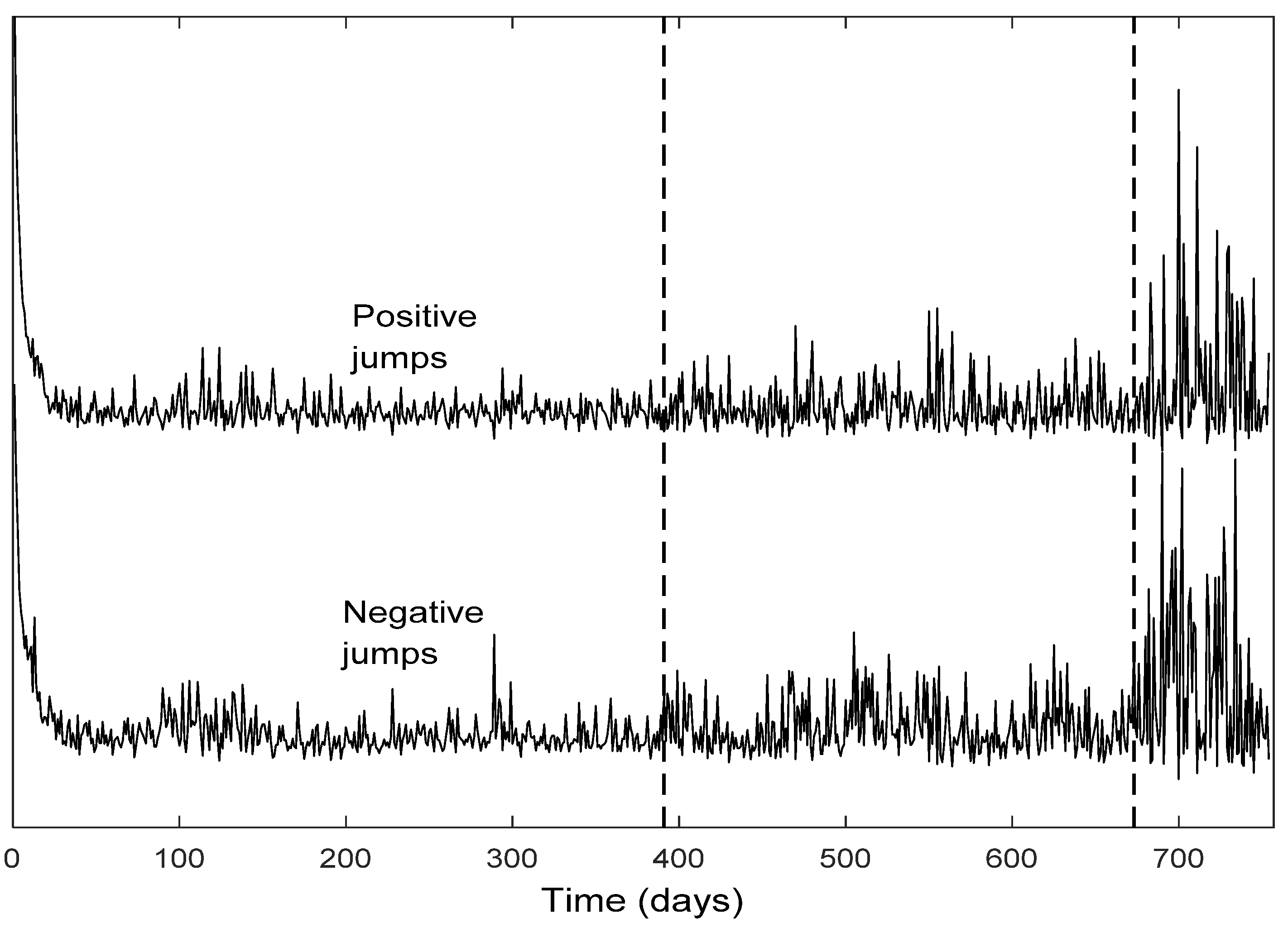
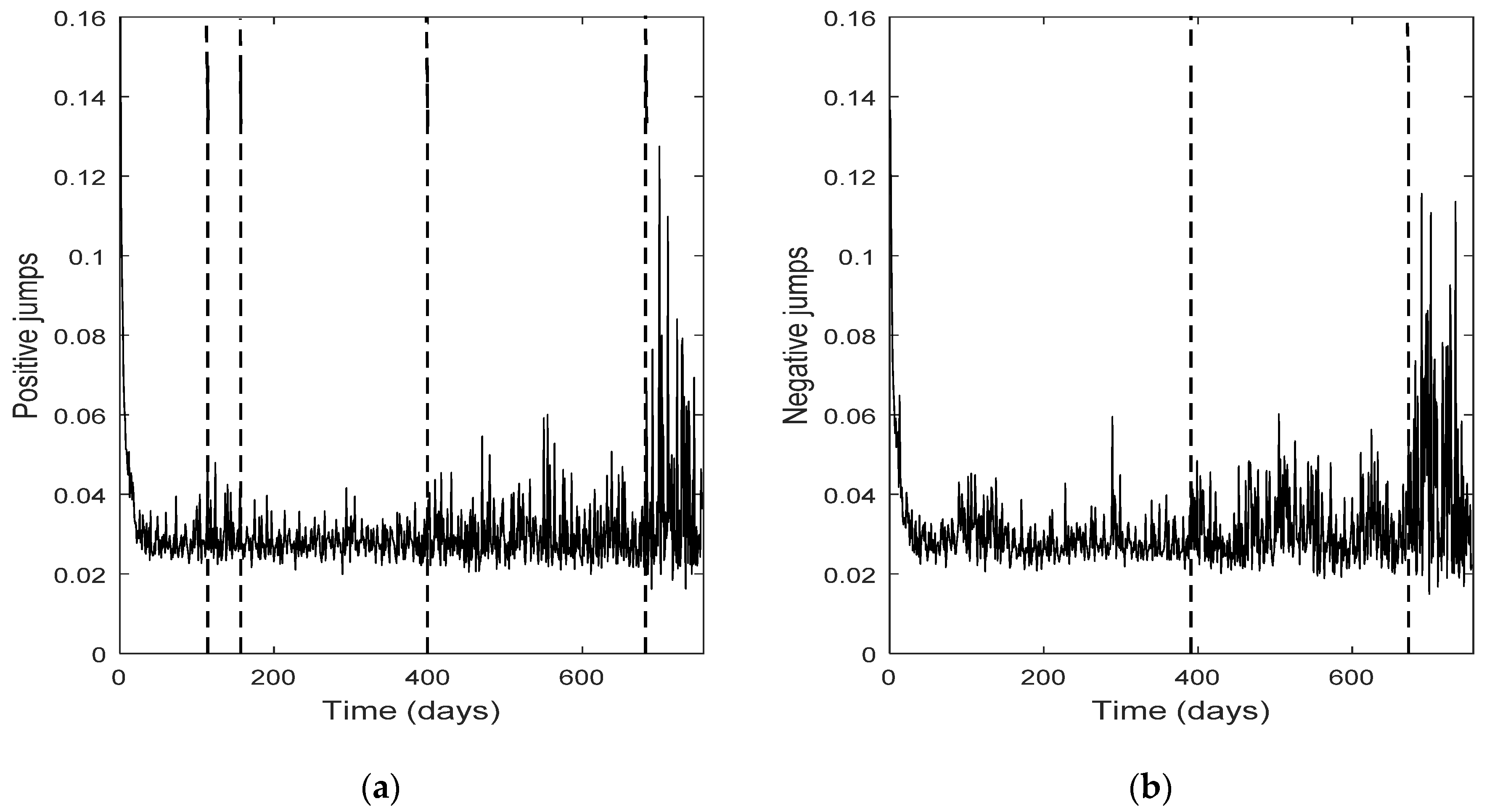
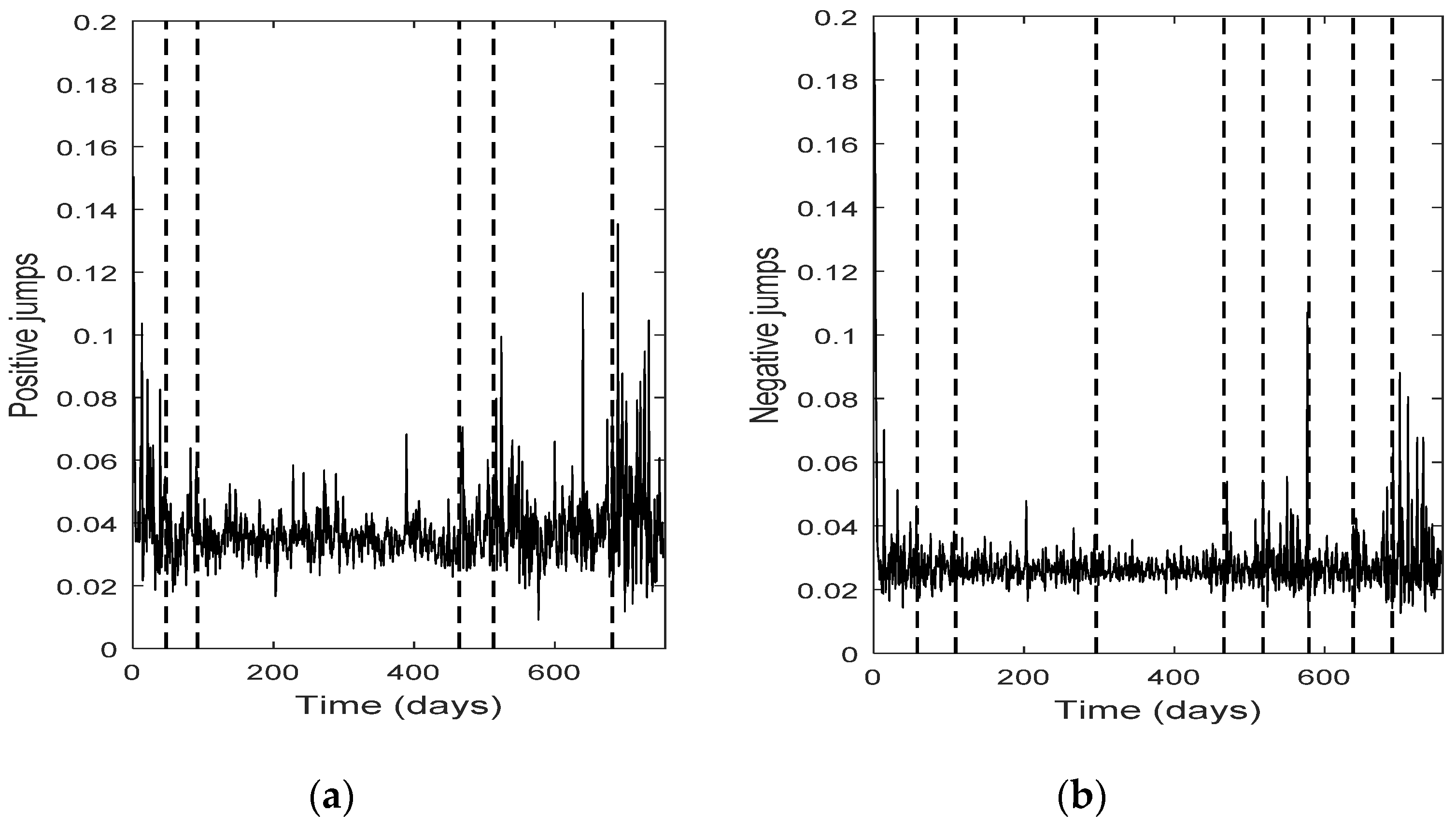
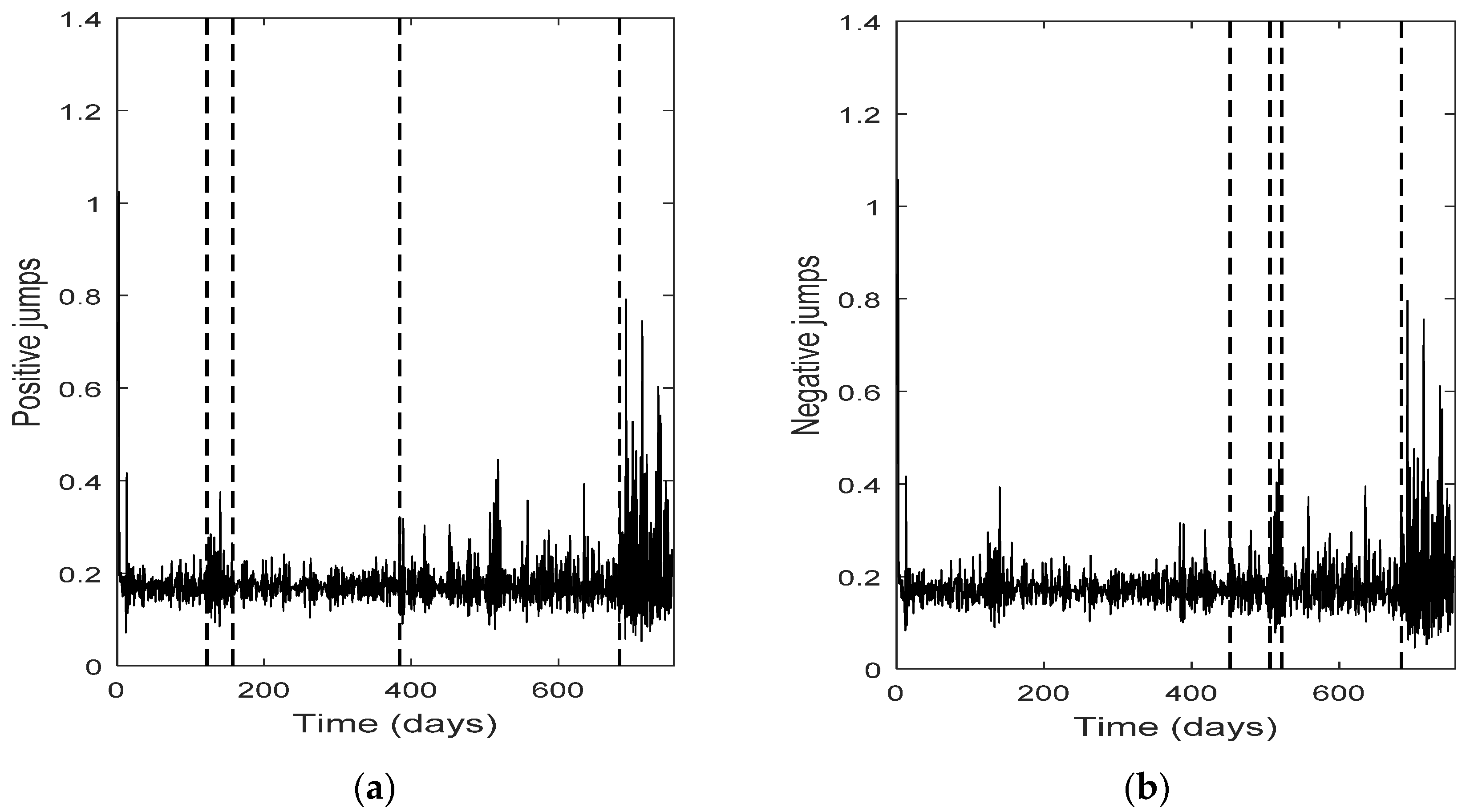
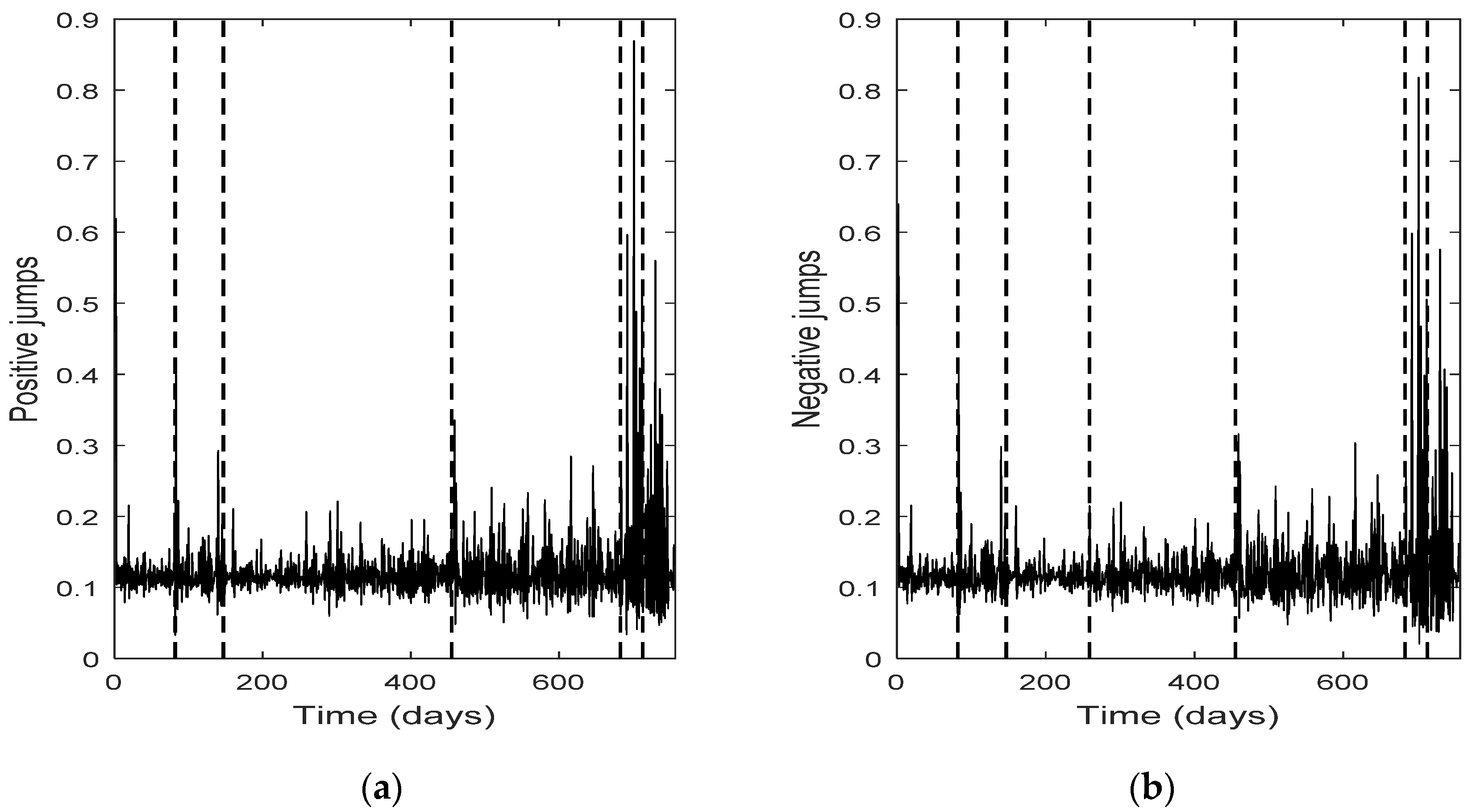
The change point detection in the final positive and negative jumps time series show that the change points of the two separate jump components usually do not coincide, while the intersection of the two corresponding change point sets is not empty; it consists of the change points with the highest test statistic value (An). Each marginal jump time series includes change points detected in the bivariate time series and the time series of the empirical returns, and probably other points too. The cardinality of the set of change points for the bivariate time series is, in all four cases, the smallest one.
Furthermore, the set of the change points for the bivariate jump time series consists of those change points of the univariate jump components which have the highest values of the test statistic. In other words, the higher the value of the test statistic for a change point detected by examining the jump components separately, the more probable is for that change point to be detected in the bivariate jump time series too. We notice that in three out of four cases examined (only Intel demonstrates a slight difference), the set of the change points for the bivariate jump time series is a subset of the set of the change points of the empirical returns. Finally, the appearance of different change points in the positive and negative jumps means that the resultant bivariate time series does not necessarily force both jump components to exhibit simultaneously the same (change in) behavior; that is, positive and negative news may affect the evolution of the corresponding jump components in a different way, at different change point times (-and this is realistic). The change points can indicate the time of these (probably different) non-observable changes.
As mentioned in
Section 2, the coefficients of the state space model presented in model (1)–(2) (at the first stage) are time-invariant. In future study, it would be interesting to incorporate time-varying coefficients in the model—for example, time-dependent variances. Moreover, a different method for estimating the hidden factors would be to use nonlinear filtering methods, e.g., particle filtering. However, this would come with the cost of high computational burden.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}