
Determining Number of Factors in Dynamic Factor Models Contributing to GDP Nowcasting

Department of Statistics, Iowa State University, Ames, IA 50011, USA
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(22), 2865; https://doi.org/10.3390/math9222865
Submission received: 14 October 2021
/
Revised: 5 November 2021
/
Accepted: 6 November 2021
/
Published: 11 November 2021
(This article belongs to the Special Issue Statistical Simulation and Computation II)
Abstract
:Real-time nowcasting is a process to assess current-quarter GDP from timely released economic and financial series before the figure is disseminated in order to catch the overall macroeconomic conditions in real time. In economic data nowcasting, dynamic factor models (DFMs) are widely used due to their abilities to bridge information with different frequencies and to achieve dimension reduction. However, most of the research using DFMs assumes a fixed known number of factors contributing to GDP nowcasting. In this paper, we propose a Bayesian approach with the horseshoe shrinkage prior to determine the number of factors that have nowcasting power in GDP and to accurately estimate model parameters and latent factors simultaneously. The horseshoe prior is a powerful shrinkage prior in that it can shrink unimportant signals to 0 while keeping important ones remaining large and practically unshrunk. The validity of the method is demonstrated through simulation studies and an empirical study of nowcasting U.S. quarterly GDP growth rates using monthly data series in the U.S. market.
1. Introduction
Real-time nowcasting is a process to assess current-quarter GDP from timely released economic and financial series before the figure is disseminated in order to catch the overall macroeconomic conditions in real time. This is of interest because most data are released with a lag and are released subsequently. In theory, any release, no matter at what frequency, may affect current-quarter estimates and their precision potentially. Both forecasting and nowcasting are important tasks for central banks for policy decision-making; for example, monetary policies need to be made in real time and are based on assessments of current and future economic conditions. Additionally, estimated current-quarter GDP figures are often used as relevant inputs for model-based longer-term forecasting exercises in banks.
Real-time nowcasting faces some difficulties. The first one is how to bridge monthly data series with the quarterly GDP. Bafigi et al. [1], Rünstler and Sédillot [2], and Kitchen and Monaco [3] studied the idea of bridge equations which use small models to “bridge” the information contained in one or a few key monthly data with the quarterly growth rate of GDP. However, they involve judgmental nowcasts and only deal with a few monthly data series. The second difficulty is how to deal with a large number of monthly data series. For macroeconomic forecasting, factor models (FMs) are widely used at central banks and other institutions to achieve dimension reduction. Many authors, such as Boivin and Ng [4], Forni et al. [5], and D’Agostino and Giannone [6], have shown that these models are successful in this regard. However, they did not use FMs specifically for the problem of real-time nowcasting. There are other existing approaches to tackle the high dimensional issue. One example is Eraslan and Schröder [7] who dealt with this over-parameterized issue in GDP nowcasting by implementing the dynamic model averaging method (Raftery et al. [8]). However, they did not talk about how to handle the unbalanced structure of the data caused by different release dates with different lags in each month. Moreover, they assumed a fixed number of factors, while in our paper the focus is to determine the number of factors contributing to GDP nowcasting. The third challenge is that a large number of monthly data series are released with different lags, causing unbalanced data at the end of the sample. Some authors, including Croushore and Stark [9], Koenig et al. [10] and Orphanides [11], discussed about this issue, but they are not focusing on the statistical estimation.
Giannone et al. [12] provided a frequentist inference framework for the parametric dynamic factor models (DFMs). In their framework, they took advantage of different data releases throughout the month and updated the nowcast based on each new data release. The authors combined the idea of connecting monthly series with the nowcast of quarterly GDP and the idea of using data with different releases within a single statistical framework. Their model combines principal component analysis (PCA) with modified Kalman Filter (KF) to deal with the unbalanced feature of the data. Hereafter, we call the method proposed in Giannone et al. the GRS approach.
In this paper, we borrow the idea of DFMs from Giannone et al. [12] and propose a Bayesian Monte Carlo Markov Chain (MCMC) approach to deal with the real-time nowcasting problem. For DFMs, one important aspect is to determine the number of factors. In the GRS approach, the number of factors is assumed to be fixed, which is determined by looking at the cumulative proportions of variances explained by the first few principle components from PCA, and the same set of factors is assumed to have prediction power on GDP. Bai and Ng [13] showed that the number of factors could be estimated consistently in a large panel of data setting. In this paper, we impose a cap on the number of factors in the DFM structure but allow an unknown number of factors to contribute to GDP prediction. We propose to apply the horseshoe shrinkage (Carvalho et al. [14,15]) on the coefficients of factors in the prediction equation. One big advantage of the horseshoe shrinkage over other traditional shrinkages is that it can shrink unimportant signals to 0 while keeping important ones large and practically unshrunk (more details will be discussed in Section 2). After estimation, any coefficient that is shrunk to 0 indicates its corresponding factor has no prediction power. As a result, the number of coefficients that remain large after strong shrinkage is a good estimate of an unknown number of factors with prediction power on GDP. Our Bayesian MCMC approach can also provide a more natural way to deal with the unbalanced data structure due to real-time data releasing and estimate all parameters, including the number of contributing factors and latent dynamic factors in a single framework. We refer to this Bayesian approach as the BAY approach. Through simulation studies, we evaluate the abilities of our BAY approach in estimating an unknown number of contributing factors and in producing reliable nowcasts in real time. The validity of the BAY approach is also examined by applying it to nowcast U.S. quarterly GDP growth rates.
The rest of this paper is organized as follows. Section 2 sets up the model structure, introduces the horseshoe shrinkage into our model, and stylizes the data structure. In Section 3, we introduce the Bayesian MCMC estimation method with nowcasting equations. In Section 4, we conduct simulation studies. In Section 5, an empirical study of nowcasting U.S. GDP growth rates is presented. Section 6 concludes the paper. A list of abbreviations used in this paper is provided in Abbreviations.
2. Model Set-Ups, Horseshoe Shrinkage, and Data Structure
In Section 2.1, the model set-ups used in the BAY approach are illustrated. In Section 2.2, we introduce the horseshoe shrinkage idea and how to implement it in our BAY approach to estimate number of contributing factors. In Section 2.3, we formalize the unbalanced data structure.
2.1. Dynamic Factor Models
In this section, we introduce the Dynamic Factor Model structure and how it can reduce dimension and bridge our monthly released series with quarterly released GDP.
Since the number of monthly series is vast, modeling GDP on all available series can involve too many parameters; hence, the model would perform poorly in forecasting because of large uncertainty in the parameters’ estimation. The fundamental idea of Giannone et al. [12] is to use DFMs to exploit the collinearity of the series by summarizing all the available information into a few common latent factors. Due to collinearity, a linear combination of the common factors is able to capture the dynamic interaction among the series and to provide a model that only requires a limited number of parameters and thus works well in forecasting. In this paper, our DFM is specified in the following ways.
First, assume that the monthly series are linear functions of a few unobserved common factors ,
where is the monthly series vector at month t, for , is the common factor vector at month t, r is the number of latent factors () which is usually assumed to be known and fixed, is the factor loading, is the mean vector, and the error vector . Note that the difference between Equation (1) and regular multiple regression is that the factors are unobserved latent variables, while the predictors in multiple regression are observed. The latent factors serve an important role of bridging information from monthly series to quarterly GDP.
Then, we further specify the dynamic of the common factors as a vector auto-regression:
where and with . It is known that factor dynamic models can suffer from non-identifiable issues. Following Stock and Watson [16], we construct two sets of restrictions: and for . These restrictions together with the prior distribution of (specified later) satisfy the identification assumptions in Stock and Watson [16], and can identify factors up to a change of sign.
Finally, we assume that the nowcast of the GDP at quarter k is a linear function of the common factors at each month in the current quarter and the GDP from the previous quarter:
where and are scalars, , , are vectors and for . Here, the number T (the end of monthly series) and the number K (the end of quarterly GDP series) satisfy . The DFMs specified this way can successfully bridge quarterly released GDP with monthly financial or economic series and achieve dimension reduction.
2.2. Horseshoe Shrinkage
In this section, the horseshoe shrinkage idea is introduced, and we discuss how it can be implemented in our model framework to estimate the number of contributing factors.
In Carvalho et al. [14], the horseshoe prior was first introduced as a shrinkage prior. Follett and Yu [17] shown that the horseshoe prior competes favorably with shrinkage schemes commonly used in Bayesian multivariate regression models. To illustrate the idea, let us first consider a simple mean model for . We assume is sparse and some might be equal to 0. We can assign the horseshoe prior to for by letting with . Here, is referred to as the global shrinkage prior and is referred to as the local shrinkage prior. Figure 1 plots the densities for the horseshoe (setting for simplicity), Laplacian, and Student-t priors, respectively. As shown in Figure 1, compared to Laplacian or Student-t priors, the horseshoe has flat tails which allow strong signals that remain un-shrunk. It also has an “infinitely” tall spike at the center which can provide severe shrinkage for elements near zero. This feature makes the horseshoe prior a very useful shrinkage prior.
Furthermore, it was showed in Carvalho et al. [14] that, for ,
where . When , , it indicates that the signal from data dominates; when , , it means that is shrunk to 0. Thus, is referred to as the Shrinkage Profile which measures the shrinkage level:
The Half Cauchy prior on implies a prior on the Shrinkage Profile . Figure 2 shows the implied prior on for the horseshoe prior, the student’s t prior, and the Laplacian prior. As shown in the figure, unlike the Laplacian prior and t prior, the density of implied by the horseshoe prior is unbounded at both 0 and 1 with a small mass in between (a horseshoe shape). Being unbounded at 0 allows effects to grow large (little shrinkage) while being unbounded at 1 can shrink effects until they are fully removed from the equation.
We apply this horseshoe shrinkage idea to the prediction Equation (3) as follows:
where , and R is the largest possible number of latent factors. The cap R is predetermined, satisfying . Now, , , are vectors, are common factors at month t, and dimensions for , , and are changed accordingly.
In this specification, is the global shrinkage prior and ( ) are local shrinkage priors. We set , where . In this way, we assume that the importance of factors decreases when j goes from 1 to R. If we put priors , , and define , then , and Equation (5) changes to be
It can be seen that is the coefficient connecting factor j to GDP in the prediction equation. By such a specification, we successfully impose the horseshoe shrinkage prior on the coefficients ’s. The magnitudes of the estimated profiles, (for ), give us some information about which should be shrunk to 0 and which should not. If is close to 1, indicating extremely strong shrinkage on , factor j then has no prediction power on GDP. As a consequence, the number of remaining un-shrunk determines the number of contributing factors.
2.3. The Unbalanced Structure of the Data
In this section, we provide descriptions of the unbalanced data structure and notations used to represent the unbalanced structure.
In real time, macroeconomic series are released with diverse lags. At a particular release date, some series have observations up through the current month, whereas for others, the most recent observations maybe come from previous months. Dealing with these kinds of unbalanced data is vital for nowcasting.
Let be the vector denoting n monthly data series at month T (the end of the sample), and be quarterly GDP at quarter K. Assume there are Q different release dates at each month. Each release date is denoted as , representing the qth release date in month T, where . New series are released on each release date. Since some series for the current month may be released in the future, let denote the latest month in which the data are balanced. For , the releasing set collects indexes of all s that have been released at or before the release date , and this set of available series is denoted as . Without loss of generality, for each month, we assume the release dates for all series are fixed.
Table 1 gives a simple example of the data set available for nowcasting. In this example, there are monthly series, , released at three (i.e., ) releasing dates. For month T, cells with gray color represent series that are available before T. Suppose are released at the first releasing date , are released at the second releasing date , and are released at the third releasing date . Thus, for the third releasing date , , , , and , . If we want to nowcast GDP in the current quarter at the first release date in the second month of the quarter, so here . The series available to use at the release date are highlighted in gray and orange color, i.e., . The series available to use at the release date are highlighted in gray, orange, and green, i.e., .
The goal is to nowcast with all available information including series and series at each releasing date in month T. Here, , indicating the first month, second month, and third month nowcast. At every new release date , model parameters are updated with new information added from the new released series, and nowcast of is re-produced. How to deal with this unbalanced data in our BAY approach will be discussed in details in Section 3.
3. Estimation Method and Nowcasting
In Section 3.1, we introduce the Bayesian MCMC algorithm to estimate model parameters and latent factors and to determine the number of contributing factors. In Section 3.2, nowcasting formulas are provided.
3.1. Estimating Dynamic Factor Models Using Bayesian MCMC
In this section, we first introduce our method of implementing the unbalanced data into our model framework naturally. Then, we finish our model specification by assigning priors in Bayesian Framework. Finally, the MCMC procedure is discussed in detail.
As discussed in Section 2, macroeconomic series are released with diverse lags in real time. Thus, a difficulty in real-time nowcasting is to deal with unbalanced data. In this section, we develop a computational Bayesian MCMC approach that can tackle this issue naturally.
To deal with the missing data in at the end of the sample, we introduce the indicator matrix by deleting the ith row from the identity matrix if . For the example discussed in Section 2, at the third releasing date in month T, . Therefore, removing the fifth and sixth row of gives us
Similarly, for the index set , deleting the last four rows of leads to
Then, we can simply rewrite as
To better derive the posterior distributions, we express the dynamic of in Equation (1) as:
where , is a vector representing the ith row of , , and the symbol ⊗ denotes the Kronecker product. Thus, for the qth releasing date in month T, the conditional density for is
the conditional density of is
and the conditional density of is
for . In this way, the unbalanced structure of the data is built into our model framework through this indicator matrix .
Let denote all parameters to be estimated. Suppose we are at releasing date q in month T of quarter , our task is to use observations and to estimate parameters and latent factors , then conduct the nowcast for .
The joint posterior distribution can be written as a product of individual conditionals,
where , , , and can be derived according to Equations (7)–(9), respectively. is the prior distribution for the parameter set .
We finish the model specification by assigning prior distributions in Bayesian framework. We set prior for as . The prior for is defined as . This prior on , along with two restrictions we set in Section 2 ( and for ), satisfy the identification assumptions in Stock and Watson [16]. The prior for is defined as , where is a scalar and pre-specified to be so that the expectation of is . The prior for is the standard normal truncated at , that is: for
where and are PDF and CDF for standard normal distribution. Then, . The priors for the diagonal elements of are defined as for , where and are scalars and pre-specified to be 2 and , accordingly. Then, . The prior for is . The prior for is set to be for ( is set to be 1). As discussed in Section 2.2, these prior specifications of and imply a horseshoe shrinkage on the coefficients ’s. The prior for is , where and are scalars and pre-specified to be 4 and , accordingly, to provide a reasonable mean and variance of .
All priors are assumed to be independent. Based on the derived complete conditional posterior distributions for each parameter and latent variable, we obtain posterior samples using Metropolis–Hastings within Gibbs sampling since some conditional posterior distributions do not have closed forms. In estimation, we use the means of posterior samples as estimates for parameters and latent factors. Complete conditional posterior distributions for all model parameters and latent factors are provided in Appendix A.
3.2. Nowcasting Formulas
In this section, nowcasting formulas are provided. Suppose we are at , the qth () releasing date in month T. As discussed in Section 3.1, the available information are and , here T can be the first (), second (), or third () month of the quarter . Our goal is to nowcast GDP . Let , , (), , , , and () be the gth posterior draws for parameters and latent factors after the burn-in period, where . We nowcast using the following formulas.
- When , the nowcast of using BAY is given by:
- When , the nowcast of using BAY is given by:
- When , the nowcast of using BAY is given by:
Note that for some releasing dates, if , meaning that no monthly series are available at releasing date , then posterior samples cannot be generated. As a solution, we use to replace in nowcasting equations. All of the parameter and factor estimations are updated in every single release within a month. Then, is re-produced for each release date.
4. Simulation Study
In this section, we will investigate three aspects of the Bayesian approach through numerical simulations. In Section 4.1, we evaluate whether it can successfully determine the true number of latent factors that can contribute to GDP nowcasting, i.e., the number of contributing factors. In Section 4.2, we study the accuracy of estimated latent factors . In Section 4.3, we examine out-of-sample nowcasting performances of the BAY approach.
In the simulation study, we simulate data following the model in Equations (1), (2) and (4) with (months), (quarters), (true number of contributing latent factors), (monthly series), and release dates in each month. The releasing pattern follows Table 2 with 20 new monthly series released in each release date, that is: at , release , at , release and at , release .
Our method requires a predetermined cap R as the largest possible number of factors. Theoretically, R can be as large as the number of monthly series n. However, in practice, we use a smaller number to avoid extreme computational burden. In this simulation study, we choose because a preliminary PCA analysis shows that the first six principle components can explain at least of total variation for all six simulations. For all simulations, some of the parameter settings used in generating data are common: we set , ; , (), , and . is simulated from , each element of equals to 10, and is simulated from .
Specifications of () for each of the simulation are shown in Table 3. For all six simulations, we assume only the first two factors majorly contribute to our nowcasting equations. Simulation 1 and Simulation 2 represent the group with high signals for the first two factors. Simulation 3 and Simulation 4 represent the group of moderate signals, while Simulation 5 and Simulation 6 are in the group of weak signals. Within each group, one of the simulations is configured with true sparsity, that is for , while for another simulation, we assign non-sparsity with small noise ( for ) as a comparison. In this way, we can investigate how our method performs when changing magnitudes of the true signals from strong to weak, and when the non-true signals are contaminated with small noise or not.
For each simulation, we conduct one-step ahead nowcasts for the last 20 quarters using a moving window with a length of 10 years (40 quarters). For each quarter, nowcasting is made in each release date within each month. Thus, there are nowcasts in each simulation. In our MCMC procedure, we discard the first 10,000 iterations as burn-in and run 1000 more for posterior summaries.
4.1. Estimating the Number of Contributing Factors
In this section, we validate our Bayesian Approach’s ability in determining true number of contributing factors through six sets of simulation studies. The ability of the algorithm to determine the true number of contributing factors is investigated as follows. First, we check whether our approach can perform as expected when true signals of the first two factors are high, moderate, and low, and the non-true signals are exactly equal to 0. Secondly, we check if its performance will be undermined if we add some noise to the non-true signals.
For each simulation, every estimate of the shrinkage profiles () is calculated using the average of 1000 posterior draws after the burn-in period, that is for . Figure 3 shows box-plots of estimated shrinkage profiles () based on 180 nowcast estimates in each simulation. In Simulation 1 and Simulation 2, and are near 0 while to are generally close to 1, indicating that the algorithm can successfully detect high signals for the first two contributing factors and shrink the other four to zero. In Simulation 3 and Simulation 4, when we decrease signals of the first two factors from high to moderate, our algorithm can still detect signals of the first two and shrinkage signals of the last four to 0. However, if we only apply low signals for the first two factors, as shown in Simulation 5 and Simulation 6, the algorithm can only detect one contributing factor while shrinking all others to 0. When comparing results between right column (Simulation 2, 4, and 6 for true sparsity) and left column (Simulation 1, 3, and 5 for small noise), our algorithm can extremely shrink all four non-true factors (i.e., having ) in all three scenarios with different strengths of true signals, disregarding whether the non-true factors are contaminated with noise or not. The findings in Figure 3 validate our algorithm’s ability to detect the true number of contributing factors with moderate to high signals.
Figure 4 shows a scatterplot of posterior means ’s ( versus ’s from 180 nowcast estimates. There are two general patterns observed across all six simulations. The first is that the estimated profile ’s get closer to zero (little shrinkage) when the values of ’s increase horizontally to very large numbers, while ’s approach to one (strong shrinkage) when ’s become very small. The second pattern is that the dots are separated into two clear segmentations in each picture. The vertical distance between two groups is the largest for the strong signal cases (Simulation 1 and 2), then becomes smaller for the moderate signals (Simulation 3 and 4). However, for the last row (the weak signal cases), the distance almost diminishes. This is consistent with the findings in Figure 3.
4.2. Estimation of Latent Factors
We then investigate whether the BAY method can accurately estimate the latent factors . In our approach, latent variables are also estimated with posterior means, i.e., , , and is the number of MCMC iterations after the burn-in period. Figure 5 plots the estimated first two latent factors from BAY approach, together with the true latent factors, in the first 100 months (in-sample period) of the data for six simulations. The absolute values are compared since the factors are identified up to a change of sign (Section 2.1). Figure 5 shows that, generally, the estimation from the BAY approach is close to the true factors, especially for the first four simulations in which the true number of contributing latent factors is successfully detected.
4.3. Out-of-Sample Nowcasting Performances
In this section, we prove that our Bayesian Apporach can provide exceptional out-of-sample nowcasting performances compared to the Random Walk.
Out-of-sample nowcasting performances are assessed based on 20 one-step-ahead nowcasting. For each simulation, whenever there are new series released in a month, the model parameters and latent factors will be updated. Therefore, there are 180 nowcasts in total.
Figure 6 presents the nowcasting performances for all six simulations. In each panel (representing each simulation), the first, second, and third row represent nowcasting trends over 20 quarters in the first, second, and third month, respectively. In each subplot of each panel, the black curve represents the true GDP, while colored curves with different symbols represent nowcasts from different releases. Figure 6 shows that BAY approach can capture trends and changes in simulated GDP really well. For all six simulations, within the same month, there is no obvious difference in nowcasting performance between release 1 and release 2. However, nowcasting curves for release 3 are slightly closer to true curves than that of the other two releases. Moreover, we can see obvious improvements from nowcasts in the first month to nowcasts in the third month.
In order to better understand nowcasting results, we use mean absolute nowcasting error (MANE) to measure nowcasting accuracy. Let be the nowcast at qth release date of month T, where and . Then, . We compare the nowcasting performances of BAY with that of the random walk (RW) approach, which uses the previous quarter GDP to predict the current quarter GDP, by calculating MANE reduction relative to RW (i.e., ). Table 4 provides MANE reductions (in percentage) for BAY approach compared with that of the RW. For instance, indicates that BAY can reduce of MANE of the RW. Table 4 shows that, moving from the first month to the third month, there are significant reductions in terms of MANE ratios. Within each month, there is no obvious difference in MANE ratios between release 1 and release 2, while release 3 can provide larger MANE reduction than the other two. The possible reason is that, in the releasing pattern of this simulation study, series of the current month are only released in the third release of each month.
In summary, this simulation study suggests that our BAY approach can successfully detect true number of contributing factors with moderate to high signals. It also has the ability to estimate latent dynamic factors accurately and produce reliable nowcasting results.
5. Empirical Study
In this section, we examine empirical performance of the BAY method using U.S. quarterly GDP growth rates. The Federal Reserve Bank of New York built a platform that has been nowcasting U.S. GDP growth rates since April 2016. The methodology behind the platform is based on the GRS method, and details can be found in Bok et al. [18]. We borrow their data from Github (https://github.com/FRBNY-TimeSeriesAnalysis/Nowcasting) in 20 April 2021. This data set contains 26 monthly series released by both government agencies and private institutions. Based on economic insights, those monthly series are assigned to nine different categories, such as labor, international trade, manufacturing, surveys, and others. All series are updated in real time; thus, the release dates for each one vary from month to month. Based on the approximate release dates for each individual series, we roughly group these series into three release dates: before 10th, from 10th to 20th, and after the 20th of a month. Table 5 provides the release pattern of the real data. The same transformations as in Bok et al. [18] are applied to monthly series to achieve stationarity. Detailed information of transformations and release patterns are available in Table 6 and Table 7.
We choose the data span from 1993Q1 to 2016Q4, which gives us data series with 288 months (96 quarters). In-sample data is chosen to be in the period from 1993Q1 to 2002Q4, while the nowcasting horizon covers 2003Q1 to 2016Q4. The GDP growth rate used in this empirical study is the annualized quarter over quarter percentage change, which is defined as:
where is the real GDP of quarter k. Figure 7 plots the GDP growth rate with nowcasting horizon on the right side of the dashed blue line. In Figure 7, we see a severe drop at around 2009Q1 which is due to the financial crisis around 2007–2008.
We apply our BAY approach to this real U.S. GDP data. In this empirical study, we assign the same prior settings as in the simulation study; the largest possible number of latent factors R is also assumed to be six as the first six principle components from PCA explain of the variation observed in monthly series, and we still use iterations after 10,000 burn-in period in the MCMC sampling. Estimations of shrinkage profiles are used to determine the number of contributing factors. Out of all estimates of shrinkage profiles, we find there are two main scenarios occurring. Figure 8 plots two examples for each of them, respectively. The left panel is the boxplot for posterior draws of shrinkage profile ’s when nowcasting 2000Q4 in the first release of the first month. This plot shows that the first factor is clearly detected to be different from the other five factors, although its value is not small. The right panel is the boxplot for ’s when nowcasting 2000Q2 in the first release of the first month. This plot, however, shows that no factor contributes to the GDP nowcasting.
Table 8 shows proportions of all nowcasts in which one factor is detected. Generally speaking, more than of cases have one factor detected to have contribution for GDP nowcasting. This is consistent with Bok et al. [18], where they assume one single common factor in their DFMs setting.
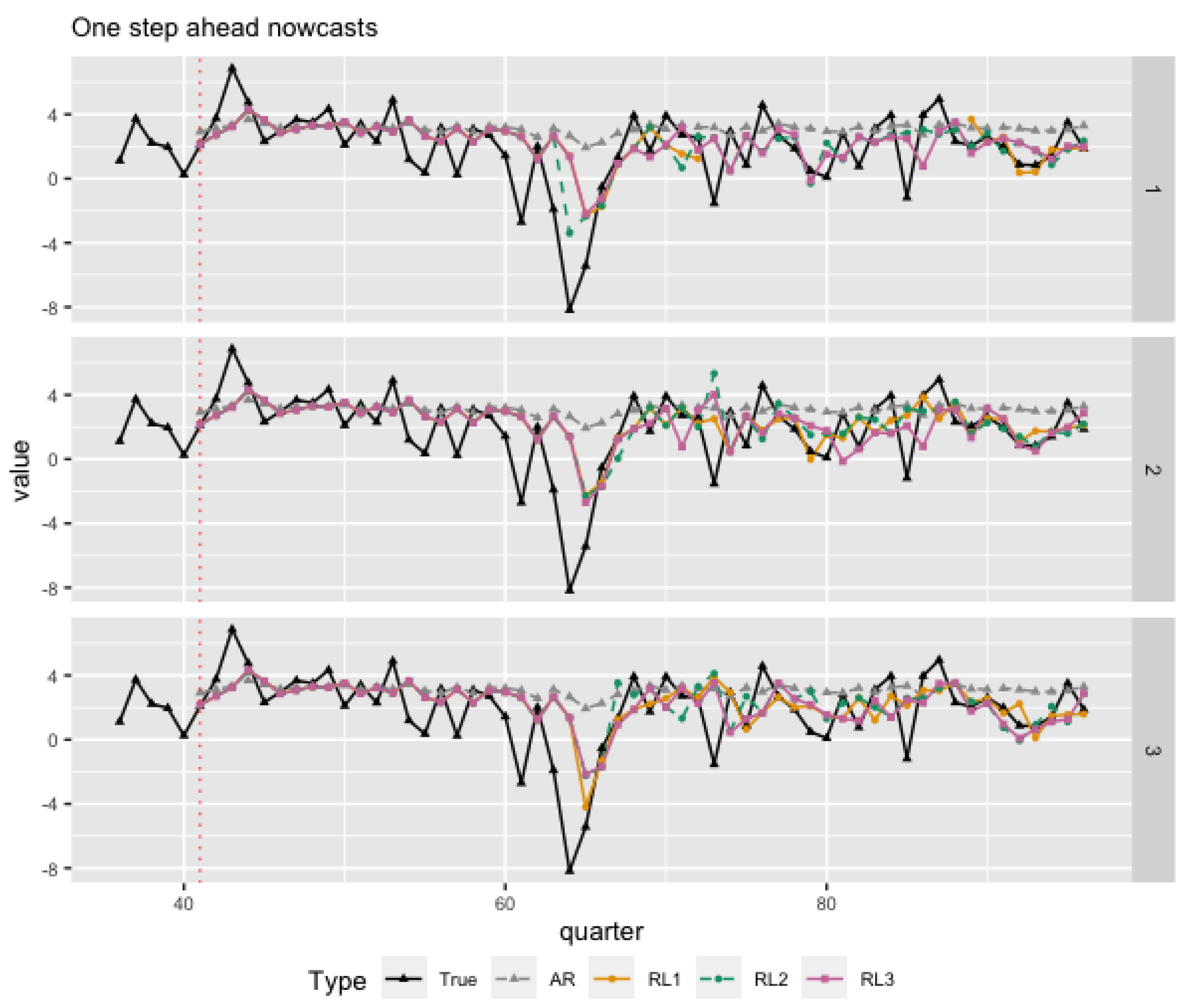
Figure 9 plots out-of-sample GDP nowcasts over last 56 quarters for each release in each month. Three rows represents three nowcasting months. In this plot, we compare our BAY approach with the autoregressive model of order 1 (AR(1)) . The AR(1) is equivalent to the case where no factor is detected. Figure 9 shows that our BAY approach can successfully capture the economic downfall due to the financial crisis at 2009Q1 with one lag delay. However, the AR(1) failed to capture it.
For the empirical study, we calculate MANE to measure nowcasting errors. Here, apart from AR(1), we also compare our BAY approach with another Bayesian model with no shrinkage priors, and we refer this model as NS. The NS model is proposed as the following: keep all other settings the same and remove from Equation (5). More specifically, in the NS model, we impose Normal priors on the ’s instead of horseshoe priors. Table 9 provides MANE reductions of BAY approach, relative to RW, AR(1), and NS. The first sub-table reports the percentage of reduction in MANEs relative to RW accross three nowcasting months, while the middle sub-table reports the percentage of reduction in MANEs relative to AR(1), and the last sub-table reports the percentage of reduction in MANEs relative to NS. Table 9 shows that our BAY approach can produce smaller nowcasting errors than the RW approach. On average, the percentages of reduction relative to RW do not have an obvious difference from first month to third month. This indicates that, for real data, having more monthly series does not necessarily lead to better nowcasting performances. One potential reason is that the quality of the data might not be perfect. Adding more series means adding more noise and thus may not guarantee more accurate nowcasts of GDP. The MANE reduction relative to AR(1) are lower than those relative to RW. However, our BAY approach can still have approximately reduction in nowcasting errors when being compared with the AR(1). This indicates that even if no factor is detected in nearly of the cases, the ones with one factor detected indeed contribute and enhance our nowcasting performance. The MANE reduction relative to NS for the first two nowcasting months are comparable and are lower than those relative to AR(1), the MANE reduction for the third month is higher than those relative to AR(1). This result indicates that using the horseshoe shrinkage idea to shrink unimportant factors to 0 can further increase our model’s nowcasting performance.
In summary, this empirical analysis demonstrates the empirical relevance of the BAY approach in nowcasting U.S. GDP. It suggests that at most one factor is sufficient for our BAY approach to provide a good performance.
6. Conclusions
Real-time nowcasting has become important in making policy decisions and long-term forecasting. In this paper, we adopt the DFM model framework and introduce a Bayesian MCMC approach for real-time nowcasting. Unlike other nowcasting methods based on DFMs, our Bayesian approach allows an unknown number of contributing factors and utilizes the horseshoe shrinkage to determine the number of contributing factors. Through the simulation study, we have shown that our Bayesian approach can identify the number of contributing factors correctly with high to moderate signals and estimate latent factors accurately. Both simulation study and empirical study validate our Bayesian approach’s ability to provide reliable real-time nowcasting results.
In this paper, we are not able to add the horseshoe shrinkage to Equation (1) due to the non-identifiable issue in DFMs. If we add as in Equation (1), there will be two layers of non-identifiable issues, which is difficult to solve. Furthermore, in this paper, the horseshoe shrinkage is only used in detecting the number of contributing factors. In our DFMs framework, we assume the GDP of quarter k depends on factors with up to two lags, i.e., factors of , , and (see Equation (3)). We might argue that this lag should not be fixed and can also be determined using the horseshoe shrinkage. These are two possible research directions that we want to explore in future investigation.
Author Contributions
Formal analysis, J.L.; Methodology, J.L. and C.L.Y.; Supervision, C.L.Y.; Writing —original draft, J.L. and C.L.Y.All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AR | Autoregressive Model |
| DFMs | Dynamic Factor Models |
| GRS | Model proposed in Giannone et al. (2008) |
| KF | Kalman Filter |
| MANE | Mean Absolute Nowcasting Error |
| MCMC | Markov Chain Monte Carlo |
| PCA | Principle Component Analysis |
| RW | Random Walk |
Appendix A. Posterior Distributions
In this Appendix, complete conditional distributions for each parameter and latent factor are provided. An MCMC algorithm is applied to draw posterior samples. For most parameters, conditional posterior distributions have closed forms, which allows for Gibbs sampling method. However, and () do not have closed-form posterior distributions, for which we use an independent Metropolis–Hastings within Gibbs sampler to generate posterior samples.
Appendix A.1. Posterior Samples for Mean of Monthly Series μ
The conditional posterior for the mean of monthly series, , is a multivariate normal distribution:
where
Appendix A.2. Posterior Samples for Factor Loading Matrix Θ
Let . The conditional posterior for the is a multivariate normal distribution:
let , then
Appendix A.3. Posterior Samples for Covariance in Monthly Series Ω
The conditional posterior for is
which is not in a closed form. We need to use Metropolis–Hastings within Gibbs sampling method to draw . The first two parts combined together yield an inverse Wishart distribution , with and . Therefore, we purpose from and use the last piece in the posterior distribution, denoted as , to construct the acceptance–rejection rate. That is, the proposal is accepted with probability
where denotes the current state of .
Appendix A.4. Posterior Samples for AR(1) Coefficients aj
For , the conditional posterior of each coefficient is:
where and .
Appendix A.5. Posterior Samples for Covariance Matrix in the Factor Equation Σ
For , the conditional posterior of each diagonal element of , , is an inverse gamma distribution:
where and .
Appendix A.6. Posterior Samples for Coefficients in GDP Equation β
The conditional posterior of coefficients connecting factors with GDP, , is a multivariate normal distribution:
where , and
where .
Appendix A.7. Posterior Samples for Variance in GDP Equation η2
The conditional posterior of the variance in GDP equation, , is an inverse gamma distribution:
where , and .
Here, , and .
Appendix A.8. Posterior Samples for Each Element in S Matrix, λj
For simplicity, we assume . The posterior for is
where is the jth element in for . This posterior does not have a closed form, and the Metropolis–Hastings within Gibbs sampling method is required to draw . If we define , the first part of the posterior yields a gamma distribution for , i.e., . Therefore, we purpose from , obtain , and use the last piece in the conditional posterior distribution to construct the acceptance–rejection rate. That is, the proposal is accepted with probability
where denotes the current state of .
Appendix A.9. Sampling the Latent Factors Ft
The posterior distribution for has different forms depending on t. Suppose is the largest integer such that , , as defined in Section 2. For , we have the most general form defined as follows:
First, we write t as for , where represents that we are in the first, second, and third month of quarter k. Then, at , enters the joint likelihood through , , and by
where is a function of i defined as
Therefore,
and
By weighted regression, for , and , draw
For other t, the posterior distribution for is of the same form with some modifications on , , and due to different availability. For example, if , since and are not available, corresponding entries to and are deleted. For , monthly series are unbalanced, change entries corresponding to in , , and .
References
- Baffgi, A.; Golinelli, R.; Parigi, G. Bridge models to forecast the euro area GDP. Int. J. Forecast. 2004, 20, 447–460. [Google Scholar] [CrossRef]
- Rünstler, G.; Sédillot, F. Short-Term Estimates of Euro Area Real GDP by Means of Monthly Data; Working Paper Series 276; European Central Bank: Frankfurt, Germany, 2003. [Google Scholar]
- Kitchen, J.; Monaco, R. Real-Time Forecasting in Practice: The U.S. Treasury Staff’s Real-Time GDP Forecast System. Bus. Econ. 2003, 38, 10–19. [Google Scholar]
- Boivin, K.; Ng, S. Understanding and Comparing Factor-Based Forecasts. Int. J. Cent. Bank. 2005, 1, 117–151. [Google Scholar]
- Forni, M.; Hallin, M.; Lippi, M.; Reichlin, L. The Generalized Dynamic Factor Model: One-Sided Estimation and Forecasting. J. Am. Stat. Assoc. 2005, 100, 830–840. [Google Scholar] [CrossRef] [Green Version]
- D’Agostino, A.; Giannone, D. Comparing Alternative Predictors Based on Large-Panel Factor Models; Working Paper Series 680; European Central Bank: Frankfurt, Germany, 2006. [Google Scholar]
- Eraslan, S.; Schröder, M. Nowcasting GDP with a Large Factor Model Space. Deutsche Bundesbank Discussion Paper No. 41/2019. 2019, Volume 41. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3507664 (accessed on 20 December 2020).
- Raftery, A.E.; Kárný, M.; Ettler, P. Online Prediction Under Model Uncertainty via Dynamic Model Averaging: Application to a Cold Rolling Mill. Technometrics 2010, 52, 52–66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Croushore, D.; Stark, T. A real-time data set for macroeconomists. J. Econom. 2001, 105, 111–130. [Google Scholar] [CrossRef] [Green Version]
- Koenig, E.F.; Dolmas, S.; Piger, J. The Use and Abuse of Real-Time Data in Economic Forecasting. Rev. Econ. Stat. 2003, 85, 618–628. [Google Scholar] [CrossRef]
- Orphanides, A. Monetary policy rules and the Great Inflation. J. Am. Econ. Assoc. 2002, 92, 115–120. [Google Scholar]
- Giannone, D.; Reichlin, L.; Small, D. Nowcasting: The real-time informational content of macroeconomic data. J. Monet. Econ. 2008, 55, 665–676. [Google Scholar] [CrossRef]
- Bai, J.; Ng, S. Determining the Number of Factors in Approximate Factor Models. Econometrica 2002, 70, 191–221. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, C.M.; Polson, N.G.; Scott, J.G. Handling sparsity via the horseshoe. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; Volume 5. [Google Scholar]
- Carvalho, C.M.; Polson, N.G.; Scott, J.G. The horseshoe estimator for sparse signals. Biometrika 2010, 97, 465–480. [Google Scholar] [CrossRef] [Green Version]
- Stock, J.H.; Watson, M.W. Forecasting Using Principal Components From a Large Number of Predictors. J. Am. Stat. Assoc. 2002, 97, 1167–1179. [Google Scholar] [CrossRef] [Green Version]
- Follett, L.; Yu, C. Achieving parsimony in Bayesian vector autoregressions with the horseshoe prior. Econom. Stat. 2019, 11, 130–144. [Google Scholar] [CrossRef]
- Bok, B.; Caratelli, D.; Giannone, D.; Sbordone, A.M.; Tambalotti, A. Macroeconomic Nowcasting and Forecasting with Big Data. Annu. Rev. Econ. 2018, 10, 615–643. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Densities of the implied prior on based on the horseshoe prior, the t prior, and the Laplacian prior.
Figure 1.
Densities of the implied prior on based on the horseshoe prior, the t prior, and the Laplacian prior.
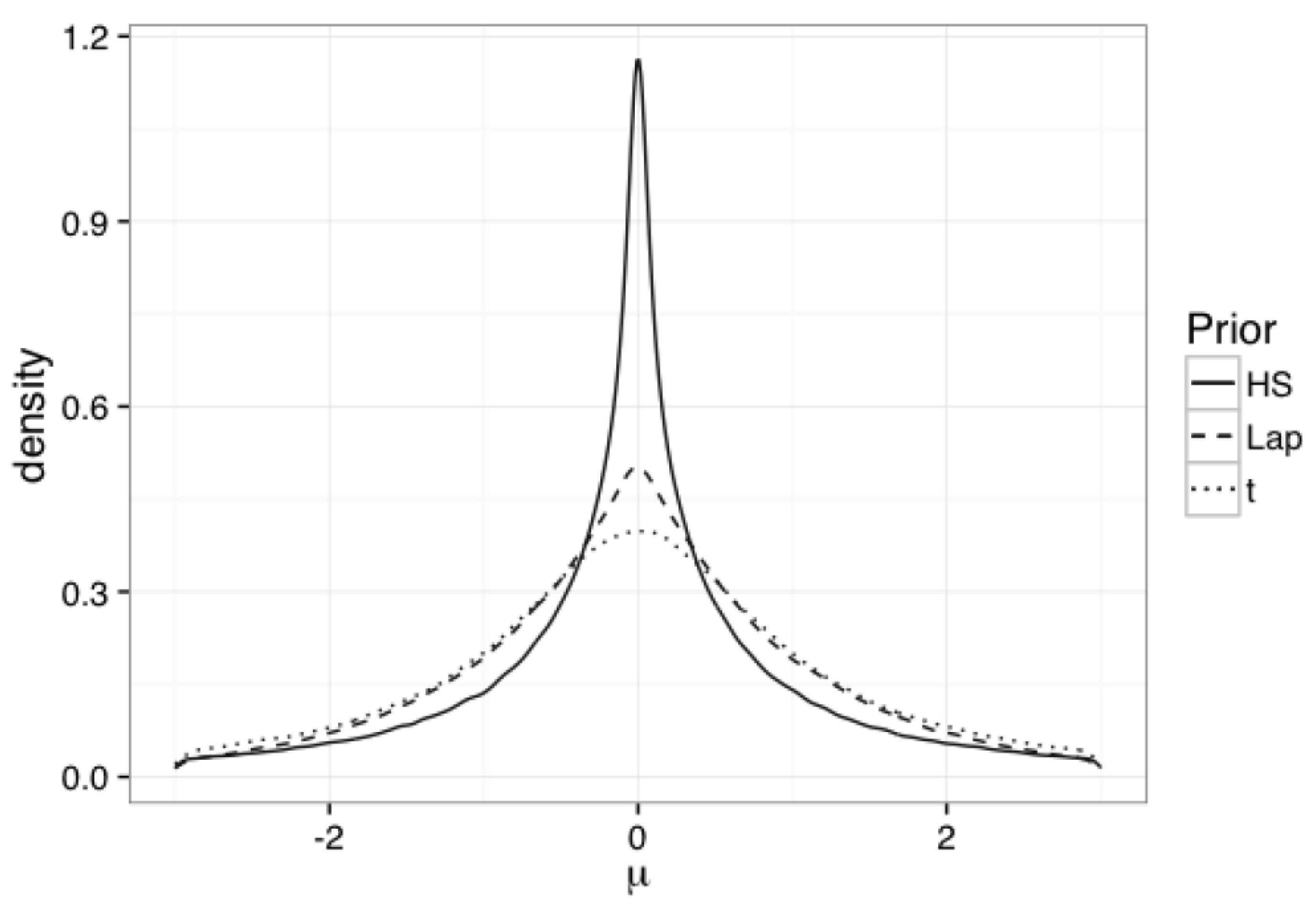
Figure 2.
Densities of the shrinkage profile based on the horseshoe prior, the t prior, and the Laplacian prior. means no shrinkage and means total shrinkage.
Figure 2.
Densities of the shrinkage profile based on the horseshoe prior, the t prior, and the Laplacian prior. means no shrinkage and means total shrinkage.

Figure 3.
Box-plots of shrinkage profile estimations for from 180 nowcast estimates. Here, . Each subplot represents the result for each simulation.
Figure 3.
Box-plots of shrinkage profile estimations for from 180 nowcast estimates. Here, . Each subplot represents the result for each simulation.
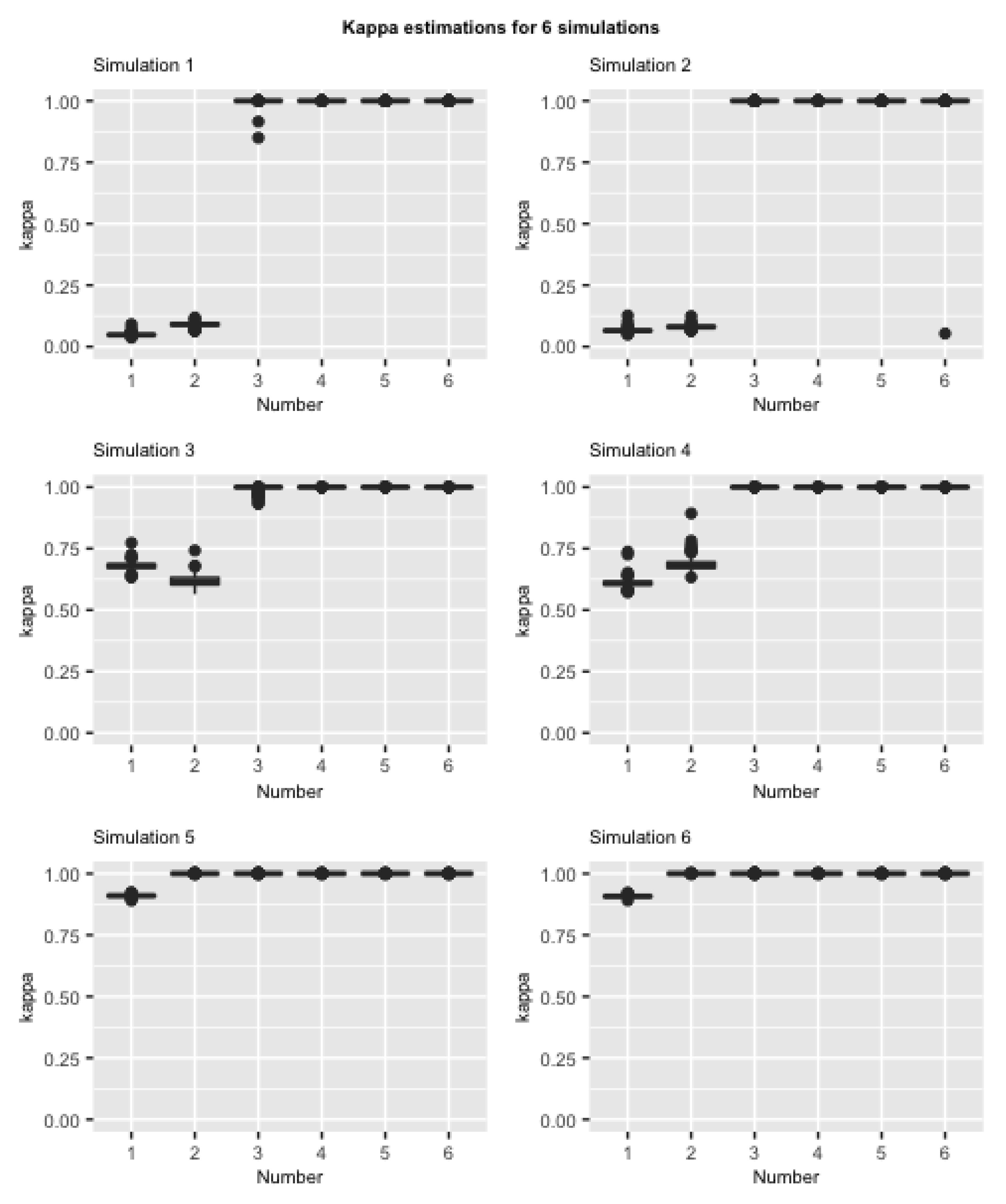
Figure 4.
Scatter splots of shrinkage profile estimations (y-axis) versus (x-axis) from 180 nowcast estimates. Each subplot represents the result for each simulation.
Figure 4.
Scatter splots of shrinkage profile estimations (y-axis) versus (x-axis) from 180 nowcast estimates. Each subplot represents the result for each simulation.
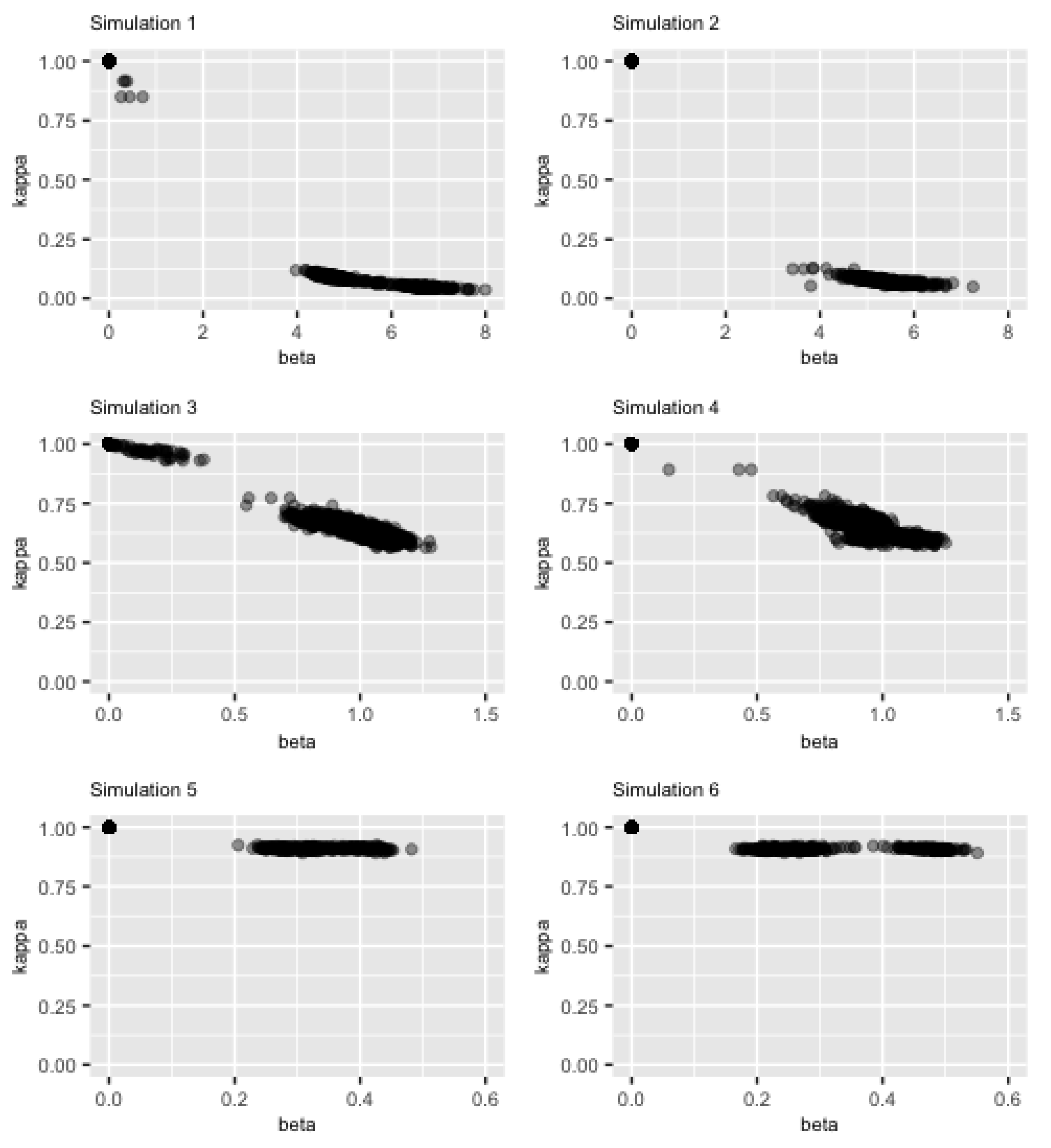
Figure 5.
In-sample fit of the latent factors for 6 simulations. Absolute value is used for both true factors and in-sample fits. Yellow lines represent in-sample fitted value and gray lines represent true value. In each subplot, the upper panel represents the comparison for the first factor, and the lower panel shows the comparison for the second factor.
Figure 5.
In-sample fit of the latent factors for 6 simulations. Absolute value is used for both true factors and in-sample fits. Yellow lines represent in-sample fitted value and gray lines represent true value. In each subplot, the upper panel represents the comparison for the first factor, and the lower panel shows the comparison for the second factor.

Figure 6.
Nowcasting performance for six simulations. Three rows in each subplot represent the first, second, and third month’s nowcasts for the last 20 quarters, respectively. Black curve represents true simulated GDP, and colored curves with different shapes represent nowcasts from different releases.
Figure 6.
Nowcasting performance for six simulations. Three rows in each subplot represent the first, second, and third month’s nowcasts for the last 20 quarters, respectively. Black curve represents true simulated GDP, and colored curves with different shapes represent nowcasts from different releases.

Figure 7.
Real U.S. GDP growth rate from 1993Q1 to 2016Q4. Period after 2003Q1 (after blue dashed line) is the nowcasting horizon.
Figure 7.
Real U.S. GDP growth rate from 1993Q1 to 2016Q4. Period after 2003Q1 (after blue dashed line) is the nowcasting horizon.
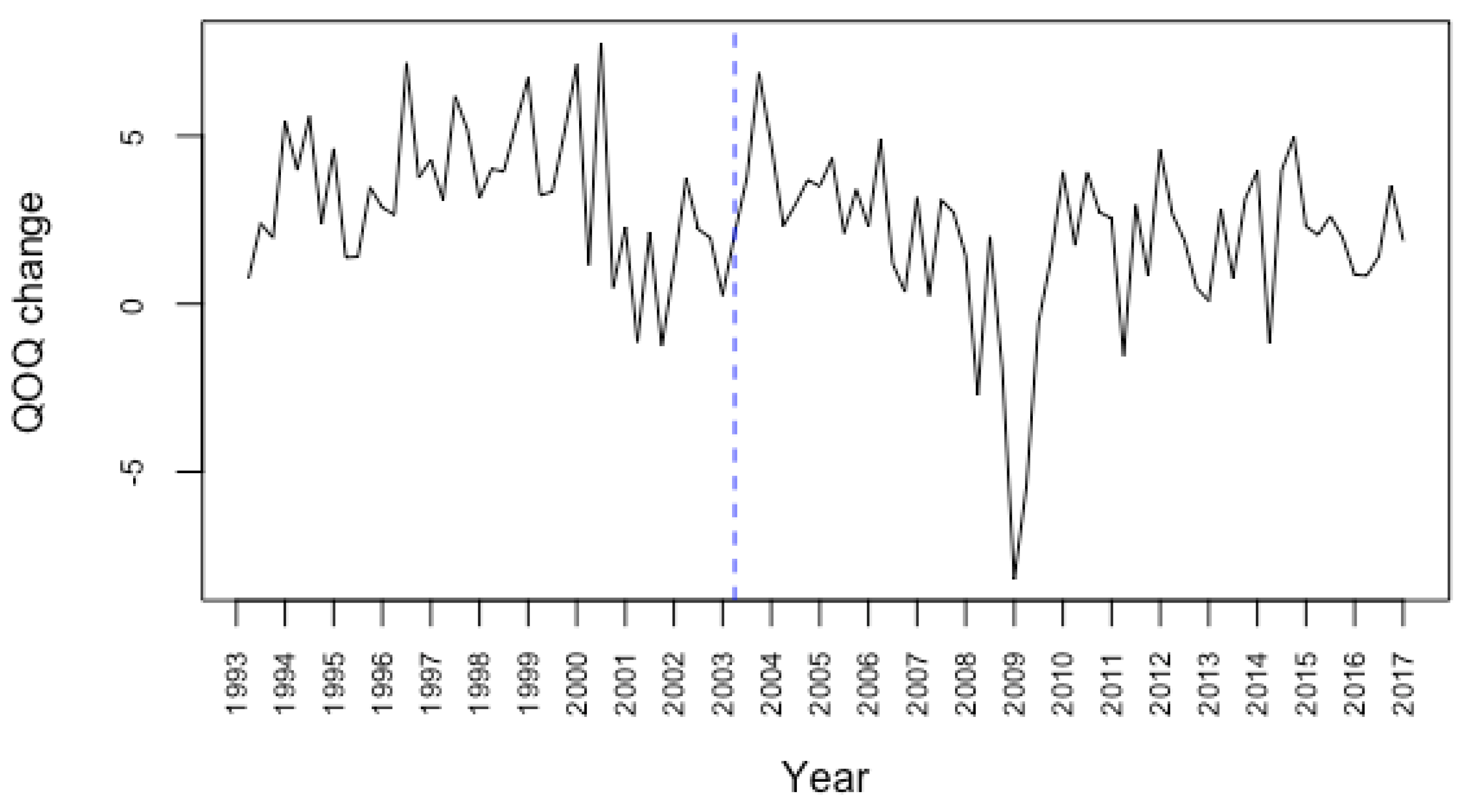
Figure 8.
Two examples of boxplots for posterior draws of . Left panel represents the one for nowcasting GDP of 2000Q4 in the first release of the first month. Right panel represents the one for nowcasting GDP of 2000Q2 in the first release of the first month.
Figure 8.
Two examples of boxplots for posterior draws of . Left panel represents the one for nowcasting GDP of 2000Q4 in the first release of the first month. Right panel represents the one for nowcasting GDP of 2000Q2 in the first release of the first month.
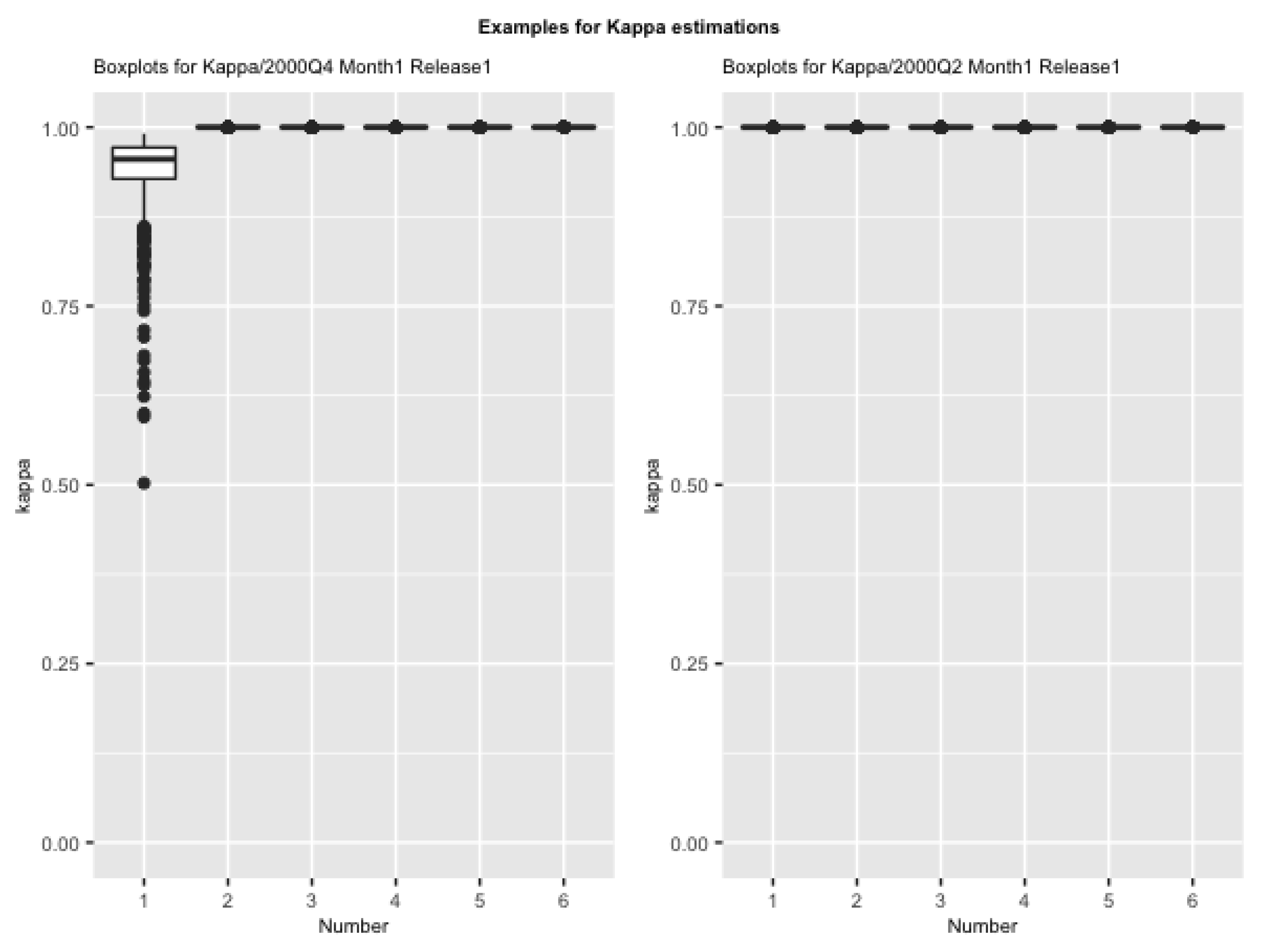
Figure 9.
Nowcasting over 2003Q1 to 2016Q4. Three rows represent three nowcasting months, respectively. Black curve represents the real GDP, while curves of different colors and shapes represent nowcasting results from 3 different release dates and AR(1).
Figure 9.
Nowcasting over 2003Q1 to 2016Q4. Three rows represent three nowcasting months, respectively. Black curve represents the real GDP, while curves of different colors and shapes represent nowcasting results from 3 different release dates and AR(1).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
An example of the overall releasing pattern. Gray colored cells represent available series before T. Orange, green, and blue represent the 1st, 2nd, and 3rd release within T, respectively.
Table 1.
An example of the overall releasing pattern. Gray colored cells represent available series before T. Orange, green, and blue represent the 1st, 2nd, and 3rd release within T, respectively.
| k | 1 | … | K | K + 1 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| t | 1 | 2 | 3 | … | T − 4 | T − 3 | T − 2 | T − 1 | T | T + 1 |
| … | NA | |||||||||
| … | NA | |||||||||
| … | NA | NA | ||||||||
| … | NA | NA | ||||||||
| … | NA | NA | NA | |||||||
| … | NA | NA | NA | |||||||
| … | ||||||||||
Table 2.
Data releasing structure for simulation study when nowcasting quarter ’s GDP in month T. “RL” represents release. Orange color represents release 1, green represents release 2, and blue represents release 3.
Table 2.
Data releasing structure for simulation study when nowcasting quarter ’s GDP in month T. “RL” represents release. Orange color represents release 1, green represents release 2, and blue represents release 3.
| Month | T-3 | T-2 | T-1 | T |
|---|---|---|---|---|
| Series 1–20 | Known | Known | Known | RL3 |
| Series 21–40 | Known | Known | RL2 | |
| Series 41–60 | Known | RL1 |
Table 3.
Settings for . For each simulation, the first 2 factors are contributing factors, and other 4 factors contribute little or 0 to GDP prediction.
Table 3.
Settings for . For each simulation, the first 2 factors are contributing factors, and other 4 factors contribute little or 0 to GDP prediction.
| Simulation | |||
|---|---|---|---|
| 1 | |||
| 2 | 0 | ||
| 3 | |||
| 4 | 0 | ||
| 5 | |||
| 6 | 0 |
Table 4.
This table reports percentages of reduction in MANE relative to RW, which are calculated as , for six simulation studies.
Table 4.
This table reports percentages of reduction in MANE relative to RW, which are calculated as , for six simulation studies.
| Simulation | 1 | 2 | ||||
|---|---|---|---|---|---|---|
| Release | 1st Month | 2nd Month | 3rd Month | 1st Month | 2nd Month | 3rd Month |
| 1st | ||||||
| 2nd | ||||||
| 3rd | ||||||
| Average | ||||||
| Simulation | 3 | 4 | ||||
| Release | 1st Month | 2nd Month | 3rd Month | 1st Month | 2nd Month | 3rd Month |
| 1st | ||||||
| 2nd | ||||||
| 3rd | ||||||
| Average | ||||||
| Simulation | 5 | 6 | ||||
| Release | 1st Month | 2nd Month | 3rd Month | 1st Month | 2nd Month | 3rd Month |
| 1st | ||||||
| 2nd | ||||||
| 3rd | ||||||
| Average | ||||||
Table 5.
Data releasing structure in the empirical study when nowcasting quarter ’s GDP in month T. RL stands for release, with release 1 colored in orange, released 2 colored in green, and release 3 colored in blue. The number in parentheses represents number of series for that particular release.
Table 5.
Data releasing structure in the empirical study when nowcasting quarter ’s GDP in month T. RL stands for release, with release 1 colored in orange, released 2 colored in green, and release 3 colored in blue. The number in parentheses represents number of series for that particular release.
| Month | T-3 | T-2 | T-1 | T |
|---|---|---|---|---|
| Set 1 (2) | Known | Known | Known | RL2 (2) |
| Set 2 (2) | Known | Known | RL1 (2) | |
| Set 3 (10) | Known | Known | RL2 (10) | |
| Set 4 (7) | Known | Known | RL3 (7) | |
| Set 5 (5) | Known | RL1 (5) | ||
| Set 6 (3) | Known | RL2 (3) |
Table 6.
Data transformation types: represents raw data, and represents the transformed data.
| Type | Transformation | Description |
|---|---|---|
| 1 | No transformation | |
| 2 | Level change | |
| 3 | Month-to-month change |
Table 7.
Release groups, transformation types, and lag information for monthly series used in the empirical study.
Table 7.
Release groups, transformation types, and lag information for monthly series used in the empirical study.
| Release | Block | Name | Transformation | Lag |
|---|---|---|---|---|
| 1st | Housing and construction | TTLCONS | 3 | 2 |
| International trade | BOPTEXP | 3 | 2 | |
| BOPTIMP | 3 | 2 | ||
| Manufacturing | BUSINV | 3 | 2 | |
| Labor | PAYEMS | 2 | 1 | |
| JTSJOL | 2 | 2 | ||
| UNRATE | 2 | 1 | ||
| 2nd | International trade | IR | 3 | 1 |
| IQ | 3 | 1 | ||
| Retail and consumption | RSAFS | 3 | 1 | |
| Survey | GACDISA066MSFRBNY | 1 | 0 | |
| GACDFSA066MSFRBNY | 1 | 0 | ||
| Manufacturing | INDPRO | 3 | 1 | |
| TCU | 2 | 1 | ||
| Other | CPIAUCSL | 3 | 1 | |
| CPILFESL | 3 | 1 | ||
| PPIFIS | 3 | 1 | ||
| Housing and construction | HOUST | 3 | 1 | |
| PERMIT | 2 | 1 | ||
| 3rd | Manufacturing | DGORDER | 3 | 1 |
| WHLSLRIMSA | 3 | 1 | ||
| Housing and construction | HSNIF | 3 | 1 | |
| Income | DSPIC96 | 3 | 1 | |
| Retail and consumption | PCEC96 | 3 | 1 | |
| Other | PCEPI | 3 | 1 | |
| PCEPILIFE | 3 | 1 |
Table 8.
This table reports percentages of nowcasts in which one factor is detected.
| Method | BAY | ||
|---|---|---|---|
| Release | 1st Month | 2nd Month | 3rd Month |
| 1st | |||
| 2nd | |||
| 3rd | |||
| Average | |||
Table 9.
This table reports percentages of reduction in MANE’s relative to RW, AR(1), and NS, i.e., , here * can be RW, AR(1), or NS.
Table 9.
This table reports percentages of reduction in MANE’s relative to RW, AR(1), and NS, i.e., , here * can be RW, AR(1), or NS.
| Compare with | RW | ||
|---|---|---|---|
| Release | 1st Month | 2nd Month | 3rd Month |
| 1st | |||
| 2nd | |||
| 3rd | |||
| Average | |||
| Compare with | AR(1) | ||
| Release | 1st Month | 2nd Month | 3rd Month |
| 1st | |||
| 2nd | |||
| 3rd | |||
| Average | |||
| Compare with | NS | ||
| Release | 1st Month | 2nd Month | 3rd Month |
| 1st | |||
| 2nd | |||
| 3rd | |||
| Average | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Luo, J.; Yu, C.L. Determining Number of Factors in Dynamic Factor Models Contributing to GDP Nowcasting. Mathematics 2021, 9, 2865. https://doi.org/10.3390/math9222865
AMA Style
Luo J, Yu CL. Determining Number of Factors in Dynamic Factor Models Contributing to GDP Nowcasting. Mathematics. 2021; 9(22):2865. https://doi.org/10.3390/math9222865
Chicago/Turabian StyleLuo, Jiayi, and Cindy Long Yu. 2021. "Determining Number of Factors in Dynamic Factor Models Contributing to GDP Nowcasting" Mathematics 9, no. 22: 2865. https://doi.org/10.3390/math9222865
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.