A New Descent Algorithm Using the Three-Step Discretization Method for Solving Unconstrained Optimization Problems


Abstract
:1. Introduction
- 1.
- Specify the initial starting vector ,
- 2.
- Find an appropriate search direction ,
- 3.
- Specify the convergence criteria for termination,
- 4.
- Minimize along the direction to find a new point from the following equation
2. Related Work
2.1. Steepest Descent Method
2.2. Newton Method
2.3. Conjugate Gradient Methods
3. New Descent Algorithm
3.1. Three-Step Discretization Algorithm
| Algorithm 1 Pseudo-code of the three-step discretization method |
 |
3.2. Theoretical Analysis of the Three-Step Discretization Algorithm
4. Convergence
- (i)
- the modified Armijo conditionis satisfied for all , where
- (ii)
- for fixed the step size generated by the backtracking algorithm with modified Armijo condition (9) terminates with
- (i)
- the modified Armijo conditionis satisfied for all , where
- (ii)
- for fixed the step size generated by the backtracking algorithm with modified Armijo condition of Equation (12) terminates with
- (i)
- the Armijo conditionis satisfied for all , where
- (ii)
- for fixed the step size generated by the backtracking algorithm with Armijo condition of Equation (14) terminates with
- (i)
- , for some and ,
- (ii)
- ,,
- (iii)
- ,.
5. Numerical Experiments
- Iterative numbers (denote by NI) for attaining the same stopping criterion .
- Evaluation numbers of f (denote by Nf)
- Evaluation numbers of (denote by Ng)
- Difference between the value of the function at the optimal point and the value of the function at the last calculated point as the accuracy of the method; i.e., .
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Ahookhosh, M.; Ghaderi, S. On efficiency of nonmonotone Armijo-type line searches. Appl. Math. Model. 2017, 43, 170–190. [Google Scholar] [CrossRef]
- Andrei, N. A new three-term conjugate gradient algorithm for unconstrained optimization. Numer. Algorithms 2015, 68, 305–321. [Google Scholar] [CrossRef]
- Edgar, T.F.; Himmelblau, D.M.; Lasdon, L.S. Optimization of Chemical Processes; McGraw-Hill: New York, NY, USA, 2001. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer Verlag: New York, NY, USA, 2006. [Google Scholar]
- Shi, Z.J. Convergence of line search methods for unconstrained optimization. Appl. Math. Comput. 2004, 157, 393–405. [Google Scholar] [CrossRef]
- Vieira, D.A.G.; Lisboa, A.C. Line search methods with guaranteed asymptotical convergence to an improving local optimum of multimodal functions. Eur. J. Oper. Res. 2014, 235, 38–46. [Google Scholar] [CrossRef]
- Yuan, G.; Wei, Z.; Lu, X. Global convergence of BFGS and PRP methods under a modified weak Wolfe-Powell line search. Appl. Math. Model. 2017, 47, 811–825. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, D. Derivative-free restrictively preconditioned conjugate gradient path method without line search technique for solving linear equality constrained optimization. Comput. Math. Appl. 2017, 73, 277–293. [Google Scholar] [CrossRef]
- Zhou, G. A descent algorithm without line search for unconstrained optimization. Appl. Math. Comput. 2009, 215, 2528–2533. [Google Scholar] [CrossRef]
- Zhou, G.; Feng, C. The steepest descent algorithm without line search for p-Laplacian. Appl. Math. Comput. 2013, 224, 36–45. [Google Scholar] [CrossRef]
- Koks, D. Explorations in Mathematical Physics: The Concepts Behind an Elegant Language; Springer Science: New York, NY, USA, 2006. [Google Scholar]
- Dennis, J.E., Jr.; Schnabel, R.B. Numerical Methods for Unconstrained Optimization and Nonlinear Equations; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Otmar, S. A convergence analysis of a method of steepest descent and a two-step algorothm for nonlinear ill–posed problems. Numer. Funct. Anal. Optim. 1996, 17, 197–214. [Google Scholar] [CrossRef]
- Ebadi, M.J.; Hosseini, A.; Hosseini, M.M. A projection type steepest descent neural network for solving a class of nonsmooth optimization problems. Neurocomputing 2017, 193, 197–202. [Google Scholar] [CrossRef]
- Yousefpour, R. Combination of steepest descent and BFGS methods for nonconvex nonsmooth optimization. Numer. Algorithms 2016, 72, 57–90. [Google Scholar] [CrossRef]
- Gonzaga, C.C.; Schneider, R.M. On the steepest descent algorithm for quadratic functions. Comput. Optim. Appl. 2016, 63, 523–542. [Google Scholar] [CrossRef]
- Jiang, C.B.; Kawahara, M. A three-step finite element method for unsteady incompressible flows. Comput. Mech. 1993, 11, 355–370. [Google Scholar] [CrossRef]
- Kumar, B.V.R.; Kumar, S. Convergence of Three-Step Taylor Galerkin finite element scheme based monotone schwarz iterative method for singularly perturbed differential-difference equation. Numer. Funct. Anal. Optim. 2015, 36, 1029–1045. [Google Scholar]
- Kumar, B.V.R.; Mehra, M. A three-step wavelet Galerkin method for parabolic and hyperbolic partial differential equations. Int. J. Comput. Math. 2006, 83, 143–157. [Google Scholar] [CrossRef]
- Cauchy, A. General method for solving simultaneous equations systems. Comp. Rend. Sci. 1847, 25, 46–89. [Google Scholar]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Dai, Y.H.; Fletcher, R. Projected Barzilai-Borwein methods for large-scale box-constrained quadratic programming. Numer. Math. 2005, 100, 21–47. [Google Scholar]
- Hassan, M.A.; Leong, W.J.; Farid, M. A new gradient method via quasicauchy relation which guarantees descent. J. Comput. Appl. Math. 2009, 230, 300–305. [Google Scholar] [CrossRef]
- Leong, W.J.; Hassan, M.A.; Farid, M. A monotone gradient method via weak secant equation for unconstrained optimization. Taiwan. J. Math. 2010, 14, 413–423. [Google Scholar] [CrossRef]
- Tan, C.; Ma, S.; Dai, Y.; Qian, Y. Barzilai-Borwein step size for stochastic gradient descent. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Raydan, M. On the Barzilai and Borwein choice of steplength for the gradient method. IMA J. Numer. Anal. 1993, 13, 321–326. [Google Scholar] [CrossRef]
- Dai, Y.H.; Liao, L.Z. R-linear convergence of the Barzilai and Borwein gradient method. IMA J. Numer. Anal. 2002, 26, 1–10. [Google Scholar] [CrossRef]
- Dai, Y.H. A New Analysis on the Barzilai-Borwein Gradient Method. J. Oper. Res. Soc. China 2013, 1, 187–198. [Google Scholar] [CrossRef]
- Yuan, Y. A new stepsize for the steepest descent method. J. Comput. Appl. Math. 2006, 24, 149–156. [Google Scholar]
- Manton, J.M. Modified steepest descent and Newton algorithms for orthogonally constrained optimisation: Part II The complex Grassmann manifold. In Proceedings of the Sixth International Symposium on Signal Processing and its Applications (ISSPA), Kuala Lumpur, Malaysia, 13–16 August 2001. [Google Scholar]
- Shan, G.H. Gradient-Type Methods for Unconstrained Optimization. Bachelor’s Thesis, University Tunku Abdul Rahman, Petaling Jaya, Malaysia, 2016. [Google Scholar]
- Hestenes, M.R.; Stiefel, M. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H. A survey of nonlinear conjugate gradient methods. Pac. J. Optim. 2006, 2, 35–58. [Google Scholar]
- Dai, Y.H.; Liao, L.Z. New conjugacy conditions and related nonlinear conjugate gradient methods. Appl. Math. Optim. 2001, 43, 87–101. [Google Scholar] [CrossRef]
- Kobayashi, M.; Narushima, M.; Yabe, H. Nonlinear conjugate gradient methods with structured secant condition for nonlinear least squares problems. J. Comput. Appl. Math. 2010, 234, 375–397. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Li, D. Global convergence of a modified Fletcher-Reeves conjugate gradient method with Armijo-type line search. Numer. Math. 2006, 104, 561–572. [Google Scholar] [CrossRef]
- Sugiki, K.; Narushima, Y.; Yabe, H. Globally convergent three-term conjugate gradient methods that use secant conditions and generate descent search directions for unconstrained optimization. J. Optim. Theory Appl. 2012, 153, 733–757. [Google Scholar] [CrossRef]
- Jamil, M.; Yang, X.S. A literature survey of benchmark functions for global optimization problems. Int. J. Math. Model. Numer. Optim. 2013, 4, 150–194. [Google Scholar]
- Molga, M.; Smutnicki, C. Test Functions for Optimization Needs, 2005. Available online: http://www.robertmarks.org/Classes/ENGR5358/Papers/functions.pdf (accessed on 30 June 2013).
- Papa Quiroz, E.A.; Quispe, E.M.; Oliveira, P.R. Steepest descent method with a generalized Armijo search for quasiconvex functions on Riemannian manifolds. J. Math. Anal. Appl. 2008, 341, 467–477. [Google Scholar] [CrossRef]
- Moré, J.J.; Garbow, B.S.; Hillstrome, K.E. Testing unconstrained optimization software. ACM Trans. Math. Softw. 1981, 7, 17–41. [Google Scholar]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. Ser. A 2002, 91, 201–213. [Google Scholar]
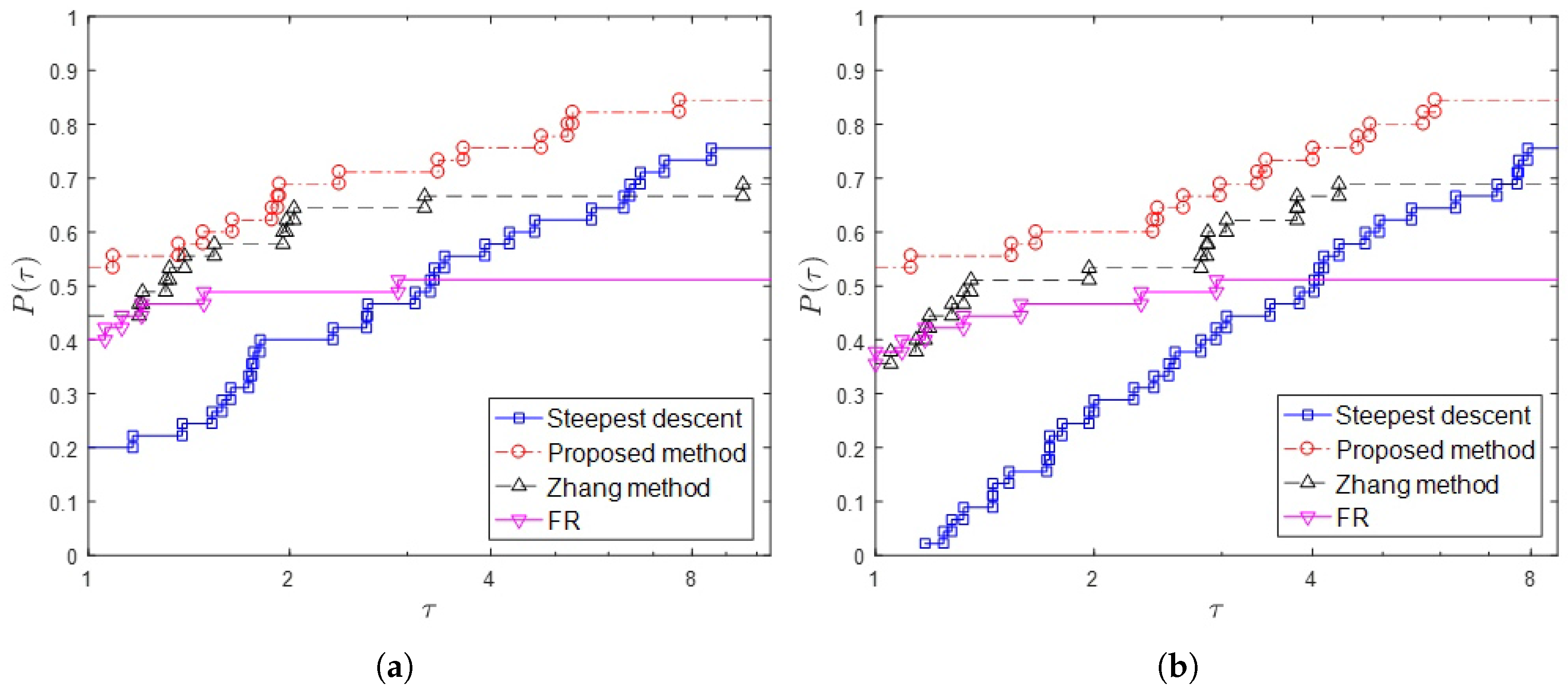

{kind=link}
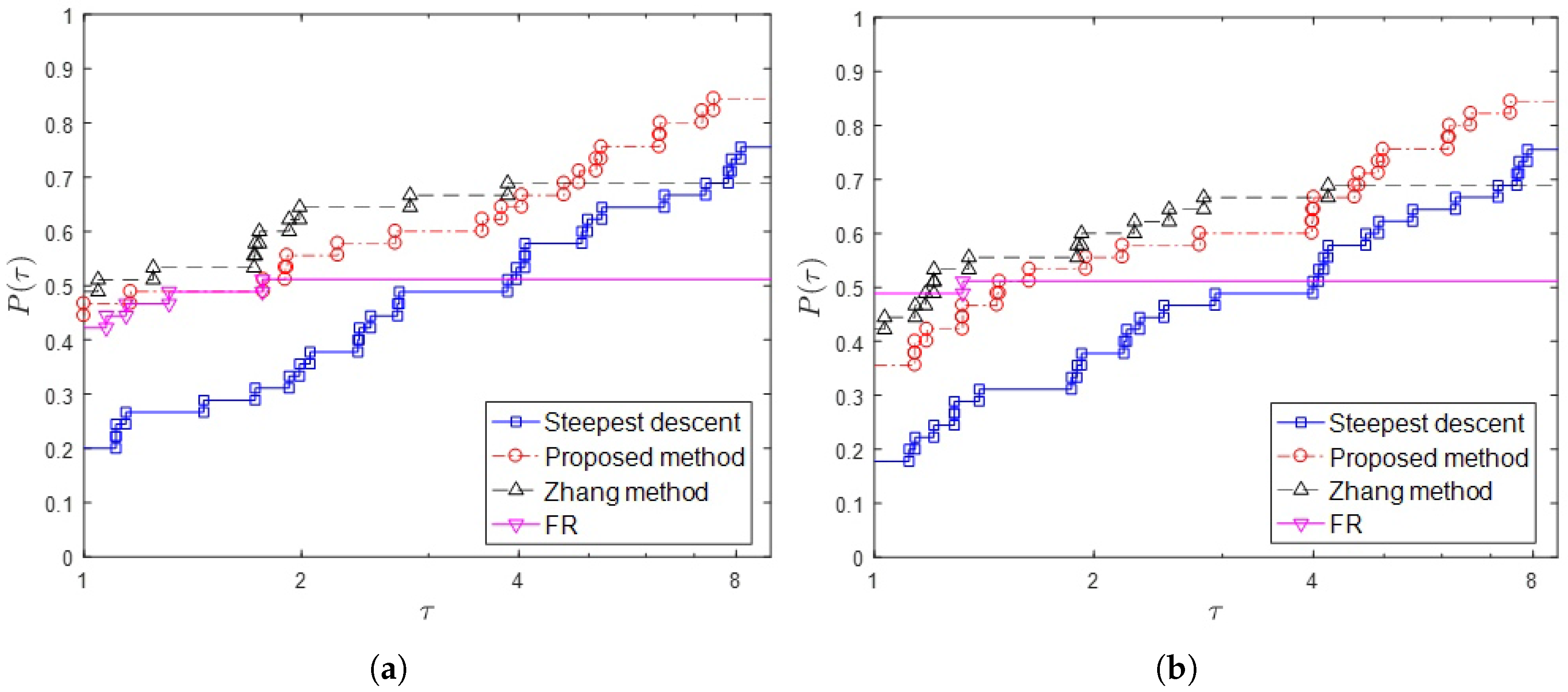
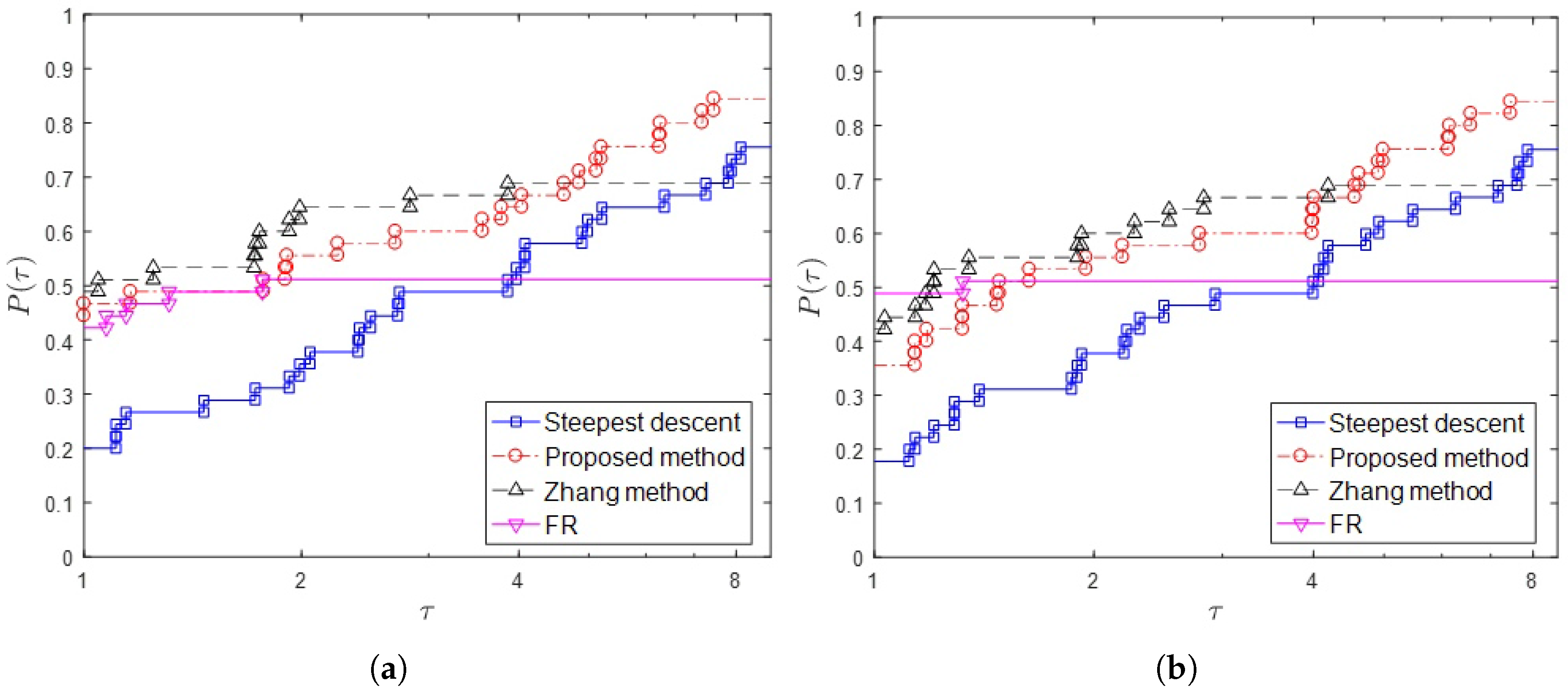{kind=link}
| 2 | Freudenstein and Roth | 2 | Rosenbrock | 2 | Powell Badly Scaled | 2 | Brown Badly Scaled | 2 | |
| Helical Valley | 3 | Bard | 3 | Gaussian | 3 | Meyer | 3 | Powell Singular | 4 |
| Wood | 4 | Kowalik and Osborne | 4 | Brown and Dennis | 4 | Biggs EXP6 | 6 | Variably Dimensioned | 10 |
| 10 | 10 | 10 | Broyden Banded | 10 | Penalty I | 10 | |||
| Zakharov | 10 | Qing | 10 | Extended Rosenbrock | 16 | Zakharov | 40 | Alpine N. 1 | 40 |
| Trigonometric | 50 | Extended Rosenbrock | 100 | Extended Powell Singular | 100 | Penalty I | 100 | Discrete Integral Equation | 100 |
| Broyden Tridiagonal | 100 | Broyden Banded | 100 | Zakharov | 100 | Dixon-Price | 100 | Penalty I | 1000 |
| Rotated Hyper-ellipsoid | 1000 | Rastrigin | 1000 | Exponential function | 1000 | Sum-Squares | 1000 | Periodic function | 1000 |
| Ackley | 1000 | Griewank | 1000 | Sphere | 1000 | Shubert | 1000 | Quartic | 1000 |
| Function | Dimension | Steepest Descent | FR | Zhang Method | Proposed Method |
|---|---|---|---|---|---|
| 2 | F | F | F | 2 | |
| Bard | 3 | 10,381 | F | F | 3600 |
| Kowalik and Osborne | 4 | 123 | F | 24 | 23 |
| Brown and Dennis | 4 | F | F | 90 | 117 |
| 10 | 66 | 17 | 66 | 8 | |
| Extended Rosenbrock | 16 | 6504 | 27 | 42 | 663 |
| Zakharov | 40 | F | F | F | 2 |
| Alpine N. 1 | 40 | F | F | F | 2 |
| Trigonometric | 50 | 33 | F | 22 | 10 |
| Penalty I | 100 | 12 | 5 | 28 | 2 |
| Discrete Integral Equation | 100 | 21 | 9 | 21 | 3 |
| Broyden Banded | 100 | 100 | F | F | 7 |
| Rotated Hyper-ellipsoid | 1000 | 60 | 28 | 24 | 18 |
| Rastrigin | 1000 | 7 | 4 | 28 | 2 |
| Periodic function | 1000 | 163 | 8 | 163 | 8 |
| Function | Dimension | Steepest Descent | FR | Zhang Method | Proposed Method |
|---|---|---|---|---|---|
| 2 | F | F | F | 9 | |
| Bard | 3 | 49,479 | F | F | 44,354 |
| Kowalik and Osborne | 4 | 360 | F | 68 | 152 |
| Brown and Dennis | 4 | F | F | 1468 | 5521 |
| 10 | 1123 | 283 | 1123 | 393 | |
| Extended Rosenbrock | 16 | 64,567 | 232 | 384 | 17,876 |
| Zakharov | 40 | F | F | F | 73 |
| Alpine N. 1 | 40 | F | F | F | 7 |
| Trigonometric | 50 | 42 | F | 43 | 31 |
| Penalty I | 100 | 69 | 32 | 84 | 25 |
| Discrete Integral Equation | 100 | 43 | 15 | 43 | 13 |
| Broyden Banded | 100 | 700 | F | F | 133 |
| Rotated Hyper-ellipsoid | 1000 | 351 | 164 | 163 | 285 |
| Rastrigin | 1000 | 64 | 47 | 29 | 37 |
| Periodic function | 1000 | 334 | 23 | 334 | 46 |
| Function | Dimension | Steepest Descent | FR | Zhang Method | Proposed Method |
|---|---|---|---|---|---|
| 2 | F | F | F | 7 | |
| Bard | 3 | 10,382 | F | F | 9354 |
| Kowalik and Osborne | 4 | 124 | F | 25 | 70 |
| Brown and Dennis | 4 | F | F | 91 | 352 |
| 10 | 67 | 18 | 67 | 25 | |
| Extended Rosenbrock | 16 | 6505 | 28 | 43 | 1987 |
| Zakharov | 40 | F | F | F | 7 |
| Alpine N. 1 | 40 | F | F | F | 7 |
| Trigonometric | 50 | 34 | F | 23 | 31 |
| Penalty I | 100 | 13 | 6 | 29 | 7 |
| Discrete Integral Equation | 100 | 22 | 10 | 22 | 10 |
| Broyden Banded | 100 | 101 | F | F | 22 |
| Rotated Hyper-ellipsoid | 1000 | 61 | 29 | 25 | 55 |
| Rastrigin | 1000 | 8 | 5 | 29 | 7 |
| Periodic function | 1000 | 164 | 9 | 164 | 25 |
| Function | Dimension | Steepest Descent | FR | Zhang Method | Proposed Method |
|---|---|---|---|---|---|
| 2 | F | F | F | ||
| Bard | 3 | F | F | ||
| Kowalik and Osborne | 4 | F | |||
| Brown and Dennis | 4 | F | F | ||
| 10 | |||||
| Extended Rosenbrock | 16 | ||||
| Zakharov | 40 | F | F | F | |
| Alpine N. 1 | 40 | F | F | F | |
| Trigonometric | 50 | F | |||
| Penalty I | 100 | ||||
| Discrete Integral Equation | 100 | ||||
| Broyden Banded | 100 | F | F | ||
| Rotated Hyper-ellipsoid | 1000 | ||||
| Rastrigin | 1000 | ||||
| Periodic function | 1000 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torabi, M.; Hosseini, M.-M. A New Descent Algorithm Using the Three-Step Discretization Method for Solving Unconstrained Optimization Problems. Mathematics 2018, 6, 63. https://doi.org/10.3390/math6040063
Torabi M, Hosseini M-M. A New Descent Algorithm Using the Three-Step Discretization Method for Solving Unconstrained Optimization Problems. Mathematics. 2018; 6(4):63. https://doi.org/10.3390/math6040063
Chicago/Turabian StyleTorabi, Mina, and Mohammad-Mehdi Hosseini. 2018. "A New Descent Algorithm Using the Three-Step Discretization Method for Solving Unconstrained Optimization Problems" Mathematics 6, no. 4: 63. https://doi.org/10.3390/math6040063
APA StyleTorabi, M., & Hosseini, M.-M. (2018). A New Descent Algorithm Using the Three-Step Discretization Method for Solving Unconstrained Optimization Problems. Mathematics, 6(4), 63. https://doi.org/10.3390/math6040063