

An Approach Based on Intuitionistic Fuzzy Sets for Considering Stakeholders’ Satisfaction, Dissatisfaction, and Hesitation in Software Features Prioritization

 ,
,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Related Work
2.1. Overview of Software Requirements/Features Prioritization Methods
- Measuring Scales:
- Nominal: Candidate requirements/features are classified into classes, with items in each class deemed of equal priority, yet without any inherent ordering.
- Ordinal: Techniques produce an ordered list of requirements/features in an intuitive manner.
- Ratio scale-based: Methods provide information about the relative difference between any two requirements/features.
- Level of Automation:
- Manual: All steps of the prioritization process are performed manually.
- Automated: All steps are executed by automated tools or algorithmic techniques without stakeholder intervention.
- Semi-automated: Some steps are manual, while others are executed by tools/computational techniques.
- Consideration of Stakeholder Importance [8]:
- Subjective methods: Few approaches in the literature emphasize prioritizing stakeholders based on their impact, often with limitations such as being time-consuming and lacking automation.
- Project Size:
- Handling Dependencies:
- Consideration or lack thereof of dependencies among requirements/features, acknowledging that some may functionally or logically depend on each other and should be treated as a group for prioritization and subsequent development planning [23].
2.2. Comparison of the Proposed Approach with Existing Prioritization Methods
2.3. Stakeholders’ Satisfaction and Dissatisfaction as Prioritization Criteria
2.4. Fuzzy Sets-Based Methods in Software Requirements/Features Prioritization
3. Problem and Method Description
3.1. Mapping Features Rankings into IFSs
3.2. Quantifying the Hesitation of Stakeholders
3.3. Computing Rankings Weights and Features Priorities
4. Prioritization Case Study
4.1. Case Study Context
4.2. Stakeholders Selection
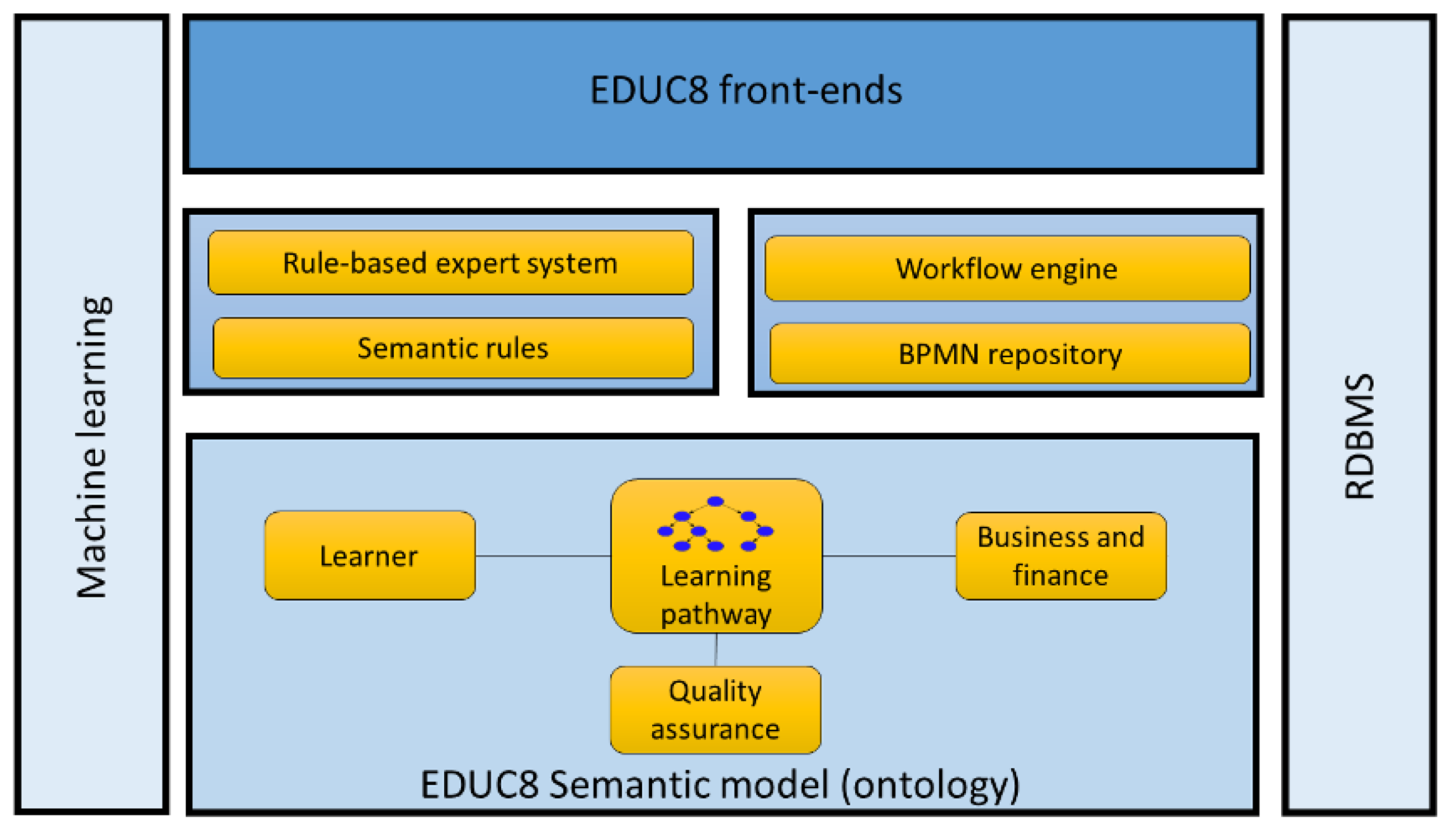
4.3. Architectural Description of Software
4.4. Application of the Proposed Approach
- Calculating total hesitation solely due to tied features using Equation (6).
- Calculating total hesitation exclusively due to unknown features via Equation (7).
- Determining total hesitation attributed to tied features with a modified weighting approach based on Equation (8), assigning lower weights to rankings with a higher number of tied features at top positions.
- I feel familiar with the features considered for prioritization: 4.2;
- The method was simple to use: 4.0;
- I have understood the key ideas of the method: 4.4;
- I agree with the key ideas of the method: 3.6;
- The method can effectively prioritize software features: 4.2;
- The method can efficiently support the feature prioritization process: 3.6;
- It was easy to learn how to use the BSTV tool: 4.4;
- I believe that the method can be easily applied in practice: 3.2;
- I believe the proposed method increases the chances of recommending the most valuable features to be implemented: 4.2;
- Overall, I am satisfied with the method results: 4.0.
5. Discussion
5.1. Case Study Design and Planning
5.2. Collection of Data
5.3. Analysis of Collected Data
- The prioritization method employs two asymmetric criteria (satisfaction and dissatisfaction), highlighting the asymmetry in the perceived value of features.
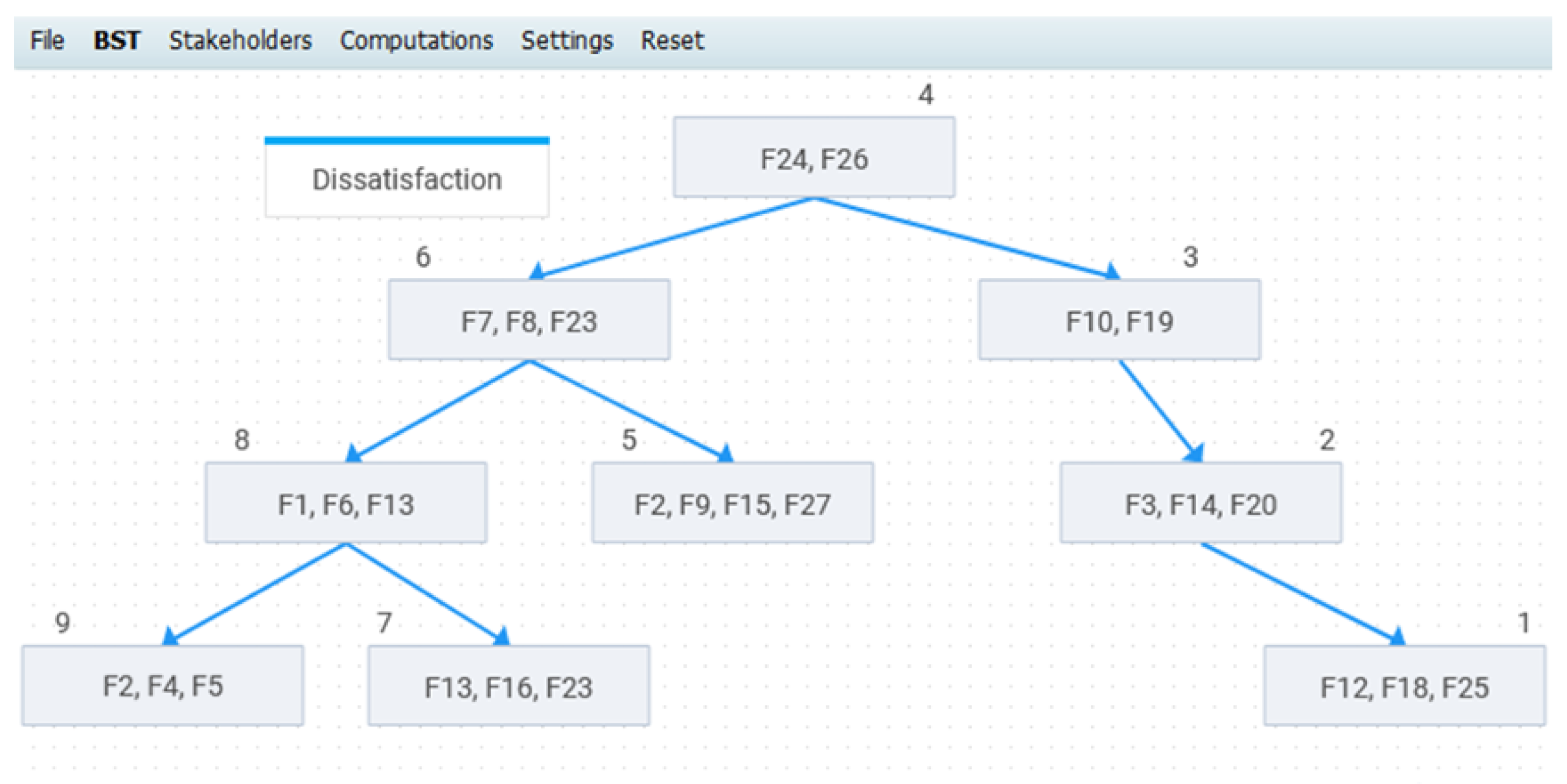
- The method utilizes the Binary Search Tree (BST) technique, known for its efficiency and accuracy in the ordinal ranking of medium to large sets of features. The application is facilitated by the BSTV tool, implementing a modified version of the BST technique to handle tied and unranked features effectively.
- The proposed method translates feature rankings into Intuitionistic Fuzzy Sets (IFSs), providing a quantitative measure of stakeholders’ hesitation.
- Objective stakeholders’ weights are calculated in multiple ways, incorporating stakeholders’ hesitation and mitigating subjectivity in assigning weights.
- The method is semi-automated, requiring minimal human intervention.
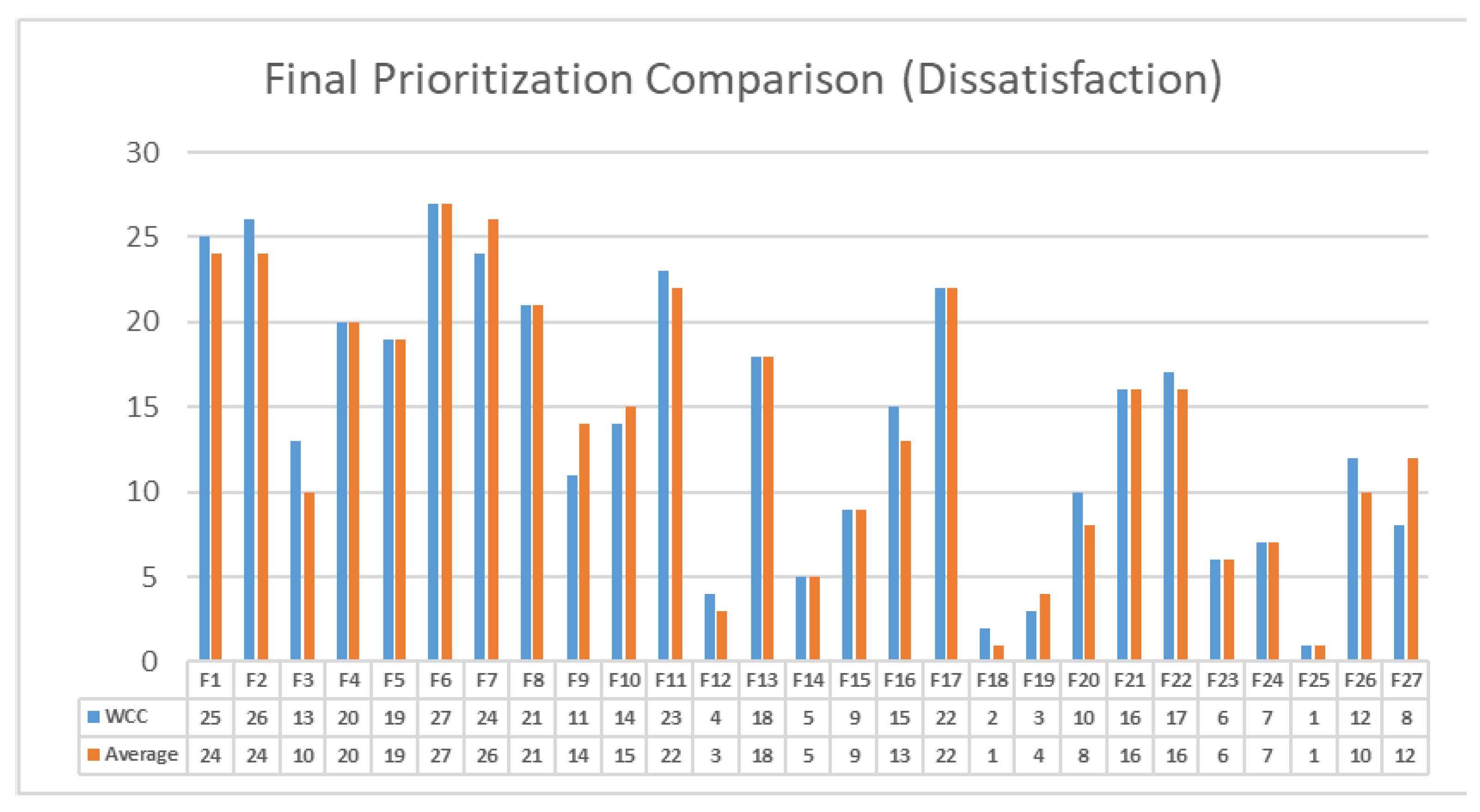
- The method yields final feature priorities, ensuring that no two or more features share the same prioritization value.
6. Threats to Validity
- The tool-driven approach: The reliance on a tool ensures that if the same input is provided to the tool, it would produce identical output. This inherent feature contributes to the reliability of the case study results.
- Selection of stakeholders: The choice of knowledgeable stakeholders with significant experience in the domain under study enhances the reliability of the results. Less experienced or less knowledgeable stakeholders could introduce variability and compromise the reliability of the findings. Thus, the careful selection of stakeholders is a deliberate measure to ensure reliability.
- Stakeholders’ responses: While it is natural to expect some variations in responses to qualitative surveys, the structured nature of the approach, including the use of a Likert scale, mitigates the potential for large variations. The reliability of the results is further reinforced by the consistency in stakeholders’ responses, making the outcomes more dependable.
- Dual criteria evaluation: The dual evaluation of features based on both satisfaction and dissatisfaction contributes to increased reliability. The consideration of these two criteria often leads to asymmetric evaluations, providing richer information for decision making. This enhanced information contributes to more reliable and repeatable results in future applications.
- Sensitivity analysis on stakeholders’ weights: The reliability of the results is confirmed by the sensitivity analysis conducted on stakeholders’ weights. Three variants were used to calculate these weights based on different components of hesitation. Importantly, the prioritization of features remained consistent across these variants, indicating that the results are not highly sensitive to the calculation of objective weights. This resilience contributes to the overall reliability of the findings.
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wiegers, K.; Beatty, J. Software Requirements, 3rd ed.; Microsoft Press: Redmond, WA, USA, 2013. [Google Scholar]
- Chen, K.; Zhang, W.; Zhao, H.; Mei, H. An approach to constructing feature models based on requirements clustering. In Proceedings of the 3th IEEE International Conference on Requirements Engineering (RE’05), Paris, France, 29 August–2 September 2005; pp. 31–40. [Google Scholar]
- Achimugu, P.; Selamat, A.; Ibrahim, R.; Mahrin, M. A systematic literature review of software requirements prioritization research. Inf. Softw. Technol. 2014, 56, 568–585. [Google Scholar] [CrossRef]
- Hujainah, F.; Bakar, R.B.; Abdulgabber, M.A.; Zamli, K.Z. Software requirements prioritisation: A systematic literature review on significance, stakeholders, techniques and challenges. IEEE Access 2018, 6, 71497–71523. [Google Scholar] [CrossRef]
- Svensson, R.B.; Gorschek, T.; Regnell, B.; Torkar, R.; Shahrokni, A.; Feldt, R.; Aurum, A. Prioritization of quality requirements: State of practice in eleven companies. In Proceedings of the 19th IEEE International Requirements Engineering Conference, Washington, DC, USA, 29 August–2 September 2011; pp. 69–78. [Google Scholar]
- Karlsson, J.; Ryan, K. A cost-value approach for prioritizing requirements. IEEE Softw. 1997, 14, 67–74. [Google Scholar] [CrossRef]
- Lehtola, L.; Kauppinen, M.; Kujala, S. Requirements prioritization challenges in practice. In Product Focused Software Process Improvement; Springer: Berlin/Heidelberg, Germany, 2004; pp. 497–508. [Google Scholar]
- Hujainah, F.; Bakar, R.B.A.; Al-haimi, B.; Abdulgabber, M.A. Stakeholder quantification and prioritisation research: A systematic literature review. Inf. Softw. Technol. 2018, 102, 85–99. [Google Scholar] [CrossRef]
- Pohl, K. Requirements Engineering: Fundamentals, Principles, and Techniques; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Lima, D.; Freitas, F.; Campos, G.; Souza, J. A fuzzy approach to requirements prioritization. In Proceedings of the Search Based Software Engineering: Third International Symposium, SSBSE 2011, Szeged, Hungary, 10–12 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 64–69. [Google Scholar]
- Gerogiannis, V.C.; Tzikas, G. Using fuzzy linguistic 2-tuples to collectively prioritize software requirements based on stakeholders’ evaluations. In Proceedings of the 21st Panhellenic Conference on Informatics, Larissa, Greece, 28–30 September 2017. [Google Scholar]
- Gerogiannis, V.C.; Fitsilis, P.; Kakarontzas, G.; Borne, C. Handling vagueness and subjectivity in requirements prioritization. In Proceedings of the 22nd Panhellenic Conference on Informatics, Athens, Greece, 29 November–1 December 2018; pp. 150–155. [Google Scholar]
- Gerogiannis, V.C.; Tsoni, E.; Born, C.; Iatrellis, O. Software features prioritization based on stakeholders’ satisfaction/dissatisfaction and hesitation. In Proceedings of the 46th Euromicro Conference on Software Engineering and Advanced Applications, IEEE, Portoroz, Slovenia, 26–28 August 2020; pp. 265–271. [Google Scholar]
- Iatrellis, O.; Kameas, A.; Fitsilis, P. A novel integrated approach to the execution of personalized and self-evolving learning pathways. Educ. Inf. Technol. 2019, 24, 781–803. [Google Scholar] [CrossRef]
- Nayebi, M.; Ruhe, G. Asymmetric release planning: Compromising satisfaction against dissatisfaction. IEEE Trans. Softw. Eng. 2019, 45, 839–857. [Google Scholar] [CrossRef]
- Bebensee, T.; van de Weerd, I.; Brinkkemper, S. Binary priority list for prioritizing software requirements. In Requirements Engineering: Foundation for Software Quality: 16th International Working Conference, REFSQ 2010, Essen, Germany, 30 June–2 July 2010; Lecture Notes in Computer Science; Wieringa, R., Persson, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6182. [Google Scholar]
- Atanassov, K.T. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic Fuzzy Sets: Theory and Applications; Physica-Verlag: Heidelberg, Germany, 2010. [Google Scholar]
- Ladyzynski, P.; Grzegorzewski, P. Vague preferences in recommender systems. Expert Syst. Appl. 2015, 42, 9402–9411. [Google Scholar] [CrossRef]
- Bloch, M.; Blumberg, S.; Laartz, J. Delivering Large-Scale IT Projects on Time, on Budget, and on Value; Technical Report; McKinsey Digital: Berlin, Germany, 2012. [Google Scholar]
- Babar, M.A.; Ghazali, M.; Jawawi, D.N.A.; Shamsuddin, S.M.; Ibrahim, N. PHandler: An expert system for a scalable software requirements prioritization process. Knowl. Based Syst. 2015, 84, 179–202. [Google Scholar] [CrossRef]
- Hujainah, F.; Bakar, R.B.A.; Nasser, A.; Al-haimi, B.; Zamli, K. SRPTackle: A semi-automated requirements prioritisation technique for scalable requirements of software system projects. Inf. Softw. Technol. 2021, 131, 106501. [Google Scholar] [CrossRef]
- Carlshamre, P.; Sandahl, K.; Lindvall, M.; Regnell, B.; Natt och Dag, J. An industrial survey of requirements interdependencies in software product release planning. In Proceedings of the 5th IEEE International Symposium on Requirements Engineering (RE’01), Toronto, ON, Canada, 27–31 August 2001; pp. 84–91. [Google Scholar]
- Ma, B. The Effectiveness of Requirements Prioritization Techniques for a Medium to Large Number of Requirements: A Systematic Literature Review. Master’s Thesis, Auckland University of Technology, Auckland, New Zealand, 2009. [Google Scholar]
- Ahl, V. An Experimental Comparison of Five Prioritization Methods: iNvestigating Ease of Use, Accuracy And Scalability. Master’s Thesis, Blekinge Institute of Technology, School of Engineering, Department of Systems and Software Engineering, Karlskrona, Sweden, 2005. [Google Scholar]
- Vogelsang, A. Feature dependencies in automotive software systems: Extent, awareness, and refactoring. J. Syst. Softw. 2020, 160, 110458. [Google Scholar] [CrossRef]
- Hujainah, F.; Bakar, R.B.A.; Abdulgabber, M.A. StakeQP: A semi-automated stakeholder quantification and prioritisation technique for requirement selection in software system projects. Decis. Support Syst. 2021, 121, 94–108. [Google Scholar] [CrossRef]
- Lim, S.W.; Finkelstein, A. StakeRare: Using social networks and collaborative filtering for large-scale requirements elicitation. IEEE Trans. Softw. Eng. 2012, 38, 707–735. [Google Scholar]
- Rodríguez, P.; Urquhart, C.; Mendes, E. A theory of value for value-based feature selection in software engineering. IEEE Trans. Softw. Eng. 2020, 48, 466–484. [Google Scholar] [CrossRef]
- Bessey, A.; Block, K.; Chelf, B.; Chou, A.; Fulton, B.; Hallem, S.; Henri-Gros, C.; Kamsky, A.; McPeak, S.; Engler, D. A few billion lines of code later: Using static analysis to find bugs in the real world. Commun. ACM 2010, 53, 66–75. [Google Scholar] [CrossRef]
- Malgaonkar, S.; Licorish, S.; Savarimuthu, B. Understanding requirements prioritisation: Literature survey and critical evaluation. IET Softw. 2020, 14, 607–622. [Google Scholar] [CrossRef]
- Zhang, X.; Li, J.; Eres, H.; Zheng, C. Prioritizing and aggregating interacting requirements for product-service system development. Expert Syst. Appl. 2021, 185, 115636. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Xie, T. Software feature refinement prioritization based on online user review mining. Inf. Softw. Technol. 2019, 108, 30–34. [Google Scholar] [CrossRef]
- Rojas, L.A.; Macías, J.A. Toward collisions produced in requirements rankings: A qualitative approach and experimental study. J. Syst. Softw. 2019, 158, 110417. [Google Scholar] [CrossRef]
- Ibrahim, O.; Nosseir, A. A combined AHP and source of power schemes for prioritising requirements applied on human resources. MATEC Web Conf. 2016, 20, 04016. [Google Scholar] [CrossRef]
- Perini, A.; Susi, A.; Avesani, P.A. Machine learning approach to software requirements prioritization. IEEE Trans. Softw. Eng. 2012, 39, 445–461. [Google Scholar] [CrossRef]
- Shao, F.; Peng, R.; Lai, H.; Wang, B. DRank: A semi-automated requirements prioritization method based on preferences and dependencies. J. Syst. Softw. 2016, 126, 141–156. [Google Scholar] [CrossRef]
- Azar, J.; Smith, R.K.; Cordes, D. Value-oriented requirements prioritization in a small development organization. IEEE Softw. 2007, 24, 32–37. [Google Scholar] [CrossRef]
- Mizuno, S.; Akao, Y.; Ishihara, K. QFD: The Customer-driven Approach to Quality Planning & Deployment; Quality Resources: Richmond Heights, OH, USA, 1994. [Google Scholar]
- Kakar, A.K. Investigating the penalty reward calculus of software users and its impact on requirements prioritization. Inf. Softw. Technol. 2015, 65, 56–68. [Google Scholar] [CrossRef]
- Karlsson, J.; Wohlin, C.; Regnell, B. An evaluation of methods for prioritizing software requirements. Inf. Softw. Technol. 1998, 39, 939–947. [Google Scholar] [CrossRef]
- Sadiq, M.; Devi, V. Fuzzy-soft set approach for ranking the functional requirements of software. Expert Syst. Appl. 2021, 193, 116452. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, M.; Yue, T.; Ali, S.; Li, Y. Uncertainty-wise requirements prioritization with search. ACM Trans. Softw. Eng. Methodol. 2021, 30, 1–54. [Google Scholar] [CrossRef]
- Martinis, A.; Tzimos, D.; Gerogiannis, V.; Son, H.Y. A Multiple Stakeholders’ Software Requirements Prioritization Approach based on Intuitionistic Fuzzy Sets. In Proceedings of the 4th International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), Suzhou, China, 22–24 April 2022; pp. 1–5. [Google Scholar]
- Singh, Y.V.; Kumar, B.; Chand, S.; Kumar, J. A comparative analysis and proposing ‘ANN fuzzy AHP model’ for requirements prioritization. Int. J. Inf. Technol. Comput. Sci. 2018, 4, 65. [Google Scholar] [CrossRef]
- Tzimos, D.; Gerogiannis, V.; Son, H.; Karageorgos, A. A Recommender System based on Intuitionistic Fuzzy Sets for Software Requirements Prioritization. In Proceedings of the 25th Pan-Hellenic Conference on Informatics (PCI 2021), Volos, Greece, 26–28 November 2021; Association for Computing Machinery: New York, NY, USA, 2022; pp. 466–471. [Google Scholar]
- Alrashoud, M.; Abhari, A. Planning for the next software release using adaptive network-based fuzzy inference system. Intell. Decis. Technol. 2017, 11, 153–165. [Google Scholar] [CrossRef]
- Regnell, B.; Höst, M.; Dag, J.N.; Beremark, P.; Hjelm, T. An industrial case study on distributed prioritisation in market-driven requirements engineering for packaged software. Requir. Eng. 2001, 6, 51–62. [Google Scholar] [CrossRef]
- Leffingwell, D.; Widrig, D. Managing Software Requirements: A Use Case Approach; Addison-Wesley: Boston, MA, USA, 2003. [Google Scholar]
- Chatzipetrou, P.; Angelis, L.; Rovegard, P.; Wohlin, C. Prioritization of issues and requirements by cumulative voting: A compositional data analysis framework. In Proceedings of the 36th EUROMICRO Software Engineering and Advanced Applications (SEAA) Conference, Lille, France, 1–3 September 2010; pp. 361–370. [Google Scholar]
- Ye, J. Fuzzy decision-making method based on the weighted correlation coefficient under intuitionistic fuzzy environment. Eur. J. Oper. Res. 2010, 205, 202–204. [Google Scholar] [CrossRef]
- Ma, J.; Fan, Z.P.; Huang, L.H. A subjective and objective integrated approach to determine attribute weights. Eur. J. Oper. Res. 1999, 112, 397–404. [Google Scholar] [CrossRef]
- EDUC8: Personalized and Self-Evolving Learning Pathways. Available online: http://www.cs.teilar.gr/EDUC8/ (accessed on 7 December 2023).
- Iatrellis, O.; Savvas, I.; Fitsilis, P.; Gerogiannis, V. A two-phase machine learning approach for predicting student outcomes. Educ. Inf. Technol. 2020, 26, 69–88. [Google Scholar] [CrossRef]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer Publishing Company: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Marciuska, S.; Cencel, G.; Abrahamsson, P. Exploring how feature usage relates to customer perceived value: A case study in a startup company. In Proceedings of the Lecture Notes in Business Information Processing, Porto, Portugal, 7–8 February 2013; Volume 150. [Google Scholar]
- Chen, T.Y.; Li, C.H. Determining objective weights with intuitionistic fuzzy entropy measures: A comparative analysis. Inf. Sci. 2010, 180, 4207–4222. [Google Scholar] [CrossRef]
- Lee, H.C.; Chang, C.T. Comparative analysis of MCDM methods for ranking renewable energy sources in Taiwan. Renew. Sustain. Energy Rev. 2018, 92, 883–896. [Google Scholar] [CrossRef]
- Alvo, M.; Cabilio, P. Rank correlation methods for missing data. Can. J. Stat./La Rev. Can. De Stat. 1995, 23, 345–358. [Google Scholar] [CrossRef]
- Cleff, T. Exploratory Data Analysis in Business and Economics; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Bukhsh, F.; Bukhsh, Z.; Daneva, M. A systematic literature review on requirement prioritization techniques and their empirical evaluation. Comput. Stand. Interfaces 2019, 69, 103389. [Google Scholar] [CrossRef]
- Tsoni, E. Handling Uncertainty in Requirements Prioritization; Technical Report HOU-CS-UGP-2018-6; Hellenic Open University: Thermi, Greece, 2018. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Ranking of Features According to Satisfaction | Ranking of Features According to Dissatisfaction | ||||||
|---|---|---|---|---|---|---|---|---|
| Position | Position | |||||||
| 1 | 0.885 | 0 | 0.115 | 3 | 0.462 | 0.269 | 0.269 | |
| 2 | 0.846 | 0.038 | 0.115 | 2 | 0.577 | 0.115 | 0.308 | |
| 3 | 0.615 | 0.077 | 0.308 | N | 0 | 0 | 1.000 | |
| 4 | 0.462 | 0.308 | 0.231 | 1 | 0.731 | 0 | 0.269 | |
| 3 | 0.615 | 0.077 | 0.308 | 1 | 0.731 | 0 | 0.269 | |
| 3 | 0.615 | 0.077 | 0.308 | 2 | 0.577 | 0.115 | 0.308 | |
| 3 | 0.615 | 0.077 | 0.308 | 5 | 0.269 | 0.462 | 0.269 | |
| 3 | 0.615 | 0.077 | 0.308 | 2 | 0.577 | 0.115 | 0.308 | |
| 3 | 0.615 | 0.077 | 0.308 | N | 0 | 0 | 1.000 | |
| 4 | 0.462 | 0.308 | 0.231 | 1 | 0.731 | 0 | 0.269 | |
| 4 | 0.462 | 0.308 | 0.231 | 2 | 0.577 | 0.115 | 0.308 | |
| 4 | 0.462 | 0.308 | 0.231 | 3 | 0.462 | 0.269 | 0.269 | |
| 5 | 0.346 | 0.462 | 0.192 | 7 | 0.115 | 0.654 | 0.231 | |
| 5 | 0.346 | 0.462 | 0.192 | 8 | 0.077 | 0.731 | 0.192 | |
| 5 | 0.346 | 0.462 | 0.192 | 3 | 0.462 | 0.269 | 0.269 | |
| 6 | 0.192 | 0.577 | 0.231 | 9 | 0 | 0.769 | 0.231 | |
| 6 | 0.192 | 0.577 | 0.231 | 7 | 0.115 | 0.654 | 0.231 | |
| 6 | 0.192 | 0.577 | 0.231 | 5 | 0.269 | 0.462 | 0.269 | |
| 6 | 0.192 | 0.577 | 0.231 | 9 | 0 | 0.769 | 0.231 | |
| 7 | 0.115 | 0.731 | 0.154 | 6 | 0.192 | 0.577 | 0.231 | |
| 7 | 0.115 | 0.731 | 0.154 | N | 0 | 0 | 1.000 | |
| 8 | 0.077 | 0.808 | 0.115 | 4 | 0.385 | 0.385 | 0.231 | |
| 9 | 0 | 0.846 | 0.154 | 4 | 0.385 | 0.385 | 0.231 | |
| 9 | 0 | 0.846 | 0.154 | 6 | 0.192 | 0.577 | 0.231 | |
| N | 0 | 0 | 1.000 | N | 0 | 0 | 1.000 | |
| N | 0 | 0 | 1.000 | 5 | 0.269 | 0.462 | 0.269 | |
| N | 0 | 0 | 1.000 | N | 0 | 0 | 1.000 | |
| Total Hesitation = 8.230 | Total Hesitation = 10.692 | |||||||
| Average Total Hesitation (Total Hesitation/No. of Features) = 0.304 | Average Total Hesitation (Total Hesitation/No. of Features) = 0.396 | |||||||
| Weight = 0.535 | Weight = 0.464 | |||||||
| Feature | Results in the Numerator of Equation (11) | Results in the Denumerator of Equation (11) | WCC (Final Features’ Priorities) | |||
|---|---|---|---|---|---|---|
| 0.688 | 0.419 | 0.133 | 0.551 | 0.743 | 0.926 | |
| 0.721 | 0.384 | 0.161 | 0.545 | 0.738 | 0.977 | |
| 0.329 | 0.206 | 0 | 0.206 | 0.454 | 0.726 | |
| 0.587 | 0.165 | 0.248 | 0.413 | 0.643 | 0.913 | |
| 0.669 | 0.206 | 0.248 | 0.454 | 0.674 | 0.993 | |
| 0.598 | 0.206 | 0.161 | 0.367 | 0.606 | 0.987 | |
| 0.454 | 0.206 | 0.133 | 0.339 | 0.582 | 0.781 | |
| 0.598 | 0.206 | 0.161 | 0.367 | 0.606 | 0.987 | |
| 0.329 | 0.206 | 0 | 0.206 | 0.454 | 0.726 | |
| 0.587 | 0.165 | 0.248 | 0.413 | 0.643 | 0.913 | |
| 0.515 | 0.165 | 0.161 | 0.326 | 0.571 | 0.903 | |
| 0.462 | 0.165 | 0.133 | 0.297 | 0.545 | 0.846 | |
| 0.239 | 0.178 | 0.205 | 0.383 | 0.619 | 0.386 | |
| 0.221 | 0.178 | 0.251 | 0.429 | 0.655 | 0.337 | |
| 0.400 | 0.178 | 0.133 | 0.311 | 0.558 | 0.717 | |
| 0.103 | 0.198 | 0.275 | 0.473 | 0.688 | 0.150 | |
| 0.157 | 0.198 | 0.205 | 0.403 | 0.635 | 0.247 | |
| 0.228 | 0.198 | 0.133 | 0.331 | 0.575 | 0.397 | |
| 0.103 | 0.198 | 0.275 | 0.473 | 0.688 | 0.150 | |
| 0.151 | 0.293 | 0.172 | 0.465 | 0.682 | 0.222 | |
| 0.062 | 0.293 | 0 | 0.293 | 0.541 | 0.114 | |
| 0.220 | 0.352 | 0.138 | 0.490 | 0.700 | 0.314 | |
| 0.179 | 0.383 | 0.138 | 0.521 | 0.722 | 0.248 | |
| 0.089 | 0.383 | 0.172 | 0.555 | 0.745 | 0.120 | |
| 0 | 0 | 0 | 0 | 0 | 0 | |
| 0.125 | 0 | 0.133 | 0.133 | 0.364 | 0.344 | |
| 0 | 0 | 0 | 0 | 0 | 0 | |
| Feature | Feature Name | Description (Functional Goal) |
|---|---|---|
| Incomplete tasks view | View pending or incomplete tasks associated with a particular workflow | |
| Push notifications | Add push notifications as a way of alerting users to information from EDUC8 | |
| Multiple file upload mechanism | Upload multiple files using a single input file element | |
| Enhanced language options | Add a new menu as a language selector | |
| Drag and drop feature | Copy, reorder, and delete objects using the mouse in various sections | |
| Handling multiple concurrent programs | Support the execution of multiple concurrent educational programs | |
| Event viewer to track changes | Log EDUC8 messages, including errors, information messages, and warnings | |
| Search by program | Allow users to filter search results by programs | |
| Graphical learning pathway designer | Implement an integrated Business Process Model Notation (BPMN) diagram tool | |
| View individuals by category | Display instances of a specific class | |
| Built-in analytics | Incorporate predictive analytics modules to drive decision making | |
| Email notifications | Automated email notifications for specific tasks | |
| Keyboard shortcuts | Add keyboard shortcuts that trigger specific actions | |
| Graphical Semantic Web Rule Language (SWRL) rule designer | Implement a visual modeling tool for the design and storage of semantic rules | |
| What You See Is What You Get (WYSIWYG) editors | Replace simple text areas with WYSIWYG editors to enrich content creation | |
| Single sign-on | Connect with the University’s Lightweight Directory Access Protocol (LDAP) directory | |
| Advanced search by student | Narrow student results by adding more search terms | |
| Improve error handling | Add error descriptions in clear and simple language | |
| Human Resource Management System integration | Integrate with the University’s human resource management system | |
| Student Information System integration | Integrate with the University’s student information system | |
| Improve user profile settings | Implement a tabbed user interface | |
| “Forgot password” functionality | Add a password recovery option | |
| Grant Management System integration | Integrate with the grant management system | |
| “Remember Me” login functionality | Allow users to store their login information on their local computer | |
| Real-time chat | Provide a live transmission of text messages between end-users | |
| Fully responsive design | Preserve the user experience and look and feel across all devices | |
| GUI role-based adaptation | Show or hide features for specific roles |
| Stakeholder | Role |
|---|---|
| Stakeholder #1 | IT Team Head |
| Stakeholder #2 | Ontology Engineer |
| Stakeholder #3 | Academic Advisor |
| Stakeholder #4 | BPMN Process Analyst |
| Stakeholder #5 | Manager |
| Features (a) | Stakeholder #1 | Stakeholder #2 | Stakeholder #3 | Stakeholder #4 | Stakeholder #5 | Features’ Priorities (WCCs) Based on Satisfaction (v) | Final Priority (w) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ranking (b) | (c) | u (d) | (e) | Ranking (f) | (g) | u (h) | (i) | Ranking (j) | (k) | u (l) | (m) | Ranking (n) | (o) | u (p) | (q) | Ranking (r) | (s) | u (t) | (u) | |||
| 1 | 0.885 | 0 | 0.115 | 4 | 0.462 | 0.308 | 0.231 | 3 | 0.385 | 0.346 | 0.269 | 6 | 0.346 | 0.538 | 0.115 | N | 0 | 0 | 1.000 | 0.709 | 11 | |
| 9 | 0 | 0.885 | 0.115 | 6 | 0.192 | 0.577 | 0.231 | 5 | 0.115 | 0.692 | 0.192 | N | 0 | 0 | 1.000 | 7 | 0 | 0.808 | 0.192 | 0.089 | 27 | |
| 9 | 0 | 0.885 | 0.115 | 4 | 0.462 | 0.308 | 0.231 | 2 | 0.577 | 0.192 | 0.231 | N | 0 | 0 | 1.000 | 7 | 0 | 0.808 | 0.192 | 0.310 | 20 | |
| 4 | 0.538 | 0.269 | 0.192 | 6 | 0.192 | 0.577 | 0.231 | 5 | 0.115 | 0.692 | 0.192 | 4 | 0.577 | 0.269 | 0.154 | 2 | 0.577 | 0.154 | 0.269 | 0.643 | 13 | |
| 8 | 0.077 | 0.769 | 0.154 | 6 | 0.192 | 0.577 | 0.231 | 5 | 0.115 | 0.692 | 0.192 | 8 | 0.115 | 0.769 | 0.115 | 5 | 0.231 | 0.538 | 0.231 | 0.204 | 24 | |
| 6 | 0.346 | 0.538 | 0.115 | 6 | 0.192 | 0.577 | 0.231 | 6 | 0 | 0.808 | 0.192 | 1 | 0.885 | 0 | 0.115 | 3 | 0.423 | 0.308 | 0.269 | 0.537 | 15 | |
| 5 | 0.423 | 0.423 | 0.154 | 7 | 0.115 | 0.731 | 0.154 | 6 | 0 | 0.808 | 0.192 | 2 | 0.769 | 0.077 | 0.154 | 1 | 0.731 | 0 | 0.269 | 0.564 | 14 | |
| 7 | 0.192 | 0.615 | 0.192 | 7 | 0.115 | 0.731 | 0.154 | 6 | 0 | 0.808 | 0.192 | 7 | 0.192 | 0.615 | 0.192 | N | 0 | 0 | 1.000 | 0.166 | 25 | |
| 5 | 0.423 | 0.423 | 0.154 | 4 | 0.462 | 0.308 | 0.231 | 2 | 0.577 | 0.192 | 0.231 | 2 | 0.769 | 0.077 | 0.154 | 1 | 0.731 | 0 | 0.269 | 0.895 | 2 | |
| 8 | 0.077 | 0.769 | 0.154 | 2 | 0.692 | 0.115 | 0.192 | 2 | 0.577 | 0.192 | 0.231 | 7 | 0.192 | 0.615 | 0.192 | N | 0 | 0 | 1.000 | 0.489 | 18 | |
| 8 | 0.077 | 0.769 | 0.154 | N | 0 | 0 | 1.000 | N | 0 | 0 | 1.000 | 8 | 0.115 | 0.769 | 0.115 | 5 | 0.231 | 0.538 | 0.231 | 0.146 | 26 | |
| 7 | 0.192 | 0.615 | 0.192 | 8 | 0 | 0.808 | 0.192 | 1 | 0.731 | 0 | 0.269 | 9 | 0 | 0.846 | 0.154 | 6 | 0.077 | 0.654 | 0.269 | 0.260 | 22 | |
| 3 | 0.692 | 0.154 | 0.154 | 2 | 0.692 | 0.115 | 0.192 | 3 | 0.385 | 0.346 | 0.269 | 5 | 0.423 | 0.385 | 0.192 | 3 | 0.423 | 0.308 | 0.269 | 0.859 | 4 | |
| 6 | 0.346 | 0.538 | 0.115 | 5 | 0.346 | 0.462 | 0.192 | 1 | 0.731 | 0 | 0.269 | 1 | 0.885 | 0 | 0.115 | 4 | 0.346 | 0.462 | 0.192 | 0.769 | 8 | |
| N | 0 | 0 | 1.000 | 8 | 0 | 0.808 | 0.192 | 4 | 0.231 | 0.538 | 0.231 | 7 | 0.192 | 0.615 | 0.192 | 4 | 0.346 | 0.462 | 0.192 | 0.251 | 23 | |
| 3 | 0.692 | 0.154 | 0.154 | 1 | 0.808 | 0 | 0.192 | 1 | 0.731 | 0 | 0.269 | 3 | 0.692 | 0.192 | 0.115 | 1 | 0.731 | 0 | 0.269 | 0.986 | 1 | |
| 4 | 0.538 | 0.269 | 0.192 | 3 | 0.615 | 0.231 | 0.154 | 4 | 0.231 | 0.538 | 0.231 | 4 | 0.577 | 0.269 | 0.154 | 3 | 0.423 | 0.308 | 0.269 | 0.799 | 7 | |
| 7 | 0.192 | 0.615 | 0.192 | 2 | 0.692 | 0.115 | 0.192 | 1 | 0.731 | 0 | 0.269 | 9 | 0 | 0.846 | 0.154 | 6 | 0.077 | 0.654 | 0.269 | 0.458 | 19 | |
| 1 | 0.885 | 0 | 0.115 | 1 | 0.808 | 0 | 0.192 | 3 | 0.385 | 0.346 | 0.269 | 6 | 0.346 | 0.538 | 0.115 | N | 0 | 0 | 1.000 | 0.755 | 9 | |
| 2 | 0.808 | 0.077 | 0.115 | 5 | 0.346 | 0.462 | 0.192 | 3 | 0.385 | 0.346 | 0.269 | 5 | 0.423 | 0.385 | 0.192 | 2 | 0.577 | 0.154 | 0.269 | 0.815 | 6 | |
| 4 | 0.538 | 0.269 | 0.192 | N | 0 | 0 | 1.000 | N | 0 | 0 | 1.000 | 4 | 0.577 | 0.269 | 0.154 | 6 | 0.077 | 0.654 | 0.269 | 0.519 | 16 | |
| 2 | 0.808 | 0.077 | 0.115 | 3 | 0.615 | 0.231 | 0.154 | 4 | 0.231 | 0.538 | 0.231 | 5 | 0.423 | 0.385 | 0.192 | 2 | 0.577 | 0.154 | 0.269 | 0.819 | 5 | |
| 3 | 0.692 | 0.154 | 0.154 | 5 | 0.346 | 0.462 | 0.192 | 3 | 0.385 | 0.346 | 0.269 | 3 | 0.692 | 0.192 | 0.115 | 2 | 0.577 | 0.154 | 0.269 | 0.860 | 3 | |
| N | 0 | 0 | 1.000 | 8 | 0 | 0.808 | 0.192 | 4 | 0.231 | 0.538 | 0.231 | 7 | 0.192 | 0.615 | 0.192 | 3 | 0.423 | 0.308 | 0.269 | 0.278 | 21 | |
| 7 | 0.192 | 0.615 | 0.192 | 1 | 0.808 | 0 | 0.192 | 1 | 0.731 | 0 | 0.269 | 9 | 0 | 0.846 | 0.154 | 5 | 0.231 | 0.538 | 0.231 | 0.519 | 17 | |
| 4 | 0.538 | 0.269 | 0.192 | N | 0 | 0 | 1.000 | N | 0 | 0 | 1.000 | 5 | 0.423 | 0.385 | 0.192 | 1 | 0.731 | 0 | 0.269 | 0.685 | 12 | |
| 5 | 0.423 | 0.423 | 0.154 | 4 | 0.462 | 0.308 | 0.231 | 2 | 0.577 | 0.192 | 0.231 | 2 | 0.769 | 0.077 | 0.154 | 6 | 0.077 | 0.654 | 0.269 | 0.735 | 10 | |
| Total Hesitation = 5.846 | Total Hesitation = 7.769 | Total Hesitation = 8.692 | Total Hesitation = 5.846 | Total Hesitation = 9.769 | ||||||||||||||||||
| Weight = 0.218 | Weight = 0.198 | Weight = 0.189 | Weight = 0.218 | Weight = 0.177 | ||||||||||||||||||
| Features (a) | Stakeholder #1 | Stakeholder #2 | Stakeholder #3 | Stakeholder #4 | Stakeholder #5 | Features’ Priorities (WCCs) Based on Satisfaction (v) | Final Priority (w) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ranking (b) | (c) | u (d) | (e) | Ranking (f) | (g) | u (h) | (i) | Ranking (j) | (k) | u (l) | (m) | Ranking (n) | (o) | u (p) | (q) | Ranking (r) | (s) | u (t) | (u) | |||
| 8 | 0.115 | 0.769 | 0.115 | 9 | 0.038 | 0.846 | 0.115 | 4 | 0.577 | 0.346 | 0.077 | N | 0 | 0 | 1.000 | 9 | 0 | 0.846 | 0.154 | 0.227 | 25 | |
| 7 | 0.231 | 0.654 | 0.115 | 5 | 0.385 | 0.500 | 0.115 | 11 | 0 | 0.923 | 0.077 | 7 | 0.115 | 0.654 | 0.231 | N | 0 | 0 | 1.000 | 0.220 | 26 | |
| 2 | 0.769 | 0.115 | 0.115 | N | 0 | 0 | 1.000 | 1 | 0.885 | 0 | 0.115 | 6 | 0.231 | 0.538 | 0.231 | 7 | 0.154 | 0.692 | 0.154 | 0.641 | 13 | |
| 7 | 0.231 | 0.654 | 0.115 | 6 | 0.269 | 0.577 | 0.154 | 6 | 0.385 | 0.538 | 0.077 | 7 | 0.115 | 0.654 | 0.231 | N | 0 | 0 | 1.000 | 0.352 | 20 | |
| 7 | 0.231 | 0.654 | 0.115 | 5 | 0.385 | 0.500 | 0.115 | 6 | 0.385 | 0.538 | 0.077 | 7 | 0.115 | 0.654 | 0.231 | N | 0 | 0 | 1.000 | 0.391 | 19 | |
| 8 | 0.115 | 0.769 | 0.115 | 8 | 0.115 | 0.769 | 0.115 | 11 | 0 | 0.923 | 0.077 | N | 0 | 0 | 1.000 | 8 | 0.077 | 0.769 | 0.154 | 0.084 | 27 | |
| 6 | 0.346 | 0.538 | 0.115 | 9 | 0.038 | 0.846 | 0.115 | 10 | 0.077 | 0.846 | 0.077 | 4 | 0.500 | 0.308 | 0.192 | 9 | 0 | 0.846 | 0.154 | 0.241 | 24 | |
| 6 | 0.346 | 0.538 | 0.115 | 8 | 0.115 | 0.769 | 0.115 | 10 | 0.077 | 0.846 | 0.077 | 1 | 0.731 | 0 | 0.269 | 8 | 0.077 | 0.769 | 0.154 | 0.334 | 21 | |
| 5 | 0.462 | 0.385 | 0.154 | 7 | 0.192 | 0.692 | 0.115 | 1 | 0.885 | 0 | 0.115 | 5 | 0.346 | 0.385 | 0.269 | 5 | 0.308 | 0.500 | 0.192 | 0.663 | 11 | |
| 3 | 0.692 | 0.231 | 0.077 | 10 | 0 | 0.923 | 0.077 | 1 | 0.885 | 0 | 0.115 | 3 | 0.577 | 0.231 | 0.192 | 7 | 0.154 | 0.692 | 0.154 | 0.602 | 14 | |
| 9 | 0 | 0.885 | 0.115 | 6 | 0.269 | 0.577 | 0.154 | 9 | 0.154 | 0.769 | 0.077 | N | 0 | 0 | 1.000 | 4 | 0.423 | 0.423 | 0.154 | 0.248 | 23 | |
| 1 | 0.885 | 0 | 0.115 | 1 | 0.808 | 0 | 0.192 | 5 | 0.462 | 0.423 | 0.115 | 1 | 0.731 | 0 | 0.269 | 3 | 0.500 | 0.269 | 0.231 | 0.920 | 4 | |
| 8 | 0.115 | 0.769 | 0.115 | 7 | 0.192 | 0.692 | 0.115 | 4 | 0.577 | 0.346 | 0.077 | N | 0 | 0 | 1.000 | 5 | 0.308 | 0.500 | 0.192 | 0.395 | 18 | |
| 2 | 0.769 | 0.115 | 0.115 | 3 | 0.538 | 0.269 | 0.192 | 3 | 0.654 | 0.231 | 0.115 | 6 | 0.231 | 0.538 | 0.231 | 1 | 0.769 | 0 | 0.231 | 0.873 | 5 | |
| 5 | 0.462 | 0.385 | 0.154 | 1 | 0.808 | 0 | 0.192 | 7 | 0.308 | 0.615 | 0.077 | 5 | 0.346 | 0.385 | 0.269 | 1 | 0.769 | 0 | 0.231 | 0.778 | 9 | |
| N | 0 | 0 | 1.000 | 2 | 0.692 | 0.154 | 0.154 | 5 | 0.462 | 0.423 | 0.115 | 8 | 0 | 0.769 | 0.231 | 2 | 0.654 | 0.154 | 0.192 | 0.598 | 15 | |
| 9 | 0 | 0.885 | 0.115 | 6 | 0.269 | 0.577 | 0.154 | 8 | 0.231 | 0.692 | 0.077 | 8 | 0 | 0.769 | 0.231 | 4 | 0.423 | 0.423 | 0.154 | 0.252 | 22 | |
| 1 | 0.885 | 0 | 0.115 | 1 | 0.808 | 0 | 0.192 | 3 | 0.654 | 0.231 | 0.115 | 1 | 0.731 | 0 | 0.269 | 3 | 0.500 | 0.269 | 0.231 | 0.961 | 2 | |
| 3 | 0.692 | 0.231 | 0.077 | 1 | 0.808 | 0 | 0.192 | 2 | 0.769 | 0.115 | 0.115 | 3 | 0.577 | 0.231 | 0.192 | 3 | 0.500 | 0.269 | 0.231 | 0.950 | 3 | |
| 2 | 0.769 | 0.115 | 0.115 | N | 0 | 0 | 1.000 | 2 | 0.769 | 0.115 | 0.115 | 6 | 0.231 | 0.538 | 0.231 | 5 | 0.308 | 0.500 | 0.192 | 0.700 | 10 | |
| 5 | 0.462 | 0.385 | 0.154 | 4 | 0.462 | 0.423 | 0.115 | 9 | 0.154 | 0.769 | 0.077 | 5 | 0.346 | 0.385 | 0.269 | 6 | 0.231 | 0.615 | 0.154 | 0.509 | 16 | |
| 9 | 0 | 0.885 | 0.115 | 3 | 0.538 | 0.269 | 0.192 | 8 | 0.231 | 0.692 | 0.077 | 8 | 0 | 0.769 | 0.231 | 1 | 0.769 | 0 | 0.231 | 0.401 | 17 | |
| 6 | 0.346 | 0.538 | 0.115 | 2 | 0.692 | 0.154 | 0.154 | 2 | 0.769 | 0.115 | 0.115 | 4 | 0.500 | 0.308 | 0.192 | 2 | 0.654 | 0.154 | 0.192 | 0.868 | 6 | |
| 4 | 0.615 | 0.308 | 0.077 | 2 | 0.692 | 0.154 | 0.154 | 7 | 0.308 | 0.615 | 0.077 | 2 | 0.654 | 0.154 | 0.192 | 2 | 0.654 | 0.154 | 0.192 | 0.838 | 7 | |
| 1 | 0.885 | 0 | 0.115 | 3 | 0.538 | 0.269 | 0.192 | 3 | 0.654 | 0.231 | 0.115 | 1 | 0.731 | 0 | 0.269 | 1 | 0.769 | 0 | 0.231 | 0.962 | 1 | |
| 4 | 0.615 | 0.308 | 0.077 | 4 | 0.462 | 0.423 | 0.115 | N | 0 | 0 | 1.000 | 2 | 0.654 | 0.154 | 0.192 | 6 | 0.231 | 0.615 | 0.154 | 0.654 | 12 | |
| 5 | 0.462 | 0.385 | 0.154 | 3 | 0.538 | 0.269 | 0.192 | 5 | 0.462 | 0.423 | 0.115 | 5 | 0.346 | 0.385 | 0.269 | 3 | 0.500 | 0.269 | 0.231 | 0.791 | 8 | |
| Total Hesitation = 4.000 | Total Hesitation = 5.692 | Total Hesitation = 3.462 | Total Hesitation = 9.385 | Total Hesitation = 7.538 | ||||||||||||||||||
| Weight = 0.219 | Weight = 0.203 | Weight = 0.224 | Weight = 0.168 | Weight = 0.185 | ||||||||||||||||||
| Features (a) | Priorities Based on Satisfaction (b) | Priorities Based on Dissatisfaction (c) | Features with Priorities Higher than 0.5 Based on Satisfaction (d) | Features with Priorities Higher than 0.5 Based on Dissatisfaction (e) | Selected Features (f) |
|---|---|---|---|---|---|
| 0.709 | 0.227 | ||||
| 0.089 | 0.220 | ||||
| 0.310 | 0.641 | ||||
| 0.643 | 0.352 | ||||
| 0.204 | 0.391 | ||||
| 0.537 | 0.084 | ||||
| 0.564 | 0.241 | ||||
| 0.166 | 0.334 | ||||
| 0.895 | 0.663 | ||||
| 0.489 | 0.602 | ||||
| 0.146 | 0.248 | ||||
| 0.260 | 0.920 | ||||
| 0.859 | 0.395 | ||||
| 0.769 | 0.873 | ||||
| 0.251 | 0.778 | ||||
| 0.986 | 0.598 | ||||
| 0.799 | 0.252 | ||||
| 0.458 | 0.961 | ||||
| 0.755 | 0.950 | ||||
| 0.815 | 0.700 | ||||
| 0.519 | 0.509 | ||||
| 0.819 | 0.401 | ||||
| 0.860 | 0.868 | ||||
| 0.278 | 0.838 | ||||
| 0.519 | 0.962 | ||||
| 0.685 | 0.654 | ||||
| 0.735 | 0.791 |
| Stakeholder | Hindet Calculated Using Equation (6) | Weight | Hindet Calculated Using Equation (8) | Weight |
|---|---|---|---|---|
| Stakeholder #1 | 5.846 | 0.218 | 13.000 | 0.238 |
| Stakeholder #2 | 7.769 | 0.198 | 14.692 | 0.209 |
| Stakeholder #3 | 8.692 | 0.189 | 17.846 | 0.156 |
| Stakeholder #4 | 5.846 | 0.218 | 12.769 | 0.242 |
| Stakeholder #5 | 9.769 | 0.177 | 17.846 | 0.156 |
| Average | 7.584 | 0.200 | 15.231 | 0.200 |
| St. Dev. | 1.738 | 0.016 | 2.500 | 0.038 |
| Stakeholder | Correlation Based on Satisfaction | Correlation Based on Dissatisfaction |
|---|---|---|
| Stakeholder #1 | 0.799 | 0.806 |
| Stakeholder #2 | 0.545 | 0.752 |
| Stakeholder #3 | 0.302 | 0.647 |
| Stakeholder #4 | 0.670 | 0.556 |
| Stakeholder #5 | 0.691 | 0.662 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gerogiannis, V.C.; Tzimos, D.; Kakarontzas, G.; Tsoni, E.; Iatrellis, O.; Son, L.H.; Kanavos, A. An Approach Based on Intuitionistic Fuzzy Sets for Considering Stakeholders’ Satisfaction, Dissatisfaction, and Hesitation in Software Features Prioritization. Mathematics 2024, 12, 680. https://doi.org/10.3390/math12050680
Gerogiannis VC, Tzimos D, Kakarontzas G, Tsoni E, Iatrellis O, Son LH, Kanavos A. An Approach Based on Intuitionistic Fuzzy Sets for Considering Stakeholders’ Satisfaction, Dissatisfaction, and Hesitation in Software Features Prioritization. Mathematics. 2024; 12(5):680. https://doi.org/10.3390/math12050680
Chicago/Turabian StyleGerogiannis, Vassilis C., Dimitrios Tzimos, George Kakarontzas, Eftychia Tsoni, Omiros Iatrellis, Le Hoang Son, and Andreas Kanavos. 2024. "An Approach Based on Intuitionistic Fuzzy Sets for Considering Stakeholders’ Satisfaction, Dissatisfaction, and Hesitation in Software Features Prioritization" Mathematics 12, no. 5: 680. https://doi.org/10.3390/math12050680
APA StyleGerogiannis, V. C., Tzimos, D., Kakarontzas, G., Tsoni, E., Iatrellis, O., Son, L. H., & Kanavos, A. (2024). An Approach Based on Intuitionistic Fuzzy Sets for Considering Stakeholders’ Satisfaction, Dissatisfaction, and Hesitation in Software Features Prioritization. Mathematics, 12(5), 680. https://doi.org/10.3390/math12050680