

A Tracklet-before-Clustering Initialization Strategy Based on Hierarchical KLT Tracklet Association for Coherent Motion Filtering Enhancement
 , ,
, ,
Abstract
:1. Introduction
- A Hierarchical Tracklet Association (HTA) algorithm is proposed as an initialization strategy to optimize coherent motion clustering. The purpose of the proposed framework is to address the disconnected tracklets problem of the input KLT features and carry out proper trajectories repair to enhance the performance of motion crowd clustering. In other words, HTA can be described as an enhanced initialization strategy for tracklet-before clustering.
- The coherent motion clustering results of the crowd were comprehensively examined and analysed on a crowd dataset, which is openly available to the public and contains a huge number of video clips.
2. Related Works
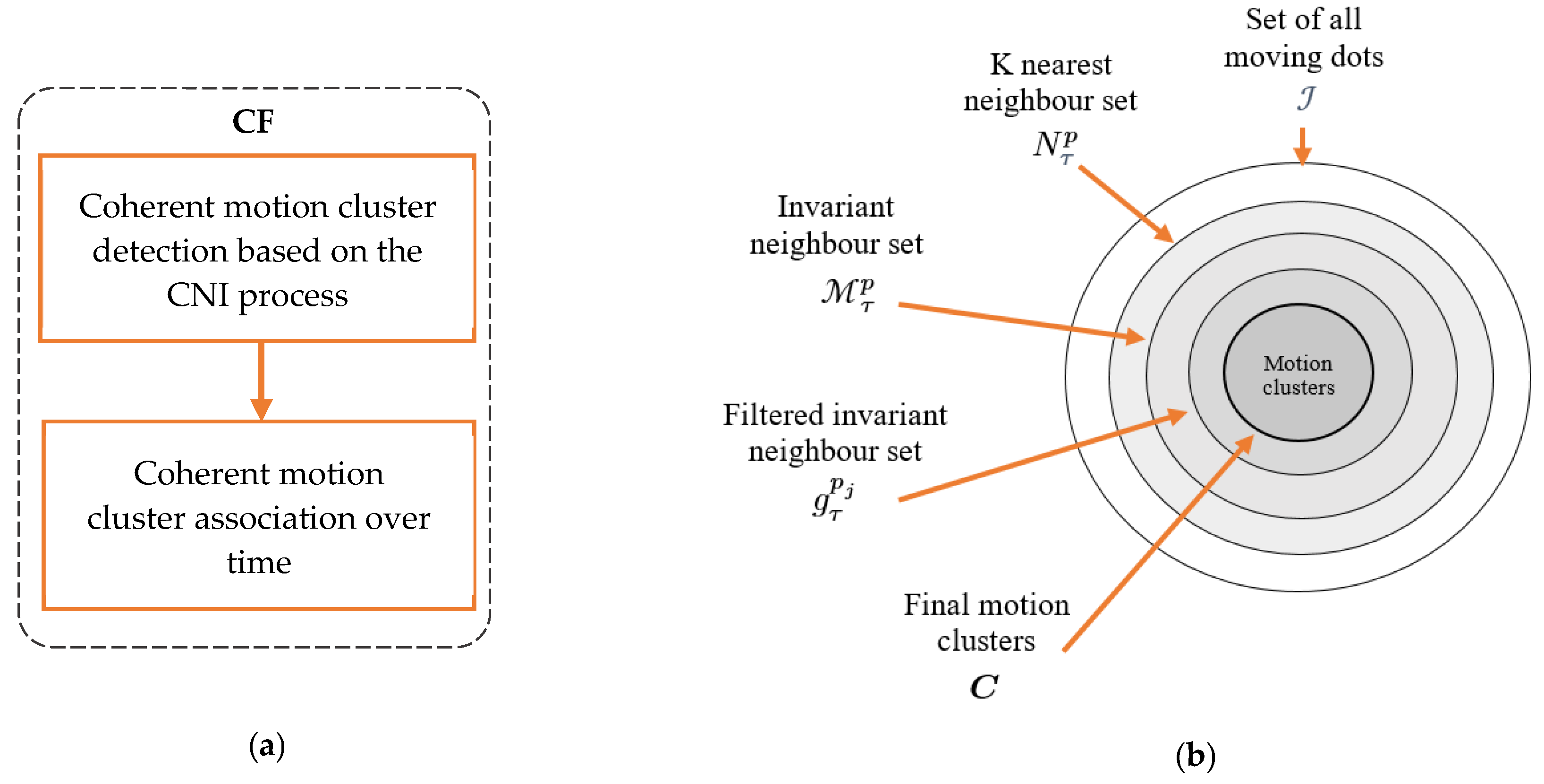
3. The Fundamental of Coherent Filtering (CF) Clustering
3.1. Coherent Motion Cluster Detection Based on Coherent Neighbor Invariance (CNI)
3.1.1. Spatio-Temporal Invariant Points by Using Euclidian Distance Metric Stage
3.1.2. Velocity Correlated Invariant Points Stage
3.2. Coherent Motion Cluster Association over Time
4. Hierarchical KLT Tracklets Association (HTA) Process for Coherent Motion Detection
4.1. Stage-1 (S1): Tracklets at Region of Interest (ROI)
- Step-1:
- On the video sequence , the area in which the missing path problem will be addressed, is determined manually as the region of interest (ROI).
- Step-2:
- From the tracklets pool , search for all the tracklets, which ended inside ROI, and represent it as the parent or main tracklet set, . Minutely, are the tracklets that started before a specific time and were suddenly lost at a specific time , as defined in Equation (4),where represents an individual tracklet that ended at ROI; is the total number of tracklets that ended inside ROI.
- Step-3:
- Also, search for tracklets that can be connected to the tracklets in . These tracklets are described as paths, which started their lifetime at ROI and are presented in another group called , as defined in Equation (5),where is a temporal window stride of , is the total number of tracklets that started inside ROI, and represents an individual tracklet, which started at any time from to in ROI.
- Step-4:
- Lastly, the main and sub-tracklet sets at time of this stage will be grouped, as represented in Equation (6),
4.2. Stage-2 (S2): Short-Path Filtering Layer (SPFL)
- Step-1:
- Calculate the lengths of all collected tracklets from Stage-1 and get the average as given in Equation (7),where and are the total tracklet number for and , respectively. Finding the average result provides information about the lengths of the normal paths. This value is useful in filtering very short lengths, as can be seen in the next step.
- Step-2:
- Keep the tracklets that can be considered candidate tracklets based on an average threshold , where the value of is an empirical value, which varies from video to video. For example, to remove the short-path tracklets from the set, Equation (8) is considered,where represents the tracklets length consistency. This filtering process is applied to and to remove all the short paths in both sets.
- Step-3:
- As a result, the updated tracklets sets after filtering the short paths will be considered in Equation (9),where L is the total tracklet number of and K is the total tracklet number of .
4.3. Stage-3 (S3): Position Filtering Layer (PFL)
- Step-1:
- For an individual tracklet at time , find its end-point position in and from the tracklet-position matrix, as given in Equation (10),
- Step-2:
- Find the start-point positions of the entire candidate tracklets from , as given in Equation (11),
- Step-3:
- Calculate the position coordinates Euclidian distance of the endpoint with all the start points of the sub-tracklets, as given in Equation (12),
- Step-4:
- Apply the position consistency to filter out tracklets that do not satisfy the neighbouring condition, as given in Equation (13),where and represent the tracklet’s total number of updated set. The represents the neighbourhood threshold; it is an empirical value that varies from video to video.
- Step-5:
- The updated tracklet set in this step is represented as the end, as given in Equation (14),
4.4. Stage-4 (S4): Orientation Filtering Layer (OFL)
- Step-1:
- The orientation of an individual main tracklet at time is calculated by considering the directions of its position points in a frame distance, as given in Equation (15),where is a frame distance that and .
- Step-2:
- Likewise, if the sub-tracklet is assumed to start from time , then its orientation can be calculated, as given in Equation (16),where .
- Step-3:
- Apply the orientation consistency to filter out sub-tracklets that do not satisfy the orientation condition with the main tracklet , as given in Equation (17),where and represents the total number of updated set and represents the orientation threshold; it is an empirical value that varies from video to video.
- Step-4:
- The updated match tracklets set in this layer will be finally grouped, as given in Equation (18),
4.5. Stage-5 (S5): Correlation Filtering Layer (CFL)
- Step-1:
- At time , find the position of the endpoint of the tracklet in the image plane. Then, calculate its intensity pixel values matrix , where and represent the size of adjacent pixels window.
- Step-2:
- From time to , find the position of the start point of a sub-tracklet set. For example, the intensity pixel value of the endpoint of in the image, the plane is represented as .
- Step-3:
- Measure the pixel correlation coefficient among positions and , as given in Equation (19),where and are the mean of and , respectively. The correlation coefficient ranges from for perfect negatively correlated results, through when there is no correlation, to when the results are identical.
- Step-4:
- Then, apply correlation consistency to filter out all sub-tracklets that do not satisfy the correlation condition with the main tracklet, as given in Equation (20),where and represent the total number of updated set and represents the correlation threshold, which is an empirical value that varies from video to video. Lastly, the updated match tracklets set in this step are given in Equation (21),
- Step-5:
- The final match sub-tracklets from Equation (21) are ranked in ascending order as from the closest correlation related to the least correlation related.
- Step-6:
- Then, the first sub-tracklet in will be the best candidate to be connected with as one big path, as given in Equation (22),where is the new tracklet after connecting and .
- Step-7:
- Update to the enhanced KLT tracklets’ set.
| Algorithm 1: The proposed HTA algorithm. |
| Input: Video clip frames F. |
| Output: Coherent motion cluster |
 |
5. Evaluation Metrics
6. Experimental Results
6.1. CUHK Crowd Dataset
6.2. Disconnected Trajectories on Raw KLT Features
6.3. Qualitative Result Discussion of Motion Crowd Clustering Using HTA
6.4. Quantitative Result Discussion of Motion Crowd Clustering Using HTA
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chaudhary, D.; Kumar, S.; Dhaka, V.S. Video Based Human Crowd Analysis Using Machine Learning: A Survey. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022, 10, 113–131. [Google Scholar] [CrossRef]
- Muhammed, D.A.; Rashid, T.A.; Alsadoon, A.; Bacanin, N.; Fattah, P.; Mohammadi, M.; Banerjee, I. An Improved Simulation Model for Pedestrian Crowd Evacuation. Mathematics 2020, 8, 2171. [Google Scholar] [CrossRef]
- Martín-Santamaría, R.; López-Sánchez, A.D.; Delgado-Jalón, M.L.; Colmenar, J.M. An Efficient Algorithm for Crowd Logistics Optimization. Mathematics 2021, 9, 509. [Google Scholar] [CrossRef]
- Bendali-Braham, M.; Weber, J.; Forestier, G.; Idoumghar, L.; Muller, P.-A. Recent Trends in Crowd Analysis: A Review. Mach. Learn. Appl. 2021, 4, 100023. [Google Scholar] [CrossRef]
- Yang, G.; Zhu, D. Survey on Algorithms of People Counting in Dense Crowd and Crowd Density Estimation. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]
- Fan, Z.; Zhang, H.; Zhang, Z.; Lu, G.; Zhang, Y.; Wang, Y. A Survey of Crowd Counting and Density Estimation Based on Convolutional Neural Network. Neurocomputing 2022, 472, 224–251. [Google Scholar] [CrossRef]
- Zhong, M.; Tan, Y.; Li, J.; Zhang, H.; Yu, S. Cattle Number Estimation on Smart Pasture Based on Multi-Scale Information Fusion. Mathematics 2022, 10, 3856. [Google Scholar] [CrossRef]
- Saleh, S.A.M.; Suandi, S.A.; Ibrahim, H. Recent Survey on Crowd Density Estimation and Counting for Visual Surveillance. Eng. Appl. Artif. Intell. 2015, 41, 103–114. [Google Scholar] [CrossRef]
- Wei, X.; Liu, J.-C.; Bi, S. Uncertainty Quantification and Propagation of Crowd Behaviour Effects on Pedestrian-Induced Vibrations of Footbridges. Mech. Syst. Signal Process. 2022, 167, 108557. [Google Scholar] [CrossRef]
- Yu, Y.; Shen, W.; Huang, H.; Zhang, Z. Abnormal Event Detection in Crowded Scenes Using Two Sparse Dictionaries with Saliency. J Electron. Imaging 2017, 26, 33013. [Google Scholar] [CrossRef]
- Yi, S.; Li, H.; Wang, X. Understanding Pedestrian Behaviors from Stationary Crowd Groups. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–15 June 2015; pp. 3488–3496. [Google Scholar]
- Fradi, H.; Luvison, B.; Pham, Q.C. Crowd Behavior Analysis Using Local Mid-Level Visual Descriptors. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 589–602. [Google Scholar] [CrossRef]
- Al-Sa’d, M.; Kiranyaz, S.; Ahmad, I.; Sundell, C.; Vakkuri, M.; Gabbouj, M. A Social Distance Estimation and Crowd Monitoring System for Surveillance Cameras. Sensors 2022, 22, 418. [Google Scholar] [CrossRef]
- Pai, A.K.; Chandrahasan, P.; Raghavendra, U.; Karunakar, A.K. Motion Pattern-Based Crowd Scene Classification Using Histogram of Angular Deviations of Trajectories. Vis. Comput. 2022, 39, 557–567. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, S.; Yang, R.; Zheng, A.; Chen, Z.; Tang, J.; Luo, B. Pedestrian Attribute Recognition: A Survey. Pattern Recognit. 2022, 121, 108220. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A Survey of Recent Advances in Cnn-Based Single Image Crowd Counting and Density Estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef] [Green Version]
- Shao, J.; Loy, C.C.; Kang, K.; Wang, X. Crowded Scene Understanding by Deeply Learned Volumetric Slices. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 613–623. [Google Scholar] [CrossRef]
- Lohithashva, B.H.; Aradhya, V.N.M. Violent Video Event Detection: A Local Optimal Oriented Pattern Based Approach. In Proceedings of the International Conference on Applied Intelligence and Informatics, Nottingham, UK, 30 July 2021; pp. 268–280. [Google Scholar]
- Yu, J.; Lee, Y.; Yow, K.C.; Jeon, M.; Pedrycz, W. Abnormal Event Detection and Localization via Adversarial Event Prediction. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3572–3586. [Google Scholar] [CrossRef]
- Jebur, S.A.; Hussein, K.A.; Hoomod, H.K.; Alzubaidi, L.; Santamaría, J. Review on Deep Learning Approaches for Anomaly Event Detection in Video Surveillance. Electronics 2023, 12, 29. [Google Scholar] [CrossRef]
- Wang, J.; Xu, Z. Spatio-Temporal Texture Modelling for Real-Time Crowd Anomaly Detection. Comput. Vis. Image Underst. 2016, 144, 177–187. [Google Scholar] [CrossRef]
- Zhou, T.; Zheng, L.; Peng, Y.; Jiang, R. A Survey of Research on Crowd Abnormal Behavior Detection Algorithm Based on YOLO Network. In Proceedings of the 2022 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 14–16 January 2022; pp. 783–786. [Google Scholar]
- Lalit, R.; Purwar, R.K. Crowd Abnormality Detection Using Optical Flow and GLCM-Based Texture Features. J. Inf. Technol. Res. (JITR) 2022, 15, 1–15. [Google Scholar] [CrossRef]
- Ekanayake, E.M.C.L.; Lei, Y.; Li, C. Crowd Density Level Estimation and Anomaly Detection Using Multicolumn Multistage Bilinear Convolution Attention Network (MCMS-BCNN-Attention). Appl. Sci. 2023, 13, 248. [Google Scholar] [CrossRef]
- Benabbas, Y.; Ihaddadene, N.; Djeraba, C. Motion Pattern Extraction and Event Detection for Automatic Visual Surveillance. EURASIP J. Image Video Process. 2010, 2011, 163682. [Google Scholar] [CrossRef] [Green Version]
- Han, T.; Yao, H.; Sun, X.; Zhao, S.; Zhang, Y. Unsupervised Discovery of Crowd Activities by Saliency-Based Clustering. Neurocomputing 2016, 171, 347–361. [Google Scholar] [CrossRef]
- Solmaz, B.; Moore, B.E.; Shah, M. Identifying Behaviors in Crowd Scenes Using Stability Analysis for Dynamical Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2064–2070. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Tang, X.; Wang, X. Learning Collective Crowd Behaviors with Dynamic Pedestrian-Agents. Int. J. Comput. Vis. 2015, 111, 50–68. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded Scene Analysis: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 367–386. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.; Shah, M. A Lagrangian Particle Dynamics Approach for Crowd Flow Segmentation and Stability Analysis. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–6. [Google Scholar]
- Mehran, R.; Moore, B.E.; Shah, M. A Streakline Representation of Flow in Crowded Scenes. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 439–452. [Google Scholar]
- Wu, S.; San Wong, H. Crowd Motion Partitioning in a Scattered Motion Field. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 1443–1454. [Google Scholar]
- Song, L.; Jiang, F.; Shi, Z.; Katsaggelos, A.K. Understanding Dynamic Scenes by Hierarchical Motion Pattern Mining. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Zhou, B.; Wang, X.; Tang, X. Random Field Topic Model for Semantic Region Analysis in Crowded Scenes from Tracklets. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3441–3448. [Google Scholar]
- Fu, W.; Wang, J.; Li, Z.; Lu, H.; Ma, S. Learning Semantic Motion Patterns for Dynamic Scenes by Improved Sparse Topical Coding. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 296–301. [Google Scholar]
- Zhou, B.; Tang, X.; Wang, X. Coherent Filtering: Detecting Coherent Motions from Crowd Clutters. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 857–871. [Google Scholar]
- Shao, J.; Change Loy, C.; Wang, X. Scene-Independent Group Profiling in Crowd. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2219–2226. [Google Scholar]
- Li, N.; Zhang, Y.; Luo, W.; Guo, N. Instant Coherent Group Motion Filtering by Group Motion Representations. Neurocomputing 2017, 266, 304–314. [Google Scholar] [CrossRef]
- Saleh, S.A.M.; Suandi, S.A.; Ibrahim, H. Impact of Similarity Measure Functions on the Performance of Coherent Filtering Detection. In Proceedings of the 11th International Conference on Robotics, Vision, Signal Processing and Power Applications; Mahyuddin, N.M., Mat Noor, N.R., Mat Sakim, H.A., Eds.; Springer: Singapore, 2022; pp. 501–506. [Google Scholar]
- Li, X.; Chen, M.; Wang, Q. Quantifying and Detecting Collective Motion in Crowd Scenes. IEEE Trans. Image Process. 2020, 29, 5571–5583. [Google Scholar] [CrossRef]
- Shi, J. Good Features to Track. In Proceedings of the 1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Tomasi, C.; Kanade, T. Detection and Tracking of Point. Int. J. Comput. Vis. 1991, 9, 137–154. [Google Scholar] [CrossRef]
- Baker, S.; Matthews, I. Lucas-Kanade 20 Years On: A Unifying Framework. Int. J. Comput. Vis. 2004, 56, 221–255. [Google Scholar] [CrossRef]
- Zhou, B.; Tang, X.; Wang, X. Measuring Crowd Collectiveness. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3049–3056. [Google Scholar]
- Raptis, M.; Soatto, S. Tracklet Descriptors for Action Modeling and Video Analysis. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 577–590. [Google Scholar]
- Aldayri, A.; Albattah, W. Taxonomy of Anomaly Detection Techniques in Crowd Scenes. Sensors 2022, 22, 80. [Google Scholar] [CrossRef]
- Arshad, M.H.; Bilal, M.; Gani, A. Human Activity Recognition: Review, Taxonomy and Open Challenges. Sensors 2022, 22, 6463. [Google Scholar] [CrossRef]
- Khan, K.; Albattah, W.; Khan, R.U.; Qamar, A.M.; Nayab, D. Advances and Trends in Real Time Visual Crowd Analysis. Sensors 2020, 20, 5073. [Google Scholar] [CrossRef]
- Elbishlawi, S.; Abdelpakey, M.H.; Eltantawy, A.; Shehata, M.S.; Mohamed, M.M. Deep Learning-Based Crowd Scene Analysis Survey. J. Imaging 2020, 6, 95. [Google Scholar] [CrossRef]
- Bhuiyan, M.R.; Abdullah, J.; Hashim, N.; al Farid, F. Video Analytics Using Deep Learning for Crowd Analysis: A Review. Multimed. Tools Appl. 2022, 81, 27895–27922. [Google Scholar] [CrossRef]
- Fan, Z.; Jiang, J.; Weng, S.; He, Z.; Liu, Z. Adaptive Crowd Segmentation Based on Coherent Motion Detection. J. Signal Process. Syst. 2018, 90, 1651–1666. [Google Scholar] [CrossRef]
- Chen, M.; Wang, Q.; Li, X. Patch-Based Topic Model for Group Detection. Sci. China Inf. Sci. 2017, 60, 113101. [Google Scholar] [CrossRef] [Green Version]
- Pai, A.K.; Karunakar, A.K.; Raghavendra, U. Scene-Independent Motion Pattern Segmentation in Crowded Video Scenes Using Spatio-Angular Density-Based Clustering. IEEE Access 2020, 8, 145984–145994. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, M.; Nie, F.; Li, X. Detecting Coherent Groups in Crowd Scenes by Multiview Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 46–58. [Google Scholar] [CrossRef]
- Shao, J.; Loy, C.C.; Wang, X. Learning Scene-Independent Group Descriptors for Crowd Understanding. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1290–1303. [Google Scholar] [CrossRef]
- Japar, N.; Kok, V.J.; Chan, C.S. Collectiveness Analysis with Visual Attributes. Neurocomputing 2021, 463, 77–90. [Google Scholar] [CrossRef]
- Kolekar, M.H. Intelligent Video Surveillance Systems: An Algorithmic Approach; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Dikbaş, F. A Novel Two-Dimensional Correlation Coefficient for Assessing Associations in Time Series Data. Int. J. Climatol. 2017, 37, 4065–4076. [Google Scholar] [CrossRef]
- Asuero, A.G.; Sayago, A.; González, A.G. The Correlation Coefficient: An Overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Zhao, Y.; Karypis, G. Empirical and Theoretical Comparisons of Selected Criterion Functions for Document Clustering. Mach. Learn. 2004, 55, 311–331. [Google Scholar] [CrossRef] [Green Version]
- Rand, W.M. Objective Criteria for the Evaluation of Clustering Methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Ceri, S.; Bozzon, A.; Brambilla, M.; della Valle, E.; Fraternali, P.; Quarteroni, S. An Introduction to Information Retrieval. In Web Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–11. [Google Scholar]
- Newman, M.E.J.; Cantwell, G.T.; Young, J.-G. Improved Mutual Information Measure for Clustering, Classification, and Community Detection. Phys. Rev. E 2020, 101, 42304. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef] [Green Version]
- Kvålseth, T.O. On Normalized Mutual Information: Measure Derivations and Properties. Entropy 2017, 19, 631. [Google Scholar] [CrossRef] [Green Version]
- Harman, D. Information Retrieval: The Early Years. Found. Trends® Inf. Retr. 2019, 13, 425–577. [Google Scholar] [CrossRef]
- CUHK Crowd Dataset. Available online: http://www.ee.cuhk.edu.hk/~xgwang/CUHKcrowd.html (accessed on 28 June 2014).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Input frame | |
| Total frames number for a given video sequence | |
| A single tracklet | |
| Tracklets pool | |
| Tracklets total number | |
| One point position of a tracklet in x and y axis | |
| Tracklet-position matrix of the input video | |
| Tracklet that ended in ROI | |
| Tracklet that started in ROI | |
| End-point position of tre tracklet | |
| Start-point position of trs tracklet | |
| Tracklets vector that ended in ROI | |
| Tracklets vector that started in ROI | |
| Tracklet orientation |
| Parameter | Discerption | Value |
|---|---|---|
| Average threshold | ||
| Position threshold | 5 | |
| Orientation threshold | ||
| Correlation threshold | 0.5 | |
| Time/frame distance | 5 | |
| Temporal window stride | 5 |
| Index | Video Clips with a Percentage of Disconnected Tracklets | CF on Raw KLT | CF on Enhanced KLT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Purity | NMI | RI | Fm | Purity | NMI | RI | Fm | ||
| 1 | 68 video clips with (≥6%) | 0.85 | 0.44 | 0.79 | 0.81 | 0.89 | 0.47 | 0.82 | 0.84 |
| 2 | 91 video clips with (≥3% & <6%) | 0.84 | 0.44 | 0.76 | 0.77 | 0.87 | 0.48 | 0.79 | 0.79 |
| 3 | 141 video clips with (<3%) | 0.86 | 0.51 | 0.79 | 0.82 | 0.86 | 0.51 | 0.79 | 0.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saleh, S.A.M.; Kadarman, A.H.; Suandi, S.A.; Ghaleb, S.A.A.; Ghanem, W.A.H.M.; Shuib, S.; Hamad, Q.S. A Tracklet-before-Clustering Initialization Strategy Based on Hierarchical KLT Tracklet Association for Coherent Motion Filtering Enhancement. Mathematics 2023, 11, 1075. https://doi.org/10.3390/math11051075
Saleh SAM, Kadarman AH, Suandi SA, Ghaleb SAA, Ghanem WAHM, Shuib S, Hamad QS. A Tracklet-before-Clustering Initialization Strategy Based on Hierarchical KLT Tracklet Association for Coherent Motion Filtering Enhancement. Mathematics. 2023; 11(5):1075. https://doi.org/10.3390/math11051075
Chicago/Turabian StyleSaleh, Sami Abdulla Mohsen, A. Halim Kadarman, Shahrel Azmin Suandi, Sanaa A. A. Ghaleb, Waheed A. H. M. Ghanem, Solehuddin Shuib, and Qusay Shihab Hamad. 2023. "A Tracklet-before-Clustering Initialization Strategy Based on Hierarchical KLT Tracklet Association for Coherent Motion Filtering Enhancement" Mathematics 11, no. 5: 1075. https://doi.org/10.3390/math11051075