This section presents the structure of the proposed system and describes how the algorithms interact with each other. The system is intended to produce flight-by-flight engine performance analysis during a full service life. It is composed of three main algorithms:
3.1. Feature Extraction Algorithm
Considering the structure of Equation (
1), a baseline function with one measured variable and four operating conditions [
23] has the following form:
As performance degradation is dependent on the engine’s operation time, a variable of the relative flight number
, which is a measure of deterioration severity, is added to the arguments of the baseline function to produce a Degraded Engine Model (DEM) [
17]:
When the DEM is constant in the interval of analysis, it is called a Fixed Degraded Engine Model (FDEM); there are two of these, FDEM1 and FDEM2. If the coefficients of the DEM are updated with time, it is called an Adaptive Degraded Engine Model (ADEM). Residuals employing FDEM1 can reveal deterioration trends, and are employed by the deterioration prognostics algorithm. After the unknown model coefficients
x have been determined using Equation (
1), FDEM1 can be converted into a baseline function by setting
and obtaining residuals
:
In the same way, residuals
are computed as follows:
The ADEM is computationally light and easily adapts to capture the current level of deterioration that grows with engine operation. Without the presence of faults, the signals from Equation (
6) behave as random errors without any trend, as they are just differences between deterioration values. When a fault appears, the anomaly detection and fault identification algorithm verifies significant changes in
values to make a diagnostic decision. When the fault has been detected and identified, ADEM stops updating to become FDEM2 with the last adapted model coefficients (i.e.,
). From this moment on, the residuals are computed as follows:
These last residuals are utilized in the fault diagnostics and prognostics algorithm. Residuals contain both the influence of the long-term degradation accumulated over time and the influence of the fault, which is evolving at a certain rate.
For better diagnostic performance, all types of residuals are smoothed using an exponential moving average [
25]:
where
i is the measured variable,
j is the current flight, and
is a factor with values 0 to 1 that controls the smoothing level.
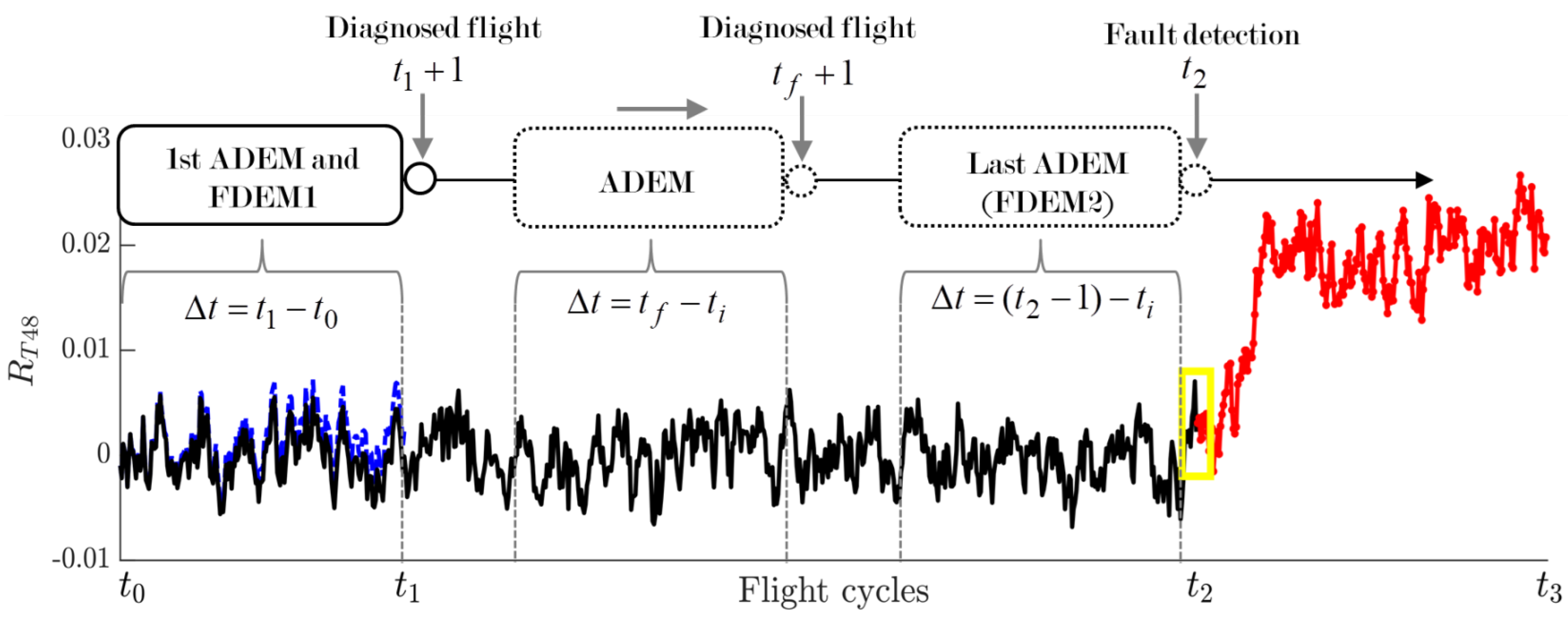
Figure 2 displays an example of the system as a function of flight cycles
t, showing the behavior of the residuals for a temperature variable (
—temperature at high-pressure compressor outlet,
Table A2). The total interval of the engine performance analysis (
) is partitioned into three intervals:
Interval 1 (
). The feature extraction algorithm is active from the beginning of the monitoring analysis and lasts until it ends. Because at initial engine operation there are insufficient data to create an adequate degradation model, a pre-built CFAM with different healthy engines is implemented to obtain the required residuals for monitoring and diagnostics. As mentioned before, CFAM can be effectively applied for a short time in low-degradation cases. FDEM1, the first ADEM, and the corresponding residuals are only available when flight
is reached, and use the data that have been accumulated in the interval
, where
and
are the initial and final flights coinciding with
and
, respectively.
Figure 3 is a close-up of Interval 1; the similar behavior of the three types of residuals can be observed, confirming that CFAM can temporarily replace FDEM and ADEM.
Interval 2 (). FDEM1 is computed at , and does not change throughout the entire second interval. Residuals and begin to separate from each other after due to the deterioration growth captured by residuals (manifested, for example, by the increase of temperature). The deterioration prognostics algorithm receives these last residuals to train a deep neural network and forecast the deterioration behavior.
As for residuals
, the first ADEM is also obtained at
, then the model coefficients are constantly renewed by shifting the measured variables and operating conditions according to the currently diagnosed flight using the interval
that precedes it. The optimal number of required flights
is selected based on the model’s accuracy after testing different values (in this paper,
). Because each update involves the last flights, ADEM is always adapted to the current level of engine deterioration, producing an adequate reference function in the computation of residuals
. The model stops updating at
after a fault is detected by the anomaly detection and fault identification algorithm. From the start of engine monitoring, this algorithm needs a pretrained neural network with CFAM-based residuals in order to recognize a variety of fault classes, including healthy cases.
Figure 4 schematizes how the FDEM and ADEM are created over time from
to
.
Interval 3 (). When a fault is detected, FDEM2 (the last ADEM) remains the same throughout Interval 3 to compute residuals . As before, the same type of deep neural network is employed to predict the behavior of the fault, which evolves along with the deterioration. In practice, the fault prognosis analysis should be performed within a short period in order to take rapid maintenance actions. When an engine presents no faults or only small faults that are impossible to detect and identify, the monitoring system remains in active operation to the end of the engine’s service life.
3.3. Prognostic Algorithm
The proposed system employs the LSTM architecture to forecast the behavior of both engine deterioration and faults. LSTM was selected for this task due to its proven effectiveness in learning long-term dependencies between time steps of sequence data. When used in prognostics problems, the general architecture of the network includes a sequence input layer (inputs as sequences or time series), an LSTM layer, a fully connected layer, and a regression output layer. More information about LSTM can be found, for example, in [
27].
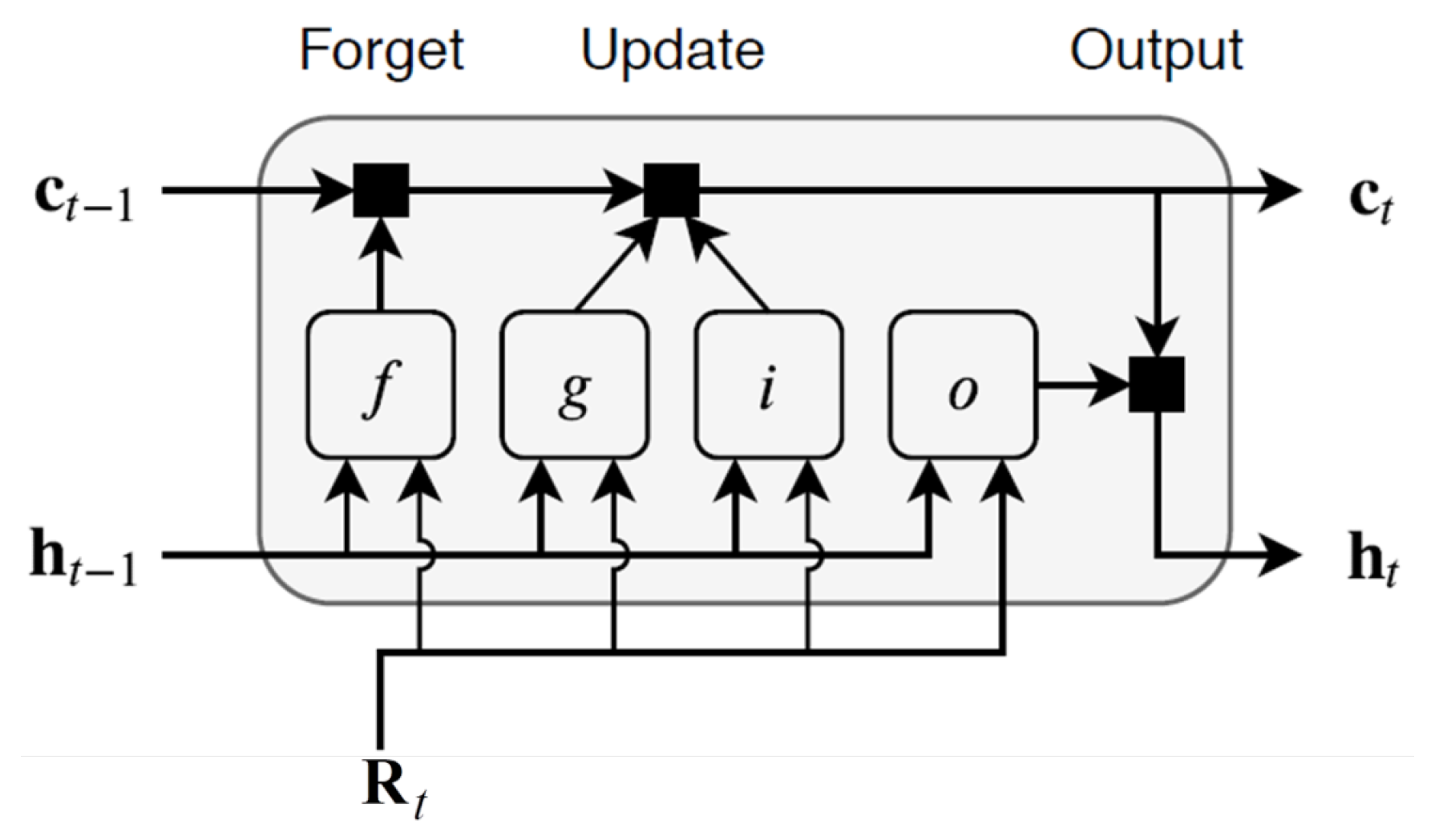
An LSTM layer works with a time series (in this case, either residuals
or
) with
m features and
S time steps as input to the layer. Here,
and
correspond to the cell state and the hidden state with
D units at time step
t (flight), respectively. The cell state retains learned information from previous steps, while the hidden state is the output of the LSTM layer at a given time step. The first LSTM block receives the initial state and the first time step (vector of residuals) to produce the first output and the corresponding updated cell state. At step
t, the output and the cell state are computed using the previous network state (
and
) and the next sequence step. At each time step, the LSTM layer adds or deletes information from the cell state through internal elements called gates, as shown in
Figure 6. The forget gate
f controls which information should be retained or discarded. The input gate
i controls the level of cell state update. The cell state can be updated with the generated gate outputs. The output gate
o decides what the next hidden state will be. After being computed, both the new
and the new
are carried over to the next time step. The gates ensure that only relevant information is transmitted through the sequence chain, resulting in improved predictions.
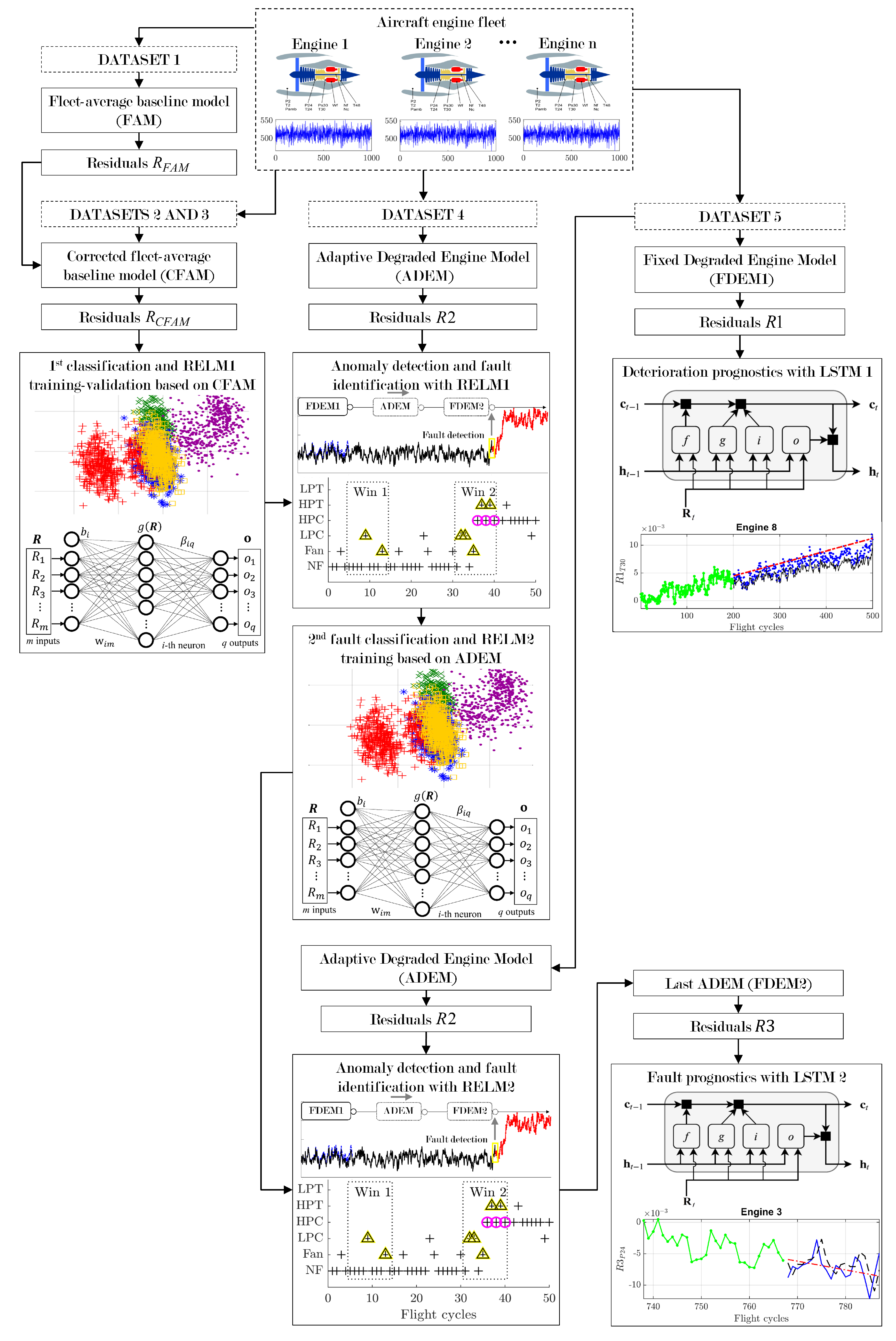
3.4. Datasets and Flowchart of the PHM System
Five datasets were generated through ProDiMES to develop and internally evaluate the system (
Table 1). The datasets contained flight cycles (with registered measured parameters and operating conditions) from different fleets with engines experiencing fault and no-fault conditions under cruise regimes as well as progressive deterioration. Based on the previous descriptions of the individual algorithms and techniques employed,
Figure 7 displays the flowchart of the proposed system working with the generated datasets.
Dataset 1 was used for FAM creation with 100 healthy engines. Only the first 90 flights out of 5000 were used for the model, ensuring low degradation in the engines.
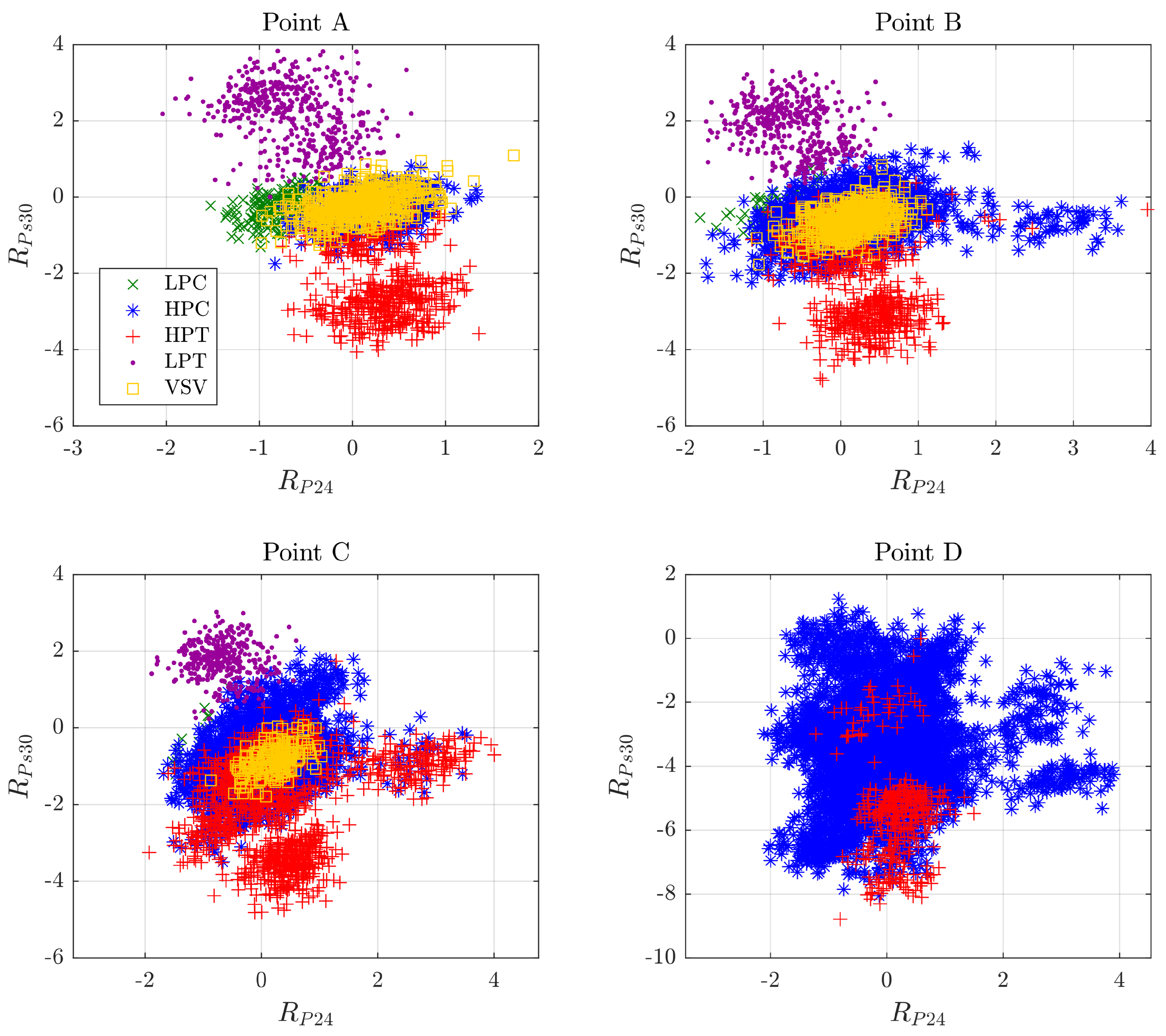
Datasets 2 and 3 were generated with the same characteristics, and were intended for constructing a training set and a validation set, respectively. Together, they constituted the first fault classification used for training and validating a preliminary classification network (RELM1) with corrected residuals using CFAM. The datasets had the same size. and each of them contained 95,000 flights (19 fault conditions × 100 engines per condition × 50 flights per engine), from which 19,000 were used for residual correction with the first ten flights in each engine and 76,000 were used for diagnostics. Because the number of flights for each engine was only 50, the level of deterioration was randomly selected through ProDiMES. In this way, RELM1 was trained with a representative classification containing all 19 health conditions and with different levels of deterioration that are possible in the fleet. As an important remark, RELM1 does not solve the problem of reduced recognition accuracy due to the baseline model’s inadequacy in long-term diagnostics; however, it can assist in recognizing fault conditions from the beginning of monitoring analysis and during the first implementation of the ADEM-based procedure. The optimal network training configurations were found by the trial-and-error method, with different architectures tested to obtain the one with the highest classification accuracy value. For RELM1, the network size was 7 (measured variables as inputs) × 6000 (hidden neurons) × 19 (fault scenarios as output neurons), = 0.4493, the size of output layer weight matrix was 19 classes × 6000 hidden neurons, and the size of target matrix was 19 classes × 76,000 samples.
Dataset 4 served to implement the ADEM-based algorithm. The number of flights per engine was 5000 in order to allow for the full development of the engine deterioration profile. Thus, the total amount of samples to be diagnosed was 1,824,000 (19 fault conditions × 20 engines per condition × 4800 flights per engine). When the ADEM-based procedure is in operation, RELM1 helps to produce diagnoses flight by flight in each engine in the dataset. At the current flight, both the update of ADEM and the corresponding computed residual depend on the diagnosis made by the network in the previous flight, either indicating a healthy condition or detecting a fault. After all the engines have been analyzed, a second fault classification is created using all of the computed residuals (those related to the diagnostics stage) and their predicted labels. With this new classification, a second RELM network (RELM2) is trained based on the ADEM-based procedure. The intention of creating RELM2 is to replace the CFAM-based network in future applications. For RELM2, the optimal training architecture consists of seven inputs, 8000 hidden neurons, and 19 outputs, = 0.6703, the size of output layer weight matrix is 19 classes × 8000 hidden neurons, and the size of target matrix is 19 classes × 1,824,000 samples.
Dataset 5 had the same structure and size as Dataset 4, and was intended for validating RELM2 by applying the ADEM-based procedure in the same manner as before. In addition, this dataset allowed us to compare different state-of-the-art methods, verify different approaches for long-term diagnostics, and evaluate the prognostics algorithm. In the first case, the stage of deterioration prognostics was used to train an LSTM network (LSTM1) with residuals as the inputs. Because long-term performance deterioration evolves much more slowly than a fault, the algorithm has sufficient time to collect a considerable amount of training data. LSTM1 learns to forecast the residual values of future time steps to analyze the deterioration trend and take maintenance decisions if the residual has surpassed a given threshold value. As a reminder, both the residuals and for an engine are computed flight-by-flight, meaning that the anomaly detection–fault identification algorithm and the deterioration prognostics algorithm work simultaneously. When a fault is detected, deterioration prediction is switched to fault prognostics. Residuals are computed using the last updated ADEM, and serve as inputs to train a second LSTM network (LSTM2) and predict the evolution of the fault, which contains the influence of the accumulated deterioration. In contrast to LSTM1, LSTM2 is expected to work within a short interval. Our proposed network architecture for LSTM1 used the following parameters in each layer: (1) sequence input layer (input size = 7); (2) LSTM layer (number of hidden neurons = 800, state activation function = tanh, gate activation function = sigmoid, size of the hidden state vector = 800 × 1, size of the cell state vector = 800 × 1, size of the input weight matrix = 3200 × 7, size of the recurrent weight matrix= 3200 × 200, size of the bias vector = 3200 × 1); (3) fully connected layer (input size = 800, output size = 7, size of the weight matrix = 7 × 800); (4) regression output layer (loss function = mean squared error). Other training specifications were: number of iterations (epochs) = 600; gradient threshold = 1; initial learning rate = 0.01; learning rate drop period = 125; and learning rate drop factor = 0.2. For RELM2, the same parameters were considered in each layer, with the only differences being that the number of hidden neurons = 200, the size of the input weight matrix = (4 × 200 neurons) × 7 (from the concatenation of the four gate matrices), the number of iterations = 200, and the initial learning rate = 0.005.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













