Intercomparison of Univariate and Joint Bias Correction Methods in Changing Climate From a Hydrological Perspective


Abstract
:1. Introduction
- How does the relative performance of bias adjustment methods vary when assessing them from the perspective of the impacts of climate change on different hydrological variables rather than from climate modeling perspective?
- What is the added value of bias correcting inter-variable relationships between daily mean temperature and precipitation in comparison to the adjustment of their marginal distributions only?
2. Materials and Methods
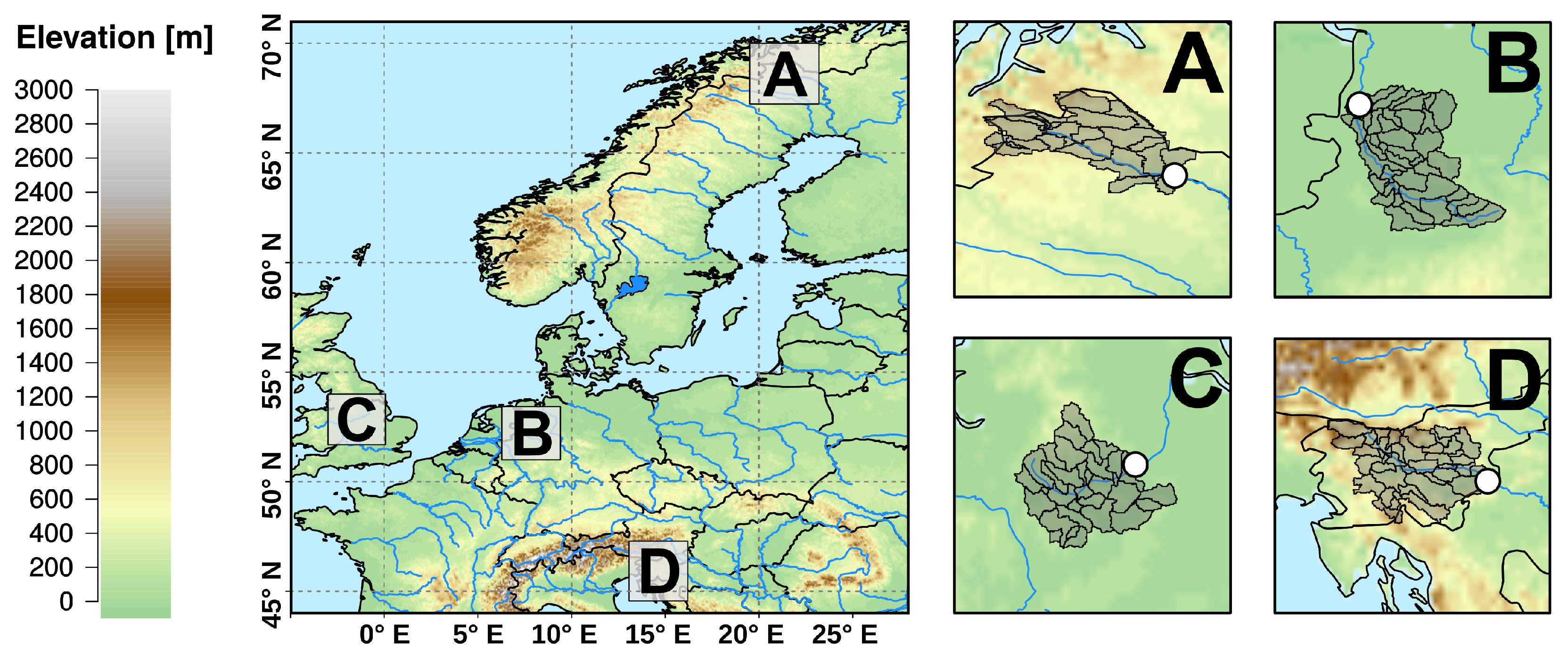
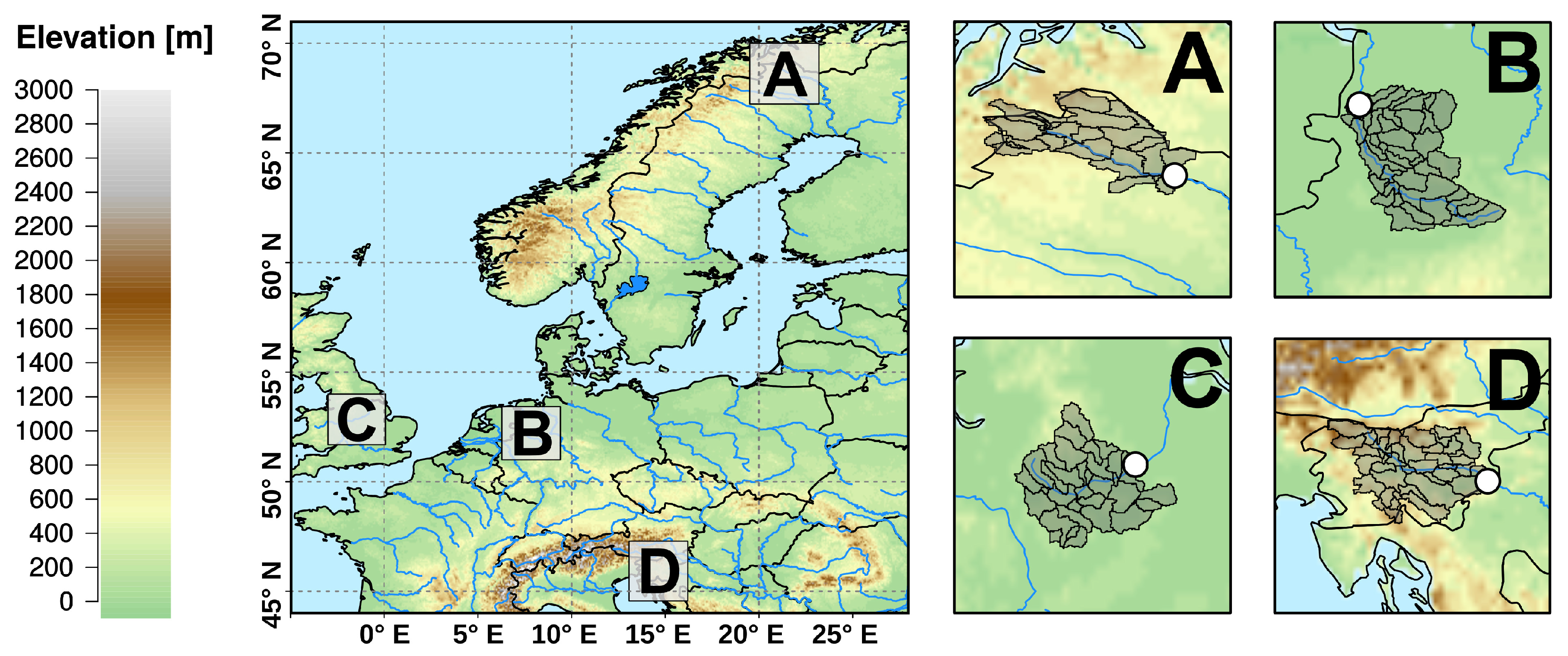
2.1. Reference Data
2.2. GCM-RCM Data
2.3. Hydrological Simulations
2.4. Model Output Statistics
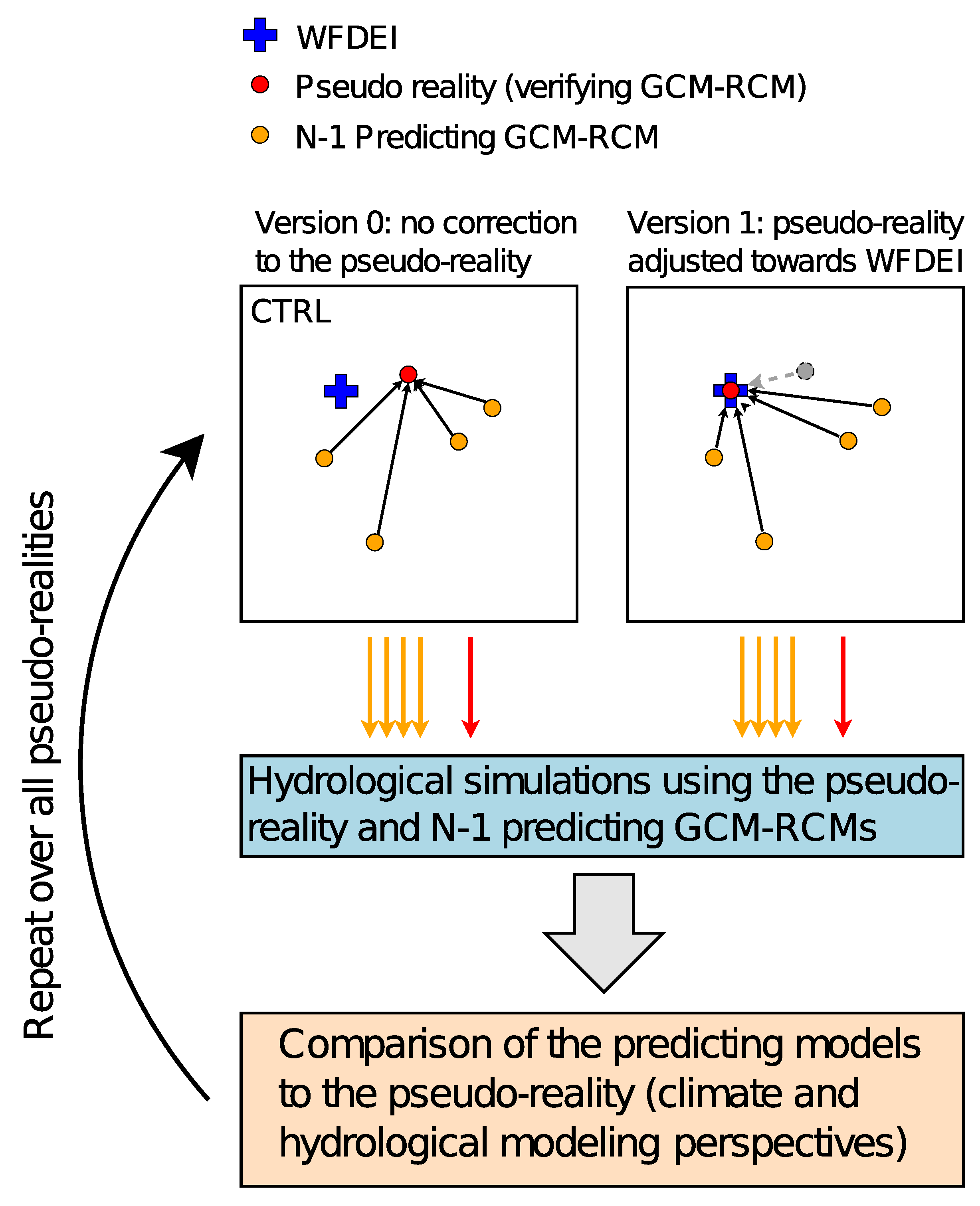
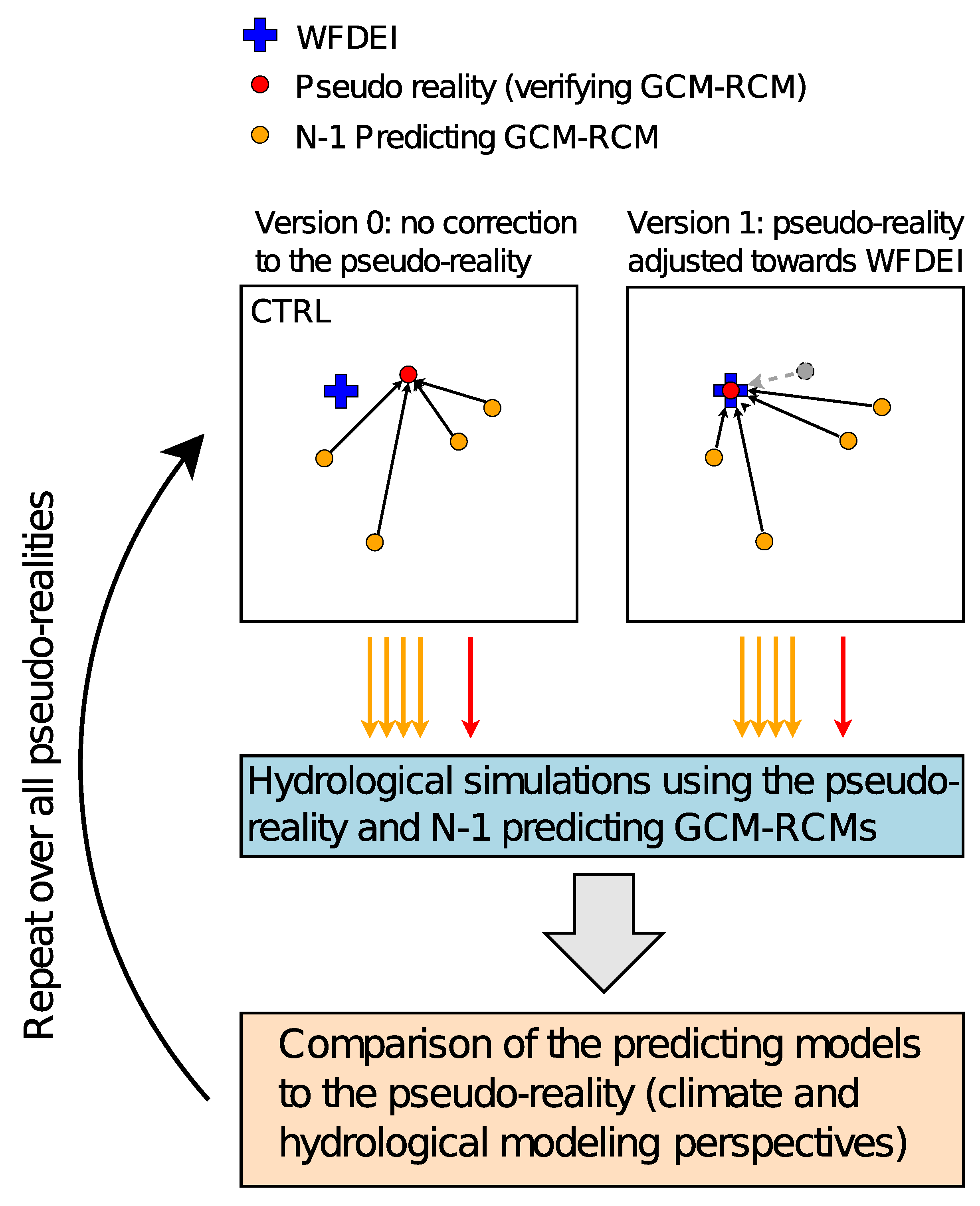
2.5. Pseudo-Reality Framework
2.6. Metrics for GCM-RCM Simulations
2.7. Metrics for Hydrological Simulations
3. Results
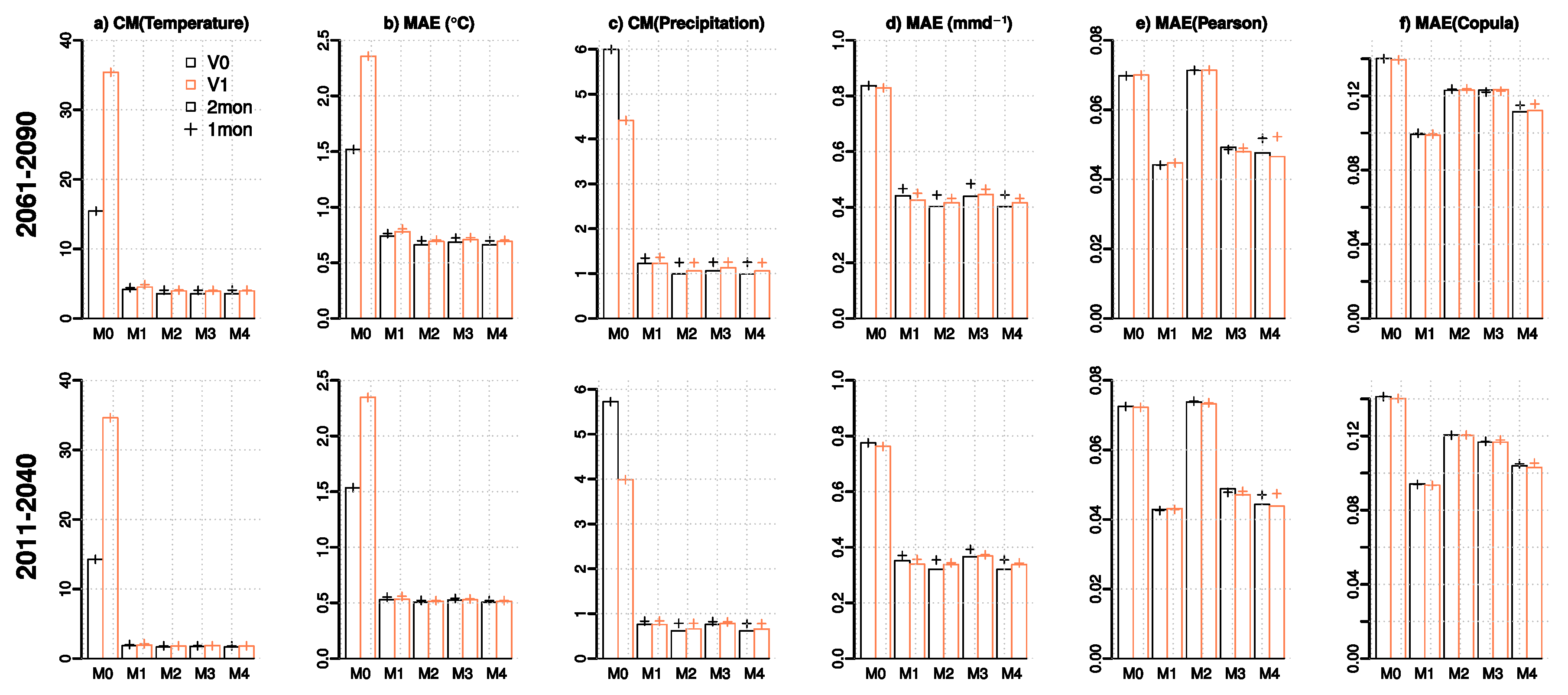
3.1. Distribution-Averaged Statistics for Daily Mean Temperature and Precipitation
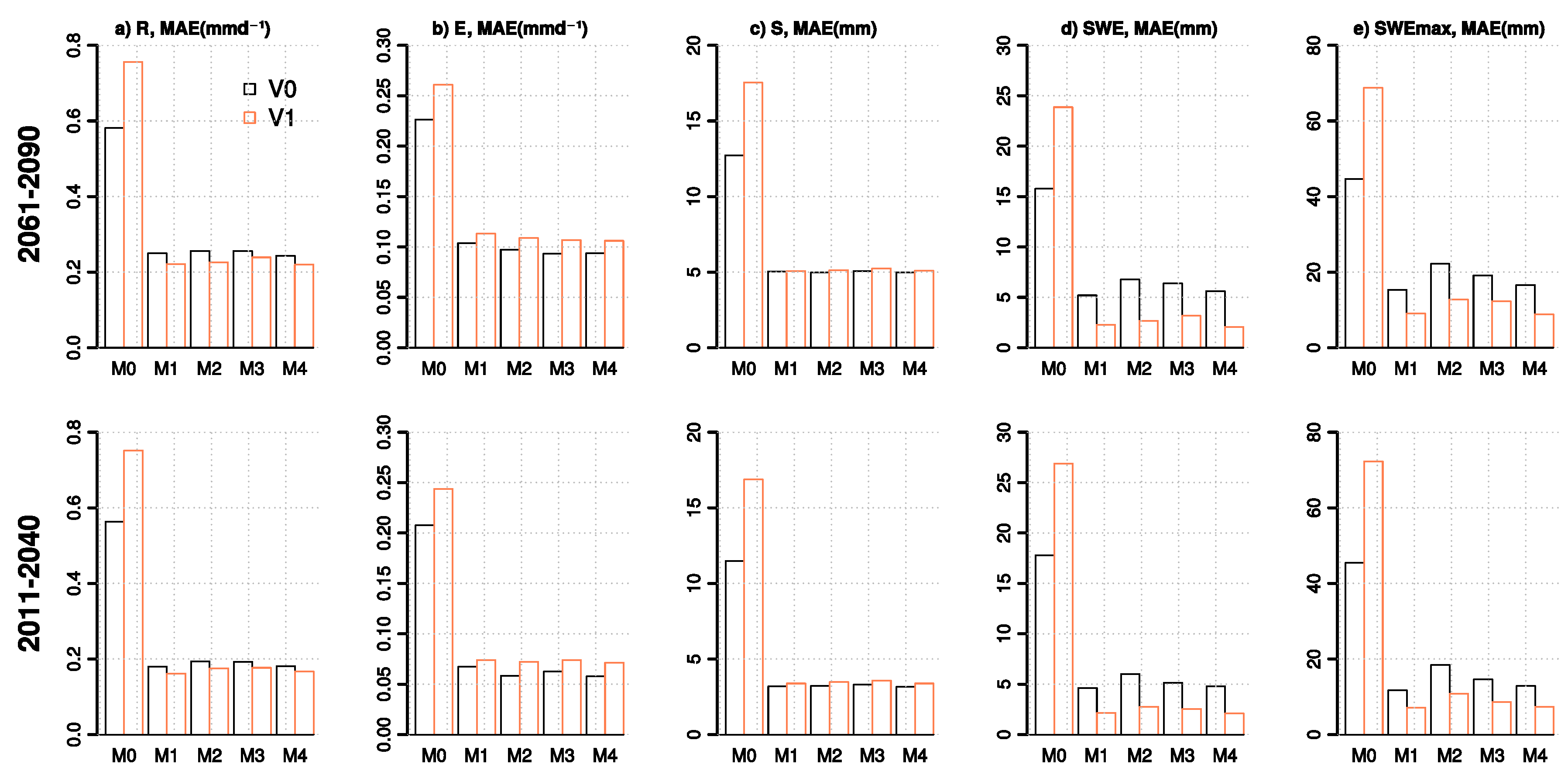
3.2. Cross-Validation Statistics for Hydrological Simulations
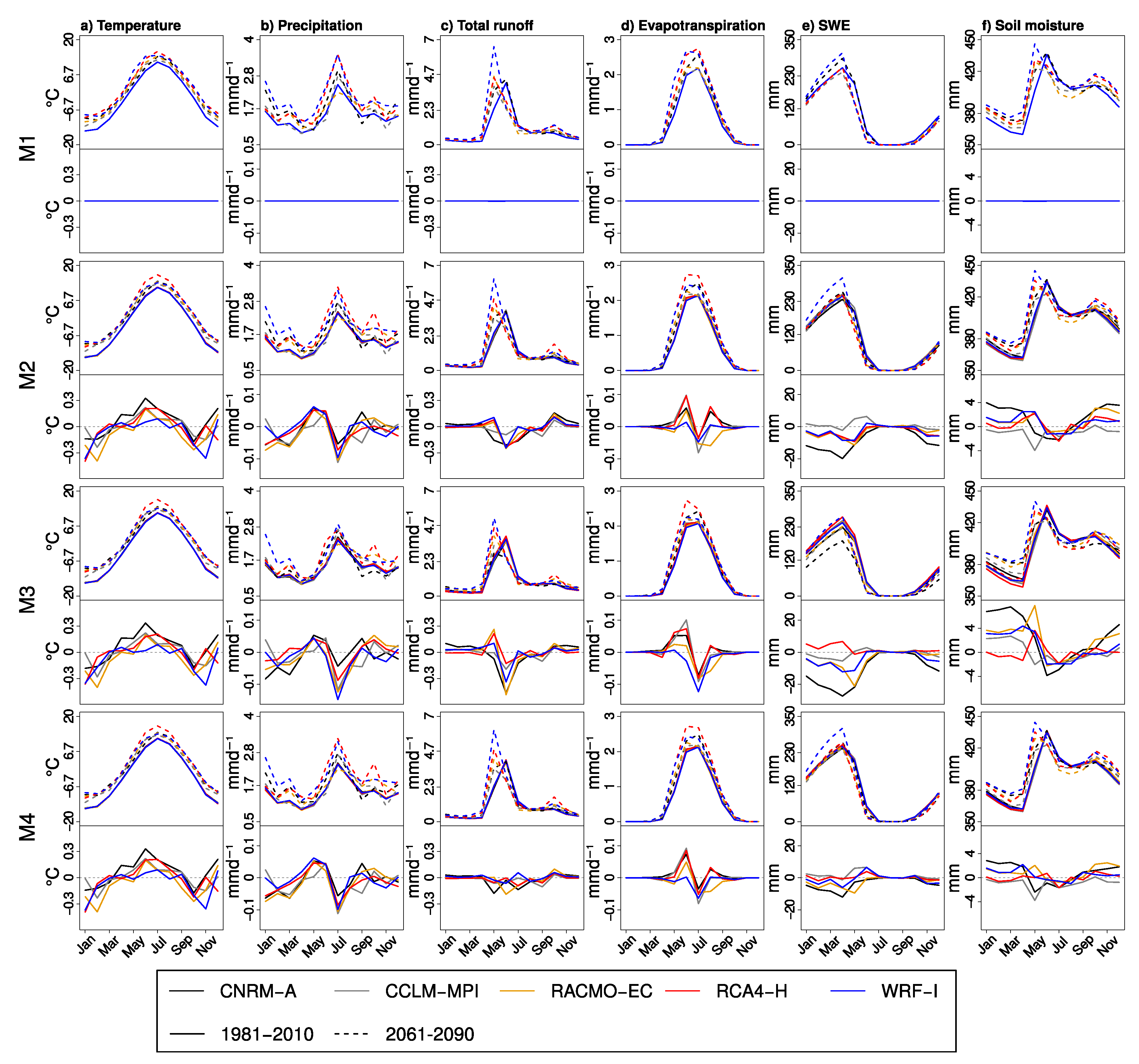
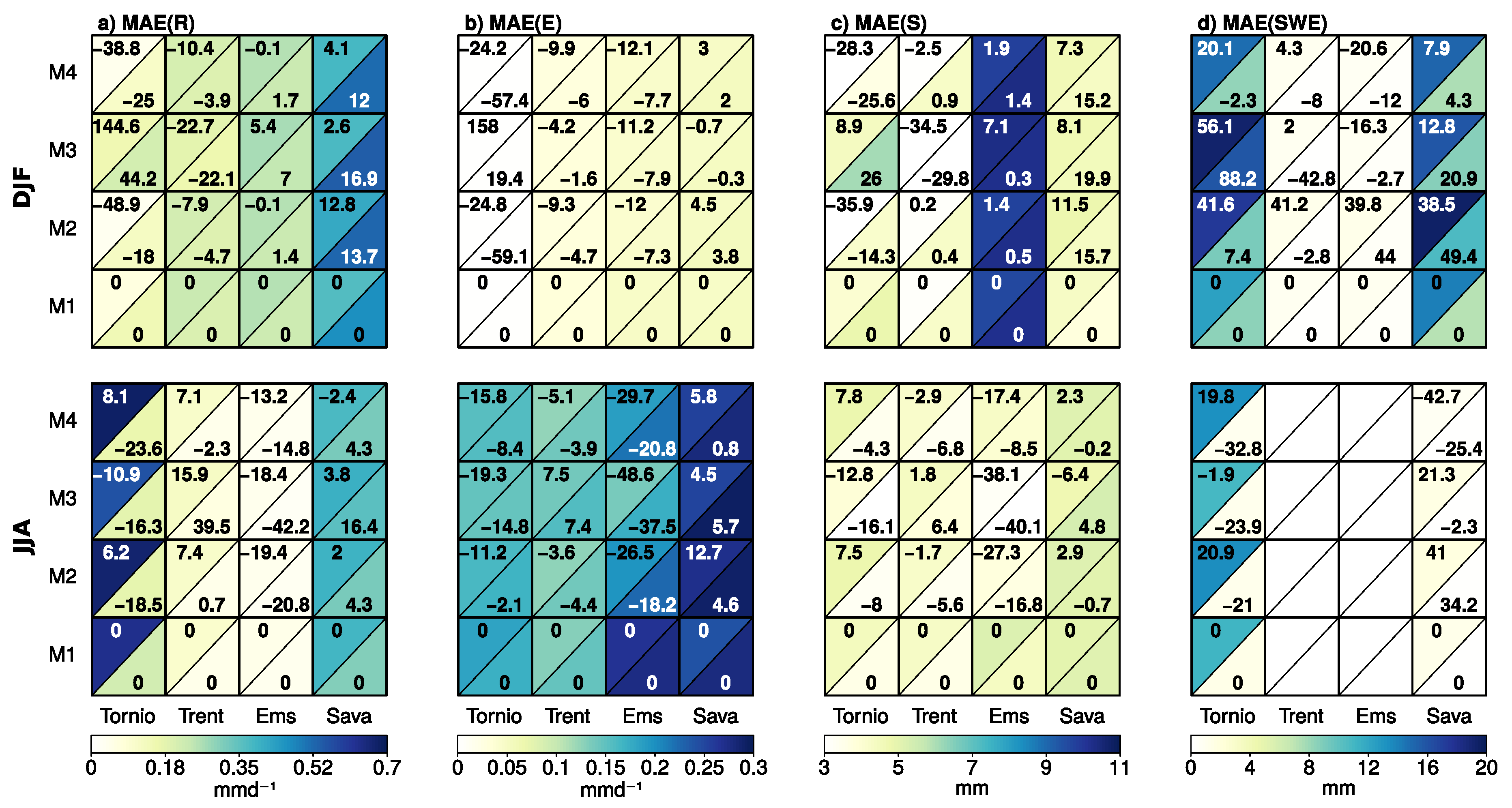
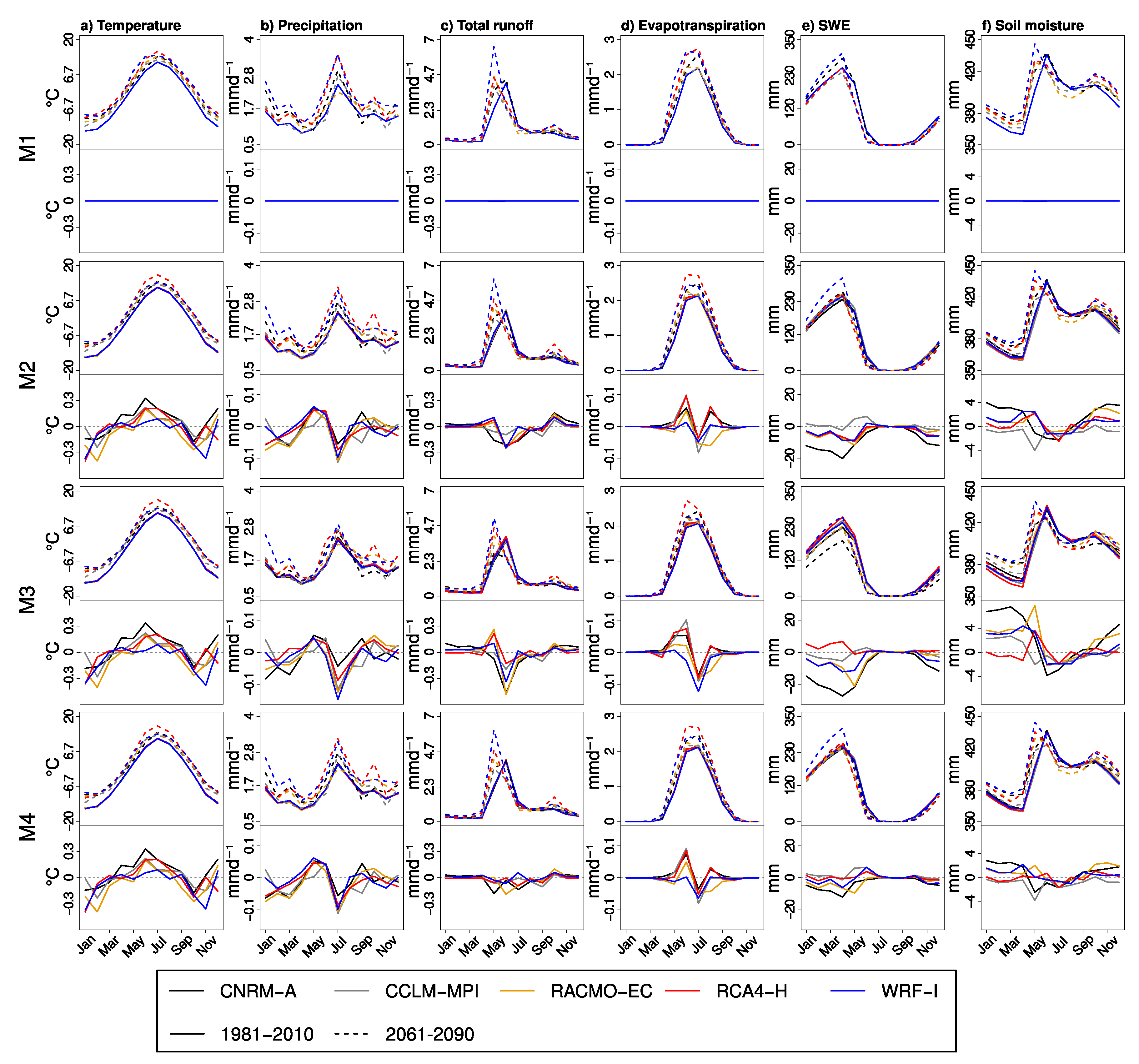
3.2.1. Spatially Distributed Variables
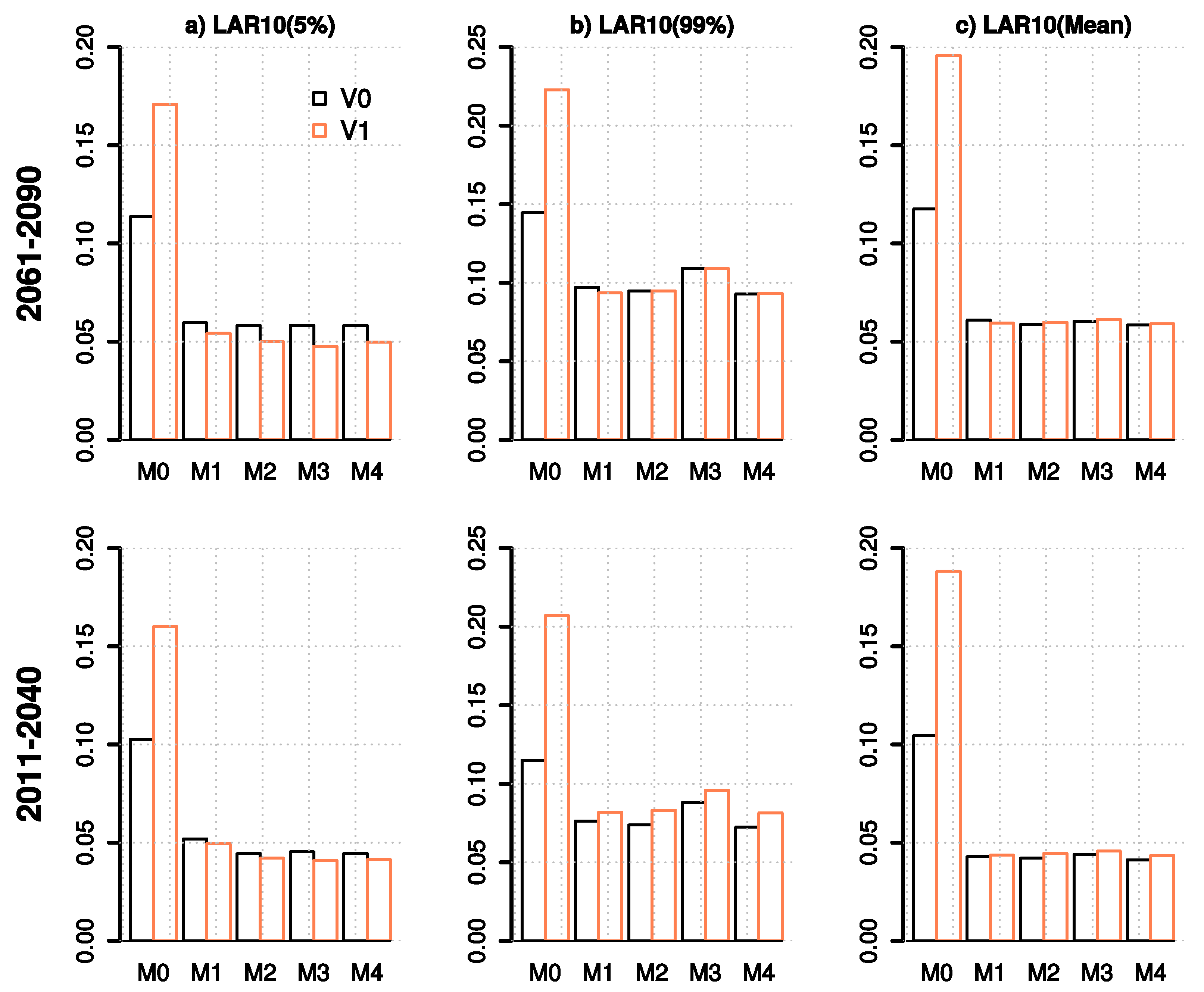
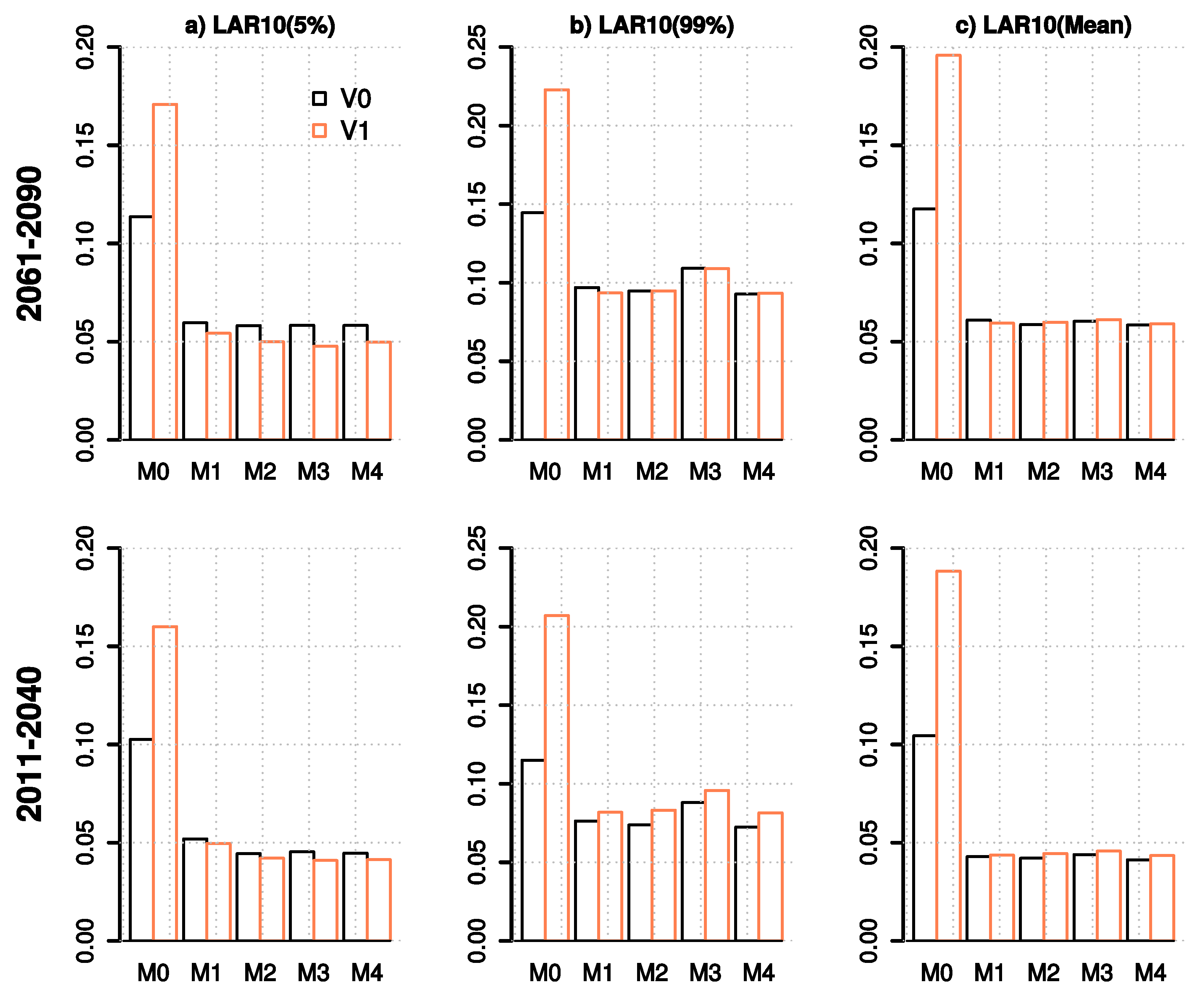
3.2.2. Evaluation of Future River Discharges
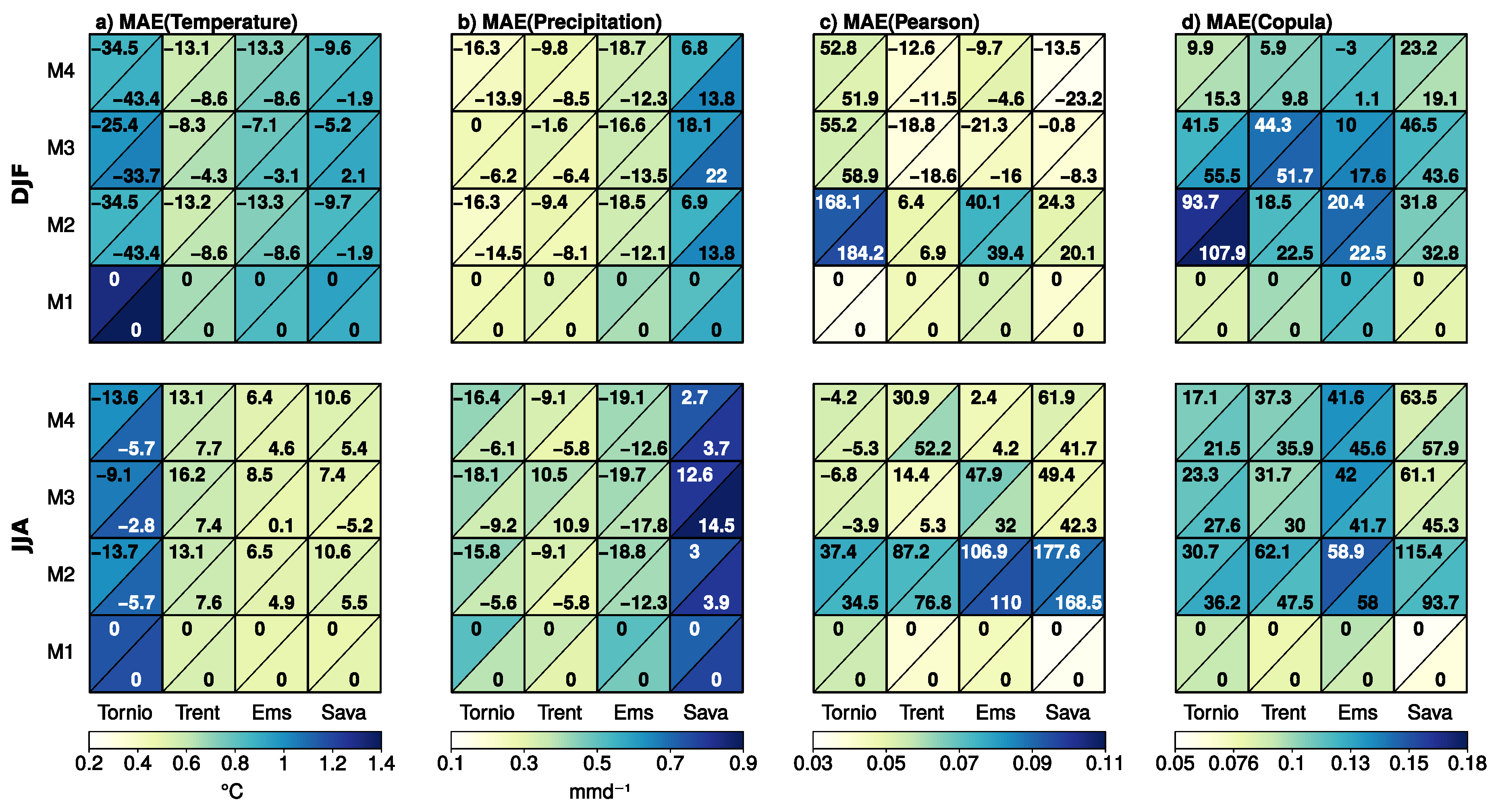
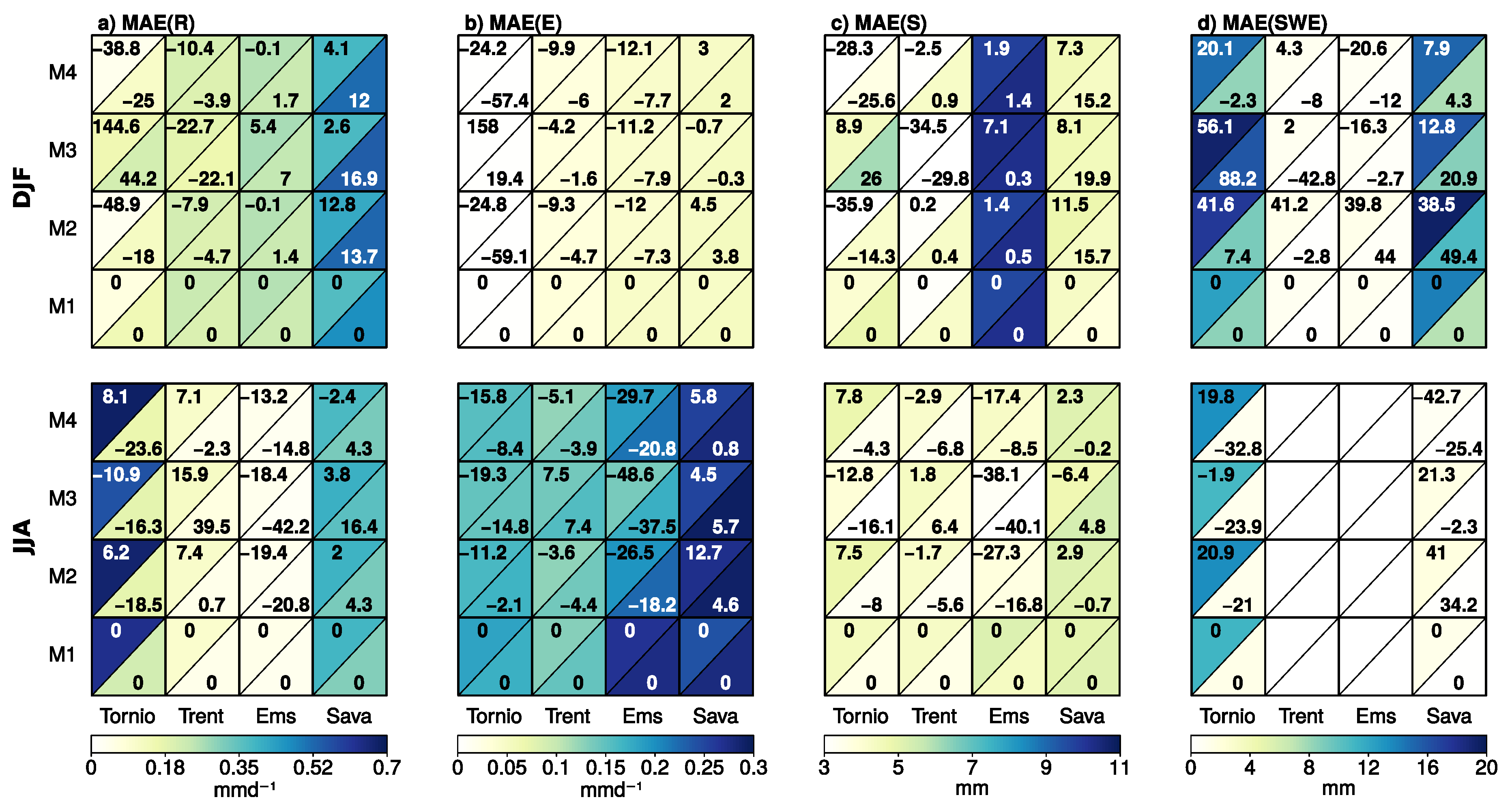
3.3. Temporal and Spatial Variations in the Cross-Validation Statistics
4. Discussion and Conclusions
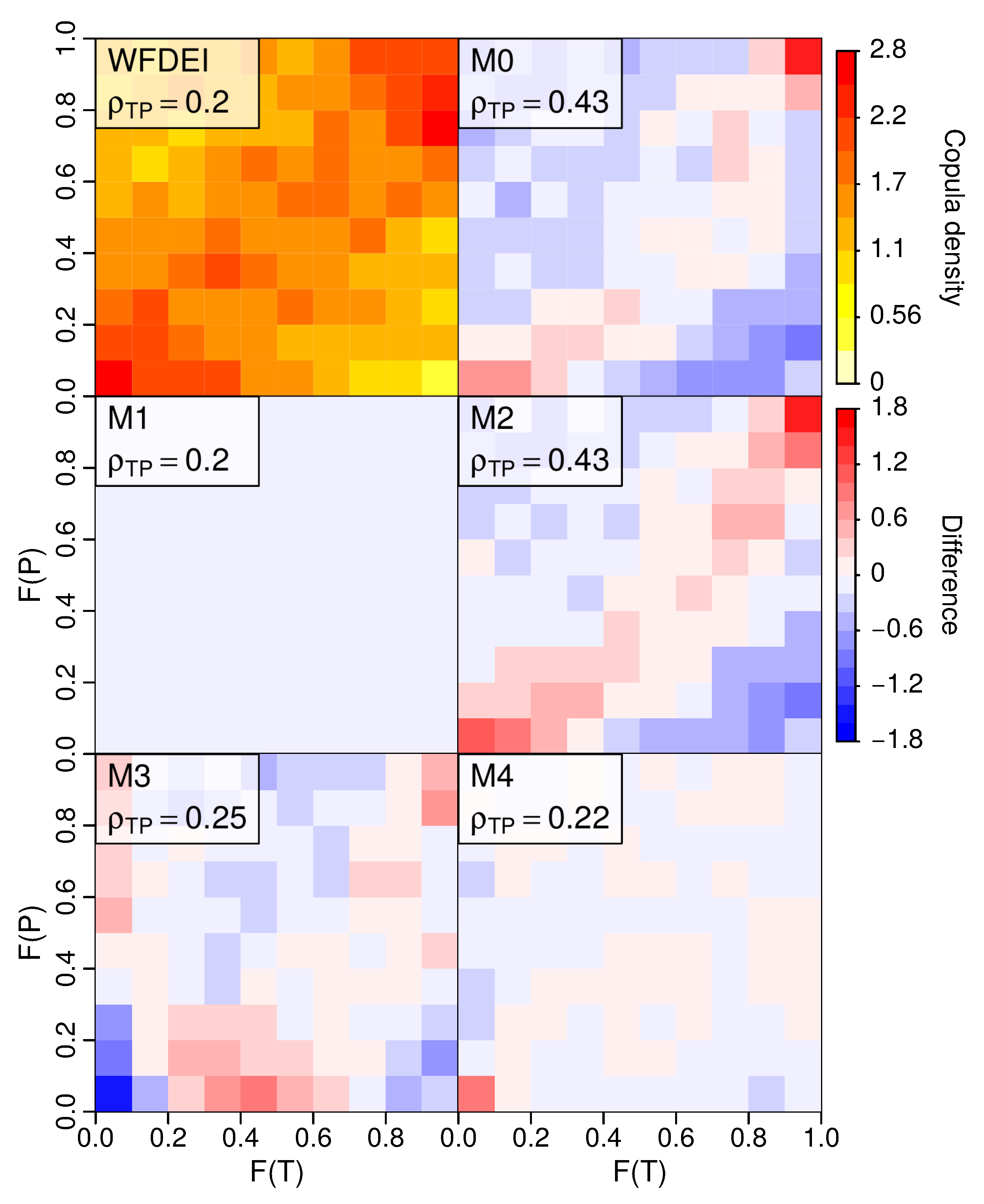
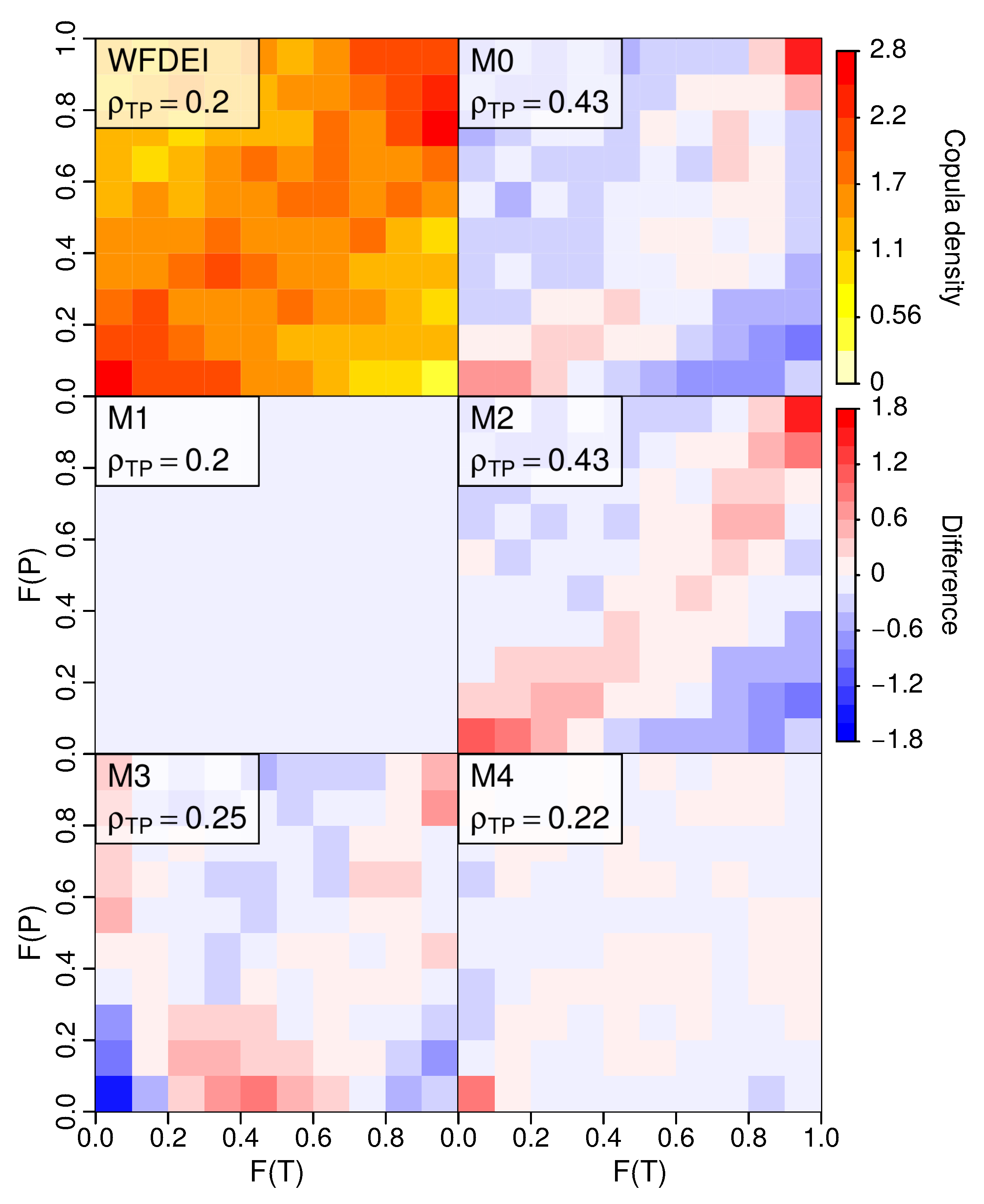
- By design, joint bias correction brings the inter-variable correlations closer to the observed one in the baseline period. In particular, the iterative N-pdft algorithm (M4) reproduces the full dependence structure (as measured by the MAE in the empirical copula density) well in comparison to univariate quantile mapping (M2). The adjustment of inter-variable correlation in M3 might fail in certain situations, as the method tends to have larger remaining biases in the copula structure in winter conditions in HYPE Tornio sub-model.
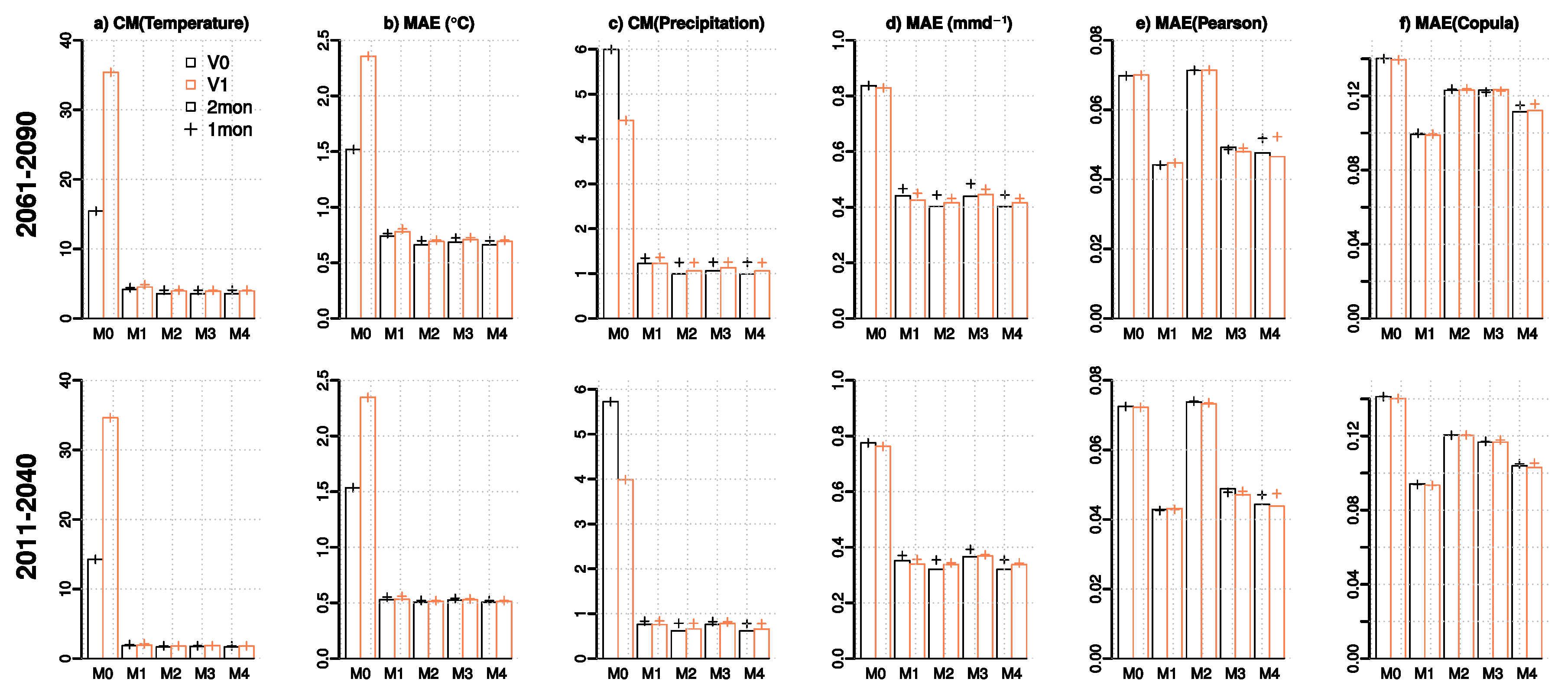
- Cross-validation statistics in years 2011–2040 and 2061–2090 indicate that although the correlation structure is improved in terms of Pearson correlation, the benefit of bi-variate methods is less clear when the full dependence structure is considered. Part of the modest improvement is likely explained by the limited sample size, which might lead to over-fitting to the present-day climatic conditions. On the other hand, quantile mapping applied in the delta change mode (M1) often performs better than the other methods, which indicates that retaining present-day correlation structures of temperature and precipitation might be sufficient also in future projections.
- The results suggest that the pseudo-reality approach is potentially useful for evaluating the relative performance of bias adjustment methods from hydrological modeling perspective in the future climate. However, to improve the validity of the conclusions in these types of studies, the implementation of pseudo-reality framework needs to be designed on case-by-case basis, for example by first bias adjusting the pseudo-reality GCM-RCMs to avoid unrealistic shifts in hydrological regimes.
- For the hydrological variables, the bi-variate approaches offered no substantial advantage over the univariate methods with M4 often having similar performance to M2. Only marginal improvements in comparison to methods M1 and M2 are seen in the cross-validation statistics for high flows and for the monthly mean and annual maximum snow water equivalent in Tornio and Sava. Although quantile mapping applied as a delta change method (M1) has slightly poorer performance in projecting marginal distributions of temperature and precipitation than quantile mapping-based bias correction (M2) and its bi-variate version (M4), the cross-validation statistics indicate that it has a relatively good ability to capture the future hydrological conditions. Nevertheless, for the hydrological variables studied (apart from snow), there were only small differences in cross-validation statistics between the tested methods, indicating that care should be taken when selecting MOS methods for particular purposes and (ideally) several methods should be used in parallel. Overall, the results highlight the difficulty to illustrate the added value of more complex methods, when applying them in producing projections for daily mean temperature and precipitation.
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Déqué, M. Frequency of precipitation and temperature extremes over France in an anthropogenic scenario: Model results and statistical correction according to observed values. Glob. Planet. Chang. 2007, 57, 16–26. [Google Scholar] [CrossRef]
- Yang, W.; Andréasson, J.; Phil Graham, L.; Olsson, J.; Rosberg, J.; Wetterhall, F. Distribution-based scaling to improve usability of regional climate model projections for hydrological climate change impacts studies. Hydrol. Res. 2010, 41, 211–229. [Google Scholar] [CrossRef]
- Olsson, J.; Berggren, K.; Olofsson, M.; Viklander, M. Applying climate model precipitation scenarios for urban hydrological assessment: A case study in Kalmar City, Sweden. Atmos. Res. 2009, 92, 364–375. [Google Scholar] [CrossRef]
- Li, H.; Sheffield, J.; Wood, E.F. Bias correction of monthly precipitation and temperature fields from Intergovernmental Panel on Climate Change AR4 models using equidistant quantile matching. J. Geophys. Res. Atmos. 2010, 115. [Google Scholar] [CrossRef]
- Maraun, D.; Wetterhall, F.; Ireson, A.M.; Chandler, R.E.; Kendon, E.J.; Widmann, M.; Brienen, S.; Rust, H.W.; Sauter, T.; Themeßl, M.; et al. Precipitation downscaling under climate change: Recent developments to bridge the gap between dynamical models and the end user. Rev. Geophys. 2010, 48, RG3003. [Google Scholar] [CrossRef]
- Themeßl, M.J.; Gobiet, A.; Leuprecht, A. Empirical-statistical downscaling and error correction of daily precipitation from regional climate models. Int. J. Climatol. 2011, 31, 1530–1544. [Google Scholar] [CrossRef]
- Hempel, S.; Frieler, K.; Warszawski, L.; Schewe, J.; Piontek, F. A trend-preserving bias correction –the ISI-MIP approach. Earth Syst. Dyn. 2013, 4, 219–236. [Google Scholar] [CrossRef]
- Cannon, A.J.; Sobie, S.R.; Murdock, T.Q. Bias Correction of GCM Precipitation by Quantile Mapping: How Well Do Methods Preserve Changes in Quantiles and Extremes? J. Clim. 2015, 28, 6938–6959. [Google Scholar] [CrossRef]
- Teutschbein, C.; Seibert, J. Bias correction of regional climate model simulations for hydrological climate-change impact studies: Review and evaluation of different methods. J. Hydrol. 2012, 456–457, 12–29. [Google Scholar] [CrossRef]
- Chen, J.; Brissette, F.P.; Chaumont, D.; Braun, M. Finding appropriate bias correction methods in downscaling precipitation for hydrologic impact studies over North America. Water Resour. Res. 2013, 49, 4187–4205. [Google Scholar] [CrossRef]
- Trenberth, K.E.; Shea, D.J. Relationships between precipitation and surface temperature. Geophys. Res. Lett. 2005, 32, L14703. [Google Scholar] [CrossRef]
- Berg, P.; Haerter, J.O.; Thejll, P.; Piani, C.; Hagemann, S.; Christensen, J.H. Seasonal characteristics of the relationship between daily precipitation intensity and surface temperature. J. Geophys. Res. Atmos. 2009, 114. [Google Scholar] [CrossRef]
- Piani, C.; Haerter, J.O. Two dimensional bias correction of temperature and precipitation copulas in climate models. Geophys. Res. Lett. 2012, 39. [Google Scholar] [CrossRef]
- Li, C.; Sinha, E.; Horton, D.E.; Diffenbaugh, N.S.; Michalak, A.M. Joint bias correction of temperature and precipitation in climate model simulations. J. Geophys. Res. Atmos. 2014, 119, 153–162. [Google Scholar] [CrossRef]
- Mehrotra, R.; Sharma, A. A Multivariate Quantile-Matching Bias Correction Approach with Auto- and Cross-Dependence across Multiple Time Scales: Implications for Downscaling. J. Clim. 2016, 29, 3519–3539. [Google Scholar] [CrossRef]
- Cannon, A.J. Multivariate Bias Correction of Climate Model Output: Matching Marginal Distributions and Intervariable Dependence Structure. J. Clim. 2016, 29, 7045–7064. [Google Scholar] [CrossRef]
- Cannon, A.J. Multivariate quantile mapping bias correction: An N-dimensional probability density function transform for climate model simulations of multiple variables. Clim. Dyn. 2017, 50, 31–49. [Google Scholar] [CrossRef]
- Ehret, U.; Zehe, E.; Wulfmeyer, V.; Warrach-Sagi, K.; Liebert, J. HESS Opinions “Should we apply bias correction to global and regional climate model data?”. Hydrol. Earth Syst. Sci. 2012, 16, 3391–3404. [Google Scholar] [CrossRef]
- Maraun, D. Bias Correcting Climate Change Simulations—A Critical Review. Curr. Clim. Chang. Rep. 2016, 2, 211–220. [Google Scholar] [CrossRef]
- Maraun, D. Nonstationarities of regional climate model biases in European seasonal mean temperature and precipitation sums. Geophys. Res. Lett. 2012, 39, L06706. [Google Scholar] [CrossRef]
- Räisänen, J.; Räty, O. Projections of daily mean temperature variability in the future: cross-validation tests with ENSEMBLES regional climate simulations. Clim. Dyn. 2013, 41, 1553–1568. [Google Scholar] [CrossRef]
- Räty, O.; Räisänen, J.; Ylhäisi, J.S. Evaluation of delta change and bias correction methods for future daily precipitation: intermodel cross-validation using ENSEMBLES simulations. Clim. Dyn. 2014, 42, 2287–2303. [Google Scholar] [CrossRef]
- Van Schaeybroeck, B.; Vannitsem, S. Assessment of calibration assumptions under strong climate changes. Geophys. Res. Lett. 2016, 43, 1314–1322. [Google Scholar] [CrossRef]
- Maraun, D.; Widmann, M.; Gutiérrez, J.M.; Kotlarski, S.; Chandler, R.E.; Hertig, E.; Wibig, J.; Huth, R.; Wilcke, R.A. VALUE: A framework to validate downscaling approaches for climate change studies. Earth’s Future 2015, 3, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Velázquez, J.A.; Troin, M.; Caya, D.; Brissette, F. Evaluating the Time-Invariance Hypothesis of Climate Model Bias Correction: Implications for Hydrological Impact Studies. J. Hydrometeorol. 2015, 16, 2013–2026. [Google Scholar] [CrossRef]
- Jacob, D.; Petersen, J.; Eggert, B.; Alias, A.; Christensen, O.B.; Bouwer, L.M.; Braun, A.; Colette, A.; Déqué, M.; Georgievski, G.; et al. EURO-CORDEX: New high-resolution climate change projections for European impact research. Reg. Environ. Chang. 2014, 14, 563–578. [Google Scholar] [CrossRef]
- Weedon, G.P.; Balsamo, G.; Bellouin, N.; Gomes, S.; Best, M.J.; Viterbo, P. The WFDEI meteorological forcing data set: WATCH Forcing Data methodology applied to ERA-Interim reanalysis data. Water Resour. Res. 2014, 50, 7505–7514. [Google Scholar] [CrossRef]
- Rust, H.W.; Kruschke, T.; Dobler, A.; Fischer, M.; Ulbrich, U. Discontinuous Daily Temperatures in the WATCH Forcing Datasets. J. Hydrometeorol. 2015, 16, 465–472. [Google Scholar] [CrossRef] [Green Version]
- Federated ESGF-CoG Nodes. Available online: https://esgf.llnl.gov/nodes.html (accessed on 27 April 2016).
- Moss, R.H.; Edmonds, J.A.; Hibbard, K.A.; Manning, M.R.; Rose, S.K.; van Vuuren, D.P.; Carter, T.R.; Emori, S.; Kainuma, M.; Kram, T.; et al. The next generation of scenarios for climate change research and assessment. Nature 2010, 463, 747–756. [Google Scholar] [CrossRef] [PubMed]
- Donnelly, C.; Andersson, J.C.; Arheimer, B. Using flow signatures and catchment similarities to evaluate the E-HYPE multi-basin model across Europe. Hydrolog. Sci. J. 2016, 61, 255–273. [Google Scholar] [CrossRef]
- Lindström, G.; Pers, C.; Rosberg, J.; Strömqvist, J.; Arheimer, B. Development and testing of the HYPE (Hydrological Predictions for the Environment) water quality model for different spatial scales. Hydrol. Res. 2010, 41, 295–319. [Google Scholar] [CrossRef]
- HYPE Open Source Code. Available online: http://hypecode.smhi.se/ (accessed on 13 December 2016).
- Donnelly, C.; Greuell, W.; Andersson, J.; Gerten, D.; Pisacane, G.; Roudier, P.; Ludwig, F. Impacts of climate change on European hydrology at 1.5, 2 and 3 degrees mean global warming above preindustrial level. Clim. Chang. 2017, 143, 13–26. [Google Scholar] [CrossRef]
- Gennaretti, F.; Sangelantoni, L.; Grenier, P. Toward daily climate scenarios for Canadian Arctic coastal zones with more realistic temperature-precipitation interdependence. J. Geophys. Res. Atmos. 2015, 120, 862–877. [Google Scholar] [CrossRef]
- Pitié, F.; Kokaram, A.C.; Dahyot, R. Automated colour grading using colour distribution transfer. Comput. Vis. Image Underst. 2007, 107, 123–137. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- BCUH: University of Helsinki bias adjustment tools. Available online: https://github.com/RatyO/BCUH (accessed on 9 April 2018).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Cannon, A. MBC: Multivariate Bias Correction of Climate Model Outputs. Available online: https://CRAN.R-project.org/package=MBC (accessed on 20 April 2017).
- Reiter, P.; Gutjahr, O.; Schefczyk, L.; Heinemann, G.; Casper, M. Does applying quantile mapping to subsamples improve the bias correction of daily precipitation? Int. J. Climatol. 2017, 38, 1623–1633. [Google Scholar] [CrossRef]
- Rajczak, J.; Kotlarski, S.; Schär, C. Does Quantile Mapping of Simulated Precipitation Correct for Biases in Transition Probabilities and Spell Lengths? J. Clim. 2016, 29, 1605–1615. [Google Scholar] [CrossRef]
- Anderson, T.W. On the distribution of the two-sample Cramer-von Mises criterion. Ann. Math. Stat. 1962, 33, 1148–1159. [Google Scholar] [CrossRef]
- Hagemann, S.; Chen, C.; Haerter, J.O.; Heinke, J.; Gerten, D.; Piani, C. Impact of a Statistical Bias Correction on the Projected Hydrological Changes Obtained from Three GCMs and Two Hydrology Models. J. Hydrometeorol. 2011, 12, 556–578. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | GCM Component | RCM Component | Institution |
|---|---|---|---|
| CNRM-A | CNRM-CM5 | ALADIN | CNRM |
| CCLM-MPI | MPI-ESM-LR | CCLM4.8.17 | CLM Community |
| RACMO-EC | EC-EARTH | RACMO22E | KNMI |
| RCA4-H | HadGEM | RCA4 | SMHI |
| WRF-I | IPSL-CMA5-MR | WRF | IPSL-INERIS |
| Sub-Model | NSE | RE (%) |
|---|---|---|
| Tornio | 0.78 | −17.0 |
| Trent | 0.66 | −3.0 |
| Ems | 0.83 | 3.1 |
| Sava | 0.52 | 6.0 |
| Name | Description | References |
|---|---|---|
| M1 | Univariate delta change: quantile mapping with smoothing | Räisänen and Räty [21], Räty et al. [22] |
| M2 | Univariate bias correction: quantile mapping with smoothing | Räisänen and Räty [21], Räty et al. [22] |
| M3 | Bi-variate bias correction: copula-based, precipitation conditioned on temperature | Li et al. [14], Gennaretti et al. [35] |
| M4 | Bi-variate bias correction: full 2-dimensional distribution using the N-pdft algorithm | Pitié et al. [36], Cannon [17] |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Räty, O.; Räisänen, J.; Bosshard, T.; Donnelly, C. Intercomparison of Univariate and Joint Bias Correction Methods in Changing Climate From a Hydrological Perspective. Climate 2018, 6, 33. https://doi.org/10.3390/cli6020033
Räty O, Räisänen J, Bosshard T, Donnelly C. Intercomparison of Univariate and Joint Bias Correction Methods in Changing Climate From a Hydrological Perspective. Climate. 2018; 6(2):33. https://doi.org/10.3390/cli6020033
Chicago/Turabian StyleRäty, Olle, Jouni Räisänen, Thomas Bosshard, and Chantal Donnelly. 2018. "Intercomparison of Univariate and Joint Bias Correction Methods in Changing Climate From a Hydrological Perspective" Climate 6, no. 2: 33. https://doi.org/10.3390/cli6020033