1. Introduction
Soil erosion models are a useful tool for predicting the amount of soil erosion, guiding the allocation of soil and water conservation measures, and optimizing the utilization of water and soil resources in basins. As soil erosion has become a global environmental problem influenced by both natural and human factors, soil erosion modelling is a research topic that has drawn widespread attention around the world. Since the last century, researchers have established various soil erosion models from the prototype experiments and observations. In the early stages, the empirical statistical models were developed based on statistical analyses of observational data collected in plot and small watersheds with sheet and rill erosion. Examples of empirical models include the universal soil loss equation (USLE) [
1] or its derivatives (e.g., the revised universal soil loss equation, RUSLE) [
2] and Chinese soil loss equation (CSLE) [
3,
4]. These models have often been applied for on-site soil erosion estimates without considering the spatial heterogeneity of the soil erosion process [
5]. With advances in geographic information system and remote-sensing technology, models and predictions of soil erosion have been developed from empirical statistical models. Now, many models are spatially distributed or physically based models. The spatially distributed models account for watershed heterogeneity, as reflected by the land use, soil types, topography, and rainfall, measured in the field or estimated through digital elevation models (DEMs) or remote-sensing images, and estimates of the sediment yield are generated in various spatial domains [
6]. The Water Erosion Prediction Project (WEPP) model is a well-known and commonly used example; it is a process-based, spatially distributed parameter, and continuous simulation and erosion prediction model [
7]. From a computational perspective, soil erosion models, especially spatially distributed models, all involve raster data, such as precipitation, topographic, soil, and vegetation data. Moreover, such models include various computational subprocesses and are characterized by large data volumes and intensive computational tasks. These computations, which involve exceptionally detailed high-resolution soil erosion modelling, are limited by the data storage and computing speed of the corresponding computing platforms.
In recent years, with the rapid development of information technology, massive amounts of data have been produced in different fields. To analyse and utilize these big data resources, related parallel computing methods must be used. Conventional methods usually include high-performance computing platforms (HPCs) and parallel programming models, such as message-passing-interface (MPI) and open multi-processing (OpenMP), to split the computational tasks and combine the final computing results [
8]. Additionally, with the development of graphics processing hardware, the ability of graphics processing units (GPUs) has been improved, leading to the development of the computing unified device architecture (CUDA) and open computing language (OpenCL) parallel computing framework [
9]. In the GIS and Remote Sensing (RS) field, Guan et al. [
10] developed the parallel raster processing library (pRPL) for raster analysis in GIS. Integrated data management class, a Geospatial Data Abstraction Library (GDAL)-based raster data Input/Output (I/O) mechanism and a static and dynamic load-balancing mode were added to pRPL 2.0. Miao et al. [
11] implemented a parallel GeoTIFF I/O library (pGTIOL) based on an asynchronized I/O mechanism that displayed better performance than using GDAL as the I/O interface. Both the pRPL and pGTIOL are MPI-enabled libraries. Qin et al. [
12] designed and implemented a set of parallel raster-based geocomputation operators (PaRGO) to overcome the poor transferability of parallel programs. The PaRGO is compatible with three types of parallel computing platforms: GPUs, the MPI, and OpenMP. This approach makes the details of the parallel programming and the parallel hardware architecture transparent to users. Zhang et al. [
13] introduced a parallel approach to quadtree construction and implemented on general purpose GPUs. A performance test yielded a significant speedup for the studied tasks. Although these libraries rely on parallel computing capabilities for raster data processes, they are limited by particular hardware environments (GPU/multi central processing unit (CPU)) and software frameworks, making them difficult to scale or expand.
The MapReduce parallel computing model for big data analysis developed by Google performs the parallel processing of massive amounts of data through cheaper server clusters [
14]. This model has advantages such as few hardware requirements, rapid scaling, and easy modelling [
15]. After the launch of the Hadoop open-source platform, MapReduce has been extensively used in big data processing and has formed a complete ecosystem [
16]. There are several platforms for spatial big data processing and analysis such as Hadoop-GIS [
17], SpatialHadoop [
18], ST-Hadoop [
19], GeoSpark [
20], MrGeo [
21], GIS Tools for Hadoop [
22], Geotrellis [
23] and others. In specific areas of spatial data analysis, a series of Hadoop application cases has also emerged. In the climate data analysis area, Li et al. [
24] proposed a spatiotemporal indexing method that can effectively manage and process large climate datasets using the MapReduce programming model in the Hadoop platform and built a high-performance query analytical framework for climate data using the Structured Query Language (SQL) style query (HiveQL) [
25]. Gao et al. [
26] harvest crowd-sourced gazetteer entries running on a spatially enabled Hadoop cluster. Similar research areas include atmospheric analysis [
27], large-scale Light Detection and Ranging (LiDAR) data analysis [
28], remote sensing [
29], trip recommendation [
30], and others [
31,
32]. These platforms and cases are suitable for different spatial data and can be applied in different applications and domains. In this paper, we focus on integrating the Hadoop platform with GIS for parallel computing involving soil erosion modelling.
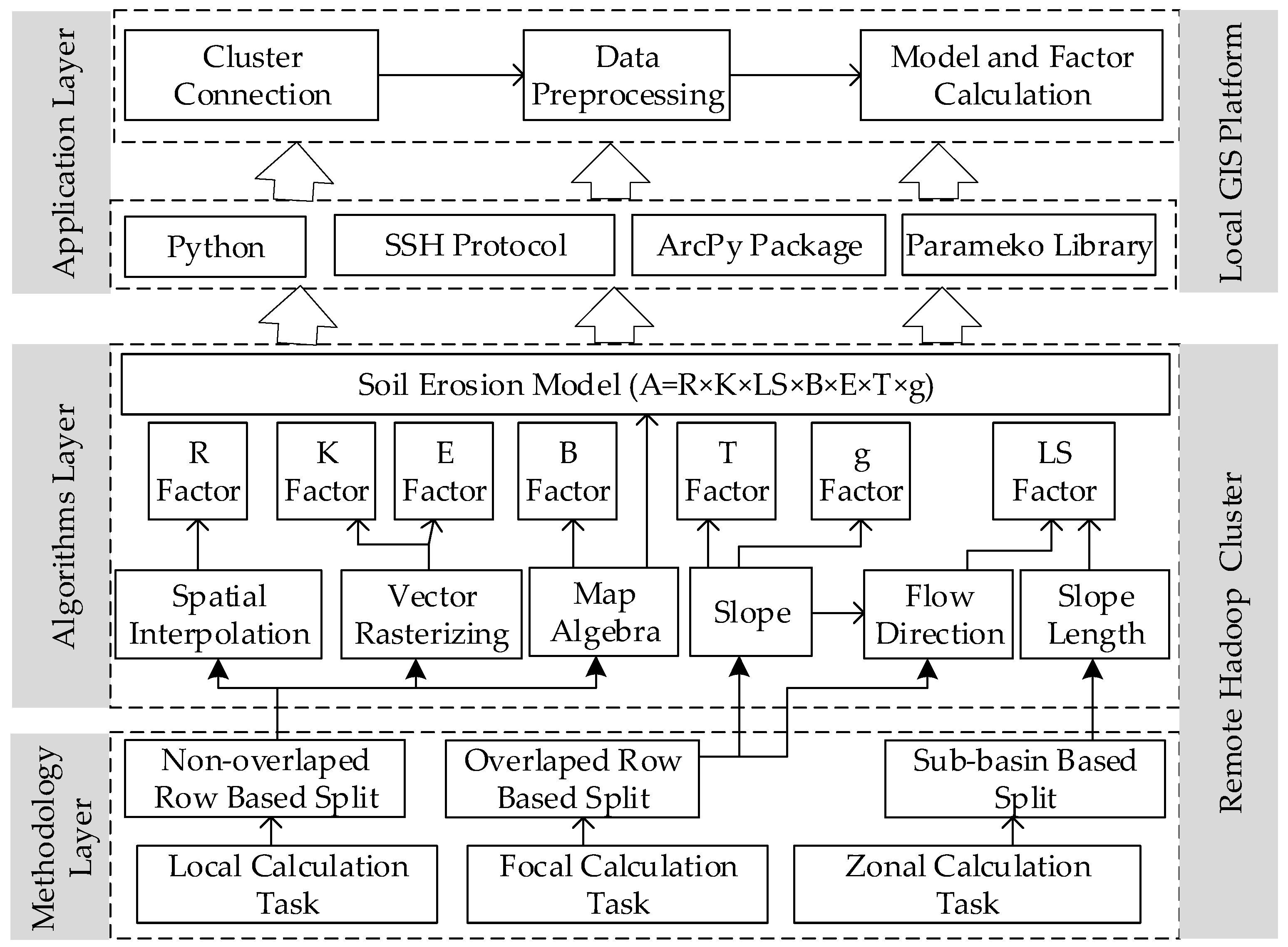
With the rapid development of geographic information technology, three-dimensional laser scanning technology can be applied to obtain high-precision geographic information data such as DEM data at the basin scale. As the resolution of raster data has increased, the data volume has exponentially grown, thus demanding a higher requirement for refined large- to medium-scale soil erosion modelling in basins. The Hadoop parallel computing platform can be used to build a parallel computing framework for soil erosion modelling and then be tightly integrated or coupled with GIS for refined soil erosion modelling. In this study, we implemented a parallel computing framework (Mr4Soil) integrated with the GIS platform. The framework includes three layers: the methodology layer, algorithms layer, and application layer. We designed two types of parallel computing strategies as rows-oriented and sub-basin-oriented methods using a spatially distributed model for annual sediment yield associated with soil erosion. We developed parallel algorithms for soil erosion modelling in the Hadoop platform based on the MapReduce parallel computing method. A series of experiments showed that Mr4Soil yielded better performance than other conventional serial programming methods. Thus, the proposed approach provides a solution for the refined soil erosion modelling on the Hadoop platform, which is integrated with a GIS platform.
3. Parallel Algorithms Design
The parallel algorithms of model consist of 3 levels: (1) the parallel model operators, which are used to define the basic analysis algorithm; (2) the parallel factor algorithms, which are used to achieve parallel computing of different model factors; and (3) the parallel model algorithm, which is used to calculate soil erosion according to Equation (1). The parallel model operators are at the bottom level. The model factor and model calculations can be completed by calling the corresponding operators. Based on the data structure definition and data preprocessing, this section focuses on the algorithm design for parallel model operators.
3.1. Data Structure and Data Preprocessing
The Hadoop platform supports the reading and writing of structured text data and binary data. To simplify the calculations, the (key, value) pair in text format is applied to define the data structure involved in parallel model computing. There are two types of input data used in model computations: vector and raster data. Vector data mainly include rainfall data collected at rain gauge stations (point) in the basin, soil type data, soil and water conservation measure data (polygon), and sub-basin boundary data (polygon). The volume of these data is relatively small, and there is no need for splitting in the calculation. Vector data are converted into a text format supported by the Hadoop platform. In this study, vector data are converted into GeoCSV format. The geographic entity code is used as the key. Spatial data, which are stored in well-known text (WKT) format, together with property data are used as the value and can be directly read by the Hadoop distributed file system (HDFS) API and used in calculations. The raster data mainly include the basin DEM, land-use data, and normalized difference vegetation index (NDVI) data. First, these data are converted into two-dimensional text data. Then, two types of (key, value) pairs are defined: (1) an entire row is used as a (key, value) pair, where key is the row number and value is the set of the corresponding raster cell values of the row; and (2) a raster cell is used as a (key, value) pair, where the row number and column number of a raster cell are defined as the composite key, and the value of the raster cell is defined as the value. The raster data are preprocessed, and the corresponding (key, value) pairs in text format are generated and used as input data in different parallel algorithms.
3.2. Parallel Algorithms Based on the Row-Splitting Method
The row-splitting method is suitable for local and neighbourhood operations. By using an entire row as a (key, value) pair for input data, the calculation process includes 2 steps: (1) in the map step, the splitting function is defined according to the key of the row of the input raster data, and the raster data row is assigned to the corresponding computing nodes; (2) in the reduce step, based on the different analysis algorithms, calculations are performed involving the slices of data rows. The results of the slices are sorted according to the key, combined and output. In local operation tasks, there is no need to consider the overlap among slices. The (key, value) pair raster data in text format can be directly used in calculations. In focal operation tasks, the corresponding raster rows must be duplicated in the first and last rows of each slice according to the size of the neighborhood windows. Herein, the spatial interpolation parallel operators based on the inverse distance weighting (IDW) method are used as an example. The input parameters of the parallel algorithm include: (1) the observation station data as GeoCSV, which stores the station position and its observation value. The data volume is small and can be used for each computational node without data splitting. (2) The row key-value pair raster data in text format (the initial value of a raster cell is set to −1). The key is row number, and the value is the cell list of the row. Spatial interpolation is the process of calculation each raster cell value based on the observation station data. The calculation steps are as follows (
Figure 5).
(1) Data input. Read the key-value text of the row, and parse the row number and the raster cell list; read and parse the GeoCSV text to get the station position and value.
(2) Data splitting. The number of raster rows allocated by each node is calculated according to formula (2) and cluster size, and then the rows are assigned to the corresponding computational node by customizing the MapReduce splitter (partitioner) to perform non-overlapping row segmentation according to the line number.
(3) Data parsing and distance calculation. The coordinates of the raster cell center are calculated from the cell width and row/column number. The distance from the raster cell and all of the station are measured to generate a set {(di, vi)}, where di is the distance and vi is the observation value.
(4) Spatial interpolation. According to the IDW interpolation method, the interpolation points within a certain range of the current raster cell by the distance are selected. The interpolation calculation is weighted by the distance, and the values of the corresponding raster cells (cij) are updated.
(5) Output. A list is generated based on the interpolation result of each raster cell of the row, and written to the HDFS along with the row number (
Figure 6).
3.3. Parallel Algorithms Based on the Sub-Basin Splitting Method
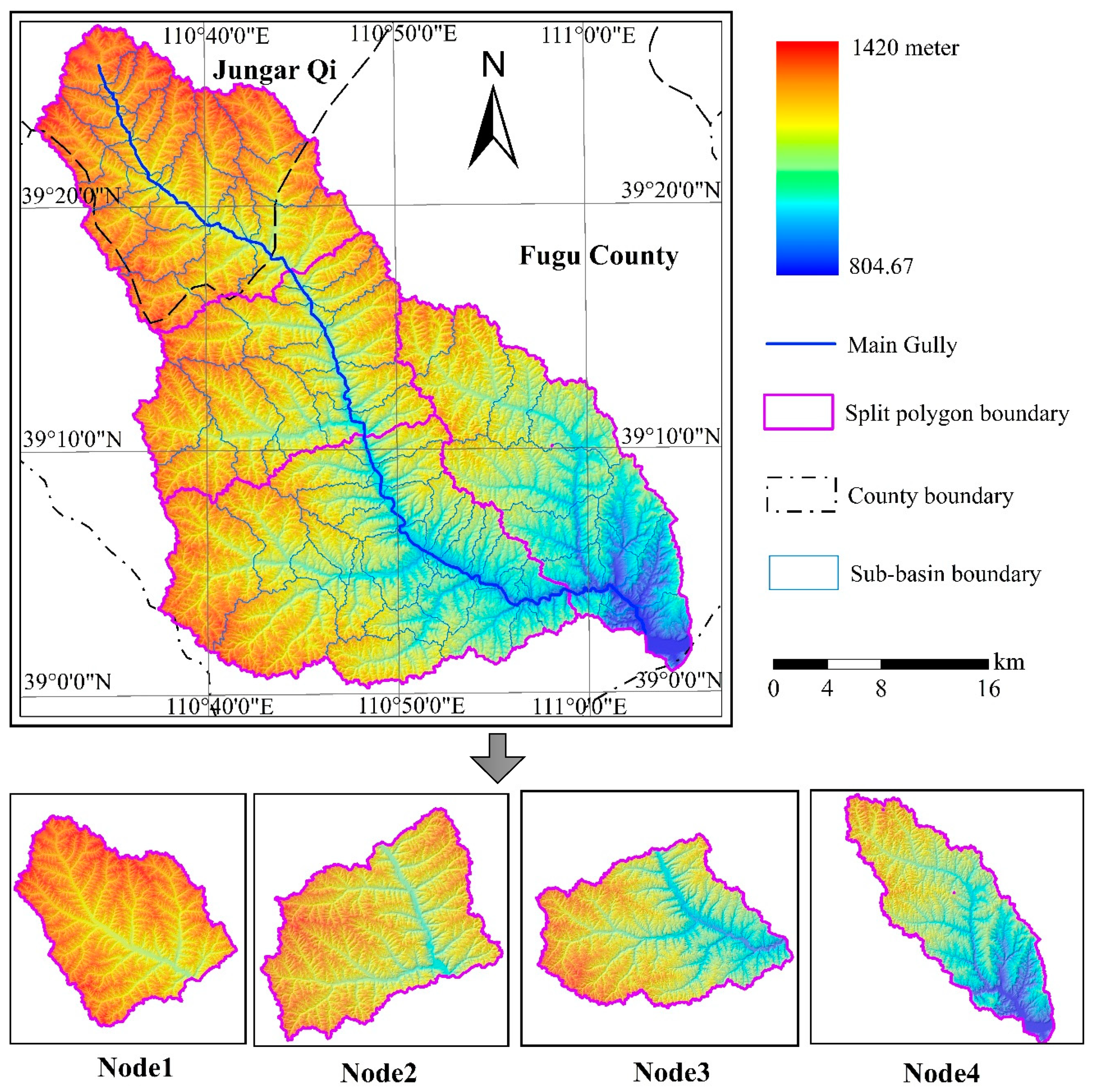
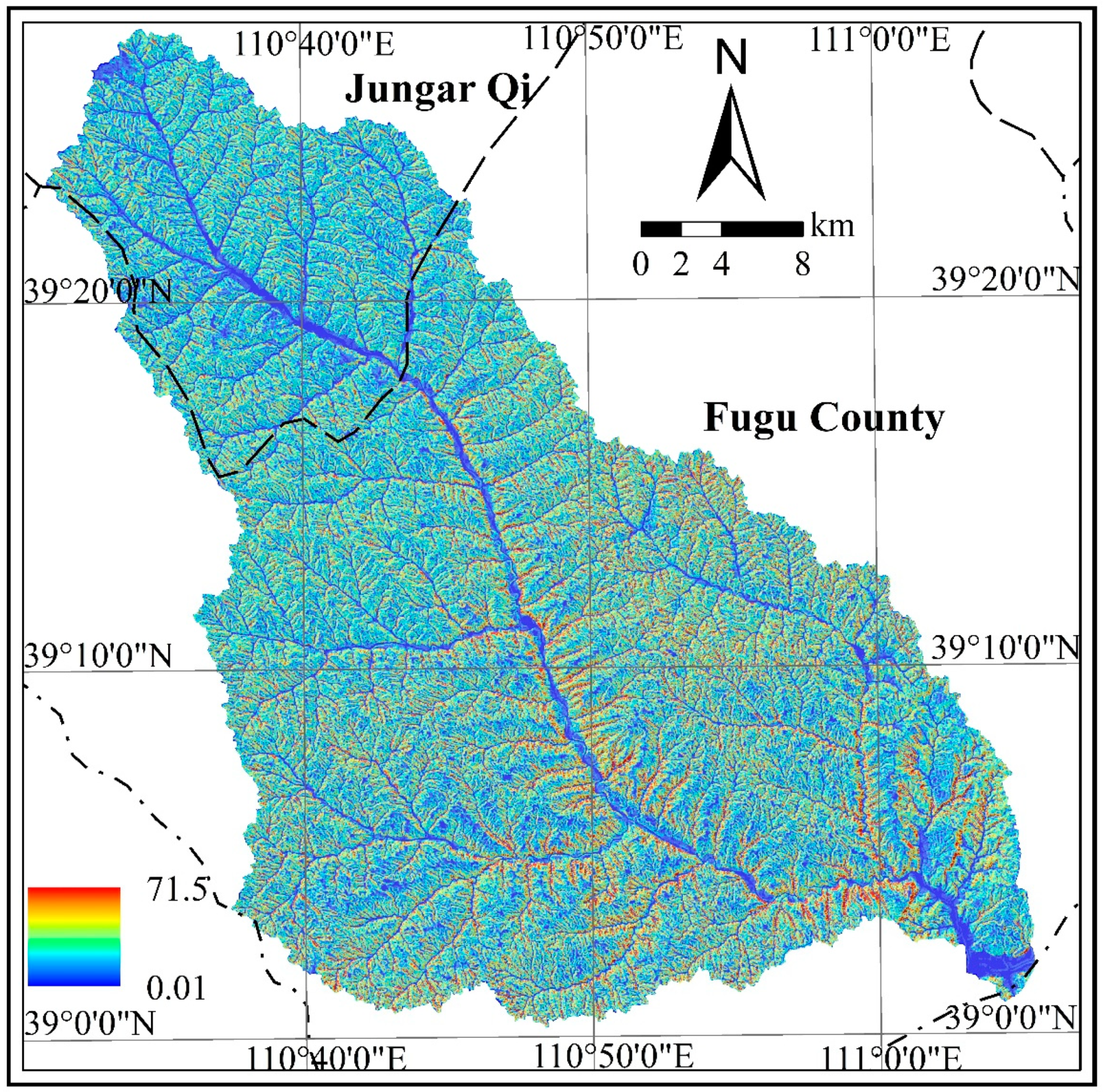
Among the topographic factors of the model, slope length is a key parameter that affects soil erosion. The serial computing process of the slope length includes steps such as slope and flow direction determination, flow accumulation, cut-off detection, cell slope length determination, and cumulative slope length calculations. Among these steps, the flow accumulation and cumulative slope length calculation steps involve cumulative process and different raster cells according to the flow path. Parallel computations cannot be directly performed following the row-splitting strategy. The flow paths include two subsets, namely, the flow paths in each sub-basin and the main gully in the basin. Flow accumulation can be calculated independently in the sub-basins, whereas flow accumulation in the main gully of the basin involves fewer raster cells, and thus, no data splitting is needed. Flow accumulation in the main gully can be completed directly in the reduce phase after the sub-basin calculations are performed. Based on the analysis above, the sub-basin splitting strategy can be used to parallelize slope length extraction. The algorithm can be implemented by using the master-slave parallel computing processes in MapReduce. Slave computing processes mainly refer to subprocesses in which only some of the data are involved and no global data need to be considered. The computing results serve as intermediate data that are input into the master computing process. The input data of the algorithm are the raster-based (key, value) pairs in text format (DEM, slope and flow direction) and the GeoCSV data of the splitting polygon which store the polygon ID and boundary coordinates. The main steps are as
Figure 7 shown.
(1) Data input. Read the key-value text of the raster, parse the row and column number of the cell and calculate the cell center coordinates. Read and parse the GeoCSV text to get the splitting polygon ID and boundary coordinates.
(2) Splitting polygon identification and data splitting. The ray casting method for point-in-polygon testing is used to determine the splitting polygon in which the cell is located, and get the polygon ID to customize the partitioner to perform sub-basin splitting. Then the raster cells are sent to different computational nodes.
(3) Slope length calculation for cells in the sub-basin. For each raster cell assigned to the worker node, the flow accumulation, cut-off detection, cell slope length, and cumulative slope length are calculated using the serial calculation method of the slope length; and output the cumulative slope length of each cell.
(4) Slope length calculation for cells in the main gully. According to the result of the flow accumulation in (3), the main gully cell is determined. The flow accumulation, cut-off detection, cell slope length, and cumulative slope length of these cells is computed by the same process as step (3).
(5) Combination and output. The slope length for cells in the sub-basin and the main gully is merged with the rules as follows: if the cell is in the main gully, the slope length generated by step (4) are the slope length value of the cell; otherwise is the step (3). The slope length of the complete watershed is written to HDFS. The LS factor is then calculated according to the corresponding method in
Table 1 (
Figure 8).
According to the two parallel algorithms described above, spatial interpolation, vector rasterization, map algebra, slope gradient, flow direction, and slope length operations are implemented using the MapReduce programming interface. Based on the model factors and model structure, the corresponding parallel operators are called to calculate model factors and perform model calculations in the basin.
4. Toolbox Development Integrated with Geographic Information System (GIS)
The Hadoop platform is operated on a Linux parallel computing cluster that consists of multiple computing nodes. Thus, multiple Linux and Hadoop commands must be executed to complete the corresponding computing tasks. The process also involves uploading or downloading model data to/from clusters, which complicates the parallel computing tasks in the model described above. To improve the usability and ease of operation of parallel computing functions in the model, a geoprocessing toolbox is compiled from the model parallel computing functions using a Python script based on the ArcGIS platform. This toolbox allows for the direct calling and the visualization of the computational results in the ArcGIS platform, thus achieving the integration of the parallel computing functions of the model with ArcGIS.
As the toolbox runs on the ArcGIS platform of the local machine, the SSH (secure shell) protocol is used to complete the communication between the local machine and the remote cluster. The SSH protocol is a method of securing remote login operations from one computer to another. The Linux platform provides an SSH access protocol for remote login and other operations. On the Windows platform of the local machine, we use Paramiko, an SSH access library in Python, to interact with the Linux platform. Paramiko provides two types of objects: SSHClient, which is used to implement login to remote hosts and perform various command operations, and SFTPClient, which is used to implement upload and download files. The calculation pipeline of the Mr4Soil is shown in
Figure 9. First, according to the internet protocol (IP) address of the remote host, network port, and other information, a user can connect to the master node of the Hadoop cluster via the SSHClient and SFTPClient objects on the local machine and then convert the data in GIS format to GeoCSV format or a key-value text file through the ArcPy package. Second, the converted data can be uploaded to the master node by calling the put method of SFTPClient. Next, these files on the master node are transferred to the HDFS of the Cluster using Hadoop platform file operation command and the EXEC_COMMAND function of SSHClient. Then, the corresponding MapReduce program is executed using the Hadoop platform Java Archive (JAR) operation command in the same way to compute the various factors and perform soil erosion calculations. Finally, the user can download the results to the local machine and convert them to GIS format and use the ArcGIS platform for browsing and viewing.
There are three tools in the application layer of the framework (
Figure 10a). (1) The cluster connection tool. Using the Paramiko module and the SSH protocol to login to the cluster remotely, files can be uploaded and downloaded through SFTP (SSH file transfer protocol). For a flexible connection method, the cluster login IP and network service port are set as login parameters. Parameter passing occurs through the ArcGIS customization tool. Remote login to the clusters in the Windows environment is then achieved (
Figure 10b). (2) The data preprocessing tool. This tool is mainly used to achieve two-way interoperability between native GIS data and text data for the HDFS of the cluster. The tool converts GIS vector data to GeoCSV format and GIS raster data to key-value pair text format using the data access and conversion functions in ArcPy. Then, the data processing tool uploads the data to HDFS to read in model operations through the SFTPClient object of the Paramiko library (
Figure 10c). (3) The model computing tool. Model computation is a process based on the calculation function of each model factor and soil erosion. This process compiles these functions into JAR packages, uploads the packages to the cluster master nodes, and calls the packages. The model computing tool encapsulates this process. After the user specifies the computing task, the corresponding JAR package is executed by the SSHClient object, thereby completing the model computation and writing the results to the HDFS (
Figure 10d).
6. Summary and Discussion
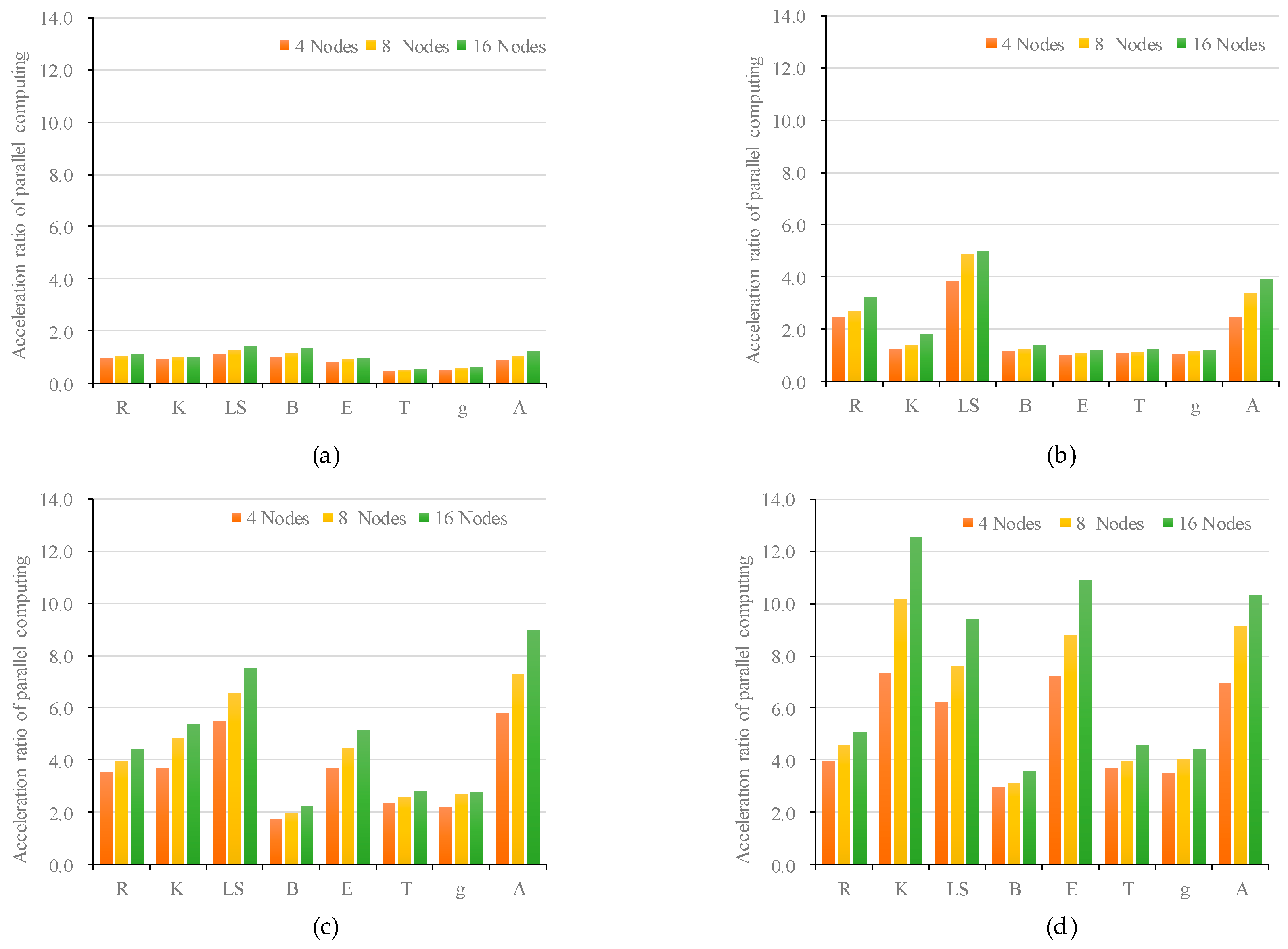
With the continuous development of geographic information acquisition technology, the requirements for soil erosion modelling and calculations have increased due to the broader availability of high-resolution data. Based on the Hadoop platform, an empirical model of soil erosion for annual sediment yield is selected to implement the Mr4Soil parallel computing framework. For three types of computing tasks, including local, focal, and zonal operations, two types of data-splitting strategies (row-based and sub-basin-based) are designed. Six parallel operators are defined, including spatial interpolation, vector rasterization, map algebra, slope gradient, flow direction, and slope length operators. The corresponding parallel algorithm is designed. A geoprocessing toolbox for model calculations is developed using the Python language based on the ArcGIS platform. The performance of the framework is analysed by taking the Gushanchuan basin on the Loess Plateau, China, as an example. With increases in the data resolution and volume, the computational efficiency of different model factors significantly improves, and a higher parallel acceleration ratio is achieved. The main contributions of this paper are as follows: (1) two data-splitting methods, row-based and sub-basin-based methods, and six parallel operators for local, focal and zonal soil erosion modelling computing tasks are developed; (2) a complete parallel computing framework for soil erosion modelling based on Hadoop platform is proposed; (3) a geoprocessing toolbox that integrates the parallel computing for soil erosion modelling with the GIS platform is constructed.
After analysing the performance of the implementation of the Mr4Soil, we found that, compared to parallel computing frameworks such as MPI, GPU, and UDA, the advantages of the proposed Mr4Soil framework are as follows: first, the Mr4Soil framework does not require specialized hardware, such as GPUs, and can achieve a high computational efficiency for a large-scale basin with high-resolution data. Moreover, the framework can be directly implemented on mainstream cloud computing platforms and has high scalability and usability. Second, the Mr4Soil framework was integrated with a GIS platform using a geoprocessing toolbox. It is easy to use for GIS users and provides essential support for using high-precision data to refine soil erosion modelling. Third, the Mr4Soil framework focuses on the parallel computing of soil erosion modelling, which is fully functional for different computing tasks and model factors.
For the parallel algorithm and geoprocessing toolbox development of the integration of GIS and soil erosion modelling parallel computing, this paper only describes a situation in which the GIS platform on a desktop and spatially distributed model are used. Further studies of the following two topics should be performed: (1) the creation of a service interface for the soil erosion model with parallel computing tasks, which could be based on a web service and conveniently applied in practice; and (2) the development of a physically based soil erosion model with parallel computing based on the Hadoop platform. These findings could extend parallel modelling studies of soil erosion.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}