Relevance Assessment of Crowdsourced Data (CSD) Using Semantics and Geographic Information Retrieval (GIR) Techniques


Abstract
:1. Introduction
2. Review of Current Literature
2.1. Adapting Geographic Information Retrieval Process for Crowdsourced Data Relevance Analysis
2.1.1. Managing the Thematic Relevance
2.1.2. Managing the Geographic Relevance
2.2. Relevance Ranking and Merging the Thematic and Geographic Relevance
2.3. Quality Assessment of the Crowdsourced Data Relevance Analysis
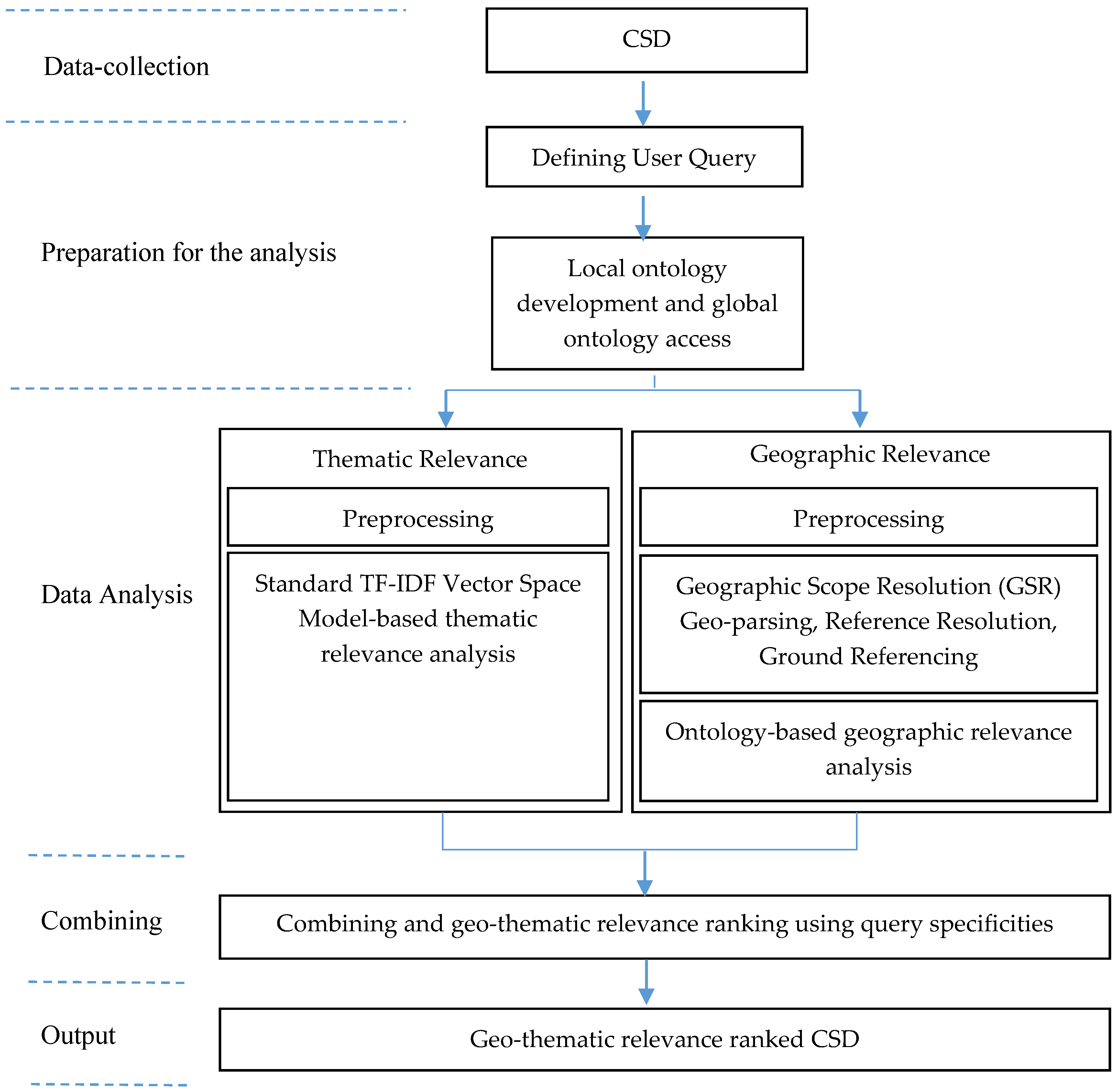
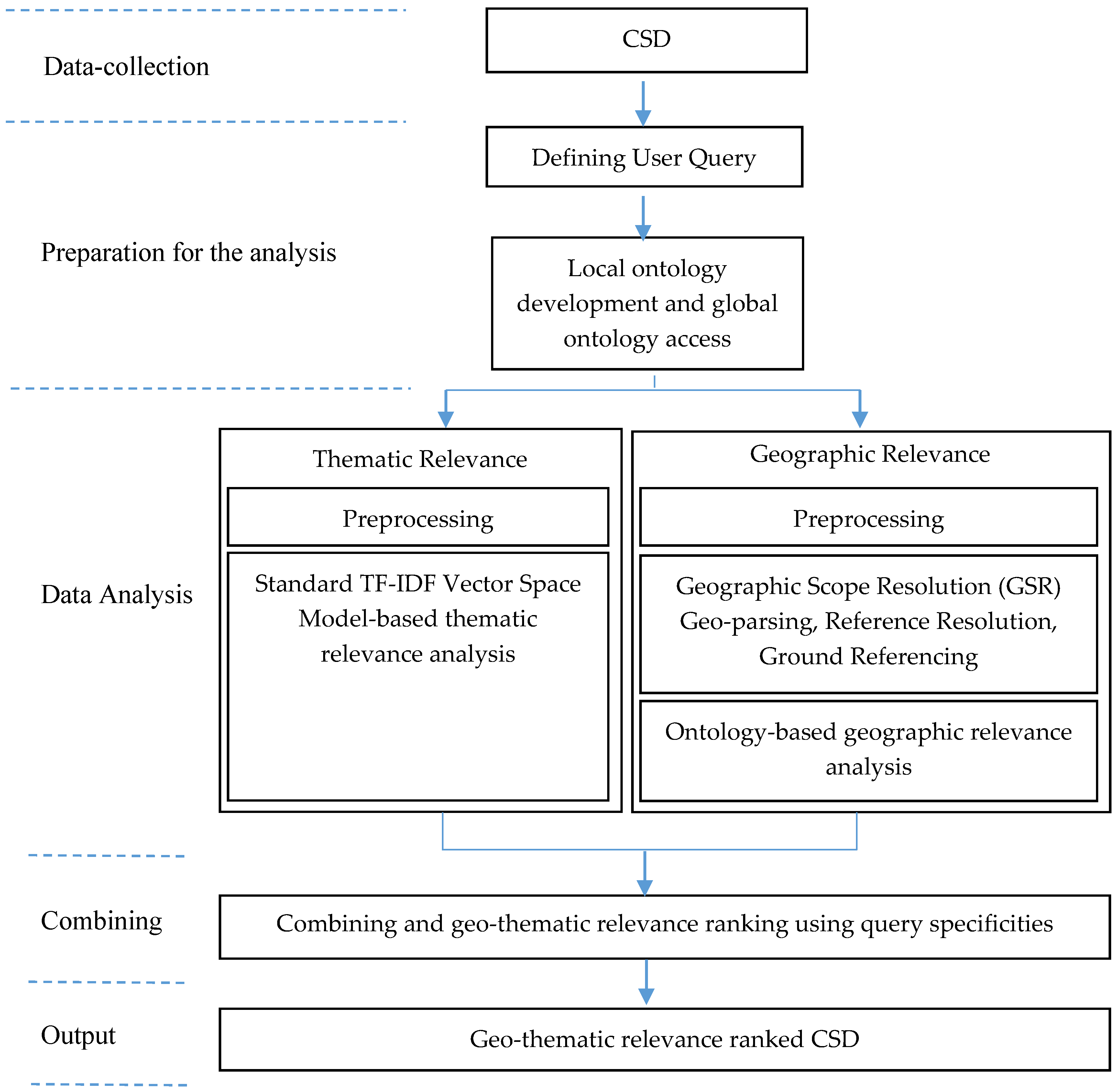
3. Materials and Methods
3.1. Thematic Relevance Analysis
3.1.1. Preprocessing
3.1.2. Term Frequency Thematic Relevance Analysis
3.2. Geographic Relevance Analysis
3.2.1. Preprocessing
3.2.2. Geographic Scope Resolution (GSR)
3.2.3. Ontology-Based Geographic Relevance Analysis
- The function “inside (Insd)” returns no value as the scopes do not spatially overlap;
- The function “proximity (Proxm)” returns a value based on the distances D and d, as indicated in Figure 3;
- The function “siblings (Sib)” returns the value 1, as the two scopes are both siblings of the larger region in the ontology.
3.3. Combining the Geographic and Thematic Relevance Rankings
4. Results and Discussion
4.1. Results of the Thematic Relevance Analysis
4.2. Results of the Geographic Relevance Analysis
4.3. Results of the Final Geo-Thematic Relevance Ranking
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Koswatte, S.; McDougall, K.; Liu, X. Ontology driven VGI filtering to empower next generation SDIs for disaster management. In Proceedings of the Research @ Locate 2014, Canberra, Australia, 7–9 April 2014. [Google Scholar]
- Keler, A.; Mazimpaka, J.D. Safety-aware routing for motorised tourists based on open data and VGI. J. Location Based Serv. 2016, 10, 64–77. [Google Scholar] [CrossRef]
- Zipf, A.; Mobasheri, A.; Rousell, A.; Hahmann, S. Crowdsourcing for individual needs—The case of routing and navigation for mobility-impaired persons. In European Handbook of Crowdsourced Geographic Information; Capineri, C., Haklay, M., Huang, H., Antoniou, V., Kettunen, J., Ostermann, F., Purves, R., Eds.; Ubiquity Press: London, UK, 2016; p. 325. [Google Scholar]
- Prandi, F.; Soave, M.; Devigili, F.; De Amicis, R.; Astyakopoulos, A. Collaboratively Collected Geodata to Support Routing Service for Disabled People. In Proceedings of the 11th International Symposium on Location-Based Services, Vienna, Austria, 26–28 November 2014; pp. 67–79. [Google Scholar]
- Haworth, B.; Bruce, E. A review of volunteered geographic information for disaster management. Geogr. Compass 2015, 9, 237–250. [Google Scholar] [CrossRef]
- Horita, F.E.; de Albuquerque, J.P. An approach to support decision-making in disaster management based on volunteer geographic information (VGI) and spatial decision support systems (SDSS), In Proceedings of the 10th International ISCRAM Conference, Baden-Baden, Germany, 12–15 May 2013.
- Granell, C.; Ostermann, F.O. Beyond data collection: Objectives and methods of research using VGI and geo-social media for disaster management. Comput. Environ. Urban Syst. 2016, 59, 231–243. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Senaratne, H.; Mobasheri, A.; Ali, A.L.; Capineri, C.; Haklay, M. A review of volunteered geographic information quality assessment methods. Int. J. Geogr. Inf. Sci. 2016, 1–29. [Google Scholar] [CrossRef]
- Spinsanti, L.; Ostermann, F. Automated geographic context analysis for volunteered information. Appl. Geogr. 2013, 43, 36–44. [Google Scholar] [CrossRef]
- O’Donovan, J.; Kang, B.; Meyer, G.; Hollerer, T.; Adalii, S. Credibility in context: An analysis of feature distributions in twitter. In Proceedings of the 2012 International Conference on Privacy, Security, Risk and Trust and 2012 International Conference on Social Computing, Amsterdam, The Netherlands, 3–5 September 2012; pp. 293–301. [Google Scholar]
- Parker, C.J.; May, A.; Mitchell, V. Relevance of volunteered geographic information in a real world context, In Proceedings of the GISRUK 2011 Conference, Portsmouth, UK, 26–29 April 2011.
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Cowan, T. A Framework for Investigating Volunteered Geographic Information Relevance in Planning. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2013. [Google Scholar]
- Koswatte, S.; McDougall, K.; Liu, X. VGI and crowdsourced data credibility analysis using spam email detection techniques. Int. J. Digit. Earth 2017, 1–13. [Google Scholar] [CrossRef]
- Raper, J. Geographic relevance. J. Doc. 2007, 63, 836–852. [Google Scholar] [CrossRef]
- Cai, G. GeoVSM: An integrated retrieval model for geographic information. In International Conference on Geographic Information Science (GIScience 2002); Egenhofer, M.J., Mark, D.M., Eds.; Springer: Boulder, CO, USA, 2002; pp. 65–79. [Google Scholar]
- Mobasheri, A. A rule-based spatial reasoning approach for OpenStreetMap data quality enrichment; case study of routing and navigation. Sensors 2017, 17, 2498. [Google Scholar] [CrossRef] [PubMed]
- White, H.D. Relevance theory and citations. J. Pragmat. 2011, 43, 3345–3361. [Google Scholar]
- Saracevic, T. Relevance reconsidered. In Proceedings of the Second Conference on Conceptions of Library and Information Science (CoLIS 2), Copenhagen, Denmark, 13–16 October 1996; pp. 201–218. [Google Scholar]
- MacEachren, A.M.; Jaiswal, A.; Robinson, A.C.; Pezanowski, S.; Savelyev, A.; Mitra, P.; Zhang, X.; Blanford, J. Senseplace2: Geotwitter analytics support for situational awareness. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 181–190. [Google Scholar]
- Borlund, P. The concept of relevance in IR. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 913–925. [Google Scholar] [CrossRef]
- Larson, R.R. Geographic information retrieval and spatial browsing. In Proceedings of the 1995 Clinic on Library Applications of Data Processing, Urbana, IL, USA, 10–12 April 1995; Smith, L.C., Gluck, M., Eds.; University of Illinois at Urbana–Champaign: Champaign, IL, USA, 1996. [Google Scholar]
- Andrade, L.; Silva, M.J. Relevance Ranking for Geographic IR. In Proceedings of the Workshop on Geographic Information Retrieval, Seattle, WA, USA, 10–11 August 2006. [Google Scholar]
- De Sabbata, S.; Reichenbacher, T. A probabilistic model of geographic relevance. In Proceedings of the 6th Workshop on Geographic Information Retrieval, Zurich, Switzerland, 18–19 February 2010; p. 23. [Google Scholar]
- Janowicz, K.; Raubal, M.; Kuhn, W. The semantics of similarity in geographic information retrieval. J. Spat. Inf. Sci. 2011, 2011, 29–57. [Google Scholar] [CrossRef]
- Kumar, C. Relevance and ranking in geographic information retrieval. In Proceedings of the Fourth BCS-IRSG conference on Future Directions in Information Access, Koblenz, Germany, 31 August 2011; pp. 2–7. [Google Scholar]
- Wang, C.; Xie, X.; Wang, L.; Lu, Y.; Ma, W.Y. Detecting geographic locations from web resources. In Proceedings of the Workshop on Geographic Information Retrieval, Bremen, Germany, 31 October–5 November 2005; pp. 17–24. [Google Scholar]
- Jones, C.B.; Purves, R.S. Geographical information retrieval. Int. J. Geogr. Inf. Sci. 2008, 22, 219–228. [Google Scholar] [CrossRef] [Green Version]
- Jones, C.B.; Alani, H.; Tudhope, D. Geographical information retrieval with ontologies of place. In Spatial Information Theory; Springer: London, UK, 2001; pp. 322–335. [Google Scholar]
- Amitay, E.; Har’El, N.; Sivan, R.; Soffer, A. Web-a-where: Geotagging web content. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 273–280. [Google Scholar]
- Zaila, Y.L.; Montesi, D. Geographic information extraction, disambiguation and ranking techniques. In Proceedings of the 9th Workshop on Geographic Information Retrieval, Paris, France, 26–27 November 2015; pp. 1–7. [Google Scholar]
- Purves, R.S.; Clough, P.; Jones, C.B.; Hall, M.H.; Murdock, V. Geographic Information Retrieval: Progress and Challenges in Spatial Search of Text. Found. Trends Inf. Retr. 2018, 12, 164–318. [Google Scholar] [CrossRef]
- Yu, B.; Cai, G. A query-aware document ranking method for geographic information retrieval. In Proceedings of the 4th ACM Workshop on Geographical Information Retrieval, Lisbon, Portugal, 6–10 November 2007; pp. 49–54. [Google Scholar]
- Tomaszewski, B.; Blanford, J.; Ross, K.; Pezanowski, S.; MacEachren, A.M. Supporting geographically-aware web document foraging and sensemaking. Comput. Environ. Urban Syst. 2011, 35, 192–207. [Google Scholar] [CrossRef]
- Tomaszewski, B.M.; MacEachren, A.M.; Pezanowski, S.; Liu, X.; Turton, I. Supporting humanitarian relief logistics operations through online geo-collaborative knowledge management. In Proceedings of the 2006 International Conference on Digital Government Research, San Diego, CA, USA, 21–24 May 2006; pp. 358–359. [Google Scholar]
- Martins, B.; Silva, M.J.; Andrade, L. Indexing and ranking in Geo-IR systems. In Proceedings of the Workshop on Geographic Information Retrieval, Bremen, Germany, 4 November 2005; pp. 31–34. [Google Scholar]
- Stowe, K.; Paul, M.; Palmer, M.; Palen, L.; Anderson, K. Identifying and Categorizing Disaster-Related Tweets. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, Texas, USA, 1–5 November 2016; pp. 1–6. [Google Scholar]
- Monteiro, B.R.; Davis, C.A.; Fonseca, F. A survey on the geographic scope of textual documents. Comput. Geosci. 2016, 96, 23–34. [Google Scholar] [CrossRef]
- Alexopoulos, P.; Ruiz, C.; Villazon-terrazas, B. KLocator: An Ontology-Based Framework for Scenario-Driven Geographical Scope Resolution. Int. J. Adv. Intell. Syst. 2013, 6, 177–187. [Google Scholar]
- Leidner, J.L.; Lieberman, M.D. Detecting geographical references in the form of place names and associated spatial natural language. SIGSPATIAL Spec. 2011, 3, 5–11. [Google Scholar] [CrossRef]
- Koswatte, S.; McDougall, K.; Liu, X. Semantic Location Extraction from Crowdsourced Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 543–547. [Google Scholar] [CrossRef]
- Frontiera, P.; Larson, R.; Radke, J. A comparison of geometric approaches to assessing spatial similarity for GIR. Int. J. Geogr. Inf. Sci. 2008, 22, 337–360. [Google Scholar] [CrossRef]
- Lieberman, M.D.; Samet, H.; Sankaranarayanan, J.; Sperling, J. STEWARD: Architecture of a spatio-textual search engine. In Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems, Seattle, WA, USA, 7–9 November 2007; p. 25. [Google Scholar]
- Inkpen, D. Information Retrieval on the Internet. 2007. Available online: http://www.site.uottawa.ca/diana/csi4107/IR_draft.pdf (accessed on 05 December 2015).
- Buckland, M.; Gey, F. The relationship between recall and precision. J. Am. Soc. Inf. Sci. 1994, 45, 12. [Google Scholar] [CrossRef]
- Criscuolo, L.; Carrara, P.; Bordogna, G.; Pepe, M.; Zucca, F.; Seppi, R.; Oggioni, A.; Rampini, A. Handling quality in crowdsourced geographic information. In European Handbook of Crowdsourced Geographic Information; Capineri, C., Haklay, M., Huang, H., Antoniou, V., Kettunen, J., Ostermann, F., Purves, R., Eds.; Ubiquity Press: London, UK, 2016; pp. 57–74. [Google Scholar] [Green Version]
- Spinsanti, L.; Ostermann, F. Validation and relevance assessment of volunteered geographic information in the case of forest fires. In Proceedings of the Validation of Geo-Information Products for Crisis Management Workshop (ValGeo 2010), Ispra, Italy, 11–13 October 2010. [Google Scholar]
- Cambria, E.; Rajagopal, D.; Olsher, D.; Das, D. Big social data analysis. Big Data Comput. 2013, 13, 401–414. [Google Scholar]
- Barbier, G.; Zafarani, R.; Gao, H.; Fung, G.; Liu, H. Maximizing benefits from crowdsourced data. Comput. Math. Organ. Theory 2012, 18, 257–279. [Google Scholar] [CrossRef]
- Lewis, S.C.; Zamith, R.; Hermida, A. Content Analysis in an Era of Big Data: A Hybrid Approach to Computational and Manual Methods. J. Broadcast. Electron. Media 2013, 57, 34–52. [Google Scholar] [CrossRef]
- Okolloh, O. Ushahidi, or ‘testimony’: Web 2.0 tools for crowdsourcing crisis information. Particip. Learn. Action 2009, 59, 65–70. [Google Scholar]
- Potts, M.; Lo, P.; McGuinness, R. Ushahidi Queensland Floods Trial Evaluation Paper: A Collaboration between ABC Innovation and ABC Radio; ABC Australia: Ultimo, Australia, 2011. [Google Scholar]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Liu, T.-Y. Learning to Rank for Information Retrieval. Found. Trends Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Query |
|---|---|
| 1 | Road closed flood Toowoomba |
| 2 | Highway closed |
| 3 | Evacuation center open |
| 4 | Heavy rainfall Toowoomba |
| 5 | Flash flooding Toowoomba |
| No. | Query | # Hits | Average Precision | P@5 | P@10 |
|---|---|---|---|---|---|
| 1 | Road closed flood Toowoomba | 120 | 0.655 | 0.600 | 0.300 |
| 2 | Highway closed | 69 | 0.897 | 0.800 | 0.600 |
| 3 | Evacuation center open | 21 | 0.595 | 0.400 | 0.300 |
| 4 | Heavy rainfall Toowoomba | 45 | 0.911 | 0.800 | 0.600 |
| 5 | Flash flooding Toowoomba | 55 | 0.903 | 0.800 | 0.500 |
| Rank | CSD Report |
|---|---|
| 1 | Flash flooding has caused a shopping center in Toowoomba to be closed. |
| 2 | Flash flooding caused landslide at Toowoomba range. |
| 3 | Flash flooding in Toowoomba region experiencing roadways cut off in town. Recent Heavy falls within the last hour have managed to cut off some minor and major roads in Toowoomba CBD and surrounding suburbs. |
| 4 | The Warrego Highway at the Toowoomba Range is closed in both directions. Motorists are advised to seek an alternative route. |
| 5 | The Warrego Highway is presently closed at Jondaryan following heavy rain in the area. |
| 6 | Toowoomba Regional Council crews and SES personnel are assessing road damage after today’s severe flash flooding in Toowoomba. The main areas impacted were in the vicinity of East and West creeks which run through the center of the city. |
| 7 | Flash flooding has caused a library to be evacuated. |
| 8 | The Clifton-Leyburn Road is OPEN WITH CAUTION from Clifton to Condamine River to all vehicles. There is no access to the Toowoomba-Karara Road and Ryeford-Pratten Road due to flood waters and pavement damage. Drivers are urged not to enter floodwaters. |
| 9 | Water bird habitat damaged-fences down at Toowoomba water bird habitat. |
| 10 | Road closed on Griffiths Street East of Mort Street. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koswatte, S.; McDougall, K.; Liu, X. Relevance Assessment of Crowdsourced Data (CSD) Using Semantics and Geographic Information Retrieval (GIR) Techniques. ISPRS Int. J. Geo-Inf. 2018, 7, 256. https://doi.org/10.3390/ijgi7070256
Koswatte S, McDougall K, Liu X. Relevance Assessment of Crowdsourced Data (CSD) Using Semantics and Geographic Information Retrieval (GIR) Techniques. ISPRS International Journal of Geo-Information. 2018; 7(7):256. https://doi.org/10.3390/ijgi7070256
Chicago/Turabian StyleKoswatte, Saman, Kevin McDougall, and Xiaoye Liu. 2018. "Relevance Assessment of Crowdsourced Data (CSD) Using Semantics and Geographic Information Retrieval (GIR) Techniques" ISPRS International Journal of Geo-Information 7, no. 7: 256. https://doi.org/10.3390/ijgi7070256
APA StyleKoswatte, S., McDougall, K., & Liu, X. (2018). Relevance Assessment of Crowdsourced Data (CSD) Using Semantics and Geographic Information Retrieval (GIR) Techniques. ISPRS International Journal of Geo-Information, 7(7), 256. https://doi.org/10.3390/ijgi7070256