
A Novel System Based on Selection Strategy and Ensemble Mode for Non-Ferrous Metal Futures Market Management




Abstract
:1. Introduction
1.1. Background
1.2. Main Works
1.3. Novelty of This Study
- (1)
- A novel prediction system is developed based on optimal sub-model selection strategy and ensemble mode for point and interval forecasting in the non-ferrous metals price forecasting field. The developed system is composed of data pretreatment module, sub-model forecasting module, model selection module, ensemble module. Different from most previous studies, this study can realize point and interval non-ferrous metals price prediction by mining and giving full play to the role of a certain type of model. The developed ensemble prediction system works well in the datasets copper and zinc.
- (2)
- Data pretreatment module is established on the ground on SVMD techniques, which can improve the forecasting results of different models. The latest SVMD data pretreatment technique is used for the first time to decompose metal price time series, which can solve the drawbacks that most scholars’ research on data pretreatment methods focuses on the direct application of single data pretreatment method. Moreover, the SVMD algorithm can adaptively determine the number of subsequences decomposition and perform effective decomposition according to data features.
- (3)
- A novel sub-model selection strategy based on the proposed MRMIT index is designed in this study. This can effectively obtain the optimal model of each subseries from the sub-model library based on the ELM series models. Moreover, the proposed sub-model selection strategy can avoid the disadvantage that most model selection strategies adopt a single model or simple mixed model. Besides, the proposed model selection index MRMIT can not only consider the accuracy and stability consistency of the system but also enhance the computational efficiency of the system to some extent.
- (4)
- The novel ensemble mode for non-ferrous metals price fills the research gap in the field of non-ferrous metals price prediction. Different from the current ensemble methods that simply add the results of sub-models or determine the weight of sub-models based on optimization algorithms, this study established a nonlinear ensemble mode based on the ORELM model, and the experimental results demonstrate that the proposed ensemble mode performs better than other models and can prominently enhance the precision and stability of prediction.
- (5)
- The novel non-ferrous metal price forecasting system proposed in this paper can not only achieve high precision point prediction but also achieve reliable interval prediction. This method does not need to set the interval distribution, but can still achieve ideal results, and greatly increases the efficiency of prediction, which can provide stakeholders with future risks in the management of the non-ferrous metal price futures market.
2. The Literature Review
- (1)
- However, the VMD algorithm has the defect that it is troublesome to effectively confirm the number of decomposition layers, which may play a crucial role in the final prediction accuracy. To solve this problem, some researchers use other algorithms that can automatically determine the number of modes to determine the predefined parameters. Although this problem can be solved to some extent, the parameters determined by another algorithm may not be optimal.
- (2)
- The existing researchers ignore the in-depth analysis and mining of some types of models, mostly pay more attention to the application of individual advanced models, and rarely involve the significance of model selection in decomposition ensemble prediction. Thus, further improvement is necessary from the point of view of the in-depth study of similar models and employing a valid optimal sub-predictor selection approach.
- (3)
- Due to its outstanding performance in the field of prediction, the ELM model has attracted quite a lot of attention from researchers. However, researchers of ELM-based models are more inclined to use the improved version of ELM, and few studies explore the applicability of different ELM models in prediction.
- (4)
- In non-ferrous metal price forecasting, the ensemble approach is less innovative, which the current ensemble methods that simply add the results of sub-models or determine the weight of sub-models based on optimization algorithms.
- (5)
- Compared with point forecasting, interval forecasting is a significant link in the research of prediction problems, and its results contain more information. And the effective interval forecast results can quantify the uncertainty of the financial market, to provide more reliable forecasting results for enterprises and investors. Wang et al. [50] have conducted in-depth research on the application of interval prediction in wind energy, which can guarantee the stable operation of the power grid to a certain extent. However, in non-ferrous metal prices forecasting, the majority of previous research paid attention to the deterministic prediction, while ignoring the uncertainty of metal prices.
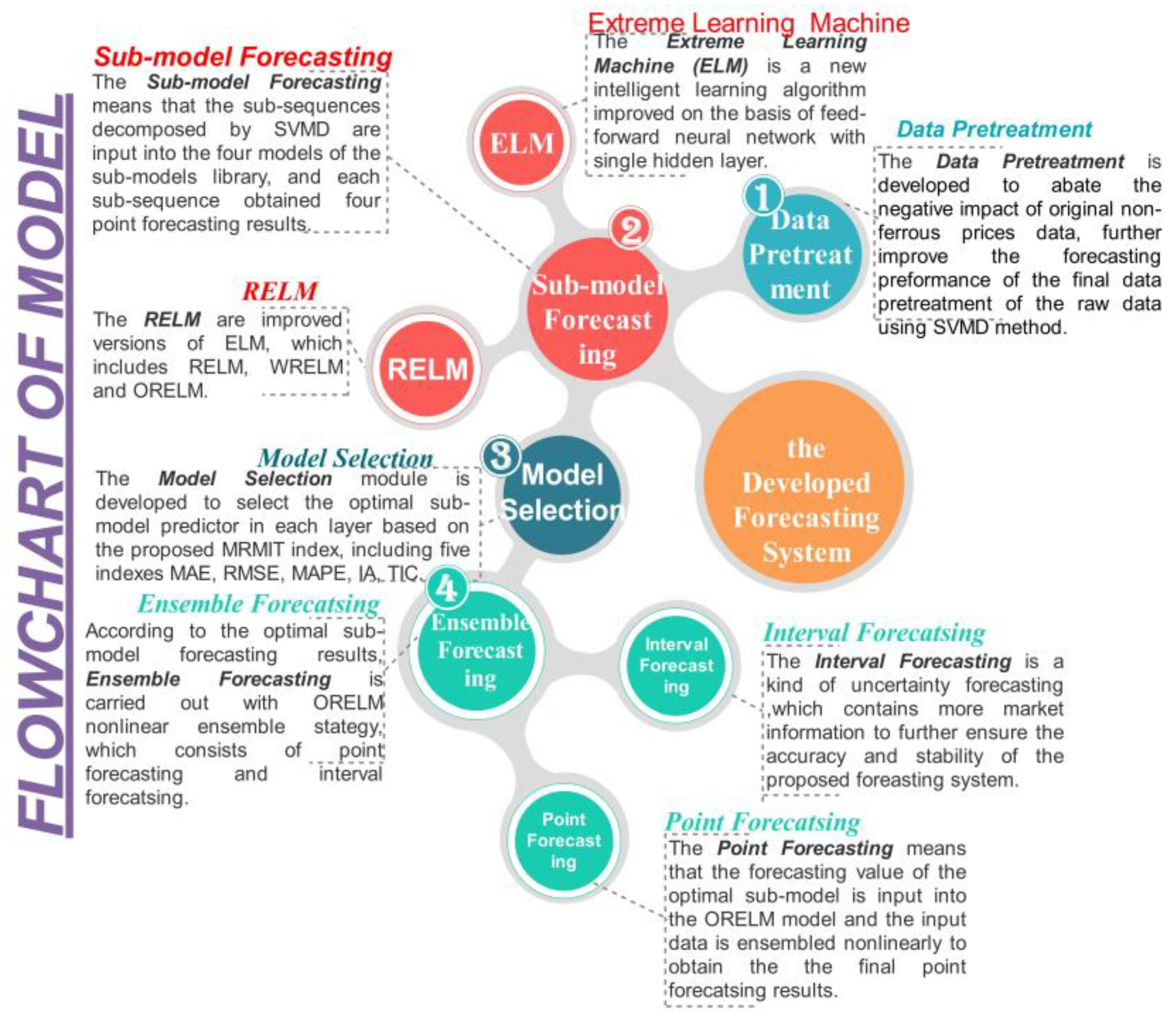
3. Modular Design of the Non-Ferrous Metal Prices Forecasting System
3.1. Data Pretreatment Module
3.1.1. Variational Mode Decomposition
3.1.2. Successive Variational Mode Decomposition
- (1)
- Each mode should be closely around its central frequency. Therefore, it can be achieved by minimizing the following constraints. satisfies the following criteria:
- (2)
- The spectral overlap between and modes should be minimum. To ensure that this constraint can be implemented stably, the filter with frequency response is used, and its frequency response is as follows:Meanwhile, the penalty function is defined as Equation (10) and employed.where is the impulse response of the filter .
- (3)
- By minimizing and constraints, the order mode and the first K − 1 order mode may not be effectively distinguished. Therefore, based on the establishment idea of constraint , the frequency response of the filter used is:Thus, the established constraint is:
- (4)
- During decomposition, the following constraints are established to ensure that signals can be completely reconstructed:Thus, the problem of extracting modal components can be formulated as a constrained minimization problem as follows:where is a parameter of .
3.2. Forecasting Module
3.2.1. Extreme Learning Machine
3.2.2. Regularized Extreme Learning Machine
- (1)
- Set the target function:where is the regularization coefficient; is the connection weight matrix between neurons in the output layer and hidden emerging neuron.
- (2)
- Construct the Lagrange equation.where is the Lagrangian operator.
- (3)
- The partial derivatives of variables are obtained to obtain the output weight matrix.where I is the unit matrix.
- (4)
- Finally, the RELM prediction model is:where y is the non-ferrous metal price prediction matrix.
3.2.3. Weighted Regularized Extreme Learning Machine
- (1)
- Set the target function:where ; is regular coefficient.
- (2)
- Construct the Lagrange equation.where is the Lagrangian operator; is the output matrix of the hidden layer.
- (3)
- The partial derivatives of variables are obtained to obtain the output weight matrix.where I is the unit matrix.
- (4)
- Finally, the WRELM prediction model is:where y is the non-ferrous metal price prediction matrix.
3.2.4. Outlier Robust Extreme Learning Machine
- (1)
- The objective function is defined as:where, represents the regularization parameter and represents the prediction error of N training data.
- (2)
- Construct the Lagrange equation:The Lagrange function can be solved by:and can be solved by:
3.3. Optimal Sub-Model Selection Module
- (1)
- The five metric values are calculated for all candidate sub-predictors.
- (2)
- The obtained five values of evaluation criteria are normalized by Equation (37).
- (3)
- The i-th sub-predictor MRMIT value is computed as follows:
- (4)
- For the developed forecasting system, the sub-predictor with the minimum MRMIT value is chosen as the optimal sub-predictor.
3.4. Ensemble Modules
4. Framework of the Developed Ensemble Non-Ferrous Metal Prices Forecasting System
5. Experiments and Analysis
5.1. Studied Data
5.2. Performance Metrics
5.3. Experiment I: Sub-Model Selection Based on MRMIT
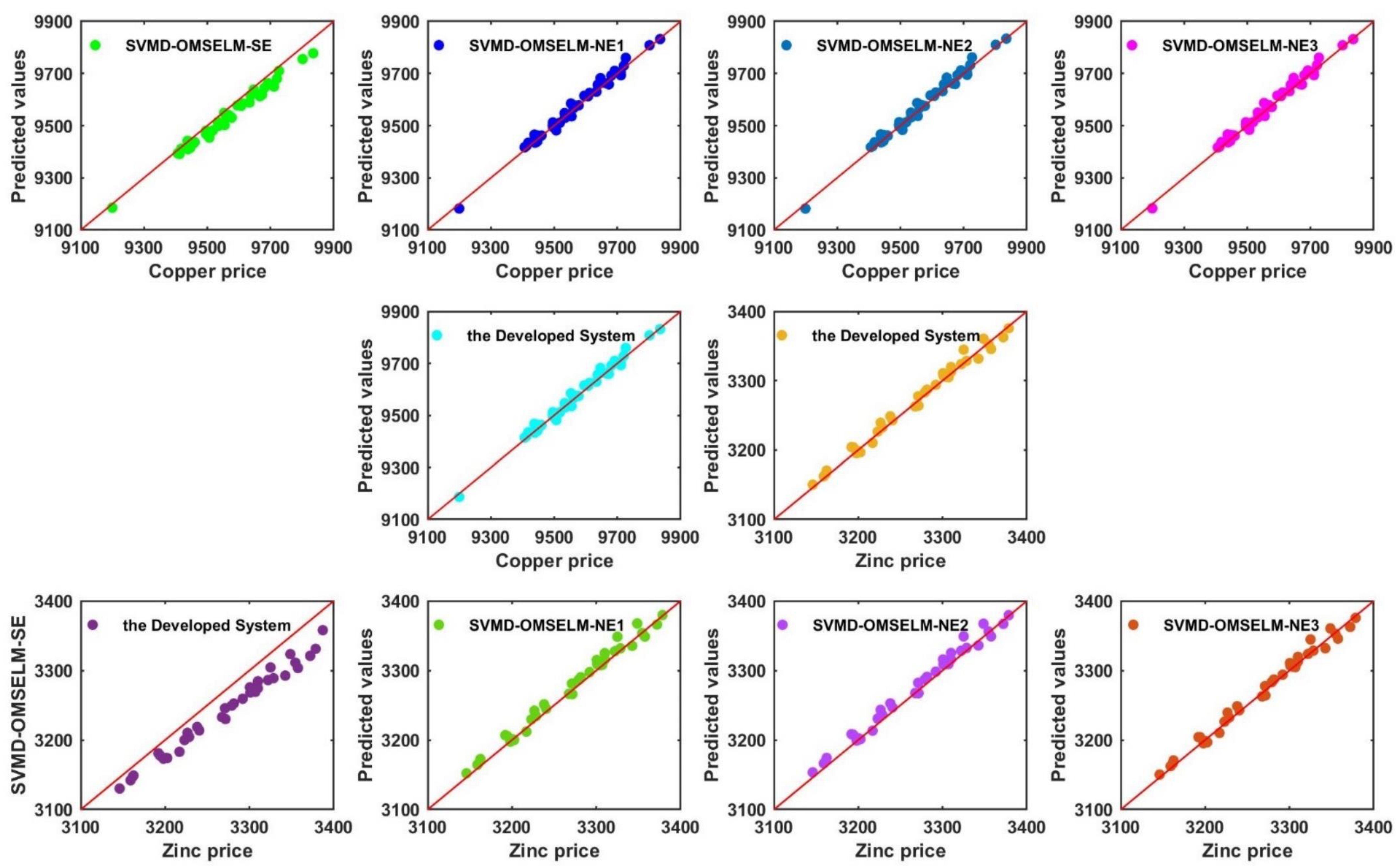
5.4. Experiment II: Comparison of the Developed System with Some Typical Benchmarks
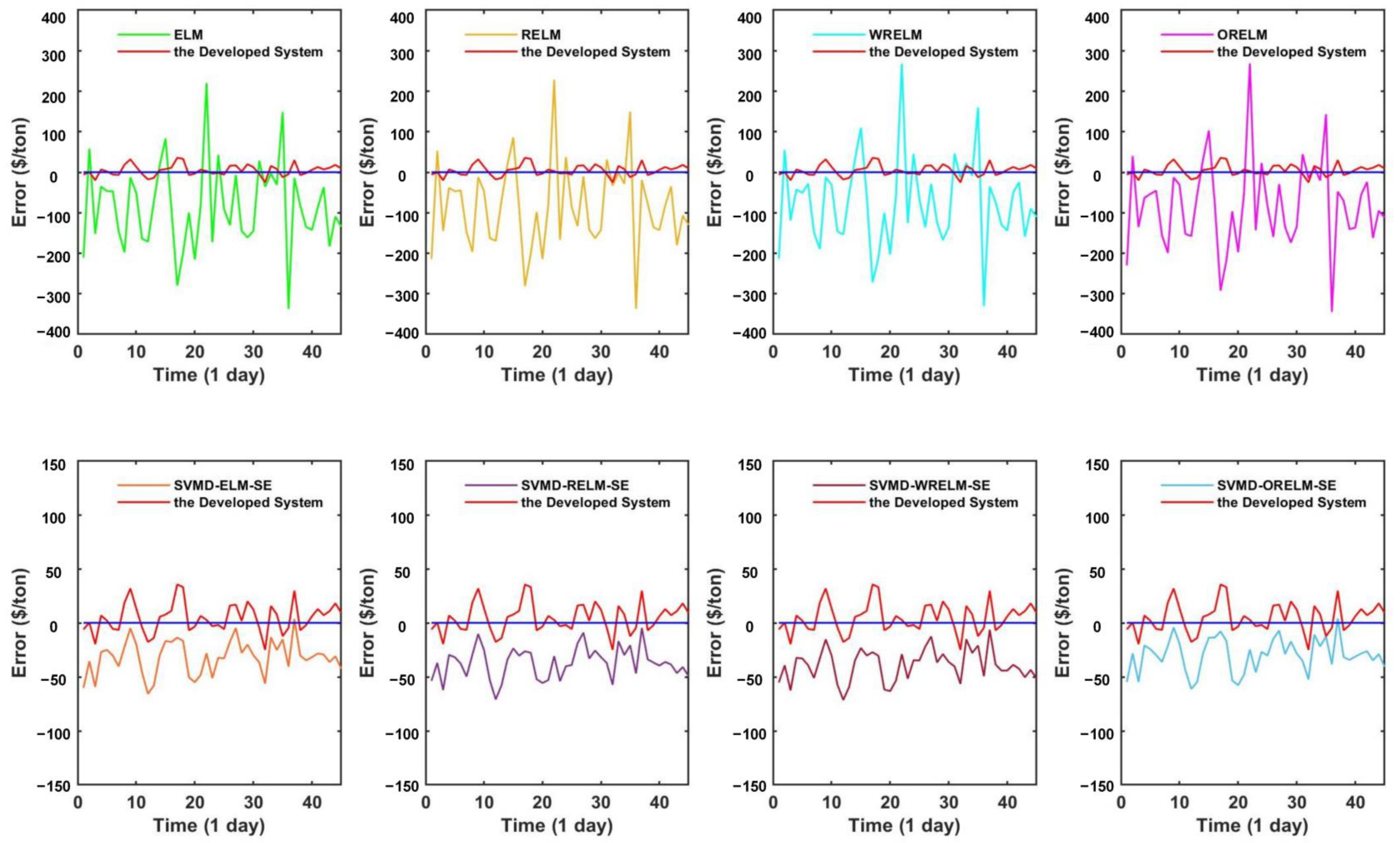
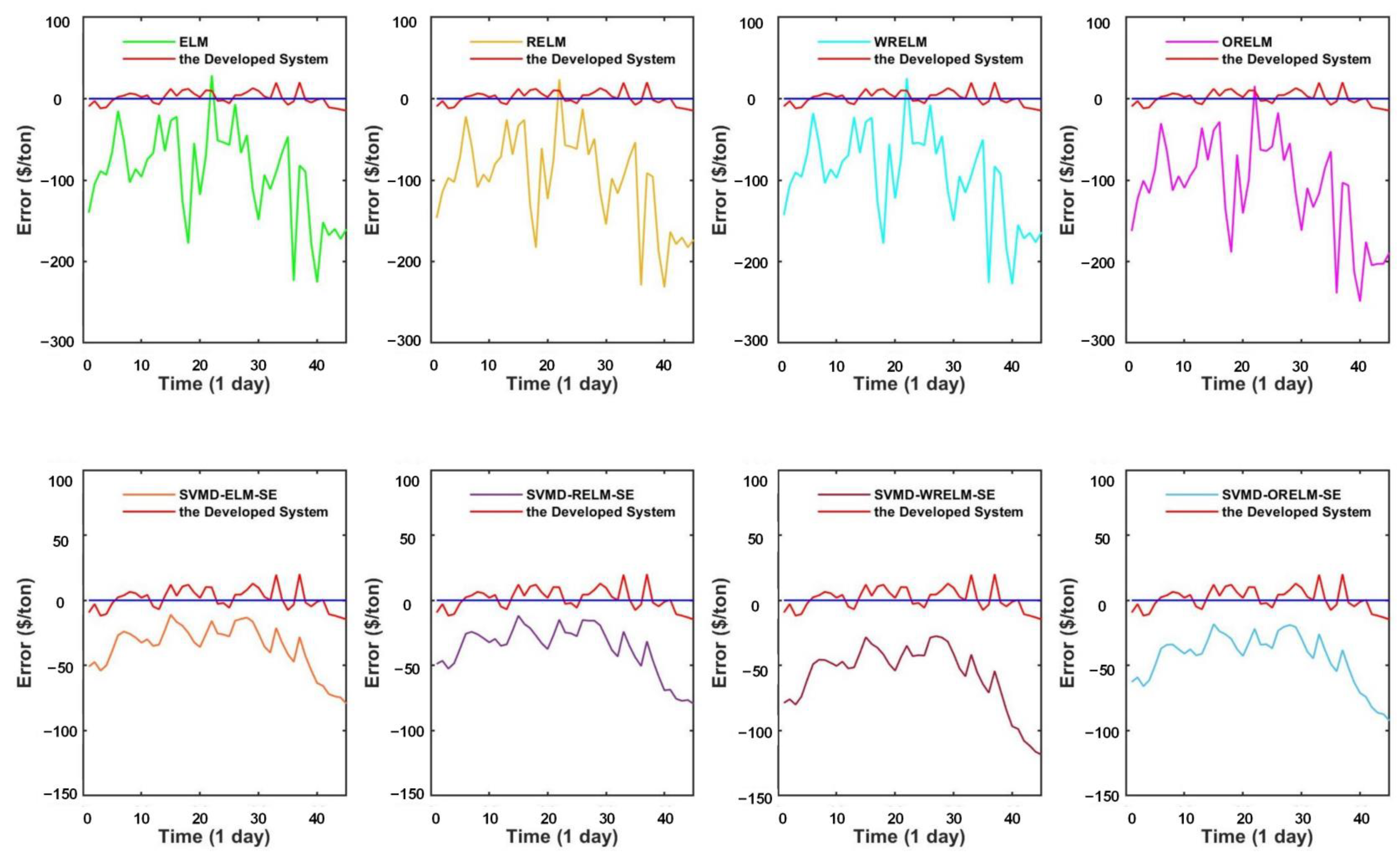
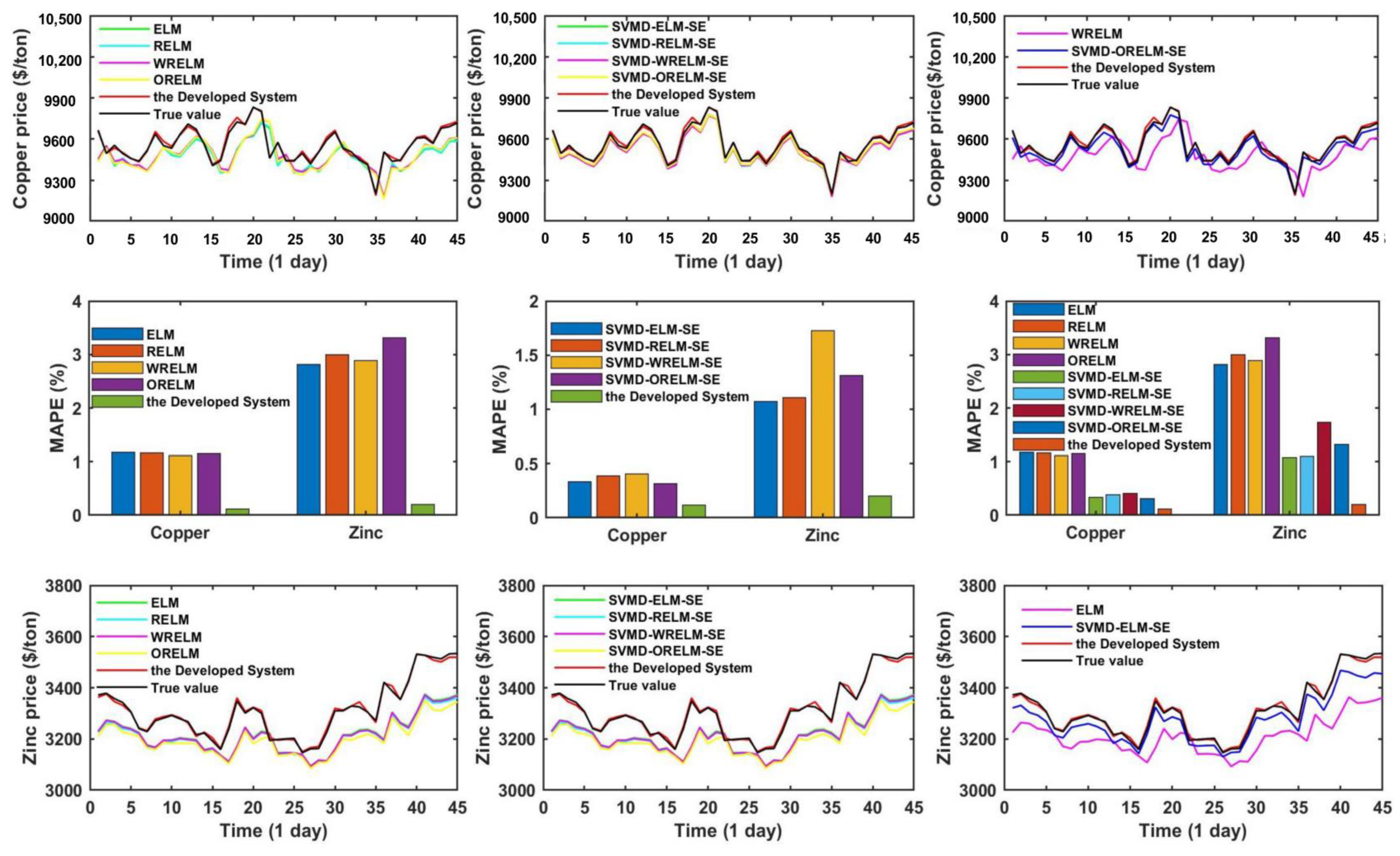
- (a)
- The comparison of point prediction accuracy among the simple ensemble models with some single models. In this sub-session, several independent forecasting models are selected, mainly including ELM and three improved versions of ELM, i.e., RELM, WRELM, and ORELM. From Table 4, it is obvious to see that the forecasting accuracy of the simple ensemble models is stronger than that of the individual models. Taking dataset copper as an example, the WRELM obtains the most satisfying prediction prevision in individual models with the MAPE index value of 1.108749%. For the single model WRELM, other index values are , , , , . Concerning simple ensemble models in Experiment II, the SVMD-ORELM-SE has the best forecasting performance both in simple ensemble models and individual models, whose corresponding values are , , , , .
- (b)
- The comparison of point prediction accuracy between the designed system and single models. According to Table 4, it is obvious that the forecasting prevision of the designed system is stronger than those single models. For dataset copper, the model which has the highest accuracy in individual models is WRELM, and the corresponding index values are mentioned above in part (a). Compared to an individual model, the developed forecasting system has a great improvement, such as the MAPE value of 1.108479% and 0.118460% for WRELM and the proposed system, respectively. In addition to this, the other corresponding index values for the developed system are , , , , .
- (c)
- The comparison of point prediction accuracy between the proposed system and simple ensemble models. According to Table 4, taking dataset zinc as an example, the SVMD-ELM-SE achieves the most satisfying results in simple ensemble models with the corresponding index values of , , , , . Meanwhile, the Developed System index values are , , , , . Through the experimental results, there is no doubt that the prediction precision of the developed system is much better than those simple ensemble models.
5.5. Experiment III: Ensemble Point Forecasting Based on the Optimal Model Selection Strategy
- (a)
- The developed system is compared with the SVMD-OMSELM-SE model Table 5 displays that in the case of dataset copper, the developed system has a lower MAPE value than SVMD-OMSELM-SE, with values of 0.118469% and 0.310760%, which indicates that the developed system has better prediction precision. Moreover, for the developed system, the other evaluation criteria are mentioned above in Experiment II: (b). Corresponding to this is SVMD-OMSELM-SE, the corresponding indexes are , , , , respectively. From this, it is believed that the developed system is prominently superior to the SVMD-OMSELM-SE based on the five comprehensive evaluation indicators and it can be further concluded that ORELM nonlinear ensemble is better than the simple ensemble.
- (b)
- The developed system is compared with SVMD-OMSELM based on different nonlinear ensemble methods, such as RELM-nonlinear ensemble, WRELM-nonlinear ensemble, and ORELM-nonlinear ensemble. From Table 5, taking the dataset copper as an example, we can see that the best forecasting model among the SVMD-OMSELM based on three different nonlinear ensemble is SVMD-OMSELM-NE1, whose assessment indexes are , , , , , respectively. And the indexes of the proposed system are mentioned above specifically. By contrast, the developed system forecasting results surpass SVMD-OMSELM-NE1, that’s to say, the proposed system has the best forecasting prevision.
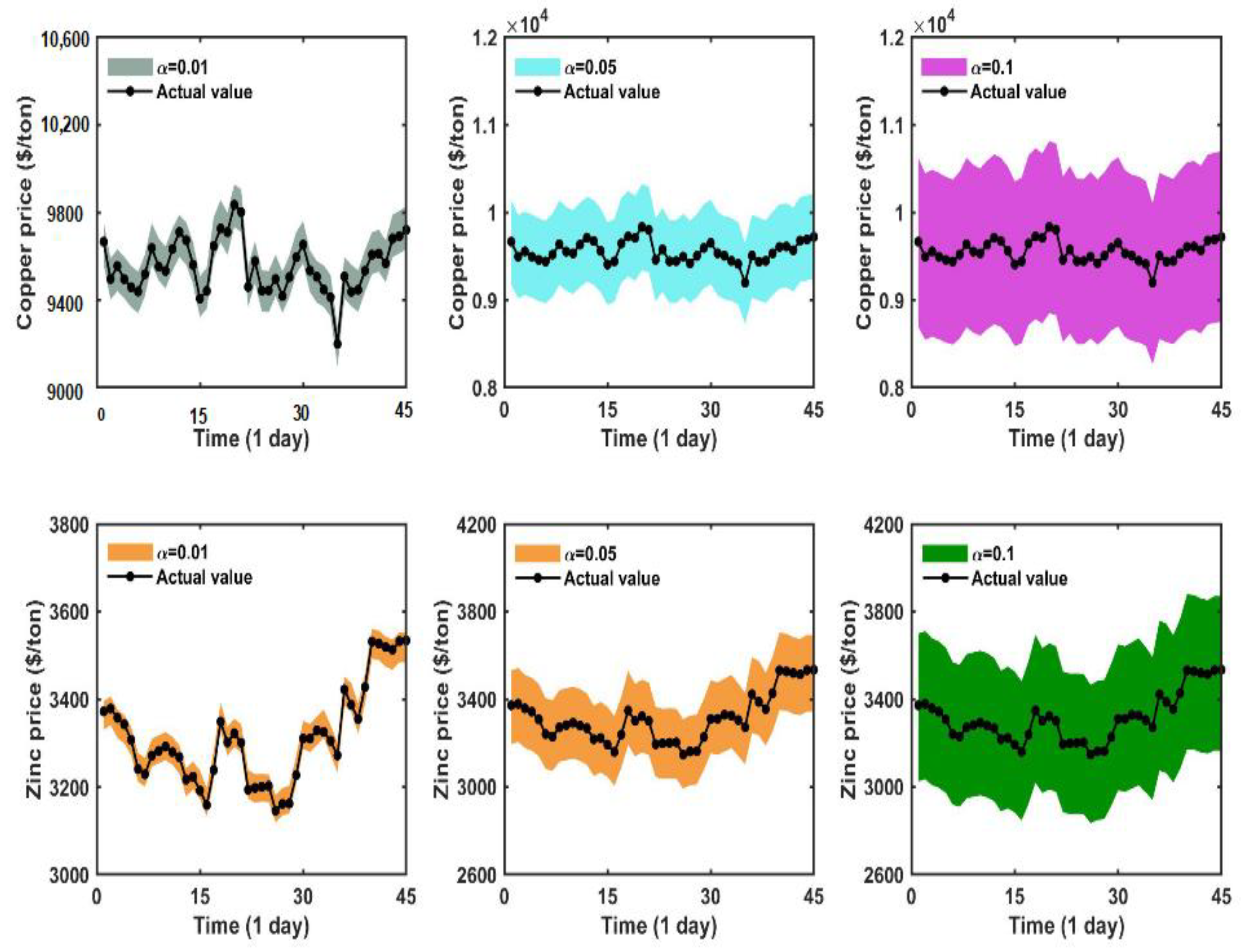
5.6. Experiment IV: Interval Forecasting
6. Discussion
6.1. Forecasting Stability
6.2. Forecasting Effectiveness
6.3. Statistical Significance
- (a)
- For dataset Copper, except , all the comparative models passed the test under . The residual model DM values are greater than , with the minimum DM value is 2.811426. This means the developed system has 99% probability to reject , that is to say, under 99% confidence interval, the developed system has excellent prediction accuracy. For degrees of freedom 44, taking dataset copper as an example, except , other P values are lower than the significance level . Of the remaining MDM-P values, the largest is , which indicates that the developed system has 99% probability to reject . However, at the significance level of , all the comparative models reject .
- (b)
- As for the comparative models of Zinc, 100% of the results passed the significance test of . Under different ensemble strategies, , , , , , , , , it shows that the proposed forecasting system has the best prediction ability. The results of the MDM hypothesis test show that besides the performance of SVMD-OMSELM-NE1 are , all the results are lower than , which demonstrates that the proposed forecasting has 99% probability to reject .
6.4. The Superiority of Each Module in the Developed System
- (a)
- By comparing SVMD-OMSELM-SE and SVMD-ELM-SE, SVMD-OMSELM-SE and SVMD-RELM-SE, SVMD-OMSELM-SE and SVMD-WRELM-SE, SVMD-OMSELM-SE and SVMD-ORELM-SE, can prove the superiority of the newly introduced optimal model selection mode. And in the comparison between SVMD-OMSELM-SE and SVMD-WRELN-SE, model selection shows the best superiority, the , , , and index values on average are 30.8827%, 28.1601%, 30.9649%, 3.6435%, and 28.2820%, respectively. At the same time, by comparing SVMD-OMSELM-NE1 and SVMD-ELM-SE, SVMD-OMSELM-NE2 and SVMD-RELM-SE, SVMD-OMSELM-NE3 and SVMD-WRELM-SE, SVMD-OMSELM-NE4 and SVMD-ORELM-SE, can further prove that model selection is effective in improving the prediction system with nonlinear strategies. There is no doubt from Table A4 that under the nonlinear ensemble method, the comparison of SVMD-OMSELM-NE3 and SVMD-WRELM-SE, the optimal sub-predictor, has the best effect on point forecasting accuracy. On average the , , , and metrics are 77.9806%, 74.4655%, 77.8866%, 6.4755% and 74.5771%, respectively. In addition, it is reasonable to demonstrate the superiority of the nonlinear ensemble mode.
- (b)
- According to the improvement rates of the developed system with the SVMD-OMSELM-SE, SVMD-OMSELM-NE1, SVMD-OMSELM-NE2, and SVMD-OMSELM-NE3 models, the effectiveness of the ORELM nonlinear ensemble approach in the developed system is verified. On top of that, the ORELM nonlinear ensemble approach is a great improvement over a simple ensemble and on average the , , , and metrics are 71.5818%, 68.0750%, 71.4459%, 2.7481%, and 68.1724%.
- (c)
- The comparison of the developed system with SVMD-ELM-SE, SVMD-RELM-SE, and SVMD-ORELM-SE, respectively, not only validates the effectiveness of model selection but also clearly explains the prospective of the ORELM nonlinear ensemble mode.
6.5. Comparison with Existing Models
7. Conclusions
- (1)
- Compared with other comparative models, the developed system can achieve better metal price forecasting performance due to the combination of different components, such as data decomposition techniques, sub-model selection strategy, and nonlinear ensemble methods. In addition, in this paper, the ELM, RELM, WRELM, and ORELM model are considered and analyzed, and the prediction result is better than the comparison models. Therefore, the in-depth analysis and mining of a certain type of model can be paid more attention to in the future;
- (2)
- The successive variational mode decomposition (SVMD) algorithm is introduced to determine the number of decomposed sub-sequences according to the intrinsic characteristics of the data, which can effectively reduce the occurrence of errors. Specifically, the SVMD data pretreatment algorithm can reduce the volatility and non-linearity of non-ferrous metal data by decomposing the original data into multiple sub-sequences, and improve the prediction performance;
- (3)
- Based on the proposed MRMIT index, the optimal predictor is selected for each decomposed sub-sequence, which enhances the prediction accuracy as well as expands the application scope of the forecasting system. The experimental results show that the model selection introduced into the non-ferrous metal price forecasting field is effective;
- (4)
- Compared with the single model, simple ensemble method, ELM, RELM, and WRELM nonlinear ensemble method, the proposed ORELM nonlinear ensemble mode has better forecasting precision and consistency, which verifies the validity of the novel nonlinear ensemble mode;
- (5)
- The developed system is superior to the comparative models in the non-ferrous metal trading market. For the dataset copper and zinc, the mean MAPE values of the developed system are 0.118469 and 0.203406, respectively. The interval forecasting results show that at the significance level of 0.01, PICP values are 100.000000 and 100.000000; PIAW values are 190.713983 and 65.090031, respectively; PINAW values are 0.300101 and 0.167758; SCORE values are −3.814280 and −1.301801, respectively. Therefore, the developed system in this paper is an effective complement to the existing non-ferrous metal price forecasting research framework, which is conducive to the operation and management of the non-ferrous metal market.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | VAR |
|---|---|---|
| Copper | ELM | 11,286.993097 |
| RELM | 11,336.186827 | |
| WRELM | 11,968.801480 | |
| ORELM | 12,181.008417 | |
| SVMD-ELM-SE | 252.066521 | |
| SVMD-RELM-SE | 212.343312 | |
| SVMD-WRELM-SE | 219.031314 | |
| SVMD-ORELM-SE | 243.856001 | |
| SVMD-OMSELM-SE | 244.223998 | |
| SVMD-OMSELM-NE1 | 191.637117 | |
| SVMD-OMSELM-NE2 | 197.689493 | |
| SVMD-OMSELM-NE3 | 197.740229 | |
| The Developed System | 188.906506 | |
| Zinc | ELM | 3215.968100 |
| RELM | 3329.516374 | |
| WRELM | 3251.063837 | |
| ORELM | 3779.192421 | |
| SVMD-ELM-SE | 321.593545 | |
| SVMD-RELM-SE | 339.918353 | |
| SVMD-WRELM-SE | 611.193976 | |
| SVMD-ORELM-SE | 384.366274 | |
| SVMD-OMSELM-SE | 319.900086 | |
| SVMD-OMSELM-NE1 | 77.863428 | |
| SVMD-OMSELM-NE2 | 79.968606 | |
| SVMD-OMSELM-NE3 | 83.227507 | |
| The Developed System | 70.112261 |
| Dataset | Model | FE1 | FE2 |
|---|---|---|---|
| Copper | ELM | 0.988279 | 0.980377 |
| RELM | 0.988383 | 0.980444 | |
| WRELM | 0.988913 | 0.980959 | |
| ORELM | 0.988470 | 0.980227 | |
| SVMD-ELM-SE | 0.996655 | 0.995058 | |
| SVMD-RELM-SE | 0.996126 | 0.994635 | |
| SVMD-WRELM-SE | 0.995917 | 0.994408 | |
| SVMD-ORELM-SE | 0.996873 | 0.995308 | |
| SVMD-OMSELM-SE | 0.996892 | 0.995328 | |
| SVMD-OMSELM-NE1 | 0.998795 | 0.997853 | |
| SVMD-OMSELM-NE2 | 0.998753 | 0.997750 | |
| SVMD-OMSELM-NE3 | 0.998756 | 0.997783 | |
| The Developed System | 0.998815 | 0.997887 | |
| Zinc | ELM | 0.971854 | 0.956776 |
| RELM | 0.969984 | 0.954638 | |
| WRELM | 0.971185 | 0.955986 | |
| ORELM | 0.966815 | 0.950374 | |
| SVMD-ELM-SE | 0.989278 | 0.984363 | |
| SVMD-RELM-SE | 0.988938 | 0.983902 | |
| SVMD-WRELM-SE | 0.982712 | 0.976083 | |
| SVMD-ORELM-SE | 0.986860 | 0.981534 | |
| SVMD-OMSELM-SE | 0.989290 | 0.984390 | |
| SVMD-OMSELM-NE1 | 0.997639 | 0.995927 | |
| SVMD-OMSELM-NE2 | 0.997529 | 0.995736 | |
| SVMD-OMSELM-NE3 | 0.997624 | 0.996060 | |
| The Developed System | 0.997966 | 0.996500 |
| Dataset | Model | DM | MDM | MDM-P |
|---|---|---|---|---|
| Copper | ELM | 5.461142 | 5.400121 | 2.546700 × 10−6 |
| RELM | 5.372157 | 5.312131 | 3.418049 × 10−6 | |
| WRELM | 5.001746 | 4.945858 | 1.152746 × 10−5 | |
| ORELM | 4.994495 | 4.938688 | 1.180302 × 10−5 | |
| SVMD-ELM-SE | 5.866314 | 5.800767 | 6.617725 × 10−7 | |
| SVMD-RELM-SE | 7.544789 | 7.460487 | 2.430326 × 10−9 | |
| SVMD-WRELM-SE | 7.917927 | 7.829456 | 7.098852 × 10−10 | |
| SVMD-ORELM-SE | 5.466845 | 5.405761 | 2.499056 × 10−6 | |
| SVMD-OMSELM-SE | 5.450666 | 5.389763 | 2.636570 × 10−6 | |
| SVMD-OMSELM-NE1 | 1.313350 | 1.298675 | 2.008207 × 10−1 | |
| SVMD-OMSELM-NE2 | 2.969721 | 2.936539 | 5.262398 × 10−3 | |
| SVMD-OMSELM-NE3 | 2.811426 | 2.780013 | 7.967935 × 10−3 | |
| The Developed System | ||||
| Zinc | ELM | 6.307776 | 6.237296 | 1.510907 × 10−7 |
| RELM | 6.553817 | 6.480588 | 6.624987 × 10−8 | |
| WRELM | 6.392678 | 6.321249 | 1.136804 × 10−7 | |
| ORELM | 6.757235 | 6.681733 | 3.352119 × 10−8 | |
| SVMD-ELM-SE | 6.478134 | 6.405751 | 8.537268 × 10−8 | |
| SVMD-RELM-SE | 6.462337 | 6.390130 | 9.001363 × 10−8 | |
| SVMD-WRELM-SE | 7.373679 | 7.291289 | 4.286835 × 10−9 | |
| SVMD-ORELM-SE | 7.190442 | 7.110099 | 7.886491 × 10−9 | |
| SVMD-OMSELM-SE | 6.481959 | 6.409533 | 8.428536 × 10−8 | |
| SVMD-OMSELM-NE1 | 2.581770 | 2.552922 | 1.422681 × 10−2 | |
| SVMD-OMSELM-NE2 | 3.217786 | 3.181831 | 2.683958 × 10−3 | |
| SVMD-OMSELM-NE3 | 3.424765 | 3.386498 | 1.500084 × 10−3 | |
| The Developed System | - | - | - |
| Copper | Zinc | Average | Copper | Zinc | Average | Copper | Zinc | Average | Copper | Zinc | Average | Copper | Zinc | Average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SVMD-OMSELM-SE vs. | SVMD-OMSELM-SE vs. | SVMD-OMSELM-NE3 vs. | The Developed System vs. | The Developed System vs. | |||||||||||
| SVMD-ELM-SE | SVMD-ORELM-SE | SVMD-WRELM-SE | SVMD-OMSELM-NE1 | SVMD-ELM-SE | |||||||||||
| MAE | 7.0678 | 0.1133 | 3.5906 | 0.6295 | 18.3435 | 9.4865 | 69.5705 | 86.3908 | 77.9806 | 1.6528 | 13.612 | 7.6324 | 64.6517 | 81.2215 | 72.9366 |
| RMSE | 6.0928 | 0.1427 | 3.1178 | 0.522 | 16.7136 | 8.6178 | 63.9291 | 85.0019 | 74.4655 | 1.5392 | 13.4568 | 7.498 | 59.6162 | 79.1837 | 69.3999 |
| MAPE | 7.1045 | 0.1107 | 3.6076 | 0.6286 | 18.4909 | 9.5597 | 69.5174 | 86.2559 | 77.8866 | 1.6997 | 13.8313 | 7.7655 | 64.5859 | 81.0294 | 72.8076 |
| IA | 0.2594 | 0.0125 | 0.136 | 0.0223 | 1.7355 | 0.8789 | 2.8186 | 10.1325 | 6.4755 | 9.78 × 10−7 | 0.0506 | 0.0302 | 1.9535 | 3.8195 | 2.8865 |
| TIC | 6.1041 | 0.1433 | 3.1237 | 0.5231 | 16.816 | 8.6695 | 64.0141 | 85.1402 | 74.5771 | 1.5372 | 13.4172 | 7.4772 | 59.6936 | 79.3012 | 69.4974 |
| SVMD-OMSELM-SE vs. | SVMD-OMSELM-NE1 vs. | The Developed System vs. | The Developed System vs. | The Developed System vs. | |||||||||||
| SVMD-RELM-SE | SVMD-ELM-SE | SVMD-ORELM-SE | SVMD-OMSELM-NE2 | SVMD-RELM-SE | |||||||||||
| MAE | 19.706 | 3.2039 | 11.455 | 64.0577 | 78.2626 | 71.1601 | 62.2028 | 84.6488 | 73.4258 | 4.9404 | 17.2478 | 11.0941 | 69.4589 | 81.8025 | 75.6307 |
| RMSE | 16.1141 | 3.1622 | 9.6381 | 58.9848 | 75.9469 | 67.4659 | 57.2205 | 82.638 | 69.9293 | 5.9168 | 17.0816 | 11.4992 | 63.9257 | 79.8131 | 71.8694 |
| MAPE | 19.7734 | 3.1771 | 11.4753 | 63.9736 | 77.9843 | 70.9789 | 62.1171 | 84.5201 | 73.3186 | 4.9698 | 17.672 | 11.3209 | 69.4156 | 81.6117 | 75.5137 |
| IA | 0.8259 | 0.2896 | 0.5577 | 1.9435 | 3.767 | 2.8552 | 1.7123 | 5.608 | 3.6601 | 0.0426 | 0.0704 | 0.0565 | 2.5295 | 4.1071 | 3.3183 |
| TIC | 16.147 | 3.1800 | 9.6635 | 59.0643 | 76.0937 | 67.579 | 57.2978 | 82.7572 | 70.0275 | 5.9086 | 17.0352 | 11.4719 | 64.0047 | 79.9307 | 71.9677 |
| SVMD-OMSELM-SE vs. | SVMD-OMSELM-NE2 vs. | The Developed System vs. | The Developed System vs. | The Developed System vs. | |||||||||||
| SVMD-WRELM-SE | SVMD-RELM-SE | SVMD-OMSELM-SE | SVMD-OMSELM-NE3 | SVMD-WRELM-SE | |||||||||||
| MAE | 23.8358 | 37.9296 | 30.8827 | 67.8716 | 78.0097 | 72.9407 | 61.9634 | 81.2002 | 71.5818 | 4.7954 | 14.256 | 9.5257 | 71.0297 | 88.3309 | 79.6803 |
| RMSE | 20.0512 | 36.2689 | 28.1601 | 61.657 | 75.6545 | 68.6558 | 56.996 | 79.1539 | 68.0750 | 4.6844 | 11.4193 | 8.0518 | 65.6188 | 86.7146 | 76.1667 |
| MAPE | 23.8805 | 38.0494 | 30.9649 | 67.8161 | 77.6646 | 72.7404 | 61.8775 | 81.0083 | 71.4429 | 4.8025 | 14.3966 | 9.5996 | 70.9813 | 88.2345 | 79.6079 |
| IA | 1.1447 | 6.1422 | 3.6435 | 2.4858 | 4.0338 | 3.2598 | 1.6896 | 3.8065 | 2.7481 | 0.0342 | 0.0454 | 0.0398 | 2.8537 | 10.1825 | 6.5181 |
| TIC | 20.0912 | 36.4829 | 28.2870 | 61.7443 | 75.8099 | 68.7771 | 57.0733 | 79.2715 | 68.1724 | 4.6786 | 11.3981 | 8.0383 | 65.6978 | 86.8339 | 76.2658 |
| Dataset | Model | MAE | RMSE | MAPE(%) | IA | TIC |
|---|---|---|---|---|---|---|
| Copper | Model proposed by [54] | 344.220000 | 421.454000 | 5.292000 | X | 0.032000 |
| Model proposed by [33] | 49.650600 | 74.677200 | 0.943100 | 0.988200 | X | |
| The Developed system | 11.332665 | 14.359648 | 0.118469 | 0.996536 | 0.000751 | |
| Zinc | Model proposed by [9] | 11.691300 | 14.611400 | 0.435800 | 0.999600 | X |
| Model proposed by [55] | 85.700000 | 112.000000 | X | X | X | |
| The Developed system | 6.757693 | 8.351136 | 0.203406 | 0.998478 | 0.001260 |
References
- Zhong, M.; He, R.; Chen, J.; Huang, J. Time-Varying Effects of International Nonferrous Metal Price Shocks on China’s Industrial Economy. Phys. A Stat. Mech. Its Appl. 2019, 528, 121299. [Google Scholar] [CrossRef]
- Liu, D.; Li, Z. Gold Price Forecasting and Related Influence Factors Analysis Based on Random Forest. In Proceedings of the Advances in Intelligent Systems and Computing; Springer: Singapore, 2017. [Google Scholar]
- Wang, J.; Hu, M.; Rodrigues, J.F.D. The Evolution and Driving Forces of Industrial Aggregate Energy Intensity in China: An Extended Decomposition Analysis. Appl. Energy 2018, 228, 2195–2206. [Google Scholar] [CrossRef]
- He, K.; Lu, X.; Zou, Y.; Keung Lai, K. Forecasting Metal Prices with a Curvelet Based Multiscale Methodology. Resour. Policy 2015, 45, 144–150. [Google Scholar] [CrossRef]
- Brown, P.P.; Hardy, N. Forecasting Base Metal Prices with the Chilean Exchange Rate. Resour. Policy 2019, 62, 256–281. [Google Scholar] [CrossRef]
- Fernandez, V. Copper Mining in Chile and Its Regional Employment Linkages. Resour. Policy 2021, 70, 101173. [Google Scholar] [CrossRef]
- Sánchez Lasheras, F.; de Cos Juez, F.J.; Suárez Sánchez, A.; Krzemień, A.; Riesgo Fernández, P. Forecasting the COMEX Copper Spot Price by Means of Neural Networks and ARIMA Models. Resour. Policy 2015, 45, 37–43. [Google Scholar] [CrossRef]
- Baur, D.G.; Smales, L.A. Hedging Geopolitical Risk with Precious Metals. J. Bank. Financ. 2020, 117, 105823. [Google Scholar] [CrossRef]
- Du, P.; Wang, J.; Yang, W.; Niu, T. Point and Interval Forecasting for Metal Prices Based on Variational Mode Decomposition and an Optimized Outlier-Robust Extreme Learning Machine. Resour. Policy 2020, 69, 101881. [Google Scholar] [CrossRef]
- Torres, J.L.; García, A.; De Blas, M.; De Francisco, A. Forecast of Hourly Average Wind Speed with ARMA Models in Navarre (Spain). Sol. Energy 2005, 79, 65–77. [Google Scholar] [CrossRef]
- Aasim; Singh, S.N.; Mohapatra, A. Repeated Wavelet Transform Based ARIMA Model for Very Short-Term Wind Speed Forecasting. Renew. Energy 2019, 136, 758–768. [Google Scholar] [CrossRef]
- Louka, P.; Galanis, G.; Siebert, N.; Kariniotakis, G.; Katsafados, P.; Pytharoulis, I.; Kallos, G. Improvements in Wind Speed Forecasts for Wind Power Prediction Purposes Using Kalman Filtering. J. Wind Eng. Ind. Aerodyn. 2008, 96, 2348–2362. [Google Scholar] [CrossRef] [Green Version]
- Kriechbaumer, T.; Angus, A.; Parsons, D.; Rivas Casado, M. An Improved Wavelet-ARIMA Approach for Forecasting Metal Prices. Resour. Policy 2014, 39, 32–41. [Google Scholar] [CrossRef] [Green Version]
- Gangopadhyay, K.; Jangir, A.; Sensarma, R. Forecasting the Price of Gold: An Error Correction Approach. IIMB Manag. Rev. 2016, 28, 6–12. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; He, K.; Zhang, C. A Novel Grey Wave Forecasting Method for Predicting Metal Prices. Resour. Policy 2016, 49, 323–331. [Google Scholar] [CrossRef]
- Hao, Y.; Tian, C.; Wu, C. Modelling of Carbon Price in Two Real Carbon Trading Markets. J. Clean. Prod. 2020, 244, 118556. [Google Scholar] [CrossRef]
- Niu, X.; Wang, J. A Combined Model Based on Data Preprocessing Strategy and Multi-Objective Optimization Algorithm for Short-Term Wind Speed Forecasting. Appl. Energy 2019, 241, 519–539. [Google Scholar] [CrossRef]
- Zhang, H.; Nguyen, H.; Vu, D.A.; Bui, X.N.; Pradhan, B. Forecasting Monthly Copper Price: A Comparative Study of Various Machine Learning-Based Methods. Resour. Policy 2021, 73, 102189. [Google Scholar] [CrossRef]
- Fan, X.; Wang, L.; Li, S. Predicting Chaotic Coal Prices Using a Multi-Layer Perceptron Network Model. Resour. Policy 2016, 50, 86–92. [Google Scholar] [CrossRef]
- Mustaffa, Z.; Yusof, Y. Inter Related Metal Price Prediction Based on EABC-LSSVM. In Proceedings of the 2012 International Conference on Computer and Information Science, ICCIS 2012—A Conference of World Engineering, Science and Technology Congress, ESTCON 2012—Conference Proceedings, Kuala Lumpur, Malaysia, 12-14 June 2012. [Google Scholar]
- Liu, Y.; Yang, C.; Huang, K.; Gui, W. Non-Ferrous Metals Price Forecasting Based on Variational Mode Decomposition and LSTM Network. Knowl. Based Syst. 2020, 188, 105006. [Google Scholar] [CrossRef]
- Qiu, X.; Ren, Y.; Suganthan, P.N.; Amaratunga, G.A.J. Empirical Mode Decomposition Based Ensemble Deep Learning for Load Demand Time Series Forecasting. Appl. Soft Comput. J. 2017, 54, 246–255. [Google Scholar] [CrossRef]
- Aly, H.H.H. An Intelligent Hybrid Model of Neuro Wavelet, Time Series and Recurrent Kalman Filter for Wind Speed Forecasting. Sustain. Energy Technol. Assess. 2020, 41, 100802. [Google Scholar] [CrossRef]
- Cheng, H.; Ding, X.; Zhou, W.; Ding, R. A Hybrid Electricity Price Forecasting Model with Bayesian Optimization for German Energy Exchange. Int. J. Electr. Power Energy Syst. 2019, 110, 653–666. [Google Scholar] [CrossRef]
- Niu, H.; Xu, K.; Liu, C. A Decomposition-Ensemble Model with Regrouping Method and Attention-Based Gated Recurrent Unit Network for Energy Price Prediction. Energy 2021, 231, 120941. [Google Scholar] [CrossRef]
- Jiang, H.; Luo, S.; Dong, Y. Simultaneous Feature Selection and Clustering Based on Square Root Optimization. Eur. J. Oper. Res. 2021, 289, 214–231. [Google Scholar] [CrossRef]
- Zhu, B.; Ye, S.; Wang, P.; Chevallier, J.; Wei, Y.M. Forecasting Carbon Price Using a Multi-Objective Least Squares Support Vector Machine with Mixture Kernels. J. Forecast. 2022, 41, 100–117. [Google Scholar] [CrossRef]
- Jiang, H.; Tao, C.; Dong, Y.; Xiong, R. Robust Low-Rank Multiple Kernel Learning with Compound Regularization. Eur. J. Oper. Res. 2021, 295, 634–647. [Google Scholar] [CrossRef]
- Hao, Y.; Niu, X.; Wang, J. Impacts of Haze Pollution on China’s Tourism Industry: A System of Economic Loss Analysis. J. Environ. Manag. 2021, 295, 113051. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, S.; Xiao, L.; Fu, T. Wind Speed Forecasting Based on Multi-Objective Grey Wolf Optimisation Algorithm, Weighted Information Criterion, and Wind Energy Conversion System: A Case Study in Eastern China. Energy Convers. Manag. 2021, 243, 114402. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, M.; Zhou, H.; Yan, F. A Multi-Model Fusion Based Non-Ferrous Metal Price Forecasting. Resour. Policy 2022, 77, 102714. [Google Scholar] [CrossRef]
- Du, P.; Guo, J.; Sun, S.; Wang, S.; Wu, J. Multi-Step Metal Prices Forecasting Based on a Data Preprocessing Method and an Optimized Extreme Learning Machine by Marine Predators Algorithm. Resour. Policy 2021, 74, 102335. [Google Scholar] [CrossRef]
- Guo, H.; Wang, J.; Li, Z.; Lu, H.; Zhang, L. A Non-Ferrous Metal Price Ensemble Prediction System Based on Innovative Combined Kernel Extreme Learning Machine and Chaos Theory. Resour. Policy 2022, 79, 102975. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, X.; Wang, M.; Lim, M.K.; Ghadimi, P. Predictive Analytics of the Copper Spot Price by Utilizing Complex Network and Artificial Neural Network Techniques. Resour. Policy 2019, 63, 101414. [Google Scholar] [CrossRef]
- Liu, C.; Hu, Z.; Li, Y.; Liu, S. Forecasting Copper Prices by Decision Tree Learning. Resour. Policy 2017, 52, 427–434. [Google Scholar] [CrossRef]
- Hussein, S.F.M.; Shah, M.B.N.; Jalal, M.R.A.; Abdullah, S.S. Gold Price Prediction Using Radial Basis Function Neural Network. In Proceedings of the 2011 4th International Conference on Modeling, Simulation and Applied Optimization, ICMSAO 2011, Kuala Lumpur, Malaysia, 19–21 April 2011. [Google Scholar]
- Li, B. Research on WNN Modeling for Gold Price Forecasting Based on Improved Artificial Bee Colony Algorithm. Comput. Intell. Neurosci. 2014, 2014, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Cheng, J.; Yi, J. Copper Price Forecasted by Hybrid Neural Network with Bayesian Optimization and Wavelet Transform. Resour. Policy 2022, 75, 102520. [Google Scholar] [CrossRef]
- Wang, J.; Li, H.; Wang, Y.; Lu, H. A Hesitant Fuzzy Wind Speed Forecasting System with Novel Defuzzification Method and Multi-Objective Optimization Algorithm. Expert Syst. Appl. 2021, 168, 114364. [Google Scholar] [CrossRef]
- Manickavasagam, J.; Visalakshmi, S.; Apergis, N. A Novel Hybrid Approach to Forecast Crude Oil Futures Using Intraday Data. Technol. Forecast. Soc. Chang. 2020, 158, 120126. [Google Scholar] [CrossRef]
- Hao, Y.; Zhou, Y.; Gao, J.; Wang, J. A Novel Air Pollutant Concentration Prediction System Based on Decomposition-Ensemble Mode and Multi-Objective Optimization for Environmental System Management. Systems 2022, 10, 139. [Google Scholar] [CrossRef]
- Deng, S.; Zhu, Y.; Duan, S.; Fu, Z.; Liu, Z. Stock Price Crash Warning in the Chinese Security Market Using a Machine Learning-Based Method and Financial Indicators. Systems 2022, 10, 108. [Google Scholar] [CrossRef]
- Lorenzo-Espejo, A.; Muñuzuri, J.; Guadix, J.; Escudero-Santana, A. A Hybrid Metaheuristic for the Omnichannel Multiproduct Inventory Replenishment Problem. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 476–492. [Google Scholar] [CrossRef]
- Andrade, A.D.O.; Marques, L.G.; Resende, O. Prediction and Visualisation of SICONV Project Profiles Using Machine Learning. Systems 2022, 10, 252. [Google Scholar]
- Zhao, Y.; Li, Y.; Feng, C.; Gong, C.; Tan, H. Early Warning of Systemic Financial Risk of Local Government Implicit Debt Based on BP Neural Network Model. Systems 2022, 10, 207. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, J.; Liu, Z. What Should Lenders Be More Concerned About? Developing A Profit-Driven Loan Default Prediction Model. Expert Syst. Appl. 2022, 213, 118938. [Google Scholar] [CrossRef]
- Lee, C.; Xu, X.; Lin, C.C. Using Online User-Generated Reviews to Predict Offline Box-Office Sales and Online DVD Store Sales in the O2O Era. J. Theor. Appl. Electron. Commer. Res. 2019, 14, 68–83. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.; Tsai, M.; Chang, C. A Time Series Model Based on Deep Learning and Integrated Indicator Selection Method for Forecasting Stock Prices and Evaluating Trading Profits. Systems 2022, 10, 243. [Google Scholar] [CrossRef]
- Febres, G.L.; Gershenson, C. A Deterministic–Statistical Hybrid Forecast Model: The Future of the COVID-19 Contagious Process in Several Regions of Mexico. Systems 2022, 10, 138. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Nazari, M.; Sakhaei, S.M. Successive Variational Mode Decomposition. Signal Process. 2020, 174, 107610. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Luo, M. Outlier-Robust Extreme Learning Machine for Regression Problems. Neurocomputing 2015, 151, 1519–1527. [Google Scholar] [CrossRef]
- Luo, H.; Wang, D.; Cheng, J.; Wu, Q. Multi-Step-Ahead Copper Price Forecasting Using a Two-Phase Architecture Based on an Improved LSTM with Novel Input Strategy and Error Correction. Resour. Policy 2022, 79, 102962. [Google Scholar] [CrossRef]
- Drachal, K. Forecasting Prices of Selected Metals with Bayesian Data-Rich Models. Resour. Policy 2019, 64, 101528. [Google Scholar] [CrossRef]
- Yang, W.; Hao, M.; Hao, Y. Innovative Ensemble System Based on Mixed Frequency Modeling for Wind Speed Point and Interval Forecasting. Inf. Sci. 2023, 622, 560–586. [Google Scholar] [CrossRef]
- Zhuang, X.; Yu, Y.; Chen, A. A Combined Forecasting Method for Intermittent Demand Using the Automotive Aftermarket Data. Data Sci. Manag. 2022, 5, 43–56. [Google Scholar] [CrossRef]
- Yang, Y.; Guo, J.; Sun, S. Tourism Demand Forecasting and Tourists’ Search Behavior: Evidence from Segmented Baidu Search Volume. Data Sci. Manag. 2021, 4, 1–9. [Google Scholar] [CrossRef]
- Zhang, K.; Yin, K.; Yang, W. Predicting Bioenergy Power Generation Structure Using a Newly Developed Grey Compositional Data Model: A Case Study in China. Renew. Energy 2022, 198, 695–711. [Google Scholar] [CrossRef]






| Dataset | Number | Mean | Std | Min | Max | Kurtosis | Skewness |
|---|---|---|---|---|---|---|---|
| Copper | |||||||
| Training | 720 | 6376.111111 | 913.093217 | 4630.000000 | 9412.500000 | 2.010163 | 1.461172 |
| Validation | 135 | 9601.925926 | 365.311641 | 8894.000000 | 10,460.000000 | −0.409698 | 0.586835 |
| Testing | 45 | 9555.422222 | 122.390023 | 9199.500000 | 9835.000000 | 0.547678 | −0.032925 |
| All Samples | 900 | 7018.948889 | 1529.610952 | 4630.000000 | 10,460.000000 | −0.824881 | 0.825347 |
| Zinc | |||||||
| Training | 720 | 2467.443056 | 271.680217 | 1815.500000 | 3178.000000 | −0.443849 | −0.374203 |
| Validation | 135 | 3031.100000 | 163.270136 | 2814.000000 | 3794.500000 | 6.714848 | 2.434975 |
| Testing | 45 | 3311.277778 | 110.050792 | 3146.000000 | 3534.000000 | −0.245023 | 0.679581 |
| All Samples | 900 | 2594.183333 | 361.556747 | 1815.500000 | 3794.500000 | −0.131702 | 0.190299 |
| Metric | Equation |
|---|---|
| MAE | |
| RMSE | |
| MAPE | |
| IA | |
| TIC | |
| PICP | |
| PINAW | |
| PIAW | |
| Score |
| Mode | Copper | Zinc | Yes or No? |
|---|---|---|---|
| Mode No1 | ORELM | ELM | No |
| Mode No2 | WRELM | WRELM | Yes |
| Mode No3 | ORELM | ELM | No |
| Dataset | Model | MAE | RMSE | MAPE(%) | IA | TIC |
|---|---|---|---|---|---|---|
| Copper | ELM | 112.334560 | 135.637098 | 1.172072 | 0.662147 | 0.007129 |
| RELM | 111.333267 | 134.997478 | 1.161670 | 0.665282 | 0.007095 | |
| WRELM | 106.203165 | 130.771381 | 1.108749 | 0.678176 | 0.006869 | |
| ORELM | 110.438731 | 135.872875 | 1.152984 | 0.675115 | 0.007139 | |
| SVMD-ELM-SE | 32.060023 | 35.557911 | 0.334526 | 0.977442 | 0.001864 | |
| SVMD-RELM-SE | 37.106249 | 39.805757 | 0.387352 | 0.971950 | 0.002087 | |
| SVMD-WRELM-SE | 39.118255 | 41.766036 | 0.408252 | 0.968886 | 0.002190 | |
| SVMD-ORELM-SE | 29.982821 | 33.566644 | 0.312725 | 0.979759 | 0.001759 | |
| The Developed System | 11.332665 | 14.359648 | 0.118469 | 0.996536 | 0.000751 | |
| Zinc | ELM | 94.530373 | 108.820780 | 2.814554 | 0.725792 | 0.016660 |
| RELM | 100.782507 | 114.889654 | 3.001630 | 0.702154 | 0.017607 | |
| WRELM | 96.771240 | 111.029926 | 2.881543 | 0.717259 | 0.017004 | |
| ORELM | 111.434073 | 126.324646 | 3.318488 | 0.653617 | 0.019392 | |
| SVMD-ELM-SE | 35.986381 | 40.118159 | 1.072213 | 0.961745 | 0.006088 | |
| SVMD-RELM-SE | 37.135380 | 41.369084 | 1.106171 | 0.959088 | 0.006279 | |
| SVMD-WRELM-SE | 57.910982 | 62.859317 | 1.728839 | 0.906204 | 0.009571 | |
| SVMD-ORELM-SE | 44.020481 | 48.100182 | 1.313996 | 0.945457 | 0.007308 | |
| The Developed System | 6.757693 | 8.351136 | 0.203406 | 0.998478 | 0.001260 |
| Dataset | Model | MAE | RMSE | MAPE(%) | IA | TIC |
|---|---|---|---|---|---|---|
| Copper | SVMD-OMSELM-SE | 29.794091 | 33.391426 | 0.310760 | 0.979977 | 0.001750 |
| SVMD-OMSELM-NE1 | 11.523120 | 14.584133 | 0.120518 | 0.996438 | 0.000763 | |
| SVMD-OMSELM-NE2 | 11.921647 | 15.262713 | 0.124665 | 0.996111 | 0.000798 | |
| SVMD-OMSELM-NE3 | 11.903481 | 15.065372 | 0.124446 | 0.996195 | 0.000788 | |
| The Developed System | 11.332665 | 14.359648 | 0.118469 | 0.996536 | 0.000751 | |
| Zinc | SVMD-OMSELM-SE | 35.945599 | 40.060919 | 1.071027 | 0.961865 | 0.006079 |
| SVMD-OMSELM-NE1 | 7.822494 | 9.649678 | 0.236055 | 0.997973 | 0.001455 | |
| SVMD-OMSELM-NE2 | 8.166177 | 10.071516 | 0.247068 | 0.997776 | 0.001519 | |
| SVMD-OMSELM-NE3 | 7.881242 | 9.427713 | 0.237614 | 0.998025 | 0.001422 | |
| The Developed System | 6.757693 | 8.351136 | 0.203406 | 0.998478 | 0.001260 |
| Dataset | Alpha | PICP | PIAW | PINAW | SCORE |
|---|---|---|---|---|---|
| Copper | 0.010000 | 100.000000 | 190.713983 | 0.300101 | −3.814280 |
| 0.050000 | 100.000000 | 955.486526 | 1.503519 | −95.548653 | |
| 0.100000 | 100.000000 | 1912.229981 | 3.009016 | −573.668994 | |
| Zinc | 0.010000 | 100.000000 | 65.090031 | 0.167758 | −1.301801 |
| 0.050000 | 100.000000 | 331.094291 | 0.853336 | −33.109429 | |
| 0.100000 | 100.000000 | 663.347551 | 1.709659 | −132.66951 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Yang, W.; Zhang, K.; Hao, Y. A Novel System Based on Selection Strategy and Ensemble Mode for Non-Ferrous Metal Futures Market Management. Systems 2023, 11, 55. https://doi.org/10.3390/systems11020055
Yang S, Yang W, Zhang K, Hao Y. A Novel System Based on Selection Strategy and Ensemble Mode for Non-Ferrous Metal Futures Market Management. Systems. 2023; 11(2):55. https://doi.org/10.3390/systems11020055
Chicago/Turabian StyleYang, Sibo, Wendong Yang, Kai Zhang, and Yan Hao. 2023. "A Novel System Based on Selection Strategy and Ensemble Mode for Non-Ferrous Metal Futures Market Management" Systems 11, no. 2: 55. https://doi.org/10.3390/systems11020055