Vector Spatial Big Data Storage and Optimized Query Based on the Multi-Level Hilbert Grid Index in HBase

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Works
3. Vector Spatial Data Storage
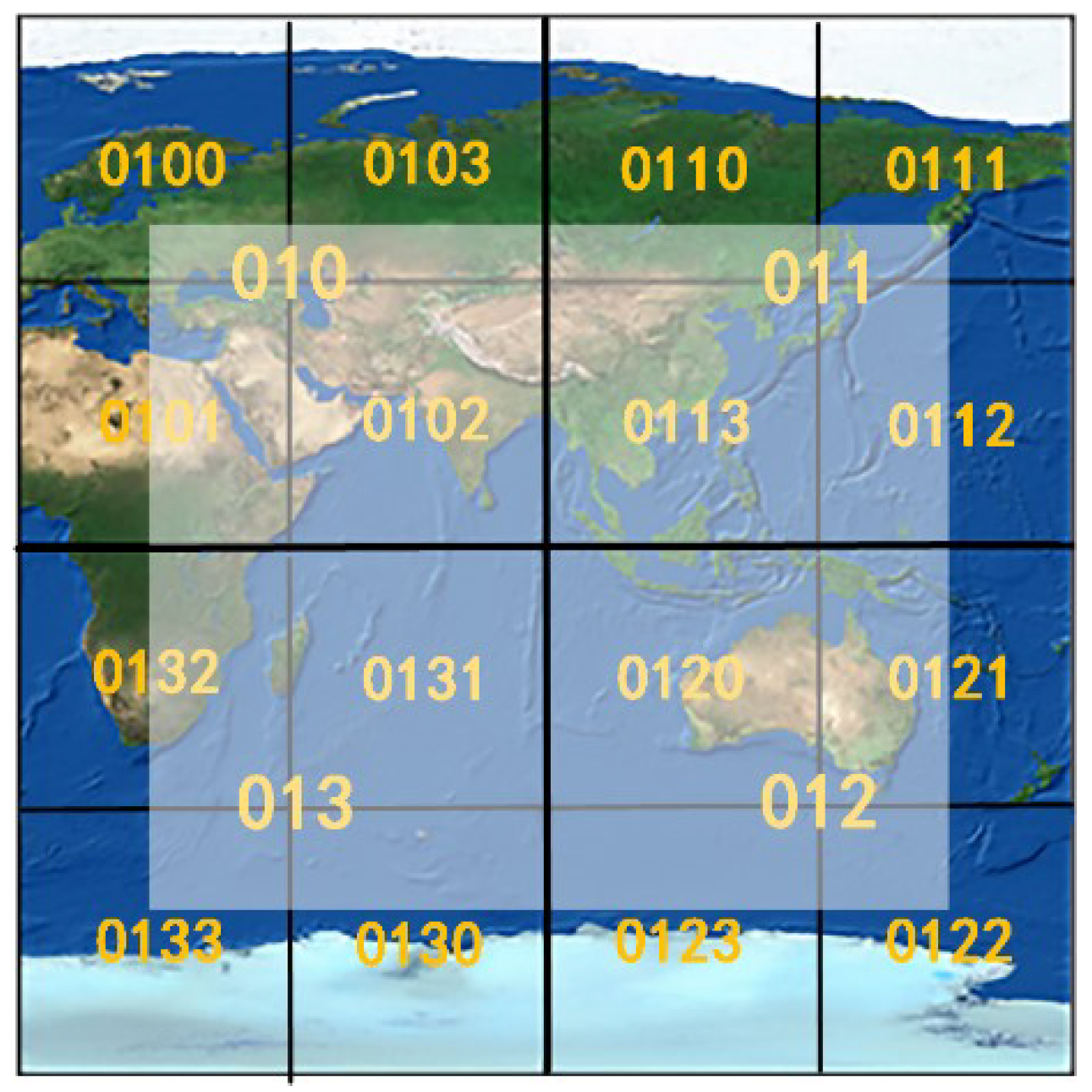
3.1. Rowkey Design
- High spatial aggregation. Rows in HBase are sorted lexicographically [23] by rowkey. Vector data are first sorted by grid cell code, then by the layer identifier and the order code. Such a rowkey design makes spatial objects that are close in distance be able to be stored closely on disks. This feature is beneficial to region query.
- Uniqueness. The layer identifier and order code make sure that the rowkey in HBase is unique by distinguishing grid cells belonging to more than one object. A vector object is never stored more than once, which reduces the storage space.
- Strong query flexibility. In addition to ensuring the uniqueness of rowkeys, the design of a rowkey also takes the application requirements of querying or extracting spatial data by layer into account. Through filtering the rowkey, we can quickly retrieve certain layer data, thereby increasing the flexibility of the spatial query.
3.2. Column Family Design
4. Vector Spatial Data Optimized Query
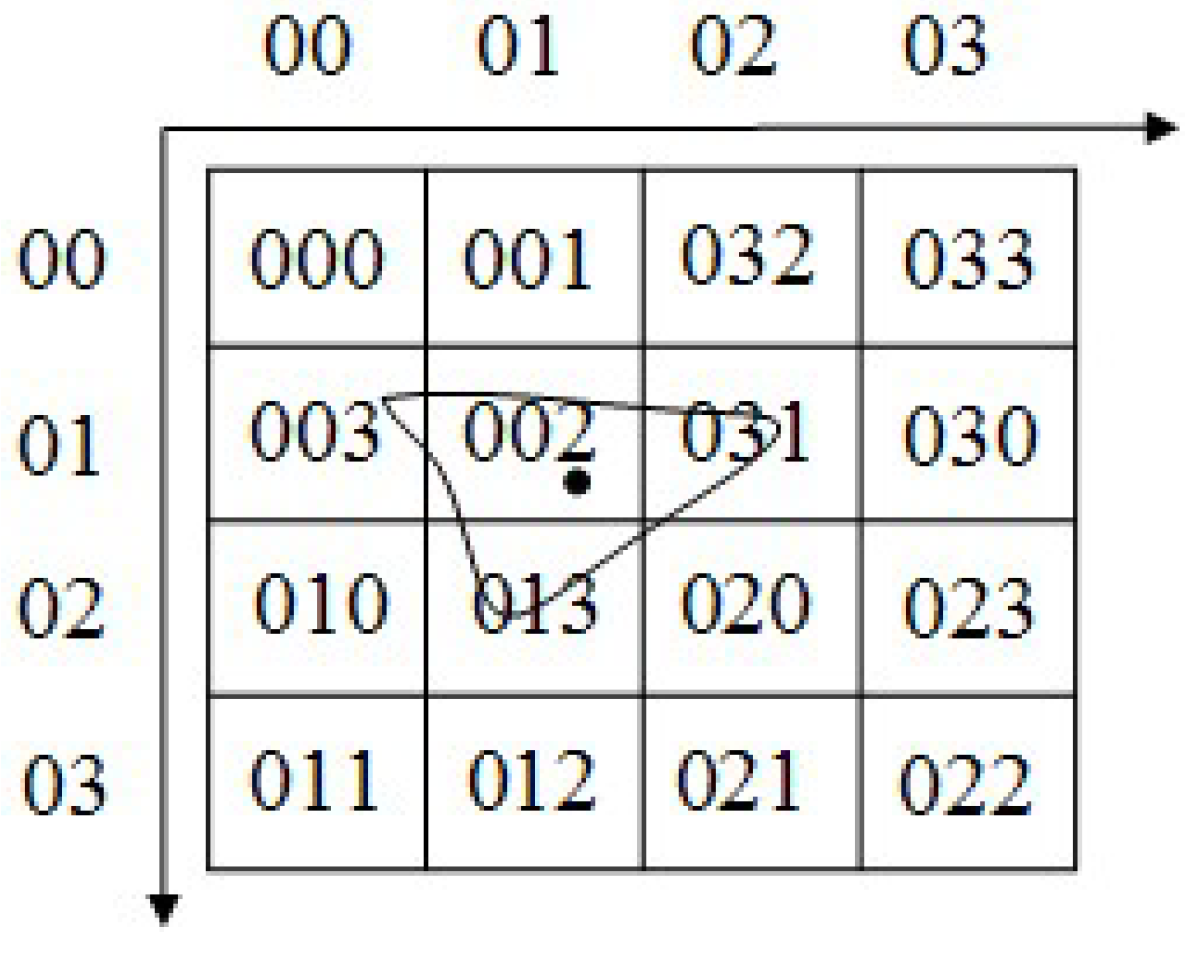
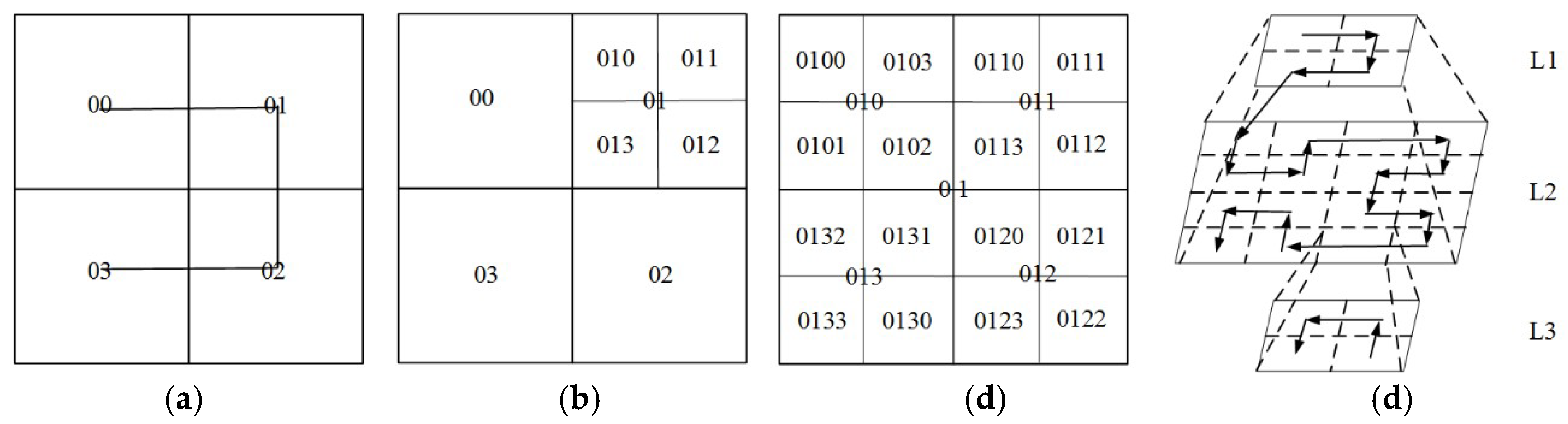
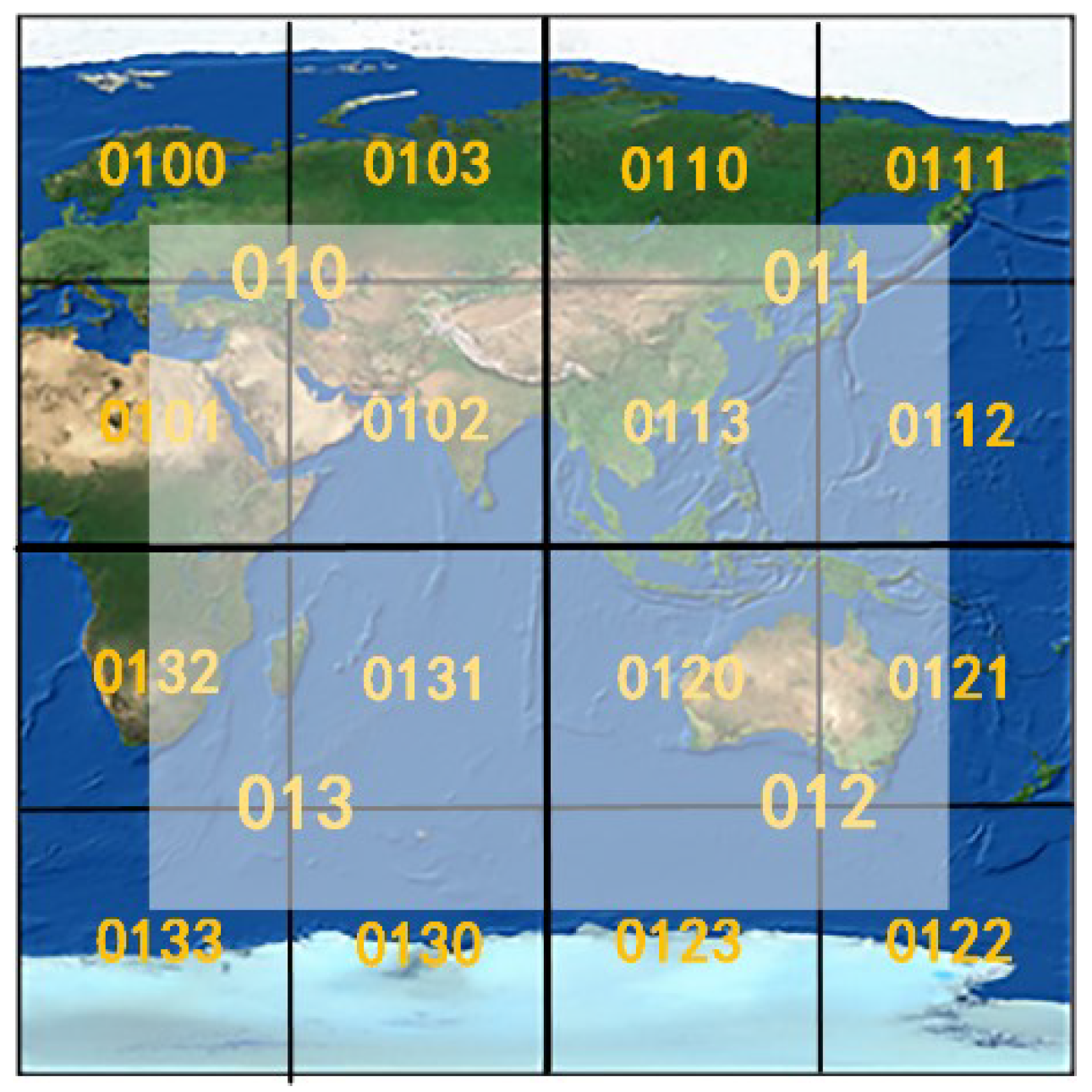
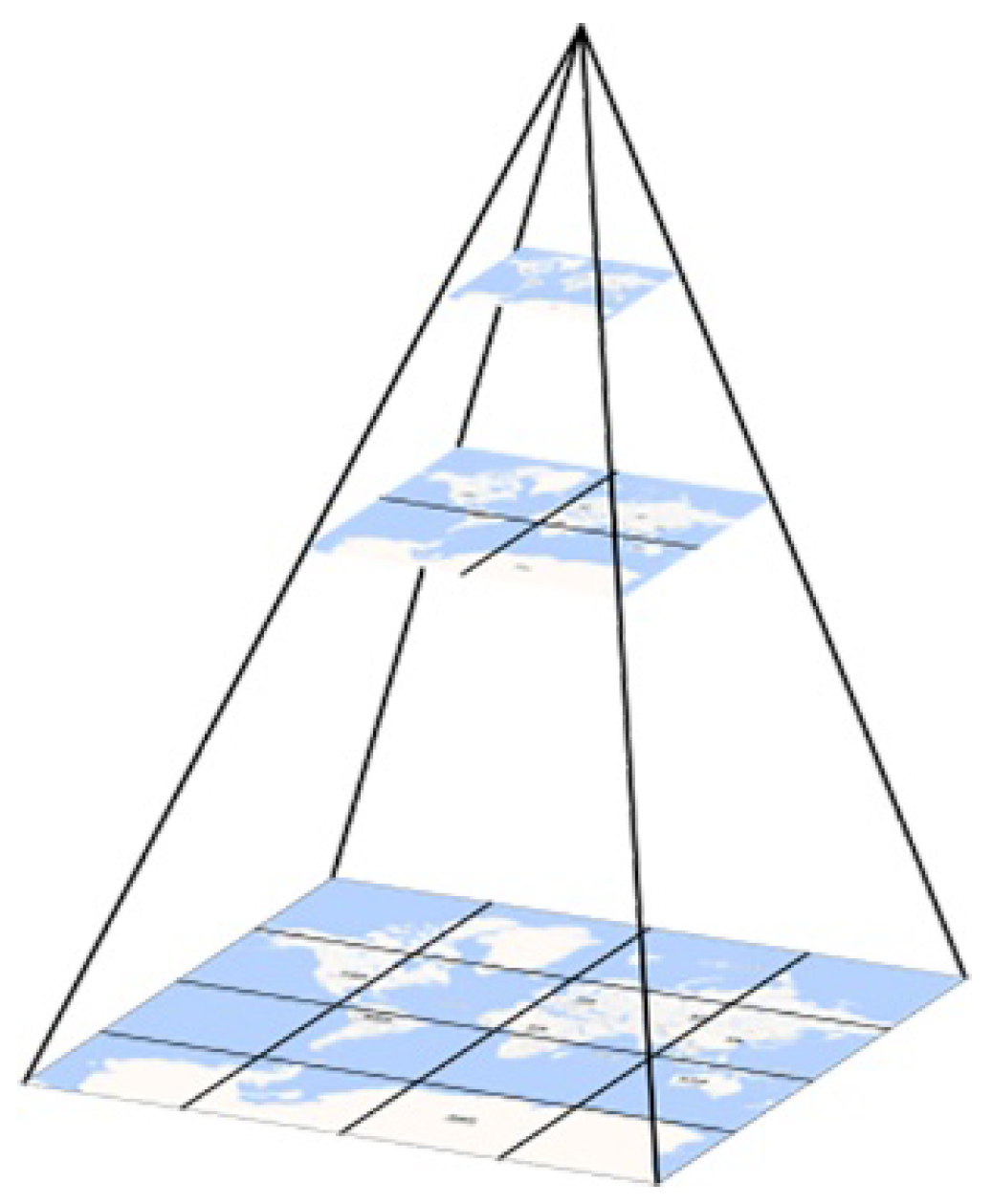
4.1. Quadtree-Hilbert-Based Multi-Level Grid Index
4.1.1. Algorithm of the Index
| Algorithm 1. Generate hierarchical Hilbert codes of grid cells. |
| Input:r, c: row value and column value of a grid cell, l: level of the grid cell; Output: h: hierarchical Hilbert code of the grid cell (r, c) |
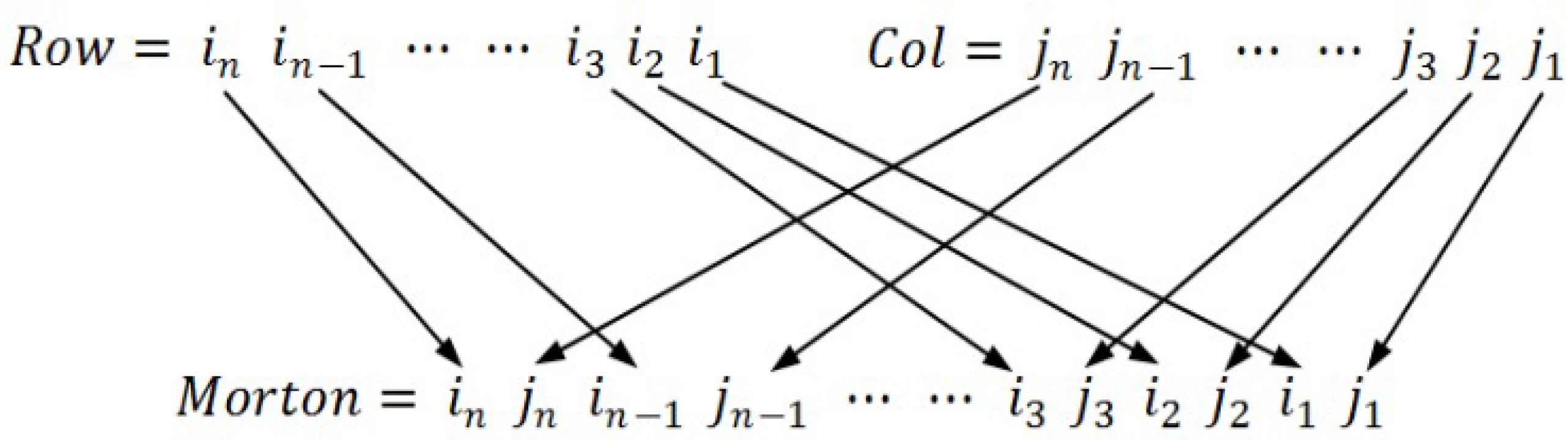
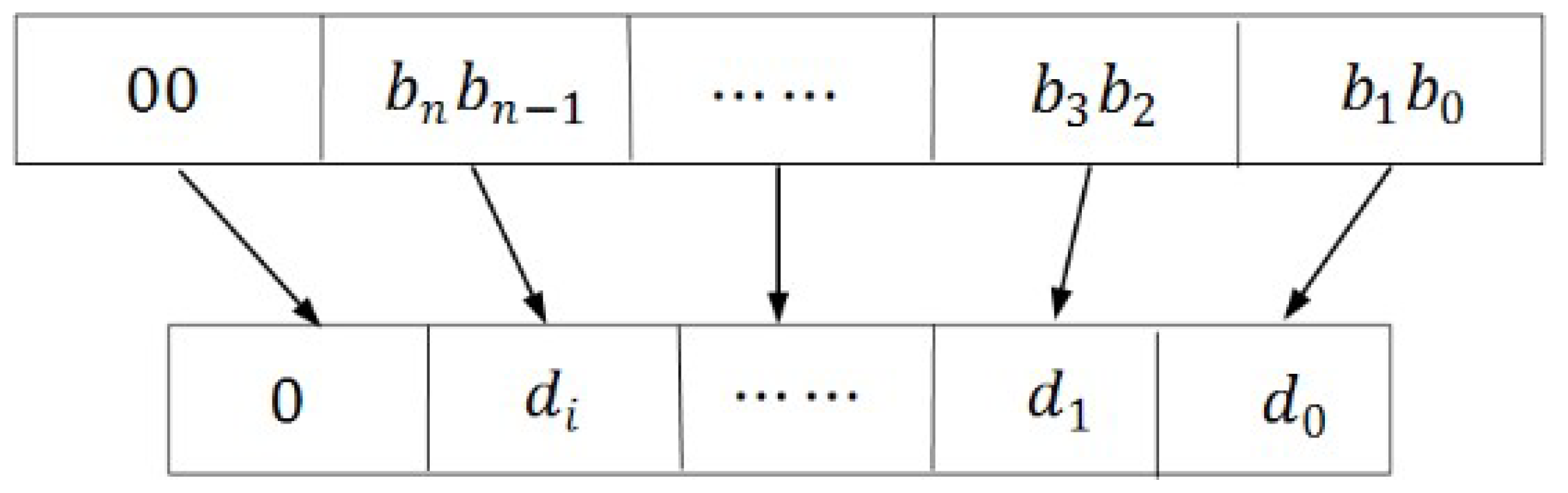
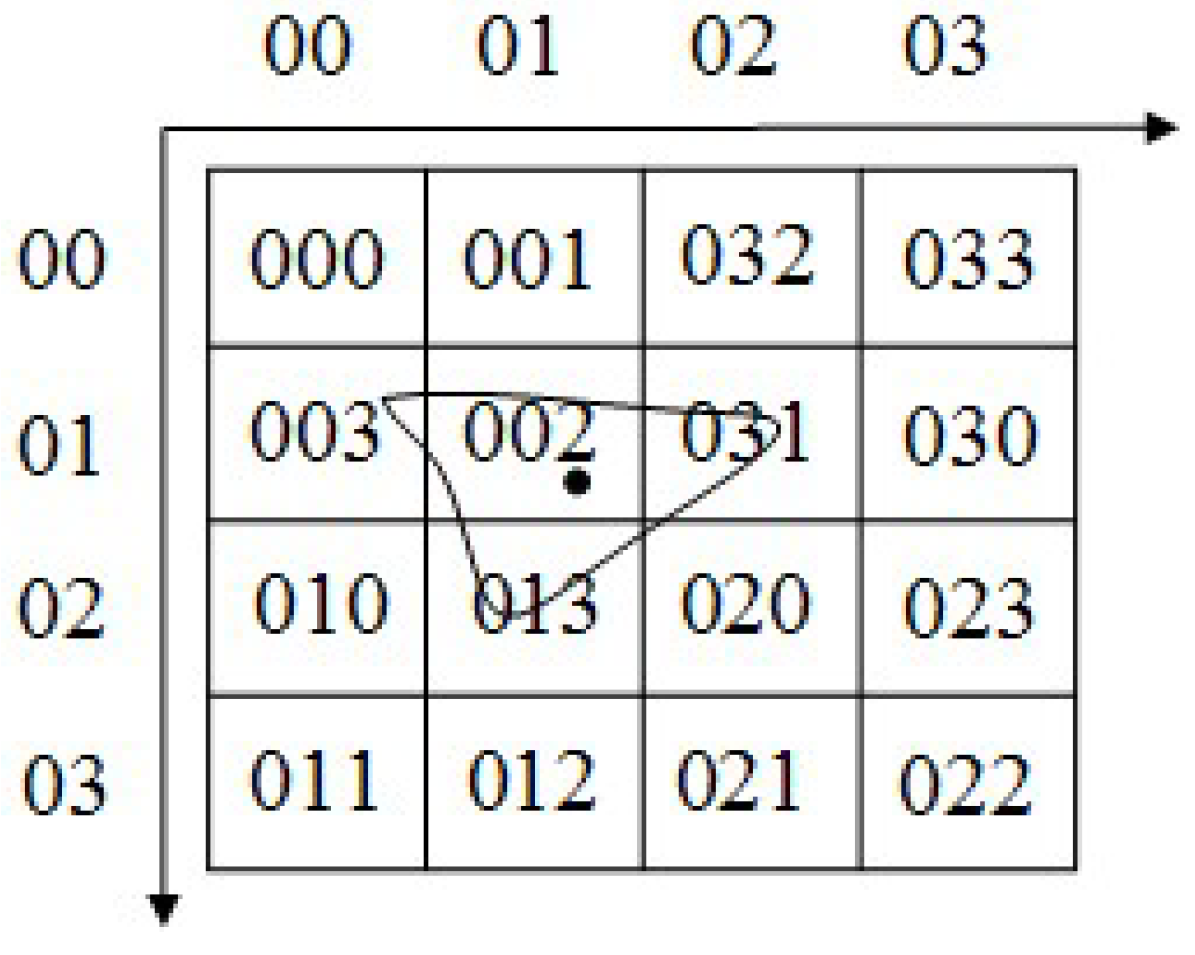
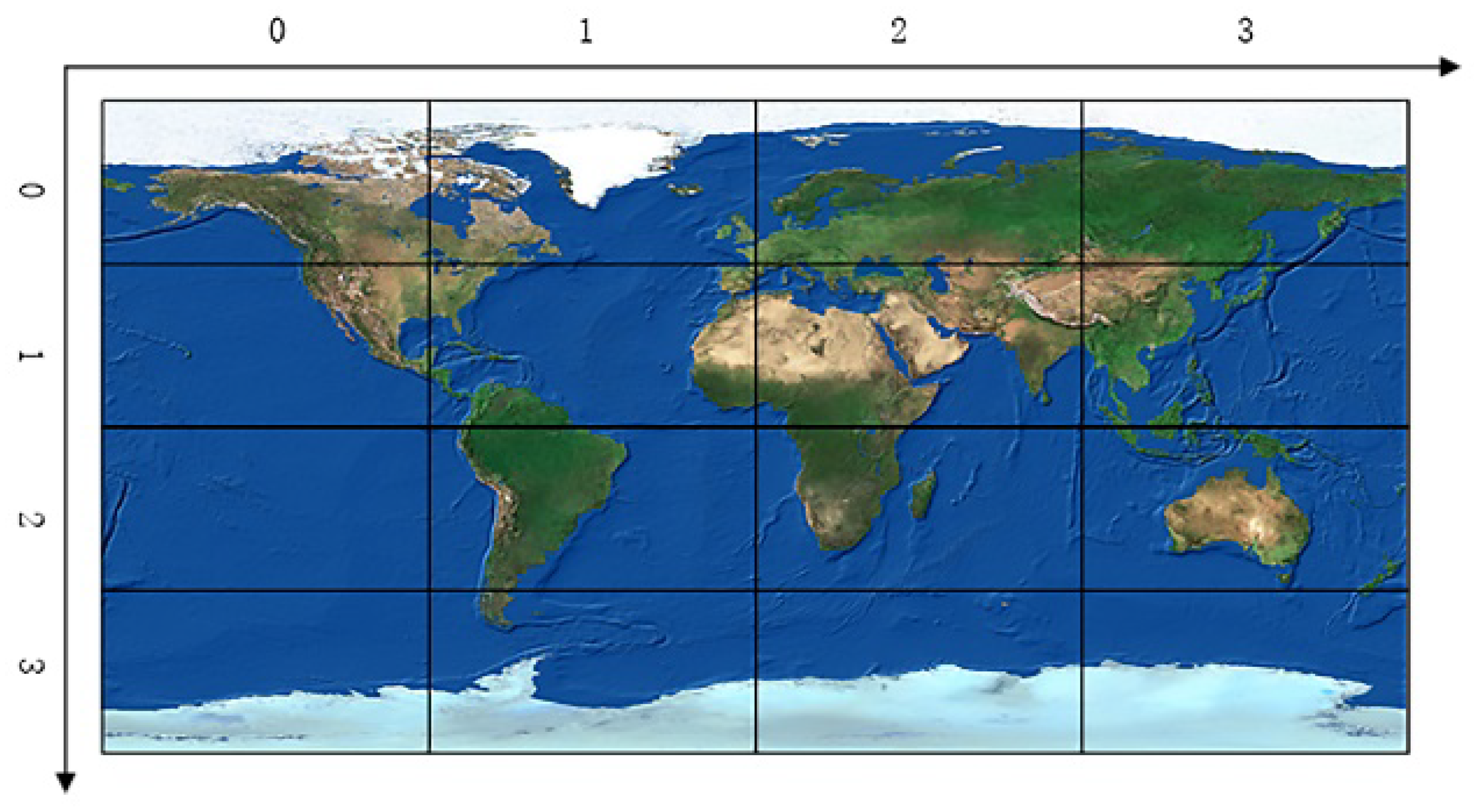
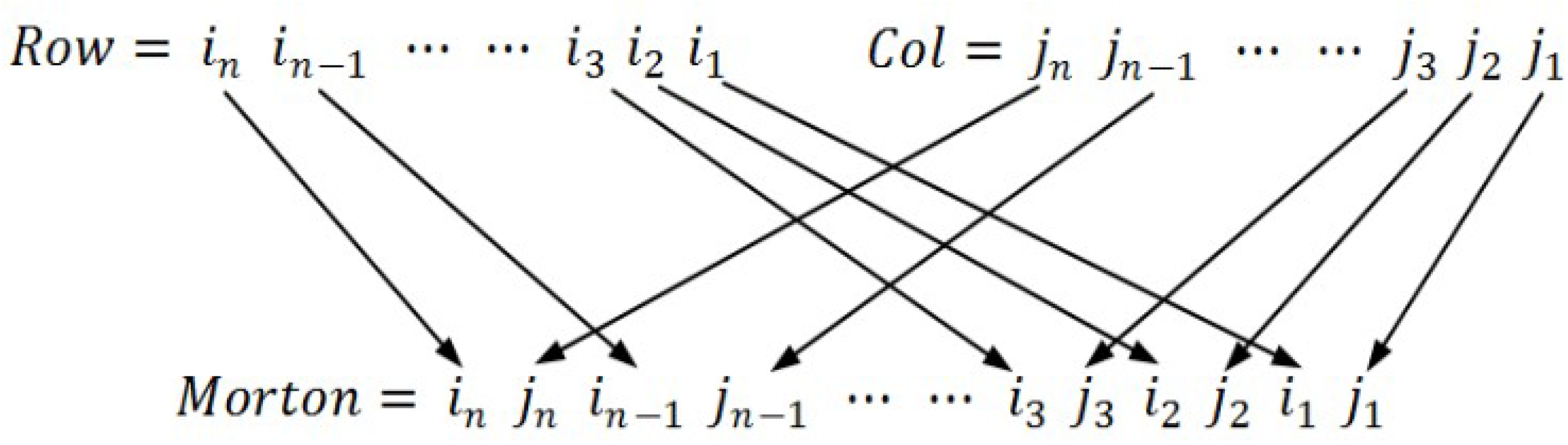
| 1. Step (1) transform r and c into L + 1-bit binary number, and then 2. turn it into the corresponding Morton code by interleaving bits of the two binary numbers (see Figure 5); |
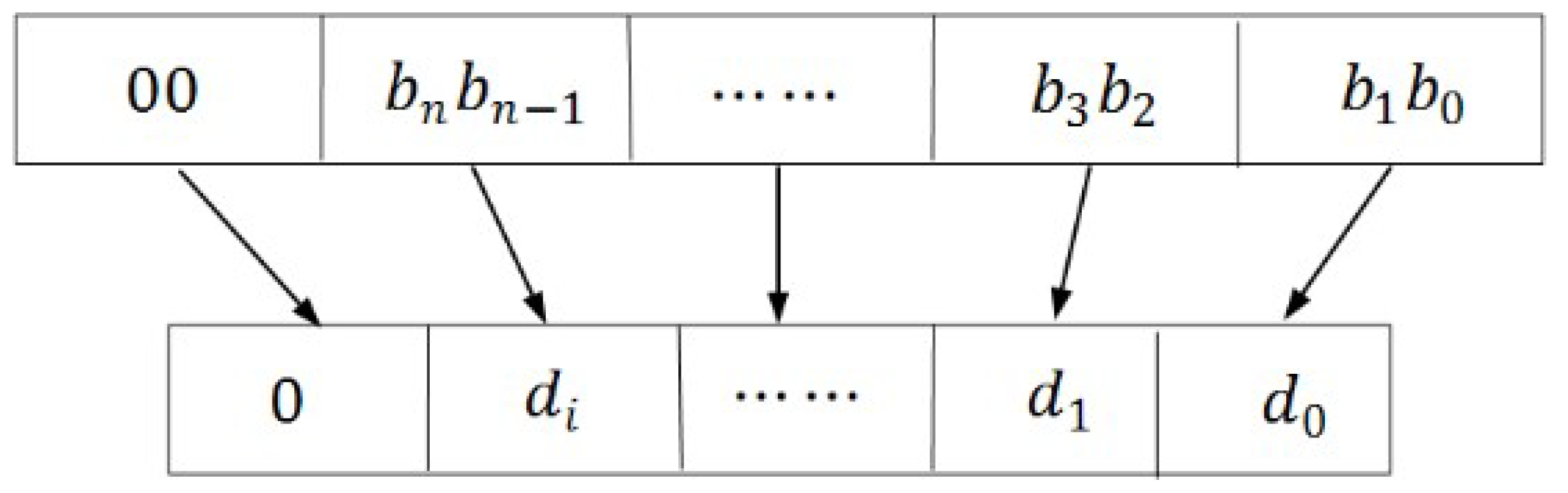
| 3. Step (2) divide the Morton code from left to right into 2-bit strings, and then 4. swap every ‘10’ and ‘11’; |
| 5. Step (3) (i = 1, …, N) represents above every 2-bit string from left to right; 6. If = ‘00’, then 7. swap every following occurrence of ‘01’ and every following occurrence of ‘11’; 8. Else if = ‘11’, then 9. swap every following occurrence of ‘10’ and ‘00’; |
| 10. Step (4) from left to right, calculate the decimal values of each 2-bit string; see Figure 6; |
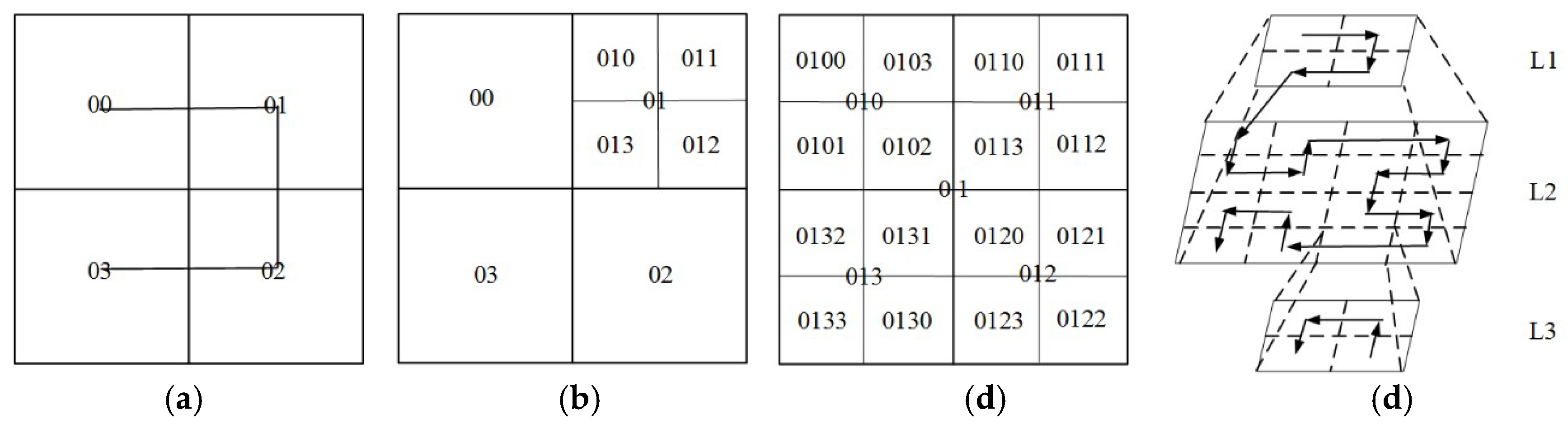
| 11. Step (5) from left to right, concatenate all the decimal values in order and return the hierarchical |
| 12. Hilbert code h; see Figure 7. |
| 13. End |
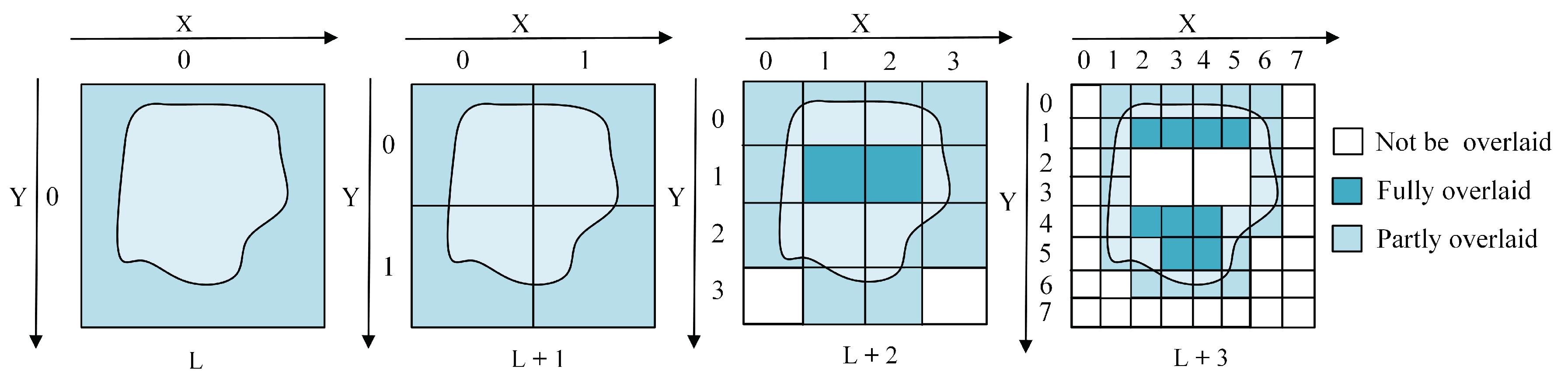
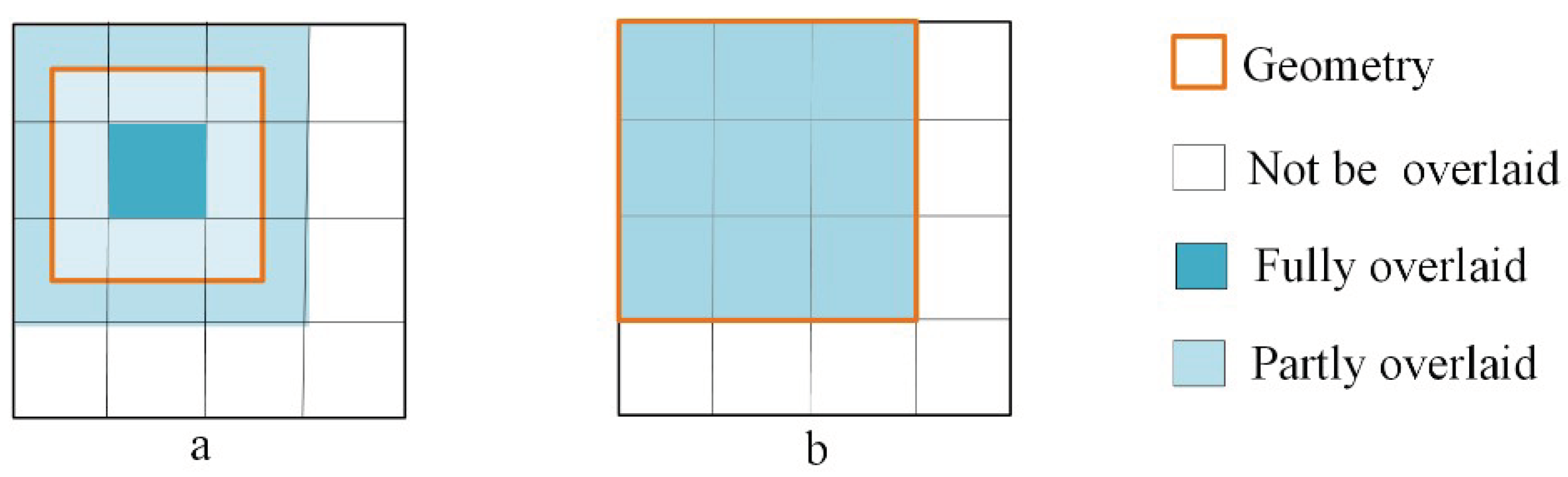
- In the same grid level, the vector spatial data that are close in space are represented closely, which reduces the times of disk access, in particular for range query.
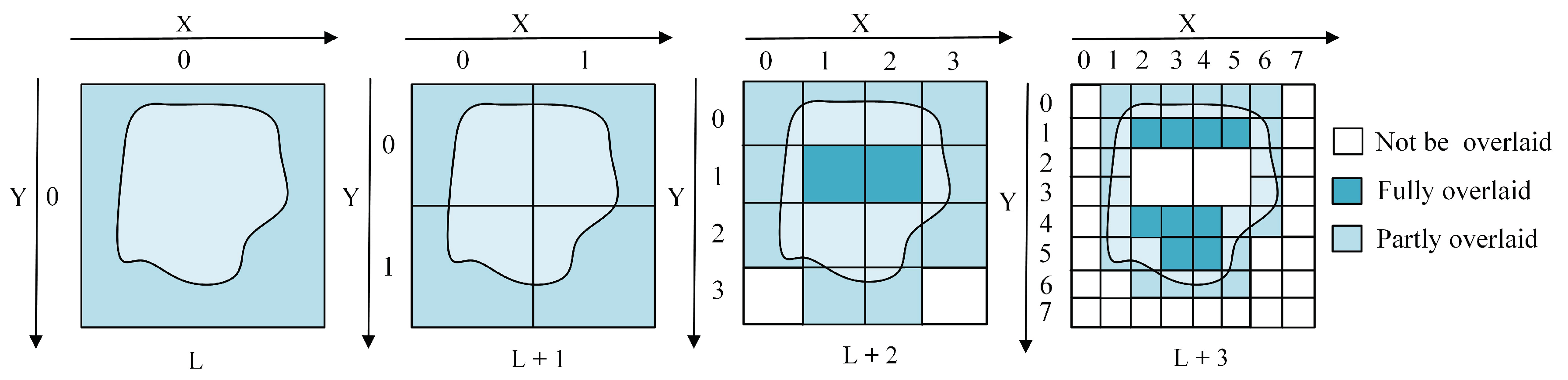
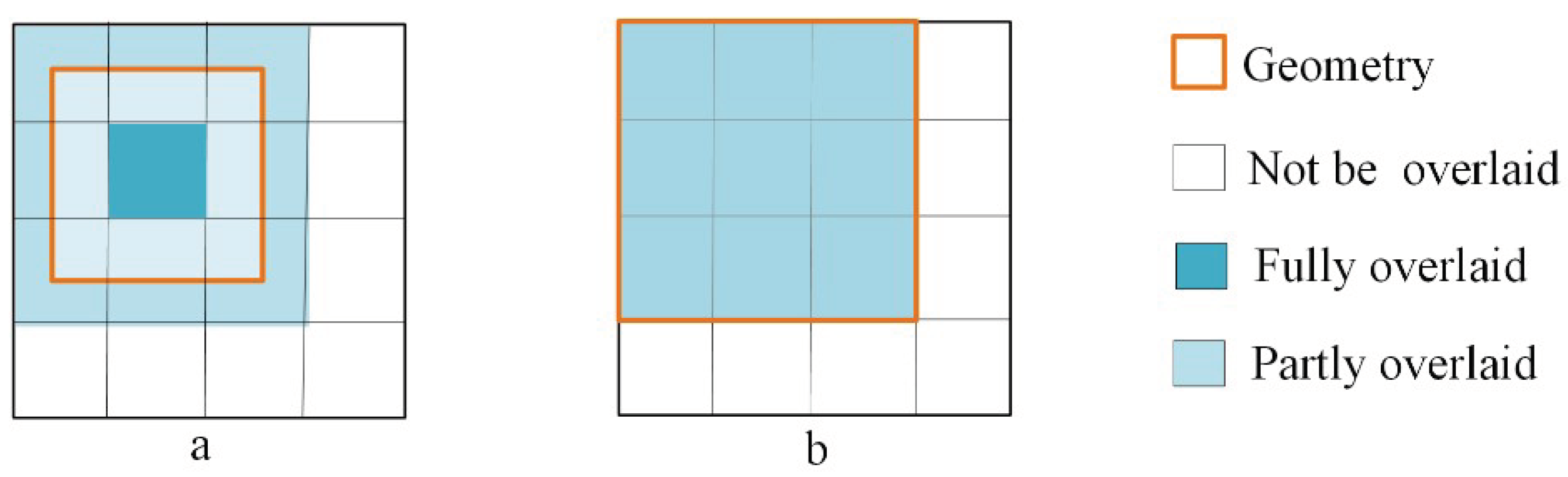
- By using this Q-HBML grid index, we only need to further divide the grid cells that are partly overlaid by MBR of an object entity until reaching the end level, which reduces the grid cells’ redundant construction and improves the efficiency and precision of the spatial query.
- The Hilbert code structure is relatively simple and highly scalable, and there is no need to pre-specify the code length. The length of the code can be dynamically expanded as the grid level increases.
- The query operation is simpler. It is easy and quick to locate the query object indexes in the index table through the grid level and grid-object spatial relationships.
4.1.2. Index Table Architecture
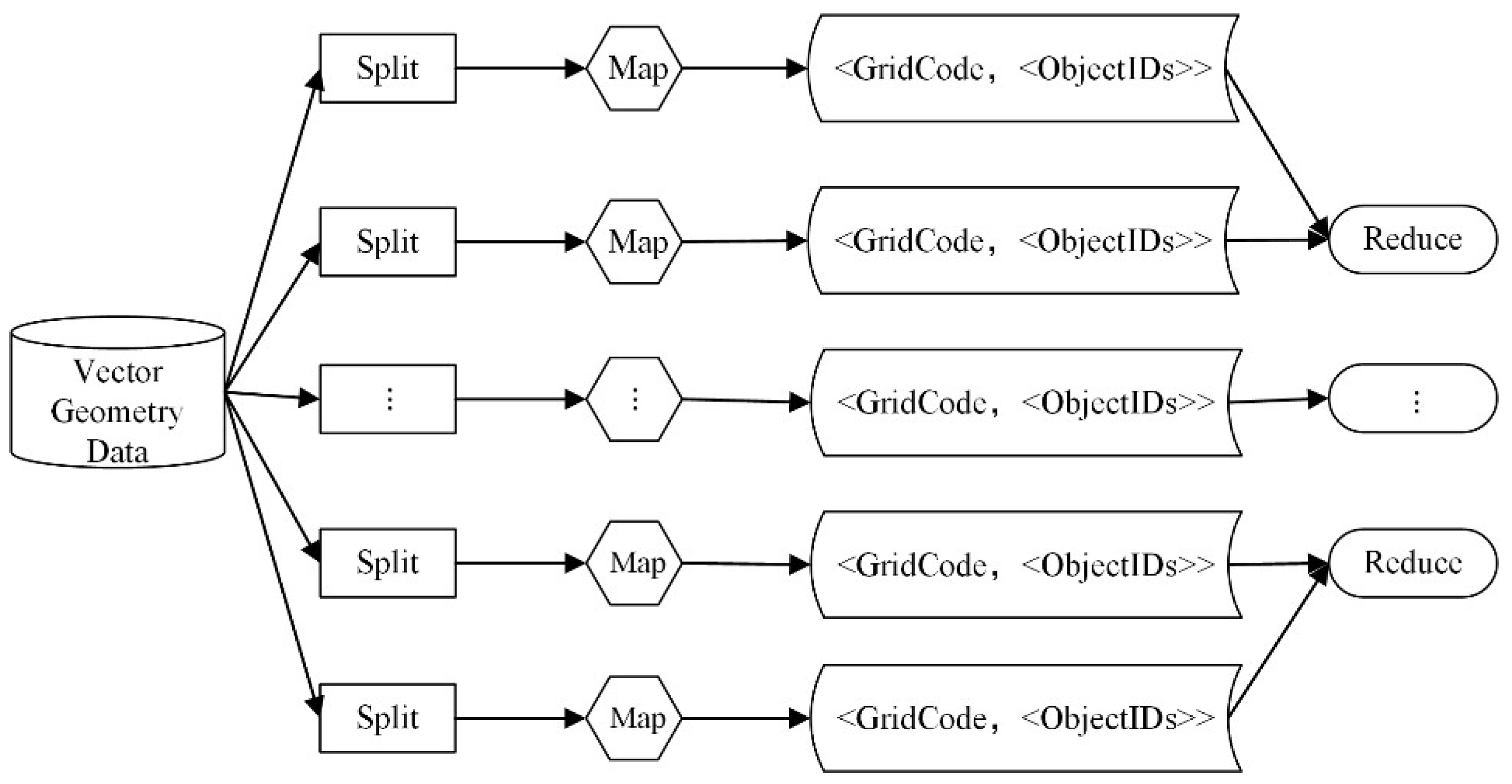
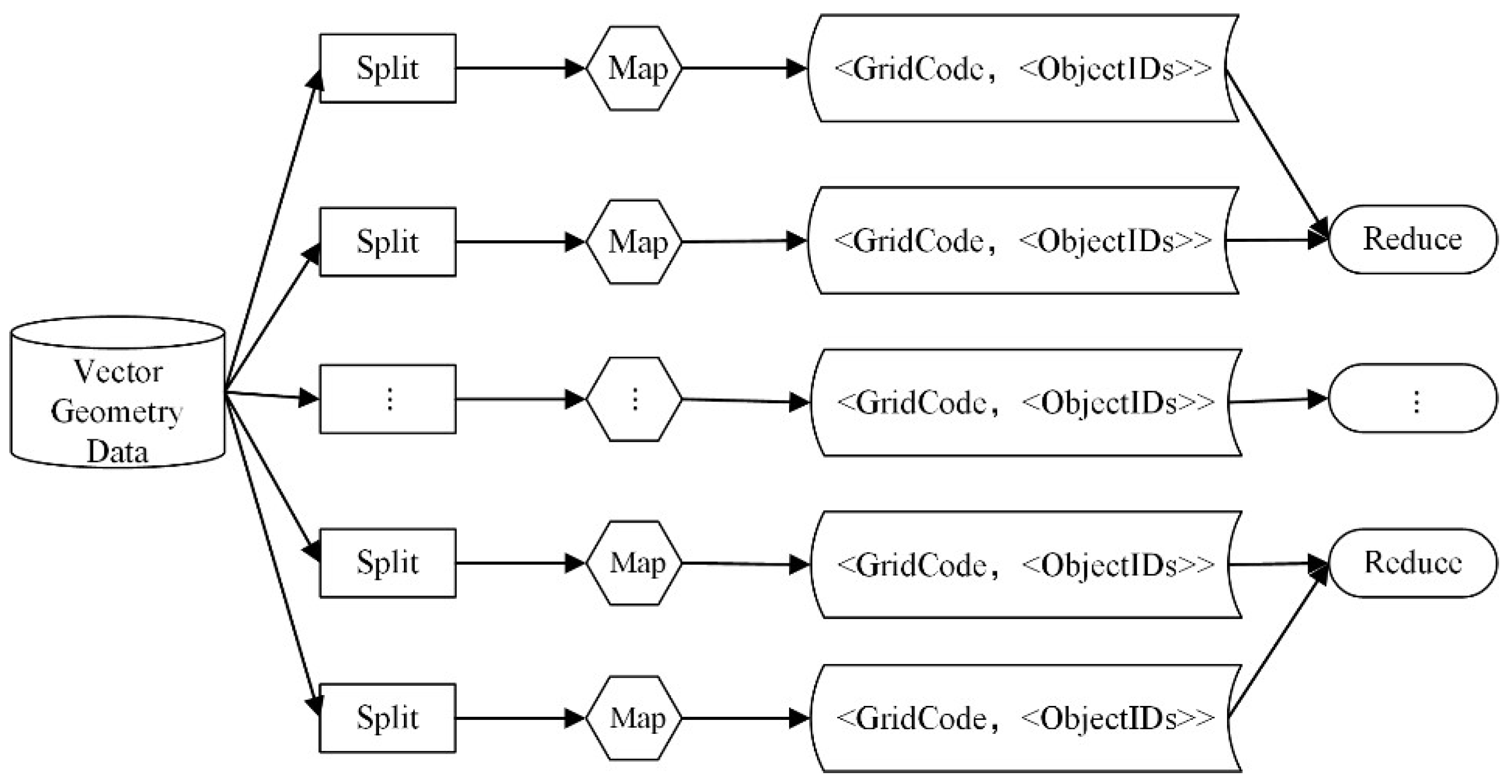
4.1.3. Index Parallel Construction
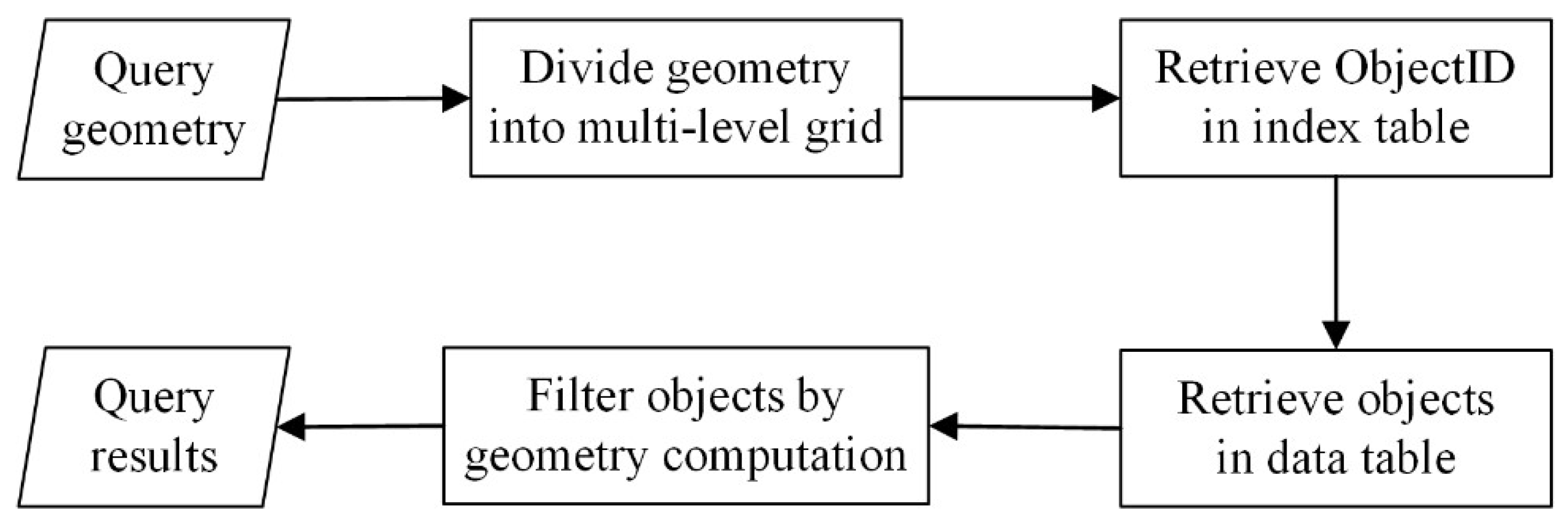
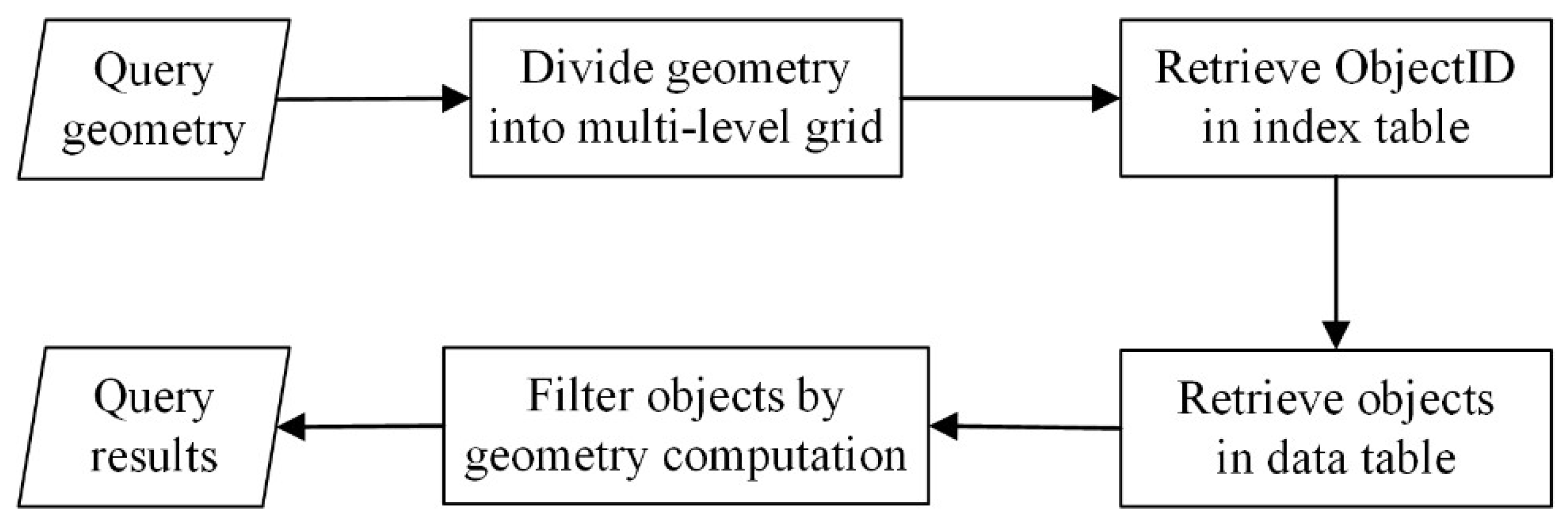
4.2. Query Optimization Strategies
4.3. Optimized Topological Query
| Algorithm 2. Topology optimized query. |
| Input: g: spatial query geometry; : start level in index table, : end level in index table, r: query topological relationship type; |
| Output: S: array of vector spatial data; 1. Step (1) Calculate the start level of g by CalculatePartitionStartLevel (see Algorithm 3); 2. Step (2) if , then 3. Calculate the grid cells where the center point of g is located from to ; 4. otherwise, next; 5. Step (3) grid cells at the level -1 , grid cells at the level Calculate the multi-level 6. grids mapping of g from the level to the level , then next; |
| 7. Step (4) Determine the computation methods according to the topological relationship r. 8. If r is one of contain, within, intersect, equal and overlap, then 9. enter the next step; 10. else if r is one of cross, touch and disjoint, then 11. skip to Step (7); 12. Step (5) Merge all continuous grid cell codes at the levels -1 and 13. Merge , |
| 14. Merge , 15. Merge , then next; |
| 16. Step (6) Scan the index table by the grid-object spatial relations, and get corresponding unique 17. vector IDs 18. Scan index table for , and get corresponding index values through r, 19. Scan index table filter unrelated index values by the grid-object spatial 20. relations for , and get corresponding index values through r, |
| 21. Scan index table filter unrelated index values by the grid-object spatial 22. relations for , and get corresponding index values through r, |
| 23. , then skip to Step 9; |
| 24. Step (7) Merge all continuous grid cell codes at the level 25. Merge , 26. Merge , then next; 27. Step (8) Scan index table by the grid-object spatial relations, and get corresponding unique 28. vector IDs 29. Scan index table for , and get corresponding index values through r, 30. Scan index table and filter unrelated index values by the grid-object spatial 31. relations for through r, 32. , then next; |
| 34. Step (9) Take geometry operations for according to r, filter useless objects, and get 35. results. 36. return 37. End. |
| Algorithm 3. Calculate the start level of the partition. |
| Input:g: spatial query geometry; Output: : the start partition level of g |
| 1. Compute the MBR of g; 2. Compute the largest level in the Q-HBML index whose grid size contains the width of ; 3. the largest level in the Q-HBML index whose grid size contains the length of ; 4. If , then 5. return ; 6. else 7. return ; 8. End. |
5. Evaluation
5.1. Experimental Environment
5.2. Experimental Data
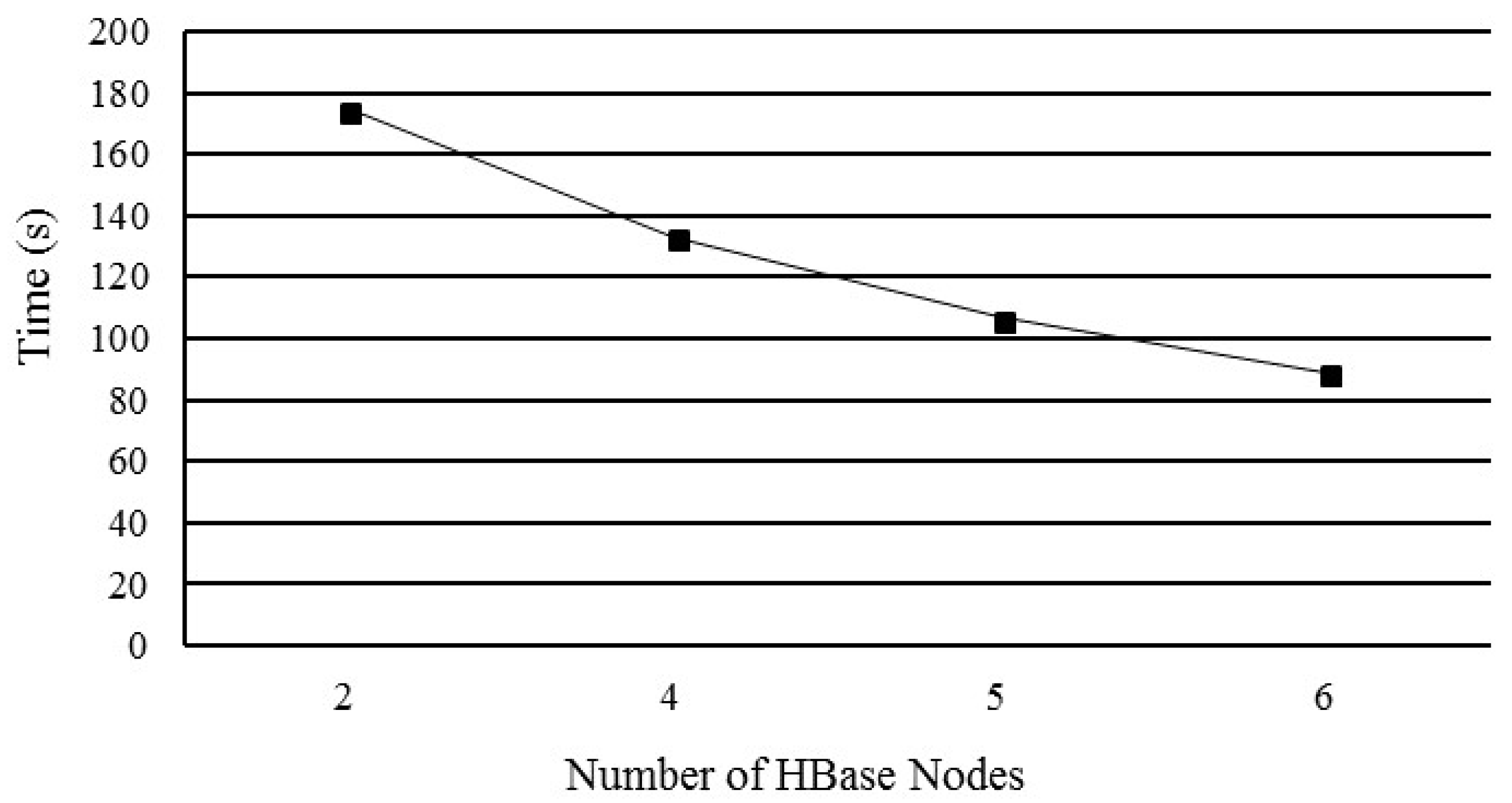
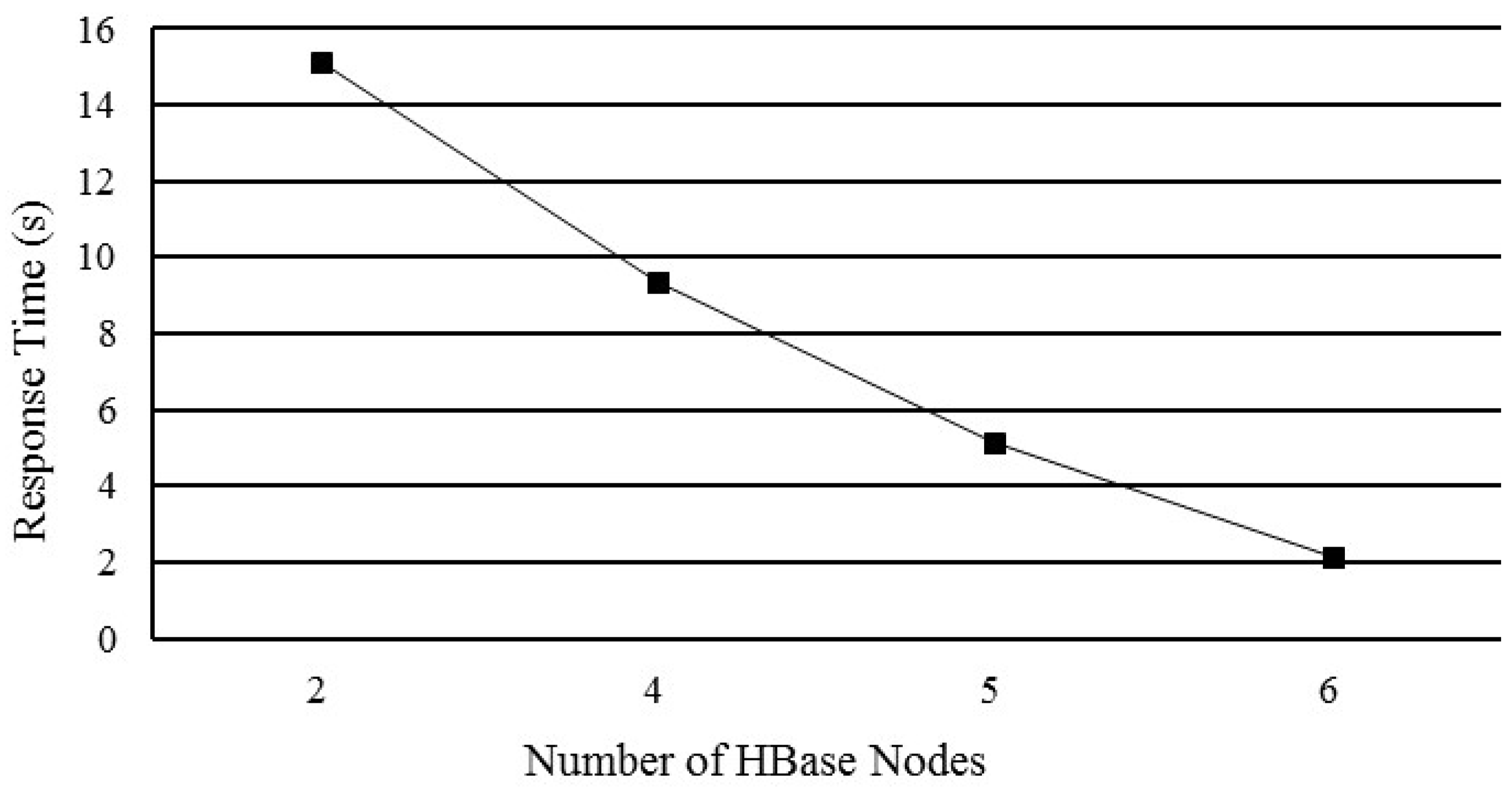
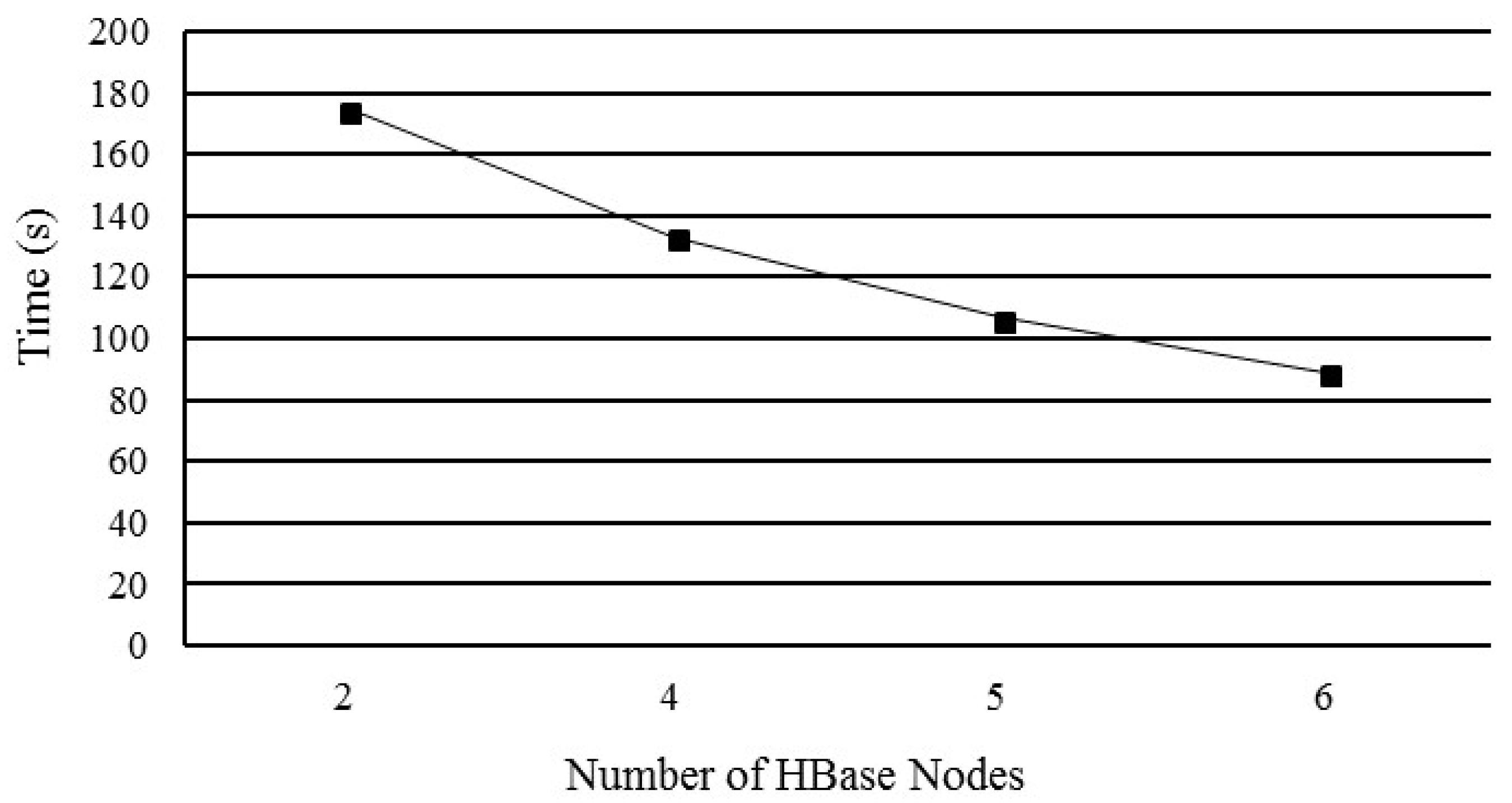
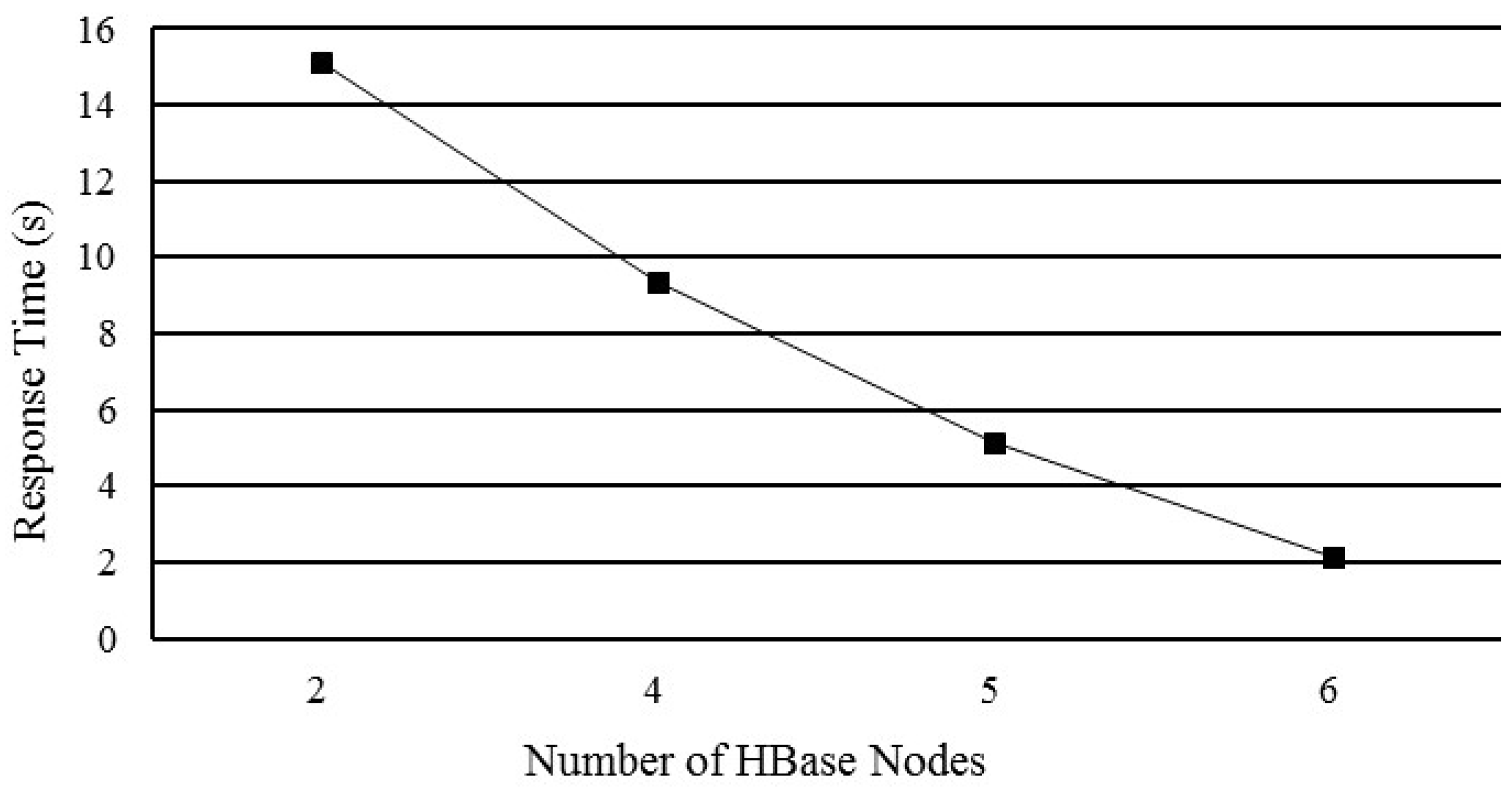
5.3. Performance of Horizontal HBase Cluster Expansion
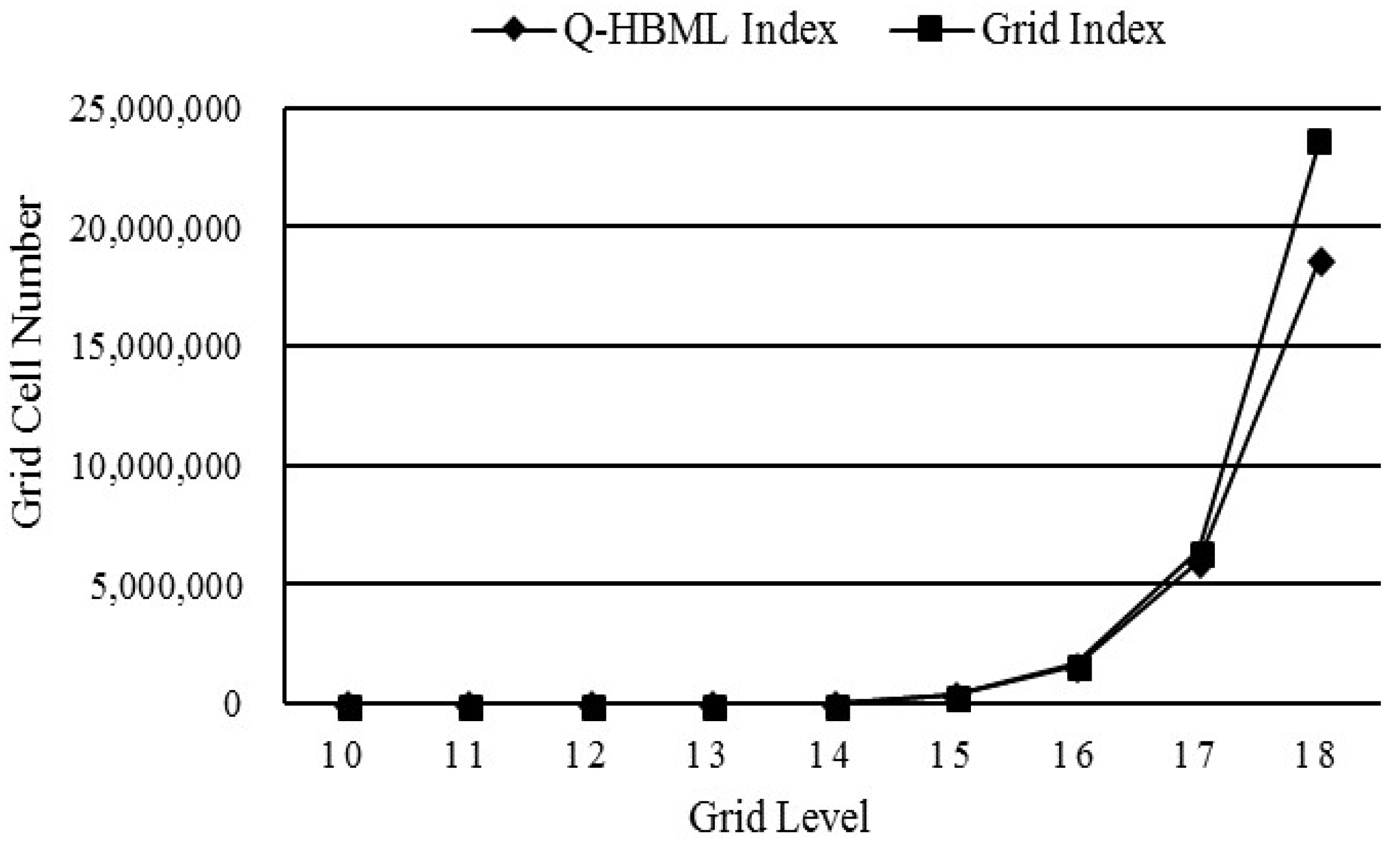
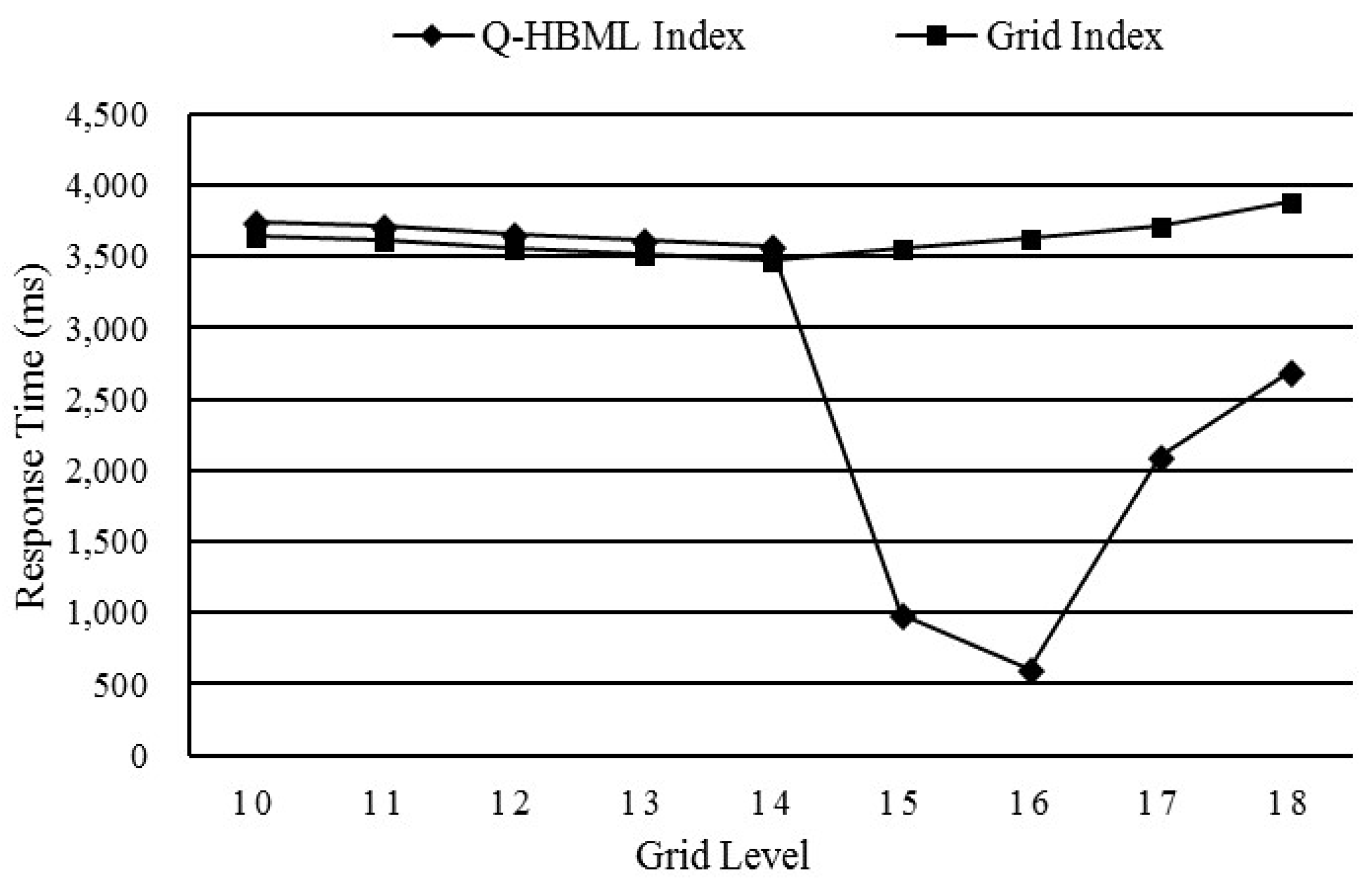
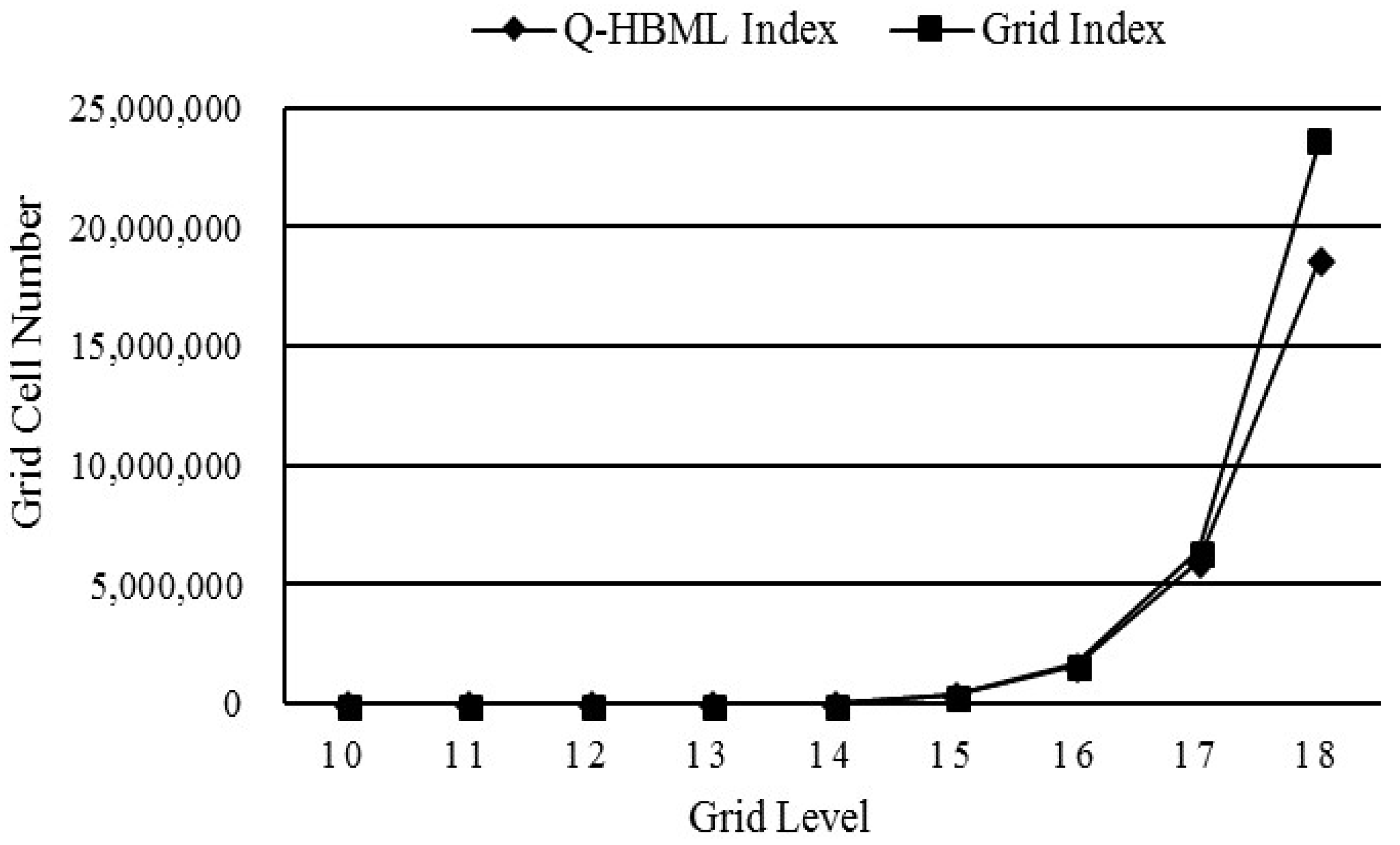
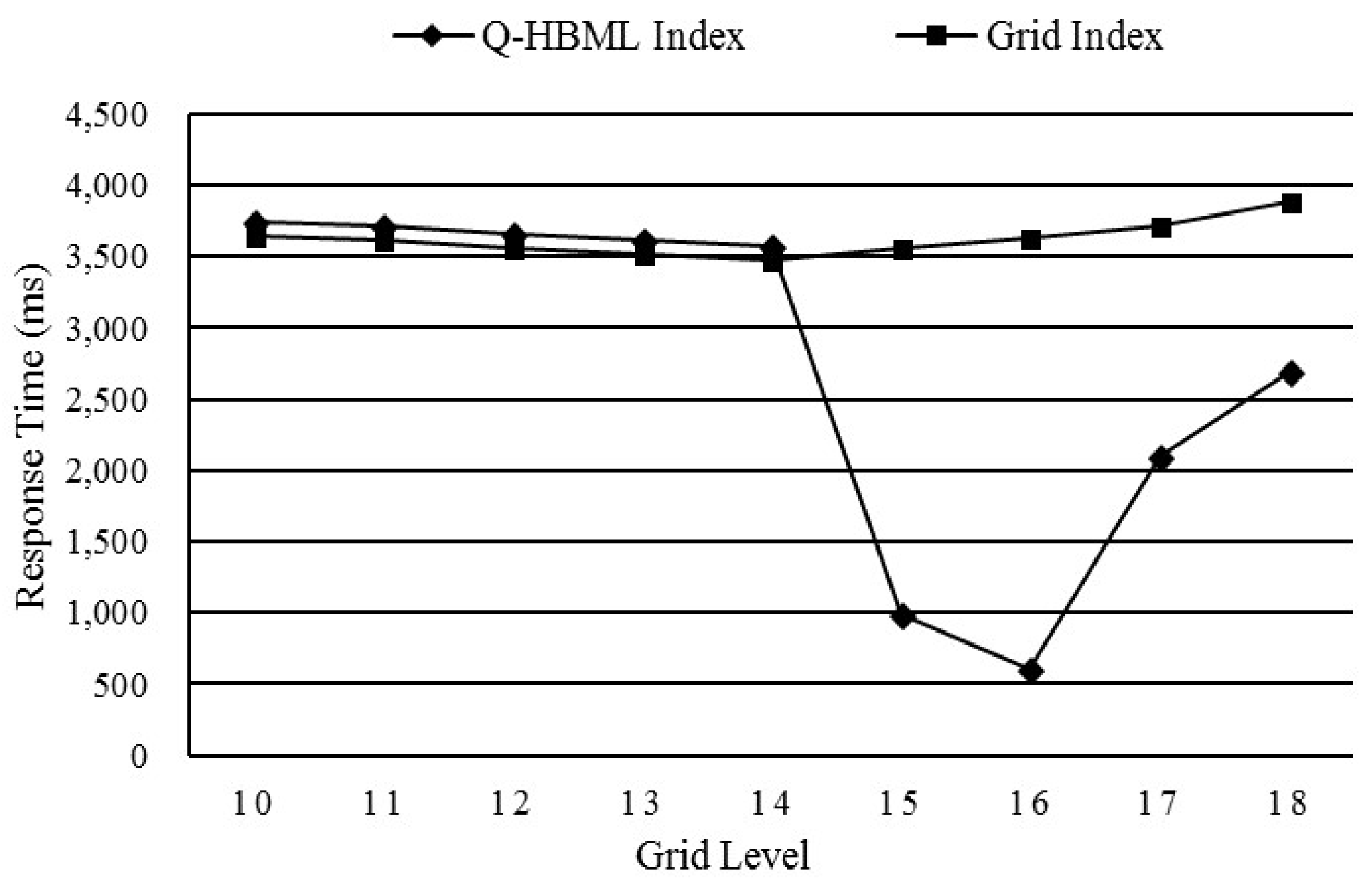
5.4. Comparison of the Q-HBML Index and the Regular Grid Index
5.5. Performance of the Spatial Query Optimization Strategy
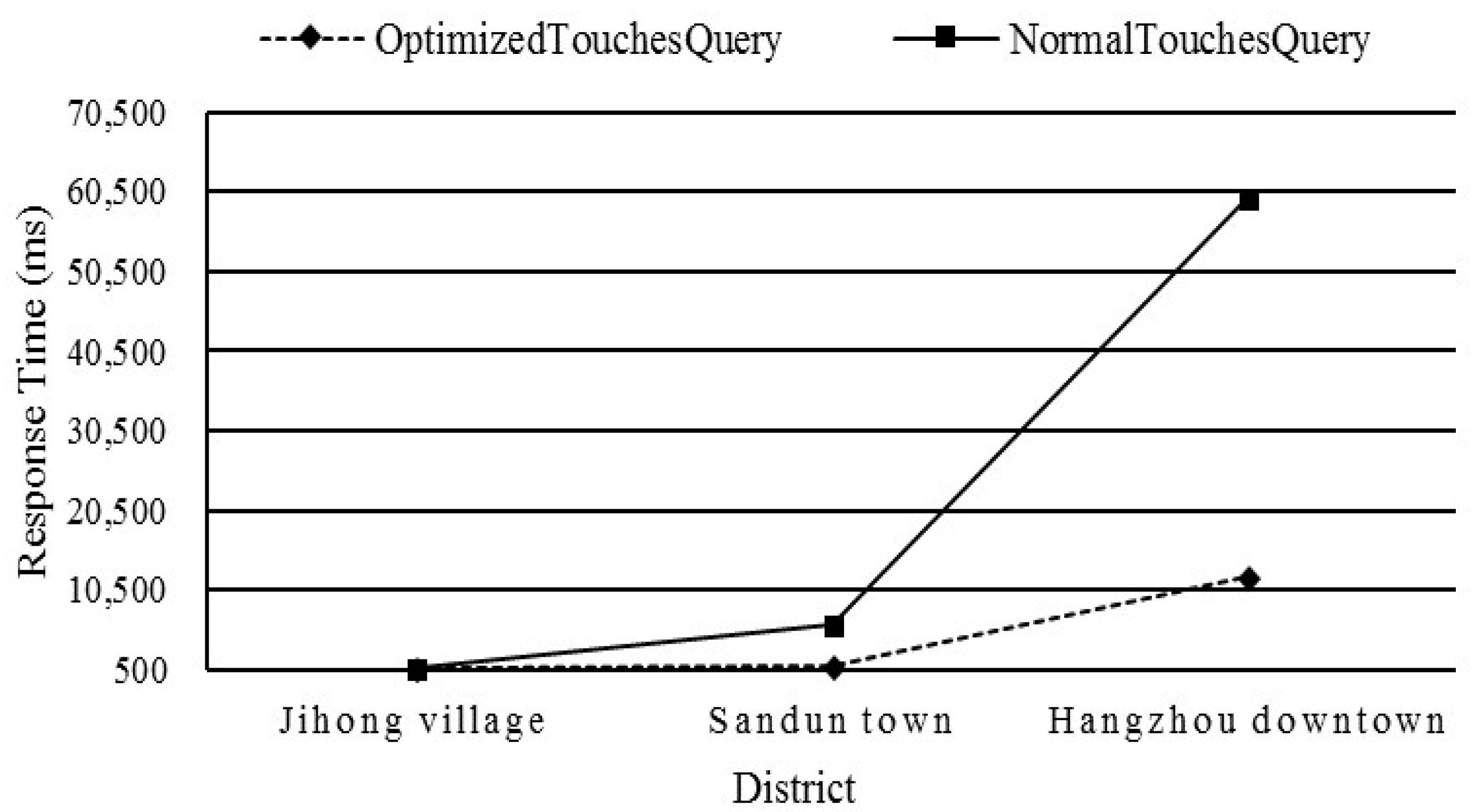
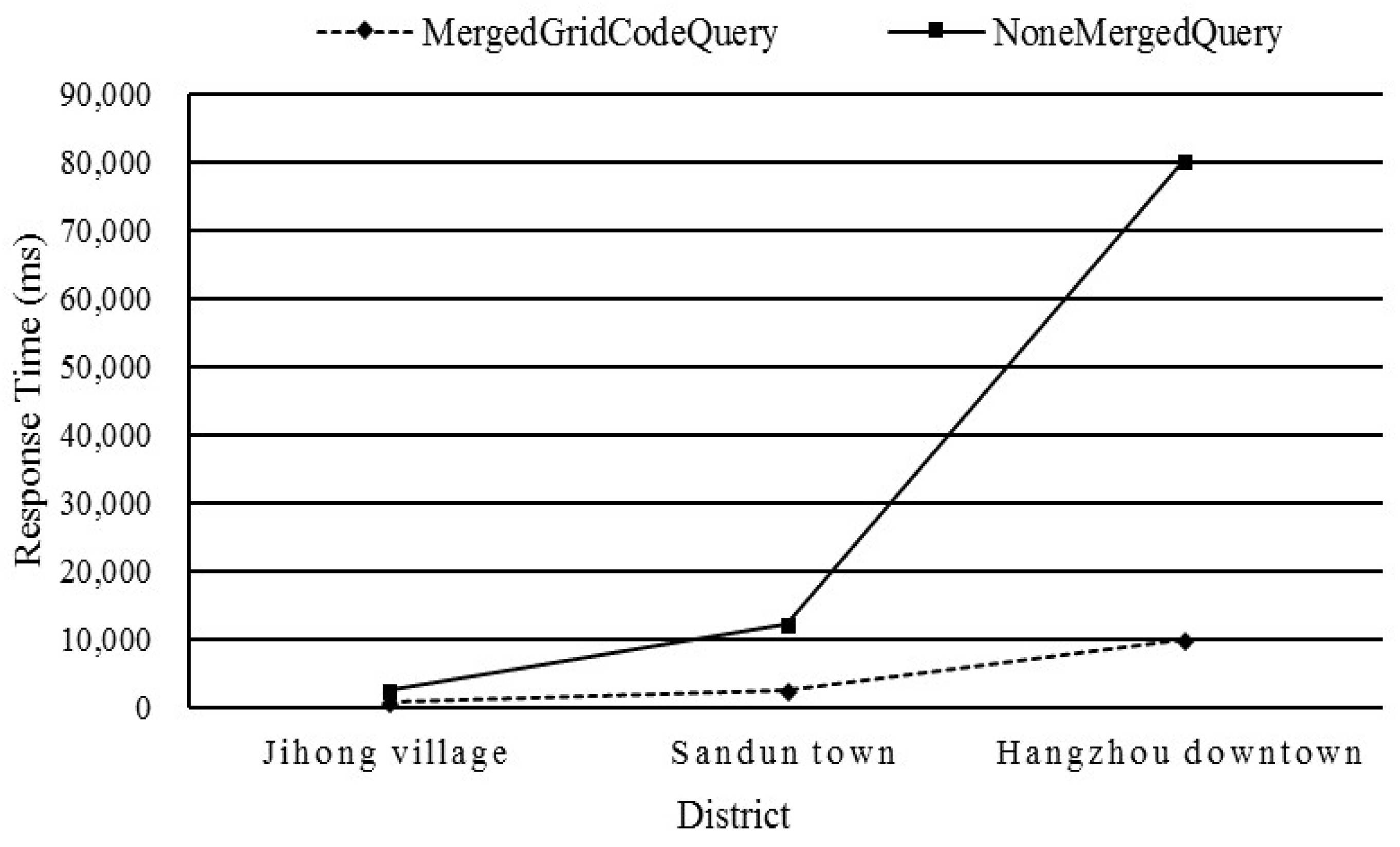
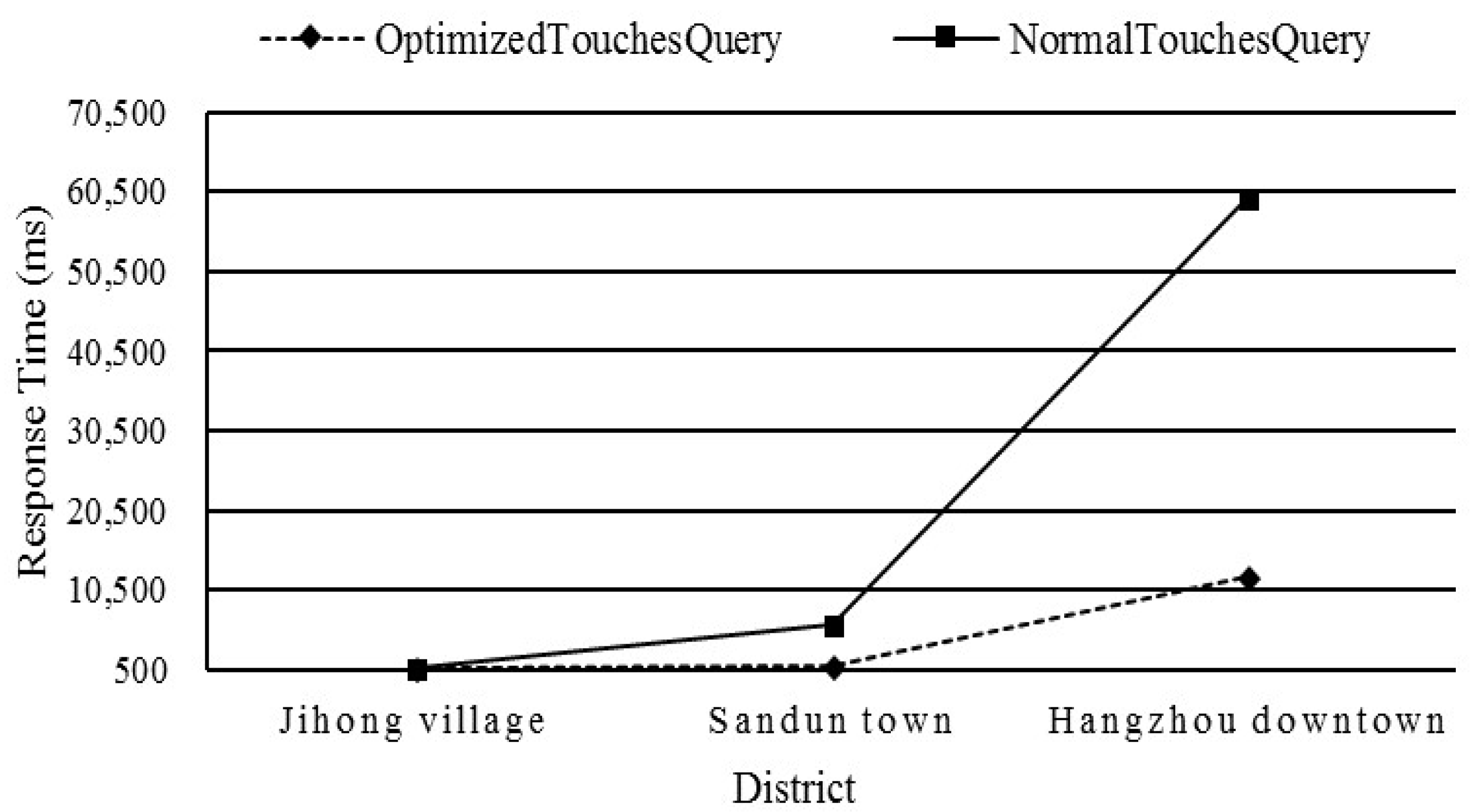
5.5.1. Test 1: Influence of the Optimized Strategy on the Spatial Query Operator
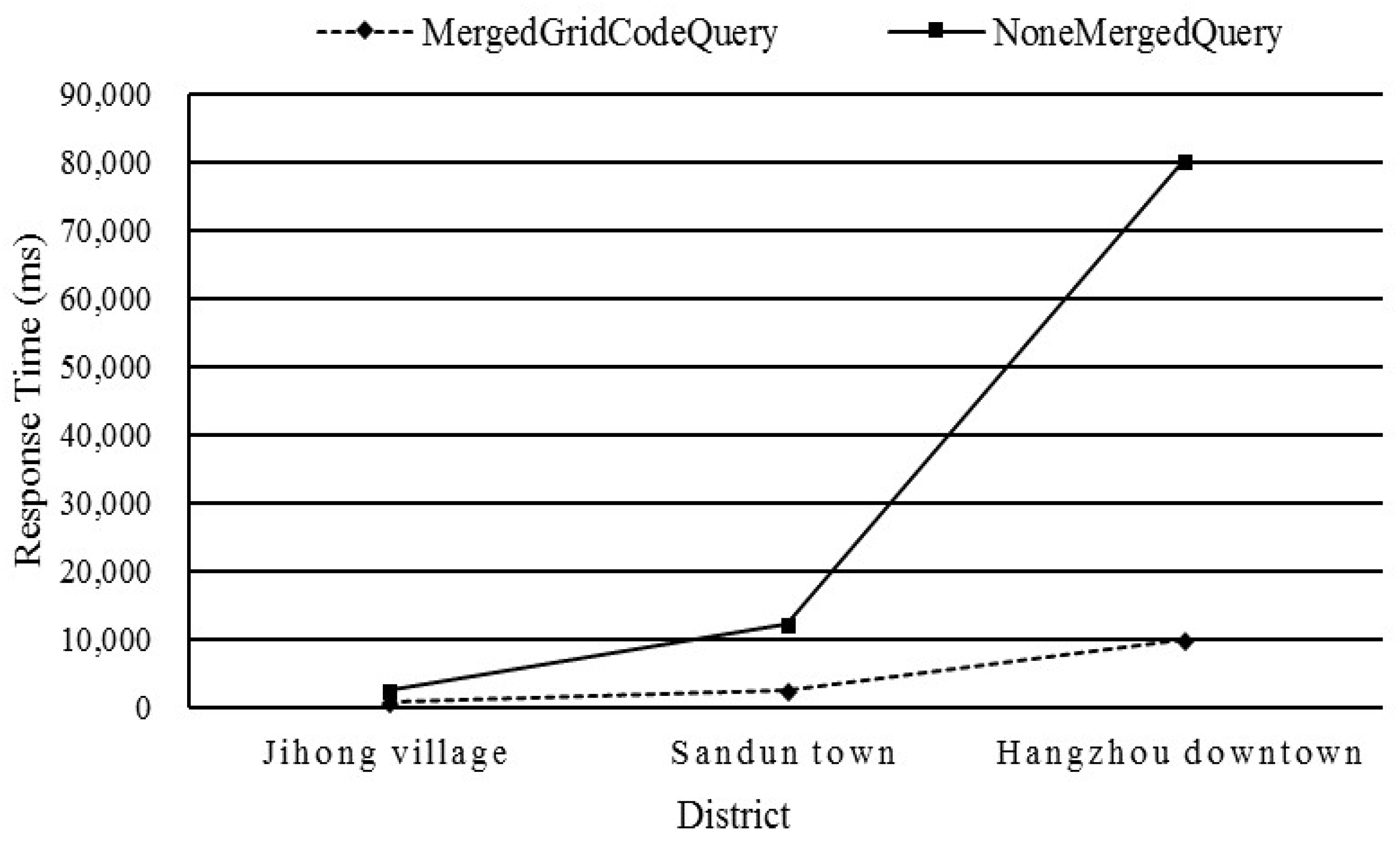
5.5.2. Test 2: Influence of the Optimized Strategy on the Merging Grid Cell Codes
5.6. Comparison of PostGIS, Regular Grid Index, GeoMesa and GeoWave
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Li, C.; Li, M.; Liu, Z. Hbase Storage Schemas for Massive Spatial Vector Data. Clust. Comput. 2017, 20, 1–10. [Google Scholar] [CrossRef]
- Zhang, N.; Zheng, G.; Chen, H.; Chen, J.; Chen, X. Hbasespatial: a Scalable Spatial Data Storage Based on Hbase. In Proceedings of the 2014 IEEE 13th International Conference on Trust, Security and Privacy in Computing and Communications, Beijing, China, 24–26 September 2014; pp. 644–651. [Google Scholar]
- Wang, L.; Chen, B.; Liu, Y. Distributed Storage and Index of Vector Spatial Data Based on Hbase. In Proceedings of the 21st International Conference on Geoinformatics, Kaifeng, China, 20–22 June 2013; pp. 1–5. [Google Scholar]
- Nishimura, S.; Das, S.; Agrawal, D.; El Abbadi, A. MD-Hbase: Design and Implementation of an Elastic Data Infrastructure for Cloud-Scale Location Services. Distrib. Parallel Databases 2013, 31, 289–319. [Google Scholar] [CrossRef]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. In Proceedings of the 7th USENIX Symposium On Operating Systems Design And Implementation—Volume 7, Seattle, WA, USA, 6–8 November 2006; USENIX Association: Berkeley, CA, USA, 2006; p. 15. [Google Scholar]
- Apache Phoenix. Available online: http://Phoenix.Apache.Org/ (accessed on 14 March 2018).
- Han, D.; Stroulia, E. Hgrid: A Data Model for Large Geospatial Data Sets In Hbase. In Proceedings of the 2013 IEEE Sixth International Conference on Cloud Computing, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 910–917. [Google Scholar]
- Guttman, A. R-Trees: A Dynamic Index Structure for Spatial Searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data, Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar]
- Sharifzadeh, M.; Shahabi, C. Vor-Tree: R-Trees with Voronoi Diagrams for Efficient Processing of Spatial Nearest Neighbor Queries. Proc. VLDB Endow. 2010, 3, 1231–1242. [Google Scholar] [CrossRef]
- Dutton, G. Improving Locational Specificity of Map Data—A Multi-Resolution, Metadata-Driven Approach And Notation. Int. J. Geogr. Inf. Syst. 1996, 10, 253–268. [Google Scholar]
- Nievergelt, J.; Hinterberger, H.; Sevcik, K.C. The Grid File: An Adaptable, Symmetric Multikey File Structure. ACM Trans. Database Syst. 1984, 9, 38–71. [Google Scholar] [CrossRef]
- Finkel, R.A.; Bentley, J.L. Quad Trees A Data Structure for Retrieval On Composite Keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhu, Q.; Zhang, Y. GIS Spatial Data Partitioning Method for Distributed Data Processing. In International Symposium on Multispectral Image Processing and Pattern Recognition; SPIE: Wuhan, China, 2007; Volume 6790, pp. 1–7. [Google Scholar]
- Wang, Y.; Hong, X.; Meng, L.; Zhao, C. Applying Hilbert Spatial Ordering Code to Partition Massive Spatial Data In PC Cluster System. In Geoinformatics 2006: GNSS And Integrated Geospatial Applications; SPIE: Wuhan, China, 2006; Volume 642, pp. 1–7. [Google Scholar]
- Faloutsos, C.; Roseman, S. Fractals for Secondary Key Retrieval. In Proceedings of the Eighth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems; ACM: Philadelphia, PA, USA, 1989; pp. 247–252. [Google Scholar]
- Shaffer, C.A.; Samet, H.; Nelson, R.C. Quilt: A Geographic Information System Based on Quadtrees. Int. J. Geogr. Inf. Syst. 1990, 4, 103–131. [Google Scholar] [CrossRef]
- Li, G.; Li, L. A Hybrid Structure of Spatial Index Based on Multi-Grid And QR-Tree. In Proceedings of the Third International Symposium on Computer Science and Computational Technology, Jiaozuo, China, 14–15 August 2010; pp. 447–450. [Google Scholar]
- Geomesa. Available online: http://www.Geomesa.Org/ (accessed on 12 April 2018).
- Böxhm, C.; Klump, G.; Kriegel, H. XZ-Ordering: A Space-Filling Curve for Objects with Spatial Extension. In Advances in Spatial Databases; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Geowave. Available online: https://Github.Com/Locationtech/Geowave (accessed on 12 April 2018).
- Elasticsearch. Available online: https://www.Elastic.Co (accessed on 12 April 2018).
- Hulbert, A.; Kunicki, T.; Hughes, J.N.; Fox, A.D.; Eichelberger, C.N. An Experimental Study of Big Spatial Data Systems. In Proceedings of the IEEE International Conference On Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 2664–2671. [Google Scholar]
- Dimiduk, N.; Khurana, A.; Ryan, M.H.; Stack, M. Hbase in Action; Manning Shelter Island: Shelter Island, NY, USA, 2013. [Google Scholar]
- Tak, S.; Cockburn, A. Enhanced Spatial Stability with Hilbert And Moore Treemaps. IEEE Trans. Vis. Comput. Graph. 2013, 19, 141–148. [Google Scholar] [CrossRef] [PubMed]
- Geotools. Available online: http://Geotools.Org/ (accessed on 12 April 2018).
- Egenhofer, M.; Herring, J. A Mathematical Framework for the Definition of Topological Relationships. In Proceedings of the Fourth International Symposium On Spatial Data Handling, Zurich, Switzerland, 23–27 July 1990; pp. 803–813. [Google Scholar]
- Haverkort, H.; Walderveen, F. Locality and Bounding-Box Quality of Two-Dimensional Space-Filling Curves. In Proceedings of the 16th Annual European Symposium on Algorithms; Springer: Karlsruhe, Germany, 2008; pp. 515–527. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rowkey | Timestamp | Column Family: GeometryInfo | |||||
|---|---|---|---|---|---|---|---|
| C0: Time | C1: Cor | C2: MBR | C3: Type | C4: Area | C5: Perimeter | C6: LID | |
| 013_L_001 | t1 | cor1 | 1 | L | |||
| 001_L_001 | t2 | cor2 | mbr2 | 4 | 3400 | 1000 | L |
| … | … | … | … | … | … | … | … |
| Rowkey | …… |
|---|---|
| 01 | …… |
| 010 | …… |
| 0100 | …… |
| …… | …… |
| 011 | …… |
| 0110 | …… |
| 0111 | …… |
| …… | …… |
| 012 | …… |
| 0120 | …… |
| …… | …… |
| 013 | …… |
| 0130 | …… |
| …… | …… |
| Rowkey | …… |
|---|---|
| 03_0100 | …… |
| 03_0101 | …… |
| 03_0102 | …… |
| 03_0103 | …… |
| 03_0110 | …… |
| 03_0111 | …… |
| 03_0112 | …… |
| 03_0113 | …… |
| 03_0120 | …… |
| 03_0121 | …… |
| 03_0122 | …… |
| 03_0123 | …… |
| 03_0130 | …… |
| …… | …… |
| Items | Parameters |
|---|---|
| Node configuration | Intel(R) Core(TM) i5-2400 CPU @ 3.10 GHz (4 CPUs), 4 G RAM, 1 T Disk, 10,000 M network |
| Node operation system | CentOS 7.1.1503 |
| Hadoop version | 2.7.3 |
| HBase version | 1.3.1 |
| GeoMesa | 2.0.0 |
| PostGIS | 2.4.4 |
| Switch | 10,000 M switches |
| Items | Parameters |
|---|---|
| CPU | Intel(R) Core(TM) i7-4770 CPU @ 3.40 GHZ (8 CPUs) |
| RAM | 8G |
| Disk | 1 T Disk |
| Operation system | Windows 7 SP1 |
| Network adapter | Broadcom NetXtreme Gigabit Ethernet * 3 |
| Region | Range | Target Objects | Region | Range | Target Objects |
|---|---|---|---|---|---|
| R1 | 118.607, 29.199, 118.605, 29.463 | 5010 | R2 | 118.607, 29.199, 118.752, 29.538 | 11,023 |
| R3 | 118.607, 29.199, 118.786, 29.677 | 118,968 | R4 | 118.607, 29.199, 118.928, 29.797 | 191,844 |
| R5 | 118.607, 29.199, 119.176, 29.971 | 600,111 | R6 | 118.607, 29.199, 119.344, 30.174 | 960,004 |
| R7 | 118.607, 29.199, 119.612, 30.327 | 1,950,321 | R8 | 118.607, 29.199, 119.787, 30.438 | 2,881,104 |
| R9 | 118.607, 29.199, 120.071, 30.496 | 3,840,010 | R10 | 118.607, 29.199, 120.701, 30.635 | 5,761,201 |
| Region | PostGIS | Regular Grid Index | GeoMesa | GeoWave | Ours |
|---|---|---|---|---|---|
| R1 | 0.153 | 0.282 | 0.236 | 0.235 | 0.237 |
| R2 | 0.212 | 0.314 | 0.301 | 0.299 | 0.300 |
| R3 | 1.421 | 1.582 | 0.454 | 0.451 | 0.453 |
| R4 | 6.112 | 2.121 | 0.679 | 0.675 | 0.677 |
| R5 | 30.568 | 5.212 | 1.259 | 1.258 | 1.259 |
| R6 | 36.671 | 7.911 | 2.021 | 2.011 | 2.018 |
| R7 | 330.781 | 10.420 | 3.247 | 3.231 | 3.243 |
| R8 | 390.691 | 16.351 | 3.961 | 3.948 | 3.955 |
| R9 | 720.108 | 20.342 | 6.013 | 5.995 | 6.007 |
| R10 | 1110.325 | 38.235 | 8.035 | 8.022 | 8.028 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, H.; Kang, J.; Du, Z.; Zhang, F.; Huang, X.; Liu, R.; Zhang, X. Vector Spatial Big Data Storage and Optimized Query Based on the Multi-Level Hilbert Grid Index in HBase. Information 2018, 9, 116. https://doi.org/10.3390/info9050116
Jiang H, Kang J, Du Z, Zhang F, Huang X, Liu R, Zhang X. Vector Spatial Big Data Storage and Optimized Query Based on the Multi-Level Hilbert Grid Index in HBase. Information. 2018; 9(5):116. https://doi.org/10.3390/info9050116
Chicago/Turabian StyleJiang, Hua, Junfeng Kang, Zhenhong Du, Feng Zhang, Xiangzhi Huang, Renyi Liu, and Xuanting Zhang. 2018. "Vector Spatial Big Data Storage and Optimized Query Based on the Multi-Level Hilbert Grid Index in HBase" Information 9, no. 5: 116. https://doi.org/10.3390/info9050116
APA StyleJiang, H., Kang, J., Du, Z., Zhang, F., Huang, X., Liu, R., & Zhang, X. (2018). Vector Spatial Big Data Storage and Optimized Query Based on the Multi-Level Hilbert Grid Index in HBase. Information, 9(5), 116. https://doi.org/10.3390/info9050116