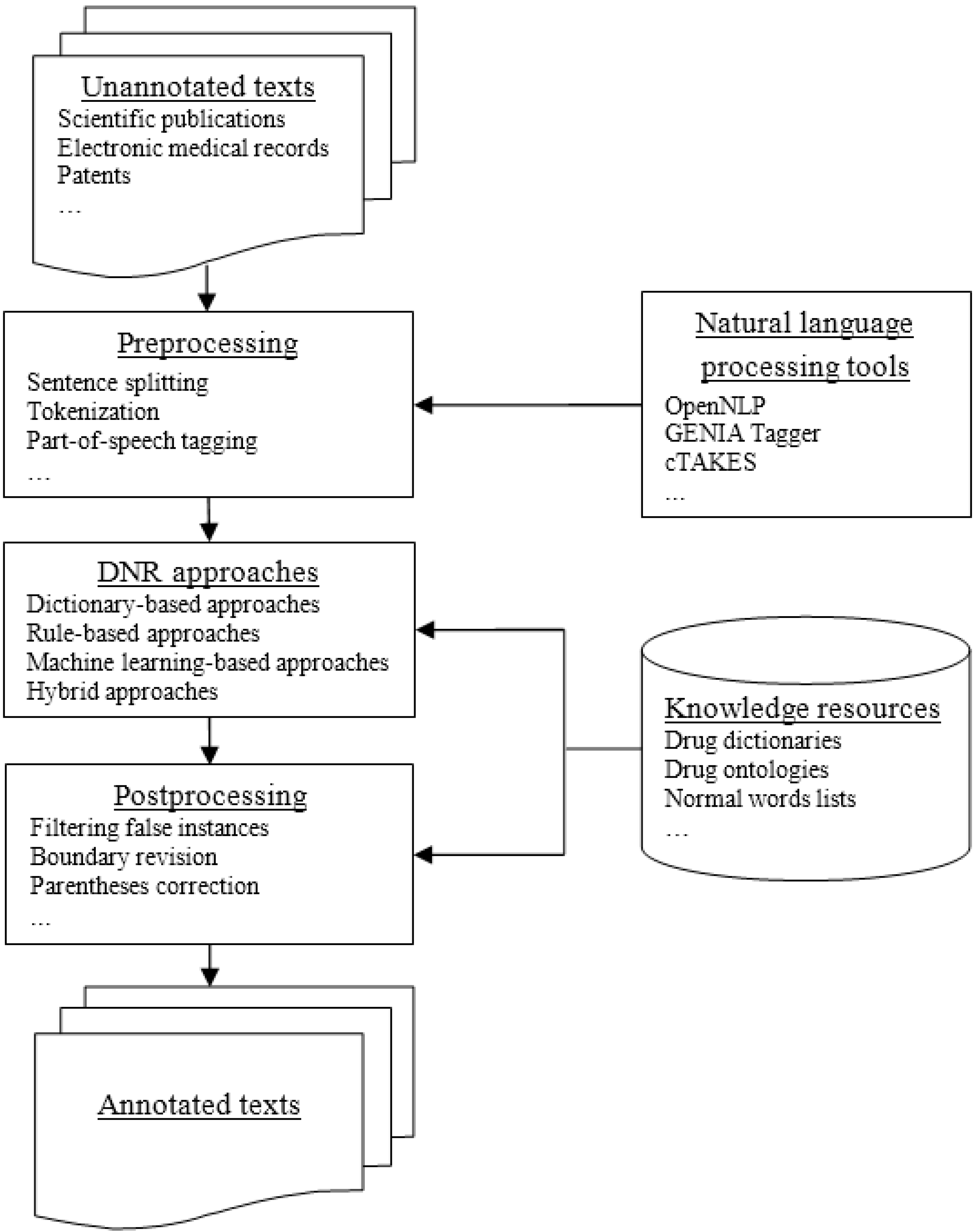
Approaches for DNR can be classified into four categories: dictionary-based, rule-based, machine learning-based and hybrid approaches.
5.1. Dictionary-Based Approaches
Drug dictionaries refer to collections of drug names. They can be constructed manually or automatically from publicly available knowledge resources such as databases and ontologies containing synonyms or spelling variants of drug names. Different knowledge resources contain different terms. Some knowledge resources focus on drugs, while others focus on general chemicals. Therefore, drug dictionaries are usually constructed by merging several knowledge resources. Before reviewing the dictionary-based approaches, we introduce some freely available knowledge resources and describe how to construct drug dictionaries from them. The web-accessible URLs of the knowledge sources are listed in
Table 3.
DrugBank is an online database that contains chemical, pharmacological and pharmaceutical information about drugs and comprehensive drug target information [
33]. Fields such as “name”, “synonyms” and “international-brands” in DrugBank can be extracted to build a drug name dictionary.
Kyoto Encyclopedia of Genes and Genomes (KEGG) DRUG is a drug information resource for approved drugs in Japan, USA and Europe [
34]. The “Name” field in KEGG DRUG can be used for the creation of drug name dictionary.
Pharmacogenomics Knowledgebase (PharmGKB) is a comprehensive resource that curates knowledge about the impact of genetic variation on drug response [
35]. It provides a drug list and the “name”, “generic names” and “trade names” fields in the drug list can be collected to construct a drug name dictionary.
Comparative Toxicogenomics Database (CTD) is a publicly available database that provides manually curated information about chemical-gene interactions, chemical-disease and gene-disease relationships [
36]. The “ChemicalName” field can be extracted to build a drug name dictionary.
RxNorm is a standardized nomenclature for clinical drugs [
37]. It is created by the United States National Library of Medicine (NLM) to let various systems using different drug nomenclatures share and exchange data efficiently. The “ingredient (IN)” and “brand name (BN)” fields can be extracted to build a drug name dictionary.
RxTerms is a drug interface terminology derived from RxNorm for prescription writing or medication history recording [
38]. The “FULL_GENERIC_NAME”, “BRAND_NAME” and “DISPLAY_NAME” fields can be used to build a drug name dictionary.
Drugs@FDA is provided by the United States Food and Drug Administration (FDA). It contains information about FDA-approved drug names, generic prescription, over-the-counter human drugs, etc. Drug names can be extracted from the “drug name” and “activeingred” fields of Drugs@FDA.
Therapeutic Targets Database (TTD) is a database that provides information about therapeutic targets and corresponding drugs [
39]. It contains many drugs including approved, clinical trial and experimental drugs. The “Name”, “Synonyms” and “Trade Name” fields in TTD can be collected to build a drug dictionary.
Chemical Entities of Biological Interest (ChEBI) is a freely available dictionary of molecular entities [
40]. In addition, it incorporates an ontological classification, whereby the relationships between molecular entities, classes of entities and their parents, children and siblings are specified. The fields such as “ChEBI name”, “International Nonproprietary Name (INN)” and “Synonyms” can be extracted for dictionary creation. Moreover, the class information in ChEBI ontology can be used to classify drugs.
Medical Subject Headings (MeSH) is a controlled vocabulary thesaurus from NLM. It consists of sets of terms named descriptors [
41]. MeSH descriptors are used for indexing, cataloging and searching for biomedical and health-related information and documents. MeSH descriptors are divided into 16 categories. Each category is further divided into some subcategories. Within each subcategory, descriptors are organized in a hierarchical structure. The category “D” covers drugs and chemicals. Terms belonging to category “D” can be extracted to build a drug dictionary.
PubChem is a public repository for biological properties of small molecules [
42]. It consists of three interconnected databases: PubChem Substance, PubChem Compound and PubChem BioAssay. PubChem Substance contains entries of mixtures, extracts, complexes and uncharacterized substances and provides synonyms of the substances. PubChem Compound is a subset of PubChem Substance. It contains pure and characterized chemical compounds but no synonyms. In order to build a high quality dictionary consisting of as many synonyms as possible, names and synonyms of PubChem Substance entries that have links to PubChem Compound entries are usually collected.
Unified Medical Language System (UMLS) Metathesaurus is a large, multi-purpose, and multi-lingual thesaurus that contains millions of biomedical and health related concepts from over 100 vocabularies, their synonymous names and relationships among them [
43]. Each concept in UMLS Metathesaurus is assigned to at least one semantic type. The concepts in the UMLS Metathesaurus with semantic types such as “Pharmacological Substance (PHSU)” and “Antibiotics (ANTB)” can be collected to build a drug dictionary.
The joint chemical dictionary (Jochem) is a dictionary developed for the identification of drugs and small molecules in texts. It combines information from UMLS, MeSH, ChEBI, and so on [
44]. Concepts in Jochem can be extracted to build a drug dictionary.
Dictionary-based approaches identify drug names by matching drug dictionaries against given texts. Exact matching approaches [
45,
46] usually achieve high precision, but suffer from low recall. This is because there are spelling mistakes or variants of drug names not covered by drug dictionaries. Therefore, approximate matching is used to improve the recall of dictionary-based approaches. Lexical similarity measures and approximate string matching methods such as edit distance [
47], SOUNDEX [
48] and Metaphone [
49] can be used for approximate matching. For example, Levin
et al. [
50] used Metaphone to match generic and trade names of drugs in RxNorm [
37] against anesthesia electronic health records. Moreover, there are approaches utilizing existing systems to map textual terms to drug dictionaries [
51,
52]. For example, Rindflesch
et al. [
51] utilized the UMLS MetaMap program [
53] to map biomedical texts to UMLS Metathesaurus concepts. Phrases that were mapped to concepts with the semantic type “Pharmacological Substance” were considered to be drug names.
Dictionary-based approaches also may yield low precisions because of low quality of drug dictionaries. Sirohi
et al. [
54] investigated the effects of using varying drug dictionaries to extract drugs from electronic medical records and concluded that the precision and recall could be considerably enhanced by refining the dictionaries. Many methods have been used to improve the quality of drug dictionaries [
44,
55,
56]. Hettne
et al. [
44] proposed several filtering rules to filter terms in a dictionary developed for DNR. For example, the short token filtering rule removed a term if the term was a singular character or an Arabic number after tokenization and removal of stop words. Moreover, they manually checked highly frequent terms in a set of randomly selected MEDLINE abstracts. If a term corresponded to a normal English word, it was added to a list of unwanted terms. Xu
et al. [
55] compared the drug dictionary with the SCOWL list [
57], which is a list of normal English words. They manually reviewed ambiguous words and removed unlikely drug terms from the dictionary. At the same time, they expanded the dictionary by adding drug names annotated in a training dataset.
Due to the rapid development of pharmaceutical research, new drugs are constantly developed and enter the market. However, drug dictionaries cannot be updated regularly. It is impossible for a drug dictionary to cover all existing drugs. Therefore, approaches that do not rely too much on drug dictionaries are necessary for DNR.
5.3. Machine Learning-Based Approaches
Machine learning-based approaches usually formalize DNR as a classification problem or a sequence labeling problem. Each token is presented as a set of features and then is labeled by machine learning algorithms with a class label. The class label denotes whether a token is part of a drug name and its position in a drug name.
BIO is the most popular tagging scheme used for DNR. Tags in the
BIO tagging scheme respectively represent that a token is at the beginning (
B) of a drug name, inside (
I) of a drug name and outside of a drug name (
O).
Figure 2 shows an example of
BIO tagging results of a sentence from the DDIExtraction 2013 dataset, where four types of drugs (
drug,
brand,
group,
non-human) are defined. Moreover, there are some more expressive tagging schemes such as
BEIO,
BESIO and
B12EIO [
63]. The tagging schemes are derived from
BIO. Tag
E represents that a token is at the end of a drug name. Tag
S represents a single token drug name. Tags
B1 and
B2 in
B12EIO stand for the first token in a drug name and the second but not the last token in a drug name, respectively. Dai
et al. [
16] compared the effects of above four tagging schemes on DNR. It was demonstrated that
BESIO outperformed other tagging schemes under the same experimental settings.
Figure 2.
An example of BIO tagging results of a sentence from the DDIExtraction 2013 dataset.
The selection of machine learning models is very important for machine learning-based approaches. Classification models commonly used for DNR include Maximum Entropy (ME) [
64] and Support Vector Machine (SVM) [
65]. They only consider individual tokens or phrases and do not take the order of tokens into account. Different from classification models, sequence tagging models such as Hidden Markov Model (HMM) [
66] and Conditional Random Fields (CRF) [
31,
67,
68,
69] consider the complete sequence of tokens in a sentence. They aim at predicting the most probable sequence of tags for a given sentence. CRF is widely used and demonstrated to be superior to other machine learning models used for DNR. For example, CRF-based systems achieved the best performances in the DNR tasks of i2b2 medication extraction [
67], CHEMDNER [
31] and DDIExtraction 2013 [
68] challenges. In most cases, only one machine learning model is used in a machine learning-based DNR approach. However, there are approaches using multiple models [
31,
70,
71,
72,
73]. For example, Leaman
et al. [
31] employed two independent CRF models with different tokenization strategies and feature sets. Results of the two models were combined with heuristic rules. Lu
et al. [
70] used a character-level CRF and a token-level CRF to learn the internal structure and context of drugs, respectively. Results of the two CRF models were also merged in a heuristic method. Lamurias A.
et al. [
72] train multiple CRF models on different training datasets and combine the confidence scores returned by the models to rank and filter the identified drug names. Sikdar
et al. [
73] combine one SVM model and six CRF models that use different features to recognize drug names based on an ensemble framework.
Table 4 lists some open source toolkits that can be used as implementations of commonly used machine learning models.
Performances of machine learning-based approaches highly depend on the features they used. Various types of features have been explored for DNR.
Table 5 lists some features that are commonly used in machine learning-based DNR systems. Features based on the linguistic, orthographic and contextual information of tokens are widely used and the effectiveness of them is extensively studied. For example, Campos
et al. [
71] investigated the effects of features including lemma, POS, text chunking, dependency parsing,
etc. Lemma, POS and text chunking features produced significant positive impacts on the performance of the CRF-based approach, while dependency parsing brought negative effects on the performance. Halgrim [
64] examined the effects of POS, affix and orthographic feature in a ME-based approach and all the features provided positive outcomes.
Table 5.
Features used in machine learning-based DNR systems.
| Feature | Description | Reference |
|---|
| Character feature | N-grams of characters in a word. | [17,31,68,70,71,74] |
| Word feature | N-grams of words in a context window. | [17,31,64,68,70,71,74,75] |
| Lemma | N-grams of lemmas of words. | [17,31,68,71,74] |
| Stem | N-grams of stems of words. | [31,74] |
| POS | N-grams of POS tags. | [17,31,64,68,71,74,75] |
| Text chunking | N-grams of text chunking tags. | [17,71,75] |
| Dependency parsing | Dependency parsing results of words in a sentence. | [71] |
| Affix | Suffixes and prefixes of a word. | [17,31,64,68,71,74,75] |
| Orthographic feature | Starting with a uppercase letter, containing only alphanumeric characters, containing a hyphen, digits and capitalized characters counting, etc. | [17,31,64,68,71,74,75] |
| Word shape | Uppercase letters, lowercase letters, digits, and other characters in a word are converted to “A”, “a”, “0” and “O”, respectively. For example, “Phenytoin” is mapped to “Aaaaaaaaa”. | [17,31,68,71,74,75] |
| Dictionary feature | Whether an n-gram matches with part of a drug name in drug dictionaries. | [17,31,64,68,71,74,75] |
| Outputs of NER tools | Features derived from the output of existing chemical NER tools. | [31,68,74] |
| Word representation | Word representation features based on Brown clustering, word2vec, etc. | [70,75] |
| Conjunction feature | Conjunctions of different types of features, e.g., conjunction of lemma and POS features. | [17,71,75] |
Domain-specific features such as dictionary features and features derived from outputs of existing chemical NER are also widely used. For example, Batista-Navarro
et al. [
17] compiled dictionaries from domain-specific knowledge resources including ChEBI, DrugBank, Jochem,
etc. Each token was tagged by the dictionaries and the tagging results were used as features by a CRF-based approach. Rocktäschel
et al. [
68] generated domain-specific features from ChEBI, Jochem and the outputs of ChemSpot [
76], which is a chemical NER tool. In general, domain-specific features can significantly improve the performances of machine learning-based approaches.
Recently, word representation features are exploited and demonstrated to be effective for DNR. Word representation features are generated by unsupervised machine learning algorithms on unstructured texts. They contain rich syntactic and semantic information of words. Many unsupervised machine learning algorithms have been proposed to learn word representation features and Brown Clustering algorithm [
77] and word2vec [
78] are most commonly used. For example, Lu
et al. [
70] employed Brown Clustering algorithm and word2vec to learn word representation features on MEDLINE documents. Then the word representation features were used to improve the performances of CRF-based DNR systems.
Moreover, conjunction features that combine different types of features are also used for DNR. Conjunction features can capture multiple linguistic characteristic of a word. For example, Batista-Navarro
et al. [
17] used conjunction features that combined lemmas and POS tags. Liu
et al. [
75] selected 8 types of features including word feature, POS, text chunking,
etc., and combine them into conjunction features in two ways in their CRF-based DNR system.
Noisy features can significantly affect the performances and efficiencies of machine learning-based approaches. Therefore, the selection of informative and discriminative features is very important. However, determining the optimal subset of features by testing different combinations of features is time-consuming. Moreover, it is very likely that the optimal feature subset on a dataset will not perform well on another dataset. Therefore, automatic feature selection is necessary. In [
75], Liu
et al. employed three automatic feature selection methods, Chi-square [
79], mutual information [
80] and information gain [
81], to eliminate noisy features for a CRF-based DNR system. Experimental results showed that each feature selection method could improve the performance of the CRF-based system.
Although machine learning-based approaches can achieve promising results, they require a sufficiently large and high quality annotated dataset for training. However, the creation of an annotated dataset is costly and time-consuming. Moreover, domain experts are required in the process of creating an annotated dataset.



{kind=link}
{kind=link}