A Model for Information

Capgemini UK, No. 1, Forge End, Woking, Surrey, GU21 6DB, UK
Information 2014, 5(3), 479-507; https://doi.org/10.3390/info5030479
Submission received: 2 July 2014
/
Revised: 27 August 2014
/
Accepted: 11 September 2014
/
Published: 18 September 2014
Abstract
:This paper uses an approach drawn from the ideas of computer systems modelling to produce a model for information itself. The model integrates evolutionary, static and dynamic views of information and highlights the relationship between symbolic content and the physical world. The model includes what information technology practitioners call “non-functional” attributes, which, for information, include information quality and information friction. The concepts developed in the model enable a richer understanding of Floridi’s questions “what is information?” and “the informational circle: how can information be assessed?” (which he numbers P1 and P12).
1. Introduction
In the Information Technology (IT) industry, questions about complicated systems (including variants of “what is the system?”) are addressed by developing a variety of models [1]. This paper takes the same approach to information itself and the question “what is information?” This question was asked by Floridi in [2] and has since triggered what the authors of [3] call a “cottage industry”.
Section 2 examines the relationship between information and selection. Selection processes drive improvements in efficiency and quality. Research in psychology provides a revealing example and indicates why people find information a difficult concept to understand.
Section 3 develops the model for information (MfI). It includes tools for modelling different kinds of connection which, together, describe how physical processes and information artefacts are related. Starting with direct connections as a result of physical processes, MfI shows how abstract concepts are related to the physical world. The model integrates evolutionary, dynamic and static views.
Computer systems modelling distinguishes between functional attributes of systems (the behaviour of a system) and non-functional (the qualities of a system—like performance, availability, scalability, maintainability). Within MfI, non-functional attributes correspond to information quality (IQ) and information friction (IF). IF is a measure of the resources needed for some information-related task. The discussion about IQ uses ideas about scientific measurement applied to the geometry implicit in information to define some measures of information quality. IQ is addressed in Section 4 and IF in Section 5.
In [2], Floridi articulated a number of questions about information. In Section 6, the question “what is information?” is addressed (this is Floridi’s question P1). MfI also sheds some light on some of Floridi’s other questions. Since MfI is based on the relationship between information and the physical world it also tackles the following question directly: “the informational circle: how can information be assessed? If information cannot be transcended but can only be checked against further information—if it is information all the way up and all the way down—what does this tell us about our knowledge of the world?” This question (P12) is also addressed in Section 6.
2. Information and Selection
Many authors (for example [2,4,5]) have looked at the relationship between information, selection and evolution. Examples of selection include, for example: natural selection [6], market selection (through which the “invisible hand” [7] operates), political selection through voting (in democracies) and personal selection by which people make choices.
These types of selection all have some elements in common. The form of an entity is determined by a process which is, to some extent, governed by a design pattern (using the term in the sense of [8] rather than in the (related) sense of [9]). The patterns include DNA, system architecture or organisational operating model.
Versions of entities are derived from other versions through some physical process using the pattern. Children are derived from their parents, new versions of computer systems are based on design changes to the original system and organisations develop by changing their structure, processes, roles, locations and so forth. There may be no derived entity, one, several or many for any original entity. In some cases the derived entity may be a completely new entity (“reproduction” in biological terms); in some cases, it may be the existing entity (“growth” in biological terms).
All of these processes involve interaction between an entity and its environment. Each interaction changes the properties of the entity and the environment. In some cases, the interactions of an entity impact, or rely on, the health of another entity or entities. Examples of this include a spouse, a parent and an organisation using a computer system. In these cases, a favourable outcome for the entity relies on the health of the other entity or entities.
As a result, a selection process can be considered as two feedback mechanisms. In the first one, interactions impact the properties of an entity and its ability to achieve favourable outcomes. In the second one, the interactions impact the pattern of the derived entity.
For the rest of the paper we will refine the use of the term Interacting Entity (IE) to refer to an entity which participates in such a selection process. Humans, animals, computer systems and organisations are all examples of IEs in this sense. To improve the favourability of outcomes, such IEs require the following capabilities:
- to sense what is taking place in the environment
- to actuate—to cause an impact on the environment
- to remember, search and retrieve what has been remembered
- to connect the various elements together to enable the IE to link environment states to actions and potential outcomes and choose more favourable alternatives from the options.
Figure 1.
A generic Interacting Entity (IE) model.
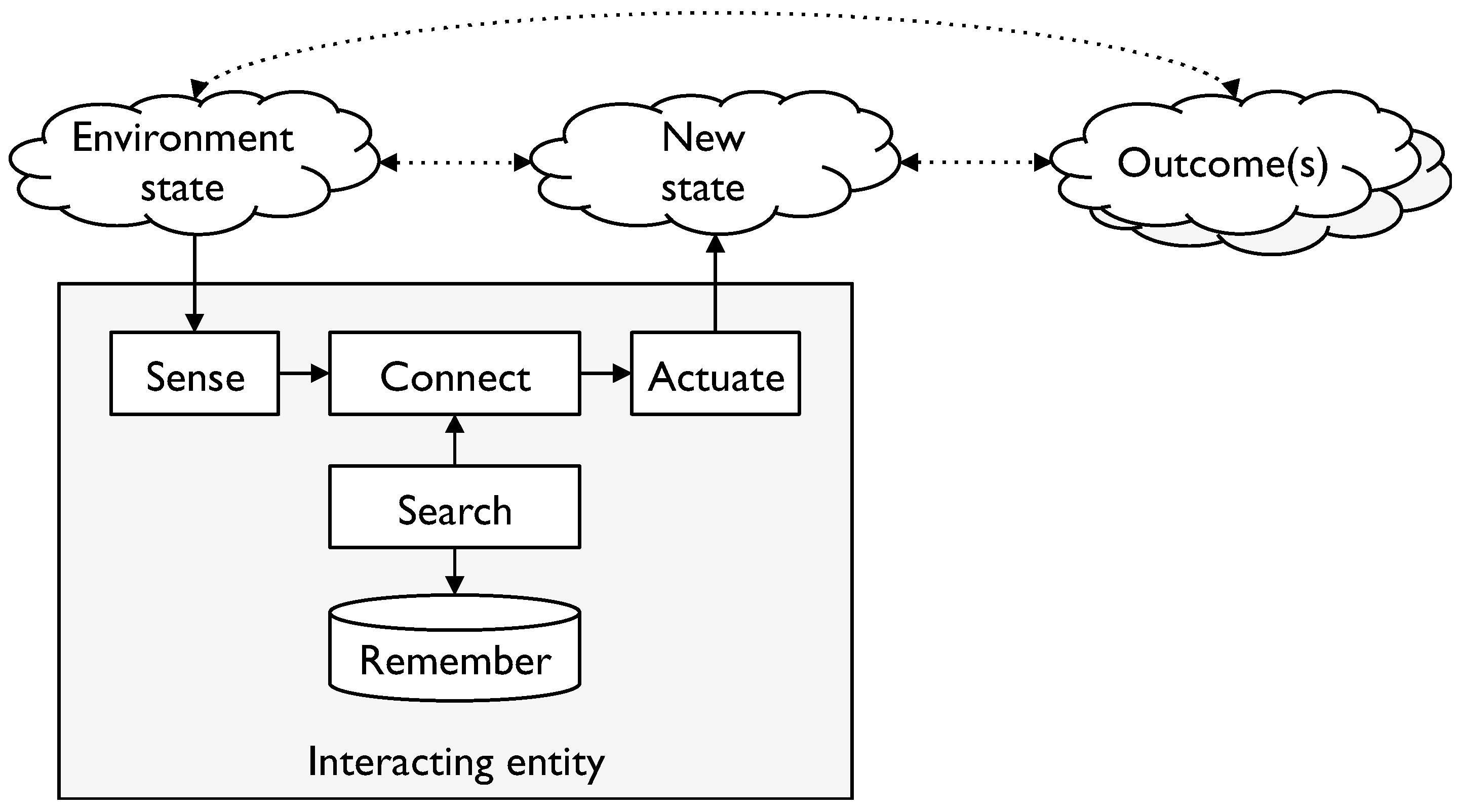
(In [2], Floridi divided information into three categories: “information as reality”, “information about reality” and “information for reality”. If we call them types 1, 2, and 3, then the generic IE model highlights the role of types 2 and 3.)
Other things being equal, an increase in information quality will generate more favourable outcomes. However, improvements in efficiency may also generate more favourable outcomes.
An example of this is provided by research in psychology summarised by Kahneman in [10]. He describes two modes of thinking he calls “System 1” and “System 2”. As he puts it:
“System 1 operates automatically and quickly, with little or no effort and no sense of voluntary control. System 2 allocates attention to the effortful mental activities that demand it, including complex computations. The operations of System 2 are often associated with the subjective experience of agency, choice and concentration.”“…most of what you (your System 2) think and do originates in your System 1, but System 2 takes over when things get difficult, and it normally has the last word. The division of labour between System 1 and System 2 is highly efficient: it minimizes effort and optimizes performance. ... System 1 has biases, however, systematic errors that it is prone to make in specified circumstances.”
This has a major impact on the way in which we respond to information. Kahneman says:
The distinction between Systems 1 and 2 highlights one of the impacts of selection pressures. Changes may improve efficiency or quality or both, but their reconciliation is not always elegant.“When information is scarce, which is a common occurrence, System 1 acts as a machine for jumping to conclusions.”“System 1 is radically insensitive to both the quality and quantity of information that gives rise to impressions and intuitions.”
In the natural world, evolution has driven the creation of numerous ecosystems. The same is true of information—selection processes drive the creation, development and specialisation of information ecosystems (usually referred to as just ecosystems where the context is clear). As the authors state in [3]: “every separate realm of knowledge has legitimately distinguished a separate form of information.” English speakers can communicate in English with each other but not (necessarily) with non-English speakers. Mathematicians can communicate with each other in a form incomprehensible to non-mathematicians. Each ecosystem includes some types of IE and includes the conventions by which they communicate. This topic is discussed more in Section 4.
3. The Model for Information (MfI)
In this section we use an approach based on that used in the discipline of technical architecture (see, for example, [1]). The specific purpose is to link information with the physical world so the overall model describes the following types of model and their relationship:
- Physical Connection Models (PCM) which model physical entities and their interactions;
- Extended Connection Models (ECM) which model aggregations of entities and interactions;
- Virtual Connection Models (VCM) which model more abstract connections;
- Information Artefact Models (IAM) which model Information Artefacts (IAs).
Starting with PCM, which models the physical world, these models show how elements of abstraction can be successively layered in top of the basic ideas in a way which links back to the physical world. The models are built on interactions and different types of connection between entities, so first we include some definitions which support the development of the ideas.
3.1. Definitions
Call a slice a contiguous subset of space-time. A slice can correspond to an entity at a point in time (or more properly within a very short interval of time), a fixed piece of space over a fixed period of time or, much more generally, an event which moves through space and time. This definition allows great flexibility in discussing information. By using slices rather than space and time separately we can apply a common approach in different cases. For example, slices are sufficiently general to support a common discussion of both nouns and verbs, the past and the future.
We also use the following to describe the physical world:
- properties: each slice has a set of properties and for each property there is one or more physical processes (which we call measurement) that takes the slice as input and generates the value of the property for the slice;
- entity: a type of slice corresponding to a substance;
- interaction: a physical process that relates the properties of two entities.
Any d-interaction takes place at a specific time (or over a specific time period), but the same type of interaction may take place many times. For example, there are many examples of light being emitted from one entity and absorbed by another. Call these types of interaction or d-interaction. D-interaction or interaction types can have the same properties as interactions or d-interactions (respectively) with the exception of space-time properties. For this reason it is useful to consider the space-time properties to be relative.
Define a pointer to be a tuple (l, v, S) for which:
- l is a label: lab (c);
- S is a set which is the set of all possible values of the pointer: cont (c);
- v is the value (a member of S or ∅): val (c).
If x is a slice, then define:
- the set of properties of x, Px = {pi: pi is a pointer representing the i-th property of x};
- the number of properties of x, |x| = |Px|;
- a disposition δ is an |x|-tuple (val (p1),..., val (p|x|)), pi∈ Px ;
- the set of all dispositions of x, or disposition space of x, Δx.
When the properties of an entity meet certain conditions, then an interaction will be triggered. If α is a d-interaction type from entity x to y, then not all of the properties of x and y necessarily affect or are affected by α. Define:
- Pxoα the set of properties which can trigger α (“o” stands for output);
- Δxoα the corresponding disposition space (the projection of Δx onto Pxoα);
- Pyiα the set of properties altered by α (“i” stands for input);
- Δyiα the corresponding disposition space (the projection of Δy onto Pyiα).
Then for any x and y, α has the following two associated functions:
- the output function, oα: Δxoα x T → Δxoα which maps any disposition of x before α is output to the disposition afterwards;
- the input function, iα: Δyiα x T → Δyiα which maps any disposition of y before α is input to the disposition afterwards.
We can write:
- oα: (δx, t)→ δxoα for δx in the domain of oα;
- iα: (δy, t) → δyiα for δy in the domain of iα.
We can define a d-interaction function tα as follows:
- tα: Δxoα x Δyiα x T → Δyiα and tα(δx, δy, t) = δyiα.
- tα(δx, δy, t) = tα(δx, δ’y, t) for all δy, δ’y∈ Δy and for all t ∈ T.
The effect of a transmission does not rely on the disposition of the destination entity or time, only on the nature of the d-interaction itself. In this case we can write
- tα: Δxoα → Δyiα and tα(δx) = δyiα.
Examples of transmissions include writing to computer memory and transmissions in the more usual sense (e.g., transmission of electronic messages).
Suppose that α1, …, αn-1 is a series of d-interaction types connecting entities x1, ..., xn. They have the same effect as a single d-interaction if the range of one d-interaction input function is contained in or equal to the domain of the next output function. The effect on x1 and xn is the same as if there was a d-interaction type, β, connecting x1 and xn. In this case, though the transmission function tβ has the following form:
- tβ: Δx1oα x…x Δxioα x…x Δxniαm → Δxniαm and tβ(δ1, …,δi, …,δn) = δniαm.
As Floridi discusses in [2], abstraction is concerned with leaving out detail. We use the term “pattern” for this. In this case, the term is linked to the usage in the computer systems architecture world [8] rather than the sense in which is it used by Burgin [11], for example.
To make this more precise and to describe structures and connections more generally, we use an approach based on graph theory. This approach is consistent with the approach (using static schemas) used by Burgin in [11] but allows a more natural use of some graph theory-based ideas.
An unrooted linnet (where “linnet” stands for “linked net”) C is a tuple (V, E, N) which satisfies the following conditions:
- V is a finite set of vertices;
- E is a finite set of connectors;
- V and E are disjoint;
- N is the set of connections of D where N ⊆ {(a, e, b): a, b ∈ V ∪ E, e ∈ E};
- if e ∈ E and (a, e, b), (a’, e, b’) ∈ N, then a = a’ and b = b’.
Define the proximity of a vertex to be 0. If (e1, e, e2) is a connection, then the proximity of e, prox (e), is defined as follows: if (e1, e, e2) is a connection then prox (e) = min(prox (e1), prox (e2)) + 1 where min is undefined if either prox (e1) or prox (e2) is undefined. A connector is rooted if its proximity is defined. A linnet is an unrooted linnet in which all connectors are rooted. So in a linnet all connectors connect back to vertices.
If C and D are linnets, then (by analogy with graphs—see [12]) C is a sub-linnet of D and D is a super-linnet of C if:
- V(C) ⊆ V(D);
- E(C) ⊆ E(D);
- N(C) ⊆ N(D).
In the examples we will be interested in below, the sets V(C) and E(C) will contain pointers—call the linnet in this case pointed, otherwise unpointed. From here on only pointed linnets will be considered and the term “linnet” will apply to pointed linnets unless otherwise qualified.
When all connections in C are edges, then C is a directed graph. (More precisely and using the terminology of [12], C is a directed multi-graph since more than one edge can connect two vertices.)
A dynamic linnet DC is a set of linnets {Ci: ti ∈ T} for which T is a set of times. Call
- V(DC) = ∪ V(Ci) and E(DC) = ∪ E(Ci)
If C is a (pointed) linnet, then C is:
- instantiated if all the pointers in V(C) and E(C) are instantiated;
- uninstantiated if all the pointers in V(C) and E(C) are uninstantiated;
- partially instantiated if it is not instantiated.
Burgin provides a thorough discussion of structures in [11]. He shows that his definition of structure, defined in terms of static schemas, is sufficiently rich to model structures associated with information. If vertices in linnets are associated with object variables in static schemas and connectors are associated with connection variables, then linnets have the same potential.
3.2. Physical Connection Models
A Physical Connection Model (PCM) is a dynamic linnet which represents entities and the d-interactions between them. The rationale for using pointers in linnets is that it allows us to separate two different purposes of each vertex or connector. In each case the pointer label allows consumers of the model (e.g., readers of this paper) to identify the different components. The pointer value represents the value accessible by other elements within the model itself. In other words, the label and value are accessed and used by (potentially) different entities and processes inhabiting (potentially) different ecosystems.
We can define the Physical Connection Linnet (PCL), Ck, for entities {xi} and their d-interactions {ej} at time tk in the following way:
- let v(xik) be the pointer with label xi and value δxik, where δxik is the disposition of xi at time tk;
- let e(ejk) be the pointer with label ej and value δejk, where δejk is the disposition of ej at time tk;
- let V(Ck) = ∪i {v(xik)} and E(Ck) = ∪j {e(ejk)};
- N(Ck) = {(v, e, w}: v, w ∈ V(Ck), e ∈ E(Ck), the d-interaction represented by e connects the entities represented by v and w};
- Ck = (V(Ck), E(Ck), N(Ck)).
3.3. Extended Connection Models
A PCM models individual d-interactions between entities, but in many cases, there are more complicated forms of connection. Suppose that:
- X = {xj: 1 ≤ j ≤ n} is a set of entities;
- Y = {xj: 1 ≤ j ≤ m} for some m < n;
- Α is a set of interactions between elements of X;
- A|Y = {α ∈ Α: α is an interaction between elements of Y}.
- C is a linnet;
- e is an edge of C corresponding to the connection (v1, e, v2);
- v ∉ V(C) ∪ E(C)
- V(C\e) = (V(C) ∪ {v})\{v1, v2};
- E(C\e) = E(C)\{e};
- N(C\e) = N(C)\{n: n ∈ N(C), e ∈ n};
- any occurrence of v1 or v2 in C is replaced with v in C\e;
- any occurrence of e in C is replaced with v in C\e.
Generalising the terminology in [12], C\e is known as an elementary contraction of C. A linnet D is contractible to a linnet C, or is a contraction of a linnet C, if C can be obtained from D by a sequence of elementary contractions. By extension we can define C\F for any subset F of edges of E(C).
So, to return to the example above, if C is the linnet induced by X and Α, F is the set of edges of C corresponding to A|Y. Then C\F is a linnet. So we can treat the set of entities Y as a single aggregated entity for which
- ΔY = Δx1 x ... x Δxm.
If Ck is a PCL for some time tk, and EC ={Ck} is the corresponding PCM, then we can create an Extended Connection Model (ECM) by contraction. If E ⊆ E(EC) define ECk = Ck\(E ∩ E(Ck)); ECk is an Extended Connection Linnet (ECL). {ECk} is an ECM which we can call EC\E. With this definition, the individual components of an IE (see Figure 1) are ECMs and the IE as whole is an ECM.
3.4. Connections and Relations
PCMs and ECMs model entities and their interactions but there are other types of connection we want to consider. Consider first the properties of slices. Since properties are something that can be measured there is a physical process which takes the slice as input and creates an Information Artefact (IA) as output which represents the property.
This appears to be the start of an infinite regress. A property of one entity can be explained by a process which creates a specific property in another entity. However, the IA belongs in an ecosystem (all IAs and processes that create them belong in an ecosystem) so we will investigate ecosystems and symbols before returning to this question.
In the natural world, evolution has driven the creation of numerous ecosystems. In each case there are a set of conventions which apply to relevant IEs and what they are communicating. The scope of these conventions includes:
- the symbols which are used;
- the structure of IAs and the rules that apply to them;
- the ways in which concepts are connected;
- the syntax of IAs and how they are created;
- the channels which are used to interact (and the associated sensor and actuator patterns).
Call such a set of conventions a modelling tool. Languages and Mathematics are modelling tools, for example. There is a close relationship between information ecosystems and modelling tools. We can define an information ecosystem to be the set of IEs, IAs and channels that support a particular modelling tool. (Of course, a particular ecosystem may be a subset of other ecosystems and therefore support other modelling tools.)
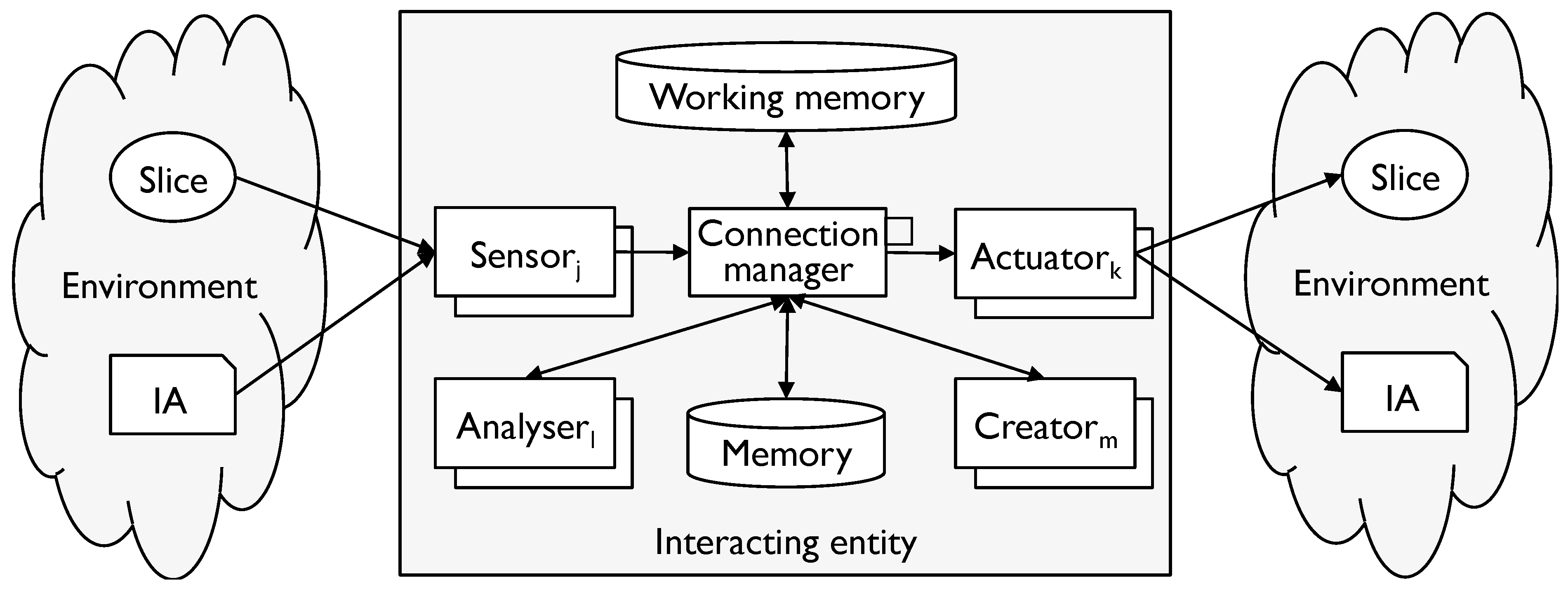
Use of a modelling tool requires special processing from IEs, so we can redraw the elements of the generic IE model as in Figure 2.
Figure 2.
The generic IE and modelling tools.
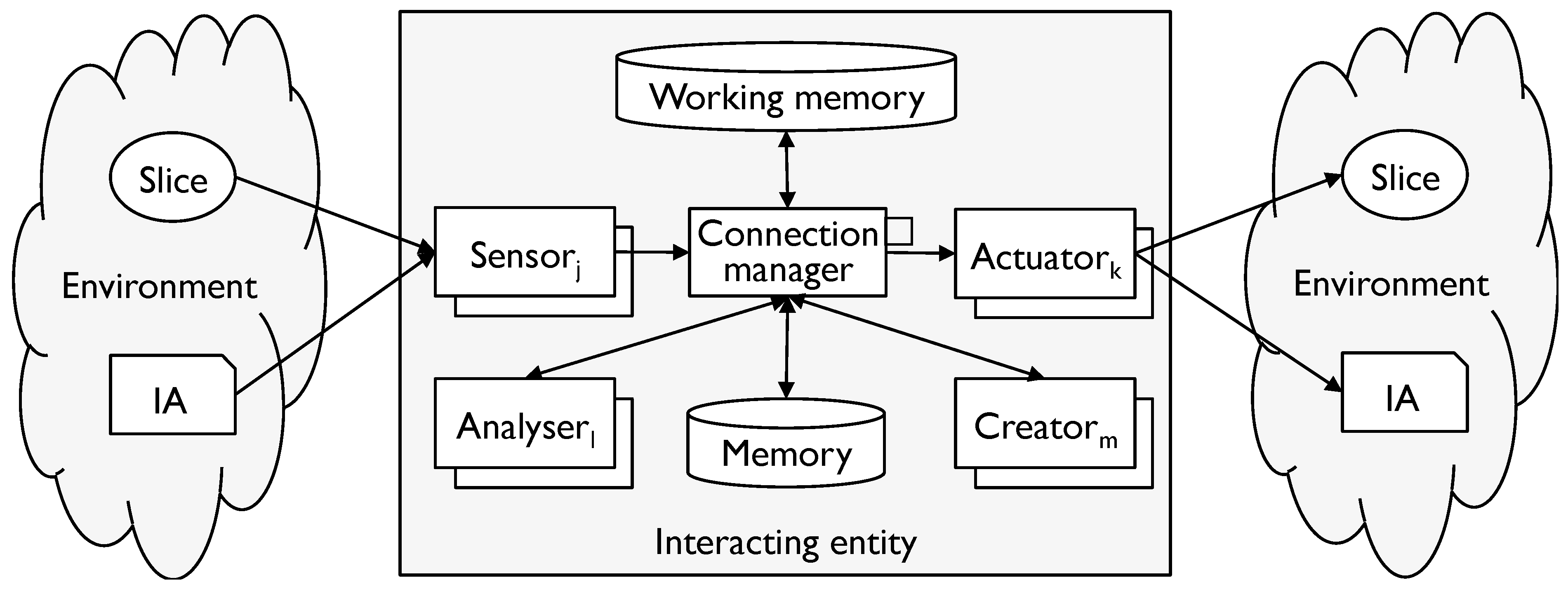
Working memory holds transitory information as it is worked on. Analysers take the output of a sensor and convert it into a standard form appropriate to the modelling tool. Creators do the opposite for an actuator. In particular, they detect and aggregate symbols using the rules of the modelling tool.
We can define these concepts in terms of the discussion of the paper to date, starting with symbols. Suppose that:
- E is a set of IEs in an ecosystem corresponding to a modelling tool M;
- A is a set of IAs in the ecosystem;
- AP is a pattern for each instance of the M analysers for all e ∈ E (the existence of a modelling tool and ecosystem guarantees the existence of such a pattern).
- ∀ e ∈ E, a ∈ A, ∃ δa∈ Δa such that Pe maps each δa to the same disposition δe and each δe represents each other δe with respect to all M interactions.
What this means is that the analysers map all “symbol” dispositions representing the symbol to the same thing and they are interchangeable in ecosystem interactions. Even when the formats are completely different, the modelling tool patterns in M ensure that they are convertible between each other. MTs also have patterns for structuring symbols in IAs and IEs so that there are MT conventions for their relative structure (e.g., sequence). Any set of symbol instances which meet such structuring requirements we call a content instance. Similarly we can define a content type. Call any disposition which is contained in a content type symbolic. Not all dispositions are symbolic.
With these definitions we can convert symbolic dispositions to symbolic content and, in later elements of MfI, refer to content within the context of a modelling tool in a way which is consistent with the earlier models about properties and entities.
So, in MfI, a modelling tool M is a tuple (I, S, Cp, A, Ch) defined by the following:
- a set of IE patterns, I = IE(M) (each including patterns for sensing, actuation, analysing, creating and connecting);
- a set of symbol types, S = ST(M);
- a set of content patterns, based on ST(M), Cp = CT(M);
- a set of IA patterns, based on ST(M), A = IA(M);
- a set of channel patterns, Ch = CH(M);
- each sensor instance consistent with a pattern in IE(M) consumes IAs which are consistent with a pattern in IA(M) over a channel consistent with a pattern in CH(M);
- each actuator instance consistent with a pattern in IE(M) produces IAs which are consistent with a pattern in IA(M) over a channel consistent with a pattern in CH(M);
- each IA consistent with a pattern in IA(M) is consumed or produced by all IEs consistent with at least one pattern in IE(M);
- each IA consistent with a pattern in IA(M) contains content consistent with at least one pattern in CT(M);
- each channel consistent with a pattern in CH(M) is used by at least one IE consistent with a pattern in IE(M).
From the definitions, it seems that the definitions are mutually dependent since symbols rely on modelling tools and vice versa. However, the reality is that they co-evolve over time.
If M is a modelling tool, then there is an associated information ecosystem Eco(M) = (E, A, C) for which:
- E = {e: e is an instance of some pattern in IE(M)};
- A = {a: a is an instance of some pattern in IA(M)};
- C = {c: c is an instance of some pattern in Chan(M)}.
With these pieces in place we can now continue the discussion started earlier about relations and types of connection. Any property of a slice or slices or relation between any number of slices corresponds to a physical process as shown in the following Table 1.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Type of connection | Equivalent as physical process |
|---|---|---|
| 1 | Physical process instance | Physical process instance (as in PCMs or ECMs) |
| 2 | m slices satisfy relation | There is an ecosystem process, which is an instance of a modelling tool pattern, which takes m slices as input and generates a content instance which is part of the content type “true” as output when the relation is satisfied |
| 3 | m slices have a property | There is an ecosystem process, which is an instance of a modelling tool pattern, which takes m slices as input and generates a content instance which is part of the ecosystem content type as output representing the value of the property |
For any connection of types two and three in the table, we can say that the connection supports entities and processes of particular types if the corresponding physical process or process type (in the right hand column of the table) requires the corresponding ecosystem patterns.
3.5. Virtual Connection Models
Virtual Connection Models (VCMs) differ from PCMs and ECMs in that the types of connection shown in Table 1 are included and ecosystem content, as described above, is also represented. These ideas are applied to the generic IE model. The term “virtual” is used because, with the exception of connections representing physical process instances, the additional types of connection represent “what ifs”. They define what would happen if a particular process type was applied to particular slices.
Let C be a content type corresponding to some connections defined in the manner of Table 1. We can define the Virtual Connection Linnet (VCL), Ck, for entities {xi} and their d-interactions {ej} and connections C at time tk in the following way.
- let v(xik) be the pointer with label xi and value δxik, where δxik is the disposition of xi at time tk;
- let e(ejk) be the pointer with label ej and value δejk, where δejk is the disposition of ej at time tk;
- let c(clk) be a pointer with label lab(c(clk)) ∈ C and value representing the relevant ecosystem process;
- let V(Ck) = ∪i {v(xi)}, E1(Ck) = ∪j {e(ejk)}, E2(Ck) = ∪l {c(clk)} and E(Ck) = E1(Ck) ∪ E2(Ck);
- N1(Ck) = {(v, e, w}: v, w ∈ V(Ck), e ∈ E1(Ck), the d-interaction represented by e connects the entities represented by v and w};
- N2(Ck) = {(x, e, y}: x, y ∈ V(Ck) ∪ E(Ck), e ∈ E2(Ck), the process represented by e supports x and y};
- N(Ck) = N1(Ck) ∪ N2(Ck);
- Ck = (V(Ck), E(Ck), N(Ck)).
Figure 3 shows the relationship between a generic IE and its environment with the interfaces between elements numbered.
Figure 3.
A generic IE in the context of Virtual Connection Models (VCM).
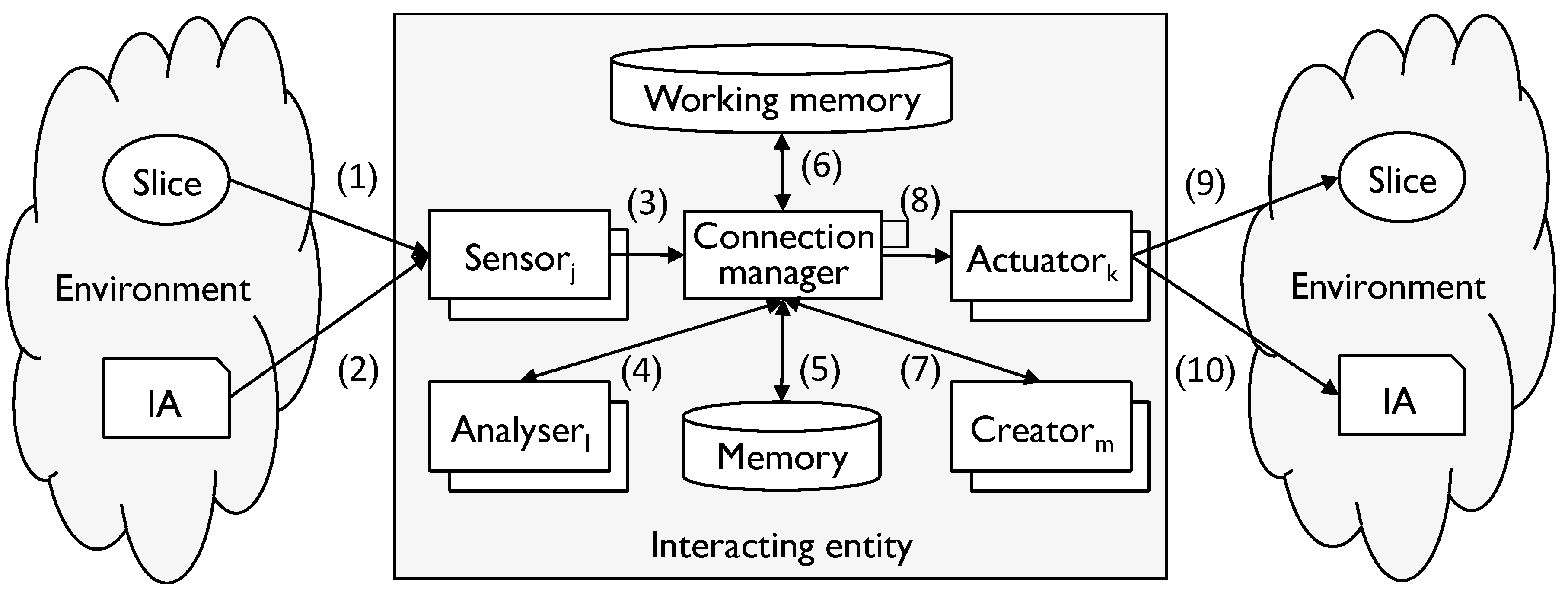
The different stages are as follows:
- (1)
- Environment input: an input interaction with the environment;
- (2)
- IA input: an input interaction with the environment in which the source of the input is an IA;
- (3)
- Converted input: the input converted into a form which can be manipulated by the IE;
- (4)
- MT-converted input: the input converted into a form consistent with the relevant modelling tool (if any);
- (5)
- Memories: material collected from memory;
- (6)
- Attention: the short-term picture created by the IE in working memory;
- (7)
- MT-converted output: output converted into a form consistent with the rules of a modelling tool;
- (8)
- Converted output, environment output, IA output: the reverse of the corresponding input.
In a VCM we can model memory by defining the inputs and outputs in terms of linnets. In principle (and subject to physical limitations) any linnet can be stored, but it is important to note that there are two different types. The output from an analyser is symbolic, whereas environment input is not.
Storage of these different types corresponds to different types of human and computer memory. Humans have semantic memory and episodic memory [15]. Computer databases include symbolic records and also binary large objects (things like media files). For IEs in general we use the terms symbolic memory and event memory to distinguish between them.
Retrieval of memories faces a combinatorial problem so selection pressures demand a way of specifying a manageable portion. In computing, languages like SQL [14] have been defined for that purpose. In MfI, queries are based on patterns which are linnets in which there is the potential for pointers to be uninstantiated. The response to a query is an aggregated linnet which contains copies of linnets in memory that match the pattern. The scope of the query pattern has a large impact on the results. A larger linnet pattern (in the sense of super-linnet) will constrain the search more.
3.6. Information Artefact Models
IAs are physical entities and their behaviour as physical entities can be incorporated in ECMs. However, they are also the repositories of ecosystem content. Information Artefacts Models (IAMs) will consider this aspect. Previous sections have shown how content is related to physical properties, so IAMs support just content connections. Each modelling tool, M, has a set of IA patterns, IA(M)—each of which is a linnet—which defines the permissible structures for M in terms of the symbol types of M, ST(M).
Symbols can correspond to characters (as in written language), gestures (including some human or animal gestures or, in a more complex example, sign language), images (as in computer icons) or, more generally, any slice. So in the light of the discussions above we need to be precise about content pointers and how we represent them.
Define:
- SS(M) to be the set of ordered sequences of elements of ST(M);
- CS(M) to be the subset of SS(M) containing permissible modelling tool content.
- lab(c) ∈ CS(N) (where N is the modelling tool for consumers of the model);
- val(c) ∈ CS(M).
Suppose that:
- ap ∈ IA(M) for a modelling tool M;
- UV(ap) is the set of uninstantiated pointers in ap.
- instantiating c ∈ UV(ap) means that val(c) is given the value vc for some vc ∈ CS(M);
- an Information Artefact Linnet (IAL) conforming to ap is obtained by instantiating all elements of UV(ap).
The discussion above relates IAs to a single modelling tool whereas in reality different modelling tools can be used. For example, a document may contain English text and calculus, or text and images. So we need to define a Composite Information Artefact (CIA), A0, which is an IA conforming to modelling tool MT0, which is instantiated (in part, at least) with pointers whose values are IAs, Ai for i > 0, conforming to modelling tool MTj. In turn the Ai may be instantiated with IAs conforming to other modelling tools and so forth.
4. Information Quality (IQ)
This section discusses Information Quality (IQ) in the context of MfI. We are all familiar with reasons why the quality of information degrades. For example:
- the human memory is fallible;
- digital media wear out and fail (as anyone who has suffered a computer disc head crash can attest);
- transmission over a network can be unreliable.
It pays to be careful about IQ. Kahneman [10] presents a clear warning about the difficulties that people have with IQ and there are entire areas of human experience which rely on those difficulties. Magic provides a good example; in [16], the authors show how the tricks involved in magic are linked to neuroscience.
IQ is in the same position as information as a whole—there is no clear agreement as to what it is. Burgin [11] provides a thorough review. So we need to be clear what we mean by information quality (IQ) and how it can be measured. If x is an IA we can ask the following questions:
- how well does x represent what it is intended to represent?
- how useful is x in what an IE needs to achieve?
4.1. Interpretation
Section 3 above shows that the relationship of information with the physical world takes place in IEs and, more specifically, in the connections made in working memory. However, what is the nature of those connections? And what is being connected?
We can understand more about information by examining the relationship of information with the physical world. One possibility is that information describes one or more slices—the subject of the information. So, for example, “grass is green” describes grass. More generally, in the traditional view of grammar, the predicate provides a property that the subject is characterised by.
But a model for information should support all kinds of information. So also consider, for example, scientific laws encoded as mathematical equations and how they apply to the world. In this case, what is being described: the right hand side of the equation or the left? Clearly in this case the equation is stating that two things, described in different ways, are the same.
The same idea applies, in a sense, to language. “Some grass is green” and “some green things are grass” are logically equivalent and provide the same information, but have different subjects. This means that the direction is a function of language to focus attention on the subject, not fundamental to the inherent information. When the direction matters we can refer to the subject and qualifier.
Whether or not the direction is relevant depends on the purpose of the information. Consider the following examples:
- the whodunit question: what is the “something” (the subject) that some information describes?
- the completeness question: what other information is there about the subject?
For example, consider the following sentence: C = “John from Rome wore a coat”. Suppose then, that:
- Sc = slices corresponding to people wearing coats;
- Sj = slices corresponding to people called John;
- Sr = slices corresponding to people from Rome.
So, how does this relate to the description of MfI above? To understand this question better we need to look more at modelling tools. Content in modelling tools is of the following types:
- atom: the fundamental indivisible level of content in the modelling tool (note that this definition is different from the definition of “atom” in [17]) ;
- chunk: groups of atoms;
- assertion: the smallest piece of content that is a piece of information—again composed of two chunks in a manner that conforms to an assertion pattern;
- passage: a related sequence of assertions.
| Component | Examples | Interpretation |
|---|---|---|
| Atom | Language: a word Mathematics: a variable Programming: a variable | A set of slices |
| Chunk | Language: a phrase Mathematics: a function with variables Programming: an expression | A set of slices that further constrains the slices corresponding to individual atoms |
| Assertion | Language: a sentence Mathematics: an equation Programming: an assignment statement | A set theoretic relationship between two sets of differently defined slices |
| Passage | Language: a paragraph (of assertions about the same things) Mathematics: simultaneous equations Programming: a function or subroutine | Multiple set theoretic relationships between sets of differently defined slices |
To make this more precise let us first consider the relationship between interpretation and content. The following diagram (Figure 4) shows the generic IE model taking this into account.
Figure 4.
The generic IE and content.
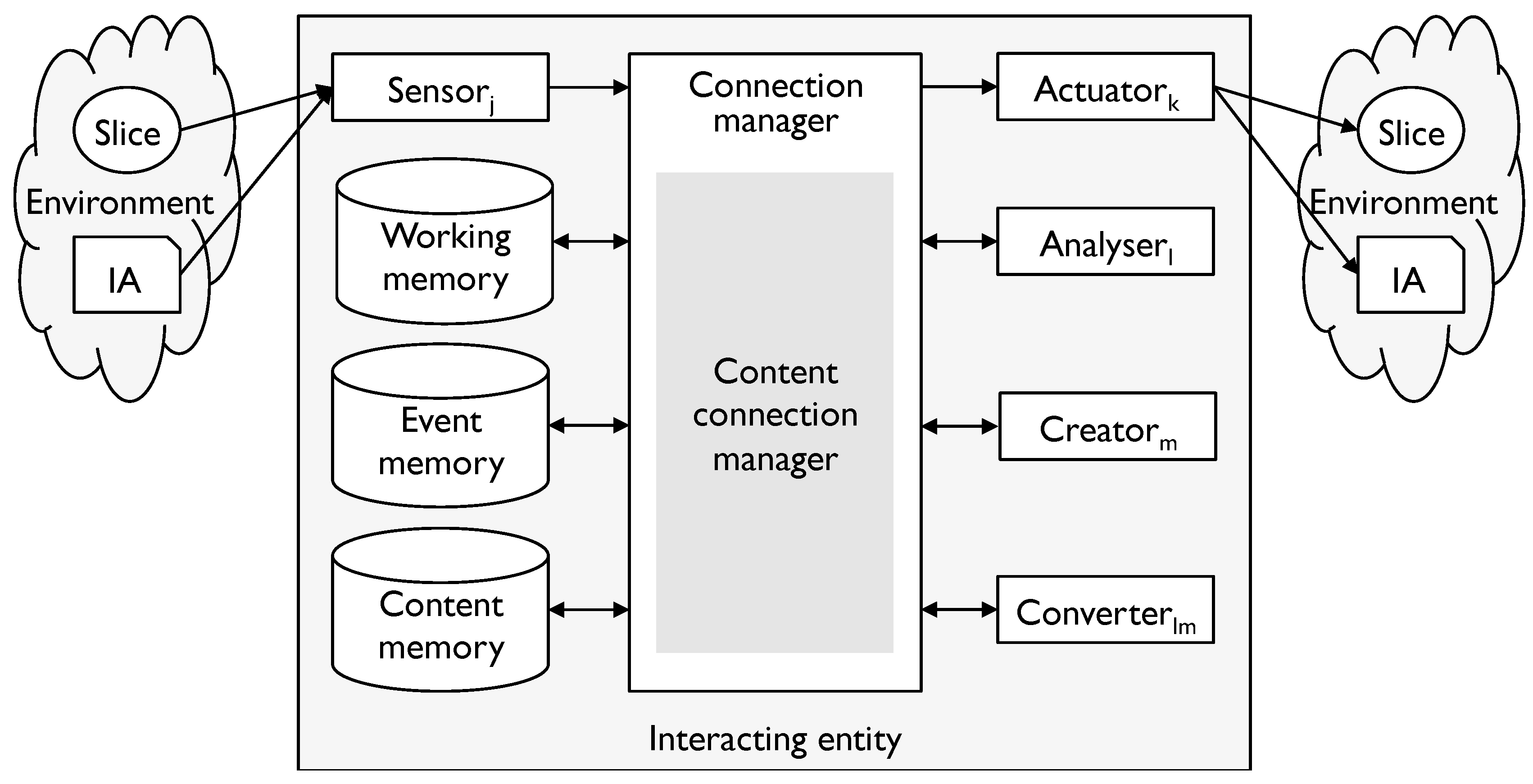
The diagram shows three kinds of memory. Working memory is the same as before, but persistent memory has been split into event memory and content memory. The diagram also recognises that IEs work with more than one modelling tool and may convert between them. This might include, for example:
- humans converting between French and English;
- computer programs converting between messages using a banking protocol and their database structure.
When we are dealing with content we can define variants of the transmission function since we can use content types instead of dispositions. Suppose that M and M’ are modelling tools, x and y are entities and α a transmission type. Let us make the following definitions:
- ΓΜ is the set of content in M;
- ΓcΜ is the set of chunk content in M;
- ΓaΜ is the set of assertion content in M;
- ΓpΜ is the set of passage content in M;
- Ξ is the set of set theoretic relationships (including ⊆, ⊇, ⊂, ⊃, ∩ = ∅, ∩ ≠ ∅);
- Σ is the set of all slices and Σ’ ∈ Σ;
- T is a set of discrete times.
- analysis (M) dcMα: Δxoα x T → ΓΜ (from disposition to content with modelling tool M);
- creation (M) cdMα: ΓΜ x T→ Δyiα (from content to disposition with modelling tool M);
- conversion (M,M) ccMα: ΓΜ x T→ ΓΜ (from content to content within modelling tool M);
- conversion (M, M’) ccMM’α: ΓΜ x T→ ΓΜ’ (from content to content, converting from M to M’).
- chunk interpretation (M) ciM: ΓcΜ x T → 2Σ’ (the set of slices which is the interpretation of a chunk with modelling tool M at a specific time);
- assertion interpretation (M) aiM: ΓaΜ x T → 2Σ’ x Ξ x 2Σ’ (the sets of slices and relation which is the interpretation of an assertion with modelling tool M at a specific time).
- passage interpretation (M) piM: ΓpΜ x T → 2Σ’ x Ξ x 2Σ’ (the sets of slices and relation which is the interpretation of a passage with modelling tool M at a specific time).
- S iλt = {s ∈ Σ’: i(λ, t) = (s, r, u), for some u ∈ Σ};
- U iλt = {u ∈ Σ’: i(λ, t) = (s, r, u) for some s ∈ Σ}.
These definitions allow us to look at interpretation by IEs. Interpretation by an IE depends on the nature of its connections in memory and the degree to which they are exercised. Depending on the type of connection developed in working memory, a piece of chunk content will be connected to other content and memories in event memory. The net result will be the capability to match (or not) any given slice corresponding to a chunk interpretation. If two pieces of chunk content are combined in an assertion, the same capability will correspond to an assertion interpretation. Each connection constrains the set of slices that may match so the more extensive the connection the greater the constraint.
The amount of “effort” exerted by an IE is linked to the extent to which it exercises the connection and determines the constraints. Kahneman’s Systems 1 and 2 (see [10]) provide an example.
The matching is, like the connections above of which it is an example, a “what if”—it is not necessarily validated. Any interpretation produced by an IE can, in principle, be tested. (Popper [18] showed the significance of hypotheses and refutation in the scientific method and science is an example of the large scale ecosystem interpretation of information.)
4.2. Geometry and Information
The discussion of interpretation forms the foundation for a discussion of information quality. Comparisons of pieces of information with respect to some quantity lead naturally to the following questions:
- When are two pieces of information the same with respect to the quantity?
- When does one piece of information have more of the quantity than another?
The pointers defining the domain and range of a content function α can be either continuous (normally real numbers) or discrete and either single dimensional or multi-dimensional. The nature of the pointers determines the nature of the order (if any) that applies. In some cases a total order applies—in some cases, partial. The following Table 3 provides some examples.
| # | Example | Disposition pointer(s) | Content pointer(s) | Order |
|---|---|---|---|---|
| 1 | Temperature | Continuous, single dimensional | Discrete, single dimensional | Total |
| 2 | Length of the mercury in a tube | Continuous, single dimensional | Discrete, single dimensional | Total |
| 3 | A number as a finite string of digits | Discrete, single dimensional | Discrete, single dimensional | Total |
| 4 | Personal assessment of temperature into one of {cool, cold, warm, hot} | Discrete, single dimensional | Discrete, single dimensional | Partial (there may be an overlap between “cool” and “cold” for example) |
| 5 | Shape | Continuous, multi-dimensional | Discrete, multi-dimensional | Partial (induced by the total order for each dimension) |
| 6 | Species (e.g., lion, cheetah, leopard) | Discrete, single dimensional | Discrete, single dimensional | No order |
Note that content, by its nature, is always discrete (even if it represents a number, it is only to a finite number of decimal places). In some cases (for example, number 4 in the table) the order is a convention of the ecosystem.
In some cases properties are preserved, in other cases not. Define tonic to be either monotonic or antitonic if the domain and range have the same order type (total or partial) and p-tonic where the domain is total and the range is partial. A function is discriminating if either of the following holds:
- The range is discrete;
- The range is continuous and contains two or more disjoint subsets.
| Example | Domain | Range | Transmission function | Metric |
|---|---|---|---|---|
| Reading a mercury thermometer | Continuous, total order | Continuous, total order | Tonic | Yes |
| Reading a digital thermometer | Continuous, total order | Discrete, total order | Tonic | Yes |
| Personal assessment of temperature into one of {cold, cool, warm, hot} | Continuous, total order | Discrete, partial order | P-tonic, discriminating | No |
| Recognition of cat species into {lion, leopard, cheetah} | Continuous, multi-dimensional, no order | Discrete | Discriminating | No |
4.3. Measurement
Science has some well-established concepts for measuring the quality of scientific information. This section examines whether we can generalise these to support the wider concepts of information quality. Three key measures are accuracy, precision and resolution which can be defined as follows:
- Accuracy is the degree to which a measurement is close to the true value;
- Precision defines the extent to which repeated measurements give the same result;
- Resolution defines the size of change in a property which produces a change in the measurement.
The discussion about geometry above indicates some of the limitations that apply to transmissions but similar ideas also apply to interpretation functions. The sections below look at chunks first. All of the discussion applies to an IE and a modelling tool M.
Suppose that c, c’ are chunk interpretation functions, t ∈ T and λ ∈ ΓcΜ. Define:
- c < λt c’ if c (λ, t) ⊂ c’ (λ, t);
- c ≤ λt c’ if c (λ, t) ⊆ c’ (λ, t);
- c = λt c’ if c (λ, t) = c’ (λ, t).
The concept of “true value” is not always clear in real life. Some art forms (e.g., the “whodunit”) are based on the difficulties associated with it. Even for fundamental examples in science the nature of “true value” and how it is measured changes (think, for example, of the changes in definition of fundamental units like the metre). This shows that “true value” is based on a consensus about one or more measurement processes. This concept translates easily to MfI in the form of the ecosystem. Let us assume that for all t ∈ T and λ ∈ ΓcΜ, ∃ an ecosystem chunk interpretation function cE. The ecosystem chunk interpretation function determines the “true value” with respect to the ecosystem.
These ideas lead to definitions of accuracy. Suppose that c, c’ are chunk interpretation functions, t ∈ T and λ ∈ ΓcΜ. Then we can say that:
- c is accurate (with respect to t and λ) if c =λt cE;
- c is inaccurate (with respect to t and λ) if c (λ, t) ∩ cE (λ, t) = ∅;
- c is more accurate than c’ (with respect to t and λ) if cE ≤λt c <λt c’ or cE ≥λt c >λt c’; (and similarly less accurate);
- c is as accurate as c’ (with respect to t and λ) if cE ≤λt c ≤λt c’ or cE ≥λt c ≥λt c’;
- c is partially accurate if it is not accurate, inaccurate, or more or less accurate than cE.
One interpretation has greater resolution than another if more chunks of content map to sets of slices. So, for any t ∈ T, Σ’ ∈ Σ define:
- res (c, Σ’, t) = |{λ ∈ ΓcΜ: σ ∈ c(λ, t), for some σ ∈ Σ’}|;
- c has greater resolution than c’ (with respect to t and Σ’) if res (c, Σ’, t) > res (c’, Σ’, t);
- c has lower resolution than c’ (with respect to t and Σ’) if res (c, Σ’, t) < res (c’, Σ’, t);
- c has resolution as good as c’ (with respect to t and Σ’) if res (c, Σ’, t) ≥ res (c’, Σ’, t);
- c has the same resolution as c’ (with respect to t and Σ’) if res (c, Σ’, t) = res (c’, Σ’, t).
Precision measures the variation in interpretation of a chunk over time. For any λ ∈ ΓcΜ define:
- the ∩-range of c with respect to λ, ∩-ran (c, λ) = {σ: σ ∈ c (λ, t) ∀ t ∈ T};
- the ∪-range of c with respect to λ, ∪-ran (c, λ) = {σ: ∃ t ∈ T such that σ ∈ c (λ, t)};
- c is precise (with respect to λ) if ∩-ran (c, λ) = ∪-ran (c, λ);
- c is imprecise (with respect to λ) if ∩-ran (c, λ) = ∅;
- c is more precise than c’ (with respect to λ) if
- ∩-ran (c, λ) ⊃ ∩-ran (c’, λ) and ∪-ran (c, λ) ⊆ ∪-ran (c’, λ), or
- ∩-ran (c, λ) ⊇ ∩-ran (c’, λ) and ∪-ran (c, λ) ⊂ ∪-ran (c’, λ);
- c is as precise as c’ (with respect to λ) if
- ∩-ran (c, λ) ⊇ ∩-ran (c’, λ) and ∪-ran (c, λ) ⊆ ∪-ran (c’, λ).
An assertion consists of two chunks and a relationship. The definitions above show how accuracy, precision and resolution apply to chunks. What can be said of the relationship? Each member of Ξ is discrete and there is no implied partial order. So the only comparison that makes sense is equality.
Therefore, suppose that:
- a1 is an assertion interpretation with induced chunk interpretations c1 and c1’ and relationship r1;
- a2 is an assertion interpretation with induced chunk interpretations c2 and c2’ and relationship r2;
- t ∈ T, Σ’ ∈ Σ, λ ∈ ΓcΜ.
- a1 is accurate (with respect to t and λ) if c1 is accurate and c1’ is accurate and r1 = rE (where rE has the obvious definition);
- a1 is more accurate than a2 (with respect to t and λ) if
- r1 = r2 and
- c1 is more accurate than c2 and c1’ is as accurate as c2’, or
- c1 is as accurate as c2 and c1’ is more accurate than c2’;
- a1 has greater resolution than a2 (with respect to t and Σ’)
- r1 = r2 and
- c1 has greater resolution than c2 and c1’ has resolution as good as c2’, or
- c1 has resolution as good as c2 and c1’ has greater resolution than c2’;
- a1 is more precise than a2 (with respect to λ) if
- r1 = r2 and
- c1 is more precise than c2 and c1’ is as precise as c2’, or
- c1 is as precise as c2 and c1’ is more precise than c2’.
Precision applies to interpretations of the same content at different times. This may include multiple instances of the same piece of content in the same passage. In this case, as in others, the context may determine that the different interpretations should be different—that, according to the interpretation, they are intended to refer to different sets of slices. In this case we need to narrow the measures to groups of content, that is content which, according to the rules of the MT are intended to refer to the same thing.
The largest unit to which IQ applies is the passage—a related sequence of assertions. Using the above definitions we can consider how the notion of quality applies to a passage and, in particular, to some adjectives that are sometimes applied. In [19] the authors say that accuracy, completeness, consistency and timeliness are “frequently mentioned dimensions” of IQ. Consider these in turn.
The accuracy of a passage depends on the accuracy of the individual assertions which comprise the passage.
Completeness is a more difficult topic. An IA can never be a complete description of a slice. This is the “blind men and the elephant” point discussed, for example, in [20] and [21]. So completeness does not fit well with intrinsic IQ. However, with action IQ the position is different. The question here is the following: is an IA sufficiently complete to enable the IE to choose reliably between different options for action? This question breaks down into two components:
- coverage: does the IA contain content which is derived from enough properties?
- resolution: does the interpretation provide sufficient resolution to discriminate between the options available?
- a chunk c is the subject of assertions a1, …, an;
- λn is the passage which contains a1 to an in sequence.
Consistency addresses the question: is the interpretation of a given chunk (or atom) the same in different parts of the passage? Precision measures changes in interpretation so we can use precision to measure consistency.
Timeliness is a measure of a totally different type. It measures the gap between the time of measurement of properties and the time of interpretation.
Therefore, we can characterise the two types of IQ in the following way. Intrinsic IQ is a combination of accuracy, precision, resolution and timeliness. Action IQ adds in coverage as well.
4.4. Assessing IQ
The definitions above compare an IE’s interpretation with an ecosystem interpretation given a particular IA. However, if the process by which the IA was created can be examined then a further avenue is opened up. Any IA is created through a repeated process of sensing, interpretation and creation, potentially combining many different elements.
In theory, the measures described above can be applied to each stage of interpretation, but there is also a reverse process in which a set of connections inside an IE is converted into an IA. Again we can apply the measures above in exactly the same way as before to this position (only the time order has changed—we are still comparing an IE interpretation with an ecosystem interpretation).
So, theoretically, if there is sufficient evidence available, it is possible to examine the various processes at work to assess IQ. However, this can be a very resource intensive process to which different ecosystems have different approaches. The following Table 5 provides some examples.
| Ecosystem | MT | Assessment of IQ | Characteristics |
|---|---|---|---|
| Science | Mathematics (often) | Careful design of experiments Peer review Transparency | High IQ Resource intensive |
| English Law | Legal English | Rigorous evidence gathering Trials and cross-examination | Relatively high IQ Resource intensive |
| Computer protocols | Tools like XML | Careful specification Careful implementation and testing Message validation | IQ linked to quality of definition Relatively resource intensive definition and implementation but efficient use (generally) |
| English speakers | Spoken English | Questions and answers | Variable IQ Relatively efficient |
Because of the potential heavy resource overhead, it is natural that selection pressures have identified shortcuts that are good enough in many circumstances. However, nevertheless, since IQ is important, it is important that IEs can determine if the quality of an IA is good or not. Consider the following examples:
- people trust brands for information just as they trust brands for other products (think of news organisations, for example);
- when users use a computer system they rely on the testing that has been carried out.
In these cases, the IE trusts that the IE providing the IA is reliable and that the reliability will transfer to the IA. This trust is not universal—it is an attribute of information ecosystems. The topic of trust in relation to IT is analysed in [23].“For information has trouble, as we all do, testifying on its own behalf. Its only recourse in the face of doubt is to add more information. ... Piling up information from the same source doesn’t increase reliability. In general, people look beyond information to triangulate reliability.”
5. Information Friction (IF)
Selection pressures drive improvements in both IQ and efficiency. We can measure efficiency using the concept of information friction (IF). In [24], the authors were among many to talk of the frictionless economy, capitalism or information. Definitions vary and often include IQ as a component, but in this paper the term friction is used as a measure of the amount of resource used in measuring, transporting, converting and interpreting information. “Resource” is a general term which encompasses effort, food, fuel, equipment, expenses and so forth. To enable comparison we will assign a single value to resource usage. This is the approach taken in business in which all assets are assigned a (financial) value.
Suppose that:
- Φ is the set of all d-interaction function types;
- Ψ is the set of all space-time locations;
- N is the set of natural numbers;
Friction applies along all parts of the derivation of an IA so, in turn, we will consider measurement friction, transmission friction, conversion friction and interpretation friction. In each case, friction is a primarily a pragmatic issue, not a theoretical one.
Measurement friction measures the cost of measuring the physical properties of slices. There is a large range of possibilities here ranging from the complicated and man-made (the Large Hadron Collider) with very high IF to the complicated and natural (human senses) with low IF.
Transmission friction has seen the largest impact of changes in technology.
Conversion changes the modelling tool used for an IA. Simple examples include:
- translation from one (human) language to another
- translation from one computer data structure to another (perhaps storing an incoming message in a database).
Interpretation friction includes many of the examples which make working with information difficult. Examples include:
- interacting with a computer (in which both parties are trying to interpret the other!)
- deciphering an ancient document
- reading a news story.
Improvements in technology have seen a large reduction in IF. Two centuries ago sending a message to the other side of the world required a ship. Now we can send an email. IQ has not improved at the same rate. The discussion above clarifies this point. For the most part, technological changes have reduced transmission friction—they make it much easier to copy IAs from place to place. This does not, in itself, improve IQ except with respect to timeliness. This effect is exacerbated by Kahneman’s Systems 1 and 2. We are not instinctively aware of deficiencies in IQ so the selection pressures to improve it are smaller.
6. Floridi’s Questions
In [2], Floridi articulated a number of questions about information. This section examines the relationship with the following questions, which MfI tackles directly:
- (P1) “what is information?”;
- (P12) “the informational circle: how can information be assessed? If information cannot be transcended but can only be checked against further information—if it is information all the way up and all the way down—what does this tell us about our knowledge of the world?”.
6.1. What is Information?
Floridi poses the following question: “what is information?”. In [25], Dodig Crnkovic and Hofkirchner provide the following summary:
MfI provides a response to this statement and shows how these different elements combine. Consider each element in turn.“Information can be understood as range of possibilities (the opposite of uncertainty); as correlation (and thus structure), and information can be viewed as code, as in DNA .... Furthermore, information can be seen as dynamic rather than static; it can be considered as something that is transmitted and received, it can be looked upon as something that is processed, or it can be conceived as something that is produced, created, constructed .... It can be seen as objective or as subjective. It can be seen as thing, as property or as relation. It can be seen from the perspective of formal theories or from the perspective of informal theories .... It can be seen as syntactic, as semantic or as pragmatic phenomenon, and it can be seen as manifesting itself throughout every realm of our natural and social world.”
“Range of possibilities (the opposite of uncertainty)”
IEs need to be able to recognise and discriminate states in the environment which can lead to more or less favourable outcomes. They need to be able to maximise the quality of the link between these states and possible actions and outcomes. Moreover, they need to convert the assessment into instructions which cause actions which increase the chance that the outcomes will be favourable.
Section 4 discusses these questions in the context of IQ. Each step requires an interpretation which links connections in working memory reliably to external slices and which enables accurate discrimination of states and outcomes. This analysis links MfI, for example, to the following definitions:
“As correlation (and thus structure)”
Within MfI, linnets model structures and different information ecosystems use different modelling tools which embed some of these structures. The structures model many different types of connection and correlation.
“As code”
IAs have a structure (including “code” in the sense of the quote above) which forms part of one or more modelling tools. The structure and processing co-evolve in information ecosystems.
“Dynamic, rather than static”
All of MfI is based on the operation of physical processes so it is inherently dynamic. The Physical Connection Models and Extended Connection Models described in Section 3 provide the link to physical processes which underpins the other models.
“Transmitted and received”
MfI is based on d-interactions in which properties of an entity and its environment are updated. Under some circumstances (which is called transmission in Section 3) and under the right ecosystem conventions this includes transmission and reception in the normal sense.
“Processed, produced, created, constructed”
The generic IE model described throughout the paper shows that IAs are sensed, analysed, created and actuated by IEs.
“Objective or subjective”
In MfI interpretation plays a central role (see Section 4). By its nature, interpretation is particular to an IE and in this sense can be considered subjective (if the term can apply to inanimate objects). When an interpretation is common to an ecosystem or many ecosystems then it may be considered objective.
“Thing, as property or as relation”
Within MfI, information is about models of relations between properties of slices, and this is required for IEs to connect environment states to outcomes. So, information is inherently about things, properties and relations.
“Formal theories or informal theories”
MfI generalises the idea of theory to that of modelling tool. Section 4 describes modelling tools which can be formal or informal.
“Syntactic and semantic”
Modelling tools and the connections using them embody syntax. Other connections, especially the links to outcomes embody semantics.
We can also use MfI to explore some of the other facets of information. The literature (e.g., [2,11,28]) discusses the relationship between different types of information such as facts, data, knowledge and so forth. Within MfI, these are all related to combinations of the following:
- the information ecosystem(s) under consideration;
- information quality;
- the degree of connection implied in an IA or created in an IE.
MfI also reinforces the view that information is relative. In [11], Burgin says that: “the information in a message is a function of the recipient as well as the message.” Logan reviews the relativity of information in [9] and concludes that: “information is not an absolute but depends on the context in which it is being used.” This idea is embedded in MfI. The generic IE model and the discussion about interpretation and connections in working memory make this point clear.
We can also apply MfI to the word “information” itself. Just like any other word, the interpretation of the word “information” is ecosystem- and IE-dependent (which is, in itself, an explanation for the numerous definitions of information [2,11]). It is clear from the IQ discussion that modelling tools are more or less appropriate for different purposes; language is not appropriate if high levels of accuracy, precision and resolution are required (this is why science uses mathematics). This implies that a language-based definition of information may be more open to different interpretations than definitions using more rigorous modelling tools. One of the lessons of MfI is that the right set of modelling tools is required for any purpose.
Information is relative in a different sense—it depends on what is measured, how it is measured and the processes which deliver the information to an IE. It is impossible to capture the entire state of a slice (see [20,21]). However, once the information is measured it may be sensed, interpreted, combined and transmitted many times. The IQ measures discussed in Section 4 provide a mechanism for analysing this further. One conclusion is that two identical IAs may have different IQ when both are assessed (for example, the same words from an expert or a neophyte).
6.2. How can Information be Assessed?
In [2], Floridi poses the following question:
The different MfI models show how information is linked directly to the properties of physical entities. Consider, in turn, the different elements of this question.“The informational circle: how can information be assessed? If information cannot be transcended but can only be checked against further information—if it is information all the way up and all the way down—what does this tell us about our knowledge of the world?”
In MfI, the relationship between physical properties and content is the distinction between PCMs and IAMs (discussed in Section 3), and the development of these elements of MfI shows the relationship. As an example, consider sunlight shining on a rock to which a thermometer is attached, which person A reads and tells person B, as in the following diagram (Figure 5).“If information cannot be transcended but can only be checked against further information— if it is information all the way up and all the way down…”
Figure 5.
Physical properties and content.
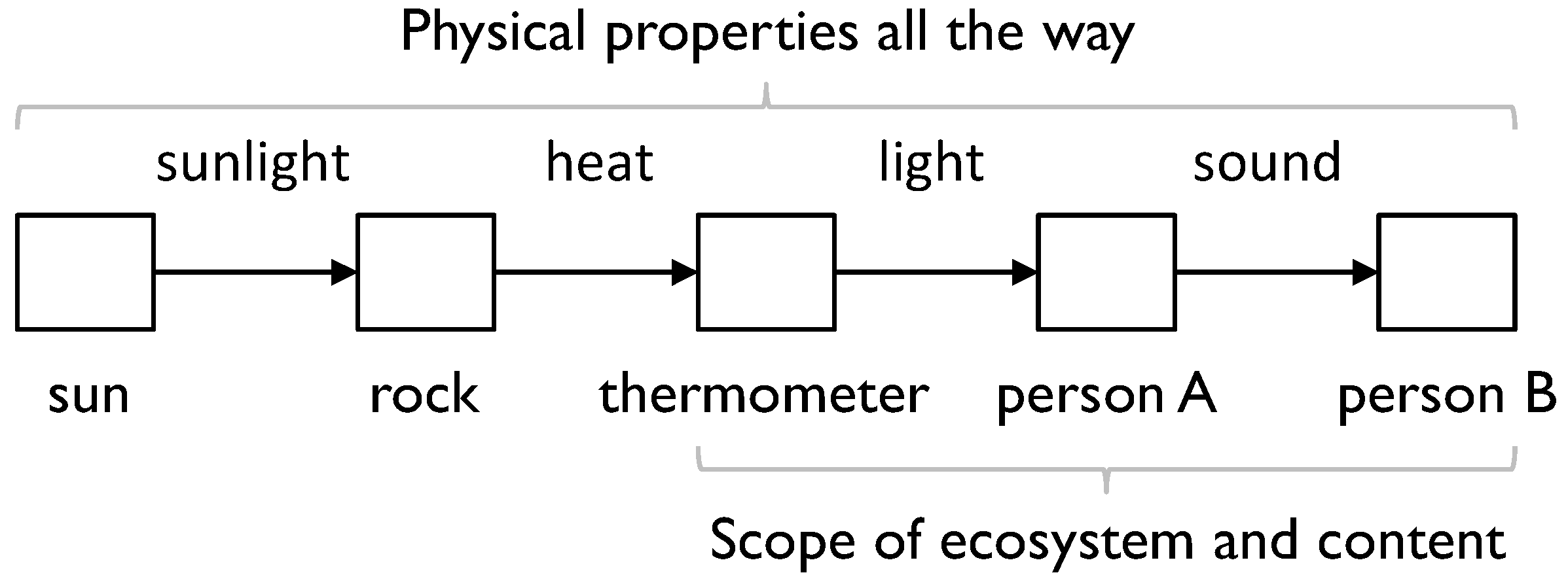
In this example, an ecosystem convention defines the point at which properties become content.
Content is connected to the properties of physical content in two ways. As defined and analysed in Section 3, content is a set of physical properties which (according to ecosystem conventions and processes) is processed in a particular way. Content is also derived from the properties of other physical entities. This can happen in the following ways:
- through interaction (as in the example above);
- through processing existing content within an IE, in which case the new content is derived from the properties of the physical entities which represent the existing content within the IE by some physical processes;
- through the creation of the IE, in which case it is based on a set of physical processes acting on a pattern (which again comprises some properties of physical entities—see Section 2).
Some of the examples created through processing form an interesting category. They include falsehoods, syntactically correct nonsense or imagined ideas—in each case not directly linked to external entities. They are still created in the working memory of an IE by linking content and are properties of physical entities but the difference is that they have very low (or undefined) IQ.
So, according to MfI, instead of the statement above it is more correct to say:
“It is properties of physical entities all the way up and all the way down and, according to ecosystem conventions, some are treated as content.”
Now consider the following question:
According to MfI the premise for this is incorrect, so the question as posed becomes immaterial. However, MfI shines some light on this question when separated from the premise. As described in Section 4, information purports to describe set theoretic relationships between slices characterised using different combinations of properties. This purpose is subject to the vagaries of IQ and, as a result, is delivered with varying degrees of success. This purpose enables IEs to link environment states with potential outcomes in order to help the IE navigate towards a relatively favourable outcome.“What does this tell us about our knowledge of the world?”
7. Conclusions
This paper shows that a model for information which integrates evolutionary, static and dynamic viewpoints provides a richer understanding of the nature of information than a focus on definitions alone and, as a result, provides a sound basis for examining some important questions about information.
The model discusses modelling tools in relation to information. Modelling tools such as language and Mathematics have their advantages and disadvantages. High IQ is difficult with language. Mathematics provides high IQ but at the cost of high IF. This prompts some questions: what other forms of modelling tool strike a different balance? Can we use them to understand information itself better? The application of the tools of MfI to these questions in addition to some of Floridi’s other questions points to directions for further research.
Acknowledgments
Many thanks are due to the referees for their constructive comments.
Conflicts of Interest
The author declares no conflict of interest.
References
- Silver, G.; Silver, M. Systems Analysis and Design; Addison Wesley: Reading, MA, USA, 1989. [Google Scholar]
- Floridi, L. The Philosophy of Information; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Del Moral, R.; Navarro, J.; Marijuán, P. New Times and New Challenges for Information Science: From Cellular Systems to Human Societies. Information 2014, 5, 101–119. [Google Scholar]
- Hofkirchner, W. Emergent Information: A Unified Theory of Information Framework; World Scientific Publishing: Singapore, Singapore, 2013. [Google Scholar]
- Burgin, M. Evolutionary Information Theory. Information 2013, 4, 124–168. [Google Scholar]
- Darwin, C. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life; John Murray: London, UK, 1859. [Google Scholar]
- Smith, A. An Inquiry into the Nature and Causes of the Wealth of Nations; Strahan and Cadell: London, UK, 1776. [Google Scholar]
- Avgeriou, P.; Uwe, Z. Architectural patterns revisited: A pattern language. In Proceedings of 10th European Conference on Pattern Languages of Programs (EuroPlop 2005), Bavaria, Germany, July 2005.
- Wolff, J. The SP Theory of Intelligence: Benefits and Applications. Information 2014, 5, 1–27. [Google Scholar]
- Kahneman, D. Thinking, Fast and Slow; Macmillan: London, UK, 2011. [Google Scholar]
- Burgin, M. Theory of Information: Fundamentality, Diversity and Unification; World Scientific Publishing: Singapore, Singapore, 2010. [Google Scholar]
- Harary, F. Graph Theory; Addison-Wesley: Reading, MA, USA, 1969. [Google Scholar]
- Harary, F.; Gupta, G. Dynamic Graph Models. Math. Comput. Model. 1997, 25, 79–87. [Google Scholar]
- ISO/IEC 9075-11: Information technology—Database languages—SQL—Part 11: Information and Definition Schemas (SQL/Schemata). Available online: http://www.iso.org/iso/catalogue_detail.htm?csnumber=38645 (accessed on 15 September 2014).
- Tulving, E. Episodic and semantic memory. In Organization of Memory; Tulving, E., Donaldson, W., Eds.; Academic Press: New York, NY, USA, 1972; pp. 381–403. [Google Scholar]
- Macknik, S.L.; Martinez-Conde, S. Sleights of Mind; Picador: Surrey, UK, 2011. [Google Scholar]
- Kohlas, J.; Schmid, J. An Algebraic Theory of Information: An Introduction and Survey. Information 2014, 5, 219–254. [Google Scholar]
- Popper, K.R. The Logic of Scientific Discovery; Hutchinson: London, UK, 1959. [Google Scholar]
- Huang, K.-T.; Lee, Y.W.; Wang, R.Y. Quality Information and Knowledge; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Fields, C. Equivalence of the Symbol Grounding and Quantum System Identification Problems. Information 2014, 5, 172–189. [Google Scholar] [CrossRef]
- Brenner, J. Information: A Personal Synthesis. Information 2014, 5, 134–170. [Google Scholar]
- Brown, J.S.; Duguid, P. The Social Life of Information; Harvard Business Press: Boston, MA, USA, 2000. [Google Scholar]
- DeVries, W. Some Forms of Trust. Information 2011, 2, 1–16. [Google Scholar]
- Gates, B.; Myhrvold, N.; Rinearson, P. The Road Ahead; Viking Penguin: New York, NY, USA, 1995. [Google Scholar]
- Dodig Crnkovic, G.; Hofkirchner, W. Floridi’s “Open Problems in Philosophy of Information”, Ten Years Later. Information 2011, 2, 327–359. [Google Scholar]
- Mackay, D.M. Information, Mechanism and Meaning; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Bateson, G. Steps to an Ecology of Mind; Ballantine Books: New York, NY, USA, 1972. [Google Scholar]
- Lenski, W. Information: A Conceptual Investigation. Information 2010, 1, 74–118. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Walton, P. A Model for Information. Information 2014, 5, 479-507. https://doi.org/10.3390/info5030479
AMA Style
Walton P. A Model for Information. Information. 2014; 5(3):479-507. https://doi.org/10.3390/info5030479
Chicago/Turabian StyleWalton, Paul. 2014. "A Model for Information" Information 5, no. 3: 479-507. https://doi.org/10.3390/info5030479