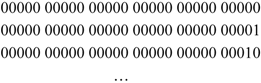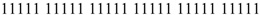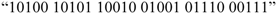4.2. Information and Computing—towards the Identity of Information and (Dynamic) Structure, and out of a Discouraging Representationalism
The creative process of restructuring the experience is characterized by the newly created links of distributed contexts of knowledge. The cultural framework, the “living world” of people has a considerable influence on the structure of new inventions. In the beginning, writing and sketching was not invented to record poems, but to organize trade. Numbers were invented as bundling or grouping of similar elements (for example a bundling of sheep). Similar bundles were named by phonetic articulations: the invention of numbers. Hierarchies of numbers were invented: bundles of bundles, etc. Algebraic systems were invented in order to visualize or to proof different kinds of operations with regards to the activity of bundling and de-bundling. The entire organization of the social system is reflected in those kinds of mathematics. In the beginning, different kinds of numbering were used for different kinds of objects (example: different kinds of numbering for animals, for cereals or for fluids). Even different kinds of number systems were used (for example, Sumerian people used a system to the base of 60; typically, the numbers were also used to interpret more “abstract” entities of the social system: A year for example counted 360 days, which was divided in parts of 60; or the circumference counted three).
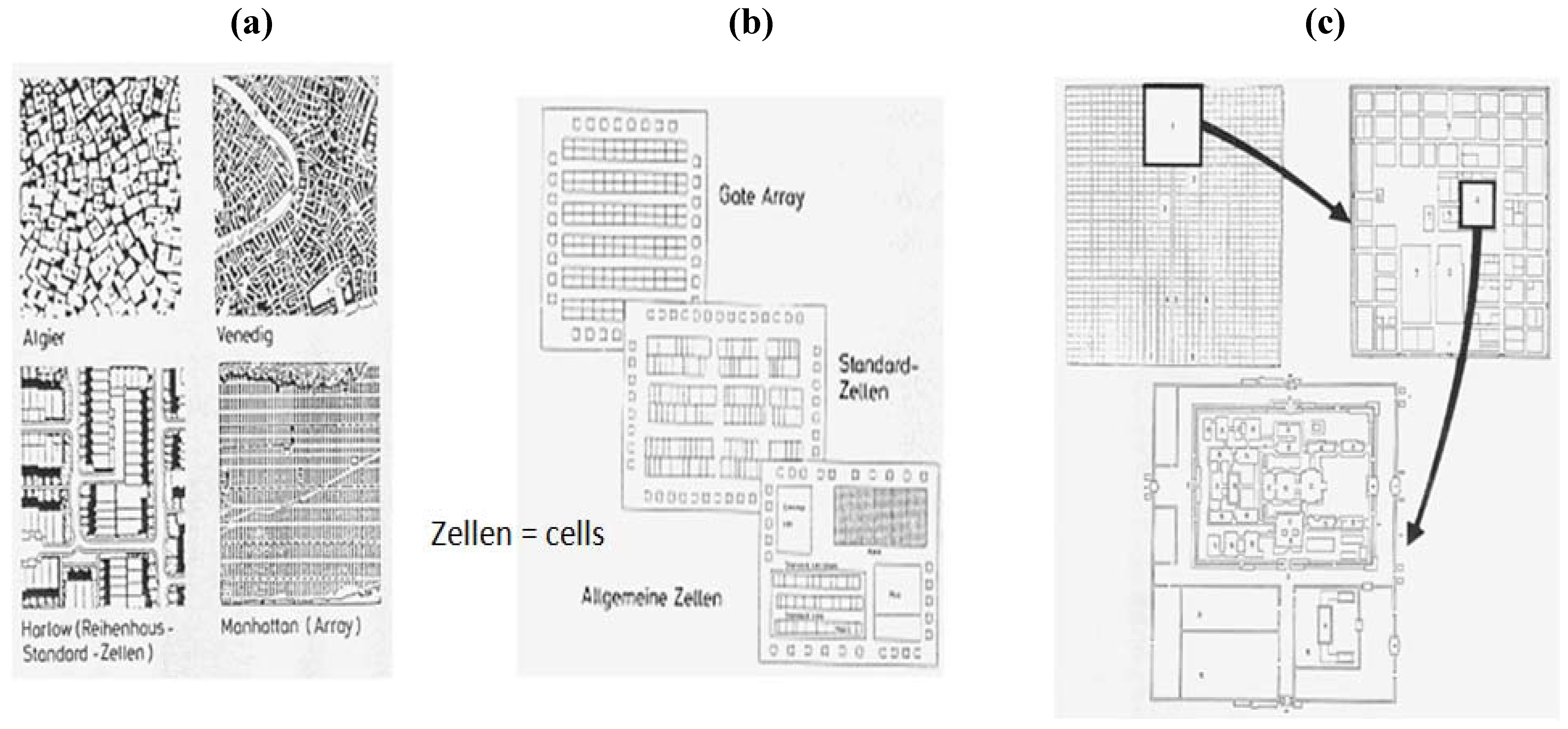
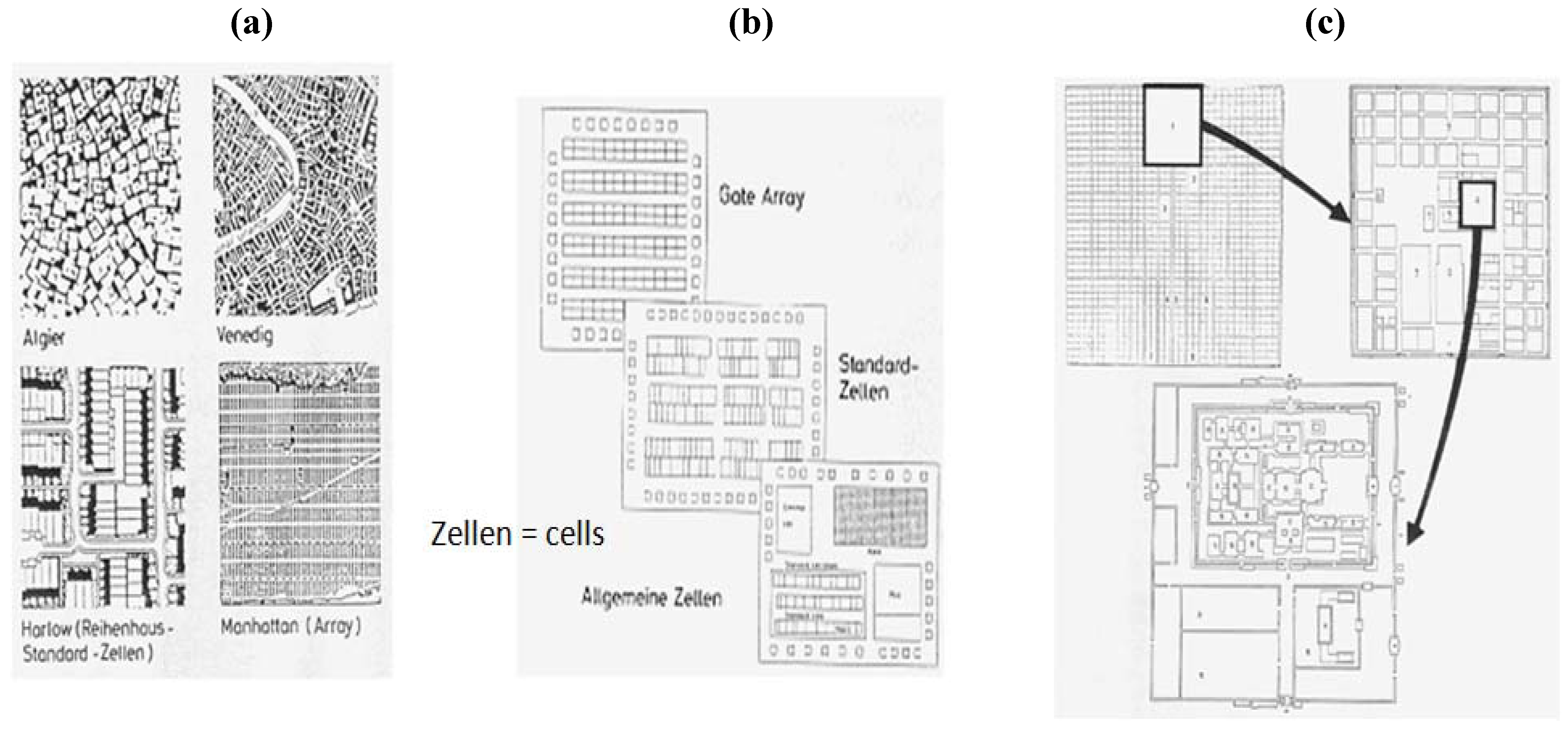
The invention of microelectronics also provides good evidence for the transformation of cultural structures (“ways of living”) into technical developments. The study of older and newer maps of cities leads us to really striking similarities to microchip layouts. The way social functions are reflected in urban development (for example the structures of dwelling houses, work places, supply and recreation structures), as well as the technician who grows up in such surroundings will most likely use such personal thought patterns in his daily work. Microchips do not just look like cities, they even share a comparable functional structurization (common structural elements for transportation, storage (housing), transformations for specific functionalities).
Therefore, they are made at different places at almost the same time, like the invention of the microprocessor by the American Gilbert P. Hyatt in 1969 and—a little later—by Intel. And it becomes clearer that for example the Japanese culture was able to catch up in the semiconductor industry, even without owning the basic patents.
Figure 2 also shows a city in Japan, including the king’s palace. We also have to note that Japan’s science and industry success in catching up in microelectronics was part of the democratic development of the country.
Figure 2.
Similarities between the architecture of integrated circuits ((
a) different kinds of city architecture; (
b) architectures of integrated circuits; (
c) the king’s palace in a city in Japan) and the cultural environment of the engineer (picture from Rüchardt [
32], with kind permission).
During the evolution and development of agriculture, the concept of numbers became concrete and familiar enough for counting. However, the first notation systems for periodic (pre-algorithmic) events had already been known since 20,000 BC and earlier. Hunters marked and counted the appearance of animal herds and—correspondingly—the different seasons. One of the first automated calculation systems was Abacus, which appeared in the ancient Babylon in 2400 BC. Indeed, the first automatic machines were invented in terms of wind-mills or water-mills. Such automats (greek automatos: self moving) are characterized in the way that humans do not directly influence the machine cycle anymore. People remain more and more on an indirect supporting and control level. In fact, this is the birth of information processing machines (in terms that users have to work with an abstract transformational/informational model of such machines). Consequently, Muslim engineers developed the first programmable machines, such as the programmable flute player. The application of more flexible algorithms to computing devices pointed to a next step of modern, symbolic oriented computing machines. Gottfried Wilhelm Leibniz invented the binary system and argued for a unity in thinking and acting—a precursor and enabler of real information processing systems. It is not surprising that he also proposed the usage of empirical databases—the world wide web of the 17th century.
It took slightly more than another decade in order to invent the first programmable computer. Konrad Zuse’s Z1 was still a mechanical computer and was built in 1935–1938. It had already all the basic ingredients of modern computing systems, using the binary system. Zuse’s 1936 patent application (Z23139/GMD Nr. 005/021) also suggests a
von Neumann architecture (re-invented in 1945) with a program and data modifiable in storage. This was the invention of symbolic machines: The world of symbols and their possible transformations characterizes the concept of well-specified,
actual information. Within this world of engineering, Claude Shannon gave a first proposal for a concept of information. But Shannon’s theory of information remained a concept for technically communicating systems and could not be used in order to understand semantics or model semantic-based systems (see Part I of this study). Consequently, the declaration of the content of any message or information seems to be a unique property of human thinking: “Compters process data, not information”, as the German-Austrian computer scientist Peter Rechenberg judged ([
33], translation GL). But we can now give a more precise description of the scenario. We have to argue that the potential dimension of information (in terms of stimulated through received messages) is bound to the receiver and her or his specific capabilities and history. But the lower level or framing parts of any information hold a common and actual content. That is, computers may correctly transform (structures of) actual information. This will be shown in more detail.
The lack of knowledge about this potential dimension of information led to the common (mis-)understanding that the category of information is consequently bound to the subjective dimension of human beings, which cannot be characterized by a physical and compositional concept of information. And for this reason, not all information can be transformed or realized through physical structures. From a pragmatic perspective, the von Neumann architecture is used to implement many different kinds of algorithms. And these algorithms are somehow aligned to human practice; they lack a common physical description, which would support a systematic translation of software-oriented algorithmicity into hardware-oriented structures. Finally, for this intrinsic reason, the domain of computer science is subsequently divided into two different communities: the software community and the hardware community. Those communities follow somewhat different and separated agendas. The software community deals with topics like the logic of programming, structural programming, or object orientation. The hardware community follows the so-called Moore’s law, which indicates that the number of transistors (or the number of capacitors) on an integrated circuit doubles approximately every two years. Consequently, there is a seemingly unbridgeable gap between the approach of designing computer hardware and the approach of designing computer software. In other words: It is not possible to transform an informational software concept into an adequate physical hardware structure. Of course there are approaches from the perspective of engineering. But there is not yet a continuous informational concept.
There is another aspect to be considered. There are considerable efforts to build a computing system with the size and structure of a brain. They are based on so-called neuromorphic processors and “aim to understand information processing in the brain at different scales ranging from individual neurons to whole functional brain areas” [
34]. Those activities indicate a third community of computing system designers. This community supports the idea that information and information processing can be based on a physical fundament. But such an artificial neuromorphic brain would consume up to 10 megawatts of power (which is equivalent to the power consumption of a city). It has already been mentioned that power consumption in computing is becoming a crucial point. The worldwide CO
2 emission of all computing devices has already passed the CO
2 emission of the worldwide air traffic [
35]. There are quite a lot of activities to reduce the required power, which are entitled “green computing”. But those activities have already been taken into account the calculated 10 megawatts of power for an artificial brain.
Those entire problems lead to a crucial point of culmination. How could it be possible to overcome those problems? What would be a path forward to support the further development of the information society? An answer to those questions has already been given by the German engineer and computer scientist Karl Steinbuch (1917–2005). He introduced and used the terminus of “information” in a quite similar manner as outlined in this study: “The human mind’s task is to receive, to process and to store information. It is seemingly implausible that brain functions cannot be explained by methods and data.” ([
36], translation GL) His 1961 book (Machine and Man [
36]) is an example that a modern concept of information has to be based not only on engineering design or physics, but also on anthropology and human sciences. The intent of his book is twofold: Starting from a description of new computing devices and their physical foundation, he then introduces a concept of human information processing and discusses the influence of computing systems on the society.
In his book he already described an invention of artificial neural networks, which he called “learning matrices”. Steinbuch solved some fundamental problems of the so-called “Perceptron”, which was invented by Frank Rosenblatt in 1958 [
37]. Apart from the known diode Steinbuch integrated other elements with configurable and non-linear response curves in his system. However, his basic progress relies on the design of a multi-layered system instead of the one-layer perceptron. He published his ideas in the IEE Transaction on Electronic Computers in 1963, together with U.A.W. Piske [
38].
Steinbuch’s work was not well-known in the US, and for this reason Minsky and Papert came to their negative judgment on artificial neural nets in 1969 [
39]. This book had an overwhelming influence and stopped the research activities in the domain of artificial neural networks for more than one decade.
Besides the successful re-established work on artificial neural networks during the last years, there is another basic structural outcome: This is the concept of associative memory and associative computing. It is of high interest that applications of this approach have been made in the field of Databases and Image Processing [
40]. Especially Database systems, which are used for large-scale Information Retrieval systems like those of Google, are major consumers of energy. Research activities have been made in the US by the University of Berkeley and the Kent State University. Jerry Potter and others developed an “Associative Computing Paradigm” [
41]. The base concept is a method to directly access data by its content, rather than by an artificially calculated address (as it is usually done in commercial database systems). Jerry Potter’s solution is that each data item, which needs to be retrieved, is stored separately and managed by cells. Each cell consists of a Processing element (PE) and a local Memory. The memory of an associative computer consists of an array of cells. Each PE can only access the memory of its own cell. There should be more cells than data. During data retrieval, a search item is handed over to all cells in parallel (“associative search” [
41]). Each PE of each cell executes in parallel the comparison of the search item and the content of the memory of each cell. As a result, each PE propagates logical information, using one or few bits. For example, the PE propagates bit information of “1”, if the comparison was successful (and correspondingly a value of “0”, if the comparison was not successful). Given this scheme, a parallelized search can be implemented. In a next step, further processing of the results can take place. The complete data of the identified cells could be red, and other things (grouping, merging,
etc.) could take place. PE’s are typically made of 8-bit processing units, which perform the required operation. The team described in [
40] the structure and functioning of a newly developed 8-bit associative RISC processor, supporting 36 PE’s. Finally it has to be noted that those implementations are based on adaptations of the von Neumann architecture. And they still implement and execute a SEARCH function to retrieve data, whereas a FIND function would be required. Such a data FIND function has already been proposed by Steinbuch’s learning matrices. We may recall that Steinbuch reported already in 1961 the problem of energy consumption and explored the possibility of saving energy in comparison to von-Neumann implementations, if more hardware-oriented concepts of associative mechanisms were used (
i.e., his learning matrices, [
38]).
Now, taking all those activities into account: Which structural gap does still exist which hinders or slows down the required progress towards more efficient systems? Karl Steinbuch already talked about a required physical foundation of a concept of information and proposed an extension of Shannon’s concept of information. He claimed that the structure of the receiver and his environment (living world) has to be considered as well. There are two blocking points that need to be overcome:
Blocking Point 1: The paradigm of the probabilistic base of information;
Blocking Point 2: The paradigm, that any information is only and ultimately bound to subjects.
Steinbuch’s proposed extension of Shannon’s information concept notably attacked Blocking Point 1. His solutions and examples at least with a first approximation rely on the physical structure of the objects, which have to be processed. For example, for pattern recognition, Steinbuch claims that a learning matrix has to be designed in a way that invariant characteristics of the objects to be recognized have to be implemented within the structure of the learning matrix. But the “probabilistic spirit” of the task of pattern recognition somehow remains and he could not drill it down to an overall physical fundament. In the end, this probabilistic base of information processing dominates the scene up to now. On the other hand, semantic data analysis and systems design is a very important issue in computer science (as keywords like the semantic web or domain ontology in computing might indicate). That is, there seems to be a level of the world, which is common to all people and which should be describable in a semantic-physical manner.
Blocking Point 2 is a legacy of the somehow dominating philosophy of representationalism; but is also a consequence of Blocking Point 1. In simple words, we usually think that the world we see in conscious experience is not the real world itself, but a miniature form of replication of that world in an internal representation. Consequently, those internal forms of representation are primarily bound to the subject itself and cannot by physically captured. We may recall the statement of Rechenberg: “Computers process data, not information.” Peter Rechenberg is a well known scientist in informatics and computer science. His position is holding a paradigmatic character: It is the outcome of a nowadays dominating representationalism, or subjectivism. If we accept this position then there does not exist a path to physically structure our perceptions and thoughts—not even theoretically. The philosopher Erwin Tegtmeier analyzed the roots of this position. Initially developed by Descartes, “re-presentations” are the way how the mind develops mental states. Descartes considered a causal and similar relation between representation and object. Bu then the importance of the role of (physical) causality gets more and more lost. “The main difficulty of representationalism concerns the relation between representation and object. Descartes and his disciples consider causation and similarity. With respect to the knowledge of physical objects Descartes rules out similarity because he takes the mental and the physical to be radically different. He assumes a causal transaction between the physical object and certain semi-physical entities in the mind. But the causal chain from object to mind seemed neither to him nor to the Cartesians a satisfactory candidate for the basic cognitive relation. The latter remained a mystery and that created scepticism.” ([
42], pp. 78) Kant was right when he mentioned that humans are capable to create and initiate new causally active chains of events [
28]. But Tegtmeier than shows that “Kant dissolves the realism problem by turning physical into mental objects and non-mental objects into unknowables” ([
42], pp. 79), which indeed “is absurd” (ibd.). Tegmeier then concludes, that this influence is still dominating modern philosophy.
This influence is indeed of high risky and danger, because it hinders us towards liable and responsible acting and thinking. Pragmatism (linking of practice and theory) seems to be a valuable way out. But it neither offers a satisfactory solution, because it misses a physical foundation. Tegtmeier found a solution in Brentano’s analysis of the relations of objects with respect to intentionality. To summarize, Brentano’s and Frege’s works are predecessors for the proposed concept of information. But—besides the logical analysis of those problems—I am very much concerned of this topic, because this representationalist (or idealist) way of thinking adds an unnecessary amount of arbitrariness to the wholeness of our (moral) stance. It causes a vacuum which becomes successively filled by an avoidable egocentrism. If we organize our acting towards a growing structurization (in terms of an enriching phase space) we will save energy in a physical and non-metaphoric sense. This indeed indicates an inherent towards the information society. To sum up, this false subjectivism has to be unmasked as the root blocking point for the design of new computing systems.
The escape route is to replace the representationalist position by the position of (structural) identity, as initially developed by Gottlob Frege (see Part I of this study). Of course it has to be mentioned that such an approach requires much more conceptual elaboration. However, as nature has already developed such an approach—it seems to be our task to rely on this concept.
This state needs to be highlighted. It has to become clear that the common representationalism—this bondage and ligation to the dimension of an absolute and therefore non-natural subjectivity—deeply discourages and demotivates an approach towards a physically oriented computing science. It does even shed a discouraging light towards the movement to the information society. And it does explicitly steal the possibility to design computing systems, which operate with minimum energy and offer maximum performance at the same time; and are based on a physical foundation. Theoretically, the incoming signals to a computing device may already contain the amount of energy, which is required to fulfill the intended computing task. The escape route was already indicated in Part I of this study, when it was explained (initially shown by Charles H. Bennett) that any computing program could be implemented in terms of a reversible system. Some kinds of “billiard computers” have been designed in order to visualize and validate this approach. The program would exist of billiard balls, surrounded by certain specific and stable bars and reflectors. An initial throw of a billiard ball would already contain the required energy and transfer this energy and movement to all other balls, which would collide. Finally all balls would carry an ending position. This ending position equals the result of such reversible computation. Theoretically, the energy brought to the system may finally leave the system, so that the overall energy consumption would be zero.
The maximum speed of such a computing process can be achieved if the degree of parallelization is maximized. Within a physical framework, a system of highest parallelization is a linear system. That is, input entities point in an explicit manner to output entities. Furthermore, many input entities can be overlaid at the same time. This is the basis of quantum mechanics, and the reader might also think about quantum computing systems. In fact, we will now work towards such highly parallelized computing systems, which simulate the behavior of real quantum systems. This is done by an application of the proposed concept of information. It will be shown that the content of any informational transformation is laid down within the overall system structure. This overall system structure defines the concept of identity of such systems. That is, any incoming signal in such a new computing device will not cause the activation of somehow arbitrarily defined algorithms, but will automatically FIND the place (=address) of its value and thereby activate all further data, which is bound to its content. We will proceed in two steps. In a first step, we will expand on such computing capabilities with regard to linear physical systems. The second step expands on the transformation of physical computing systems to digital computing devices.
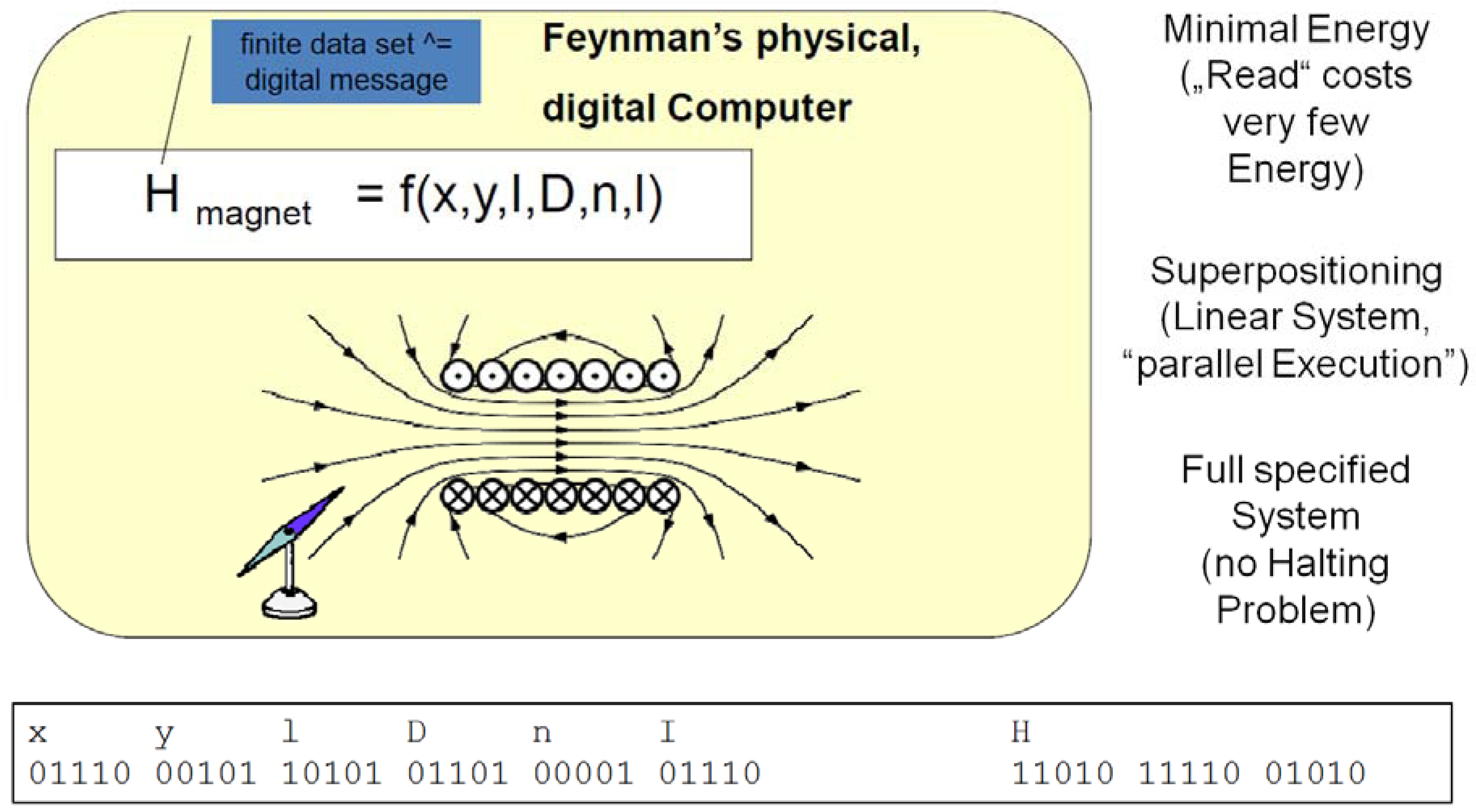
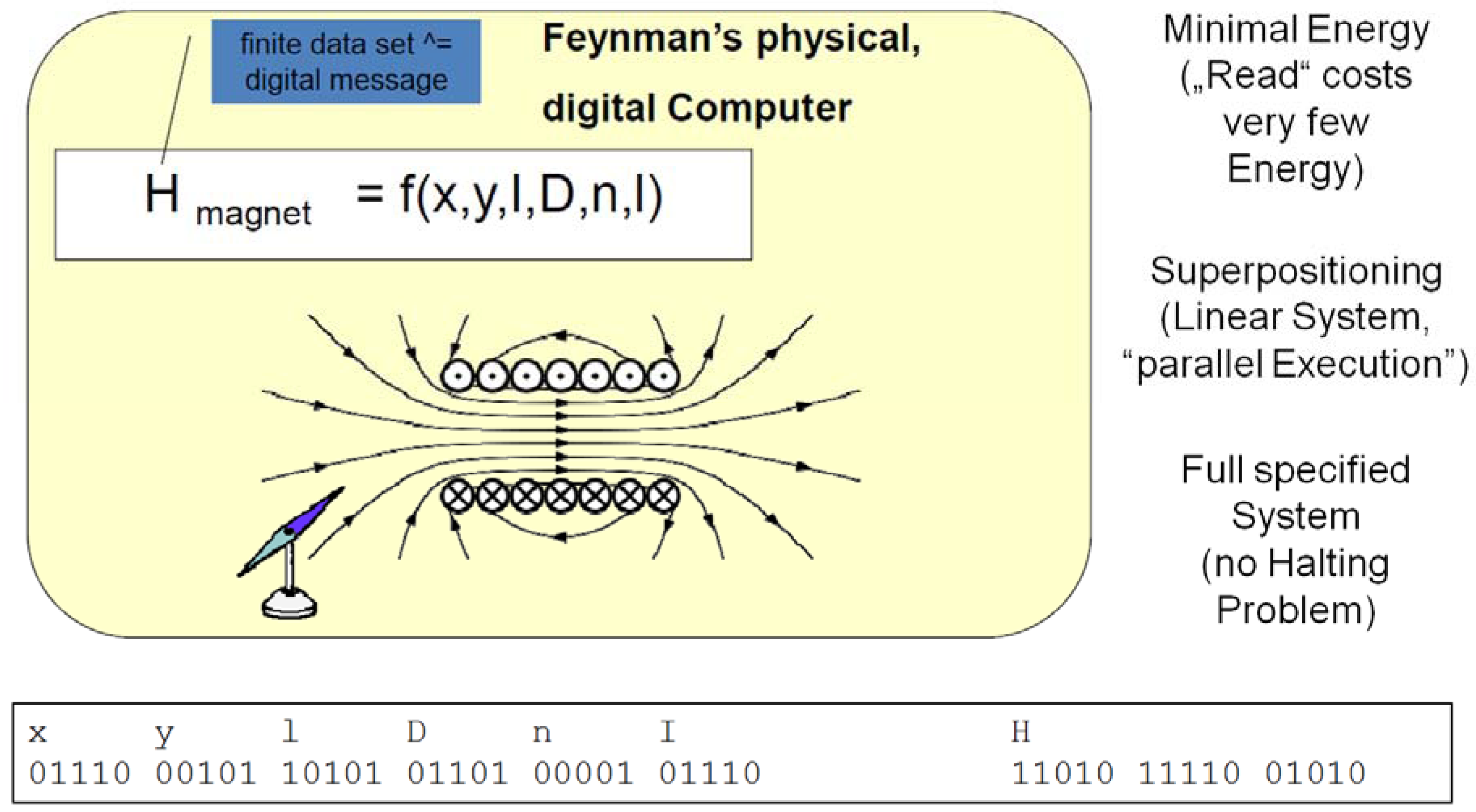
First Step: We need to integrate some thoughts of the physicist Richard Feynman. He claimed that nature has the potentiality to compute and that already something like a magnet can be called a computing device. The identity of the magnetic field is given by a physical transformation (the “formula” or the “code”). For any point in the space, such a formula calculates the magnetic force. The heart of a new computing concept is that this magnet itself creates
in advance any information, which could be retrieved later by a user. The formula is executed once, and the information is stored by such a computing device. Any user will then directly access the kind of information of interest, without the need to execute complex algorithms and dissipate huge amounts of energy. The next figure illustrates an example (
Figure 3). Feynman gave another argument towards a broad and comprehensive physical foundation of such a computing system. He argues that the world is made of quanta, and all quanta are countable. He concludes that in a next step all parameters, which are contained by the formula are fully and sufficiently digitizable. That is, there exists a comprehensive physical foundation on which to build digital, physical computing systems. And it is a fully parallelized system, like those proposed by Steinbuch.
Such kinds of ideas were already introduced by Konrad Zuse. In his book “Calculating Space”, Zuse explored a first vision of digital physics [
43]. He explained that the entire universe could be conceptualized as a computing machine, and he argued for a physical basis of such a concept. Similar ideas were promoted in the US by Ed Franklin. But they did not yet include explicitly the idea of a potential dimension of information in his thoughts. Nevertheless, a first step in this new direction is the kind of physical computing system, which has been mentioned by Richard Feynman in one of his speeches [
44]. And one of his examples holds the identity of “structure” and “meaning”, which is the entry point for the design of computing systems, which are based on the concept of structural identities rather than on a mere heuristic concept of algorithmic approximation.
Figure 3 shows an electromagnet, which is made by an electrical coil (the wires of the coil have been cut off in the drawing: this sign ⊙ indicates a cut off wire, where the electrons move towards the reader; this sign V marks the contrary case: the electrons move into the surface of the drawing). “H” is the sign for the magnetic force;
x,
y are coordinates, which identify each single point of the magnetic field; I is the amperage; D is the diameter of the coil; n is the number of convolutions of the wire; and l is the length of the coil. There is one magnetic needle drawn in the figure, which may indicate for any given position
x,
y the direction of the magnetic field H. The reader may note that many such needles could be operated in parallel. We might also imagine that such needles consume very little energy. In facts, they consume zero energy, if they are once brought towards the direction of the magnetic field. Their consumption of energy is only given by the friction, which is forced by the needle during its movement.
Figure 3.
A digital, physical computing system.
Now we can setup a vector, which totally covers this physical system. At first we have to analyze the number of binary digits, which are required in order to represent each of those parameters. We have already mentioned that this number must be finite. In our example we represent each number by the usage of five binary digits. Then we have to concatenate (to line up) all parameters into one single vector. Then, ultimately, we have to consequently permutate this vector from its initial value:
To its ending and last value:
Then, in the last step, we have to associate the value of the magnet field H to each line of the vector. This is done in
Figure 3 for one single line as an example. Once all associations have been done, the new physical computing system is ready for operation. We may now ask for the value of H for one single line of the vector. Or we may ask for a couple of different lines. Or we may even ask for unary fields within this vector: maybe for all lines between the following lines:
All those lines could be activated in one single step, and all corresponding values of the magnetic force H could be red in one step. We have also to underline that all those vectors hold a unary order. That is, we can always very simply post a data retrieval command for an “in between” qualifier. This is a very important structural characteristic and opens the path towards a semantic interpretation of any kind of interrogation of such kind of vectors. In fact, the “semantic interpretation” of this scenario is nothing else than the consistent definition of physical law or regularity, which is given by the transformation of the vector. That is, as long as physics is consistent, any such kind of transformation will hold a semantically well-defined structure and meaning. Let us summarize:
(1) The system operates with a minimal amount of energy (which is maybe already given by the impetus of the incoming signals);
(2) The system holds a unary order;
(3) Many interrogations of the system can be done in parallel;
(4) To sum up, the system holds the characteristics of a quantum computer.
The reader might already imagine that such kinds of systems hold a preferable structure with regard to computing tasks, which are characterized by an important amount of data read activity (that is, many users access huge amounts of data; Google might be an example).
Second Step: Transformation of Physical Computing Systems to Digital Computing Systems.
Let us first characterize the different kinds of tasks, which are usually fulfilled by computing systems. In a simplified and general manner we can divide this world into two domains: The first domain includes the systems and programs, which can typically be bought on the market. It also includes the usage of the World Wide Web and any other kind of application, where data is stored by certain data providers, and then this data is read (and maybe updated) by users. The second domain covers the creation and execution of sophisticated and maybe large programs, like weather forecasting, or any kind of scientific calculation. The second domain is characterized by few users and few repetition cycles of such programs (nevertheless, the results may be propagated to the www or other databases). The first domain’s characteristics are a big—or even huge—number of users or readers and a huge amount of execution of the same software. As an example, the reader might think of the usage of data providing systems like Google. Many users may access those systems (maybe simultaneously) and search for data. All those search processes are now executed in a huge amount of numbers, which costs huge amounts of energy. The reader might already imagine that it is worthwhile to transform this domain into a structure, so that energy savings could be addressed from within a sustainable and structural level.
Applications like those of Google spread all their data into huge computer farms. Google may nowadays operate hundreds of thousands of computing nodes. If you send a question to the Google search engine, many sophisticated algorithms are executed in order to find the required location of your query (data center) and to finally retrieve your data. During this process, thousands of computer nodes will dissipate huge amounts of energy, because each interim result of all those algorithms has to be stored. This process of storing a huge amount of interim data (of which the user has no idea) costs energy and time. Google has successfully developed very fast algorithms, which on the other hand use huge amounts of hardware. A simple calculation shows that more than hundred millions of dollars are required in order to pay the fee for electrical power per year.
A new computing architecture may help to overcome such problems. This concept permits retrieving any required data with a few steps (instead of hundreds of steps). A concept of semantics will be introduced from the beginning: This concept is built on the identity of any data in terms of “meaning” and “storage address” by using what we have called a code. Let us look at an example: A list of names and some additional information. Using our language, we want to store all kinds of words, which are made of letters. Let us use a code, which exists of five bit in order to decode a single letter. We may decode up to 36 letters, which includes all letters of the alphabet. The letter “A” might be represented by the bit-pattern “00001”. The name “TURING” is given by following pattern:
In a next step we may store any other kind of data at this address (
i.e., first name, birth date, telephone, email-address,
etc.). The decoded message is identical to its address within the computing device. We conceptualize an identity between the meaning of any message to the user and its address in the computer. This approach gives the name to this concept: iBIT = identity Based Information Transformation. A basic example of this concept has already been defined; it incorporates a set of reversible transformations, which do not require the usage of a CPU [
45]. The iBIT concept has also been developed for a pattern recognition application. A prototype of an iBIT system has already successfully been tested in microelectronics production. The core of this concept is a non-probabilistic, non-CPU.based system, which automatically identifies so-called semiconductor wafers. Such wafers are made of monocrystalline silicon substrates and show very intensive and challenging light reflection characteristics. They look like metallic mirrors and change their color and reflectivity during the production process quite intensively. This new iBIT architecture has the structure of a quantum computer: Many simultaneous input patterns (vectors) may overlay at the same time and deliver synchronously required output data.
The usage of codes is nothing new in computing science. What is new is the approach to identify the identity of any language area (Sprachraum) by the analysis of the coding (with regard to the usage of phonemes and morphemes). By using the coding scheme, any language expression will be positioned within the Sprachraum by a codified transformation of the atomic elements (phonemes) into a digital representation. This digital representation serves as the identity of content/meaning and address of any language expression within the Sprachraum. There are many applications known to calculate storage locations for data items (hashing, binary trees, etc.). Database systems execute sophisticated algorithms in order to calculate the storage location for different kinds of data. However, all those mechanisms are driven by a process (an algorithm). The proposed solution does not use any algorithm, but enables the transformation of the content of a data (sequence of phonemes) into an appropriate location place within one or few steps. For this reason, any algorithmic search process will be replaced by a direct find process. Also similarly looking applications (like CAM: Content-addressable Memory) implement a search process (algorithm) in order to retrieve certain data. We have posted a patent application for this new approach in computing. Another outcome of this approach is the elimination of the halting problem. Alan Turing has shown that it is not possible to predict if a computer program will once stop. As a conclusion, each program has to be validated and tested separately and very intensively. However, those classical computer programs are implemented on computers with a von Neumann architecture (every von Neumann architecture implements the Turing machine). The new concept does not implement the Turing machine, but a linear vector space. Within a linear space only linear, vector transformations are defined; consequently there exists no Halting problem.
Three research projects have been started in order to explore and develop the iBIT concept at Technical University Dresden, Germany. The scientific goal of this project is to deliver a conceptual framework, which enables the design of new computing systems, which comprise maximum performance and minimum energy consumption.


{kind=link}
{kind=link}
{kind=link}
{kind=link}