Beyond Bayes: On the Need for a Unified and Jaynesian Definition of Probability and Information within Neuroscience

Abstract
:
1. Introduction
2. The Computational Goal of the Nervous System

3. Information and Probability
3.1. Two Definitions of Probability

| Definition | Frequentist | Jaynesian |
|---|---|---|
| Answer | Probabilities are unknown and undefined because there are no frequencies | 1/4 = 0.25 |
| Meaning | Probabilities come from measuring frequencies | Probabilities describe information (from any source) |
| Derivation | A collection of ad hoc rules allow us to estimate probabilities | Logic (common sense) precisely specifies probabilities through the principle of maximum entropy |
| Attribution | Probabilities are a property of a physical system | Probabilities are a property of an observer of a physical system |
3.2. A Very Brief History of Probability Theory
3.3. The Jaynesian Definition of Probability: The Maximum Entropy Principle
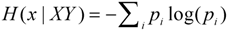
3.4. Quantifying the Amount of Information
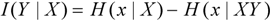
3.5. Bayes’s Theorem
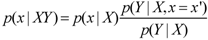
3.6. The General Method of Jaynes
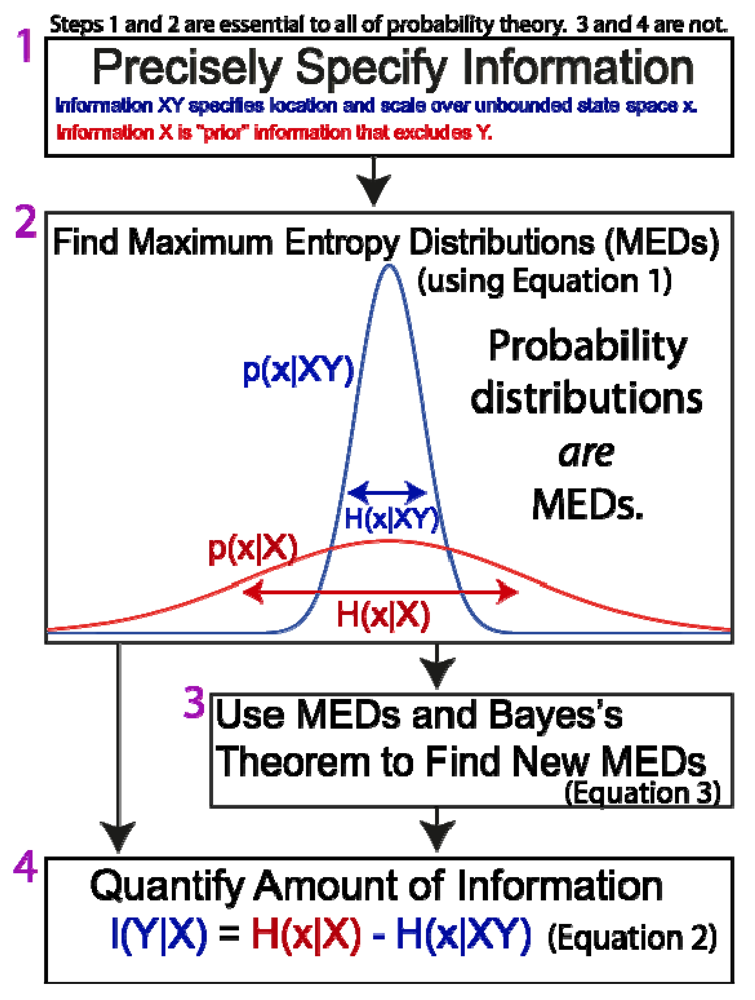
- Precisely and explicitly state the information upon which the probabilities should be conditional. In the view of Jaynes, this is the most important step. Ambiguity or failure to explicitly acknowledge information at the outset has led to severe confusion and misunderstanding about the meaning of probabilities and their derivation (in addition to countless examples provided by Jaynes [35], there has been decades of debate about the “Monty Hall problem”, one of many trivial applications of probability theory that are made needlessly controversial by ambiguity about the relevant information). Agreement and understanding requires that all observers are utilizing the same information (a fact which is universally apparent to anyone above a certain mental age, and which is not at all unique to probability theory). It should be noted that this first and most critical step in the method of Jaynes does not involve mathematics.
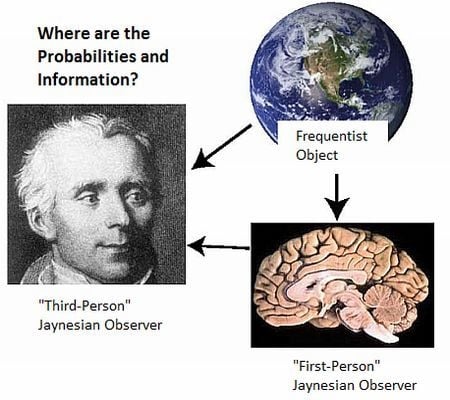
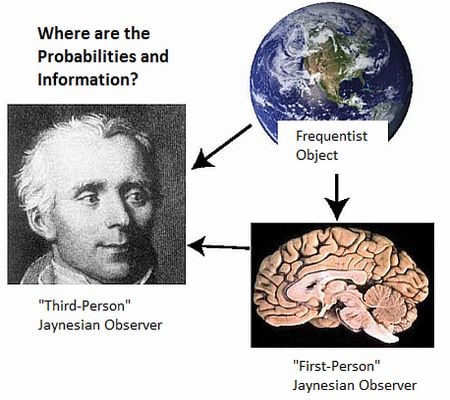
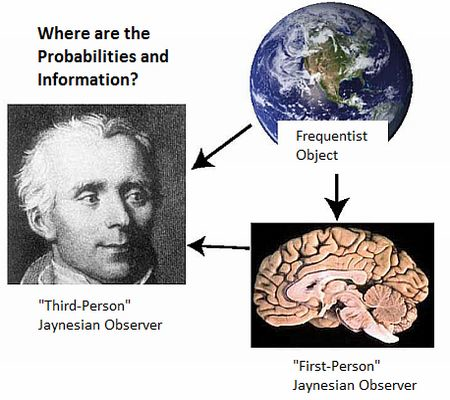
- There is a further stipulation that is particularly critical for understanding the brain and the physical basis of information and inference. In addition to precisely stating the information, we must also specify where we believe that information to be, and if possible, its putative physical basis. “Where” must at least specify whether it is possessed by a scientist, a neural system under investigation, or whether it is in the environment external to the neural system (Figure 1). Failure to do so has resulted in the misattribution of the information possessed by scientists to the physical systems they study (such as brains; documented in Sections 4 and Sections 5.2 ).
Figure 2. The General Methodological Sequence of Jaynes.![Information 03 00175 g002]()
- Maximize entropy. The function that correctly describes the information is the one that maximizes the entropy of Equation 1 (and sums to one, as all probability distributions must). This is conceptually simple, although the mathematical difficulty can range from trivial to intractable, depending on whether the information state is simple or complex (for example, estimating the value of a company based on one sample of trading value on a stock market, versus a diverse set of financial and economic data). All “correct” probability distributions are MEDs.
- Use MEDs and Bayes’s Theorem to derive new MEDs. Since the general goal of probability theory is to derive probabilities distributions (MEDs), and since in principle this can be done directly through entropy maximization, BT is not essential, in principle. As a practical matter, it is extremely useful because it allows us to generate new MEDs from existing MEDs in a manner that is much easier mathematically than directly maximizing entropy. Faced with a complex set of information, it can be useful to break the information into simpler “pieces”, maximize entropy to find a MED for each piece, and then use BT to derive a single distribution for the whole set of information.
- Quantify the amount of information. For inference and most applications, this is not necessary.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3.7. Response to Criticisms of Jaynesian Probabilities
- Jaynesian probabilities have been criticized as being “subjective”, and thus ambiguous and not appropriate for science. The simple characterization of Jaynesian probabilities as “subjective” can be misleading. As expressions of logic, Jaynesian probabilities are objective properties of information without any ambiguity. Two observers with the same information will apply the same probabilities, and two observers with different information will apply different probabilities. The information is subjective in the sense that it tends to differ across observers, in accord with reality. It is the ability of Jaynesian probabilities to objectively describe subjective information that makes them so useful in understanding brain function.
- A second criticism of Jaynesian probabilities is that it is not always clear how they should be calculated. Although this is undoubtedly true, it is not a valid criticism of Jaynesian methods. To derive Jaynesian probability distributions, one must first be able to specify precisely what information is relevant, and then perform the mathematics. In the case of brain research, each of these might be difficult or even impossible as a practical matter, but there is no reason to think that it cannot be done as a matter of principle. Furthermore, there is reason to think this may not be so challenging with respect to the neural basis of inference (see Section 5.3).
- A third criticism stems from confusion of the subjective aspect of Jaynesian probabilities with our conscious attempts at quantifying the strength of our beliefs. Jaynesian probabilities are not simply a number that a person verbally reports based upon introspection. A person typically struggles to state the probability that one of their beliefs is true. This may be in part for the same reason that scientists and experts on probability theory struggle to rationally calculate probabilities in cases in which a great diversity of information is relevant. Of perhaps greater importance is the fact that, although human behavior is routinely based upon perceptions of what is probable and what is not, to be asked to verbally state (or consciously perceive) a probability is highly unusual and seldom important. To solve any particular problem, the brain must have information about some relevant aspect of the world (with a corresponding state space). If the brain is then asked to verbally specify a probability, the relevant aspect of the world (and its state space) now corresponds to the abstract notion of “probabilities” themselves, and the problem facing the brain has radically changed. The brain may have substantial information about some aspect of the world, but may have little information about the probabilities. In other words, information about “X” is not the same as information about the probability of “X”.The former concerns the probability of “X”, whereas the latter concerns the probability of a probability of “X”.
- A fourth criticism is not aimed at Jaynesian probabilities themselves, but rather questions their utility in understanding brain function on the grounds that behavior is not rational (optimal in its use of information). Although a full discussion of this issue is beyond the scope of the present work, several important points should be noted.
- Humans are capable of reason, and there are numerous instances in which brain function is at least semi-rational.
- To assess whether a brain is rational, we first must know what relevant information is in the brain. We should not confuse ignorance with lack of reason.
- We know for a fact that the brain does not rationally integrate all of its information at all times. However, logical integration of smaller amounts of information, perhaps at the level of single neurons, is certainly conceivable.
- Although the application of Jaynesian principles to the brain is often viewed as prescriptive, specifying how the brain ought to function, my view is that Jaynesian principles are better viewed as descriptive (see Section 5.3). In this view, a pathological brain could be just as Jaynesian as a healthy brain (though likely possessing less information) [45].
3.8. Faults with the Frequentist Definition of Probability
- The frequentist definition contradicts intuition, and is of limited use, because it completely fails to account for information that is obviously relevant to probabilities. The simple example given above is the statement that “there are ‘N’ mutually exclusive states” (Table 1). It is obvious that this statement is informative, but a frequentist definition cannot even attempt to specify any probability distribution as a matter of principle. The problem is not merely that frequency distributions may not be available as a practical matter, but rather that in many cases no relevant frequency distribution could ever exist. A more glaring illustration of this fault, with respect to neuroscience, is that a frequentist view has no means to address the plain fact that different brains have different information and therefore place different probabilities on the same event. Thus, frequentist methods are frequently inapplicable.
- In those cases in which frequency distributions are available, it is unclear over what finite range or period they ought to be measured in order to derive probabilities. It is common to assume that the world is “stationary” and then to extrapolate an observed frequency to its limit as one imagines an infinite set of observations. But the real world is seldom if ever known to be stationary, and the actual data is always finite. To imagine otherwise is wishful thinking. Without any real, unique, and well-defined frequency distribution, the concept of a “true” probability, which we try to estimate, is just fantasy.
- Because measurement of a frequency distribution over a finite period is never sufficient to fully specify a probability distribution, derivation of a probability distribution requires incorporation of additional information that is not present in the observed frequency distribution. This is done in the form of “assumptions”, which in many cases are not stated explicitly and thus remain hidden. Statisticians assume “stationarity”, or a “Gaussian process”, or “statistical independence”. These assumptions actually constitute relevant information (or lack thereof) that the statistician possesses and uses. But conventional (frequentist) statistics does not have overarching principles for how to use this information, only a collection of ad hoc rules. Regardless of how this “hidden” information is used, its use contradicts the pretense that probabilities are derived directly from measurable frequencies and are thus “objective”.
- Empirical evidence has shown that given the same information, there are many cases in which frequentist methods make less accurate predictions than Jaynesian methods [35]. Thus frequentist methods do not consistently make optimal (logical) use of information.
- A common perception is that while some probabilities come directly from frequencies, others are conditional on information, and therefore the frequentist definition is applicable in some situations and the Jaynesian definition in others. But Jaynesian methods have no problem incorporating information derived from frequency distributions. In those cases in which frequentist methods succeed, they give the same probabilities that could be derived from Jaynesian methods. At their best, frequentist methods are a special case of the more general Jaynesian methods. Thus there is no virtue or advantage to the frequentist definition of probability.
- The most glaring faults of frequentist probabilities are not evident in conventional applications of probability theory in which scientists are always the observer, but arise solely when an observer (such as a scientist) wishes to understand how another observer (such as a brain) can perform inference.
- Frequentist methods are narrow in their objective and do not address inference in general.
- Frequentist methods do not incorporate logic in a formal sense, and thus cannot help in understanding its neural basis.
- The most severe fault is the misattribution of knowledge. When frequentist approaches have been used to study the neural basis of inference [27,28,29,30,31,32,33], the result has been that scientists have mistakenly attributed their own information (and ignorance) to the brain. Thus probabilities attributed to a brain under investigation have in fact been entirely a property of the scientist’s brain, an error of gross proportions.
3.9. Jaynesian and Not Merely Bayesian
4. Conventional Approaches to Probability and Information in Neuroscience
4.1. The Frequentist View in Neuroscience
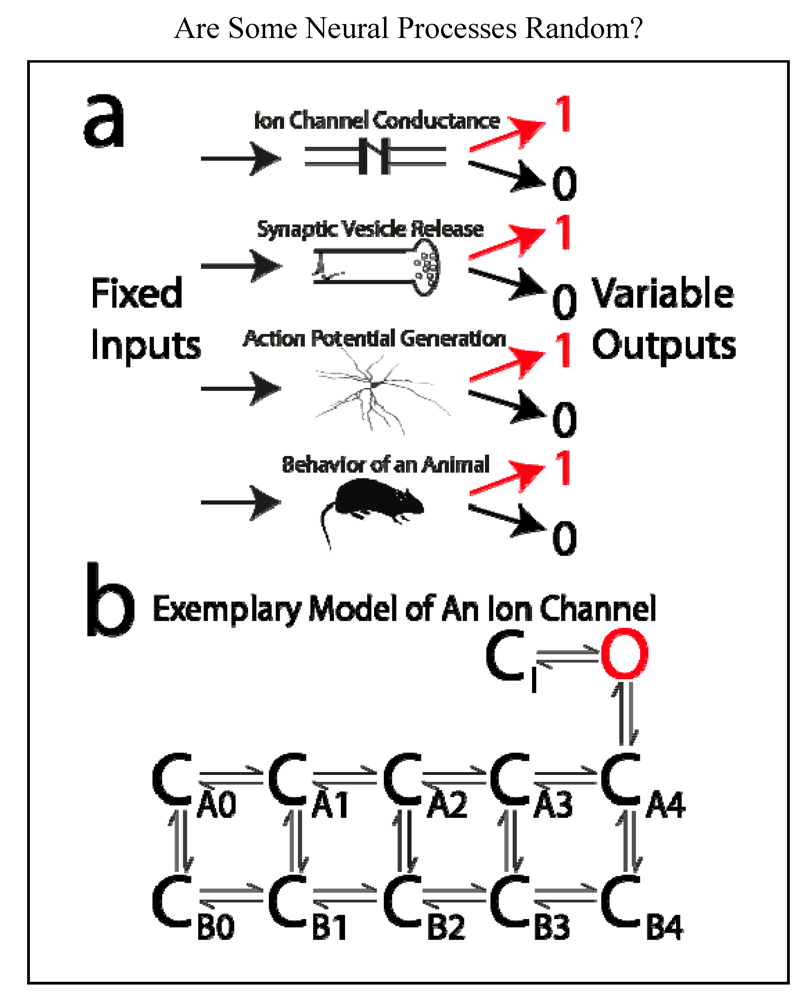
4.2. What is a “Random Process”?
- An ion channel is either open or closed.
- A vesicle containing neurotransmitter is either released or not released from a presynaptic terminal.
- A neuron either generates an action potential or it does not.
- In a “tail-flick assay”, a rat either removes its tail from a hotplate or it does not.

4.3. “Random” Neural Activity in Models of Bayesian Inference
5. Jaynesian Approaches in Neuroscience
5.1. Why Is a Strict Jaynesian View Critical to Neuroscience?
5.2. Two Jaynesian Approaches: First-person (Neurocentric) versus Third-person (Xenocentric)
5.3. Beyond Bayes’s Theorem
- First, these models presume that the brain needs to “know the probabilities” and that a probability is the answer to an inference problem and should thus correspond to a neuronal output. This implies that a brain could have information and yet be incapable of inference because of its inability to do the math. But although the brain needs to know about aspects of the real world, it is not at all clear that it needs to “know about the probabilities” of aspects of the real world. Information about “X”is not the same as information about the probability of “X”,the latter relating to the probability of the probability of “X”(Section 3.6). As Jaynes emphasized, probabilities describe knowledge about the real world, but they are not “real” in themselves anymore than any number is real. Their status is epistemic and not ontological.
- Second, if the brain does in fact need to calculate probabilities, then the first calculations must identify maximum entropy distributions that are conditional on the brain’s information. BT is useless until probabilities are available. Thus it is at best premature to focus on the math of BT rather than the more fundamental precursor of entropy maximization. And if maximization of entropy can somehow be achieved readily, even for complex sets of information, then BT is unnecessary.
- Third, it has been proposed that neurons perform BT, taking a prior and one or more likelihood functions as inputs, and generating an output that represents the posterior [6,27,28,29,30,31]. It is important to keep in mind that BT is merely an equality in which the same information is represented on both sides of the equation; the posterior simply describes the information with one distribution rather than two or more. Thus the inputs and output of a neuron that performs BT would have the same information content. This contradicts the common and well supported notion that by transforming inputs to output, a neuron transforms information about one object (“stimulus” or “cause”, as determined by its receptive field) into information about another object. For example, the output of a neuron in primary visual cortex can signify information about orientation, whereas none of its individual presynaptic input neurons does so. BT does not specify any transformation of information, it only expresses the same information in alternate forms. In this regard, BT is fully analogous to a statement of the form 12 = 3 × 4 = 24/2, etc. To suggest that BT captures the essential feature of higher brain function, and that the brain should “compute BT” because the posterior (“12”) is in some way better than the product of the prior and likelihood (“3 × 4”), is to suggest that a calculator is an apt analogy for the essential computational function of t
5.4. Characterizing the Information that One Physical System Has about Another
6. Conclusions
Acknowledgements
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar]
- Kandel, E.R.; Schwartz, J.H.; Jessel, T.M. Principles of Neural Science, 4th ed; McGraw-Hill: New York, NY, USA, 2000. [Google Scholar]
- Dayan, P.; Abbott, L.F. Theoretical Neuroscience; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- von Helmholz, H. Concerning the Perceptions in General. In Treatise on Physiological Optics, 1896; Reprinted in Visual Perception; Yantis, S., Ed.; Psychology Press: Philadelphia, PA, USA, 2001; pp. 24–44. [Google Scholar]
- Fiorillo, C.D. Towards a general theory of neural computation based on prediction by single neurons. PLoS One 2008, 3, e3298. [Google Scholar] [CrossRef]
- Friston, K. The free energy principle: A unified brain theory? Nat. Rev. Neurosci. 2010, 11, 127–138. [Google Scholar] [CrossRef]
- Gregory, R.L. Perceptions as hypotheses. Philos. Trans. R. Soc. Lond. B 1980, 290, 181–197. [Google Scholar] [CrossRef]
- Wolpert, D.M.; Ghahramani, Z.; Jordan, M.I. An internal model for sensorimotor integration. Science 1995, 269, 1880–1882. [Google Scholar]
- Knill, D.C.; Richards, R.W. Perception as Bayesian Inference; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Seidenberg, M.S. Language acquisition and use: Learning and applying probabilistic constraints. Science 1997, 275, 1599–1603. [Google Scholar] [CrossRef]
- Gregory, R.L. Knowledge in perception and illusion. Philos. Trans. R. Soc. Lond. B 1997, 352, 1121–1128. [Google Scholar] [CrossRef]
- Weiss, Y.; Simoncelli, E.P.; Adelson, E.H. Motion illusions as optimal percepts. Nat. Neurosci. 2002, 5, 598–604. [Google Scholar] [CrossRef]
- Ernst, M.O.; Banks, M.S. Humans integrate visual and haptic information in a statistically optimal fashion. Nature 2002, 415, 429–433. [Google Scholar]
- Rao, R.P.N.; Olshausen, B.A.; Lewicki, M.S. Probabilistic Models of the Brain: Perception and Neural Function; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Yang, Z.; Purves, D. A statistical explanation of visual space. Nat. Neurosci. 2003, 6, 632–640. [Google Scholar] [CrossRef]
- Purves, D.; Lotto, R.B. Why We See What We Do: An Empirical Theory of Vision; Sinauer Associates Inc.: Sunderland, MA, USA, 2003. [Google Scholar]
- Niemeier, M.; Crawford, J.D.; Tweed, D. Optimal transsaccadic integration explains distorted spatial perception. Nature 2003, 422, 76–80. [Google Scholar]
- Singh, K.; Scott, S.H. A motor learning strategy reflects neural circuitry for limb control. Nat. Neurosci. 2003, 6, 399–403. [Google Scholar] [CrossRef]
- Kording, K.P.; Wolpert, D.M. Bayesian integration in sensorimotor learning. Nature 2004, 427, 244–247. [Google Scholar]
- Vaziri, S.; Diedrichsen, J.; Shadmehr, R. Why does the brain predict sensory consequences of oculomotor commands? Optimal integration of the predicted and the actual sensory feedback. J. Neurosci. 2006, 26, 4188–4197. [Google Scholar] [CrossRef]
- Howe, C.Q.; Lotto, R.B.; Purves, D. Comparison of Bayesian and empirical ranking approaches to visual perception. J. Theor. Biol. 2006, 241, 866–875. [Google Scholar] [CrossRef]
- Oaksford, M.; Chater, N. Bayesian Rationality: The Probabilistic Approach to Human Reasoning; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Oaksford, M.; Chater, N. Precis of bayesian rationality: The probabilistic approach to human reasoning. Behav. Brain Sci. 2009, 32, 69–120. [Google Scholar] [CrossRef]
- Daunizeau, J.; Den Ouden, H.E.M.; Pessiglione, M.; Stephan, K.E.; Friston, K.J. Observing the observer (I): meta-Bayesian models of learning and decision making. PLoS One 2010, 5, e15554. [Google Scholar]
- Purves, D.; Wojtach, W.T.; Lotto, R.B. Understanding vision in wholly empirical terms. Proc. Natl. Acad. Sci. USA 2011, 108, 15588–15595. [Google Scholar]
- Purves, D.; Lotto, R.B. Why We See What We Do Redux; Sinauer Associates Inc.: Sunderland, MA, USA, 2011. [Google Scholar]
- Pouget, A.; Dayan, P.; Zemel, R. Information processing with population codes. Nat. Rev. Neurosci. 2000, 1, 125–132. [Google Scholar] [CrossRef]
- Deneve, S.; Latham, P.E.; Pouget, A. Efficient computation and cue integration with noisy population codes. Nat. Neurosci. 2001, 4, 826–831. [Google Scholar] [CrossRef]
- Ma, W.J.; Beck, J.M.; Latham, P.E.; Pouget, A. Bayesian inference with probabilistic population codes. Nat. Neurosci. 2006, 9, 1432–1438. [Google Scholar] [CrossRef]
- Jazayeri, M.; Movshon, J.A. Optimal representations of sensory information by neural populations. Nat. Neurosci. 2006, 9, 690–696. [Google Scholar] [CrossRef]
- Beck, J.M.; Ma, W.J.; Kiani, R.; Hanks, T.; Churchland, A.K.; Roitman, J.; Shadlen, M.N.; Latham, P.E.; Pouget, A. Probabilistic population codes for Bayesian decision making. Neuron 2008, 60, 1142–1152. [Google Scholar] [CrossRef]
- Deneve, S. Bayesian spiking neurons I: Inference. Neural Comput. 2008, 20, 91–117. [Google Scholar] [CrossRef]
- Rieke, F.; Warland, D.; de Ruyter van Steveninck, R.R.; Bialek, W. Spikes: Exploring the Neural Code; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 120–130. [Google Scholar]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Laplace, P.S. Essai Philosophique sur les Probabilitiés; Courier Imprimeur: Paris, France, 1819. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and its Applications; Wiley: New York, NY, USA, 1950. [Google Scholar]
- Howson, C.; Urbach, P. Bayesian reasoning in science. Nature 1991, 350, 371–374. [Google Scholar] [CrossRef]
- Barlow, H.B. Possible Principles Underlying the Transformation of Sensory Messages. In Sensory Communication; Rosenblith, W.A., Ed.; MIT Press: Cambridge, MA, USA, 1961; pp. 217–234. [Google Scholar]
- de Ruyter van Steveninck, R.R.; Laughlin, S.B. The rate of information transfer at graded potential synapses. Nature 1996, 379, 642–645. [Google Scholar] [CrossRef]
- Juusola, M.; French, A.S. The efficiency of sensory information coding by mechanoreceptor neurons. Neuron 1997, 18, 959–968. [Google Scholar] [CrossRef]
- Brenner, N.; Bialek, W.; de Ruyter van Steveninck, R.R. Adaptive rescaling maximizes information transmission. Neuron 2000, 26, 695–702. [Google Scholar] [CrossRef]
- Fairhall, A.L.; Lewen, G.D.; Bialek, W.; de Ruyter van Steveninck, R.R. Efficiency and ambiguity in an adaptive neural code. Nature 2001, 412, 787–792. [Google Scholar]
- Simoncelli, E.P.; Olshausen, B.A. Natural image statistics and neural representation. Ann. Rev. Neurosci. 2001, 24, 1193–1216. [Google Scholar] [CrossRef]
- Corlett, P.; Gancsos, M.E.; Fiorillo, C.D. The Bayesian Self and Its Disruption in Psychosis. In Phenomenological Neuropsychiatry: How Patient Experience Bridges Clinic with Clinical Neuroscience; Mishara, A., Corlett, P., Fletcher, P., Schwartz, M., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2012; in press. [Google Scholar]
- Fiorillo, C.D. A neurocentric approach to bayesian inference. Nat. Rev. Neurosci. 2010. [Google Scholar]
- Friston, K. Is the free-energy principle neurocentric? Nat. Rev. Neurosci. 2010. [Google Scholar]
- MacKay, D.J.C. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Trappenberg, T.P. Fundamentals of Computational Neuroscience, 2nd ed; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Schultz, W.; Preuschoff, K.; Camerer, C.; Hsu, M.; Fiorillo, C.D.; Tobler, P.N.; Bossaerts, P. Explicit neural signals reflecting reward uncertainty. Philos. Trans. R. Soc. B 2008, 363, 3801–3811. [Google Scholar] [CrossRef] [Green Version]
- Yu, A.J.; Dayan, P. Uncertainty, neuromodulation, and attention. Neuron 2006, 46, 681–692. [Google Scholar]
- Jaynes, E.T. Probability in Quantum Theory. In Complexity, Entropy, and the Physics of Information; Zurek, W.H., Ed.; Addison-Wesley: Reading, MA, USA, 1990; pp. 381–400, (Revised and extended version available online: http://bayes.wustl.edu/etj/node1.html). [Google Scholar]
- Hille, B. Ionic Channels of Excitable Membranes,3rd ed.; Sinauer Associates Inc.: Sunderland, MA, USA, 2001. [Google Scholar]
- Shadlen, M.N.; Newsome, W.T. The variable discharge of cortical neurons: Implications for connectivity, computation, and information coding. J. Neurosci. 1998, 18, 3870–3896. [Google Scholar]
- London, M.; Roth, A.; Beergen, L.; Hausser, M.; Latham, P.E. Sensitivity to perturbations in vivo implies high noise and suggests rate coding in cortex. Nature 2010, 466, 123–127. [Google Scholar]
- Phillips, W.A. Self-organized complexity and Coherent Infomax from the viewpoint of Jaynes’s probability theory. Information 2012, 3, 1–15. [Google Scholar] [CrossRef]
- Kay, J.; Phillips, W.A. Coherent Infomax as a computational goal for neural systems. Bull. Math. Biol. 2011, 73, 344–372. [Google Scholar] [CrossRef]
- Seung, H.S.; Sompolinsky, H. Simple models for reading neural population codes. Proc. Natl. Acad. Sci. USA 1993, 90, 10749–10753. [Google Scholar] [CrossRef]
- Sanger, T.D. Probability density estimation for the interpretation of neural population codes. J. Neurophysiol. 1996, 76, 2790–2793. [Google Scholar]
- Knill, D.C.; Pouget, A. The Bayesian brain: The role of uncertainty in neural coding and computation. Trends Neurosci. 2004, 27, 712–719. [Google Scholar] [CrossRef]
- Fiorillo, C.D. A New Approach to the Information in Neural Systems. In Integral Biomathics: Tracing the Road to Reality; Simeonov, P.L., Smith, L.S., Ehresmann, A.C., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Fiorillo, C.D. Beyond Bayes: On the Need for a Unified and Jaynesian Definition of Probability and Information within Neuroscience. Information 2012, 3, 175-203. https://doi.org/10.3390/info3020175
Fiorillo CD. Beyond Bayes: On the Need for a Unified and Jaynesian Definition of Probability and Information within Neuroscience. Information. 2012; 3(2):175-203. https://doi.org/10.3390/info3020175
Chicago/Turabian StyleFiorillo, Christopher D. 2012. "Beyond Bayes: On the Need for a Unified and Jaynesian Definition of Probability and Information within Neuroscience" Information 3, no. 2: 175-203. https://doi.org/10.3390/info3020175