
Decomposed Two-Stage Prompt Learning for Few-Shot Named Entity Recognition


Abstract
:1. Introduction
- We propose a few-shot prompt learning framework that decomposes the NER task into two sub-tasks, entity locating and entity typing. The two sub-tasks perform entity localization and type recognition functions separately, addressing the issues of time consumption and inconsistency with pre-trained training objectives.
- We explore the application of distant labels in the entity locating stage accompanied by several experiments. The experimental results show that the entity locating model performed well with the help of distant labels.
- The experimental results demonstrate that in terms of F1 score our framework outperforms other prompt-based methods by 2.3–12.9% on average while the average inference speed is 1313.5 times faster than the template-based method and 1.4 times faster than the enhanced template-free method. These results indicate that our framework strikes a balance between accuracy and inference speed, making it an excellent trade-off for NER tasks.
2. Related Work
2.1. Few-Shot NER
2.2. Distantly-Supervised NER
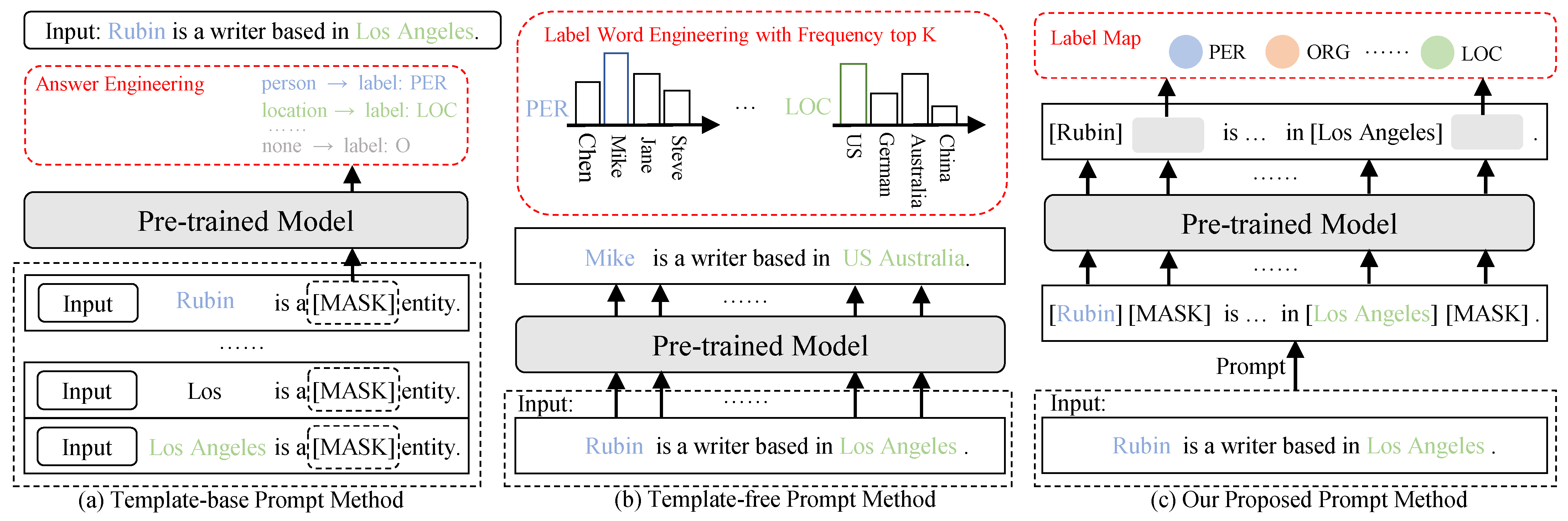
2.3. Prompt Learning NER
3. Task Definition
3.1. Problem Setup
3.2. Distant Label Construction
3.3. Few-Shot Data Construction
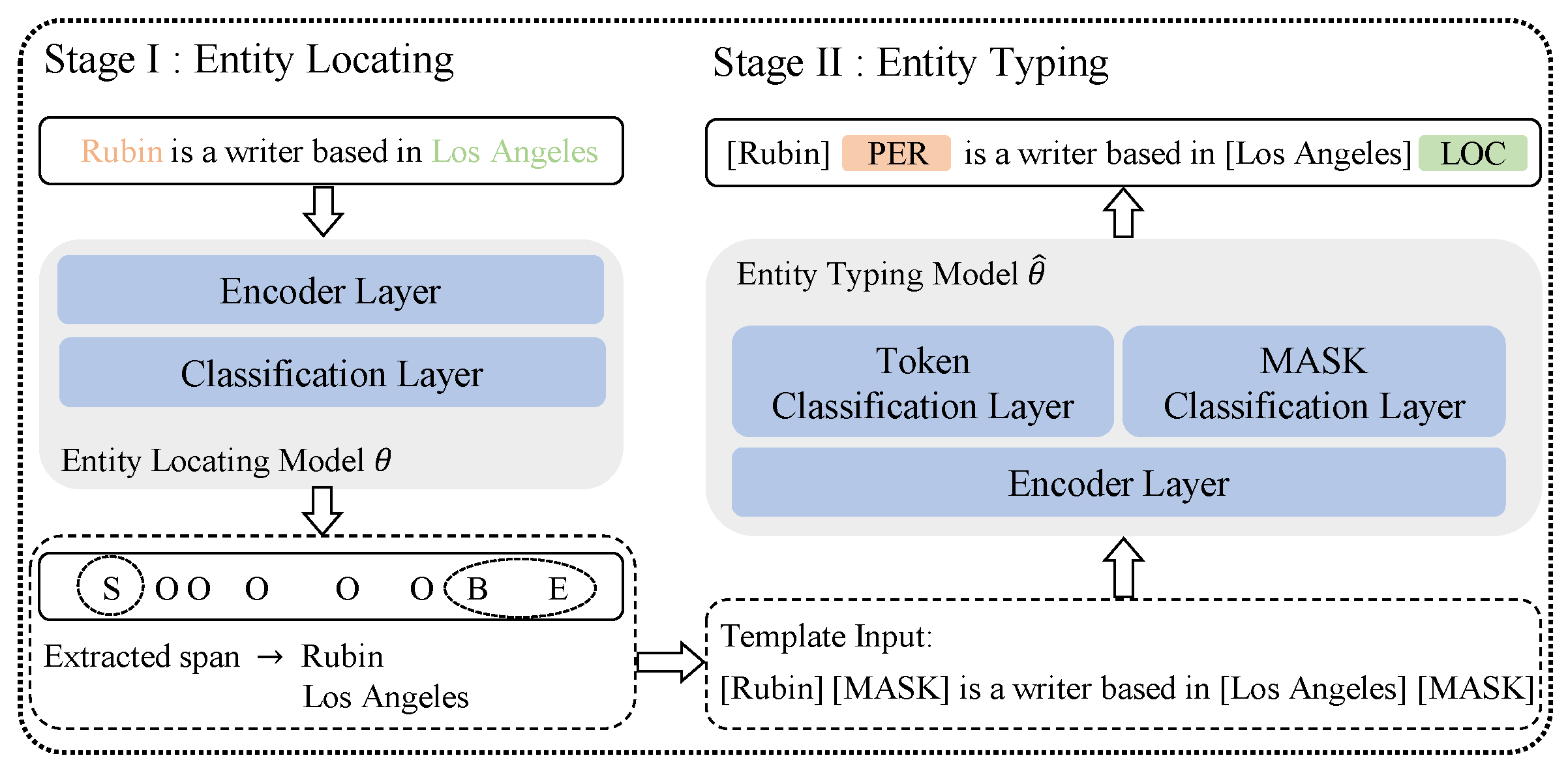
4. Model
4.1. Stage I: Entity Locating
4.1.1. Entity Locating Model
4.1.2. Training of Entity Locating Model
| Algorithm 1 Pseudo-code of the training for entity locating. |
|
4.2. Stage II: Entity Typing
4.2.1. Entity Typing Model
Rubin is a writer based in Los Angeles.
[Rubin] [MASK] is a writer based in [Los Angeles] [MASK].
4.2.2. Training of Entity Typing Model
| Algorithm 2 Pseudo-code of the training for entity typing. |
|
4.3. Inference Process
The construction of Hong Kong Disneyland began two years ago in 2003.
O O O B I E O O O O O O O
The construction of [Hong Kong Disneyland] [MASK] began two years ago in 2003.
5. Experiment Settings
5.1. Implementation Details
5.2. Datasets
- The CoNLL2003 is a common open-source dataset for the news domain. It includes four types of entities (i.e., PER, LOC, ORG, and MISC).
- The OntoNote5.0 dataset includes 18 types of entities. Our model focuses on 11 named entities, i.e., PER, NORP, FAC, ORG, GPE, LOC, PRODUCT, EVENT, WORK OF ART, LAW, and LANGUAGE. Similar to Ma et al. [16], we exclude seven entity types related to value, numerical, time, and date (i.e., DATA, TIME, PERCENT, MONEY, QUANTITY, ORDINAL, and CARDINAL) in our training and evaluation. These excluded entity types are marked as non-entities in our approach.
5.3. Evaluation Index
6. Results
6.1. Baselines
- BERT-NER: The BERT-based model provides a strong baseline that fine-tunes the BERT model with a label classifier. For NER, the hidden vectors of each token are fed into the classifier to calculate the probability distribution.
- NNShot and StructShot [5]: The classical metric-based few-shot approaches. NNShot leverages a nearest-neighbor classifier for few-shot prediction after pre-training on the source domain. StructShot further proposed a method to capture the label dependencies between entity tags by using the abstract tag transition distribution estimated on the source domain data. Note that these two approaches are based on domain transfer settings. Following Ma et al. [16], we also considered the scenario where the source domain is unavailable. For StructShot, we use distant labels to provide the tag transition distribution rather than the source domain data from the original paper.
- TemplateNER [14]: The method enumerates all possible entities span matching with all the entity types and then generates the prompt templates for training. In inference, it queries all the templates to the pre-trained model to calculate the scores and finds the most probable entity by score ranking.
- EntLM and EntLM-Struct [16]: The template-free prompt method uses distant labels to obtain prototype words of each type in the dataset. Then, it designs a task in which the target entity token goes through the pre-trained model to predict the prototype words of the corresponding type while the O-tag token predicts itself. As for EntLM-Struct, they use the same method as StructShot to further extend EntLM.
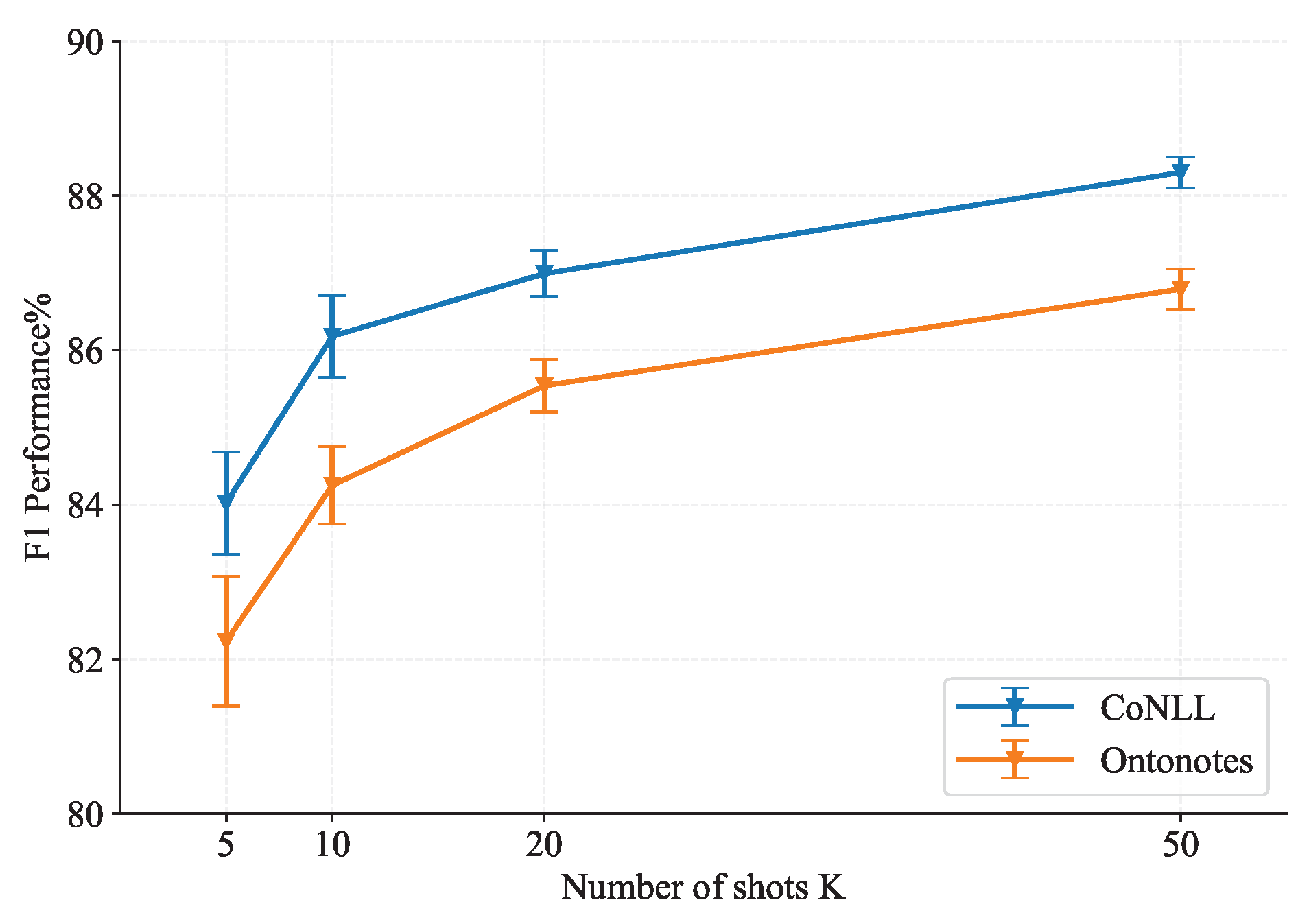
6.2. Main Results
6.3. Ablation Study
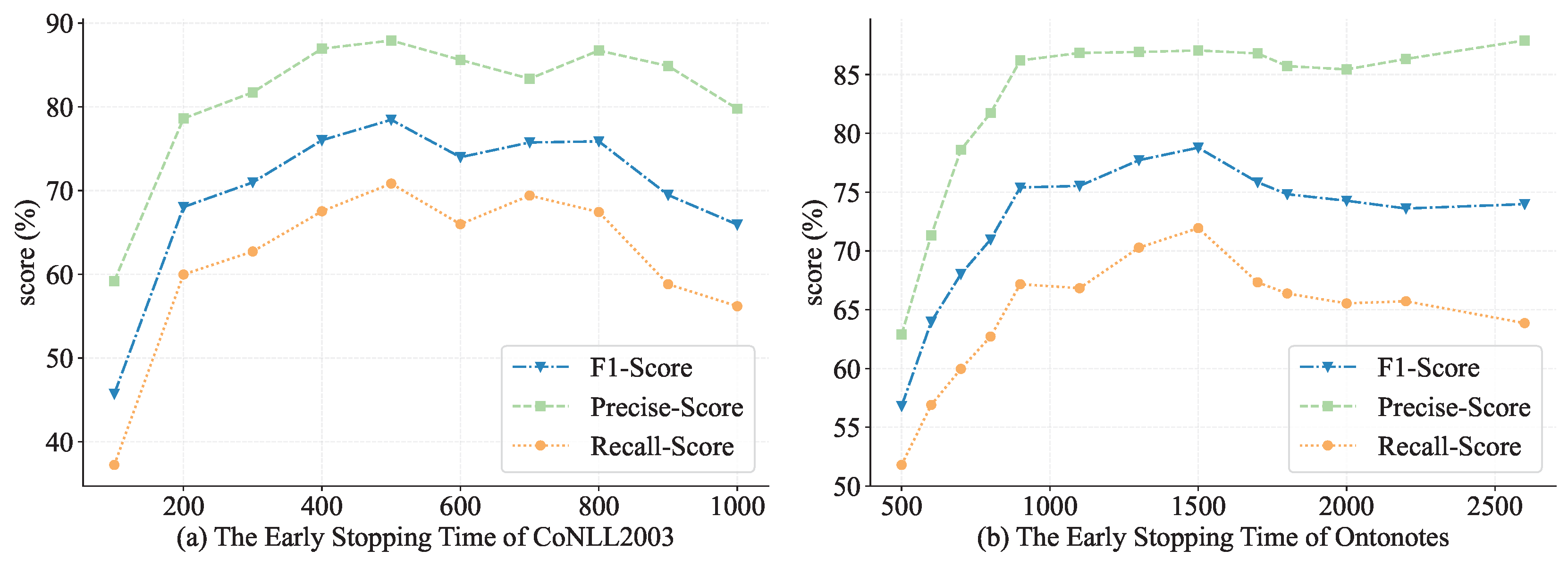
6.3.1. Ablation Experiments of Entity Locating
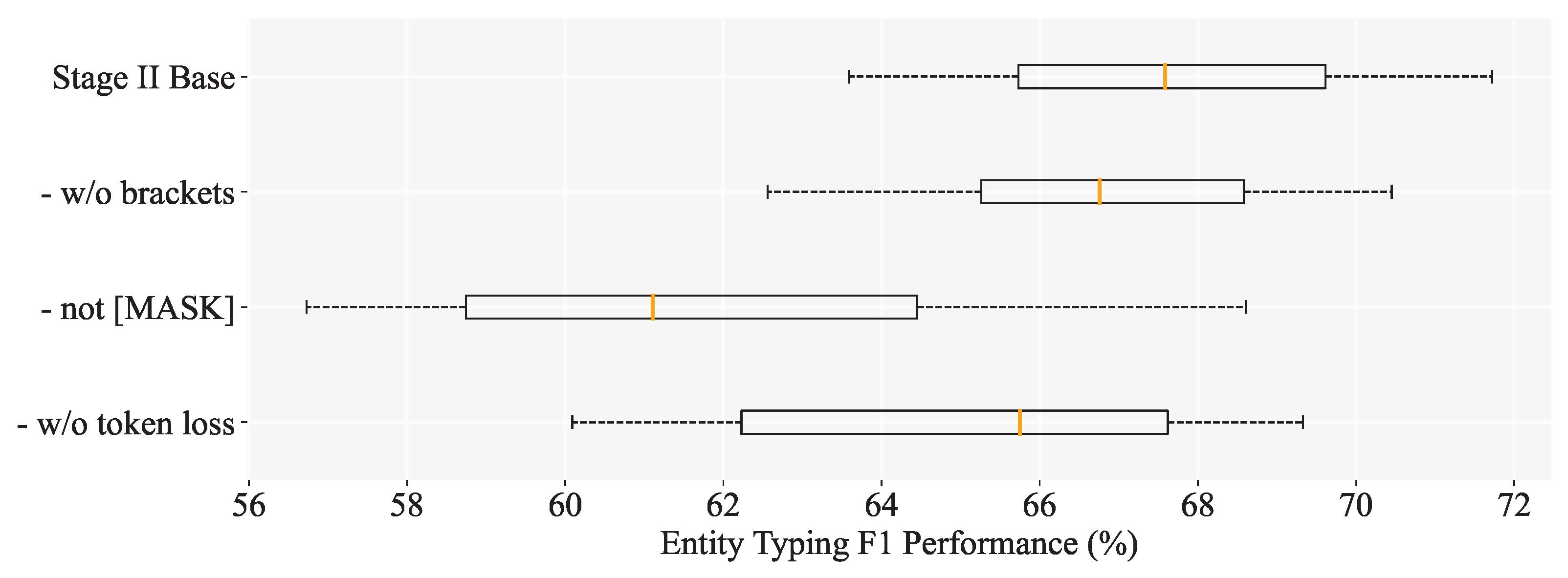
6.3.2. Ablation Experiments of Entity Typing
6.3.3. Case Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| PLM | Pre-Trained Language Model |
| MRC | Machine Reading Comprehension |
| FFN | Feed-Forward Network |
| BERT | Bidirectional Encoder Representation from Transformers |
| GPT-3 | Generative Pre-Trained Transformer 3 |
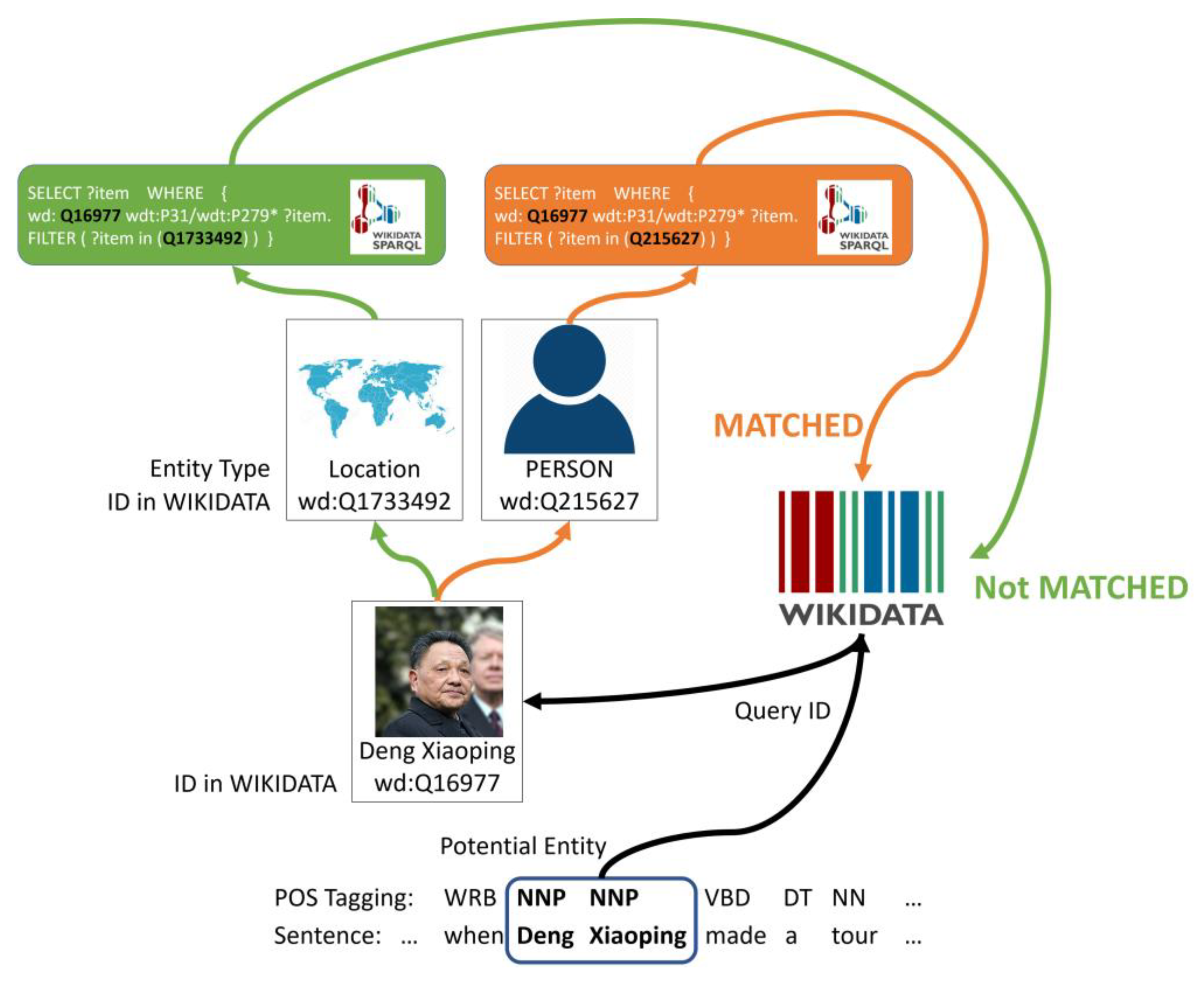
Appendix A. KB-Matching Method
Appendix B. Greedy Sampling Method
| Algorithm A1 Greedy sampling. |
|
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Chapter of the Association for Computational Linguistics: Human Language Technologies, (Long and Short Papers), Proceedings of the 2019 Conference of the North American, Cambridge, MA, USA, 8–11 November 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Fritzler, A.; Logacheva, V.; Kretov, M. Few-shot classification in named entity recognition task. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 993–1000. [Google Scholar]
- Yang, Y.; Katiyar, A. Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6365–6375. [Google Scholar]
- Huang, J.; Li, C.; Subudhi, K.; Jose, D.; Balakrishnan, S.; Chen, W.; Peng, B.; Gao, J.; Han, J. Few-shot named entity recognition: An empirical baseline study. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 10 May 2021; pp. 10408–10423. [Google Scholar]
- Hou, Y.; Che, W.; Lai, Y.; Zhou, Z.; Liu, Y.; Liu, H.; Liu, T. Few-shot Slot Tagging with Collapsed Dependency Transfer and Label-enhanced Task-adaptive Projection Network. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1381–1393. [Google Scholar]
- Ma, J.; Ballesteros, M.; Doss, S.; Anubhai, R.; Mallya, S.; Al-Onaizan, Y.; Roth, D. Label Semantics for Few Shot Named Entity Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1956–1971. [Google Scholar]
- Ma, T.; Jiang, H.; Wu, Q.; Zhao, T.; Lin, C.Y. Decomposed Meta-Learning for Few-Shot Named Entity Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1584–1596. [Google Scholar]
- Wang, Y.; Chu, H.; Zhang, C.; Gao, J. Learning from Language Description: Low-shot Named Entity Recognition via Decomposed Framework. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 17 April 2021; pp. 1618–1630. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT. Available online: https://openai.com/blog/chatgpt/ (accessed on 8 March 2023).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-Based Named Entity Recognition Using BART. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1835–1845. [Google Scholar]
- Chen, X.; Zhang, N.; Li, L.; Xie, X.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Lightner: A lightweight generative framework with prompt-guided attention for low-resource ner. arXiv 2021, arXiv:2109.00720. [Google Scholar]
- Ma, R.; Zhou, X.; Gui, T.; Tan, Y.; Li, L.; Zhang, Q.; Huang, X. Template-free Prompt Tuning for Few-shot NER. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 5721–5732. [Google Scholar]
- Ding, N.; Chen, Y.; Han, X.; Xu, G.; Wang, X.; Xie, P.; Zheng, H.; Liu, Z.; Li, J.; Kim, H.G. Prompt-learning for Fine-grained Entity Typing. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6888–6901. [Google Scholar]
- Das, S.S.S.; Katiyar, A.; Passonneau, R.; Zhang, R. CONTaiNER: Few-Shot Named Entity Recognition via Contrastive Learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 6338–6353. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 22–27 May 2021; pp. 3816–3830. [Google Scholar]
- Shang, J.; Liu, L.; Ren, X.; Gu, X.; Ren, T.; Han, J. Learning named entity tagger using domain-specific dictionary. arXiv 2018, arXiv:1809.03599. [Google Scholar]
- Peng, M.; Xing, X.; Zhang, Q.; Fu, J.; Huang, X. Distantly supervised named entity recognition using positive-unlabeled learning. arXiv 2019, arXiv:1906.01378. [Google Scholar]
- Liang, C.; Yu, Y.; Jiang, H.; Er, S.; Wang, R.; Zhao, T.; Zhang, C. BOND: Bert-Assisted Open-Domain Named Entity Recognition with Distant Supervision. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Online, 6–10 July 2020. [Google Scholar]
- Meng, Y.; Zhang, Y.; Huang, J.; Wang, X.; Zhang, Y.; Ji, H.; Han, J. Distantly-supervised named entity recognition with noise-robust learning and language model augmented self-training. arXiv 2021, arXiv:2109.05003. [Google Scholar]
- Ying, H.; Luo, S.; Dang, T.; Yu, S. Label Refinement via Contrastive Learning for Distantly-Supervised Named Entity Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, USA, 10–15 June 2022; pp. 2656–2666. [Google Scholar]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How Can We Know What Language Models Know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan IV, R.L.; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4222–4235. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT Understands, Too. arXiv 2021, arXiv:2103.10385. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 22–27 May 2021; pp. 4582–4597. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Qin, G.; Eisner, J. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5203–5212. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 2225–2240. [Google Scholar]
- Min, S.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Noisy Channel Language Model Prompting for Few-Shot Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 5316–5330. [Google Scholar]
- Li, C.; Gao, F.; Bu, J.; Xu, L.; Chen, X.; Gu, Y.; Shao, Z.; Zheng, Q.; Zhang, N.; Wang, Y.; et al. SentiPrompt: Sentiment Knowledge Enhanced Prompt-Tuning for Aspect-Based Sentiment Analysis. arXiv 2021, arXiv:2109.08306. [Google Scholar]
- Han, X.; Zhao, W.; Ding, N.; Liu, Z.; Sun, M. PTR: Prompt Tuning with Rules for Text Classification. AI Open 2021, 3, 182–192. [Google Scholar] [CrossRef]
- Sainz, O.; Lopez de Lacalle, O.; Labaka, G.; Barrena, A.; Agirre, E. Label Verbalization and Entailment for Effective Zero and Few-Shot Relation Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 1199–1212. [Google Scholar]
- Tan, Z.; Zhang, X.; Wang, S.; Liu, Y. MSP: Multi-Stage Prompting for Making Pre-trained Language Models Better Translators. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 6131–6142. [Google Scholar]
- Wang, S.; Tu, Z.; Tan, Z.; Wang, W.; Sun, M.; Liu, Y. Language Models are Good Translators. arXiv 2021, arXiv:2106.13627. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 255–269. [Google Scholar]
- Schick, T.; Schütze, H. It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 4 November 2021; pp. 2339–2352. [Google Scholar]
- Gu, Y.; Han, X.; Liu, Z.; Huang, M. PPT: Pre-trained Prompt Tuning for Few-shot Learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 8410–8423. [Google Scholar]
- Zheng, Y.; Zhou, J.; Qian, Y.; Ding, M.; Liao, C.; Jian, L.; Salakhutdinov, R.; Tang, J.; Ruder, S.; Yang, Z. FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 501–516. [Google Scholar]
- Wu, Q.; Lin, Z.; Wang, G.; Chen, H.; Karlsson, B.F.; Huang, B.; Lin, C.Y. Enhanced meta-learning for cross-lingual named entity recognition with minimal resources. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 7–12 February 2020; Volume 34, pp. 9274–9281. [Google Scholar]
- Jiang, H.; Zhang, D.; Cao, T.; Yin, B.; Zhao, T. Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 1775–1789. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Boston, MA, USA, 20–23 August 2017. [Google Scholar]
- Tjong Kim Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL, Edmonton, AB, Canada, 31 May 2003; pp. 142–147. [Google Scholar]
- Weischedel, R.; Palmer, M.; Marcus, M.; Hovy, E.; Pradhan, S.; Ramshaw, L.; Xue, N.; Taylor, A.; Kaufman, J.; Franchini, M.; et al. OntoNotes Release 5.0 LDC2013T19. Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 2013. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Domain | Type Number | Training Set Size | Test Set Size |
|---|---|---|---|---|
| CoNLL2003 | News | 4 | 14.0 k | 3.5 k |
| OntoNotes5.0 * | General | 11 | 60.0 k | 8.3 k |
| Datasets | K = 5 | K = 10 | K = 20 | K = 50 |
|---|---|---|---|---|
| CoNLL2003 | 0.07% | 0.14% | 0.26% | 0.59% |
| OntoNotes5.0 | 0.06% | 0.13% | 0.27% | 0.64% |
| Datasets | Methods | K = 5 | K = 10 | K = 20 | K = 50 |
|---|---|---|---|---|---|
| CoNLL2003 | BERT-NER | 41.87 (±12.12) | 59.91 (±10.65) | 68.66 (±5.13) | 73.20 (±3.09) |
| NNShot † | 42.31 (±8.92) | 59.24 (±11.71) | 66.89 (±6.09) | 72.63 (±3.42) | |
| StructShot † | 45.82 (±10.30) | 62.37 (±10.96) | 69.51 (±6.46) | 74.73 (±3.06) | |
| Template NER † | 43.04 (±6.15) | 57.86 (±5.68) | 66.38 (±6.09) | 72.71 (±2.13) | |
| EntLM | 53.43 (±2.26) | 63.32 (±2.78) | 69.11 (±2.01) | 73.58 (±1.50) | |
| EntLM+Struct | 53.10 (±7.67) | 64.79 (±3.85) | 69.51 (±2.60) | 73.60 (±1.56) | |
| Our | 55.38 (±6.41) | 66.75 (±5.22) | 70.15 (±3.46) | 75.07 (±1.37) | |
| OntoNote5.0 | BERT-NER | 34.77 (±7.16) | 54.47 (±8.31) | 60.21 (±3.89) | 68.37 (±1.72) |
| NNShot † | 34.52 (±7.85) | 55.57 (±9.20) | 59.59 (±4.20) | 68.27 (±1.54) | |
| StructShot † | 36.46 (±8.54) | 57.15 (±5.84) | 62.22 (±5.10) | 68.31 (±5.72) | |
| Template NER † | 40.52 (±8.86) | 49.89 (±3.66) | 59.53 (±2.25) | 65.15 (±2.95) | |
| EntLM | 44.80 (±3.68) | 54.67 (±3.04) | 66.00 (±1.82) | 72.54 (±1.07) | |
| EntLM + Struct | 45.62 (±10.26) | 57.30 (±4.18) | 67.90 (±3.50) | 73.57 (±2.10) | |
| Our | 60.81 (±4.64) | 69.50 (±4.36) | 74.22 (±2.29) | 76.80 (±1.23) |
| Method | CoNLL | OntoNotes |
|---|---|---|
| BERT-NER † | 19.59 | 23.03 |
| TemplateNER † | 14,836.57 | 48,425.06 |
| EntLM | 20.64 | 24.48 |
| EntLM + Struct | 29.71 | 33.75 |
| Our | 21.03 | 25.23 |
| Model | CoNLL (Span F1) | OntoNotes (Span F1) |
|---|---|---|
| Stage I (entity locating) | 84.02 | 84.23 |
| w/o distant labels | 55.45 | 74.14 |
| w/o fine-tune | 78.45 | 81.80 |
| w/o early stopping | 80.22 | 83.23 |
| w/o early stopping and w/o fine-tune | 71.42 | 80.63 |
| Model | Span F1 | Type F1 | Finall F1 |
|---|---|---|---|
| EntLM-Struct | N/A | N/A | 45.62 |
| Our | 84.23 | 60.81 | |
| w/o distant labels in Stage I | 74.14 | 70.94 | 49.26 |
| w/o fine-tune in Stage I | 81.80 | 54.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, F.; Huang, L.; Liang, S.; Chi, K. Decomposed Two-Stage Prompt Learning for Few-Shot Named Entity Recognition. Information 2023, 14, 262. https://doi.org/10.3390/info14050262
Ye F, Huang L, Liang S, Chi K. Decomposed Two-Stage Prompt Learning for Few-Shot Named Entity Recognition. Information. 2023; 14(5):262. https://doi.org/10.3390/info14050262
Chicago/Turabian StyleYe, Feiyang, Liang Huang, Senjie Liang, and KaiKai Chi. 2023. "Decomposed Two-Stage Prompt Learning for Few-Shot Named Entity Recognition" Information 14, no. 5: 262. https://doi.org/10.3390/info14050262
APA StyleYe, F., Huang, L., Liang, S., & Chi, K. (2023). Decomposed Two-Stage Prompt Learning for Few-Shot Named Entity Recognition. Information, 14(5), 262. https://doi.org/10.3390/info14050262