1. Introduction
The educational system of Uruguay has experienced important problems associated with backwardness and disengagement in recent decades [
1]. Even though the system is characterized by universal coverage at the primary level, it is possible to observe that the student grade retention, dropout rates, and non-enrollment rates increase as the education system progresses, while age-appropriate coverage decreases [
2]. As a result, a signification portion of the students has difficulty remaining enrolled in the educational system [
3,
4].
For instance, during the transition from primary to secondary education, the educational system of Uruguay usually experiences a drop in students of 10%. Moreover, from the total of students at the age of 13 years old, 26% are overage for their grades, and 3% are dropping out the system. In secondary education, during the transition from basic secondary education to upper secondary education (when students are from 15 to 17 years old), there is an increase of 20% in students that are overage for their grades, and the proportion of students who drop out of the educational system increases by 27%. In the year 2015, Uruguay experienced the lowest graduation rates during the 12 years of compulsory education. Lastly, 31% of student graduations occurred at the age of 19 years old, and 40% were at the age of 24 years old [
3].
Previous work conducted by Pereda [
5] explored the social, economical, historical, and political aspects associated with this situation in Uruguay. According to Pereda [
5], lag, dropping out, and absenteeism are the three most important explanatory factors related to educational disengagement. Therefore, the identification of these aspects in educational trajectories allows one to establish early action in order to mitigate the risks and increase the chances of academic success.
The abundant amount of data generated by the digitalization of academic management systems has opened new perspectives for the analysis of educational data. The approach known as learning analytics [
6] seeks to understand and improve educational processes through the multi-technical processing of data and products generated by students and teachers [
7]. The field of learning analytics aims to develop data based educational solutions that can be useful for the many stakeholders involved in the teaching and learning processes so that such process can be constantly improved [
8].
Among the techniques used by learning analytics, one can mention statistical models, educational data mining (EDM), machine learning, natural language processing (PLN), computer vision, and new algorithms resulting from research in artificial intelligence. These techniques allow the processing of large volumes of data from different educational systems to generate solutions that support decisions focused on the improvement of different educational scenarios [
9,
10,
11,
12,
13].
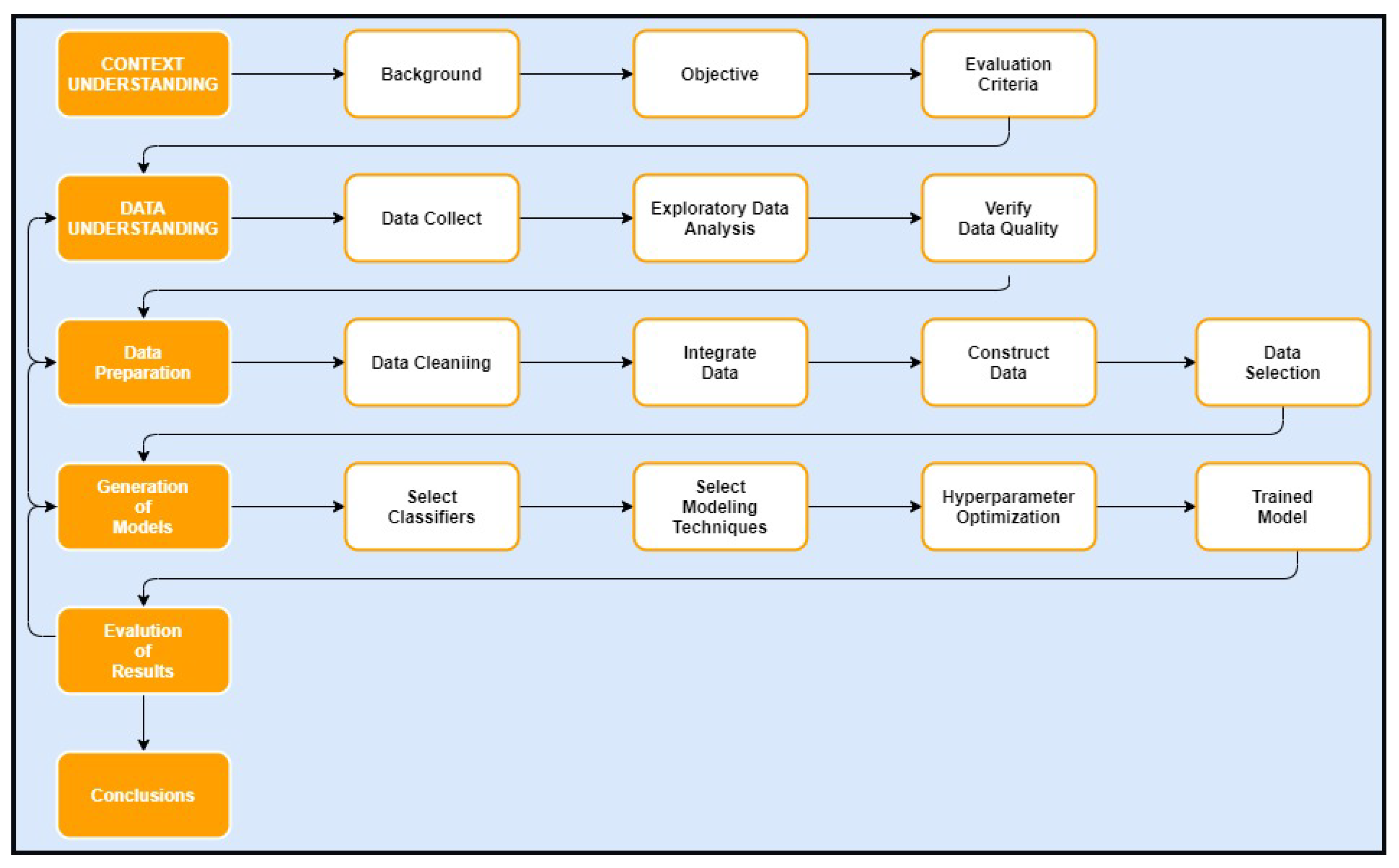
The present paper presents the methodology followed for the development of automated models to detect students at risk of dropping out at the secondary level in Uruguay. For this, the Clow cycle method [
12] was adopted as a baseline for the steps executed. In addition to the creation of the predictive models, this paper covers a deep exploratory analysis of the data used for the work together with the description of the resulting system developed to identify students at risk of disengagement. The experiments and implementation developed in this work continue the previous work conducted in [
14,
15]. Moreover, the work presented here was conducted under the fAIrLAC initiative of the Inter-American Development Bank (IDB). The fAIrLAC initiative intends to influence public policies by promoting the development of artificial intelligence (AI) solutions in a responsible and ethical way [
16,
17].
The present paper intends to answer the following research questions:
RQ1: Is it possible to generate an LA-based methodology that encompasses data acquisition, data transformation, and the generation of models that can help to identify students at risk of dropping out at secondary level early?
RQ2: Is the transformation of data from different databases into time series a viable alternative from a preprocessing point of view? If so, are the final results generated by the prediction models using this technique satisfactory?
RQ3: Is it possible to generate and analyze explainable models based on machine learning so that biases can be identified and corrected when necessary?
RQ4: Which features are the most important to predict students at risk of dropping out in Uruguay at the secondary level early?
The remainder of this paper is organized as follows.
Section 2 describes some characteristics of the educational system in Uruguay, and
Section 3 presents the theoretical background and related works.
Section 4 explains the methodology followed in the present work, and
Section 5 describes the models generated for predicting students at risk.
Section 6 presents the most important results achieved by this project, and
Section 7 depicts how the predictive models are deployed to the authorities. Finally,
Section 9 remarks on the most important findings of this work.
2. Context Understanding: An Overview of Education in Uruguay
Uruguay is located to the extreme south of Latin America, with a population of around 3.4 million inhabitants and comprising 176,215 million square kilometers. Uruguay presents a huge concentration of its population in urban areas (92% of the population). Moreover, about 50% of the population lives in the metropolitan region of the capital (Montevideo). In the context of Latin America, Uruguay is the third country in the Human Development Index (HDI) with a rating of 0.817 [
18,
19], and it currently has one of the highest levels of connectivity in Latin America, with more than 80% of the population having access to the internet [
20].
The Uruguayan basic education system comprises preschool and primary and secondary education, with public schools accounting for around 85% of enrollments [
21]. In addition to this, university education is characterized by a policy of free and unrestricted admission, with no other condition than the completion of high school to be admitted to a university. The University of the Republic (UDELAR) is the most important player, with 90% of the enrollments in higher education [
11,
22]. The educational system as a whole is managed by the National Administration of Public Education (ANEP) (Administración Nacional de Educación Pública;
https://www.anep.edu.uy/acerca-anep, accessed on 10 January 2022), a government agency responsible for planning and managing public educational policies. For the present initiative, ANEP is the key stakeholder interested in the predictive models, and it is responsible for providing all the databases required for that.
Uruguay has been developing a series of social policies to combat inequality. Within these policies, one can highlight the Ceibal Plan [
23,
24]. The Ceibal Plan is a series of educational programs aimed at the digital inclusion of the Uruguayan population. These programs are based on a tripod of proposals aimed at students, teachers, and students’ families. In this context, a series of activities is developed, seeking to improve the quality of education through technological systems based on information and communication technologies (ICTs).
For instance, one of the outstanding programs within Ceibal is called “One laptop per child”, where since 2007, the government has distributed a laptop to each child enrolled in basic education and created a network of technological assistance for such equipment throughout the country. In addition, there are several other programs that seek to include the tripod involved in the project, with programs aimed at training and qualifying teachers, involving families in educational activities, producing technological educational resources, providing free internet to students in schools and at home, and technological educational activities aimed at student development, such as teaching robotics.
However, despite these multiple efforts, the Uruguayan educational system still faces high rates of student retention and disengagement. This situation is already being experienced in the early years of primary education. For instance, in 2012, around 27% of fourth-year students in primary education experienced some kind of delay in their training [
1].
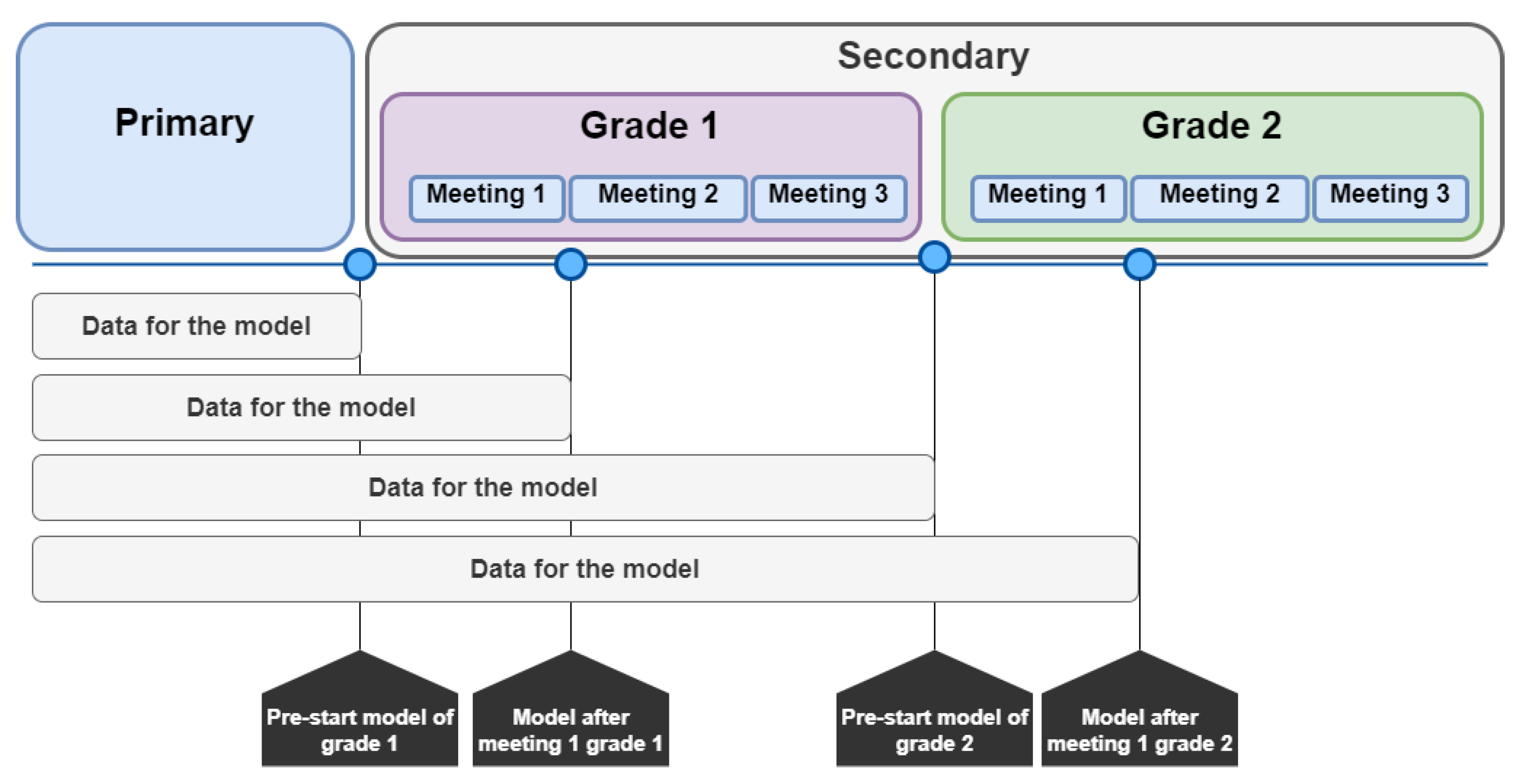
Primary education in Uruguay begins at the first grade (for children at the age of 6) and ends at the sixth grade (for children at the age of 11). Secondary education is divided into two cycles (basic and upper secondary education), each with a duration of 3 years. The basic cycle of secondary education comprises the seventh, eighth, and ninth grades for children from 12 and 14 years old. Upper secondary education is also known as bachillerato, which lasts 3 years and completes the education cycle for young people. This cycle can be compared to high school in Brazil and the United States.
This work focuses on basic secondary education (seventh, eighth, and ninth grades). Education for children in these groups is divided into two different models in Uruguay: normal secondary education (named CES) and technical vocational education (named UTU). These different teaching models have their own characteristics, such as different methodologies, calendars, schools, and courses. Still, these educational models present several sub-models of their own, which will be briefly mentioned later in this work.
7. Predictive Models Deployment
LA is distinguished for defining a greater focus on the process and how the developed solutions are used to improve teaching and learning in a continuous way. The results provided by LA solutions should be incorporated into the teaching and learning cycle, allowing interventions and providing new and improved scenarios that are again continuously improved by these solutions.
The deployment of the predictive models and the strategies for retraining them are essential for completing a fruitful LA solution. As was previously mentioned, the models developed here are recommended to be retrained twice a year (at the beginning of the school year and after the first evaluation meeting). Together with these recommendations, this project also developed a web API to use the models and provide the classification of the students according to their risk.
The API was developed using Python together with the Flask framework (
https://flask.palletsprojects.com/en/2.1.x/) (accessed on 10 May 2022) to build the web server. The Pandas and Celery (
https://docs.celeryq.dev/en/stable/) (accessed on 10 May 2022) libraries were used in the API. Pandas is a library that facilitates the manipulation and treatment of data, and Celery is an asynchronous queue of tasks implemented in Python and oriented to the passing of distributed messages in real time.
Queue handling was performed using RabbitMQ (
https://www.rabbitmq.com/) (accessed on 10 May 2022) as a broker to transport messages between processes. Version v4 of RabbitMq was used, and as in later versions, messages larger than 128 MB were not handled by default, as required by this project. A Redis (
https://redis.io/ (accessed on 10 May 2022)) was used as a backend in Celery, as it is a very efficient key value database for searching the results of tasks. Docker and Docker Compose were used to create Celery containers for the Redis, Rabbit, and API applications. To interact with the API, Python scripts and the application’s frontend were developed. On the frontend, the javascript programming language and the ReactJS framework (
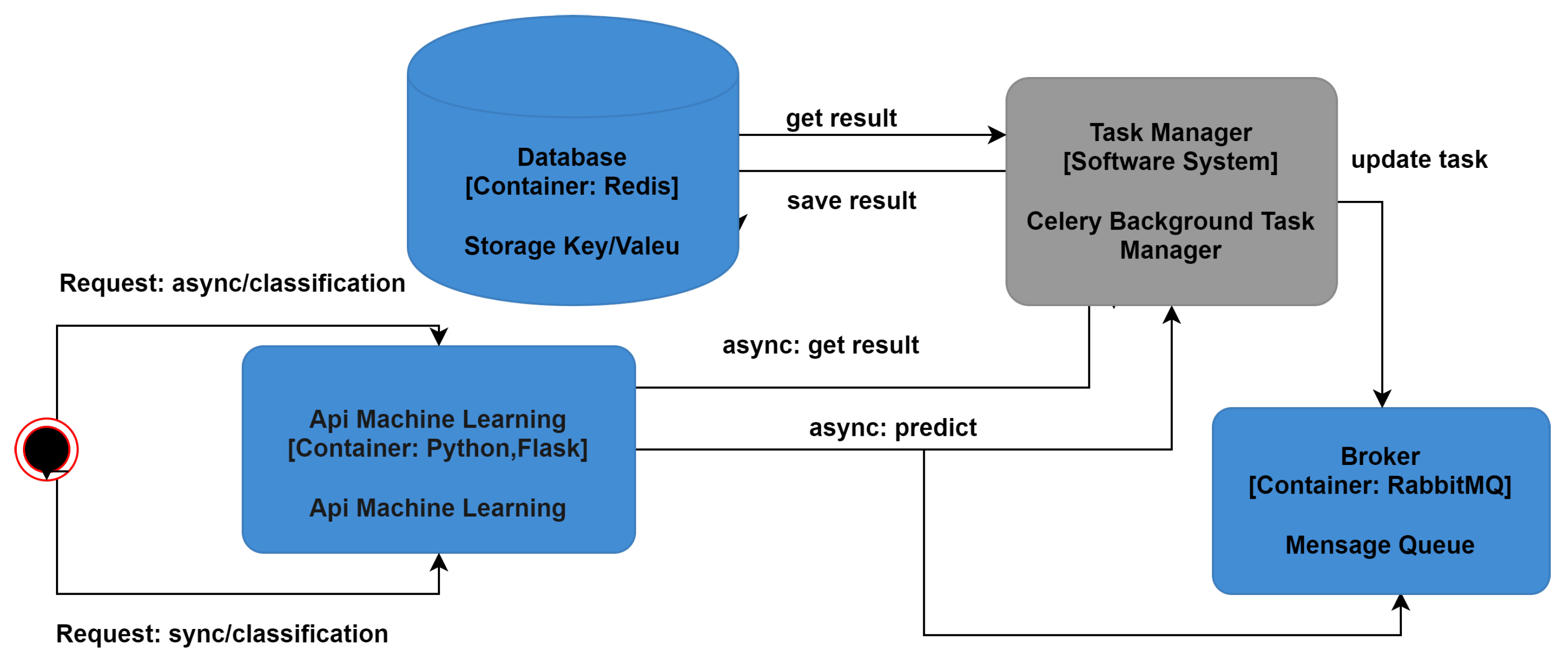
https://reactjs.org/) (accessed on 10 May 2022) were used to style the CSS3 frontend application. The machine learning API architecture was designed to support both asynchronous and synchronous predictions.
Figure 8 presents an overview of how the API operates.
In asynchronous prediction, the user will send the CSV file containing the students’ data and will immediately receive a token to check the prediction results afterward. The API will receive an HTTP/POST request with the CSV appended and the information of which model to use. This information may be sent from the web interface or from a terminal running a Python script. Celery is used by the asynchronous system to process the prediction task in the background, which will collect the information received in the HTTP request from the queue in RabbitMq. Then, Celery will start processing the forecast. When processing is complete, a message is sent to the queue with the results of the prediction. Therefore, when the query is made by the user through the token, the prediction result will be retrieved. At this point, a cache of results will be created in Redis, and the result will be sent to the user in HTML and CSV formats, along with the information displayed in the interface. In case the API has not finished processing the predictions while the user is consulting the results, the user will receive a message that the prediction is in progress and that the user will need to try to retrieve the results again later.
At the end of the prediction process, the user can consult the results and use them to make descriptions, such as the final statuses of the students (approved or possible problem) by region, by school, or by participating in social welfare programs, among other factors. It is important to highlight that the classification of each instance involves uncertainties. Together with the results for the final statuses of the students, the API also presents the probability of certainty of the classification provided by the automated model.
In synchronous prediction, the API will receive an HTTP/POST request. Together with the request, it will be sent the CSV file containing the data and the information about which model should perform the prediction (e.g., M1G1-CES or M1G2-UTU). In this model, the API will process the CSV file and start making the prediction. The user who requested the prediction must wait for the process to finish before receiving the results. Once the prediction is completed, the user will receive the results in the HTML and CSV formats together with other information about the prediction.
8. Discussion
RQ1: Is it possible to generate an LA-based methodology that encompasses data acquisition, data transformation, and the generation of models that can help to identify early students at risk of dropping out at the secondary level?
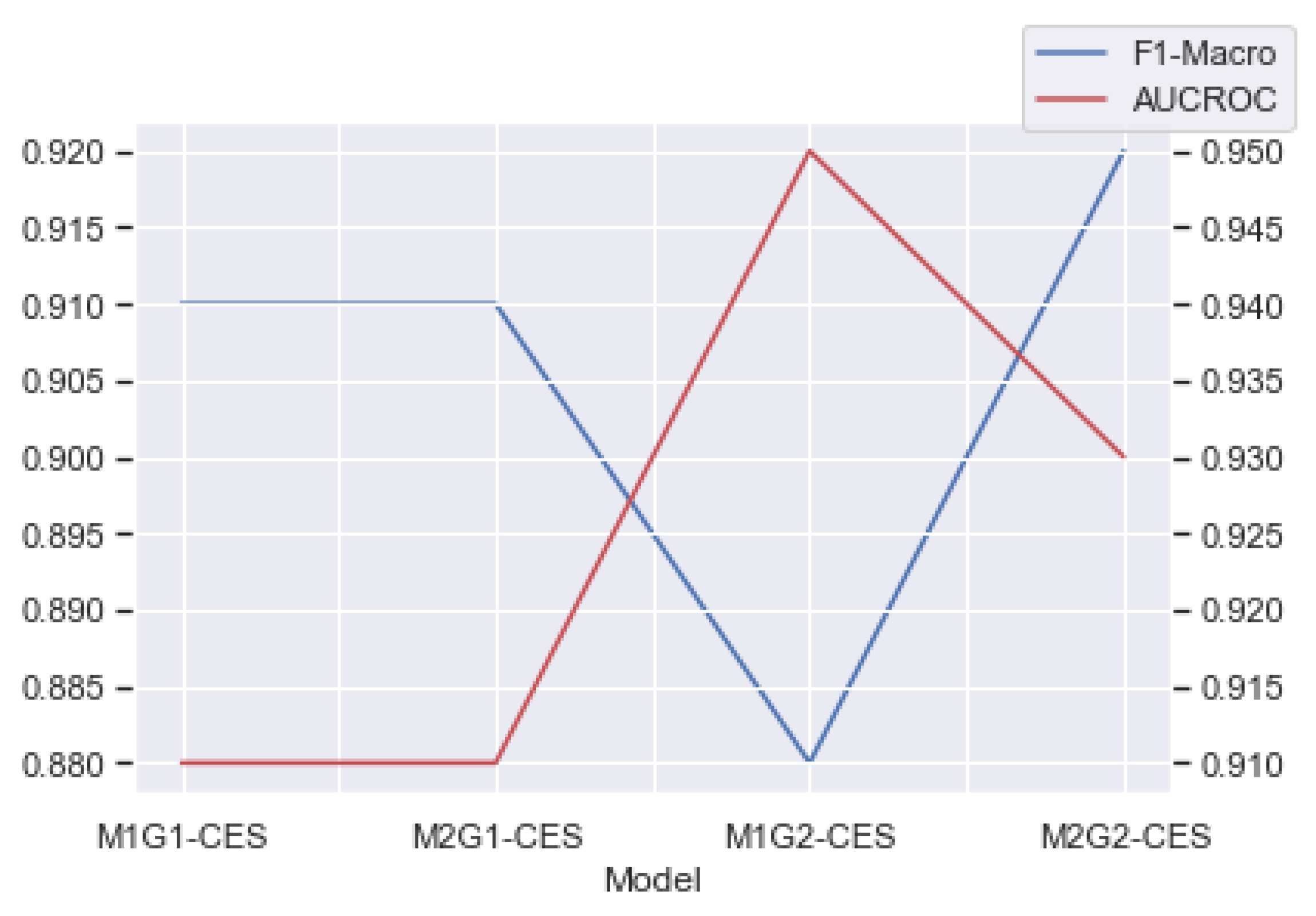
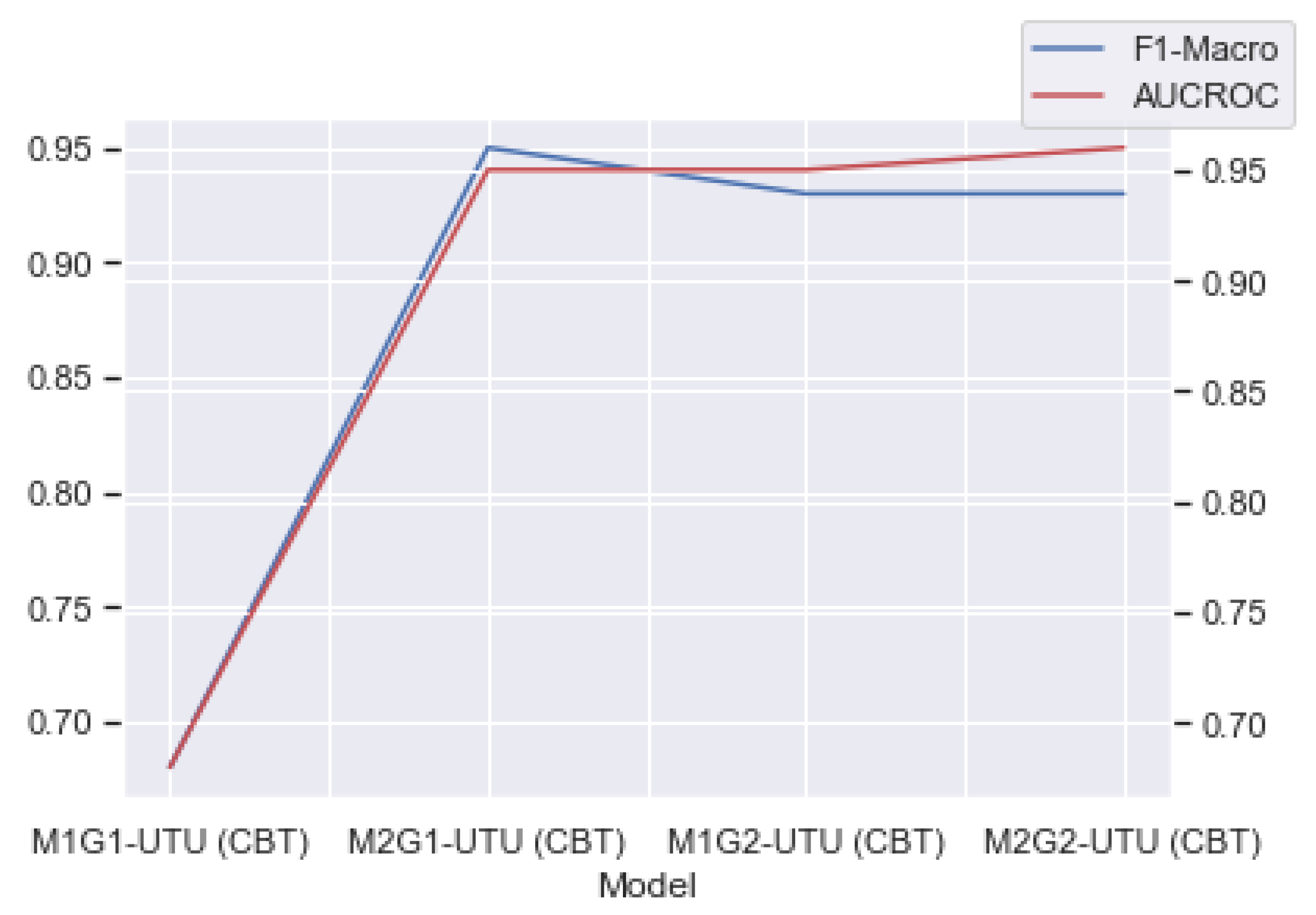
Yes, it is possible to generate this methodology. In general, the results found were satisfactory, with only one model (among the eight) not showing good results and being discarded. All other models achieved AUROC values higher than 0.91, which is an outstanding discrimination when considering the scale provided by Gašević et al. [
69]. These results were also confirmed by the F1-macro values, where the worst value was 0.88. Specifically, when one analyzed only the four pre-start models for the CES and UTU databases (M1G1 and M1G2), three of them were able to classify students who would face a possible problem (failure or dropping out) at that given grade and with great performance. Moreover, the four post-meeting 1 models for the CES and UTU databases (M2G1 and M2G2) presented great performance and were able to be used to classify students who were at risk. These results confirm the viability of the proposed methodology to identify early students at risk at the beginning of the school year and after the first evaluation meeting of the school year. Moreover, from the results obtained by the models, it is possible to see that their performances increased as more information was provided as input for them.
However, this methodology still has some limitations, such as the need for annual manual collection of data, annual preprocessing, and retraining of the predictive models. Future works will be focused on the direct integration of the predictive models with the different databases so that the data collection step can be automated, thus facilitating the process and optimizing the time spent in this part of the workflow.
Another issue to be deeply discussed in the next phases of the project is related to which stakeholders should have access to the prediction results. From the beginning, this project was designed to solely grant ANEP’s managers access to the results so that these results could help the development of institutional and educational policies based on the data. Considering this, teachers and students would not have access to the results at this initial phase, which is a practice aligned with the current learning analytics literature and recommendations for this kind of work [
70]. Whether or not other stakeholders should also access the results of these predictions is still subject to future discussion.
RQ2: Is the transformation of data from different databases into time series a viable alternative from a preprocessing point of view? If so, are the final results generated by the prediction models using this technique satisfactory?
Yes, from the preprocessing point of view, it was possible to generate time series from the collection and integration of data from the different databases, thus generating information and knowledge about the educational system and students.
Regarding the results, the models presented very good performances (with the exception of M1G1-UTU). The results found in the experiments show that it is possible to generate predictive models that can help in the identification of students with a tendency to face some problems (dropout or failure) during secondary school. However, these models need to be trained annually with new data that can represent the changes taking place in the student population. This can generate a complex situation, since these models used data prior to the COVID-19 pandemic and may not present good results with data from the pandemic period. It is understood that new educational scenarios that emerged from the pandemic will possibly require future adaptations in the predictive models.
RQ3: Is it possible to generate and analyze explainable models based on machine learning so that biases can be identified and corrected when necessary?
Yes, this is possible. In this project, the random forest algorithm was chosen, considering this as the algorithm to generate the models so that the reasoning of the models could be open and understood by humans. Moreover, currently, there are several techniques and libraries that can assist in testing and verifying possible biases in machine learning models. In this work, the What-if tool was used to help in this part of the analysis. The tool allowed us to analyze the models regarding the bias in the attributes that were previously selected as protected. In the analyses performed, only one model generated bias (M1G1-UTU). This model was eliminated from the work, as it was not possible to correct this bias after several interactions.
RQ4: Which features are the most important to predict students at risk in secondary school in Uruguay early?
A large number of attributes were generated that served as input for the models. The strategy adopted to avoid the curse of dimensionality was the application of procedures for selecting input variables and to reduce them to the 20 most important ones, together with the use of the random forest algorithm, which was particularly suited to dealing with this problem [
71].
Thus, for each predictive model, a prior step was carried out: selecting the top 19 most important features that could help with classification. To calculate the most important features to be used as input for the models, the predictive power score (PPS) was used. This metric calculates a value between 0 (no predictive power) and 1 (perfect predictive power), representing the relationship between the different attributes against the target [
72,
73]. This metric is widely used in time series, as it has the ability to point out how much a given variable says about another.
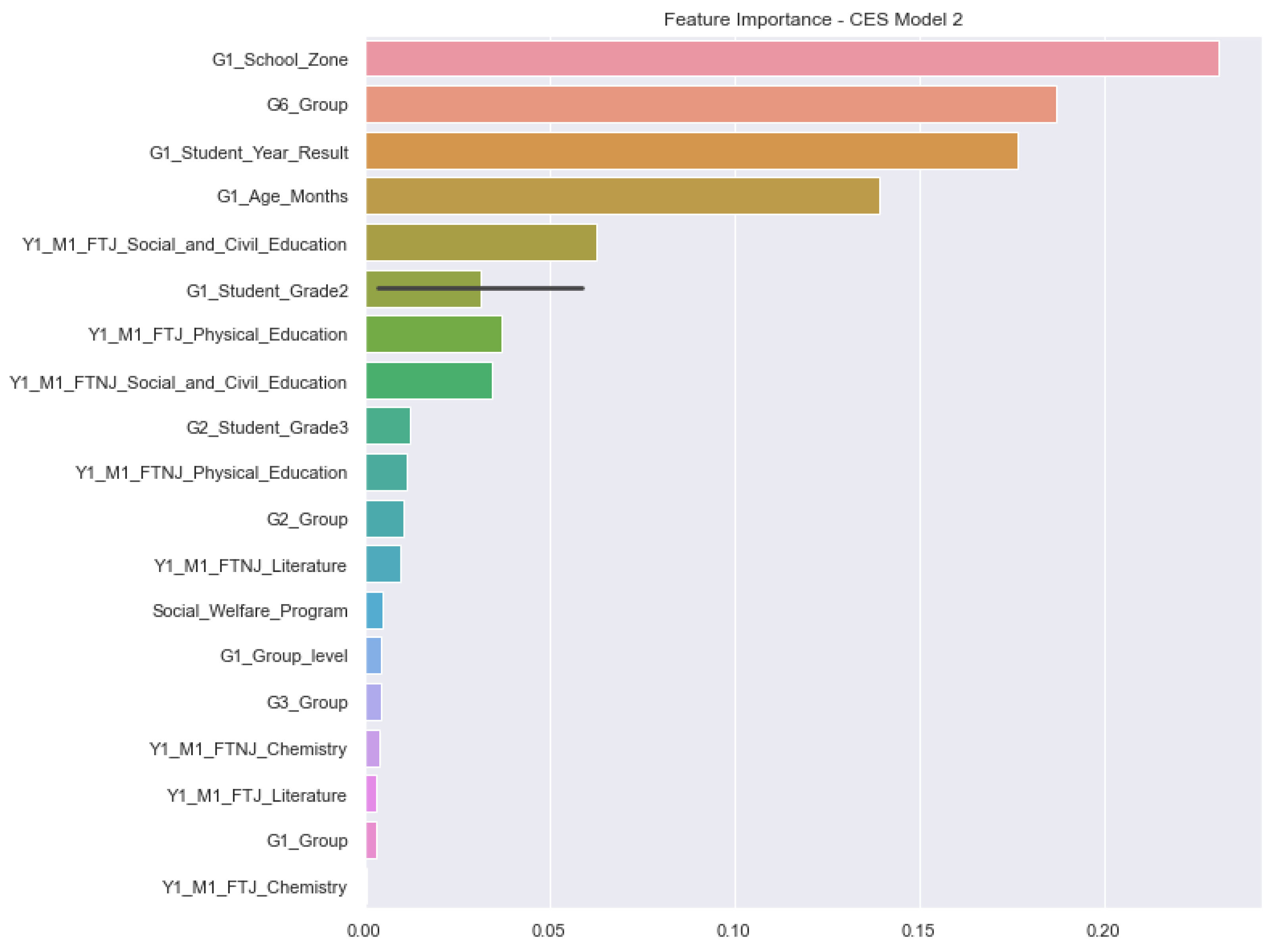
Figure 9 presents the list of the most important features for M2G1-CES as an example. As can be seen in the figure, the most important features for this model combine information related to primary education together with information about the first meeting of secondary education. The two most important attributes for this model are related to the school zone (rural or urban) in the first year in primary school and the student grouping based on their assessments in the sixth year of primary school.
From the analysis, it is also possible to see that from the 10 most important features (attributes), the first 5 of them and the tenth one are related to information from primary education. This demonstrates that educational problems in the studied context may have their origins in the first years of school. This finding corroborates previous findings in the literature [
74,
75,
76]. Aside from that, this also confirms the findings of Nagy and Molontay [
49] and Hernández-Leal et al. [
51], who highlighted the importance of using information about the performance of the students in the early years of education in order to predict their performance in secondary education.
For instance, for this model, the attribute G1_School_Zone presented a PPS of 0.23, followed by the attribute G6_Group with a PPS of 0.19. Moreover, the findings for the M2G1-CES model were very similar to the ones for the M2G1-UTU model in terms of the most important features. For the second year (grade 2), the assessment of the students in some of the subjects (disciplines) was among the top 10 most important features to be used as input by the models (M1G2-CES, M2G2-CES, M1G2-UTU, and M2G2-UTU). This again confirmed the importance of using data from primary education to predict students at risk at the secondary level.
9. Conclusions
Learning analytics is a new research area that is gradually growing and consolidating itself. However, the main focus of the research in this field is still toward higher education, with less attention directed to the primary and secondary educational levels [
13,
44,
45,
77]. The present research specifically covers the adoption of LA in secondary education, and at the same time, it seeks to assist Uruguay in the formation of institutional and governmental policies by detecting at-risk students early.
The present work proposed a methodology to predict at-risk students in secondary education at a national level. Together with the proposal, it was also possible to present the performances of the models running with real data collected from students and covering their school cycles from the first year of primary education to the second year of secondary education. A total of eight models were generated and tested to avoid any bias, and seven of them were approved to be adopted. Moreover, an API was developed and described so that these models could be deployed to the authorities responsible for running them. As the learning analytics process is cyclical, several manuals, reports, and training videos were also generated to facilitate the annual retraining of the models by the stakeholders of ANEP.
The data understanding stage allowed the establishment of an initial set of main variables that could be used in the process of generating early prediction models for students at risk at the secondary level. Initial results suggest that the primary school data, together with the sociocultural student data, helped to partially improve the performance of the predictive models by approximately 4%. Moreover, exploratory data analysis revealed sensitive issues that were hidden in the data, such as that the population of students who participated in some kind of social welfare program during primary school had fewer problems during secondary school than the population that did not participate in social welfare programs. This situation was observed for both the CES and UTU databases and may indicate that current social policies are aimed in the right direction.
Throughout the process, several limitations were encountered for the advancement of the project. We can highlight some of them, such as the failure to obtain budget data, which could reveal new information about schools and the relationship between investment and results. Moreover, issues related to the crossing of data with the states and regions of the country and the gross domestic product (GDP) were not explored in this project and should be considered in future improvements.
Future works should also focus on adding new functionalities to the developed API. Possible improvements could be the development of graphical visualization of the results, the analysis and cross-referencing of the data, new statistical metrics to evaluate the results, and the automation of tasks related to preprocessing. Ideas for reports and dashboards for this context were already previously proposed by Macarini et al. [
15].
Another possible future work is the evaluation of the features that are considered the most important for prediction. For this, the graphical visualization of those features, together with the application of clustering algorithms, may help with the identification of potential groups of at-risk students.
In this same direction, the use of alternative classification algorithms may result in better performance by the models. Algorithms such as the ones proposed by Saberi-Movahed et al. [
78] use evolutionary programming in different moments of classification, and they demonstrated satisfactory improvements in the performances of the models. Finally, the use of different metrics for the evaluation of the models may allow a more in-depth overview of the results.
At the current stage of the project, it was possible to verify the efficiency of the predictive models in the task they were proposed to perform and, at the same time, guarantee their fairness and explainability. However, it is still necessary to assess how the adoption and interpretation of the predictive results will be effective in allowing governmental institutions to take actions to prevent dropouts and foster public policies. It is expected that the process of adoption of the LA solution will be arduous, as was already mentioned by previous works in the field [
45,
79]. It is important to highlight that the work developed here is the first initiative toward the adoption of a learning analytics solution in secondary education at the national level in Latin America [
44].


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}