1. Introduction
Deep neural networks (DNN) underpin state-of-the-art applications of artificial intelligence (AI) in almost all fields, such as image, speech and natural language processing (NLP). However, DNN architectures [
1] are often data-, compute-, space-, power- and energy-hungry, typically requiring powerful graphic processing units (GPUs) or large-scale clusters to train and deploy, which has been viewed as a “non-green” technology [
2].
As a result of the European Green Deal
https://ec.europa.eu/info/strategy/priorities-2019-2024/european-green-deal_en (accessed on 2 December 2021) and the Horizon Europe Work Programme for 2021–2022 adopted on 15 June 2021, the European Commission has committed to making Europe the world’s first climate-neutral continent by 2050. If this important goal is to be achieved, more efficient AI models have to play their part in helping to reduce the amounts of energy that are required for data storage and algorithm training.
The concept of ‘green labs’ in the natural sciences is nowadays quite well-known
https://www.mygreenlab.org/ (accessed on 2 December 2021). Ultimately, researchers could no longer avoid the issue, given the amount of plastic waste right in front of their eyes in the lab at the end of any given day. In contrast, in computing, the GPUs on which we build our models and run our experiments are hidden away in the cloud or in a refrigerated machine room somewhere out of sight. Accordingly, most AI practitioners fail to consider the amount of electricity consumed and C
generated by the machine learning models that they (we!) build. That is starting to change
https://datacenters.lbl.gov/ (accessed on 2 December 2021) but much more can—and needs to—be done.
In MT, shared tasks focusing on efficiency
http://www.statmt.org/wmt21/efficiency-task.html (accessed on 2 December 2021) are helping in this regard. A recent paper by Yusuf et al. [
3] tracks the energy consumption of training translation models across different language pairs, but this was met with a somewhat mixed reaction on Twitter, but at least it turned the topic into a discussion point and provoked a response.
While the current paper concentrates on how smaller, greener models of MT might be built, the seemingly inexorable drive towards larger DNNs has received attention in the area of image classification, where Thompson et al. [
4] gathered data from more than a thousand research papers on deep learning and discussed their findings in detail. After analysing the data they found that, in practice, in order to halve the error rate, approximately 500 times the amount of resources used nowadays are required. If the gains obtained in recent years continue, by 2025 the error level in the best AI systems designed for recognising objects in the ImageNet [
5] dataset might be reduced to just 5%.
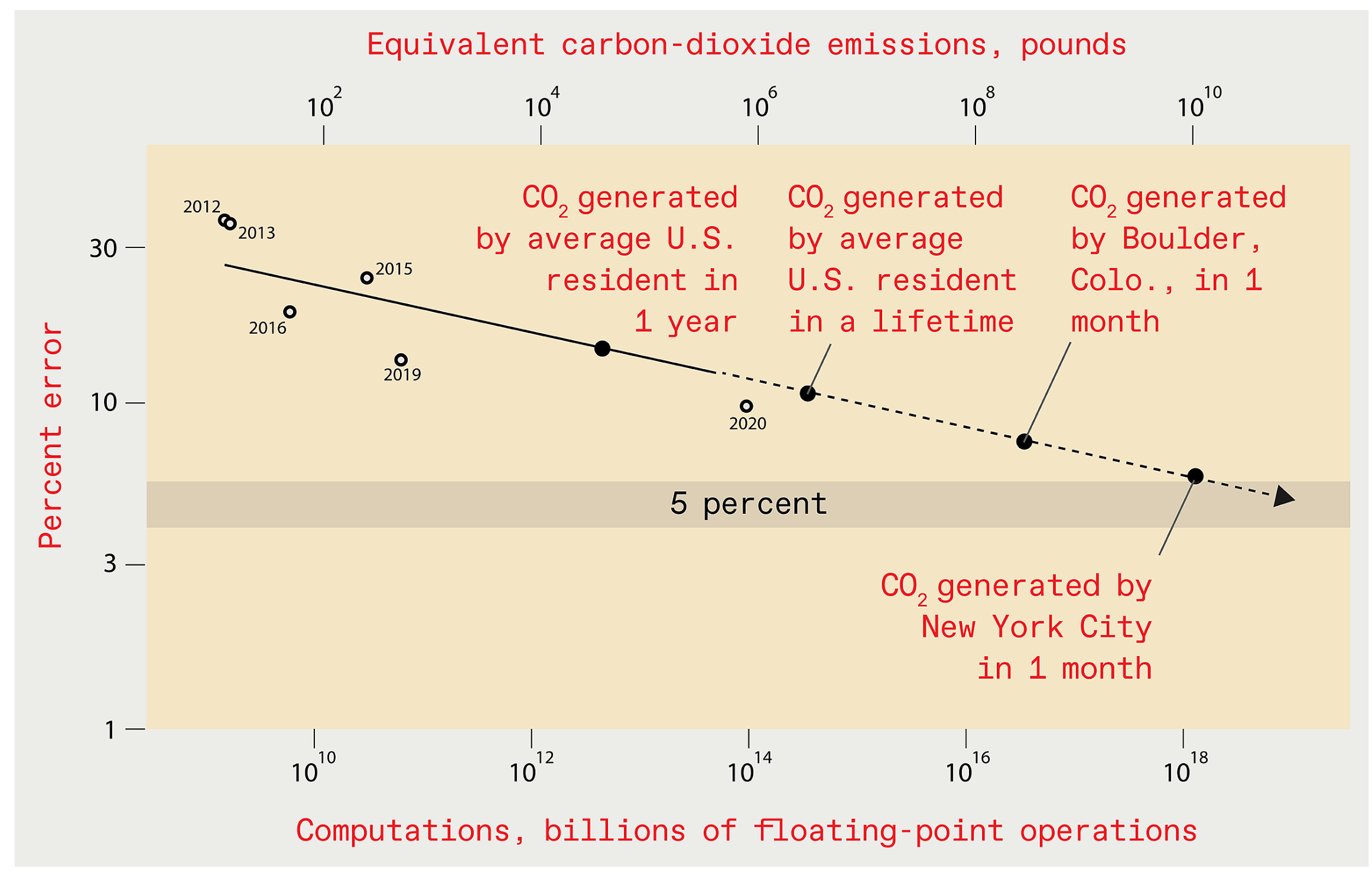
Figure 1 shows the infeasible amount of computing resources required to achieve such a small error rate, and the concomitant amount of CO
emitted. In the same vein,
Table 1 shows the estimated CO
emissions from training common NLP models as calculated by Strubell et al. [
2], compared to how much CO
is emitted over the lifetime of the average human, the average American, and a typical car.
The main idea behind model compression is to “compress” an ensemble of large models into a smaller model with minimal performance loss. This is generally done by using a small, fast model to approximate the function learned by a much larger and slower model with better performance [
6]. Hinton et al. [
7] show that compressing the knowledge from a cumbersome model into a smaller model can be seen as a mapping from input vectors to output vectors, and the relative probabilities of incorrect outputs can provide insight into how the cumbersome model tends to generalise. The work mentioned so far mainly investigated non-recurrent models used for classification tasks.
Knowledge distillation [
6] can be used to transfer the knowledge from a teacher network (a large, slow model) to a student network (a small, fast model). This is a promising technique to disrupt the current situation for NLP tasks where almost all systems tend to use cumbersome DNN architectures.
The methods described by Bucilua et al. [
6] and Hinton et al. [
7] can be used for word-level knowledge distillation, since NMT models make use of multi-class prediction at the word-level. These models, however, need to predict complete sequences that are dependent on previous predictions as well.
Kim and Rush [
8] proposed sequence-level knowledge distillation, where a new training set is generated by translating a dataset with the teacher model using beam search. The newly generated training set is then used to train a smaller student model. They show how the usual training criteria for multi-class classifiers can be used to develop a function for knowledge distillation, which can be expanded even further to be used for word-level knowledge distillation and finally sequence-level knowledge distillation.
Assume we want to classify the data in the set
into a set of classes
V. The aim is to minimise the cross-entropy between the data distribution and model distribution
p parameterised by
. This can be done by minimising the negative log-likelihood (NLL) for each training example, as in (1):
where
is the indicator function. In terms of knowledge distillation, we have a model distribution
, learned by the teacher, so Equation
(1) can be rewritten as (2):
We can now use
to define functions for knowledge distillation for NMT. First, standard knowledge distillation can be applied to NMT models since word NLL is minimised during training. The standard function becomes (3):
where
V is the target vocabulary and
t and
s the target and source sentences, respectively. Finally, a loss function for sequence-level knowledge will be derived, since word-level knowledge distillations can easily lead to the forward propagation of incorrect predictions. Once again, we can use a probability distribution derived from the teacher model to define a loss function. Sequence distributions from the teacher model are used instead of word distributions and Equation (2) can thus be rewritten as (4):
where
represents the sequence distribution over all possible sequences. This loss function, however, is complex to handle since it sums over an exponential number of terms. Kim and Rush [
8] suggest the use of beam search to approximate Equation (4), which reduces the complexity of
. It is worth noting that this method of knowledge distillation is difficult to apply when the domain of the training data is not well defined.
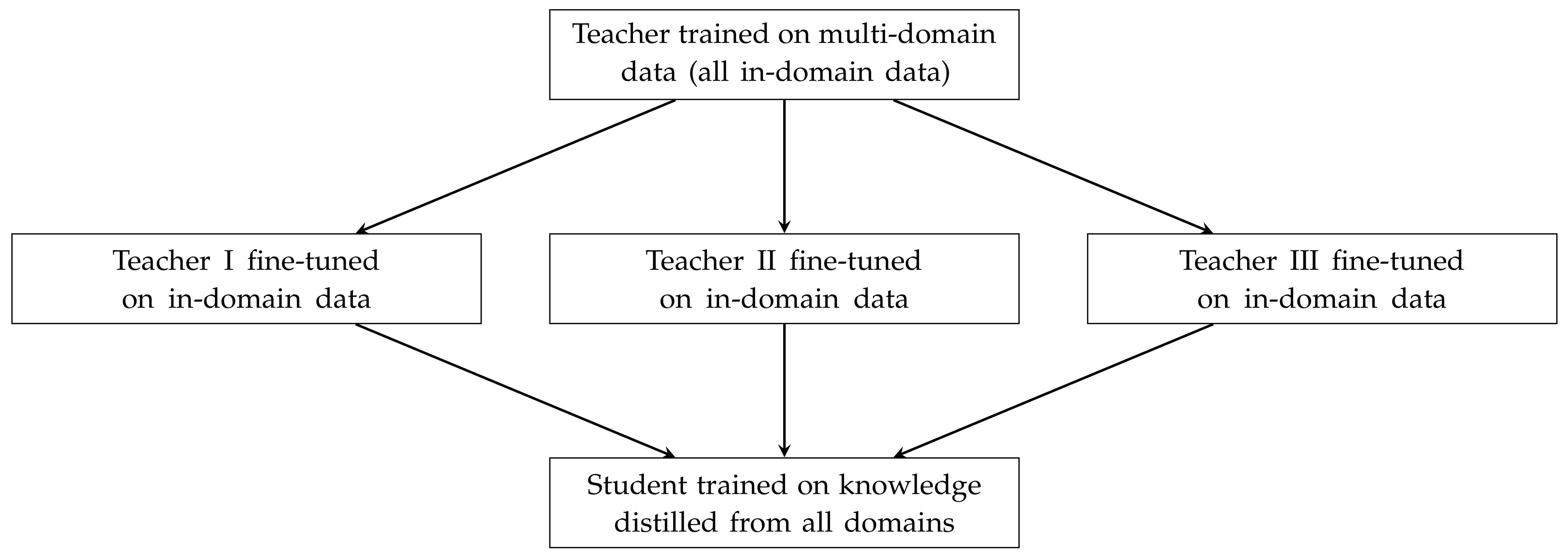
Currey et al. [
9] introduce generalised sequence-level knowledge distillation to distil translations from domain-specific teacher models, and the knowledge distilled in their approach is then used to train a smaller, multi-domain student model. This approach is referred to as ‘multi-domain knowledge distillation’ (cf.
Figure 2). It is worth noting that this method of knowledge distillation is difficult to apply when the domain of the training data is not well defined.
Both Currey et al. [
9] and Gordon and Duh [
10] use similar architectures for their models, that is, teacher models with 12 encoder and decoder layers and student models with six encoder and decoder layers. Training teacher models with this type of architecture requires a large amount of memory and GPUs.
Zhang et al. [
11] propose an adapted method of sequence-level knowledge distillation named ’dual knowledge distillation’. This method utilises bidirectional translation models to significantly improve translation in both directions.
Wang et al. [
12] propose two strategies to select distilled knowledge for training student models, namely batch-level selection and global-level selection. The authors show the impact that different words and sentences have as carriers of knowledge, and how consistent improvements on various datasets can be achieved using these strategies.
Passban et al. [
13] describe a new approach called ‘attention-based layer projection’ for knowledge distillation. In this approach, the output of each layer of the student model is compared to that of the teacher model, in order to help the student to produce better outputs.
Dakwale [
14] uses knowledge distillation to address the problem of catastrophic degradation during domain adaptation. This was applied using an in-house NMT system rather than a recurrent neural network [
15].
We take inspiration from this body of work, and summarise the main contributions of this paper as follows:
We use sequence-level knowledge distillation and show that small student models can outperform large teacher models;
We show that small student models prove to be very useful in the case where MT models need to be deployed in environments where constraining the available hardware is important;
We demonstrate a translation industry scenario where knowledge distillation in NMT is used for translating sentences in large-scale projects. For a real, current provider, we focus on three parameters of translation projects which are of crucial importance in industrial settings, namely translation time, translation cost, and carbon emissions, and demonstrate that savings of almost 50% can be achieved;
As our investigation focuses on the performance evaluation of small and large NMT models in a low-resource set-up, the findings in this paper add value to the current research on sustainable MT development;
Our research provides an alternative, realistic solution to SMEs who are currently unable to provide MT solutions to their clients due to the huge deployment costs associated with large-scale NMT models;
Our findings help to demonstrate that the sort of energy reductions required to achieve climate neutrality may be achieved.
When discussing our results in terms of the carbon emissions generated by these models, we use the framework of Henderson et al. [
16] for tracking energy consumption and carbon emissions.
2. Experimental Setup
We use the Europarl
https://opus.nlpl.eu/Europarl-v3.php (accessed on 2 December 2021) [
17] corpus with parallel sentences in German and English for our NMT simulation experiments described in this section for the language direction German to English. The corpus is randomly divided into three subsets, namely the training set, validation set and test set. The training set consists of roughly 2 million sentences and the validation and test sets of 3000 sentences, respectively.
As for the preprocessing of the data, the Moses [
18] toolkit was used to tokenize and clean the three datasets mentioned above by removing all sentences with a length greater than 100. The toolkit was also used to decase all sentences before training and after training, we used a pretrained truecaser to recase all translated sentences. Furthermore, SubwordNMT
https://github.com/rsennrich/subword-nmt (accessed on 2 December 2021) was used to segment the sentences in the corpus into subword units as described by Sennrich et al. [
19]. More specifically, the Byte Pair Encoding (BPE) vocabularies were set to
words.
The performance of all our models was measured with three evaluation metrics, namely BLEU [
20], TER [
21] and chrF
https://github.com/m-popovic/chrF (accessed on 2 December 2021) [
22], using the MultEval toolkit [
23]
https://github.com/jhclark/multeval (accessed on 2 December 2021). Of course, these metrics provide an indication of the quality of the translations produced by our NMT systems, but do not provide insight into the efficiency of our systems in terms of model size, number of parameters and training times.
The training set size, number of GPUs, time taken, electricity consumption and CO production and the balance between these constraints and performance need to be taken into account if we are to report on the efficiency of our systems. Electricity consumption and CO emissions can be estimated by taking training time and GPU specifications into account. In addition, human evaluation methods can provide better insight into the optimal balance of these factors, as automatic evaluation methods do not give an accurate indication of any deterioration in quality seen when smaller models are used. By the same token, continuing to train our DNN models for further epochs may result in gains according to automatic metrics which are not discernible to humans.
We use the MarianNMT
https://github.com/marian-nmt/marian (accessed on 2 December 2021) toolkit [
24] and Transformer [
25] architecture to train the models for our experiments. All models were trained for a maximum of 20 epochs, since that was the lowest number of epochs needed to finish training for one of our models.
Listing 1 shows an example training setup with most notable parameters for one of our baseline models.
The same script is used to train the student models, where the only difference is the training datasets used for training. The baseline and student models have the same architectures, since we want to determine the impact of the knowledge distilled from the teacher models on the efficiency of our systems.
Furthermore, we experimented with the hyperparameters of the student models by training these models with four Transformer heads, compared to eight heads, as shown in line 6 of
Listing 1. We also tested the performance of our student models by limiting the vocabulary sizes to
and
tokens. The results of this set of experiments are presented in
Section 3.4.
Listing 1.
Baseline model parameters.
--mini -batch -fit -w 9000 --mini - batch 1000 --maxi - batch 1000 \
--valid -mini - batch 64 \
--cost - type =ce -mean - words \
--beam - size 12 -- normalize 1 \
--enc - depth 3 --dec - depth 3 \
--transformer - heads 8 \
--transformer - postprocess -emb d \
--transformer - postprocess dan \
--transformer - dropout 0.1 --label - smoothing 0.1 \
--learn - rate 0.0003 \
--lr - warmup 16000 --lr -decay -inv - sqrt 16000 --lr - report \
--optimizer - params 0.9 0.98 1e -09 --clip - norm 5 \
--tied - embeddings --exponential - smoothing
|
As for the teacher models, the
--enc-depth and
--dec-depth parameters were set to 6, instead of 3. Other than the difference in encoder and decoder layers, the script remains the same and the teacher models are trained on the same training sets as the baseline models.
Table 2 summarises the three types of models that were used in our experiments and changes in their architectures.
4. Discussion
When comparing the results of the baseline models to the results of the teacher models, as can be seen from
Table 3 and
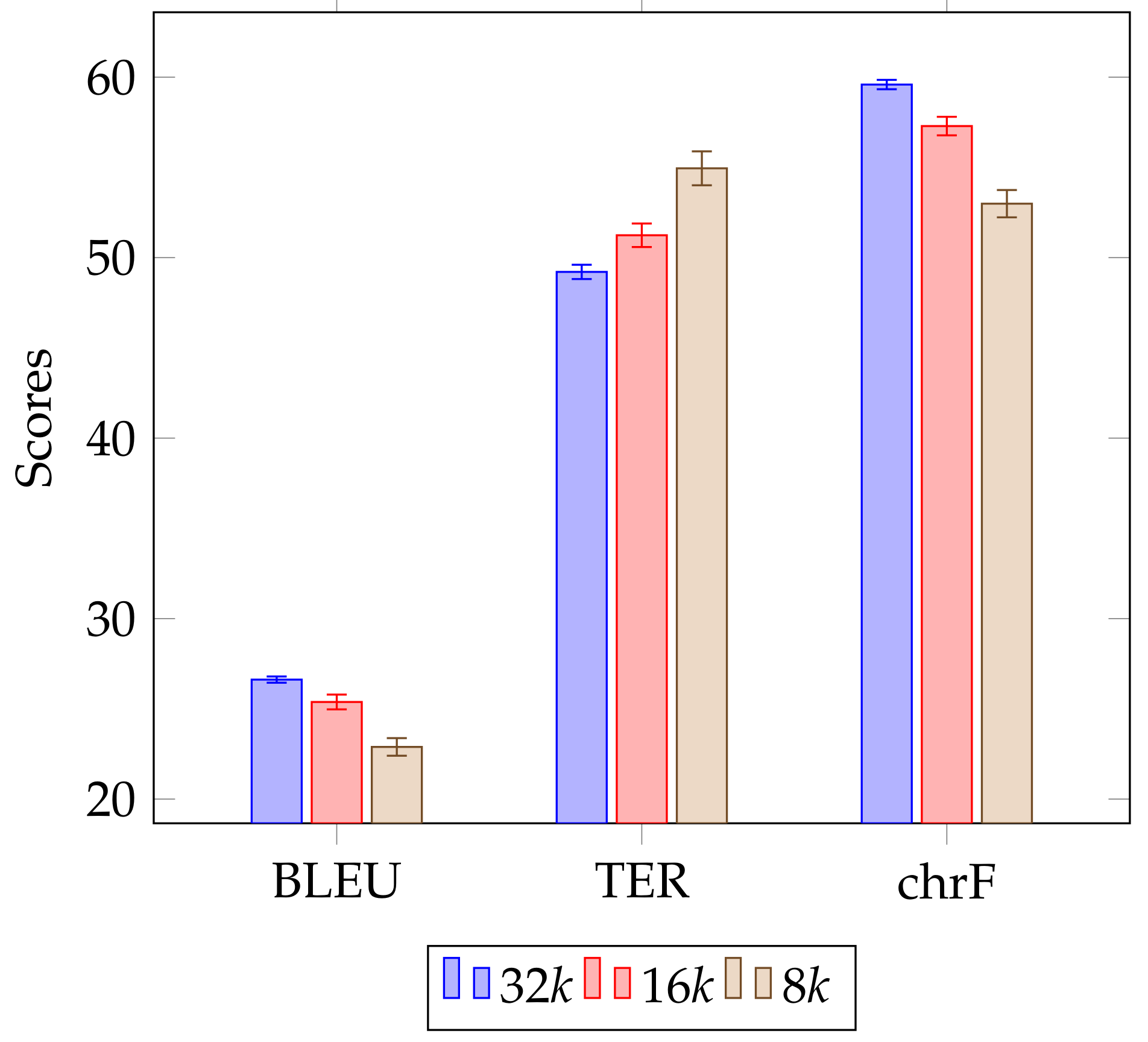
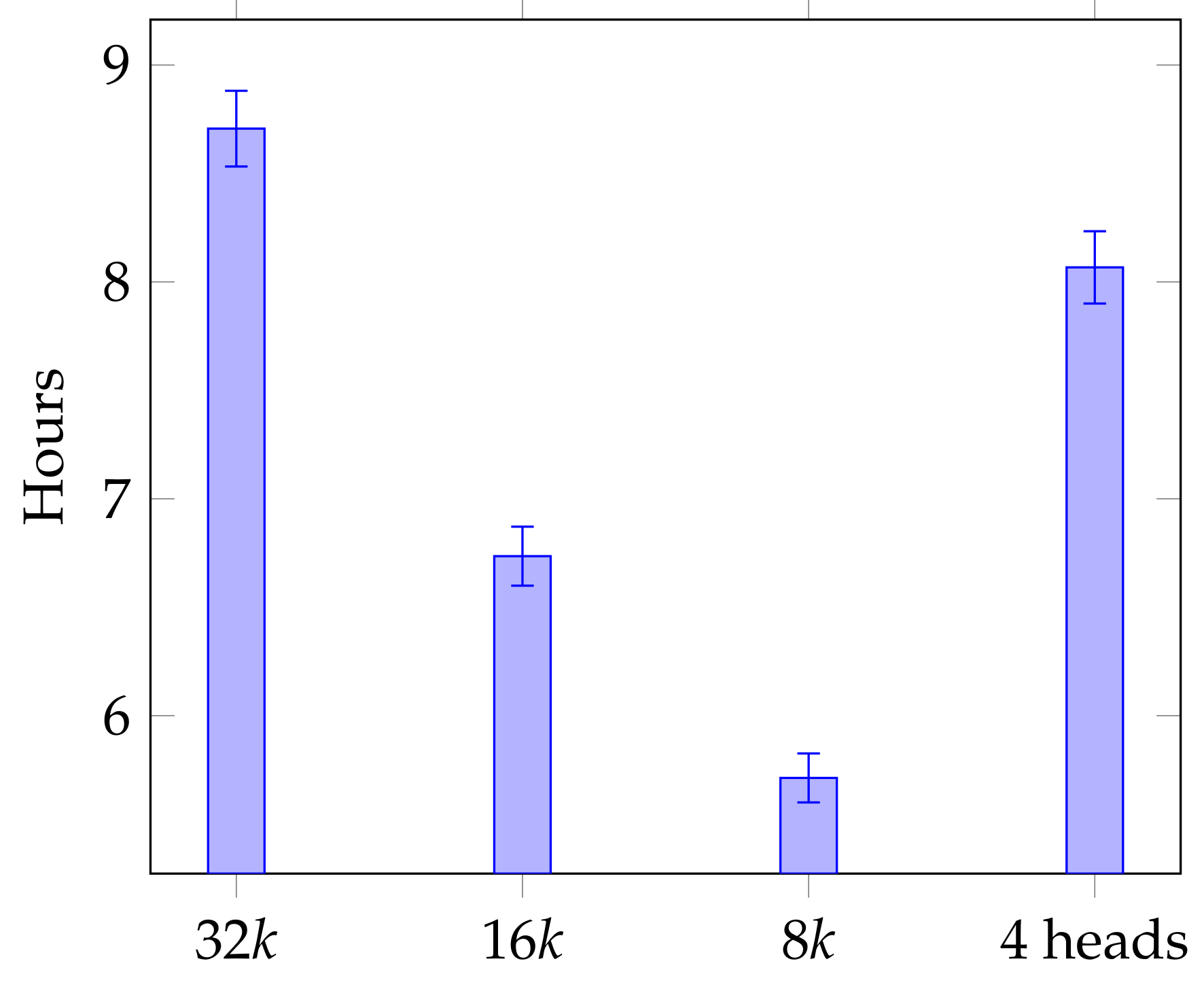
Table 4, the teacher models perform better than the baseline models as far as all three automatic metrics are concerned. When the vocabulary size is varied, as shown in
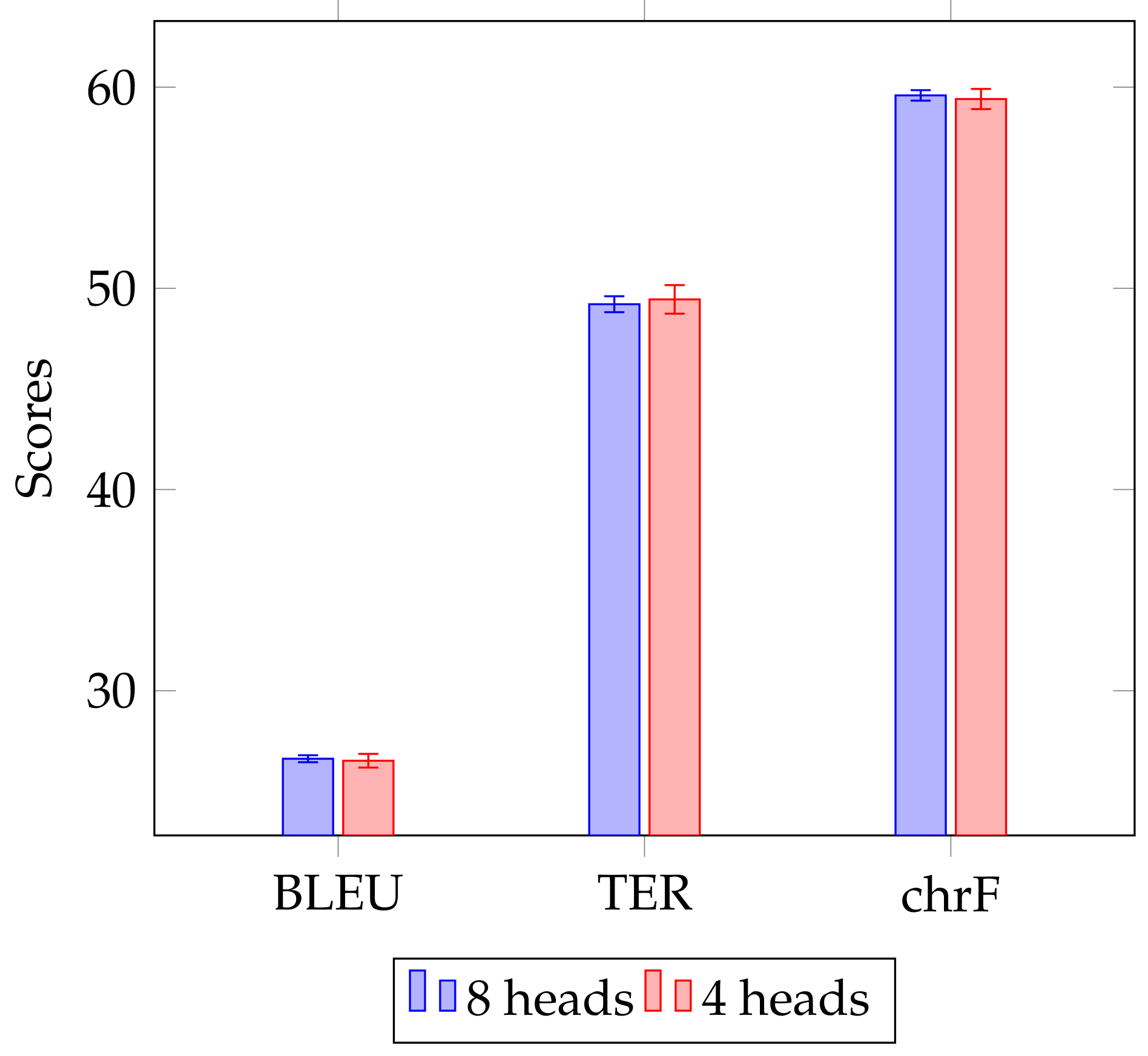
Figure 3, the performance of the student models decreases consistently with each halving of vocabulary size, for all three evaluation metrics. However, lowering the number of Transformer heads does not seem to significantly affect quality, as
Figure 4 shows.
In terms of the training times for the baseline models compared to the teacher models, the scores improve marginally, but the training times are longer than those of the baseline models. In fact, the best scores are obtained with Teacher-4GPU.
Figure 5 shows the average training time for the various student models and it is clear that the models with smaller vocabularies (
and
) trained faster on average, albeit with lower quality in terms of runtime performance as we have just seen. In comparison, the models with 4 Transformer heads (and a vocabulary size of
) trained slightly faster than the original student models, and with no significant deterioration in quality.
As for Baseline-4GPU and Teacher-4GPU, we compared translations and observed that even though there is a statistically significant difference in BLEU scores (calculated via approximate randomisation using the MultEval tool), the actual translations produced by both models do not differ significantly in quality from a human perspective. Example translations produced by the MT systems are shown in
Table 8, where from a human point of view, the translations produced by the two systems are equally valid. Accordingly, it appears that training a model with only three encoder and decoder layers is justifiable in the case of limited computing resources, since the sentences in both cases remain accurate and fluent, and no worse than a model using twice the amount of layers.
If we compare Student-KD and Teacher models, training time is almost half the amount of time for all Student models. For Student-KD-1GPU, the BLEU score is nearly identical to that of the corresponding Teacher model, but the TER and chrF scores show it to be a little worse. If we compare the Student-KD models to the Student-KD+EP models, the latter takes longer to train and leads to better scores for all automatic metrics.
From
Figure 3, it is clear that limiting the size of the vocabulary causes the experimental student models to train faster than the original student models (by up to 2 h). The accuracy, however, is lower (by about 2.5 BLEU points, or 10% relative), especially for models trained only on the KD set. The anomaly when using 2 GPUs appears in
Table 6 for both vocabulary sizes too, and it again occurs when the model iteration is not saved during the last epoch.
Interestingly, the model with the best accuracy was trained on the EuroParl+KD training set using 2 GPUs and only 4 Transformer heads. In some cases the student models with 4 Transformer heads were slightly quicker to train and more accurate than the original student models with 8 Transformer heads.
Figure 4 shows that the accuracy is on average very similar when using the different number of Transformer heads during training, but the average training time for models trained using only 4 Transformer heads is 7 h less than when using 8 Transformer heads.
Kim and Rush [
8] showed that when using a long short-term memory architecture, some smaller student MT models outperformed large teacher models. This is also the case for our Transformer models when using the original (Europarl) and KD training set as shown in
Table 9.
Impact
In this section, we consider a number of matters which are important industry concerns in the post-deployment phase, where only the translation process itself is taken into account and not the preceding training process. To the best of our knowledge, this study is the first of its type to take a realistic scenario from an actual service provider and estimate the savings that can be achieved from distilling larger models into small ones.
Table 10 shows the time (in seconds) it took for our models to translate the test set we used for evaluation, as described in
Section 2.
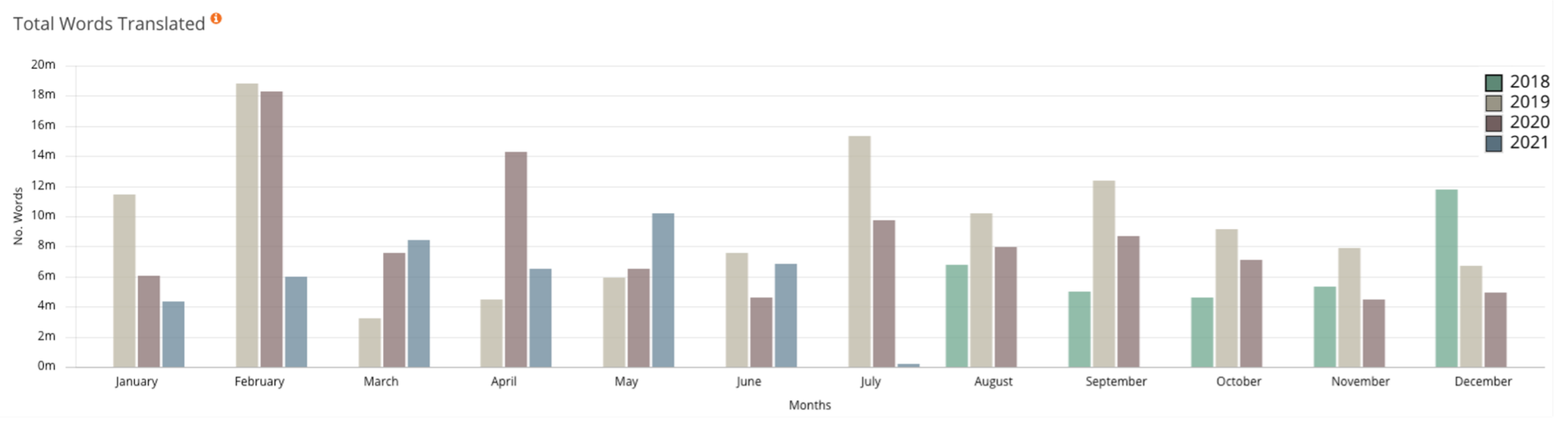
Figure 6 shows some of the site statistics available on the KantanMT Platform
https://www.kantanmt.com/ (accessed on 2 December 2021). It is clear from
Table 10 that the student models translate the source sentences much faster than the teacher models. Somewhat more interestingly, we observe that using 2 GPUs for translation yields the fastest translation time; more specifically, model Student-KD+EP-2GPU takes 29.49 s to translate 3000 sentences. Furthermore, there are 69,543 German words in the test file that was translated, so model Student-KD+EP-2GPU translated on average 2358 words per second.
Taking the statistics in
Figure 6 as an example of where MT is used in the translation industry, an average of 255,546,342 words are translated per month. This average is denoted as
. We based our calculations of the cost and carbon emissions on using an NMT model to translate this average amount of words per month. These results are only estimates, and in the future we aim to track these variables more precisely, but they are quite insightful nonetheless. Schwartz et al. [
27] point out that tracking these variables is very dependable on the deployment environment since carbon emissions are highly dependable both on the local electricity infrastructure and the type of hardware that is used. Thus, we will need to repeat these experiments in a controlled environment in future work.
Estimates of the carbon emissions were conducted using the Machine Learning Impact Calculator presented by Lacoste et al. [
28].
As for the cost, we used the AWS Pricing Calculator. The AWS Pricing Calculator (
https://calculator.aws/#/) (accessed on 2 December 2021) provides only an estimate of one’s AWS fees to estimate the cost of using AWS GPUs for a given amount of hours per month. We use the
p3.8xlarge https://aws.amazon.com/ec2/instance-types/p3/ (accessed on 2 December 2021) instance for pricing calculations which provides access to 4 NVIDIA
https://www.nvidia.com/en-us/ (accessed on 2 December 2021) Tesla V100 GPUs, as well as 32 GB EBS Storage. The On-Demand Instances pricing is used.
In order to estimate a translation time for the cost and carbon emissions, we first calculated the average number of words translated per second by each model and then estimated the time it would take to translate
words. These estimates are shown in
Table 11. They show pretty clearly that the student models are much more efficient in terms of cost and CO
emissions when a model is deployed by industry to provide MT as a service. While the results are preliminary, and further investigation is required, we believe them to be encouraging, and a tentative endorsement of the role that distilled models can play in reducing the carbon footprint of the AI models that we build.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





