Object Recognition Using Non-Negative Matrix Factorization with Sparseness Constraint and Neural Network

Abstract
:1. Introduction
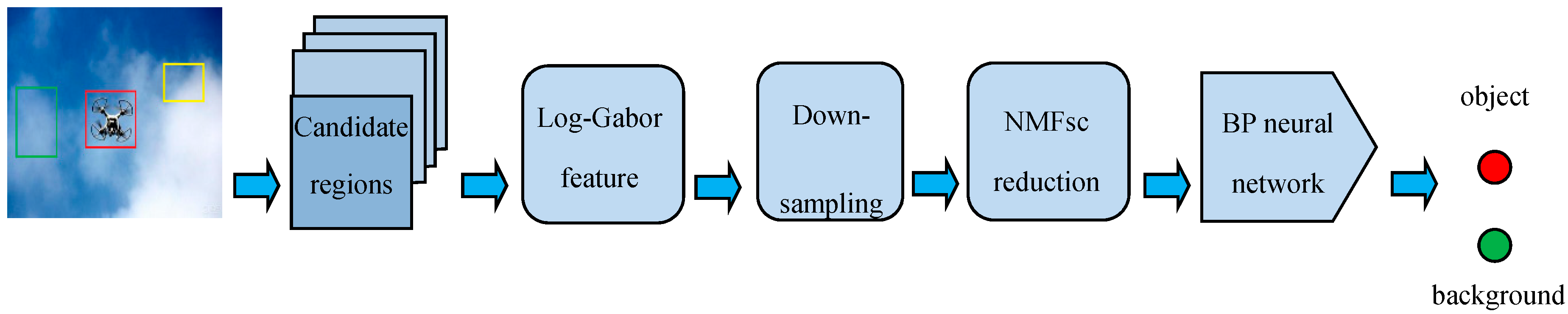
2. UAV Interesting Candidate Regions: Generation and Selection
2.1. Related Algorithms of Region Proposal
2.2. UAV Interesting Candidate Regions Selection
3. Feature Extraction and Dimension Reduction
3.1. Log-Gabor Feature Extraction
3.2. Preprocessing for Log-Gabor Feature Reduction by Downsampling
3.3. Feature Reduction by Non-Negative Matrix Factorization with Sparseness Constraints (NMFsc)
- (a)
- Vectorization of the UAV sample image. The pixels of sample image are rearranged by column. The two-dimensional matrix Ai (i = 1, 2, …, m) of p × q is converted to n × 1 one-dimensional column vector vi (where n = p × q). Then, m samples form n × m matrix V = [v1 v2 … vm], of which each column of the matrix represents a sample image.
- (b)
- The formula Vn×m ≈ Wn×r Hr×m is written as vi = Whi of column form, where the one column vi of V corresponds to one column hi of H. In other words, vi is the linear combination of all row vectors of the base matrix W and the weight coefficient hi. Therefore, under the W subspace, the hi of low dimension can replace the original sample vi of high dimension. When the NMF coefficient matrix of UAV image is solved, the image feature is obtained. The quality of projection coefficient hi is determined by the base matrix W. The few base vectors of W should satisfy the description and approximation of raw data.
4. Target Recognition Using BP Neural Network
4.1. Principle of BP Neural Network
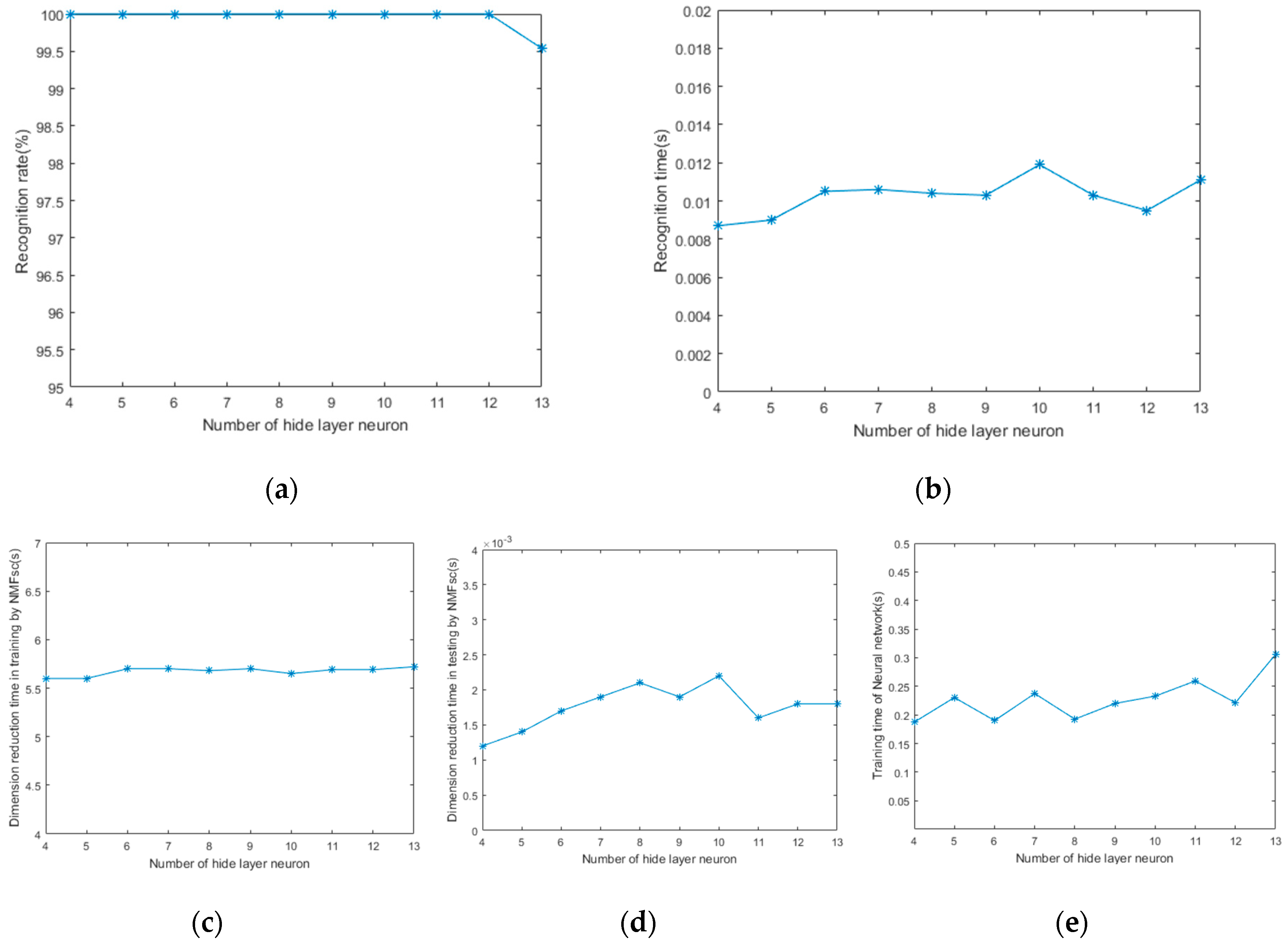
4.2. The Design of the BP Neural Network Classifier
- (1)
- Designing the input layer: the input node equals the extracted feature dimension of image. The actual input node is the reduction feature dimension by NMFsc in this paper.
- (2)
- Designing the hidden layer:
- (a)
- The number of hidden layers—increasing the number of hidden layers can improve the generalization performance of the network, reduce the error, and increase the recognition rate, but also make the network complex and the training time long. Hence, three layers of neural network are used in this paper.
- (b)
- The number of hidden layer neurons—the number of the hidden layer neurons should be in a reasonable range. Too few and it will be easy to fall into the local minimum and the trained network may not converge, with low recognition rate and poor fault tolerance. Too many will make the network structure complex, generalization ability poor, training time long, real-time performance bad, and recognition rate low. The recommended empirical formulas are provided for reference in practice:
- (3)
- Designing output layer—the categories of identifying target are directly used for the output node of the neural network. In this paper, as only the UAV target needs to be identified, the number of output nodes is set to 1.
- (4)
- Initialization of weight and threshold with uniformly distributed random numbers—it is very important for the initialization of weight and threshold in nonlinear systems. If the initial weight is too large, the weighted input will be entered into the saturation area of the activation function, which leads to the stagnation of the adjustment. Randomization is particularly important in the implementation of the BP model. If the weights are not initialized randomly, the learning process may not converge. In this paper, the initial weights are taken from the random numbers between (−1,1).
- (5)
- Giving the input samples, desired output, neuron activation function, and learning rate—the activation function has a considerable influence on the convergence effect of the network. Each input of the neuron corresponds to a specific weight, and the weighted sum of the input determines the activation state of the neuron. The learning rate determines the variation of the weight during each training. Too high a learning rate leads to network oscillation, and too low a learning rate leads to slow convergence and long training times. In general, it tends to choose a smaller learning rate to ensure the stability of the system. In this paper, expected error is set to 0.01, the transfer function of the hidden layer neuron is a tangent S function ‘tansig’, the transfer function of the output layer is a linear function ‘purelin’, the training function is ‘LM’, and the number of learning times is set to 10,000.
- (6)
- Training the sample data—with the sample data inputted, the actual output of the hidden layer and output layer are obtained, and the hidden layer error and the output layer error are calculated. If the error cannot reach the set value, the error signal is returned along the original path, and the network weight and threshold are corrected according to the error feedback. When the error or the learning time reach the set value through repeating the above process, the training is completed.
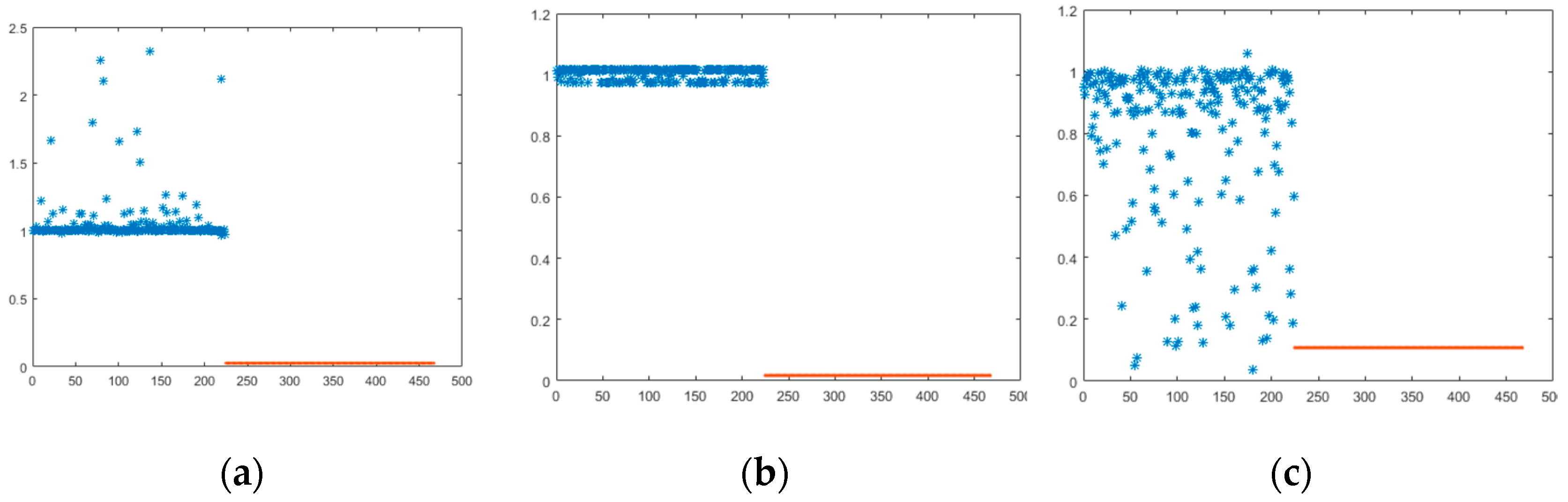
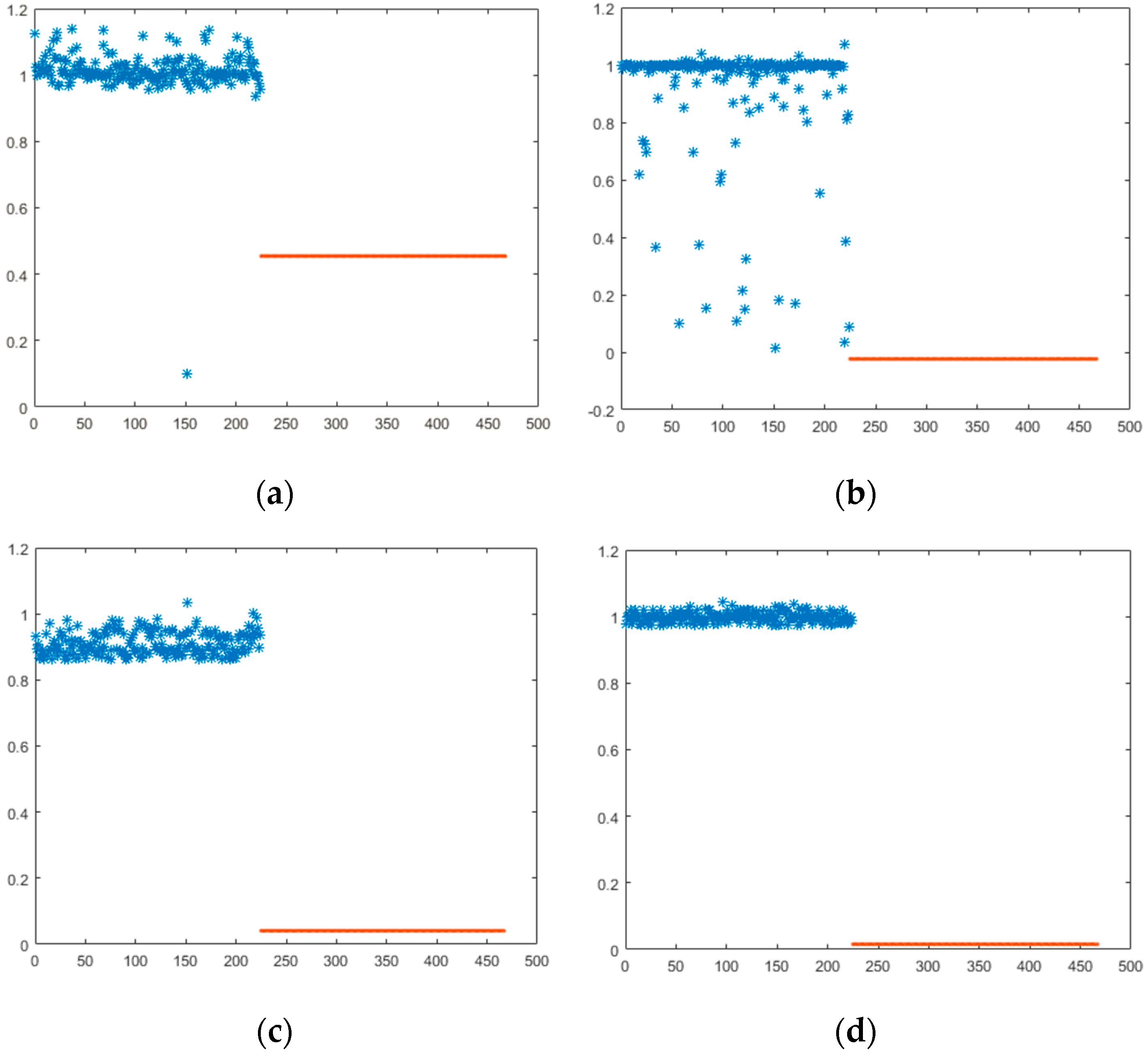
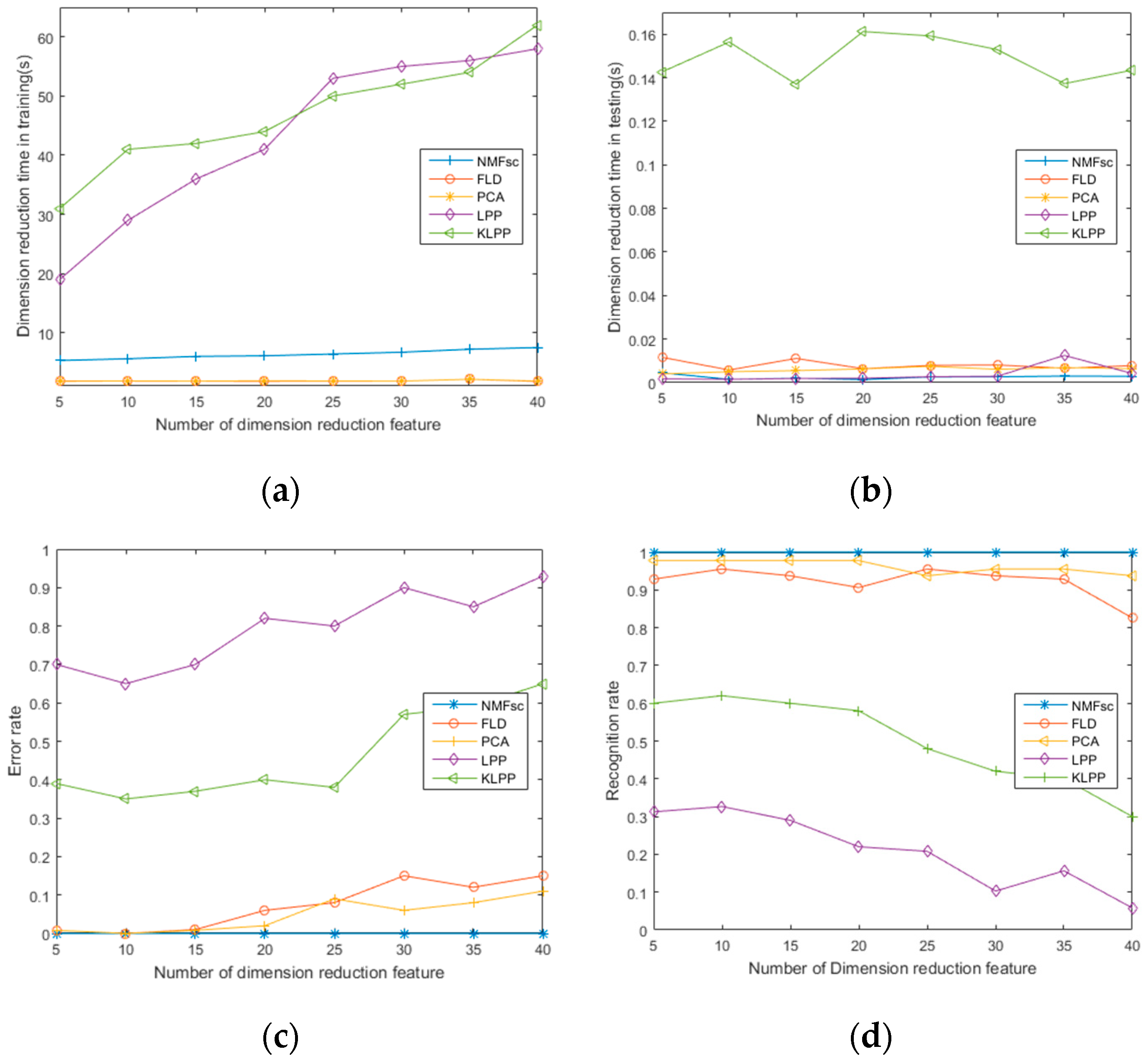
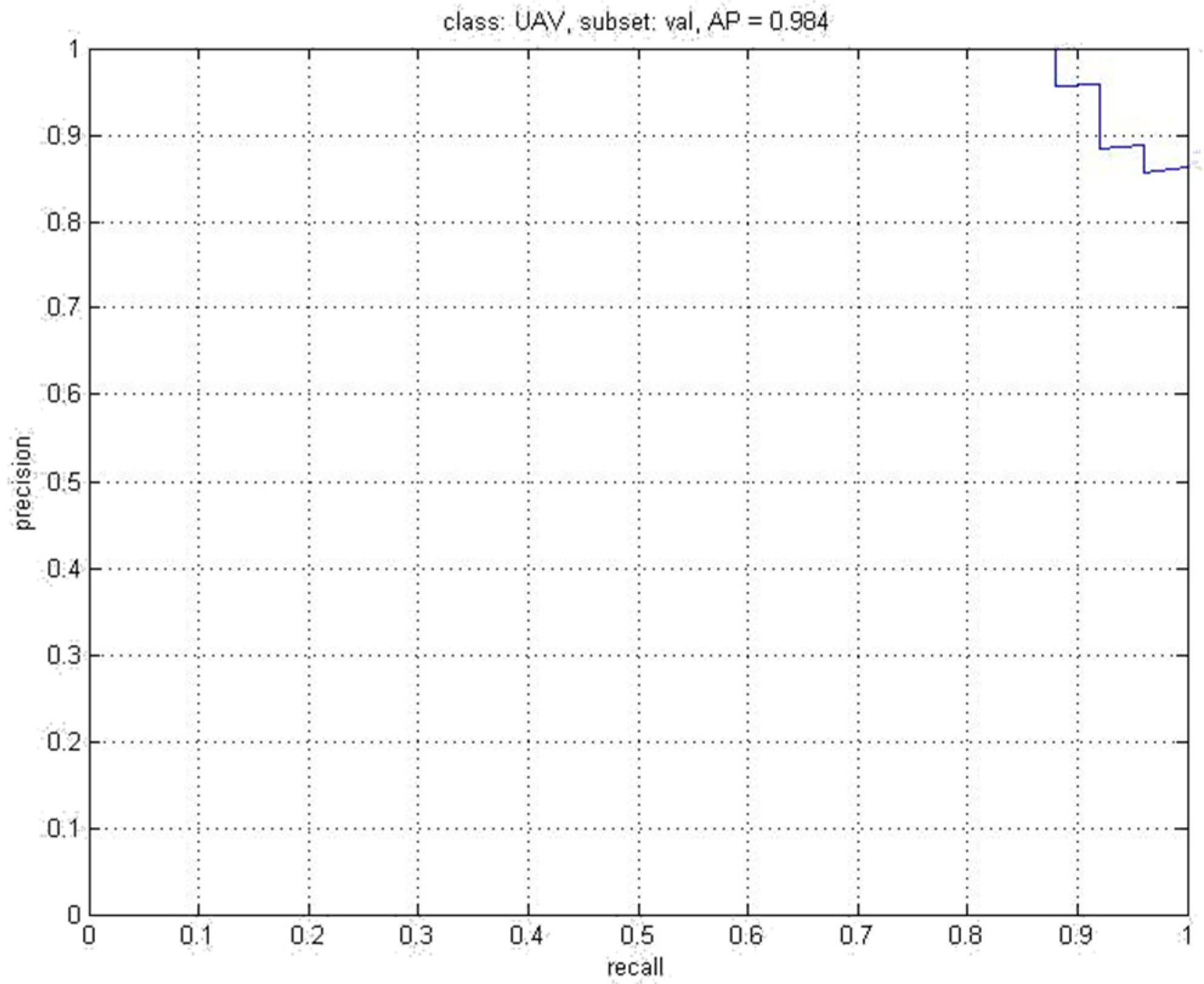
5. Experiments Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jian, C.F.; Li, M.; Qiu, K.Y.; Zhang, M.Y. An improved NBA-based step design intention feature recognition. Future Gener. Comput. Syst. Int. J. Escienc. 2018, 88, 357–362. [Google Scholar] [CrossRef]
- Zhao, Y.X.; Zhou, D.; Yan, H.L. An improved retrieval method of atmospheric parameter profiles based on the BP neural network. Atmos. Res. 2018, 213, 389–397. [Google Scholar] [CrossRef]
- Qiao, J.F.; Li, M.; Liu, J. A fast pruning algorithm for neural network. Acta Electron. Sinca 2010, 38, 830–834. [Google Scholar]
- Sheng, Y.X. Drivers’ state recognition and behavior analysis based on BP neural network algorithm. J. Yanshan Univ. 2016, 40, 367–371. [Google Scholar]
- Zhao, R.; Qi, C.J.; Duan, L.F. Identification of rice rolling leaf based on BP neural network. J. South. Agric. 2018, 49, 2103–2109. [Google Scholar]
- Liu, Y.G.; Hou, L.L.; Qin, D.T.; Hu, M.H. Coal Seam Hardness Hierarchical Identification Method Based on BP Neural Network. J. Northeast. Univ. (Natl. Sci.) 2018, 39, 1163–1168. [Google Scholar]
- Gan, L.; Tian, L.H.; Li, C. Traffic sign recognition method based on multi-feature combination and BP neural network. Comput. Eng. Des. 2017, 38, 2783–2813. [Google Scholar]
- Ma, Y.; Lv, Q.B.; Liu, Y.Y. Image sparsity evaluation based on principle component analysis. Acta Phys. Sin. 2013, 62, 1–11. [Google Scholar]
- Zhang, L.M.; Qiao, L.S.; Chen, S.C. Graph-optimized locality preserving projections. Pattern Recognit. 2010, 43, 1993–2002. [Google Scholar] [CrossRef]
- Raghavendra, U.; Rajendra Acharya, U.; Ng, E.Y.K.; Tan, J.H.; Gudigar, A. An integrated index for breast cancer identification using histogram of oriented gradient and kernel locality preserving projection features extracted from thermograms. Quant. InfraRed Thermogr. J. 2016, 13, 195–209. [Google Scholar] [CrossRef]
- Cui, Z.Y.; Cao, Z.J.; Yang, J.Y.; Feng, J.L.; Ren, H.L. Target recognition in synthetic aperture radar images via non-negative matrix factorisation. IET Radar Sonar Navig. 2015, 9, 1376–1385. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Uijlings, J.; van de Sande, K.; Gevers, T.; Smeulders, A. Selective search for object recognition. Int. J. Comp. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv, 2014; arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv, 2015; arXiv:1504.08083. [Google Scholar]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1312–1328. [Google Scholar] [CrossRef] [PubMed]
- Endres, I.; Hoiem, D. Category-independent object proposals with diverse ranking. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 222–234. [Google Scholar] [CrossRef]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the objectness of image windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [PubMed]
- Rahtu, E.; Kannala, J.; Blaschko, M. Learning a category independent object detection cascade. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1052–1059. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. Lecture Notes in Computer Science. In Computer Vision–ECCV; Springer: Cham, Switzerland, 2014; pp. 391–405. [Google Scholar]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300 fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293. [Google Scholar]
- Rantalankila, P.; Kannala, J.; Rahtu, E. Generating object segmentation proposals using global and local search. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2417–2424. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Y.; Zhang, Y.; Chen, X.; Yin, E.; Jin, J.; Wang, X.Y.; Cichocki, A. Sparse group representation model for motor imagery EEG classification. IEEE J. Biomed. Health Inform. 2018. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Nam, C.S.; Zhou, G.X.; Jin, J.; Wang, X.Y.; Cichocki, A. Temporally constrained sparse group spatial patterns for motor imagery BCI. IEEE Trans. Cybern. 2018, 1–11. [Google Scholar] [CrossRef]
- Ding, S.F.; Su, C.Y.; Yu, J.Z. An optimizing BP neural network algorithm based on genetic algorithm. Artif. Intell. Rev. 2011, 36, 153–162. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Approach | Time (s) | Recall Results | Detection Results |
|---|---|---|---|---|
| SelectiveSearch [13] | Grouping | 10 | *** | *** |
| Rantalankila [22] | Grouping | 10 | · | ** |
| CPMC [16] | Grouping | 250 | ** | * |
| Endres and Hoiem [17] | Grouping | 100 | *** | ** |
| Objectness [18] | Window scoring | 3 | * | · |
| Rahtu [19] | Window scoring | 3 | · | * |
| EdgeBoxes [20] | Window scoring | 0.3 | *** | *** |
| Bing [21] | Window scoring | 0.2 | * | · |
| Feature Dimensions of Log-Gabor | Number of Downsampling | Dimension Reduction Time by NMFsc in Training (s) | Recognition Rate (%) | Error Rate (%) |
|---|---|---|---|---|
| 24,576 | 0 | 97 | 91 | 0 |
| 6144 | 1 | 22 | 100 | 0 |
| 1536 | 2 | 5.6 | 100 | 0 |
| 384 | 3 | 1.5 | 100 | 0 |
| 96 | 4 | 0.4 | 99.5 | 0 |
| 24 | 5 | 0.09 | 94 | 0 |
| 24 | 6 | Not using NMFsc | 91 | 0 |
| 12 | 6.5 | Not using NMFsc | 85 | 0 |
| 6 | 7 | Not using NMFsc | 48 | 0 |
| Recognition Rate (%) | Error Rate (%) | Average Dimension Reduction Time in Training (s) | Average NN Training Time (s) | Average Dimension Reduction Time in Testing (s) | Average Recognition Time (s) | |
|---|---|---|---|---|---|---|
| NMFsc | 100 | 0 | 5 | 0.2416 | 0.0021 | 0.0105 |
| NMF | 0.9967 | 0 | 15 | 0.2459 | 0.0026 | 0.0121 |
| Method | Average Time for Training Sample (s) | Average Time for Testing Sample (s) |
|---|---|---|
| PCA | 1.87 | 0.006 |
| FLD | 1.88 | 0.021 |
| NMFsc | 5.6 | 0.002 |
| LPP | 43 | 0.004 |
| KLPP | 48 | 0.153 |
| Precision (%) | Average Testing Time (s) | Average Training Time | Computer Cost | Image Annotation | |
|---|---|---|---|---|---|
| Faster R-CNN [27] | 98.4 | 0.12 | 14 h | High | Many |
| Our method | 98.6 | 0.16 | seconds | Low | Less |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, S.; Zhang, B.; Wang, Y.; Dong, B.; Li, X.; Xiao, F. Object Recognition Using Non-Negative Matrix Factorization with Sparseness Constraint and Neural Network. Information 2019, 10, 37. https://doi.org/10.3390/info10020037
Lei S, Zhang B, Wang Y, Dong B, Li X, Xiao F. Object Recognition Using Non-Negative Matrix Factorization with Sparseness Constraint and Neural Network. Information. 2019; 10(2):37. https://doi.org/10.3390/info10020037
Chicago/Turabian StyleLei, Songze, Boxing Zhang, Yanhong Wang, Baihua Dong, Xiaoping Li, and Feng Xiao. 2019. "Object Recognition Using Non-Negative Matrix Factorization with Sparseness Constraint and Neural Network" Information 10, no. 2: 37. https://doi.org/10.3390/info10020037
APA StyleLei, S., Zhang, B., Wang, Y., Dong, B., Li, X., & Xiao, F. (2019). Object Recognition Using Non-Negative Matrix Factorization with Sparseness Constraint and Neural Network. Information, 10(2), 37. https://doi.org/10.3390/info10020037