3.1. Assessing RNA Quality
Good RNA quality is an important prerequisite for obtaining reliable results from a microarray gene expression experiment. RNA quality propagates from the hybridized sample to the obtained gene expression estimates and consequently also to differential expression results. Combined with the previous detection of a noticeable degradation effect upon the majority of microarray samples [
31], variability of RNA quality has a high risk of being a major source of technical bias.
The RNA Integrity Number (RIN) provides a measure for RNA quality that is determined for most microarray samples before hybridization [
32]. RIN values scale between 1 and 10, and using only samples with RIN ≥ 7 is recommended [
33]. However, RIN values are unfortunately seldom stored in conjunction with the experimental data. The so-called d
k degradation index provides a sensitive estimate of RNA-quality that can be computed from raw GeneChip microarray data. It was shown to correlate well with RIN [
26]. For fresh tissue, the cutoff of RIN ≥ 7 corresponds to a cut off of the degradation index of d
k ≥ 0.45. Note that d
k values are not only sensitive, but also specific for RNA quality since only RNA degradation and amplification have such a systematic effect on this value estimated by means of the probe intensity decay with increasing distance between the probe location and the transcription start site [
26].
We have computed the d
k values for all 8131 samples of the HumanArraySet which were either included or excluded from the HumanExpressionAtlas data set as described above.
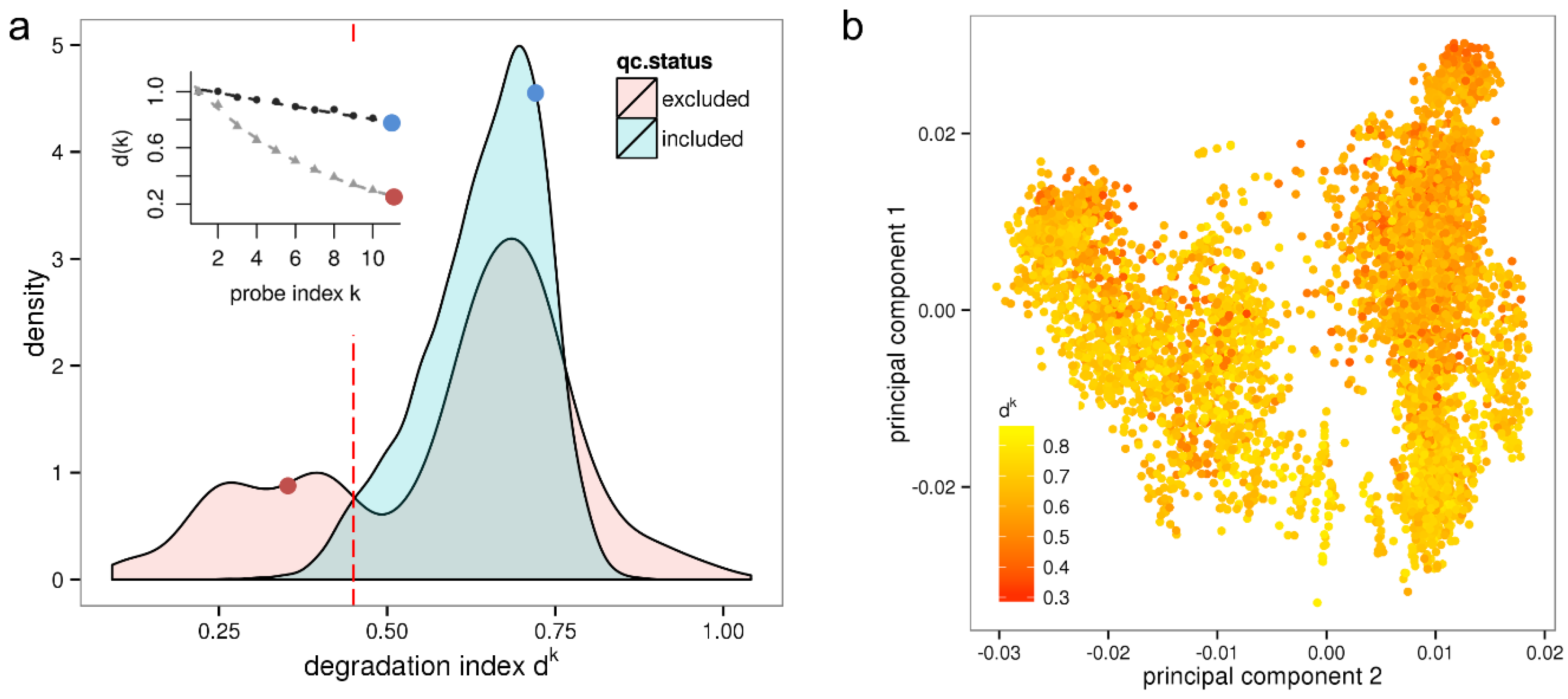
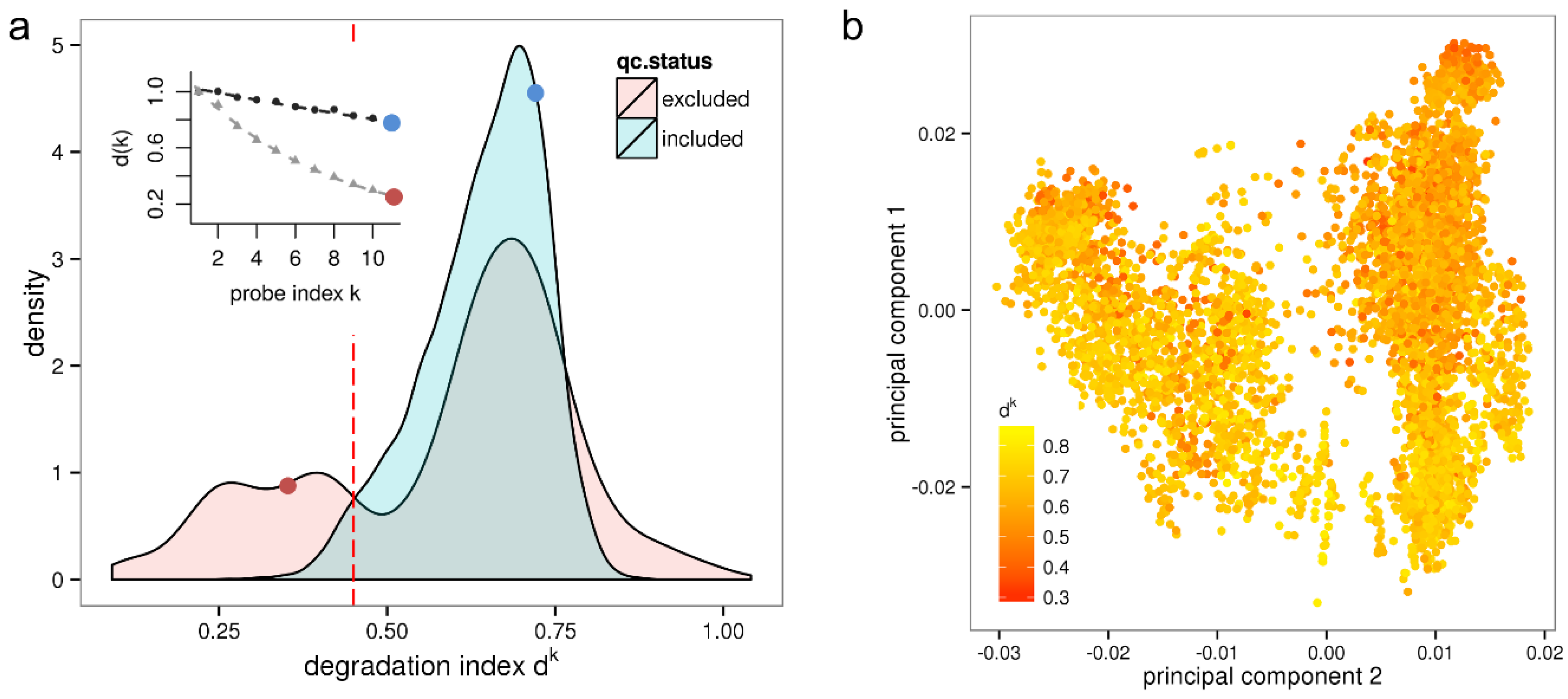
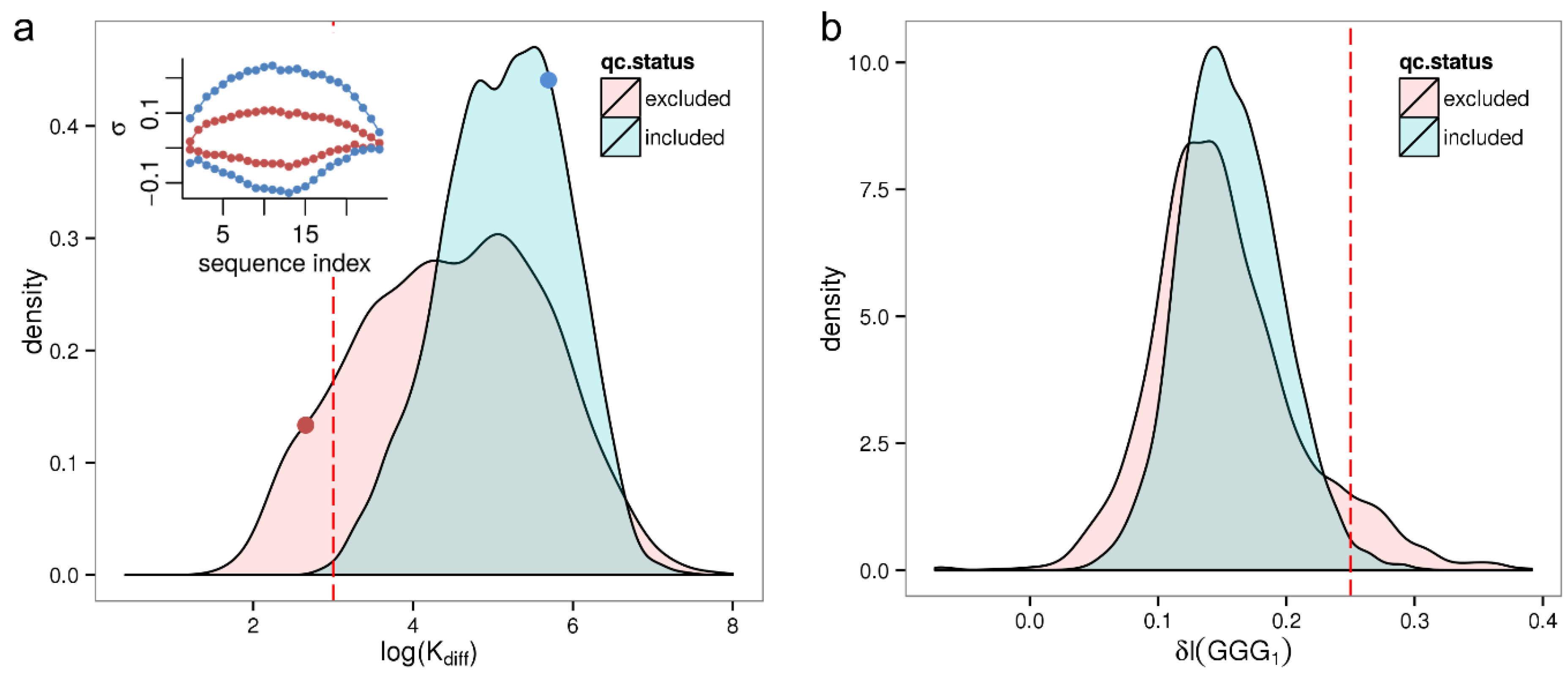
Figure 1a shows the resulting density distribution of d
k for the qc-included/qc-excluded sample sets. Most samples included after quality control have a degradation index between 0.5 ≤ d
k ≤ 0.8 referring to acceptable RNA quality. On the other hand, a large fraction of the qc-excluded samples exhibits values of d
k < 0.45 referring to critically low RNA quality. This applies to 25% of the qc-excluded samples and to 10% (868) of all investigated samples. Note that some of these samples might be part of an experiment that is entirely based on low input RNA and multiple rounds of amplification, respectively. Such an experiment can provide valuable information when analyzed individually.
Figure 1.
Variation of RNA quality among a large set of microarray samples and its impact on expression results. Panel (a) shows the density distribution of dk values measuring the degradation for samples either included or excluded in the HumanExpressionAtlas data set by independent quality control. The red line indicates the low quality threshold corresponding to RIN ≤ 7. The inset shows RNA degradation plots for two selected samples. The corresponding dk values (red and blue dots) are shown in the inset and in the density distribution, respectively; Panel (b) shows the first two principal components of the HumanExpressionAtlas expression space where sample points are colored according to their RNA quality measure dk.
Figure 1.
Variation of RNA quality among a large set of microarray samples and its impact on expression results. Panel (a) shows the density distribution of dk values measuring the degradation for samples either included or excluded in the HumanExpressionAtlas data set by independent quality control. The red line indicates the low quality threshold corresponding to RIN ≤ 7. The inset shows RNA degradation plots for two selected samples. The corresponding dk values (red and blue dots) are shown in the inset and in the density distribution, respectively; Panel (b) shows the first two principal components of the HumanExpressionAtlas expression space where sample points are colored according to their RNA quality measure dk.
Furthermore, 3% (162) of the qc-included samples are so severely degraded that they should have been excluded by RIN analysis. Expression estimates of these samples are biased, with negative consequences for the reliability of downstream results. That these samples were included in the HumanExpressionAtlas suggests that a more rigorous assessment of RNA-quality should be applied in quality control procedures. Note that our results agrees well with a previous estimation that about 2% of samples of large microarray series have low RNA-quality [
34].
Interestingly, only few qc-included samples have d
k values larger than 0.8, which obviously represents an upper limit referring to the “weakest possible intensity decay”. This limit can be attributed either to the insufficiency of the clean-up assays to fully stop RNAase activity or, alternatively, to the incomplete amplification of aRNA fragments. On the other hand, a fraction of 8.1% of the qc-excluded samples has values of d
k > 0.8 which could be also due to uncertainties in estimating d
k at large signal noise levels [
26].
We next investigate how the d
k parameter changes together with different batches of samples for which we suspect technical variation. To this end, sample groups were defined using a combination of experiment id and experimental date as extracted from the HumanExpressionAtlas. For the experimental date we use the month in which the microarray sample has been hybridized, which can be extracted from Affymetrix raw data files.
Supplementary Figure S1 shows the d
k parameters for the samples ordered by these batches. Using a simple linear model we obtained a generalized R
2 statistic with a value R
2 = 0.67 indicating that a considerable covariation between the batches and the degradation index d
k.
To test for confounding of the HumanExpressionAtlas with the effect of variable RNA quality we plot its first two principal components of the “expression space” referring to the pre-processed data as available in ArrayExpress in
Figure 1b. The same representation was shown in [
7] where the data points were however colored according to biological groups. It could be shown that the first principal axis (“hematopoietic axis”) differentiates the biological groups hematopoietic system, solid tissues, connective tissues and incompletely differentiated cell types, and that the second principal axis (“malignancy axis”) differentiates cell lines, neoplasms and normal/non-neoplastic disease tissues. Here, the samples are not colored according to biological groups but instead according to the value of the degradation index d
k. The resulting plot in
Figure 1b shows a clear color gradient along the second principal axis with, in general, lower RNA quality (red spots) at the top and higher RNA quality (yellow spots) at the bottom. The sample groups “normal/non-neoplastic disease tissues” are here associated with better RNA quality and neoplasms with worse RNA quality. Altogether, the correlation coefficient between the degradation index d
k and the second principal component is
r = −0.44. Hence, on average the RNA used for hybridization lost quality with increasing malignancy of the samples.
3.2. Assessing RNA Quantity
Before continuing the analysis of potential sources of batch effects, let us first introduce suitable metrics for the assessment of the amounts of RNA available for hybridization in a given sample. To this end, we computed so-called λ and β chip summary measures estimating the relative specific (λ) and non‑specific (β) transcript abundance levels in negative decadic logarithmic scale (see
Methods Section) for all samples of the Gene Logic dilution experiment. In this experiment two distinct types of RNA samples, liver tissue and CNS cell line (SNB-19), have been hybridized to Affymetrix Human Genome U95A arrays at varying concentrations [
35]. Multiple samples have been prepared from total RNA according to the manufacturers’ protocol and the resulting aRNA has been collected into one master solution for each of the two RNA types. The master solutions, whose RNA concentrations have been determined using an electropherometer (at 260 nm), were then diluted to generate solutions with nominal aRNA masses between 1.25 and 20 µg. Five technical replicates were processed for each concentration, leaving a total of 50 samples.
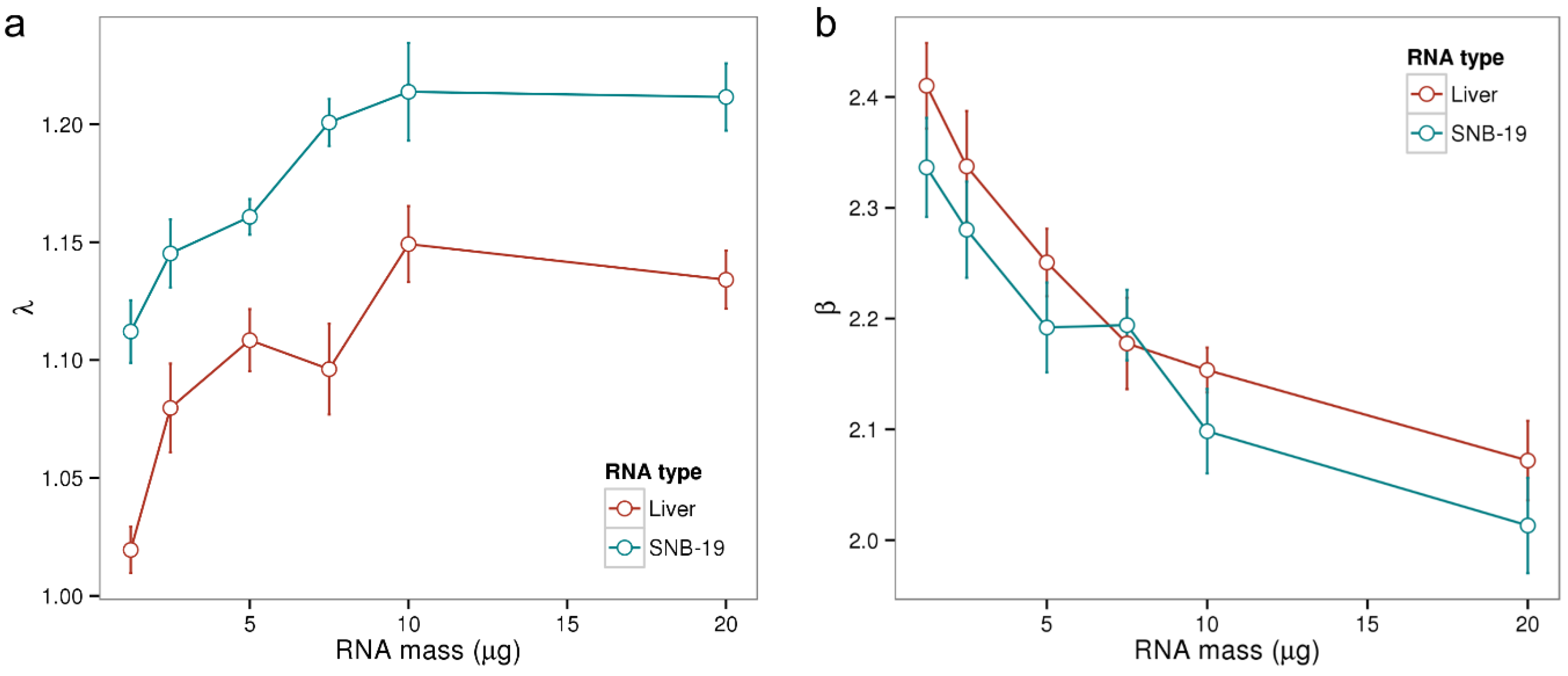
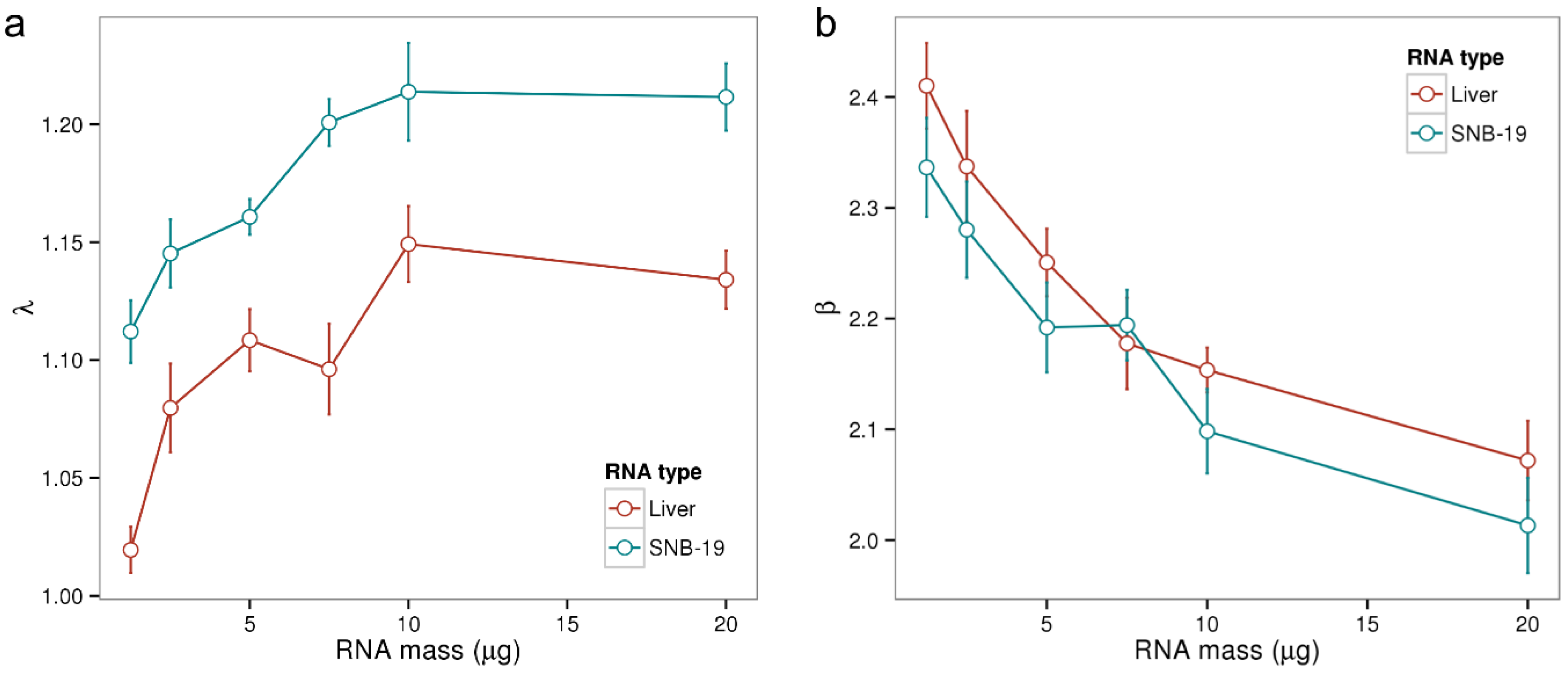
Panel a of
Figure 2 displays the obtained λ parameters in dependence of RNA mass for the 50 microarray samples. λ increases with increasing RNA mass between 1 and 10 µg with Pearson correlation coefficients of
r = 0.71 for liver tissue and
r = 0.78 for SNB‑19. However, λ does not increase further for a RNA mass of 20 µg which can be explained by the up-down effect: increasing RNA concentrations result in a larger non-specific background accompanied by a smaller effective specific binding constant due to bulk dimerization [
21]. The λ summary measure averages the ratio of specifically and non-specifically bound transcripts (see Equation (4)). It is not collinear with RNA mass, as the effect of bulk dimerization is not considered in the hybridization model. In summary, λ describes the amounts of aRNA of a particular microarray hybridization in a non-linear, yet for typical RNA ranges sensitive fashion.
The β parameter from Equation (5) characterizes the dynamic range of the specific hybridization signal (see [
5] for a detailed discussion of this chip-specific parameter). As shown in
Figure 2b the parameter β decreases with increasing RNA amount. The increasing concentration of RNA in the hybridization solution here results in an increased signal contribution due to non-specific binding and thus in a non-linear, negative effect on the measuring range β.
Figure 2.
Chip-specific summary parameters λ and β in dependence of the amount of hybridized RNA. We computed both parameters for the samples of Gene Logic’s dilution data set where two types of RNA (liver and SNB-19) have been hybridized at varying concentrations with 5 replicate samples for each concentration. In Panel (a) λ increases roughly linear with increasing RNA mass between 1 and 10 µg (Pearson correlations of r > 0.7), but saturates at 20 µg; Panel (b) shows how β decreases with increasing RNA mass. An amount of 10 µg aRNA is recommended for the employed HG-U95A platform.
Figure 2.
Chip-specific summary parameters λ and β in dependence of the amount of hybridized RNA. We computed both parameters for the samples of Gene Logic’s dilution data set where two types of RNA (liver and SNB-19) have been hybridized at varying concentrations with 5 replicate samples for each concentration. In Panel (a) λ increases roughly linear with increasing RNA mass between 1 and 10 µg (Pearson correlations of r > 0.7), but saturates at 20 µg; Panel (b) shows how β decreases with increasing RNA mass. An amount of 10 µg aRNA is recommended for the employed HG-U95A platform.
3.3. Amounts of Hybridized RNA
Ideally sufficiently large amounts of aRNA transcripts at constant levels should be used for hybridization to the surface-attached microarray probes to obtain good quality data. In practice this ideal is hard to archive, e.g., due to the considerable variation in the amount of available source RNA. Too high amounts of aRNA can reduce the dynamic range of the fluorescence signals whereas too low amounts increase the signal-to-noise ratio. Consequently, varying RNA amounts can affect gene expression estimates and reduce data quality.
The density distribution of the λ parameter is separately shown for the qc-included/qc-excluded sample sets (
Figure 3a). For most good quality samples λ ranges between 1.0 and 1.5 with the peak at λ = 1.2. Interestingly, the peak of the distribution is significantly shifted to the left to λ = 1.05 for samples excluded by quality control, showing that low quality samples tend to have decreased relative specific transcript levels (see below).
Virtually none (<0.1%) of the samples that passed stringent quality control exhibit values smaller than λ = 0.95, which we consequently consider a conservative threshold for samples of critically low quality due to decreased specific RNA amounts. We find that 133 (1.6%) of all samples exhibit λ values below this threshold. This equals a fraction of 4.6% from the qc-excluded samples.
The parameter λ describes the average logged specific transcript level in units of the non-specific one. Low expression levels of some genes can have other origins than low RNA amounts, for example local surface deficiencies appearing as weakly shining blurs. Low RNA amounts can also be a result of degradation due to the overlap between the effects of RNA quality and RNA quantity.
The density distribution of the β parameters describing the measurement range of the microarray hybridization is shown in
Figure 3b. Low RNA amounts are associated with a larger β values whereas high RNA amounts increase the non-specific background with negative consequences for the measuring range, and thus the signal calibration [
5]. For qc-included samples the summary values are distributed closely around the peak at β = 2.25 ± 0.3 whereas for qc-excluded samples the β values spread much broader with a second peak for smaller measuring ranges. Selecting a threshold of β < 1.8, we find that 344 samples (4.2%) have a critically low measurement range.
Figure 3.
Distribution of the λ and β parameters characterizing the amount of hybridized RNA for qc included/qc-excluded samples (panels (a) and (b)). The inset shows the hook curves for two selected samples and the corresponding λ and β values (red and blue dots in the same color as the curves). Panel (c) shows the principal components two and four of the HumanExpressionAtlas expression space where points are colored according to the value of λ.
Figure 3.
Distribution of the λ and β parameters characterizing the amount of hybridized RNA for qc included/qc-excluded samples (panels (a) and (b)). The inset shows the hook curves for two selected samples and the corresponding λ and β values (red and blue dots in the same color as the curves). Panel (c) shows the principal components two and four of the HumanExpressionAtlas expression space where points are colored according to the value of λ.
We also assessed the impact of λ and β by relating them with the first five principal components of the expression space of the HumanExpressionAtlas data set. We obtained a correlation of
r = −0.61 of λ with the fourth principal component (see
Figure 3c). Furthermore, a correlation of
r = −0.33 with the second principal component, which we previously showed to relate with RNA quality, was found. The other three components show only low correlations of −0.16 <
r < 0.21. With coefficients of −0.04 <
r < 0.01, the β parameter exhibits no correlation with the first five principal components. In summary, the relative specific signal shows significant systematic effects on the expression measures whereas the amount of non-specific hybridization does essentially not.
3.4. Sequence Effect Size
Nucleic acid folding and formation of DNA/DNA or DNA/RNA duplexes on surfaces are fundamental reactions for any microarray assay and largely depend on the hybridization conditions. For example, the temperature and ion composition of the hybridization reactions can affect nucleic acid binding [
36]. Different hybridization conditions can lead to sequence-dependent variations in the probe intensity signals, which can further propagate to the gene expression estimates and therefore constitute potential artifacts.
We assess the sequence effect using the parameter log(K
diff) referring to the maximum pairwise difference between all positional-dependent NN-sensitivity profiles (see Methods
Section 2.3). For example, a value of log(K
diff) = 5 for a particular hybridization means that, on the average, two hypothetical probes (most likely with the sequences AAA…A and CCC…C) would differ in their intensity values by 5 orders of magnitude. log(K
diff)can thus be thought of as the maximum strength, or impact, of the sequence effect.
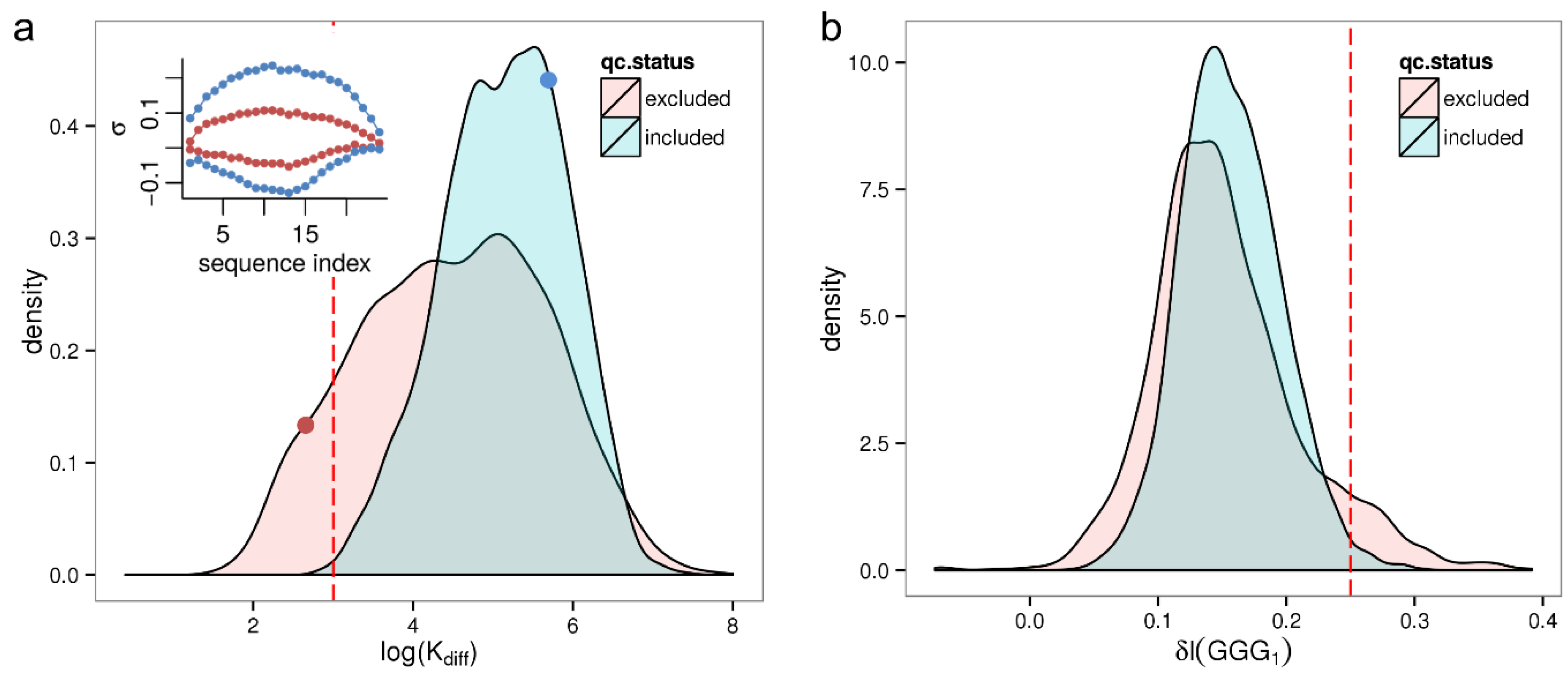
As previously we computed log(K
diff) for all 8131 samples of the HumanArraySet plotting the respective density distribution in
Figure 4a. By trend qc-excluded samples show a lower maximum sensitivity amplitude, rendering it a potential marker for low quality samples. Based on the observation that barely any good quality samples (<0.1%) exhibit a smaller maximum sensitivity amplitude, log(K
diff) = 3 is chosen as conservative threshold selecting samples with critically low sequence effect size. This applies to a fraction of 4.1% of all samples.
Figure 4.
Distribution of summary parameters related to sequence effects for qc-included/qc-excluded samples of the HumanExpressionAtlas. Panel (a) shows the parameter log(Kdiff) as a measure of the total strength of the sequence effect. The inset shows the corresponding sequence profiles for two selected samples (red and blue dots, in the same color as the profiles); Panel (b) shows the intensity increase due to the (GGG)1 motif, δI(GGG)1.
Figure 4.
Distribution of summary parameters related to sequence effects for qc-included/qc-excluded samples of the HumanExpressionAtlas. Panel (a) shows the parameter log(Kdiff) as a measure of the total strength of the sequence effect. The inset shows the corresponding sequence profiles for two selected samples (red and blue dots, in the same color as the profiles); Panel (b) shows the intensity increase due to the (GGG)1 motif, δI(GGG)1.
The largest correlation of the log(Kdiff) parameter with the first five principal components of the HumanExpressionAtlas (in absolute scales) is r = −0.17 with the third principal component. Correlations for the remaining principal components are smaller than |r| = 0.11. In conclusion, the sequence effect size is not a technical variable with a large impact on the most common patterns in the expression space.
3.5. Guanine Effects
It was previously found that runs of guanines within the probe sequence, particularly runs of guanines as long or longer than three, significantly affect the obtained signal intensities [
34]. We showed that this (GGG)
1 effect propagates through the various preprocessing methods of microarray data analysis and can lead to biased expression estimates [
25]. The origin of the (GGG)
1 effect lies in the formation G-quadruplex structures. The formation of duplexes between negatively charged nucleic acids in general, and between G-quadruplexes in particular, depends on the ionic strength and thus on the employed solution buffer [
37]. This dependency on the ionic strength also applies to hybridization reactions on solid surfaces [
38].
We here define the strength of the guanine effect in terms of the
intensity increase due to the (GGG)1 motif as follows
A value of δI(GGG)
1 = 0.3 thus reflects an on the average 10
0.3 ≈ 2 times as large intensity of probes containing the (GGG)
1 motif compared to probes containing (TTT) anywhere in their sequence. The average intensity of (TTT) containing probes here serves as appropriate baseline.
Figure 4b shows the density distribution of the δI(GGG)
1 parameter which varies between 0 < δI(GGG)
1 < 0.3 for qc-included samples. We consider samples with a threshold of δI(GGG)
1 > 0.25 to be significantly affected by GGG
1 effect—this reflects an intensity increase of +75% and would lead to a significant bias in the expression estimates of transcripts being targeted by the respective probes. Accordingly, 254 (3.1%) of the samples have a GGG
1 related intensity bias. Many of them are removed by strict quality control; only 63 (1.1%) of qc-included samples are above the threshold.
Assessing the correlation of δI(GGG)
1 with the first five principal components of the HumanExpressionAtlas expression data we observe correlation coefficients between 0.14 < |r| < 0.19. Consequently, guanine effects have only a minor impact on the common patterns in the expression space. Note that the RMA method was used for the preprocessing of the HumanExpressionAtlas calibration, and we showed previously that its expression estimates are in general susceptible to GGG
1 effects [
25].
3.6. Discussion
We have studied the general prevalence and impact of a RNA quality, RNA quantity and sequence effects using a large and representative set of microarray samples from the Affymetrix HG-U133a platform. We defined parameters, or used previously defined ones, that quantify each technical artifact based on systematic changes in the microarray intensity signals. We determined appropriate thresholds indicating samples of questionable quality, which associate with or even potentially cause biased expression estimates due to the respective factors. The impact of the technical variables on the expression estimates was analyzed by computing correlations with the first five principal components of the expression space of the HumanExpressionAtlas. The results are summarized in
Table 1.
Table 1.
Prevalence and impact of technical factors that constitute potential sources of batch effects in gene expression experiments. The second column shows the percentage of samples that are critically affected by the respective technical artifact. The selection of appropriate thresholds is reasoned in the respective subsections. Column two denotes the prevalence among all samples in the HumanArraySet, in column three among the subset of samples that have been selected after quality control independently performed by [
7]. Column four shows the correlation of the technical variable with the principal components of the expression space, and last column how it changes along with known batches.
Table 1.
Prevalence and impact of technical factors that constitute potential sources of batch effects in gene expression experiments. The second column shows the percentage of samples that are critically affected by the respective technical artifact. The selection of appropriate thresholds is reasoned in the respective subsections. Column two denotes the prevalence among all samples in the HumanArraySet, in column three among the subset of samples that have been selected after quality control independently performed by [7]. Column four shows the correlation of the technical variable with the principal components of the expression space, and last column how it changes along with known batches.
| Parameter | Prevalence (all) | Prevalence (qc Included) | Correlation with Principal Component (pc) | Adjusted R2 with Batch (Lm) |
|---|
| Degradation index dk | 10.6% | 3.0% | −0.44 (2) | 0.67 |
| Specific transcript level λ | 1.6% | (0.1%) | −0.61 (4) | 0.62 |
| Measuring range β | 4.2% | (0.1%) | 0.04 (1) | 0.24 |
| Sequence effect size | 4.1% | (0.1%) | −0.17 (3) | 0.76 |
| Guanine effects | 3.1% | 1.1% | 0.19 (5) | 0.76 |
We found that a large fraction of 10% of the 8131 samples are so severely degraded that they should be excluded from further analysis. While most of these samples where indeed excluded from the HumanExpressionAtlas, further 3% of the low-quality RNA samples passed quality control, highlighting the need for a more rigorous assessment of RNA quality in microarray data analysis.
A fraction of 1.6% of the samples has decreased specific transcript levels λ, relating to low amounts of hybridized RNA. Samples excluded by quality control in general have smaller λ values. Analysis of the β parameter shows that about 4% of the samples have low measurement ranges and that β has almost no impact on the predominant variation patterns in the expression space.
Importantly, RNA quality and RNA abundance variation were found to have potentially an unexpectedly high impact on the gene expression results. Both technical variables strongly correlate with the most common patterns of expression variation in the HumanExpressionAtlas. The RNA quality measure dk correlates with the second principal component for which previously a biological interpretation was found. The relative specific transcript level parameter λ is highly correlated with another principal component. Together with the observed high prevalence of these artifacts, these technical factors thus constitute major sources of batch effects.
We found that sequence effects are highly variable in the investigated Affymetrix HG-U133a platform. The sequence effect size is particularly low among low-quality samples where 4% of the samples are affected. 3% of the samples have a strong guanine-run (GGG
1) effect with critical impact on some transcripts [
25]. They constitute an important technical artifact, which, however, only affects the expression estimates of some genes in some of microarray samples. It obviously does not affect the majority of features and is consequently not a major determinant of systematic variation in the expression space. The overall impact of the studied sequence effects on the expression space is relatively low.
The term “technical artifact” used in this publication refers to all factors which cause improperly calibrated expression measures which then do not properly reflect the amount of mRNA in the object of study [
39]. Recall that expression microarrays were designed to measure the relative abundance of mRNA in the samples of interest in a gene- (or exon-) specific fashion. Consequently, correct expression measures by definition should be independent of characteristics such as RNA quality or RNA quantity used for hybridization and also of probe sequences interrogating the respective gene. On the one hand, technical artifacts can be caused by improper sample handling (e.g., by using degraded mRNA or an unsuitable amount of mRNA) or improper instrument settings (e.g., of the scanner or fluidic station). On the other hand, technical artifacts can be inherent in the measuring principle of the microarray technology due to surface hybridization effects not related to transcript abundance, even if samples and instruments were handled ideally. That means that also “biological” effects such as the massive changes of transcript composition in the cell and/or of their total abundance level e.g., with changing malignancy can cause systematic variations of quality measures. Although of biological origin we also assign such variations as “technical’ effects because they are related to unwanted side effects of the microarray technology. We have shown in our previous work (see
Methods Section) that these side effects can cause systematic errors of the gene-related expression values with potential impact for the interpretation of the studies in terms of biological function. Hence, the identification of batches of samples differing in their technical characteristics potentially reflects improper calibration and in final consequence biased expression measures.
In this publication we used the correlation of selected quality measures with the principal components of the expression data as a surrogate measure of the resulting bias, which reflects associations between the expression measures and the respective technical factor. In worst case, this observation indicates that the change of expression values described by the principal component(s) is affected or even determined by systematic errors caused by the respective technical factors. In best case, the gradient of expression values is “correct” in the sense that it is not affected by the technical factors. In this case the associated gradient of quality measures can reflect an independent variation of the respective technical parameters, which can have their origin also in biological factors such as the malignancy of the tumor samples. In the former situation the expression values and their interpretation is questionable whereas the latter situation potentially indicates unexpected and possibly interesting systematic changes of biological factors such as global changes of total expression level in the cells which, for example, can shift the relation between absent and present genes. Unfortunately the “worst” case is much more common according to our experience and it is hard to explain what, e.g., the Guanine-effect or truncated transcripts have to do with changes of transcriptional regulation. On the other hand, the second situation cannot be excluded owing to interferences between the different quality measures and/or with other, still unknown biological factors.
A more detailed analysis should extract consequences on gene level to identify the particular causes of the observed biases of gene expression and of the quality measures in the samples studied. Such forthcoming studies are of high interest because they not only can help to improve the calibration of microarrays. They will also enable new insights into biological mechanisms underlying the observed biases such as the systematic variation of the total expression level as a function of biological factors.
Methods to gradually correct these biases are required at the level of data analysis. A natural first choice are the existing batch effect removal methods (see [
4] for a review) which can help significantly reducing technical variation. These methods rely on batch information and thus cannot cope with covariation patterns more complex than available surrogates/sample groupings. For some covariates, additional parameters can be estimated using physico-chemical measures of the microarray hybridization. This can also be used to correct specific technical effects as we have shown previously for RNA degradation and sequence effects (see [
5,
25,
40] for discussion and software tools). However, such methods are currently only available for a limited set of expression quantification technologies such as the GeneChip expression arrays.
It is therefore of great importance to consider the downstream effects of the unavoidable technical variation already in the lab. Recording and storing independent measures for technical parameters such as RNA quality and quantity should be mandatory for all processed samples. Only with the help of this meta-data known technical variation can be reliably separated from biological variation in large-scale expression studies and integrative analyses. It is highly probable that these factors affect not only the GeneChip microarrays investigated here but also other gene expression technologies such as RNA-seq for which only recently quality control measures have been established [
41].





{kind=link}
{kind=link}
{kind=link}
{kind=link}