The engine is a heart of an airplane. With the emergence of action cycles, system faults and the deterioration process would inevitably occur. To improve the system’s performance and dependability, it is also important to determine how frequently such breakdowns will occur. Prognostics and Health Management (PHM) is a framework for health system management that provides integrated yet individualized approaches. The most complex and technically demanding comprehensive technique in prognosis and health management is aircraft engine prognostics, as it determines an engine’s actual health [
1]. The length from the current time to the failure of a system is characterized as remaining useful life (RUL), and its forecast methodologies are classed as follows: the model-based technique (also known as the physics of failure technique), data-driven technique, and hybrid technique are all examples of model-based techniques [
2]. The model-based method uses an accurate physical model that represents the system’s dynamics and combines it with calculated data to determine model parameters and predict potential behavior. The Corrosion Model, Abrasion Model, Taylor Tool Wear Model, and Hidden Markov Models (HMMs) are examples of model-based techniques [
3,
4]. The model-based approach is simple to implement and maintain, and the model may be reused. Model development, on the other hand, necessitates a detailed understanding of the system, and high-fidelity models are computationally demanding [
5]. The data-driven method analyzes the characteristics of the current damage condition and models the future trend using a portion of the previously gathered data (training data). Regression analysis, neural networks, fuzzy logic, Bayesian, Random Forest (RF), Gradient Boosting (GB), Support Vector Machine (SVM), Genetic Algorithm (GA), and Relevance Vector Machine (RVM) are examples of data-driven methodologies [
6]. The data-driven technique is simple and quick to deploy, and it can uncover relationships that were previously overlooked. However, it necessitates a balanced approach, and there is a risk of overlearning and overgeneralization [
7,
8]. For Li-ion battery health management, a capacity estimation study based on the class of Support Vector Regressors (SVR) models is proposed in [
9]. To build the capacity estimate framework, NASA’s publicly accessible battery information, which has limited data, is used to extract the multi-channel profile of voltage, current, and temperature. To detect abnormalities in the wind turbine gearbox, a technique based on adaptive threshold and Twin Support Vector Machine (TWSVM) is used. Data from Supervisory Control and Data Acquisition (SCADA) are sampled every 10 min and checked for abnormalities [
10]. The significance of feature selection for wind turbine condition monitoring is discussed in [
11]. There are a lot of variations in today’s SCADA data; therefore, it is important to eliminate any unnecessary information. SVR, neural networks, decision trees, and logistic regression are among the approaches being tested for regression analysis [
11]. A hybrid technique combines model and data-driven approaches. The data are used to train the model parameters, and knowledge about the physical process is used to choose which type of regression analysis to utilize (linear, polynomial, exponential, etc.). Particle filters, Kalman filters, and other hybrid techniques are examples [
12]. The hybrid technique takes the best of both approaches, relying on data when system understanding is inadequate and physics where data are scarce. On the other hand, it necessitates a thorough understanding of the system as well as the collection of relevant data [
13]. For structural health monitoring, a novel technique based on convolutional neural networks and deep transfer learning has been suggested to recognize distinct types of acoustic emissions sources [
14]. Damage detection is handled using Convolutional Neural Network (CNN) and deep learning classifiers that are entirely trained by numerically generated structural responses, resulting in a revolutionary structural health monitoring technique [
15]. The lack of suitable data labels, i.e., fault categories, in experimental data obtained provides a significant obstacle for practical gear malfunction diagnosis. To address this issue, one study develops a novel fuzzy classification algorithm for diagnosing gear faults with few data labels [
16]. An unsupervised deep learning network (UDLN) technique for fault diagnostics of rotating machinery is presented in [
17]. The suggested technique takes full advantage of the benefits of unsupervised learning to increase fault diagnostic accuracy and automatic diagnosis capacity.
In comparison to model-based approaches, the impression that most initiatives are centered on data-driven approaches appears to reflect the need to extract low-hanging targets, despite the difficulty of obtaining statistically significant quantities of run-to-failure data and common metrics that allow different approaches to be compared. Neural networks are one of the most widely utilized data-driven methodologies for prognostics. Artificial Neural Networks (ANN) have become increasingly popular in recent years because of their superior capacity to approximate functions [
18]. ANN is based on data from continuous monitoring programs, which include preparation samples [
18]. The most widely used method for calculating the useful life of turbofan engines is Artificial Neural Networks (ANN) [
19]. In certain literature, related work has been conducted. Long Short-Term Memory (LSTM) is one of the methods used to estimate the RUL of turbofan engines; it can figure out how long old data should be remembered, when it should be forgotten, and when new data should be used. In order to increase estimation accuracy, an initial RUL of 97 was chosen, and it performed better than an initial RUL of 130 [
20]. LSTM outperformed other methods such as Multilayer Perceptron (MLP), Support Vector Regression (SVR), Relevance Vector Regression (RVR), and Convolutional Neural Network (CNN). With time-series data, LSTM performs well, but it takes a long time to converge [
21]. Convolution Neural Networks (CNN) were developed to forecast the RUL of the same engine [
22]. It uses a time window technique for sample processing, which may yield more deterioration detail. As a result, the number of model inputs grows, making the building of a neural network model a difficult task: how to set up network nodes and network layers to avoid overfitting. Recurrent Neural Network based on Statistical Recurrent Unit (SRU) was proposed for the RUL prediction of the C-MAPSS dataset of a turbofan engine [
23]. It can find hidden partners from multivariate time-series sensor data with varied operating state faults and defects, and it outperforms other dynamic deep learning algorithms because it uses linear combinations of few averages to obtain a plurality of historical perspectives. RUL prediction of turbofan engines using Recurrent Neural Network (RNN) has been proposed, in which the recurrent neural network is trained with back-propagation by time gradient calculations, an Expanded Kalman Filter training process, and evolutionary algorithms to create an accurate and compact algorithm [
24]. When compared to MLP, the results reveal a higher level of accuracy. Various topologies, such as MLP, SVR, RVR, CNN, and LSTM, have been employed for RUL prediction of the turbofan engine, as previously noted.
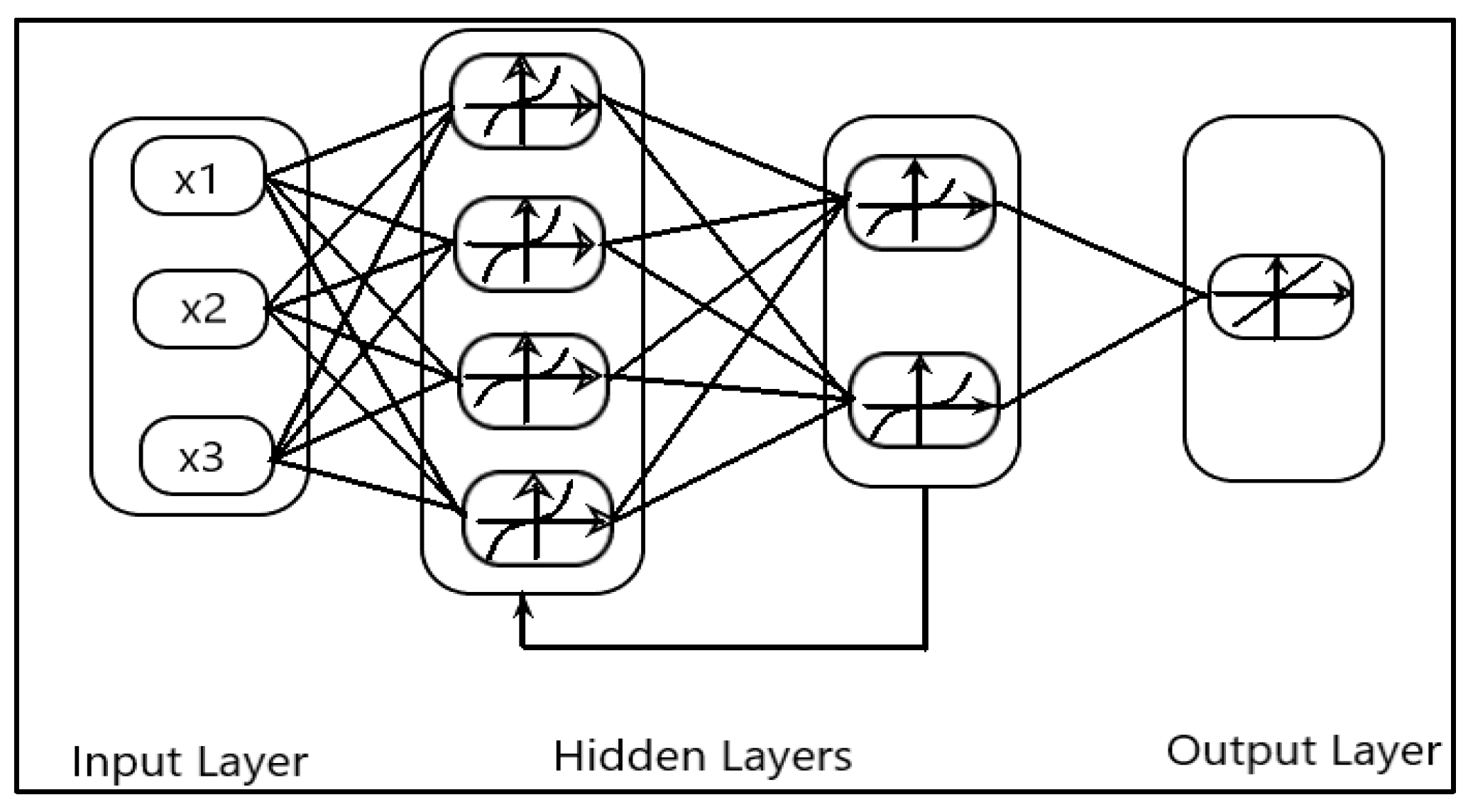
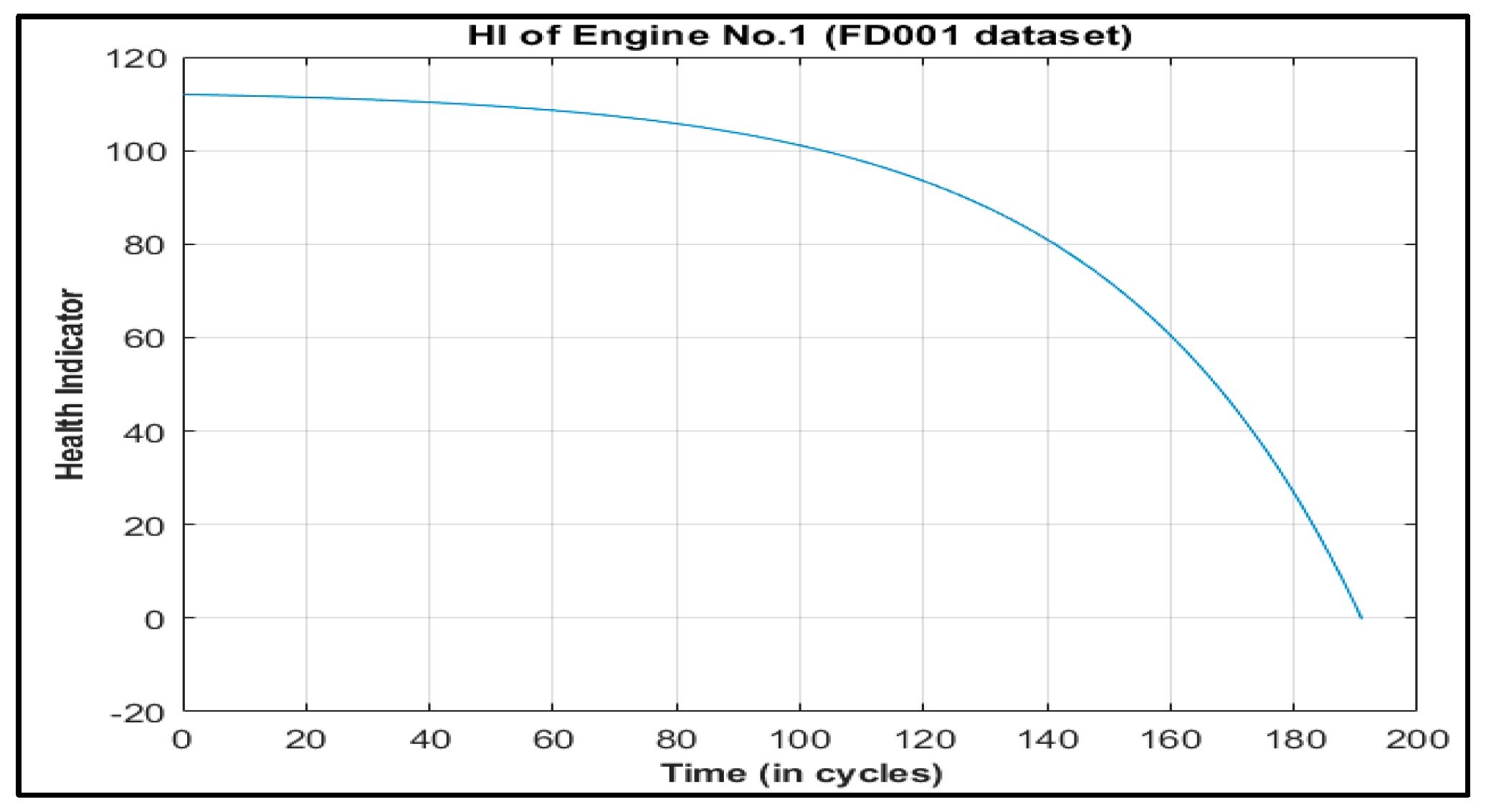
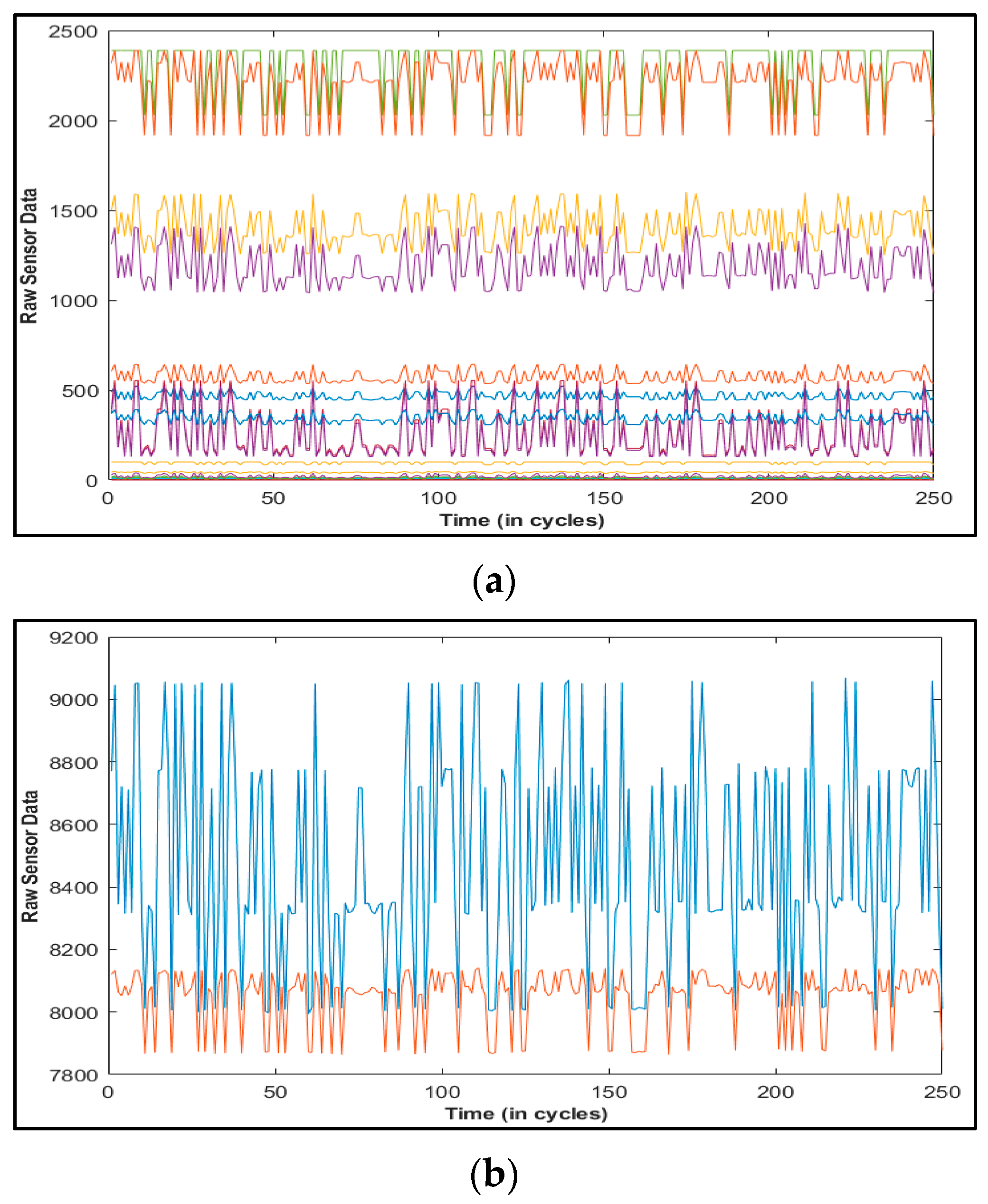
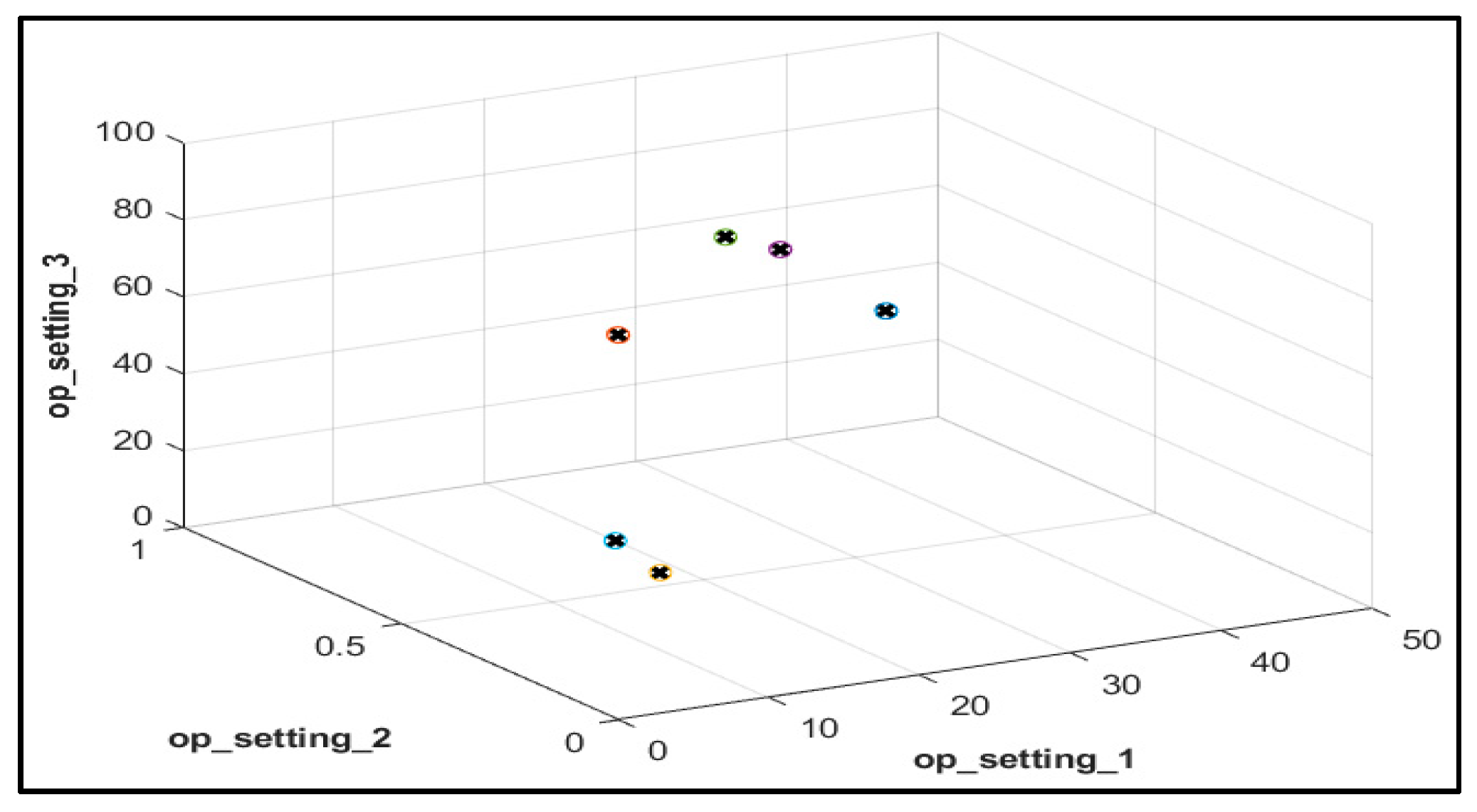
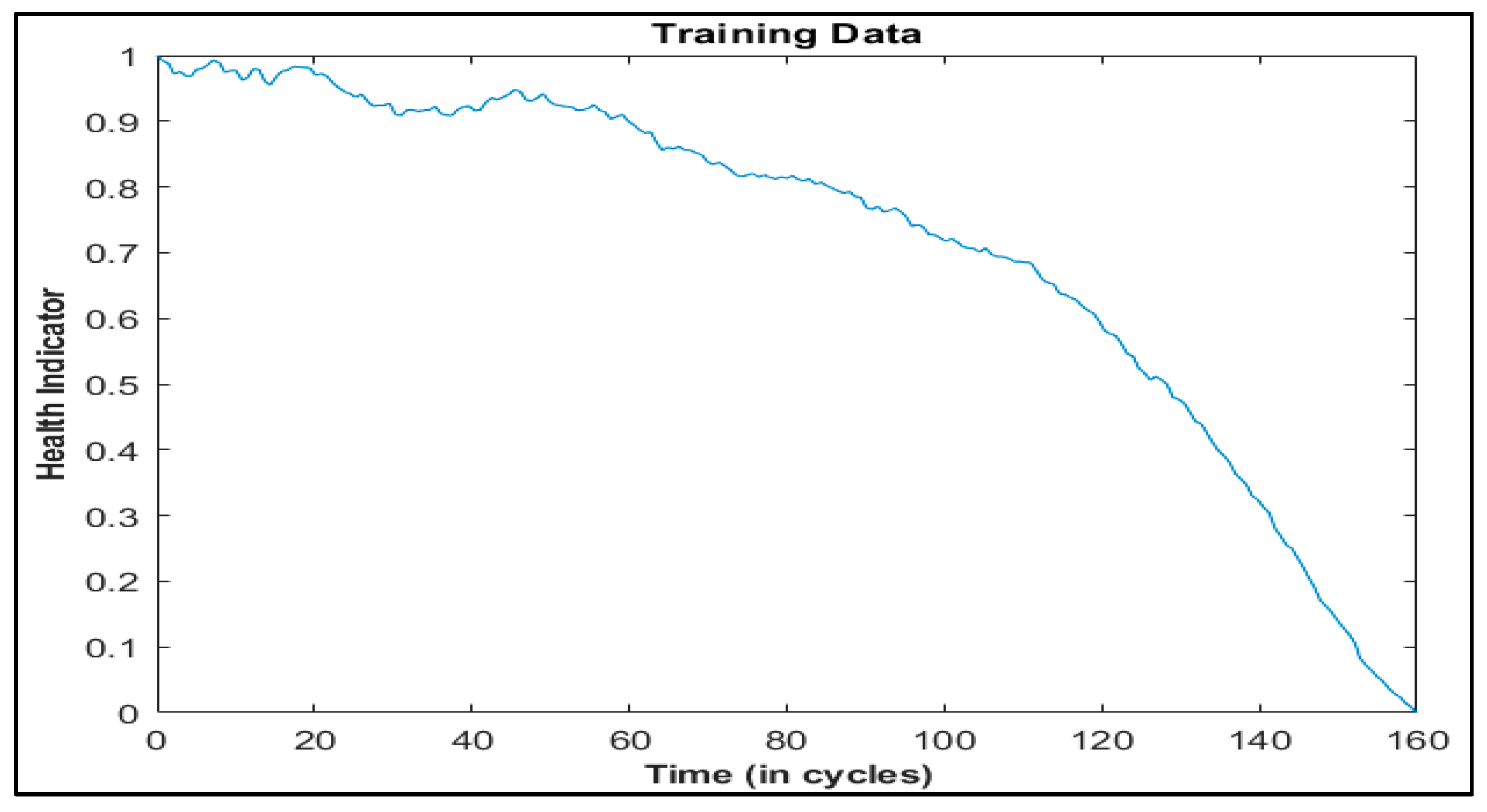
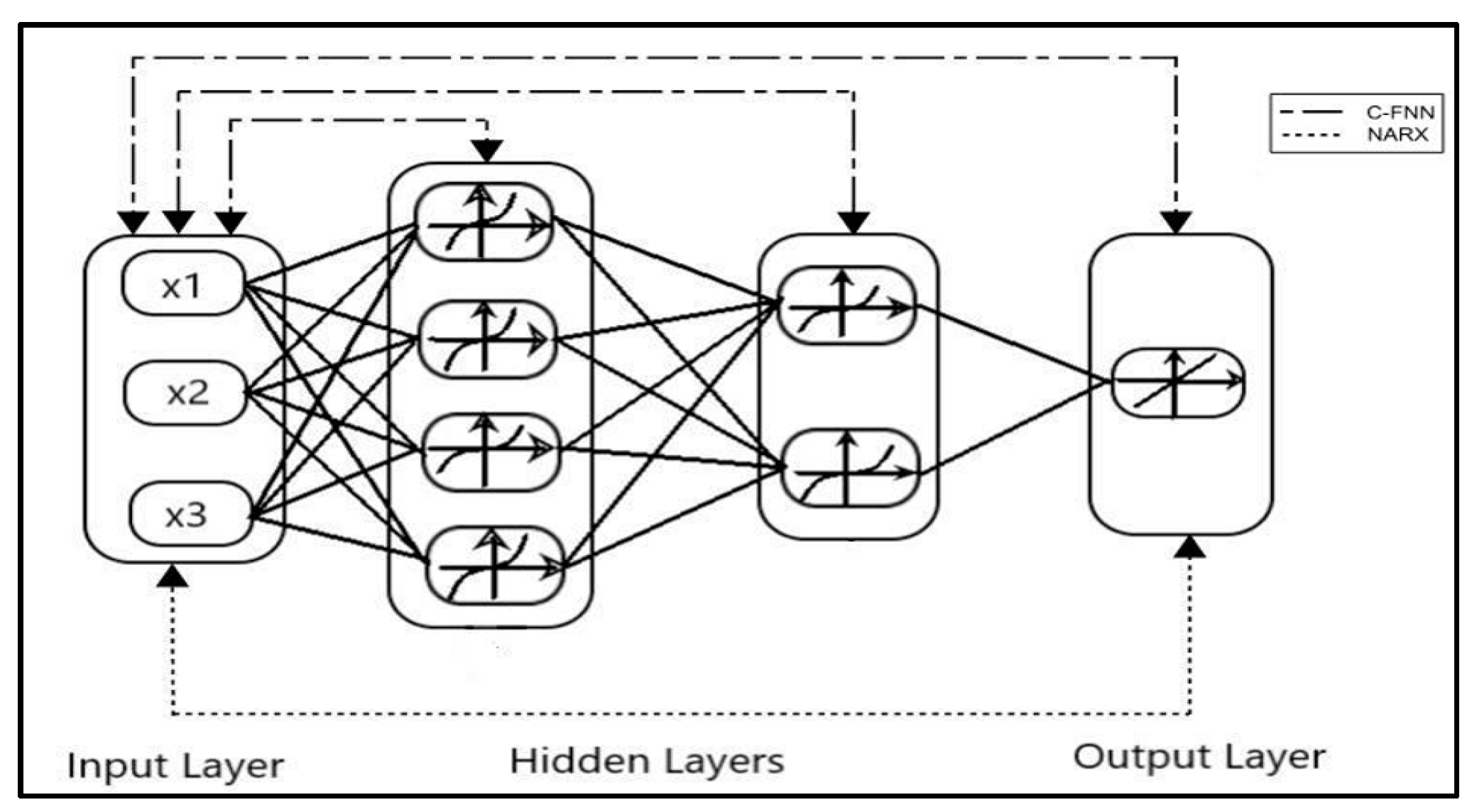
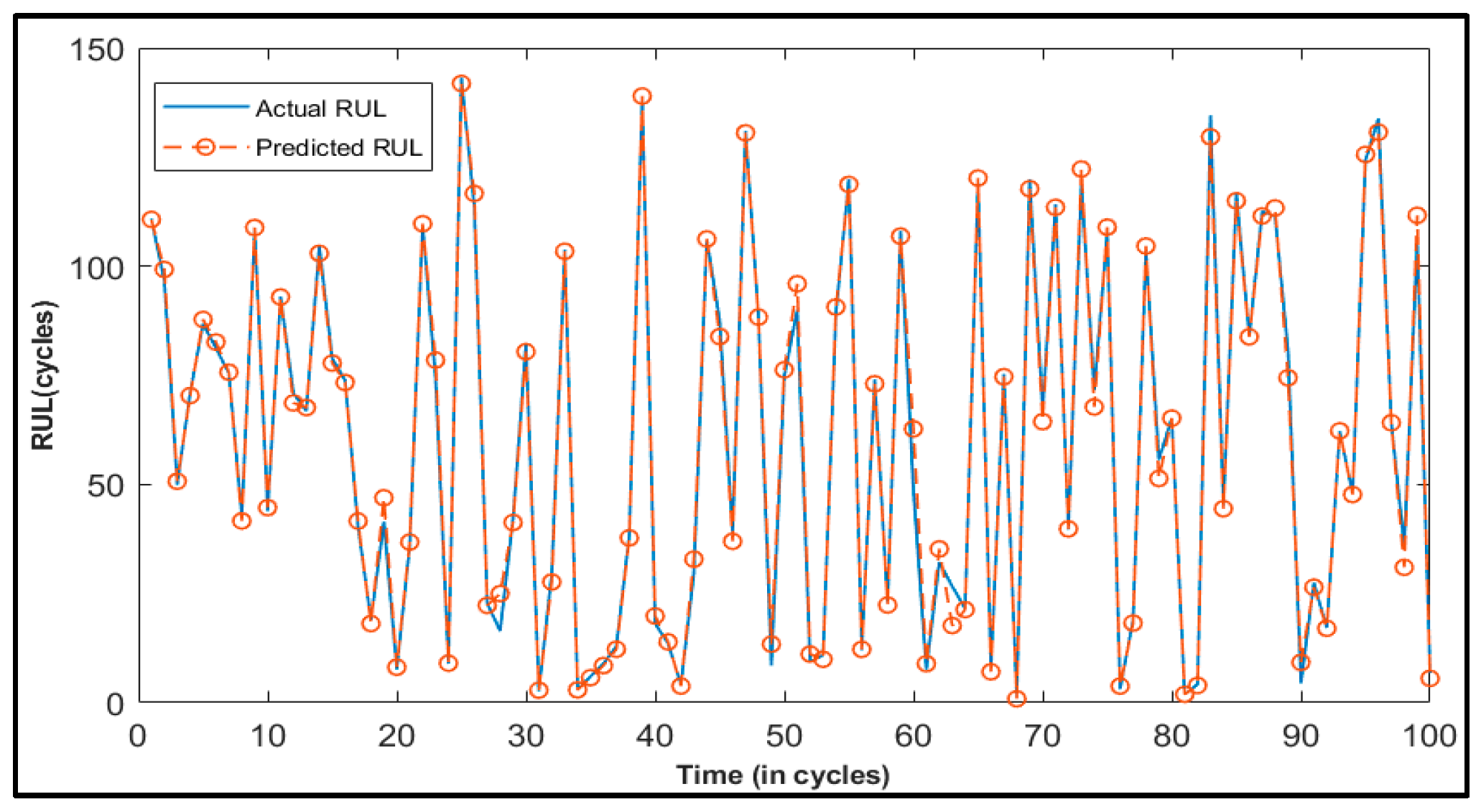
Unlike these methods, this paper presents Deep Layer-Recurrent Neural Network (DL-RNN) as a novel topology to predict the RUL of the turbofan engine. To the best of the authors’ knowledge, this is one of the few, if not the only, attempts to use DL-RNN to estimate RUL for a turbofan engine. A thorough comparison is also made against three topologies: MLP, NARX, and CFNN. The performance of our proposed method and the current method are compared. Comparative results reveal that the proposed strategy is superior in terms of accurately predicting RUL. The turbofan engine failure experimental data collection from the US National Aeronautics and Space Administration (NASA) Prognostics Center of Excellence is the subject of this article’s data analysis. Firstly, this paper illustrates the pre-processing steps performed on raw sensor data of run-to-failure engines, followed by the health indicator construction, and then, it matches test data based on data from the model library. Analysis of similarity enables having the RUL according to the outcome that fits.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}