
The Fuzzy u-Chart for Sustainable Manufacturing in the Vietnam Textile Dyeing Industry



1
[-15]Department of Industrial Engineering and Management, National Kaohsiung University of Applied Sciences, Kaohsiung 80778, Taiwan
2
Faculty of Finance-Banking, Lac Hong University, Dong Nai 810000, Vietnam
3
Office of Scientific Research, Lac Hong University, Dong Nai 810000, Vietnam
4
Department of Industrial Engineering and Management, Cheng Shiu University, Kaohsiung 83347, Taiwan
*
Author to whom correspondence should be addressed.
Symmetry 2017, 9(7), 116; https://doi.org/10.3390/sym9070116
Submission received: 31 May 2017
/
Revised: 30 June 2017
/
Accepted: 7 July 2017
/
Published: 12 July 2017
(This article belongs to the Special Issue Fuzzy Sets Theory and Its Applications)
Abstract
:The inevitability of measurement errors and/or humans of subjectivity in data collection processes make accumulated data imprecise, and are thus called fuzzy data. To adapt to this fuzzy domain in a manufacturing process, a traditional u control chart for monitoring the average number of nonconformities per unit is required to extend. In this paper, we first generalize the u chart, named fuzzy u-chart, whose control limits are built on the basis of resolution identity, which is a well-known fuzzy set theory. Then, an approach to fuzzy-logic reasoning, incorporating the decision-maker’s varying levels of optimism towards the online process, is proposed to categorize the manufacturing conditions. In addition, we further develop a condition-based classification mechanism, where the process conditions can be discriminated into intermittent states between in-control and out-of-control. As anomalous conditions are monitored to some extent, this condition-based classification mechanism can provide the critical information to deliberate the cost of process intervention with respect to the gain of quality improvement. Finally, the proposed fuzzy u-chart is implemented in the Vietnam textile dyeing industry to replace its conventional u-chart. The results demonstrate that the industry can effectively evade unnecessary adjustments to its current processes; thus, the industry can substantially reduce its operational cost and potential loss.
1. Introduction
Competitive marketplaces require industrial manufacturers to provide consistent and reliable quality products to preserve their survival and sustainable growth. Therefore, the manufacturers keenly explore for optimal strategies to not only lower their percentage of nonconformists, but to also slash manufacturing costs, and to fulfill customer satisfaction [1]. Nowadays, manufacturers pay special efforts in establishing effective quality management systems and programs. Walpole et al. [2] confirmed that the quality-control scheme has been utilized as a powerful tool for manufacturers to achieve their production effectiveness as well as to sustain their quality-based competitive advantages.
Practically, any mistaken intervention of processes, delay of alarming excessive product defects, and scraps or reworks of final products will result in an increase of production costs. Thus, in the monitoring and controlling of online manufacturing processes, Shewhart-type control charts have been widely employed due to their notable capability of early detection of an abnormal process [1,3]. The Shewhart-type control charts fall into two categories, called variable and attribute control charts. While the former monitors the variable-type data, which can be quantitatively measured on a continuous scale such as a thermometer, a weighing scale, or a tape rule, the latter monitors the attribute-type data, which can be qualitatively described, for example, as good or defective, as possessing or not possessing a particular characteristic.
A typical control chart consists of a center line () and upper and lower control limits ( and ) for monitoring the process’s key quality characteristic (KQC). Their constructions are based on a moderate number of subgroup KQC samples, where each subgroup sample (randomly drawn) has either an equal or unequal sample size. According to the statistics information of sequentially collected KQC sample data, the control limits categorize the online process condition. When an outlier or any systematic pattern is detected on the chart, it implies the process is affected by some assignable causes where the subsequently well-structured corrective actions are necessitated; otherwise, we conclude that the process is in statistical control, a desired (stable) state where no interference is needed [1].
The establishment of control charts requires fully precise random data gathered from the KQC of the process. However, the natural limitations inherited in practical applications have dampened this possibility. For example, the inevitability of gague errors existing in a measurement system [4,5] and in data collection processes where the human subjectivity arises from the decision-makers’ vast variety of intelligence perceptions and experiences all make accumulated data imprecise [6,7,8,9]. Moreover, for the monitoring and controlling of online manufacturing processes, the traditional control charts carrying a binary classification of the process condition, namely in control and out of control,"have failed to effectively adapt to this fuzzy domain. The extensions of traditional control charts, named “ fuzzy control charts”, become mandated [7,9,10,11,12,13,14].
Over the past decade, worldwide scholars have paid a special interest in proposing and constructing a number of fuzzy control charts; examples include Senturk and Erginel [9] with fuzzy and control charts, Shu and Wu [14] with fuzzy and R control charts, Nguyen et al. [15] with fuzzy and s control charts, Shu et al. [4] with fuzzy MaxGWMA control chart, and Morabia et al. [16] with fuzzy control chart to deal with multiple objective decision-making problems. The core issue of the contributions above is centered on the fuzzy-variable control charts.
For the fuzzy-attribute control charts, Wang and Raz [17] pioneered with the linguistic-type KQCs such as perfect, good, medium, poor and bad; unfortunately, Kanagawa et al. [18] claimed that Wang and Raz’s [17] development failed to incorporate the probability distributions for linguistic data when constructing the control charts. Although their assertion is rational in theory, in practice the justifiable probability distributions are not easily determined [19,20]. For other declarations, Shu and Wu [14] and Woodall et al. [21] also emphasized the invalidity of lingistic-type control charts, if their membership functions of linguistic terms were arbitrarily assumed on a given scale without contemplation of induced fuzziness from the judgment of experts.
Moreover, in the fuzzy environment, the binary categorization of the online manufacturing condition still has certain arguments to be fulfilled. Many previous methods performed the binary categorization by defuzzing data on the basis of the fuzzy midrange, fuzzy mode, fuzzy median and fuzzy average; however, such techniques have also raised another consequence of losing the fuzziness information in the manufacturing data where the misclassified possibility of the manufacturing process could be intolerable [14,22,23].
Thus, several approaches to preserve the fuzziness of vague data have been proposed. The evidence can be seen from the necessity index of strict dominance (NISD) by Grzegorzeski and Hryniewicz [24], acceptable percentage index called direct fuzzy approach (DFA) by Gülbay and Kahraman [13], fuzzy dominance approach (FDA) by Shu and Wu [14]. Certain limitations exist in their methods. While the NISD is content-dependent [25], the DFA fails to obtain the fuzzy sample means and variances with the simple using of -cuts [14]. In addition, the FDA approach can only perform nicely at a dominance degree greater than 0.5 [15,26].
To overcome the aforementioned issues, we first generalize the u chart, named fuzzy u-chart whose control limits are built on the basis of Resolution Identity, a well-known fuzzy set theory. Then, an approach of fuzzy-logic reasoning is proposed for the fuzzy control limits to categorize the online manufacturing conditions. Furthermore, we develop a condition-based classification mechanism, where the process conditions can be discriminated into intermittent states between in-control and out-of-control. It can be noted that this novel classification mechanism is rooted on a robust fuzzy-ranking scheme that assesses the magnitude of left-right areas and centroids of fuzzy numbers to provide more satisfactory reasoning [27].
This paper is organized as follows. Section 2 briefly provides key characteristics of the traditional u chart to support part of Section 3, the procedure of constructing the fuzzy u-chart. It is well noted that these two sections depart from the approach presented in [26,28]. Here, the core issue is centered on the fuzzy-attributed control charts, fuzzy u-chart, while Nguyen et al. [26] and Shu et al. [28] stressed on the fuzzy-variable control charts, and s control charts. Section 4 first reviews the Nguyen and Hien’s method [27] which is then extended for better performance of ranking results. We further develop a condition-based classification mechanism, where the process conditions can be discriminated into intermittent states between in-control and out-of-control states. In Section 5, the established fuzzy u-chart is implemented in the Vietnam textile dyeing industry to replace its conventional u-chart. Some concluding remarks make up the last section.
2. Review of Traditional -Chart
Literally, the term “u-chart” is usually used to monitor the average number of nonconformities per unit when the subgroup sample size is either only one inspection unit or several units [1,2]. A nonconformity (also known as a defect) is the product that deviates from a specification, a standard, or an expectation. A nonconforming product usually contains one or more non-conformists whose severity directly influences on the product quality. Typically, the u-chart is constructed as follows:
In m initial samples, let denote the number of non-conformities in the sample which has inspection units (). Then, the average number of non-conformists per unit, notated by , is calculated by
The grand average of u and variance of each sample are defined as
3. Construction of Fuzzy -Chart
Let us consider m samples each with sample size. Let be fuzzy observations (fuzzy data) which are assumed to be fuzzy real numbers. Based on those observed fuzzy data, a fuzzy set theory [29,30,31] will be applied to construct the upper and lower control limits for u-chart, which is named fuzzy u-chart.
For any given (called cut), the corresponding real-value data (-level set) and for are easily acquired. Then the real-value data and () are used in the Equations (1) and (2) for estimating the fuzzy control limits of and . The outcome is
(a) Construction of Fuzzy Upper Control Limit
Let’s consider the closed interval according to the results above. We define
where
By applying the resolution-identity theorem [29,30,31], the membership function of the upper control limit, one of the control limits’ fuzzy numbers (CLFNs) can be defined as
Since each is a fuzzy real number, and are continuous with respect to on [0, 1]. As a consequence, the -level set of fuzzy upper control limit can be simply rewritten as
where and are shown in Equations (5) and (6).
Furthermore, from Equation (7), the relationship between and is found as
Similarly, the relationship between and is
(b) Construction of Fuzzy Lower Control Limit
Likewise, let us consider the closed interval . We define
where
From the resolution-identity theorem [29,30,31], the membership function of the lower control limit, one of CLFNs is determined by
Since each is a fuzzy real number, and are continuous over on [0, 1]. Hence, the -level set of fuzzy upper control limit can be simply attained as
where and are expressed in Equations (10) and (11).
From Equation (12), the corresponding between and is realized as
Likewise, the relation between and is
4. Classification Conditions
In this section, we will first review a fuzzy ranking method proposed by Nguyen and Hien [27], and then extend their ranking rules to provide more satisfactory reasoning for classifying manufacturing process conditions. Its preferable performance over the previous study in certain cases is illustrated by the comparative analysis shown in Section 5.
4.1. Ranking Fuzzy Numbers with Nguyen & Hien’s Approach
Let’s consider n fuzzy numbers . The membership functions of the i th number are defined as
Let and respectively denote the inverse functions of and . We also define and .
Definition 1.
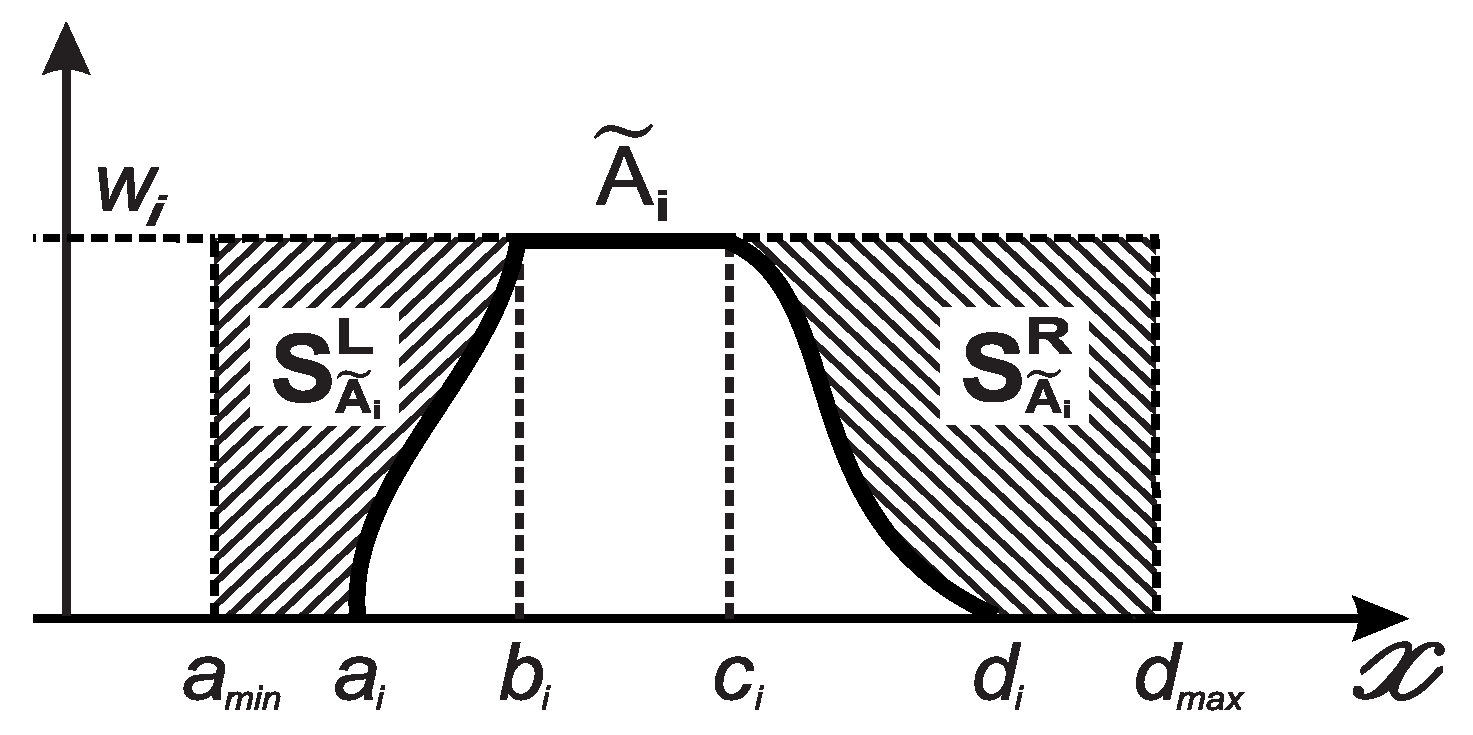
(Left-Right areas) The left area of , , which is from the to , can be defined as
and its right area, , which goes from to , can be set as
From the statistical point of view, is the weighted mean of . It implies that when , we can have .
From the above definitions, Nguyen and Hien [27] proposed a ranking index for at each level of , denoted by .
where is called “level of optimism” that presents the decision-maker’s attitude towards risk. The indicates “the decision-maker with a totally pessimistic attitude towards risk”, indicates “the decision-maker with a totally optimistic attitude towards risk”, and indicates “the decision-maker with a neutral attitude towards risk”.
Two fuzzy numbers and can be ranked by applying the following rules:
- at the optimism level of if and only if .
- at the optimism level of if and only if .
- at the optimism level of if and only if .
4.2. Our Extended Ranking Rules
Now, let’s consider , the disparity amount of ’s and ’s ranking indexes at the optimism level of .
where and .
With Equation (19), the ranking rules mentioned in Section 4.1 can be rewritten as
- at the optimism level of if and only if .
- at the optimism level of if and only if .
- at the optimism level of if and only if .
Because , expressed in Equation (19), is a monotonous function of , then can only occur in the following two cases
- and ; or,
- and .
Furthermore, to sufficiently represent the fuzziness information residing in the collected data, we propose an alternative approach. This approach is capable of comparing two fuzzy numbers into four linguistic-sense consequences that include larger “≻”, rather larger “⪰”, rather smaller “⪯”, and smaller “≺”.
To achieve this, we first define three new terms, namely “benchmark level ”, “step of change in the optimism level ” and “unit ranking”.
Definition 3.
The benchmark level is an optimism level at which is equal to 0.
Definition 4.
The step of change in the optimism level () is the fixed difference between two consecutive optimism levels. The is a constant for the n optimism levels .
Definition 5.
The unit disparity is the disparity of ranking indexes of and caused by the step of change of the optimism level.
In addition, in consideration of the difference of at , the Definition 5 can be further derived as
Here represents a change difference of the disparity obtained from ’s and ’s ranking indexes. For a given , the can be easily acquired.
Therefore, two arbitrarily chosen fuzzy numbers and can be ranked according to the following rules
- (1)
- if and only if one of the conditions below occurs
- (2)
- if and only if one of the below conditions holds
- (3)
- at the optimism level if and only if
- (4)
- at the optimism level if and only if
4.3. Proposed Classification
By integrating the aforementioned fuzzy u-chart and fuzzy ranking approach, we are able to categorize the online manufacturing conditions.
Based on , a fuzzy average number obtained from Section 3, we further develop condition-based classification rules with respect to a certain optimism level , where the process conditions can be discriminated into intermittent states between in-control and out-of-control.
- (1)
- The process is in-control if one of the below situations holds
- (2)
- The process is out of control if one of the following conditions is true
- (3)
- The process is rather in-control if one of the below situations occurs
- (4)
- The process is rather out-of-control if one of the following conditions is fulfilled
Remark 1.
The procedure to conduct our fuzzy u-chart and evaluate the process performance is briefly generalized as follows:
- Step 1:
- From the collected data, we first construct the fuzzy control limits as presented in Section 3.
- Step 2:
- With each , , and , calculate its left area, right area and expected centroid as shown in Definition 1 and 2.
- Step 3:
- For each β, calculate , , and for each pair (, ) and (, ) from Equation (19).
- Step 4:
- With a given , calculate for each pair (, ) and (, ) from Equation (20).
- Step 5:
- The results obtained from Step 3 and 4 are used in the classification mechanism presented in Section 4.3.
5. Practical Application
The recent advances in science, technology, and global integration have led to profound competition amongst businesses. As customers nowadays have a stronger negotiating power, providing them better quality products/services with a reasonable price becomes ever so critical to the survival and development of every business organization [41,42]. Lee et al. [43] indicated that a failure in achieving customers’ expected quality will lead to a long production cycle time, an increase in production and warranty cost, as well as a significant defection in the number of customers.
In practice, there are several controllable and uncontrollable factors affecting the quality of industrial products. In several labor-intensive industries, for example, textile/garment and footwear industries, workmanship is identified as one of the key factors. The importance of workmanship is derived from major parts of the processes being handled by workers practical working experience, which directly influences the quality of the products manufactured. In such industries, the quality of final products practically depends on the subjective perception, knowledge, mood and behavior of the inspectors, also known as quality controllers or assurers who check individual parts, semi-products and final products at different stages in the processes to make sure that their products meet certain specifications set by customers [41]. Consequently, with the manual inspection of random samples, certain limitations in terms of inaccuracy, inconsistency and inefficiency, are obviously inevitable; hence, the recorded data are considered fuzzy [4,41,44]. To have more objective evaluation, automatic inspection systems have been preferably installed despite of their high cost [42].
Literally, Wong et al. [41] provided a critical review of several approaches in detecting different defects and found that their focus was mainly on defect detection instead of defect diagnosis to identify root causes of defects and implement corrective actions. Lee et al. [43] further pinpointed that the existing detection methods treat defects individually without considering their relationships. As a consequence, the general performance of manufacturing processes fails to be appropriately monitored to implement proper adjustments to improve the product quality. To fulfill the gap in the fuzzy environment, this paper proposes using the fuzzy u-chart with the classification mechanism discussed in Section 4.3. To evaluate the performance of our proposed fuzzy u-chart, we employed the chart in a typical example of monitoring the defects in dyed cloth in textile industry.
5.1. Construction of Fuzzy u-Chart
This study investigates dyeing defects in eleven large textile dyeing companies with strong brands located in the South of Vietnam. In each company, we worked with experienced quality controllers who were asked to identify defects/nonconformities occurring in several rolls of dyed cloth based on their practical experience and knowledge of customer’s expectation. Figure 2 shows the common nonconformities in the dyeing industry.
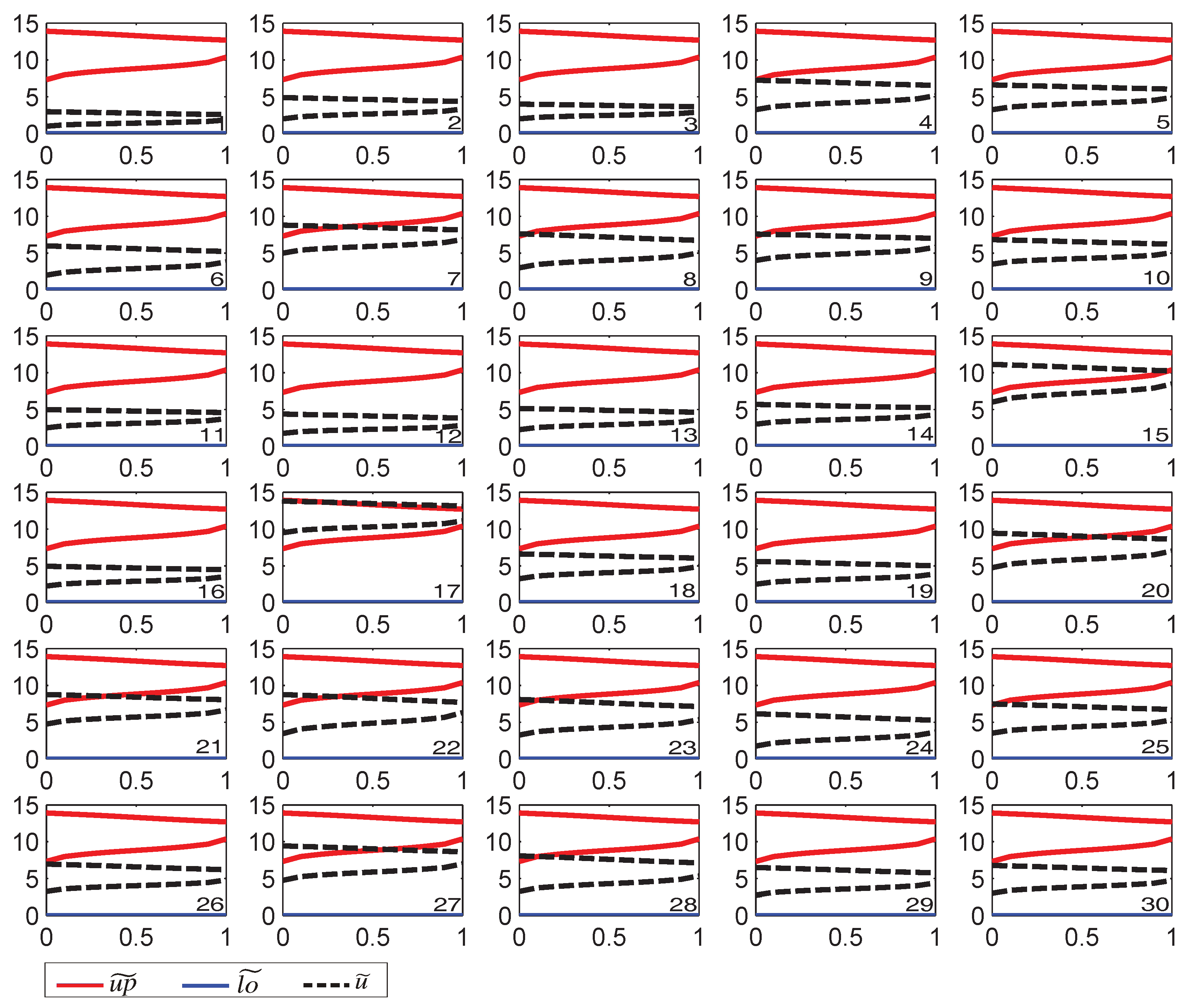
In each sample, four to five rolls of 50 square meters were randomly selected for inspection; and the number of non-conformists of thirty actual observations were recorded. Table 1 shows a typical example of white spot data collected from one of the eleven companies. Specifically, each subgroup was appropriately labeled and each quality controller inspected two certain subgroups randomly three times at different intervals. It was found that the number of nonconformists detected each time in the same subgroup was different, indicating that the human subjectivity obviously affects the counting of the dyed defects; thus, the recorded data are considered as fuzzy numbers.
5.2. Comparative Analysis
Apparently, the categorization rules shown in Section 4.3 are identical to those of Shu et al. [44]. Here, we perform a comparative analysis between two approaches.
Based on the proposed classification mechanism, the performance of the current dyeing process can be effectively monitored with a u-chart. For brevity, this section displays the classifying results for only five different values = 0.5, 0.6, 0.7, 0.8 as shown in Table 2 and Table 3. We can observe that twenty-nine out of the thirty subgroups investigated are considered in-control at these optimism levels. For a comparative analysis between Shu et al. [44] and Nguyen and Hien [27] in this case, both approaches all show a warning signal at the 17th subgroup. While the former classifies the sample as rather out-of-control at the optimism level of 0.5, rather in-control at 0.6 and in-control if the optimism level is larger than 0.6, the latter classifies it as out-of-control for the optimism level less than 0.8 and rather out-of-control at the level of 0.8. It implies that in this case Nguyen and Hien’s [27] approach provides a more discriminatory power.
These results also indicate that for more optimistic decision-makers, the process is more likely to be considered in statistical control. This finding shows that the evaluation of the dyed quality or the process status is critically affected by human behavior, i.e., the level of optimism. More importantly, an investigation is also conducted to look for the assignable causes occurred in the production of the mentioned sample. Once the significant causes are found, having proper corrective actions undertaken to either eliminate or reduce their negative impacts can greatly improve the cloth dyeing quality.
6. Conclusions
In several industrial manufacturing industries, the existence of errors in measurement systems and the human subjectivity in decision-making process makes the collected data imprecise, also called fuzzy data. Consequently, in the fuzzy environment, traditional Shewhart-type control charts turn out to be inappropriate because they require crisp data to categorize manufacturing process conditions.
In this paper, the fuzzy u-chart is constructed to monitor the fuzzy average number of nonconformities per unit. Its fuzzy control limits are first obtained based on the results of the resolution-identity theorem. Moreover, in order to monitor the process based on the fuzzy control chart, we first extend a recent developed fuzzy ranking method proposed by Nguyen and Hien [27]. The ranking strategy is based on the quantity of fuzzy numbers’ left-right areas and centroids to provide more satisfactory reasoning. Then thorough evaluation rules are established to classify the manufacturing process with four different linguistic states, including In-control, Out-of-control, Rather out-of control and Rather in-control. Basically, the incorporation of optimism level into the ranking index provides critical flexibility in decision-making procedure, so decision-makers can exert their savvy experiences in implementing proper actions to fully control the quality of manufactured products. In the empirical case study of Vietnam textile dyeing industry, the results show that the deployment of our proposed fuzzy u-chart can be of great benefit in early detecting the occurrence of assignable causes.
Finally, as to some extent of anomalous conditions is monitored, this intermediate classification mechanism can provide critical information to determine whether a further action taken is required by contemplating the intervention cost as opposed to the quality gain. Thus, this approach can obviously avoid not only unnecessary adjustment to the current process but also the potential loss in their business. As such, our proposed fuzzy u-chart can fulfill the current literature of the conventional u-chart in terms of effectiveness when fuzzy data is inevitably present in the manufacturing process.
Acknowledgments
This research was partially supported by Ministry of Science and Technology of Taiwan under the grant MOST104-2221-E-151-018-MY3.
Author Contributions
We have all worked together to complete this research. Kim-Phung Truong and Thanh-Lam Nguyen reviewed the current literature of traditional u-chart while Ming-Hung Shu and Bi-Min Hsu put more effort on the construction of the fuzzy u-chart. The Matlab codes for the construction were developed by Ming-Hung Shu and Thanh-Lam Nguyen. Ming-Hung Shu, Bi-Min Hsu and Thanh-Lam Nguyen developed the classification mechanism and its Matlab codes. Kim-Phung Truong and Thanh-Lam Nguyen collected the data which were then analyzed by Ming-Hung Shu and Thanh-Lam Nguyen.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CLFNs | Control-limits’ fuzzy numbers |
| CL | Center line |
| UCL | Upper control limit |
| LCL | Lower control limit |
| NISD | Necessity index of strict dominance |
| DFA | Direct fuzzy approach |
| FDA | Fuzzy dominance approach |
| LV | Left integral values |
| RV | Right integral values |
| DS | Unit disparity |
| R-In | Rather in-control |
| R-Out | Rather out-of-control |
References
- Montgomery, D.C. Statistical Quality Control—A Modern Introduction; Wiley & Sons: Singapore, 2013. [Google Scholar]
- Walpole, R.E.; Myers, R.H.; Myers, S.L.; Ye, K. Probability and Statistics for Engineers and Scientists, 9th ed.; Prentice Hall: Boston, MA, USA, 2012. [Google Scholar]
- Evans, J.R.; Lindsay, W.M. The Management and Control of Quality, 8th ed.; South-Western College Publishing: New York, NY, USA, 2011. [Google Scholar]
- Shu, M.H.; Nguyen, T.L.; Hsu, B.M. Fuzzy MaxGWMA chart for identifying abnormal variations of on-line manufacturing processes with imprecise information. Expert Syst. Appl. 2014, 41, 1342–1356. [Google Scholar] [CrossRef]
- Lu, K.P.; Chang, S.T.; Yang, M.S. Change-point detection for shifts in control charts using fuzzy shift change-point algorithms. Comput. Ind. Eng. 2016, 93, 12–27. [Google Scholar] [CrossRef]
- Ghobadi, S.; Noghodarian, K.; Noorossana, R.; Mirhosseini, S.M. Developing a multivariate approach to monitor fuzzy quality profiles. Qual. Quant. 2012. [Google Scholar] [CrossRef]
- Gülbay, M.; Kahraman, C.; Ruan, D. α-cut fuzzy control charts for linguistic data. Int. J. Intell. Syst. 2004, 19, 1173–1196. [Google Scholar] [CrossRef]
- Hsieh, C.S.; Chen, Y.W.; Wu, C.H. Characteristics of fuzzy synthetic decision methods for measuring student achievement. Qual. Quant. 2012, 46, 523–543. [Google Scholar] [CrossRef]
- Senturk, S.; Erginel, N. Development of fuzzy and control charts using α-cuts. Inf. Sci. 2009, 179, 1542–1551. [Google Scholar] [CrossRef]
- Faraz, A.; Shapiro, A.F. An application of fuzzy random variables to control charts. Fuzzy Sets Syst. 2010, 161, 2684–2694. [Google Scholar] [CrossRef]
- Faraz, A.; Moghadam, M.B. Fuzzy control chart a better alternative for Shewhart average chart. Qual. Quant. 2007, 41, 375–385. [Google Scholar] [CrossRef]
- Gülbay, M.; Kahraman, C. Development of fuzzy process control charts and fuzzy pattern analyses. Comput. Stat. Data Anal. 2006, 51, 434–451. [Google Scholar] [CrossRef]
- Gülbay, M.; Kahraman, C. An alternative approach to c-fuzzy control charts: direct fuzzy approach. Inf. Sci. 2007, 177, 1463–1480. [Google Scholar] [CrossRef]
- Shu, M.H.; Wu, H.C. Fuzzy and R control charts: Fuzzy dominance approach. Comput. Ind. Eng. 2011, 61, 676–685. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Hsu, B.M.; Shu, M.H. New quantitative approach based on index of optimism for fuzzy judgement of online manufacturing process. Mater. Res. Innov. 2014, 18, 2–4. [Google Scholar] [CrossRef]
- Morabia, Z.S.; Owliaa, M.S.; Bashirib, M.; Doroudyana, M.H. Multi-objective design of control charts with fuzzy process parameters using the hybrid epsilon constraint PSOs. Appl. Soft Comput. 2015, 30, 390–399. [Google Scholar] [CrossRef]
- Wang, J.H.; Raz, T. On the construction of control charts using linguistic variables. Int. J. Prod. Res. 1990, 28, 477–487. [Google Scholar] [CrossRef]
- Kanagawa, A.; Tamaki, F.; Ohta, H. Control charts for progress average and variability based on linguistic data. Int. J. Prod. Res. 1993, 31, 913–922. [Google Scholar] [CrossRef]
- Laviolette, M.; Seaman, J.W.; Barrett, J.D.; Woodall, W.H. A probabilistic and statistical view of fuzzy methods, with discussions. Technometrics 1995, 37, 249–292. [Google Scholar] [CrossRef]
- Asai, K. Fuzzy Systems for Management; IOS Press: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Woodall, W.; Tsui, K.L.; Tucker, G.L. A Review of statistical and fuzzy control charts based on categorical data. In Frontiers in Statistical Quality Control 5; Lenz, H.J., Wilrich, P.T., Eds.; Physica: Heidelberg, Germany, 1997. [Google Scholar]
- Cheng, C.B. Fuzzy process control: Construction of control charts with fuzzy numbers. Fuzzy Sets Syst. 2005, 154, 287–303. [Google Scholar] [CrossRef]
- Guo, R.; Zhao, R.; Cheng, C. Quality control charts for random fuzzy manufacturing environments. J. Qual. 2008, 15, 101–115. [Google Scholar]
- Grzegorrzewski, P.; Hryniewicz, O. Soft methods in statistical quality control. Control Cybern. 2000, 29, 119–140. [Google Scholar]
- Chien, C.F.; Chen, J.H.; Wei, C.C. Constructing a comprehensive modular fuzzy ranking framework and illustrations. J. Qual. 2011, 18, 333–349. [Google Scholar]
- Nguyen, T.L.; Shu, M.H.; Huang, Y.F.; Hsu, B.M. Fuzzy and s charts: Left & Right dominance approach. In Advanced Methods for Computing Collective Intelligence; Nguyen, N.T., Trawiński, B., Katarzyniak, R., Jo, G.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 355–366. [Google Scholar]
- Nguyen, T.L.; Hien, L.T. Innovatively ranking fuzzy numbers with left-right areas and centroids. J. Inf. Math. Sci. 2016, 8, 167–174. [Google Scholar]
- Shu, M.H.; Dang, D.C.; Nguyen, T.L.; Hsu, B.M. Fuzzy and s control charts: A data-adaptability and human-acceptance approach. Complexity 2017. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Wu, H.C. Evaluate fuzzy Riemann integrals using the Monte Carlo method. J. Math. Anal. Appl. 2001, 264, 324–343. [Google Scholar] [CrossRef]
- Wu, H.C. Fuzzy estimation on lifetime data. Comput. Stat. 2004, 19, 613–633. [Google Scholar] [CrossRef]
- Yu, V.F.; Chi, H.T.X.; Chen, C.W. Ranking fuzzy numbers based on epsilon-deviation degree. Appl. Soft Comput. 2013, 13, 3621–3627. [Google Scholar] [CrossRef]
- Yu, V.F.; Chi, H.T.X.; Dat, L.Q.; Phuc, P.N.K.; Chen, C.W. Ranking generalized fuzzy numbers in fuzzy decision making based on left and right transfer coefficients and areas. Appl. Math. Model. 2013, 37, 8106–8117. [Google Scholar] [CrossRef]
- Yu, V.F.; Dat, L.Q. An improved ranking method for fuzzy numbers with integral values. Appl. Soft Comput. 2014, 14, 603–608. [Google Scholar] [CrossRef]
- Nejad, A.M.; Mashinchi, M. Ranking fuzzy numbers based on the areas on the left and the right sides of fuzzy number. Comput. Math. Appl. 2011, 61, 431–442. [Google Scholar] [CrossRef]
- Wang, Y.M.; Luo, Y. Area ranking of fuzzy numbers based on positive and negative ideal points. Comput. Math. Appl. 2009, 58, 1769–1779. [Google Scholar] [CrossRef]
- Singh, P. A new approach for the ranking of fuzzy sets with different heights. J. Appl. Res. Technol. 2012, 10, 941–949. [Google Scholar]
- Phuc, P.N.K.; Yu, V.F.; Chou, S.Y.; Dat, L.Q. Analyzing the ranking method for L-R fuzzy numbers based on deviation degree. Comput. Ind. Eng. 2012, 63, 1220–1226. [Google Scholar] [CrossRef]
- Chu, T.C.; Tsao, C.T. Ranking fuzzy numbers with an area between the centroid point and original point. Comput. Math. Appl. 2002, 43, 111–117. [Google Scholar] [CrossRef]
- Mitchell, H.B.; Schaefer, P.A. On ordering fuzzy numbers. Int. J. Intell. Syst. 2000, 15, 981–993. [Google Scholar] [CrossRef]
- Wong, W.K.; Yuen, C.W.M.; Fan, D.D.; Chan, L.K.; Fung, E.H.K. Stitching defect detection and classification using wavelet transform and BP neural network. Expert Syst. Appl. 2009, 36, 3845–3856. [Google Scholar] [CrossRef]
- Yuen, C.W.M.; Wong, W.K.; Qian, S.Q.; Chan, L.K.; Fung, E.H.K. A hybrid model using genetic algorithm and neural network for classifying garment defects. Expert Syst. Appl. 2009, 36, 2037–2047. [Google Scholar] [CrossRef]
- Lee, C.K.H.; Choy, K.L.; Ho, G.T.S.; Chin, K.S.; Law, K.M.Y.; Tse, Y.K. A hybrid OLAP-association rule mining based quality management system for extracting defect patterns in the garment industry. Expert Syst. Appl. 2013, 40, 2435–2446. [Google Scholar] [CrossRef]
- Shu, M.H.; Chiu, C.C.; Nguyen, T.L.; Hsu, B.M. A demerit-fuzzy rating system, monitoring scheme and classification for manufacturing processes. Expert Syst. Appl. 2014, 41, 7878–7888. [Google Scholar] [CrossRef]
Figure 1.
Left and right areas of .

Figure 2.
Common defects in dyed cloth. (a) Cloudy; (b) Shade variation; (c) Tonal variation; (d) Poor light fastness; (e) Dyed stain; (f) Color crocking; (g) White spot; (h) White spot.
Figure 2.
Common defects in dyed cloth. (a) Cloudy; (b) Shade variation; (c) Tonal variation; (d) Poor light fastness; (e) Dyed stain; (f) Color crocking; (g) White spot; (h) White spot.

Figure 3.
u-Chart for monitoring the white spots in dyed cloth.


{kind=link}
{kind=link}
{kind=link}
Table 1.
The number of white spots detected.
| Sub. | Size | Sub. | Size | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 1 | 2 | 3 | 16 | 5 | 3 | 4 | 5 |
| 2 | 4 | 2 | 4 | 5 | 17 | 5 | 10 | 13 | 14 |
| 3 | 4 | 2 | 3 | 4 | 18 | 4 | 4 | 5 | 6 |
| 4 | 5 | 3 | 6 | 7 | 19 | 5 | 4 | 5 | 6 |
| 5 | 5 | 3 | 5 | 6 | 20 | 4 | 5 | 8 | 10 |
| 6 | 4 | 2 | 5 | 6 | 21 | 4 | 5 | 7 | 8 |
| 7 | 5 | 5 | 7 | 9 | 22 | 5 | 6 | 7 | 9 |
| 8 | 4 | 4 | 6 | 7 | 23 | 5 | 4 | 7 | 8 |
| 9 | 5 | 4 | 6 | 7 | 24 | 5 | 2 | 5 | 6 |
| 10 | 5 | 4 | 5 | 6 | 25 | 5 | 4 | 6 | 7 |
| 11 | 5 | 3 | 4 | 5 | 26 | 5 | 4 | 5 | 7 |
| 12 | 4 | 2 | 3 | 4 | 27 | 5 | 5 | 8 | 9 |
| 13 | 4 | 3 | 4 | 5 | 28 | 5 | 4 | 6 | 8 |
| 14 | 5 | 3 | 4 | 5 | 29 | 4 | 3 | 5 | 6 |
| 15 | 5 | 6 | 10 | 11 | 30 | 4 | 3 | 5 | 7 |
Table 2.
u-Chart classification based on Shu et al.’s [44] approach.
Table 2.
u-Chart classification based on Shu et al.’s [44] approach.
| Sub. | 0.5 | 0.6 | 0.7 | 0.8 | 0.5 | 0.6 | 0.7 | 0.8 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2.6312 | 2.6459 | 2.6606 | 2.6753 | 0.0147 | In | In | In | In |
| 2 | 2.2522 | 2.2657 | 2.2792 | 2.2927 | 0.0135 | In | In | In | In |
| 3 | 2.3114 | 2.3228 | 2.3342 | 2.3456 | 0.0114 | In | In | In | In |
| 4 | 1.4553 | 1.4699 | 1.4845 | 1.4991 | 0.0146 | In | In | In | In |
| 5 | 1.6654 | 1.6739 | 1.6824 | 1.6909 | 0.0085 | In | In | In | In |
| 6 | 1.9181 | 1.9316 | 1.9451 | 1.9586 | 0.0135 | In | In | In | In |
| 7 | 1.1658 | 1.1871 | 1.2084 | 1.2297 | 0.0213 | In | In | In | In |
| 8 | 1.4466 | 1.4641 | 1.4816 | 1.4991 | 0.0175 | In | In | In | In |
| 9 | 1.4144 | 1.4241 | 1.4338 | 1.4435 | 0.0097 | In | In | In | In |
| 10 | 1.5025 | 1.5128 | 1.5231 | 1.5334 | 0.0103 | In | In | In | In |
| 11 | 2.2784 | 2.2999 | 2.3214 | 2.3429 | 0.0215 | In | In | In | In |
| 12 | 2.8702 | 2.8820 | 2.8938 | 2.9056 | 0.0118 | In | In | In | In |
| 13 | 2.2506 | 2.2569 | 2.2632 | 2.2695 | 0.0063 | In | In | In | In |
| 14 | 1.9564 | 1.9685 | 1.9806 | 1.9927 | 0.0121 | In | In | In | In |
| 15 | 0.9199 | 0.9961 | 1.0723 | 1.1485 | 0.0762 | In | In | In | In |
| 16 | 2.1772 | 2.1829 | 2.1886 | 2.1943 | 0.0057 | In | In | In | In |
| 17 | −0.0083 | 0.0015 | 0.0113 | 0.0211 | 0.0098 | R-Out | R-In | In | In |
| 18 | 1.3923 | 1.4051 | 1.4179 | 1.4307 | 0.0128 | In | In | In | In |
| 19 | 1.8529 | 1.8666 | 1.8803 | 1.8940 | 0.0137 | In | In | In | In |
| 20 | 1.1172 | 1.1283 | 1.1394 | 1.1505 | 0.0111 | In | In | In | In |
| 21 | 1.1382 | 1.1449 | 1.1516 | 1.1583 | 0.0067 | In | In | In | In |
| 22 | 1.2306 | 1.2371 | 1.2436 | 1.2501 | 0.0065 | In | In | In | In |
| 23 | 1.4805 | 1.4894 | 1.4983 | 1.5072 | 0.0089 | In | In | In | In |
| 24 | 1.9884 | 1.9959 | 2.0034 | 2.0109 | 0.0075 | In | In | In | In |
| 25 | 1.8368 | 1.8447 | 1.8526 | 1.8605 | 0.0079 | In | In | In | In |
| 26 | 1.8165 | 1.8217 | 1.8269 | 1.8321 | 0.0052 | In | In | In | In |
| 27 | 1.0131 | 1.0229 | 1.0327 | 1.0425 | 0.0098 | In | In | In | In |
| 28 | 1.3446 | 1.3507 | 1.3568 | 1.3629 | 0.0061 | In | In | In | In |
| 29 | 1.4602 | 1.4695 | 1.4788 | 1.4881 | 0.0093 | In | In | In | In |
| 30 | 1.4558 | 1.4625 | 1.4692 | 1.4759 | 0.0067 | In | In | In | In |
Notes: .
Table 3.
u-Chart classification based on Nguyen & Hien’s [27] approach.
Table 3.
u-Chart classification based on Nguyen & Hien’s [27] approach.
| Sub. | 0.5 | 0.6 | 0.7 | 0.8 | 0.5 | 0.6 | 0.7 | 0.8 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 3.2995 | 3.3180 | 3.3365 | 3.355 | 0.0185 | In | In | In | In |
| 2 | 2.8243 | 2.8415 | 2.8587 | 2.8759 | 0.0172 | In | In | In | In |
| 3 | 2.8985 | 2.9129 | 2.9273 | 2.9417 | 0.0144 | In | In | In | In |
| 4 | 1.8249 | 1.8433 | 1.8617 | 1.8801 | 0.0184 | In | In | In | In |
| 5 | 2.0884 | 2.0991 | 2.1098 | 2.1205 | 0.0107 | In | In | In | In |
| 6 | 2.4053 | 2.4224 | 2.4395 | 2.4566 | 0.0171 | In | In | In | In |
| 7 | 1.4619 | 1.4887 | 1.5155 | 1.5423 | 0.0268 | In | In | In | In |
| 8 | 1.8142 | 1.8363 | 1.8584 | 1.8805 | 0.0221 | In | In | In | In |
| 9 | 1.7737 | 1.7859 | 1.7981 | 1.8103 | 0.0122 | In | In | In | In |
| 10 | 1.8841 | 1.8972 | 1.9103 | 1.9234 | 0.0131 | In | In | In | In |
| 11 | 2.8571 | 2.8842 | 2.9113 | 2.9384 | 0.0271 | In | In | In | In |
| 12 | 3.5992 | 3.6139 | 3.6286 | 3.6433 | 0.0147 | In | In | In | In |
| 13 | 2.8223 | 2.8302 | 2.8381 | 2.846 | 0.0079 | In | In | In | In |
| 14 | 2.4533 | 2.4685 | 2.4837 | 2.4989 | 0.0152 | In | In | In | In |
| 15 | 1.1536 | 1.2495 | 1.3454 | 1.4413 | 0.0959 | In | In | In | In |
| 16 | 2.7302 | 2.7374 | 2.7446 | 2.7518 | 0.0072 | In | In | In | In |
| 17 | −0.0384 | −0.0281 | −0.0178 | −0.0075 | 0.0103 | Out | Out | Out | R-Out |
| 18 | 1.7459 | 1.7621 | 1.7783 | 1.7945 | 0.0162 | In | In | In | In |
| 19 | 2.3235 | 2.3407 | 2.3579 | 2.3751 | 0.0172 | In | In | In | In |
| 20 | 1.4012 | 1.4154 | 1.4296 | 1.4438 | 0.0142 | In | In | In | In |
| 21 | 1.4273 | 1.4357 | 1.4441 | 1.4525 | 0.0084 | In | In | In | In |
| 22 | 1.5432 | 1.5514 | 1.5596 | 1.5678 | 0.0082 | In | In | In | In |
| 23 | 1.8565 | 1.8677 | 1.8789 | 1.8901 | 0.0112 | In | In | In | In |
| 24 | 2.4935 | 2.5029 | 2.5123 | 2.5217 | 0.0094 | In | In | In | In |
| 25 | 2.3033 | 2.3131 | 2.3229 | 2.3327 | 0.0098 | In | In | In | In |
| 26 | 2.2779 | 2.2844 | 2.2909 | 2.2974 | 0.0065 | In | In | In | In |
| 27 | 1.2704 | 1.2828 | 1.2952 | 1.3076 | 0.0124 | In | In | In | In |
| 28 | 1.6861 | 1.6938 | 1.7015 | 1.7092 | 0.0077 | In | In | In | In |
| 29 | 1.8311 | 1.8428 | 1.8545 | 1.8662 | 0.0117 | In | In | In | In |
| 30 | 1.8256 | 1.8340 | 1.8424 | 1.8508 | 0.0084 | In | In | In | In |
Notes: .
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Truong, K.-P.; Shu, M.-H.; Nguyen, T.-L.; Hsu, B.-M. The Fuzzy u-Chart for Sustainable Manufacturing in the Vietnam Textile Dyeing Industry. Symmetry 2017, 9, 116. https://doi.org/10.3390/sym9070116
AMA Style
Truong K-P, Shu M-H, Nguyen T-L, Hsu B-M. The Fuzzy u-Chart for Sustainable Manufacturing in the Vietnam Textile Dyeing Industry. Symmetry. 2017; 9(7):116. https://doi.org/10.3390/sym9070116
Chicago/Turabian StyleTruong, Kim-Phung, Ming-Hung Shu, Thanh-Lam Nguyen, and Bi-Min Hsu. 2017. "The Fuzzy u-Chart for Sustainable Manufacturing in the Vietnam Textile Dyeing Industry" Symmetry 9, no. 7: 116. https://doi.org/10.3390/sym9070116
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.