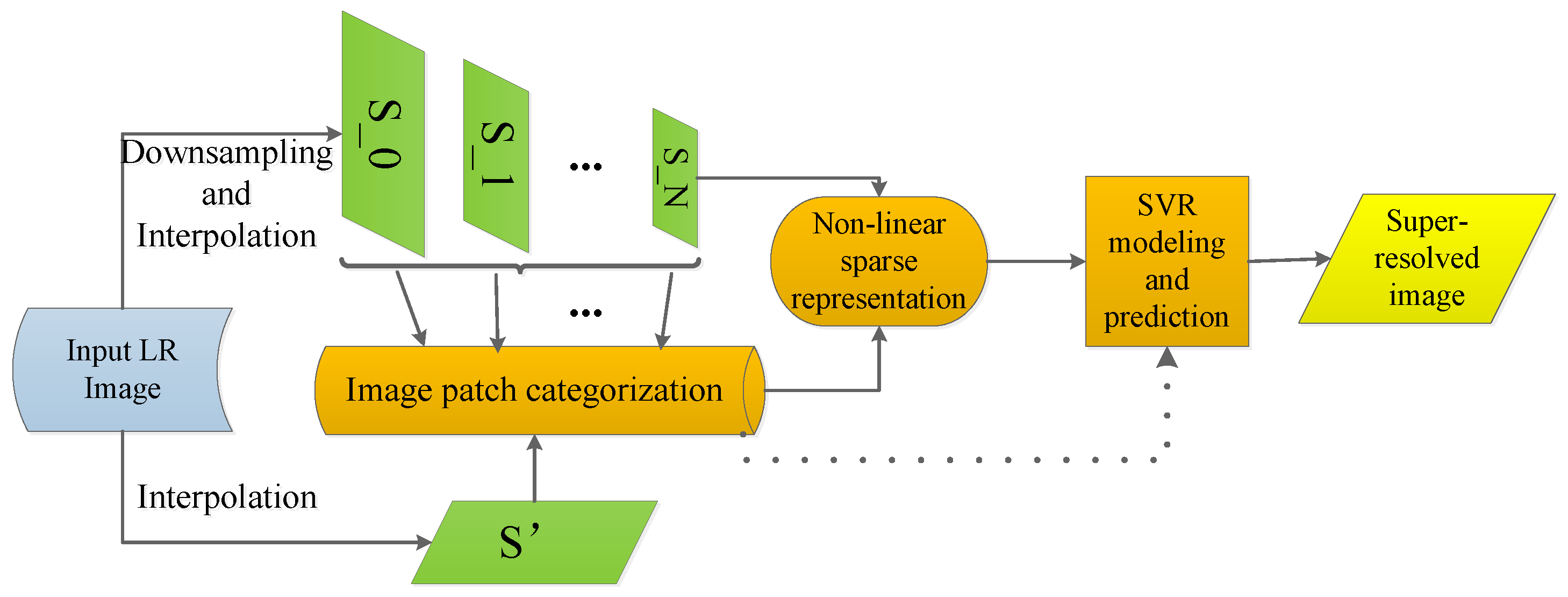
The proposed single image SR method is presented in this section. The main framework of our proposed method can be seen in
Figure 1, where the input LR image is first downsampled with several factors to obtain several images in different scales. Then, a classical interpolation method such as bicubic interpolation can be used for each image to produce the
,
…,
in the figure. For each image of {
,
…,
}, image patches are extracted and categorized as ‘high frequency’ or ‘low frequency’. Then, the non-linear sparse representation is utilized to represent each image patch. Meanwhile, the original input image is directly interpolated to produce a high resolution image
. The image patches extracted from
will later be used for predicting the final SR result (the dot line in
Figure 1).
In previous sparsity-based methods such as [
8,
10], the sparse model is trained by using a small number of randomly selected image patches, and this indicates that their methods may only be effective on those images that contain similar structures. Example-based methods such as [
5,
29] may produce artifacts around the edges. To tackle the problem, further processing techniques are needed. To solve the aforementioned problems, some researchers proposed treating the salient regions (especially edge regions) and the smooth regions separately. Using image segmentation techniques such as widely used edge detectors, image patches can be labelled as different types such as ‘high frequency’ (patches contain edge pixels) and ‘low frequency’ (smooth patches). Different learning models thus can be built for different types of image patches. During the image refinement stage, different models then can be selected for different types of image patches in the input image. The technique of categorization of image patches obtained promising results in some SISR tasks [
28,
30,
34]. In this paper, the technique of categorization of image patches is also used.
The learned non-linear sparse representation of image patches is then used to establish the SVR models. Finally, the obtained SVR models are used for selecting the best candidate patch in {,…,} for the refinement of each image patch in to generate the final SR image.
3.1. Non-Linear Sparse Representation
The non-negative sparse coding (NNSC) stresses both the non-negativity and sparseness for data representation. Therefore, given a set of data
Y, the NNSC can be defined as the following minimization problem:
where
X is the sparse matrix containing sparse vectors, and
D is the dictionary.
In an NNSC data representation procedure, the first stage is to optimize the sparse matrix
X. The global minimization can be obtained by quadratic programming or gradient descent. In [
19], a multiplicative algorithm was proposed for obtaining the sparse matrix. The algorithm can be described as the following iterative update rule:
where ⊙ and
denote element-wise multiplication and division, respectively.
λ is the tradeoff between sparseness and accurate reconstruction, and a typical choice is
, where
x is a vector in the sparse matrix
X. The scalar
λ is added to every element of the matrix
.
In the second stage, the dictionary
D is learned. The obtained sparse matrix
X is fixed here. Then,
D can be obtained by dictionary learning algorithms. For example, Hoyer [
19] proposed a gradient descent based algorithm to learn the dictionary with a non-negative constraint. Other dictionary learning algorithms can also be used for updating
D. However, the non-negative constraints must be considered to keep the non-negativity of the learned dictionary. The aforementioned two stages of NNSC are iteratively processed in turn for updating the sparse matrix and the dictionary, respectively.
Unlike the prior sparsity-based SR methods, the non-linear sparse representation is used here. The main idea of the kernel KSVD is briefly introduced in this section. The kernelized KSVD [
16] is used for image patch feature representation, as it was investigated in [
16], that the kernelized KSVD outperforms kernelized MOD and kernel PCA in the experimental image analysis applications.
The goal of kernel dictionary learning is to obtain a non-linear dictionary
in a Hilbert space
. Define
as a non-linear mapping from
to a Hilbert space
, where
. To obtain the non-linear dictionary
D, one has to solve the following optimization problem:
where
is the Frobenius norm of a matrix, for a matrix
M has the dimension of
, and it can be obtained as:
.
.
is a sparse matrix, and each column
in
X is a sparse vector that has a maximum of
T non-zero elements.
The dimension of the Hilbert space
can possibly be infinite. Therefore, the traditional dictionary learning methods such as KSVD and MOD are incapable of the optimization task. In order to tackle the optimization problem in Equation (
3), the kernel KSVD (KKSVD) dictionary learning [
16] was proposed. KKSVD consists of two stages. First, the kernel orthogonal matching pursuit (KOMP) is used for sparse coding. Then, the kernel KSVD is used for a dictionary update.
In the sparse coding stage, by introducing kernel mapping, the problem in Eqquation (
3) can be rewritten as:
Note the dictionary
D in Equation (
3) is changed to a coefficient matrix,
A, as it is proved that there exists an optimal solution
, which has the form
. [
16].
Therefore, now the problem in Equation (
4) can be solved by any pursuit algorithms. For example, a kernelized version of the orthogonal matching pursuit algorithm (OMP) [
35] is used in [
16]. In the sparse coding stage, the coefficient matrix
A is fixed and the KOMP algorithm can be used to search for the sparse matrix
X. The details of the KOMP algorithm can be found in [
16].
In the dictionary update stage, the kernel KSVD is used. Let
and
represent the
k-th column and the
j-th row of
A and
X, respectively. The approximation error:
can be written as:
where
,
.
demonstrates the distance between the true signals and the estimated signals when removing the
k-th dictionary atom, while
specifies the contribution of the
k-th dictionary atom to the estimated signals.
In the dictionary update stage, as
is a constant for each
k, the minimization of Equation (
6) is indeed to find the best
and
for the rank-1 matrix
to produce the best approximation of
. Using a singular value decomposition (SVD), one can obtain the solution. However, it is impossible to directly use SVD in this scenario. Using SVD here may greatly increase the number of non-zero elements in
X. Moreover, the matrix may have infinitely large row dimensions, which is computationally prohibitive.
Instead of working on all columns of
, one can only work on a subset of columns, as there is a fact that the columns of
associated with the zero-elements in
are all zero, and these columns do not affect the objective function. Therefore, these zero columns can be discarded and only the non-zero elements in
are allowed to vary. Therefore, the sparsities are preserved [
15].
Let
be the set of indices of the signals
that use the dictionary atom
. Then,
can be defined as:
Denote
as a matrix of size
. It has ones on the
-th entries and zeroes elsewhere. Using
multiplies
, by discarding zeroes,
will have the length of
. Then, the
and
in Equation (
6) are changed to:
By applying SVD decomposition, one can get:
where
is a positive semidefinite matrix
, and
is a mercer kernel defined as
.
,
. Using an iterative procedure, in each iteration,
can be updated as:
where
is the first vector of
V corresponding to the largest singular value
in Δ.
The coefficient vector
is updated as:
For the overall procedure, in the first stage, the KOMP algorithm is used for sparse coding. Then, the KSVD is used in the second stage for dictionary update. The aforementioned two stages are repeated until a stopping criterion is met.
3.2. Non-Negative Kernel KSVD Model
Based on the introduced kernel KSVD model, in this section, the proposed non-negative kernel KSVD model is discussed.
For some applications such as image recognition, using sparse representations and overcomplete dictionaries together with forcing non-negativity on both the dictionary and the coefficients, the learned sparse vectors and the dictionary still comprise only additive elements. This may lead to the ‘ingredient’ form, and all of the training samples are built as an ‘ingredient’ of image contents [
18]. With the non-negative constraint, the dictionary atoms become sparser and converge to the building blocks of the training samples [
36]. However, the existing non-negative sparse models are all based on linear learning algorithms, and their inability to capture the non-linear data distribution inspires us to embed the non-negativity into the non-linear sparse models.
Although there are other non-linear dictionary learning models such as kernel MOD or kernel PCA can be selected for our task, we prefer to use the kernel KSVD, as in [
16], and the authors have demonstrated that the kernel KSVD outperforms other non-linear models in image classification tasks. As we try to make the kernel KSVD produce the non-negative dictionaries and coefficient matrices, it is necessary to vary the original kernel KSVD model. With the non-negative and non-linear constraints, the goal of the sparse coding is now changed to:
In the sparse coding stage, a pursuit algorithm should be used in order to keep the coefficients non-negative. In [
18], an iterative method for non-negative sparse coding is introduced:
where
t represents the iteration number.
and
represent entry-wise multiplication and division. However, this iterative rule is designed for linear coding. In order to use it in the non-linear scenarios, using the kernel trick, Equation (
13) can be varied as:
It can also be proven that using the iterative update rule in Equation (
14), the objective Equation (
12) is non-increasing. Moreover, it is guaranteed that
x can still be non-negative using this update rule, as the elements in
x are updated by simply multiplying with some non-negative factors.
In the dictionary update stage, the dictionary atoms must be kept non-negative as well. Using the same techniques of the kernel KSVD, under the non-negative constraint, the minimization problem in Equation (
6) now has been changed to:
In Equation (
15), one can see that it has the same nature with KSVD, and we try to find the best rank-1 matrix that can approximate the error matrix
. However, in order to keep the non-negativity and to reach the local minima, the KSVD cannot be used here directly. An iterative algorithm is used here, as illustrated in Algorithm 1.
| Algorithm 1 Iterative algorithm for non-negative approximation for . |
| Initialization: Set
where , , as has been introduced in Equation (10) and Equation (11). |
| Repeat step 1 to 2 for J times: |
| 1: Update . If , set . Otherwise, keep unchanged. i runs for the every entry of the vector. |
| 2: Update . If , set . Otherwise, keep unchanged. i runs for every entry of the vector. |
| Output: , . |
Given this non-negative approximation algorithm for the dictionary and the coefficient matrix, now the proposed non-negative kernel KSVD (NNK-KSVD) algorithm for learning the dictionary
A and the sparse coefficient matrix
X is given in Algorithm 2:
| Algorithm 2 The NNK-KSVD algorithm. |
| Input: Training sample set Y, kernel function κ. |
| Initialization: Find a random position in each column of , and set the corresponding element to 1. Normalize each column of to a unit norm. Set the iteration number to . |
| 1: Sparse coding: Use the iterative update rule in Equation (14) to obtain the sparse coefficient matrix with the dictionary fixed. |
| 2: Dictionary update: Use the kernel KSVD algorithm to obtain and . |
| 3: Update and with Algorithm 1. |
| 4: Set and repeat step 1 to 4 until a stopping criterion is met. |
| Output: A, X. |
In Algorithm 2, at the dictionary update stage (step 2), the Kernel KSVD is used to obtain the elements in the dictionary (rank-1 approximation to solve Equation (
15)). However, in order to keep the non-negativity, Algorithm 1 is then used to update the values. The proposed Algorithm 2 is from kernel KSVD, which is a rank-1 approximation. Although some elements in the results were forced to be non-negative, we believe this does not change its nature as a rank-1 approximation. The theoretical analysis on the convergence of Algorithm 2 has not been investigated. However, during the experiments, the effectiveness of the algorithm is illustrated.
3.3. Support Vector Regression for SR
In
Figure 1, the input LR image
I is first downsampled to produce a set of images with different scales. Let us name them {
}. Each image in this set is then interpolated by bicubic interpolation to generate another set of images {
}. Now, the SVR is used to establish relationships between images of two image pyramids
and
. For each scale, an SVR regression model can be learned. Therefore, we now have an SVR models set {
}. With the non-linear sparse representation
of the
j-th image patch in image
, the
j-th patch in image
can be reconstructed as
, where
i is the scale label from 0 to
N. The reconstruction error
can be obtained by:
Once the reconstruction errors of all image patches in scale
i are obtained, denoted as
, another SVR model
can be established between the image
and
. Then, for each image scale
i, an
is trained. The
indicates that, for an input, the image patch needs to be super-resolved for which image patch in which scale should be used for the final refinement. In other words, for an input image patch, each
is used for final prediction, and the one that gives the minimum reconstruction error will be selected for the final refinement. It has been theoretically proved in [
30] that this choosing scheme can guarantee a smallest reconstruction error for each image patch and is thus a large PSNR value.
Note that the image patches in the input low resolution image are also divided into ‘high frequency’ and ‘low frequency’ patches. Therefore, for a ‘high frequency’ input, the image patch needs to be super-resolved, and its refinement is performed by the regressors trained from the ’high frequency’ training patches. The regressor that gives the minimum reconstruction error will be selected for the final output. The same scheme is also used for the ‘low frequency’ input patches.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}