
Ranking Features on Psychological Dynamics of Cooperative Team Work through Bayesian Networks

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.1.1. Procedure
2.2. Instruments and Material
2.2.1. Leadership Behaviors
2.2.2. Group Environment Questionnaire
2.2.3. Work Experience and Expectations
- Work experience: “How many times have you played in this team?”.
- Expectations: we asked players and managers to predict what position they believed they would occupy in the standings at the end of the season.
2.2.4. Specificity Workplace
2.3. Bayesian Networks Modeling
2.3.1. Conditional Independence of Triplets of Random Variables
2.3.2. Bayesian Network Model
2.3.3. Naive Bayes
2.3.4. Tree Augmented Naive Bayes
2.3.5. Validation
2.3.6. Performance Comparison
2.3.7. Conditional Entropy
3. Results
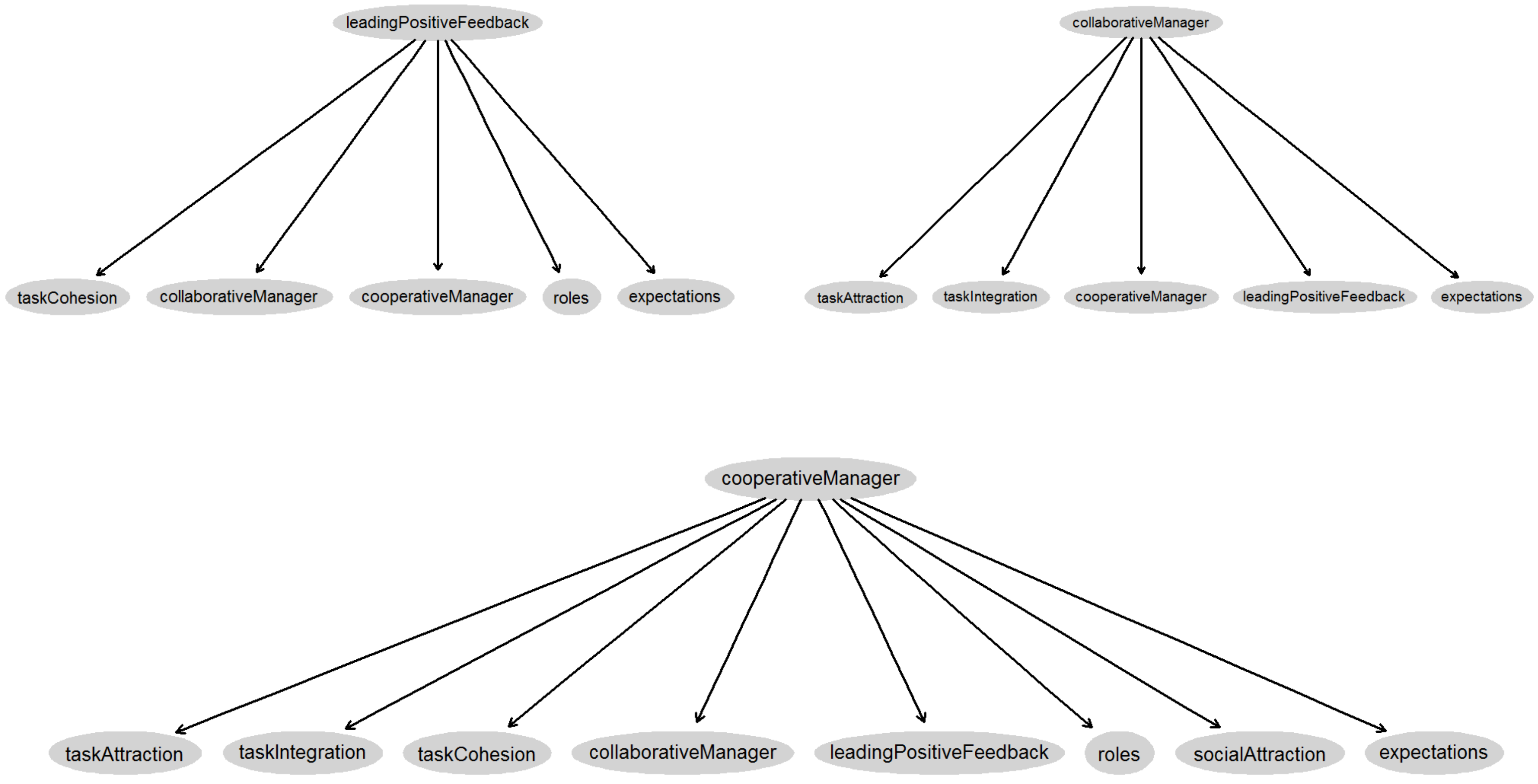
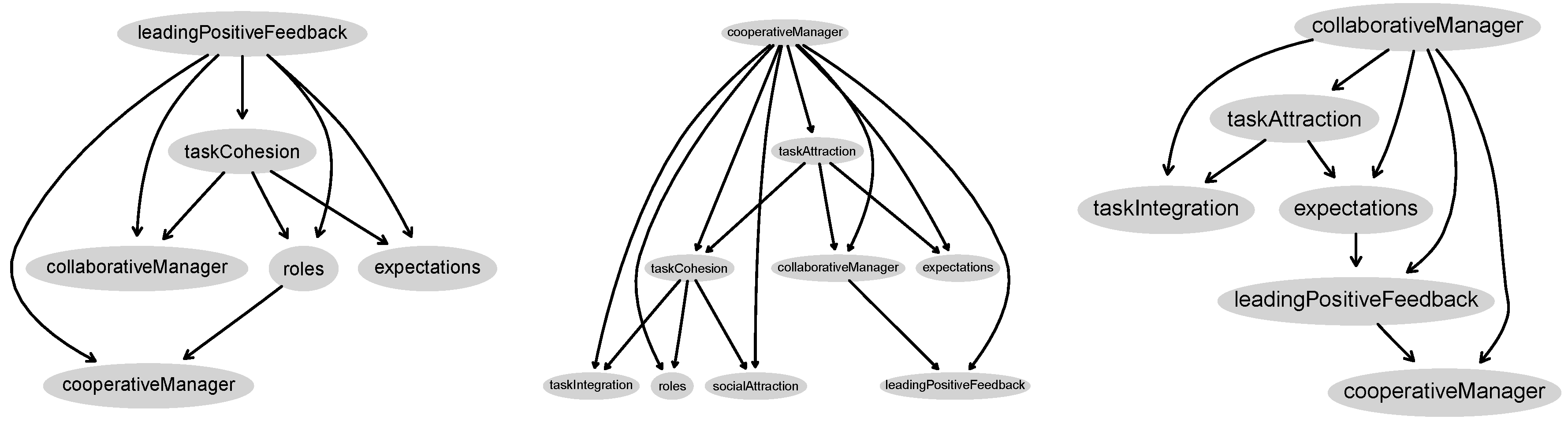
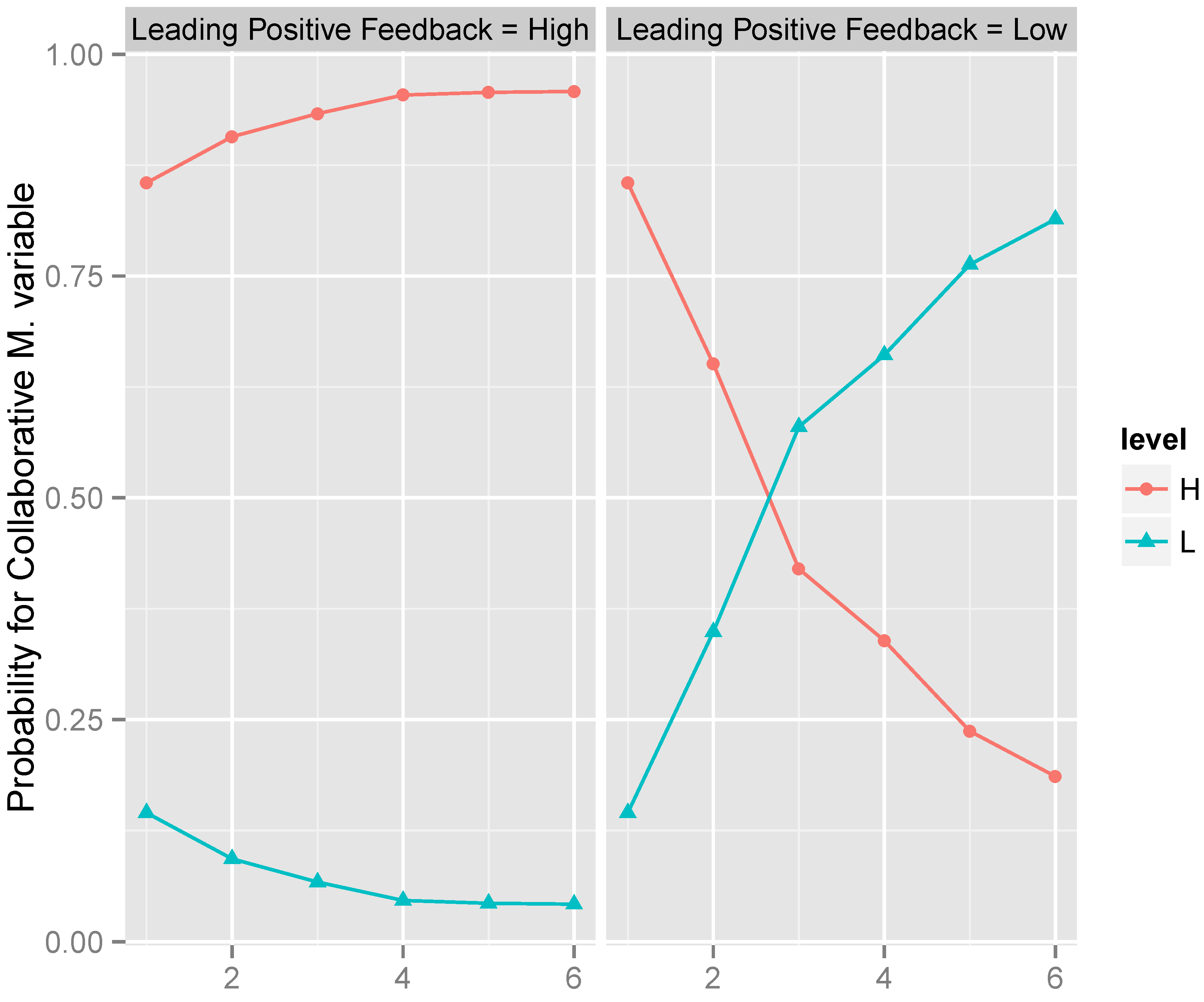
3.1. BN Model for Leading Positive Feedback
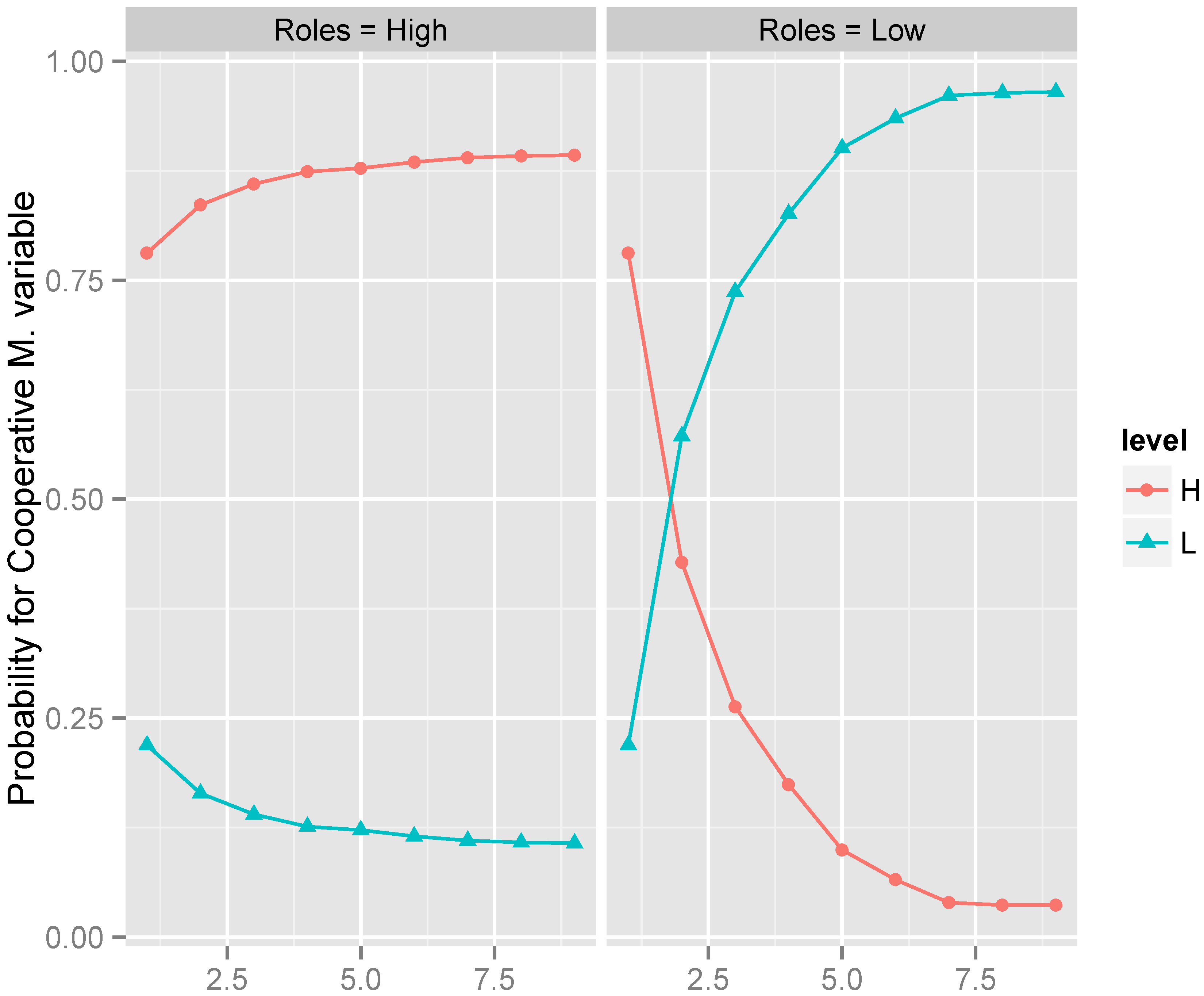
3.2. BN Model for the Cooperative Manager
3.3. BN Model for the Collaborative Manager
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Dataset
Appendix B. The R code
# Load libraries
library(Rgraphviz)
library(bnlearn)
#Download the data
soccerR <- read.table("D:/dataset01.txt", header=T, quote="\"")
#Average Bayesian network
start = random.graph(nodes=names(soccerR),num=1000)
netlist = lapply(start, function(net) {
tabu(soccerR, score = "aic", start = net)
})
arcs = custom.strength(netlist, nodes = names(soccerR), cpdag = FALSE)
arcs[(arcs$strength > 0.85) & (arcs$direction >= 0.5),]
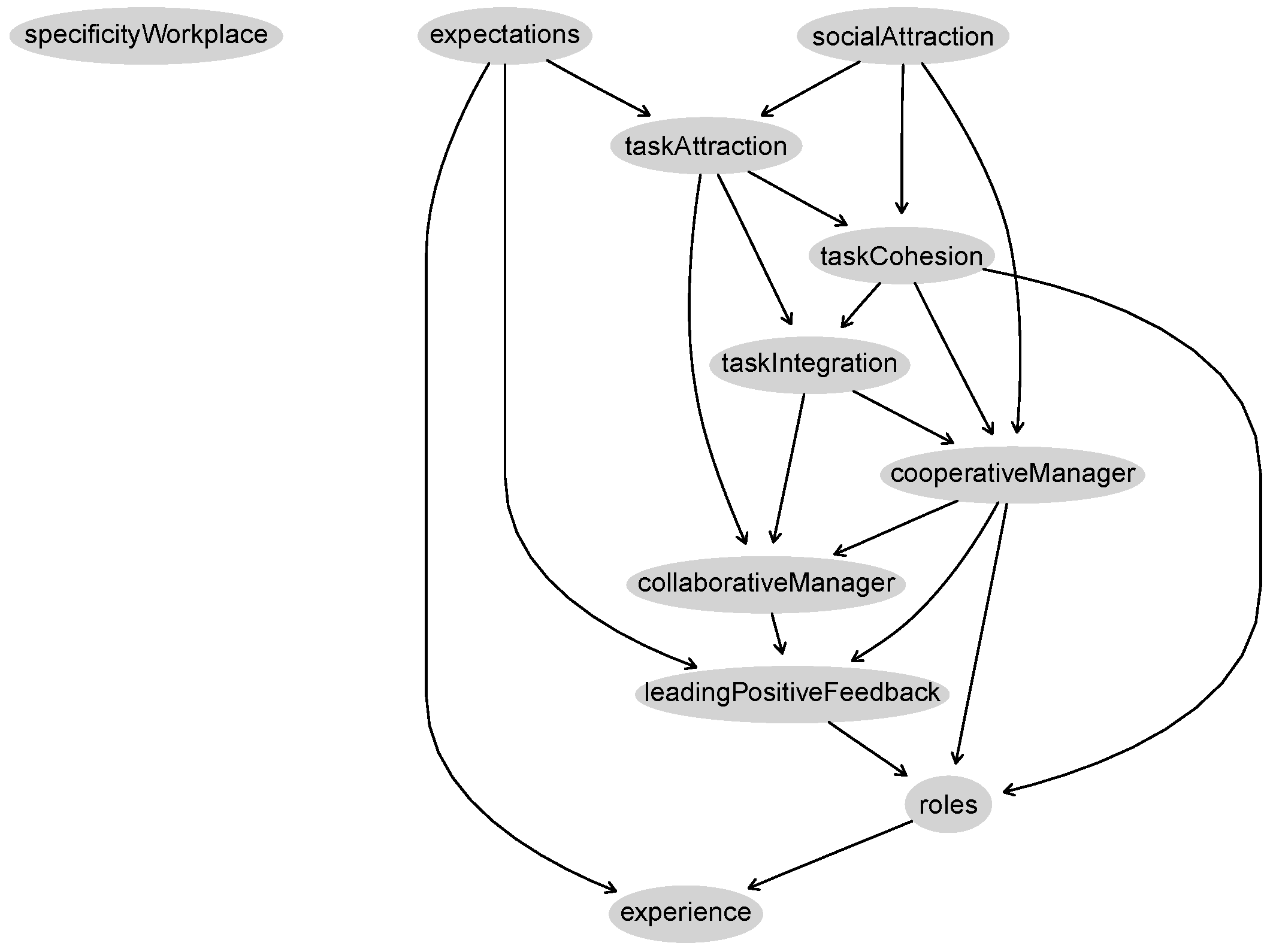
modelstring(averaged.network(arcs))
plot(averaged.network(arcs))
#Plot with Graphviz
graphviz.plot(averaged.network(arcs),highlight=list(nodes=c("cooperativeManager",
"specificityWorkplace","experience","taskAttraction","taskIntegration",
"socialAttraction","taskCohesion","collaborativeManager","leadingPositiveFeedback",
"roles","expectations"),col=c("lightgrey"),fill=c("lightgrey")),layout="dot",
shape="ellipse",main=NULL,sub=NULL)
bncoll = naive.bayes(coll, "collaborativeManager") bncoop = naive.bayes(coop, "cooperativeManager") bnlead = naive.bayes(lead, "leadingPositiveFeedback")
tancoll = tree.bayes(coll, "collaborativeManager") tancoop = tree.bayes(coop, "cooperativeManager") tanlead = tree.bayes(lead, "leadingPositiveFeedback")
References
- Callow, N.; Smith, M.J.; Hardy, L.; Arthur, C.A.; Hardy, J. Measurement of transformational leadership and its relationship with team cohesion and performance level. J. Appl. Sport Psychol. 2009, 22, 395–412. [Google Scholar] [CrossRef]
- Carron, A.V.; Brawley, L.R.; Widmeyer, W.N. Measurement of cohesion in sport and exercise. In Advances in Sport and Exercise Psychology Measurement; Duda, J.L., Ed.; Fitness Information Technology: Morgantown, WV, USA, 1998; pp. 213–226. [Google Scholar]
- Heuzé, J.P.; Raimbault, N.; Fontayne, P. Relationships between cohesion, collective efficacy and performance in professional basketball teams: An examination of mediating effects. J. Sports Sci. 2006, 24, 59–68. [Google Scholar] [CrossRef] [PubMed]
- Myers, N.D.; Payment, C.A.; Feltz, D.L. Reciprocal relationships between collective efficacy and team performance in women’s ice hockey. Group Dyn.-Theor. Res. 2004, 8, 182–195. [Google Scholar] [CrossRef]
- Wilson, D.S.; Ostrom, E.; Cox, M.E. Generalizing the core design principles for the efficacy of groups. J. Econ. Behav. Organ. 2013, 90S, S21–S32. [Google Scholar] [CrossRef]
- Mathieu, J.; Maynard, M.T.; Rapp, T.; Gilson, L. Team effectiveness 1997-2007: A review of recent advancements and a glimpse into the future. J. Manag. 2008, 34, 410–476. [Google Scholar] [CrossRef]
- Cannon-Bowers, J.A.; Salas, E. Teamwork competencies: The interaction of team members knowledge, skills, and attittudes. In Workforce Readiness: Competencies and Assessment; O’Neil, H.F., Ed.; Erlbaum: Mahwah, NJ, USA, 1997; pp. 151–174. [Google Scholar]
- Fuster-Parra, P.; García-Mas, A.; Ponseti, F.J.; Leo, F.M. Team performance and collective efficacy in the dynamic psychology of competitive team: A Bayesian network analysis. Hum. Mov. Sci. 2015, 40, 98–118. [Google Scholar] [CrossRef] [PubMed]
- Beal, D.J.; Cohen, R.R.; Burke, M.J.; McLendon, C.L. Cohesion and performance in groups: A meta-analytic clarification of construct relations. J. Appl. Psychol. 2003, 88, 989–1004. [Google Scholar] [CrossRef] [PubMed]
- Carron, A.V.; Bray, S.R.; Eys, M.A. Team cohesion and team success in sport. J. Sports Sci. 2002, 20, 119–126. [Google Scholar] [CrossRef] [PubMed]
- Eys, M.A.; Carron, A.V.; Beauchamp, M.R.; Bray, S.R. Role ambiguity in sport teams. J. Sport Exerc. Psychol. 2003, 25, 534–550. [Google Scholar]
- Jirotka, M.; Gilbert, N.; Luff, P. On the social organisation of organisations. Comput. Support. Coop. Work J. 1992, 1, 95–118. [Google Scholar] [CrossRef]
- Lameiras, J.; Almeida, P.L.; García-Mas, A. Relationships between cooperation and goal orientation among male professional and semi-professional team athletes. Percept. Motor Skills 2014, 119, 851–860. [Google Scholar] [CrossRef] [PubMed]
- Heckerman, D. Bayesian networks for data mining. Data Min. Knowl. Discov. 1997, 1, 79–119. [Google Scholar] [CrossRef]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs; Information Science & Statistics; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2007. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models. Principles and Techniques; The MIT Press: Cambridge, MA, USA; London, UK, 2010. [Google Scholar]
- Korb, K.B.; Nicholson, A.E. Bayesian Artificial Intelligence; Chapman and Hall/CRC Press: London, UK, 2010. [Google Scholar]
- Pearl, J. Causality. Models, Reasoning and Inference; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Fuster-Parra, P.; García-Mas, A.; Ponseti, F.J.; Palou, P.; Cruz, J. A Bayesian network to discover relationships between negative features in sport: A case study of teen players. Qual. Quant. 2014, 48, 1473–1491. [Google Scholar] [CrossRef]
- Fuster-Parra, P.; García-Mas, A.; Cantallops, J.; Ponseti, F.J. Cooperative team work analysis and modeling: A Bayesian network approach. In Cooperative Design, Visualization and Engineering; Luo, Y., Ed.; Springer International Publishing: Berlin, Germany, 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Fuster-Parra, P.; Tauler, T.; Bennasar-Veny, M.; Ligȩza, A.; López-González, A.A.; Aguiló, A. Bayesian network modeling: A case study of an epidemiologic system analysis of cardiovascular risk. Comput. Methods Progr. Biomed. 2016, 126, 128–142. [Google Scholar] [CrossRef] [PubMed]
- DeFelipe, J.; López-Cruz, P.L.; Benavides-Piccione, R.; Bielza, C.; Larrañaga, P.; Anderson, S.; Burkhalter, A.; Cauli, B.; Fairén, A.; Feldmeyer, D.; et al. New insights into the classification and nomenclature of cortical GABAergic interneurons. Nat. Neurosci. 2013, 14, 202–216. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ligȩza, A.; Fuster-Parra, P. AND/OR/NOT causal graphs. A model for diagnostic reasoning. Int. J. Appl. Math. Comput. Sci. 1997, 7, 185–203. [Google Scholar]
- Cooper, G.F.; Herskovits, E. A Bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning Bayesian networks: The combination of knowledge and statistical data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef]
- Butz, C.J.; Hua, S.; Chen, J.; Yao, H. A simple graphical approach for understanding probabilistic inference in Bayesian networks. Inf. Sci. 2009, 179, 699–716. [Google Scholar] [CrossRef]
- Glymour, C. The Mind’s Arrows: Bayes Nets and Graphical Causal Models in Psychology; The MIT Press: New York, NY, USA, 2003. [Google Scholar]
- Druzdzel, M.J.; Glymour, C. What do college ranking data tell us about student retention: Causal discovery in action. Intelligent Information Systems IV. In Proceedings of the Workshop Held in Augustów, Poland, 5–9 June 1985; pp. 1–10.
- Glymour, C.; Scheines, R.; Spirtes, P.; Kelly, K. Discovering Causal Structure; Academic Press: New York, NY, USA, 1987. [Google Scholar]
- Spirtes, P.; Glymour, C.; Scheines, R. Causation, Prediction and Search, 2nd ed.; Adaptive Computation and Machine Learning; The MIT Press: New York, NY, USA, 2001. [Google Scholar]
- Darwiche, A. Bayesian networks. In Handbook of Knowledge Representation, Foundations of Artificial Intelligence; Van Harmelen, A., Lifschitz, V., Porter, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2008; p. 1034. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufman: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Felipe, S.C.; Pires, D.S.; Nassar, S.M. Analysis of bayesian classifier accuracy. J. Comput. Sci. 2013, 9, 1487–1495. [Google Scholar]
- García Mas, A.; Fuster-Parra, P.; Ponseti, J.; Palou, P.; Olmedilla, A.; Cruz, J. Análisis de las relaciones entre motivación, el clima motivacional y la ansiedad competitiva entre jóvenes jugadores de equipo mediante una red Bayesiana. An. Psicol.-Spain 2015, 1, 355–366. [Google Scholar] [CrossRef]
- Crespo, M.; Balaguer, I.; Atienza, F.L. Análisis psicométrico de la versión española de la escala de liderazgo en el deporte de Chelladurai y Saleh en la versión de entrenadores. Rev. Psicol. Soc. AP 1994, 4, 5–28. [Google Scholar]
- Carron, A.V.; Eys, M.A. Group Dynamics in Sport; Fitness Information Technology: Morgantown, WV, USA, 2012. [Google Scholar]
- Iturbide, L.M.; Elosua, P.; Yanes, F. Medida de la cohesión en equipos deportivos. Adaptación al español del Group Environment Questionnaire (GEQ). Psicothema 2010, 22, 482–488. [Google Scholar] [PubMed]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Duda, R.; Hart, P.; Stork, D. Pattern Classification; John Wiley and Sons: New York, NY, USA, 2001. [Google Scholar]
- Bielza, C.; Larrañaga, P. Discrete Bayesian network classifiers: A survey. ACM Comput. Surv. 2014, 47, 5:1–5:43. [Google Scholar] [CrossRef]
- Domingos, P.; Pazzani, M. On the optimality of the simple Bayesian classifier under zero-one loss. Mach. Learn. 1997, 29, 103–130. [Google Scholar] [CrossRef]
- Nagarajan, R.; Scutari, M.; Lèbre, S. Bayesian Networks in R: With Applications in Systems Biology; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2013. [Google Scholar]
- Scurati, M. Learning Bayesian networks with the bnlearn R package. J. Stat. Softw. 2010, 35, 1–22. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; [Computer Software]; R Foundation for Statistical Computing: Vienna, Austria; Available online: http://www.R-project.org/ (accessed on 20 March 2012).
- Claeskens, G.; Hjort, N.L. Model Selection and Model Averaging; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Neapolitan, N.E. Learning Bayesian Networks; Prentice Hall, Inc.: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell. Labs Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprenhensive Foundation; Prentice Hall: New York, NY, USA, 1989. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Olmedilla, A.; Ortega, E.; Almeida, P.; Lameiras, J.; Villalonga, T.; Sousa, C.; Torregrosa, M.; Cruz, J.; Garcia-Mas, A. Cohesión y cooperación en equipos deportivos. An. Psicol. 2011, 27, 232–238. [Google Scholar]
- Costa, A. Work team Trust and efectiveness. Pers. Rev. 1994, 32, 605–672. [Google Scholar] [CrossRef]
- Cohen, S.G.; Bailey, D.E. What makes team work: Group effectiveness research from the shop floor to the executive suite. J. Manag. 1997, 23, 239–290. [Google Scholar] [CrossRef]
- Rico, R.; Alcover de la Hera, C.M.; Tabernero, C. Efectividad de los equipos de trabajo: Una revisión de la última década de investigación (1999–2009) (Efectiveness of Workteams: A review over the last decade of research (1999–2000). Rev. Psicol. Trab. Organ. 2010, 26, 47–71. [Google Scholar]
- Taggar, S.; Brown, T.C. Problem-solving team behaviors: Development and validation of BOS and a hierarchical factor structure. Small Group Res. 2001, 32, 698–726. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | AUC | Accuracy |
|---|---|---|
| Task Attraction | 0.8834 (±0.0038) | 87.3450% (±0.2280) |
| Task Integration | 0.8898 (±0.0034) | 90.5707% (±0.4290) |
| Task Cohesion | 0.9747 (±0.0033) | 93.3002% (±0.3833) |
| Collaborative Manager | 0.8011 (±0.0023) | 87.0968% (±0.3133) |
| Cooperative Manager | 0.7745 (±0.0041) | 84.6154% (±0.3255) |
| Leading Positive Feedback | 0.7851 (±0.0026) | 90.0744% (±0.3265) |
| Experience | 0.6250 (±0.0110) | 80.6951% (±0.3519) |
| Roles | 0.7450 (±0.0037) | 95.7816% (±0.3050) |
| Social Attraction | 0.6772 (±0.0103) | 78.4119% (±0.3400) |
| Expectations | 0.7100 (±0.0030) | 76.4268% (±0.3781) |
| Algorithms | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| BN | 90.07% (±0.3265) | 0.9178 (±0.0024) | 0.6538 (±0.0039) | 0.9746 (±0.0032) |
| NB | 88.09% (±0.3519) | 0.8810 (±0.0035) | 0.6470 (±0.0005) | 0.8590 (±0.0033) |
| TAN | 90.07% (±0.3342) | 0.9156 (±0.0030) | 0.6667 (±0.0053) | 0.9775 (±0.0048) |
| MP | 88.83% (±0.3267) | 0.8880 (±0.0033) | 0.6640 (±0.0232) | 0.8660 (±0.0059) |
| LR | 88.09% (±0.3781) | 0.8810 (±0.0038) | 0.7550 (±0.0269) | 0.8480 (±0.0082) |
| Id3 | 88.09% (±0.3708) | 0.8810 (±0.0038) | 0.7550 (±0.0247) | 0.8480 (±0.0132) |
| RF | 88.09% (±0.3400) | 0.8810 (±0.0034) | 0.7550 (±0.0356) | 0.8480 (±0.0073) |
| Algorithms | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| BN | 82.63% (±0.3255) | 0.8329 (±0.0036) | 0.7500 (±0.0062) | 0.9748 (±0.0058) |
| NB | 75.68% (±0.4598) | 0.7570 (±0.0047) | 0.5400 (±0.0054) | 0.7420 (±0.0041) |
| TAN | 83.87% (±0.3638) | 0.8462 (±0.0043) | 0.7692 (±0.0028) | 0.9716 (±0.0022) |
| MP | 76.67% (±1.1174) | 0.7670 (±0.0110) | 0.5460 (±0.0194) | 0.7470 (±0.0103) |
| LR | 79.40% (±0.6455) | 0.7940 (±0.0064) | 0.5730 (±0.0114) | 0.7650 (±0.0088) |
| Id3 | 80.89% (±0.6129) | 0.8090 (±0.0061) | 0.5690 (±0.0171) | 0.7840 (±0.0094) |
| RF | 80.40% (±1.1219) | 0.8040 (±0.0113) | 0.5280 (±0.0203) | 0.7820 (±0.0138) |
| Algorithms | Accuracy | Sensitivity | Specificity | Precision |
|---|---|---|---|---|
| BN | 87.10% (±0.3642) | 0.9829 (±0.0068) | 0.5000 (±0.0108) | 0.9829 (±0.0062) |
| NB | 84.86% (±0.2280) | 0.8490 (±0.0023) | 0.7100 (±0.0139) | 0.8180 (±0.0036) |
| TAN | 87.09% (±0.3826) | 0.8824 (±0.0036) | 0.5000 (±0.0042) | 0.9829 (±0.0096) |
| MP | 86.85% (±0.4290) | 0.8680 (±0.0041) | 0.8060 (±0.0233) | 0.8220 (±0.0101) |
| LR | 86.85% (±0.3813) | 0.8680 (±0.0033) | 0.8220 (±0.0007) | 0.8180 (±0.0081) |
| Id3 | 86.85% (±0.3139) | 0.8680 (±0.0030) | 0.8390 (±0.0119) | 0.8130(±0.0118) |
| RF | 86.35% (±0.5290) | 0.8640 (±0.0053) | 0.7570 (±0.0247) | 0.8230 (±0.0094) |
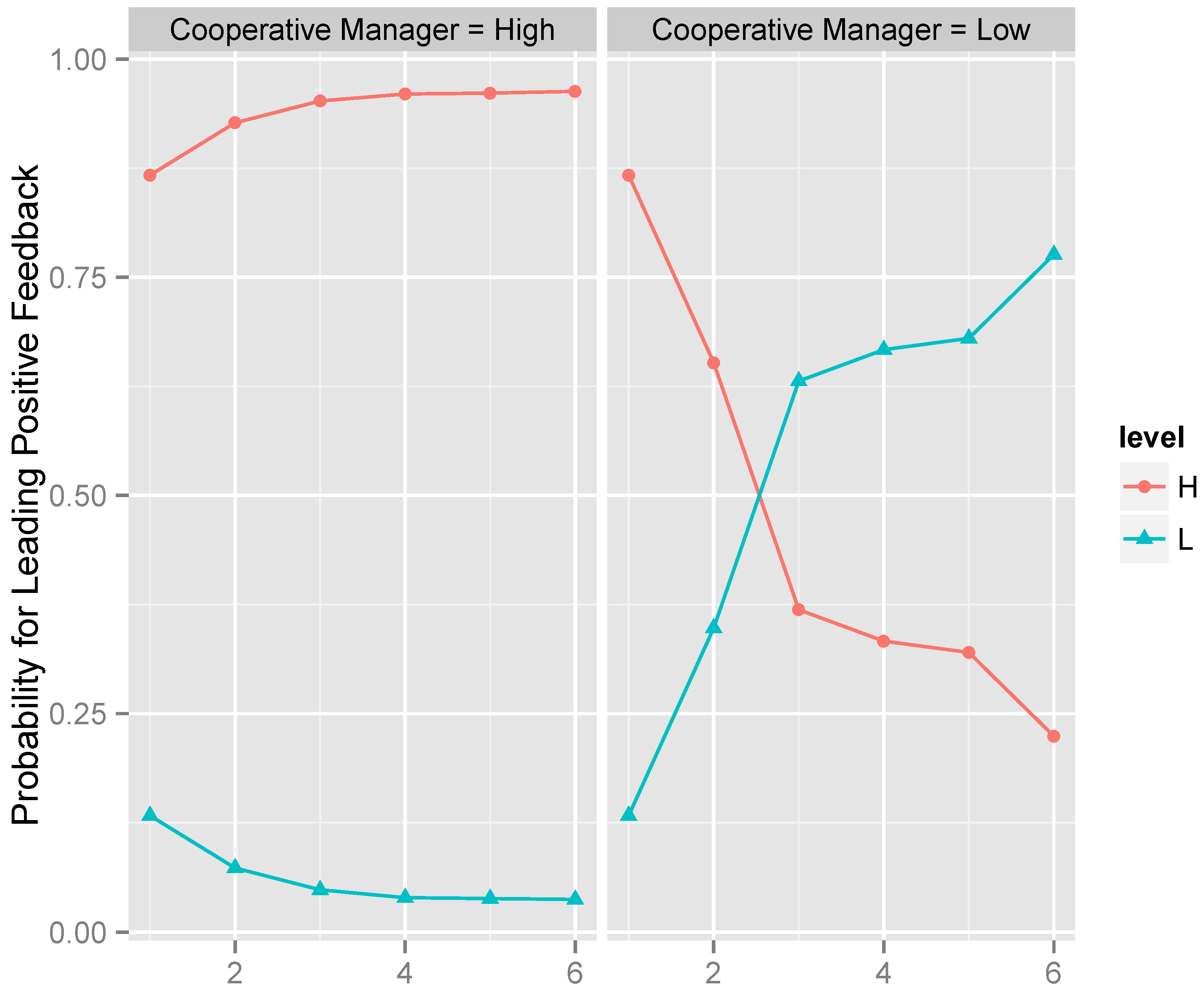
| Step | Instantiated Variable | Value | Leading Positive Feedback = High | |
|---|---|---|---|---|
| 1 | none | = | – | |
| 2 | cooperative manager | = | High | |
| 3 | expectations | = | Low | |
| 4 | collaborative manager | = | High | |
| 5 | roles | = | High | |
| 6 | task cohesion | = | Low |
| Step | Instantiated Variable | Value | Leading Positive Feedback = Low | |
|---|---|---|---|---|
| 1 | none | = | – | |
| 2 | cooperative manager | = | Low | |
| 3 | collaborative manager | = | Low | |
| 4 | expectations | = | High | |
| 5 | roles | = | High | |
| 6 | task cohesion | = | Low |
| Step | Instantiated Variable | Value | Cooperative Manager = High | |
|---|---|---|---|---|
| 1 | none | = | – | |
| 2 | leading positive feedback | = | High | |
| 3 | task cohesion | = | High | |
| 4 | social attraction | = | High | |
| 5 | expectations | = | High | |
| 6 | collaborative manager | = | High | |
| 7 | task attraction | = | High | |
| 8 | task integration | = | High | |
| 9 | roles | = | High |
| Step | Instantiated Variable | Value | Cooperative Manager = Low | |
|---|---|---|---|---|
| 1 | none | = | – | |
| 2 | leading positive feedback | = | Low | |
| 3 | collaborative manager | = | Low | |
| 4 | roles | = | Low | |
| 5 | task attraction | = | High | |
| 6 | task integration | = | High | |
| 7 | social attraction | = | Low | |
| 8 | expectations | = | Low | |
| 9 | task cohesion | = | High |
| Step | Instantiated Variable | Value | Collaborative Manager = High | |
|---|---|---|---|---|
| 1 | none | = | – | |
| 2 | task attraction | = | High | |
| 3 | cooperative manager | = | High | |
| 4 | task integration | = | High | |
| 5 | leading positive feedback | = | High | |
| 6 | expectations | = | Low |
| Step | Instantiated Variable | Value | Collaborative Manager = Low | |
|---|---|---|---|---|
| 1 | none | = | – | |
| 2 | leading positive feedback | = | Low | |
| 3 | task integration | = | Low | |
| 4 | task attraction | = | Low | |
| 5 | expectations | = | Low | |
| 6 | cooperative manager | = | Low |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuster-Parra, P.; García-Mas, A.; Cantallops, J.; Ponseti, F.J.; Luo, Y. Ranking Features on Psychological Dynamics of Cooperative Team Work through Bayesian Networks. Symmetry 2016, 8, 34. https://doi.org/10.3390/sym8050034
Fuster-Parra P, García-Mas A, Cantallops J, Ponseti FJ, Luo Y. Ranking Features on Psychological Dynamics of Cooperative Team Work through Bayesian Networks. Symmetry. 2016; 8(5):34. https://doi.org/10.3390/sym8050034
Chicago/Turabian StyleFuster-Parra, Pilar, Alex García-Mas, Jaume Cantallops, F. Javier Ponseti, and Yuhua Luo. 2016. "Ranking Features on Psychological Dynamics of Cooperative Team Work through Bayesian Networks" Symmetry 8, no. 5: 34. https://doi.org/10.3390/sym8050034