Data Deduplication System Based on Content-Defined Chunking Using Bytes Pair Frequency Occurrence


Abstract
:1. Introduction
- The proposed system defines chunk boundaries based on the bytes frequency of occurrence instead of the byte offset (as in the fixed-size chunking technique), so any change in one chunk will not affect the next one, and the effect will be limited to the changed chunk only.
- Content-defined chunking consumes substantial processing resources to calculate hash values using SHA1 or MD5 for data fingerprinting, while the proposed system uses mathematical functions to generate three hashes that consume fewer computing resources. Furthermore, compared to the traditional TTTD method, the number of bits needed to store these three hashes is 48 bits, which is less than the number of bits needed to save the hash value in SHA1 (160 bits) and MD5 (128 bits).
2. Related Work
3. Methodology
3.1. Content-Defined Chunking
3.1.1. Basic Sliding Window (BSW) (Usually Known as Rabin CDC)
3.1.2. Two Threshold Two Divisors Chunking (TTTD)
3.1.3. The Proposed Bytes Frequency Based Chunking (BFBC)
| Algorithm 1 Chunking algorithm | |
| Objective: | Divide the file into chunks based on Tmin, List of Divisors, and Tmax |
| Input: | File of any type or size Tmin, Tmax, List of Divisors |
| Output: | Number of variable sized chunks |
| Step1: | Set Breakpoint ← 0, Pbreakpoint ← 0 |
| Step2: | Read File as array of bytes Set Length ← File size, Set Full Length ← File size |
| Step3: | If length equals zero Go to Step2 |
| Step4: | If Length <= Tmin Consider it as a chunk and send it to the Triple hash function, Algorithm (2) Length = Full Length—chunk length |
| Step5: | If Length between Tmin and Tmax Search for the pair divisors bytes from breakpoint + Tmin until Full Length If found Consider the chunk from Pbreakpoint until the divisor byte position Send the chunk to the Triple hash function, Algorithm (2) Breakpoint = chunk length +1 Length = Full length − breakpoint |
| Step6: | If Length equals Tmax Consider the chunk from Pbreakpoint until Full Length Send the chunk to the Triple hash function, Algorithm (2) Breakpoint= chunk length +1 Length = Full Length—breakpoint |
| Step7: | If Length > Tmax Search for the pair divisors bytes from breakpoint + Tmin until Pbreakpoint + Tmax If found Consider the chunk from Pbreakpoint until the breakpoint Send the chunk to the Triple hash function, Algorithm (2) Pbreakpoint = breakpoint Length = Full Length—breakpoint |
| Step8: | Go to step 3 |
3.2. Triple Hashing Algorithm
| Algorithm 2 Triple hash algorithm | |
| Objective: | Generate three unique hash values for each chunk |
| Input: | Chunk as array of bytes Chunk Length HF1: array of integer contains 202 random values HF2: array of integer contains 202 random values HF2: array of integer contains 202 random values |
| Output: | Three hash values for the chunk |
| Step1: | Initialization Hash1 ← 3, Hash2 ← 37, Hash3 ← 17 Li ← 0 |
| Step2: | Compute three hash values for the chunk For I = 0 to Chunk Length-1 Do Li = Li +1 If Li > 202 Li = Li - 202 Hash1 = Hash1 + (HF1[Li] * Chunk[I]) If Hash1 > 65535 Hash1 = Hash1 & 65535 Hash2 = Hash2 + (HF2[Li] * Chunk[I]) If Hash2 > 65535 Hash2 = Hash2 & 65535 Hash3 = Hash3 + (HF3[Li] * Chunk[I]) If Hash3 > 65535 Hash3 = Hash3 & 65535 End For |
3.3. Experimental Datasets
4. The Proposed System
- Stage 1: Load the dataset.
- Stage 2: Divisors Analysis and Selection. The BFBC applies a content frequency scan to obtain the most frequent pair of bytes to be used as divisors (D) in the next stage.
- Stage 3: BFBC Chunking. The proposed BFBC algorithm is applied to obtain chunks. The input file is divided into variable-size chunks using multi divisors and two thresholds. The values of the divisors and the threshold are optimized.
- Stage 4: Triple Hashing, Indexing, and Matching. At this stage, a new hashing technique is suggested to enhance the matching process by generating the three hashes computed in the hashing stage. It consists of two steps:
- -
- Hash generation in which fingerprints of data content are created;
- -
- Hash judgement in which hashes are compared against already-stored hashes to find duplicated chunks (if matching occurs for the first hash value of the compared chunks, then it will compare the second and third).
4.1. Load the Dataset
4.2. Divisors Analysis and Selection
4.3. BFBC Chunking
- Scan the sequence of bytes starting from the last chunk boundary and apply a minimum threshold to the chunk sizes (Tmin).
- At each position after Tmin, check the current pair of bytes with the list of divisors to look for matches.
- If a D-match is found before reaching the threshold Tmax, use that position as a breakpoint.
- If the search for a D-match fails and the Tmax threshold is reached (without finding a D-match), use the current position (threshold Tmax) as a breakpoint.
- ○
- The size of the file is smaller than Tmin;
- ○
- The fragment, from the last breakpoint to the end of the file, is smaller than Tmin;
- ○
- The algorithm cannot find any breakpoint from the last breakpoint to the end of the file, even if the size of the chunk is larger than Tmin.
4.4. Triple Hashing, Indexing, and Matching Stage
- Unique data. Non-duplicated chunks are produced by the algorithm.
- Metadata. To rebuild the dataset again, address information related to the chunks needs to be stored. Regardless of whether chunks contain unique data or not, the related metadata needs to be available for future retrieving stage. Accordingly, the total metadata number equals the total number of chunks.
- Hash index. Hash values for each non-duplicated chunk are stored as the chunk’s fingerprint for use in detecting duplicated chunks. Each record within the hash index table is considered as a chunk ID. Table 4 shows an example of a hash index table.
5. Experiment
5.1. Experimental Setup
- ○
- CPU: Intel Core i7-3820QM @ 2.70 GHz 4-core processor;
- ○
- RAM: 16 GB DDR3;
- ○
- Disk: 1TB PCIe SSD;
- ○
- Operating system: Windows 10 64-bit.
5.2. Experimental Results
5.2.1. Choosing the Optimum Chunk Size (Optimizing Storage Saving by Setting the Expected Chunk Size)
5.2.2. Chunk Distribution Based on the Number of Divisors
5.2.3. The Impact of the Number of Divisors Selected on the Data Duplication Ratio
5.2.4. Proposed Chunking Algorithim Efficiency
5.2.5. The Impact of the Proposed Hashing Function
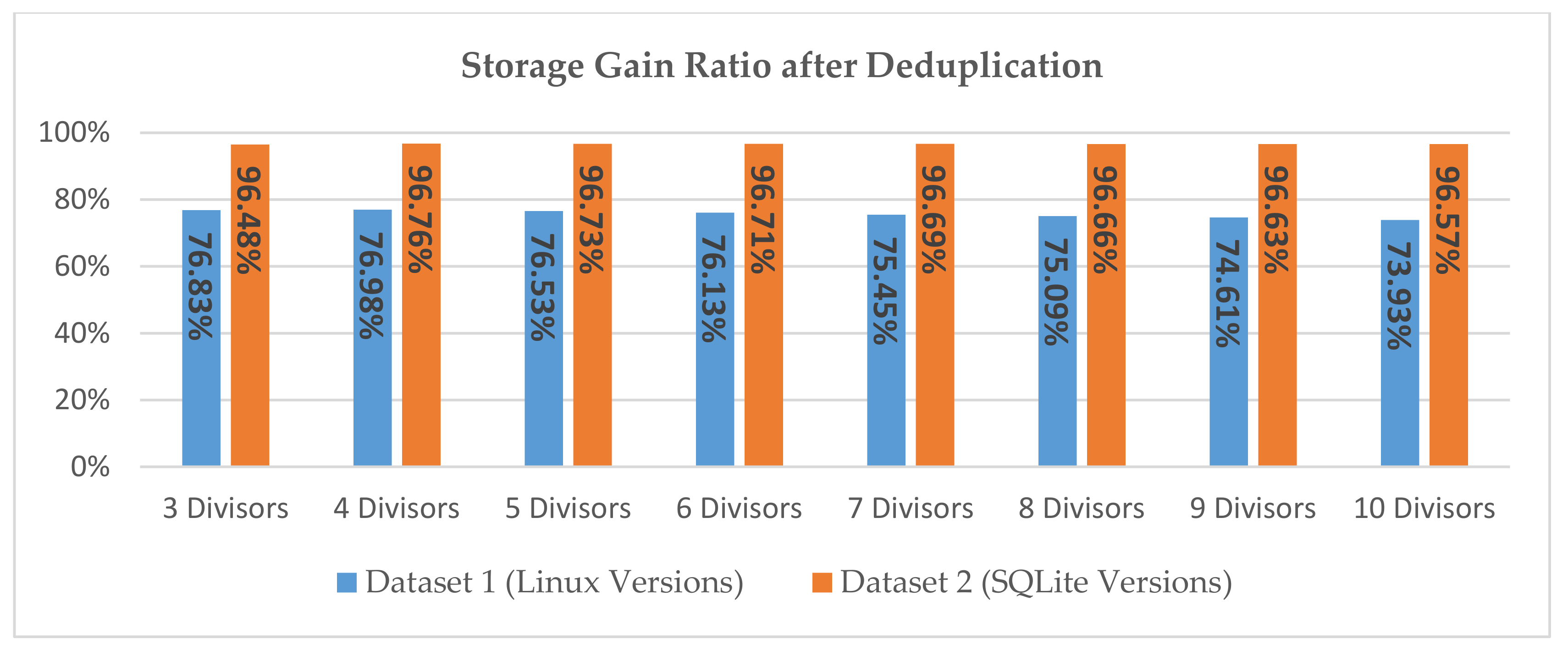
5.2.6. Data Size after Deduplication and the Deduplication Elimination Ratio (DER)
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Xia, W.; Jiang, H.; Feng, D.; Douglis, F.; Shilane, P.; Hua, Y.; Fu, M.; Zhang, Y.; Zhou, Y. A comprehensive study of the past, present, and future of data deduplication. Proc. IEEE 2016, 104, 1681–1710. [Google Scholar] [CrossRef]
- Kambo, H.; Sinha, B. Secure Data Deduplication Mechanism Based on Rabin CDC and MD5 in Cloud Computing Environment. In Proceedings of the 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 19–20 May 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Manogar, E.; Abirami, S. A Study on Data Deduplication Techniques for Optimized Storage. In Proceedings of the 2014 Sixth International Conference on Advanced Computing (ICoAC), Chennai, India, 17–19 December 2014; IEEE: New York, NY, USA, 2014. [Google Scholar]
- Lu, G.; Jin, Y.; Du, D.H. Frequency based chunking for data de-duplication. In Proceedings of the 2010 IEEE International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, Miami Beach, FL, USA, 17–19 August 2010; IEEE: New York, NY, USA, 2010. [Google Scholar]
- Puzio, P.; Molva, R.; Önen, M.; Loureiro, S. Block-level de-duplication with encrypted data. Open J. Cloud Comput. 2014, 1, 10–18. [Google Scholar]
- Zhang, Y.; Jiang, H.; Feng, D.; Xia, W.; Fu, M.; Huang, F.; Zhou, Y. AE: An asymmetric extremum content defined chunking algorithm for fast and bandwidth-efficient data deduplication. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Xia, W.; Jiang, H.; Feng, D.; Tian, L.; Fu, M.; Wang, Z. P-dedupe: Exploiting parallelism in data deduplication system. In Proceedings of the 2012 IEEE Seventh International Conference on Networking, Architecture, and Storage, Xiamen, China, 28–30 June 2012; IEEE: New York, NY, USA, 2012. [Google Scholar]
- Zhang, Y.; Wu, Y.; Yang, G. Droplet: A distributed solution of data deduplication. In Proceedings of the 2012 ACM/IEEE 13th International Conference on Grid Computing, Beijing, China, 20–23 September 2012; IEEE: New York, NY, USA, 2012. [Google Scholar]
- Zhang, C.; Qi, D.; Cai, Z.; Huang, W.; Wang, X.; Li, W.; Guo, J. MII: A novel content defined chunking algorithm for finding incremental data in data synchronization. IEEE Access 2019, 7, 86932–86945. [Google Scholar] [CrossRef]
- Venish, A.; Sankar, K.S. Study of chunking algorithm in data deduplication. In Proceedings of the International Conference on Soft Computing Systems; Springer, New Delhi, India; 2016. [Google Scholar]
- Kumar, N.; Antwal, S.; Samarthyam, G.; Jain, S.C. Genetic optimized data deduplication for distributed big data storage systems. In Proceedings of the 2017 4th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 21–23 September 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Ha, J.-Y.; Lee, Y.-S.; Kim, J.-S. Deduplication with block-level content-aware chunking for solid state drives (SSDs). In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013; IEEE: New York, NY, USA, 2013. [Google Scholar]
- Yu, C.; Zhang, C.; Mao, Y.; Li, F. Leap-based content defined chunking—theory and implementation. In Proceedings of the 2015 31st Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 30 May–5 June 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Attarde, D.; Vijayan, M.K. Extensible Data Deduplication System and Method. U.S. Patent 8,732,133, 20 May 2014. [Google Scholar]
- Zhou, B.; Zhang, S.; Zhang, Y.; Tan, J. A bit string content aware chunking strategy for reduced CPU energy on cloud storage. J. Electr. Comput. Eng. 2015, 2015, 242086. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Dong, X.; Zhang, X.; Guo, F.; Wang, Y.; Gong, W. A logistic based mathematical model to optimize duplicate elimination ratio in content defined chunking based big data storage system. Symmetry 2016, 8, 69. [Google Scholar] [CrossRef] [Green Version]
- Kaur, R.; Chana, I.; Bhattacharya, J. Data deduplication techniques for efficient cloud storage management: A systematic review. J. Supercomput. 2018, 74, 2035–2085. [Google Scholar] [CrossRef]
- Zhang, Y.; Feng, D.; Jiang, H.; Xia, W.; Fu, M.; Huang, F.; Zhou, Y. A fast asymmetric extremum content defined chunking algorithm for data deduplication in backup storage systems. IEEE Trans. Comput. 2017, 66, 199–211. [Google Scholar] [CrossRef]
- Nie, J.; Wu, L.; Liang, J. Optimization of De-duplication Technology Based on CDC Blocking Algorithm. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Ni, F. Designing Highly-Efficient Deduplication Systems with Optimized Computation and I/O Operations; University of Texas at Arlington: Arlington, TX, USA, 2019. [Google Scholar]
- Xia, W.; Zou, X.; Jiang, H.; Zhou, Y.; Liu, C.; Feng, D.; Hua, Y.; Hu, Y.; Zhang, Y. The Design of Fast Content-Defined Chunking for Data Deduplication Based Storage Systems. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2017–2031. [Google Scholar] [CrossRef]
- Maqdah, R.G.; Tazda, R.G.; Khakbash, F.; Marfsat, M.B.; Asghar, S.A. CA-Dedupe: Content-aware deduplication in SSDs. J. Supercomput. 2020, 76, 8901–8921. [Google Scholar]
- Chang, B. A running Time Improvement for Two Thresholds Two Divisors Algorithm. Master’s Thesis, San Jose State University, San Jose, CA, USA, 2009. [Google Scholar]
- Linux, The Linux Kernel Archives. Available online: http://kernel.org/ (accessed on 4 March 2020).
- D.RichardHipp, SQLite Kernel Archives. Available online: https://www.sqlite.org/chronology.html (accessed on 1 October 2020).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dataset 1 | Dataset 2 |
| Dataset Name | Linux Kernel | SQLite |
| Dataset Type | Linux source codes (3.16.57-4.18-rc6) | 309 release of SQLite from version 1.0 to 3.33.0 |
| No. of Files | 450,441 | 212,741 |
| Dataset Size (in MB) | 6072 | 6596 |
| Dataset 1 (Linux Versions) Top 10 Pairs of Bytes Occurrence | Dataset 2 (SQLite Versions) Top 10 Pairs of Bytes Occurrence | ||||||
|---|---|---|---|---|---|---|---|
| Pair Bytes Value Symbols | Pair Bytes Value Description | No. of Occurrence | Pair Bytes Value Symbols | Pair Bytes Value Description | No. of Occurrence | ||
| Space | Space | Space—Space | 213,150,255 | NUL | NUL | Null—Null | 643,401,100 |
| LF | HT | Line Feed—Horizontal Tab | 98,879,678 | Space | Space | Space—Space | 335,181,944 |
| HT | HT | Horizontal Tab—Horizontal Tab | 83,978,466 | LF | Space | Line Feed—Space | 64,205,375 |
| i | n | Lowercase i—Lowercase n | 55,197,438 | Space | t | Space—Lowercase t | 57,427,195 |
| e | Space | Lowercase e—Space | 54,008,419 | e | Space | Lowercase e—Space | 50,525,015 |
| ; | LF | Semicolon—Line Feed | 52,619,629 | 0 | 0 | Zero—Zero | 47,909,305 |
| , | Space | Comma—Space | 47,951,864 | s | e | Lowercase s—Lowercase e | 41,087,776 |
| d | e | Lowercase d—Lowercase e | 44,203,960 | t | Space | Lowercase t—Space | 38,889,278 |
| r | e | Lowercase r—Lowercase e | 42,285,606 | i | n | Lowercase i—Lowercase n | 33,847,741 |
| t | Space | Lowercase t—Space | 40,881,129 | , | Space | Comma—Space | 32,878,767 |
| Parameter | Purpose |
|---|---|
| Tmin (minimum threshold) | To reduce the number of very small chunks |
| Divisors (D) | To determine breakpoints |
| Tmax (maximum threshold) | To reduce the number of very large chunks |
| Chunk Size (In Byte) | Pair Divisor (In Decimal) | Hash1 | Hash2 | Hash3 | |
|---|---|---|---|---|---|
| 166 | 105 | 110 | 62,724 | 944 | 3581 |
| 148 | 32 | 32 | 65,132 | 23,057 | 51,437 |
| 138 | 105 | 110 | 45,542 | 52,089 | 33,677 |
| 432 | 32 | 32 | 53,535 | 60,344 | 15,897 |
| 369 | 105 | 110 | 8070 | 25,948 | 50,716 |
| 147 | 32 | 32 | 52,628 | 46,251 | 3768 |
| Dataset 1 (Linux Versions) | Dataset 2 (SQLite Versions) | |
|---|---|---|
| Tmin–Tmax | Dataset Size after Deduplication (MB) | Dataset Size after Deduplication (MB) |
| 128–256 | 1239 | 219.2 |
| 128–512 | 1224 | 214.9 |
| 128–1024 | 1225 | 220.9 |
| 128–2048 | 1225 | 221.5 |
| 128–4096 | 1225 | 221.9 |
| 128–8192 | 1226 | 222.2 |
| 256–512 | 1525 | 280.9 |
| 256–1024 | 1520 | 285.1 |
| 256–2048 | 1521 | 285.5 |
| 256–4096 | 1521 | 285.8 |
| 256–8192 | 1521 | 286.2 |
| 512–1024 | 1875 | 390.3 |
| 512–2048 | 1873 | 390.0 |
| 512–4096 | 1874 | 390.2 |
| 512–8192 | 1874 | 390.4 |
| 1024–2048 | 2163 | 518.4 |
| 1024–4096 | 2163 | 517.6 |
| 1024–8192 | 2163 | 517.8 |
| 2048–4096 | 2382 | 626.1 |
| 2048–8192 | 2382 | 625.9 |
| 4096–8192 | 2550 | 701.1 |
| Divisor Type | 2D | 3D | 4D | 5D | 6D | 7D | 8D | 9D | 10D |
|---|---|---|---|---|---|---|---|---|---|
| 10 9 | 22,973,671 | 22,284,893 | 19,199,186 | 17,492,783 | 9,953,964 | 8,330,810 | 7,873,710 | 7,374,764 | 6,779,877 |
| 32 32 | 6,092,243 | 5,837,677 | 4,685,335 | 4,255,047 | 4,174,575 | 3,958,998 | 3,913,365 | 3,829,970 | 3,769,410 |
| 9 9 | 2,486,258 | 1,770,387 | 1,684,706 | 1,617,595 | 1,571,559 | 1,552,364 | 1,528,012 | 1,512,120 | |
| 105 110 | 9,884,948 | 8,039,422 | 7,400,438 | 6,836,950 | 4,235,299 | 3,943,700 | 3,566,692 | ||
| 101 32 | 5,474,256 | 5,276,818 | 4,928,659 | 4,251,855 | 3,513,049 | 3,072,207 | |||
| 59 10 | 9,094,685 | 7,276,476 | 6,718,100 | 6,085,059 | 5,758,142 | ||||
| 44 32 | 5,384,122 | 4,905,076 | 4,539,605 | 4,258,704 | |||||
| 100 101 | 5,144,276 | 4,883,201 | 4,431,435 | ||||||
| 114 101 | 3,228,453 | 2,943,306 | |||||||
| 116 32 | 3,216,933 | ||||||||
| Max | 1,543,861 | 1,097,639 | 161,528 | 117,745 | 117,745 | 89,660 | 87,154 | 85,693 | 72,411 |
| Tail | 450,316 | 450,316 | 450,316 | 430,287 | 430,287 | 431,530 | 431,955 | 433,090 | 433,136 |
| Chunking Category (Tmin–Tmax) | Total No. of Chunks | No. of Chunks Generated Using Divisors | No. of Chunks Generated Using Tmax | No. of Tail Chunks | Divisors Chunks Ratio | Tmax Chunks Ratio | Tail Chunks Ratio |
|---|---|---|---|---|---|---|---|
| 128–256 | 39,908,873 | 39,260,746 | 197,811 | 450,316 | 98.38% | 0.50% | 1.13% |
| 128–512 | 39,814,373 | 39,291,646 | 72,411 | 450,316 | 98.69% | 0.18% | 1.13% |
| 128–1024 | 39,776,247 | 39,294,163 | 31,768 | 450,316 | 98.79% | 0.08% | 1.13% |
| 128–2048 | 39,759,163 | 39,294,699 | 14,148 | 450,316 | 98.83% | 0.04% | 1.13% |
| 128–4096 | 39,751,564 | 39,294,788 | 6460 | 450,316 | 98.85% | 0.02% | 1.13% |
| 128–8192 | 39,747,969 | 39,294,796 | 2857 | 450,316 | 98.86% | 0.01% | 1.13% |
| 256–512 | 20,921,695 | 20,395,370 | 76,009 | 450,316 | 97.48% | 0.36% | 2.15% |
| 256–1024 | 20,883,699 | 20,401,331 | 32,052 | 450,316 | 97.69% | 0.15% | 2.16% |
| 256–2048 | 20,866,807 | 20,402,286 | 14,205 | 450,316 | 97.77% | 0.07% | 2.16% |
| 256–4096 | 20,859,297 | 20,402,512 | 6469 | 450,316 | 97.81% | 0.03% | 2.16% |
| 256–8192 | 20,855,734 | 20,402,561 | 2857 | 450,316 | 97.83% | 0.01% | 2.16% |
| 512–1024 | 10,814,367 | 10,330,633 | 33,418 | 450,316 | 95.53% | 0.31% | 4.16% |
| 512–2048 | 10,797,458 | 10,332,812 | 14,330 | 450,316 | 95.70% | 0.13% | 4.17% |
| 512–4096 | 10,790,036 | 10,333,241 | 6479 | 450,316 | 95.77% | 0.06% | 4.17% |
| 512–8192 | 10,786,472 | 10,333,295 | 2861 | 450,316 | 95.80% | 0.03% | 4.17% |
| 1024–2048 | 5,592,898 | 5,127,700 | 14,882 | 450,316 | 91.68% | 0.27% | 8.05% |
| 1024–4096 | 5,585,435 | 5,128,612 | 6507 | 450,316 | 91.82% | 0.12% | 8.06% |
| 1024–8192 | 5,581,935 | 5,128,756 | 2863 | 450,316 | 91.88% | 0.05% | 8.07% |
| 2048–4096 | 2,938,586 | 2,481,627 | 6643 | 450,316 | 84.45% | 0.23% | 15.32% |
| 2048–8192 | 2,935,094 | 2,481,902 | 2876 | 450,316 | 84.56% | 0.10% | 15.34% |
| 4096–8192 | 1,611,792 | 1,158,565 | 2911 | 450,316 | 71.88% | 0.18% | 27.94% |
| Chunk Size (In Byte) | Divisor (In Decimal) | Hash1 | Hash2 | Hash3 | No. of Duplicated Chunks | |
|---|---|---|---|---|---|---|
| 365 | 32 | 32 | 11,413 | 20,379 | 56,737 | 4753 |
| 280 | 32 | 32 | 21,996 | 52,614 | 5429 | 4227 |
| 409 | 32 | 32 | 47,374 | 4130 | 36,809 | 3690 |
| 257 | 32 | 32 | 23,630 | 9669 | 17,229 | 3593 |
| 286 | 105 | 110 | 50,852 | 51,897 | 47,689 | 3495 |
| 313 | 105 | 110 | 54,191 | 58,279 | 1797 | 2883 |
| 380 | 105 | 110 | 34,997 | 55,857 | 5919 | 2856 |
| 292 | 10 | 9 | 1674 | 49,658 | 23,838 | 2824 |
| 292 | 10 | 9 | 2938 | 51,192 | 26,116 | 2824 |
| 380 | 105 | 110 | 3978 | 55,689 | 16,358 | 2636 |
| Chunking Time (Second) | Chunking Throughput (MB/s) | |||||
|---|---|---|---|---|---|---|
| BSW | TTTD | BFBC | BSW | TTTD | BFBC | |
| Dataset 1 (Linux Versions) | 557 | 189 | 58 | 10.9 | 32.1 | 104.7 |
| Dataset 2 (SQLite Versions) | 614 | 210 | 60 | 10.7 | 31.4 | 109.9 |
| Hashing Index Table Size (MB) | |||
|---|---|---|---|
| SH1 | MD5 | Triple Hash Function | |
| Dataset 1 (Linux Versions) | 157.4 | 126.0 | 47.2 |
| Dataset 2 (SQLite Versions) | 20.3 | 16.2 | 6.1 |
| Hashing Time (Seconds) | Hashing Throughput (MB/s) | |||||
| SH1 | MD5 | Triple Hash Function | SH1 | MD5 | Triple Hash Function | |
| Dataset 1 (Linux Versions) | 462.9 | 424.2 | 87.5 | 13.1 | 14.3 | 69.4 |
| Dataset 2 (SQLite Versions) | 533.0 | 493.0 | 114.0 | 12.4 | 13.4 | 57.9 |
| Size after Deduplication in MB | Deduplication Elimination Ratio (DER) | |||||
|---|---|---|---|---|---|---|
| BSW | TTTD | BFBC | BSW | TTTD | BFBC | |
| Dataset 1 (Linux Versions) | 1928 | 1539 | 1224 | 3.15 | 3.95 | 4.96 |
| Dataset 2 (SQLite Versions) | 489 | 396 | 214 | 13.49 | 16.66 | 30.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, A.S.M.; George, L.E. Data Deduplication System Based on Content-Defined Chunking Using Bytes Pair Frequency Occurrence. Symmetry 2020, 12, 1841. https://doi.org/10.3390/sym12111841
Saeed ASM, George LE. Data Deduplication System Based on Content-Defined Chunking Using Bytes Pair Frequency Occurrence. Symmetry. 2020; 12(11):1841. https://doi.org/10.3390/sym12111841
Chicago/Turabian StyleSaeed, Ahmed Sardar M., and Loay E. George. 2020. "Data Deduplication System Based on Content-Defined Chunking Using Bytes Pair Frequency Occurrence" Symmetry 12, no. 11: 1841. https://doi.org/10.3390/sym12111841
APA StyleSaeed, A. S. M., & George, L. E. (2020). Data Deduplication System Based on Content-Defined Chunking Using Bytes Pair Frequency Occurrence. Symmetry, 12(11), 1841. https://doi.org/10.3390/sym12111841