A Coarse-to-Fine Approach for 3D Facial Landmarking by Using Deep Feature Fusion


Abstract
:1. Introduction
- We propose using the deep CNN feature extracted from five kinds of facial attribute maps to estimate 3D landmarks jointly, instead of using any handcrafted features.
- We propose a global estimation stage and a local refinement stage for 3D landmarks’ prediction based on coarse-to-fine strategy and feature fusion.
- Tested in the public 3D face datasets named Bosphrous and BU-3DFE databases, the performances have been state-of-the-art.
2. Related Work
2.1. Facial Landmarking on 2D Images
2.2. Facial Landmarking on 3D Facial Data
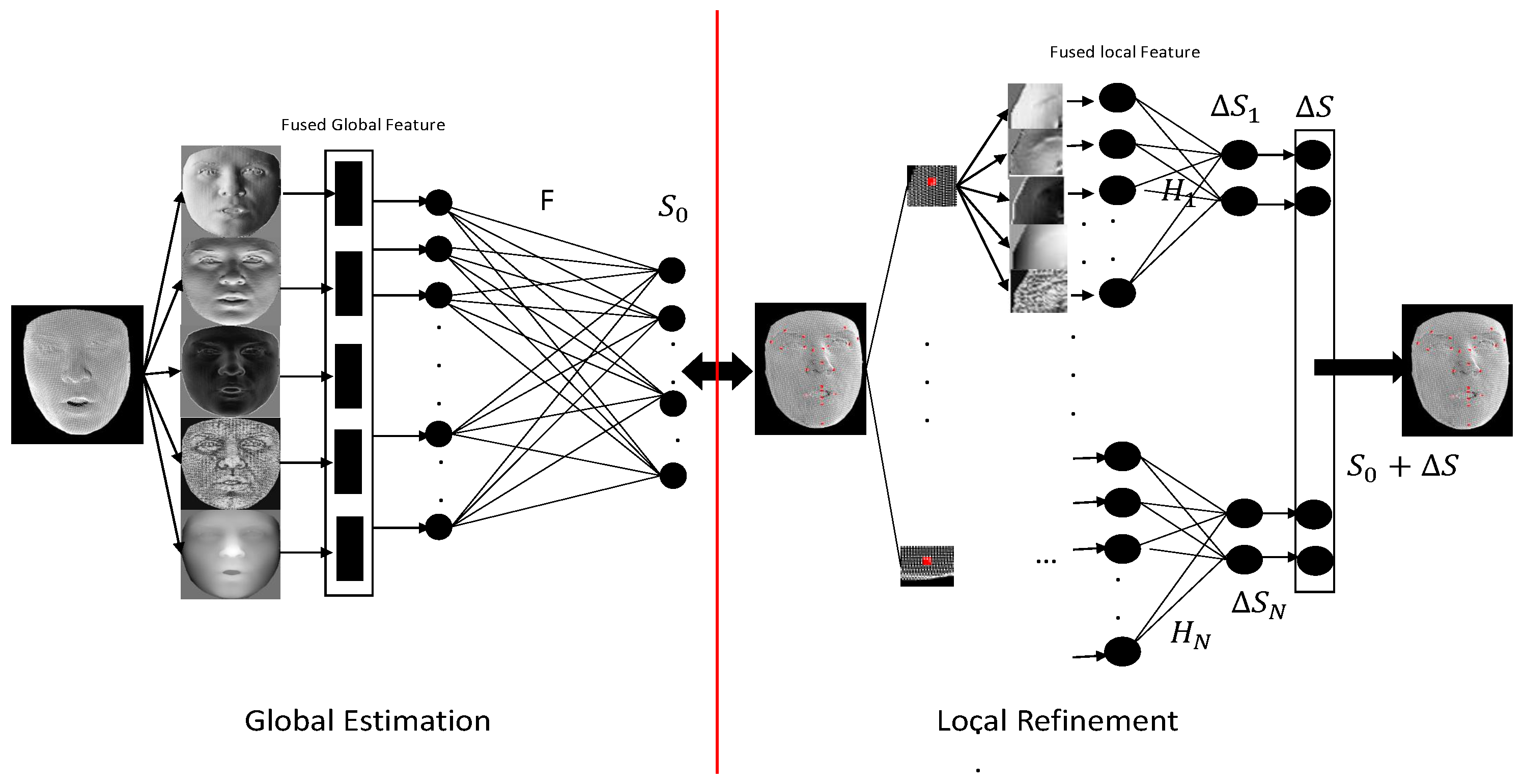
3. Methodology
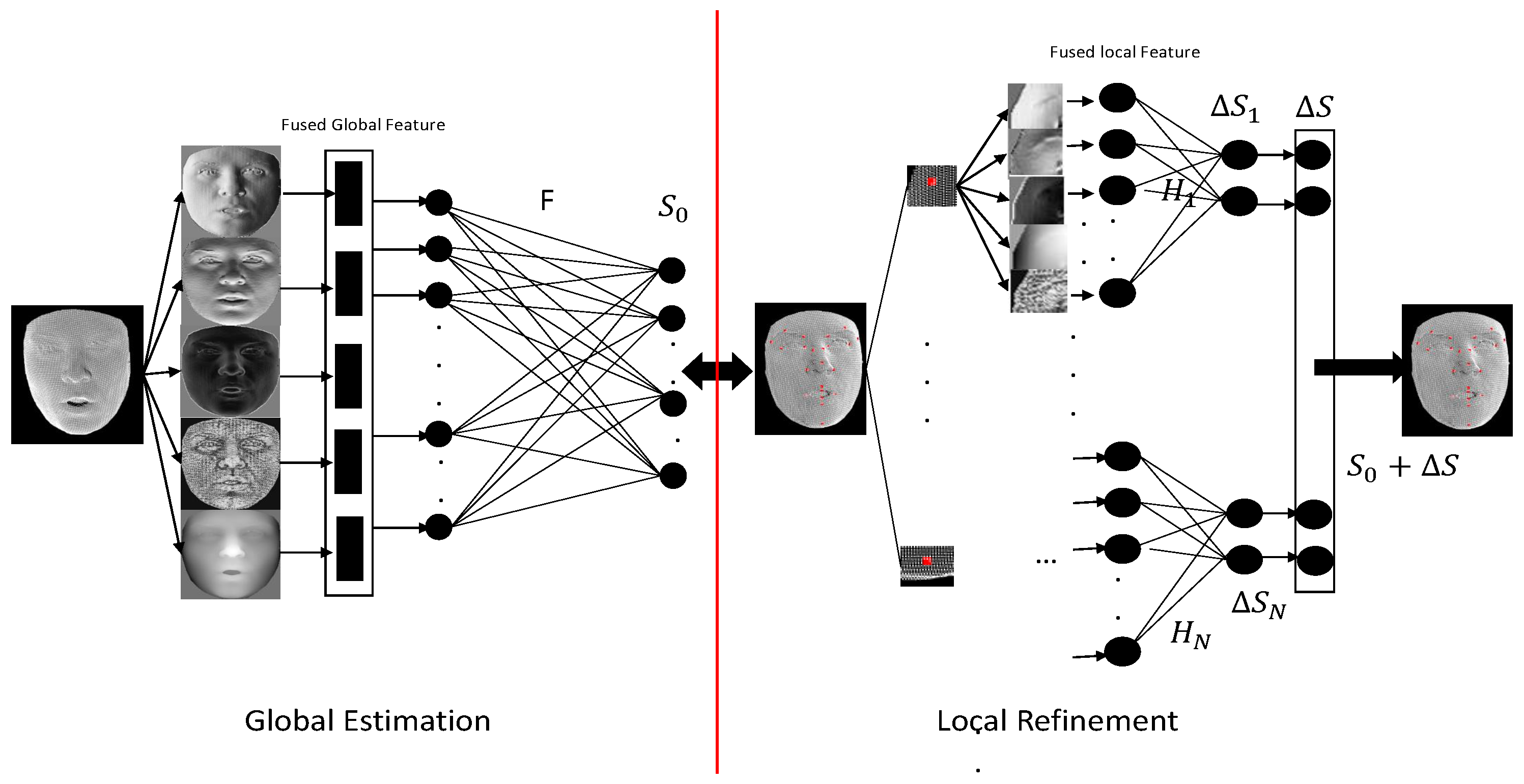
3.1. Overview
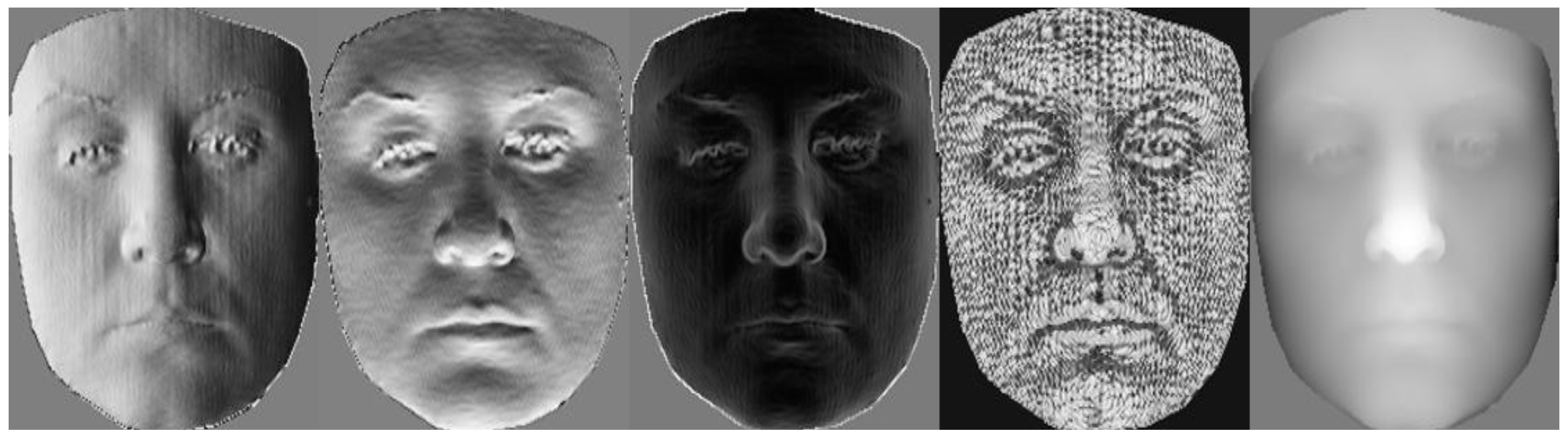
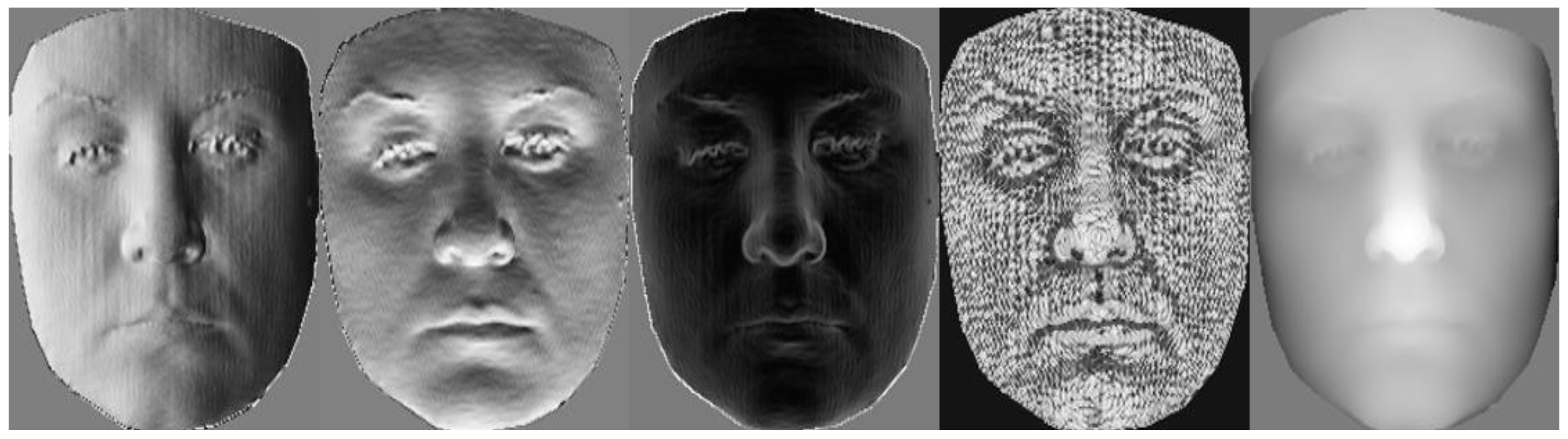
3.2. Facial Attribute Maps
3.2.1. Surface Curvature Feature
3.2.2. Surface Normal Maps
3.3. Global Estimation
- Convolutional Layer and ReLU Non-linearity.
- Fully Connected layers.
3.4. Local Refinement
4. Experiments
4.1. Datasets
4.2. Data Pre-Processing
4.3. Data Augmentation
4.4. Experimental Setting
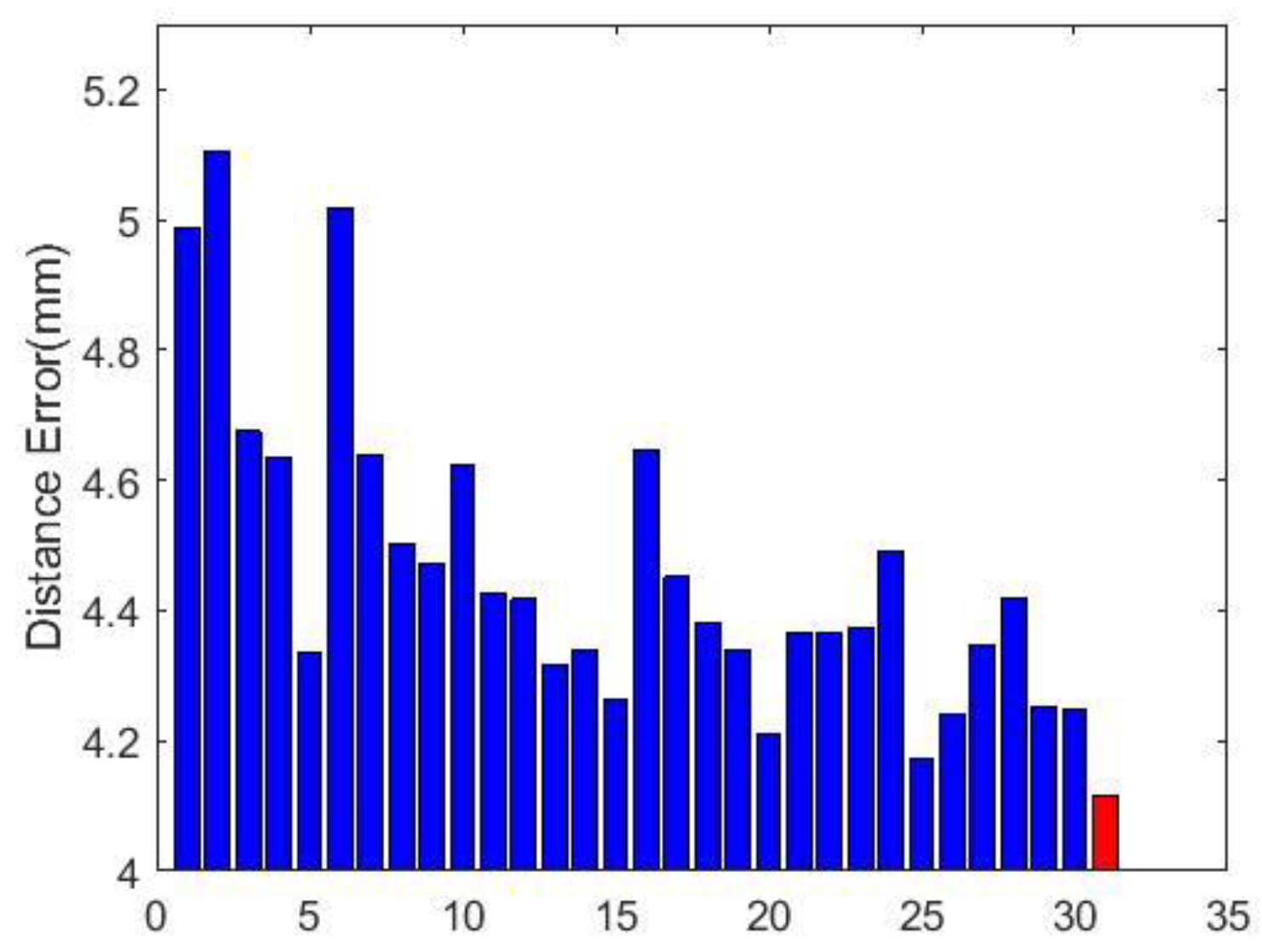
4.5. Convergence and Model Selection
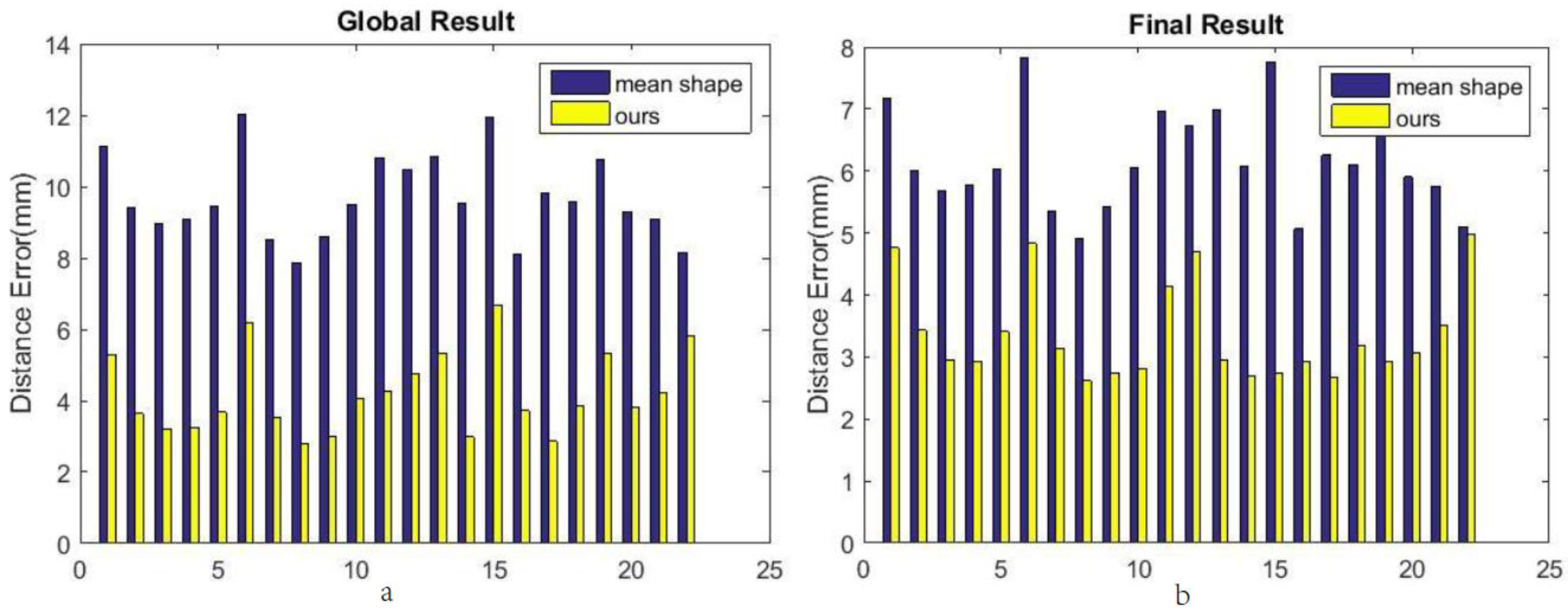
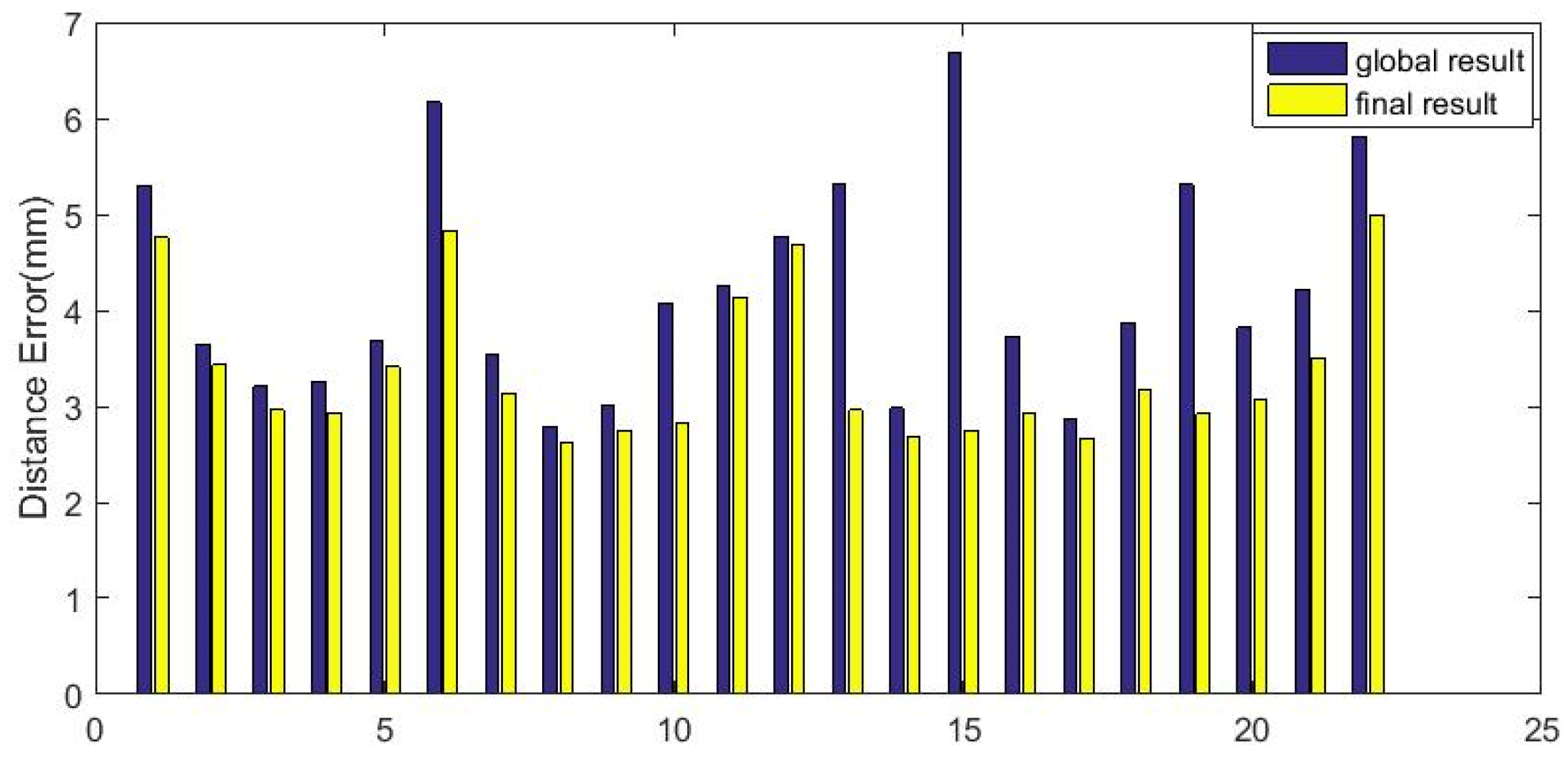
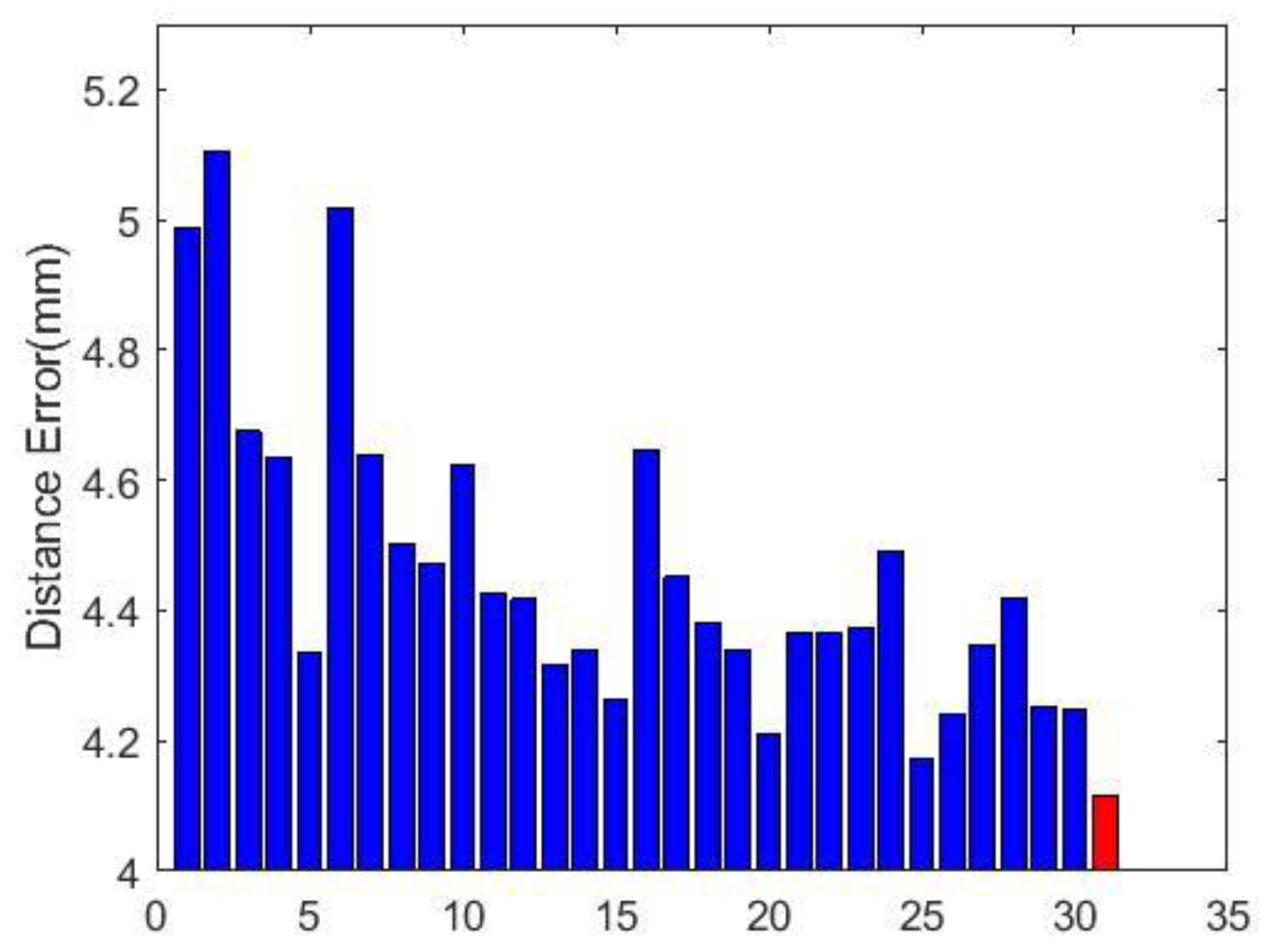
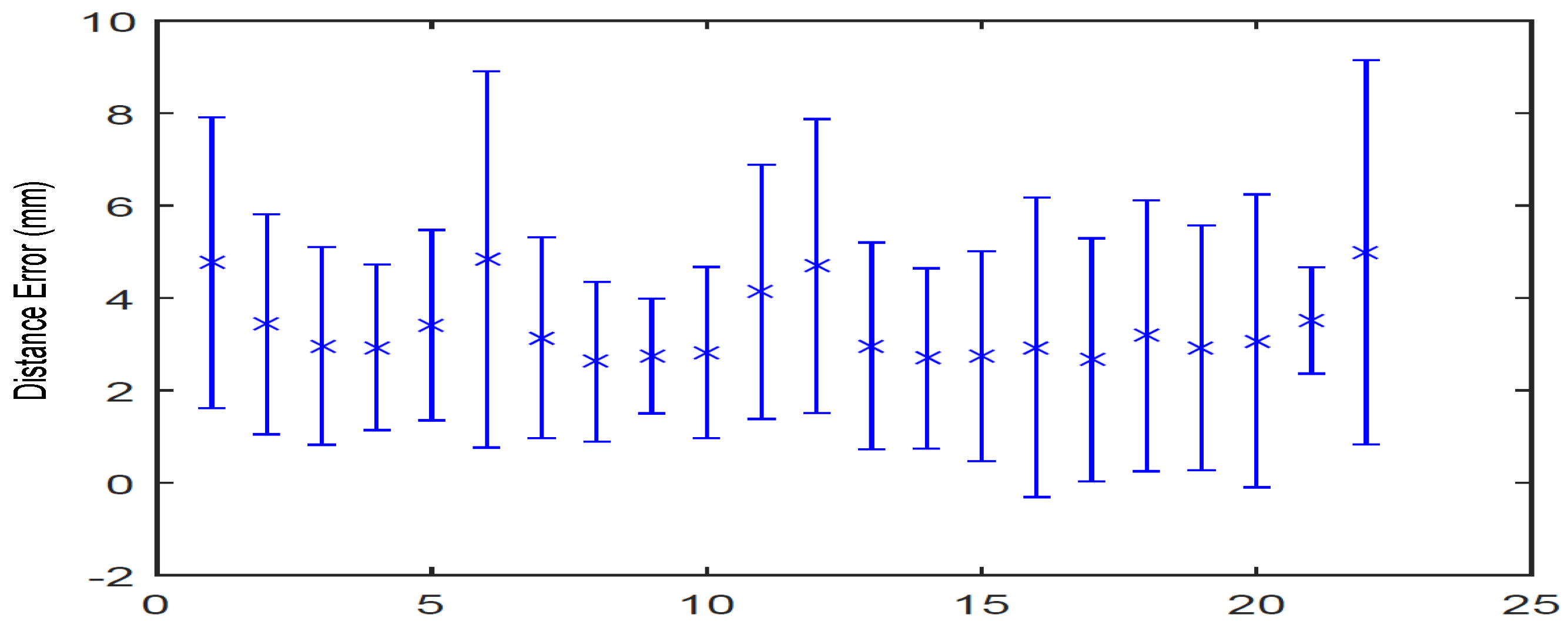
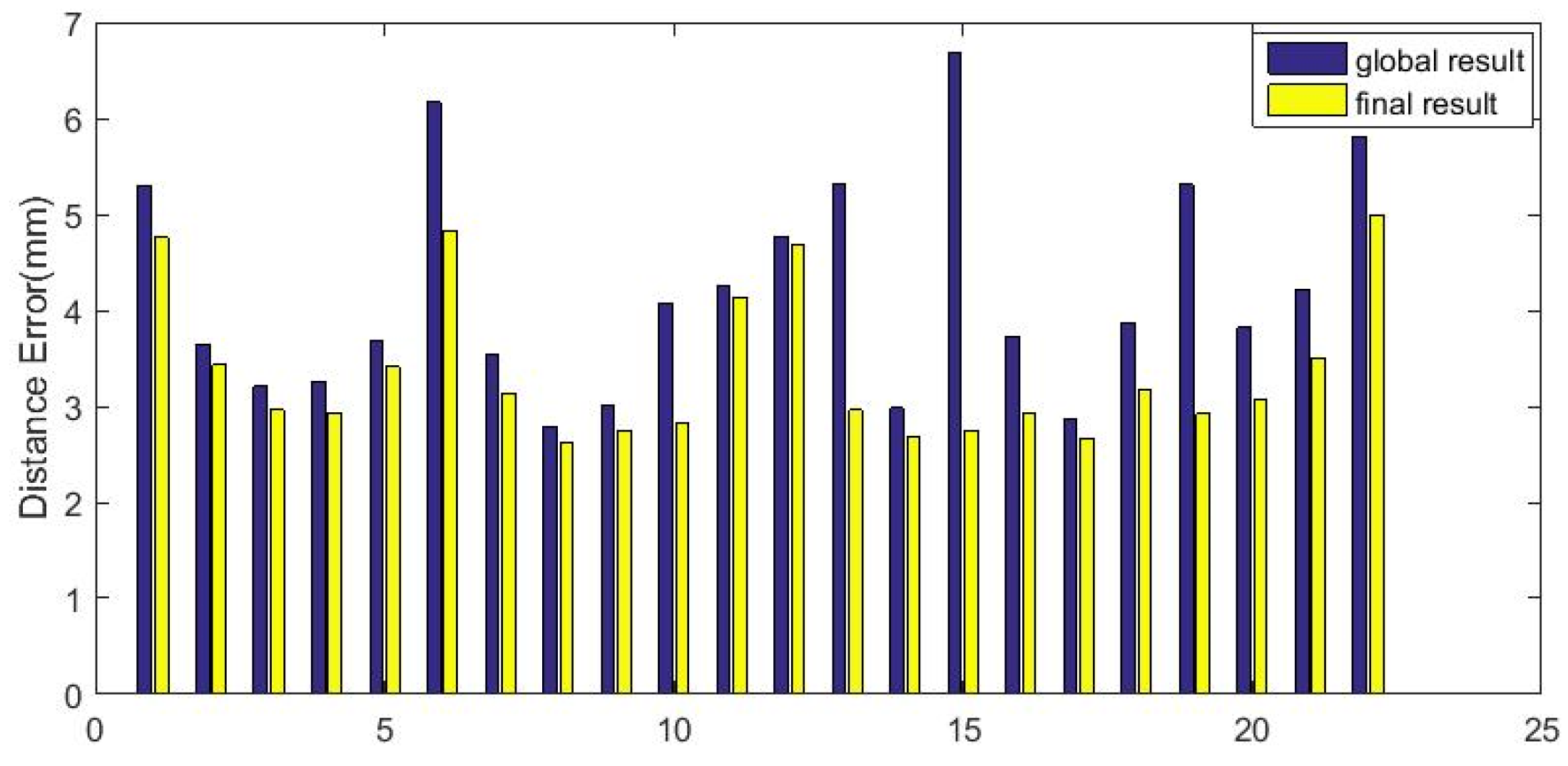
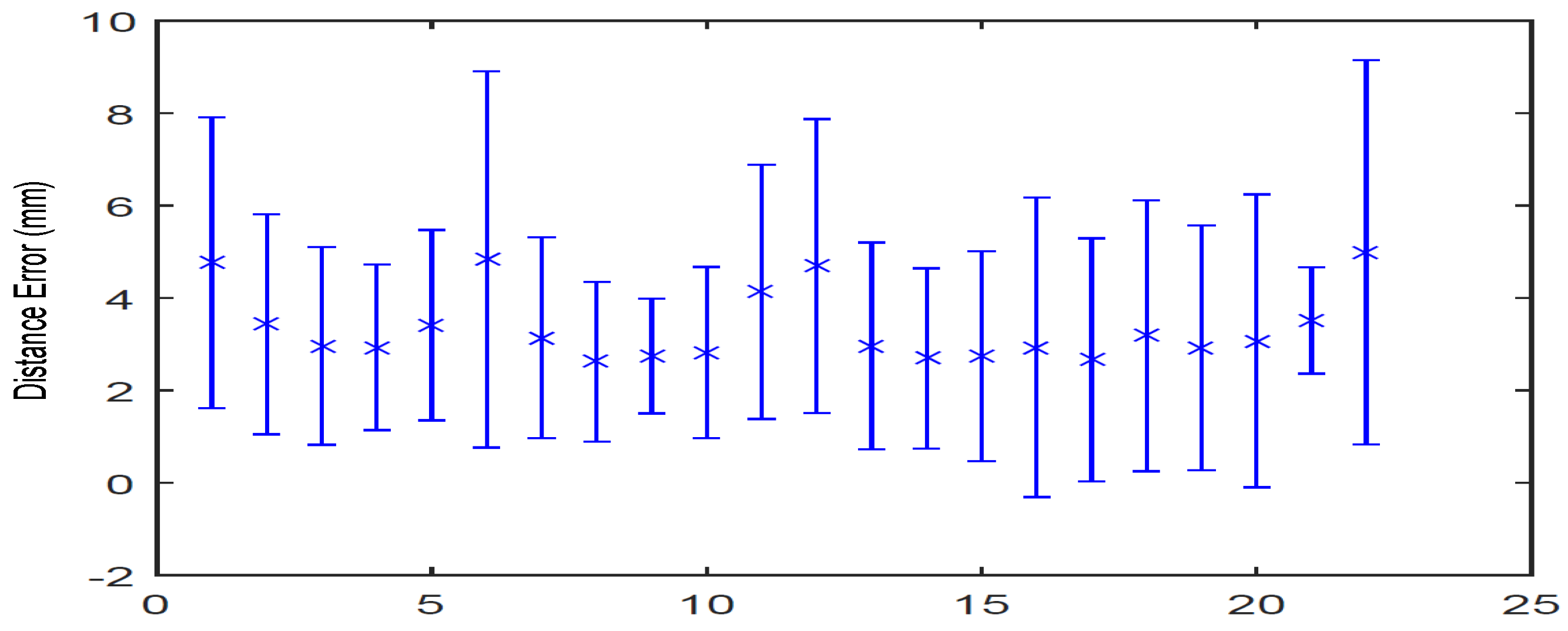
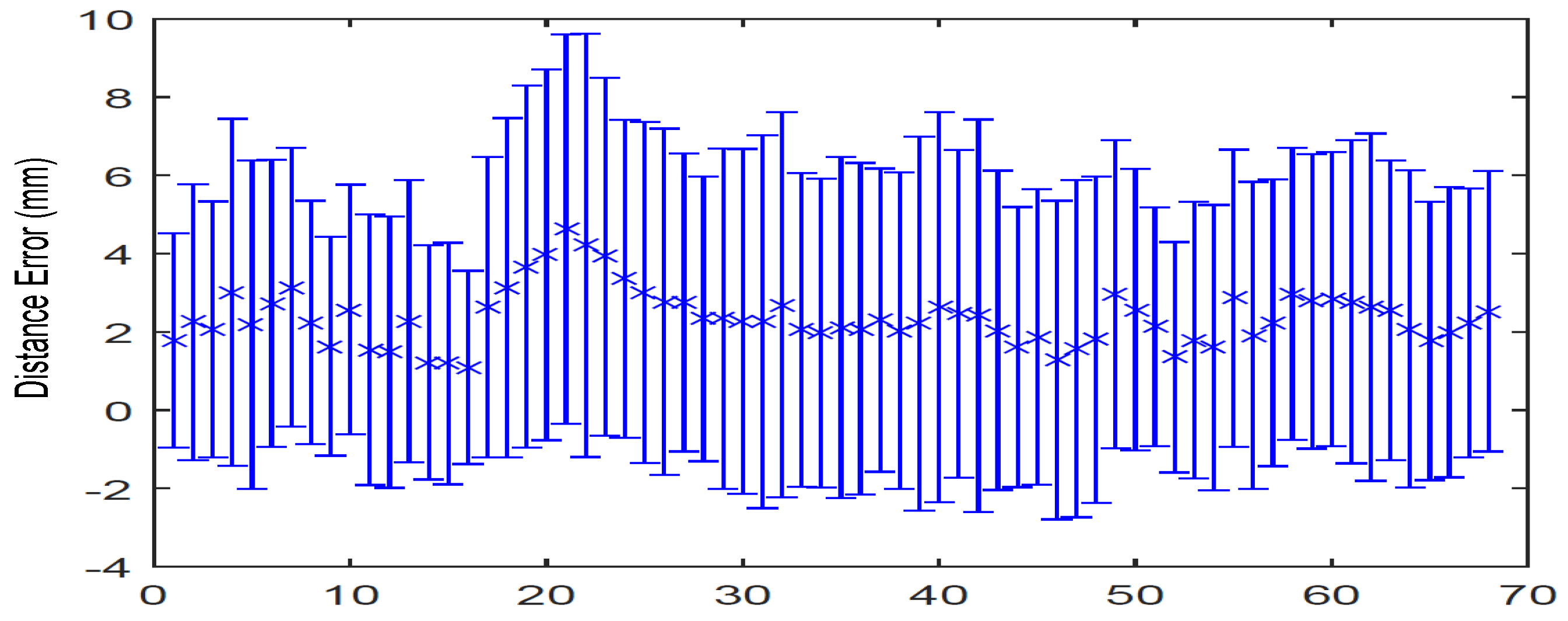
4.6. Evaluation
4.7. Comparison with Other Methods
4.7.1. Comparison with Handcrafted Features
4.7.2. Comparison with Pre-Trained Models
4.7.3. Comparison on the Bosphorus Dataset
4.7.4. Comparison on the BU-3DFE Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active Appearance Models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models—Their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Cristinacce, D.; Cootes, T.F. Feature Detection and Tracking with Constrained Local Models. In Proceedings of the British Machine Vision Conference 2006, Edinburgh, UK, 4–7 September 2006; pp. 929–938. [Google Scholar]
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Ren, S.; Cao, X.; Wei, Y.; Sun, J. Face Alignment at 3000 FPS via Regressing Local Binary Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1685–1692. [Google Scholar]
- Xiong, X.; Torre, F.D.L. Supervised Descent Method and Its Applications to Face Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Dollar, P.; Welinder, P.; Perona, P. Cascaded pose regression. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1078–1085. [Google Scholar]
- Savran, A.; Sankur, B.; Bilge, M.T. Regression-based intensity estimation of facial action units. Image Vis. Comput. 2012, 30, 774–784. [Google Scholar] [CrossRef]
- Feng, Z.H.; Huber, P.; Kittler, J.; Christmas, W.; Wu, X.J. Random Cascaded-Regression Copse for Robust Facial Landmark Detection. IEEE Signal Process. Lett. 2014, 22, 76–80. [Google Scholar] [CrossRef]
- Zhu, S.; Li, C.; Chen, C.L.; Tang, X. Face alignment by coarse-to-fine shape searching. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4998–5006. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face Alignment Across Large Poses: A 3D Solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Jourabloo, A.; Liu, X. Pose-Invariant 3D Face Alignment. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2016; pp. 3694–3702. [Google Scholar]
- Kakadiaris, I.A.; Passalis, G.; Toderici, G.; Murtuza, M.N.; Lu, Y.; Karampatziakis, N.; Theoharis, T. Three-dimensional face recognition in the presence of facial expressions: An annotated deformable model approach. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 640. [Google Scholar] [CrossRef] [PubMed]
- Perakis, P.; Theoharis, T.; Passalis, G.; Kakadiaris, I.A. Automatic 3D facial region retrieval from multi-pose facial datasets. In Proceedings of the Eurographics Conference on 3D Object Retrieval, Munich, Germany, 29 March 2009; pp. 37–44. [Google Scholar]
- Perakis, P.; Passalis, G.; Theoharis, T.; Toderici, G.; Kakadiaris, I.A. Partial matching of interpose 3D facial data for face recognition. In Proceedings of the IEEE International Conference on Biometrics: Theory, Applications, and Systems, Washington, DC, USA, 28–30 September 2009; pp. 1–8. [Google Scholar]
- Xu, C.; Tan, T.; Wang, Y.; Quan, L. Combining local features for robust nose location in 3D facial data. Pattern Recognit. Lett. 2006, 27, 1487–1494. [Google Scholar] [CrossRef]
- D’Hose, J.; Colineau, J.; Bichon, C.; Dorizzi, B. Precise Localization of Landmarks on 3D Faces using Gabor Wavelets. In Proceedings of the IEEE International Conference on Biometrics: Theory, Applications, and Systems, Crystal City, VA, USA, 27–29 September 2007; pp. 1–6. [Google Scholar]
- Colbry, D.; Stockman, G.; Jain, A. Detection of Anchor Points for 3D Face Veri.cation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Bevilacqua, V.; Casorio, P.; Mastronardi, G. Extending Hough Transform to a Points’ Cloud for 3D-Face Nose-Tip Detection. In Proceedings of the International Conference on Intelligent Computing: Advanced Intelligent Computing Theories and Applications—With Aspects of Artificial Intelligence, Shanghai, China, 15–18 September 2008; pp. 1200–1209. [Google Scholar]
- Zhao, X.; Dellandréa, E.; Chen, L.; Kakadiaris, I.A. Accurate landmarking of three-dimensional facial data in the presence of facial expressions and occlusions using a three-dimensional statistical facial feature model. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2011, 41, 1417–1428. [Google Scholar] [CrossRef] [PubMed]
- Nair, P.; Cavallaro, A. 3-D Face Detection, Landmark Localization, and Registration Using a Point Distribution Model. IEEE Trans. Multimedia 2009, 11, 611–623. [Google Scholar] [CrossRef] [Green Version]
- Jahanbin, S.; Choi, H.; Jahanbin, R.; Bovik, A.C. Automated facial feature detection and face recognition using Gabor features on range and portrait images. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 2768–2771. [Google Scholar]
- Huibin, L.I.; Sun, J.; Zongben, X.U.; Chen, L. Multimodal 2D+3D Facial Expression Recognition with Deep Fusion Convolutional Neural Network. IEEE Trans. Multimedia 2017, 19, 2816–2831. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. DeepID3: Face Recognition with Very Deep Neural Networks. arXiv, 2015; arXiv:1502.00873. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Chang, F.J.; Tran, A.T.; Hassner, T.; Masi, I.; Nevatia, R.; Medioni, G. ExpNet: Landmark-Free, Deep, 3D Facial Expressions. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Convolutional Network Cascade for Facial Point Detection. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3476–3483. [Google Scholar]
- Zhang, J.; Shan, S.; Kan, M.; Chen, X. Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 1–16. [Google Scholar]
- Zhang, Z.; Luo, P.; Chen, C.L.; Tang, X. Facial Landmark Detection by Deep Multi-task Learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 94–108. [Google Scholar]
- Yang, J.; Liu, Q.; Zhang, K. Stacked Hourglass Network for Robust Facial Landmark Localisation. In Proceedings of the Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2025–2033. [Google Scholar]
- Kumar, A.; Chellappa, R. Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How Far are We from Solving the 2D and 3D Face Alignment Problem? (and a Dataset of 230,000 3D Facial Landmarks). In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Lu, X.; Jain, A.K.; Colbry, D. Matching 2.5D Face Scans to 3D Models. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 31–43. [Google Scholar] [PubMed]
- Dibeklioglu, H.; Salah, A.A.; Akarun, L. 3D Facial Landmarking under Expression, Pose, and Occlusion Variations. In Proceedings of the IEEE International Conference on Biometrics: Theory, Applications and Systems, Arlington, VA, USA, 29 September–1 October 2008; pp. 1–6. [Google Scholar]
- Colombo, A.; Cusano, C.; Schettini, R. 3D face detection using curvature analysis. Pattern Recognit. 2006, 39, 444–455. [Google Scholar] [CrossRef]
- Boehnen, C.; Russ, T. A Fast Multi-Modal Approach to Facial Feature Detection. In Proceedings of the Seventh IEEE Workshops on Application of Computer Vision, Breckenridge, CO, USA, 5–7 January 2005; pp. 135–142. [Google Scholar]
- Wang, Y.; Chua, C.S.; Ho, Y.K. Facial feature detection and face recognition from 2D and 3D images. Pattern Recognit. Lett. 2002, 23, 1191–1202. [Google Scholar] [CrossRef]
- Salah, A.A.; Çinar, H.; Akarun, L.; Sankur, B. Robust facial landmarking for registration. Ann. Télécommun. 2007, 62, 83–108. [Google Scholar]
- Lu, X.; Jain, A.K. Automatic Feature Extraction for Multiview 3D Face Recognition. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006; pp. 585–590. [Google Scholar] [Green Version]
- Savran, A.; Akarun, L. Bosphorus Database for 3D Face Analysis. In Biometrics and Identity Management; Springer: Berlin/Heidelberg, Germany, 2008; pp. 47–56. [Google Scholar]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the FGR’06 International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Doha, Qatar, 26–29 November 2012; pp. 1097–1105. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Alyüz, N.; Gökberk, B.; Akarun, L. Regional registration for expression resistant 3-D face recognition. IEEE Trans. Inf. Forensics Secur. 2010, 5, 425–440. [Google Scholar] [CrossRef]
- Creusot, C.; Pears, N.; Austin, J. A Machine-Learning Approach to Keypoint Detection and Landmarking on 3D Meshes. Int. J. Comput. Vis. 2013, 102, 146–179. [Google Scholar] [CrossRef]
- Sukno, F.M.; Waddington, J.L.; Whelan, P.F. 3-D Facial Landmark Localization With Asymmetry Patterns and Shape Regression from Incomplete Local Features. IEEE Trans. Cybern. 2017, 45, 1717–1730. [Google Scholar] [CrossRef] [PubMed]
- Camgöz, N.C.; Gökberk, B.; Akarun, L. Facial landmark localization in depth images using Supervised Descent Method. In Proceedings of the Signal Processing and Communications Applications Conference, Malatya, Turkey, 16–19 May 2015; pp. 378–383. [Google Scholar]
- Fanelli, G.; Dantone, M.; Gool, L.V. Real time 3D face alignment with Random Forests-based Active Appearance Models. In Proceedings of the IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Sun, J.; Huang, D.; Wang, Y.; Chen, L. A coarse-to-fine approach to robust 3D facial landmarking via curvature analysis and Active Normal Model. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–7. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landmarks | SIFT | LBP | HOG | Deep Features |
|---|---|---|---|---|
| Outer left eyebrow | 6.13 ± 3.97 | 6.45 ± 4.11 | 6.38 ± 4.37 | 4.76 ± 3.15 |
| Middle left eyebrow | 5.37 ± 2.15 | 4.95 ± 2.07 | 5.68 ± 3.62 | 3.43 ± 2.38 |
| Inner left eyebrow | 5.14 ± 3.23 | 5.28 ± 3.45 | 5.48 ± 2.08 | 2.96 ± 2.14 |
| Inner right eyebrow | 5.04 ± 2.78 | 5.18 ± 2.96 | 5.34 ± 3.05 | 2.93 ± 1.79 |
| Middle right eyebrow | 4.88 ± 2.86 | 5.03 ± 2.54 | 5.08 ± 2.86 | 3.41 ± 2.06 |
| Outer right eyebrow | 6.02 ± 3.50 | 5.97 ± 3.45 | 6.17 ± 3.74 | 4.83 ± 4.07 |
| Outer left eye corner | 4.16 ± 2.05 | 4.83 ± 2.36 | 4.97 ± 2.60 | 3.14 ± 2.17 |
| Inner left eye corner | 4.53 ± 2.53 | 4.12 ± 2.27 | 5.02 ± 3.10 | 2.62 ± 1.73 |
| Inner right eye corner | 3.71 ± 2.19 | 4.03 ± 2.30 | 4.34 ± 2.62 | 2.74 ± 1.24 |
| Outer right eye corner | 4.09 ± 2.51 | 3.89 ± 2.84 | 4.13 ± 2.74 | 2.82 ± 1.85 |
| Nose saddle left | 7.85 ± 4.03 | 7.71 ± 3.96 | 7.91 ± 4.07 | 4.13 ± 2.75 |
| Nose saddle right | 8.23 ± 4.29 | 8.35 ± 4.02 | 8.41 ± 4.72 | 4.69 ± 3.18 |
| Left nose peak | 3.54 ± 2.06 | 3.67 ± 2.17 | 3.97 ± 2.37 | 2.96 ± 2.24 |
| Nose tip | 3.84 ± 2.43 | 3.91 ± 2.59 | 4.01 ± 2.77 | 2.69 ± 1.95 |
| Right nose peak | 3.53 ± 2.34 | 3.81 ± 2.61 | 3.48 ± 2.22 | 2.74 ± 2.27 |
| Left mouth corner | 4.39 ± 2.82 | 4.13 ± 2.58 | 4.47 ± 3.01 | 2.93 ± 3.24 |
| Upper lip outer middle | 4.73 ± 3.12 | 4.99 ± 3.19 | 4.45 ± 3.08 | 2.66 ± 2.63 |
| Right mouth corner | 6.32 ± 3.83 | 6.41 ± 3.95 | 7.04 ± 4.37 | 3.18 ± 2.93 |
| Upper lip inner middle | 4.86 ± 2.75 | 4.64 ± 2.67 | 4.93 ± 3.15 | 2.92 ± 2.65 |
| Lower lip inner middle | 5.15 ± 5.02 | 5.61 ± 4.96 | 5.89 ± 5.12 | 3.07 ± 3.17 |
| Lower lip outer middle | 6.19 ± 4.19 | 6.20 ± 3.95 | 6.07 ± 4.12 | 3.51 ± 3.15 |
| Chin middle | 7.69 ± 5.39 | 7.93 ± 5.62 | 8.01 ± 5.70 | 4.99 ± 4.16 |
| Mean error | 5.25 ± 3.18 | 5.32 ± 3.21 | 5.51 ± 3.43 | 3.37 ± 2.72 |
| landmarks | AlexNet | Google Inception | VGG-Net |
|---|---|---|---|
| Outer left eyebrow | 4.93 ± 2.54 | 4.47 ± 2.31 | 4.76 ± 3.15 |
| Middle left eyebrow | 4.19 ± 3.18 | 3.62 ± 2.47 | 3.43 ± 2.38 |
| Inner left eyebrow | 3.05 ± 2.43 | 2.88 ± 2.04 | 2.96 ± 2.14 |
| Inner right eyebrow | 3.16 ± 2.17 | 3.04 ± 1.92 | 2.93 ± 1.79 |
| Middle right eyebrow | 3.61 ± 2.58 | 3.55 ± 1.99 | 3.41 ± 2.06 |
| Outer right eyebrow | 4.02 ± 4.16 | 4.23 ± 4.35 | 4.83 ± 4.07 |
| Outer left eye corner | 3.16 ± 2.00 | 3.46 ± 2.10 | 3.14 ± 2.17 |
| Inner left eye corner | 2.39 ± 1.60 | 2.30 ± 1.40 | 2.62 ± 1.73 |
| Inner right eye corner | 3.10 ± 2.49 | 2.87 ± 1.54 | 2.74 ± 1.24 |
| Outer right eye corner | 3.01 ± 2.05 | 2.77 ± 1.94 | 2.82 ± 1.85 |
| Nose saddle left | 4.61 ± 3.56 | 4.88 ± 3.67 | 4.13 ± 2.75 |
| Nose saddle right | 5.71 ± 4.13 | 5.30 ± 3.71 | 4.69 ± 3.18 |
| Left nose peak | 3.51±2.99 | 3.11 ± 2.69 | 2.96 ± 2.24 |
| Nose tip | 3.31 ± 2.21 | 3.01 ± 2.07 | 2.69 ± 1.95 |
| Right nose peak | 2.56 ± 2.04 | 2.88 ± 2.50 | 2.74 ± 2.27 |
| Left mouth corner | 4.10 ± 3.74 | 3.43 ± 3.34 | 2.93 ± 3.24 |
| Upper lip outer middle | 3.29 ± 3.01 | 2.97 ± 2.85 | 2.66 ± 2.63 |
| Right mouth corner | 4.19 ± 3.45 | 3.57 ± 3.22 | 3.18 ± 2.93 |
| Upper lip inner middle | 3.61 ± 3.42 | 2.87 ± 3.15 | 2.92 ± 2.65 |
| Lower lip inner middle | 4.15 ± 5.04 | 3.59 ± 4.13 | 3.07 ± 3.17 |
| Lower lip outer middle | 4.19 ± 3.89 | 3.81 ± 3.77 | 3.51 ± 3.15 |
| Chin middle | 5.05 ± 5.04 | 5.13 ± 5.13 | 4.99 ± 4.16 |
| Mean error | 3.77 ± 3.08 | 3.53 ± 2.83 | 3.37 ± 2.72 |
| Inner Eye Corners | Outer Eye Corners | Nose Tip | Nose Corners | Mouth Corners | Chin | |
|---|---|---|---|---|---|---|
| Manual [46] | 2.51 | - | 2.96 | 1.75 | - | - |
| Alyuz [46] | 3.70 | - | 3.05 | 3.10 | - | - |
| Creusot [47] | 4.14 ± 2.63 | 6.27 ± 3.98 | 4.33 ± 2.62 | 4.16 ± 2.35 | 7.95 ± 5.44 | 15.38 ± 10.49 |
| Sukno [48] | 2.85 ± 2.02 | 5.06 ± 3.67 | 2.33 ± 1.78 | 3.02 ± 1.91 | 6.08 ± 5.13 | 7.58 ± 6.72 |
| Camgoz (SIFT) [49] | 2.26 ± 1.79 | 4.23 ± 2.94 | 2.72 ± 2.19 | 4.57 ± 3.62 | 3.14 ± 2.71 | 5.72 ± 4.31 |
| Camgoz (HOG) [49] | 2.33 ± 1.92 | 4.11 ± 3.01 | 2.69 ± 2.20 | 4.49 ± 3.62 | 3.16 ± 2.70 | 5.87 ± 4.19 |
| Ours | 2.66 ± 1.49 | 3.64 ± 2.01 | 2.69 ± 1.95 | 4.40 ± 2.61 | 3.06 ± 3.09 | 4.99 ± 4.16 |
| Landmark | Fanelli [50] | Zhao [20] | Nair [21] | Sun [51] | Our Method |
|---|---|---|---|---|---|
| Inner corner of left eye | 2.60 ± 1.80 | 2.93 ± 1.40 | 11.89 | 3.35 ± 5.67 | 2.79 ± 1.63 |
| Outer corner of left eye | 3.60 ± 2.40 | 4.11 ± 1.89 | 19.38 | 3.89 ± 6.38 | 3.58 ± 2.27 |
| Inner corner of right eye | 2.80 ± 2.00 | 2.90 ± 1.36 | 12.11 | 3.27 ± 5.51 | 3.11 ± 2.24 |
| Outer corner of right eye | 4.00 ± 2.80 | 4.07 ± 2.00 | 20.46 | 3.73 ± 6.14 | 4.20 ± 2.18 |
| Left corner of nose | 3.90 ± 2.00 | 3.32 ± 1.94 | - | 3.60 ± 4.01 | 3.77 ± 1.87 |
| Right corner of nose | 4.10 ± 2.20 | 3.62 ± 1.91 | - | 3.43 ± 3.74 | 4.98 ± 2.63 |
| Left corner of mouth | 4.70 ± 3.50 | 7.15 ± 4.64 | - | 3.95 ± 4.17 | 3.88 ± 2.86 |
| center of upper lip | 3.50 ± 2.50 | 4.19 ± 2.34 | - | 3.09 ± 3.06 | 2.94 ± 1.35 |
| Right corner of mouth | 4.90 ± 3.60 | 7.52 ± 4.57 | - | 3.76 ± 4.05 | 3.94 ± 2.96 |
| Center of lower lip | 5.20 ± 5.20 | 8.82 ± 7.12 | - | 4.36 ± 6.03 | 3.73 ± 2.97 |
| Outer corner of left brow | 5.80 ± 3.80 | 6.26 ± 3.72 | - | 5.29 ± 6.93 | 4.92 ± 2.69 |
| Inner corner of left brow | 3.80 ± 2.70 | 4.87 ± 2.99 | - | 4.62 ± 5.92 | 3.81 ± 2.75 |
| Inner corner of right brow | 4.00 ± 3.00 | 4.88 ± 2.97 | - | 4.59 ± 5.76 | 3.85 ± 2.63 |
| Outer corner of right brow | 6.20 ± 4.30 | 6.07 ± 3.35 | - | 5.29 ± 7.04 | 5.98 ± 4.63 |
| Mean results | 4.22 ± 2.99 | 5.05 ± 3.01 | - | 4.02 ± 5.32 | 3.96 ± 2.55 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Zhao, X.; Gao, W.; Zou, J. A Coarse-to-Fine Approach for 3D Facial Landmarking by Using Deep Feature Fusion. Symmetry 2018, 10, 308. https://doi.org/10.3390/sym10080308
Wang K, Zhao X, Gao W, Zou J. A Coarse-to-Fine Approach for 3D Facial Landmarking by Using Deep Feature Fusion. Symmetry. 2018; 10(8):308. https://doi.org/10.3390/sym10080308
Chicago/Turabian StyleWang, Kai, Xi Zhao, Wanshun Gao, and Jianhua Zou. 2018. "A Coarse-to-Fine Approach for 3D Facial Landmarking by Using Deep Feature Fusion" Symmetry 10, no. 8: 308. https://doi.org/10.3390/sym10080308