Invariant Graph Partition Comparison Measures

Karlsruhe Institute of Technology, Institute of Information Systems and Marketing, Kaiserstr. 12, 76131 Karlsruhe, Germany
*
Author to whom correspondence should be addressed.
Symmetry 2018, 10(10), 504; https://doi.org/10.3390/sym10100504
Submission received: 10 September 2018
/
Revised: 10 October 2018
/
Accepted: 11 October 2018
/
Published: 15 October 2018
(This article belongs to the Special Issue Discrete Mathematics and Symmetry)
Abstract
:Symmetric graphs have non-trivial automorphism groups. This article starts with the proof that all partition comparison measures we have found in the literature fail on symmetric graphs, because they are not invariant with regard to the graph automorphisms. By the construction of a pseudometric space of equivalence classes of permutations and with Hausdorff’s and von Neumann’s methods of constructing invariant measures on the space of equivalence classes, we design three different families of invariant measures, and we present two types of invariance proofs. Last, but not least, we provide algorithms for computing invariant partition comparison measures as pseudometrics on the partition space. When combining an invariant partition comparison measure with its classical counterpart, the decomposition of the measure into a structural difference and a difference contributed by the group automorphism is derived.
1. Introduction
Partition comparison measures are routinely used in a variety of tasks in cluster analysis: finding the proper number of clusters, assessing the stability and robustness of solutions of cluster algorithms, comparing different solutions of randomized cluster algorithms or comparing optimal solutions of different cluster algorithms in benchmarks [1], or in competitions like the 10th DIMACS graph-clustering challenge [2]. Their development has been for more than a century an active area of research in statistics, data analysis and machine learning. One of the oldest and still very well-known measure is the one of Jaccard [3]; more recent approaches were by Horta and Campello [4] and Romano et al. [5]. For an overview of many of these measures, see Appendix B. Besides the need to compare clustering partitions, there is an ongoing discussion of what actually are the best clusters [6,7]. Another problem often addressed is how to measure cluster validity [8,9].
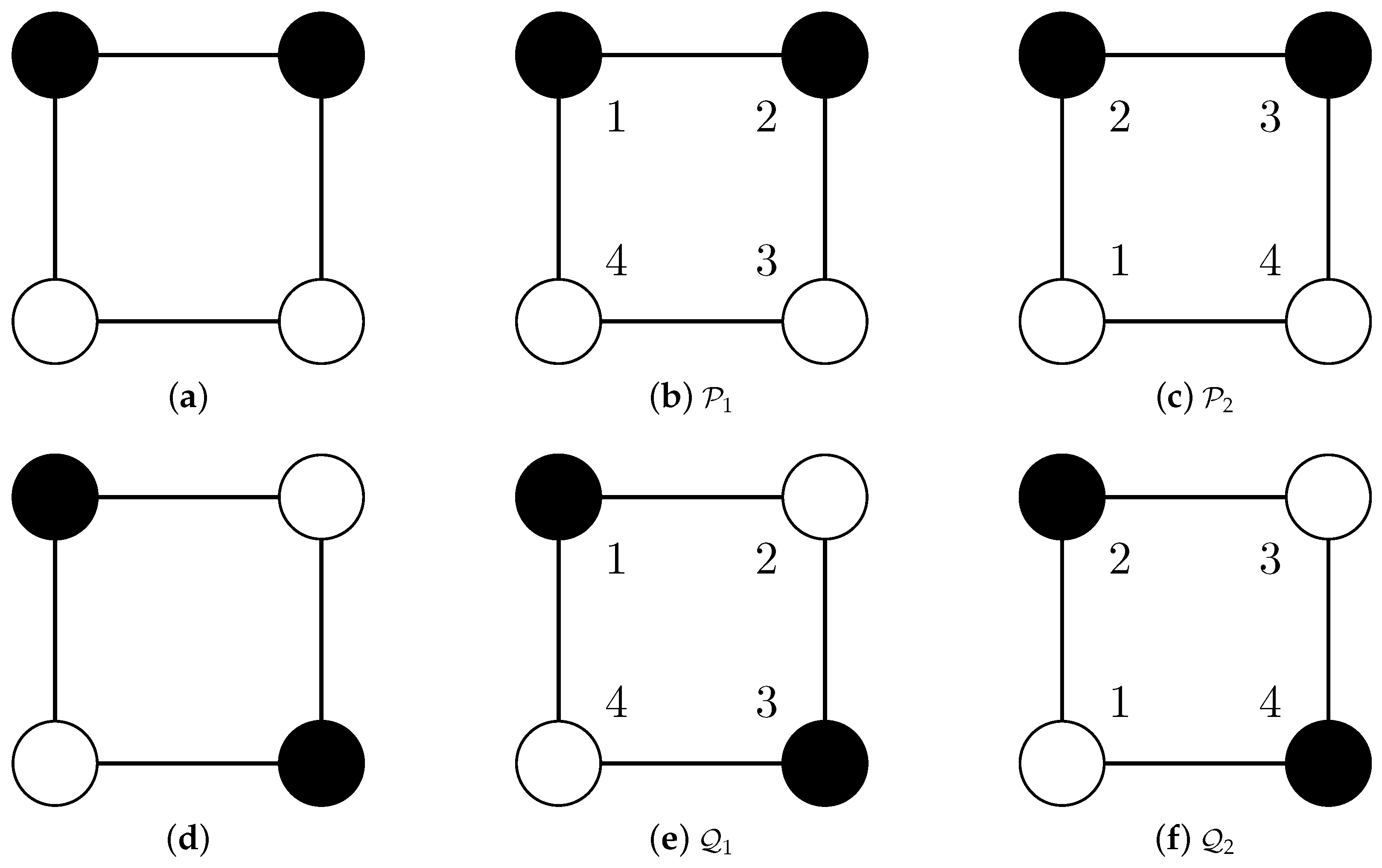
However, the comparison of graph partitions leads to new challenges because of the need to handle graph automorphisms properly. The following small example shows that standard partition comparison measures have unexpected results when applied to graph partitions: in Figure 1, we show two different ways of partitioning the cycle graph (Figure 1a,d). Partitioning means grouping the nodes into non-overlapping clusters. The nodes are arbitrarily labeled with 1 to 4 (Figure 1b,e), and then, there are four possibilities of relabeling the nodes so that the edges stay the same. One possibility is relabeling 1 by 2, 2 by 3, 3 by 4 and 4 by 1, and the images resulting from this relabeling are shown in Figure 1c,f. The relabeling corresponds to a counterclockwise rotation of the graph by 90°, and formal details are given in Section 2. The effects of this relabeling on the partitions and are different:
- Partition is mapped to the structurally equivalent partition .
- Partition is mapped to the identical partition .
Table 1 illustrates the failure of partition comparison measures (here, the Rand Index (RI)) to recognize structural differences:
- Because and are structurally equivalent, the RI should be one (as for Cases 1, 2 and 3) instead of .
- Comparisons of structurally different different partitions (Cases 4 and 5) and comparisons of structurally equivalent partitions (Case 6) should not result in the same value.
One may argue that graphs in real applications contain symmetries only rarely. However, recent investigations of graph symmetries in real graph datasets show that a non-negligible proportion of these graphs contain symmetries. MacArthur et al. [10] state that “a certain degree of symmetry is also ubiquitous in complex systems” [10] (p. 3525). Their study includes a small number of biological, technological and social networks. In addition, Darga et al. [11] studied automorphism groups in very large sparse graphs (circuits, road networks and the Internet router network), with up to five million nodes with eight million links with execution times below 10 s. Katebi et al. [12] reported symmetries in 268 of 432 benchmark graphs. A recent large-scale study conducted by the authors of this article for approximately 1700 real-world graphs revealed that about three quarters of these graphs contain symmetries [13].
The rather frequent occurrence of symmetries in graphs and the obvious deficiencies of classic partition comparison measures demonstrated above have motivated our analysis of the effects of graph automorphisms on partition comparison measures.
Our contribution has the following structure: Permutation groups and graph automorphisms are introduced in Section 2. The full automorphism group of the butterfly graph serves as a motivating example for the formal definition of stable partitions, stable with regard to the actions of the automorphism group of a graph. In Section 3, we first provide a definition that captures the property that a measure is invariant with regard to the transformations in an automorphism group. Based on this definition, we first give a simple proof by counterexample for each partition comparison measure in Appendix B, that these measures based on the comparison of two partitions are not invariant to the effects of automorphisms on partitions. The non-existence of partition comparison measures for which the identity and the invariance axioms hold simultaneously is proven subsequently. In Section 4, we construct three families of invariant partition comparison measures by a two-step process: First, we define a pseudometric space by defining equivalence classes of partitions as the orbit of a partition under the automorphism group . Second, the definitions of the invariant counterpart of a partition comparison measure are given: we define them as the computation of the maximum, the minimum and the average of the direct product of the two equivalence classes. The section also contains a proof of the equivalence of several variants of the computation of the invariant measures, which—by exploiting the group properties of —differ in the complexity of the computation. In Section 5, we introduce the decomposition of the measures into a structurally stable and unstable part, as well as upper bounds for instability. In Section 6, we present an application of the decomposition of measures for analyzing partitions of the Karate graph. The article ends with a short discussion, conclusion and outlook in Section 7.
2. Graphs, Permutation Groups and Graph Automorphisms
We consider connected, undirected, unweighted and loop-free graphs. Let denote a graph where V is a finite set of nodes and E is a set of edges. An edge is represented as . Nodes adjacent to (there exists an edge between u and those nodes) are called neighbors. A partition of a graph G is a set of subsets of V with the usual properties: (i) , (ii) and (iii) . Each subset is called a cluster, and it is identified by its labeled nodes.
As a partition quality criterion, we use the well-known modularity measure Q of Newman and Girvan [14] (see Appendix A). It is a popular optimization criterion for unsupervised graph clustering algorithms, which try to partition the nodes of the graph in a way that the connectivity within the clusters is maximized and the number of edges connecting the clusters is minimized. For a fast and efficient randomized state-of-the-art algorithm, see Ovelgönne and Geyer-Schulz [15].
Partitions are compared by comparison measures, which are functions of the form where denotes the set of all possible partitions of the set V. A survey of many of these measures is given in Appendix B.
A permutation on V is a bijection . We denote permutations by the symbols and h. Each permutation can be written in cycle form: for a permutation with a single cycle of length r, we write . c maps to , to and leave all other nodes fixed. Permutations with more than one cycle are written as a product of disjoint cycles (i.e., no two cycles have a common element). means that the element remains fixed, and for brevity, these elements are omitted.
Permutations are applied from the right: The image of u under the permutation g is . The composition of g and h is , with ∘ being the permutation composition symbol. For brevity, is written as , so that holds. Computer scientists call this a postfix notation; in prefix notation, we have . Often, we also find , which we will use in the following. For k compositions , we write and .
A set of permutation functions forms a permutation group H, if the usual group axioms hold [16]:
- Closure:
- Unit element: The identity function acts as the neutral element:
- Inverse element: For any g in H, the inverse permutation function is the inverse of g:
- Associativity: The associative law holds:
If is a subset of H and if is a group, is a subgroup of H (written ). The set of all permutations of V is denoted by . is a group, and it is called the symmetric group (see [17]). iff with ∼ denoting isomorphism. A generator of a finite permutation group H is a subset of the permutations of H from which all permutations in H can be generated by application of the group axioms [18].
Groups acting on a set V also act on combinatorial structures defined on V [20] (p. 149), for example the power set , the set of all partitions or the set of graphs . We denote combinatorial structures as capital calligraphic letters; in the following, only partitions () are of interest because they are the results of graph cluster algorithms. The action of a permutation g on a combinatorial structure is performed by pointwise application of g. For instance, for , the image of g is .
Let H be a permutation group. When H acts on V, a node u is mapped by the elements of H onto other nodes. The set of these images is called the orbit of u under H:
The group of permutations that fixes u is called the stabilizer of u under H:
The orbit stabilizer theorem is given without proof [16]. It links the order of a permutation group with the cardinality of an orbit and the order of the stabilizer:
Theorem 1.
The relation:
holds.
The action of H on V induces an equivalence relation on the set: for , let iff there exists so that . All elements of an orbit are equivalent, and the orbits of a group partition the set V. An orbit of length one (in terms of set cardinality) is called trivial. Analogously, for a partition , the definition is:
Definition 1.
The image of the action of H on a partition (or the orbit of under H) is the set of all equivalent partitions of partition under H
A graph automorphism f is a permutation that preserves edges, i.e., , .
The automorphism group of a graph contains all permutations of vertices that map edges to edges and non-edges to non-edges. The automorphism group of G is defined as:
where . Of course, .
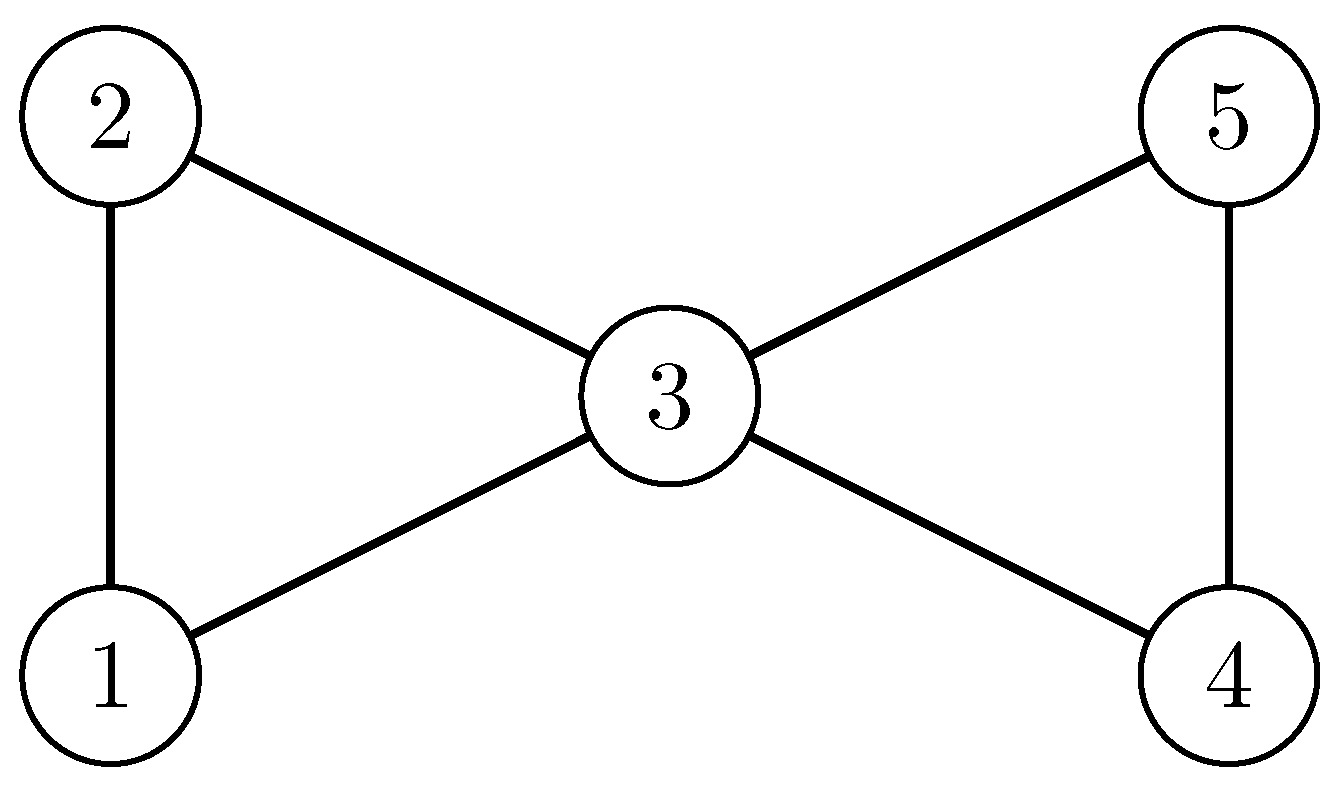
Example 1.
Let be the butterfly graph (Figure 2, e.g., Erdős et al. [21], Burr et al. [22]) whose full automorphism group is given in Table 2 (first column). The permutation is not an automorphism, because it does not preserve the edges from 1 to 2 and from 5 to 4. The butterfly graph has the two orbits and . The group is a subgroup of .
Definition 2.
Let be a graph. A partition is called stable, if , otherwise it is called unstable.
Stability here means that the automorphism group of the graph does not affect the given partition by tearing apart clusters.
Example 2.
Only in Table 2 is stable because its orbit is trivial. The two modularity optimal partitions (e.g., and ) are not stable because . Furthermore, .
For the evaluation of graph clustering solutions, the effects of graph automorphisms on graph partitions are of considerable importance:
3. Graph Partition Comparison Measures Are Not Invariant
When comparing graph partitions, a natural requirement is that the partition comparison measure is invariant under automorphism.
Definition 3.
A partition comparison measure is invariant under automorphism, if:
for all and , .
Observe that if , then such a measure m cannot distinguish between and , since by definition.
However, unfortunately, as we show in the rest of this section, such a partition comparison measure does not exist. In the following, we present two proofs of this fact, which differ both in their level of generality and sophistication.
3.1. Variant 1: Construction of a Counterexample
Theorem 2.
The measures for comparing partitions defined in Appendix B do not fulfill Definition 3 in general.
Proof.
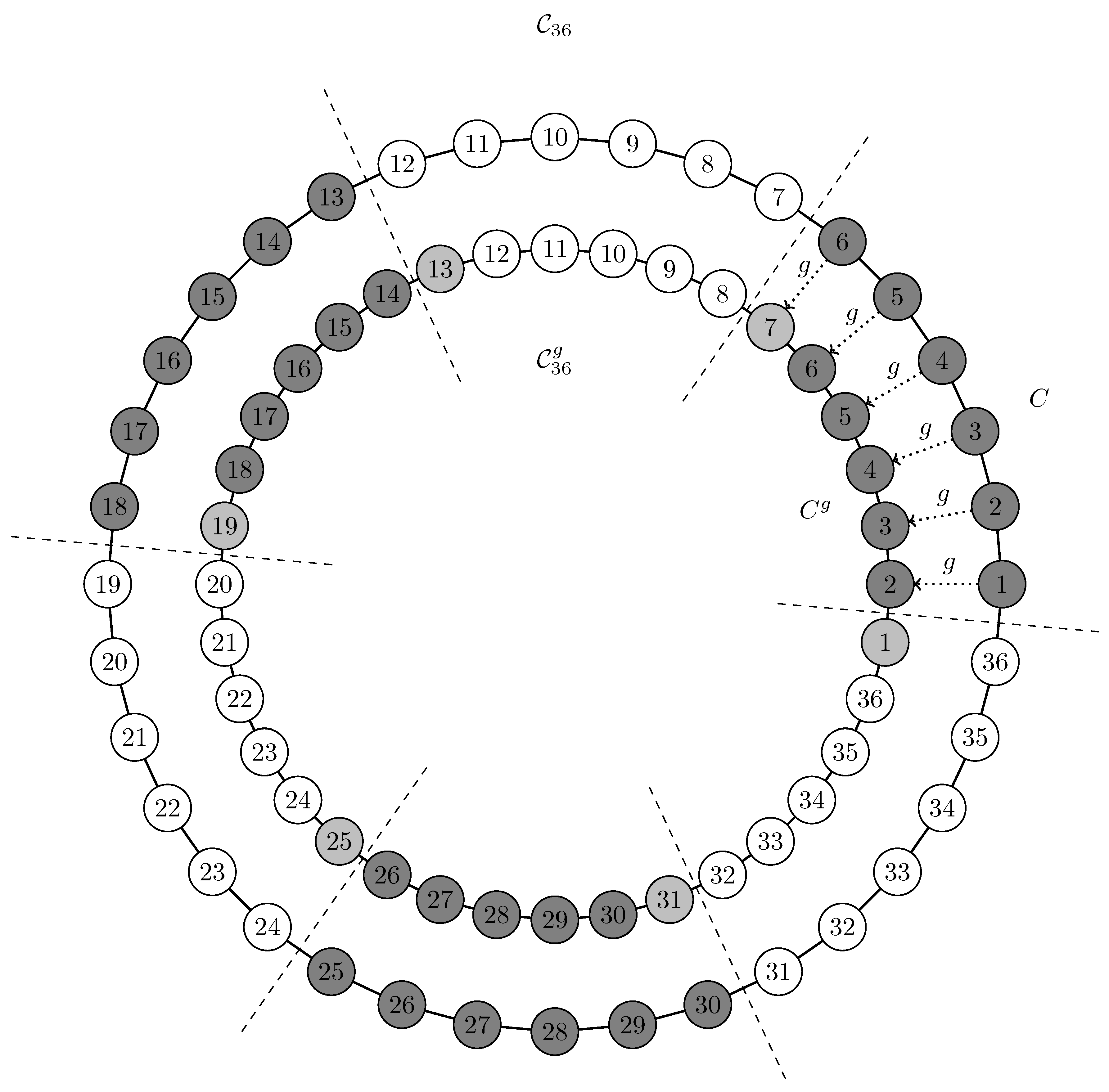
We choose the cycle graph and compute all modularity maximal partitions with . Each of these six partitions has six clusters, and each of these clusters consists of a chain of six nodes (see Figure 3).
Clearly, since all partitions are equivalent, an invariant partition comparison measure should identify them as equivalent:
3.2. Variant 2: Inconsistency of the Identity and the Invariance Axiom
Theorem 3.
Let be a graph with and nontrivial . For partition comparison measures , it is impossible to fulfill jointly the identity axiom , if and only if (e.g., for a distance measure , for a similarity measure , etc.) for all and the axiom of invariance (from Definition 3) .
Proof.
- Since is nontrivial, a nontrivial orbit with at least two different partitions, namely and , exists because . It follows from the invariance axiom that .
- The identity axiom implies that it follows from that .
- This contradicts the assumption that and are different.
□
4. The Construction of Invariant Measures for Finite Permutation Groups
The purpose of this section is to construct invariant counterparts for most of the partition comparison measures in Appendix B. We proceed in two steps:
- We construct a pseudometric space from the images of the actions of on partitions in (Definition 1).
- We extend the metrics for partition comparison by constructing invariant metrics on the pseudo-metric space of partitions.
4.1. The Construction of the Pseudometric Space of Equivalence Classes of Graph Partitions
We use a variant of the idea of Doob’s concept of a pseudometric space [24] (p. 5). A metric for a space S (with ) is a function for which the following holds:
- Symmetry: .
- Identity: if and only if .
- Triangle inequality: .
A pseudometric space relaxes the identity condition to . The distance between two elements of an equivalence class is defined as by Definition 3.
For graphs, S is the finite set of partitions and is the partition of into orbits of :
A partition in S corresponds to its orbit in . The relations between the spaces used in the following are:
- is a metric space with and with the function .
- is a metric space with and the function : . We construct three variants of in Section 4.2.
- is the pseudometric space with and with the metric . The partitions in S are mapped to arguments of by the transformation , which is defined as .
Table 4 illustrates (the space of equivalence classes) of the pseudometric space of the butterfly graph (shown in Figure 2). is the partition of into 17 equivalence classes. Only the four classes , , and are stable because they are trivial orbits. The three partitions from Table 2 are contained in the following equivalence classes: , , and .
4.2. The Construction of Left-Invariant and Additive Measures on the Pseudometric Space of Equivalence Classes of Graph Partitions
In the following, we consider only partition comparison measures, which are distance functions of a metric space. Note that a normalized similarity measure s can be transformed into a distance by the transformation .
In a pseudometric space , we measure the distance between equivalence classes (which are sets) of partitions instead of the distance between partitions. The partitions and are formal arguments of , which are expanded to equivalence classes by and . The standard construction of a distance measure between sets has been developed for the point set topology and is due to Felix Hausdorff [25] (p. 166) and Kazimierz Kuratowski [26] (p. 209). For finite sets, it requires the computation of the distances for all pairs of the direct product of the two sets. Since for finite permutation groups, we deal with distances between two finite sets of partitions, we use the following definitions for the lower and upper measures, respectively. Both definitions have the form of an optimization problem:
and:
The diameter of a finite equivalence class of partitions is defined by
The third option of defining a distance between two finite equivalence classes of partitions of taking the average distance is due to John von Neumann [27]:
Note that the definitions for , and require the computation of the minimal, maximal and average distance of all pairs of the direct product . The computational complexity of this is quadratic in the size of the larger equivalence class.
Posed as a measurement problem, we can instead fix one partition in one of the orbits and measure the minimal, maximal and average distance between all pairs of either the direct product of or . The complexity of this is linear in the size of the smaller equivalence class.
Theorems 4 and 5 and their proofs are based on these observations. They are the basis for the development of algorithms for the computation of invariant partition comparison measures of a computational complexity of at most linear order and often of constant order.
Theorem 4.
For all , the following equations hold:
For :
Proof.
Let , and , that is and . Then, since the orbits of both partitions are generated by , the following identities between distances hold:
as well as:
and:
Furthermore, let .
- For , we have:by switching the reference systems. In the next sequence of equations, we establish that taking the minimum over all reference systems is equivalent to finding the minimum for one arbitrarily fixed reference system.
- For the proof of for we substitute max for min in the proof of .
Theorem 5.
For all , the following equations hold:
Proof.
For the proof of the equality of the identities of , we use the property of an average of n observations with k identical groups of size m with , :
The computation of an average over the group equals the result of the computation of an average over the orbit, because the orbit stabilizer Theorem 1 implies that each element of the orbit is generated times, and this means that we average groups of identical values and that Equation (9) applies. This establishes the equality of Expressions (3) and (4), as well as of Expressions (5) and (6) and of Expressions (7) and (8), respectively.
Note that these proofs also show that , and are invariant. Next, we prove that the three measures , and are invariant measures.
Theorem 6.
The lower pseudometric space has the following properties:
- Identity: , if .
- Invariance: , for all and , .
- Symmetry: .
- Triangle inequality:
These properties also hold for the upper pseudometric space and the average pseudometric space .
Proof.
- Identity holds because of the definition of the distance between two elements in an equivalence class of the pseudometric space .
- Invariance of , and is proven by Theorems 4 and 5.
- Symmetry holds, because d is symmetric, and min, max and the average do not depend on the order of their respective arguments.
- To proof the triangular inequality, we make use of Theorems 4 and 5 and of the fact that d is a metric for which the triangular inequality holds:
- (a)
- For follows:
- (b)
- For the proof of the triangular inequality for , we substitute max for min and for in the proof of the triangular inequality for .
- (c)
- For , it follows:
□
5. Decomposition of Partition Comparison Measures
In this section, we assess the structural (dis)similarity between two partitions and the effect of the group actions by combining a partition comparison measure and its invariant counterpart defined in Section 4. The distances , , and allow the decomposition of a partition comparison measure (transformed into a distance) into a structural component and the effect of the automorphism group :
measures the effect of the automorphism group on the equivalence class (see the last column of Table 4). is an upper bound of the automorphism effect on the distance of two partitions and :
This follows from Theorem 4. Note that , as Case 1 in Table 5 shows.
In Table 5, we show a few examples of measure decomposition for partitions of the butterfly graph for the Rand distance :
- In Case 1, we compare two partitions from nontrivial equivalence classes: the difference of between and indicates that the potential maximal automorphism effect is larger than the lower measure. In addition, it is also smaller (by ) than the automorphism effect in each of the equivalence classes. That is zero for the lower measure implies that the pair is a pair with the minimal distance between the equivalence classes. The fact that is the mid-point between the lower and upper measures indicates a symmetric distribution of the distances between the equivalence classes.
- That is zero for the upper measure in Case 2 means that we have found a pair with the maximal distance between the equivalence classes.
- In Case 3, we have also found a pair with maximal distance between the equivalence classes. However, the maximal potential automorphism effect is smaller than for Cases 1 and 2. In addition, the distribution of distances between the equivalence classes is asymmetric.
- Case 4 shows the comparison of a partition from a trivial with a partition from a non-trivial equivalence class. Note, that in this case, all three invariant measures, as well as coincide and that no automorphism effect exists.
A different approach to measure the potential instability in clustering a graph G is the computation of the Kolmogorov–Sinai entropy of the finite permutation group acting on the graph [28]. Note, that the Kolmogorov–Sinai entropy of a finite permutation group is a measure of the uncertainty of the automorphism group. It cannot be used as a measure to compare two graph partitions.
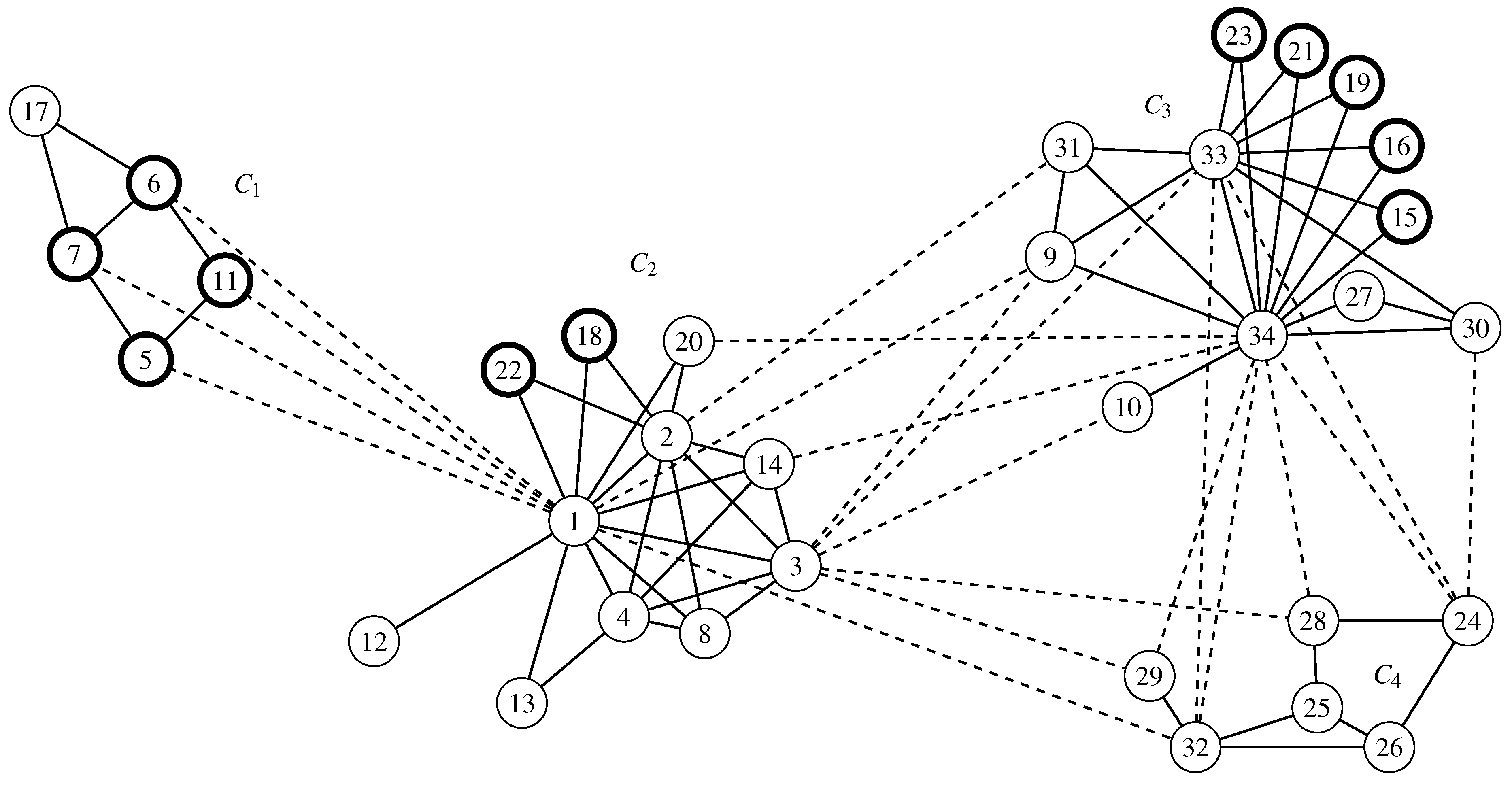
6. Invariant Measures for the Karate Graph
In this section, we illustrate the use of invariant measures for the three partitions , and of the Karate graph K [29], which is shown in Figure 4. is of order 480, and it consists of the three subgroups with , with and . In addition to the modularity optimal partition (with its clusters separated by longer and dashed lines in Figure 4), we use the partitions and :
Both partitions are affected by the orbits and , each overlapping two clusters. The dissimilarity to is larger for , which is reflected in Table 6 and Table 7.
For the optimal partition of type , the upper bound of the size of the equivalence class is 480 [30] (p. 112). The actual size of the equivalence class of is one, which means the optimal solution is not affected by . Partition , which is of the same type as , also has an upper bound of 480 for its equivalence class. The actual size of the equivalence classes of both and is 20. Note that the actual size of the equivalence classes that drive the complexity of computing invariant measures is in our example far below the upper bound. Table 6 shows the diameters of the equivalence classes of the partitions.
Table 7 illustrates the decomposition into structural effects and automorphism effects for the three partitions of the Karate graph. We see that for the comparison of a stable partition () with one of the unstable partitions, the classic partition comparison measures are sufficient. However, when comparing the two unstable partitions and , the structural effect () is dominated by the maximal automorphism effect (). Furthermore, we note that the distribution of values over the orbit of the automorphism group is asymmetric (by looking at , and ).
The analysis of the effects of the automorphism group of the Karate network showed that the automorphism group does not affect the stability of the optimal partition. However, the first results show that the situation is different for other networks like the Internet AS graph with 40,164 nodes and 85,123 edges (see Rossi et al. [31], and the data of of the graph tech-internet-as are from Rossi and Ahmed [32]): for this graph, several locally optimal solutions with a modularity value above exist, all of which are unstable. Further analysis of the structural properties of the solution landscape of this graph is work in progress.
7. Discussion, Conclusions and Outlook
In this contribution, we study the effects of graph automorphisms on partition comparison measures. Our main results are:
- A formal definition of partition stability, namely is stable iff .
- A proof of the non-invariance of all partition comparison measures if the automorphism group is nontrivial ().
- The construction of a pseudometric space of equivalence classes of graph partitions for three classes of invariant measures concerning finite permutation groups of graph automorphisms.
- The proof that the measures are invariant and that for these measures (after the transformation to a distance), the axioms of a metric space hold.
- The space of partitions is equipped with a metric (the original partition comparison measure) and a pseudometric (the invariant partition comparison measure).
- The decomposition of the value of a partition comparison measure into a structural part and a remainder that measures the effect of group actions.
Our definitions of invariant measures have the advantage that any existing partition comparison measure (as long as it is a distance or can be transformed into one) can still be used for the task. Moreover, the decomposition of measures restores the primary purpose of the existing comparison measures, which is to quantify structural difference. However, the construction of these measures leads directly to the classic graph isomorphism problem, whose complexity—despite considerable efforts and hopes to the contrary [33]—is still an open theoretical problem [34,35]. However, from a pragmatic point of view, today, quite efficient and practically usable algorithms exist to tackle the graph isomorphism problem [34]. In addition, for very large and sparse graphs, algorithms for finding generators of the automorphism group exist [11]. Therefore, this dependence on a computationally hard problem in general is not an actual disadvantage and allows one to implement the presented measure decomposition. The efficient implementation of algorithms for the decomposition of graph partition comparison measures is left for further research.
Another constraint is that we have investigated the effects of automorphisms on partition comparison measures in the setting of graph clustering only. The reason for this restriction is that the automorphism group of the graph is already defined by the graph itself and, therefore, is completely contained in the graph data. For arbitrary datasets, the information about the automorphism group is usually not contained in the data, but must be inferred from background theories. However, provided we know the automorphism group, our results on the decomposition of the measures generalize to arbitrary cluster problems.
All in all, this means that this article provides two major assets: first, it provides a theoretic framework that is independent of the preferred measure and the data. Second, we provide insights into a source of possible partition instability that has not yet been discussed in the literature. The downsides (symmetry group must be known and graph clustering only) are in our opinion not too severe, as we discussed above. Therefore, we think that our study indicates that a better understanding of the principle of symmetry is important for future research in data analysis.
Supplementary Materials
The R package partitionComparison by the authors of this article that implements the different partition comparison measures is available at https://cran.r-project.org/package=partitionComparison.
Author Contributions
The F.B. implemented the R package mentioned in the Supplementary Materials and conducted the non-invariance proof by counterexample. The more general proof of the non-existence of invariant measures, as well as the idea of creating a pseudometric to repair a measure’s deficiency of not being invariant is mainly due to the A.G.-S. Both authors contributed equally to writing the article and revising it multiple times.
Funding
We acknowledge support by Deutsche Forschungsgemeinschaft and the Open Access Publishing Fund of the Karlsruhe Institute of Technology.
Acknowledgments
We thank Andreas Geyer-Schulz (Institute of Analysis, Faculty of Mathematics, KIT, Karlsruhe) for repeated corrections and suggestions for improvement in the proofs.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Modularity
Newman’s and Girvan’s modularity [14] is defined as:
with the edge fractions:
and the cluster density:
We have to distinguish and because of the set-based definition E. is the fraction of edges from cluster to cluster and , vice versa. Therefore, the edges are counted twice, and thus, the fraction has to be weighted with . The second part of Q is the marginal distribution:
High values of Q indicate good partitions. The range of Q is . Even if the modularity has some problems by design (e.g., the resolution limit [36], unbalanced cluster sizes [37], multiple equivalent, but unstable solutions generated by automorphisms [38]), maximization of Q is the de facto standard formal optimization criterion for graph clustering algorithms.
Appendix B. Measures for Comparing Partitions
We classify the measures that are used in the literature to compare object partitions as three categories [39]:
- Pair-counting measures.
- Set-based comparison measures.
- Information theory based measures.
All these measures come from a general context and, therefore, may be used to compare any object partitions, not only graph partitions. The flip side of the coin is that they do not consider any adjacency information from the underlying graph at all.
The column Abbr. of Table A1, Table A2, Table A3 and Table A4 denotes the Abbreviations used throughout this paper; the column denotes the value resulting when identical partitions are compared (max stands for some maximum value depending on the partition).
Appendix B.1. Pair-Counting Measures
All the measures within the first class are based on the four coefficients that count pairs of objects (nodes in our context). Let be partitions of the node set V of a graph G. C and denote clusters (subsets of vertices ). The coefficients are defined as:
Please note that . One easily can see that for identical partitions , because two nodes either occur in a cluster together or not. Completely different partitions result in . All the measures we examined are given in Table A1 and Table A2. The RV coefficient is used by Youness and Saporta [40] for partition comparison, and p and q are the cluster counts (e.g., ) for the two partitions. For a detailed definition of the Lerman index (especially the definitions of the expectation and standard deviation), see Denœud and Guénoche [41].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
The pair counting measures used in Table 3 [42]. The above measures are similarity measures. Distance measures and non-normalized measures are listed in Table A2. For brevity: , , and . Abbr., Abbreviation.
| Abbr. | Measure | Formula | |
|---|---|---|---|
| RI | Rand [43] | ||
| ARI | Hubert and Arabie [44] | ||
| H | Hamann [45] | ||
| CZ | Czekanowski [46] | ||
| K | Kulczynski [47] | ||
| MC | McConnaughey [48] | ||
| P | Peirce [49] | ||
| WI | Wallace [50] | ||
| WII | Wallace [50] | ||
| FM | Fowlkes and Mallows [51] | ||
| Yule [52] | |||
| SS1 | Sokal and Sneath [53] | ||
| B1 | Baulieu [54] | ||
| GL | Gower and Legendre [55] | ||
| SS2 | Sokal and Sneath [53] | ||
| SS3 | Sokal and Sneath [53] | ||
| RT | Rogers and Tanimoto [56] | ||
| GK | Goodman and Kruskal [57] | ||
| J | Jaccard [3] | ||
| RV | Robert and Escoufier [58] |
Appendix B.2. Set-Based Comparison Measures
The second class is based on plain set comparison. We investigate three measures (see Table A3), namely the measure of Larsen and Aone [65], the so-called classification error distance [66] and Dongen’s metric [67].
Table A3.
References and formulas for the three set-based comparison measures used in Table 3. is the result of a maximum weighted matching of a bipartite graph. The bipartite graph is constructed from the partitions that shall be compared: the two node sets are derived from the two partitions, and each cluster is represented by a node. By definition, the two node sets are disjoint. The node sets are connected by edges of weight . As in our context , the found is assured to be a perfect (bijective) matching. n is the number of nodes .
Table A3.
References and formulas for the three set-based comparison measures used in Table 3. is the result of a maximum weighted matching of a bipartite graph. The bipartite graph is constructed from the partitions that shall be compared: the two node sets are derived from the two partitions, and each cluster is represented by a node. By definition, the two node sets are disjoint. The node sets are connected by edges of weight . As in our context , the found is assured to be a perfect (bijective) matching. n is the number of nodes .
| Abbr. | Measure | Formula | |
|---|---|---|---|
| LA | Larsen and Aone [65] | ||
| Meilǎ and Heckerman [66] | |||
| D | van Dongen [67] |
Appendix B.3. Information Theory-Based Measures
The last class of measures contains those that are rooted in information theory. We show the measures in Table A4, and we recap the fundamentals briefly: the entropy of a random variable X is defined as:
with being the probability of a specific incidence. The entropy of a partition can analogously be defined as:
The mutual information of two random variables is:
and again, analogously:
is the mutual information of two partitions [68]. Meilǎ [69] introduced the Variation of Information as .
Table A4.
Information theory-based measures used in Table 3. All measures are based on Shannon’s definition of entropy. Again, .
Appendix B.4. Summary
As one can see, all three classes of measures rely mainly on set matching between node sets (clusters), as an alternative definition of shows [42]. The adjacency information of the graph is completely ignored.
References
- Melnykov, V.; Maitra, R. CARP: Software for fishing out good clustering algorithms. J. Mach. Learn. Res. 2011, 12, 69–73. [Google Scholar]
- Bader, D.A.; Meyerhenke, H.; Sanders, P.; Wagner, D. (Eds.) 10th DIMACS Implementation Challenge—Graph Partitioning and Graph Clustering; Rutgers University, DIMACS (Center for Discrete Mathematics and Theoretical Computer Science): Piscataway, NJ, USA, 2012. [Google Scholar]
- Jaccard, P. Nouvelles recherches sur la distribution florale. Bull. Soc. Vaud. Sci. Nat. 1908, 44, 223–270. [Google Scholar]
- Horta, D.; Campello, R.J.G.B. Comparing hard and overlapping clusterings. J. Mach. Learn. Res. 2015, 16, 2949–2997. [Google Scholar]
- Romano, S.; Vinh, N.X.; Bailey, J.; Verspoor, K. Adjusting for chance clustering comparison measures. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Von Luxburg, U.; Williamson, R.C.; Guyon, I. Clustering: Science or art? JMLR Workshop Conf. Proc. 2011, 27, 65–79. [Google Scholar]
- Hennig, C. What are the true clusters? Pattern Recognit. Lett. 2015, 64, 53–62. [Google Scholar] [CrossRef]
- Van Craenendonck, T.; Blockeel, H. Using Internal Validity Measures to Compare Clustering Algorithms; Benelearn 2015 Poster Presentations (Online); Benelearn: Delft, The Netherlands, 2015; pp. 1–8. [Google Scholar]
- Filchenkov, A.; Muravyov, S.; Parfenov, V. Towards cluster validity index evaluation and selection. In Proceedings of the 2016 IEEE Artificial Intelligence and Natural Language Conference, St. Petersburg, Russia, 10–12 November 2016; pp. 1–8. [Google Scholar]
- MacArthur, B.D.; Sánchez-García, R.J.; Anderson, J.W. Symmetry in complex networks. Discret. Appl. Math. 2008, 156, 3525–3531. [Google Scholar] [CrossRef] [Green Version]
- Darga, P.T.; Sakallah, K.A.; Markov, I.L. Faster Symmetry Discovery Using Sparsity of Symmetries. In Proceedings of the 2008 45th ACM/IEEE Design Automation Conference, Anaheim, CA, USA, 8–13 June 2008; pp. 149–154. [Google Scholar]
- Katebi, H.; Sakallah, K.A.; Markov, I.L. Graph Symmetry Detection and Canonical Labeling: Differences and Synergies. In Turing-100. The Alan Turing Centenary; EPiC Series in Computing; Voronkov, A., Ed.; EasyChair: Manchester, UK, 2012; Volume 10, pp. 181–195. [Google Scholar]
- Ball, F.; Geyer-Schulz, A. How symmetric are real-world graphs? A large-scale study. Symmetry 2018, 10, 29. [Google Scholar] [CrossRef]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed]
- Ovelgönne, M.; Geyer-Schulz, A. An Ensemble Learning Strategy for Graph Clustering. In Graph Partitioning and Graph Clustering; Bader, D.A., Meyerhenke, H., Sanders, P., Wagner, D., Eds.; American Mathematical Society: Providence, RI, USA, 2013; Volume 588, pp. 187–205. [Google Scholar]
- Wielandt, H. Finite Permutation Groups; Academic Press: New York, NY, USA, 1964. [Google Scholar]
- James, G.; Kerber, A. The Representation Theory of the Symmetric Group. In Encyclopedia of Mathematics and Its Applications; Addison-Wesley: Reading, MA, USA, 1981; Volume 16. [Google Scholar]
- Coxeter, H.; Moser, W. Generators and Relations for Discrete Groups. In Ergebnisse der Mathematik und ihrer Grenzgebiete; Springer: Berlin, Germany, 1965; Volume 14. [Google Scholar]
- Dixon, J.D.; Mortimer, B. Permutation Groups. In Graduate Texts in Mathematics; Springer: New York, NY, USA, 1996; Volume 163. [Google Scholar]
- Beth, T.; Jungnickel, D.; Lenz, H. Design Theory; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Erdős, P.; Rényi, A.; Sós, V.T. On a problem of graph theory. Stud. Sci. Math. Hung. 1966, 1, 215–235. [Google Scholar]
- Burr, S.A.; Erdős, P.; Spencer, J.H. Ramsey theorems for multiple copies of graphs. Trans. Am. Math. Soc. 1975, 209, 87–99. [Google Scholar] [CrossRef]
- Ball, F.; Geyer-Schulz, A. R Package Partition Comparison; Technical Report 1-2017, Information Services and Electronic Markets, Institute of Information Systems and Marketing; KIT: Karlsruhe, Germany, 2017. [Google Scholar]
- Doob, J.L. Measure Theory. In Graduate Texts in Mathematics; Springer: New York, NY, USA, 1994. [Google Scholar]
- Hausdorff, F. Set Theory, 2nd ed.; Chelsea Publishing Company: New York, NY, USA, 1962. [Google Scholar]
- Kuratowski, K. Topology Volume I; Academic Press: New York, NY, USA, 1966; Volume 1. [Google Scholar]
- Von Neumann, J. Construction of Haar’s invariant measure in groups by approximately equidistributed finite point sets and explicit evaluations of approximations. In Invariant Measures; American Mathematical Society: Providence, RI, USA, 1999; Chapter 6; pp. 87–134. [Google Scholar]
- Ball, F.; Geyer-Schulz, A. Weak invariants of actions of the automorphism group of a graph. Arch. Data Sci. Ser. A 2017, 2, 1–22. [Google Scholar]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Bock, H.H. Automatische Klassifikation: Theoretische und praktische Methoden zur Gruppierung und Strukturierung von Daten; Vandenhoeck und Ruprecht: Göttingen, Germany, 1974. [Google Scholar]
- Rossi, R.; Fahmy, S.; Talukder, N. A Multi-level Approach for Evaluating Internet Topology Generators. In Proceedings of the 2013 IFIP Networking Conference, Trondheim, Norway, 2–4 June 2013; pp. 1–9. [Google Scholar]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Furst, M.; Hopcroft, J.; Luks, E. Polynomial-time Algorithms for Permutation Groups. In Proceedings of the 21st Annual Symposium on Foundations of Computer Science, Syracuse, NY, USA, 13–15 October 1980; pp. 36–41. [Google Scholar]
- McKay, B.D.; Piperno, A. Practical graph isomorphism, II. J. Symb. Comput. 2014, 60, 94–112. [Google Scholar] [CrossRef] [Green Version]
- Babai, L. Graph isomorphism in quasipolynomial time. arXiv, 2015; arXiv:1512.03547. [Google Scholar]
- Fortunato, S.; Barthélemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef] [PubMed]
- Lancichinetti, A.; Fortunato, S. Limits of modularity maximization in community detection. Phys. Rev. E 2011, 84, 66122. [Google Scholar] [CrossRef] [PubMed]
- Geyer-Schulz, A.; Ovelgönne, M.; Stein, M. Modified randomized modularity clustering: Adapting the resolution limit. In Algorithms from and for Nature and Life; Lausen, B., Van den Poel, D., Ultsch, A., Eds.; Studies in Classification, Data Analysis, and Knowledge Organization; Springer International Publishing: Heidelberg, Germany, 2013; pp. 355–363. [Google Scholar]
- Meilǎ, M. Comparing clusterings—An information based distance. J. Multivar. Anal. 2007, 98, 873–895. [Google Scholar] [CrossRef]
- Youness, G.; Saporta, G. Some measures of agreement between close partitions. Student 2004, 51, 1–12. [Google Scholar]
- Denœud, L.; Guénoche, A. Comparison of distance indices between partitions. In Data Science and Classification; Batagelj, V., Bock, H.H., Ferligoj, A., Žiberna, A., Eds.; Studies in Classification, Data Analysis, and Knowledge Organization; Springer: Berlin/Heidelberg, Germany, 2006; pp. 21–28. [Google Scholar]
- Albatineh, A.N.; Niewiadomska-Bugaj, M.; Mihalko, D. On similarity indices and correction for chance agreement. J. Classif. 2006, 23, 301–313. [Google Scholar] [CrossRef]
- Rand, W.M. Objective criteria for the evaluation of clustering algorithms. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar] [CrossRef]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Hamann, U. Merkmalsbestand und Verwandtschaftsbeziehungen der Farinosae: Ein Beitrag zum System der Monokotyledonen. Willdenowia 1961, 2, 639–768. [Google Scholar]
- Czekanowski, J. “Coefficient of Racial Likeness” und “Durchschnittliche Differenz”. Anthropol. Anz. 1932, 9, 227–249. [Google Scholar]
- Kulczynski, S. Zespoly roslin w Pieninach. Bull. Int. Acad. Pol. Sci. Lett. 1927, 2, 57–203. [Google Scholar]
- McConnaughey, B.H. The determination and analysis of plankton communities. Mar. Res. 1964, 1, 1–40. [Google Scholar]
- Peirce, C.S. The numerical measure of the success of predictions. Science 1884, 4, 453–454. [Google Scholar] [CrossRef] [PubMed]
- Wallace, D.L. A method for comparing two hierarchical clusterings: Comment. J. Am. Stat. Assoc. 1983, 78, 569–576. [Google Scholar] [CrossRef]
- Fowlkes, E.B.; Mallows, C.L. A method for comparing two hierarchical clusterings. J. Am. Stat. Assoc. 1983, 78, 553–569. [Google Scholar] [CrossRef]
- Yule, G.U. On the association of attributes in statistics: With illustrations from the material of the childhood society. Philos. Trans. R. Soc. A 1900, 194, 257–319. [Google Scholar] [CrossRef]
- Sokal, R.R.; Sneath, P.H.A. Principles of Numerical Taxonomy; W. H. Freeman: San Francisco, CA, USA; London, UK, 1963. [Google Scholar]
- Baulieu, F.B. A classification of presence/absence based dissimilarity coefficients. J. Classif. 1989, 6, 233–246. [Google Scholar] [CrossRef]
- Gower, J.C.; Legendre, P. Metric and euclidean properties of dissimilarity coefficients. J. Classif. 1986, 3, 5–48. [Google Scholar] [CrossRef]
- Rogers, D.J.; Tanimoto, T.T. A computer program for classifying plants. Science 1960, 132, 1115–1118. [Google Scholar] [CrossRef] [PubMed]
- Goodman, L.A.; Kruskal, W.H. Measures of association for cross classifications. J. Am. Stat. Assoc. 1954, 49, 732–764. [Google Scholar]
- Robert, P.; Escoufier, Y. A unifying tool for linear multivariate statistical methods: The RV-coefficient. J. R. Stat. Soc. Ser. C 1976, 25, 257–265. [Google Scholar] [CrossRef]
- Russel, P.F.; Rao, T.R. On habitat and association of species of anopheline larvae in south-eastern madras. J. Malar. Inst. India 1940, 3, 153–178. [Google Scholar]
- Mirkin, B.G.; Chernyi, L.B. Measurement of the distance between partitions of a finite set of objects. Autom. Remote Control 1970, 31, 786–792. [Google Scholar]
- Hilbert, D. Gesammelte Abhandlungen von Hermann Minkowski, Zweiter Band; Number 2; B. G. Teubner: Leipzig, UK; Berlin, Germany, 1911. [Google Scholar]
- Pearson, K. On the coefficient of racial likeness. Biometrika 1926, 18, 105–117. [Google Scholar] [CrossRef]
- Lerman, I.C. Comparing Partitions (Mathematical and Statistical Aspects). In Classification and Related Methods of Data Analysis; Bock, H.H., Ed.; North-Holland: Amsterdam, The Netherlands, 1988; pp. 121–132. [Google Scholar]
- Fager, E.W.; McGowan, J.A. Zooplankton species groups in the north pacific co-occurrences of species can be used to derive groups whose members react similarly to water-mass types. Science 1963, 140, 453–460. [Google Scholar] [CrossRef] [PubMed]
- Larsen, B.; Aone, C. Fast and Effective Text Mining Using Linear-time Document Clustering. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; ACM: New York, NY, USA, 1999; pp. 16–22. [Google Scholar]
- Meilǎ, M.; Heckerman, D. An experimental comparison of model-based clustering methods. Mach. Learn. 2001, 42, 9–29. [Google Scholar] [CrossRef]
- Van Dongen, S. Performance Criteria for Graph Clustering and Markov Cluster Experiments; Technical Report INS-R 0012; CWI (Centre for Mathematics and Computer Science): Amsterdam, The Netherlands, 2000. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Meilǎ, M. Comparing clusterings by the variation of information. In Learning Theory and Kernel Machines; Schölkopf, B., Warmuth, M.K., Eds.; Number 2777 in Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; pp. 173–187. [Google Scholar]
- Danon, L.; Díaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]
Figure 1.
Two structurally different partitions of the cycle graph C4: grouping pairs of neighbors (a) and grouping pairs of diagonals (d). Equally-colored nodes represent graph clusters, and the choice of colors is arbitrary. Adding, again arbitrary, but fixed, node labels impacts the node partitions and results in the failure to recognize the structural difference when comparing these partitions with partition comparison measures (see Table 1). The different images (b,c) (, and (e,f) ) emerge from the graph’s symmetry.
Figure 1.
Two structurally different partitions of the cycle graph C4: grouping pairs of neighbors (a) and grouping pairs of diagonals (d). Equally-colored nodes represent graph clusters, and the choice of colors is arbitrary. Adding, again arbitrary, but fixed, node labels impacts the node partitions and results in the failure to recognize the structural difference when comparing these partitions with partition comparison measures (see Table 1). The different images (b,c) (, and (e,f) ) emerge from the graph’s symmetry.
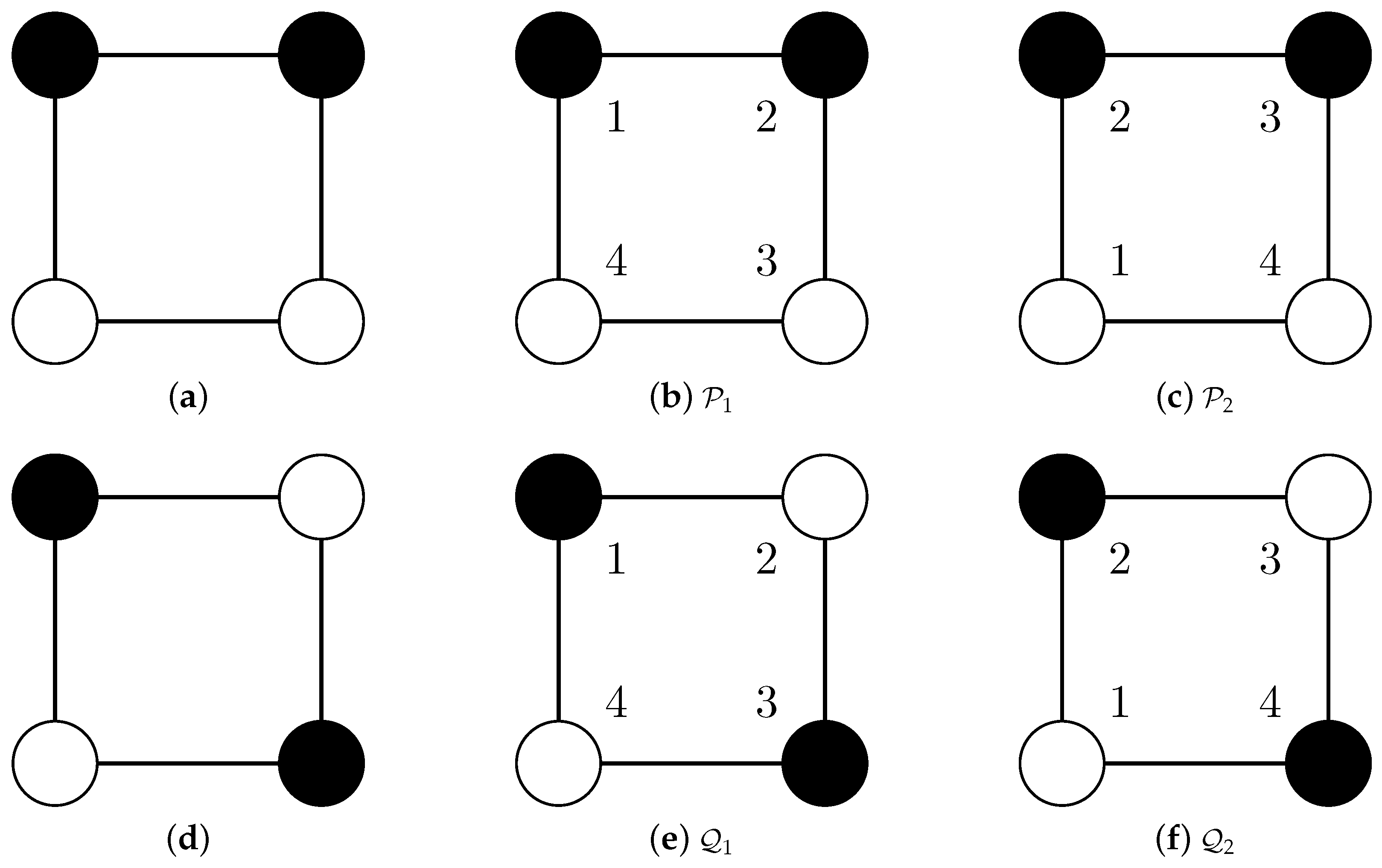
Figure 2.
The butterfly graph (five nodes, with two node pairs connected by the bridging node 3).
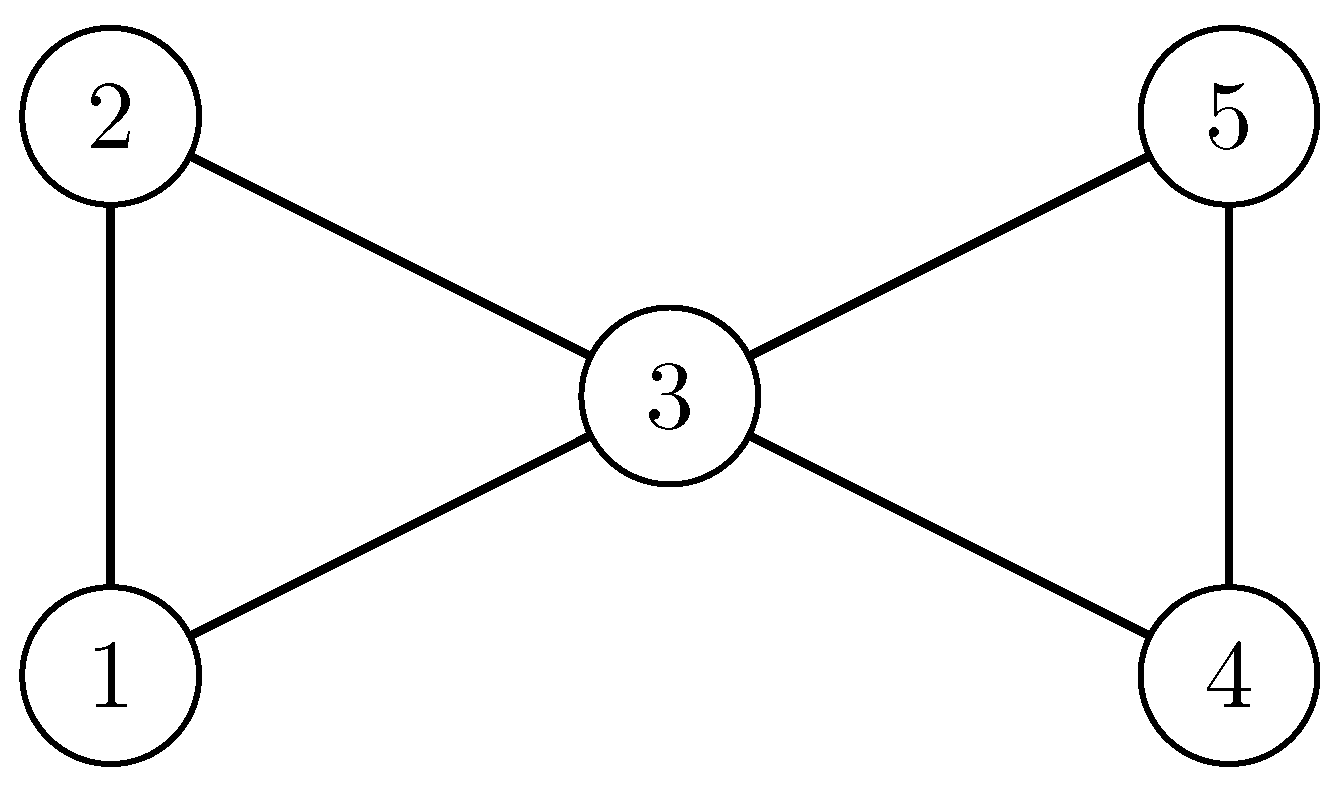
Figure 3.
The cycle graph (the “outer” cycle) and an initial partition of six clusters (connected nodes of the same color, separated by dashed lines). A single application of “rotates” the graph by one node (the “inner” cycle ). As a consequence, in each cluster, one node drops out and is added to another cluster: For instance, Node 1 drops out of the “original” cluster , and Node 7 is added, resulting in . All dropped nodes are shown in light gray.
Figure 3.
The cycle graph (the “outer” cycle) and an initial partition of six clusters (connected nodes of the same color, separated by dashed lines). A single application of “rotates” the graph by one node (the “inner” cycle ). As a consequence, in each cluster, one node drops out and is added to another cluster: For instance, Node 1 drops out of the “original” cluster , and Node 7 is added, resulting in . All dropped nodes are shown in light gray.
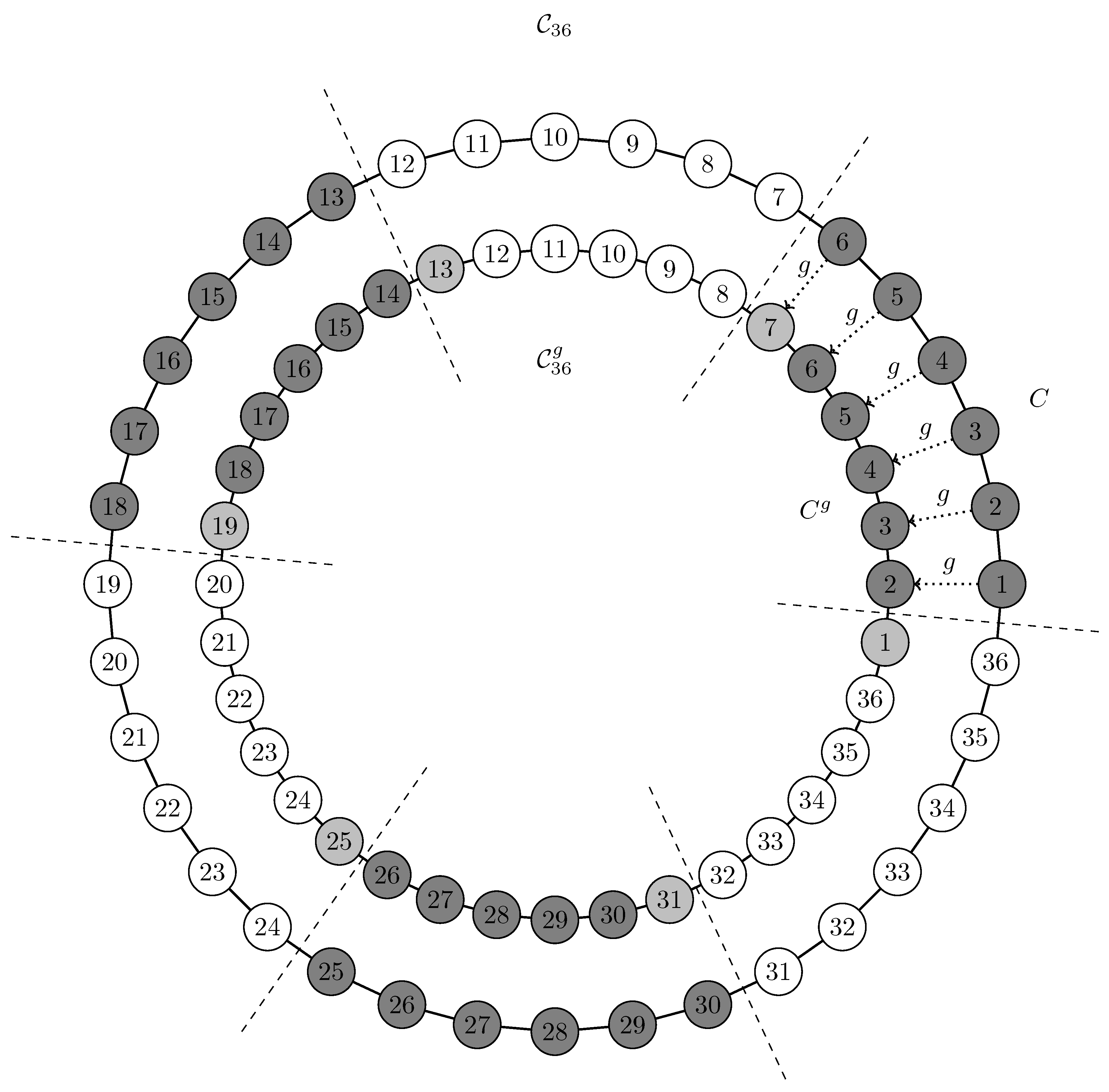
Figure 4.
Zachary’s Karate graph K with the vertices of the orbits of the three subgroups of in bold and the clusters of separated by dashed edges.
Figure 4.
Zachary’s Karate graph K with the vertices of the orbits of the three subgroups of in bold and the clusters of separated by dashed edges.
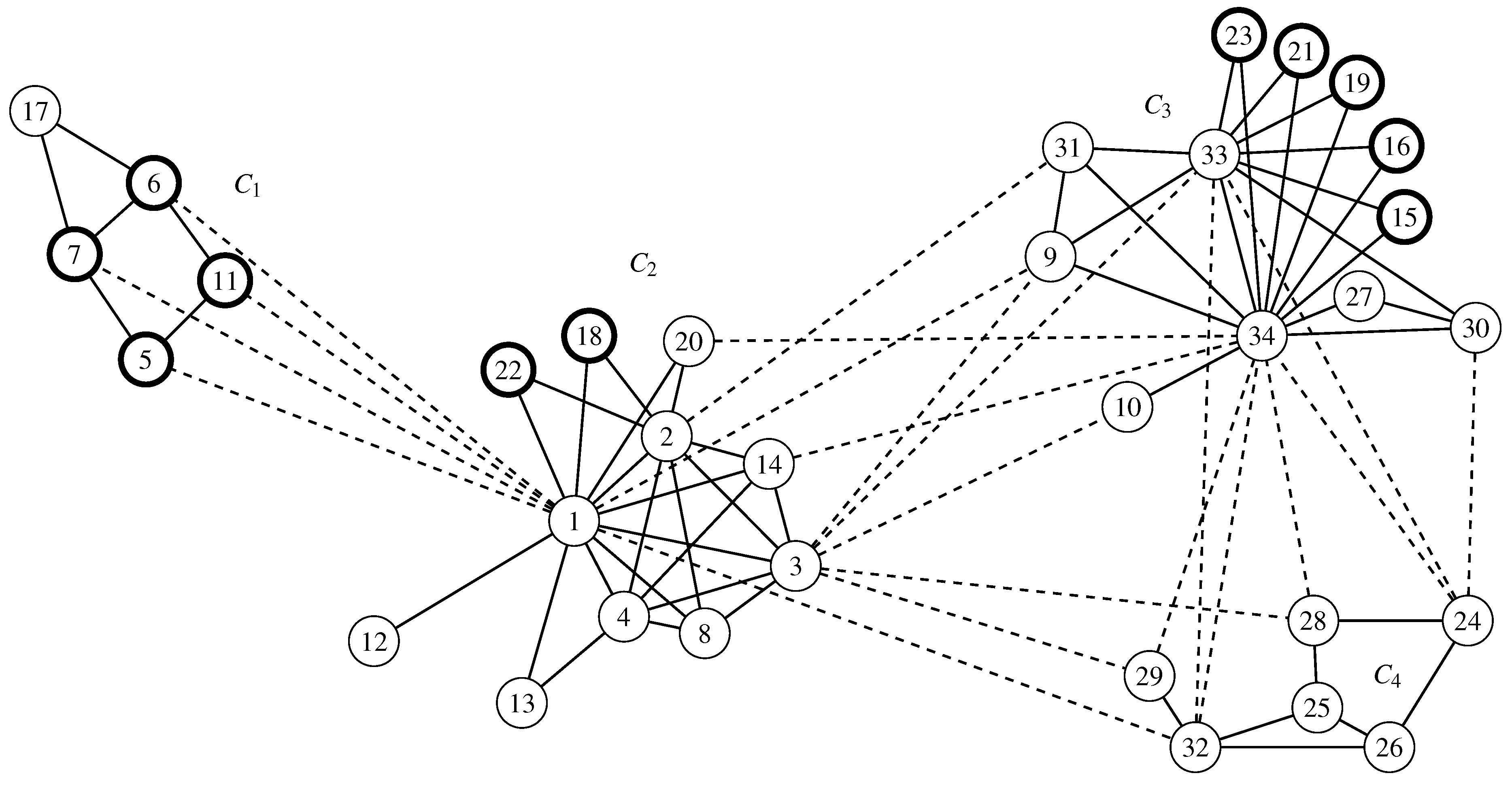
Table 1.
The Rand index is . indicates the number of nodes that are in both partitions together in a cluster; and are the number of nodes that are together in a cluster in one partition, but not in the other; and are the number of nodes that are in both partitions in different clusters. See Appendix B for the formal definitions. Partitions and are equivalent (yet not equal, denoted “∼”), and partitions and are identical (thus, also equivalent, denoted “=”). However, the comparison of the structurally different partitions (denoted “≠”) and yields the same result as the comparison between the equivalent partitions and . This makes the recognition of structural differences impossible.
Table 1.
The Rand index is . indicates the number of nodes that are in both partitions together in a cluster; and are the number of nodes that are together in a cluster in one partition, but not in the other; and are the number of nodes that are in both partitions in different clusters. See Appendix B for the formal definitions. Partitions and are equivalent (yet not equal, denoted “∼”), and partitions and are identical (thus, also equivalent, denoted “=”). However, the comparison of the structurally different partitions (denoted “≠”) and yields the same result as the comparison between the equivalent partitions and . This makes the recognition of structural differences impossible.
| Case | Compared Partitions | Relation | RI | ||||
|---|---|---|---|---|---|---|---|
| 1 | = | 2 | 0 | 0 | 4 | 1 | |
| 2 | = | 2 | 0 | 0 | 4 | 1 | |
| 3 | or or | = | 2 | 0 | 0 | 4 | 1 |
| 4 | or | ≠ | 0 | 2 | 2 | 2 | |
| 5 | or | ≠ | 0 | 2 | 2 | 2 | |
| 6 | ∼ | 0 | 2 | 2 | 2 |
Table 2.
The full automorphism group of the butterfly graph in Figure 2 and its effect on three partitions. Bold partitions are distinct. A possible generator is .
Table 2.
The full automorphism group of the butterfly graph in Figure 2 and its effect on three partitions. Bold partitions are distinct. A possible generator is .
| Permutation | |||
|---|---|---|---|
Table 3.
Comparing the modularity maximizing partitions of the cycle graph with modularity . The six optimal partitions consist of six clusters (see Figure 3). The number of pairs in the same cluster in both partitions is denoted by , in different clusters by and in the same cluster in one partition, but not in the other, by or . For the definitions of all partition comparison measures, see Appendix B. To compute this table, the R package partitionComparison has been used [23].
Table 3.
Comparing the modularity maximizing partitions of the cycle graph with modularity . The six optimal partitions consist of six clusters (see Figure 3). The number of pairs in the same cluster in both partitions is denoted by , in different clusters by and in the same cluster in one partition, but not in the other, by or . For the definitions of all partition comparison measures, see Appendix B. To compute this table, the R package partitionComparison has been used [23].
| Measure | with for k: | |||||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |
| Pair counting measures (; see Table A1 and Table A2) | ||||||
| RI | ||||||
| ARI | ||||||
| H | ||||||
| CZ | ||||||
| K | ||||||
| MC | ||||||
| P | ||||||
| WI | ||||||
| WII | ||||||
| FM | ||||||
| SS1 | ||||||
| B1 | ||||||
| GL | ||||||
| SS2 | ||||||
| SS3 | ||||||
| RT | ||||||
| GK | ||||||
| J | ||||||
| RV | ||||||
| RR | ||||||
| M | 12 | 19 | 21 | 19 | 12 | |
| Mi | ||||||
| Pe | ||||||
| B2 | ||||||
| LI | 2 | 1 | 1 | |||
| NLI | ||||||
| FMG | ||||||
| Set-based comparison measures (see Table A3) | ||||||
| LA | ||||||
| D | 1 | 2 | 3 | 2 | 1 | |
| Information theory-based measures (see Table A4) | ||||||
| MI | ||||||
| NMI (max) | ||||||
| NMI (min) | ||||||
| NMI () | ||||||
| VI | ||||||
Table 4.
The equivalence classes of the pseudometric space of the butterfly graph (see Figure 2). Classes are grouped by their partition type, which is the corresponding integer partition. k is the number of partitions per type; l is the number of clusters the partitions of a type consists of; is the diameter (see Equation (2)) of the equivalence class computed for the distance computed from the Rand Index (RI) by .
Table 4.
The equivalence classes of the pseudometric space of the butterfly graph (see Figure 2). Classes are grouped by their partition type, which is the corresponding integer partition. k is the number of partitions per type; l is the number of clusters the partitions of a type consists of; is the diameter (see Equation (2)) of the equivalence class computed for the distance computed from the Rand Index (RI) by .
| Q | |||
|---|---|---|---|
| Partition type , , | |||
| Partition type , , | |||
| Partition type , | |||
| 0 | |||
| Partition type , , | |||
| 0 | |||
| Partition type , , | |||
| Partition type , , | |||
| Partition type , , | |||
| 0 |
Table 5.
Measure decomposition for partitions of the butterfly graph for the Rand distance .
| Case | ||||||
|---|---|---|---|---|---|---|
| 1 | 0.3 | 0.3 | 0.0 | |||
| 0.3 | 0.5 | −0.2 | ||||
| 0.3 | 0.7 | −0.4 | ||||
| 2 | 0.6 | 0.2 | 0.4 | |||
| 0.6 | 0.4 | 0.2 | ||||
| 0.6 | 0.6 | 0.0 | ||||
| 3 | 0.3 | 0.1 | 0.2 | |||
| 0.3 | 0.25 | 0.05 | ||||
| 0.3 | 0.3 | 0.0 | ||||
| 4 | 0.3 | 0.3 | 0.0 | |||
| 0.3 | 0.3 | 0.0 | ||||
| (, stable) | 0.3 | 0.3 | 0.0 |
Table 6.
Diameter (computed using ), orbit size and stability of partitions , and .
| 1 | 20 | 20 | |
| stable? | yes | no | no |
Table 7.
Invariant measures and automorphism effects for the Karate graph. The R package partitionComparison has been used for the computations [23].
Table 7.
Invariant measures and automorphism effects for the Karate graph. The R package partitionComparison has been used for the computations [23].
| Measure | |||
|---|---|---|---|
| d | |||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ball, F.; Geyer-Schulz, A. Invariant Graph Partition Comparison Measures. Symmetry 2018, 10, 504. https://doi.org/10.3390/sym10100504
AMA Style
Ball F, Geyer-Schulz A. Invariant Graph Partition Comparison Measures. Symmetry. 2018; 10(10):504. https://doi.org/10.3390/sym10100504
Chicago/Turabian StyleBall, Fabian, and Andreas Geyer-Schulz. 2018. "Invariant Graph Partition Comparison Measures" Symmetry 10, no. 10: 504. https://doi.org/10.3390/sym10100504
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.