1. Introduction
Land Cover Change (LCC) is a dynamic process with spatial and temporal dependencies. The interactions within and between human and natural environmental systems propagate LCCs over space and time [
1]. These local-level interactions give rise to patterns observed at global scales [
2]. For instance, anthropogenic disturbances such as deforestation directly and indirectly induce increased CO
2 levels and affect local weather changes, making LCC important to consider as global temperatures rise [
3,
4,
5,
6]. LCC research is significant to many disciplines such as geography, urban planning, environmental science, forestry, agriculture, and resource management [
7,
8,
9].
Land changes have been previously modeled using methods that capture local-level interactions occurring over space and time. These include geographic automata approaches, comprised of Agent-Based Models (ABMs) and Cellular Automata (CA) [
10]. For instance, encoded agents can capture decision-making processes of individuals or groups [
11,
12]. Such decisions have implications on the environment represented in an ABM. CAs have also been demonstrated to capture land change over time according to pre-defined transition rules across a regular [
13,
14,
15] or irregular-grid environment [
16]. Different types of ML models have also been used in conjunction with CA, including support vector machines [
17,
18], random forests [
19], neural networks [
20], and Markov models [
21]. Another integration considered an ABM, a CA, and a system dynamics model to facilitate interactions across multiple scales that drive land changes [
22]. However, limited knowledge of individuals or disaggregated system behaviours impose limits on what type of model can be used [
23]. As such, data-driven methods may be used in situations where patterns and relationships driving land change are unknown.
Given the complexity of LCC, statistical learning approaches have been applied for analyses in this domain [
24,
25]. Earlier approaches include regression models that integrate field measurements alongside classified LC data [
26]. Throughout the past decade, data-driven modeling methods usage has been rising with the unprecedented availability of data, the Big Data paradigm shift, and the escalating capacity of computational resources [
27]. While Machine Learning (ML) algorithms automate pattern recognition with minimal manual interference, it is important to acknowledge that these techniques are deterministic approaches to modeling non-linear spatial processes. With increasing dimensionality and volume of modern datasets, ML algorithms typically perform with great efficacy. Several ML approaches previously applied for Land Cover (LC) classification and forecasting have included Neural Networks (NNs) [
28], Decision Trees [
24,
29], Random Forests [
24,
30], and Support Vector Machines [
24,
31].
A subfield of ML characterized by NNs of increasing depth and breadth is called Deep Learning (DL). DL techniques facilitate automated learning of feature representations and have demonstrated ability to capture intricate, hierarchical relationships from a dataset [
32]. A Recurrent Neural Network (RNN) is a type of NN suitable for sequential data. With internal memory allocated to each neuron, RNNs are useful for capturing dynamic, temporal dependencies [
33]. RNNs, specifically the Long Short-Term Memory (LSTM) variation, have exhibited propitious performance in previous LCC analyses [
25,
34,
35]. However, geospatial input data characteristics conducive to the success of LSTMs have not been fully studied. This motivates an investigation of the method’s response to varying geospatial data qualities by means of Sensitivity Analysis (SA).
SA is helpful for assessing the effects of geospatial input data properties on model outputs [
36]. For example, SA approaches applied to ABMs [
37] and CAs [
38] have been considered. SA approaches were also employed for super-resolution LC mapping [
39] and LCC modeling [
40,
41]. Furthermore, perturbations to inputs provided to a decision-tree modeling approach were explored with respect to overall test accuracy and the number of cells changed [
42]. Prior studies involving ML techniques have also emphasized measuring a model’s capacity to forecast changed cells correctly [
43]. Traditional NNs and DL approaches used for applications besides LCC have been explored for their sensitivity to input representations [
44], introduction of noise [
45], and input variables [
46]. While extensive numbers of parameters and permutations characterize methods such as geographic automata and data-driven approaches, it is important to consider what characteristics of an inputted dataset are conducive to or impede the usefulness of a selected method.
This compels a study to assess the implications of changing geospatial input data properties on the performance of LSTM models and to evaluate their ability to forecast localized LCCs using a SA. Facets of LCC processes such as LCC rate, temporal variations, and local-scale processes are important to consider [
47]. Previous work indicated that when considering four LC classes, the method performance was impacted by fast-changing phenomena [
48]. However, it was unknown whether this trend persisted given LC datasets with increasing cardinality. As such, the impact of both varying temporal resolution and number of LC classes is explored in this work. This research considers LCC sequences extracted along the temporal dimension for each cell within various hypothetical and real-world datasets featuring different numbers of LC classes as input to LSTM models. Hypothetical datasets are first created and utilized to reconstruct real-world LCC scenarios occurring in localized study areas. By reducing the hypothetical data complexity for this study, it is intended to highlight trends in results generated. Experiments are then conducted on real-world data to observe if trends observed in the hypothetical data trials are similar. Given the increasing availability of multi-year LC datasets, it is important to better understand what properties should be present to use this data-driven sequential method. By exploring results obtained from applying LSTM modeling scenarios to hypothetical and real-world datasets, the aim is to guide future real-world data selection for potential use with the explored method. Similarly, this research work intends to help inform researchers who have already acquired geospatial data whether this method is appropriate given the temporal resolution, number of timesteps, number of classes, and rates of change characterizing their dataset.
To explore which data properties should exist to use this method, an SA is evaluated with a collection of incremental modeling scenarios involving a selection of Kappa metrics. The main objective of this research study is to explore and evaluate the impact of varying temporal resolution on LC changes forecasted using LSTM models and datasets featuring different numbers of classes. The metrics are selected for measuring these effects with respect to how well the respective modeling scenarios forecast changed cells, since LCC typically exhibits slow or scarce changes over time. The quantities of interest are the changed cells forecasted correctly by the model. It is hypothesized that performance of these sequential DL models will be impeded by low temporal resolutions, which feature shorter sequence lengths. Likewise, it is expected that greater LCC occurrences will ensure changes are captured better in all modeling scenarios applied to hypothetical and real-world datasets. It is also anticipated that experiments considering fewer unique classes will yield more favourable results.
2. Theoretical Background and Geospatial Applications of RNNs
Traditional feed-forward NN models utilize gradient-based learning methods to update model parameters as new inputs are provided. The goal is to determine an optimal set of network weights that allow the model to generalize to new data. Inputs are fed through the network, a cost function is evaluated, and an error term is computed using the result obtained from the output layer. Derivatives are computed with respect to each weight in the network using a process called backpropagation [
49,
50]. Backpropagation informs adjustments of network weight parameters with the intent of minimizing the error term.
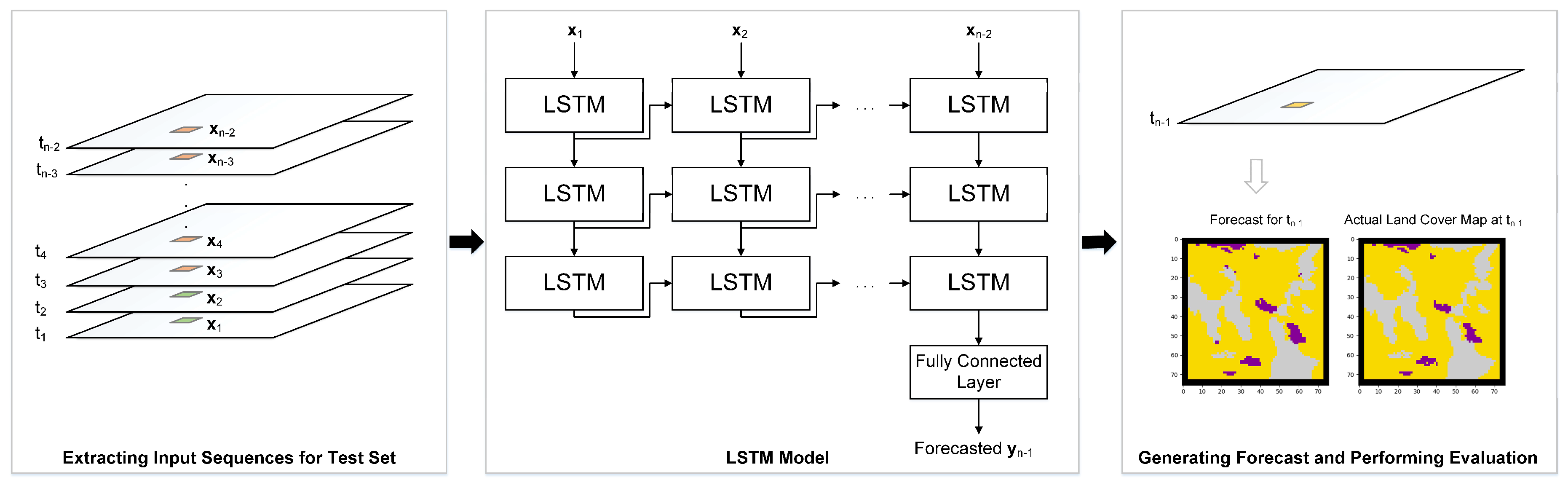
RNNs are a type of Deep Neural Network (DNN) that are best suited for problems involving sequential data, including classification and forecasting of timeseries data. By introducing a recurrence relation to the standard feed-forward neuron, information from previous timesteps is propagated to inform future cell state changes and outputs. Traditional RNNs are a specialized variation of traditional neural network neurons that maintain and update a hidden state value. The hidden state enables a recurrent neuron to maintain information regarding previously observed data in a sequence to facilitate learning of temporal correlations [
51]. However, RNN structures are impeded by a phenomenon called a “Vanishing Gradient” [
52]. This occurrence inhibits the propagation of previous information and is caused by the inability to maintain gradients to backpropagate updates with respect to the error term. Gradients that are too small (vanishing) or too large (exploding) prevent any meaningful adjustments of network weights. This required alterations to the RNN architecture to handle long-term dependencies.
A notable architecture advancement of the RNN is called Long Short-Term Memory (LSTM), developed to solve the “Vanishing Gradient” problem [
33]. This definition is characterized by the addition of
memory cells to maintain information regarding previous states and
gates to permit or prevent information to be stored within the memory cell. The idea was to maintain the error term to ensure the error signals were not lost due to the Vanishing Gradient problem [
33]. To further improve the LSTM architecture, it was suggested that a
forget gate be added to enable an LSTM to drop information that has been maintained if the contents are no longer of use [
53]. Gates in a modern LSTM cell include an
input gate,
forget gate,
output gate, and
input modulation gate, which control how much information is permitted to propagate through the cell [
25,
35]. Explanations of the updates of an LSTM cell at timestep
t when provided an input can be found at Donahue et al. [
54].
RNNs have been used for classification and forecasting tasks in geospatial applications [
9]. To apply RNNs to geospatial datasets, cell-wise (or pixel-wise) temporal sequences are provided as training data with a corresponding “training label” signifying the next data entry in the timeseries at the location being considered. Sauter et al. [
55] utilized snow cover derived from MODIS satellite data with meteorological data to develop a snow depth forecasting system using an early RNN approach. More recently, an LSTM model called REFEREE [
35] demonstrated the abilities of RNN for binary and multi-class LCC detection. The transfer learning scenario involved various study areas featuring urban, water, soil, and agriculture LCs. LSTMs have also been used to forecast sea ice concentration, with input sequences extracted along the temporal dimension for each cell in the raster dataset [
56]. In addition, RNNs have proven effective in LC classification. Provided timeseries inputs consisting of 3- and 23-timesteps, an LSTM model showed improved performance over Random Forest and Support Vector Machine methods [
25].
Though it is acknowledged that a multitude of RNN architectures and variants exist, LSTM has been selected for this study as the primary architecture to be evaluated for its capacity to model LCC. A prior study compared the performance of LSTM and its variants, demonstrating insignificant improvements obtained over the traditional LSTM architecture in applications such as handwriting recognition and music modeling [
57]. It was also demonstrated that traditional LSTM networks have the capacity to reliably obtain improved performance versus its simplified variant, the Gated Recurrent Unit (GRU) [
58], in large-scale “neural machine translation” tasks [
59]. Stacked LSTMs have also been previously explored for LCC with respect to varying temporal resolutions, rates of LCC, and errors arising from classification procedures [
48]. Considering four LC classes in experiments, the results indicated the importance of finer temporal resolutions and the inclusion of more timesteps to increase the capacity of this method to forecast LCCs.
While previous studies have demonstrated the effectiveness of RNNs and variants for geospatial applications, the performance of these methods with respect to geospatial data properties remains an open problem. Therefore, this research study explores the repercussions of temporal resolution and LC class count present in the input dataset. Changing these characteristics alters the sequence length and rates of LCCs provided as input to the LSTM models. Using SA applied to three modeling scenarios considering hypothetical and real-world data, the goal of this study is to explore the response of RNNs to varying geospatial data inputs.
5. Results
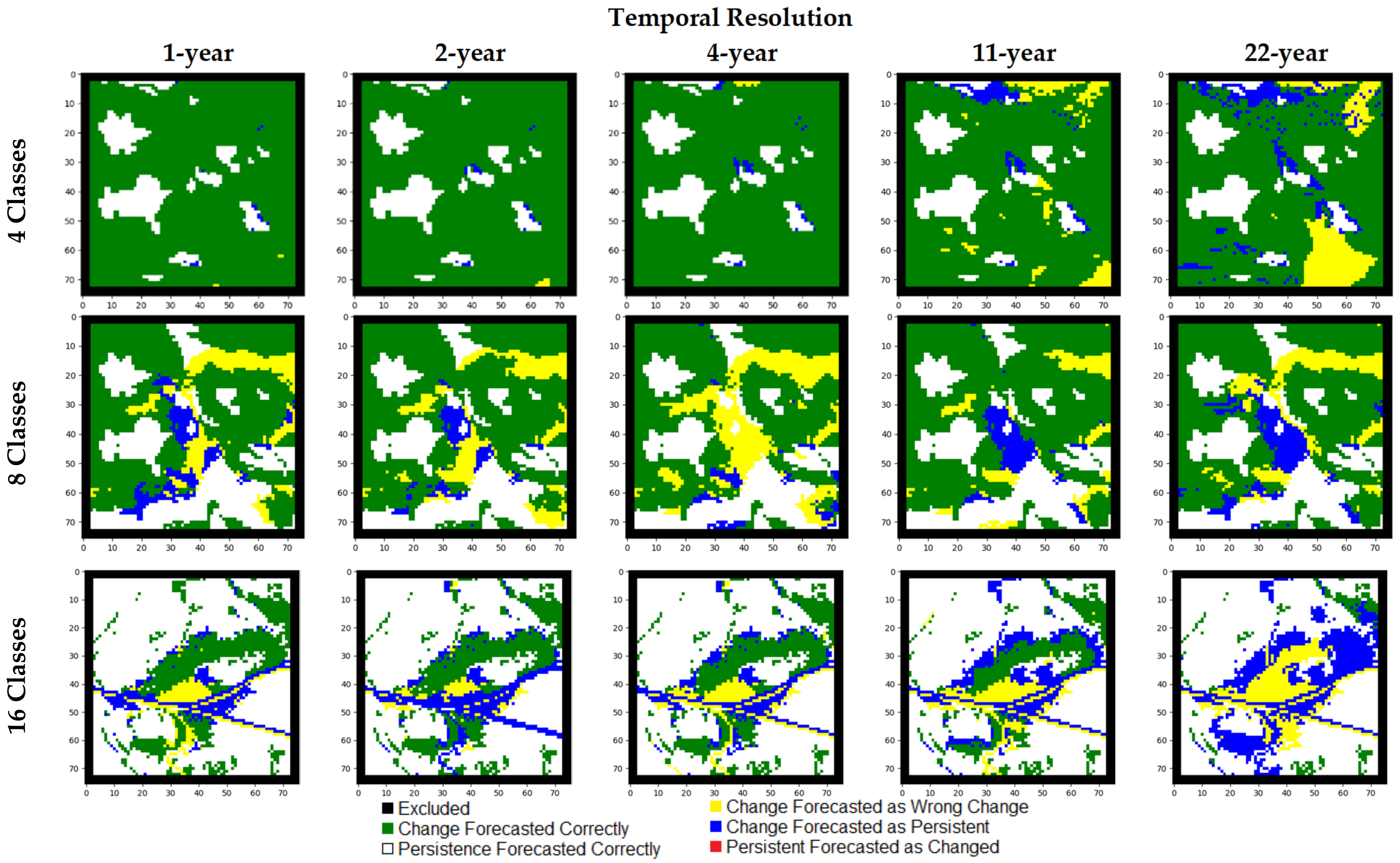
All modeling scenarios (A, B, and C) were run to generate results using the hypothetical and real-world datasets. This means that one run of a modeling scenario for the hypothetical datasets considers one of the 4, 8, or 16 class datasets, one of the full sequence or subset sequences, one of the temporal resolutions, and varying numbers of epochs to obtain one model and subsequent output. Considering the real-world datasets, each experiment considered one of the 4, 8, or 15 class datasets, one of the temporal resolutions, and varying numbers of epochs to obtain one model and the respective output. For each of the outputs generated by the respective models trained on either the hypothetical or real-world datasets, the various measures such as accuracy of changed cells and the suite of Kappa measures were computed. Additional to map comparison metrics, qualitative outputs were also produced for each model evaluation. These include simulation maps and maps featuring misses produced in the forecast. Overall, it was found that results from all three modeling scenarios were similar. Consequently, the results have been indicated by the regularized stochastic scenario (Model C) to explore the effects of temporal resolution and LC class cardinality on model performance.
5.1. Results of Experiments with Hypothetical Data
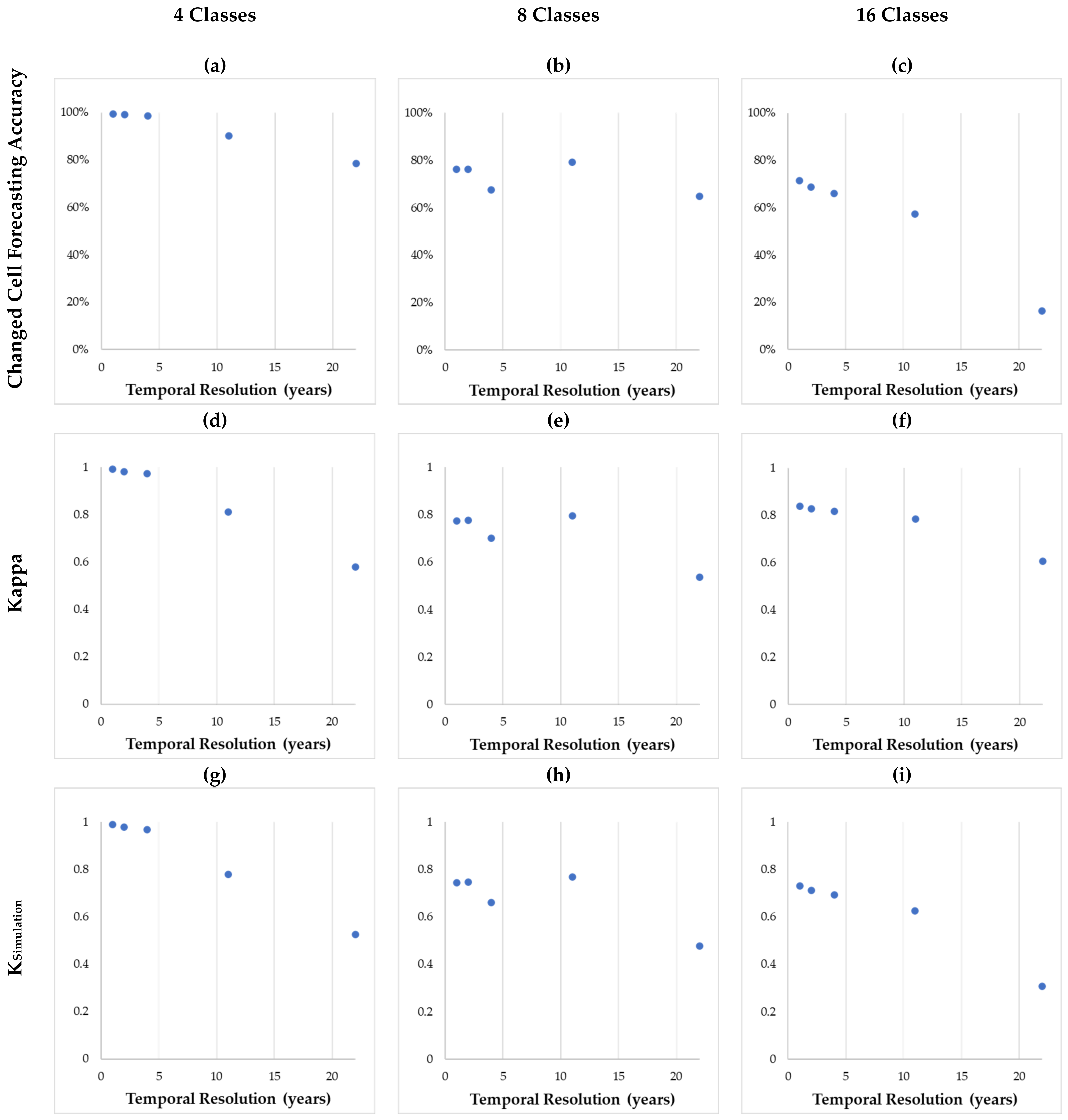
The results for
full sequence tests featuring 45 years indicate models perform better with finer temporal resolutions (
Table 7,
Figure 5). Kappa, K
Histogram, K
Simulation, and K
Transition measures exhibited distinct decreases as temporal resolution becomes coarser (i.e., fewer data layers) and as the number of classes increases. As the number of classes characterizing the study area increases, the number of errors in the forecasted map increase, demonstrated in
Figure 6. The K
Simulation measures decrease as temporal resolution becomes coarser and cardinality increases. For instance, K
Simulation measures obtained using one-year temporal resolution data with 4, 8, and 16 LC classes are 0.99, 0.74, and 0.73, respectively. In almost all configurations, high agreements of persistent cells within the reference and forecasted map outputs were achieved. Simulation maps using the
full sequence datasets are depicted in
Figure 7.
The results for 15-year sequence tests show the K
Simulation and K
Transition metrics exhibiting sharp decreases as temporal resolution becomes coarser (
Table 8,
Table 9 and
Table 10). With respect to the number of LC changes occurring, the overall map comparison metrics including Kappa, K
Histogram, and K
Location are typically higher when the number of LC changes is lower. As the number of changed cells increases, these measures of map agreement decrease. It is also observed that these shorter sequence lengths used for input to the sequential models result in lower performance metrics than in the 45-year sequence tests in most cases. Results obtained using the 15-year sequences have been shown in
Table 8,
Table 9 and
Table 10.
5.2. Results of Experiments with Real-world Data
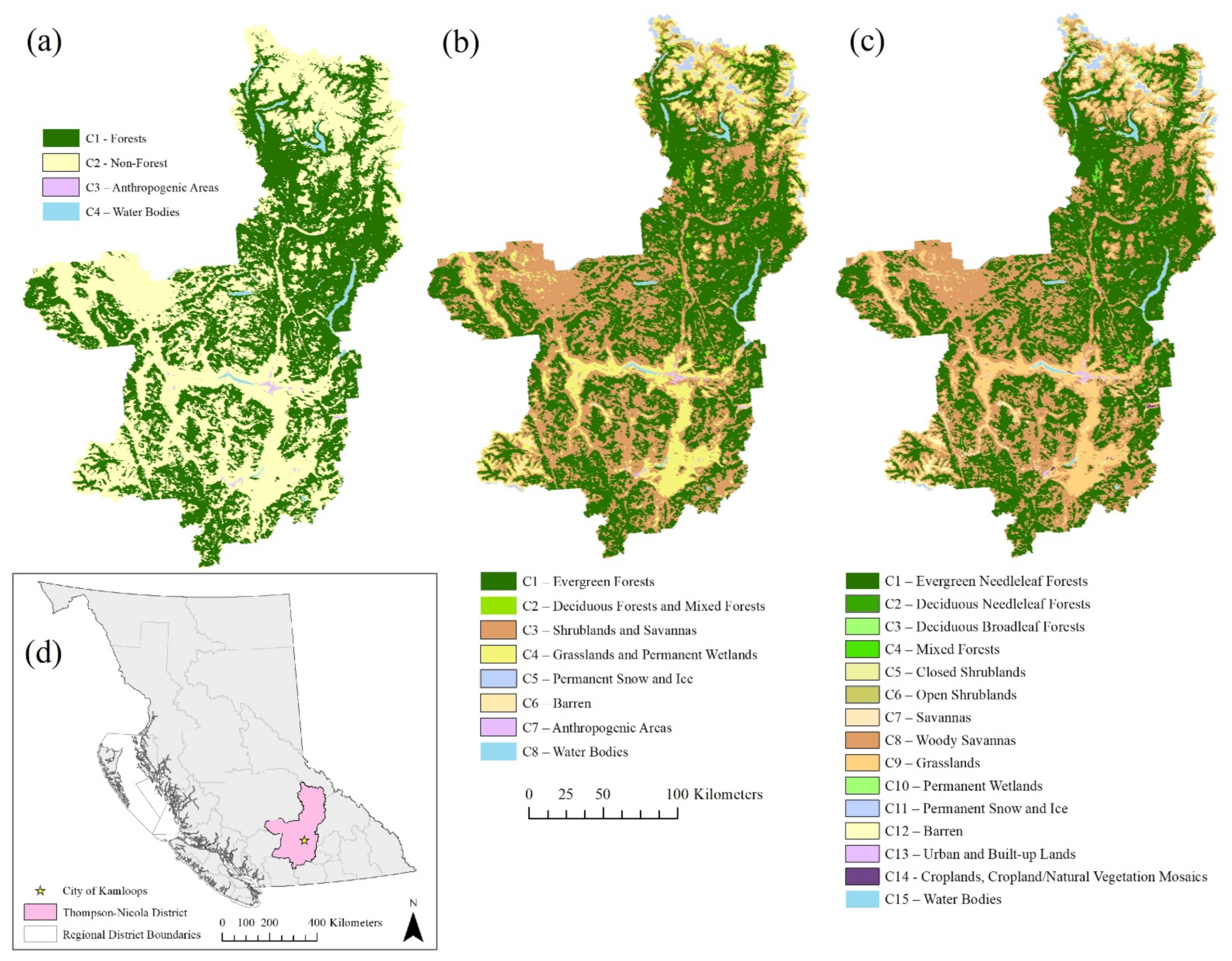
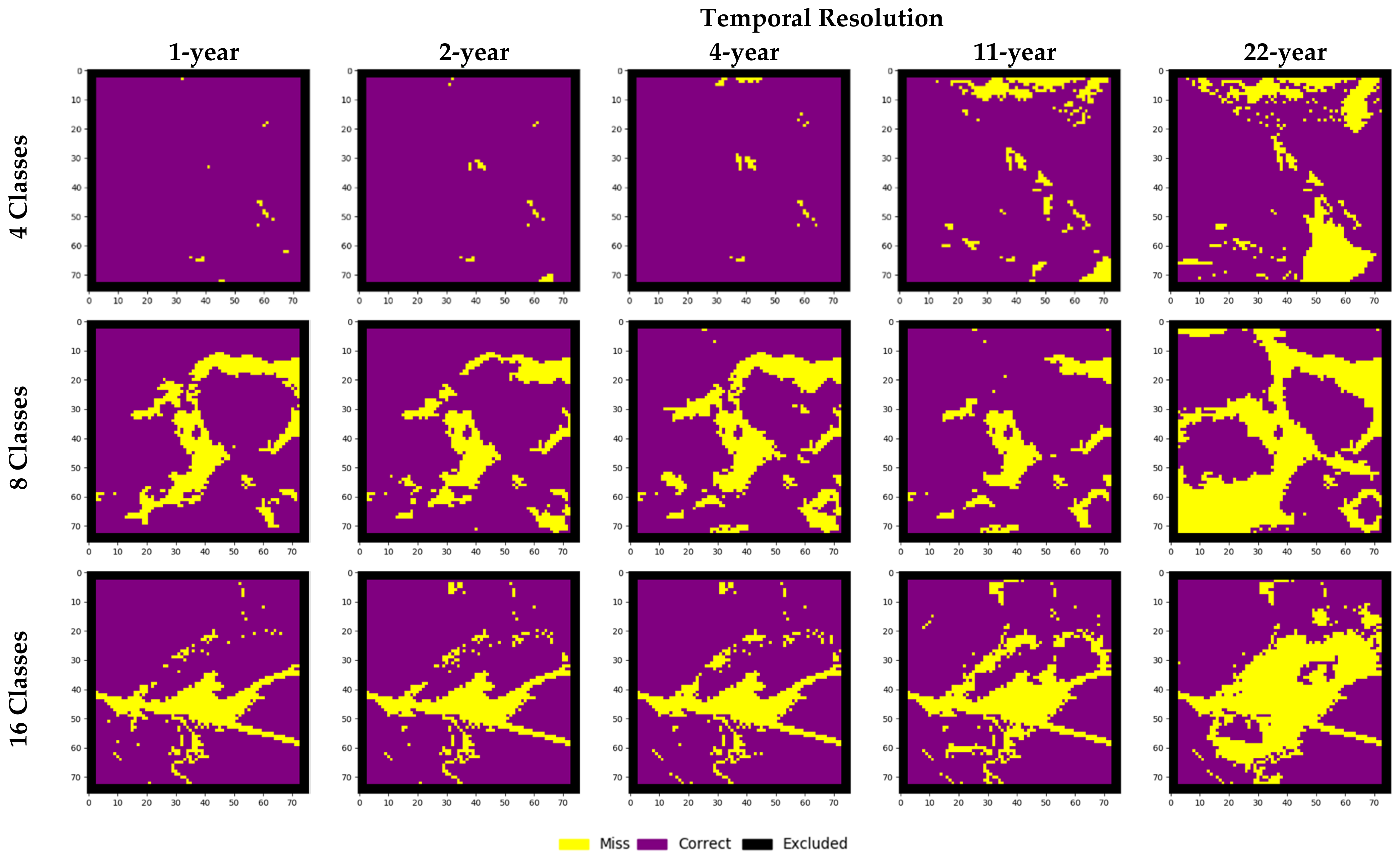
The results of the real-world data experiments considering each of the respective classes are shown in
Table 11. All measures exhibited decreases as temporal resolution became coarser, except for the changed cell forecasting accuracy and K
Location measures produced using the four-class dataset as input. Likewise, when the number of LC classes increases, it is observed that the capacity of the models to forecast changed cells decreases. This is observed in the error maps focused on the City of Kamloops (
Figure 8). The increasing number of errors in changed or persistent cells is reflected partially in the traditional Kappa metric, showing the agreement between the simulated and reference maps slightly decreasing from approximately 0.91 for the four-class dataset to 0.88 for the 15-class dataset. Larger differences between these two are exhibited in the K
Simulation measure, indicating a greater presence of errors attributed to changed cells in the 15-class dataset as temporal resolution becomes coarser. The simulation maps focused on the City of Kamloops demonstrate this aspect of the outputs, showing an increasing number of cells that wrongly changed or remained persistent as the temporal resolution increases (
Figure 9). While the K
Transition measure indicates a high agreement of the quantity of transitions in each of the outcomes, the K
Translocation measure indicates that such transitions did not meet quite as high agreement of correct locations for these forecasted LC transitions. This is the case across all temporal resolution options except for those considering the nine-year temporal resolution.
6. Discussion
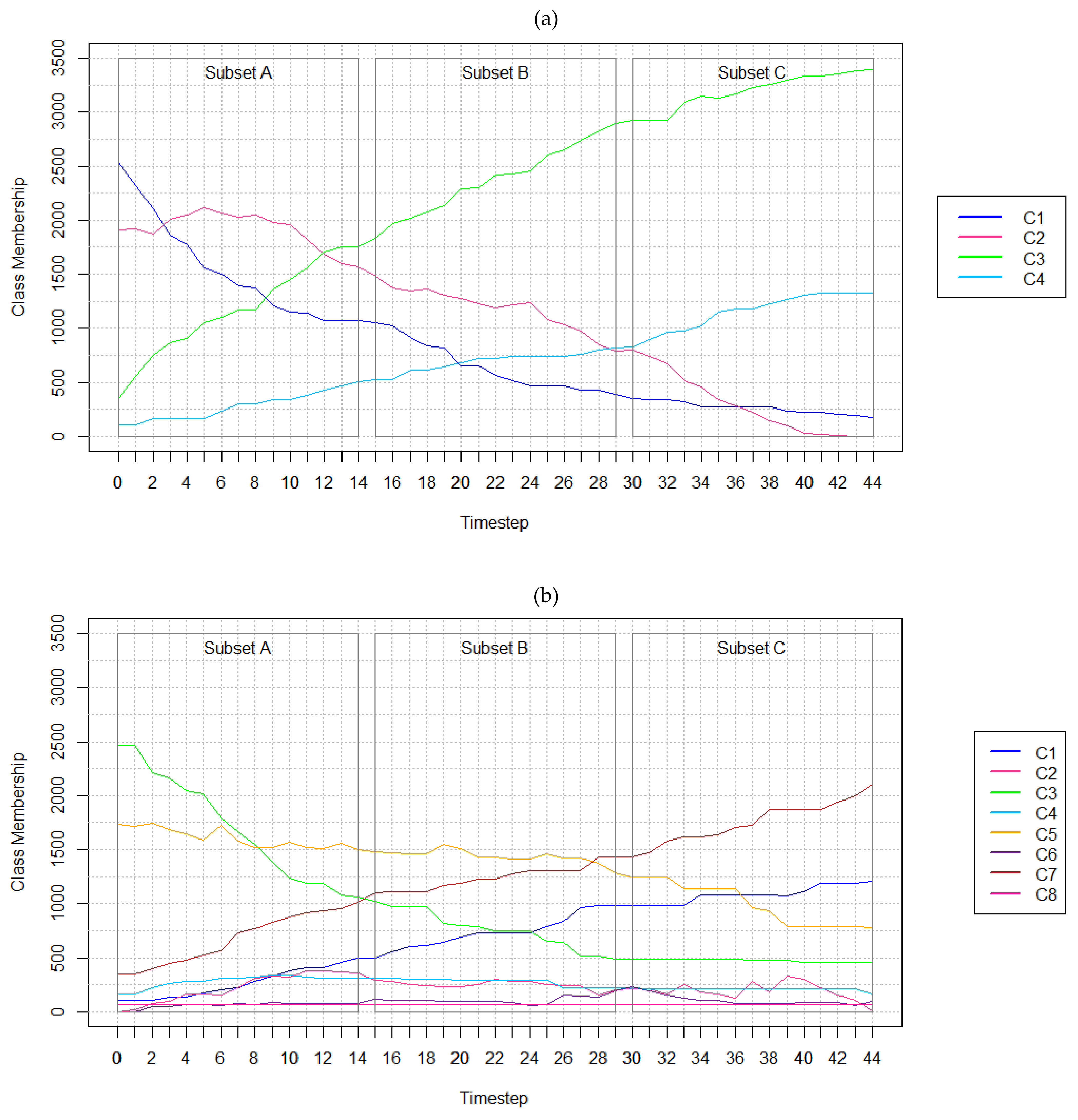
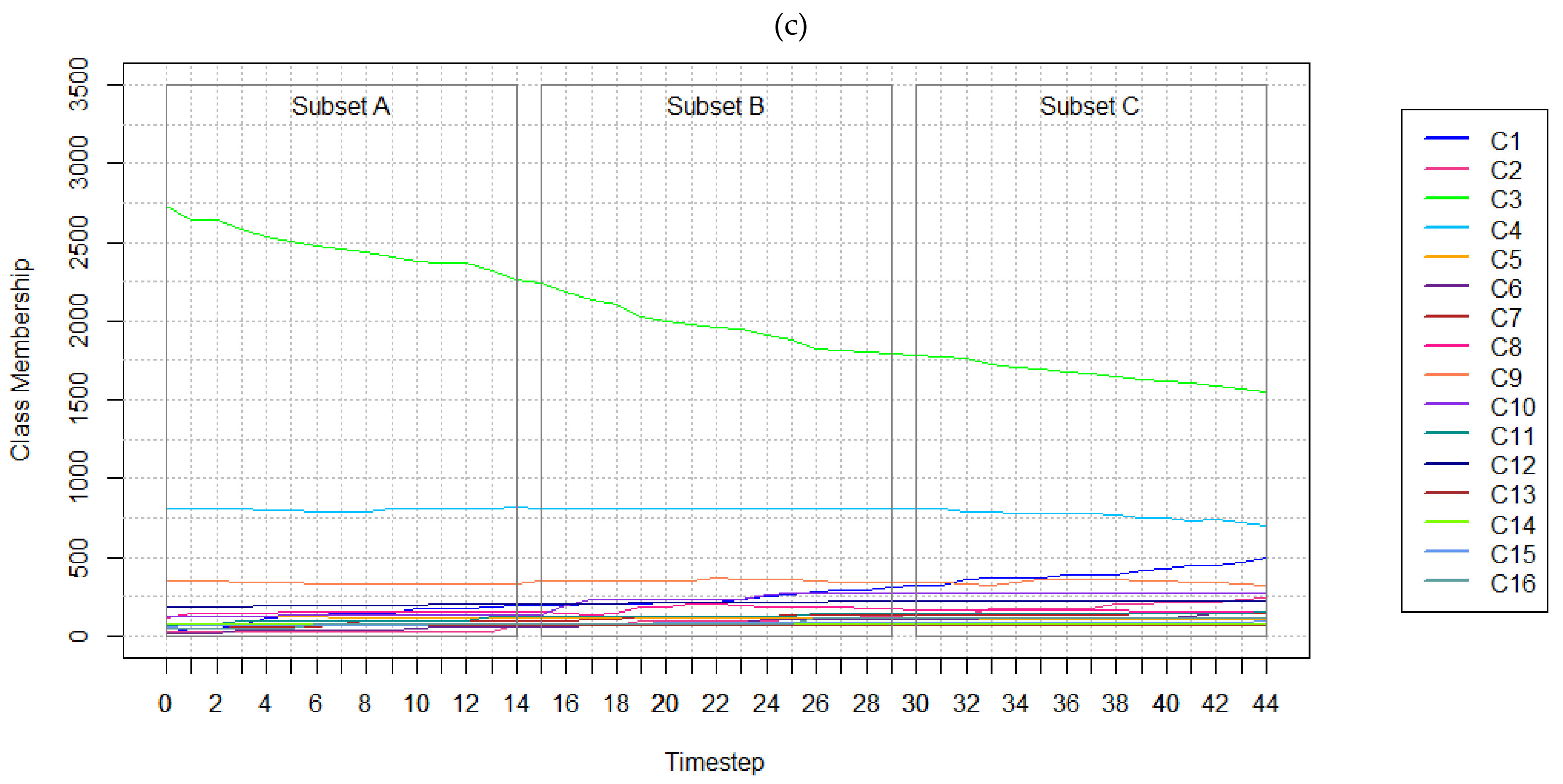
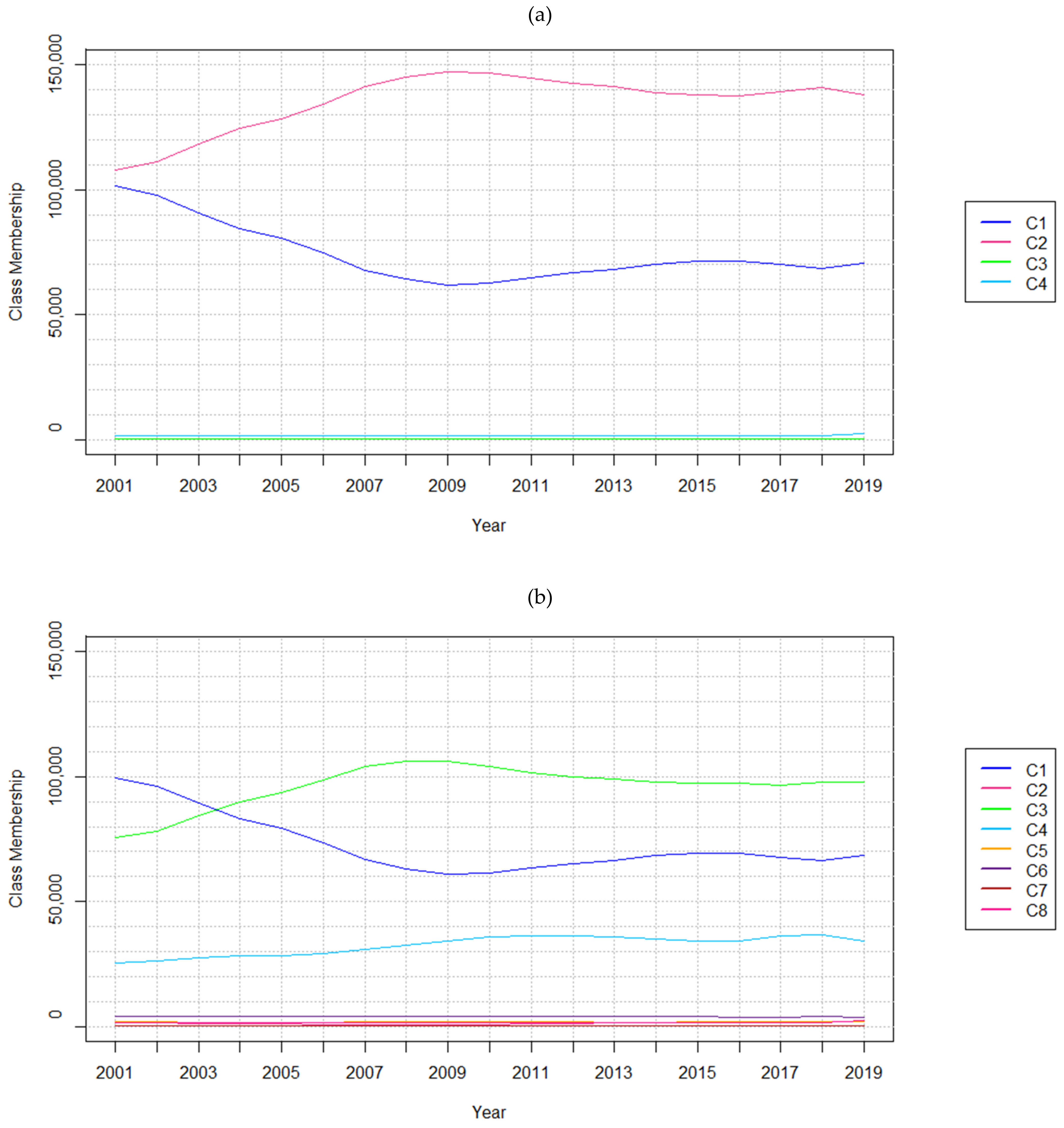
The aim of this research study was to explore the implications of varying temporal resolutions and LC classes. When analyzing results obtained from the SA conducted using the hypothetical and real-world datasets, it was observed that the methods are highly affected by temporal resolution. For instance, models trained on the hypothetical data performed better with finer temporal resolutions in most test cases. Changes that appear over coarser resolutions may appear more abrupt, impacting model performance. Considering the real-world datasets, the number of persistent cells incorrectly forecasted as changed also exhibits a sharp increase when considering nine-year temporal resolution data. This type of error is attributed to the observed class membership changing more rapidly from 2001 to 2010, as shown in
Figure 4. The model would not have been provided sufficient data to forecast that the rapid changes had ceased from 2010 to 2019, a consequence of the sampling strategy used to form the training datasets.
In addition, the hypothetical scenario features no cells that transition back to a previous class. However, the real-world dataset features many cells that transition back to a previous class because of anthropogenic or environmental disturbances or classification errors. This is exacerbated by reclassification procedures applied to aggregate the original 15-class dataset. As such, the vast LC changes attributed to temporal resolution and increasing LC class cardinality are expected. LCC processes typically occur gradually over long periods of time and finer temporal resolutions preserve more detail. Thus, finer temporal resolutions are typically associated with higher changed cell forecasting accuracy.
Using one input feature with one input label for training and testing sequences, respectively, produced poor performing models for the respective datasets, aligning with the initial assumptions. This response to using the coarsest resolution indicates this type of model may not be appropriate for geospatial input datasets featuring only three timesteps available for training and testing. Using finer temporal resolutions with more timesteps produced the best results. Datasets with higher rates of change or variability also appeared to benefit from finer temporal resolutions. For example, the tests conducted considering the 19-year datasets show that despite rapid changes occurring between 2001 to 2010 for the Evergreen Needleleaf Forest and Woody Savanna LC classes, the models could still forecast changed cells with approximately 83% accuracy when using finer temporal resolutions (
Table 11). An exception to this trend is shown in
Table 8, where the four-class, 15-year hypothetical dataset including timesteps 0 to 14 is considered. Abrupt changes occurring between each timestep from timesteps 0 to 14 are expected to have impacted performance metrics. That is, considering the four-class synthetic dataset at two-year temporal resolution, cell transition rates are observed as less erratic. This further exemplifies the method’s sensitivity to increased or inconsistent rates of LCC.
Results showed that increasing sequence length improved a model’s capacity to forecast changes. For example, as the hypothetical data input sequence length decreased, models exhibited poorer performance. This is indicated by the overall map comparison metrics including Kappa, K
Histogram, and K
Location. In cases where the smallest hypothetical data sequence lengths are used in both 45-year and 15-year test cases, K
Simulation and K
Transition indicate that models are hindered from learning LCCs. No model trained on the 15-year, four-class datasets exceeded performance measures of models trained on all 45 timesteps with one- and two-year resolution, indicating improved performance can be attributed to greater sequence length. This aligns with the experimental results conveyed by Ienco et al. [
25], where outcomes obtained with a dataset featuring a greater number of timesteps consistently exceeded performance measures computed with respect to the dataset featuring fewer timesteps.
Overall, the four-class dataset was associated with the best performance metrics of all the tests conducted using the hypothetical and real-world datasets. This confirms the initial assumption that fewer unique classes would have a positive impact on the model outcomes. The SA indicates that dataset cardinality also affects method performance. Considering the hypothetical 16-class dataset, low accuracies were obtained when forecasting changed cells. Finer temporal resolutions and increased sequence lengths also improved model performance as LC cardinality increased. The four-class dataset was associated with models that forecasted LC transitions with greater accuracy. Considering the real-world 15-class dataset, changed cell forecasting accuracies produced differed less vastly from the four and eight-class data experiments. However, the capacity of the models to forecast changed cells decreased more rapidly as the temporal resolution became coarser despite model optimizations described in
Section 3.1.1. This is attributed to the greater number of classes exhibiting changes that are not captured in detail using the coarser resolution. The results correspond with those communicated by Sun et al. [
92], which indicated that experiments conducted using all classes yielded lesser accuracies versus those obtained with a fewer number of classes. It might also be observed as a repercussion of the potential decreasing sample size per class as the sampling strategy used to form the training datasets is upheld. This may lead to undersampling in cases where there are more classes, which can remove potentially important training samples [
90].
Contrary to initial expectations, the SA demonstrated that the LSTM models were most effective when rates of LCC were more gradual. This coincides with the findings of Chi and Kim [
56], where it was found that increased melting of sea ice in summer months impeded their LSTM model forecasts. The hypothetical 16-class subsets where few changes occurred enabled models to obtain improved performance measures despite high cardinality. As the number of changes increased, model performance suffered, especially when using coarse temporal resolutions and when considering the hypothetical 16-class dataset. This was also observed in results produced with the real-world dataset featuring 15 classes. With coarser temporal resolutions, the 15-class dataset experiments demonstrated decreasing performance observed in all metrics. The less dramatic decrements of performance measures observed considering the real-world dataset versus those obtained using the 16-class hypothetical dataset may be attributed to the larger dataset available.
While overfitting to smaller datasets may be an issue, many of the overall trends observed across the hypothetical and real-world datasets were present in both sets of results. Results of this SA correspond to previous findings indicating that the number of classes undergoing changes and coarser temporal resolutions were detrimental to the method’s performance [
48]. Overall, cells featuring persistent LC were typically forecasted correctly with fine temporal resolutions across hypothetical and real-world experiments. This indicates that modifications or an alternate approach to the sampling strategy procedure used in this research study should be considered to obtain improved results that are less biased toward the majority class of cells, whether they be persistent or rapidly changing.
7. Conclusions
The primary objective of this study was to examine the impact of temporal resolutions and the number of LC classes on LSTM model performance via a SA. This SA involved measures focused on quantifying the capacity of the method to forecast LC changes explicitly rather than focus on overall accuracy measures as reported. These experiments were conducted using hypothetical and real-world datasets to observe whether trends persisted across experiments. The systematic SA identified similar responses across Modeling Scenarios A, B, and C, with inconsequential differences between them. As a result, measures reported and explored were those obtained from the optimized Model C (described in
Section 3.1.1) for this research study. Overall, similar trends in results were obtained with respect to the hypothetical and real-world datasets.
Results indicated that LSTM models are sensitive to the change of temporal resolution in all experiments conducted by forecasting different LCC outcomes as model outputs. These experiments included datasets featuring a different number of classes in both the hypothetical and real-world datasets and resulted in the same conclusions. Based on this sensitivity analysis, it was found that LSTM models perform best when datasets feature finer temporal resolution and fewer LC classes. Based on these results, it would be advisable to aggregate LC classes in cases where only coarser temporal resolution LC data is available. These findings also imply that if more input data layers were given at the shortest temporal intervals possible, this would enable LSTM models to be used for more gradual LCCs forecasting. Similarly, this study shows that RNNs become even more suitable for forecasting LCC as more timesteps and finer resolutions becomes available.
Since this study considered changes occurring at each cell over the temporal dimension, explicit spatial dependencies within or between samples were neglected. Instead, this work considers spatial dependencies implicitly due to the training procedure being influenced by all training samples. However, explicit spatial dependencies and spatial autocorrelation present
between geographic data samples is neglected in both temporal and spatiotemporal DL approaches. As a result of ML and DL methods inherently considering samples as independent and identically distributed, repercussions such as “salt-and-pepper” noise arise in resulting maps [
93]. Therefore, there is a need to investigate how leveraging explicit spatiotemporal dependencies and relationships both within and between samples may affect the performance. In addition, future work should continue to explore the capacity of spatiotemporal DL methods such as ConvLSTM for modeling LCC.
The models designed for this study were intended to focus on local changes and control input variations to assess model response given hypothetical and real-world datasets. However, it is recognized that producing categorical forecasts also has implications on results. Future work should consider the uncertainties in model outcomes attributed to the changing geospatial data characteristics examined in this work [
94]. Given the probabilistic outputs produced by the various models for each cell, it would also be possible to highlight areas of uncertainty produced in forecasts. Furthermore, this could accommodate gradual changes present in each coarse-resolution cell, rather than portraying only full LC class transitions taking place at each cell [
47]. An assessment of how well an LSTM model could forecast emerging phenomena or dissipating phenomena should also be conducted. While uncertainties present in model outputs can be compared and assessed, uncertainty quantification of RNN architectures such as LSTM could be considered under Bayesian treatment [
95,
96].
As cell-based LSTM models are fit to accommodate variation occurring across an entire study area, future work could examine the implications on method performance when using larger datasets with increased spatial heterogeneity along with appropriate metrics to consider this property. Additionally, the real-world dataset considered in this study features coarse spatial resolution and fine temporal resolution with respect to the phenomena under investigation. At present, finer resolution data typically exhibits coarser temporal resolution. For instance, the USGS National Land Cover Database provides 30-meter spatial resolution LC data every five years since 2001 [
97]. As finer spatial resolution data becomes available at finer temporal resolutions, the effects of increasing or decreasing spatial resolution should be considered with LSTM and its spatiotemporal variants. The large number of optimizations and configurations of LSTM models also provides opportunities for future exploration.
This research study aimed to evaluate the repercussions of varying geospatial data characteristics, including temporal resolution and LC class count. Changing these factors affected sequence length and rates of LCC present in the hypothetical and real-world input datasets. It is acknowledged that the measures obtained hinge upon the method and data combinations used in this work. Considering hypothetical and real-world data as LSTM model input, similar trends were observed in the method’s capacity to forecast LCCs. While it is often stated that “more data is always better” for DL methods, it is rarely quantified. Thus, this research study contributes to the quantification of how much data is required to forecast this phenomenon with this modeling approach, along with the geospatial data characteristics that would characterize a favourable or compatible dataset.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}