
Post-Processing Ensemble Precipitation Forecasts and Their Applications in Summer Streamflow Prediction over a Mountain River Basin
Abstract
:1. Introduction
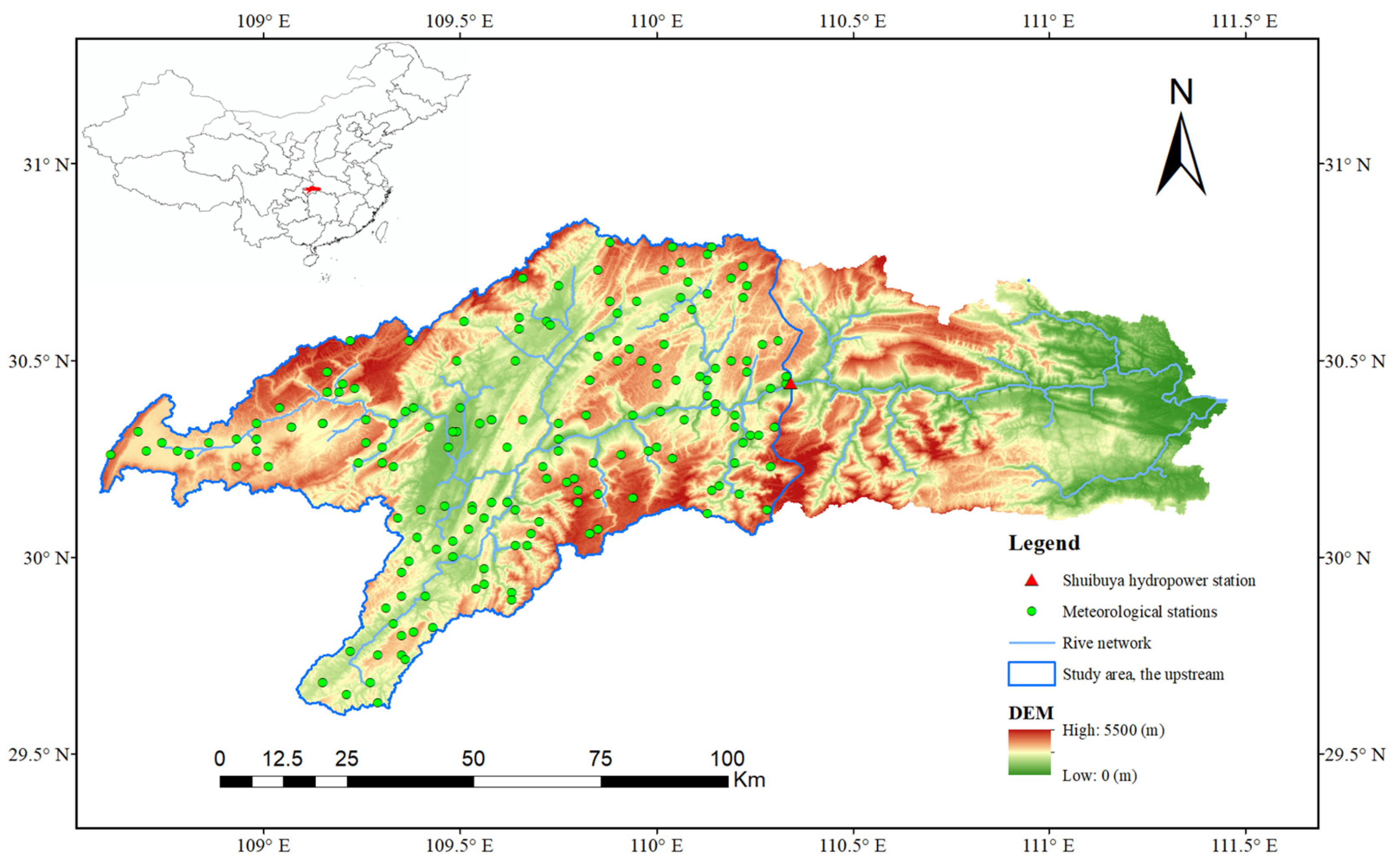
2. Study Area and Datasets
3. Methodology
3.1. Post-Processing Methods
3.1.1. The BMA Method
3.1.2. The GPP Method
3.2. Hydrological Model
3.3. Verification Metrics
4. Results
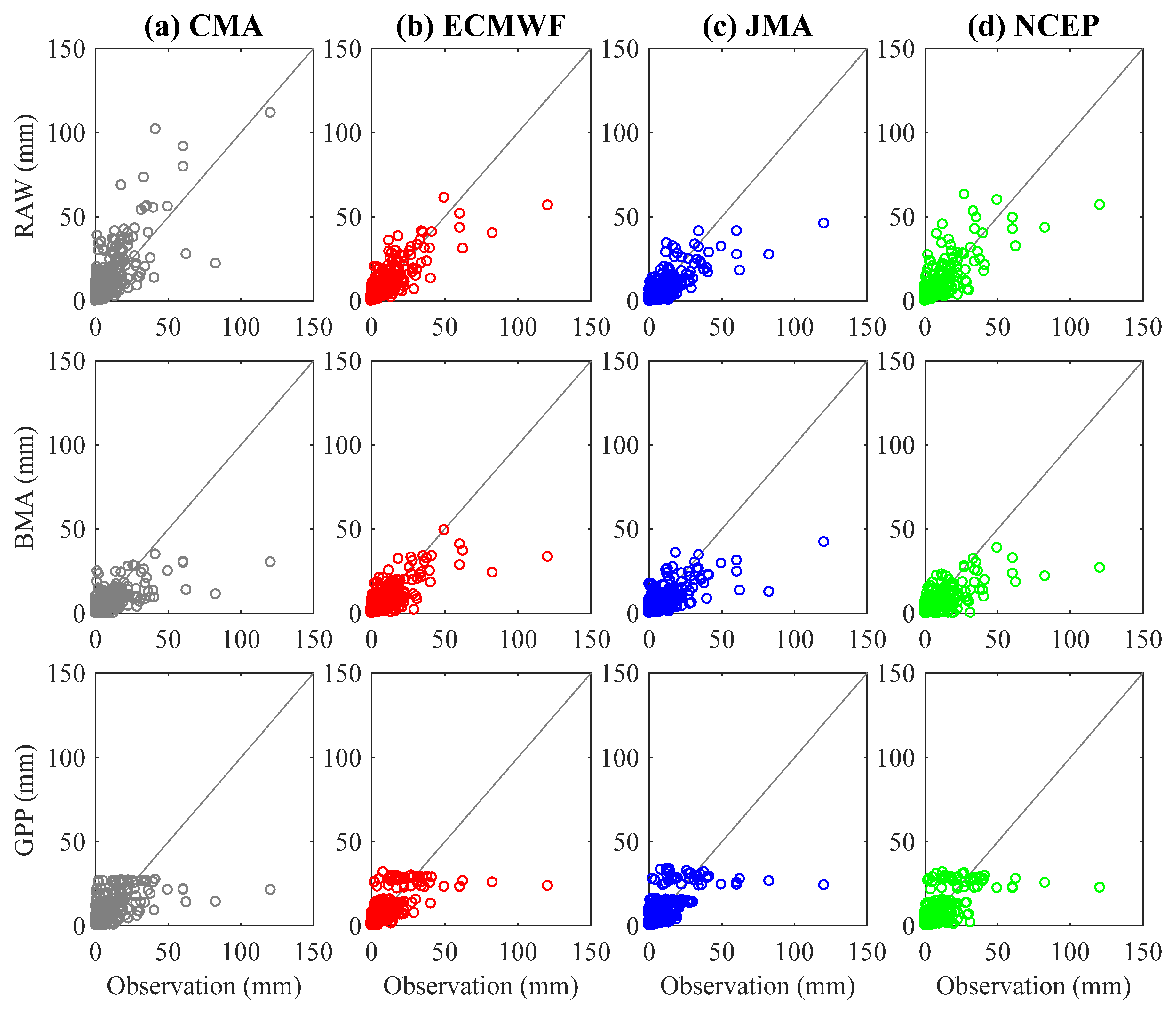
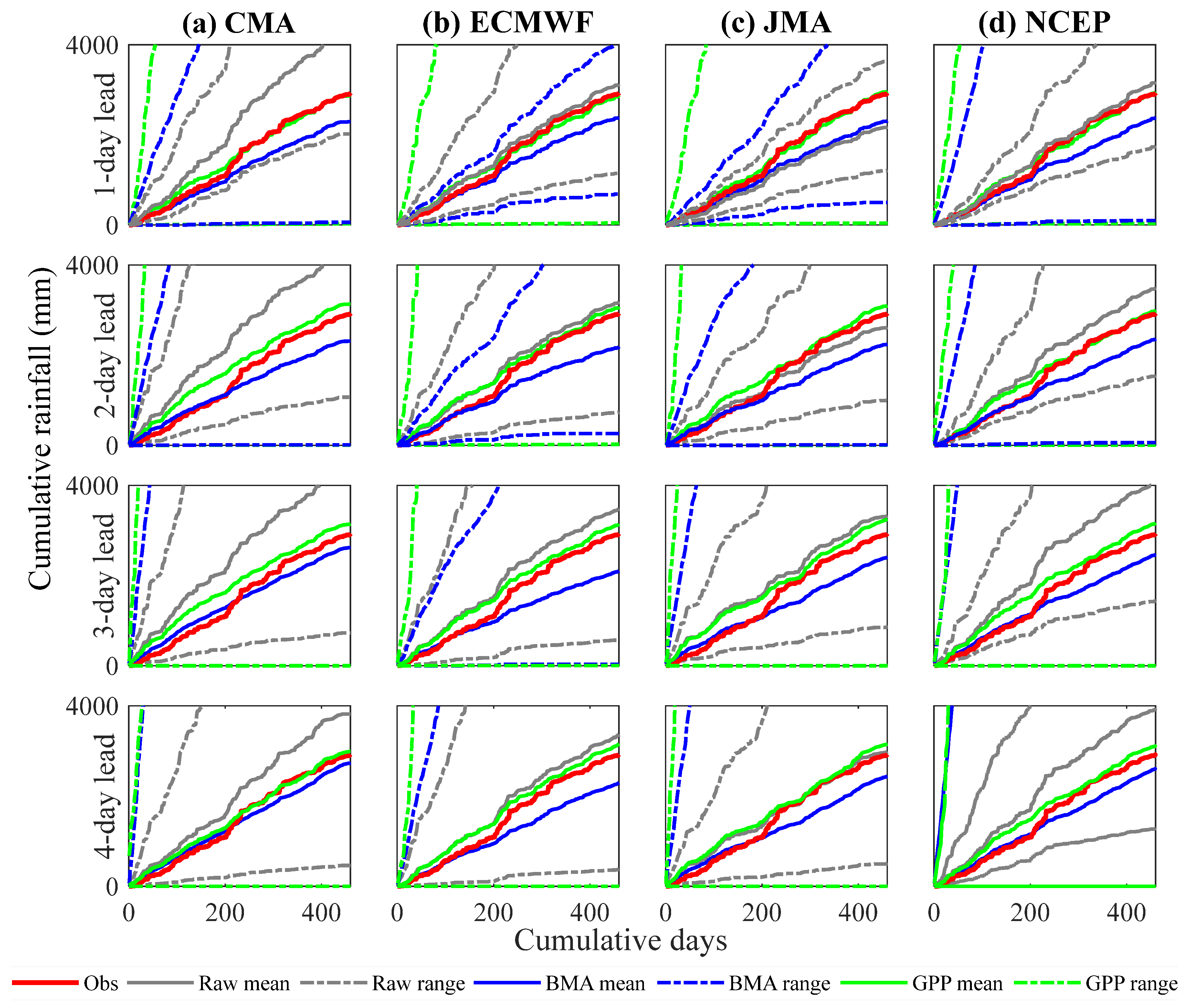
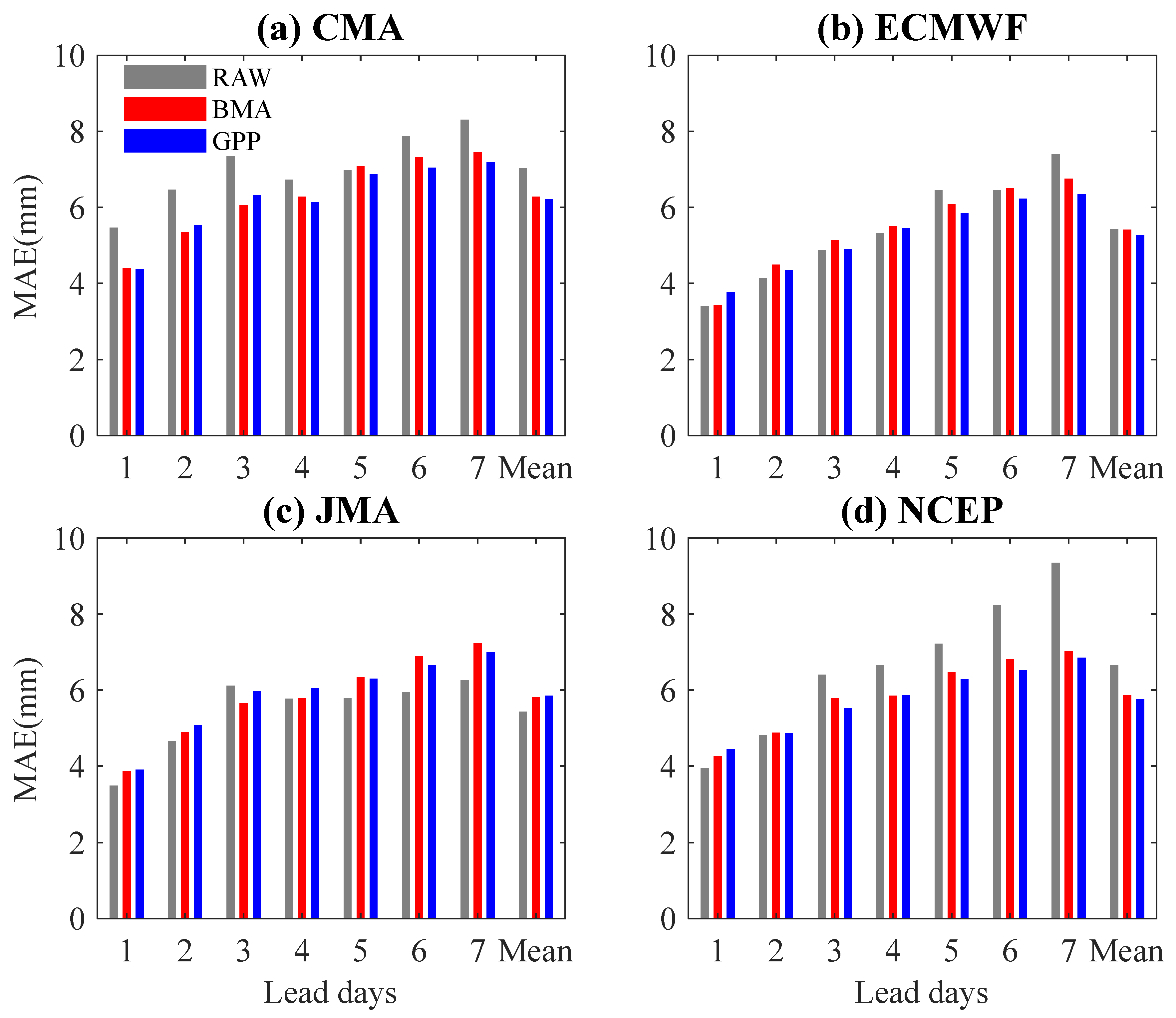
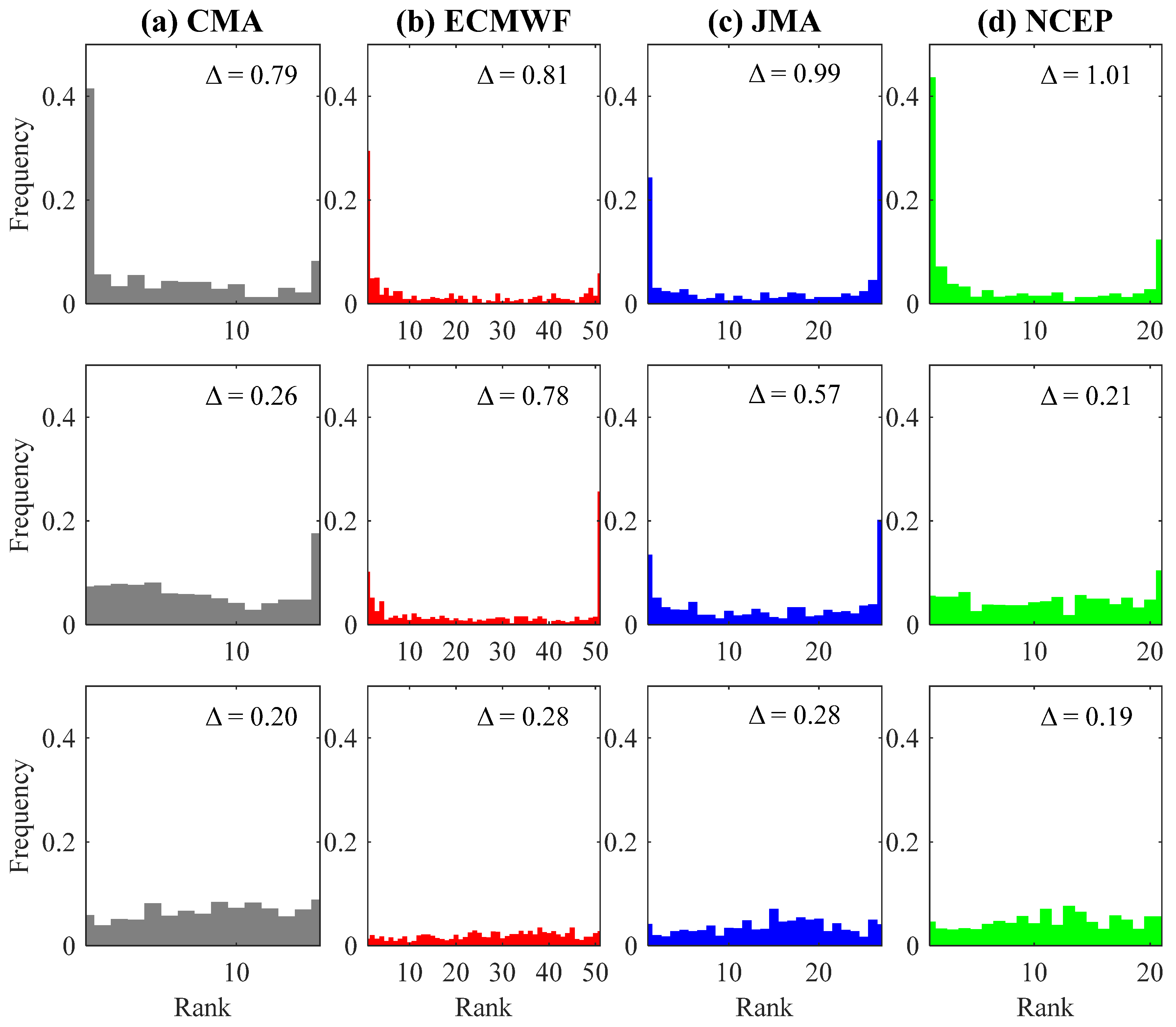
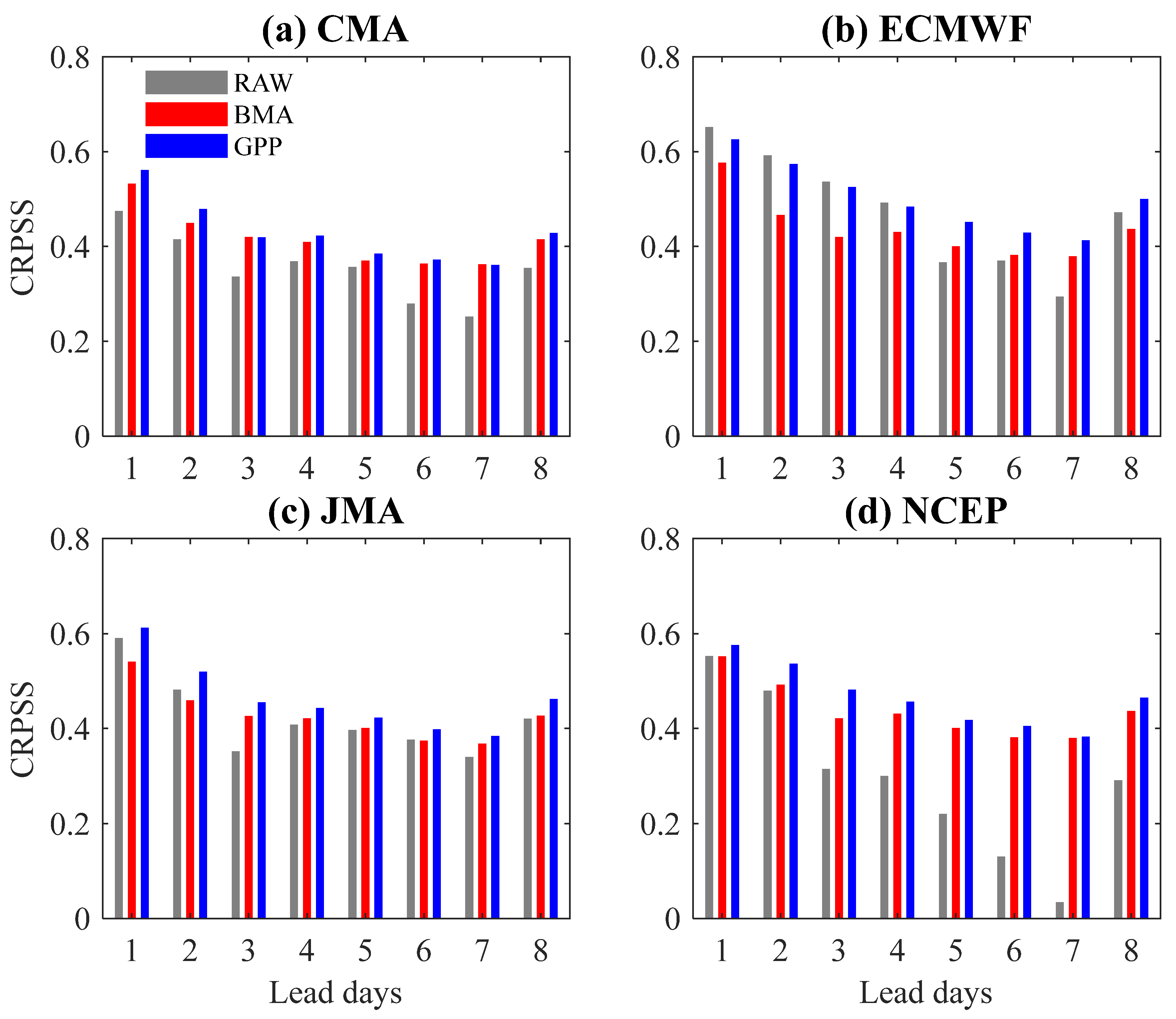
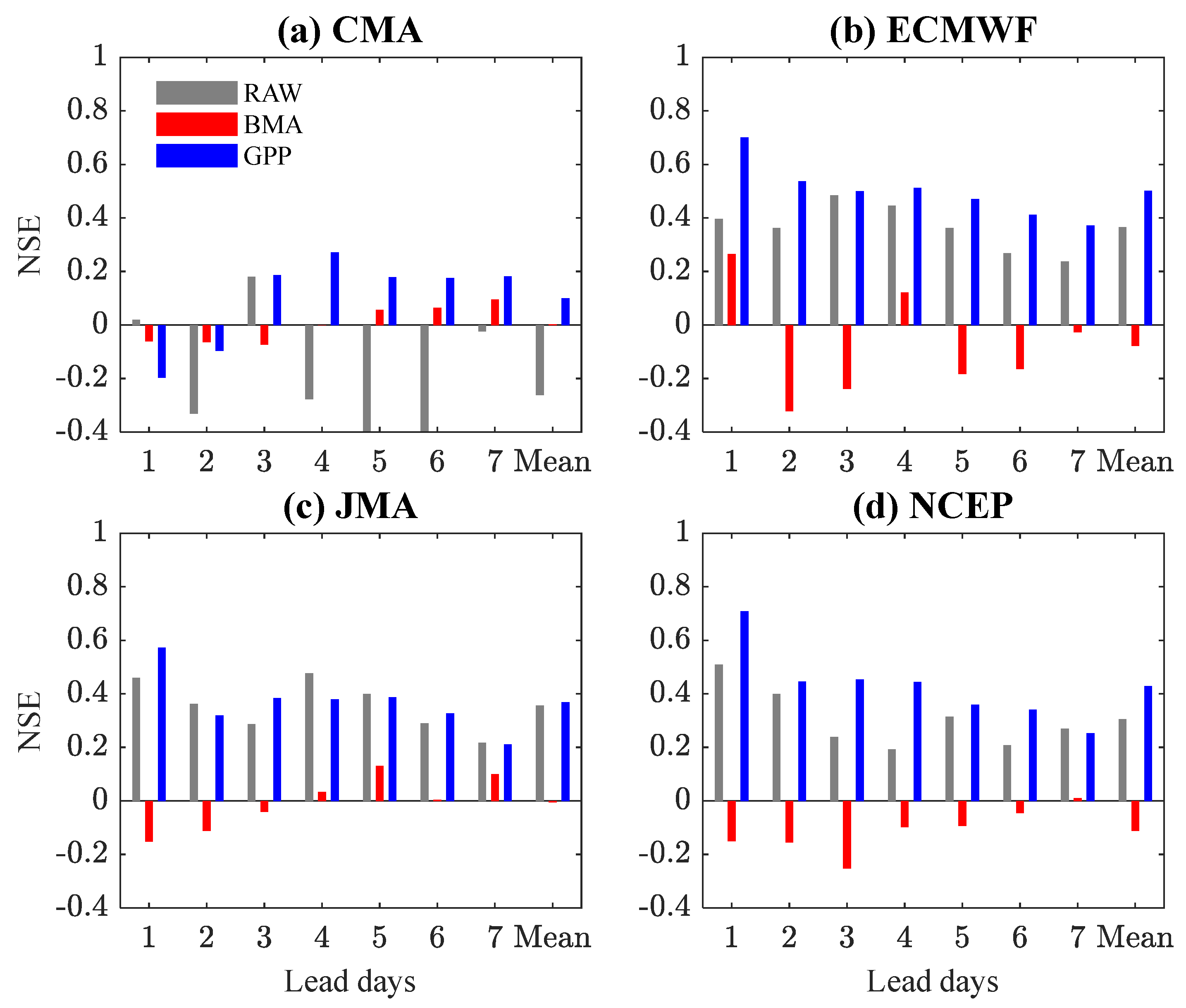
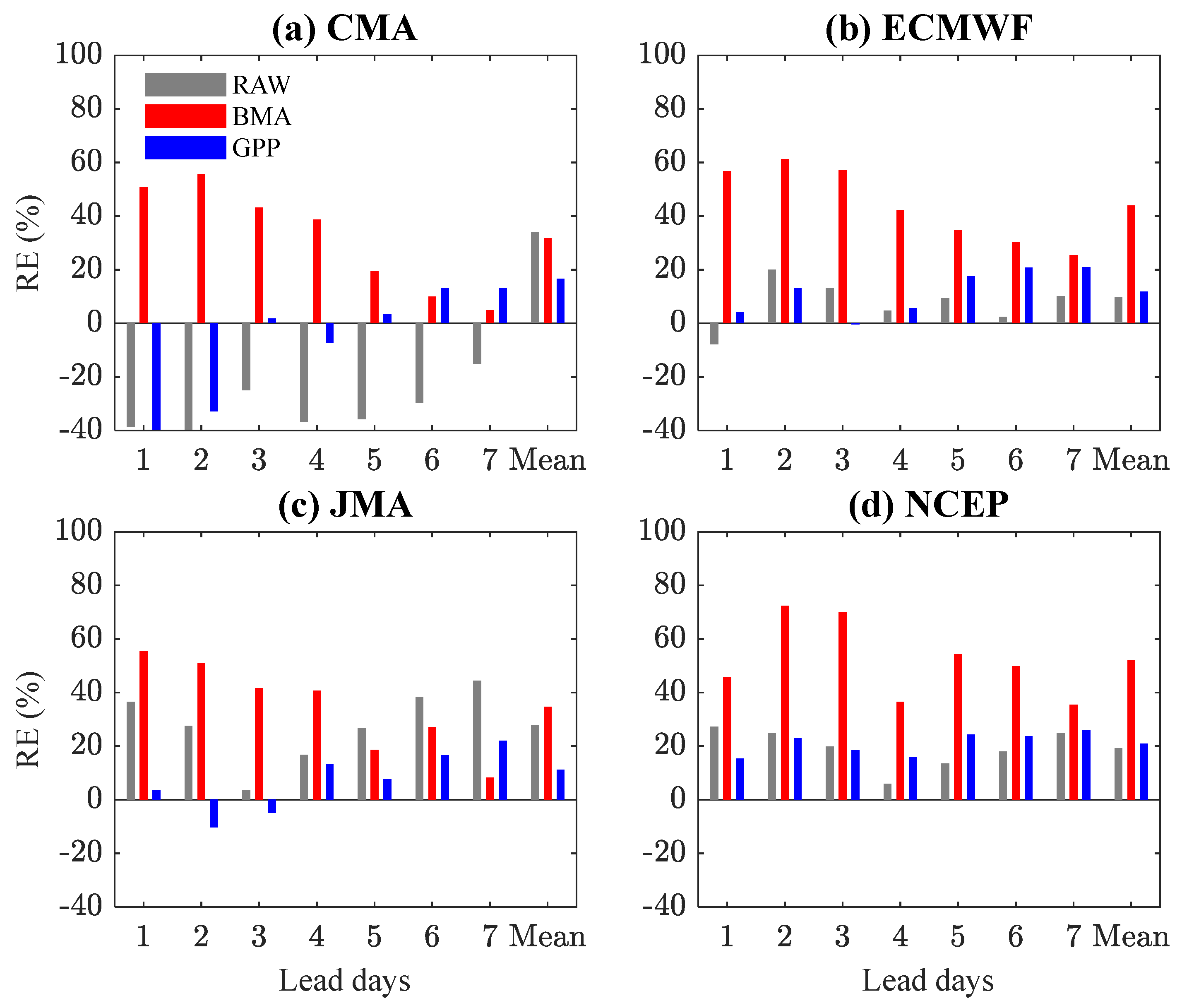
4.1. Post-Processing of the Ensemble Precipitation Forecasts
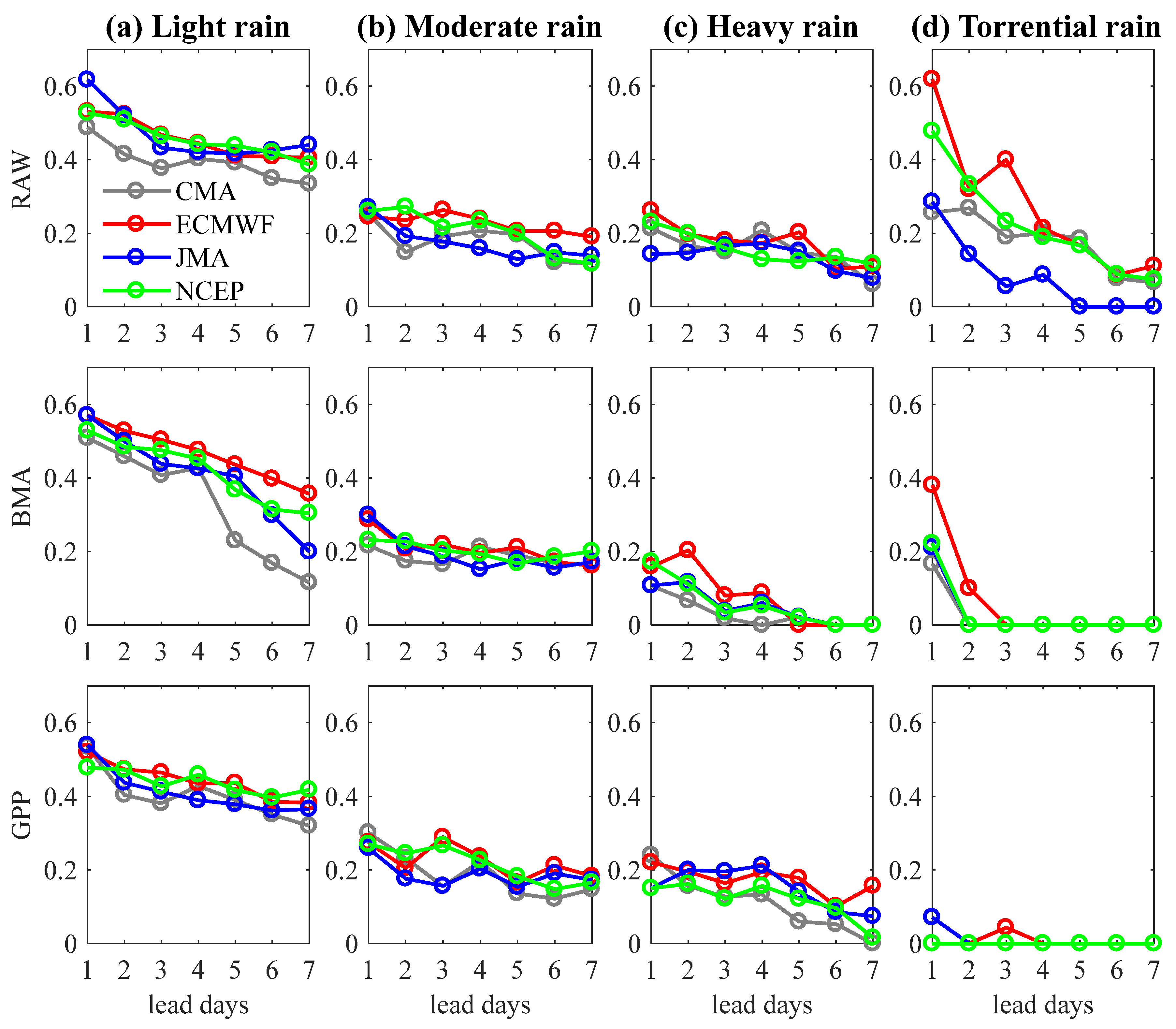
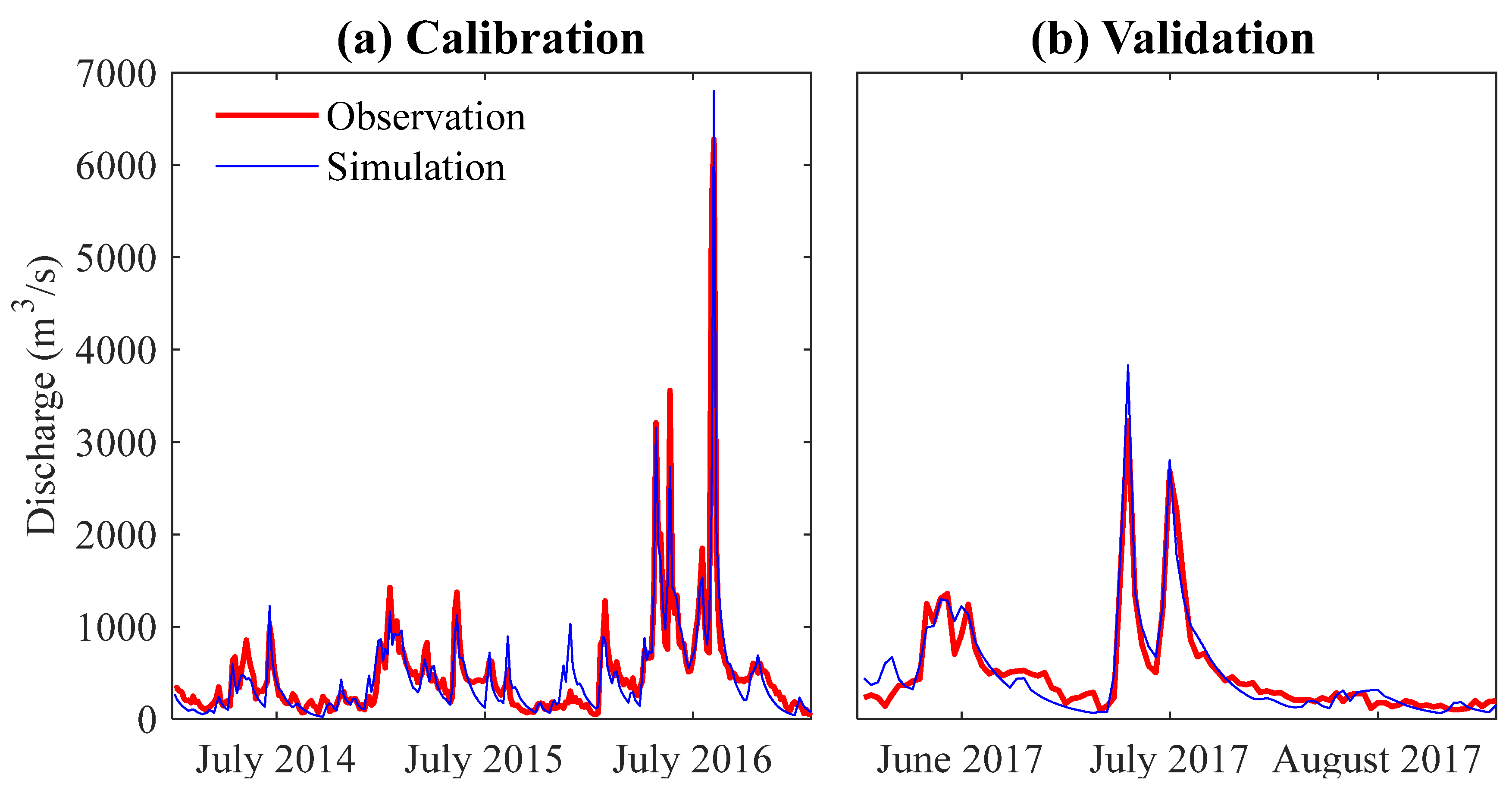
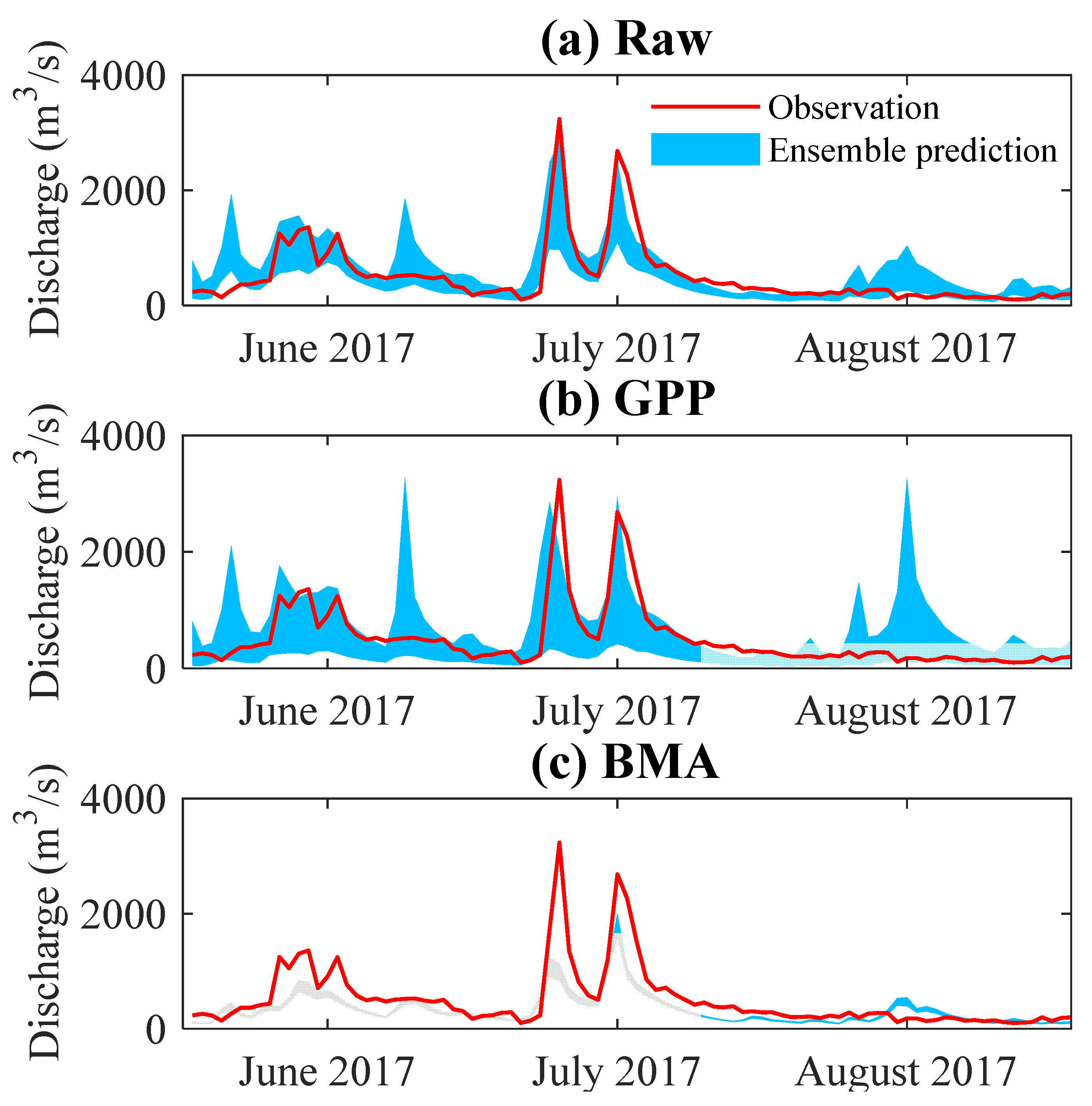
4.2. Application in Streamflow Prediction
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roulin, E. Skill and relative economic value of medium-range hydrological ensemble predictions. Hydrol. Earth Syst. Sci. 2007, 11, 725–737. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, H.; Wang, J.; Shi, C.; Hua, D.; Li, J. Ensemble streamflow forecasting based on variational mode decomposition and long short term memory. Sci. Rep. 2022, 12, 518. [Google Scholar] [CrossRef]
- Xu, Y.-P.; Tung, Y.-K. Decision-making in Water Management under Uncertainty. Water Resour. Manag. 2007, 22, 535–550. [Google Scholar] [CrossRef]
- Troin, M.; Arsenault, R.; Wood, A.W.; Brissette, F.; Martel, J. Generating Ensemble Streamflow Forecasts: A Review of Methods and Approaches Over the Past 40 Years. Water Resour. Res. 2021, 57, e2020WR028392. [Google Scholar] [CrossRef]
- Alfieri, L.; Pappenberger, F.; Wetterhall, F.; Haiden, T.; Richardson, D.; Salamon, P. Evaluation of ensemble streamflow predictions in Europe. J. Hydrol. 2014, 517, 913–922. [Google Scholar] [CrossRef]
- Aminyavari, S.; Saghafian, B. Probabilistic streamflow forecast based on spatial post-processing of TIGGE precipitation forecasts. Stoch. Environ. Res. Risk Assess. 2019, 33, 1939–1950. [Google Scholar] [CrossRef]
- Shukla, S.; Voisin, N.; Lettenmaier, D.P. Value of medium range weather forecasts in the improvement of seasonal hydrologic prediction skill. Hydrol. Earth Syst. Sci. 2012, 16, 2825–2838. [Google Scholar] [CrossRef]
- Cloke, H.; Pappenberger, F. Ensemble flood forecasting: A review. J. Hydrol. 2009, 375, 613–626. [Google Scholar] [CrossRef]
- Huang, L.; Luo, Y. Evaluation of quantitative precipitation forecasts by TIGGE ensembles for south China during the presummer rainy season. J. Geophys. Res. Atmos. 2017, 122, 8494–8516. [Google Scholar] [CrossRef]
- Weidle, F.; Wang, Y.; Smet, G. On the Impact of the Choice of Global Ensemble in Forcing a Regional Ensemble System. Weather Forecast. 2016, 31, 515–530. [Google Scholar] [CrossRef]
- Liu, L.; Gao, C.; Zhu, Q.; Xu, Y.-P. Evaluation of TIGGE Daily Accumulated Precipitation Forecasts over the Qu River Basin, China. J. Meteorol. Res. 2019, 33, 747–764. [Google Scholar] [CrossRef]
- Scheuerer, M.; Hamill, T.M. Statistical Postprocessing of Ensemble Precipitation Forecasts by Fitting Censored, Shifted Gamma Distributions. Mon. Weather Rev. 2015, 143, 4578–4596. [Google Scholar] [CrossRef]
- Dulière, V.; Zhang, Y.; Salathé, E.P. Extreme precipitation and temperature over the US Pacific Northwest: A comparison between observations, reanalysis data, and regional models. J. Clim. 2011, 24, 1950–1964. [Google Scholar] [CrossRef]
- Raftery, A.E.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using Bayesian Model Averaging to Calibrate Forecast Ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef]
- Sloughter, J.M.L.; Raftery, A.E.; Gneiting, T.; Fraley, C. Probabilistic Quantitative Precipitation Forecasting Using Bayesian Model Averaging. Mon. Weather Rev. 2007, 135, 3209–3220. [Google Scholar] [CrossRef]
- Hamill, T.M.; Hagedorn, R.; Whitaker, J.S. Probabilistic Forecast Calibration Using ECMWF and GFS Ensemble Reforecasts. Part II: Precipitation. Mon. Weather Rev. 2008, 136, 2620–2632. [Google Scholar] [CrossRef]
- Roulin, E.; Vannitsem, S. Postprocessing of ensemble precipitation predictions with extended logistic regression based on hindcasts. Mon. Weather Rev. 2012, 140, 874–888. [Google Scholar] [CrossRef]
- Chen, J.; Brissette, F.P.; Li, Z. Postprocessing of Ensemble Weather Forecasts Using a Stochastic Weather Generator. Mon. Weather Rev. 2014, 142, 1106–1124. [Google Scholar] [CrossRef]
- Schmeits, M.J.; Kok, K.J. A Comparison between Raw Ensemble Output, (Modified) Bayesian Model Averaging, and Extended Logistic Regression Using ECMWF Ensemble Precipitation Reforecasts. Mon. Weather Rev. 2010, 138, 4199–4211. [Google Scholar] [CrossRef]
- Williams, R.M.; Ferro, C.A.T.; Kwasniok, F. A comparison of ensemble post-processing methods for extreme events. Q. J. R. Meteorol. Soc. 2013, 140, 1112–1120. [Google Scholar] [CrossRef]
- Qu, B.; Zhang, X.; Pappenberger, F.; Zhang, T.; Fang, Y. Multi-Model Grand Ensemble Hydrologic Forecasting in the Fu River Basin Using Bayesian Model Averaging. Water 2017, 9, 74. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, J.; Li, X.; Chen, H.; Xie, P.; Li, W. Combining Postprocessed Ensemble Weather Forecasts and Multiple Hydrological Models for Ensemble Streamflow Predictions. J. Hydrol. Eng. 2020, 25, 04019060. [Google Scholar] [CrossRef]
- Vetter, T.; Reinhardt, J.; Flörke, M.; Van Griensven, A.; Hattermann, F.; Huang, S.; Koch, H.; Pechlivanidis, I.G.; Plötner, S.; Seidou, O.; et al. Evaluation of sources of uncertainty in projected hydrological changes under climate change in 12 large-scale river basins. Clim. Chang. 2017, 141, 419–433. [Google Scholar] [CrossRef]
- Mascaro, G.; Vivoni, E.R.; Deidda, R. Implications of Ensemble Quantitative Precipitation Forecast Errors on Distributed Streamflow Forecasting. J. Hydrometeorol. 2010, 11, 69–86. [Google Scholar] [CrossRef]
- Anderson, M.L.; Chen, Z.-Q.; Kavvas, M.L.; Feldman, A. Coupling HEC-HMS with Atmospheric Models for Prediction of Watershed Runoff. J. Hydrol. Eng. 2002, 7, 312–318. [Google Scholar] [CrossRef]
- Yang, C.; Yuan, H.; Su, X. Bias correction of ensemble precipitation forecasts in the improvement of summer streamflow prediction skill. J. Hydrol. 2020, 588, 124955. [Google Scholar] [CrossRef]
- Li, X.-Q.; Chen, J.; Xu, C.-Y.; Li, L.; Chen, H. Performance of Post-Processed Methods in Hydrological Predictions Evaluated by Deterministic and Probabilistic Criteria. Water Resour. Manag. 2019, 33, 3289–3302. [Google Scholar] [CrossRef]
- Ren-Jun, Z. The Xinanjiang model applied in China. J. Hydrol. 1992, 135, 371–381. [Google Scholar] [CrossRef]
- Xiang, Y.; Peng, T.; Gao, Q.; Shen, T.; Qi, H. Evaluation of TIGGE Precipitation Forecast and Its Applicability in Streamflow Predictions over a Mountain River Basin, China. Water 2022, 14, 2432. [Google Scholar] [CrossRef]
- Shu, Z.; Zhang, J.; Jin, J.; Wang, L.; Wang, G.; Wang, J.; Sun, Z.; Liu, J.; Liu, Y.; He, R.; et al. Evaluation and Application of Quantitative Precipitation Forecast Products for Mainland China Based on TIGGE Multimodel Data. J. Hydrometeorol. 2021, 22, 1199–1219. [Google Scholar] [CrossRef]
- Peng, T.; Wang, J.; Tang, Z.; Ding, H. Analysis for calculating critical area rainfall on different time scales in small and medium catchment based on hydrological simulation. Torrential Rain Disasters 2017, 36, 365–372. [Google Scholar] [CrossRef]
- Shi, P.; Chen, C.; Srinivasan, R.; Zhang, X.; Cai, T.; Fang, X.; Qu, S.; Chen, X.; Li, Q. Evaluating the SWAT Model for Hydrological Modeling in the Xixian Watershed and a Comparison with the XAJ Model. Water Resour. Manag. 2011, 25, 2595–2612. [Google Scholar] [CrossRef]
- Duan, Q.Y.; Gupta, V.K.; Sorooshian, S. Shuffled complex evolution approach for effective and efficient global minimization. J. Optim. Theory Appl. 1993, 76, 501–521. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Brown, J.D.; Demargne, J.; Seo, D.-J.; Liu, Y. The Ensemble Verification System (EVS): A software tool for verifying ensemble forecasts of hydrometeorological and hydrologic variables at discrete locations. Environ. Model. Softw. 2010, 25, 854–872. [Google Scholar] [CrossRef]
- Hong, J.-S. Evaluation of the High-Resolution Model Forecasts over the Taiwan Area during GIMEX. Weather Forecast. 2003, 18, 836–846. [Google Scholar] [CrossRef]
- Ma, F.; Ye, A.; Deng, X.; Zhou, Z.; Liu, X.; Duan, Q.; Xu, J.; Miao, C.; Di, Z.; Gong, W. Evaluating the skill of NMME seasonal precipitation ensemble predictions for 17 hydroclimatic regions in continental China. Int. J. Clim. 2015, 36, 132–144. [Google Scholar] [CrossRef]
- Mesinger, F. Bias Adjusted Precipitation Threat Scores. Adv. Geosci. 2008, 16, 137–142. [Google Scholar] [CrossRef]
- GB/T 20486-2006; Category of Valley Area Rainfall. Standardization Administration of China: Beijing, China, 2006. Available online: https://www.chinesestandard.net/ (accessed on 25 October 2023).
- Heinrich, C. On the number of bins in a rank histogram. Q. J. R. Meteorol. Soc. 2021, 147, 544–556. [Google Scholar] [CrossRef]
- Jha, S.K.; Shrestha, D.L.; Stadnyk, T.A.; Coulibaly, P. Evaluation of ensemble precipitation forecasts generated through post-processing in a Canadian catchment. Hydrol. Earth Syst. Sci. 2018, 22, 1957–1969. [Google Scholar] [CrossRef]
- Schaefli, B.; Gupta, H.V. Do Nash values have value? Hydrol. Processes 2007, 21, 2075–2080. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Liu, C.; Sun, J.; Yang, X.; Jin, S.; Fu, S. Evaluation of ECMWF Precipitation Predictions in China during 2015–2018. Weather Forecast. 2021, 36, 1043–1060. [Google Scholar] [CrossRef]
- Tao, Y.; Duan, Q.; Ye, A.; Gong, W.; Di, Z.; Xiao, M.; Hsu, K. An evaluation of post-processed TIGGE multimodel ensemble precipitation forecast in the Huai river basin. J. Hydrol. 2014, 519, 2890–2905. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Xu, C.-Y.; Zhang, X.J.; Xiong, L.; Guo, Q. Postprocessing Ensemble Weather Forecasts for Introducing Multisite and Multivariable Correlations Using Rank Shuffle and Copula Theory. Mon. Weather Rev. 2022, 150, 551–565. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Sources | Ensemble Members (Perturbed) | Temporal/Spatial Resolution | Temporal Coverage |
|---|---|---|---|---|
| Observed meteorological data | 175 meteorological stations | - | Daily/station | 2014–2018 summer |
| Ensemble precipitation forecasts (EPFs) | CMA (China Meteorological Administration) | 15 | Seven lead days at six hours /0.5° | 2014–2018 summer |
| ECMWF (European Centre for Medium-Range Weather Forecasts) | 50 | |||
| JMA (Japan Meteorological Administration) | 26 | |||
| NCEP (National Centers for Environmental Prediction) | 20 | |||
| Observed streamflow | Shuibuya hydropower station | - | Daily/station | 2014–2017 summer |
| Category | 24 h (mm) |
|---|---|
| Light rain | 0.1–5.9 |
| Moderate rain | 6.0–14.9 |
| Heavy rain | 15–29.9 |
| Torrential rain | >30 |
| Observations | Forecast | |
|---|---|---|
| Yes | No | |
| Yes | NA | NC |
| No | NB | ND |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Y.; Liu, Y.; Zou, X.; Peng, T.; Yin, Z.; Ren, Y. Post-Processing Ensemble Precipitation Forecasts and Their Applications in Summer Streamflow Prediction over a Mountain River Basin. Atmosphere 2023, 14, 1645. https://doi.org/10.3390/atmos14111645
Xiang Y, Liu Y, Zou X, Peng T, Yin Z, Ren Y. Post-Processing Ensemble Precipitation Forecasts and Their Applications in Summer Streamflow Prediction over a Mountain River Basin. Atmosphere. 2023; 14(11):1645. https://doi.org/10.3390/atmos14111645
Chicago/Turabian StyleXiang, Yiheng, Yanghe Liu, Xiangxi Zou, Tao Peng, Zhiyuan Yin, and Yufeng Ren. 2023. "Post-Processing Ensemble Precipitation Forecasts and Their Applications in Summer Streamflow Prediction over a Mountain River Basin" Atmosphere 14, no. 11: 1645. https://doi.org/10.3390/atmos14111645