1. Introduction
In the past century, the earth system has entered the Anthropocene epoch and human activities have made profound impacts on our planet’s ecology and ecosystem [
1,
2]. Massive air pollution emissions generated by human production and living activities in the Anthropocene epoch have induced atmospheric composition transformation and inevitably changed global and regional biogeochemical cycles, air quality, and climate [
3]. Among the critical global crises curbing world development and sustainability, air quality degradation has been a long-lasting and increasingly urgent one and it has been sufficiently proven to pose severe threats to human health and social welfare. PM
2.5 as a significant indicator for air quality assessment is particulate matter (PM) with an average aerodynamic diameter of up to 2.5 micrometers (µm). Epidemiological and experimental evidence indicates that exposure to ambient PM
2.5 has a close link with respiratory and cardiovascular mortality and morbidity rates, life expectancy [
4,
5,
6,
7,
8,
9], and even with COVID-19 basic reproduction ratio [
10]. The social and health effects of PM
2.5 exposure in developing countries and regions should receive more research and public attention because environmental justice is facing more severe challenges in these areas. Therefore, prediction models with good accuracy are urgently needed to better monitor and control PM
2.5 pollution.
Knowledge of the mechanism of PM
2.5 measurement and its sources can help us better understand the nature of PM
2.5 monitoring data. Identification and quantification of air pollution are the foundation of air pollution control and management in terms of producing more reliable real-time atmospheric data. This goal usually can be attained by conducting atmospheric particle size distribution measurements and air pollution source analysis. First, PM measurement methods have been evolving and monitoring tools have been advanced ever since the application of optical microscopy in detecting inhalable particles in the early 18th century [
11]. Benefiting from the framework of National Ambient Air Quality Standards (NAAQS) first adopted by the US, China and other developing countries established new PM
2.5 ambient air quality standards in the expectation of leapfrogging ahead in terms of monitoring and controlling PM
2.5 [
12]. Traditionally used PM
2.5 measurements such as the gravimetric method and the beta ray attenuation PM
2.5 measurement are selected to cope with different application scenarios [
13,
14,
15]. Second, PM can be sourced from either human-made or natural formation. Normally, the process of fuel combustion—such as household heating, power generation, and vehicle consumption—emits PM. In contrast, the human induced contribution to PM
2.5 concentration is much more significant than natural processes. Based on a broad survey of 51 countries worldwide, it is found that traffic, industrial activities, domestic fuel burning, unspecific human sources, and natural dust and salt contribute 25%, 15%, 20%, 22%, and 18% of urban ambient PM
2.5 pollution, respectively [
16]. However, different source proportion characteristics can be easily observed among different regions [
17,
18] and seasons [
19,
20]. In China, many studies on various cities have been conducted by adopting the source apportionment (SA) method to identify and quantify the regional source of PM
2.5 [
21]. For instance, in north China, coal combustion in the residential sector plays the most significant role in regional PM
2.5 pollution compared to other contributors [
22]. Reliable monitoring data can lay a solid foundation for PM2.5 concentrations prediction.
Generally, air pollution prediction models can be grouped into three types based on their modeling nature, viz. atmospheric chemical transport model (CTM), traditional statistical model, and machine learning model. The first type predicts air pollution concentration based on the simulation of atmospheric chemistry with consideration of the transformation and interaction of air pollutants [
23,
24]. The successful conduction of CTM requires atmospheric expertise and adequate data support. Partial least squares regression model [
25,
26,
27], Bayesian method [
28,
29], and generalized Markov model [
30] are very commonly used statistical models for air quality prediction. These models are normally simply constructed, so it is hard for them to unravel the nonlinear interactions between multi-variables, causing it to be so that favorable features might not be utterly utilized [
31]. Specifically designed for time series data analysis, time series models are employed to forecast events based on historical data. Commonly used time series models for forecasting air pollutants concentration include moving average (MA) [
32] and its variant autoregressive integrated moving average (ARIMA) [
33,
34,
35]. PM
2.5 time series data’s nature of high complexity, randomness, nonlinearity, and non-stationarity potentially create obstacles for times series models solely achieving satisfactory prediction outcomes [
36]. In spite of the merits that chemical transport models and statistical models exhibit in making predictions, machine learning has distinct advantages over these two methods. Furthermore, it has become a hot research trend by combining ANN models with the other two types [
37].
With the assistance of big data, artificial intelligence (AI) potential has been further discovered and applied in environmental management and air pollution control. Machine learning technique which is a basic subset of AI has been used in tackling the interconnections in a chaotic system. Especially given nonlinear problems, machine learning models have good performance in data fitting and learning capacity. By reviewing the existing research, it was found that such a model has been used to make predictions in a rather wide range, e.g., text classification, medical diagnosis, failure diagnosis, and especially air quality prediction. Numerous research efforts focus on the performance accuracy enhancement and the comparison of different models. For example, Adil compared the prediction performance of SVM and ANN models for PM
2.5 prediction in Delhi and found that ANN outperforms SVM in terms of regular evaluation indicators [
38]. Multilayer Perceptron (MLP), Radial Basis Function (RBF), and Square Multilayer Perceptron (SMLP) were compared so as to identify their potential uses in PM
2.5 prediction based on the air quality data on the US–Mexico border. Meanwhile, it is also found that neural models outperform classical models [
39]. Moreover, ensemble machine learning models have been established and proven to be an effective alternative to enhance prediction performance, such as Bagging model [
40] and Adaboost model [
41]. Existing research efforts on machine learning air prediction models are obsessed with prediction enhancement and do not yet pay enough attention to air prediction from the perspective of environmental, social, and economic causes. However, with the black box model structure, it is difficult for machine learning models to explain formation mechanisms and transporting processes of air pollutants. We reckon that it is beneficial to consider the environmental meanings at both the modeling stage and results interpretation stage and this can help overcome machine learning models’ shortcomings.
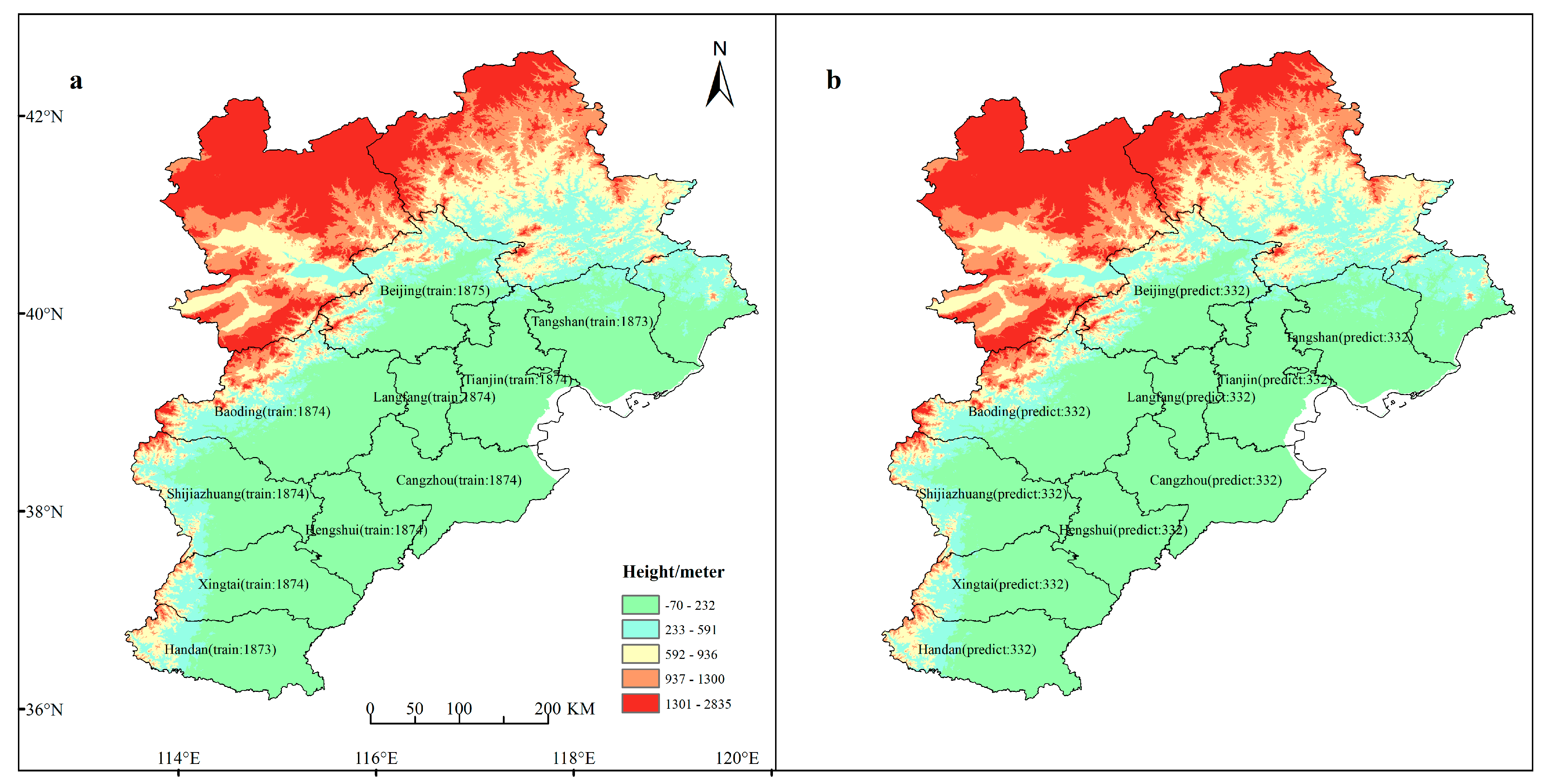
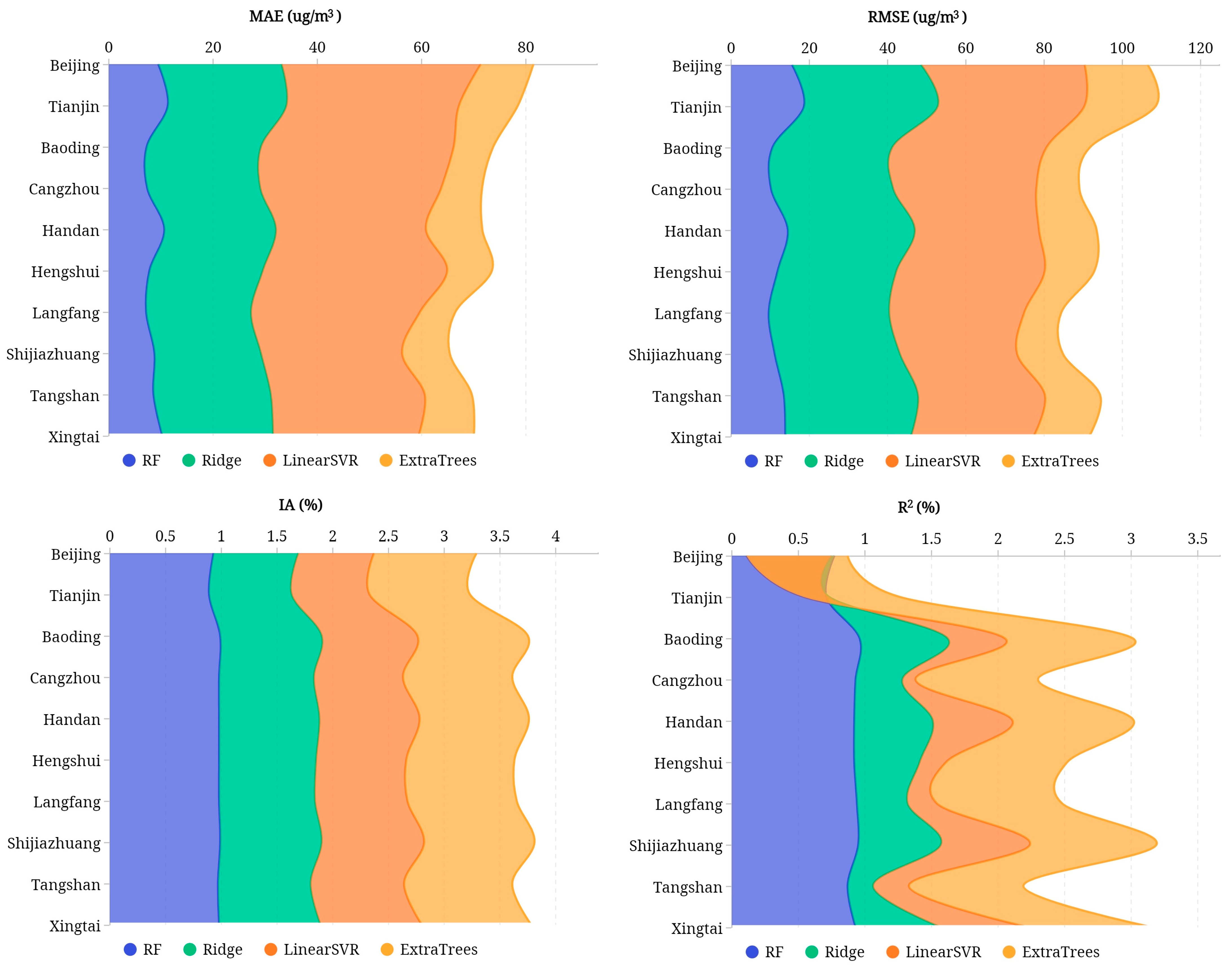
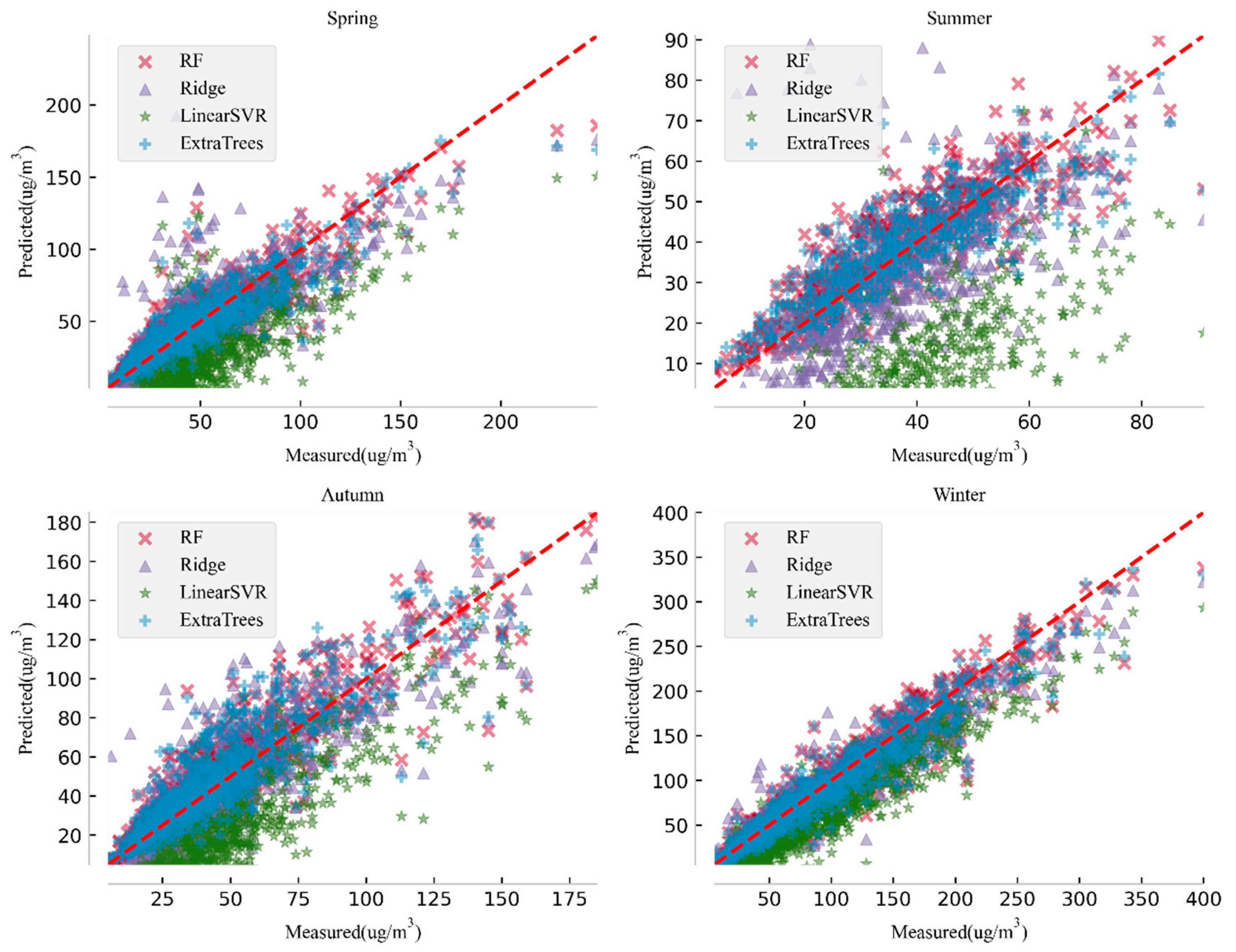
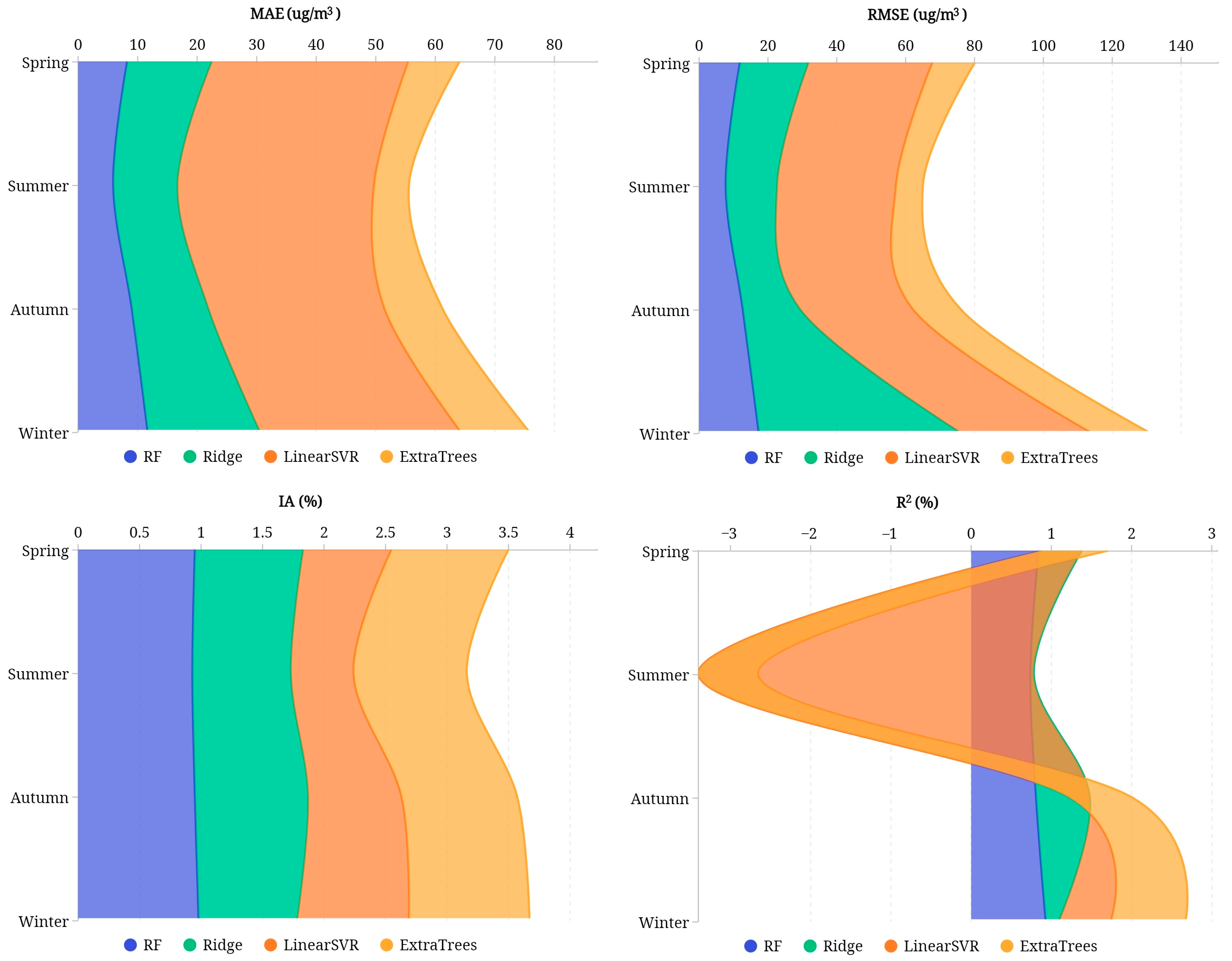
In this study, four types of machine learning models—random forest model, ridge regression model, support vector machine model, extremely randomized trees model—were adopted to predict PM2.5 based on multi-sources data including air quality and meteorological data in time series. When training the model, data were fed into the model by using the rolling prediction method to enlarge the training dataset and primary parameters, while optimal step lengths were determined by experimenting. To evaluate and compare the predictive results of the selected four models, we chose four commonly used evaluating indicators, i.e., mean absolute error (MAE), root mean square error (RMSE), index of agreement (IA), and correlation coefficient (R2). The comparative experiments show that RF and ExtraTrees models have better predicative results with lower mean absolute error and root mean square error compared to other selected models. The novelty of our research lies in the application of edge-cutting machine learning models into air pollution prediction by considering climatic, meteorological, and urban features, and raising awareness of model selection to cope with different application scenarios.
The rest of this paper is organized as follows: In
Section 2, data collection and brief descriptions of each model are introduced; In
Section 3, prediction results of four models are evaluated and compared; In
Section 4, influencing factors for air pollution in the urban setting are discussed and corresponding policy implications are given; In
Section 5, conclusions are drawn.
4. Discussion
This study agrees with the findings of the research done by Wang and colleagues [
45] who selected six monitoring sites located in Guangdong province and who proved that differences exist in PM
2.5 concentration predications for each monitoring site because of the spatial heterogeneity. However, such existing similar research lacks the discussion of seasonal comparisons and the systematic classification and research on influencing factors of air pollution prediction are still missing. Our research is designed to fill this gap. Urban is a complex gigantic system and it is composed of many sub-systems, notably, society, economy, and environment. On the level of sub-system, basic units can function properly with their own principles; however, emergence occurs as a result of the interactions of basic units from different sub-systems. For instance, environmental issues are the consequences of human activities in the complex urban system and their magnitude is strongly associated with multiple interconnected factors. Nevertheless, they are not simply the linear accumulation of individual factor effects, since chaotic characteristics have been observed in time series air pollution data [
46,
47]. Further, these factors can be roughly categorized into four types: urban development properties (urbanization rate, city industrial structure, GDP, etc.), energy consumption status (energy consumption structure, energy utility efficiency, etc.), infrastructure construction (transportation infrastructure, green infrastructure, etc.), and environmental management policies (pollution management and control policies, environmental financial policies, etc.).
Urban development properties are the core character of urban systems and represent the basic status of urban growth, while meanwhile offering a set of scientific measurements for urban performance. Further, urban development properties are the dominant factors in determining the urban development mode. For instance, in the study area the capital cities such as Beijing and Tianjin with higher urbanization rates, are such that their tertiary industries tend to occupy larger portions in the overall industrial structure compared to other cities. As a result, those cities are characterized by green energy consumption structure and higher energy utility efficiency. In contrast, some other cities such as Tangshan and Handan which excessively rely on heavy industries are facing more serious air pollution pressure. Especially when some of those cities were designated as the outflow area for the industrial transfer of particularly iron and steel production and construction material production industries, the air pollution issues become aggravated [
48].
Given the current energy structure in China, energy consumption intensity relates very closely with industrial structure. Consequently, cities in the study area exhibit various characteristics in energy consumption due to different industrial structure. The unreasonable energy consumption structure has been a long-lasting and prominent problem. In Hebei province, coal consumption occupies over 70% of the total energy consumption, higher than the national level of 56.8% in 2021. In 2017, the total coal consumption of Tangshan was 15.3 times of this value in Beijing [
49].
Urban infrastructure constructs the physical foundation of urban human habitat, offers the platform and channel for material and energy, and also generates pollutants transferring and exchanging [
50,
51]. Along with processes of urbanization, the elements cycle has been deeply interfered with by human activities. Urban functional zone layout and transportation infrastructure are the hardware for the reconstructed living habitat. Proper design can help alleviate the so-called urban diseases including severe air pollution. For example, to balance the land use of industrial use and green space, efforts include equal development of residential and industrial zones to shorten the commute distance in the aim of reducing transportation air pollution [
52] and smart transportation infrastructure design.
Unlike the first three factors, environmental management policies are designed for environmental protection purposes; therefore, it plays a crucial role in air pollutant concentration status. Owing to China’s efficient administrative system, normally the environmental regulations on a certain industry or a certain enterprise are very effectively accurate, which will inevitably cause sudden changes to air pollutants concentration, thus leading to noise data for the model prediction. Therefore, more attention should be paid when processing data with noise.
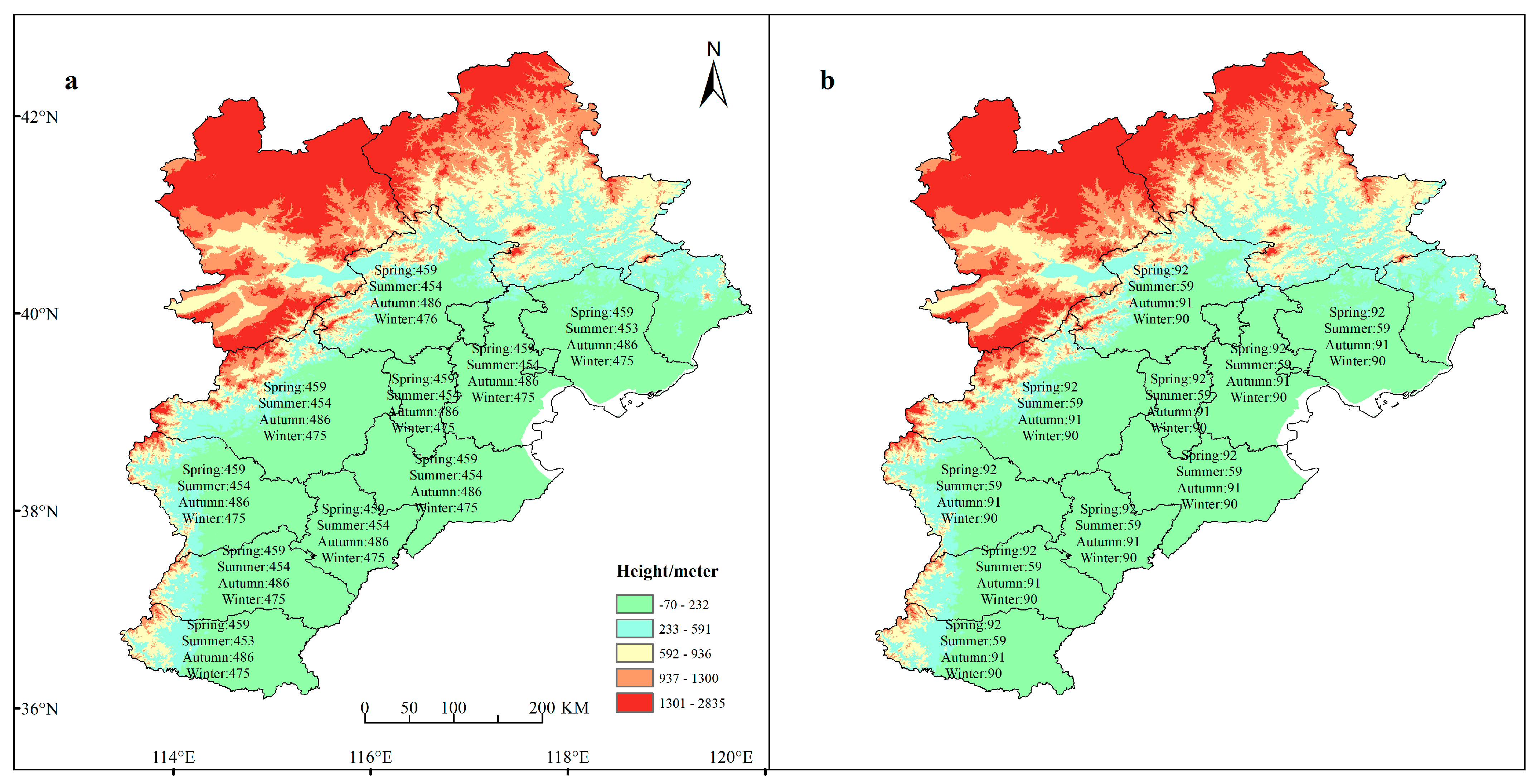
In addition to the abovementioned four urban related influencing factors, it is also very important to factor the seasonal elements into interpreting the different performances of each model for each city. While the local government is putting on stricter air pollution control regulations, the air pollution condition has been improved substantially, but new characteristics were discovered. For example, the air pollution becomes worse in winter time, while in summer time the pollution status will be substantially alleviated. This is partially because in the rural area in north China coal burning is still the primary method for heating.
However, there are still some restrictions and limitations of this research, for it still lacks consideration of various influencing factors, such as GDP, energy structure, etc. Furthermore, more advanced artificial neural network models can be discussed and adopted to gain higher prediction accuracy. For instance, Convolution Neural Network (CNN) can be adopted to further enhance the prediction accuracy and increase the applicability and decrease the dimension of features and the training time required to train the model, thus substantially enhancing the prediction capacity.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}