1. Introduction
A brain–computer interface (BCI) records, analyzes and interprets brain activity of the user and can be used for communication with the external environment, without involving muscle activity [
1]. BCIs can be utilized as communication device for severely impaired people; e.g., people suffering from spinal cord injuries, brain stem strokes, amyotrophic lateral sclerosis (ALS), or muscular dystrophies [
2]. If used as a spelling device, character output speed and classification accuracy are the most important characteristics of the system.
Code-modulated visual evoked potentials (c-VEPs) have gathered increasing research interest in the field of Brain–Computer Interfaces (BCIs) [
3,
4,
5,
6]. In a c-VEP application, a set of flickering targets, each associated with a specific binary code pattern, that determines whether the stimulus is displayed or not displayed, is presented to the user. In parallel, the user’s brain signals are recorded, typically, via electroencephalography (EEG). For classification, the system makes use of target-specific EEG templates, which have been pre-recorded in a training session. When the BCI user gazes at one of the targets, the program compares the collected EEG data to the templates and produces an output command.
Usually, time lags of an m-sequence, a type of pseudo-random code sequence with desirable autocorrelation properties, are used for stimulus modulations [
7]. In the field of BCIs, m-sequences with a code length of 63 bits are most popular; this code length is suitable for multi-target implementations on 60 Hz monitors (allowing a stimulus duration of 63/60 = 1.05 s).
In terms of implementation, synchronization between the amplifier and stimulus presentation is required as the lag between stimuli can be as low as the inverse of the monitor refresh rate. Hence, stimulus onset markers are typically sent to the EEG hardware. These timestamps can be acquired using a photo-resistor or photo-diode attached to the screen [
4,
8]. Another approach is to send the timestamps from the stimulation computer to the amplifier using the parallel port [
3].
In this article, a purely software-based approach is proposed, allowing the detection of stimulus onset without the need for additional hardware.
Typical use cases of c-VEP BCIs are spelling applications for people with severe disabilities [
9]. For these implementations, high classification accuracy and speed are desired. An issue with c-VEP BCIs is that, usually, a full cycle of the code-pattern is used to produce a command output. Moreover, it is desirable that the system is able to distinguish between intentional and unintentional target fixations. The length of the code pattern becomes a bottleneck with respect to the overall responsiveness of the system. Here, a more user friendly approach is presented, utilizing dynamic classification time windows based on classification thresholds, which we previously used in our SSVEP applications [
10,
11,
12].
Regarding the signal classification, ensemble-based methods, which are usually used in machine learning, have recently boosted performance in steady-state visual evoked potential (SSVEP)-based BCI systems [
13]. Here, such an approach is adopted for the c-VEP paradigm and compared to the conventional approach.
The character output speed can further be enhanced by implementing word prediction methods [
14]. Here, an
n-gram word prediction model was utilized [
15,
16], which offers suggestions on the word level. The system was tested on-line using an eight-target spelling interface.
In summary, the contributions of this research are threefold:
Implementation of a novel software-based synchronization between stimulus presentation and EEG data acquisition,
investigation of performance improvements in c-VEP detection utilizing an ensemble-based classification approach,
presenting dynamic on-line classification utilizing sliding classification windows and n-gram word prediction.
The article evaluates the feasibility of the proposed methods based on a test with 18 healthy participants.
2. Materials and Methods
This section describes the methods and materials as well as the experimental design. The sliding window mechanism, as well as the utilized dictionary-driven have been presented before in our previous publication [
15].
2.1. Participants
Eighteen able-bodied participants (eight female and ten male) with mean (SD) age of 23.3 (4.4) years, ranging from 19 to 31, were recruited from the Rhine-Waal University of Applied Sciences. Participants had normal or corrected-to-normal vision. They gave written informed consent in accordance with the Declaration of Helsinki before taking part in the experiment. This research was approved by the ethical committee of the medical faculty of the University Duisburg–Essen. Information needed for the analysis of the test was stored pseudonymously. Participants had the opportunity to withdraw at any time.
2.2. Hardware
The used computer (MSI GT 73VR with nVidia GTX1070 graphic card) operated on Microsoft Windows 10 Education running on an Intel processor (Intel Core i7, 2.70 GHz). A liquid crystal display screen (Asus ROG Swift PG258Q, 1920 × 1080 pixel, 240 Hz refresh rate) was used to display the user interface and present the stimuli.
All 16 channels of the utilized EEG amplifier (g.USBamp, Guger Technologies, Graz, Austria) were used; the electrodes were placed according to the international 10/5 system of electrode placement (see, e.g., [
17] for more details): P
Z, P
3, P
4, P
5, P
6, PO
3, PO
4, PO
7, PO
8, POO
1, POO
2, O
1, O
2, O
Z, O
9, and O
10. In general, good results may be achieved with a smaller number of the EEG channels, however, a higher number of EEG electrodes is beneficial to achieve higher accuracies and ITRs. In this study, the number of electrodes used was defined by the hardware (limited to 16). Further, the common reference electrode was placed at C
Z and the ground electrode at AF
Z (quite common locations of the ground and reference electrodes for BCI studies based on visual stimuli). Standard abrasive electrolytic electrode gel was applied between the electrodes and the scalp to bring impedances below 5 k
. The sampling frequency of the amplifier,
, was set to 600 Hz.
2.3. Stimulus Design
In the c-VEP system used in this study, eight boxes (230 × 230 pixel), each corresponding to one of
stimulus classes, arranged as 2 × 4 stimulus matrix (see
Figure 3) were presented. The color of a target stimuli alternated between the color of the background, ‘black’ (represented by ‘0’) and ‘white’ (represented by ‘1’) in accord with a distinct flickering pattern. To this end, the well-established 63 bit m-sequences, non-periodic binary code patterns, which can be generated using linear feedback were applied.
The m-sequences
,
were assigned to the stimulus matrix employing a circular shift of 2 bits (
had no shift,
was shifted by 2 bits to the left,
was shifted by 4 bits to the left, etc.). The initial code,
is presented in
Figure 1.
Figure 1.
Stimulus pattern of the 63 bits m-sequence used in the experiment. Each ‘1’ in the m-sequence corresponded to four frames where the associated stimulus was shown and each ‘0’ to four frames where the stimulus was not shown. Thus the duration of a stimulus cycle was 1.05 s (also achievable with common 60 Hz monitors).
Figure 1.
Stimulus pattern of the 63 bits m-sequence used in the experiment. Each ‘1’ in the m-sequence corresponded to four frames where the associated stimulus was shown and each ‘0’ to four frames where the stimulus was not shown. Thus the duration of a stimulus cycle was 1.05 s (also achievable with common 60 Hz monitors).
2.4. Synchronization
The synchronization between stimulus presentation and data acquisition is necessary, as the values for the sampling frequency of the amplifier as well as for the monitor refresh rate r are not precise and small differences might accumulate.
Two timers were used to determine the stimulus onset delay , which describes the time interval between the beginning of a signal acquisition block and stimulus onset. A time stamp was acquired directly after the command responsible for the initiation of the flickering in the thread dedicated to the stimulus presentation. A second time stamp, was acquired after receiving a block of EEG data in the thread dedicated for signal classification. The number of samples of one amplifier block is set prior to the experiment. The duration of the collection of one EEG data block in seconds is .
The time interval between drawing command and stimulus presentation can thus be calculated as .
The number of samples prior to stimulus onset, , was determined as , where denotes the nearest integer function; half integers were rounded to the nearest even integer.
Therefore, the difference between the calculated stimulus onset and the duration of the removed samples cannot surpass
. This accuracy can not as easily be achieved with hardware based triggers; when using the digital input of the amplifier, the sample corresponding to stimulus onset is either rounded down or up, the difference can therefor be higher than
. An illustration of the proposed software-based synchronization is provided in
Figure 2.
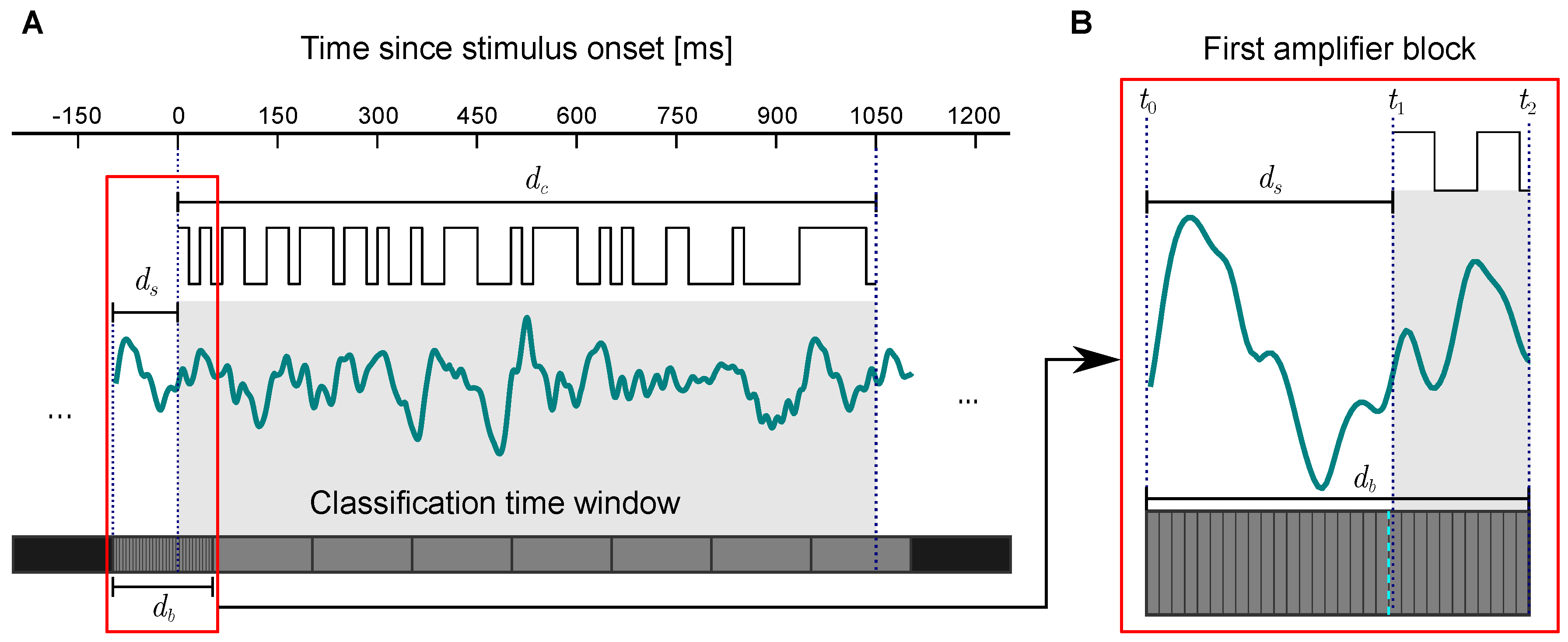
Figure 2.
Software-based synchronization between signal acquisition and stimulus presentation. (A) Real-time data analysis interprets the acquired EEG-data with respect to a classification time window; displayed is the averaged EEG response. The classification is performed block-wise (i.e., after acquisition of a new amplifier block, every ms). The EEG-data collected prior to stimulus onset need to be shuffled out. Collection of a minimum time window, e.g., the length of one stimulus cycle, , can be used as additional condition to trigger an output command. (B) The first amplifier block is shown (at the bottom). Stimulus onset duration, , was calculated after receiving the first block after the gaze-shifting period. It was determined using the block duration, , as well as time stamps and which were set in the thread dedicated to the stimulus presentation, and classification respectively. The dashed blue line indicates the last sample that is shuffled out.
Figure 2.
Software-based synchronization between signal acquisition and stimulus presentation. (A) Real-time data analysis interprets the acquired EEG-data with respect to a classification time window; displayed is the averaged EEG response. The classification is performed block-wise (i.e., after acquisition of a new amplifier block, every ms). The EEG-data collected prior to stimulus onset need to be shuffled out. Collection of a minimum time window, e.g., the length of one stimulus cycle, , can be used as additional condition to trigger an output command. (B) The first amplifier block is shown (at the bottom). Stimulus onset duration, , was calculated after receiving the first block after the gaze-shifting period. It was determined using the block duration, , as well as time stamps and which were set in the thread dedicated to the stimulus presentation, and classification respectively. The dashed blue line indicates the last sample that is shuffled out.
2.5. Experimental Procedure
First, each of the 18 participants went through a training phase, which was required to generate individual templates and spatial filters for on-line classification. Thereafter, an on-line copy spelling task was performed, which immediately followed the training phase.
In the training, data for each of the stimuli were collected. The data collection was grouped in six blocks, ; in each block each of the targets was fixated. Hence, trials were collected in total.
Each of these trials lasted for 3.15 s, i.e., the code patterns
(see
Figure 1) repeated for 3 cycles. The box at which the user needed to fixate was highlighted by a green frame. At the beginning of each of the
recording blocks, the flickering was initiated by the user by pressing the space bar. After each trial, the next box the user needed to focus on was highlighted, and the flickering paused for one second. After every eight trials (one block) the user was allowed to rest.
The training phase was followed by a familiarization run were participants spelled the word BCI. The classification threshold was adjusted manually during this familiarization run to ensure adequate speed.
Three spelling tasks were performed: First, the word BRAIN was spelled (word task), thereafter the sentence THAT_IS_FUN (to get familiar with the integrated dictionary) and an additional sentence, different for each user (individual sentence task, see
Table 1) were spelled with the BCI. Errors needed to be corrected using the integrated UNDO function. For the sentence spelling tasks, dictionary suggestions could be selected.
2.6. Dictionary Supported Spelling Interface
An eight target spelling interface as presented in [
15] was utilized. The graphical user interface (GUI) is illustrated in
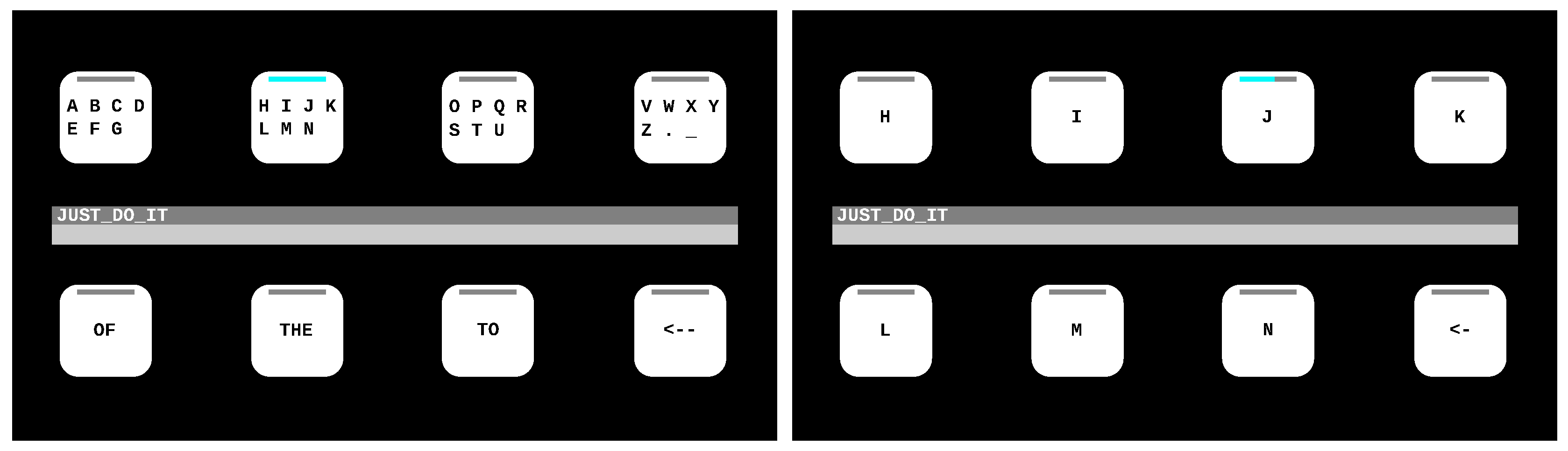
Figure 3. Selecting individual characters required two steps. The first row of GUI contained 28 characters (26 letters, underscore and full stop character) divided into four boxes (seven characters each). The second row offered three dictionary suggestions, as well as a correction option. By selecting the correction option, the last typed character or word was deleted. By selecting a letter group from the first row, the associated characters were presented individually (see
Figure 3).
Figure 3.
Interface of the eight-target speller used in the on-line experiment. In the first layer of the interface dictionary suggestions based on n-gram word prediction model were provided. By selecting a group of letters (e.g., H–N), a second layer containing individual letters was displayed.
Figure 3.
Interface of the eight-target speller used in the on-line experiment. In the first layer of the interface dictionary suggestions based on n-gram word prediction model were provided. By selecting a group of letters (e.g., H–N), a second layer containing individual letters was displayed.
The dictionary suggestions were updated after each performed selection, on the basis of an n-gram prediction model, which is used in computational linguistics.
This model considers a sequence of n items from a text database. An item (here, a word) has the probability . Here, a bi-gram () was utilized, to predict word candidates based on the previously typed/selected word.
The text database was derived from the Leipzig Corpora Collection [
16]. The corpora collection based on English news was derived from approximately 1 million sentences. It contained a word frequency list and a word bi-grams list (co-occurrences as next neighbors). The word suggestions were retrieved on-line from the database using structured query language (SQL). An example of the functioning of the dictionary-driven speller is provided in
Table 2.
Every selection was accompanied by audio and visual feedback (the size of the selected box increased for a short time). Additionally, a progress bar displayed the current certainty level of the associated class label.
2.7. Spatial Filtering and Template Generation
In this study, two approaches of spatial filtering, the conventional and the ensemble-based approach were investigated. In both approaches, Canonical-correlation analysis (CCA) [
18], a statistical method which investigates the relationship between two sets of variables
and
, was utilized (see, e.g., [
6]).
CCA determines weight vectors
and
that maximize the correlation
between the linear combinations
and
by solving
Each training trial was stored in a matrix, where m is the number of electrode channels (here all 16 signal channels of the amplifier were utilized for computation, i.e., ) and is the number of sample points (here, ).
In the conventional approach, all training trials are shifted to a zero-class trials , and than averaged yielding an averaged zero-class template .
The matrices
were inserted into (
1), yielding a filter vector
. Class specific templates
,
were generated by circular shifting the zero-shifted average
in accordance with the bit-shift of the underlying code
.
For the ensemble-based approach, individual templates
and filters
were determined for each stimulus (
). Class specific trial averages
were generated by averaging all trials corresponding to the
i-th class,
,
. The matrices,
were constructed and inserted into (
1), yielding
,
.
For both methods, the on-line classification was performed after receiving new EEG data blocks, which were automatically added to a data buffer with dynamically changing column dimension .
The data buffer was compared to reference signals , which were constructed as sub-matrix of the corresponding training template from rows and columns from for the conventional () and ensemble method (), respectively.
For signal classifications, correlations between the spatially filtered reference signals and the unlabeled EEG data were computed. For the conventional approach, correlations
, were determined as
the ensemble correlations,
, were determined as
In both cases the classification output class label
C is set to
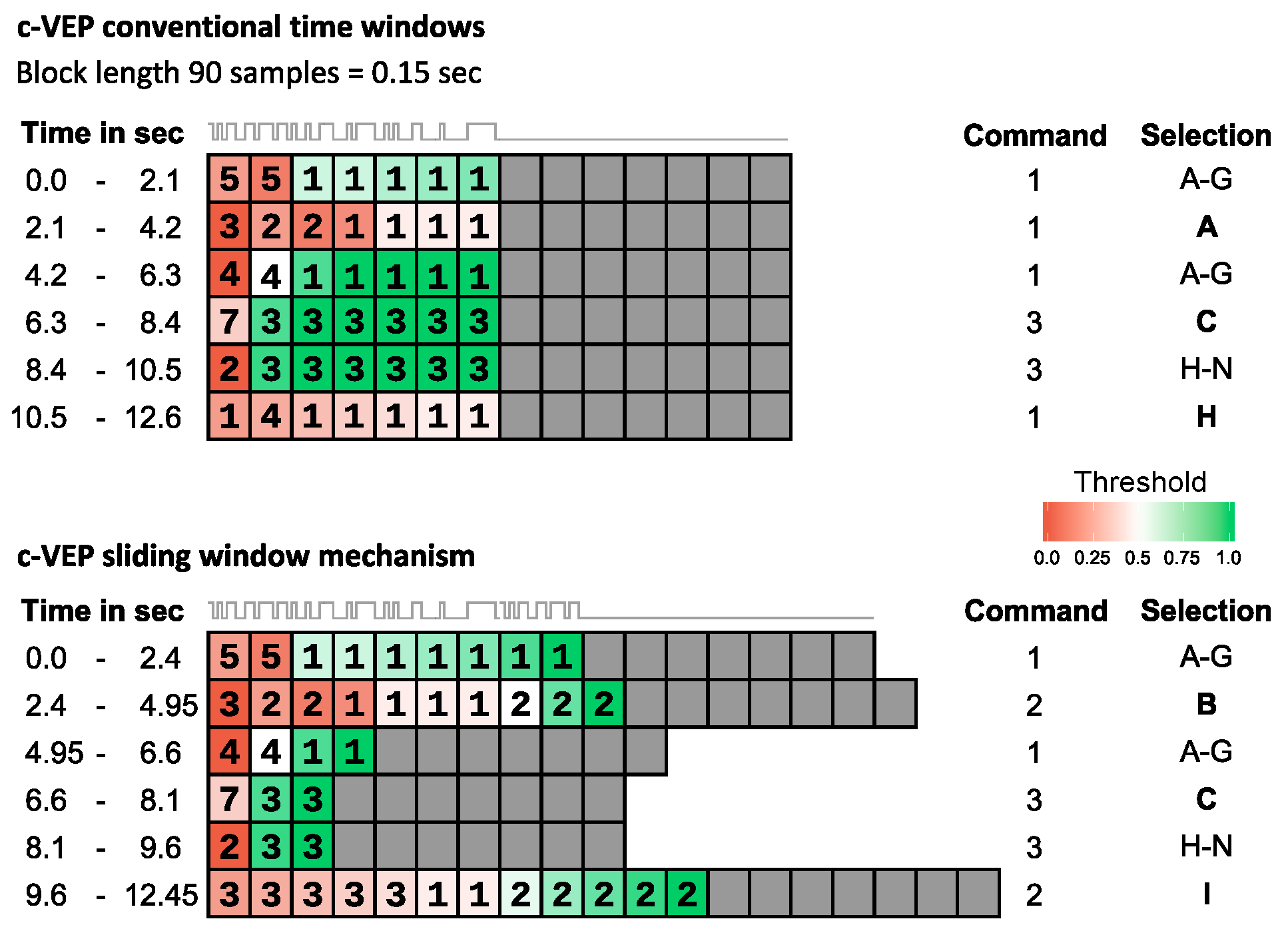
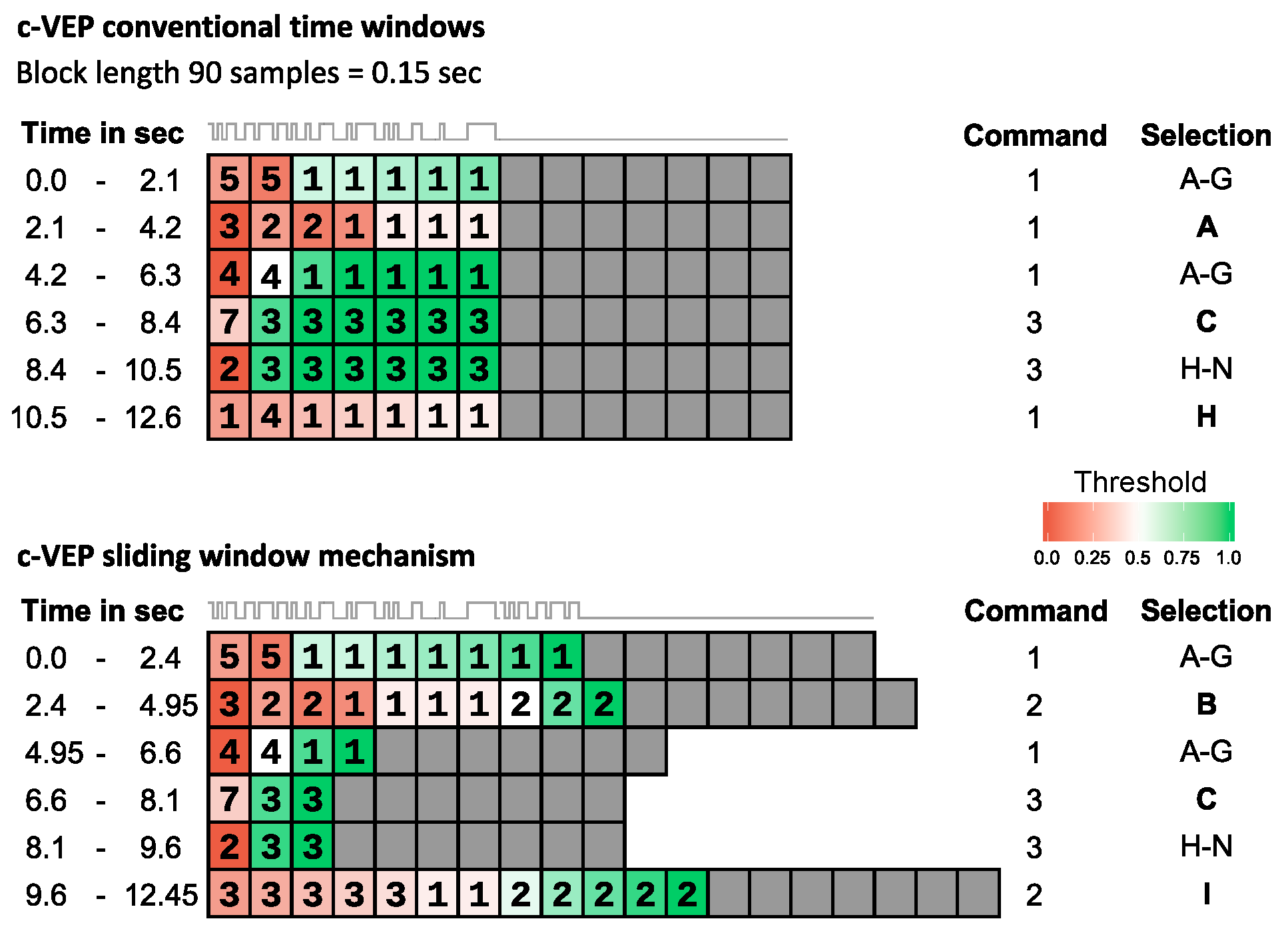
2.8. Sliding Window Mechanism
The number of samples per channel in each EEG data block was selected as a divider of the cycle length in samples (here, 30 samples). This was necessary to maintain synchronization between data collection and stimulus presentation when shuffling out old data blocks.
The output of the user interface corresponding to a classified label was only performed if additionally a threshold criterion was met. In this regard, the data buffer
, storing the EEG, changed dynamically, i.e., the length of the classification time window
was extended incrementally as long as
. The decision certainty,
, which was determined as the distance between the highest and second highest correlation needed to surpass a threshold value,
, which was set for each participant individually after the training. If this criterion was met,
, the BCI executed the associated output command, the data buffer
was cleared and a two seconds gaze shifting period followed (data collection and flickering paused).
Figure 4 illustrates the sliding window mechanism and compares it to the conventional method.
3. Results
All participants completed the on-line experiment. The two tested classification approaches were compared using off-line leave-one-out cross-validation. In this respect, all but one recording blocks were used for the training and one block was used as validation data. The cross-validation process was repeated
times, with each recording block used once as the validation data. The
results were then averaged.
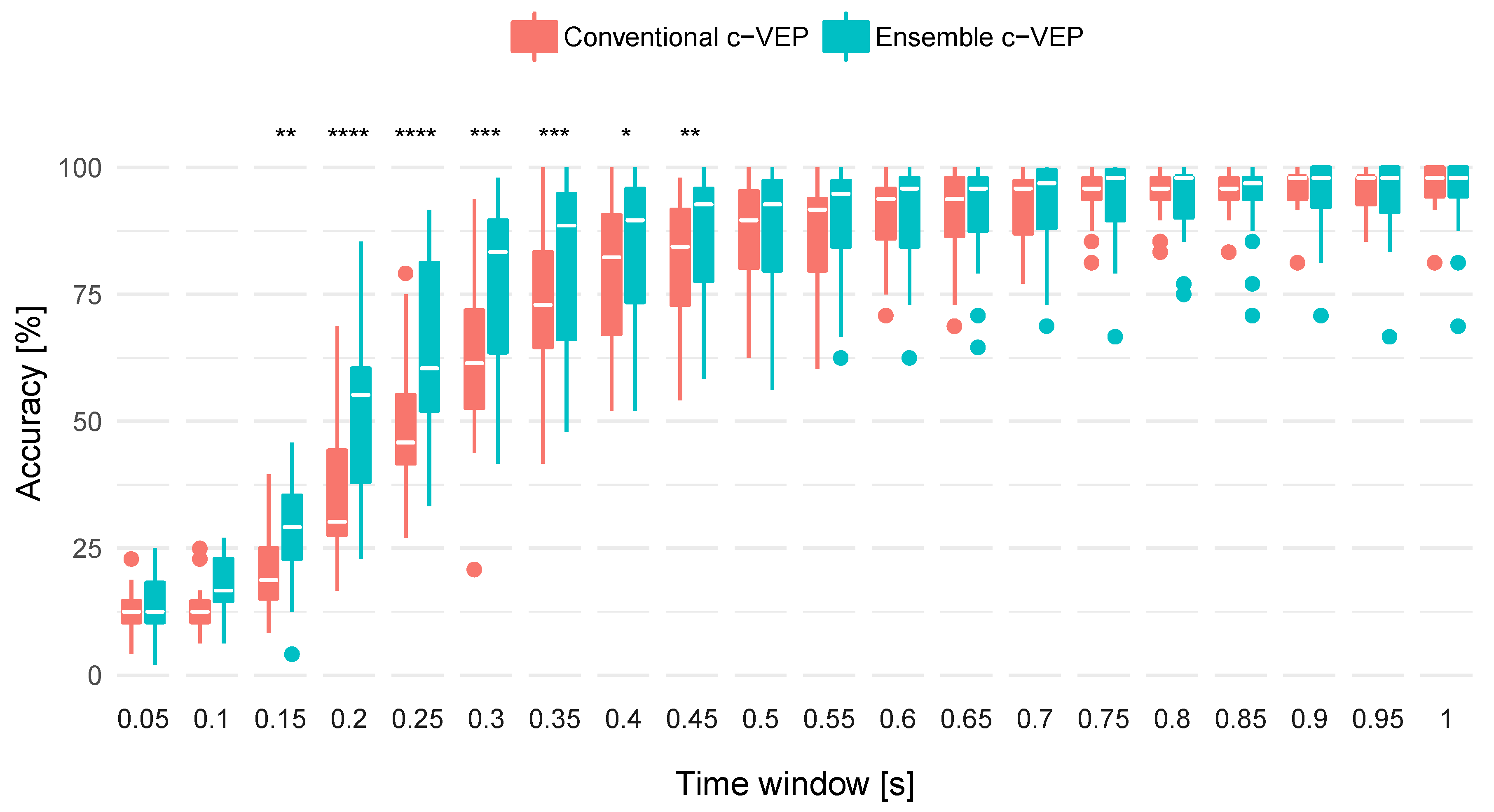
Figure 5 shows accuracies across all participants for classification time windows up to 1.05 s. The accuracies for the ensemble-based classification were significantly higher.
The on-line performance between word and sentence spelling tasks was evaluated utilizing the output command accuracy, the ITR, as well as the output characters per minute (OCM) which is a measure of typing speed. The OCM is calculated by dividing the total number of output characters by the time needed to type them [
14]. The ITR in bpm [
1] was calculated as
where
p represents the identification accuracy (the number of correctly classified commands divided by the total number of commands), and
t represents the average time between consecutive selections, (in s). A calculation tool for the ITR can be found at
https://bci-lab.hochschule-rhein-waal.de/en/itr.html.
Table 3 displays the results of the on-line spelling tasks. In terms of detection accuracy, all participants were able to complete the task with average accuracies above 80% for the word—as well as for the sentence task. For the spelling task BRAIN, a mean accuracy of 98.8% was reached; for the sentence spelling task, a mean accuracy of 95.9% was reached. Sixteen out of the eighteen participants completed the spelling task BRAIN without any errors, reaching an accuracy of 100%. For the sentence spelling tasks, still eight participants reached 100% classification accuracy.
The average ITR for the spelling task BRAIN was 75.7 bpm. For the individual sentence spelling task, it was significantly lower, 57.8 bpm (paired two-sample t-test: , , ). Across individual participants, the minimal and maximal ITR were 43.2 bpm and 125.4 bpm for the spelling task BRAIN and 34.5 bpm and 95.8 bpm for the sentence spelling task, respectively.
However, in terms of OCM, significantly better results were achieved when the dictionary integration was used. The average OCM was 12.7 char/min for spelling BRAIN and 18.4 char/min for the individual sentence task (, , ). Across individual participants, the minimal and maximal OCM were 7.7 char/min and 20.9 char/min for the spelling task BRAIN and 11.4 char/min and 20.4 char/min for the sentence spelling task, respectively.
4. Discussion
In this study, we presented a dictionary-driven c-VEP spelling application utilizing n-gram based dictionary suggestions. In this sense, implementation of flexible time windows were realized, which are rarely seen in c-VEP systems, where typically fixed time windows are used. Therefore, the presented BCI was able to accurately discriminate between intentional and unintentional fixations (i.e., if the user did not focus on a particular button, or just briefly attended it, e.g., when searching for the desired character, the threshold criterion was not met and no classification was performed).
Another advantage of the approach is the additional user feedback provided through progress bars. Typically, in c-VEP based BCIs, to our best knowledge, feedback is given on trial base only, i.e., after each trial (e.g., the selected letter is displayed, also called as discrete feedback). Here, continuous feedback was provided throughout the trial. This real-time information about the classification is also valuable to customize system parameters during familiarization. Similar methods have been incorporated into asynchronous SSVEP-based BCI systems and lead to increased user friendliness and system accuracy [
19,
20].
It should be noted, that due to the classification thresholds, the command selection time varies. Hence ITRs in achieved on-line experiments are typically much lower in comparison to results from an off-line analysis.
The selection options of the GUI changed after each selection; the dictionary suggestions were updated after each selection. Changing elements of the GUI could be handled easily due the dynamic time window approach.
It should be further noted, that for two step spelling interfaces, as the one presented here, letter by letter selection includes two selection time windows and two gaze shifting phases. It remains to be tested, if the dictionary support is as beneficial for multi target systems that require only one step to select a character.
Another addition to the state of the art, is the introduction of a novel trigger free stimulus onset determination approach. The high accuracies achieved in the study demonstrate that it is not necessary to send a trigger signal to the amplifier. The same principle can also be adopted to SSVEP systems that utilize hybrid frequency and phase coding, such as the system used by Nakanishi and colleagues [
13].
Furthermore, in addition to the latency of the stimulus presentation, some time elapses between stimulus presentation of the eye and the occurrence of a VEP. Although not applied here, some researchers achieved improvements in BCI performance by excluding samples from the beginning of the data buffer to address the latency of the visual system, e.g., Wittevrongel et al. recommended to exclude the first 150 ms of the trials from the decoding for the c-VEP paradigm [
5]. Similarly, Jia and colleagues [
21] found SSVEP latencies of different stimulus frequencies to be around 130 ms.
As evident from the off-line classification, see
Figure 5, the classifier produced accurate labels before a full stimulation cycle was completed. As expected, the accuracy increased when larger time windows were used. However, it can be seen, that for the ensemble-based approach, a time window as low as 0.35 s yielded accuracies around 90% for the majority of participants. In general, the ensemble-based approach, utilizing individual templates for each target demonstrated superior off-line performance.
This can also be observed in on-line spelling: In our previous study [
15], we used the conventional approach for copy spelling tasks utilizing the same interface. Participants completed sentences with a mean ITR of 31.08 bpm. Here, the mean ITR was roughly twice as high (57.8 bpm).
A downside of the approach utilized is the prolonged training duration. Performance typically increases when longer training sessions are conducted. Here, we averaged the data over six trials for the ensemble approach. As eight targets where used, the same data yielded 48 trials with the conventional approach.
As investigated by Nagel and colleagues [
4], target latency is dependent on the vertical position on the screen; the conventional approach can therefore benefit from a correction of these latencies. It should also be noted, that some c-VEP-BCIs have additional flickering objects around the selectable targets (principal of equivalent neighbors, see e.g., [
6]). This strategy has not been applied here, and could lead to additional differences between outer and inner targets.
Furthermore, it must be noted, that higher ITRs can be achieved utilizing the c-VEP paradigm. Spüler et al. [
6] achieved 144 bpm and an average of 21.3 error-free letters per minute in on-line spelling tasks; the authors utilized a 32 target c-VEP system with fixed classification time windows of 1.05 s. However, thanks to the dictionary integration, the average number of error-free characters achieved in the presented study (i.e., 18.4 characters/min) was quite similar, albeit using only eight targets.
The dynamic sliding window mechanism as well as the implementation of software-based stimulus synchronization utilized in this study add to a growing body of literature on c-VEP based BCIs. In a future study, we will adopt the methods described here to a multi-target interface. Typically, 32 targets are used to maximize ITR [
6,
7]. VEP-based BCIs are often compared with eye tracking interfaces, as both require control eye gaze. The responsiveness of the here presented system was promising; hence c-VEP paradigm could be hybridized e.g., with eye tracking technology as described in our previous publication [
12].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}