An Evaluation Approach for a Physically-Based Sticky Lip Model †


Abstract
:1. Introduction
2. Related Work
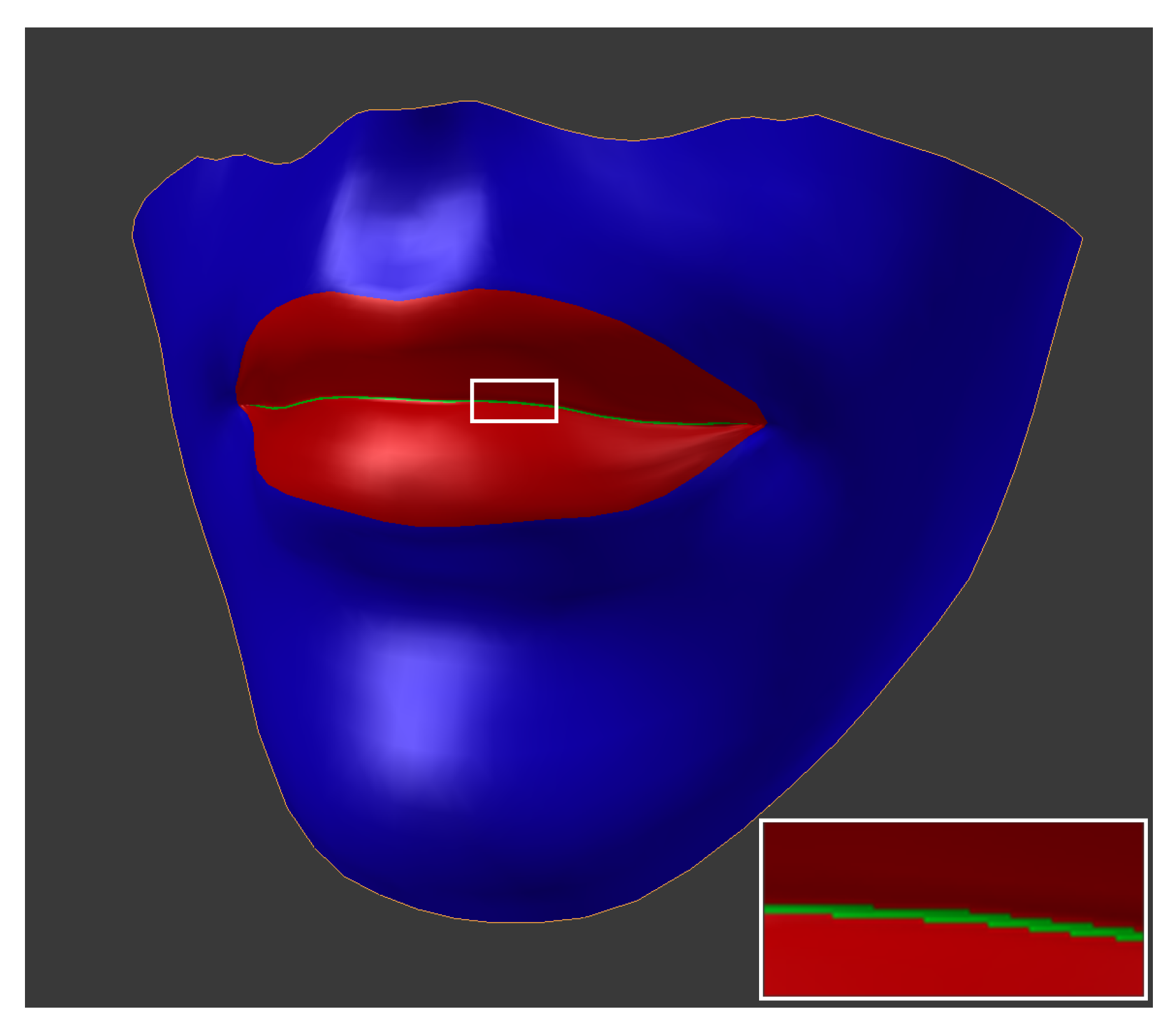
3. A Physically-Based Mouth Model
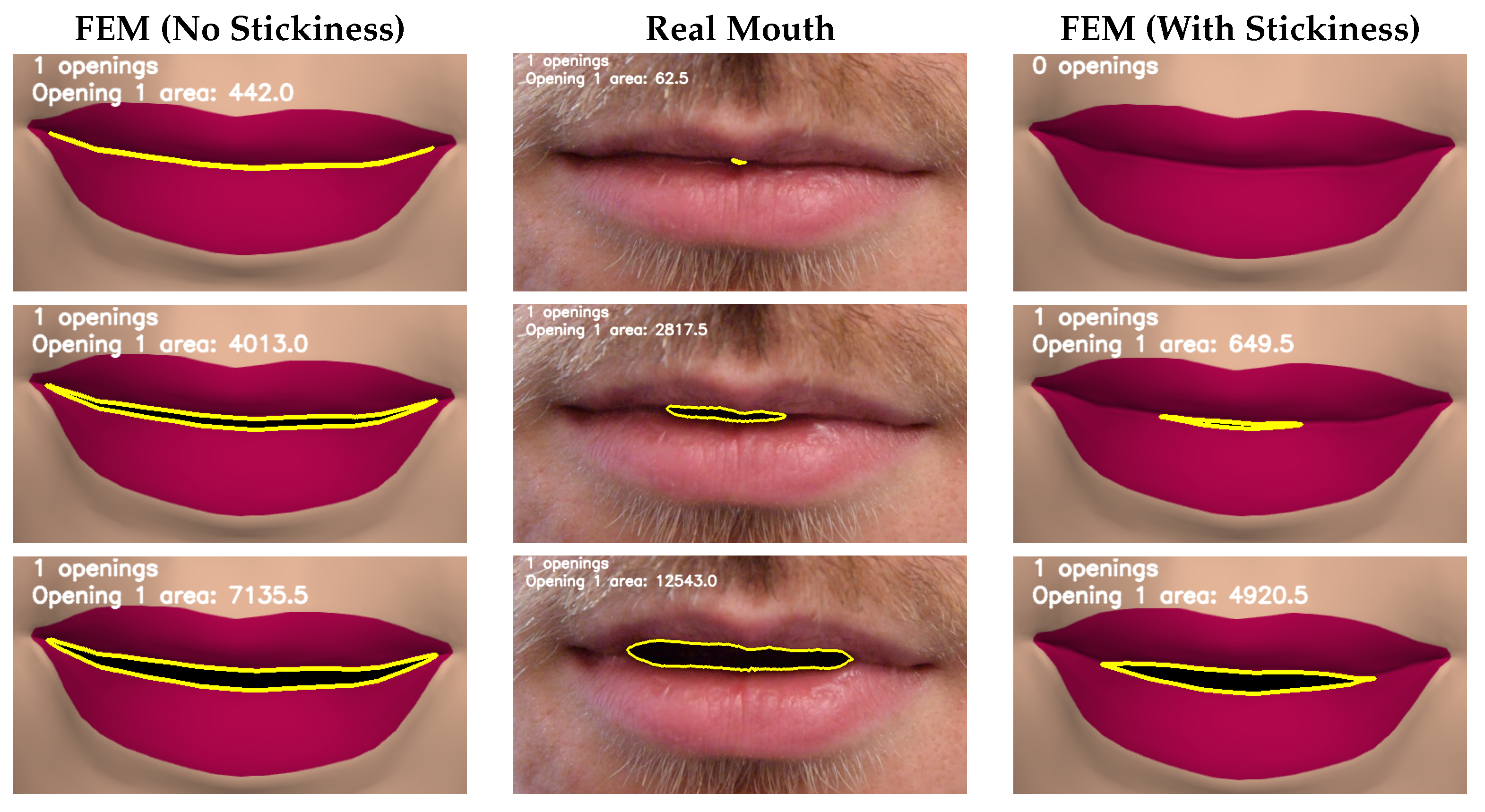
4. The Evaluation Process
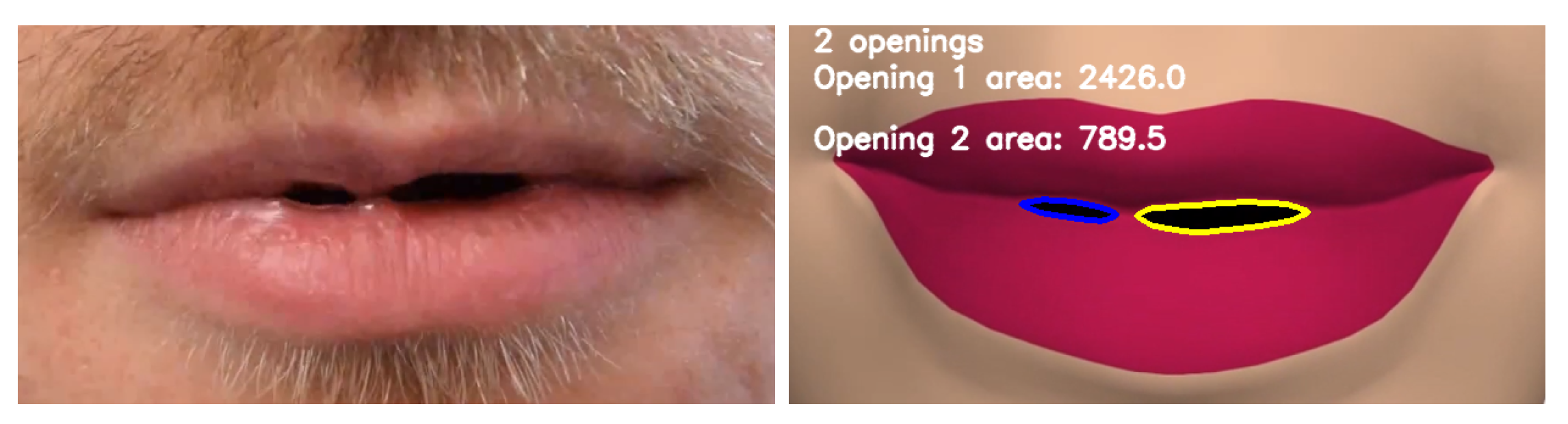
- Number of Mouth Openings: The number of individual mouth openings.
- Mouth Opening Area: The mouth opening area is the area contained within a mouth opening contour.
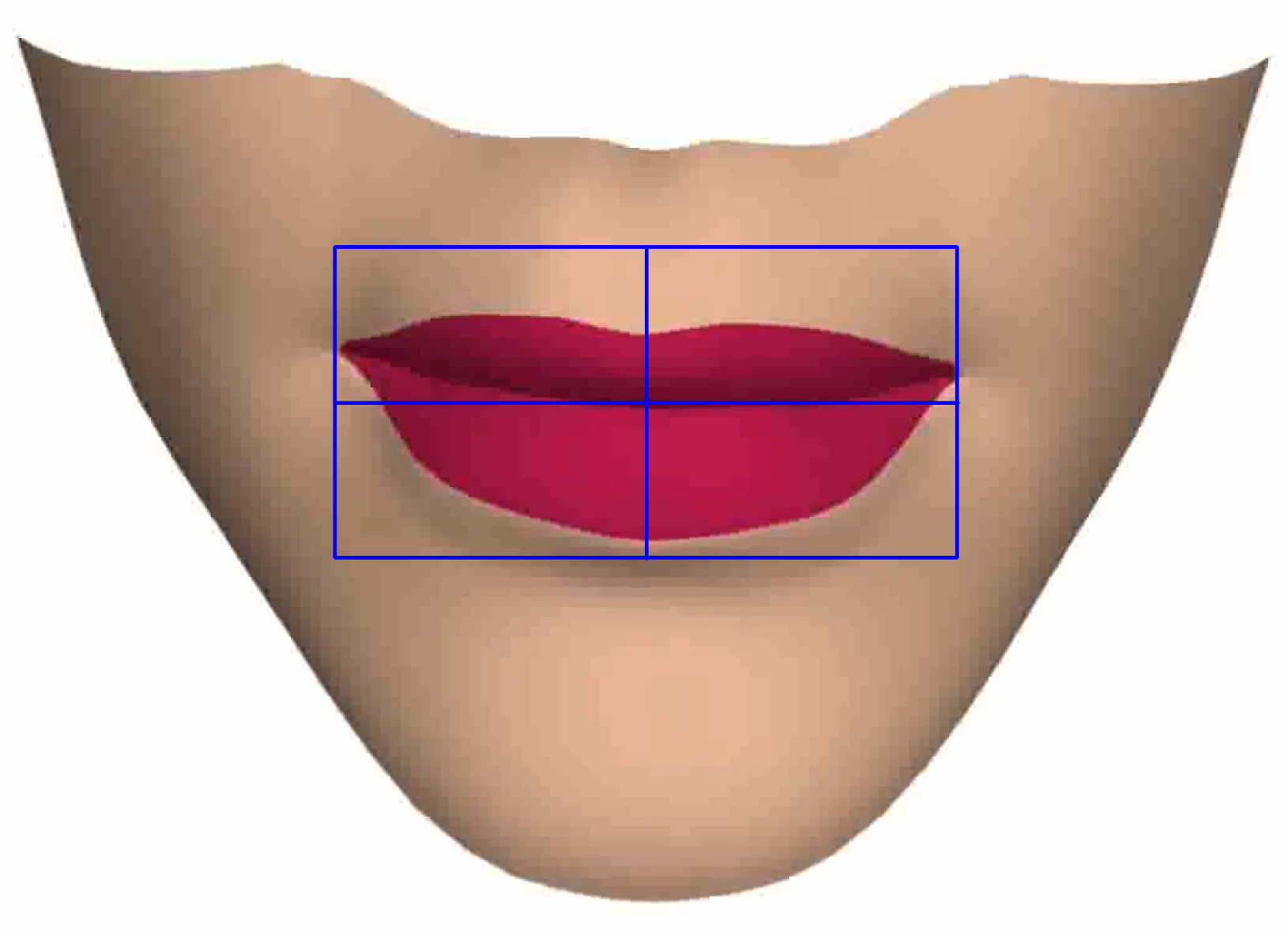
- Mouth Opening Width: The mouth opening width is computed as the difference between the greatest and least x coordinates of pixels that lie within a mouth opening.
- Mouth Opening Height: The mouth opening height is computed as the difference between the greatest and least y coordinates of pixels that lie within a mouth opening.
- Convert to greyscale
- Blur
- Threshold
- Contour detection
- Sorting/Region identification
- Metric extraction
5. Results and Discussion
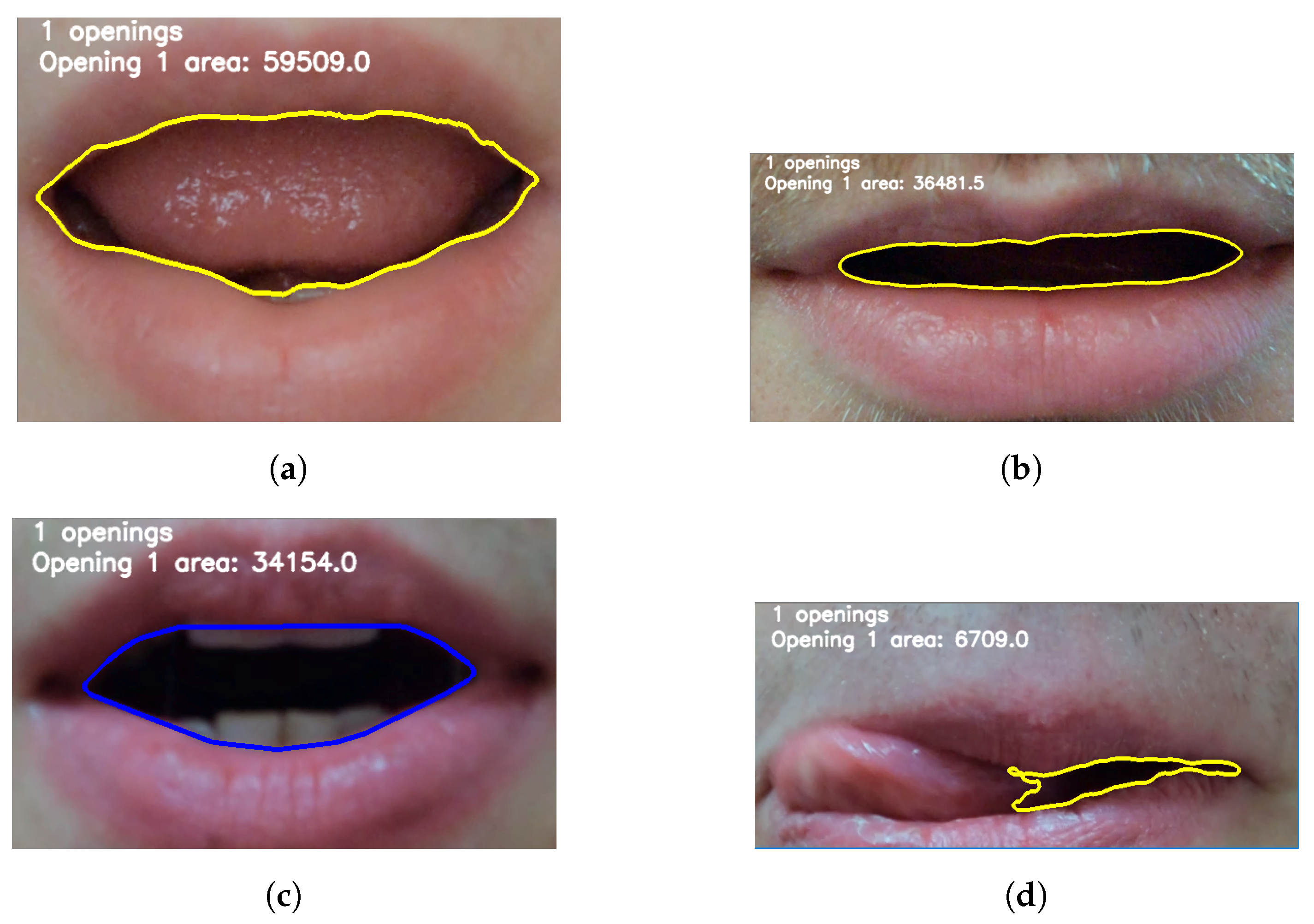
5.1. Detecting Mouth Openings
5.2. Opening over Time
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| TLED | Total Lagrangian Explicit Dynamics |
| FEM | Finite Element Method |
| AAM | Active Appearance Model |
| ASM | Active Shape Model |
References
- Leach, M.; Maddock, S. Physically-based Sticky Lips. In Proceedings of the EG UK Computer Graphics & Visual Computing, EGUK, Swansea, UK, 13–14 September 2018. [Google Scholar]
- Parke, F.I. A model for human faces that allows speech synchronized animation. Comput. Graph. 1975, 1, 3–4. [Google Scholar] [CrossRef]
- Waters, K. Physical model of facial tissue and muscle articulation derived from computer tomography data. In Proceedings of the Visualization in Biomedical Computing, International Society for Optics and Photonics, Chapel Hill, NC, USA, 13–16 October 1992; pp. 574–583. [Google Scholar]
- Lee, Y.; Terzopoulos, D.; Waters, K. Realistic modeling for facial animation. In Proceedings of the 22nd aNnual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 6–11 August 1995; ACM: New York, NY, USA, 1995; pp. 55–62. [Google Scholar]
- Waters, K. A Muscle Model for Animation Three-dimensional Facial Expression. SIGGRAPH Comput. Graph. 1987, 21, 17–24. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Manual for the Facial Action Coding System; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Chabanas, M.; Payan, Y. A 3D Finite Element Model of the Face for Simulation in Plastic and Maxillo-Facial Surgery. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Pittsburgh, PA, USA, 11–14 October 2000; pp. 1068–1075. [Google Scholar]
- Kahler, K.; Haber, J.; Seidel, H.P. Geometry-based Muscle Modeling for Facial Animation. In Proceedings of the Graphics Interface, Ottawa, ON, Canada, 7–9 June 2001; pp. 37–46. [Google Scholar]
- Scheepers, F.; Parent, R.E.; Carlson, W.E.; May, S.F. Anatomy-Based Modeling of the Human Musculature. In Proceedings of the SIGGRAPH ’97, Los Angeles, CA, USA, 3–8 August 1997; ACM: New York, NY, USA, 1997. [Google Scholar]
- Barrielle, V.; Stoiber, N.; Cagniart, C. BlendForces: A Dynamic Framework for Facial Animation. Comput. Graph. Forum 2016, 35, 341–352. [Google Scholar] [CrossRef]
- Cong, M.; Bhat, K.S.; Fedkiw, R. Art-directed muscle simulation for high-end facial animation. In Proceedings of the Symposium on Computer Animation, Zurich, Switzerland, 11–13 July 2016; pp. 119–127. [Google Scholar]
- Kozlov, Y.; Bradley, D.; Bächer, M.; Thomaszewski, B.; Beeler, T.; Gross, M. Enriching Facial Blendshape Rigs with Physical Simulation. Comput. Graph. Forum 2017, 36, 75–84. [Google Scholar] [CrossRef]
- Beeler, T.; Hahn, F.; Bradley, D.; Bickel, B.; Beardsley, P.; Gotsman, C.; Sumner, R.W.; Gross, M. High-quality passive facial performance capture using anchor frames. ACM Trans. Graph. 2011, 30, 75. [Google Scholar] [CrossRef]
- Deng, Z.; Chiang, P.Y.; Fox, P.; Neumann, U. Animating blendshape faces by cross-mapping motion capture data. In Proceedings of the 2006 Symposium on Interactive 3D Graphics and Games, Redwood City, CA, USA, 14–17 March 2006; ACM: New York, NY, USA, 2006; pp. 43–48. [Google Scholar]
- Ichim, A.E.; Kadleček, P.; Kavan, L.; Pauly, M. Phace: Physics-based face modeling and animation. ACM Trans. Graph. 2017, 36, 153. [Google Scholar] [CrossRef]
- Olszewski, K.; Lim, J.J.; Saito, S.; Li, H. High-fidelity facial and speech animation for VR HMDs. ACM Trans. Graph. 2016, 35, 221. [Google Scholar] [CrossRef]
- Alexander, O.; Rogers, M.; Lambeth, W.; Chiang, M.; Debevec, P. The Digital Emily project: Photoreal facial modeling and animation. In Proceedings of the ACM SIGGRAPH 2009 Courses, Yokohama, Japan, 16–19 December 2009; ACM: New York, NY, USA, 2009; p. 12. [Google Scholar]
- Gascón, J.; Zurdo, J.S.; Otaduy, M.A. Constraint-based simulation of adhesive contact. In Proceedings of the 2010 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Madrid, Spain, 2–4 July 2010; Eurographics Association: Aire-la-Ville, Switzerland, 2010; pp. 39–44. [Google Scholar]
- Barrielle, V.; Stoiber, N. Realtime Performance-Driven Physical Simulation for Facial Animation. Comput. Graph. Forum Wiley Online Libr. 2018. [Google Scholar] [CrossRef]
- Cosker, D.; Marshall, D.; Rosin, P.L.; Hicks, Y. Speech driven facial animation using a hidden markov coarticulation model. In Proceedings of the Pattern Recognition, 17th International Conference on (ICPR’04), Cambridge, UK, 23–26 August 2010; IEEE: Washington, DC, USA, 2004; pp. 128–131. [Google Scholar]
- Hill, A.; Cootes, T.F.; Taylor, C.J. Active shape models and the shape approximation problem. Image Vis. Comput. 1996, 14, 601–607. [Google Scholar] [CrossRef]
- Edwards, G.J.; Lanitis, A.; Taylor, C.J.; Cootes, T.F. Statistical models of face images-improving specificity. Image Vis. Comput. 1998, 16, 203–212. [Google Scholar] [CrossRef]
- Edwards, G.J.; Cootes, T.F.; Taylor, C.J. Face recognition using active appearance models. In Proceedings of the European Conference on Computer Vision, Freiburg, Germany, 2–6 June 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 581–595. [Google Scholar]
- Farnell, D.; Galloway, J.; Zhurov, A.; Richmond, S.; Marshall, D.; Rosin, P.; Al-Meyah, K.; Pirttiniemi, P.; Lähdesmäki, R. What’s in a Smile? Initial Analyses of Dynamic Changes in Facial Shape and Appearance. J. Imaging 2019, 5, 2. [Google Scholar] [CrossRef]
- Faceware. Faceware Analyzer; Faceware Technologies: Sherman Oaks, CA, USA, 2019. [Google Scholar]
- Walker, J.H.; Sproull, L.; Subramani, R. Using a human face in an interface. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 24–28 April 1994; ACM: New York, NY, USA, 1994; pp. 85–91. [Google Scholar]
- Hong, P.; Wen, Z.; Huang, T.S. Real-time speech-driven face animation with expressions using neural networks. IEEE Trans. Neural Netw. 2002, 13, 916–927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singular Inversions. FaceGen; Singular Inversions: Vancouver, BC, Canada, 2017. [Google Scholar]
- Blender Online Community. Blender—A 3D Modelling and Rendering Package; Blender: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Johnsen, S.F.; Taylor, Z.A.; Clarkson, M.J.; Hipwell, J.; Modat, M.; Eiben, B.; Han, L.; Hu, Y.; Mertzanidou, T.; Hawkes, D.J.; et al. NiftySim: A GPU-based nonlinear finite element package for simulation of soft tissue biomechanics. Int. J. Comput. Assist. Radiol. Surg. 2015, 10, 1077–1095. [Google Scholar] [CrossRef] [PubMed]
- Poynton, C. Frequently asked questions about color. Retrieved June 1997, 19, 2004. [Google Scholar]
- Suzuki, S.; Abe, K. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Liévin, M.; Delmas, P.; Coulon, P.Y.; Luthon, F.; Fristol, V. Automatic lip tracking: Bayesian segmentation and active contours in a cooperative scheme. In Proceedings of the IEEE International Conference on Multimedia Computing and Systems, Florence, Italy, 7–11 June 1999; IEEE: Washington, DC, USA, 1999; Volume 1, pp. 691–696. [Google Scholar]
- OBS Studio Contributors. Open Broadcaster Software. 2019. Available online: https://obsproject.com/ (accessed on 5 March 2019).



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Value |
|---|---|
| Time Step | 0.00001 s |
| Hourglass Coefficient | 0.075 |
| Damping Coefficient | 80 |
| Soft Tissue Material Model | Neo-Hookean |
| Soft Tissue Shear Modulus | 800 |
| Soft Tissue Bulk Modulus | 7000 |
| Soft Tissue Density | 1050 kg/m−3 |
| Saliva Material Model | Neo-Hookean Breaking |
| Saliva Shear Modulus | 7700 |
| Saliva Bulk Modulus | 191,000 |
| Saliva Density | 1050 kg/m−3 |
| Initial Moisture Level | 100 |
| Critical Moisture Level | 100 |
| Evaporation Rate | 0 |
| Single Opening/Uniform Glue Strength | 0.08 |
| Double Opening Central Glue Strength | 0.18 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leach, M.; Maddock, S. An Evaluation Approach for a Physically-Based Sticky Lip Model †. Computers 2019, 8, 24. https://doi.org/10.3390/computers8010024
Leach M, Maddock S. An Evaluation Approach for a Physically-Based Sticky Lip Model †. Computers. 2019; 8(1):24. https://doi.org/10.3390/computers8010024
Chicago/Turabian StyleLeach, Matthew, and Steve Maddock. 2019. "An Evaluation Approach for a Physically-Based Sticky Lip Model †" Computers 8, no. 1: 24. https://doi.org/10.3390/computers8010024
APA StyleLeach, M., & Maddock, S. (2019). An Evaluation Approach for a Physically-Based Sticky Lip Model †. Computers, 8(1), 24. https://doi.org/10.3390/computers8010024