In the above section, we analyzed the effectiveness of the cluster-based PRF approach (resampling). We achieved higher effectiveness than standard PRF approaches. In standard cluster-based PRF, we construct clusters with only those neighbors of clusters that have high similarity with centroids. These nearest neighbors are retrieved using the top 30 frequent terms of centroid documents by assuming that during query processing, a subset of these cluster documents would be retrieved at top rank positions, thus increasing the effectiveness of PRF by retrieving relevant documents. This assumption works quite well when the retrieval bias of the retrieval model does not cause any effect on the retrievability of documents of clusters. However, if there exists a large retrievability inequality between documents of a collection (due to retrieval bias), then high retrievable documents of clusters are frequently retrieved at top rank positions for most of the queries due only to retrieval bias. These documents decrease the effectiveness of PRF. The objective of this section is to analyze to what extent retrieval bias effects the PRF effectiveness and how to improve the effectiveness by constructing clusters with the help of high similarity and retrievability. We perform the following set of experiments in order to understand this objective.
As all of the above experiments are based on retrievability, therefore, in the following sections, we first introduce the definition of the retrievability measure in IR; then, we describe the process of creating queries for calculating retrievability; and finally, we perform all experiments as described above.
5.1. Retrievability Measure
The following description of retrievability measurement as introduced by [
9] provides a quick introduction of how it is measured.
Given a collection
D, a retrieval model accepts a user query
q and returns a ranked list of documents, which are deemed to be relevant to
q. We can thus consider the retrievability of a document as influenced by two factors: (a) how retrievable it is, with respect to the collection
D; and (b) the effectiveness of the ranking strategy of the retrieval model. In order to derive an estimate of this quantity, [
9] used query set-based sampling [
35]. The query set
Q could either be a historical sample of queries or an artificial simulated substitute similar to users’ queries. Then, each user’s
is issued to the retrieval model, and the retrieved documents along with their positions in the ranked list are recorded. Intuitively, the retrievability of a document
d is high when:
there are many probable queries in Q that can be expressed in order to retrieve d and
when retrieved, the rank r of the document d is lower than a rank cutoff (threshold) c. This is the point at which the user would stop examining the ranked list. This is a user-dependent factor and, thus, reflects a particular retrieval scenario in order to obtain a more accurate estimate of this measure. For instance, in the web-search scenario, a low c would be more accurate as users are unlikely to go beyond the first page of the results, while in the context of recall-oriented retrieval settings (for instance, legal or patent retrieval), a high c would be more accurate.
Thus, based on the
Q,
r and
c, we formulate the following measure for the retrievability of
d.
is a generalized utility/cost function, where is the rank of d in the result list of query q; c denotes the maximum rank that a user is willing to proceed down in the ranked list. The function returns a value of one if and zero otherwise. denotes the likeliness that a user actually issues query q. This probability may be hard to determine explicitly and is thus frequently set to one, i.e., to give all queries equal probabilities. More complex heuristics considering the length of the query, the specificity of the vocabulary, etc., may be considered. Defined in this way, the retrievability of a document is essentially a cumulative score that is proportional to the number of times the document can be retrieved within that cutoff c over the set Q. This fulfills our aim, in that the value of will be high when there is a large number of (highly probable) queries that can retrieve the document d at the rank less than c, and the value of will be low when only a few queries retrieve the document. Furthermore, if a document is never returned at the top ranked c positions, possibly because it is difficult to retrieve by the retrieval model, then the is zero.
The inequality between the retrievability score of documents can be further analyzed using the Lorenz curve [
36]. In economics and the social sciences, a Lorenz curve is used to visualize the inequality of the wealth in a population. This is performed by first sorting the individuals in the population in ascending order of their wealth and then plotting a cumulative wealth distribution. If the wealth in the population was distributed equally, then we would expect this cumulative distribution to be linear. The extent to which a given distribution deviates from the equality is reflected by the amount of skewness in the distribution. The work in [
9] employed a similar idea in the context of a population of documents, where the wealth of documents is represented by the
function. The more skewed the plot, the greater the amount of inequality or bias within the population. The Gini coefficient [
36]
G is used to summarize the amount of retrieval bias in the Lorenz curve and provides a bird’s eye view. It is computed as follows.
D represents the set of documents in the collection. If , then no bias is present because all documents are equally retrievable. If , then only one document is retrievable, and all other documents have . By comparing the Gini coefficients of different retrieval methods, we can analyze the retrieval bias imposed by the underlying retrieval systems on a given document collection.
5.2. Retrievability Analysis
We consider all sections (title, abstract, claims, description, background summary) of 1.2 million documents for both retrieval and query generation. Stop words are removed prior to indexing, and words stemming is performed with the Porter stemming algorithm. Additionally, we do not use those terms of the collection that have document frequency greater than 25% of the total collection size to remove high frequency stop words. For retrievability analysis, we generate the queries with the combinations of those terms that appear more than one time in the document. For these terms, all three-term and four-term combinations are used in the form of Boolean AND queries for creating the exhaustive set of queries Q, with duplicate queries being removed. Additionally, we consider only those queries that have a query result list size of more than the rank cutoff .
For calculating retrievability, we require the processing of all queries in
Q on the full 1.2 million collection. This requires large processing time and resources. Thus, in order to complete the experiments in a reasonable time, we select a subset of two million queries from
Q. However, rather than selecting this subset randomly, we select it on the basis of query quality prediction [
37,
38]. This is further motivated by earlier analysis of the relationship between query quality and retrieval bias [
11]. In this method, we first order all queries in
Q using the simplified query clarity score (SCS) [
39]. Then, we select the two million queries that have the highest SCS scores. These queries are then used for document retrieval against the complete collection of 1.2 million documents as Boolean AND queries with subsequent ranking according to the chosen retrieval model to determine the retrievability scores of documents as defined in Equation (
20).
Table 3 lists the retrieval bias of retrieval strategies using Gini coefficient for a range of rank cutoff factors. As expected, the Gini coefficient tends to decrease slowly for all query sets and models as the rank cutoff factor increases. This indicates that retrievability inequality within the collection is mitigated by the willingness of the user to search deeper down into the ranking. If users examine only the top documents, they will face a greater degree of retrieval bias. If we compare the retrieval bias of retrieval models, then we can observe that SMART has the greatest inequality between documents, while BM25 appears to provide the least inequality.
5.3. Retrieval Bias and PRF Effectiveness
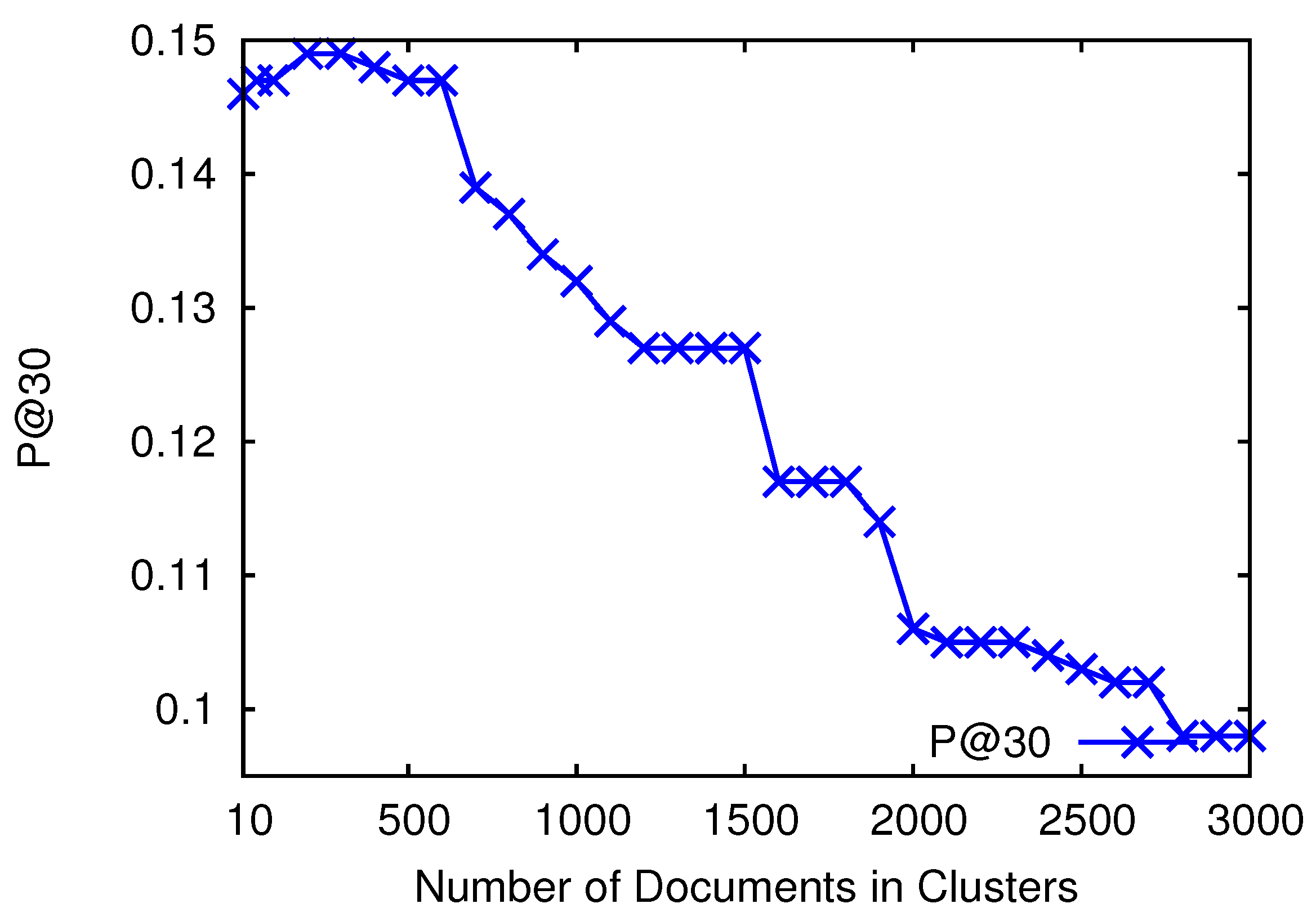
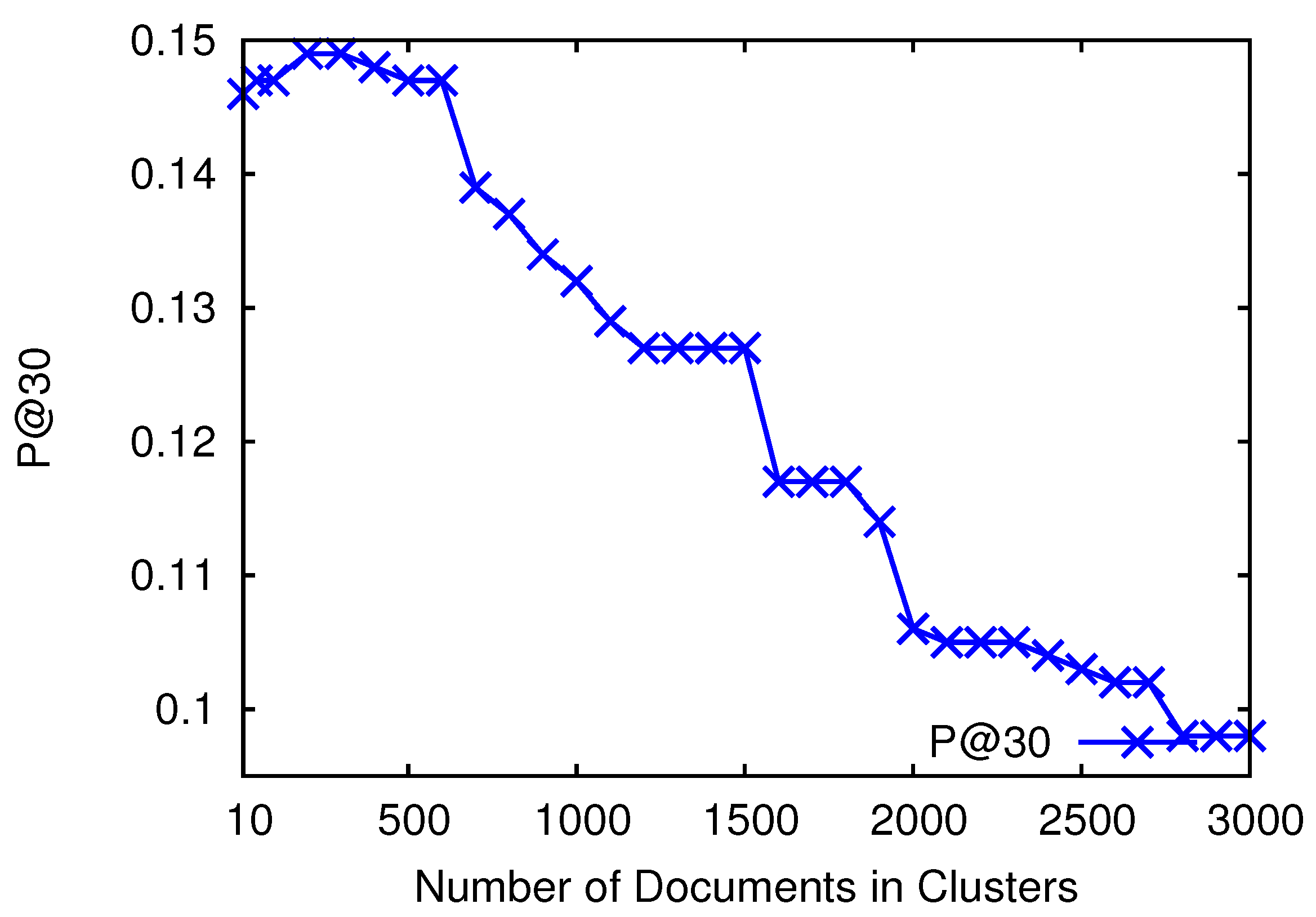
In the above experiments, we observed that retrieval models add retrieval bias in the collection making a subset of documents more highly retrievable than others. For the first experiment, we want to analyze if a collection has large retrievability inequality between documents; then, do high retrievable documents of clusters decrease the effectiveness of cluster-based PRF? We want to analyze this hypothesis with the help of various partitions of the documents of clusters grouped according to retrievability scores. We want to analyze which partitions contribute most to PRF effectiveness than others. In order to perform this, we first sort the documents of the collection in ascending order according to their retrievability scores, and then, we divide the collection into p partitions (subsets). This means that the first subset contains (Partition 1) all those documents that accounted from the bottom of the cumulative retrievability scores, and the last subset (Partition 5) would contain the most retrievable documents containing the percentile. Since we generate clusters using BM25 weighting, therefore, for the experiments, we consider the retrievability scores that we calculated using BM25. For each subset, we then individually analyze the PRF effectiveness on 1000 known prior-art topics queries as explained above by keeping only those documents of clusters that are part of the analyzed subset and ignoring all those that are not part of the subset. The idea is to issue each topic query to the whole collection and then to analyze which subsets add noise and which subsets contribute most to PRF effectiveness than others.
Table 4 shows the PRF effectiveness of subsets with
. This table also shows which subset is retrieved more frequently than others within the top 500 documents. We examine this by the retrieval probability of subsets within the top 500 documents (i.e., how many documents of a subset are retrieved within the top 500 documents). As we can observe from the results, high retrievable subsets have low PRF effectiveness than low retrievable subsets, although documents of high retrievable subsets are retrieved more frequently than the documents of low retrievable subsets (see
Table 4). Although, high retrievable documents are also a relevant part of the clusters, however, when these are frequently retrieved at top positions for many irrelevant queries just due to retrieval bias, these decrease the effectiveness by generating noisy clusters. Low retrievable documents on the other side are not frequently retrieved due to retrieval bias; thus, when we construct clusters by taking only low retrievable documents, then the noise of retrieval bias does not decrease effectiveness. We found this the main reason why low retrievable partitions have high effectiveness for PRF than high retrievable partitions. These results confirm our hypothesis that the retrieval bias of retrieval models seriously degrades the retrieval effectiveness of cluster-based PRF.
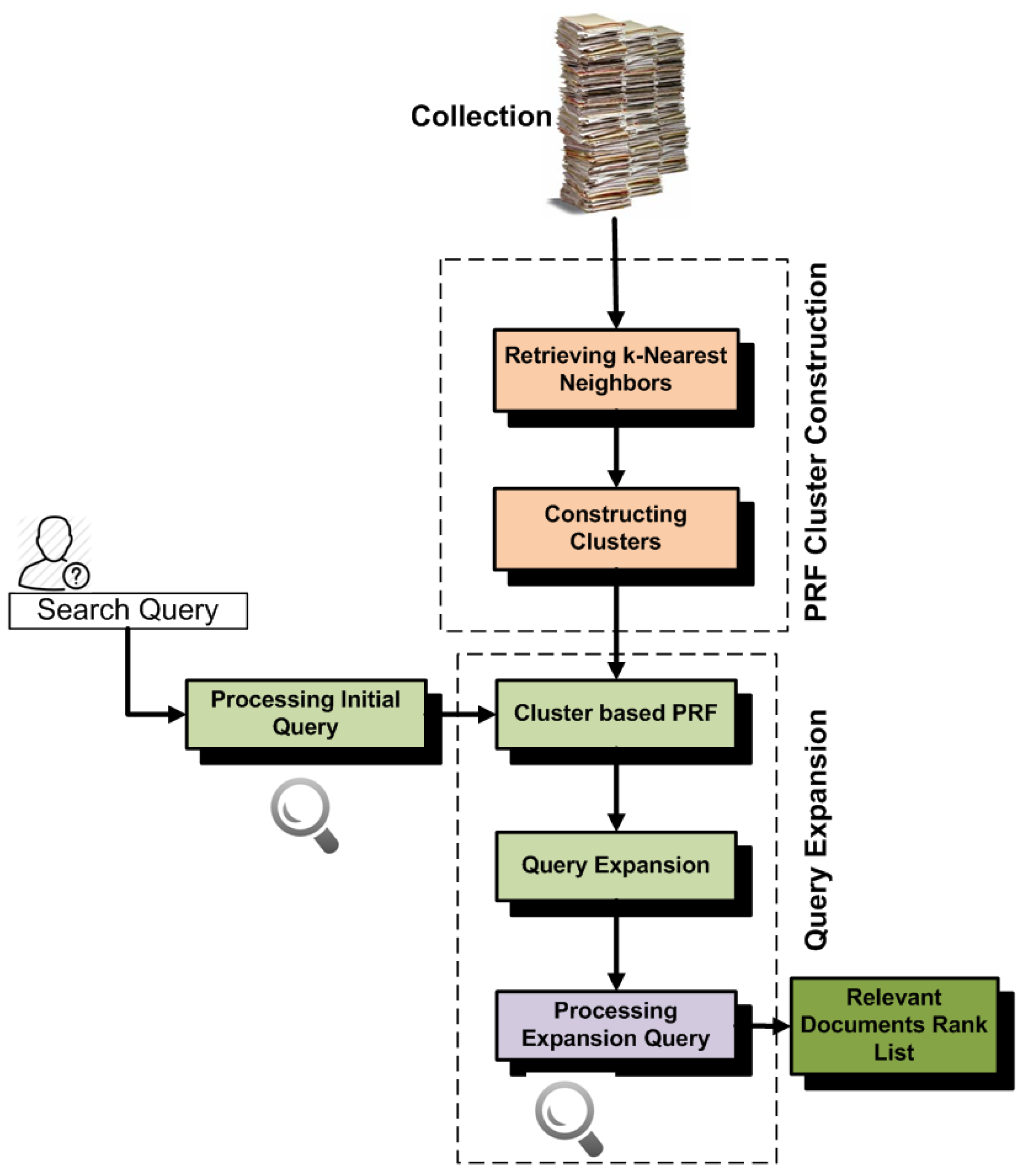
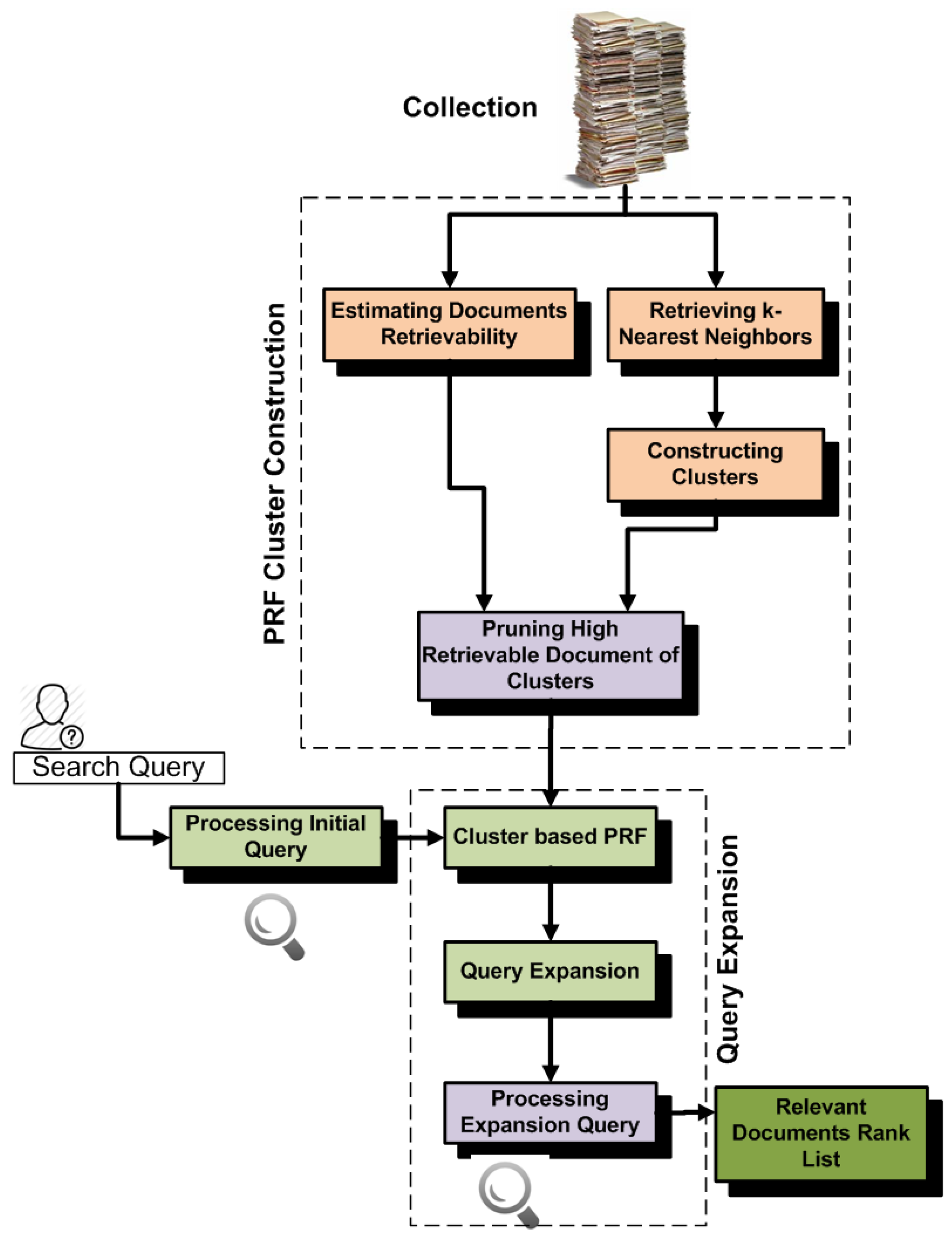
5.4. Retrievability and Cluster-Based PRF (RetrClusPRF)
From t he above experiments, we observe that the standard approach constructs clusters for PRF without carrying retrievability inequality between documents. Therefore, during query processing, high retrievable documents of clusters are frequently retrieved at top positions for most of the queries, and these drift the PRF away from relevant documents. This decreases the effectiveness of cluster-based PRF. In order to improve the effectiveness, we construct clusters by retrieving
k-nearest neighbors on the basis of high similarity and then using retrievability. For each cluster, first we rank the 2 × k-nearest neighbors of clusters on the basis of their high similarity with centroid documents, and then, we again re-rank
k-nearest neighbors from 2 × k list on the basis of low retrievability scores. The rationale behind keeping low retrievable neighbors in the clusters is that we want to minimize the effect of retrieval bias. We perform this process for all clusters, and then, we use these clusters for PRF.
Table 5 and
Table 6 show the effectiveness of this approach (RetrClusPRF) and the standard
k-nearest neighbor approach (resampling as a baseline), where we construct clusters by retrieving only similar neighbors.
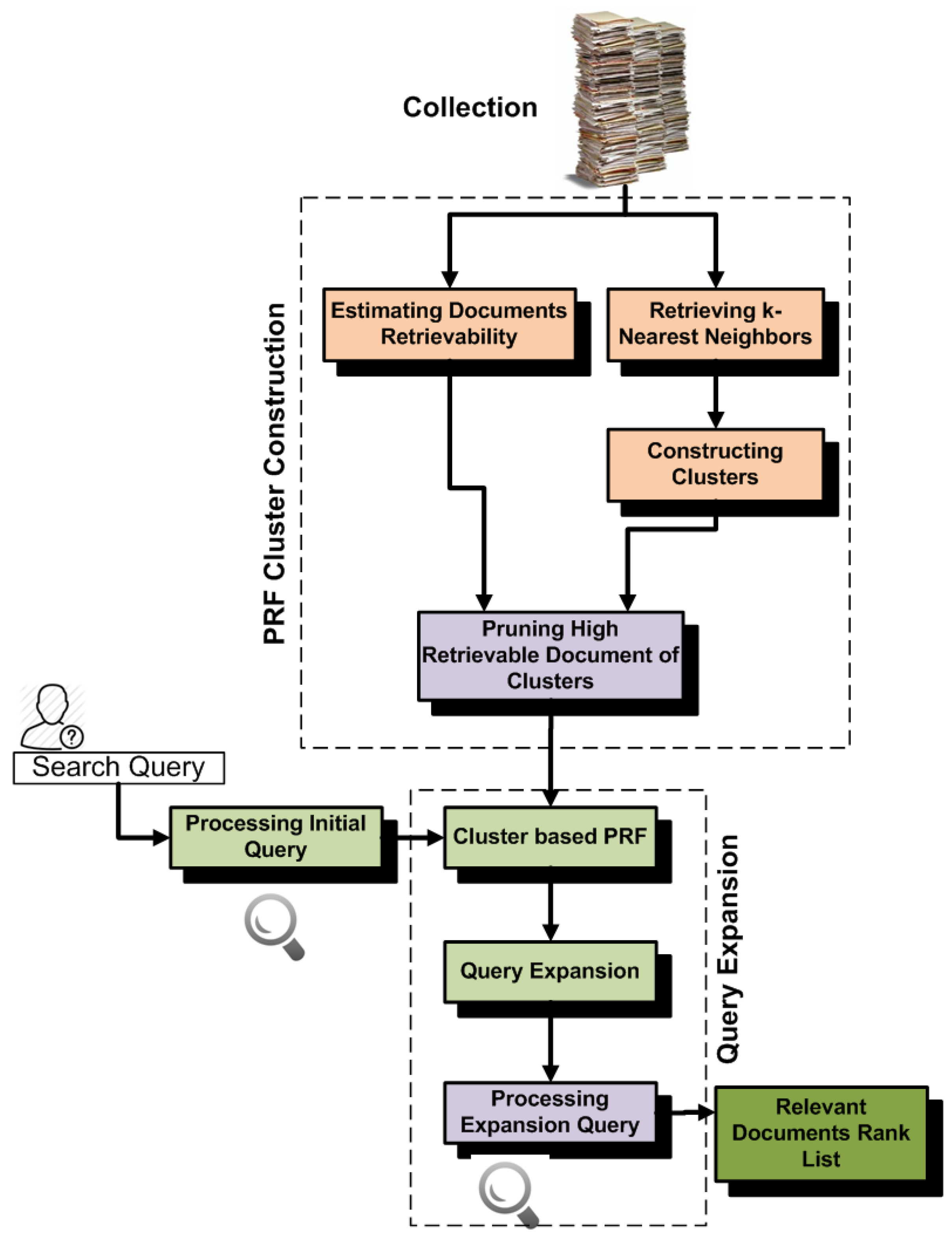
Figure 4 shows the architecture of RetrClusPRF. As we can seen from the architecture, retrievability provides help in removing noisy (high retrievable) documents from the clusters. If we analyze the results, then RetrClusPRF brings an improvement of (12%, 15%, 32%, 6%) on
,
, MAP and
b-pref as compared to resampling.
Table 6 shows the robustness of RetrClusPRF with resampling and also with other retrieval approaches. RetrClusPRF shows stronger robustness than resampling. It improves 428 queries and hurts 321. As we can observe from the results, retrievability-based PRF (RetrClusPRF) achieves significantly better effectiveness than standard cluster-based PRF technique.
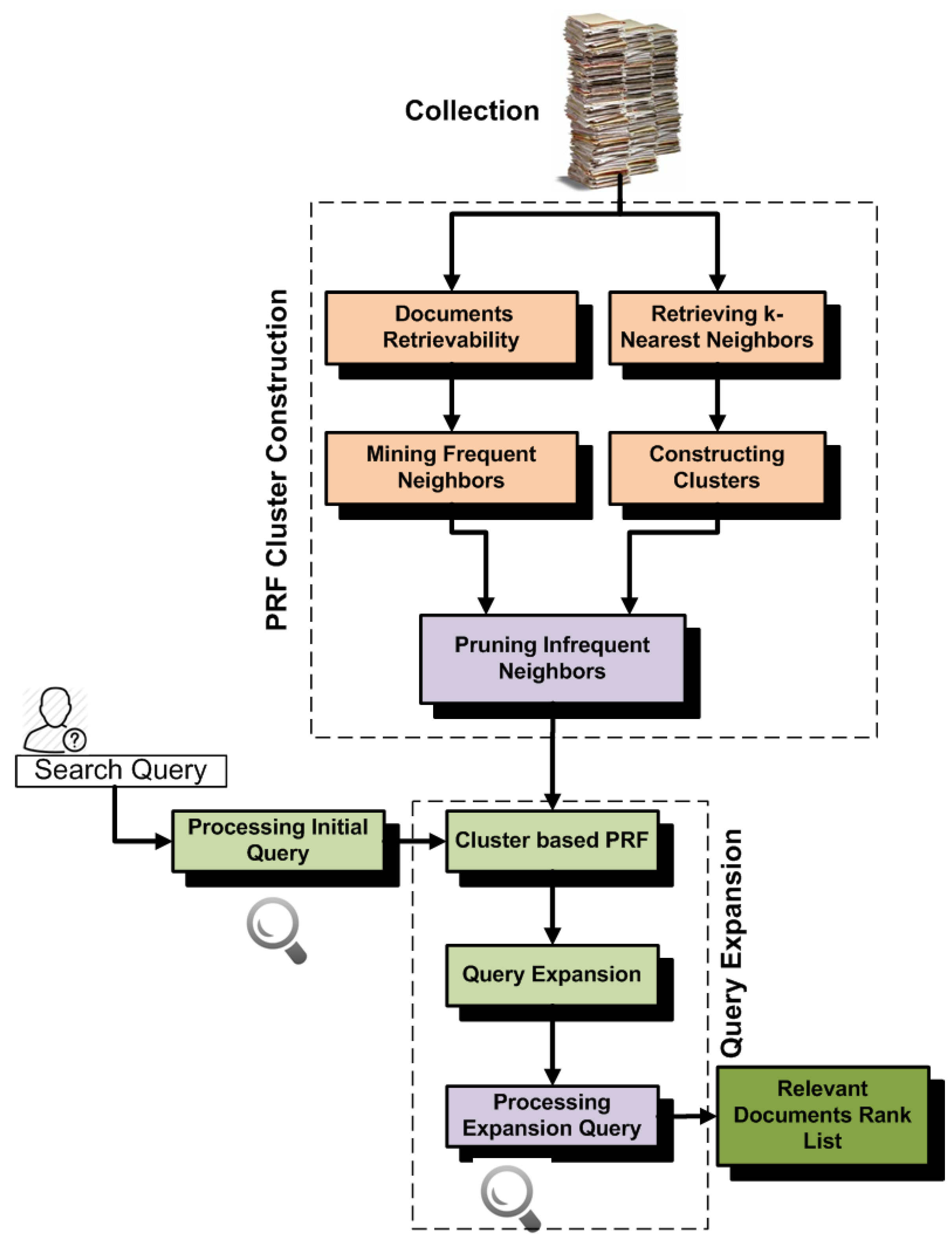
5.5. Frequent Neighbor-Based PRF (FreqNeig)
The above experiments indicate that retrievability-based clustering improves PRF effectiveness. The standard retrievability approach only analyzes individual retrievability scores of documents, but does not discover which documents are frequently retrieved together. As a result, this approach always penalizes high retrievable documents and can ignore many (high retrievable) relevant documents of clusters that are frequently retrieved with documents of the cluster. Further improvement is possible by ranking k-nearest neighbors that have a high confidence of retrieval with other documents of the cluster.
In order to mine frequent neighbors (FreqNeig), we represent the result list of queries as transactions and mine FreqNeig using the frequent itemset mining algorithm [
40]. We mine all those FreqNeig that have a length larger than one and support greater than
. After mining FreqNeig, we first rank 2 × k-nearest neighbors on the basis of their high similarity with centroids, and then, we again re-rank
k-nearest neighbors from the 2 × k list that have a high confidence of retrieval with the nearest neighbors of clusters. For each nearest neighbor, we assign a confidence score using the following approach. For each nearest neighbor
, we first obtain the set
of all those frequent itemsets that contain
. From the set
, we then remove all of those itemsets that have an item that is not present in the 2 × k set. After pruning itemsets, we generate association rules for the remaining itemsets using confidence support greater than
. For a rule
, the higher confidence for document
implies that
is more likely to retrieve in the result lists of queries that also contain documents of set
. We generate association rules for all itemsets of
, and then, we rank neighbors in the 2 × k list on the basis of their average confidence score.
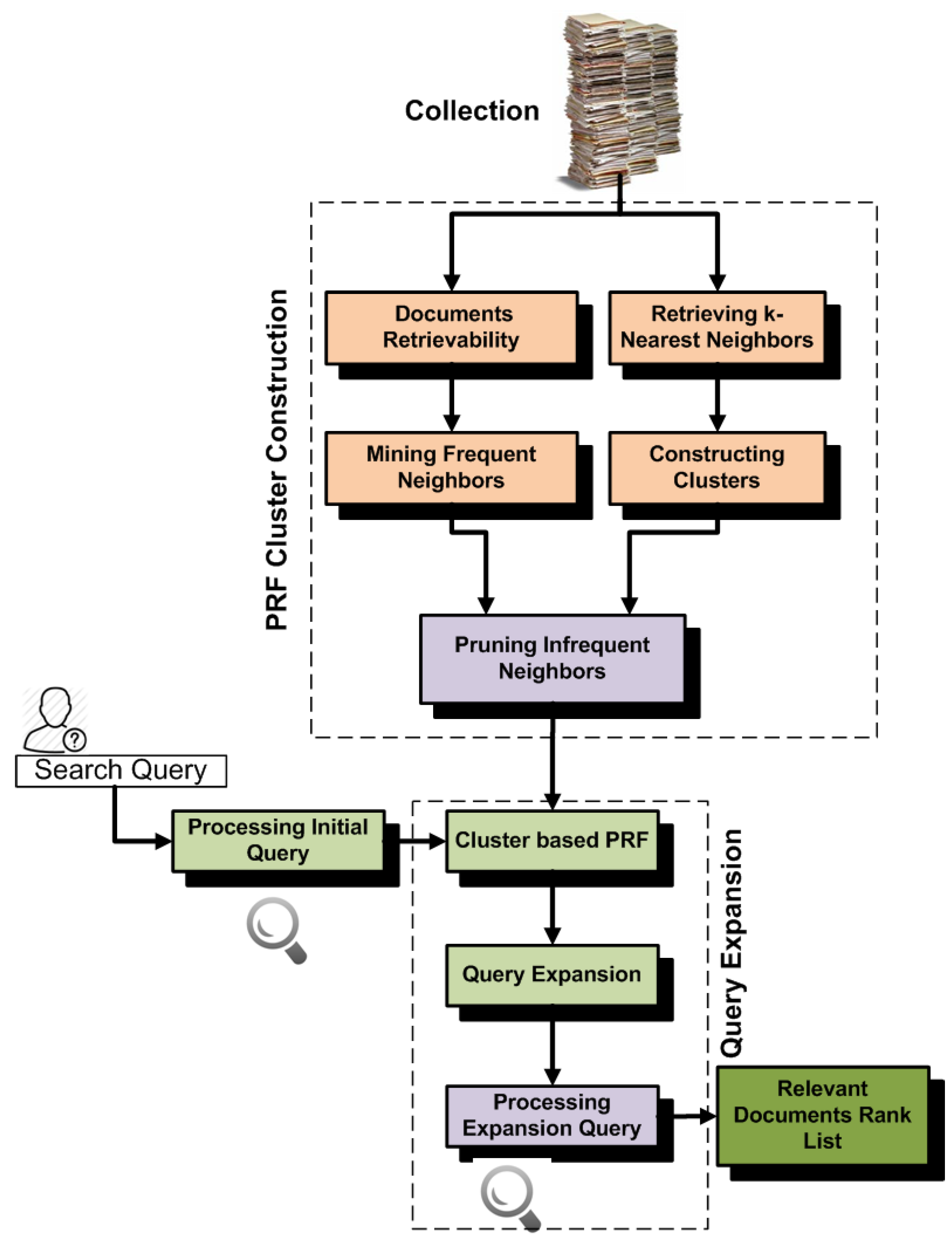
Figure 5 shows the architecture of this approach.
Table 5 and
Table 6 show the comparison of effectiveness of this approach (FreqNeigPRF) with the retrievability-based PRF (RetrClusPRF) and standard k-nearest neighbor approach (resampling) (as a baseline). FreqNeigPRF brings an improvement of (5%, 6%, 13%, 4%) on
,
, MAP and
b-pref as compared to RetrClusPRF and (18%, 22%, 49%, 9%) as compared to resampling.
Table 6 shows the robustness of resampling, RetrClusPRF and FreqNeigPRF to each other. As expected, FreqNeigPRF shows stronger robustness than resampling. It improves 441 queries and hurts 304, whereas RetrClusPRF improves 428 queries and hurts 321. Although FreqNeigPRF improves the effectiveness of only 13 more queries than RetrClusPRF, however, the improvement obtained by FreqNeigPRF is large. As we can observe from the results, frequent retrieved document-based PRF achieves significantly higher effectiveness than other two approaches.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}