4.1. Corporate Data
We have obtained from our company a corpus containing utterances in French of a typical communication between a customer and a call center of a telecom company.
There are 7765 utterances annotated by human experts that have been collected in four different datasets. The unannotated part consists of 3,911,695 utterances.
We use a corporate supervised algorithm (rule-based algorithm). We simulate in the experiments an expert (oracle) on the unannotated corpus by using the rule-based algorithm, which is trained by 7765 utterances. Note that the objective of this evaluation is to observe the improvement that can add the random exploration to the existing active learning.
In our experiments, we consider a version of the rule-based algorithm without training, where at each iteration, the active learning tries to select from the unannotated corpus the most interesting utterances to annotate and integrate into the training set of the rule-based algorithm.
By relating the results to the newer versions, one can verify the usefulness of the proposed approach. Moreover, we calculate the regret every 100 iterations, and we run the process during 2000 iterations, which corresponds to our budget in terms of labeling.
In addition to the randomness (baseline), we compare our methods by constructing four groups of algorithms: the first group is the state-of-the-art algorithms described in the related work (
Section 2), which are the sampling by committee, request uncertainty sampling and density weight method (DW).
The second group contains modified state-of-the-art algorithms, where we have added a fixed random exploration to the existing state-of-the-art algorithms, for example 0.5-QBC means that with a probability of 0.5, the algorithm does a random exploration, and otherwise, it does request by committee.
The third group contains the proposed model EG-active tested with different existing algorithms, for example EG-active(committee) means that we have used sampling by committee in our model.
In the fourth group, we have added a dynamic random exploration to the existing state-of-the-art algorithms as is done in [
4]; for example, P-US, P-QBC and P-WD are algorithms that do a random exploration with probability
P, and otherwise, they do respectively P-US, P-QBC or P-WD, these algorithms use the strategy of [
4] to compute the probability
P of the random exploration.
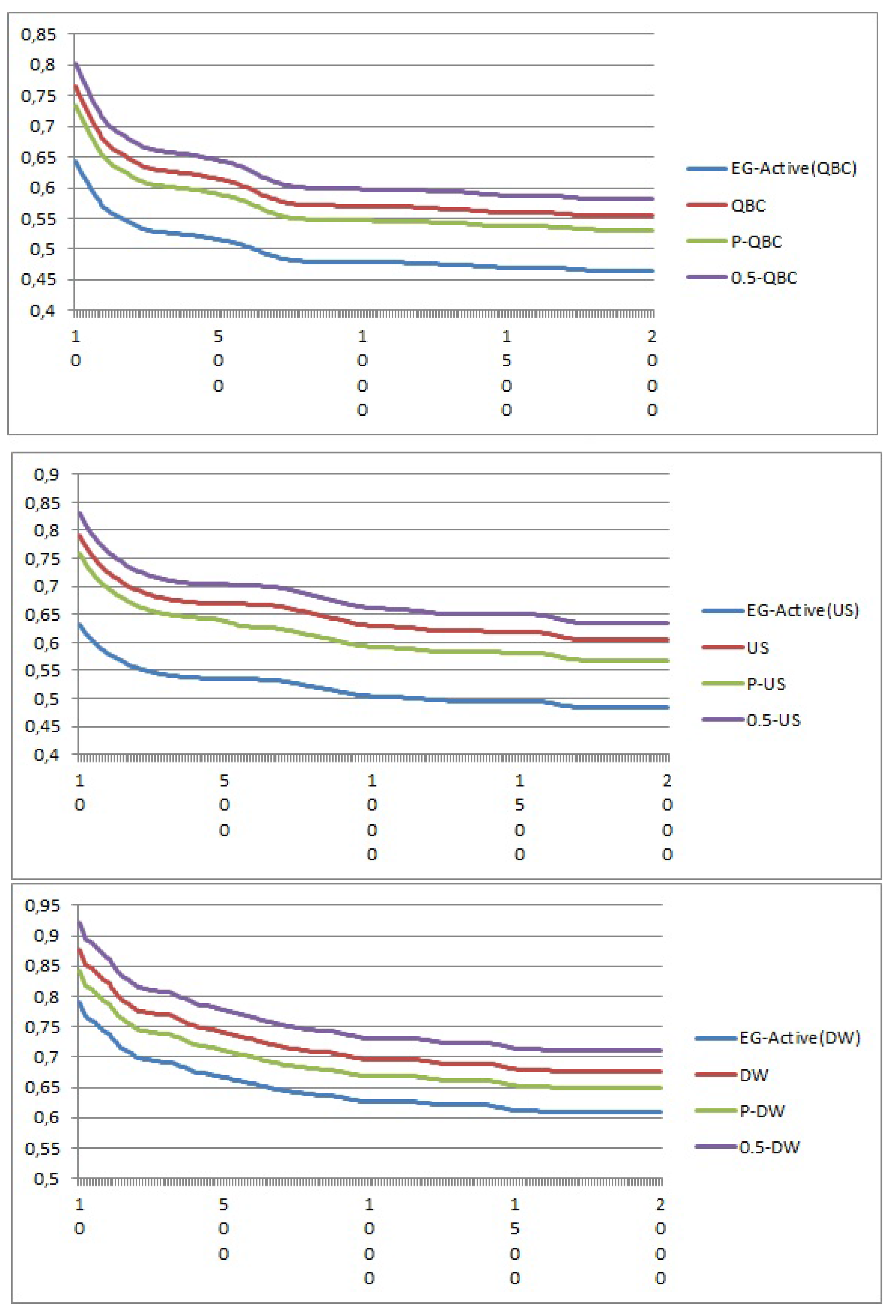
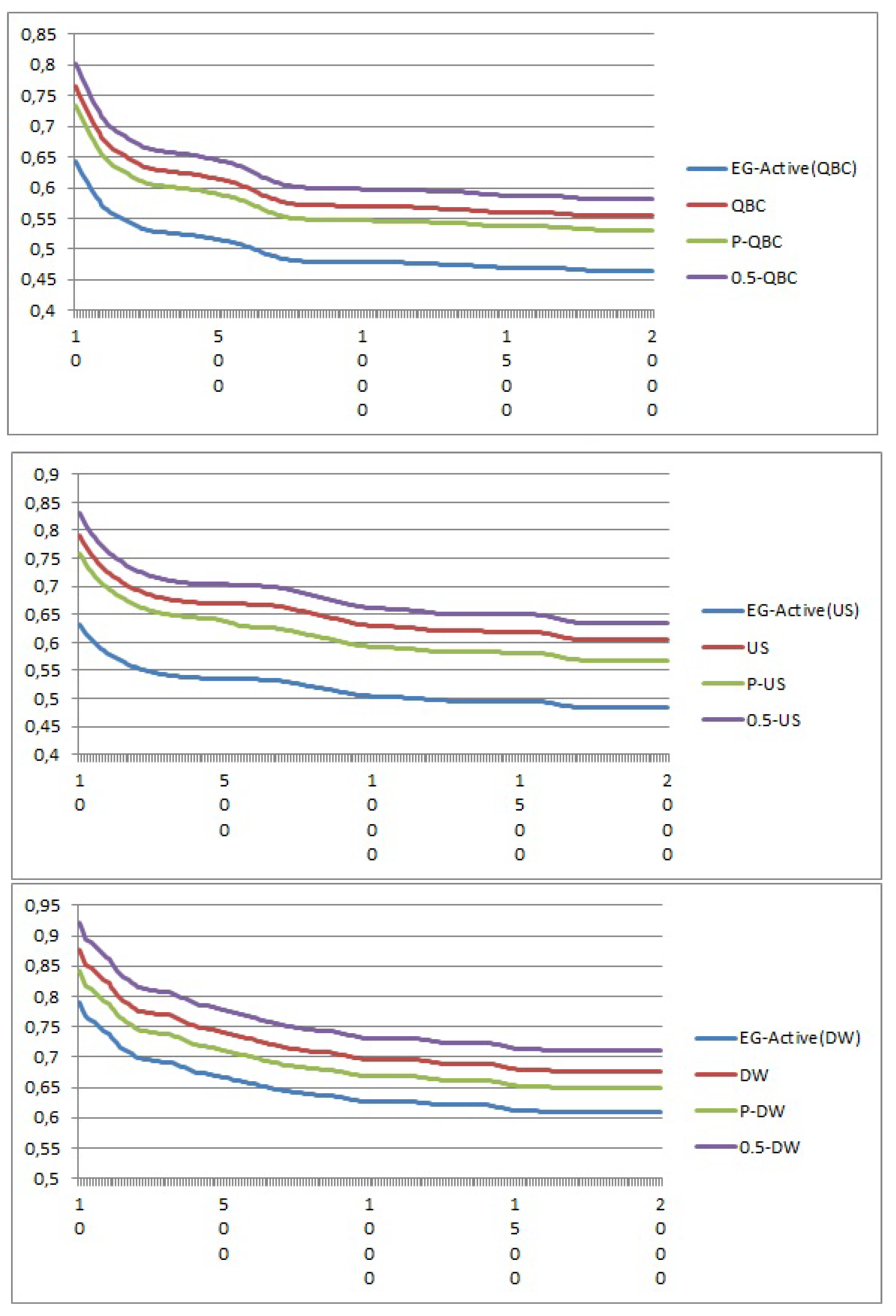
In
Figure 1, the horizontal axis represents the number of iterations, and the vertical axis is the performance metric.
Figure 1.
Average regret for active learning algorithms.
Figure 1.
Average regret for active learning algorithms.
We have several observations regarding the different active learning algorithms. We observe from the plot that a fixed and non-tuned random exploration leads to a bad result. This confirms that a pure exploration is not interesting, and it justifies the need for a dynamic random exploration tuning.
A dynamic exploration leads to an improvement result of the active learning, as is shown by P-US, P-QBC and P-WD. As expected, EG-active(US), EG-active(QBC) and EG-active(WD) effectively have the best convergence rates.
EG-active(US), EG-active(QBC) and EG-active(WD) decrease the average regret respectively by a factor of 0.84, 1.3 and 0.9 over the baseline. The improvement comes from an optimization strategy for defining exploration.
These algorithms rapidly find the optimal random exploration to use, which is not the case of the P-US, P-QBC and P-WD, which take more time.
4.2. Public Benchmarks
We randomly chose nine datasets: Abalone, Breast, Ecoli, Glass, Haberman, Iris, Wine, Wdbc and Yeast. A brief summary of the datasets is listed in
Table 1.
Table 1.
Datasets used for benchmarking. UCI, University of California, Irvine.
Table 1.
Datasets used for benchmarking. UCI, University of California, Irvine.
| UCI Datasets | Instances | Attributes | Classes |
|---|
| Abalone | 1484 | 7 | 3 |
| Breast | 699 | 9 | 2 |
| Ecoli | 336 | 7 | 8 |
| Glass | 214 | 9 | 7 |
| Haberman | 306 | 3 | 2 |
| Iris | 150 | 4 | 3 |
| Wine | 178 | 13 | 3 |
| Wdbc | 569 | 32 | 2 |
| Yeast | 1484 | 6 | 8 |
We simulate in the experiments an expert (oracle) on the unannotated corpus by using support vector machine (SVM) [
17], which is trained by 100% of the dataset. We consider a version of the SVM algorithm without training; where at each iteration, the active learning tries to select from the unannotated points the most interesting points to annotate and integrates them into the training set of the SVM algorithm.
We run the process until the algorithm reaches 10% of the dataset, and because active learning algorithms contain a degree of randomness, we repeat our evaluations 100 times. We measured the classification quality using the average accuracy.
We observe from
Table 2,
Table 3 and
Table 4 that the results in public datasets confirm our expectation, where in the three algorithms tested, the proposed EG-active performs better than the other versions. The gap between the EG-active results and the original algorithms depends on the dataset. For instance, the gap is smaller in the Yeast, Ecoli and Iris datasets than in the rest of the datasets. We also observe that the performance of EG-active depends on the type of algorithm that we use.
Table 2.
Accuracy of the query by committee (QBC) versions on the UCI datasets.
Table 2.
Accuracy of the query by committee (QBC) versions on the UCI datasets.
| UCI Datasets | QBC | 50-QBC | P-QBC | EG-active(QBC) |
|---|
| Abalone | | | | |
| Breast | | | | |
| Ecoli | | | | |
| Glass | | | | |
| Haberman | | | | |
| Iris | | | | |
| Wine | | | | |
| Wdbc | | | | |
| Yeast | | | | |
Table 3.
Accuracy of the uncertainty sampling (US) versions on the UCI datasets.
Table 3.
Accuracy of the uncertainty sampling (US) versions on the UCI datasets.
| UCI Datasets | US | 50-US | P-US | EG-active(US) |
|---|
| Abalone | | | | |
| Breast | | | | |
| Ecoli | | | | |
| Glass | | | | |
| Haberman | | | | |
| Iris | | | | |
| Wine | | | | |
| Wdbc | | | | |
| Yeast | | | | |
Table 4.
Accuracy of the density weight method (DW) versions on the UCI datasets.
Table 4.
Accuracy of the density weight method (DW) versions on the UCI datasets.
| UCI Datasets | DW | 50-DW | P-DW | EG-active(DW) |
|---|
| Abalone | | | | |
| Breast | | | | |
| Ecoli | | | | |
| Glass | | | | |
| Haberman | | | | |
| Iris | | | | |
| Wine | | | | |
| Wdbc | | | | |
| Yeast | | | | |



{kind=link}