A Review on Video-Based Human Activity Recognition



Abstract
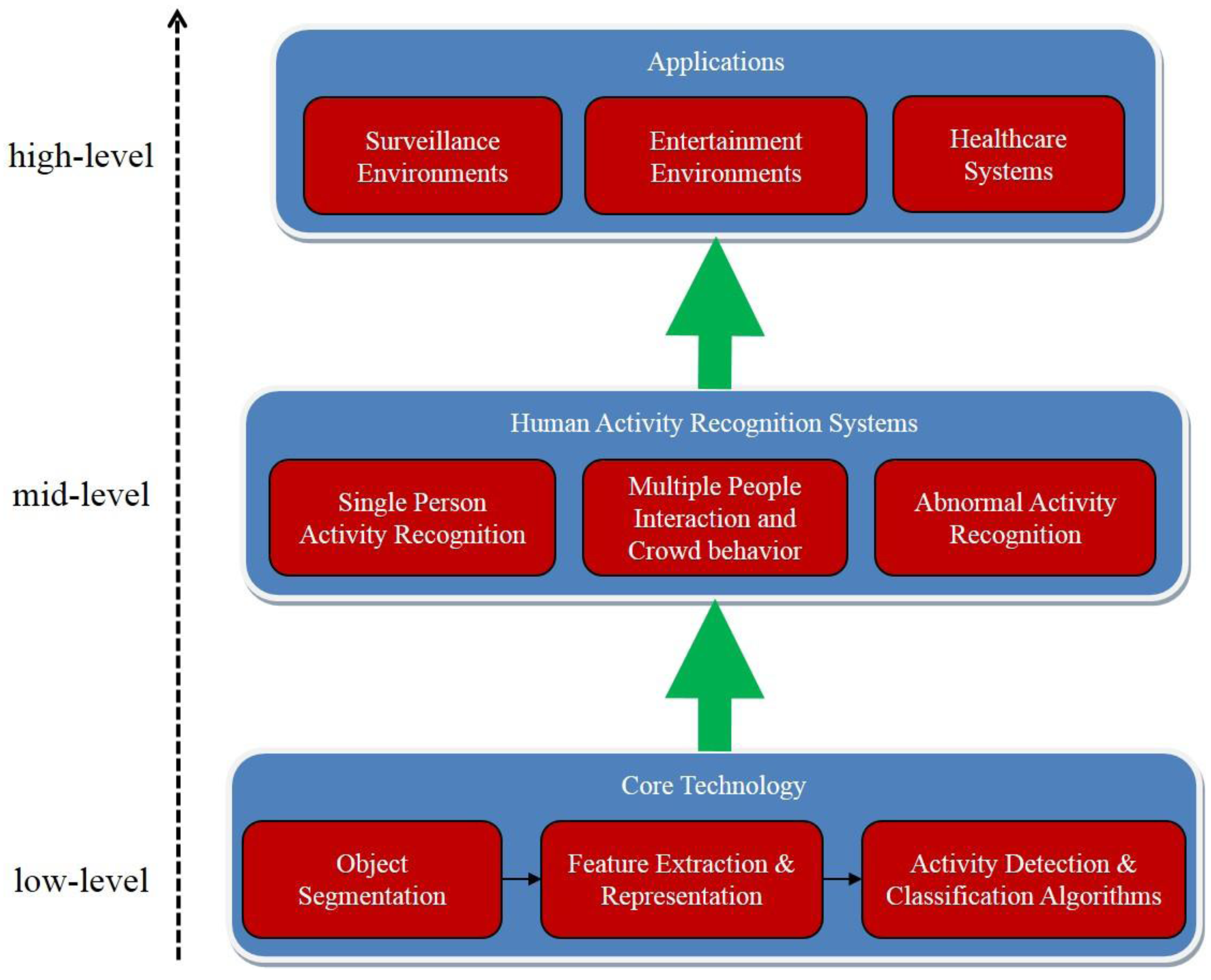
:1. Introduction
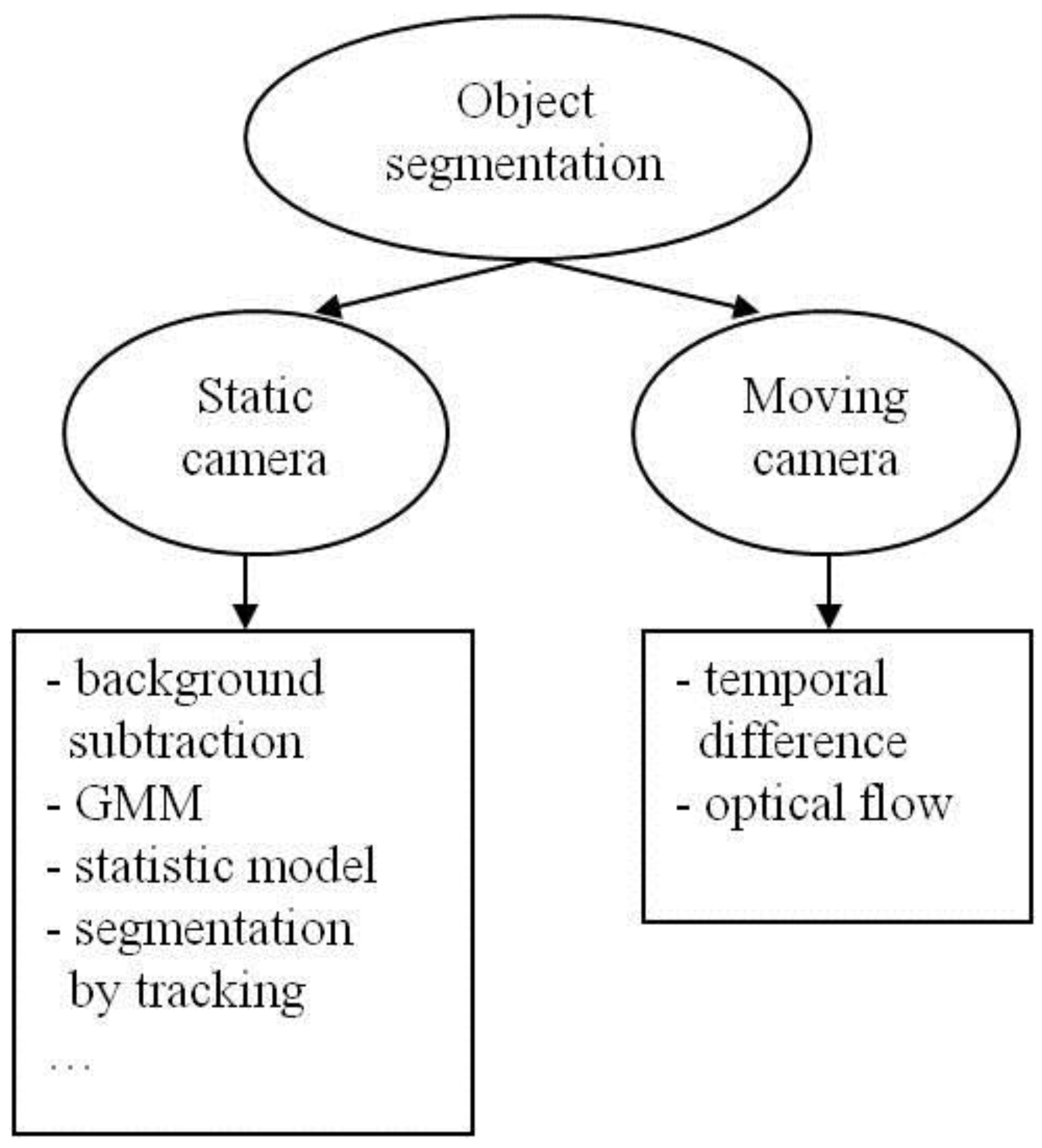
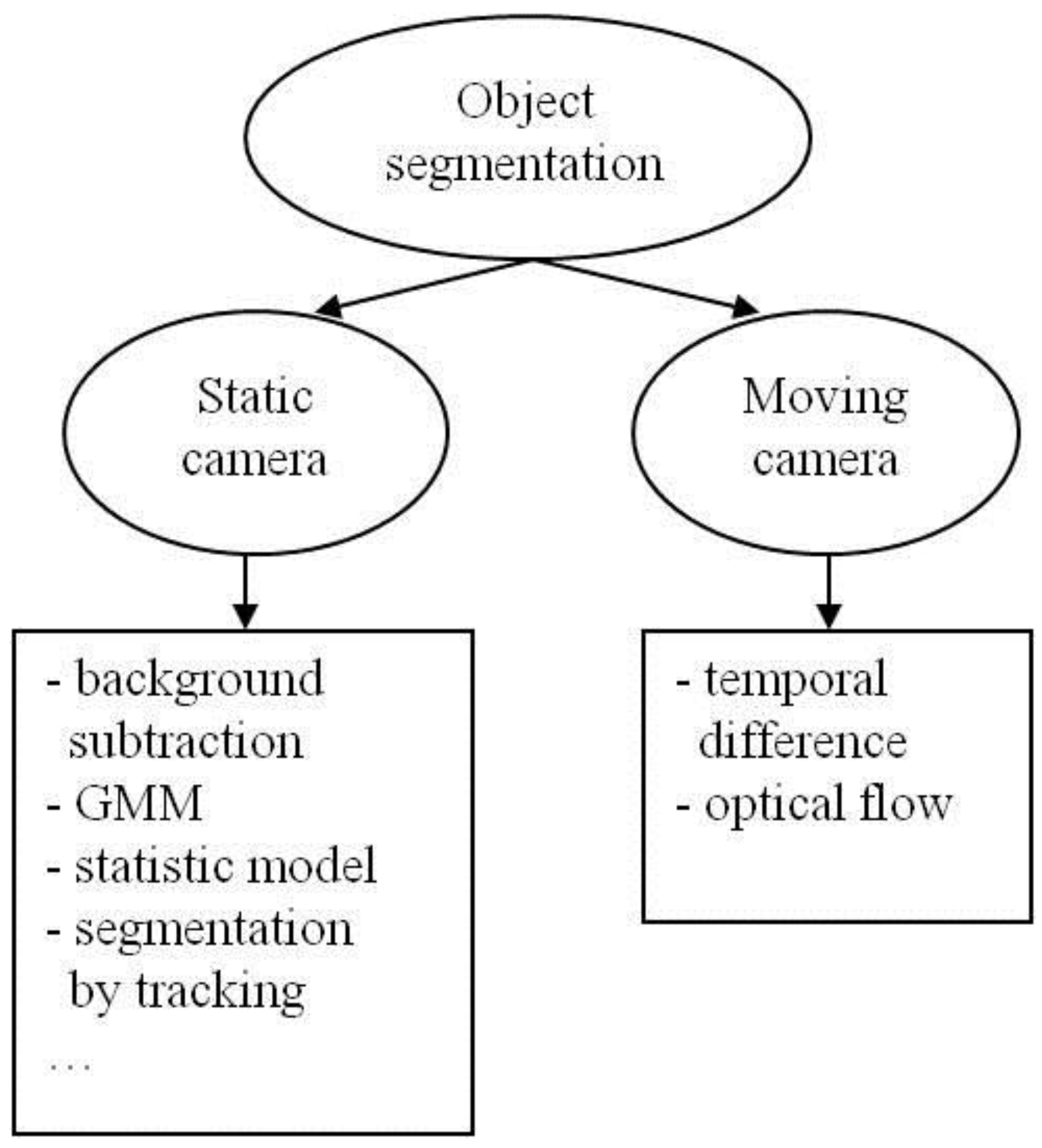
2. Object Segmentation
2.1. Static Camera
2.1.1. Background Subtraction
2.1.2. Gaussian Mixture Model (GMM)
2.1.3. Statistical Models
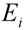 is the expected color value (say, as recorded in the background image) and
is the expected color value (say, as recorded in the background image) and 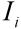 is the color value of the ith pixel. The brightness distortion (
is the color value of the ith pixel. The brightness distortion ( 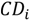 ) is defined as the shortest distance between the ith pixel and the line
) is defined as the shortest distance between the ith pixel and the line  . The chromaticity distortion is defined as the coefficient
. The chromaticity distortion is defined as the coefficient  which minimizes the brightness distortion distance, . Based on the thresholding on brightness distortion and chromaticity distortion, every pixel in the current image can be segmented (classified) into one of the following group: the original background, shadow, highlighted background, and the moving foreground. More specifically, the background pixels are classified if brightness and chromaticity distortion are small. The shadow pixels are classified if the chromaticity distortion is small but with lower brightness. And the foreground pixels are classified if the chromaticity distortion is high. Compared to GMM, the statistical models are generally more efficient in building the background model, and can be used to segment out not only the foreground objects but also the shadows.
which minimizes the brightness distortion distance, . Based on the thresholding on brightness distortion and chromaticity distortion, every pixel in the current image can be segmented (classified) into one of the following group: the original background, shadow, highlighted background, and the moving foreground. More specifically, the background pixels are classified if brightness and chromaticity distortion are small. The shadow pixels are classified if the chromaticity distortion is small but with lower brightness. And the foreground pixels are classified if the chromaticity distortion is high. Compared to GMM, the statistical models are generally more efficient in building the background model, and can be used to segment out not only the foreground objects but also the shadows.
2.1.4. Segmentation by Tracking
2.2. Moving Camera
2.2.1. Temporal Difference
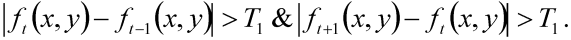
2.2.2. Optical Flow
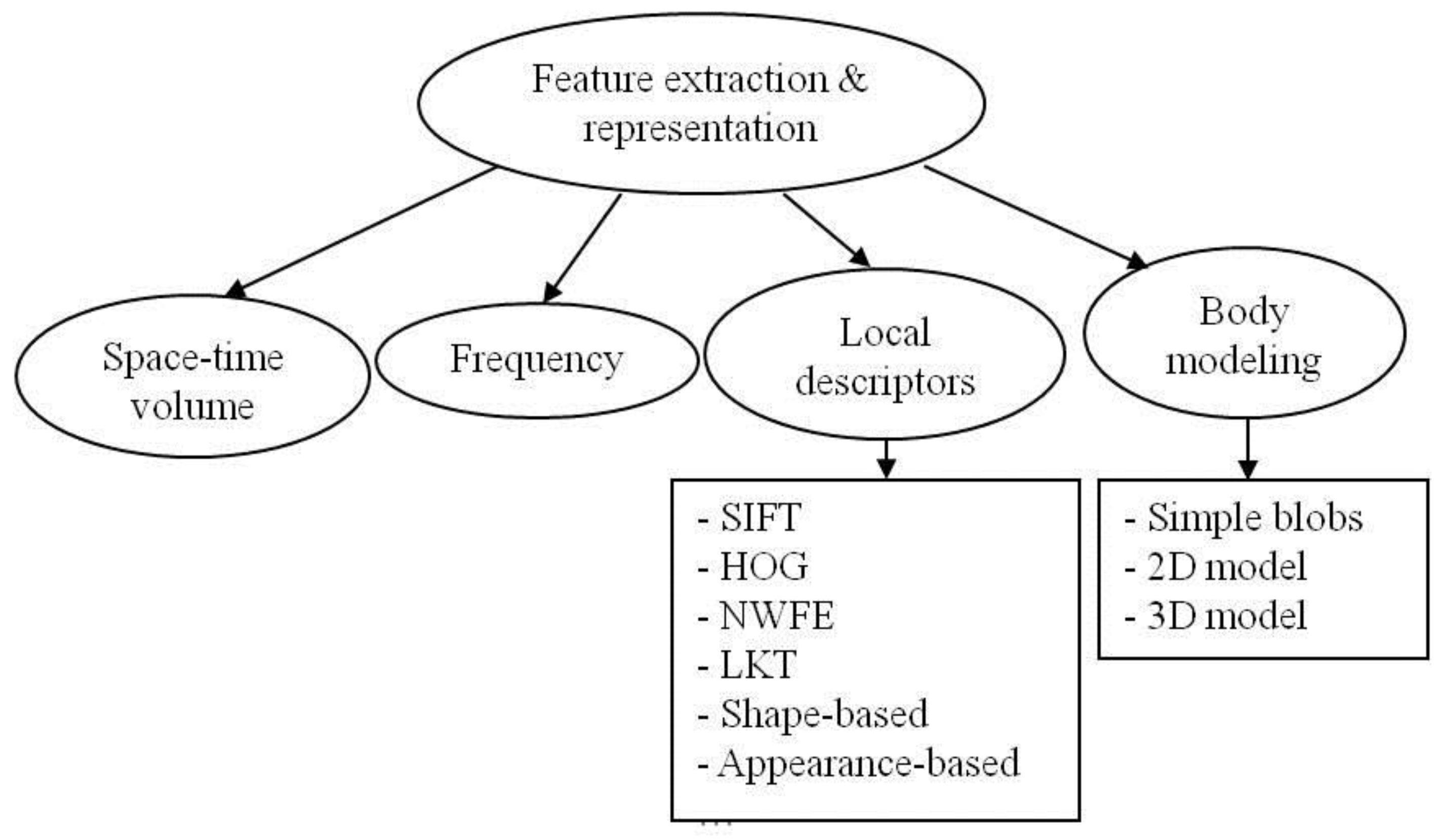
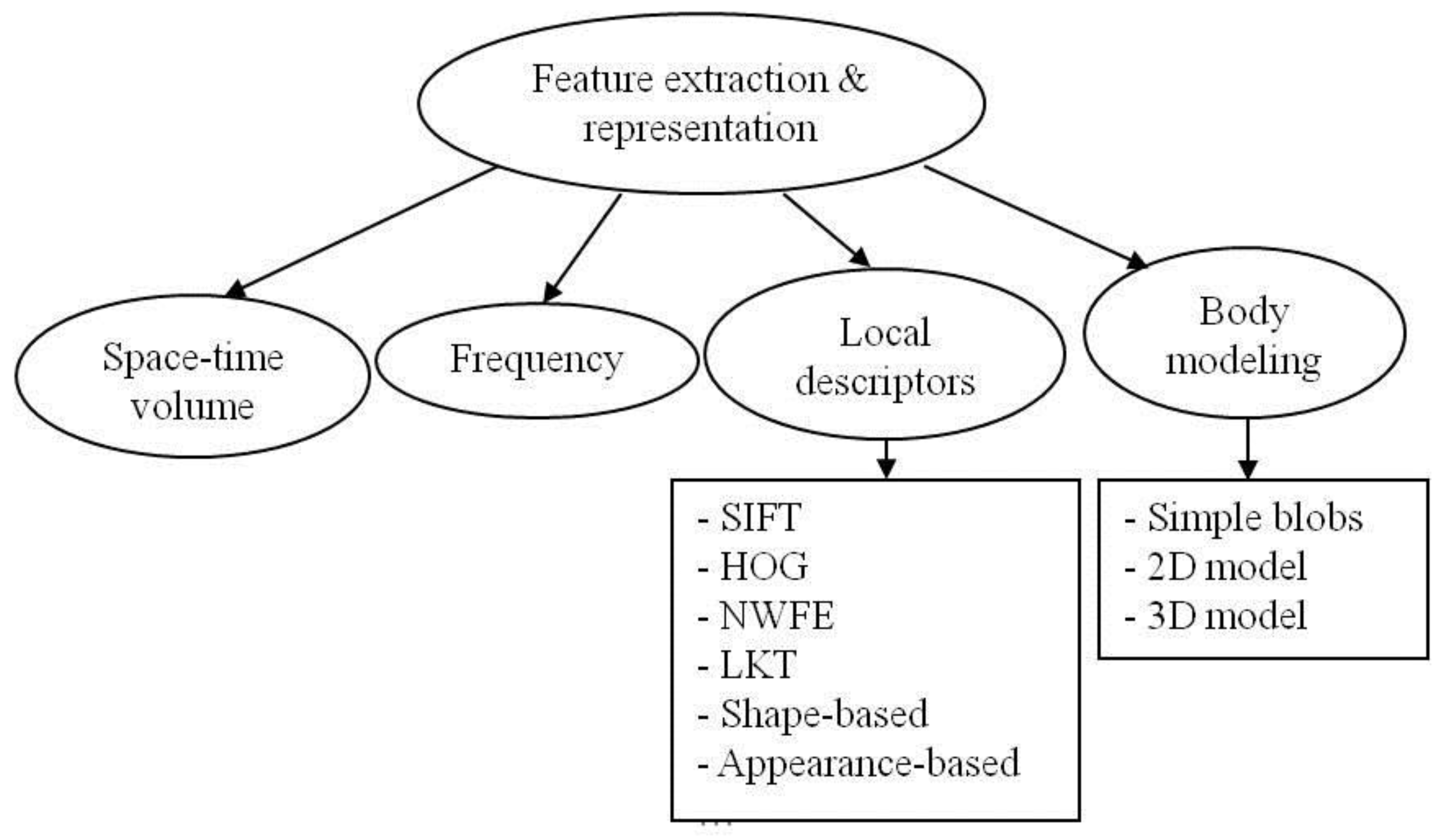
3. Feature Extraction and Representation
3.1. Space-Time Volumes (STV)
3.2. Discrete Fourier Transform (DFT)
3.3. Local Descriptors
3.3.1. SIFT Features

3.3.2. HOG Features

3.3.3. NWFE Features
3.3.4. LKT (Lucas-Kanade-Tomasi) Features

3.3.5. Shape-Based Features
3.3.6. Appearance-Based Features
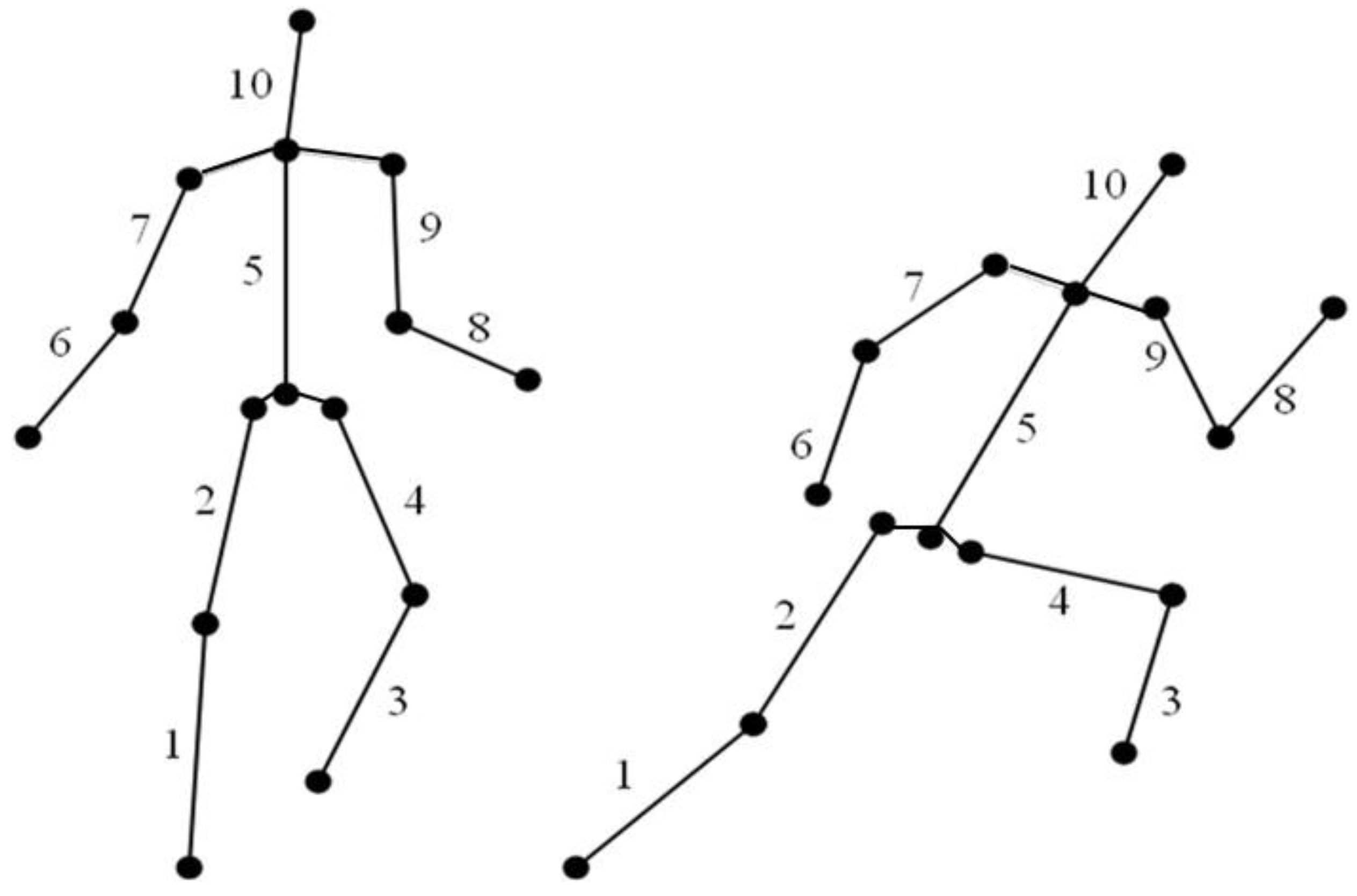
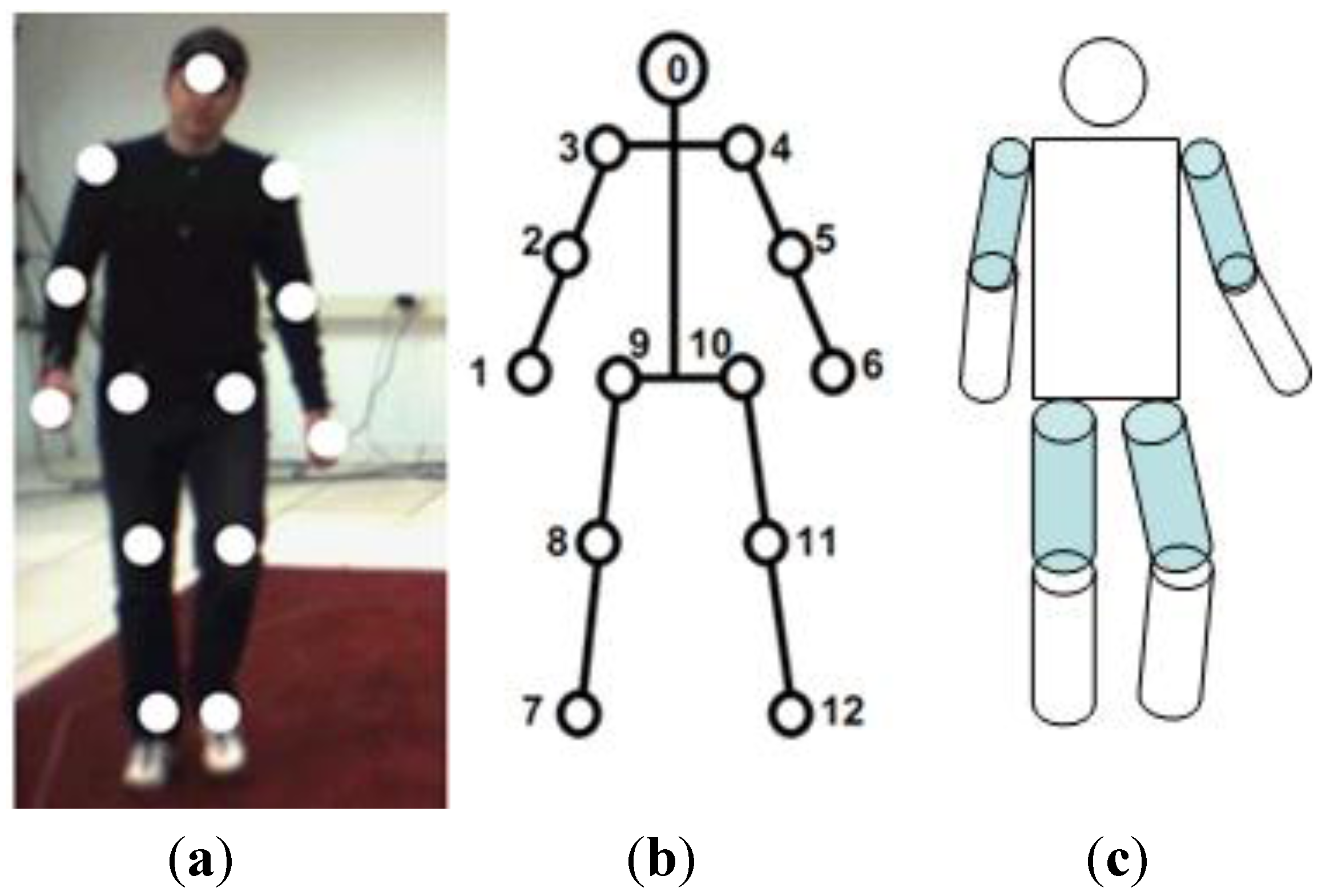
3.4. Body Modeling
3.4.1. Model-Free
3.4.2. Indirect Model
3.4.3. Direct Model
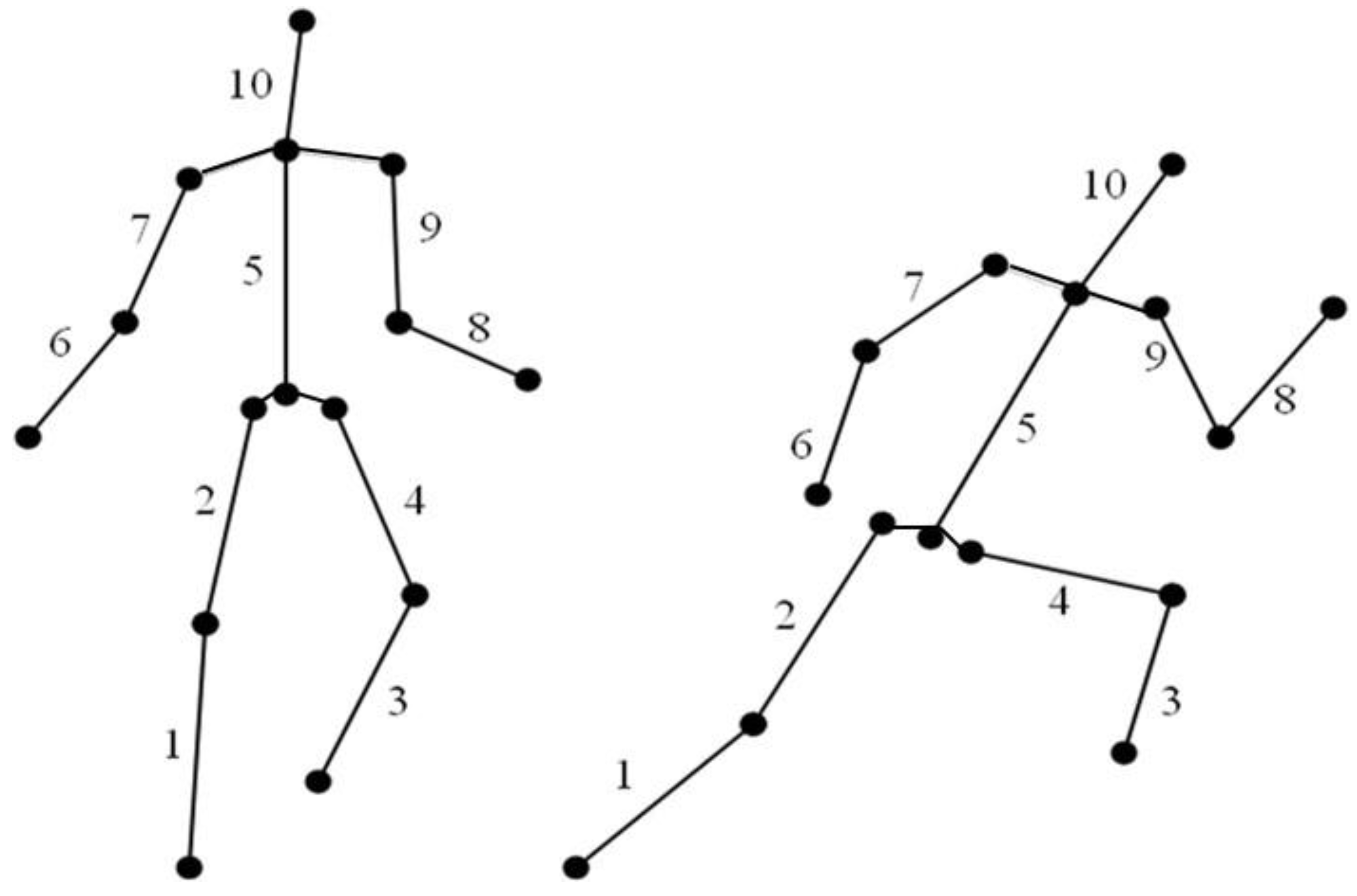
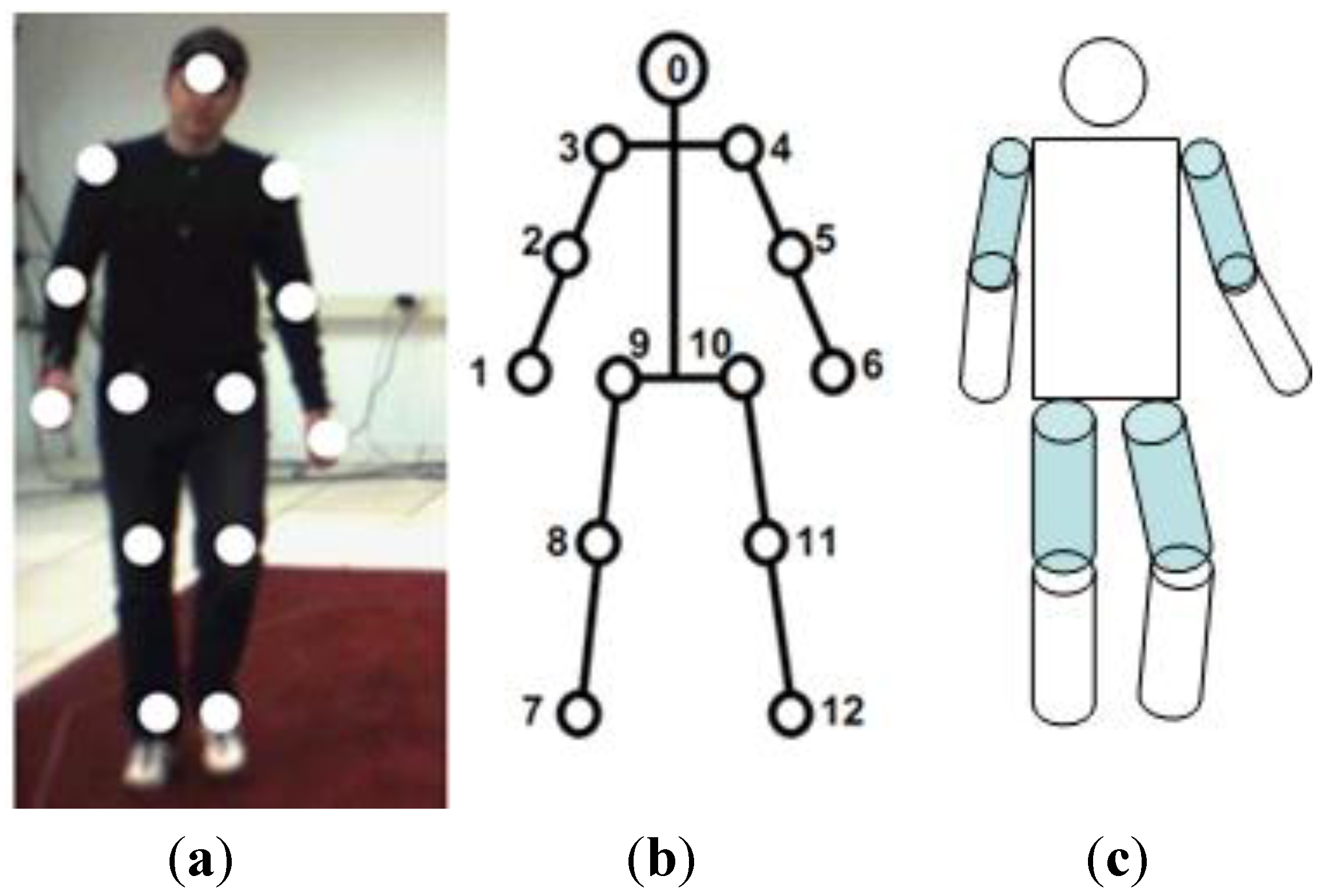
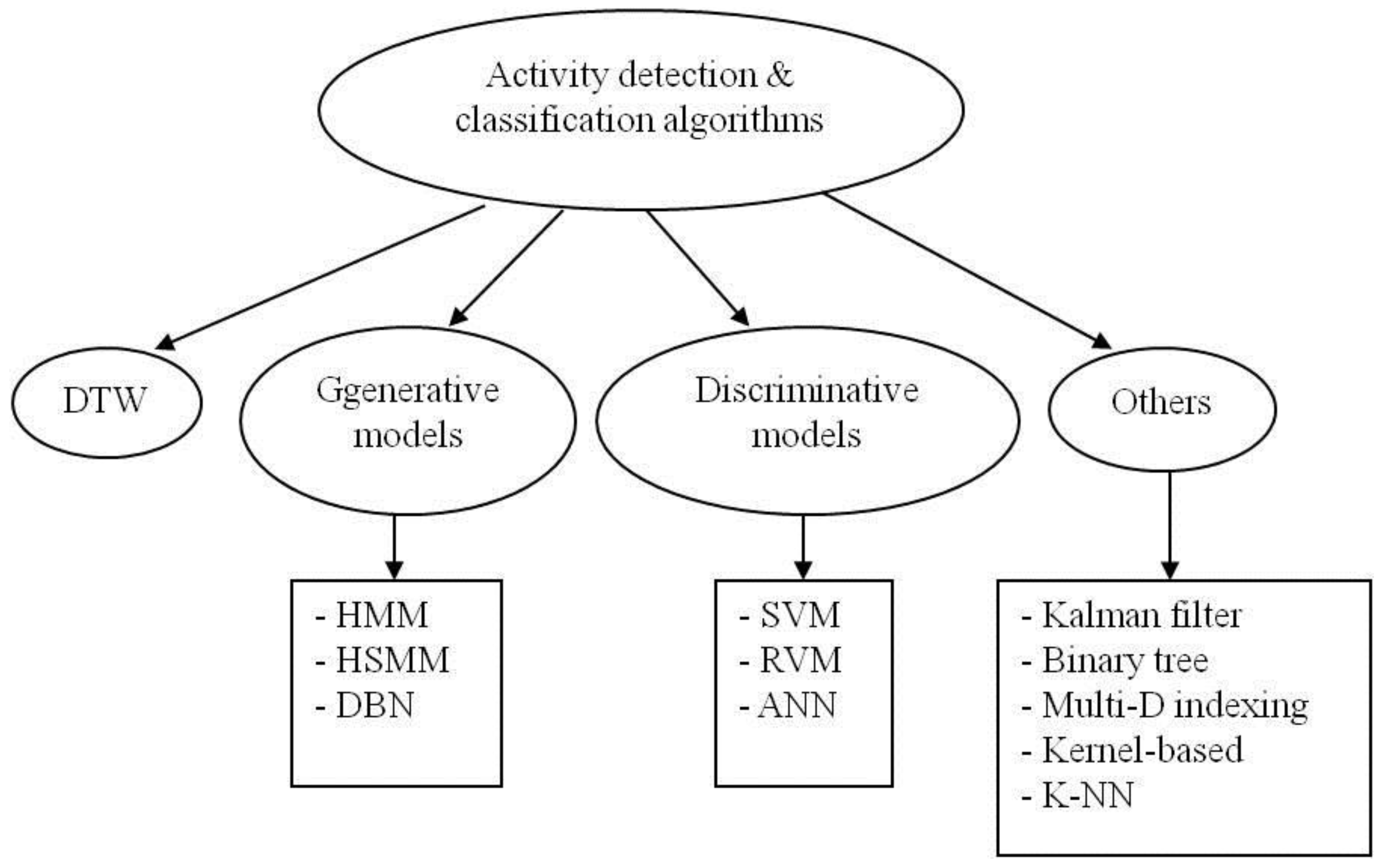
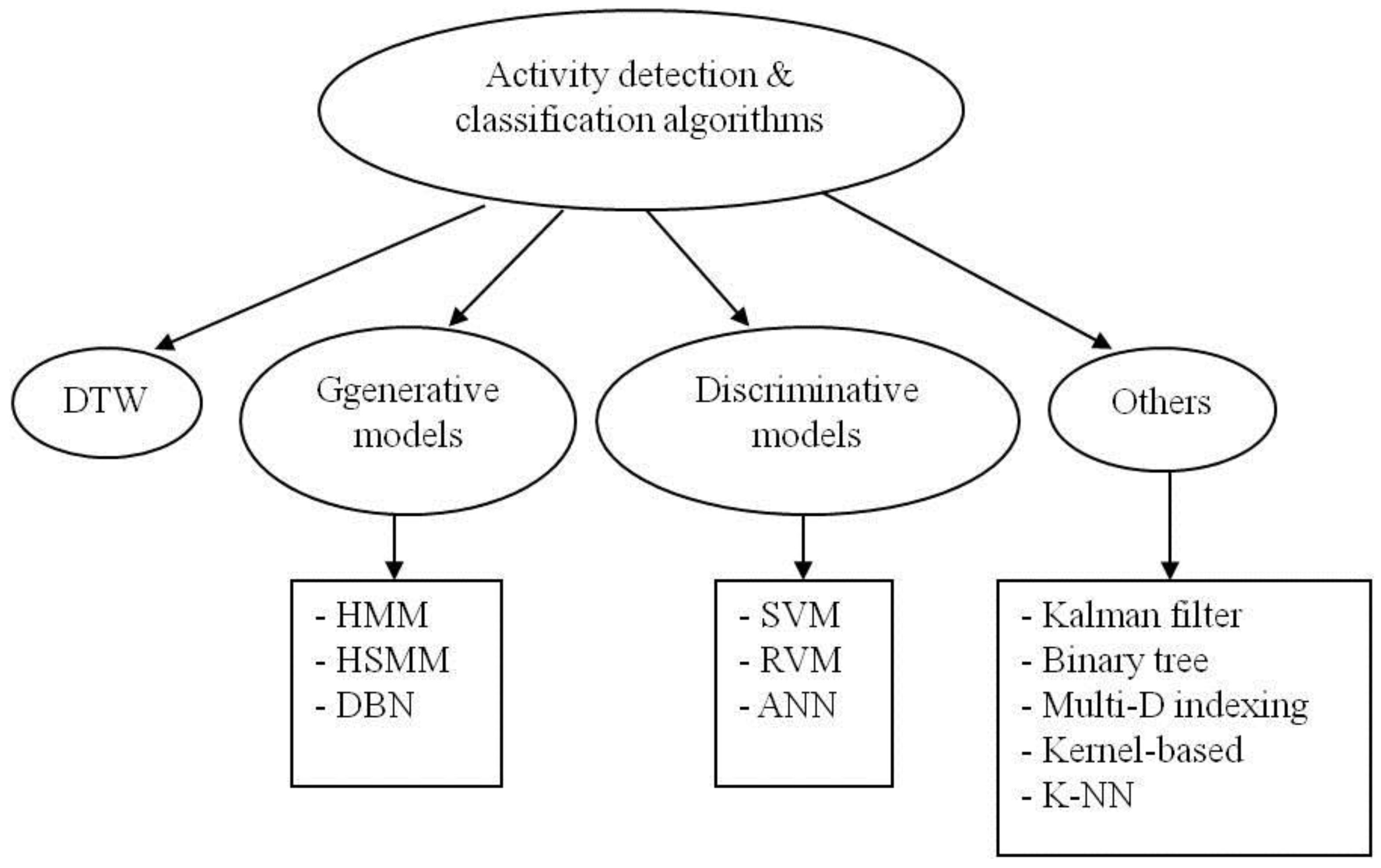
4. Activity Detection and Classification Algorithms
4.1. Dynamic Time Warping (DTW)
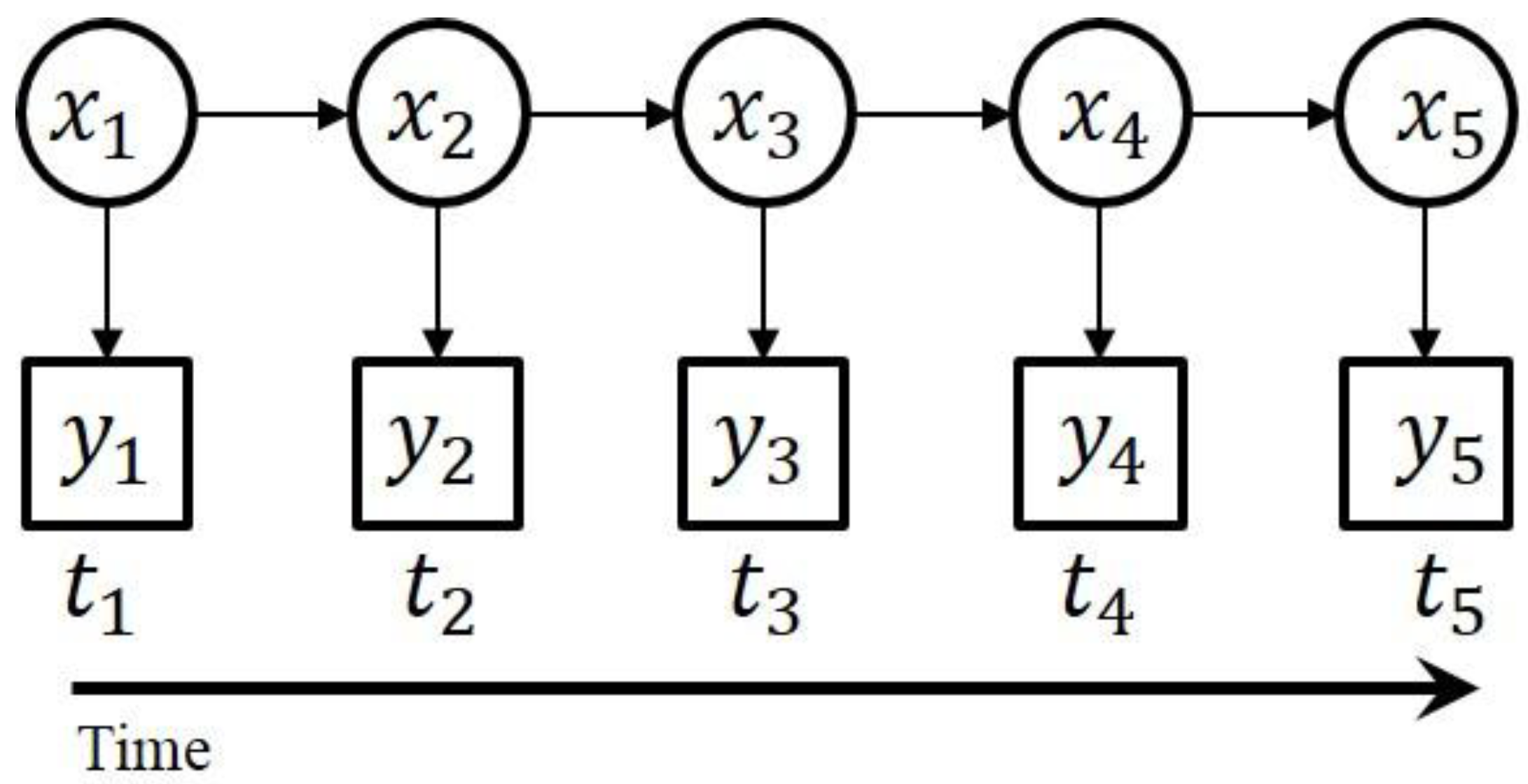
4.2. Generative Models
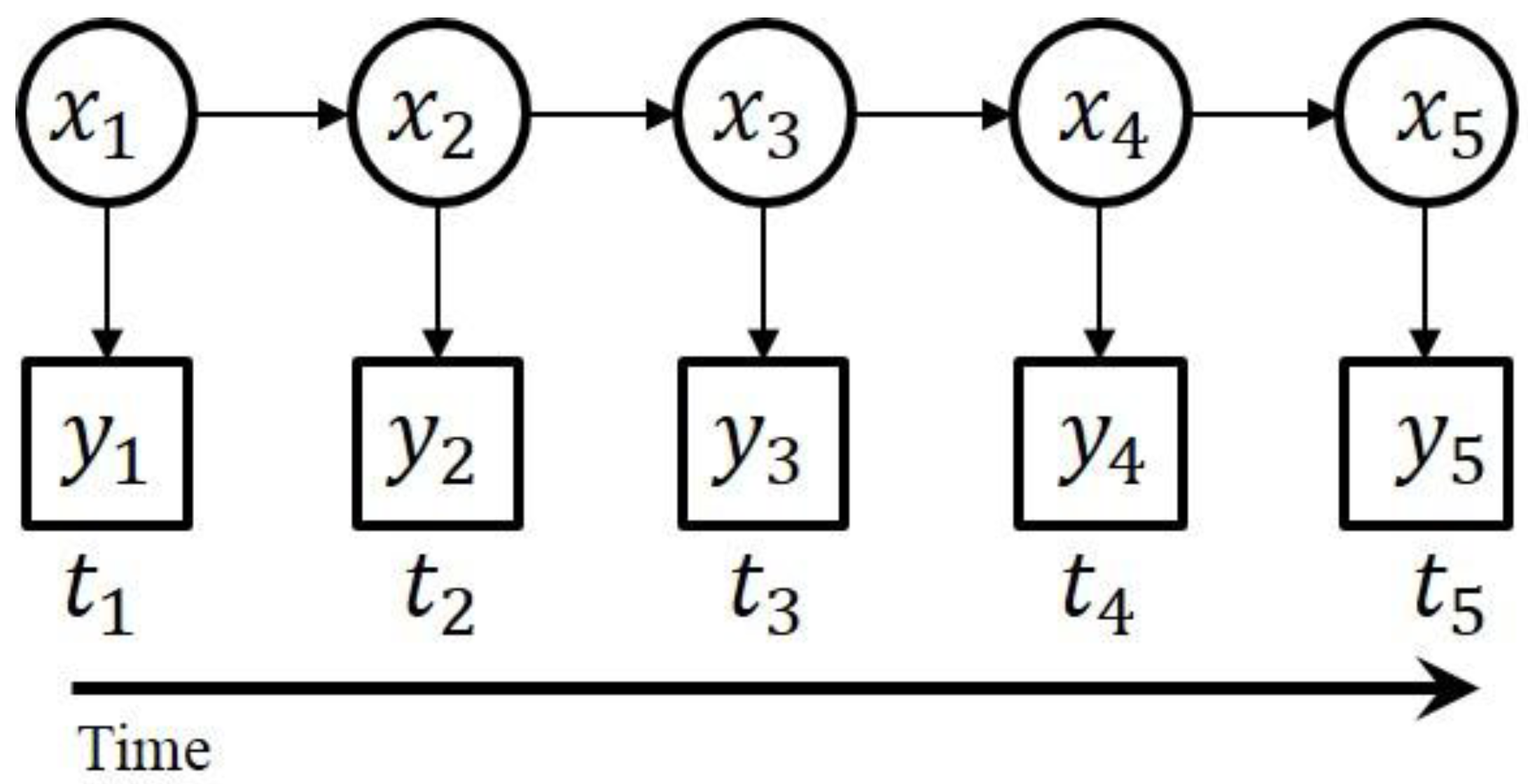
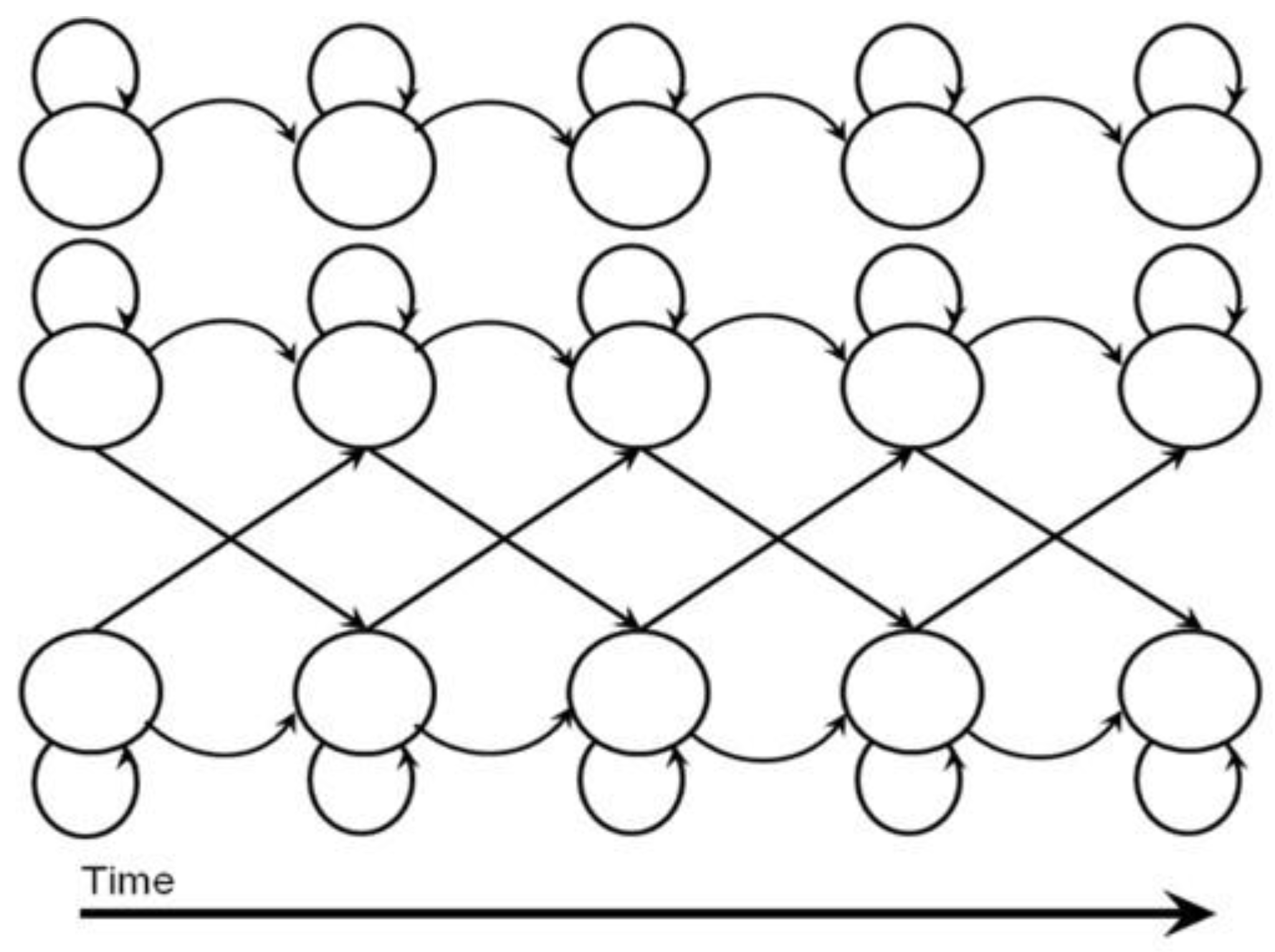
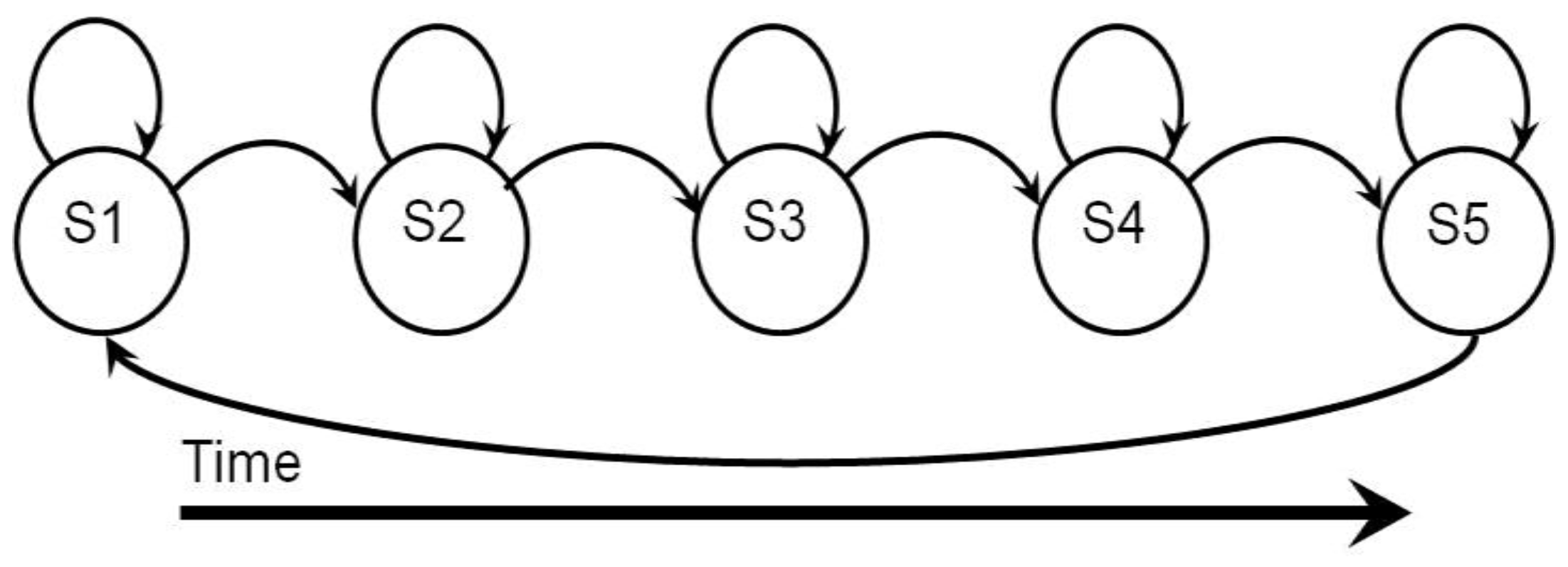
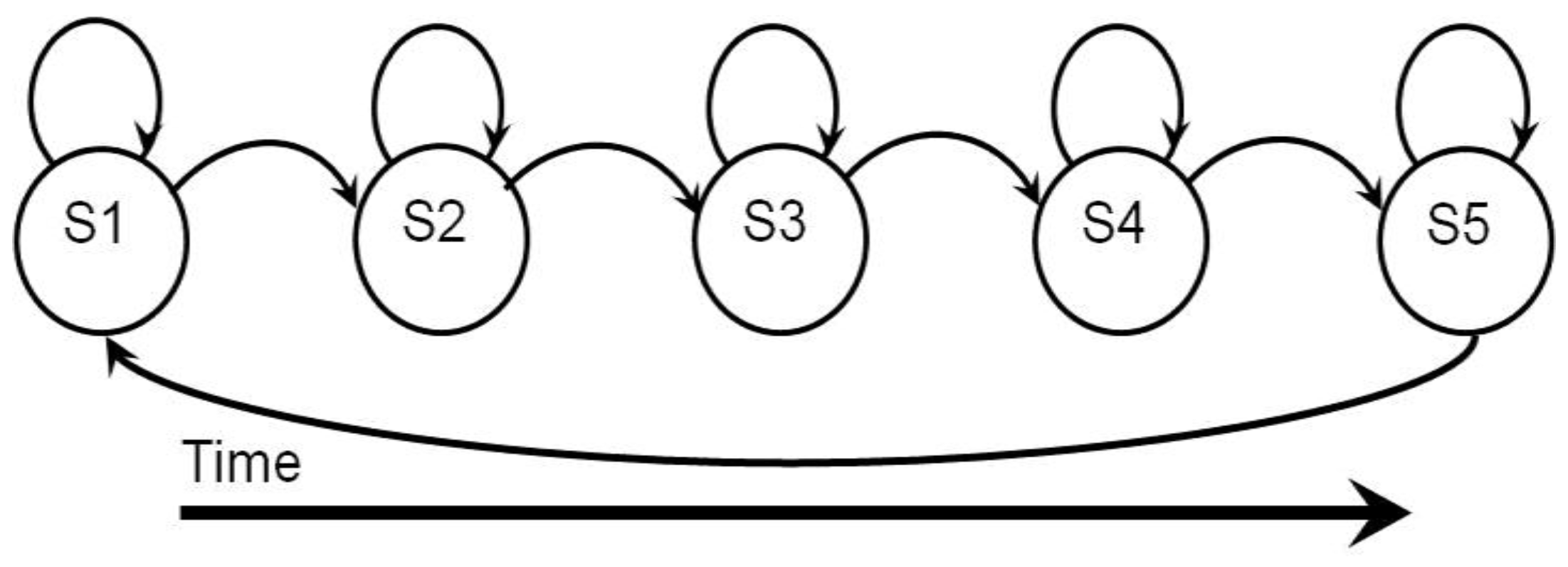
4.2.1. Hidden Markov Model (HMM)
 . The first term
. The first term  is the initial probability of hidden states. The second term (A) is the transition matrix, which specifies a transition probability from one hidden state to another hidden state. The third term (B) is the observation matrix, which specifies the probability of the observed symbol given a hidden state. As addressed in [76], three types of problems of HMMs are addressed.
is the initial probability of hidden states. The second term (A) is the transition matrix, which specifies a transition probability from one hidden state to another hidden state. The third term (B) is the observation matrix, which specifies the probability of the observed symbol given a hidden state. As addressed in [76], three types of problems of HMMs are addressed.
- The evaluation problem: Given a model Y = Φ and an observation sequence X, what is the probability (likelihood),
![Computers 02 00088 i009]() , of X given the specified model Φ? This problem can be efficiently solved by the forward/backward algorithm.
, of X given the specified model Φ? This problem can be efficiently solved by the forward/backward algorithm. - The decoding problem: Given a model Φ and an observation sequence X, what is the most likely underlying hidden state sequence that produces the observation sequence? This problem can be efficiently solved by the Viterbi algorithm.
- The learning problem: Given a model Φ and an observation sequence X, how can we adjust the model parameters
![Computers 02 00088 i007]() to maximize the conditional probability (likelihood)
to maximize the conditional probability (likelihood) ![Computers 02 00088 i010]() ? This problem can be efficiently solved by the Baum-Welch re-estimation algorithm.
? This problem can be efficiently solved by the Baum-Welch re-estimation algorithm.
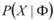
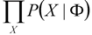
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
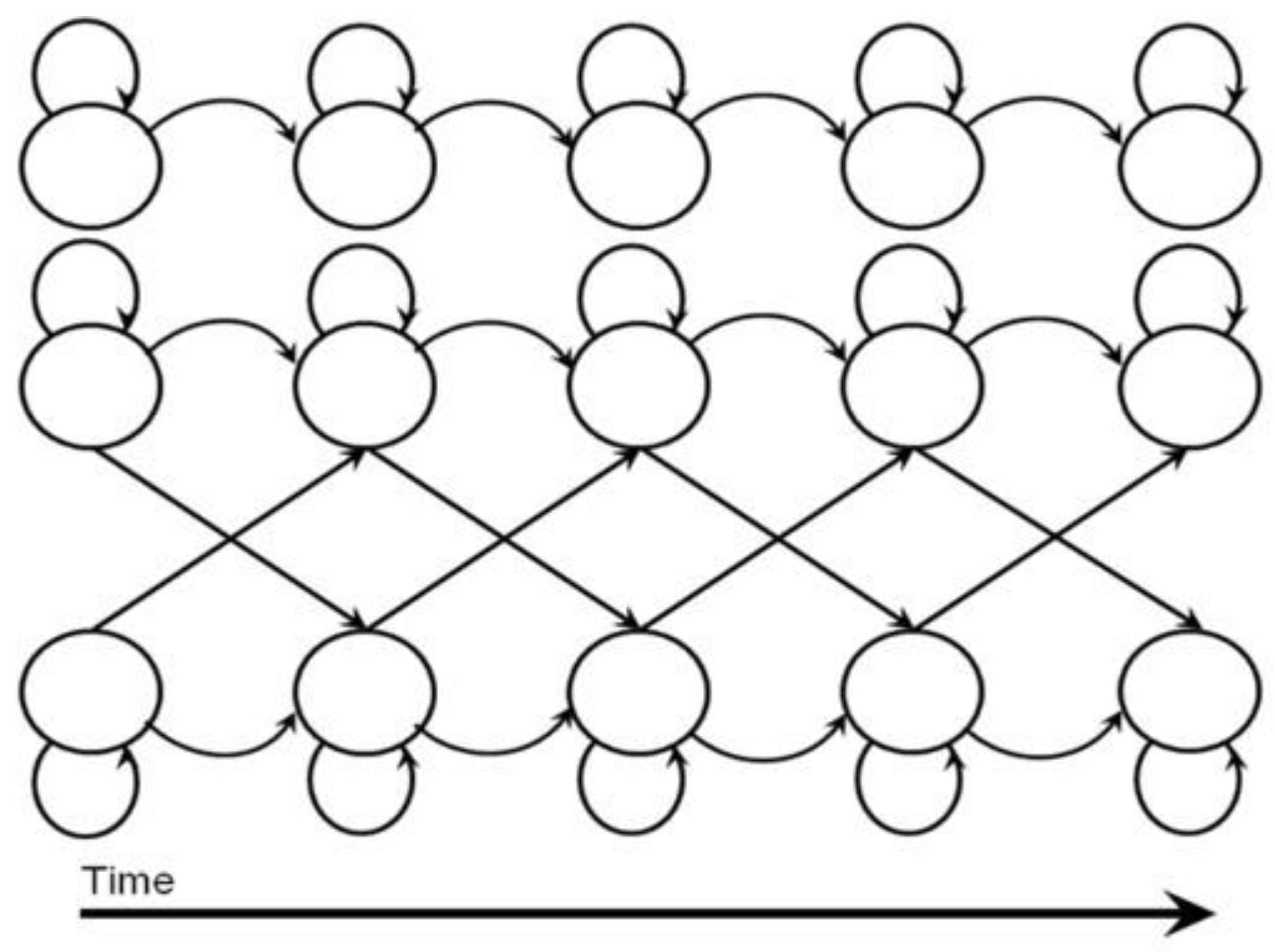

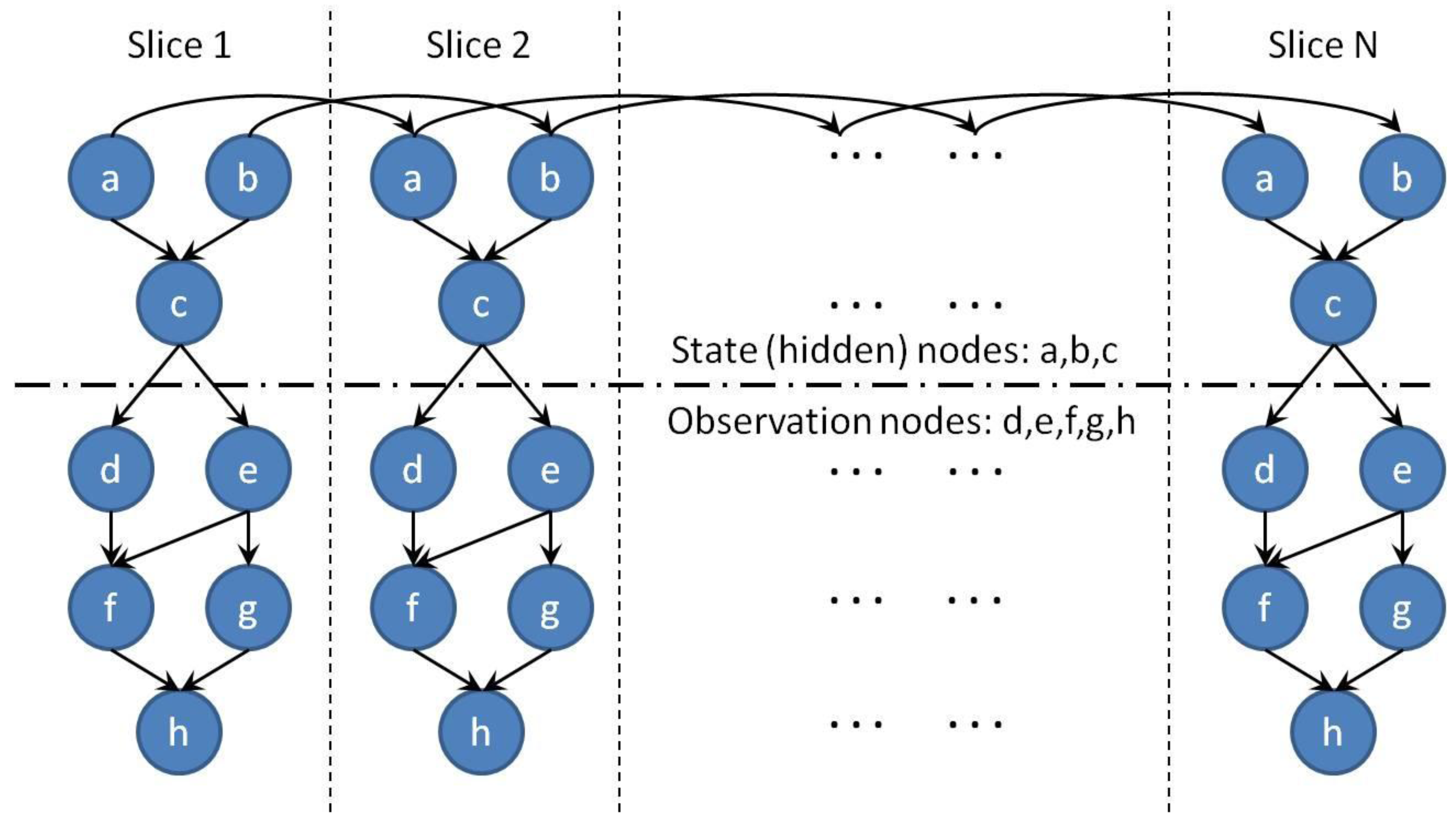
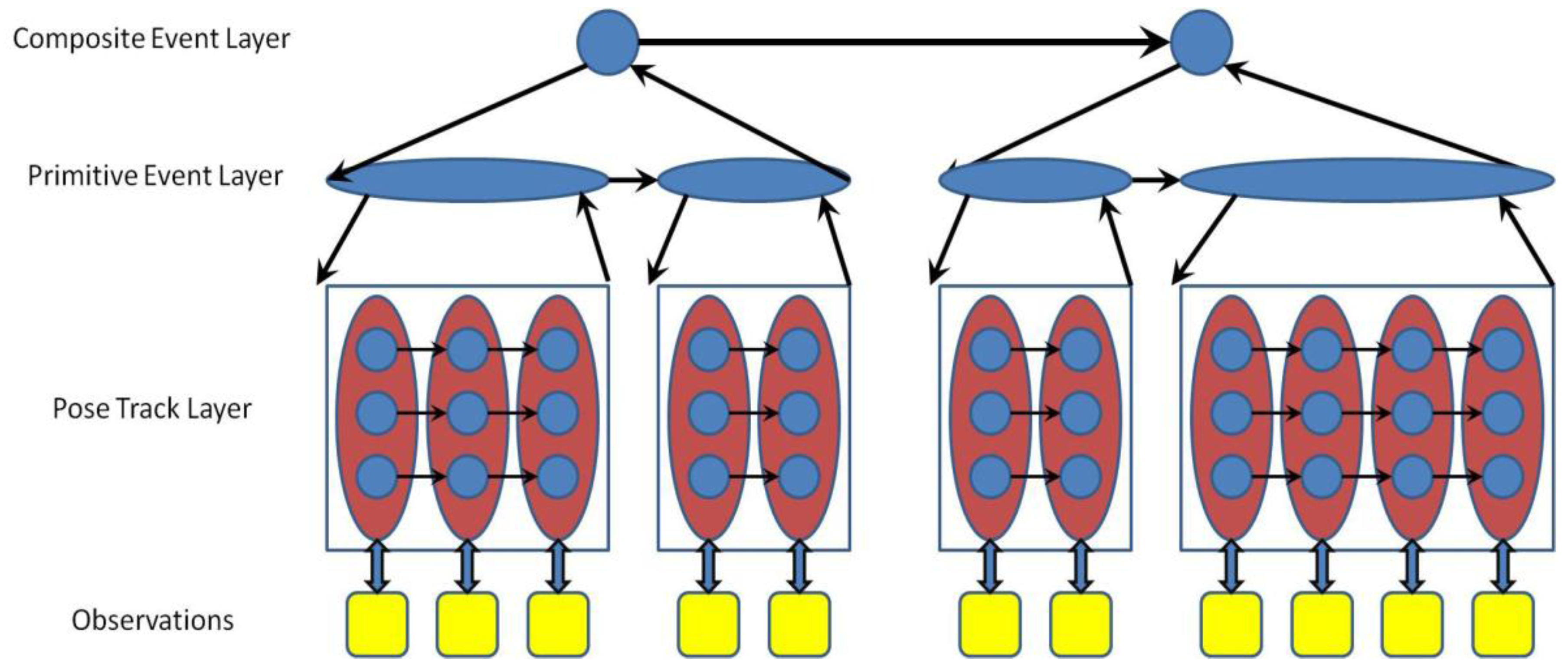
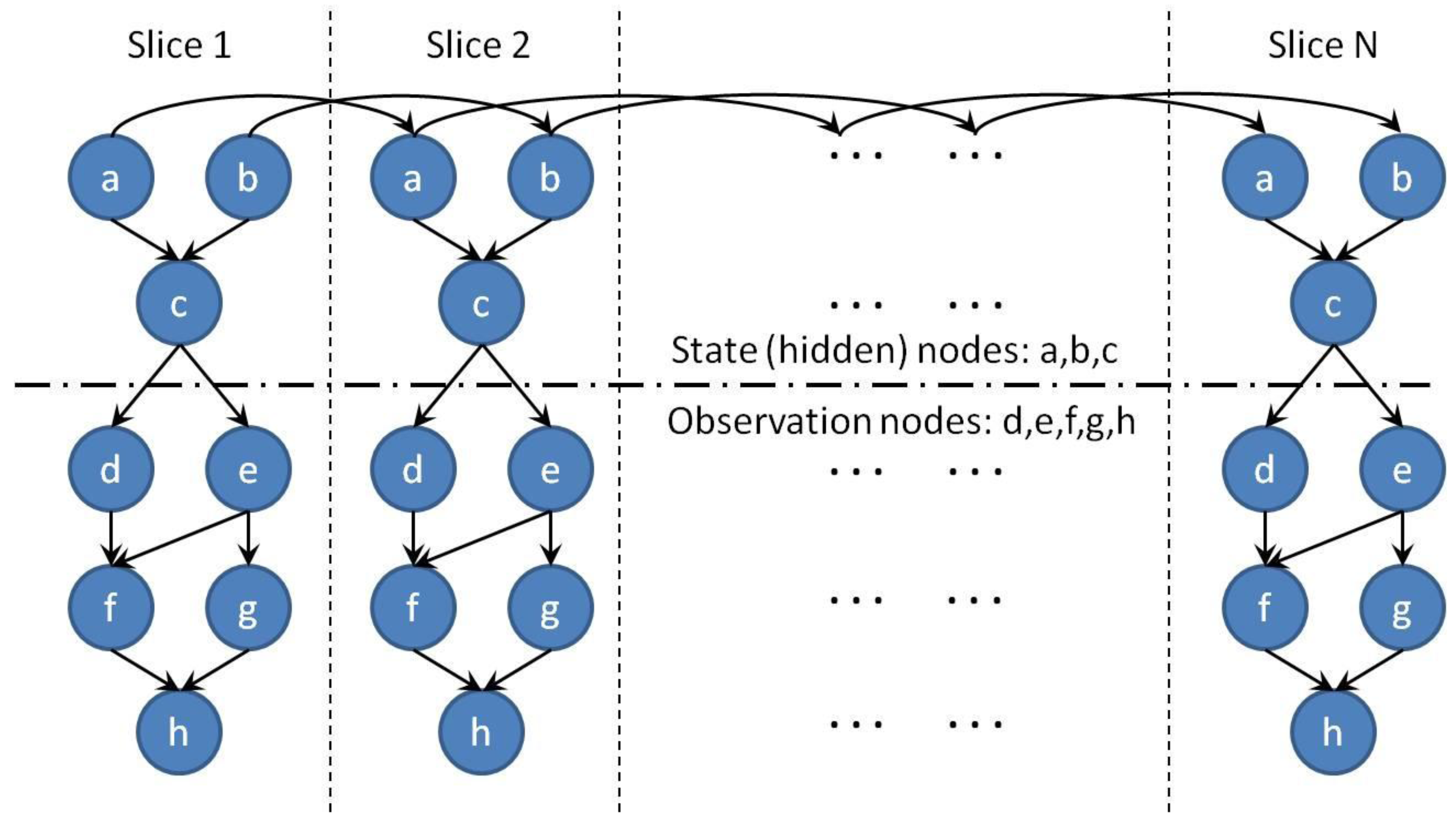
4.2.2. Dynamic Bayesian Network (DBN)
4.3. Discriminative Models
 , of a specific class label Y given the observed variable X. Compared with generative models, discriminative models cannot be used to generate samples with the joint probability P(X,Y), since the original varying-length data sequence needs to be transformed to a fixed length feature data for discriminative model based classifiers. But for some classification tasks where the categorization of the data is the only purpose instead of knowing the additional hidden state transition of the data sequences, joint probability may not be required. The examples of discriminative models are described below, including support vector machines (SVMs) [18,19,79,80], relevance vector machines (RVMs) [81,82] and artificial neural networks (ANNs) [84].
, of a specific class label Y given the observed variable X. Compared with generative models, discriminative models cannot be used to generate samples with the joint probability P(X,Y), since the original varying-length data sequence needs to be transformed to a fixed length feature data for discriminative model based classifiers. But for some classification tasks where the categorization of the data is the only purpose instead of knowing the additional hidden state transition of the data sequences, joint probability may not be required. The examples of discriminative models are described below, including support vector machines (SVMs) [18,19,79,80], relevance vector machines (RVMs) [81,82] and artificial neural networks (ANNs) [84].4.3.1. Support Vector Machine (SVM)
4.3.2. Relevance Vector Machine (RVM)
4.3.3. Artificial Neural Network (ANN)
4.4. Others
4.4.1. Kalman Filter (KF)
4.4.2. Binary Tree
4.4.3. Multidimensional Indexing
4.4.4. K-Nearest Neighbor (K-NN)
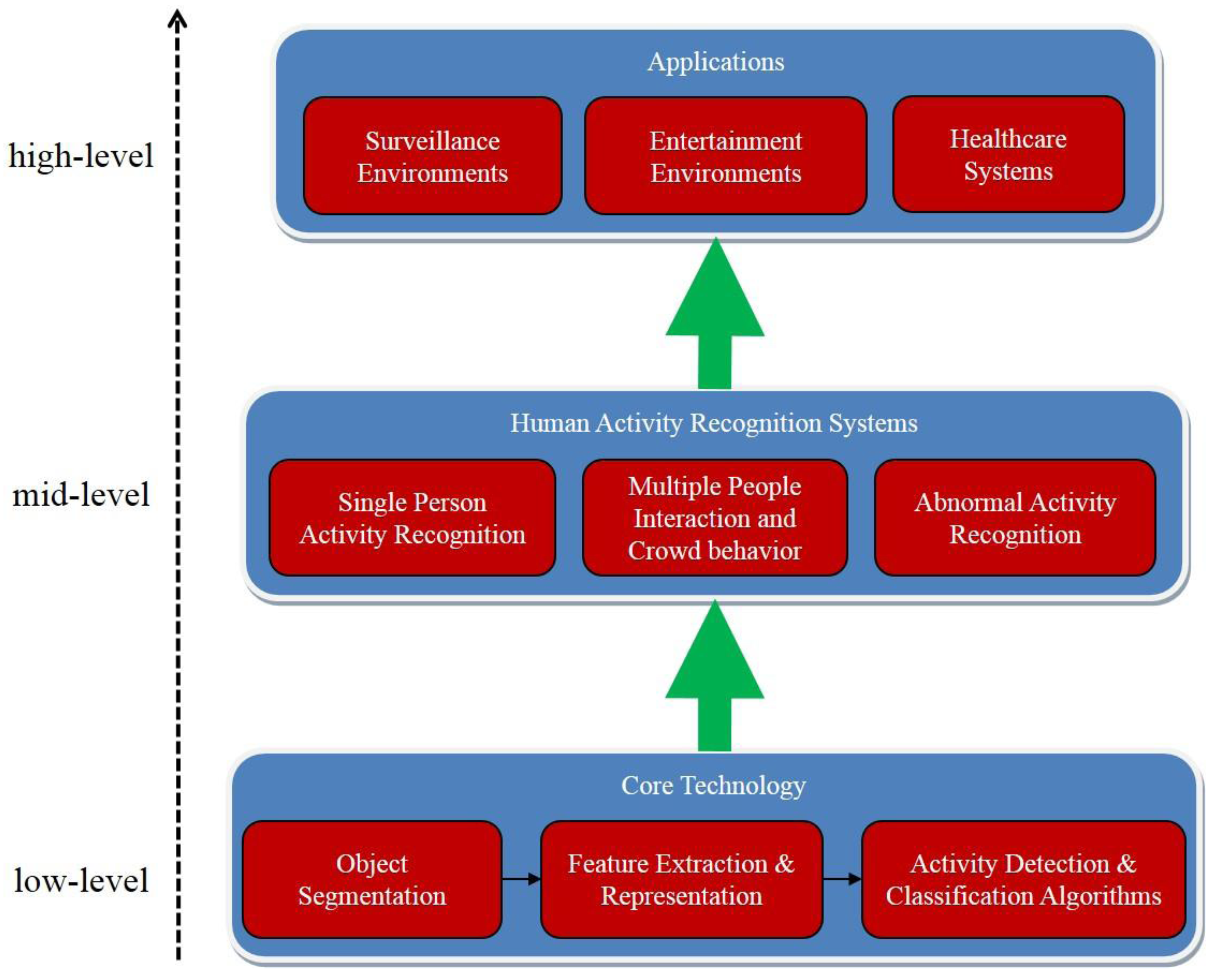
5. Human Activity Recognition Systems
5.1. Single Person Activity Recognition
5.1.1. Trajectory
5.1.2. Falling Detection
5.1.3. Human Pose Estimation
5.2. Multiple People Interaction and Crowd Behavior
5.3. Abnormal Activity Recognition
6. Applications
6.1. Surveillance Environments
6.2. Entertainment Environments
6.3. Healthcare Systems
6.3.1. Daily Life Activity Monitoring
6.3.2. Rehabilitation Applications
7. Conclusions and Future Direction
- The viewpoint issue remains the main challenge for human activity recognition. In real world activity recognition systems, the video sequences are usually observed from arbitrary camera viewpoints; therefore, the performance of systems needs to be invariant from different camera viewpoints. However, most recent algorithms are based on constrained viewpoints, such as the person needs to be in front-view (i.e., face a camera) or side-view. Some effective ways to solve this problem have been proposed, such as using multiple cameras to capture different view sequences then combining them as training data or a self-adaptive calibration and viewpoint determination algorithm can be used in advance. Sophisticated viewpoint invariant algorithms for monocular videos should be the ultimate objective to overcome these issues.
- Since most moving human segmentation algorithms are still based on background subtraction, which requires a reliable background model, a background model is needed that can be adaptively updated and can handle some moving background or dynamic cluttered background, as well as inconsistent lighting conditions. Learning how to effectively deal with the dynamic cluttered background as well as how to systematically understand the context (when, what, where, etc.), should enable better and more reliable segmentation of human objects. Another important challenge requiring research is how to handle occlusion, in terms of body–body part, human–human, human–objects, etc.
- Natural human appearance can change due to many factors such as walking surface conditions (e.g., hard/soft, level/stairs, etc.), clothing (e.g., long dress, short skirt, coat, hat, etc.), footgear (e.g., stockings, sandals, slippers, etc.), object carrying (e.g., handbag, backpack, briefcase, etc.) [143]. The change of human action appearance leads researchers to a new research direction, i.e., how to describe the activities that are less sensitive to appearance but still capture the most useful and unique characteristics of each action.
- Unlike speech recognition systems, where the features are more or less unified to be the mel-frequency cepstral coefficients (MFCCs) for HMM classifiers, there are still no clear winners on the features for human activity recognitions, nor the corresponding classifier designs. It can be expected that 3D viewpoint invariant modeling of human poses would be a good starting point for a unified effort.
Acknowledgments
Conflict of Interest
References
- Duong, T.V.; Bui, H.H.; Phung, D.Q.; Venkatesh, S. Activity Recognition and Abnormality Detection with the Switching Hidden Semi-Markov Model. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 838–845.
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-time Shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV), Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402.
- Ke, Y.; Sukthankar, R.; Hebert, M. Spatio-temporal Shape and Flow Correlation for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.
- Yamato, J.; Ohya, J.; Ishii, K. Recognizing Human Action in Time-sequential Images using Hidden Markov Model. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Champaign, IL, USA, 15–18 June 1992; pp. 379–385.
- Lu, W.; Little, J.J. Simultaneous tracking and action recognition using the PCA-HOG descriptor. In Proceedings of the 3rd Canadian Conference on Computer and Robot Vision, Quebec, PQ, Canada, 7–9 June 2006; p. 6.
- Brand, M.; Oliver, N.; Pentland, A. Coupled hidden Markov Models for Complex Action Recognition. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Juan, PR, USA, 17–19 June 1997; pp. 994–999.
- Luo, Y.; Wu, T.; Hwang, J. Object-based analysis and interpretation of human motion in sports video sequences by dynamic Bayesian networks. Comput. Vis. Image Underst. 2003, 92, 196–216. [Google Scholar] [CrossRef]
- Lu, X.; Liu, Q.; Oe, S. Recognizing Non-rigid Human Actions using Joints Tracking in Space-Time. In Proceedings of the IEEE International Conference on Information Technology: Coding and Computing (ITCC), Las Vegas, NV, USA, 5–7 April 2004; Volume 1, pp. 620–624.
- Du, Y.; Chen, F.; Xu, W. Human interaction representation and recognition through motion decomposition. IEEE Signal Process. Lett. 2007, 14, 952–955. [Google Scholar] [CrossRef]
- Bodor, R.; Jackson, B.; Papanikolopoulos, N. Vision-based Human Tracking and Activity Recognition. In Proceedings of the 11th Mediterranean Conference on Control and Automation, Rhodes, Greece, 18–20 June 2003; Volume 1, pp. 18–20.
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior Recognition via Sparse Spatio-Temporal Features. In Proceedings of the 2nd Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 65–72.
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional SIFT Descriptor and Its Application to Action Recognition. In Proceedings of the 15th International Conference on Multimedia, ACM, Augsburg, Germany, 23–28 September 2007; pp. 357–360.
- Lin, C.; Hsu, F.; Lin, W. Recognizing human actions using NWFE-based histogram vectors. EURASIP J. Adv. Signal Process. 2010, 2010, 9. [Google Scholar]
- Veeraraghavan, A.; Roy-Chowdhury, A.K.; Chellappa, R. Matching shape sequences in video with applications in human movement analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1896–1909. [Google Scholar] [CrossRef]
- Huo, F.; Hendriks, E.; Paclik, P.; Oomes, A.H.J. Markerless Human Motion Capture and Pose Recognition. In Proceedings of the 10th IEEE Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), London, UK, 6–8 May 2009; pp. 13–16.
- Sempena, S.; Maulidevi, N.U.; Aryan, P.R. Human Action Recognition Using Dynamic Time Warping. In IEEE International Conference on Electrical Engineering and Informatics (ICEEI), Bandung, Indonesia, 17–19 July 2011; pp. 1–5.
- Natarajan, P.; Nevatia, R. Online, Real-time Tracking and Recognition of Human Actions. In Proceedings of IEEE Workshop on Motion and Video Computing (WMVC), Copper Mountain, CO, USA, 8–9 January 2008; pp. 1–8.
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th IEEE International Conference on Pattern Recognition (ICPR), Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36.
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning Realistic Human Actions from Movies. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Ribeiro, P.C.; Santos-Victor, J. Human Activity Recognition from Video: Modeling, Feature Selection and Classification Architecture. In Proceedings of the International Workshop on Human Activity Recognition and Modelling (HAREM), Oxford, UK, 9 September 2005; Volume 1, pp. 61–70.
- Ben-Arie, J.; Wang, Z.; Pandit, P.; Rajaram, S. Human activity recognition using multidimensional indexing. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1091–1104. [Google Scholar] [CrossRef]
- Kumari, S.; Mitra, S.K. Human Action Recognition Using DFT. In Proceedings of the third IEEE National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Hubli, India, 15–17 December 2011; pp. 239–242.
- Kuo, Y.; Lee, J.; Chung, P. A visual context-awareness-based sleeping-respiration measurement system. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 255–265. [Google Scholar] [CrossRef]
- Gao, J.; Hauptmann, A.G.; Bharucha, A.; Wactlar, H.D. Dining Activity Analysis Using a Hidden Markov Model. In Proceedings of the 17th IEEE International Conference on Pattern Recognition (ICPR), Cambridge, UK, 23–26 August 2004; Volume 2, pp. 915–918.
- Huynh, H.H.; Meunier, J.; Sequeira, J.; Daniel, M. Real time detection, tracking and recognition of medication intake. World Acad. Sci. Eng. Technol. 2009, 60, 280–287. [Google Scholar]
- Foroughi, H.; Rezvanian, A.; Paziraee, A. Robust Fall Detection Using Human Shape and Multi-Class Support Vector Machine. In Proceedings of the IEEE Sixth Indian Conference on Computer Vision, Graphics & Image Processing (ICVGIP), Bhubaneswar, India, 16–19 December 2008; pp. 413–420.
- Foroughi, H.; Aski, B.S.; Pourreza, H. Intelligent Video Surveillance for Monitoring Fall Detection of Elderly in Home Environments. In Proceedings of the IEEE 11th International Conference on Computer and Information Technology (ICCIT), Khulna, Bangladesh, 24–27 December 2008; pp. 219–224.
- Foroughi, H.; Yazdi, H.S.; Pourreza, H.; Javidi, M. An Eigenspace-based Approach for Human Fall Detection Using Integrated Time Motion Image and Multi-class Support Vector Machine. In Proceedings of IEEE 4th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 28–30 August 2008; pp. 83–90.
- Foroughi, H.; Naseri, A; Saberi, A.; Yazdi, H.S. An Eigenspace-based Approach for Human Fall Detection Using Integrated Time Motion Image and Neural Network. In Procedings of IEEE 9th International Conference on Signal Processing (ICSP), Beijing, China, 26–29 October 2008; pp. 1499–1503.
- Lühr, S.; Venkatesh, S.; West, G.; Bui, H.H. Explicit state duration HMM for abnormality detection in sequences of human activity. PRICAI 2004: Trends Artif. Intell. 2004, 3157, 983–984. [Google Scholar]
- Duong, T.V.; Phung, D.Q.; Bui, H.H.; Venkatesh, S. Human Behavior Recognition with Generic Exponential Family Duration Modeling in the Hidden Semi-Markov Model. In Proceedings of IEEE 18th International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 202–207.
- Liu, C.; Chung, P.; Chung, Y.; Thonnat, M. Understanding of human behaviors from videos in nursing care monitoring systems. J. High Speed Netw. 2007, 16, 91–103. [Google Scholar]
- Ghali, A.; Cunningham, A.S.; Pridmore, T.P. Object and Event Recognition for Stroke Rehabilitation. In Proceedings of Visual Communications and Image Processing, Lugano, Switzerland, 8–11 July 2003; pp. 980–989.
- Ayase, R.; Higashi, T.; Takayama, S.; Sagawa, S.; Ashida, N. A Method for Supporting At-home Fitness Exercise Guidance and At-home Nursing Care for the Elders, Video-based Simple Measurement System. In Proceedings of IEEE 10th International Conference on e-health Networking, Applications and Services (HealthCom), Singapore, 7–9 July 2008; pp. 182–186.
- Goffredo, M.; Schmid, M.; Conforto, S.; Carli, M.; Neri, A.; D'Alessio, T. Markerless human motion analysis in Gauss-Laguerre transform domain: An application to sit-to-stand in young and elderly people. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 207–216. [Google Scholar] [CrossRef]
- Liao, T.; Miaou, S.; Li, Y. A vision-based walking posture analysis system without markers. In IEEE 2nd International Conference on Signal Processing Systems (ICSPS), Dalian, China, 5–7 July 2010; Volume 3, pp. 254–258.
- Leu, A.; Ristic-Durrant, D.; Graser, A. A Robust Markerless Vision-based Human Gait Analysis System. In Proceedings of 6th IEEE International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 19–21 May 2011; pp. 415–420.
- Li, Y.; Miaou, S.; Hung, C.K.; Sese, J.T. A Gait Analysis System Using two Cameras with Orthogonal View. In Proceedings of IEEE International Conference on Multimedia Technology (ICMT), Hangzhou, China, 26–28 July 2011; pp. 2841–2844.
- Wren, C.R.; Azarbayejani, A.; Darrell, T.; Pentland, A.P. Pfinder: Real-time tracking of the human body. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 780–785. [Google Scholar] [CrossRef]
- Cucchiara, R.; Grana, C.; Piccardi, M.; Prati, A. Detecting moving objects, ghosts, and shadows in video streams. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1337–1342. [Google Scholar] [CrossRef]
- Seki, M.; Fujiwara, H.; Sumi, K. A Robust Background Subtraction Method for Changing Background. In Proceedings of Fifth IEEE Workshop on Applications of Computer Vision, Palm Springs, CA, USA, 4–6 December 2000; pp. 207–213.
- Permuter, H.; Francos, J.; Jermyn, I. A study of Gaussian mixture models of color and texture features for image classification and segmentation. Pattern Recogn. 2006, 39, 695–706. [Google Scholar] [CrossRef] [Green Version]
- Yoon, S.; Won, C.S.; Pyun, K.; Gray, R.M. Image Classification Using GMM with Context Information and with a Solution of Singular Covariance Problem. In IEEE Proceedings of Data Compression Conference (DCC), Snowbird, UT, USA, 25–27 March 2003; p. 457.
- Horprasert, T.; Harwood, D.; Davis, L.S. A statistical approach for real-time robust background subtraction and shadow detection. IEEE ICCV 1999, 99, 1–19. [Google Scholar]
- Brendel, W.; Todorovic, S. Video Object Segmentation by Tracking Regions. In proceedings of IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 833–840.
- Yu, T.; Zhang, C.; Cohen, M.; Rui, Y.; Wu, Y. Monocular Video Foreground/Background Segmentation by Tracking Spatial-color Gaussian Mixture Models. In Proceedings of IEEE Workshop on Motion and Video Computing (WMVC), Austin, TX, USA, 23–24 February 2007; p. 5.
- Murray, D.; Basu, A. Motion tracking with an active camera. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 449–459. [Google Scholar] [CrossRef]
- Kim, K.K.; Cho, S.H.; Kim, H.J.; Lee, J.Y. Detecting and Tracking Moving Object Using an Active Camera. In Proceedings of IEEE 7th International Conference on Advanced Communication Technology (ICACT), Phoenix Park, Dublin, Ireland, 21–23 February 2005; Volume 2, pp. 817–820.
- Daniilidis, K.; Krauss, C.; Hansen, M.; Sommer, G. Real-time tracking of moving objects with an active camera. Real-Time Imaging 1998, 4, 3–20. [Google Scholar]
- Huang, C.; Chen, Y.; Fu, L. Real-time Object Detection and Tracking on a Moving Camera Platform. In Proceedings of IEEE ICCAS-SICE, Fukuoka, Japan, 18–21 August 2009; pp. 717–722.
- Shechtman, E.; Irani, M. Space-time Behavior Based Correlation. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 405–412.
- Sedai, S.; Bennamoun, M.; Huynh, D. Context-based Appearance Descriptor for 3D Human Pose Estimation from Monocular Images. In Proceedings of IEEE Digital Image Computing: Techniques and Applications (DICTA), Melbourne, VIC, Australia, 1–3 December 2009; pp. 484–491.
- Ramanan, D.; Forsyth, D.A.; Zisserman, A. Tracking people by learning their appearance. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 65–81. [Google Scholar] [CrossRef]
- Agarwal, A.; Triggs, B. Recovering 3D human pose from monocular images. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 44–58. [Google Scholar] [CrossRef]
- Schindler, K.; Gool, L.V. Action Snippets: How Many Frames Does Human Action Recognition Require? In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Danafar, S.; Gheissari, N. Action recognition for surveillance applications using optic flow and SVM. Comput. Vis.–ACCV 2007 2007, 4844, 457–466. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893.
- Dargazany, A.; Nicolescu, M. Human Body Parts Tracking Using Torso Tracking: Applications to Activity Recognition. In Proceedings of IEEE Ninth International Conference on Information Technology: New Generations (ITNG), Las Vegas, NV, USA, 16–18 April 2012; pp. 646–651.
- Nakazawa, A.; Kato, H.; Inokuchi, S. Human Tracking Using Distributed Vision Systems. In Proceedings of IEEE Fourteenth International Conference on Pattern Recognition, Brisbane, Qld., Australia, 20 August 1998; Volume 1, pp. 593–596.
- Iwasawa, S.; Ebihara, K.; Ohya, J.; Morishima, S. Real-time Estimation of Human Body Posture from Monocular Thermal Images. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 15–20.
- Leung, M.K.; Yang, Y. First sight: A human body outline labeling system. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 359–377. [Google Scholar] [CrossRef]
- Leong, I.; Fang, J.; Tsai, M. Automatic body feature extraction from a marker-less scanned human body. Comput.-Aided Des. 2007, 39, 568–582. [Google Scholar]
- Lee, M.W.; Cohen, I. A model-based approach for estimating human 3D poses in static images. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 905–916. [Google Scholar] [CrossRef]
- Lee, M.W.; Nevatia, R. Body Part Detection for Human Pose Estimation and Tracking. In Proceedings of IEEE Workshop on Motion and Video Computing (WMVC), Austin, TX, USA, 23–24 February 2007 ; pp. 23–23.
- Lee, M.W.; Nevatia, R. Human pose tracking in monocular sequence using multilevel structured models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 27–38. [Google Scholar] [CrossRef]
- Rogez, G.; Guerrero, J.J.; Orrite, C. View-invariant Human Feature Extraction for Video-Surveillance Applications. In Proceedings of IEEE Conference on Advanced Video and Signal Based Surveillance (AVSS), London, UK, 5–7 September 2007; pp. 324–329.
- Ke, S.; Zhu, L.; Hwang, J.; Pai, H.; Lan, K.; Liao, C. Real-time 3D Human Pose Estimation from Monocular View with Applications to Event Detection and Video Gaming. In Proceedings of Seventh IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Boston, MA, USA, 29 August–1 September 2010; pp. 489–496.
- Ke, S.; Hwang, J.; Lan, K.; Wang, S. View-invariant 3D Human Body Pose Reconstruction Using a Monocular Video Camera. In Proceedings of Fifth ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC), Ghent, Belgium, 23–26 August 2011; pp. 1–6.
- Campbell, L.W.; Becker, D.A.; Azarbayejani, A.; Bobick, A.F.; Pentland, A. Invariant Features for 3-D Gesture Recognition. In Proceedings of the Second International Conference on Automatic Face and Gesture Recognition, Killington, VT, USA, 14–16 October 1996; pp. 157–162.
- Müller, M.; Röder, T.; Clausen, M. Efficient content-based retrieval of motion capture data. ACM Trans. Graph. (TOG) 2005, 24, 677–685. [Google Scholar]
- Hoang, L.U.T.; Ke, S.; Hwang, J.; Yoo, J.; Choi, K. Human Action Recognition based on 3D Body Modeling from Monocular Videos. In Proceedings of Frontiers of Computer Vision Workshop, Tokyo, Japan, 2–4 February 2012; pp. 6–13.
- Hoang, L.U.T.; Tuan, P.V.; Hwang, J. An Effective 3D Geometric Relational Feature Descriptor for Human Action Recognition. In Proceedings of IEEE RIVF International Conference on Computing and Communication Technologies, Research, Innovation, and Vision for the Future (RIVF), Ho Chi Minh City, Vietnam, 27 February–1 March 2012; pp. 1–6.
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Huang, X.; Acero, A.; Hon, H. Spoken Language Processing; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2001; Volume 15. [Google Scholar]
- Hoang, L.U.T.; Ke, S.; Hwang, J; Tuan, P.V.; Chau, T.N. Quasi-periodic Action Recognition from Monocular Videos via 3D Human Models and Cyclic HMMs. In Proceedings of IEEE International Conference on Advanced Technologies for Communications (ATC), Hanoi, Vietnam, 10–12 October 2012; pp. 110–113.
- Murphy, K.P. Dynamic Bayesian networks: Representation, inference and learning. PhD diss., University of California, Berkeley, CA, USA, 2002. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1999. [Google Scholar]
- Vapnik, V.; Golowich, S.E.; Smola, A. Support vector method for function approximation, regression estimation, and signal processing. Adv. Neural Inf. Process. Syst. 1997, 9, 281–287. [Google Scholar]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Tipping, M.E. The relevance vector machine. Adv. Neural Inf. Process. Syst. 2000, 12, 652–658. [Google Scholar]
- Fiaz, M.K.; Ijaz, B. Vision based Human Activity Tracking using Artificial Neural Networks. In Proceedings of IEEE International Conference on Intelligent and Advanced Systems (ICIAS), Kuala Lumpur, Malaysia, 15–17 June 2010; pp. 1–5.
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Jordan, A. On discriminative vs. generative classifiers: A comparison of logistic regression and naive Bayes. Adv. Neural Inf. Process. Syst. (NIPS) 2002, 14, 841. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter. In Technical Report TR 95–041; Department of Computer Science, University of North Carolina at Chapel Hill: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Learning patterns of activity using real-time tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar]
- Aggarwal, J. K.; Park, S. Human Motion: Modeling and Recognition of Actions and Interactions. In Proceedings of IEEE 2nd International Symposium on 3D Data Processing, Visualization and Transmission (3DPVT), Thessaloniki, Greece, 6–9 September 2004; pp. 640–647.
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEE Proc. Vis. Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Moeslund, T.B.; Hilton, A; Krüger, V. A survey of advances in vision-based human motion capture and analysis. Comput. Vis. Image Underst. 2006, 104, 90–126. [Google Scholar]
- Krüger, V.; Kragic, D.; Ude, A.; Geib, C. The meaning of action: A review on action recognition and mapping. Adv. Robot. 2007, 21, 1473–1501. [Google Scholar]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine recognition of human activities: A survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2179–2195. [Google Scholar] [CrossRef]
- Candamo, J.; Shreve, M.; Goldgof, D.B.; Sapper, D.B.; Kasturi, R. Understanding transit scenes: A survey on human behavior-recognition algorithms. IEEE Trans. Intell. Transp. Syst. 2010, 11, 206–224. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. (CSUR) 2011, 43, 16. [Google Scholar]
- Jiang, Y.; Bhattacharya, S.; Chang, S.; Shah, M. High-level event recognition in unconstrained videos. In International Journal of Multimedia Information Retrieval; 2013; Volume 2, pp. 73–101. [Google Scholar]
- Enzweiler, M.; Gavrila, D.M. Monocular pedestrian detection: Survey and experiments. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2179–2195. [Google Scholar] [CrossRef]
- Piccardi, M. Background Subtraction Techniques: A Review. In Proceedings of IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; Volume 4, pp. 3099–3104.
- Zhang, Z.; Li, M.; Li, S.Z.; Zhang, H. Multi-view Face Detection with Floatboost. In Proceedings of Sixth IEEE Workshop on Applications of Computer Vision (WACV), Orlando, FL, USA, 3–4 December 2002; pp. 184–188.
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with An Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, B.C., Canada, 24–28 August 1981.
- Shi, J.; Tomasi, C. Good Features to Track. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 21–23 June 1994; pp. 593–600.
- Dedeoğlu, Y.; Töreyin, B.U.; Güdükbay, U.; Çetin, A.E. Silhouette-based method for object classification and human action recognition in video. In Proceedings of the 9th European Conference on Computer Vision (ECCV) in Human-Computer Interaction, Graz, Austria, 7–13 May 2006; pp. 64–77.
- Cherla, S.; Kulkarni, J.; Kale, A.; Ramasubramanian, V. Towards Fast, View-invariant Human Action Recognition. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Anchorage, AK, USA, 24–26 June 2008; pp. 1–8.
- Rabiner, L.; Juang, B. Fundamentals of Speech Recognition; Prentice Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Dryden, I.L.; Mardia, K.V. Statistical Analysis of Shape; Wiley: Chichester, UK, 1998. [Google Scholar]
- Ramanan, D.; Forsyth, D.A. Finding and Tracking People from the Bottom Up. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; Volume 2, pp. II-467–II-474.
- Ramanan, D.; Forsyth, D.A.; Zisserman, A. Strike a Pose: Tracking People by Finding Stylized Poses. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; vol. 1, pp. 271–278.
- Moeslund, T.B.; Granum, E. A survey of computer vision-based human motion capture. Comput. Vis. Image Underst. 2001, 81, 231–268. [Google Scholar] [CrossRef]
- Isard, M.; Blake, A. Condensation—conditional density propagation for visual tracking. Int. J. Comput. Vis. 1998, 29, 5–28. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D.J. Markov Chain Monte Carlo in Practice; Chapman & Hall/CRC: London, UK, 1996; Volume 2. [Google Scholar]
- Zhu, S.; Zhang, R.; Tu, Z. Integrating Bottom-up/Top-down for Object Recognition by Data Driven Markov Chain Monte Carlo. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 13–15 June 2000; Volume 1, pp. 738–745.
- Bird, N.D.; Masoud, O.; Papanikolopoulos, N.P.; Isaacs, A. Detection of loitering individuals in public transportation areas. IEEE Trans. Intell. Transp. Syst. 2005, 6, 167–177. [Google Scholar] [CrossRef]
- Niu, W.; Long, J.; Han, D.; Wang, Y. Human Activity Detection and Recognition for Video Surveillance. In Proceedings of IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 27–30 June 2004; Volume 1, pp. 719–722.
- Töreyin, B.U.; Dedeoğlu, Y.; Çetin, A.E. HMM based falling person detection using both audio and video. In Proceedings of the 2005 International Conference on Computer Vision (ICCV) in Human-Computer Interaction, Beijing, China, 17–20 October; pp. 211–220.
- Shieh, W.; Huang, J. Proceedings of the 2005 International Conference on Computer Vision (ICCV) in Human-Computer Interaction. In Proceedings of IEEE International Conference on Embedded Software and Systems (ICESS), HangZhou, Zhejiang, China, 25–27 May 2009; pp. 350–355.
- Ristad, E.S.; Yianilos, P.N. Learning string-edit distance. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 522–532. [Google Scholar] [CrossRef]
- Hall, P.A.; Dowling, G.R. Approximate string matching. ACM Comput. Surv. (CSUR) 1980, 12, 381–402. [Google Scholar]
- Sengto, A.; Leauhatong, T. Human Falling Detection Algorithm Using Back Propagation Neural Network. In Proceedings of IEEE Biomedical Engineering International Conference (BMEiCON), Ubon Ratchathani, Thailand, 5–7 December 2012; pp. 1–5.
- Jacques, J.C.S., Jr.; Musse, S.R.; Jung, C.R. Crowd analysis using computer vision techniques. IEEE Signal Process. Mag. 2010, 27, 66–77. [Google Scholar]
- Subburaman, V.B.; Descamps, A.; Carincotte, C. Counting People in the Crowd Using a Generic Head Detector. In Proceedings of IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance (AVSS), Beijing, China, 18–21 September 2012; pp. 470–475.
- Merad, D.; Aziz, K.E.; Thome, N. Fast People Counting Using Head Detection from Skeleton Graph. In Proceeidngs of Seventh IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Boston, MA, USA, 29 August–1 September 2010; pp. 233–240.
- Lu, C.P.; Hager, G.D.; Mjolsness, E. Fast and Globally Convergent Pose Estimation from Video Images. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 610–622. [Google Scholar] [CrossRef]
- McKenna, S.J.; Jabri, S.; Duric, Z.; Rosenfeld, A.; Wechsler, H. Tracking groups of people. Comput. Vis. Image Underst. 2000, 80, 42–56. [Google Scholar] [CrossRef]
- Chu, C.; Hwang, J.; Wang, S.; Chen, Y. Human Tracking by Adaptive Kalman Filtering and Multiple Kernels Tracking with Projected Gradients. In Proceedings of IEEE Fifth ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC), Ghent, Belgium, 23–26 August 2011; pp. 1–6.
- Saxena, S.; Brémond, F.; Thonnat, M.; Ma, R. Crowd behavior recognition for video surveillance. In Proceedings of the 10th International Conference on Advanced Concepts for Intelligent Vision Systems (ACIVS), Juan-les-Pins, France, 20–24 October 2008; pp. 970–981.
- Vu, V.; Bremond, F.; Thonnat, M. Automatic video interpretation: A novel algorithm for temporal scenario recognition. Int. Jt. Conf. Artif. Intell. 2003, 18, 1295–1302. [Google Scholar]
- Szczodrak, M.; Kotus, J.; Kopaczewski, K.; Lopatka, K.; Czyzewski, A.; Krawczyk, H. Behavior Analysis and Dynamic Crowd Management in Video Surveillance System. In Behavior Analysis and Dynamic Crowd Management in Video Surveillance System., Toulouse, France, 29 August–2 September 2011; pp. 371–375.
- Cho, S.; Kang, H. Integrated Multiple Behavior Models for Abnormal Crowd Behavior Detection. In Proceedings of IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Santa Fe, NM, USA, 22–24 April 2012; pp. 113–116.
- Mehran, R.; Oyama, A.; Shah, M. Abnormal Crowd Behavior Detection Using Social Force Model. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 935–942.
- Boiman, O.; Irani, M. Detecting Irregularities in Images and in Video. In Proceedings of Tenth IEEE International Conference on Computer Vision (ICCV), Beijing, China, 17–20 October 2005; Volume 1, pp. 462–469.
- Kim, J.; Grauman, K. Observe Locally, Infer Globally: A Space-time MRF for Detecting Abnormal Activities with Incremental Updates. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2921–2928.
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly Detection in Crowded Scenes. In Proccedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981.
- Chan, A.B.; Vasconcelos, N. Modeling, clustering, and segmenting video with mixtures of dynamic textures. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 909–926. [Google Scholar]
- Adam, A.; Rivlin, E.; Shimshoni, I.; Reinitz, D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 555–560. [Google Scholar] [CrossRef]
- Kratz, L.; Nishino, K. Anomaly Detection in Extremely Crowded Scenes Using Spatio-temporal Motion Pattern Models. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1446–1453.
- Moënne-Loccoz, N.; Brémond, F.; Thonnat, M. Recurrent Bayesian network for the recognition of human behaviors from video. In Proceedings of the 3rd International Conference on Computer Vision Systems (ICVS), Graz, Austria, 1–3 April 2003; pp. 68–77.
- Lin, W.; Sun, M.; Poovandran, R.; Zhang, Z. Human Activity Recognition for Video Surveillance. In Proceedings of IEEE International Symposium on Circuits and Systems (ISCAS), Seattle, WA, USA, 18–21 May 2008; pp. 2737–2740.
- Zin, T.T.; Tin, P.; Toriu, T.; Hama, H. A Markov Random Walk Model for Loitering People Detection. In Proceedings of IEEE Sixth International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), Darmstadt, Germany, 15–17 October 2010; pp. 680–683.
- Ran, Y.; Zheng, Q.; Chellappa, R.; Strat, T.M. Applications of a simple characterization of human gait in surveillance. IEEE Trans. Syst. Man, Cybern. Part B: Cybern. 2010, 40, 1009–1020. [Google Scholar]
- Hu, M.; Wang, Y.; Zhang, Z.; Zhang, D.; Little, J.J. Incremental learning for video-based gait recognition with LBP flow. IEEE Trans. Syst. Man, Cybern. Part B: Cybern. 2012, 43, 77–89. [Google Scholar]
- Poseidon. The lifeguard’s third eye. 2006. Available online: http://www.poseidon-tech.com/us/system.html (accessed on 22 November 2012).
- Sicre, R.; Nicolas, H. Shopping Scenarios Semantic Analysis in Videos. In Proceedings of the 8th IEEE International Workshop on Content-Based Multimedia Indexing (CBMI), Grenoble, France, 23–25 June 2010; pp. 1–6.
- Gafurov, D. A survey of biometric gait recognition: Approaches, security and challenges. In Proceedings of Norwegian Symposium on Informatics 2007 (NIK 2007), Oslo, Norway, 19–21 November 2007.
- Pantic, M.; Pentland, A.; Nijholt, A.; Huang, T.S. Human computing and machine understanding of human behavior: A survey. Artif. Intell. Hum. Comput. 2007, 4451, 47–71. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 15–29.
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Ke, S.-R.; Thuc, H.L.U.; Lee, Y.-J.; Hwang, J.-N.; Yoo, J.-H.; Choi, K.-H. A Review on Video-Based Human Activity Recognition. Computers 2013, 2, 88-131. https://doi.org/10.3390/computers2020088
Ke S-R, Thuc HLU, Lee Y-J, Hwang J-N, Yoo J-H, Choi K-H. A Review on Video-Based Human Activity Recognition. Computers. 2013; 2(2):88-131. https://doi.org/10.3390/computers2020088
Chicago/Turabian StyleKe, Shian-Ru, Hoang Le Uyen Thuc, Yong-Jin Lee, Jenq-Neng Hwang, Jang-Hee Yoo, and Kyoung-Ho Choi. 2013. "A Review on Video-Based Human Activity Recognition" Computers 2, no. 2: 88-131. https://doi.org/10.3390/computers2020088
APA StyleKe, S.-R., Thuc, H. L. U., Lee, Y.-J., Hwang, J.-N., Yoo, J.-H., & Choi, K.-H. (2013). A Review on Video-Based Human Activity Recognition. Computers, 2(2), 88-131. https://doi.org/10.3390/computers2020088