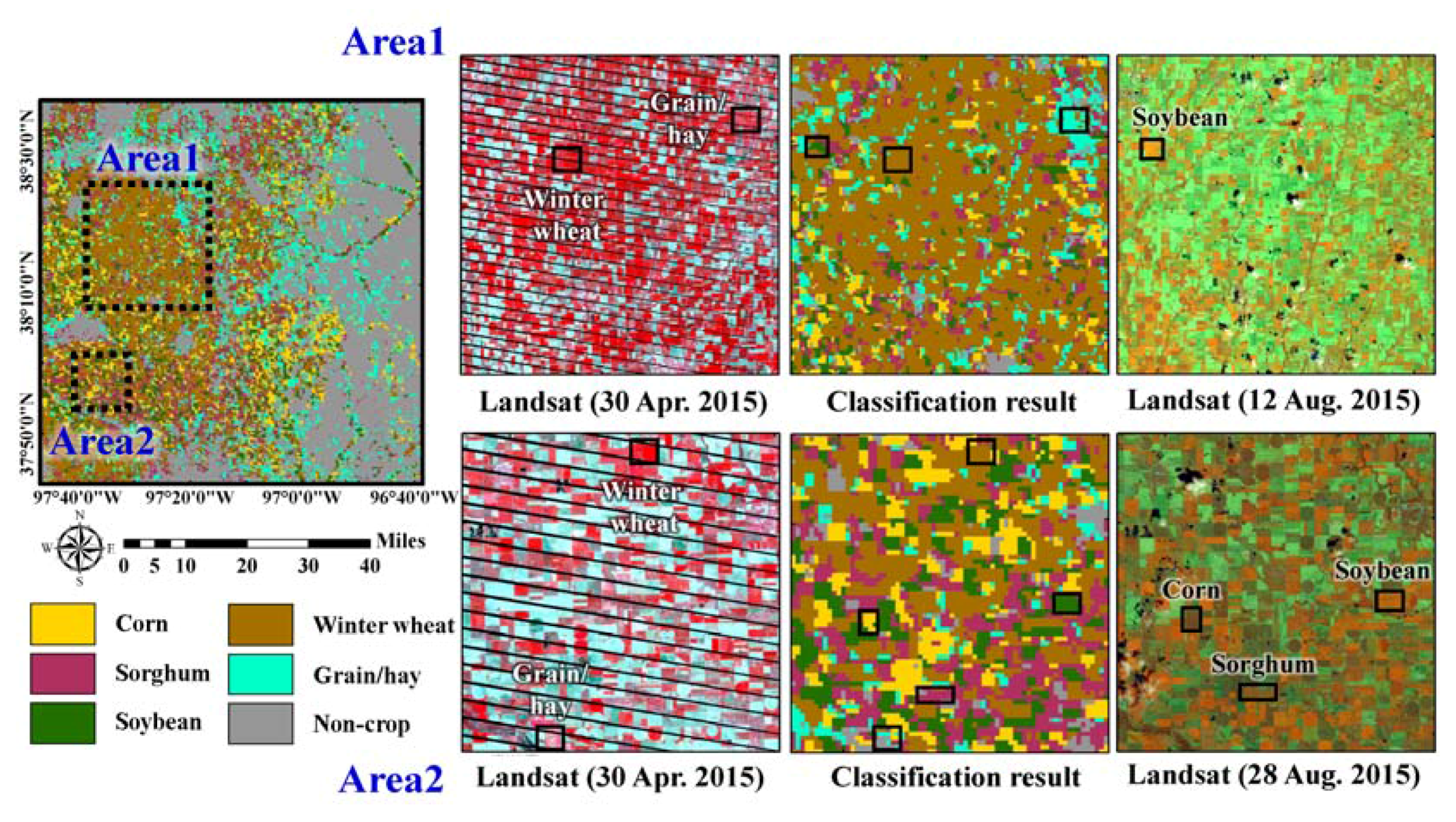
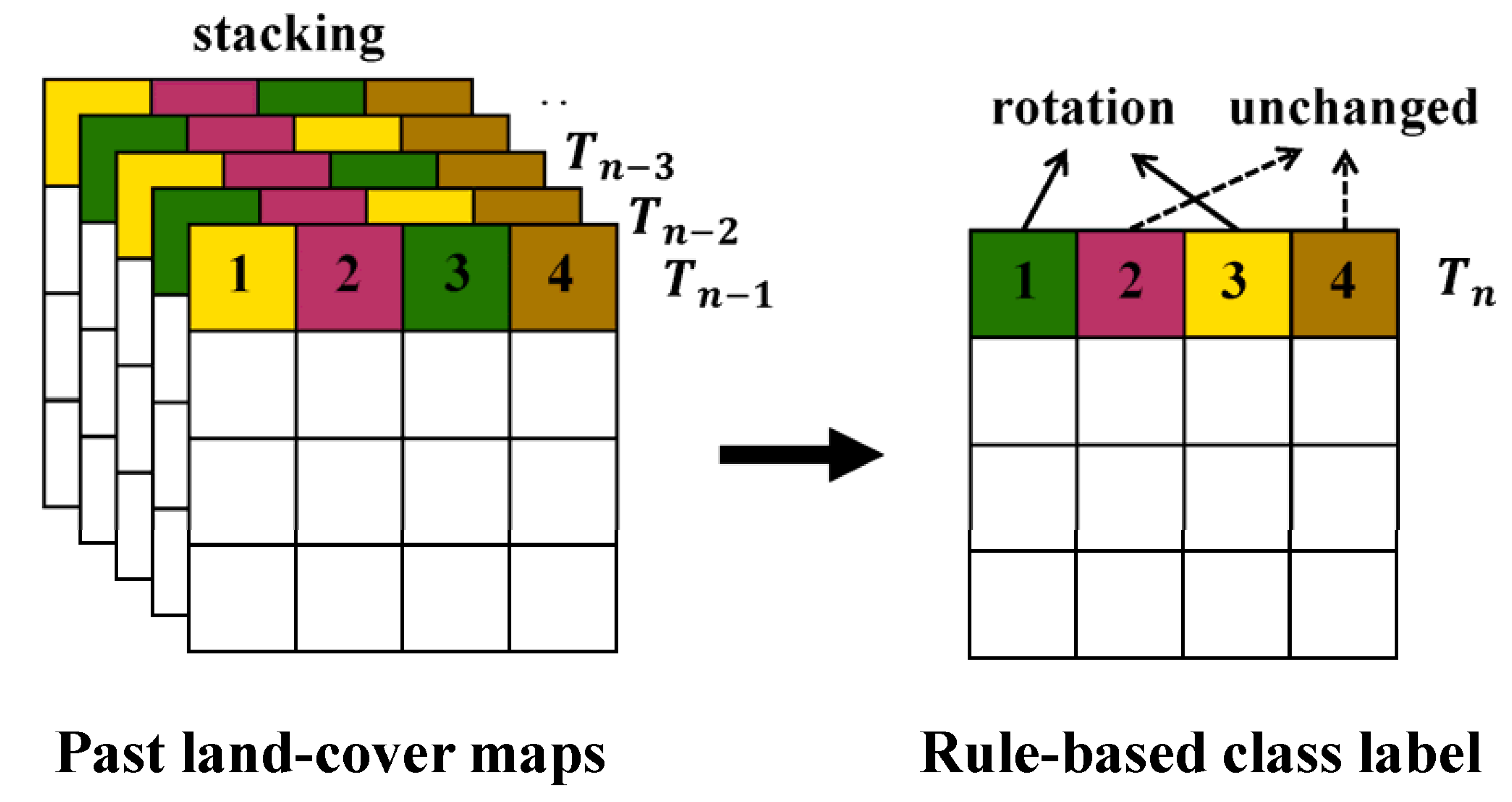
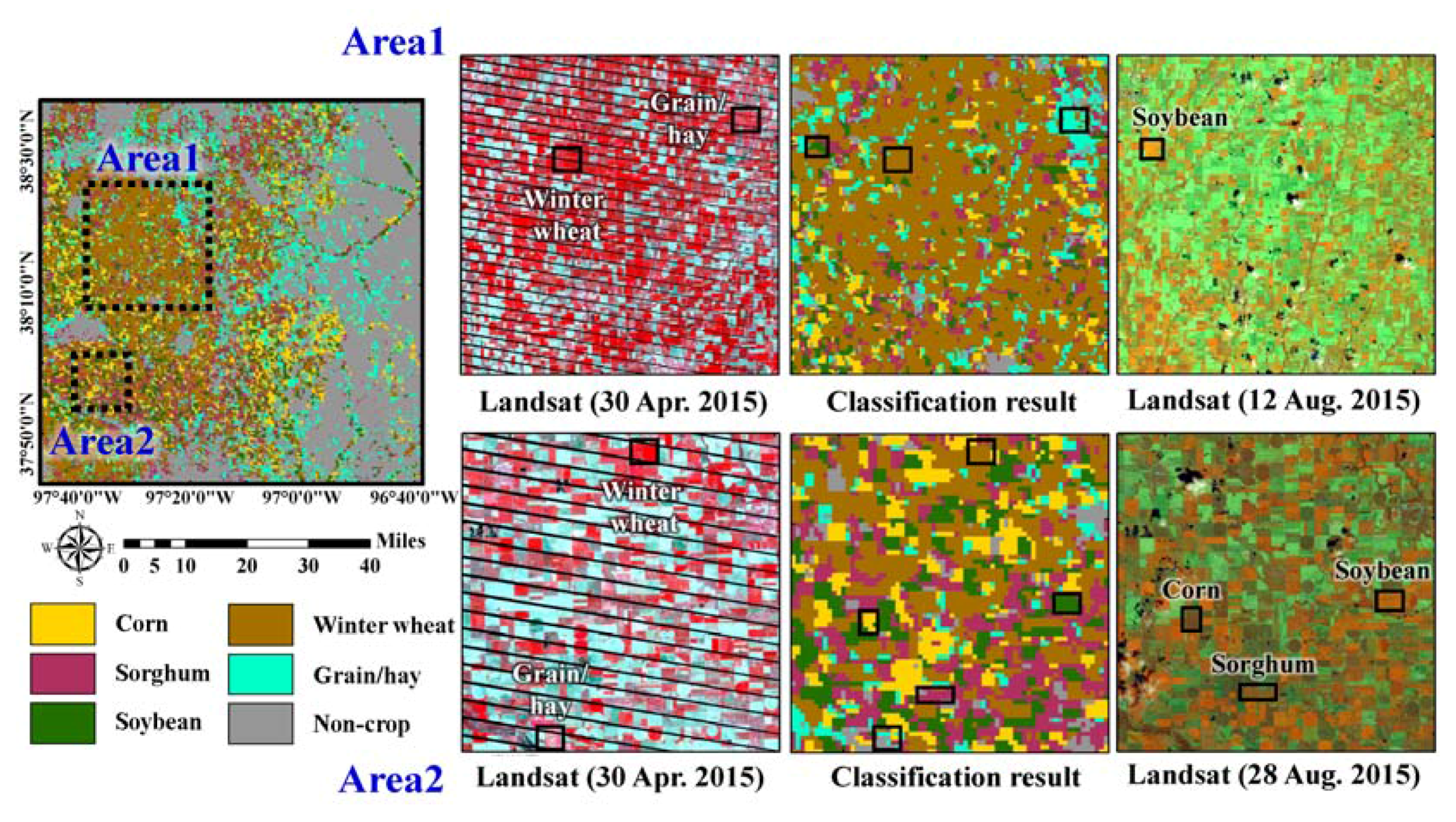
3.1. Generation of Rule-Based Class Labels
To use the most confident pixels in 250 m CDLs for the rule generation, we used only pixels whose fractions of classes assigned to the 250 m CDLs from 2010 to 2014 exceeded a specific thresholding value to define rule information. When a thresholding value of greater than 70% was applied, few pixels were extracted for most classes except for winter wheat and non-crop. Thus, the rule information was finally generated using only pixels whose fractions were greater than 60%.
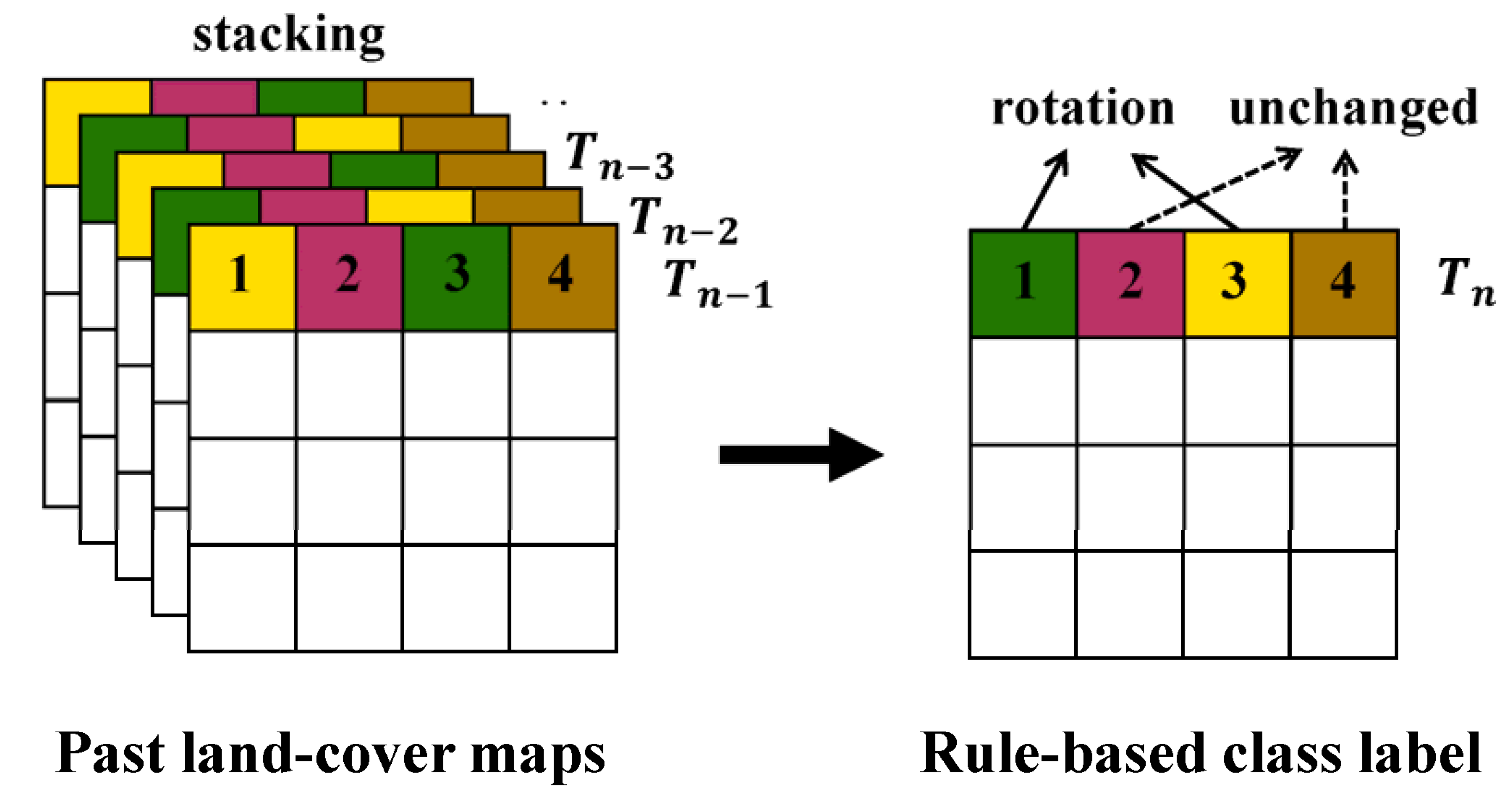
Overlaying many past CDLs generates too many unique sequence rules that have similar but not identical class sequences. It is very difficult to predict the single class label from complex rules because there are some possible class labels in 2015. To reduce the uncertainty attached to a class label assignment, all possible rules were not considered for the generation of rule-based class labels.
After analyzing typical cropping characteristics in the study area, we selected some unique sequence rules that could provide predictable information on a class label assignment. Winter wheat–fallow rotation has been known as the common cropping system in Kansas [
41]. The winter wheat–fallow rotation system allows the accumulation of soil moisture in the cultivation area during the fallow periods. Due to soil erosion potential, however, winter wheat–summer crops such as corn, sorghum, and soybean rotations are being widely planted [
41,
42,
43]. Of these crops, corn-soybean rotations dominate in Kansas.
A total of 21 rules were finally defined to predict class labels in 2015 (
Table 3). Not all 21 rules represent the frequent patterns. Some frequent patterns (e.g., rules #4 and 21 in
Table 3) were selected, but other patterns that were less frequent but facilitated the prediction of class labels in 2015 (e.g., rules #6 and 9 in
Table 3) were also selected. Although a simple heuristic approach was applied to generate rule information, the sequential patterns of land-covers between 2010 and 2014 in
Table 3 well reflect the above predominant crop rotation sequences in Kansas. Typical sequence rules in the study area include winter wheat–fallow rotation, winter wheat-summer crop rotations, and summer crop rotations, as well as continuously growing crops. In addition, grain/hay and non-crop classes including water and urban remain unchanged.
As mentioned in
Section 2.3, the effectiveness of the sequential patterns of land-covers depends on the number of CDLs used. To investigate this, the following different cases were considered to generate the rules: (1) using CDLs from 2010 to 2014 (5 years), (2) using CDLs from 2011 to 2014 (4 years), (3) using CDLs from 2012 to 2014 (3 years), and (4) using CDLs from 2013 to 2014 (2 years).
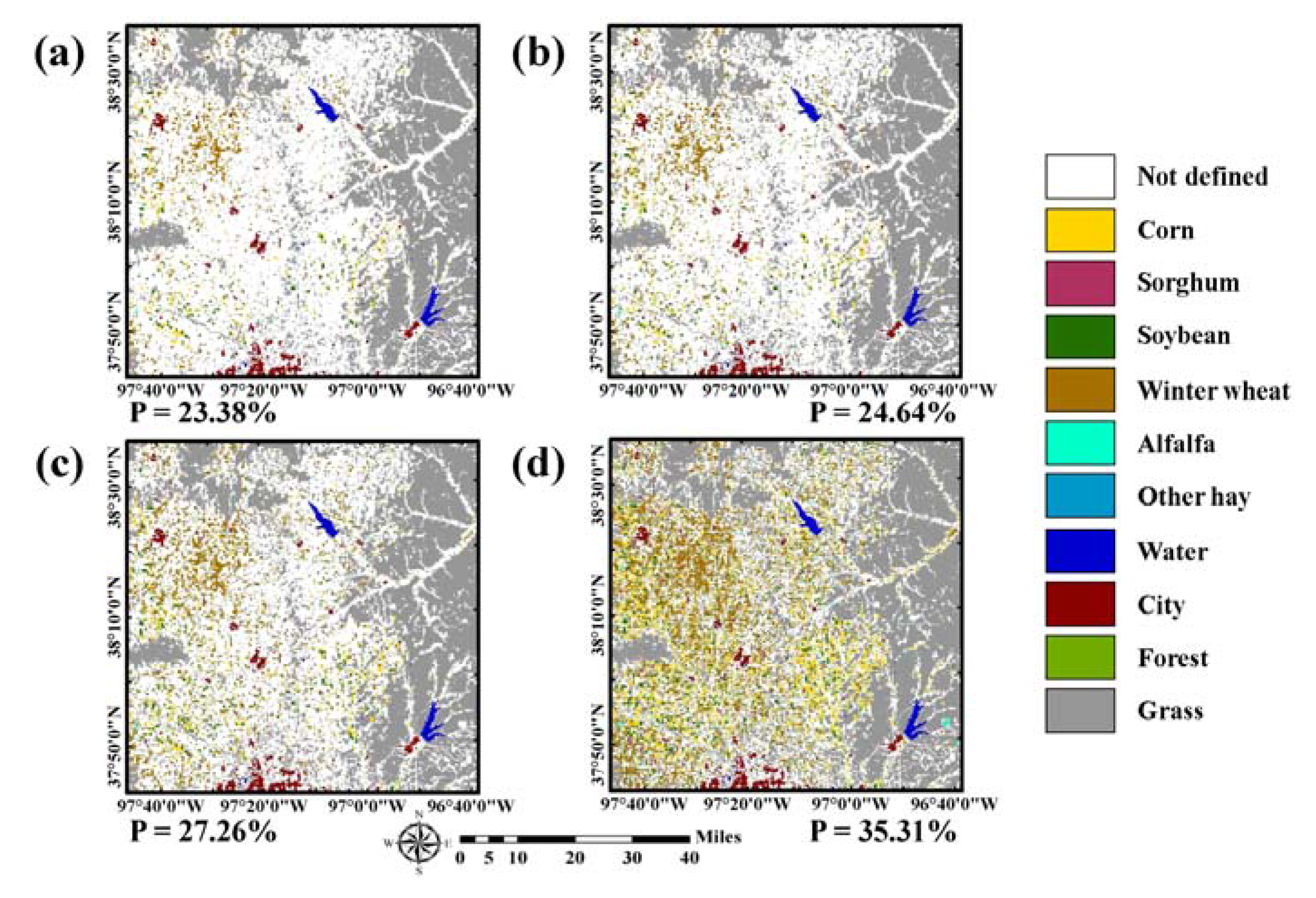
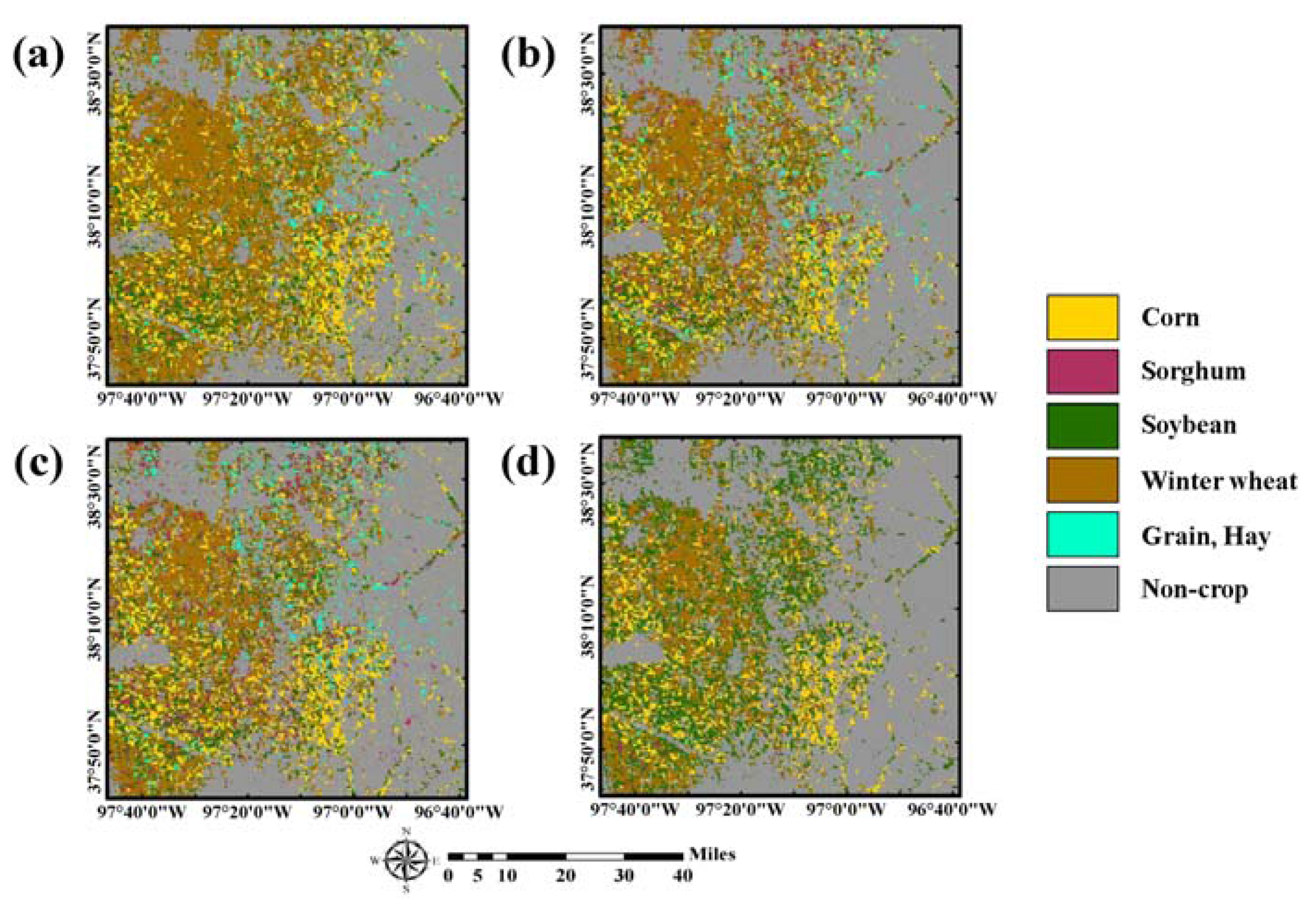
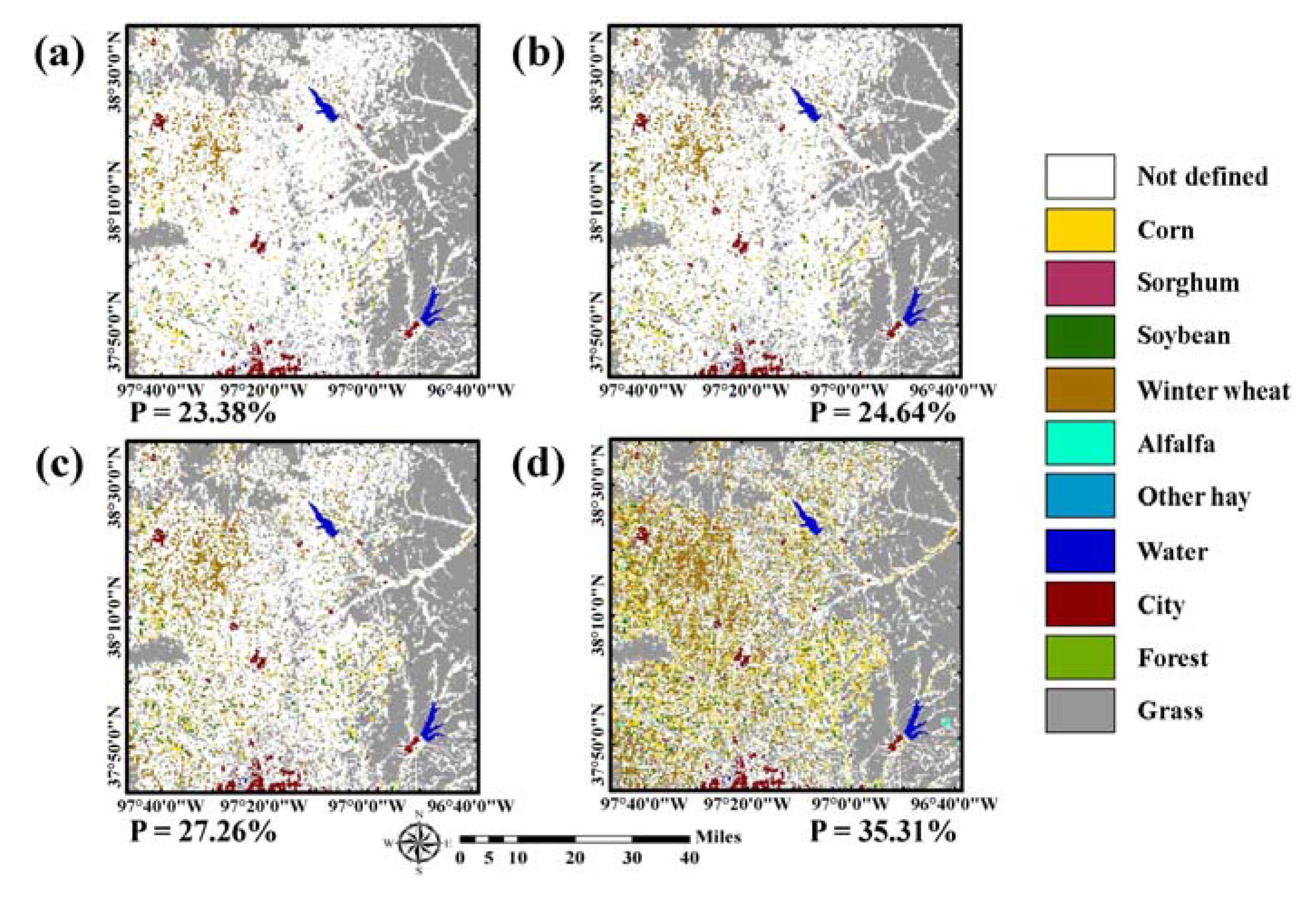
The class labels in 2015 of pixels in which sequential patterns of land-cover changes between 2010 and 2014 matched to the 21 rules were predicted as the corresponding labels of the rightmost column in
Table 3. The rule-based class label images predicted from these four different cases are given in
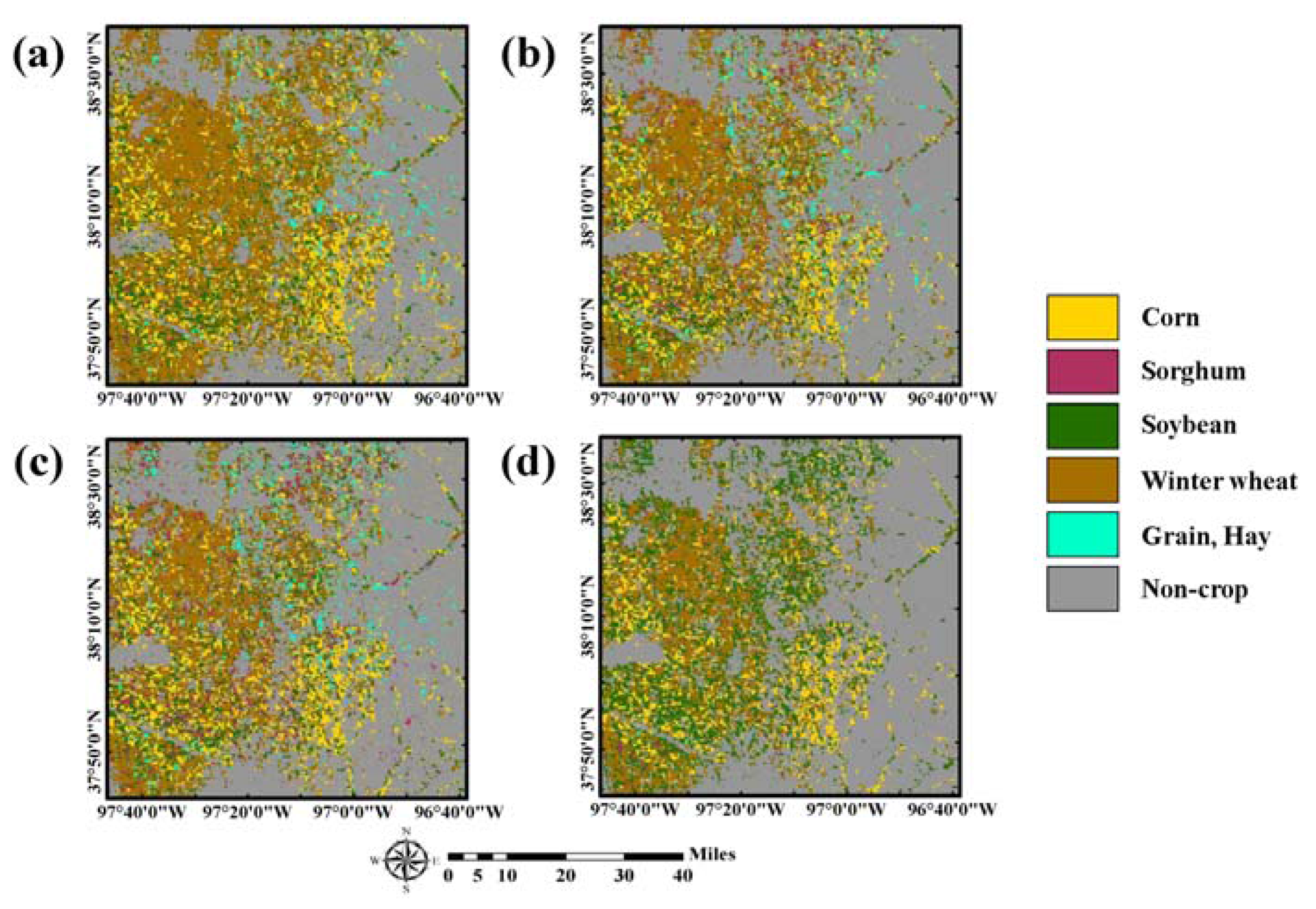
Figure 4. By superimposing the new training data candidates on the predicted label image, the class labels of the candidates were assigned automatically. Note that the rule-based class labels were not assigned to all pixels in the study area because some sequence rules were not considered and only the most confident pixels in CDLs were used to define rule information.
As the number of CDLs used to define the sequence rule decreased, the proportion of pixels in which the class labels in 2015 could be predicted increased accordingly (e.g., 23.38% (37,415 pixels) and 35.31% (56,496 pixels) for using past five-year and two-year CDLs, respectively). The fewer the CDLs, the more areas that were assigned to certain crop types such as corn, soybean, and winter wheat. By contrast, if the number of CDLs increased, relatively few areas had the rule-based class label and many areas remained unlabeled. Note that the number of pixels with rule-based class labels is much larger than that of initial training pixels (i.e., 37,415 versus 420). These rule images were separately used for further classification procedures and their classification performance were compared.
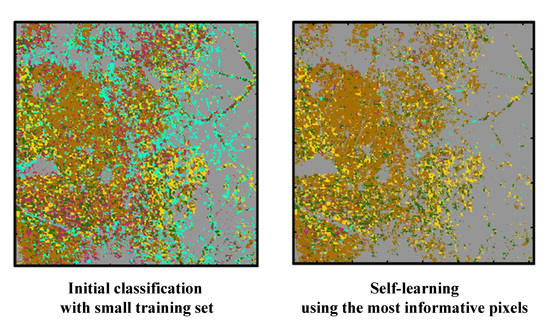
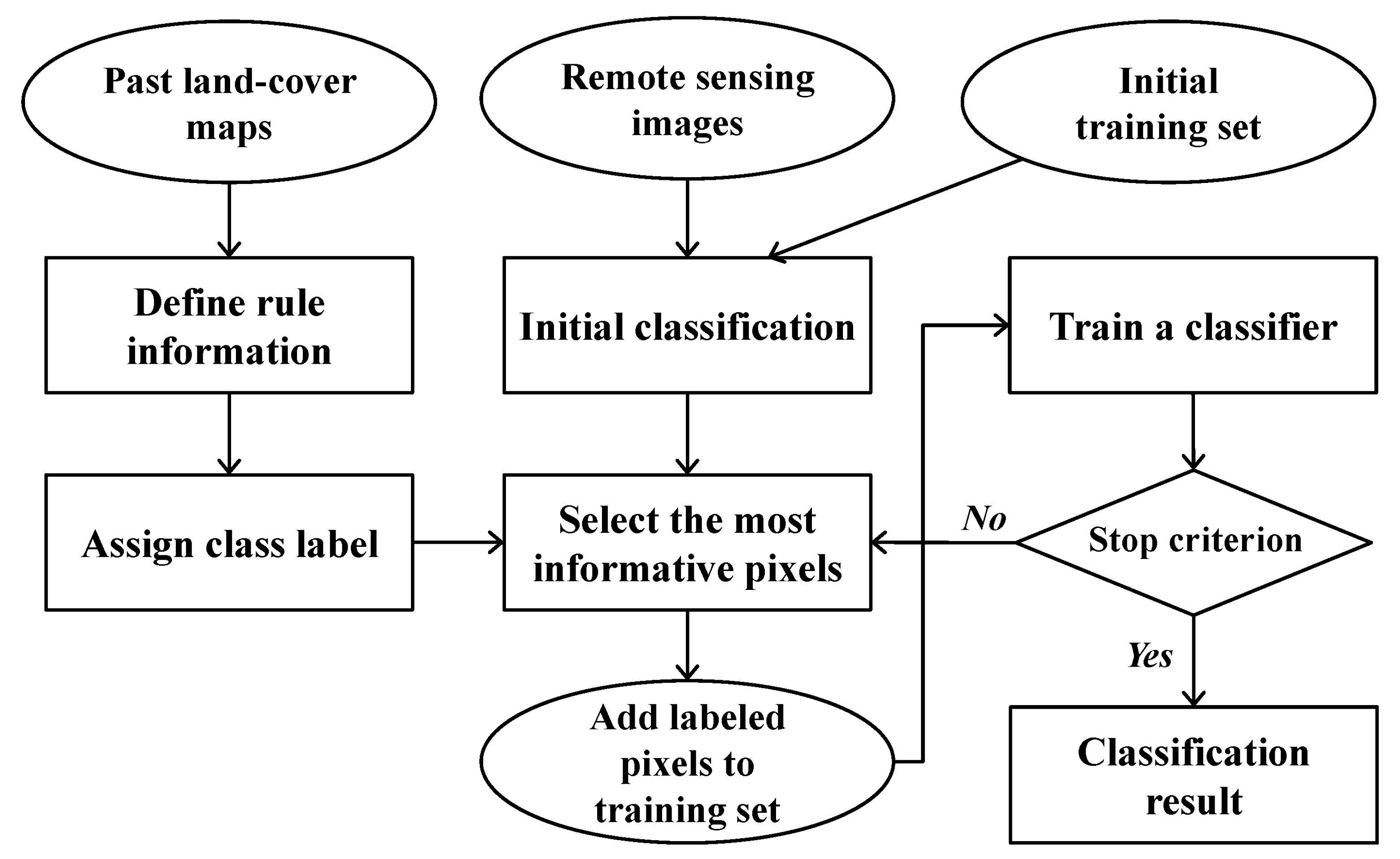
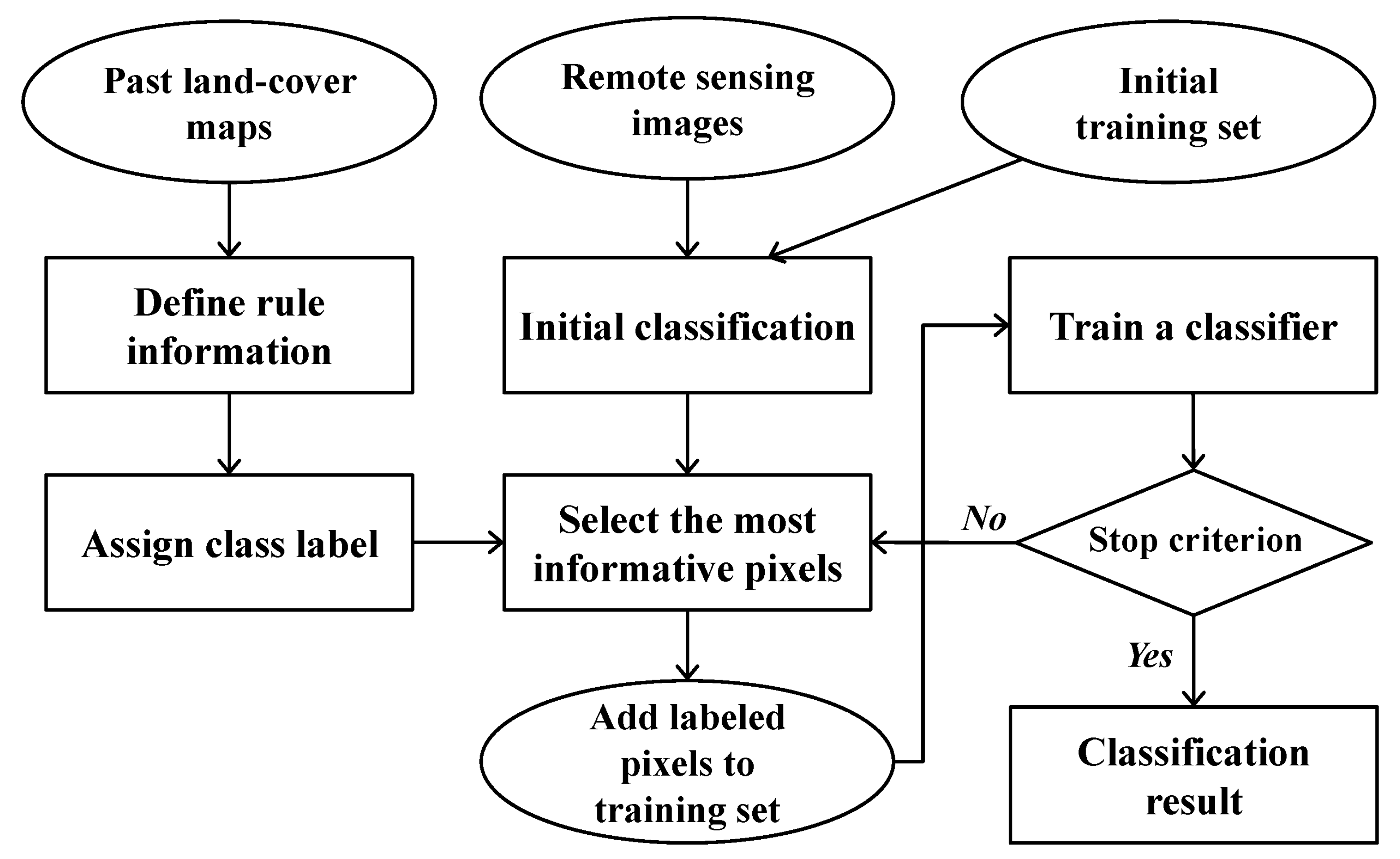
3.3. Self-Learning Classification Result
To select new training data candidates from the initial classification result, the BT algorithm was applied to the posteriori probabilities from a SVM classifier. The pixels that had a difference between the largest posteriori probability and the second largest posteriori probability of less than 0.05 were selected as the most informative pixels with higher uncertainty. Then, the class labels of the selected candidates were assigned to the rule-based class labels predicted from past CDLs.
If no restriction on the number of added training data was given, a large number of pixels were selected for winter wheat that is the major crop in the study area. As mentioned in
Section 2.4, adding too many training data for the majority class (e.g., winter wheat) might result in the over-estimation of that class. To prevent this, another criterion was applied to restrict the number of added training data. Based on a trial and error approach, the number of training data assigned to the majority class was randomly under-sampled, and the total number of newly added training data was set to maximum 300 pixels per iteration. The variations of the number of updated training data for iterative classification are listed in
Table 4. Since the number of new training pixels to be added into the previous training set was restricted, the difference of the total number of new training data was not great. However, the locations of the newly added training data were different, which led to different classification results for four CDL combination cases. Self-learning procedures for all combination cases were terminated after three or four iterations, which implied that most of pixels were mainly labeled during the first three or four iterations, and there was no significant change in the subsequent iterations.
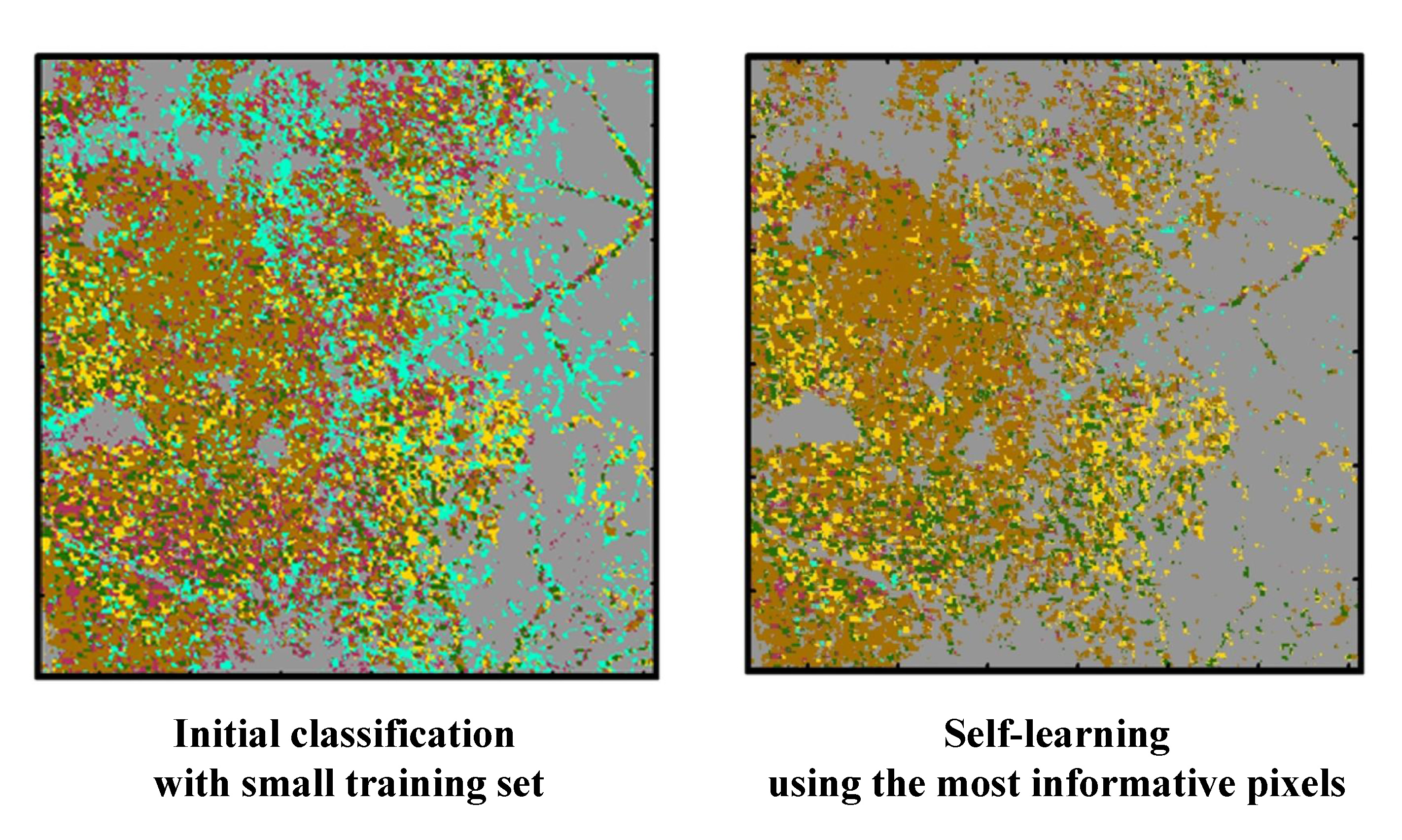
The classification results based on a self-learning approach are presented in
Figure 6. When compared with the initial classification result in
Figure 5, over-estimation of sorghum and grain/hay was greatly reduced in the four classification results. The four classification results showed similar patterns overall: crop areas mainly in the west, and grain/hay and non-crop areas in the east. However, distributions of crop areas were locally different. In particular, over-estimation of soybean and under-estimation of grain/hay were observed in the two-year CDLs classification result, compared with the others. This could be attributed to the fact that the number of new training pixels assigned to alfalfa and other hay was relatively smaller than that of other CDL combination cases, as shown in
Table 4. Conversely, sorghum was under-estimated in the five-year CDLs classification result. Therefore, it is expected that these different classification patterns from four CDL combination cases would result in the different classification accuracy assessment results.
3.4. Accuracy Assessment
For the classification accuracy assessment, accuracy statistics such as overall accuracy, Kappa coefficient, and class-wise accuracy were computed by comparing the classification result and the reference data set in
Table 2.
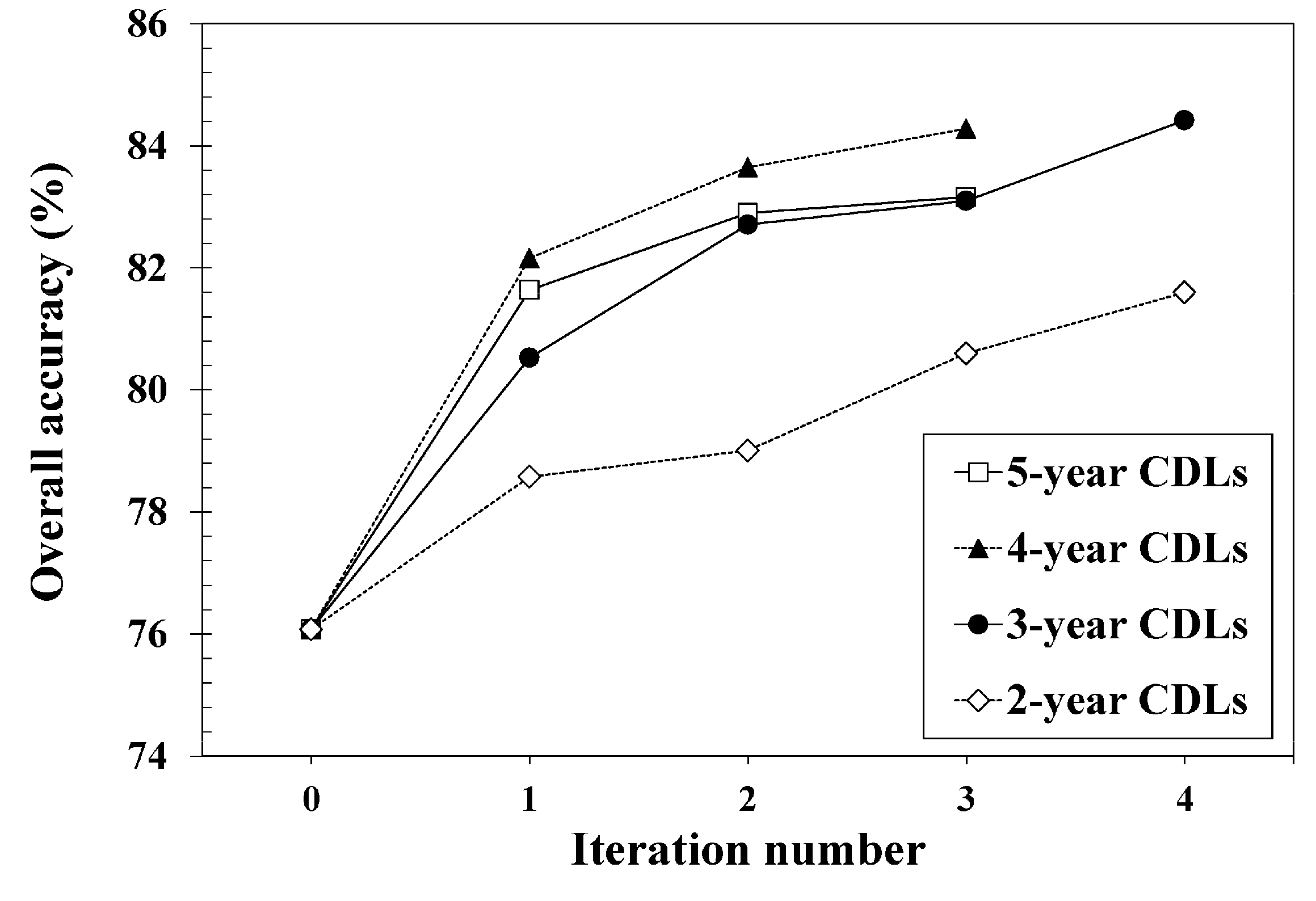
Figure 7 shows the variations of overall accuracy for each iteration of different CDL combination cases. As shown in
Figure 7, the overall accuracy increased as the number iterations increased. As a result, the self-learning approach presented in this study gave a better overall accuracy than the initial SVM classification for all different CDL combination cases. An increase of about 5.52 to 8.34 percentage points in overall accuracy was obtained by adding new training data with rule-based class labels. Based on a McNemar test [
44], the improvement of overall accuracy was statistically significant at the 5% significance level. When comparing the overall accuracy values of different CDL combination cases, the best and worst (84.42% versus 81.60%) were obtained from the three-year CDLs and two-year CDLs, respectively. The case of the four-year CDL completed with fewer iterations, yet appeared to be on a trajectory to compete with the case of the 3-year CDLs which showed the best classification accuracy.
The confusion matrices for the initial classification and self-learning classification with past CDLs are listed in
Table 5.
Table 6 also summarizes the accuracy statistics, including overall accuracy, Kappa coefficient, and class-wise accuracy, with respect to the initial classification and the four different CDL combination cases.
As indicated in
Figure 7 and
Table 6, overall, adding new training data via self-learning showed the best overall accuracy and Kappa coefficient. Except for producer’s accuracy for sorghum and grain/hay and user’s accuracy for non-crop, the class-wise accuracy for the self-learning approach is superior to that for the initial classification.
Despite the poorest overall accuracy, the initial classification result gave relatively higher producer’s accuracy for sorghum and grain/hay, but the accuracy was relatively lower than other classes. As sorghum and grain/hay are minority classes in the study area, their highest producer’s accuracy could not lead to the significant improvement in overall accuracy. As shown in
Figure 5 (e.g., northern and eastern parts in the study area), over-estimation of those classes decreased omission errors and resulted in this high producer’s accuracy. However, user’s accuracy (the probability that the probability that a pixel classified into a given class represents the actual class [
45]) was very low for sorghum and grain/hay, which indicates very poor reliability of these two classes in the initial classification map. Most pixels of these two classes were misclassified into soybean or grass, as shown in
Table 5. The accuracy for these two classes was improved by adding new training data. For sorghum, the case of the five-year CDLs showed a significant increase of approximately 56.80 percentage points in user’s accuracy. The most significant improvement of about 29.51 percentage points in user’s accuracy for grain/hay was also achieved when using past five-year CDLs. Producer’s accuracy of non-crop was the highest in the initial classification result. Despite the best accuracy of non-crop in the initial classification, this accuracy was mainly due to under-estimation of non-crop areas in the classification (see the confusion matrix in
Table 5). Meanwhile, improved accuracy of major crops such as winter wheat, corn, and soybean were obtained from self-learning with past CDLs and led to the significant improvement in overall accuracy, compared with the initial classification. In summary, the improved overall accuracy of the self-learning approach was attributed to both an increase of the number of majority classes that were correctly classified and the decrease of misclassification of sorghum and grain/hay.
When the accuracy of self-learning classification with different CDL combination cases was compared, the self-learning with the five-year CDLs did not show the best classification accuracy. The case of the three-year CDLs showed the best overall accuracy and Kappa coefficient, and the case of the four-year CDLs was the second best. The poorest overall accuracy was obtained from the case of the two-year CDLs. In addition, there was no one CDL combination case where class-wise accuracy was always superior to the initial classification across all classes. Improved classification of each case resulted from the contribution of different land-cover types. In the case of the three-year CDLs, an increase of correctly classified pixels of corn and soybean led to the best overall accuracy. The second best overall accuracy in the case of the four-year CDLS was mainly due to correct classification of soybean and non-crop. An improvement in classification accuracy of cases of the five-year and two-year CDLs, compared to the initial classification, was attributed to an increase of correct classification of winter wheat and non-crop, respectively.
The core component of the self-learning approach is to derive rule-based class labels from sequential land-cover patterns in order to assign predefined class labels to the candidates for new training data. Thus, the accuracy of the predefined class label greatly affects the classification performance. To investigate this effect, further analysis was conducted by analyzing the accuracy of rule-based class labels derived from past CDLs in
Figure 4. Since the true land-cover map (i.e., the CDL in 2015) was available, the rule-based class labels were directly compared with it.
The accuracy assessment results of rule-based class labels are listed in
Table 7. Except for the case of the two-year CDLs, the overall accuracy of all cases was very high. As the number of CDLs for deriving sequential land-cover patterns increased, the corresponding accuracy of the rule-based class labels also increased. However, this high overall accuracy was obtained by the contribution of very high accuracy of non-crop which is one of majority classes in the study area. Regardless of different CLD combination cases, non-crop and sorghum showed the best and worst accuracy values, respectively. Unlike the rules on crop rotations, non-crop was unambiguously predicted to remain unchanged from the unique sequence rule, which led to the most accuracy of the rule-based label of non-crop. The decrease in the class-wise accuracy for crops in different CDL combination cases was due to the fact that sequential patterns of land-cover changes derived from past land-cover maps during too short a period (e.g., the two-year CDLs) were not sufficient to generate accurate rule-based class labels.
Despite the best accuracy of rule-based class labels of the five-year CDLs, however, the best classification accuracy was not obtained. This result can be attributed to the number of pixels that were assigned to rule-based class labels. The more land-cover maps that were used resulted in fewer pixels having rule-based class labels (see
Figure 4). This was because more strict and stable rules were only extracted in cases that used more past-land cover maps. Although some candidate pixels with higher uncertainty were selected, their class labels cannot be assigned because no rule-based class labels were available at those pixels. As the most uncertain candidates were ignored, less uncertain candidate pixels might be selected as new training data. As a result, the selected training data might not be informative pixels. To verify these explanations, the interquartile range (IQR) of ∆
P in Equation (2) at new training pixels was computed to measure the spread of uncertainty (
Table 8). The smaller IQR implies the selection of more uncertain pixels with lower ∆
P. As expected, the case of the five-year CDLs did not show the smallest IQR values for all classes. The smallest IQRs for corn and soybean in the case of the three-year CDLs indicate that the most informative pixels with higher uncertainty were selected as new training data, resulting in an improvement of accuracy for corn and soybean, and the best overall accuracy. From these interpretation results, the three-year CDLs were efficient for the study area because the accuracy was similar or better than the other cases. To derive a guideline on the selection of the optimal number of past land-cover maps, it is necessary to conduct more experiments on other sites using the different temporal length.
Based on all accuracy evaluation results, it can be concluded that by adding the most informative pixels with rule-based class labels, the decision boundary could be positively revised, consequently leading to an accuracy improvement. It was also found that the selection of the most informative pixels was more important for classification performance than the accuracy of rule-based class labels.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}